redis配置文件详解
Redis配置参数详解

Redis配置参数详解Redis是⼀个应⽤⾮常⼴泛的⾼性能Key-Value型数据库,与memcached类似,但功能更加强⼤!本⽂将按照不同功能模块的⽅式,依次对各个功能模块的配置参数进⾏详细介绍。
GENERAL./redis-server /path/to/redis.conf 按照指定的配置⽂件启动include /path/to/other.conf 包含其它的redis配置⽂件daemonize yes 启⽤后台守护进程运⾏模式pidfile /var/run/redis.pid redis启动后的进程ID保存⽂件port 6379 指定使⽤的端⼝号bind IP 监听指定的⽹络接⼝unixsocket /tmp/redis.sock 指定监听的socket,适⽤于unix环境timeout N 客户端空闲N秒后断开连接,参数0表⽰不启⽤loglevel notice 指定服务器信息显⽰的等级,4个参数分别为debug\verbose\notice\warninglogfile “” 指定⽇志⽂件,默认是使⽤系统的标准输出syslog-enabled no 是否启⽤将记录记载到系统⽇志功能,默认为不启⽤syslog-ident redis 若启⽤⽇志记录,则需要设置⽇志记录的⾝份syslog-facility local0 若启⽤⽇志记录,则需要设置⽇志facility,可取值范围为local0~local7,表⽰不同的⽇志级别databases 16 设置数据库的数量,默认启动时使⽤DB0,使⽤“select <dbid>”可以更换数据库tcp-backlog 511 此参数确定TCP连接中已完成队列(3次握⼿之后)的长度,应⼩于Linux系统的/proc/sys/net/core/somaxconn的值,此选项默认值为511,⽽Linux的somaxconn默认值为128,当并发量⽐较⼤且客户端反应缓慢的时候,可以同时提⾼这两个参数。
Redis3.2.6配置文件详细中文说明

Redis3.2.6配置⽂件详细中⽂说明Redis3.2.6最新配置⽂件详细中⽂说明,啥都不说直接看说明############### 指定配置⽂件:################################## INCLUDES ####################################### 1 包含⽂件# 如果想要使⽤到配置⽂件,Redis服务必须以配置⽂件的路径作为第⼀个参数启动。
如:./redis-server /path/to/redis.conf# 单位说明:当需要指定内存⼤⼩时,可能会使⽤到不同的单位,如1k、5GB、4M等,这⾥给出其单位含义:# 1k => 1000 bytes# 1kb => 1024 bytes# 1m => 1000000 bytes# 1mb => 1024*1024 bytes# 1g => 1000000000 bytes# 1gb => 1024*1024*1024 bytes# s指定单位是⼤⼩写不敏感。
如1GB、1gB、1Gb是⼀样的。
# include使⽤:# ⽤于include⼀个或多个配置⽂件。
# 当需要在⼀个标准的通⽤配置模板上进⾏⼀些个性化定制,则可以使⽤include 关键字来include这些个性化配置⽂件。
# 注意:虽然admin 或Redis Sentinel下执⾏的“CONFIG REWRITE”命令(Redis 2.8 引⼊的命令)会重写配置,但并不包含“include”关键字。
也就是说“CONFIG REWRITE”覆盖“include”相关内容。
# 由于redis以最后的配置作为直接配置,所以建议将include命令放置在配置⽂件的最前⾯以防⽌配置被覆盖。
# 但是如果打算使⽤另外的配置⽂件来覆盖当前⽂件的部分或全部配置,那么则可将include命令放置到该⽂件的末尾。
redis集群 配置参数

redis集群配置参数
在Redis集群中,需要配置以下参数:
1. cluster-enabled:设置为yes来启用集群模式。
2. cluster-config-file:指定集群配置文件的路径。
3. cluster-node-timeout:指定集群节点之间的超时时间。
4. cluster-announce-ip:指定集群节点的IP地址。
5. cluster-announce-port:指定集群节点的端口号。
6. cluster-announce-bus-port:指定集群节点之间通信的端口号。
7. cluster-require-full-coverage:设置为yes来要求所有槽位都要有节点才能正常工作。
8. cluster-migration-barrier:设置为yes来阻止在槽迁移期间的对数据的写入操作。
这些参数可以在Redis的配置文件redis.conf中进行设置。
在配置文件中找到对应的参数进行修改并重启Redis服务即可生效。
redis.conf配置参数详解

logfile 日志记录方式,默认值为stdout
databases 可用数据库数,默认值为16,默认数据库为0
save <seconds> <changes> 指出在多长时间内,有多少次更新操作,就将数据同步到数据文件。这个可以多个条件配合,比如默认配置文件中的设置,就设置了三个条件。
save 900 1
900秒(15分钟)内至少有1个key被改变
save 300 10 300秒(5分钟)内至少有300个key被改变
save 60 10000 60秒内至少有10000个key被改变
rdbcompression 存储至本地数据库时是否压缩数据,默认为yes
dbfilename 本地数据库文件名,默认值为dump.rdb
maxclients 最大客户端连接数,默认不限制(注释)
maxmemory <bytes> 设置最大内存,达到最大内存设置后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理后,任到达最大内存设置,将无法再进行写入操作。(注释)
appendonly 是否在每次更新操作后进行日志记录,如果不开启,可能会在断电时导致一段时间内的数据丢失。因为redis本身同步数据文件是按上面save条件来同步的,所以有的数据会在一段时间内只存在于内存中。默认值为no
hash-max-ziverehashing yes
Redis官方文档对VM的使用提出了一些建议: 当你的key很小而value很大时,使用VM的效果会比较好.因为这样节约的内存比较大. 当你的key不小时,可以考虑使用一些非常方法将很大的key变成很大的value,比如你可以考虑将key,value组合成一个新的value. 最好使用linux ext3 等对稀疏文件支持比较好的文件系统保存你的swap文件. vm-max-threads这个参数,可以设置访问swap文件的线程数,设置最好不要超过机器的核数.如果设置为0,那么所有对swap文件的操作都是串行的.可能会造成比较长时间的延迟,但是对数据完整性有很好的保证.
Redis5.0配置文件中文参考

Redis5.0配置⽂件中⽂参考Redis 5.0 配置⽂件#是否在后台执⾏,yes:后台运⾏;no:不是后台运⾏daemonize yes#是否开启保护模式,默认开启。
要是配置⾥没有指定bind和密码。
开启该参数后,redis只会本地进⾏访问,拒绝外部访问。
protected-mode yes#redis的进程⽂件pidfile /var/run/redis/redis-server.pid#redis监听的端⼝号。
port 6379#此参数确定了TCP连接中已完成队列(完成三次握⼿之后)的长度,当然此值必须不⼤于Linux系统定义的/proc/sys/net/core/somaxconn值,默认是511,⽽Linux的默认参数值是128。
当系统并发量⼤并且客户端速度缓慢的时候,可以将这⼆个参数⼀起参考设定。
该内核参数默认值⼀般是128,对于负载很⼤的服务程序来说⼤⼤的不够。
⼀般会将它修改为2048或者更⼤。
在/etc/sysctl.conf中添加:net.core.somaxconn = 2048,然后在终端中执⾏sysctl -p。
tcp-backlog 511#指定 redis 只接收来⾃于该 IP 地址的请求,如果不进⾏设置,那么将处理所有请求bind 127.0.0.1#配置unix socket来让redis⽀持监听本地连接。
# unixsocket /var/run/redis/redis.sock#配置unix socket使⽤⽂件的权限# unixsocketperm 700# 此参数为设置客户端空闲超过timeout,服务端会断开连接,为0则服务端不会主动断开连接,不能⼩于0。
timeout 0#tcp keepalive参数。
如果设置不为0,就使⽤配置tcp的SO_KEEPALIVE值,使⽤keepalive有两个好处:检测挂掉的对端。
降低中间设备出问题⽽导致⽹络看似连接却已经与对端端⼝的问题。
高级配置之给 Redis 配置一个系统服务文件
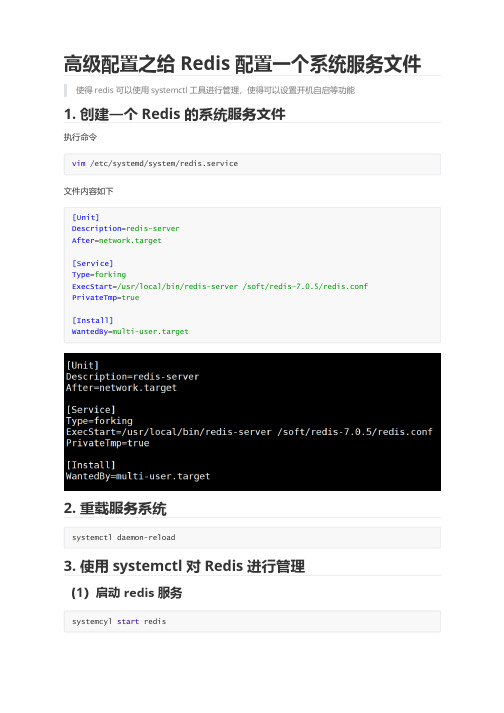
高级配置之给 Redis 配置一个系统服务文件
使得 redis 可以使用 systemctl 工具进行管理,使得可以设置开机自启等功能
1. 创建一个 Redis 的系统服务文件
执行命令 vim /etc/systemd/system/redis.service
文件内容如下 [Unit] Description=redis-server After=network.target [Service] Type=forking ExecStart=/usr/local/bin/redis-server /soft/redis-7.0.5/redis.conf PrivateTmp=true [Install] WantedBy=multi-user.target
2. 重载服务系统
systemctl daemon-reload
3. 使用 systemctl 对 Redis 进行管理
(1)启动 redis 服务
systemcyl start redis
(2)停止 redis 服务
systemctl stop redis
(3)永久停止 Redis 服务
systemctl enable redis
(4)重启 redis 服务
systemctl restart redis
(5)查看 redis 的服务状态
systemctl status redis
(6)设置 redis 的开机自启
emctl enable redis
4. 使用 Redis 客户端进行测试
直接手动运行客户端程序即可 redis-cli
Redis6.0.5版本配置文件说明(转载)

Redis6.0.5版本配置⽂件说明(转载)Redis版本此⽂章中Redis版本为6.0.5。
redis-server --versionRedis server v=6.0.5 sha=00000000:0 malloc=jemalloc-5.1.0 bits=64 build=e8c241ddd6b4e79c配置⽂件说明因Redis配置⽂件内容过多,我按照以模块的⽅式分别对配置项进⾏说明。
1、###UNIT(单位)### (了解)1k => 1000 bytes1kb => 1024 bytes1m => 1000000 bytes1mb => 1024*1024 bytes1g => 1000000000 bytes1gb => 1024*1024*1024 bytes2、###INCLUDES(包含)###(了解)可以⽤于包含(引⼊)⼀个或多个其他配置⽂件3、###MODULES(模块)###(了解)⽤于启动时加载模块。
如果服务器⽆法加载模块它将中⽌。
可以使⽤多个loadmodule指令。
4、###NETWORK(⽹络)###(需记)1. bind说明:Redis服务监听地址,⽤于Redis客户端连接,默认只监听本机回环地址。
默认配置项:bind 127.0.0.12.protected-mode说明:Protected模式是⼀层安全保护。
默认是开启的,配置bind ip或者设置访问密码访问,关闭后,外部⽹络可以直接访问。
默认配置项:protected-mode yes3.prot说明:Redis监听端⼝,默认为6379默认配置项:port 63794.tcp-backlog说明:此参数确定了TCP连接中已完成队列(完成三次握⼿之后)的长度,当然此值必须不⼤于Linux系统定义的/proc/sys/net/core/somaxconn值,默认是511。
Redis Sentinel 文档说明讲解

Redis Sentinel 文档说明Redis Sentinel 的设计目标是用来协助管理Redis实例的系统,它通常执行下面的4类任务:•监控,Sentinel会持续的检测master和slave的实例是否像期望的方式工作。
•通知,Sentinel可以通过一个API,通知系统管理员,或计算机上的其他程序,它监控的redis实例中那些事情出错了。
•自动的错误恢复,如果一个master不能像期望的那样正常工作,Sentinel 可以启动一个错误恢复的处理过程,将一个slave升级成为master,并使其他的slave成为新的master的slave,应用使用Redis server获取新master位置的通知。
•配置信息的获取,Sentinel会作为面向客户端的服务的一个发现的源头:客户端会通过与Sentinels连接,来获取当前工作的Redis master 的位置。
如果经历了错误恢复,Sentinels将会报告新的master的地址。
Sentinel的分布式本质(Distributed nature of Sentinel)Redis Sentinel是一个可分布的系统,这意味着通常你会在你的基础规划中选择运行多个Sentinel进程,而这些进程会使用gossip protocols来理解一个master是否下线,并使用agreement protocols来获取执行错误恢复的授权,或赋予一个新配置新的版本。
分布式系统具有安全(safety)和活动(liveness)的特性,如果想能使用好Redis Sentinel,你应该理解Sentinel是如果作为一个分布式系统工作的。
这些使Sentinel与单进程的程序相比,会更复杂并更具有优势,如:•一个Sentinels的群集,即便其中一部分Sentinels失效,仍然可以完成一个master的故障恢复。
•如果一个Sentinel工作不正常,或连接不上,不会得到其它的Sentinels 的授权,也就不可能做故障恢复的工作。
redis3.0集群__配置文件详解(常用配置)

redis3.0集群__配置⽂件详解(常⽤配置)参考⽂档1 #引⽤其他配置⽂件2 # include /path/to/local.conf34 #是否daemon运⾏no,yes5 daemonize no67 #pid⽂件的位置8 pidfile /tmp/redis.pid910 #开放的端⼝号11 port 63791213 #listen队列的长度14 tcp-backlog 5111516 #绑定ip地址,多个ip⽤空格分隔17 bind 127.0.0.11819 #我没有⽤到20 # unixsocket /tmp/redis.sock21 # unixsocketperm 7552223 #客户端空闲多少s后踢掉,0禁⽌24 timeout 02526 #检测挂掉的连接,单位s,0禁⽌27 tcp-keepalive 02829 #⽇志的等级,debug,verbose,notice,warning30 loglevel notice3132 #log⽂件的路径,为空的话直接显⽰在终端33 logfile ""3435 #是否使⽤系统logger,⼀直没有⽤过。
36 # syslog-enabled no/37 # syslog-ident redis38 # syslog-facility local03940 #redis中有多少个数据库,默认即可41 databases 164243 ################################ SNAPSHOTTING (快照持久化配置) ################################44 #将redis内存数据序列化到磁盘的时间和频率45 #900s有1个key改变就会序列化,其他的读者可以⾃⼰看下46 save 900147 save 3001048 save 60100004950 #序列化的时候是否停⽌写操作51 stop-writes-on-bgsave-error yes5253 #序列化的数据是否压缩54 rdbcompression yes5556 #序列化的数据是否校验其完整性57 rdbchecksum yes5859 #序列化的⽂件名,只是⽂件不能带⽬录60 dbfilename redis.rdb6162 #序列化⽂件的⽬录63 dir /tmp6465 ################################# REPLICATION (主从同步配置)#################################66 #以下是主从备份,我还没有使⽤到67 #指定master ip和port,标明⾃⼰是个从库68 #slaveof <masterip> <masterport>6970 #如果master配置了密码的话,此处也需做设置;71 # masterauth <master-password>7273 #当slave丢失与master端的连接,或者复制仍在处理,那么slave会有下列两种表现:默认值yes。
最详细的docker中安装并配置redis(图文详解)

最详细的docker中安装并配置redis(图⽂详解)⼀、找到⼀个合适的docker的redis的版本可以去docker hub中去找⼀下⼆、使⽤docker安装redissudo docker pull redis安装好之后使⽤docker images即可查看truedei@truedei:~$truedei@truedei:~$ sudo docker imagesREPOSITORY TAG IMAGE ID CREATED SIZEredis latest 987b78fc9e38 10 days ago 104MBhttpd latest a8a9cbaadb0c 2 weeks ago 166MBfjudith/draw.io latest 7b136fc80d31 3 weeks ago 683MBmysql 5.7.29 f5829c0eee9e 5 weeks ago 455MBtruedei@truedei:~$truedei@truedei:~$三、准备redis的配置⽂件因为需要redis的配置⽂件,这⾥最好还是去redis的官⽅去下载⼀个redis使⽤⾥⾯的配置⽂件即可下载后解压出来:这个redis.conf⽂件就是咱们需要的,为了保险,还是拷贝⼀下,做个备份。
四、配置redis.conf配置⽂件修改redis.conf配置⽂件:主要配置的如下:bind 127.0.0.1 #注释掉这部分,使redis可以外部访问daemonize no#⽤守护线程的⽅式启动requirepass 你的密码#给redis设置密码appendonly yes#redis持久化 默认是notcp-keepalive 300 #防⽌出现远程主机强迫关闭了⼀个现有的连接的错误默认是300五、创建本地与docker映射的⽬录,即本地存放的位置创建本地存放redis的位置;可以⾃定义,因为我的docker的⼀些配置⽂件都是存放在/data⽬录下⾯的,所以我依然在/data⽬录下创建⼀个redis⽬录,这样是为了⽅便后期管理truedei@truedei:redis-5.0.5$ sudo cp -p redis.conf /data/redis/truedei@truedei:redis-5.0.5$把配置⽂件拷贝到刚才创建好的⽂件⾥因为我本⾝就是Linux操作系统,所以我可以直接拷贝过去,如果你是windows的话,可能需要使⽤ftp拷贝过去,或者直接复制内容,然后粘贴过去。
redis使用方法

redis使用方法Redis是一款开源的高性能内存键值存储数据库,它支持多种数据结构,包括字符串、哈希表、列表、集合和有序集合等。
Redis是一种非关系型数据库,它的特点是速度快、可扩展性好、数据持久化、应用场景广泛等。
本文将介绍Redis的使用方法,包括Redis的安装、配置、基本命令、数据结构、事务和持久化等方面。
通过本文的学习,读者可以了解Redis的基本使用方法,为使用Redis提供帮助。
一、Redis的安装Redis的安装可以通过源码编译安装或者使用包管理工具安装。
下面以Ubuntu为例,介绍Redis的安装过程。
1. 使用包管理工具安装Ubuntu系统可以通过apt-get命令安装Redis。
打开终端,输入以下命令:sudo apt-get updatesudo apt-get install redis-server安装完成后,可以通过以下命令查看Redis是否已经安装成功: redis-cli ping如果返回“PONG”表示Redis已经安装成功。
2. 源码编译安装如果需要使用最新版本的Redis,可以通过源码编译安装。
首先需要下载Redis的源码包,可以从Redis官网(https://redis.io/)下载最新版本的源码包。
下载完成后,解压源码包,进入解压后的文件夹,执行以下命令进行编译和安装:makemake install安装完成后,可以通过以下命令启动Redis服务:redis-server二、Redis的配置Redis的配置文件是redis.conf,它包含了Redis的各种配置选项。
在Ubuntu系统中,配置文件位于/etc/redis/redis.conf。
下面介绍一些常用的Redis配置选项。
1. bindbind选项指定Redis监听的IP地址,如果不指定,Redis将监听所有的IP地址。
可以通过以下命令指定Redis监听的IP地址: bind 127.0.0.12. portport选项指定Redis监听的端口号,默认为6379。
redis连接参数

redis连接参数Redis是一款非常流行的开源内存数据库。
它支持多种数据结构,并提供了非常快速的读写性能。
Redis不仅可以缓存数据,还可以用于消息队列、计数器、分布式锁等场景。
在使用Redis时,需要设置连接参数来保证安全性、性能和可靠性。
本文将详细介绍Redis连接参数,帮助您更好地理解Redis。
安全性参数1. requirepass密码:Redis通过密码验证来保证连接的安全性。
在redis.conf配置文件中可以设置requirepass选项,如:requirepass yourpassword这样,每次客户端连接Redis时都必须提供正确的密码才能进行操作。
这可以有效保护Redis的数据安全性。
2. bind地址:bind选项用于设置Redis服务端所监听的网络地址。
如果设置为127.0.0.1表示只能通过本地访问,其他网络无法访问,这也可以提高Redis的安全性。
如:bind 127.0.0.13. protected-mode模式:protected-mode模式是Redis默认的安全模式,当它被启用时,只允许来自本地或受信任网络的客户端连接。
如果你要使用外部客户端连接Redis,请把protected-mode设置为no。
1. maxmemory内存限制:Redis主要是基于内存进行存储,可以用maxmemory参数来设置最大可用内存大小,如:maxmemory 1gb这里设置最大可用内存为1GB。
2. maxmemory-policy策略:当Redis的内存使用达到上述maxmemory限制时,需要一种关于如何删除数据的策略。
其中最简单的是 noeviction 策略,它表示不会发生任何删除操作,而是会返回错误信息。
Redis还提供了多种其他策略选项,例如:allkeys-lru表示删除使用LRU算法的最少使用key,volatile-lru表示在过期交集中删除最少使用的key来腾出空间,volatile-ttl表示在过期交集中删除最少使用key的时间戳。
Redis系列(一):Redis简介
Redis系列(⼀):Redis简介⼀、Redis概述 Redis是⼀个开源(遵循BSD协议)Key-Value数据结构的内存存储系统,⽤作数据库、缓存和消息代理。
它⽀持5种数据结构:字符串string、哈希hash、列表list、集合set和有序的集合sorted-set。
Redis⽀持Lua脚本,哨兵机制和集群实现⾼可⽤。
适⽤场景:缓存、投票、抽奖、分布式session、排⾏榜、计数、队列、发布订阅等;具体介绍见。
⼆、Redis安装 ②安装gcc:yum install gcc ④执⾏ cp redis‐5.0.2.tar.gz ../ ⑤ cd /root/svr 然后执⾏:tar -xvf redis‐5.0.2.tar.gz: cd redis‐5.0.2: ⑥执⾏:make install PREFIX=/root/svr/redis-5.0.2 ⑦启动redis 执⾏:bin/redis-server ../redis.conf (注意:如果要后台启动需要把redis.conf配置⾥⾯的daemonize改为yes) ⑧验证是否启动成功 ps -ef|grep redis ⑨进去redis客户端:bin/redis-cli ⑩退出客户端:quit三、redis.conf主要配置详解参数解释bind指定 Redis 只接收来⾃于该 IP 地址的请求,如果不进⾏设置,那么将处理所有请求port监听端⼝,默认6379timeout设置客户端连接时的超时时间,单位为秒。
当客户端在这段时间内没有发出任何指令,那么关闭该连接daemonize默认情况下,redis不是在后台运⾏的,如果需要在后台运⾏,把该项的值更改为yesloglevel log等级分为4级,debug, verbose, notice, 和 warning。
⽣产环境下⼀般开启noticelogfile配置log⽂件地址,默认使⽤标准输出,即打印在命令⾏终端的窗⼝上save save <seconds> <changes>⽐如save 60 10000意思60秒(1分钟)内⾄少10000个key值改变(则进⾏数据库保存--持久化rdb)dbfilename rdb⽂件的名称dir数据⽬录,2种持久化rdb、aof⽂件就在这个⽬录replicaof replicaof <masterip> <masterport>:该配置是主从的配置表⽰该redis实例是masterip:masterport的从节点masterauth master连接密码replica-serve-stale-data 当slave跟master失去连接或者正在同步数据,slave有两种运⾏⽅式:1) 如果replica-serve-stale-data设置为yes(默认设置),slave会继续响应客户端的请求。
redis tls参数

在Redis中,可以通过配置文件来启用TLS,并设置相关的参数。
以下是一些常见的TLS参数及其说明:
1.tls-cluster:用于启用集群模式的TLS。
默认情况下,只有TLSv1.2和TLSv1.3被启用。
可以明确指定要支持的TLS版本,例如"TLSv1.2
TLSv1.3"。
2.tls-protocols:用于指定要支持的TLS协议。
例如,"TLSv1.2 TLSv1.3"。
3.tls-ciphers:用于配置允许的密码套件。
可以指定具体的密码套件,也可以使用默认值。
4.tls-certfile和tls-keyfile:用于指定服务器的证书文件和私钥文件。
这些文件用于验证服务器的身份。
5.tls-ca-certs:用于指定信任的CA证书列表。
这些证书用于验证客户端的证书。
除了上述参数外,还可以配置其他与TLS相关的参数,具体取决于Redis的版本和配置要求。
请注意,启用TLS需要正确配置证书和私钥,并确保服务器和客户端都支持相同的TLS协议和密码套件。
Redis哨兵模式的配置
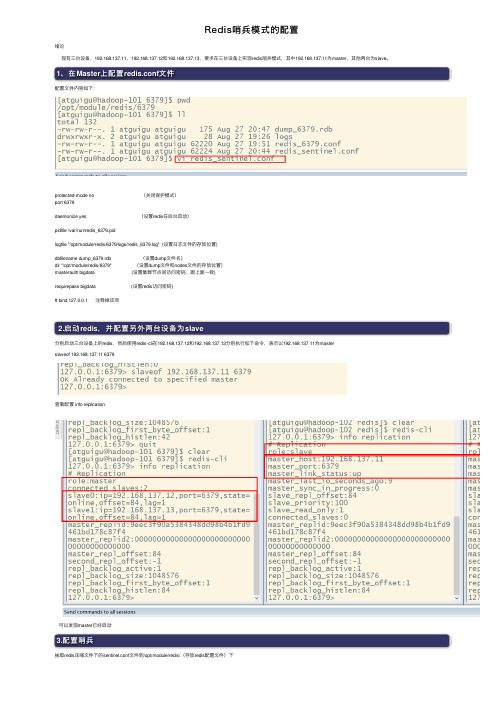
Redis哨兵模式的配置绪论现有三台设备,192.168.137.11、192.168.137.12和192.168.137.13,要求在三台设备上实现redis哨兵模式,其中192.168.137.11为master,其他两台为slave。
1、在Master上配置redis.conf⽂件配置⽂件内容如下:protected-mode no (关闭保护模式)port 6379daemonize yes (设置redis在后台启动)pidfile /var/run/redis_6379.pidlogfile "/opt/module/redis/6379/logs/redis_6379.log" (设置⽇志⽂件的存放位置)dbfilename dump_6379.rdb (设置dump⽂件名)dir "/opt/module/redis/6379" (设置dump⽂件和nodes⽂件的存放位置)masterauth bigdata (设置集群节点间访问密码,跟上⾯⼀致)requirepass bigdata (设置redis访问密码)# bind 127.0.0.1 注释掉该项2.启动redis,并配置另外两台设备为slave分别启动三台设备上的redis,然后使⽤redis-cli在192.168.137.12和192.168.137.13分别执⾏如下命令,表⽰以192.168.137.11为masterslaveof 192.168.137.11 6379 查看配置 info replication可以发现master已经启动3.配置哨兵抽取redis压缩⽂件下的sentinel.conf⽂件到/opt/module/redis/(存放redis配置⽂件)下修改配置如下:sentinel monitor hadoop-101 192.168.137.11 6379 1上⾯最后⼀个数字1,表⽰主机挂掉后salve投票看让谁接替成为主机,得票数多少后成为主机将上⾯的配置同步到其他两台机器上,并且修改Ip为被同步机器的IP。
Redis配置详解

Redis配置详解我们说 Redis 相对于 Memcache 等其他的缓存产品,有⼀个⽐较明显的优势就是 Redis 不仅仅⽀持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
本篇博客我们就将介绍这些数据类型的详细使⽤以及顺带介绍Redis系统的相关命令⽤法。
注意:Redis的命令不区分⼤⼩写,但是key 严格区分⼤⼩写0、写在前⾯ 下⾯介绍的Redis命令有很多,如果你想通过死记硬背来记住这些命令⼏乎不可能,但是如果理解了Redis的⼀些机制,这些命令其实是由很强的通⽤性的,通过理解来记忆是最好的。
另外,每种数据类型都有其适合的使⽤场景,我也会在⽂中给与说明,如果滥⽤,反⽽会适得其反。
1、string 数据类型 string 是Redis的最基本的数据类型,可以理解为与 Memcached ⼀模⼀样的类型,⼀个key 对应⼀个 value。
string 类型是⼆进制安全的,意思是 Redis 的 string 可以包含任何数据,⽐如图⽚或者序列化的对象,⼀个 redis 中字符串 value 最多可以是 512M。
①、相关命令介绍 string 数据类型在 Redis 中的相关命令: PS: ①、上⾯的 ttl 命令是返回 key 的剩余过期时间,单位为秒。
②、mset和mget这种批量处理命令,能够极⼤的提⾼操作效率。
因为⼀次命令执⾏所需要的时间=1次⽹络传输时间+1次命令执⾏时间,n个命令耗时=n次⽹络传输时间+n次命令执⾏时间,⽽批量处理命令会将n次⽹络时间缩减为1次⽹络时间,也就是1次⽹络传输时间+n 次命令处理时间。
但是需要注意的是,Redis是单线程的,如果⼀次批量处理命令过多,会造成Redis阻塞或⽹络拥塞(传输数据量⼤)。
③、setnx可以⽤于实现分布式锁,具体实现⽅式后⾯会介绍。
上⾯是 string 类型的基本命令,下⾯介绍⼏个⾃增⾃减操作,这在实际⼯作中还是特别有⽤的(分布式环境中统计系统的在线⼈数,利⽤Redis的⾼性能读写,在Redis中完成秒杀,⽽不是直接操作数据库。
redis使用方法

redis使用方法Redis是一款快速、高性能、非关系型的键值数据库,它支持多种数据结构,包括字符串、哈希、列表、集合和有序集合等。
Redis 被广泛应用于缓存、消息队列、排行榜、实时消息处理、计数器等场景。
本文将介绍Redis的使用方法,包括安装、配置、数据类型、命令等方面。
一、安装RedisRedis可以在Linux、Windows、Mac等操作系统上运行,安装Redis 的方式也有多种。
本文将以Ubuntu为例,介绍如何安装Redis。
1. 安装Redis在终端中输入以下命令安装Redis:sudo apt-get updatesudo apt-get install redis-server2. 启动Redis安装完成后,可以使用以下命令启动Redis:redis-server3. 测试RedisRedis启动后,可以使用以下命令测试Redis是否正常工作: redis-cli ping如果返回“PONG”,表示Redis已经启动并正常工作。
二、配置RedisRedis的配置文件位于/etc/redis/redis.conf,可以使用文本编辑器打开并修改配置文件。
以下是一些常用的配置项:1. 绑定IP地址bind 127.0.0.1默认情况下,Redis只能在本地访问,如果需要远程访问Redis,可以将IP地址改为0.0.0.0。
2. 设置密码requirepass yourpassword为了保护Redis的安全,可以设置密码。
设置密码后,需要在连接Redis时输入密码才能进行操作。
3. 设置内存限制maxmemory 100mbRedis默认不限制内存使用,如果需要限制内存使用,可以设置maxmemory参数。
4. 设置持久化方式save 900 1save 300 10save 60 10000Redis支持多种持久化方式,包括RDB和AOF。
RDB是将Redis的数据快照保存到磁盘上,AOF是将Redis的操作日志保存到磁盘上。
Redis及其Sentinel配置项详细说明

13.dir ./
指定本地数据库存放目录
14. slaveof <masterip> <masterport>
设置当本机为slave服务时,设置master服务的IP地址及端口,在Redis启动时,它会自动从master进行数据同步
15.slave-serve-stable-data yes
11.rdbcompression yes
指定存储至本地数据库时是否压缩数据,默认为yes,Redis采用LZF压缩,如果为了节省CPU时间,可以关闭该选项,但会导致数据库文件变的巨大
12.dbfilename dump.rdb
指定本地数据库文件名,默认值为dump.rdb
3.port 6379
指定Redis监听端口,默认端口为6379,作者在自己的一篇博文中解释了为什么选用6379作为默认端口,因为6379在手机按键上MERZ对应的号码,而MERZ取自意大利歌女Alessia Merz的名字
4.bind 127.0.0.1
绑定的主机地址
maxmemory-policy (noeviction | allkeys-lru | volatile-lru | allkeys-random | volatile-random | volatile-ttl)
当内存到达阀值时redis对于会增加内存的命令的处理策略:
noeviction:返回错误
设置Redis连接密码,如果配置了连接密码,客户端在连接Redis时需要通过masterauth提供密码,默认关闭
27 maxclients 128
设置同一时间最大客户端连接数,默认无限制,Redis可以同时打开的客户端连接数为Redis进程可以打开的最大文件描述符数,如果设置 maxclients 0,表示不作限制。当客户端连接数到达限制时,Redis会关闭新的连接并向客户端返回max number of clients reached错误信息
Redis配置文件各项参数说明及性能调优

maxclients 128
17. 指定Redis最大内存限制,Redis在启动时会把数据加载到内存中,达到最大内存后,Redis会先尝试清除已到期或即将到期的Key,当此方法处理 后,仍然到达最大内存设置,将无法再进行写入操作,但仍然可以进行读取操作。Redis新的vm机制,会把Key存放内存,Value会存放在swap区
vm-page-size 32
25. 设置swap文件中的page数量,由于页表(一种表示页面空闲或使用的bitmap)是在放在内存中的,,在磁盘上每8个pages将消耗1byte的内存。
vm-pages 134217728
26. 设置访问swap文件的线程数,最好不要超过机器的核数,如果设置为0,那么所有对swap文件的操作都是串行的,可能会造成比较长时间的延迟。默认值为4
vm-max-threads 4
27. 设置在向客户端应答时,是否把较小的包合并为一个包发送,默认为开启
glueoutputbuf yes
28. 指定在超过一定的数量或者最大的元素超过某一临界值时,采用一种特殊的哈希算法
hash-max-zipmap-entries 64
hash-max-zipmap-value 512
=============================================================
redis状态与性能监控
1、redis-benchmark
redis基准信息,redis服务器性能检测
redis-benchmark -h localhost -p 6379 -c 100 -n 100000
vm-max-memory 0
Linux下Redis集群安装部署及使用详解(在线和离线两种安装+相关错误解决方案)

Linux下Redis集群安装部署及使⽤详解(在线和离线两种安装+相关错误解决⽅案)⼀、应⽤场景介绍 本⽂主要是介绍Redis集群在Linux环境下的安装讲解,其中主要包括在联⽹的Linux环境和脱机的Linux环境下是如何安装的。
因为⼤多数时候,公司的⽣产环境是在内⽹环境下,⽆外⽹,服务器处于脱机状态(最近公司要上线项⽬,就是⽆外⽹环境的Linux,被离线安装坑惨了,⾛了很多弯路,说多了都是⾎泪史啊%>_<%)。
这也是笔者写本⽂的初衷,希望其他⼈少⾛弯路,下⾯就介绍如何在Linux安装部署Redis集群。
⼆、安装环境及⼯具 系统:Red Hat Enterprise Linux Server release 6.6 ⼯具:XShell5及Xftp5 安装包:GCC-7.1.0 Ruby-2.4.1 Rubygems-2.6.12 Redis-3.2.9(3.x版本才开始⽀持集群功能)三、安装步骤 要搭建⼀个最简单的Redis集群,我们⾄少需要6个节点:3个Master和3个Slave。
那为什么需要3个Master呢?其实就是⼀个“铁三⾓”的关系,当1个Master下线的时候,其他2个Master 和对应的Salve⽴马就能顶替上去,确保集群能够正常使⽤,如果你之前了解Mongodb/Hadoop/Strom这些的话,你就很容易⽬标⼀般分布式的最低要求基数个数节点,这样便于选举(少数服从多数的原则)。
本⽂当中,我们就偷下懒,在⼀台Linux虚拟机上搭建6个节点的Redis集群(实际真正⽣产环境,需要3台Linux服务器分布存放3个Master)1、安装GCC环境安装Redis需要依托GCC环境,先检查Linux是否已经安装了GCC,如果没有安装,则需要进⾏安装检查GCC是否安装,可以看看版本号$ gcc -v如果已经安装了GCC,则会显⽰以下信息如果没有任何信息,则我们可以通过命令yum install gcc-c++进⾏在线安装$ yum install gcc-c++如果没有⽹络的时候,我们就需要下载GCC的安装包进⾏⼿动安装了,具体⽅法还是⽐较复杂的,具体离线安装GCC的⽅法,请参考我的另外⼀篇⽂章《》2、安装Ruby和Rubygems如果有⽹的话,则通过yum命令进⾏安装,⾃动将关联的依赖包全部安装$ yum install ruby$ yum install rubygems如果是离线的状态,我们则可以选择下载Ruby和Rubygems,解压⼿动进⾏安装,具体的⽅法请参考我的另外两篇⽂件《》和《》,这⾥我们不做多讲解。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
redis 是一款开源的、高性能的键-值存储(key-value store),和 memcached 类似,redis 常被称作是一款 key-value 内存存储系统或者内存数据库,同时由于它支持丰富的数据结构,又被称为一种数据结构服务器(data structure server)。
编译完 redis,它的配置文件在源码目录下 redis.conf ,将其拷贝到工作目录下即可使用,下面具体解释redis.conf 中的各个参数:1 daemonize no默认情况下,redis 不是在后台运行的,如果需要在后台运行,把该项的值更改为 yes。
2 pidfile /var/run/redis.pid当 Redis 在后台运行的时候,Redis 默认会把 pid 文件放在/var/run/redis.pid,你可以配置到其他地址。
当运行多个 redis 服务时,需要指定不同的 pid 文件和端口3 port监听端口,默认为 63794 #bind 127.0.0.1指定 Redis 只接收来自于该 IP 地址的请求,如果不进行设置,那么将处理所有请求,在生产环境中为了安全最好设置该项。
默认注释掉,不开启5 timeout 0设置客户端连接时的超时时间,单位为秒。
当客户端在这段时间内没有发出任何指令,那么关闭该连接6 tcp-keepalive 0指定 TCP 连接是否为长连接,"侦探"信号有 server 端维护。
默认为 0.表示禁用7 loglevel noticelog 等级分为 4 级,debug,verbose, notice, 和 warning。
生产环境下一般开启 notice 8 logfile stdout配置 log 文件地址,默认使用标准输出,即打印在命令行终端的窗口上,修改为日志文件目录9 databases 16设置数据库的个数,可以使用 SELECT 命令来切换数据库。
默认使用的数据库是 0 号库。
默认 16 个库10save 900 1save 300 10save 60 10000保存数据快照的频率,即将数据持久化到 dump.rdb 文件中的频度。
用来描述"在多少秒期间至少多少个变更操作"触发 snapshot 数据保存动作默认设置,意思是:if(在 60 秒之内有 10000 个 keys 发生变化时){进行镜像备份}else if(在 300 秒之内有 10 个 keys 发生了变化){进行镜像备份}else if(在 900 秒之内有 1 个 keys 发生了变化){进行镜像备份}11 stop-writes-on-bgsave-error yes当持久化出现错误时,是否依然继续进行工作,是否终止所有的客户端 write 请求。
默认设置"yes"表示终止,一旦 snapshot 数据保存故障,那么此 server 为只读服务。
如果为"no",那么此次 snapshot 将失败,但下一次 snapshot 不会受到影响,不过如果出现故障,数据只能恢复到"最近一个成功点"12 rdbcompression yes在进行数据镜像备份时,是否启用 rdb 文件压缩手段,默认为 yes。
压缩可能需要额外的cpu 开支,不过这能够有效的减小 rdb 文件的大,有利于存储/备份/传输/数据恢复13 rdbchecksum yes读取和写入时候,会损失 10%性能是否进行校验和,是否对 rdb 文件使用 CRC64 校验和,默认为"yes",那么每个 rdb 文件内容的末尾都会追加 CRC 校验和,利于第三方校验工具检测文件完整性14 dbfilename dump.rdb镜像备份文件的文件名,默认为 dump.rdb15 dir ./数据库镜像备份的文件 rdb/AOF 文件放置的路径。
这里的路径跟文件名要分开配置是因为Redis 在进行备份时,先会将当前数据库的状态写入到一个临时文件中,等备份完成时,再把该临时文件替换为上面所指定的文件,而这里的临时文件和上面所配置的备份文件都会放在这个指定的路径当中16 # slaveof <masterip><masterport>设置该数据库为其他数据库的从数据库,并为其指定 master 信息。
17 masterauth当主数据库连接需要密码验证时,在这里指定18 slave-serve-stale-data yes当主master服务器挂机或主从复制在进行时,是否依然可以允许客户访问可能过期的数据。
在"yes"情况下,slave 继续向客户端提供只读服务,有可能此时的数据已经过期;在"no"情况下,任何向此 server 发送的数据请求服务(包括客户端和此 server 的 slave)都将被告知"error"19 slave-read-only yesslave 是否为"只读",强烈建议为"yes"20 # repl-ping-slave-period 10slave 向指定的 master 发送 ping 消息的时间间隔(秒),默认为 1021 # repl-timeout 60slave 与 master 通讯中,最大空闲时间,默认 60 秒.超时将导致连接关闭22 repl-disable-tcp-nodelay noslave 与 master 的连接,是否禁用 TCP nodelay 选项。
"yes"表示禁用,那么 socket 通讯中数据将会以 packet 方式发送(packet 大小受到 socket buffer 限制)。
可以提高 socket通讯的效率(tcp交互次数),但是小数据将会被buffer,不会被立即发送,对于接受者可能存在延迟。
"no"表示开启 tcp nodelay 选项,任何数据都会被立即发送,及时性较好,但是效率较低,建议设为 no23 slave-priority 100适用 Sentinel 模块(unstable,M-S 集群管理和监控),需要额外的配置文件支持。
slave 的权重值,默认100.当master失效后,Sentinel将会从slave列表中找到权重值最低(>0)的slave, 并提升为 master。
如果权重值为 0,表示此 slave 为"观察者",不参与 master 选举24 # requirepass foobared设置客户端连接后进行任何其他指定前需要使用的密码。
警告:因为 redis 速度相当快,所以在一台比较好的服务器下,一个外部的用户可以在一秒钟进行 150K 次的密码尝试,这意味着你需要指定非常非常强大的密码来防止暴力破解。
25 # rename-command CONFIG 3ed984507a5dcd722aeade310065ce5d (方式:MD5('CONFIG^!'))重命名指令,对于一些与"server"控制有关的指令,可能不希望远程客户端(非管理员用户)链接随意使用,那么就可以把这些指令重命名为"难以阅读"的其他字符串26 # maxclients 10000限制同时连接的客户数量。
当连接数超过这个值时,redis 将不再接收其他连接请求,客户端尝试连接时将收到 error 信息。
默认为 10000,要考虑系统文件描述符限制,不宜过大,浪费文件描述符,具体多少根据具体情况而定27 # maxmemory <bytes>redis-cache 所能使用的最大内存(bytes),默认为 0,表示"无限制",最终由 OS 物理内存大小决定(如果物理内存不足,有可能会使用 swap)。
此值尽量不要超过机器的物理内存尺寸,从性能和实施的角度考虑,可以为物理内存 3/4。
此配置需要和"maxmemory-policy"配合使用,当 redis 中内存数据达到 maxmemory 时,触发"清除策略"。
在"内存不足"时,任何 write 操作(比如 set,lpush 等)都会触发"清除策略"的执行。
在实际环境中,建议 redis 的所有物理机器的硬件配置保持一致(内存一致),同时确保 master/slave 中"maxmemory""policy"配置一致。
当内存满了的时候,如果还接收到 set 命令,redis 将先尝试剔除设置过 expire 信息的key,而不管该 key 的过期时间还没有到达。
在删除时,将按照过期时间进行删除,最早将要被过期的 key 将最先被删除。
如果带有 expire 信息的 key 都删光了,内存还不够用,那么将返回错误。
这样,redis 将不再接收写请求,只接收 get 请求。
maxmemory 的设置比较适合于把 redis 当作于类似 memcached 的缓存来使用。
28 # maxmemory-policy volatile-lru内存不足"时,数据清除策略,默认为"volatile-lru"。
volatile-lru ->对"过期集合"中的数据采取 LRU(近期最少使用)算法.如果对 key 使用"expire"指令指定了过期时间,那么此 key 将会被添加到"过期集合"中。
将已经过期/LRU 的数据优先移除.如果"过期集合"中全部移除仍不能满足内存需求,将 OOM.allkeys-lru ->对所有的数据,采用 LRU 算法volatile-random ->对"过期集合"中的数据采取"随即选取"算法,并移除选中的 K-V,直到"内存足够"为止. 如果如果"过期集合"中全部移除全部移除仍不能满足,将 OOMallkeys-random ->对所有的数据,采取"随机选取"算法,并移除选中的 K-V,直到"内存足够"为止volatile-ttl ->对"过期集合"中的数据采取 TTL 算法(最小存活时间),移除即将过期的数据. noeviction ->不做任何干扰操作,直接返回 OOM 异常另外,如果数据的过期不会对"应用系统"带来异常,且系统中 write 操作比较密集,建议采取"allkeys-lru"29 # maxmemory-samples 3默认值 3,上面 LRU 和最小 TTL 策略并非严谨的策略,而是大约估算的方式,因此可以选择取样值以便检查29 appendonly no默认情况下,redis 会在后台异步的把数据库镜像备份到磁盘,但是该备份是非常耗时的,而且备份也不能很频繁。