中科院中文分词系统调研报告
中科院分词系统分析

两天我开始看ICTCLAS的实现代码了,和吕震宇的感觉完全一样,代码真的是糟糕透顶,呵呵,非常同情吕震宇和Sinboy能够那么认真地把那些代码读完。
有了你们辛苦、认真的分析工作,让我更容易的读懂ICTCLAS的代码了,谢谢了。
阅读过程中注意到了他们分析中有些地方有点小错误。
ICTCLAS的命名好像没有正统的学过数据结构一样,对于数据结构的命名非常富有想象力,完全没有按照数据结构上大家公认的术语命名,所以给代码的读者带来很大的迷惑性。
所以我们在看名字的时候一定要抛开名字看实现,看本质,看他们到底是个啥。
呵呵。
首先就是CQueue的问题,CQueue虽然叫Queue,但是它不是FIFO的Queue。
那它是什么呢?CQueue是优先级队列Priority Queue和Stack的杂交。
但是没有半点FIFO的Queue的概念在里面。
CQueue元素有一个权重eWeight,这个权重如果不为0(或者说互相之间不等),那么CQueue 此时的含义是按照权重由小到大排序的优先级队列。
如果CQueue的所有元素的eWeight都相等,(在ICTCLAS代码里就是都为0),此时CQueue 就演变为FILO的Stack,栈。
因此这个CQueue才会有Push和Pop两种插入和删除元素的命名。
呵呵,挂着羊头卖的是狗肉,还是两只狗。
对于C#、C++、Java来说,类库里面都有现成的优先级队列和栈的实现,而且可以用List<T>重载小于号(C++)、重载CompareTo()(C#,Java)List.Sort()来代替优先级队列实现和并且具有和作者一样的Iterator的功能。
那个CQueue完全可以省略掉。
然后是Dynamic Array。
动态数组?非也。
这个是用来表示稀疏图的邻接表,每一个元素表示的是图上的一条边。
对于非稀疏的图往往喜欢用NxN的数组来表示N个节点的连接关系。
而对于稀疏图来说,无疑会浪费大量的空间,于是往往采用记录邻接两点的边的方式来记录图。
国内中文自动分词技术研究综述

国内中文自动分词技术研究综述自动分词是自然语言处理中的重要任务,主要用于将连续的文本字符串分割成有意义的词语序列。
在中文自动分词中,由于中文没有像英文那样的明显的单词边界,因此这一任务更加具有挑战性。
下面是对国内中文自动分词技术的综述:1.基于规则的方法:这种方法基于已定义的规则和词典来分词。
规则可以是基于语法、词性、词频等方面设计的。
这种方法的优点是易于理解和调整,但缺点是需要大量的人工规则和词典,且无法处理未知词。
2.基于统计的方法:这种方法通过统计分析语料库中的词语出现频率和搭配信息来进行分词。
常用的统计模型包括隐马尔可夫模型(HMM)、最大熵模型(ME)、条件随机场(CRF)等。
这种方法可以自动学习词语的概率分布,但对于未登录词的处理能力有限。
3.基于混合方法:这种方法将规则和统计方法相结合,充分利用两者的优点。
例如,可以首先用规则对已知词进行分词,然后用统计模型对未知词进行处理。
这种方法一方面可以提高分词的准确性,另一方面可以有效处理未知词。
4.基于机器学习的方法:近年来,随着深度学习等技术的发展,基于机器学习的方法在中文自动分词中得到了广泛应用。
这种方法利用神经网络等模型进行分词,可以自动学习特征表示,并具有较好的泛化能力。
总的来说,国内中文自动分词技术研究主要集中在基于规则、统计、混合和机器学习的方法上。
这些方法各有优劣,可以根据具体应用场景选择合适的方法。
随着技术的进步,中文自动分词的准确率和效率不断提升,为中文自然语言处理的应用提供了重要支撑。
中文分词算法的研究与实现

中文分词算法的探究与实现导言中文作为世界上最为复杂的语言之一,具有很高的纷繁变化性。
对于计算机来说,要理解和处理中文文本是一项极具挑战的任务。
中文分词作为自然语言处理的核心步骤之一,其目标是将连续的中文文本按照词语进行切分,以便计算机能够更好地理解和处理中文文本。
本文将谈论。
一、中文分词的重要性中文是一种高度语素丰富的语言,一个复杂的中文句子往往由若干个词汇组成,每个词汇之间没有明显的分隔符号。
若果不进行适当的中文分词处理,计算机将无法准确理解句子的含义。
例如,对于句子“我喜爱进修机器进修”,若果没有正确的分词,计算机将无法区分“进修”是动词仍是名词,从而无法准确理解这个句子。
因此,中文分词作为自然语言处理的重要工具,被广泛应用于查找引擎、信息检索、机器翻译等领域。
二、基于规则的中文分词算法基于规则的中文分词算法是最早出现的一类中文分词算法。
它通过事先定义一些规则来进行分词,如使用词表、词典、词性标注等方法。
这类算法的优点是原理简易,适用于一些固定语境的场景。
但是,这类算法对语言的变化和灵活性要求较高,对于新词和歧义词的处理效果较差。
三、基于统计的中文分词算法基于统计的中文分词算法以机器进修的方法进行训练和处理。
这类算法通过构建统计模型,利用大量的训练样本进行进修和猜测,从而裁定文本中哪些位置可以进行分词。
其中最著名的算法是基于隐马尔可夫模型(Hidden Markov Model,简称HMM)的分词算法。
该算法通过建立状态转移概率和观测概率来进行分词猜测。
此外,还有一些基于条件随机场(Conditional Random Field,简称CRF)的分词算法,通过模型的训练和优化,得到更准确的分词结果。
四、基于深度进修的中文分词算法随着深度进修的兴起,越来越多的中文分词算法开始接受深度进修的方法进行探究和实现。
深度进修通过构建多层神经网络,并利用大量的训练数据进行训练,在分词任务中表现出了很强的性能。
ICTCLAS分词系统研究
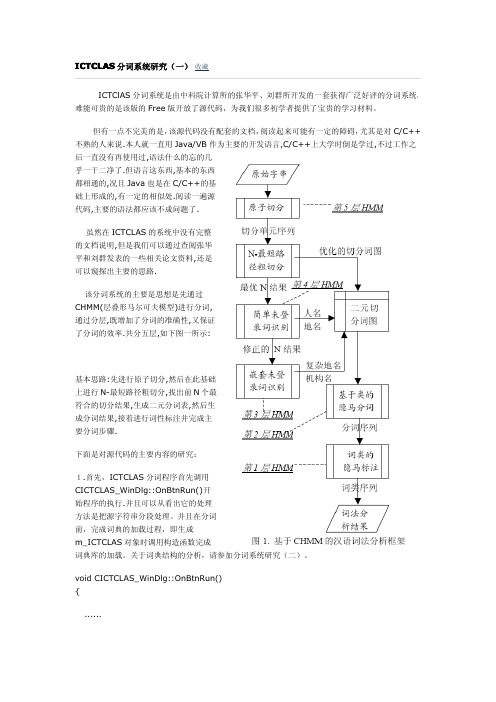
该分词系统的主要是思想是先通过 CHMM(层叠形马尔可夫模型)进行分词, 通过分层,既增加了分词的准确性,又保证 了分词的效率.共分五层,如下图一所示:
基本思路:先进行原子切分,然后在此基础 上进行 N-最短路径粗切分,找出前 N 个最 符合的切分结果,生成二元分词表,然后生 成分词结果,接着进行词性标注并完成主 要分词步骤.
//对图一中所示的 6768 个数据块进行遍历 for(i=0;i<CC_NUM;i++) { pCur=NULL; if(m_pModifyTable) {
//计算修改后有效词块的数目
nCount=m_IndexTable[.nCount+m_pModifyTable[i].nCount-m_pModifyTable[i]. nDelete;
//CC_NUM:6768,应该是 GB2312 编码中常用汉字的数目 6763 个加上 5 个空位码 for(i=0;i<CC_NUM;i++) {
//读取一个整形数字(词块的数目) fread(&(m_IndexTable[i].nCount),sizeof(int),1,fp); if(m_IndexTable[i].nCount>0)
.......
}
3.主要的分词处理是在 Processing()方法里面发生的,下面我们对它进行进一步的分析.
bool CResult::Processing(char *sSentence,unsigned int nCount) {
......
汉语自动分词词典机制的实验研究

汉语自动分词词典机制的实验研究最近,汉语自动分词词典机制的实验研究受到了很多关注。
汉语自动分词词典机制可以帮助用户轻松地识别出汉字,从而实现快速阅读,特别适用于学习新词汇。
本文将介绍汉语自动分词词典机制的实验研究的背景,基本技术原理,实验设计以及研究结果。
一、背景汉语是一门复杂的语言,由于汉语词汇库龙大,发音非常复杂,对新学习者来说,学习汉语往往是一个挑战。
随着中国经济的迅猛发展,越来越多的外国人开始学习汉语。
而汉字的分词是汉语学习的一个重要环节,也是汉语学习的第一步。
随着计算机技术的发展,自动分词技术逐渐成熟,许多语言自动分词机制已经出现,但对于汉语,目前尚未开发出系统的自动分词机制。
为了解决这一痛点,本实验将探索汉语自动分词词典机制的可行性与可行性。
二、基本技术原理汉语自动分词词典机制是利用计算机科学技术以及语言分析技术,实现汉字自动识别的应用技术。
汉语自动分词词典机制最核心的技术原理是建立语言分析模型,以获得词语之间的关联。
通过模型计算,在当前词与下一个词之间,也就是内部的词的词语关系矩阵,即可确定词语的位置与分割。
此外,还可以通过词库的直接查询,根据已经储存的词语,直接确定词之间的关系,从而快速实现汉字的分词。
三、实验设置本实验将采用构建基于词语关联矩阵的自动分词词典机制。
该词典机制通过建立模型,在当前词与下一个词之间,可以直接地确定词之间的关系,故可以实现快速识别,准确分割汉字。
1. 训练数据:实验使用清华大学的语料库对模型进行训练,语料库包含超过1000万的汉字,采用word2vec模型来建立词语关联矩阵。
2. 设计参数:设计参数主要有词语关联矩阵阈值,最小/最大词语阈值,词语分类算法(如语法、语义分析等)以及其他可能的参数。
3. 结果测试:将训练后的模型对一篇汉字文本进行分析,并计算出分词准确度,以及字识别准确度,以此来测试训练结果的合理性。
四、研究结果在实验的训练过程中,得出的结果显示,该汉语自动分词词典机制的识别效率高达90.7%,有效地提高了汉字的分词准确度。
中文分词实验报告

实验:中文分词实验小组成员:黄婷苏亮肖方定山一、实验目的:1.实验目的(1)了解并掌握基于匹配的分词方法、改进方法、分词效果的评价方法等2.实验要求(1)从互联网上查找并构建不低于10万词的词典,构建词典的存储结构;(2)选择实现一种机械分词方法(双向最大匹配、双向最小匹配、正向减字最大匹配法等),同时实现至少一种改进算法。
(3)在不低于1000个文本文件(可以使用附件提供的语料),每个文件大于1000字的文档中进行中文分词测试,记录并分析所选分词算法的准确率、召回率、F-值、分词速度。
二、实验方案:1. 实验环境系统:win10软件平台:spyder语言:python2. 算法选择(1)选择正向减字最大匹配法(2)算法伪代码描述:3. 实验步骤● 在网上查找语料和词典文本文件; ● 思考并编写代码构建词典存储结构;●编写代码将语料分割为1500 个文本文件,每个文件的字数大于1000 字;●编写分词代码;●思考并编写代码将语料标注为可计算准确率的文本;●对测试集和分词结果集进行合并;●对分词结果进行统计,计算准确率,召回率及 F 值(正确率和召回率的调和平均值);●思考总结,分析结论。
4. 实验实施实验过程:(1)语料来源:语料来自SIGHAN 的官方主页(/ ),SIGHAN 是国际计算语言学会(ACL )中文语言处理小组的简称,其英文全称为“Special Interest Group for Chinese Language Processing of the Association for Computational Linguistics”,又可以理解为“SIG 汉“或“SIG 漢“。
SIGHAN 为我们提供了一个非商业使用(non-commercial )的免费分词语料库获取途径。
我下载的是Bakeoff 2005 的中文语料。
有86925 行,2368390 个词语。
语料形式:“没有孩子的世界是寂寞的,没有老人的世界是寒冷的。
实验报告-中文分词

实验报告1 双向匹配中文分词•小组信息目录摘要--------------------------------------------------------------------------------------- 1理论描述--------------------------------------------------------------------------------- 1算法描述--------------------------------------------------------------------------------- 2详例描述--------------------------------------------------------------------------------- 3软件演示--------------------------------------------------------------------------------- 4总结--------------------------------------------------------------------------------------- 6•摘要这次实验的内容是中文分词,现有的分词算法可分为三大类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
按照是否与词性标注过程相结合,又可以分为单纯分词方法和分词与标注相结合的一体化方法。
而我们用到的分词算法是基于字符串的分词方法(又称机械分词方法)中的正向最大匹配算法和逆向匹配算法。
一般说来,逆向匹配的切分精度略高于正向匹配,遇到的歧义现象也较少。
统计结果表明,单纯使用正向最大匹配的错误率为1/169,单纯使用逆向最大匹配的错误率为1/245。
•理论描述中文分词指的是将一个汉字序列切分成一个一个单独的词。
中文自动分词若干技术的研究的开题报告

中文自动分词若干技术的研究的开题报告一、研究背景随着互联网技术的不断发展,中文信息处理的需求日益旺盛,而中文自然语言中的词语粘连现象成为了中文信息处理的难点之一。
因此,在中文自然语言处理中,中文分词技术起着至关重要的作用,但中文分词技术也存在许多挑战性问题,如歧义消解、未登录词问题等。
因此,本研究旨在探究中文自动分词技术的若干技术,通过对不同分词算法的实现和对比,进一步提高中文自动分词的准确率和效率。
二、研究目的1. 了解中文自动分词的若干技术,并对其进行研究和实现。
2. 对不同的中文分词算法进行实验和比较,分析其准确率和效率。
3. 探讨如何应对中文自动分词中的歧义消解和未登录词问题。
4. 提高中文自动分词的准确率和效率,为中文信息处理提供更好的解决方案。
三、研究内容1. 中文自动分词技术相关理论研究和分析。
2. 中文分词算法的实现和对比研究。
3. 对中文自动分词中的歧义消解和未登录词问题进行探讨。
4. 提高中文自动分词的准确率和效率的实验研究。
四、研究方法1. 对中文分词的常用算法进行实现和对比分析。
2. 在分词实现的过程中,对一些应用的特殊场景进行分析,探讨应对方法。
3. 在分词算法实现的基础上,对同类算法进行准确率和效率比较。
4. 综合实验和比较结果,提出提高中文自动分词准确率和效率的方案。
五、研究意义1. 深入探索中文自动分词若干技术的发展和应用,提高其准确率和效率。
2. 增强中文信息处理中的自动化处理能力和智能化水平。
3. 对于中文自动分词技术的不足之处进行深入剖析,并提出解决方案,为相关领域研究提供借鉴。
4. 为中文自动分词技术的更广泛应用做出贡献。
分词系统研究完整版(ICTCLAS)

分词系统研究完整版ICTClAS分词系统是由中科院计算所的张华平、刘群所开发的一套获得广泛好评的分词系统,难能可贵的是该版的Free版开放了源代码,为我们很多初学者提供了宝贵的学习材料。
但有一点不完美的是,该源代码没有配套的文档,阅读起来可能有一定的障碍,尤其是对C/C++不熟的人来说.本人就一直用Java/VB作为主要的开发语言,C/C++上大学时倒是学过,不过工作之后一直没有再使用过,语法什么的忘的几乎一干二净了.但语言这东西,基本的东西都相通的,况且Java也是在C/C++的基础上形成的,有一定的相似处.阅读一遍源代码,主要的语法都应该不成问题了.虽然在ICTCLAS的系统中没有完整的文档说明,但是我们可以通过查阅张华平和刘群发表的一些相关论文资料,还是可以窥探出主要的思路.该分词系统的主要是思想是先通过CHMM(层叠形马尔可夫模型)进行分词,通过分层,既增加了分词的准确性,又保证了分词的效率.共分五层,如下图一所示:基本思路:先进行原子切分,然后在此基础上进行N-最短路径粗切分,找出前N个最符合的切分结果,生成二元分词表,然后生成分词结果,接着进行词性标注并完成主要分词步骤.下面是对源代码的主要内容的研究:1.首先,ICTCLAS分词程序首先调用CICTCLAS_WinDlg::OnBtnRun()开始程序的执行.并且可以从看出它的处理方法是把源字符串分段处理。
并且在分词前,完成词典的加载过程,即生成m_ICTCLAS对象时调用构造函数完成词典库的加载。
关于词典结构的分析,请参加分词系统研究(二)。
void CICTCLAS_WinDlg::OnBtnRun(){......//在此处进行分词和词性标记if(!m_ICTCLAS.ParagraphProcessing((char*)(LPCTSTR)m_sSource,sResult)) m_sResult.Format("错误:程序初始化异常!");elsem_sResult.Format("%s",sResult);//输出最终分词结果......}2.在OnBtnRun()方法里面调用分段分词处理方法boolCResult::ParagraphProcessing(char*sParagraph,char*sResult)完成分词的整个处理过程,包括分词的词性标注.其中第一个参数为源字符串,第二个参数为分词后的字符串.在这两个方法中即完成了整个分词处理过程,下面需要了解的是在此方法中,如何调用其它方法一步步按照上图所示的分析框架完成分词过程.为了简单起见,我们先不做未登录词的分析。
中科院分词系统C++版本

基于一种语义相关度的集诗系统————大作业报告姓名:常超学号: P13106140 介绍本次大作业实现了一种基于简单语义相似度的自动及辅助集诗系统。
我们通过统计了大量诗词中的上下字搭配及其规律,提出了一种简单的语义相似度的概念;在算法上,将集句对诗视作一个搜索的过程,对候选诗句利用基于语义相似度的句子概率进行排序,返回最优结果;系统上,为了避免语义的偏差,提出了一种辅助集句模式。
经过实验证明,本方法能够较好的实现集句对诗的任务,但系统仍存在诸如作诗效率低、未考虑押韵及平仄。
最后对以后的相关工作进行了展望。
1 作诗规律在古代诗歌,尤其是律诗或者绝句中,作诗时应从如下几个角度考虑问题。
机器在作诗时也应该从这几个方面考虑。
1.语义上下句之间必须有语义上的联系,或继承或转折,逻辑上不能相差太大。
读者在阅读时,感觉到语义的跳动性小,整首诗看上去“一气呵成”。
这也是机器作诗结果如果想要通过图灵测试,必须实现的最基本也是最重要的要求。
2.对仗对仗是指“名词对名词,动词对动词,形容词对形容词,数量词对数量词,虚词对虚词“,同一类词放在前后两句的同一位置上。
对仗是诗词语言中的语法问题。
3.押韵平仄和韵脚,是语音方面的特征。
中国的旧体诗以平仄为抑扬,以平仄相间为节奏。
诗行的韵脚,是同韵的字(主要是元音和韵尾相同)来来回回地重复,也就是“合辙押韵”。
2 相关工作对于上述三点要求,经过调研我认为的解决方案有以下几点。
1.语义解决语义问题,最好的方法是利用语义相似度。
语义相似度的概念是指两个词语在不同的上下文中可以互相替换使用而不改变文本的句法语义结构的程度。
大多数的研究者都将句法角色、语义网络中的距离等因素加以考虑。
我们可以利用语义分析的方法实现尽量减小上下句之间语义跳动性,从而解决语义上的问题。
目前对于现代汉语的语义相似度已经有很多现成的开源项目可以利用,例如“知网的语义相似度项目”、“Xsimilarity夏天项目”、“《同义词词林》语义相似度项目”等。
中文分词算法开题报告

中文分词算法开题报告中文分词算法开题报告一、引言中文分词是自然语言处理中的一个重要任务,其目的是将连续的中文文本切分成有意义的词语。
中文分词在文本处理、信息检索、机器翻译等领域都扮演着重要的角色。
然而,中文的特殊性使得分词任务相对于英文等其他语言更加复杂和困难。
本报告将探讨中文分词算法的研究现状、挑战以及可能的解决方案。
二、中文分词算法的研究现状目前,中文分词算法可以分为基于规则的方法和基于统计的方法两大类。
基于规则的方法主要是通过人工定义一系列规则来进行分词,例如利用词典、词性标注等。
这种方法的优点是准确性较高,但需要大量的人工工作,并且对于新词和歧义词处理较为困难。
基于统计的方法则是通过大规模语料库的统计信息来进行分词,例如利用隐马尔可夫模型(HMM)、最大熵模型等。
这种方法的优点是能够自动学习分词规则,但对于未登录词和歧义词的处理效果较差。
三、中文分词算法面临的挑战中文分词算法面临着以下几个挑战:1. 歧义词处理:中文中存在大量的歧义词,即一个词可能有多种不同的词性和含义。
例如,“银行”既可以是名词也可以是动词。
如何准确地判断一个歧义词的词性和含义是中文分词算法的难点之一。
2. 未登录词处理:未登录词是指没有出现在分词词典中的词语,例如新词、专有名词等。
由于未登录词的特殊性,常规的分词算法往往不能正确切分。
如何有效地识别和处理未登录词是中文分词算法的另一个挑战。
3. 复合词处理:中文中存在大量的复合词,即由多个词语组合而成的词语。
例如,“北京大学”是一个复合词,由“北京”和“大学”组成。
如何准确地识别和切分复合词是中文分词算法的难点之一。
四、可能的解决方案为了克服中文分词算法面临的挑战,可以考虑以下解决方案:1. 结合规则和统计:可以将基于规则的方法和基于统计的方法相结合,利用规则进行初步的切分,然后利用统计模型进行进一步的优化和修正。
这样可以兼顾准确性和自动学习能力。
2. 引入上下文信息:可以利用上下文信息来帮助歧义词处理和未登录词处理。
中文分词程序实验报告

汉语分词程序实验报告一、程序功能描述:本程序每次处理时都用缓冲区的数据从头开始去存储语料库的链表中匹配一个最长的词语来输出,如若没有匹配到的词语则单独输出该首字。
为了简化程序所以语料库和预备分词文章都统一采用ASCII码的编码方式,并且不允许文中出现英语单字节编码。
别且本程序没有对未登录词和未声明数据结构格式进行处理,都按照普通汉字进行了分词,因此在最后的性能比较中这部分的准确率很差,但是在语料库有存储的部分中都是用最长匹配原则进行了分词,准确率还是达到了很高的水平。
分词符采用//+空格的方式来标记分词。
语料库的名字默认为:语料库.txt,打开方式为只读读取的文件名字默认为:resource.txt,打开方式为只读输出的文件名字默认为:result.txt,打开方式默认为追加的方式二、算法思路:(1)、从文件中读取语料库存储在内存中,组织成单链表的存储方式(2)、组织以首字的ASCII码为下标的哈希表指向语料库链表(3)、从文件中读满输入缓冲区,以缓冲区的首字的ASCII码做为下标从哈希表中查找首字相同的内存地址。
(4)、从该地址开始逐条匹配,记录其中匹配最长的词语的长度和地址。
写入文件中并写入分词符。
(5)、读满缓冲区,若文件已经读取完毕则查看缓冲区是否用尽,若已经用完则执行第(6)步,否则重复(4)过程。
(6)、释放申请的内存空间,程序结束。
三、数据结构:typedef struct coredict{//使用链表来存储语料库char data[9];struct coredict*nextPtr;}CoreDict,*CoreDictPtr;CoreDictPtr tablePtr=NULL,tailPtr=NULL,newPtr;//指向语料库链表的头和尾CoreDictPtr Hash[65536]={NULL};//一个以匹配词语的第一个字的ASCII码为下标的指向链表的哈希表int MatchLength=0;//在一个单词匹配过程中用来记录能够匹配到的最长的词语的长度CoreDictPtr MatchPtr=NULL;//在一个单词匹配过程中用来记录能够匹配到的最长的词语在链表中的地址四、函数功能:int IsEqual(char[],char[]);//判断两个汉字是否相等int LongMatch(char[],char[]);//void read(char[],FILE*);//将读入缓冲区读满void setoff(char[],int);//将已经匹配好的词语从缓冲区中删除五、性能对比分析:结果分析程序性能描述:在语义的判别和歧义消除方法只是用最长匹配法来降低误差,因此这部分的性能提升不是很明显。
中文分词技术的研究与发展

中文分词技术的研究与发展中文分词技术是自然语言处理领域的重要研究方向之一。
随着互联网和人工智能的快速发展,中文分词技术的研究与应用也日益受到关注。
本文将从历史发展、技术方法和应用领域三个方面探讨中文分词技术的研究与发展。
一、历史发展中文分词技术的历史可以追溯到上世纪70年代。
当时,由于计算机存储和计算能力的限制,研究者主要采用基于规则的方法进行中文分词。
这种方法需要人工编写大量的规则,对于复杂的语言现象处理效果有限。
随着计算机技术的进步,基于统计的方法逐渐成为主流。
统计方法利用大规模的语料库进行训练,通过计算词语之间的概率分布来确定分词边界。
这种方法不依赖于人工编写规则,能够处理更加复杂的语言现象,取得了较好的效果。
二、技术方法目前,中文分词技术主要包括基于规则的方法、基于统计的方法和基于深度学习的方法。
基于规则的方法通过人工编写规则来确定分词边界。
这种方法适用于一些特定领域的文本,但对于复杂的语言现象处理效果有限。
基于统计的方法是目前应用最广泛的方法。
该方法通过统计词语在大规模语料库中的出现频率和上下文信息,来确定分词边界。
这种方法能够处理复杂的语言现象,但对于歧义性较高的句子仍存在一定的困难。
基于深度学习的方法是近年来的研究热点。
该方法利用神经网络模型进行训练,通过学习大量语料库中的语言规律来确定分词边界。
深度学习方法在一些语言现象处理上取得了较好的效果,但对于数据量较小的领域仍存在一定的挑战。
三、应用领域中文分词技术在多个领域都有广泛的应用。
其中,搜索引擎是应用最广泛的领域之一。
搜索引擎需要对用户输入的查询进行分词,以便更好地匹配相关的搜索结果。
中文分词技术能够有效地提高搜索引擎的准确性和用户体验。
另外,中文分词技术在机器翻译、文本分类、信息抽取等领域也有重要的应用。
在机器翻译中,分词是将源语言句子切分成词语的基础,对于翻译的准确性和流畅性起到关键作用。
在文本分类和信息抽取中,分词能够提取出关键词汇,为后续的处理和分析提供基础。
国内中文自动分词技术研究综述

国内中文自动分词技术研究综述一、本文概述本文旨在全面综述国内中文自动分词技术的研究现状和发展趋势。
中文分词作为自然语言处理的基础任务之一,对于中文信息处理领域的发展具有重要意义。
本文首先介绍了中文分词的基本概念和重要性,然后分析了当前国内中文分词技术的研究现状,包括主流的分词算法、分词工具以及分词技术在各个领域的应用情况。
在此基础上,本文进一步探讨了中文分词技术面临的挑战和未来的发展趋势,旨在为相关研究人员和从业者提供有益的参考和启示。
在本文的综述中,我们将重点关注以下几个方面:介绍中文分词的基本概念、原理以及其在中文信息处理领域的重要性;分析当前国内中文分词技术的研究现状,包括主流的分词算法、分词工具以及分词技术在各个领域的应用情况;再次,探讨中文分词技术面临的挑战和未来的发展趋势,包括分词精度、分词速度、新词发现等方面的问题;总结本文的主要观点和结论,并提出未来研究的展望和建议。
通过本文的综述,我们希望能够为中文分词技术的研究和应用提供有益的参考和启示,推动中文信息处理领域的发展和创新。
二、中文分词技术概述中文分词技术,又称为中文词语切分或中文分词,是自然语言处理领域中的一项基础任务,其主要目标是将连续的中文文本切分成一个个独立的词汇单元。
这些词汇单元是中文语言理解和处理的基本元素,对于诸如信息检索、机器翻译、文本分类、情感分析、问答系统等自然语言处理应用具有至关重要的作用。
中文分词技术的研究历史悠久,早在上世纪80年代就有学者开始探索和研究。
经过多年的发展,中文分词技术已经取得了显著的进步,形成了一系列成熟、高效的算法和工具。
中文分词的方法主要可以分为三大类:基于规则的方法、基于统计的方法以及基于深度学习的方法。
基于规则的方法主要依赖于人工编写的词典和分词规则,通过匹配和切分来实现分词,这种方法简单直接,但对于未登录词和歧义词的处理能力较弱。
基于统计的方法则通过训练大量的语料库来构建统计模型,利用词语之间的统计关系来进行分词,这种方法对于未登录词和歧义词的处理能力较强,但需要大量的语料库和计算资源。
《自然语言处理导论》中文分词程序实验报告

《自然语言处理导论》中文分词程序实验报告《自然语言处理导论》中文分词实验报告一、实验目的了解中文分词意义掌握中文分词的基本方法二、实验环境Win7 64位DEV-C++编译器三、实验设计(一)分词策略目前较为成熟的中文分词方法主要有:1、词典正向最大匹配法2、词典逆向最大匹配法3、基于确定文法的分词法4、基于统计的分词方法一般认为,词典的逆向匹配法要优于正向匹配法。
基于确定文法和基于统计的方法作为自然语言处理的两个流派,各有千秋。
我设计的是根据词典逆向最大匹配法,基本思路是:1、将词典的每个词条读入内存,最长是4字词,最短是1字词;2、从语料中读入一段(一行)文字,保存为字符串;3、如果字符串长度大于4个中文字符,则取字符串最右边的4个中文字符,作为候选词;否则取出整个字符串作为候选词;4、在词典中查找这个候选词,如果查找失败,则去掉这个候选词的最左字,重复这步进行查找,直到候选词为1个中文字符;5、将候选词从字符串中取出、删除,回到第3步直到字符串为空;6、回到第2步直到语料已读完。
(二)程序设计查找算法:哈希表汉字编码格式:UTF-8 程序流程图:源代码:#include#include#include#include#include#include#include#include#define MaxWordLength 12 // 最大词长字节(即4个汉字)#define Separator " " // 词界标记#define UTF8_CN_LEN 3 // 汉字的UTF-8编码为3字节using namespace std;using namespace __gnu_cxx;namespace __gnu_cxx{template<> struct hash< std::string >{size_t operator()( const std::string& x ) const{return hash< const char* >()( x.c_str() );}};}hash_map wordhash; // 词典//读入词典void get_dict(void){string strtmp; //读取词典的每一行string word; //保存每个词typedef pair sipair;ifstream infile("CoreDict.txt.utf8");if (!infile.is_open()){cerr << "Unable to open input file: " << "wordlexicon"<< " -- bailing out!" << endl;system("pause");exit(-1);}while (getline(infile, strtmp)) // 读入词典的每一行并将其添加入哈希中{istringstream istr(strtmp);istr >> word; //读入每行第一个词wordhash.insert(sipair(word, 1)); //插入到哈希中}infile.close();}//删除语料库中已有的分词空格,由本程序重新分词string del_space(string s1){int p1=0,p2=0;int count;string s2;while (p2 < s1.length()){//删除半角空格if (s1[p2] == 32){if (p2>p1)s2 += s1.substr(p1,p2-p1);p2++;p1=p2;}else{p2++;}}s2 += s1.substr(p1,p2-p1);return s2;}//用词典做逆向最大匹配法分词string dict_segment(string s1){string s2 = ""; //用s2存放分词结果while (!s1.empty()) {int len = (int) s1.length(); // 取输入串长度if (len > MaxWordLength) // 如果输入串长度大于最大词长{len = MaxWordLength; // 只在最大词长范围内进行处理}string w = s1.substr(s1.length() - len, len);int n = (wordhash.find(w) != wordhash.end()); // 在词典中查找相应的词while (len > UTF8_CN_LEN && n == 0) // 如果不是词{len -= UTF8_CN_LEN; // 从候选词左边减掉一个汉字,将剩下的部分作为候选词w = s1.substr(s1.length() - len, len);n = (wordhash.find(w) != wordhash.end());}w = w + Separator;s2 = w + s2;s1 = s1.substr(0, s1.length() - len);}return s2;}//中文分词,先分出数字string cn_segment(string s1){//先分出数字和字母string s2;int p1,p2;p1 = p2 = 0;while (p2 < s1.length()){while ( p2 <= (s1.length()-UTF8_CN_LEN) &&( s1.substr(p2,UTF8_CN_LEN).at(0)<'0'||s1.substr(p2,UTF8_C N_LEN).at(0)>'9' )){/ /不是数字或字母p2 += UTF8_CN_LEN;}s2 += dict_segment(s1.substr(p1,p2-p1));//之前的句子用词典分词//将数字和字母分出来p1 = p2;p2 += 3;while ( p2 <= (s1.length()-UTF8_CN_LEN) &&( s1.substr(p2,UTF8_CN_LEN).at(0)>='0'&&s1.substr(p2,UTF 8_CN_LEN).at(0)<= '9' )){//是数字或字母p2 += UTF8_CN_LEN;。
分词技术研究报告

分词技术研究报告研究内容目前,国内的每个行业、领域都在飞速发展,这中间产生了大量的中文信息资源,为了能够及时准确的获取最新的信息,中文搜索引擎是必然的产物。
中文搜索引擎与西文搜索引擎在实现的机制和原理上大致雷同,但由于汉语本身的特点,必须引入对于中文语言的处理技术,而汉语自动分词技术就是其中很关键的部分。
汉语自动分词到底对搜索引擎有多大影响?对于搜索引擎来说,最重要的并不是找到所有结果,最重要的是把最相关的结果排在最前面,这也称为相关度排序。
中文分词的准确与否,常常直接影响到对搜索结果的相关度排序。
分词准确性对搜索引擎来说十分重要,但如果分词速度太慢,即使准确性再高,对于搜索引擎来说也是不可用的,因为搜索引擎需要处理数以亿计的网页,如果分词耗用的时间过长,会严重影响搜索引擎内容更新的速度。
因此对于搜索引擎来说,分词的准确性和速度,二者都需要达到很高的要求。
研究汉语自动分词算法,对中文搜索引擎的发展具有至关重要的意义。
快速准确的汉语自动分词是高效中文搜索引擎的必要前提。
本课题研究中文搜索引擎中汉语自动分词系统的设计与实现,从目前中文搜索引擎的发展现状出发,引出中文搜索引擎的关键技术------汉语自动分词系统的设计。
首先研究和比较了几种典型的汉语自动分词词典机制,指出各词典机制的优缺点,然后分析和比较了几种主要的汉语自动分词方法,阐述了各种分词方法的技术特点。
针对课题的具体应用领域,提出改进词典的数据结构,根据汉语中二字词较多的特点,通过快速判断二字词来优化速度;分析中文搜索引擎下歧义处理和未登陆词处理的技术,提出了适合本课题的自动分词算法,并给出该系统的具体实现。
最后对系统从分词速度和分词准确性方面进行了性能评价。
本课题的研究将促进中文搜索引擎和汉语自动分词新的发展。
二、汉语自动分词系统的研究现状1、几个早期的自动分词系统自80年代初中文信息处理领域提出了自动分词以来,一些实用性的分词系统逐步得以开发,其中几个比较有代表性的自动分词系统在当时产生了较大的影响。
中文分词技术的研究与优化

中文分词技术的研究与优化中文分词技术是指将连续的汉字序列切分成具有一定语言意义的词语序列的过程。
随着自然语言处理技术的普及,中文分词技术也变得越来越重要。
在信息检索、机器翻译、自然语言生成等领域,中文分词技术扮演着重要的角色。
然而,中文分词技术的研究和优化还面临着各种挑战和困难。
1. 中文分词技术的发展历程由于汉字的特殊性质(即没有词汇之间的间隔),中文分词技术一直面临着许多挑战。
在20世纪80年代中期,中国科学院自动化研究所的研究员率先提出了针对汉语的分词问题的研究方向。
在此基础上,国内外的研究者纷纷投入到了中文分词技术的研究中。
目前,中文分词技术已经得到了广泛的应用和研究。
2. 中文分词技术的主要方法中文分词技术的主要方法包括以下几种:2.1 基于规则的分词方法基于规则的分词方法是指根据一定的词法规则切分汉字序列的方法。
该方法需要人工设计规则库,将其转化为程序代码并实现。
基于规则的分词方法需要专业知识和大量的人工劳动力,因此其覆盖率较大,但是其实现复杂度非常高,无法实现高效的分词。
2.2 基于统计的分词方法基于统计的分词方法是指利用语料库中每个汉字或汉字组合出现的频率信息,通过统计学的方法来分词的方法。
该方法不需要人工干预,而是通过大量的语料库训练模型,最终得到一个较为精准的分词结果。
2.3 基于机器学习的分词方法基于机器学习的分词方法是指利用机器学习技术,从大量的标注好的数据中自动学习出分词模型,从而自动切分汉字序列的方法。
该方法的精度和效率远高于基于规则的方法。
3. 中文分词技术的优化策略当前,中文分词技术仍然需要不断地进一步改进和优化,以满足人们不断增长的需求。
以下是中文分词技术的一些优化策略:3.1 词性标注词性标注是指对分词结果进行进一步的标注,即在每个词汇后面标注上该词汇的词性。
这种标注方式可以更好地帮助用户理解句子的含义,并有助于句法分析和语义分析。
3.2 命名实体识别对于某些词语,由于含义的特殊性,其不应该被拆分成更小的单元。
中文分词研究报告

中文分词处理第一阶段报告通信10班201221*** ***目录第一部背景——有关中文分词第二部知识储备1.文件2.中文文件的存储格式3.字符编码4.GBK编码基本原理第三部实践操作1.截图2.学到的知识3.疑难问题的处理4.学习心得第一部分:背景——有关中文分词记得刚抢上案例教学名额的时候,有人问我选的是什么课题,我说中文分“字”。
可见当时对这个课题是有多么的不了解。
后来查了一些材料,问了老师学姐,一个学长推荐我读一下吴军老师的《数学之美》。
慢慢的,我开始了解。
自计算机诞生以来,计算机无与伦比的运算速度与稳定性使得计算机在很多事情上做得比人好。
但是计算机用数字记录信息,人用文字记录信息,这就好比两个来自不同地区的人说着互相不懂得话,那么计算机到底有没有办法处理自然语言呢?起初,我们希望计算机能从语法语义上理解人类的自然语言,这种希望催生了基于规则的自然语言处理方法,然而,20年的时间证明,这种办法是行不通的,语言博大的语法语义语境体系无法移植到计算机。
20年弯路之后,我们找到了一条合适的路径——基于统计的自然语言处理方法,这种方法的大体思想是:拥有一个庞大的语料库,对句子的分析变为概率分析,而概率分析是将每一个词出现的条件概率相乘,也就是说,统计语言模型是建立在词的基础上的,因为词是表达语义的最小单位。
分词处理对自然语言处理起着至关重要的作用!对于西方拼音语言来讲,词之间有明确的分界符,统计和使用语言模型非常直接。
而对于中、日、韩、泰等语言,词之间没有明确的分界符。
因此,首先需要对句子进行分词。
(补充一点的是,中文分词的方法其实不局限于中文应用,也被应用到英文处理,如手写识别,单词之间的空格就很清楚,中文分词方法可以帮助判别英文单词的边界。
)目前在自然语言处理技术中,中文处理技术比西文处理技术要落后很大一段距离,许多西文的处理方法中文不能直接采用,就是因为中文必需有分词这道工序。
中文分词是其他中文信息处理的基础,搜索引擎只是中文分词的一个应用。
中文分词算法研究的开题报告

中文分词算法研究的开题报告题目:中文分词算法研究一、研究背景和意义随着网络世界的不断发展,中文成为了信息传播的重要媒介。
然而,中文与英文不同,没有明显的单词边界,容易造成歧义和误会,因此中文分词成为了自然语言处理中的重要任务。
中文分词是将一段中文文本划分成一个一个基本语义单元的过程,这些基本语义单元帮助我们更加理解文本的意义和结构,是很多自然语言处理任务的基础。
现有的中文分词算法主要有基于规则、基于统计和基于深度学习三种类型。
其中,基于规则的算法需要手动制定一个基本语义单元划分的规则,适用于语言学专家和特定领域专家。
基于统计的算法则需要大量标注数据,通过学习语言上下文和词性等信息来进行分词,具有很好的鲁棒性和适应性。
而基于深度学习的算法则是近几年发展起来的新方法,通过神经网络对文本进行分词,具有很强的泛化能力。
本研究旨在研究比较不同类型的中文分词算法,分析其优缺点,并提出一种高效、准确的中文分词算法,为中文自然语言处理任务提供有力的支持。
二、研究内容和方法本研究将从以下几个方面展开:1.系统地调研目前主流中文分词算法,包括基于规则、基于统计和基于深度学习的算法,并分析其优缺点。
2.针对基于统计和基于深度学习的算法,对其训练数据集、特征选择和算法模型进行深入研究。
3.提出一种基于字典和统计的中文分词算法,并对其进行实验验证,与其他主流算法进行比较。
4.对研究结果进行总结与分析,并对未来的中文分词算法研究给出建议。
本研究将采用实验研究方法,首先从相关文献中收集中文分词算法信息,对其进行分类、归纳和总结,了解各种算法的实现原理与优缺点。
然后,根据实验需求,选择相应的训练数据集、特征选择和算法模型,进行中文分词实验,并将实验数据进行评测和比较分析。
最后根据实验结果总结得出结论和未来的研究方向。
三、研究进度计划1. 研究背景与文献调研:1周2. 中文分词算法分类与分析:2周3. 基于统计和深度学习的算法分析:2周4. 提出基于字典和统计的中文分词算法:2周5. 实验设计与数据处理:1周6. 中文分词实验与实验结果分析:4周7. 结论与未来研究概述:1周四、研究预期成果1. 对目前主流中文分词算法进行系统的比较和总结,为中文分词算法的研究和发展提供参考。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
自然语言处理调研报告(课程论文、课程设计)题目:最大正向匹配中文分词系统作者:陈炳宏吕荣昌靳蒲王聪祯孙长智所在学院:信息科学与工程学院专业年级:信息安全14-1指导教师:努尔布力职称:副教授2016年10月29日目录一、研究背景、目的及意义 (3)二、研究内容和目标 (4)三、算法实现 (5)四、源代码 (7)1.seg.java 主函数 (7)2. dict.txt 程序调用的字典 (10)3.实验案例 (11)五、小结 (12)一、研究背景、目的及意义中文分词一直都是中文自然语言处理领域的基础研究。
目前,网络上流行的很多中文分词软件都可以在付出较少的代价的同时,具备较高的正确率。
而且不少中文分词软件支持Lucene扩展。
但不过如何实现,目前而言的分词系统绝大多数都是基于中文词典的匹配算法。
在这里我想介绍一下中文分词的一个最基础算法:最大匹配算法(Maximum Matching,以下简称MM算法) 。
MM算法有两种:一种正向最大匹配,一种逆向最大匹配。
二、研究内容和目标1、了解、熟悉中科院中文分词系统。
2、设计程序实现正向最大匹配算法。
3、利用正向最大匹配算法输入例句进行分词,输出分词后的结果。
三、算法实现图一:算法实现正向最大匹配算法:从左到右将待分词文本中的几个连续字符与词表匹配,如果匹配上,则切分出一个词。
但这里有一个问题:要做到最大匹配,并不是第一次匹配到就可以切分的。
算法示例:待分词文本: content[]={"中","华","民","族","从","此","站","起","来","了","。
"}词表: dict[]={"中华", "中华民族" , "从此","站起来"}(1) 从content[1]开始,当扫描到content[2]的时候,发现"中华"已经在词表dict[]中了。
但还不能切分出来,因为我们不知道后面的词语能不能组成更长的词(最大匹配)。
(2) 继续扫描content[3],发现“中华民”并不是dict[]中的词。
但是我们还不能确定是否前面找到的"中华"已经是最大的词了。
因为“中华民”是dict[2]的前缀。
(3) 扫描content[4],发现“中华民族”是dict[]中的词。
继续扫描下去:(4) 当扫描content[5]的时候,发现“中华民族从”并不是词表中的词,也不是词的前缀。
因此可以切分出前面最大的词——"中华民族"。
四、源代码1.seg.java主函数package Segmentation;import java.awt.event.ActionEvent;import java.awt.event.ActionListener;import java.io.*;import java.util.ArrayList;import java.util.List;import java.util.Scanner;import javax.swing.JButton;import javax.swing.JFrame;import javax.swing.JTextArea;import com.sun.istack.internal.localization.NullLocalizable;public class Seg extends JFrame{public List<String> dictionary = new ArrayList<String>();public static String request;JFrame frame;JTextArea area1,area2;JButton button1,button2;public void newWindow(){frame=new JFrame();frame.setTitle("正向最大匹配");frame.setVisible(true);frame.setDefaultCloseOperation(JFrame.EXIT_ON_CLOSE);frame.getContentPane().setLayout(null);frame.setResizable(false);frame.setBounds(300,200,500,400);Seg seg=new Seg();area1=new JTextArea();area1.setEditable(true);area1.setBounds(50,30,400,110);frame.getContentPane().add(area1);area2=new JTextArea();area2.setEditable(false);area2.setBounds(50,240,400,110);frame.getContentPane().add(area2);button1=new JButton("获取帮助");button1.setBounds(100,165,120,50);frame.getContentPane().add(button1);button1.addActionListener(new ActionListener() {@Overridepublic void actionPerformed(ActionEvent e) {// TODO Auto-generated method stubarea2.setText("在上方文本框中输入要分词的语句,点击分词即可得到结果\n如有任何问题,请联系软件的开发人员(虽然没有什么卵用)\nVersion_5.6.2\n");}});button2=new JButton(" 分词");button2.setBounds(290,165,100,50);frame.getContentPane().add(button2);button2.addActionListener(new ActionListener() {@Overridepublic void actionPerformed(ActionEvent e) {// TODO Auto-generated method stubSeg s=new Seg();s.setDictionary();request=area1.getText()+" ";String response1=s.leftMax();area2.setText(response1);}});}public void setDictionary() {File file=new File(".","dict.txt");BufferedReader reader = null;try {reader = new BufferedReader(new FileReader(file));} catch (FileNotFoundException e) {// TODO Auto-generated catch blocke.printStackTrace();}String temp=null;try {while((temp=reader.readLine())!=null){dictionary.add(temp);}} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}try {reader.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}finally{if(reader!=null){try {reader.close();} catch (IOException e) {// TODO Auto-generated catch blocke.printStackTrace();}}}}public String leftMax() {String response = "";String s = "";for(int i=0; i<request.length(); i++) {s += request.charAt(i);if(isIn(s, dictionary) && aheadCount(s, dictionary)==1) { response += (s + "/");s = "";} else if(aheadCount(s, dictionary) > 0) {} else {response += (s + "/");s = "";}}return response;}private boolean isIn(String s, List<String> list) {for(int i=0; i<list.size(); i++) {if(s.equals(list.get(i))) return true;}return false;}private int aheadCount(String s, List<String> list) {int count = 0;for(int i=0; i<list.size(); i++) {if((s.length()<=list.get(i).length()) && (s.equals(list.get(i).substring(0, s.length())))) count ++;}return count;}public static void main(String[] args) {Seg seg = new Seg();seg.newWindow();System.out.println("请输入要分词的语句");Scanner scanner=new Scanner(System.in);request=scanner.nextLine()+" ";String response1 = seg.leftMax();System.out.println(response1);}}2. dict.txt 程序调用的字典Ctrl+左击查看字典3.实验案例图二:案例五、小结无论是哪一种分词算法都不是完美的,都有各自的优缺点:基于词典的分词算法的优点是简单,易于实现,缺点是匹配速度慢,不能很好的解决歧义问题,并且也不能很好的解决未登录词的问题;基于统计的分词算法的优点是可以发现所有的歧义切分,缺点是统计语言的精度和决策算法在很大程度上决定了解决歧义的方法,并且速度较慢,需要一个长期的学习过程才能达到一定的程度;由于汉语语言知识的笼统、复杂性,难以将各种语言信息组织成机器可直接读取的形式,因此目前基于理解的分词系统还处在试验阶段。