受限被解释变量模型
C17受限因变量模型和样本选择纠正

第17章 受限因变量模型和样本选择纠正摘要: C7中的线性概率模型是受限因变量(limited dependent variable (LDV))模型的一例子,其容易解释,但有其缺陷,本章介绍的logit 模型和probit 模型更为常用,但解释相对困难。
实际应用中,离散和连续是相对的,也就是说,实际离散的经济变量可能也适用于因变量离散的模型建模。
本节介绍的模型包括Tobit 模型,用于应对角点解响应(corner solution response);泊松回归模型(计数模型),用于建模LDV 只能取非负整数的情况;截断数据模型和对样本选择的纠正。
受限因变量模型更容易在横截面数据中被使用。
样本选择的纠正通常都源于横截面或面板数据。
17.1 二值响应的logit 模型和probit 模型线性概率模型的缺陷?二值响应模型(binary response model )关注的核心问题是响应概率(response probability):.P (y =1│x )=P(y =1|x 1,x 2,…,x n ) logit 模型和probit 模型的设定为此,需要先建一个连接函数:,P (y =1│x )=G (β0+β1x 1+β2x 2+…+βk x k )=G(β0+xβ)其中G(.)是一个取值于(0,1)的函数。
常见的连接函数有:,G (z )=exp (z )[1+exp (z )]=Λ(z)该函数是标准logistic随机变量的累积分布函数:常见的连接函数还有标准正态的累积分布函数,G 可以被表示为:G (z )=Φ(z )≡x ∫‒∞ϕ(v)dv ,.ϕ(v )=(2π)‒1/2exp(‒z 22)使用上述两个连接函数,我们分别建立了logit 模型和probit 模型。
关于logit 模型和probit 模型的推导:y ∗=β0+xβ+e ,并定义,为示性函数。
y =I(y ∗>0) I要求满足CLM 假设或高斯-马尔科夫假设。
03高级计量经济学-12

TOBIT模型的识别 模型的识别
检验是否解释变量z被忽略的LM检验
ˆ e εi x
G
' i
ˆ ε ˆ ε
G ( 2) i
ˆ ε z
G i
' i
检验异方差
ˆ e εi x
G
' i
G ( 2) i
ˆ ε
G ( 2) ' i i
z
TRUNCTED REGRESSION MODEL
y*=β0+β1x1+…+βxk+u,u~N(0,σ2) y=y*,如果y*>0 (y,x)观测不到,如果y*≤0 ≤ 似然函数
例 假设考虑已婚妇女是否参加工作,假设有3种选择: 不工作,兼职,全职。有序多元选择模型 y i* = xi' β + ε i
y1 = 1 if y i* ≤ 0 = 2 if 0 < y i* ≤ γ = 3 if y i* > γ
有序多元选择模型
概率
P ( y i = 1 | xi ) = P( y i * ≤ 0 | xi ) = Φ (− xi' β ) P ( y i = 2 | xi ) = P( y i * ≤ 0 | xi ) = Φ (γ − xi' β ) − Φ (− xi' β ) P ( y i = 3 | xi ) = P( y i * > γ | xi ) = 1 − Φ (γ − xi' β )
' i2 ' iM
P( yi = j ) =
' exp( xij β )
, j = 1,2,...M
无序多元选择模型
该模型的一个主要缺陷是independent of irrelevant alternatives(IIA) 即pi/pj与其他选择无关。 例如选择交通工具:例如选择1表示选家庭汽车, 选择2表示选蓝色长途公共汽车,根据 Multinomial logit model,不管其他选择是选择 火车还是选择红色长途公共汽车, p1/p2是一样 的。
第十八章-离散选择模型和受限因变量模型

第18章离散选择模型和受限因变量模型18.1概述在经典计量经济学模型中,被解释变量通常被假定为连续变量,但在现实的经济决策中经常面临许多选择问题。
在这样的决策问题中,或者选择问题中,人们必须对可供选择的方案作出选择。
通常被解释变量是连续的变量,但此时的因变量只取有限多个离散的值。
例如:人们对交通工具的选择,是选择坐轻轨、地铁还是公共汽车;某大型企业是否合并另一企业;对某一方案的建议持强烈反对、反对、中立、支持和强烈支持5种态度,可以分别用0,1,2,3和4表示。
以这样的选择结果作为被解释变量建立的计量经济学模型,称为离散被解释变量数据计量经济学模型(models with discrete dependent variables),或称为离散选择模型(DCM,discrete choice model)。
如果被解释变量只能有两种选择,称为二元选择模型(binary choice model);如果被解释变量有多种选择,称为多元选择模型(multiple choice model)。
20世纪70和80年代,离散选择模型普遍应用于经济布局、企业定点、交通问题、就业问题、购买决策等经济决策领域的研究。
在实际中,还会经常遇到因变量受到某种限制的情况,这种情况下,取得样本数据来自总体的一个子集,可能不能完全反映总体。
例如,小时工资、住房价格和名义利率都必须大于零。
这时需要建立的经济计量模型称为受限因变量模型(limited dependent variable model)。
这两类模型经常用于调查数据的分析中。
本章将讨论三类模型及其估计方法和软件操作。
一是定性(观测值为离散的或者表示排序);二是截取或者截断问题;三是观测值为整数值的计数模型。
18.2二元因变量模型在这个模型中,被解释变量只取两个值,可以是代表某件事发生与否的虚拟变量,也可以是两个决策中选一个,称为二元因变量模型。
例如:对样本个体是否就业的研究,个体的年龄、教育背景、种族、婚姻状况以及其他可观测的特征,作为解释变量,目的是研究个体这些特征对个体就业概率的研究。
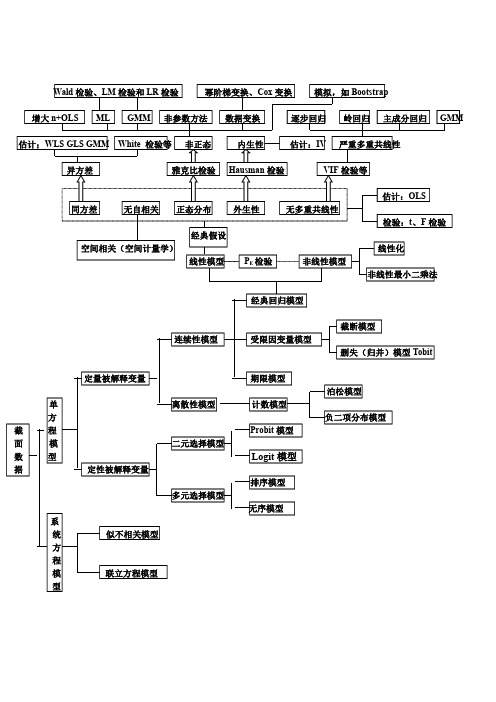
(超全)计量经济学框架图
面
模
二元选择模型
数
型
Logit 模型
据
定性被解释变量
排序模型
多元选择模型
无序模型
系
统
似不相关模型
方
程
模
联立方程模型
型
泊松模型 负二项分布模型
平稳序列 ARMA 模型
单变量序列
非平稳序列
ARIMA 模型 SARMA 模型
单方程模型
平稳序列 建模方法同截面数据
多变量序列 单位根检验
时
协整(同阶单整)
间
Wald 检验、LM 检验和 LR 检验
幂阶梯变换、Cox 变换 模拟,如 Bootstrap
增大 n+OLS ML GMM 非参数方法 数据变换
逐步回归 岭回归 主成分回归 GMM
估计;WLS GLS GMM White 检验等 非正态
内生性
估计:IV 严重多重共线性
异方差
雅克比检验 Hausman 检验
VIF 检验等
同方差
无自相关 正态分布 外生性
无多重共线性
空间相关(空间计量学)
经典假设 线性模型
PE 检验
非线性模型
估计:OLS 检验:t、F 检验 线性化 非线性最小二乘法
经典回归模型
连续性模型
受限因变量模型
截断模型 删失(归并)模型 Tobit
定量被解释变量
期限模型
单
离散性模型
计数模型
方
截
程
Probit 模型
随机效应模型
面
时间效应模型
板
数
据
PVAR
类似时间序列数据的方法
面板单位根
第十章定性选择模型与受限因变量模型

尽管因变量在这个二元选择模型中只能取两个值:0或1,可是该学生的的拟合值或预测值为 0.8。我们将该拟合值解释为该生决定读研的概率的估计值。因此,该生决定读研的可能性或概率 的估计值为0.8。需要注意的是,这种概率不是我们能观测到的数字,能观测的是读研还是不读研 的决定。
对斜率系数的解释也不同了。在常规回归中,斜率系数代表的是其他解释变量不变的情况下, 该解释变量的单位变动引起的因变量的变动。而在线性概率模型中,斜率系数表示其他解释变量不 变的情况下,该解释变量的单位变动引起的因变量等于1的概率的变动。
对每个观测值,我们可根据(10.3)式计算因变量的拟合值或预测值。在常规OLS回归中,因变 量的拟合值或预测值的含义是,平均而言,我们可以预期的因变量的值。但在本例的情况下,这种 解释就不适用了。假设学生甲的平均分为3.5,家庭年收入为5万美元,Y的拟合值为
Y ˆ 0 .7 0 .4 3 .5 0 .0 0 2 5 0 0 .8
f( Y ix i;β ) [ G ( x iβ ) ] Y i[ 1 G ( x iβ ) ] 1 Y i,Y i 0 ,1 ln li( β ) Y iln [ G ( x iβ ) ] ( 1 Y i) ln [ 1 G ( x iβ ) ]
n
lnL(β) lnli(β) i1
0.13
Observations:30
ARRdejsu2=idst0ue.ad5l8Sum=Ro02f.5S3quares =3.15
F-statistic = 11.87
t-Statistic -2.65 3.25 3.08 0.02
p-Value 0.01 0.00 0.00 0.98
如表所示,INCOME的斜率估计值为正,且在1%的水平上显著。年龄和性别不变的情况下,收 入增加1000元,选择候选人甲的概率增加0.0098。
离散选择模型完整版

离散选择模型HEN system office room 【HEN16H-HENS2AHENS8Q8-HENH1688】第五章离散选择模型在初级计量经济学里,我们已经学习了解释变量是虚拟变量的情况,除此之外,在实际问题中,存在需要人们对决策与选择行为的分析与研究,这就是被解释变量为虚拟变量的情况。
我们把被解释变量是虚拟变量的线性回归模型称为离散选择模型,本章主要介绍这一类模型的估计与应用。
本章主要介绍以下内容:1、为什么会有离散选择模型。
2、二元离散选择模型的表示。
3、线性概率模型估计的缺陷。
4、Logit模型和Probit模型的建立与应用。
第一节模型的基础与对应的现象一、问题的提出在研究社会经济现象时,常常遇见一些特殊的被解释变量,其表现是选择与决策问题,是定性的,没有观测数据所对应;或者其观测到的是受某种限制的数据。
1、被解释变量是定性的选择与决策问题,可以用离散数据表示,即取值是不连续的。
例如,某一事件发生与否,分别用1和0表示;对某一建议持反对、中立和赞成5种观点,分别用0、1、2表示。
由离散数据建立的模型称为离散选择模型。
2、被解释变量取值是连续的,但取值的范围受到限制,或者将连续数据转化为类型数据。
例如,消费者购买某种商品,当消费者愿意支付的货币数量超过该商品的最低价值时,则表示为购买价格;当消费者愿意支付的货币数量低于该商品的最低价值时,则购买价格为0。
这种类型的数据成为审查数据。
再例如,在研究居民储蓄时,调查数据只有存款一万元以上的帐户,这时就不能以此代表所有居民储蓄的情况,这种数据称为截断数据。
这两种数据所建立的模型称为受限被解释变量模型。
有的时候,人们甚至更愿意将连续数据转化为上述类型数据来度量,例如,高考分数线的设置,就把高出分数线和低于分数线划分为了两类。
下面是几个离散数据的例子。
例研究家庭是否购买住房。
由于,购买住房行为要受到许多因素的影响,不仅有家庭收入、房屋价格,还有房屋的所在环境、人们的购买心理等,所以人们购买住房的心理价位很难观测到,但我们可以观察到是否购买了住房,即我们希望研究买房的可能性,即概率(1)P Y =的大小。
受限因变量模型

用计量经济模型反映选择行为
行为主体从事的每项活动都可以看作是一种选择; 行为主体有其偏好; 人们的行为有其规则; 在经济分析中,通常认为选择基于效用最大化标准。 研究中需要考虑:
行为理论基础 计量经济学模型方法
模型设定 统计理论和数据 估计方法
应用分析
行为假定
就可以选择的活动而言,行为主体的偏好具有传递 性和完备性。 每项选择都有其相应的效用水平Uijt 每个行为主体都试图获得最大效用,当Ui1t > Ui2t 时, 行为主体会选择第一项活动。 然而我们无法观测效用本身,我们只有通过观察行 为主体做出的选来揭示其偏好
LR = -2(Lr– Lur )~ c2q 如果未受约束似然值与受约束似然值相等,说明模型效果差,未通过 检验;相反,如果未约束似然值远大于约束似然值,说明所设自变 量通过检验,模型总体效果较好。它对应于线性模型中的F值。
拟合优度
对于线性概率模型,可以直接用得到R2来判断拟合优度; Probit 模型和Logit模型没有R2,因而需要利用其他方法来反 映拟合优度。 一种方法是利用对数似然值计算伪R2(pseudo R2)或 McFadden R2,该值也被称作似然值比值指数,定义为1 – Lur/Lr
必要时给出选项 得到估计结果
用EVIEWS估计有限因变量模型
得到结果后可以在VIEW子菜单下调用:
Coefficient tests各种对系数的统计检验 Residual tests对残差的统计检验 Expectation-Prediction Table 可以得到正确和错 误推断的比例 Goodness-of-Fit Tests检验拟合优劣
得到的参数不会相同 但分析结论不会有大的差别 因而通常基于模型的统计表现和经验来决定取舍
受限被解释变量数据模型

Model with Limited Dependent Variable ——Selective Samples Model 一、经济生活中的受限被解释变量问题 二、“截断”问题的计量经济学模型
三、“归并”问题的计量经济学模型
一、经济生活中的受限被解释变量问题
cons
5759.210 4948.980 6023.560 8045.340 5666.540 5298.910 5400.240 5330.340 5540.610
incom
7041.87 6569.23 7643.57 8765.45 6806.35 6657.24 6745.32 6530.48 7173.54
二、“截断”问题的计量经济学模型
1、思路
• 如果一个单方程计量经济学模型,只能从“掐头” 或者“去尾”的连续区间随机抽取被解释变量的 样本观测值,那么很显然,抽取每一个样本观测 值的概率以及抽取一组样本观测值的联合概率, 与被解释变量的样本观测值不受限制的情况是不 同的。
• 如果能够知道在这种情况下抽取一组样本观测值 的联合概率函数,那么就可以通过该函数极大化 求得模型的参数估计量。
i 1
n
( yi X i ) 2
a X i ln1 i 1
n
yi X i i Xi n 2 ln L 2 ( yi X i ) i i 1 i 1 2 2 4 2 2 2 2
1、“截断”(truncation)问题
• 由于条件限制,样本不能随机抽取,即不能从全 部个体,而只能从一部分个体中随机抽取被解释 变量的样本观测值,而这部分个体的观测值都大 于或者小于某个确定值。 “掐头”或者“去尾”。
[Tobit模型估计方法与应用的关系]模型估计
![[Tobit模型估计方法与应用的关系]模型估计](https://img.taocdn.com/s3/m/686204385627a5e9856a561252d380eb62942364.png)
[Tobit模型估计方法与应用的关系]模型估计人们为了纪念Tobin对这类模型的贡献,把被解释变量取值有限制、存在选择行为的这类模型称之为Tobit模型。
这类模型实际上包含两种方程,一种是反映选择问题的离散数据模型;一种是受限制的连续变量模型。
第二种模型往往是文献中人们更感兴趣的部分。
本文试图从一些经典文献著作的简单介绍中,向有兴趣用这个方法分析这类问题的研究者们提供一个参考,为做实证分析的研究者们提供一个分析此类问题的方法。
本文的结构安排如下:第二部分介绍Tobit模型的分类与结构,概括了Tobit模型的特点以及其与两部模型的区别,按照不同的特征对Tobit模型进行了分类。
第三部分介绍Tobit模型的估计与应用,按照Tobit模型的特征从三个方面介绍了每种模型的估计:一是关于非联立方程的Tobit模型估计;二是关于联立方程的Tobit模型的估计,这两类文献的估计方法主要是针对截面数据或者时间序列数据;三是关于面板Tobit模型的估计。
第四部分是简要的结论,指出Tobit模型的发展方向。
二、Tobit模型:概念与分类Tobit模型也称为样本选择模型、受限因变量模型,是因变量满足某种约束条件下取值的模型。
这种模型的特点在于模型包含两个部分,一是表示约束条件的选择方程模型;一种是满足约束条件下的某连续变量方程模型。
研究感兴趣的往往是受限制的连续变量方程模型,但是由于因变量受到某种约束条件的制约,忽略某些不可度量(即:不是观测值,而是通过模型计算得到的变量)的因素将导致受限因变量模型产生样本选择性偏差。
两部模型(two-partmodel)与Tobit模型有很大的相似之处,也是研究受限因变量问题的模型;但是这两种模型在模型结构形式、估计方法、假设条件等方面也存在一定的区别。
Tobit模型的估计方法与模型结构形式有密切关系,不同类型的模型估计方法存在较大的差异,本文按照三种属性特征对Tobit模型进行了分类。
计量经济学_历史回顾与未来展望

计量经济学:历史回顾与未来展望程振源(华南师范大学经济与管理学院、华南市场经济研究中心广东广州510006)摘要:该文回顾了计量经济学的发展历程,指出了计量经济学研究未来可能的发展方向。
计量经济学;回顾;展望关键词:世界计量经济学学会于1930年12月29日成立,其会刊《计量经济学》杂志也于1933年正式创刊。
该学会的成立及其会刊的创刊是计量经济学发展史上的重要里程碑,标志着计量经济学这一学科的正式诞生,极大地推动了计量经济学的研究与发展。
计量经济学在经济学中的地位日渐突出,其取得的成就令人瞩目。
例如,从1969年诺贝尔经济学奖设立以来,因在计量经济学方面的杰出贡献而获奖的人数在经济学各分支学科中名列榜首。
1969年首届诺贝尔经济学奖获得者就是计量经济学家弗里希。
1.上世纪30~50年代计量经济学的研究1.1单方程模型上世纪30年代,以首届诺贝尔经济学奖得主弗里希为代表的计量经济学家致力于单方程计量经济学模型的研究。
但不久就将研究的重点转向了联立方程模型。
此后,单方程模型就一直未受到计量经济学家们的重视。
只是在上世纪70年代偶尔有少数几个学者涉足单方程模型这一领域,如Goldberger和Griliches(1977)等人。
1.2联立方程模型上世纪40至50年代,计量经济学家们主要致力于联立方程模型的研究,Haavelmo(1944)开创了该领域研究的先河。
不久,Andson和Rubin提出了联立方程模型的有限信息极大似然估计法(LIML)。
但该估计法过于繁琐,于是,Theil(1956)提出了两阶段最小平方法(2SLS)。
与有限信息极大似然估计法相比,两阶段最小平方法具有更稳定的性质。
并且该方法计算简便,因此很快得到推广。
但从严格意义上讲,两阶段最小平方法并不像有限信息极大似然估计法那样是一种联立方程估计法。
如果方程是过度识别的,那么对于两阶段最小平方法来说,采用何种方法对方程进行正态化是至关重要的(而有限信息极大似然估计法对标准化来说具有不变性),这与联立概念是相违背的。
chap11-受限被解释变量

(2)两步法旳heckman回归
当数据集比较大时,极大似然估计非常耗时,两步法就提 供了一种很好旳替代。键入命令:
heckman wage educ age, select(married children educ age) twostep mills(m)
其中,选项twostep表白使用两步法旳heckman回归。选择旳可能性。我们这里给该变量命名为m。
主要内容
断尾回归模型 截取回归模型 样本选择模型
试验11-1:断尾回归模型
试验基本原理
试验内容及数据起源
本书附带光盘data文件夹下旳“laborsupply.dta”工 作文件给出了1975年妇女劳动供给旳某些数据,主要 变量有:lfp=各妇女在1975年是否工作(该变量取1表 达该妇女在1975年有工作),whrs=妇女旳工作时间, kl6=年龄不大于6岁旳孩子个数,k618=年龄在6岁到18 岁之间旳孩子个数,wa=妇女旳年龄,we=妇女旳受教 育年限。很显然,当某妇女在1975年没有工作时,我 们观察到旳该妇女旳工作时间为0。
3 断尾回归旳预测
下面,我们结合本例对选项进行详细旳阐明。 1.拟合旳原则误(stdp)也被称作standard error of the fitted
value,能够将其看做观察值处于均值水平下旳原则误。预测旳 原则误(stdf)也被称作the standard error of the future or forecast value,指旳是每个观察值旳点预测旳原则误。根据两 种原则误旳计算公式可知,stdf预测旳原则误总是比stdp预测旳 要大。 我们对上面旳断尾回归进行默认预测以及stdp和stdf旳预测,采 用如下命令:
regress mpg wgt 其中,第一步为生成一种新变量wgt,其值为变量
第八章 (1) 离散和受限被解释变量模型

SC -2 -2 -2 -2 -2 -2 -2 -1 0 -2 -1 0 -2 0 -1 1 1 1 -1 -1 1 1 1 1 -1 0
JGF 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.0000 0.9979 0.0000 0.0000 1.0000 0.0000 0.0000 0.0000 0.9998 0.9999 1.0000 0.4472 0.0000 0.0000 1.0000 1.0000 0.9999 0.0000 0.0000
• 对于两个方案的选择。例如,两种出行方式的选 择,两种商品的选择。由决策者的属性和备选方 案的属性共同决定。
二、二元离散选择模型
1、原始模型
• 对于二元选择问题,可以建立如下计量经济学模 型。其中Y为观测值为1和0的决策被解释变量;X 为解释变量,包括选择对象所具有的属性和选择 主体所具有的属性。
2、重复观测值不可以得到情况下二元Probit 离散选择模型的参数估计
ln L
fi fi Xi Xi 1 Fi F y 0 y 1 i
i
i
q i f (q i X i ) Xi F (q i X i ) i 1
n i 1
n
n
• 在样本数据的支持下,如果知道概率分布函数 和概率密度函数,求解该方程组,可以得到模 型参数估计量。
三、二元Probit离散选择模型及其参数 估计
1、标准正态分布的概率分布函数
F (t )
t
(2 )
12
exp( x 2 2)dx
f ( x) (2 )
第14章-受限被解释变量

© 陈强,《高级计量经济学及Stata 应用》课件,第二版,2014年,高等教育出版社。
第14章 受限被解释变量被解释变量的取值范围有时受限制,称为“受限被解释变量”(Limited Dependent Variable)。
14.1 断 尾 回 归对线性模型i i i y ε'=+x β,假设只有满足i y c ≥的数据才能观测到。
例:i y 为所有企业的销售收入,而统计局只收集规模以上企业2数据,比如100,000i y ≥。
被解释变量在100,000处存在“左边断尾”。
断尾随机变量的概率分布随机变量y 断尾后,其概率密度随之变化。
记y 的概率密度为()f y ,在c 处左边断尾后的条件密度函数为(),P()(|)0,若若f y y c y c f y y c y c ⎧>⎪>>=⎨⎪≤⎩由于概率密度曲线下面积为1,故断尾变量的密度函数乘以因子1P()y c >。
3图14.1 断尾的效果4断尾分布的期望也发生变化。
以左边断尾为例。
对于最简单情形,~(0,1)y N ,可证明(参见附录)()E(|)1()c y y c c φ>=-Φ对于任意实数c ,定义“反米尔斯比率”(Inverse Mill ’s Ratio ,简记IMR)为()()1()c c c φλ≡-Φ则E(|)()y y c c λ>=。
5图14.2 反米尔斯比率6对于正态分布2~(,)y N μσ,定义~(0,1)y z N μσ-≡,则y z μσ=+。
故[]E(|)E(|)E ()E ()()y y c z z c z z c z z c c μσμσμσμσμσμσμσλμσ⎡⎤>=++>=+>-⎣⎦⎡⎤=+>-=+⋅-⎣⎦对于模型i i i y ε'=+x β,2|~(0,)i i N εσx ,则2|~(,)i i i y N σ'x x β,故[]E(|)()i i i i y y c c σλσ''>=+⋅-x x ββ如果用OLS 估计i i iy ε'=+x β,则遗漏了非线性项[]()i c σλσ'⋅-x β,与i x 相关,导致OLS 不一致。
stata上机实验第六讲 离散选择模型(共43张PPT)

左边断尾:truncreg y x1 x2 x3,ll(#) 右边(yòu bian)断尾:truncreg y x1 x2 x3,ul(#) 双边断尾:truncreg y x1 x2 x3,ll(#) ul(#)、
sysuse auto,clear truncreg price weight length gear_ratio, ll(10000) reg price weight length gear_ratio if price>=10000
第四页,共43页。
1。获得个体取值为1的概率。 predict p1,pr list p1 foreign 比照一下结果,判断(pànduàn)有正有误 2。对预测准确率的判断(pànduàn) estat class 结果解读
第五页,共43页。
敏感性〔Sensitivity〕指 Pr(yˆi 1|yi 1) 即真实值取1而预测准确的概率(gàilǜ); 特异性〔Specificity〕是指Pr(y ˆi 0|yi 0) 即真实值取0而预测准确的概率(gàilǜ)。 默认的门限值为0.5。
第二十八页,共43页。
tobit y x1 x2 x3,ll(#) 〔变量<#的被左截断(jié duàn)〕
tobit y x1 x2 x3,ul(#)〔变量>#的被右截断(jié duàn)〕
tobit y x1 x2 x3,ll(#) ul(#)〔l同时定义下限和 上限〕
第二十九页,共43页。
123,情况会发生变化。
第三十二页,共43页。
set seed 12345 gen x3 = uniform() set seed 12345 gen x4 = uniform() list x3 x4 in 1/50
二项式回归和二元逻辑回归

二项式回归和二元逻辑回归
二项式回归和二元逻辑回归都是统计学中常用的方法,主要用于处理因变量为分类的回归问题。
然而,这两者在处理方式和应用场景上存在一些不同。
二项式回归是一种受限的被解释变量模型,其中y的取值范围受到限定,最常见的就是概率,必须限定在「0-1」范围内。
这种模型通常使用指数函数或者概率密度函数来拟合数据。
二元逻辑回归则主要用于处理因变量只有两个选项的问题,例如是否愿意参加活动、产品是否购买等。
其分析结果可以给出不同自变量对于某一事件发生可能性的影响大小。
特别需要注意的是,Logistic回归可以分为三类:二元Logistic回归、多元有序Logistic回归和多元无序Logistic回归。
当因变量有两个选项时,如愿意和不愿意、是和否,那么应该使用二元Logistic回归。
因此,在进行选择时,您需要根据实际问题的特性和研究目标来决定使用哪种方法。
2011管理统计-二元选择模型和受限因变量

第20页,共28页。
(2)下截取(左截取)
定义类似于上截取模型。一个特殊的下截取模 型,TOBIT模型
yi
0
yi*
if if
yi* 0 yi* 0
例1,研究人们在一个月中酒方面的花费就是一个例子。有相当多的人在酒方面的 花费为零。我们不是简单的将这些观测从样本中去掉,而是建立Tobit模型。
如果Y*大于某值(如C),我们只能观察到 y=c.
第19页,共28页。
考虑潜变量模型
yi* xiβ ui
被观察数据y与潜变量 的关系 yi*
yi
yi* c
if yi* c if yi* c
即:y min( y*, c)
例如,在电影或者球赛的门票销售中,由于受到场地的限制, 门票的需求量超过了座位数C时,我们只能观察到Y=C。
L为无约束似然值,L0为参数为0约束下的似然值。
概率的正确预测率
检查Y=1或0的概率的正确性,判断拟合的好坏
预测值与真实值的相关系数
相关系数高,表明拟合越好
第14页,共28页。
4、模型的选择
直接比较三种概率模型的系数是没有意义的
线性概率模型可用于问题的初步分析 Logit模型,系数含义可以通过机会比得以解释
。
Y的期望
E(Y | Y 0) (x' ) x' (x' ) (x' )[x' (x' )]
第27页,共28页。
可以得到:
E(Yi | xi ) ( xi' )
xi
第28页,共28页。
第4页,共28页。
二、线性概率模型
1、线性概率模型: 例如,研究居民的收入和是否购买住房的关系
第五章-离散选择模型(20140429)

第五章-离散选择模型(20140429)第五章离散选择模型在初级计量经济学里,我们已经学习了解释变量是虚拟变量的情况,除此之外,在实际问题中,存在需要人们对决策与选择行为的分析与研究,这就是被解释变量为虚拟变量的情况。
我们把被解释变量是虚拟变量的线性回归模型称为离散选择模型,本章主要介绍这一类模型的估计与应用。
本章主要介绍以下内容:1、为什么会有离散选择模型。
2、二元离散选择模型的表示。
3、线性概率模型估计的缺陷。
4、Logit模型和Probit模型的建立与应用。
第一节模型的基础与对应的现象一、问题的提出在研究社会经济现象时,常常遇见一些特殊的被解释变量,其表现是选择与决策问题,是定性的,没有观测数据所对应;或者其观测到的是受某种限制的数据。
1、被解释变量是定性的选择与决策问题,可以用离散数据表示,即取值是不连续的。
例如,某一事件发生与否,分别用1和0表示;对某一建议持反对、中立和赞成5种观点,分别用0、1、2表示。
由离散数据建立的模型称为离散选择模型。
2、被解释变量取值是连续的,但取值的范围受到限制,或者将连续数据转化为类型数据。
例如,消费者购买某种商品,当消费者愿意支付的货币数量超过该商品的最低价值时,则表示为购买价格;当消费者愿意支付的货币数量低于该商品的最低价值时,则购买价格为0。
这种类型的数据成为审查数据。
再例如,在研究居民储蓄时,调查数据只有存款一万元以上的帐户,这时就不能以此代表所有居民储蓄的情况,这种数据称为截断数据。
这两种数据所建立的模型称为受限被解释变量模型。
有的时候,人们甚至更愿意将连续数据转化为上述类型数据来度量,例如,高考分数线的设置,就把高出分数线和低于分数线划分为了两类。
下面是几个离散数据的例子。
例5.1 研究家庭是否购买住房。
由于,购买住房行为要受到许多因素的影响,不仅有家庭收入、房屋价格,还有房屋的所在环境、人们的购买心理等,所以人们购买住房的心理价位很难观测到,但我们可以观察到是否购买了住房,即1,0Y ⎧=⎨⎩购买,不购买我们希望研究买房的可能性,即概率(1)P Y =的大小。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
实验2:截取回归模型
实验基本原理
实验内容及数据来源 我们要研究汽车重量对每加仑耗油下行驶的路程的影
响,使用文件名“usaauto.dta”工作文件。主要变量 有:mpg=每加仑汽油所行驶的英里数,weight=汽车 的重量等。 利用“usaauto.dta”的数据,我们会讲解截取回归的 操作及预测。
这里,我们主要是为了和后面断尾回归的结果进行比
较。
2 断尾回归的操作 断尾回归的基本命令为: truncreg depvar [indepvar] [if] [in] [weight] [,options] 其中,truncreg代表“断尾回归”的基本命令语句,
depvar代表被解释变量的名称,indepvar代表解释变 量的名称,if代表条件语句,in代表范围语句,weight 代表权重语句,options代表其他选项。表11.2显示了 各options选项及其含义。
3 断尾回归的预测
下面,我们结合本例对选项进行具体的说明。 1.拟合的标准误(stdp)也被称作standard error of the fitted
value,可以将其看做观测值处于均值水平下的标准误。预测的 标准误(stdf)也被称作the standard error of the future or forecast 种标准误的计算公式可知,stdf预测的标准误总是比stdp预测的 要大。 我们对上面的断尾回归进行默认预测以及stdp和stdf的预测,采 用如下命令: predict y predict p, stdp predict f, stdf list whrs y p f in 1/10 其中,第一步为默认预测,并将预测值命名为y;第二步预测的 是拟合的标准误,并将预测值命名为p;第三步预测的是预测的 标准误,并将其命名为f;最后一步列出原序列值whrs和各预测 值的前10个观测值。
1 ( c x
)
n c Xi n 1 2 2 2 ln L (ln(2 ) ln ) 2 (Yi Xi ) (1 ( )) 2 2 i 1 i 1
实验内容及数据来源 文件名“laborsupply.dta”工作文件给出了1975年妇女
(5)predict f,stdf(表示预测的标准误,即个别值预测标准误)
主要内容
断尾回归模型
Tobit模型
实验1:断尾回归模型
实验基本原理
注释:
1 f (y) e 2 (y )2 2 2
1
1 e 2
(
y
2
)2
1
(
y
)
p(y c) p (x c) p( c x ) 1 p( c x )
3 tobit回归的预测
小结 (1)Tobit y x,ll(0) 表示取y>0的数据进行回归分析; (2)Tobit y x,ll(0) ul(100) 表示取0<y<100的数据进行回归分析。 (3)predict yhat,xb(表示y的预测值) (4)predict p,stdp(表示拟合的标准误,即均值预测标准误) (6) predict pr, pr(20,40)(pr(20<y<40)) (7)predict yyhat,e(20,40)(E(y|20<y<40)) (8)predict ystar (E(y*),y*=max(a,min(y,b)))
事实上,我们没有必要先使用replace命令,直接使用
选项ll(20)就可以得到图11.5的结果。前面之所以要对 数据进行变换,主要是为了提醒读者,tobit命令是用 于截取数据的。在实际的研究中,如果数据类型非截 取,直接使用regress就可以了;只有在数据为截取数 据时,才有必要使用tobit。
需要说明的是,这个数据本身不是截取数据,但为了
展示tobit回归的相关操作,我们会对数据进行处理, 然后讲解相关命令的操作。
实验操作指导 1 普通最小二乘回归 为了与数据处理后的tobit回归进行比较,我们这里先
进行OLS回归。 键入命令: generate wgt=weight/1000 regress mpg wgt 其中,第一步为生成一个新变量wgt,其值为变量 weight的1/1000。第二步为mpg对wgt的回归。
2 截取回归的操作
截取回归的基本命令为: tobit depvar [indepvar] [if] [in] [weight], ll[(#)] ul[(#)] [options] 其中,tobit代表“截取回归”的基本命令语句,depvar代表被
解释变量的名称,indepvar代表解释变量的名称,if代表条件语 句,in代表范围语句,weight代表权重语句,options代表其他 选项。可用的options选项包括offset()、vce()、level()等,其含 义和断尾回归处相同。此外,ll表示左截取点,ul表示右截取点, 这两个选项至少需要设定一个,可以同时设定。对于ll和ul选项, 可以设定截取点的值,也可以不设定。当只键入ll或ul选项而不 设定截取点的值时,tobit命令会自动设定被解释变量的最小值 为左截取点(当ll选项被设定时),被解释变量的最大值为右截 取点(当ul选项被设定时)。
下面,我们通过例子来加深对命令的理解。 在“usaauto.dta”工作文件中,变量mpg的最小值为
12,最大值为41。假定我们的数据为截取数据,当 mpg的真实值小于或等于20时,我们只知道其不超过 20,而不知道具体的取值。 我们先对数据进行变换,使用命令: replace mpg=20 if mpg<=20 即,将小于或等于20的mpg值设为20。然后,我们进 行tobit回归: tobit mpg wgt, ll 这里,要注意选项是两个小写的字母el,而不是数字1。
对于“laborsupply.dta”的数据而言,1975年没有工作
的妇女的劳动时间都被设定为0,事实上也就是其具 体劳动时间的数据没有被统计到,这样,我们可以进 行一个左端断尾的回归,命令如下: truncreg whrs kl6 k618 wa we, ll(0) 这里,选项ll(0)设定左端断尾的下限为0。
劳动供给的一些数据,主要变量有:lfp=各妇女在 1975年是否工作(该变量取1表示该妇女在1975年有工 作),whrs=妇女的工作时间,kl6=年龄小于6岁的孩 子个数,k618=年龄在6岁到18岁之间的孩子个数, wa=妇女的年龄,we=妇女的受教育年限。很显然,当 某妇女在1975年没有工作时,我们观察到的该妇女的 工作时间为0。
利用这些数据,我们要研究各个因素对妇女劳动时间
的影响,并讲解断尾回归模型的拟合与预测。
实验操作指导 1 利用普通最小二乘法进行回归 我们首先利用这些数据进行普通最小二乘回归。键入
以下命令: regress whrs kl6 k618 wa we if whrs > 0 其中,被解释变量为whrs,解释变量为kl6、k618、 wa和we,条件语句if表明,我们对妇女工作时间大于 0的数据进行回归。