算法与数据结构讲义四(数据结构——树)
数据结构与算法:树和二叉树

⑵ 如果2i>n,则结点i为叶子结点,无左孩子;否则,其 左孩子结点编号是2i。
⑶ 如果2i+1>n,则结点i无右孩子;否则,其右孩子结点
编号是2i+1。
1
2
3
4
5
67
13
8 9 10 11 12
2 二叉树--满二叉树与完全二叉树
m= i/2
…i
i
i+1
i+1 … 2i
2i+1
2i
(a)
2i+1 2i+2
14
巩固练习
若有一棵有16个结点的完全二叉树,按层编号(从1 开始编号),则对于编号为7的结点,它的双亲结点
及右孩子结点的编号分别为___D____。
A 2,14 B. 2,15 C. 3, 14 D. 3,15
将一棵有100个结点的完全二叉树,从根这一层开始 ,每一层从左到右依次对结点进行编号 ,根结点编
2
1 树的基本概念
1 树的定义
树(Tree)是n(n≧0)个结点的有限集合T,若n=0时称 为空树,否则:
⑴ 有且只有一个特殊的称为树的根(Root)结点; ⑵ 若n>1时,其余的结点被分为m(m>0)个互不相交的子 集T1, T2, T3…Tm,其中每个子集本身又是一棵树,称其为 根的子树(Subtree)。
16
3 遍历二叉树
若以L、D、R分别表示遍历左子树、遍历根结点和遍历 右子树,则有六种遍历方案:DLR、LDR、LRD、DRL、 RDL、RLD。若规定先左后右,则只有前三种情况三种情况, 分别是:
DLR——先(根)序遍历。 LDR——中(根)序遍历。 LRD——后(根)序遍历。
算法与数据结构讲义四(数据结构——树)
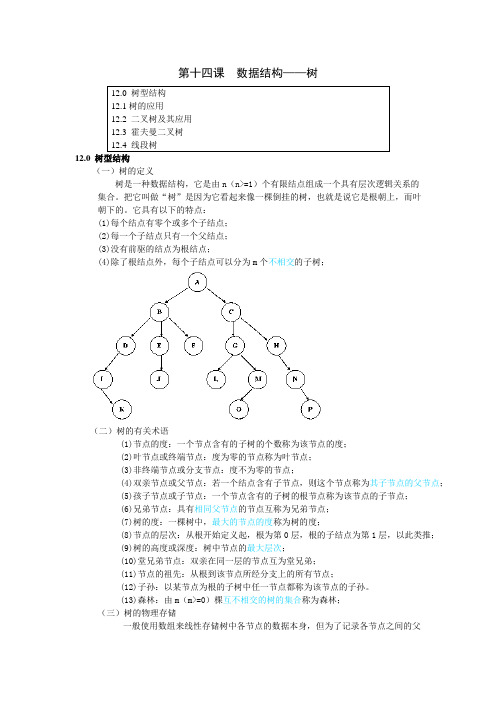
第十四课数据结构——树12.0 树型结构(一)树的定义树是一种数据结构,它是由n(n>=1)个有限结点组成一个具有层次逻辑关系的集合。
把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
它具有以下的特点:(1)每个结点有零个或多个子结点;(2)每一个子结点只有一个父结点;(3)没有前驱的结点为根结点;(4)除了根结点外,每个子结点可以分为m个不相交的子树;(二)树的有关术语(1)节点的度:一个节点含有的子树的个数称为该节点的度;(2)叶节点或终端节点:度为零的节点称为叶节点;(3)非终端节点或分支节点:度不为零的节点;(4)双亲节点或父节点:若一个结点含有子节点,则这个节点称为其子节点的父节点;(5)孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;(6)兄弟节点:具有相同父节点的节点互称为兄弟节点;(7)树的度:一棵树中,最大的节点的度称为树的度;(8)节点的层次:从根开始定义起,根为第0层,根的子结点为第1层,以此类推;(9)树的高度或深度:树中节点的最大层次;(10)堂兄弟节点:双亲在同一层的节点互为堂兄弟;(11)节点的祖先:从根到该节点所经分支上的所有节点;(12)子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
(13)森林:由m(m>=0)棵互不相交的树的集合称为森林;(三)树的物理存储一般使用数组来线性存储树中各节点的数据本身,但为了记录各节点之间的父子关系,需要附加存储父亲或孩子节点所在的位置。
1、双亲表示法:可以存储为:1 2 3 4 5 6 7 8 9 10 11优点:(1)节省空间。
(2)便于从下向上访问(记录了从孩子到父亲的逻辑关系)。
(3)便于随时插入新的子树。
缺点:不利于从上向下的访问。
(未记录父亲到孩子的逻辑关系)。
例如:利用所给边集创建双亲表达树输入:第一行两个整数n,m,表示节点个数和边的条数下面m行,每行2个整数,表示两个节点存在父子关系输出:如上的双亲表示法的树program maketree; //时间复杂度O(nlogn)const maxn=12;var inf,outf:text;bian:array[1..maxn,1..2]of integer; //存储边集tree,num:array[1..maxn]of integer; //存储树、各节点的度t:array[1..maxn]of boolean; //哈希n,m,i,j,k:integer;///////////////////////////////////////////////procedure init;beginassign(inf,'maketree.in'); assign(outf,'maketree.out');reset(inf);readln(inf,n,m);for i:=1 to m dobeginreadln(inf,bian[i,1],bian[i,2]);inc(num[bian[i,1]]); inc(num[bian[i,2]]); //统计各节点的度end;end;///////////////////////////////////////////////procedure make;begini:=1; k:=0;fillchar(t,sizeof(t),true);while k<m dobeginwhile num[i]<>1 do i:=i mod n+1; //查找度为1的节点j:=1;while not(t[j]and((bian[j,1]=i)or(bian[j,2]=i))) do inc(j); //找到包含该if j>n then break; //节点的边t[j]:=false;if bian[j,1]=i then tree[i]:=bian[j,2];if bian[j,2]=i then tree[i]:=bian[j,1];dec(num[bian[j,1]]); dec(num[bian[j,2]]);inc(k);end;end;///////////////////////////////////////////////procedure print;beginrewrite(outf);for i:=1 to n do write(outf,i:3); writeln(outf);for i:=1 to n do write(outf,tree[i]:3);close(outf);end;///////////////////////////////////////////////begininit;make;print;end.2、孩子表示法:(一般二叉树使用)1 2 3 4 5 6 7 8 9 10 11优点:(1)便于从上向下的访问。
数据结构——树

数据结构——树数据结构——树⼀、树的概念1、树的定义树是⼀种常见的⾮线性的数据结构。
树的递归定义如下:树是n(n>0)个结点的有限集,这个集合满⾜以下条件:⑴有且仅有⼀个结点没有前驱(⽗亲结点),该结点称为树的根;⑵除根外,其余的每个结点都有且仅有⼀个前驱;⑶除根外,每⼀个结点都通过唯⼀的路径连到根上(否则有环)。
这条路径由根开始,⽽未端就在该结点上,且除根以外,路径上的每⼀个结点都是前⼀个结点的后继(⼉⼦结点);由上述定义可知,树结构没有封闭的回路。
2、结点的分类结点⼀般分成三类⑴根结点:没有⽗亲的结点。
在树中有且仅有⼀个根结点。
⑵分⽀结点:除根结点外,有孩⼦的结点称为分⽀结点。
b,c,x,t,d,i。
分⽀结点亦是其⼦树的根;⑶叶结点:没有孩⼦的结点称为树叶。
w,h,e,f,s,m,o,n,j,u为叶结点。
根结点到每⼀个分⽀结点或叶结点的路径是唯⼀的。
从根r到结点i的唯⼀路径为rcti。
3、有关度的定义⑴结点的度:⼀个结点的⼦树数⽬称为该结点的度(区分图中结点的度)。
图中,结点i度为3,结点t的度为2,结点b的度为1。
显然,所有树叶的度为0。
⑵树的度:所有结点中最⼤的度称为该树的度(宽度)。
图中树的度为3。
4、树的深度(⾼度)树是分层次的。
结点所在的层次是从根算起的。
根结点在第⼀层,根的⼉⼦在第⼆层,其余各层依次类推。
图中的树共有五层。
在树中,⽗结点在同⼀层的所有结点构成兄弟关系。
树中最⼤的层次称为树的深度,亦称⾼度。
图中树的深度为5。
⼆、树的表⽰⽅法和存储结构1、树的表⽰⽅法树的表⽰⽅法⼀般有两种:⑴⾃然界的树形表⽰法:⽤结点和边表⽰树,例如上图采⽤的就是⾃然界的树形表⽰法。
树形表⽰法⼀般⽤于分析问题。
⑵括号表⽰法:先将根结点放⼊⼀对圆括号中,然后把它的⼦树按由左⽽右的顺序放⼊括号中,⽽对⼦树也采⽤同样⽅法处理:同层⼦树与它的根结点⽤圆括号括起来,同层⼦树之间⽤逗号隔开,最后⽤闭括号括起来。
数据结构——树的基本概念

数据结构——树的基本概念树是一种非线性的数据结构,它由节点和节点之间的连接关系组成。
树的基本概念包括根、节点、边、叶子节点、父节点、子节点、祖先节点和子孙节点等。
首先,树是由节点和边构成的。
每个节点代表一个实体,而边表示节点之间的连接关系。
树中有一个特殊的节点,称为根节点(Root),它没有父节点,其他所有的节点都以直接或间接的方式连接到根节点。
根节点是整个树的起点。
除了根节点外,其他节点分为父节点和子节点。
父节点是一个节点拥有的子节点的节点,一个父节点可以有多个子节点,但一个子节点只能有一个父节点。
同时,子节点也可以成为其他节点的父节点。
这种层级结构使得节点间形成了树形结构,所以树被称为一种分层结构。
树中没有子节点的节点称为叶子节点(Leaf Node),是树的末端节点。
叶子节点没有子节点,但可以有父节点。
除了叶子节点,其他节点都可能是父节点和/或子节点。
节点之间的连接关系称为边(Edge)。
边的数量等于节点数减一、边可以是有向的或无向的,有向边表示连接的方向只能是从父节点指向子节点,无向边表示连接的方向可以是任意的。
大多数情况下,树中的边是无向的。
树的节点可以沿着连接的方向进行遍历,从一个节点到另一个节点。
一个节点的直接子节点是与它直接连接的节点。
一个节点的直接父节点是与它直接相连的节点。
一个节点的祖先节点是它的父节点、父节点的父节点,以此类推,直到根节点。
反之,一个节点的子孙节点是它的所有子节点、子节点的子节点,以此类推。
树的高度是指从根节点到叶子节点的最长路径的边的数量。
树的深度是指从根节点到任意节点的路径的边的数量。
树还可以有不同的特殊形态,如二叉树、平衡树、二叉树等。
二叉树是一种每个节点最多只有两个子节点的树结构。
平衡树是指左右子树的高度差不超过一个固定数值的二叉树。
二叉树是一种特殊的二叉树,它满足左子树的所有节点的值都小于根节点的值,右子树的所有节点的值都大于根节点的值。
树的应用非常广泛。
数据结构-树的基本概念

数据结构-树的基本概念数据结构-树的基本概念1.树:⼀般以链表的⽅式存储。
(1)树可以发散为⽣活中的各种可能。
⽐如机器⼈要实现围棋,需要列出各种可能。
(2)树的遍历⽅式: 深度优先: 使⽤递归实现 - 最先根节点,然后所有左边再所有右边。
前序:根->左->右 中序:左->根->右 后序:左->右->根 ⼴度优先:使⽤队列实现 - 最先根节点,然后⼀层⼀层扩散; 优先级优先:使⽤于现实中的业务场景。
应⽤在推荐算法、深度学习等。
优缺点: 深度优先:不全部保留结点,占⽤空间少;有回溯操作(即有⼊栈、出栈操作),运⾏速度慢。
⼴度优先:保留全部结点,占⽤空间⼤;⽆回溯操作(即⽆⼊栈、出栈操作),运⾏速度快。
(3)概念: 度数:每个节点所有⼦树的个数 层数 ⾼度:树的最⼤层数。
森林:移去根节点就是森林2.⼆叉树:最多只有两个⼦节点(度数<=2) 2.1 由于N叉树N越⼤浪费的指针的⽐例越⼤,所以⼀般使⽤⼆叉树。
n叉树有m个节点,那么空指针: n * m -(m-1) = m(n-1) +1 ,浪费率为 (m(n-1) +1)/(m*n) = 1 - 1/n + 1/mn 约等于 1- 1/n ⽐如:n = 2 需要指针约1/2 n = 3 需要指针约2/3n = 4 需要指针约3/4 2.2 ⾼度为h的⼆叉树最⼤总节点数为 2^h-1 层数为K的节点数最多为2^(k-1),即2的(k-1)次⽅ 2.3 满⼆叉树:节点个数都满了。
⾼度为h,那么树的总节点数为 2^h - 1 完全⼆叉树:和满⼆叉树的区别 - 最后⼀层可以不满,但是必须满⾜顺序- 先有左节点才能有右节点。
严格⼆叉树:⾮叶⼦节点必须有左右。
斜⼆叉树(⼀根棍⼦):没有左节点的叫右斜⼆叉树;没有右节点的叫左斜⼆叉树 2.4 ⼆叉树的存储:⼀般采⽤链表。
(1)数组存储:当成满⼆叉树处理,使⽤索引值表⽰节点。
数据结构与树算法

数据结构与树算法数据结构是计算机科学中非常重要的基础知识领域,它涉及了如何组织和存储数据以便有效地使用。
而树算法则是数据结构中的一种重要应用,它能够解决许多实际问题。
本文将介绍数据结构与树算法的基本概念、常见的树结构以及树算法的实际应用。
一、数据结构的基本概念在计算机科学中,数据结构是指一组数据元素以及这些数据元素之间的关系,它可以使得我们能够有效地组织和管理数据。
常见的数据结构包括数组、链表、栈和队列等。
这些数据结构可以根据需要选择使用,以满足不同问题的需求。
二、树的基本概念树是一种层次结构的数据结构,由节点和边组成。
树的一个节点可以有多个子节点,但每个节点最多只能有一个父节点。
根节点是树的最顶层节点,叶子节点是没有子节点的节点。
树的高度是从根节点到最深的叶子节点的距离。
三、常见的树结构1. 二叉树:二叉树是一种最简单的树结构,它的每个节点最多有两个子节点。
二叉树可以分为满二叉树、完全二叉树和二叉搜索树等。
2. 平衡二叉树:平衡二叉树是一种特殊的二叉搜索树,它的左子树和右子树的高度差不超过1。
通过保持树的平衡性,平衡二叉树可以提供较快的查找和插入操作。
3. B树与B+树:B树和B+树是一种多路搜索树,它们能够应对大量数据的存储和查找需求。
B树和B+树的内部节点可以存储多个关键字,从而提高了数据的检索效率。
四、常见的树算法1. 深度优先搜索(DFS):深度优先搜索是一种经典的树遍历算法,它从根节点开始,沿着树的深度尽可能远的搜索。
DFS可以应用于解决迷宫问题、回溯问题等。
2. 广度优先搜索(BFS):广度优先搜索是一种逐层遍历树的算法,它从根节点开始,逐层遍历直到找到目标节点。
BFS可以应用于解决图的最短路径问题、社交网络的搜索等。
3. 二叉树的遍历:二叉树的遍历是指按照某种顺序访问二叉树的所有节点。
常见的遍历方式包括前序遍历、中序遍历和后序遍历,它们各自有不同的应用场景。
五、树算法的实际应用1. 文件系统:文件系统可以使用树的结构进行组织和管理,每个文件夹可以看作是一个节点,文件夹之间的层次关系形成了一棵树。
(完整版)《树》知识点总结

(完整版)《树》知识点总结本文档总结了关于"树"的知识点,旨在帮助读者更好地理解和运用这一数据结构。
1. 什么是树树是一种层次结构的数据结构,由节点和边组成。
它起始于一个根节点,每个节点可以有零个或多个子节点,子节点之间通过边连接起来。
2. 树的基本术语- 节点(Node): 树中的基本单元,存储数据和指向其子节点的指针。
节点(Node): 树中的基本单元,存储数据和指向其子节点的指针。
- 根节点(Root): 树的顶层节点,没有父节点。
根节点(Root): 树的顶层节点,没有父节点。
- 子节点(Child Node): 一个节点的直接后继,由父节点指向。
子节点(Child Node): 一个节点的直接后继,由父节点指向。
- 叶节点(Leaf Node): 没有子节点的节点。
叶节点(Leaf Node): 没有子节点的节点。
- 父节点(Parent Node): 一个节点的直接前驱,指向该节点的节点。
父节点(Parent Node): 一个节点的直接前驱,指向该节点的节点。
- 兄弟节点(Sibling Node): 具有同一父节点的节点。
兄弟节点(Sibling Node): 具有同一父节点的节点。
3. 树的常见类型3.1 二叉树(Binary Tree)二叉树是一种特殊的树结构,每个节点最多有两个子节点,分别称为左子节点和右子节点。
3.2 二叉搜索树(Binary Search Tree)二叉搜索树是一种二叉树,具有以下特性:- 每个节点的值大于其左子树中任意节点的值。
- 每个节点的值小于其右子树中任意节点的值。
- 左子树和右子树都是二叉搜索树。
3.3 平衡二叉树(Balanced Binary Tree)平衡二叉树是一种特殊的二叉搜索树,具有以下特性:- 左子树和右子树的高度差不超过1。
4. 树的遍历方式树的遍历方式分为三种:- 前序遍历(Preorder Traversal): 先访问根节点,然后递归地遍历左子树和右子树。
树数据结构及其实现算法

树数据结构及其实现算法树是计算机科学中常用的一种数据结构,以其可读性和高效性而被广泛应用于各种算法和数据处理任务中。
本文将介绍树的基本概念及其实现算法。
1. 树的基本概念树是一种非线性的数据结构,由节点和边组成。
树的特点是一个节点可以有多个子节点,但每个节点只能有一个父节点。
树的最上层节点称为根节点,最下层节点称为叶节点。
节点与节点之间的连接称为边,边可以是有向的也可以是无向的。
如果树的每个节点最多只有两个子节点,则称为二叉树。
树的高度是根节点与最深层节点的距离,深度是指从根节点到该节点的距离。
每个节点都有一个权值和一个关键字,关键字是用来对节点进行排序和检索的。
2. 树的实现算法2.1 迭代算法迭代算法是一种基于循环的算法,使用栈来存储树中的节点。
该算法将根节点入栈,然后循环执行以下步骤:(1)将栈顶元素出栈,并输出该节点的值;(2)将该节点的右子节点入栈;(3)将该节点的左子节点入栈。
循环执行以上步骤,直到栈为空。
2.2 递归算法递归算法是另一种实现树的算法。
该算法将根节点作为输入参数传递给函数,函数会执行以下操作:(1)输出该节点的值;(2)递归输出该节点的左子节点;(3)递归输出该节点的右子节点。
递归算法的基本思想是将一个大问题分解成几个小问题,并将这些小问题分别解决。
2.3 广度优先搜索算法广度优先搜索算法是一种基于队列的算法。
该算法从根节点开始,将其加入队列。
然后循环执行以下步骤:(1)取出队首元素,并输出该节点的值;(2)将该节点的左子节点加入队列;(3)将该节点的右子节点加入队列。
循环执行以上步骤,直到队列为空。
广度优先搜索算法可以用于求树的最短路径、最大宽度等问题。
3. 树的应用场景树在计算机科学中有广泛的应用场景,例如:(1)文件系统的目录结构可以看作是一棵树,每个目录都是一个节点,每个文件都是一个叶节点。
(2)数据库中的索引结构可以看作是一棵树,每个索引关键字都是一个节点,用来快速检索数据。
《数据结构课件、代码》第4章 树和二叉树

ppt课件
9
注意二:二叉叉树树或是为有空序树树, 或,它是的由子一树个有根左结右点之加分上。两
棵二分叉别树称的为度左数子不树超和过右二子,但树度的数、不互超不过交二的的二树叉
树未组必成是。二叉树。
根结点
A
右子树
B
E
左子树
C D
ppt课件
F G
HK
10
二叉树的五种基本形态:
空树
只含根结点
N
右子树为空树 左子树为空树
树根
T1
T2 ppt课件
T3
3
2. 树的表示法:
(1). 树型图示 (2).嵌套集合 (3).凹入(书目) (4). 广义表(用根作为表的名字写在表的左边)
KE B A
L
F
D MH J
I GC
ppt课件
A -----------B ---------E -------K -----L -----F -------C ---------G -------D ---------H -------M -----I --------
20+21+ +2k-1 = 2k-1
ppt课件
13
性质 3 :
对任何一棵二叉树,若它含有n0 个叶子结点、n2 个 度为 2 的结点, 则必存在关系式:n0 = n2+1。
证明:
也可以用归纳法证明
设 二叉树上结点总数: n = n0 + n1 + n2
再根据树的性质:
b = n-1 = n0 + n1 + n2 - 1
N
N
左右子 树均非
空树
N
L
数据结构--树 ppt课件

A BC D
树的度::=
madxeg (nro)ed ee
no tdreee
例如, degree of this tree = 3.
父节点(Parent) ::= 有子树的节点是 其子树根节点的父节点。
E F G HI J
KL
M
子节点(Child) ::= 若A节点是B节点的父节点,则B节点是A节点 的子节点,也叫孩子节点。
A BC D E F G HI J
KL
M
B
E
F
A
C
G
H
D
I
J
§1 预备知识
因此,每个节点的大小取决于 子树数目。噢,这样并不太好! K L M
§1 预备知识
❖ 儿子-兄弟表示法
Element FirstChild NextSibling
A BC D E F G HI JFra bibliotekKLM
A
N
B
C
D
N
E
F G HI J
第四章 树
§1 预备知识
客观世界中许多事物存在层次关系 ◦ 人类社会家谱 ◦ 社会组织结构 ◦ 图书信息管理
图书
哲
学
…
宗
教
文 学
医 药 卫
农 业 科
工 业 技
生学术
综
…
合
哲 学 理
世
欧
界 哲
…
洲 哲
宗 教
论学
学
电 工 技 术
计 算… 机
建 筑 科 学
水 利 工 程
宗 教 分 析 研 究
宗 教… 理 论 与 概 况
} }
T ( N ) = O( N )
数据结构与算法树

数据结构与算法树1.导论数据结构是计算机科学的核心领域之一,旨在研究如何在计算机存储器中组织和访问数据以及提高数据的操作效率。
而算法是解决问题的有效工具,包括了复杂度分析、搜索、排序、图形处理、动态规划等等。
数据结构与算法之间相互依存,因为在实际问题中,任何一种算法都需要借助某种数据结构来实现,而一个好的数据结构可以让算法更为高效。
本篇文章将围绕着树状结构,介绍一些常见的数据结构与算法,以及它们的应用。
2.树的基本概念树状结构是一种非线性的数据结构,它的结构可以类比于一个枝繁叶茂的树,由根节点、子节点、叶节点以及分支组成。
其中,根节点是一个特殊的节点,它没有父亲节点,只有子节点,而叶节点则是没有子节点的节点。
一个树状结构可以有多个子树,每个子树也是一棵树。
树状结构在现实中有许多的应用,例如文件系统、组织架构等等。
3.二叉树二叉树是一种特殊的树状结构,每个节点最多只有两个子节点,称为左子节点和右子节点。
其中,左子树和右子树也是二叉树。
二叉树被广泛应用于编程语言的语法分析和图像处理等领域。
在二叉树中,一些基本的操作包括遍历、搜索、插入和删除等。
4.平衡树平衡树是一种特殊的二叉树,它保持每个节点的左右子树高度差不超过1。
这样可以提高树状结构的查询性能,降低了查找时间的复杂度。
常见的平衡树包括红黑树、AVL树以及B树等。
平衡树被广泛用于数据库索引、哈希表等数据结构中。
5.堆堆是一种特殊的树状结构,常常用于优先队列的实现。
堆被设计成可以在常数时间内返回最大或者最小的元素。
常见的堆包括二叉堆和斐波那契堆,堆还可以用于图像处理、操作系统和数据压缩等。
6.图图是由边和节点组成的抽象结构,用于表示实体之间的关系。
图状结构可以被描述为带权重的边或者简单的无向边,甚至包括有向无环图等。
一些基本的操作包括遍历、搜索、排序等等。
图可以被应用于网络分析、城市规划、遗传学等领域。
7.递归与动态规划递归与动态规划是解决计算问题的基本思想。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第十四课数据结构——树12.0 树型结构(一)树的定义树是一种数据结构,它是由n(n>=1)个有限结点组成一个具有层次逻辑关系的集合。
把它叫做“树”是因为它看起来像一棵倒挂的树,也就是说它是根朝上,而叶朝下的。
它具有以下的特点:(1)每个结点有零个或多个子结点;(2)每一个子结点只有一个父结点;(3)没有前驱的结点为根结点;(4)除了根结点外,每个子结点可以分为m个不相交的子树;(二)树的有关术语(1)节点的度:一个节点含有的子树的个数称为该节点的度;(2)叶节点或终端节点:度为零的节点称为叶节点;(3)非终端节点或分支节点:度不为零的节点;(4)双亲节点或父节点:若一个结点含有子节点,则这个节点称为其子节点的父节点;(5)孩子节点或子节点:一个节点含有的子树的根节点称为该节点的子节点;(6)兄弟节点:具有相同父节点的节点互称为兄弟节点;(7)树的度:一棵树中,最大的节点的度称为树的度;(8)节点的层次:从根开始定义起,根为第0层,根的子结点为第1层,以此类推;(9)树的高度或深度:树中节点的最大层次;(10)堂兄弟节点:双亲在同一层的节点互为堂兄弟;(11)节点的祖先:从根到该节点所经分支上的所有节点;(12)子孙:以某节点为根的子树中任一节点都称为该节点的子孙。
(13)森林:由m(m>=0)棵互不相交的树的集合称为森林;(三)树的物理存储一般使用数组来线性存储树中各节点的数据本身,但为了记录各节点之间的父子关系,需要附加存储父亲或孩子节点所在的位置。
1、双亲表示法:可以存储为:1 2 3 4 5 6 7 8 9 10 11优点:(1)节省空间。
(2)便于从下向上访问(记录了从孩子到父亲的逻辑关系)。
(3)便于随时插入新的子树。
缺点:不利于从上向下的访问。
(未记录父亲到孩子的逻辑关系)。
例如:利用所给边集创建双亲表达树输入:第一行两个整数n,m,表示节点个数和边的条数下面m行,每行2个整数,表示两个节点存在父子关系输出:如上的双亲表示法的树program maketree; //时间复杂度O(nlogn)const maxn=12;var inf,outf:text;bian:array[1..maxn,1..2]of integer; //存储边集tree,num:array[1..maxn]of integer; //存储树、各节点的度t:array[1..maxn]of boolean; //哈希n,m,i,j,k:integer;///////////////////////////////////////////////procedure init;beginassign(inf,'maketree.in'); assign(outf,'maketree.out');reset(inf);readln(inf,n,m);for i:=1 to m dobeginreadln(inf,bian[i,1],bian[i,2]);inc(num[bian[i,1]]); inc(num[bian[i,2]]); //统计各节点的度end;end;///////////////////////////////////////////////procedure make;begini:=1; k:=0;fillchar(t,sizeof(t),true);while k<m dobeginwhile num[i]<>1 do i:=i mod n+1; //查找度为1的节点j:=1;while not(t[j]and((bian[j,1]=i)or(bian[j,2]=i))) do inc(j); //找到包含该if j>n then break; //节点的边t[j]:=false;if bian[j,1]=i then tree[i]:=bian[j,2];if bian[j,2]=i then tree[i]:=bian[j,1];dec(num[bian[j,1]]); dec(num[bian[j,2]]);inc(k);end;end;///////////////////////////////////////////////procedure print;beginrewrite(outf);for i:=1 to n do write(outf,i:3); writeln(outf);for i:=1 to n do write(outf,tree[i]:3);close(outf);end;///////////////////////////////////////////////begininit;make;print;end.2、孩子表示法:(一般二叉树使用)1 2 3 4 5 6 7 8 9 10 11优点:(1)便于从上向下的访问。
(2)便于随时删除子树。
缺点:占用空间过大且不确定(使用链表时例外)。
3、混合表示法:既记录双亲关系又记录孩子关系。
12.1 树的应用(一)并查集并查集是一种树型的数据结构,用于处理一些不相交集合(Disjoint Sets)的合并及查询问题。
常常在使用中以森林来表示。
并查集的存储一般采用双亲表示法。
一般为了提高使用效率,会附加储存一些信息,如:该节点下属节点个数、该节点到达根的距离等。
1、基本操作:一开始时,所有元素都分属于各个独立的集合。
(1)查找某结点的根:function get_father(x:integer):integer; //传入待查找的结点序号beginwhile father[x]<>0 do x:=father[x];get_father:=x;end;(2)合并两个不相交的集合:procedure join(x,y:integer);var xx,yy:integer;beginxx:=get_father(x); yy:=get_father(y);if xx<>yy then father[xx]:=yy;end;(3)判断两个结点是否属于一个集合:function same(x,y:integer):boolean;beginif get_father(x)=get_father(y) then same:=trueelse same:=false;end;2、并查集的优化:并查集在使用时,一旦结点多起来,就有可能退化成为一条链,这时,查找结点的祖先或判断两个结点是否是同一集合的复杂度就会称为O(n)。
(1)合并时将元素所在深度低的集合合并到元素所在深度高的集合。
(附加存储集合中根的深度rank[i])procedure join_rank(x,y:integer);var xx,yy:integer;beginxx:=get_father(x);yy:=get_father(y);if rank[xx]>rank[yy] then father[yy]:=xxelse father[xx]:=yy;if rank[xx]=rank[yy] then inc(rank[yy]);end;(2)路径压缩我们找到最久远的祖先时“顺便”把它的子孙直接连接到它上面。
function get_father(x:integer):integer;var xx,y:integer;beginxx:=x;while father[xx]<>0 do xx:=father[xx];while father[x]<>xx dobeginy:=father[x];father[x]:=xx;x:=y;end;end;3、例题:(1) 亲戚(Relations)或许你并不知道,你的某个朋友是你的亲戚。
他可能是你的曾祖父的外公的女婿的外甥的表姐的孙子。
如果能得到完整的家谱,判断两个人是否亲戚应该是可行的,但如果两个人的最近公共祖先与他们相隔好几代,使得家谱十分庞大,那么检验亲戚关系实非人力所能及.在这种情况下,最好的帮手就是计算机。
为了将问题简化,你将得到一些亲戚关系的信息,如同Marry和Tom是亲戚,Tom和B en是亲戚,等等。
从这些信息中,你可以推出Marry和Ben是亲戚。
请写一个程序,对于我们的关心的亲戚关系的提问,以最快的速度给出答案。
输入格式输入由两部分组成。
第一部分以N,M开始。
N为问题涉及的人的个数(1 ≤ N ≤ 20000)。
这些人的编号为1,2,3,…,N。
下面有M行(1 ≤ M ≤ 1000000),每行有两个数ai, bi,表示已知ai和bi是亲戚.第二部分以Q开始。
以下Q行有Q个询问(1 ≤ Q ≤ 1 000 000),每行为ci, di,表示询问ci和di是否为亲戚。
对于每个询问ci, di,若ci和di为亲戚,则输出Yes,否则输出No。
样例输入与输出输入relation.in10 72 45 71 38 91 25 62 333 47 108 9输出relation.outYesNoYes(2) 银河英雄传说【问题描述】公元五八○一年,地球居民迁移至金牛座α第二行星,在那里发表银河联邦创立宣言,同年改元为宇宙历元年,并开始向银河系深处拓展。
宇宙历七九九年,银河系的两大军事集团在巴米利恩星域爆发战争。
泰山压顶集团派宇宙舰队司令莱因哈特率领十万余艘战舰出征,气吞山河集团点名将杨威利组织麾下三万艘战舰迎敌。
杨威利擅长排兵布阵,巧妙运用各种战术屡次以少胜多,难免恣生骄气。
在这次决战中,他将巴米利恩星域战场划分成30000列,每列依次编号为1, 2, …, 30000。
之后,他把自己的战舰也依次编号为1, 2, …, 30000,让第i号战舰处于第i列(i = 1, 2, …, 30000),形成“一字长蛇阵”,诱敌深入。
这是初始阵形。
当进犯之敌到达时,杨威利会多次发布合并指令,将大部分战舰集中在某几列上,实施密集攻击。
合并指令为M i j,含义为让第i号战舰所在的整个战舰队列,作为一个整体(头在前尾在后)接至第j号战舰所在的战舰队列的尾部。
显然战舰队列是由处于同一列的一个或多个战舰组成的。
合并指令的执行结果会使队列增大。
然而,老谋深算的莱因哈特早已在战略上取得了主动。
在交战中,他可以通过庞大的情报网络随时监听杨威利的舰队调动指令。
在杨威利发布指令调动舰队的同时,莱因哈特为了及时了解当前杨威利的战舰分布情况,也会发出一些询问指令:C i j。
该指令意思是,询问电脑,杨威利的第i号战舰与第j号战舰当前是否在同一列中,如果在同一列中,那么它们之间布置有多少战舰。