中文分词工具对比
中文分词组件比较

1、收费 2、无.NET接口
1、提供的字典包括17万个中文常用单词,但这个字 典依然不够完整,如果要分词更准确,需要适当维 护一下这个字典。 2、开源免费(c#)
1、这只是个轻量级的组件,和专业分词系统相比, 功能和准确性都不是很完善 2、免费版具备所有基本功能,但分词算法和分词库 无法定制,而且不提供升级和技术支持服务。另 外,仅供个人免费试用,不要应用于商业环境。
雨痕中文分词组件
CSW中文分词组件
主要用于:数据挖掘、文档分类、自然语言理解以及凡是涉及到 信息/数据检索的各个领域 1、基于.NET平台开发,采用DLL动态链接库,提供编程接口,可 适用于网站或应用软件的数据检索 2、内置10万条汉语词库 3、词组拆分识别率高(在对数十GB的文档资料进行折分时,所 其识别率均大于90%) 4、采用倒序分词技术 5、特殊字符过滤及无意义字及敏感词过滤功能
免费版的功能受到一些限制,某些功能在企业 版或标准版中才有
中文分词组件
技术特点 1、目前被认为是国内最好的中文分词技术,其分词准确度超过99%, 目前国内的一些搜索网站如:中国搜索 是用的它的分词 2、以《现代汉语词典》为基础建立的知识库 3、在北大语料库中的评测结果显示,“海量中文智能分词”的准确率 达99.7% 4、分词效率高 5、分词效率达每分钟2000万字 提供 C/C++、Java 接口 盘古分词和KTDicSeg中文分词作者为同一人,盘古分词是KTDicSeg的 改进版 1、中文未登录词识别(对一些不在字典中的未登录词自动识别) 2、可以根据词频来解决分词的歧义问题 3、中文人名识别 4、繁体中文分词 5、全角字符支持 6、英文分词 7、停用词过滤(提供一个 StopWord.txt 文件,用户只要将需要过滤 的词加入到这个文件中,并将停用词过滤开发打开,就可以过滤掉这 些词) 8、对如下特性设置自定义权值(未登录词权值、最匹配词权值、次匹 配词权值、再次匹配词权值、强行输出的单字的权值、数字的权值、 英文词汇权值、符号的权值、强制同时输出简繁汉字时,非原来文本 的汉字输出权值) 9、提供一个字典管理工具 DictManage 通过这个工具,你可以增加, 修改,和删除字典中的单词 10、关键词高亮 11、为 提供了 接口
四大主流CAT软件对比

四大主流CAT软件对比摘要:CAT(Computer-Assisted Translation)是一种翻译工具,已成为翻译行业的主流工具之一。
随着市场的不断拓展,CAT 软件的种类也越来越多。
本文将对四大主流CAT软件进行对比,包括Trados、SDLX、Wordfast和MemoQ,探讨它们的优缺点以及适用范围。
关键词:CAT软件,翻译工具,Trados,SDLX,Wordfast,MemoQ正文:CAT软件(Computer-Assisted Translation)是一种利用计算机辅助进行翻译的工具,通过对文本进行分段、术语管理、翻译记忆等功能的支持,提高了翻译的效率和准确性。
随着翻译需求的增多,CAT软件也逐渐成为翻译行业的主流工具之一。
目前主流的CAT软件有Trados、SDLX、Wordfast和MemoQ。
1. TradosTrados是最为广泛使用的CAT软件之一,由SDL公司开发。
它提供了丰富的功能,包括术语管理、翻译记忆、自动翻译、文本分段、格式处理等等。
Trados支持多种文件格式,如Word、Excel、PPT、PDF、HTML等等。
其最大的优势是支持多种语言,包括中文、日文、韩文等少数民族语言。
不足之处在于价格半贵,使用门槛较高,需要一定的培训才能掌握。
2. SDLXSDLX是由SDL公司推出的CAT软件,是Trados的改进版。
它去掉了Trados中许多令人烦恼的功能,并提供了一些新的工具,如翻译故事(翻译时可以把源文本和目标文本同时呈现)和语境分析(可以分析上下文,帮助翻译词汇)。
SDLX也可以支持多种文件格式,如Word、Excel、PPT、PDF、HTML,但其与Trados相比,其价格更为昂贵。
3. WordfastWordfast是一种轻量级的CAT软件,强调简单易用和低成本。
它的主要功能是术语管理和翻译记忆,可支持多种文件格式,如Word、Excel、PPT、PDF、HTML。
自然语言处理中常见的文本挖掘工具(六)

自然语言处理中常见的文本挖掘工具自然语言处理(Natural Language Processing, NLP)是人工智能领域的一个重要分支,它致力于让计算机能够理解、处理和生成自然语言。
文本挖掘则是NLP的一个重要应用领域,它通过技术手段从海量文本数据中挖掘出有价值的信息,为决策支持、商业智能等领域提供了强大的工具。
在文本挖掘的过程中,使用各种工具对文本进行分析、抽取、建模等操作,本文将介绍自然语言处理中常见的文本挖掘工具。
一、分词工具分词是文本挖掘的基础工作,它将连续的文本序列切分成有意义的词语或短语。
在中文文本处理中,分词是一个特别重要的工作,因为中文中的词语并不像英文一样用空格分隔。
常见的中文分词工具包括jieba、HanLP等。
jieba是一款基于Python的中文分词工具,它具有简单易用、分词效果较好的特点。
HanLP是由哈工大讯飞联合实验室开发的自然语言处理工具包,它不仅包括了分词功能,还具有词性标注、命名实体识别等功能,是一款功能丰富的文本处理工具。
二、词性标注工具词性标注是将分词结果中的每个词语标注上其在句子中的词性,如名词、动词、形容词等。
词性标注对于理解文本语义、进行信息抽取等任务非常重要。
常见的词性标注工具包括NLTK、Stanford NLP等。
NLTK是一款Python自然语言处理工具包,它提供了丰富的语料库和算法库,包括了词性标注、句法分析等功能。
Stanford NLP是由斯坦福大学开发的自然语言处理工具包,它不仅提供了高效的词性标注功能,还具有依存句法分析、语义角色标注等功能,是一款功能强大的文本处理工具。
三、实体识别工具实体识别是从文本中抽取出命名实体(如人名、地名、组织机构名等)的过程,它对于信息抽取、知识图谱构建等任务非常重要。
常见的实体识别工具包括LTP、Spacy等。
LTP是由哈工大语言云实验室开发的自然语言处理工具包,它提供了中文实体识别、依存句法分析等功能。
自然语言处理中常见的文本挖掘工具

自然语言处理中常见的文本挖掘工具一、介绍自然语言处理(NLP)是一种涉及人类语言和计算机交互的技术,它主要关注计算机如何理解、解释和生成人类语言。
而文本挖掘则是NLP领域中的一个重要分支,它利用机器学习和数据挖掘技术,通过分析大量的文本数据,发现其中的模式、趋势和关联,从而提供有价值的信息和知识。
本文将介绍自然语言处理中常见的文本挖掘工具,以及它们在实际应用中的作用。
二、分词工具分词是文本挖掘的基础工作之一,它将文本按照一定的规则或模型进行切分,以便进行后续的处理和分析。
在中文文本挖掘中,常见的分词工具包括jieba、thulac和ltp等。
jieba是一款开源的中文分词工具,它采用了基于前缀词典的分词算法,具有高效和准确的特点,被广泛应用于中文文本处理中。
thulac是清华大学开发的一款中文词法分析工具,它结合了词性标注和命名实体识别等功能,可以帮助用户更好地理解和分析中文文本。
ltp(Language Technology Platform)是哈工大社会计算与信息检索研究中心开发的一套自然语言处理工具,其中包括了中文分词、词性标注、命名实体识别等功能,为中文文本挖掘提供了丰富的工具支持。
三、词性标注工具词性标注是对文本中每个词语进行词性标记的过程,它在文本挖掘中扮演着重要的角色,可以帮助用户更好地理解和分析文本。
在NLP领域中,词性标注工具有很多种,其中比较常见的包括nltk、stanford-nlp和snow-nlp等。
nltk是一款Python库,提供了丰富的自然语言处理功能,其中包括了词性标注、命名实体识别等功能,为用户提供了便捷的文本挖掘工具。
stanford-nlp是斯坦福大学开发的一套自然语言处理工具,其中包括了词性标注、命名实体识别、句法分析等功能,具有高准确度和稳定性,被广泛应用于NLP领域。
snow-nlp是一款轻量级的中文自然语言处理库,它提供了简单易用的词性标注功能,可以帮助用户快速进行中文文本挖掘。
自然语言处理中的中文分词工具推荐

自然语言处理中的中文分词工具推荐在自然语言处理(Natural Language Processing,NLP)领域中,中文分词是一个重要的任务,它将连续的中文文本切分成有意义的词语序列。
中文分词对于机器翻译、信息检索、文本分类等应用具有重要意义。
然而,中文的复杂性和歧义性使得中文分词成为一个具有挑战性的任务。
为了解决这个问题,许多中文分词工具被开发出来。
本文将推荐一些常用的中文分词工具,并对它们的特点进行简要介绍。
1. 结巴分词(jieba)结巴分词是目前最流行的中文分词工具之一。
它基于基于前缀词典和HMM模型的分词算法,具有高效、准确的特点。
结巴分词支持三种分词模式:精确模式、全模式和搜索引擎模式,可以根据具体需求选择不同的模式。
此外,结巴分词还提供了用户自定义词典的功能,可以根据特定领域的需求进行词汇扩充。
2. LTP分词(Language Technology Platform)LTP分词是由哈尔滨工业大学自然语言处理与社会人文计算实验室开发的中文分词工具。
它采用了基于统计的分词算法,具有较高的准确率和鲁棒性。
LTP分词还提供了词性标注、命名实体识别等功能,可以满足更多的自然语言处理需求。
3. THULAC(THU Lexical Analyzer for Chinese)THULAC是由清华大学自然语言处理与社会人文计算研究中心开发的一种中文词法分析工具。
它采用了一种基于词汇和统计的分词算法,具有较高的分词准确率和速度。
THULAC还提供了词性标注和命名实体识别功能,并支持用户自定义词典。
4. Stanford中文分词器Stanford中文分词器是由斯坦福大学自然语言处理小组开发的一种中文分词工具。
它使用了条件随机场(Conditional Random Fields,CRF)模型进行分词,具有较高的准确率和鲁棒性。
Stanford中文分词器还提供了词性标注和命名实体识别功能,可以满足更复杂的NLP任务需求。
jieba的三种分词模式

jieba的三种分词模式
jieba是一个流行的中文分词工具,它提供了三种分词模式,
分别是精确模式、全模式和搜索引擎模式。
首先是精确模式,它试图将句子最精确地切开,适合文本分析。
在这种模式下,jieba会尽量将句子切分成最小的词语单元,从而
得到更准确的分词结果。
其次是全模式,它将句子中所有可能的词语都切分出来,适合
搜索引擎构建倒排索引或者实现高频词提取。
在这种模式下,jieba
会将句子中所有可能的词语都切分出来,包括一些停用词和无意义
的词语。
最后是搜索引擎模式,它在精确模式的基础上,对长词再次切分,适合搜索引擎构建倒排索引。
在这种模式下,jieba会对长词
再次进行切分,以便更好地匹配搜索引擎的检索需求。
这三种分词模式可以根据具体的应用场景和需求进行选择,以
达到最佳的分词效果。
精确模式适合对文本进行深入分析,全模式
适合构建倒排索引或者提取高频词,搜索引擎模式则适合搜索引擎
的检索需求。
通过合理选择分词模式,可以更好地满足不同场景下的分词需求。
简易中文分词

简易中文分词中文分词是指将连续的汉字序列切分成一个个词语的任务,是中文自然语言处理领域中非常重要的任务之一。
中文分词在文本处理、机器翻译、信息检索等应用中起着至关重要的作用。
下面将介绍中文分词的基本概念、算法以及一些常见的分词工具。
一、中文分词的基本概念中文分词的目标是将一个句子或一个文本按照词语的粒度进行切分,得到一个词语序列。
中文分词的挑战在于中文没有像英文那样使用空格来分隔单词,而且往往存在词语之间重叠的情况,如“千万”、“怎么办”等。
因此,中文分词需要结合词典、规则以及统计等方法来解决这些问题。
1.词语的定义在中文分词中,词语的定义往往是基于语言学的角度,即在语义上具有一定完整含义的最小语言单位。
词语可以是单个汉字,也可以是由多个汉字组成的词组。
例如,“中国”、“人民”、“共和国”等都是一个词语。
2.分词的准则中文分词的准则主要包括正向最大匹配法、逆向最大匹配法、双向最大匹配法等。
正向最大匹配法是从左到右将句子进行扫描,每次选择最长的词语作为分词结果;逆向最大匹配法与正向最大匹配法相反,从右到左进行扫描;双向最大匹配法则是将正向和逆向两个方向的结果进行比较,选择最优的分词结果。
这些方法都是基于词典进行匹配的。
3.未登录词的处理未登录词是指在词典中没有出现的词语,比如一些新词、专有名词等。
处理未登录词是中文分词中的一个难点,可以通过统计、规则以及机器学习等方法进行处理。
二、中文分词的常见算法和方法1.基于词典的分词算法基于词典的分词算法是指利用已有的词典对文本进行匹配,找出其中的词语作为分词结果。
基于词典的方法包括正向最大匹配、逆向最大匹配、双向最大匹配等。
这些方法的优点是简单高效,但对于未登录词的处理较为困难。
2.基于统计的分词算法基于统计的分词算法是指利用已有的大规模语料库进行统计,通过分析词语的频率、邻接关系等信息来进行分词。
常用的统计方法包括隐马尔可夫模型(Hidden Markov Model,HMM)、最大熵模型(Maximum Entropy Model,MEM)、条件随机场(Conditional Random Field,CRF)等。
几款常用分词工具的比较研究

几款常用分词工具的比较研究资料来源于网络 修订于西电实验室本文档主要针对以下几个分词工具进行分析比较:1、极易中文分词,je-analysis-1.5.32、庖丁分词,paoding-analyzer.jar3、IKAnalyzer3.04、imdict-chinese-analyzer5、ictclas4j其中:JE不是开源的,官方网址:/,目前还没有支持Lucene3的版本。
paoding分词是一个开源的分词器,目前最新的非正式版3,支持Lucene3,可在网上在线获得。
ictclas4j中文分词系统是sinboy在中科院张华平和刘群老师的研制的FreeICTCLAS的基础上完成的一个java开源分词项目,简化了原分词程序的复杂度,旨在为广大的中文分词爱好者一个更好的学习机会。
imdict-chinese-analyzer是 imdict智能词典的智能中文分词模块,作者高小平,算法基于隐马尔科夫模型(Hidden Markov Model, HMM),是中国科学院计算技术研究所的ictclas中文分词程序的重新实现(基于Java),可以直接为lucene搜索引擎提供中文分词支持。
以上两个都源自中科院的ICTCLAS,官方网址:/IKAnalyzer:一个开源爱好者的作品,项目地址:/p/ik-analyzer/,作者林良益博客:/测试过程中,ictclas4j会报出各种错误,因此放弃了,希望不是因为我配置的原因。
经过测试,这几款工具中,JE和庖丁的分词效果是最好的,两者各有千秋,IKAnalyzer也不错,但是会给出多种分词结果,这个有点不能接受,希望能有好的改进,imdict-chinese-analyzer则稍差一点。
由于JE不是开源的,所以不建议采用,而且目前还没有支持Lucene3.x的release,所以本人主张使用paoding(庖丁)。
Paoding_analyzer3.0.jar可以支持到Lucene3.4,因此,在目前,这个缺少能够很好支持Lucene3.x并具备出色中文分词能力的分词工具的真空期,paoding几乎是不二选择。
介绍几款优秀的英文分词系统和中文分词系统

介绍几款优秀的英文分词系统和中文分词系统
英文分词系统:
1. NLTK:NLTK(Natural Language Toolkit)是Python的一个自然
语言处理工具包,提供了各种功能包括分词、词性标注、文本分类等,并
具有丰富的语料库支持。
2. Stanford CoreNLP:Stanford CoreNLP是一个Java库,可以用
于对英文文本进行分词、词性标注、句法分析等多种自然语言处理任务。
3. spaCy:spaCy是一个用于自然语言处理的Python库,具有高速
和高效的特点。
其中包含了分词、词性标注、命名实体识别等功能。
4. Apache OpenNLP:Apache OpenNLP是一个Java库,提供了分词、词性标注、句法分析等自然语言处理功能,可以用于英文分词任务。
中文分词系统:
1. jieba:jieba是Python中常用的中文分词工具,具有简单易用、分词效果较好的特点。
2. HanLP:HanLP是一款Java开源的自然语言处理工具包,提供了
包括分词、词性标注、命名实体识别等多种功能,并且支持多种分词模型。
3.THULAC:THULAC是一款中文词法分析工具包,具有词性标注和实
体识别功能,适用于处理大规模中文文本数据。
4. LTP:LTP(Language Technology Platform)是一套基于开源的
中文自然语言处理系统,其中包含了中文分词、词性标注、命名实体识别
等功能。
以上是一些较为常用和优秀的英文分词系统和中文分词系统,可以根据具体的需求选择使用。
中文分词的三种方法

中文分词的三种方法
中文分词是对汉字序列进行切分和标注的过程,是许多中文文本处理任务的基础。
目前常用的中文分词方法主要有基于词典的方法、基于统计的方法和基于深度学习的方法。
基于词典的方法是根据预先构建的词典对文本进行分词。
该方法将文本与词典中的词进行匹配,从而得到分词结果。
优点是准确率较高,但缺点是对新词或专业术语的处理效果不佳。
基于统计的方法是通过建立语言模型来实现分词。
该方法使用大量的标注语料训练模型,通过统计词语之间的频率和概率来确定分词结果。
优点是对新词的处理有一定的鲁棒性,但缺点是对歧义性词语的处理效果有限。
基于深度学习的方法是利用神经网络模型进行分词。
该方法通过训练模型学习词语与其上下文之间的依赖关系,从而实现分词。
优点是对新词的处理效果较好,且具有较强的泛化能力,但缺点是需要大量的训练数据和计算资源。
综上所述,中文分词的三种方法各自具有不同的优缺点。
在实际应用中,可以根据任务需求和资源条件选择合适的方法进行处理。
例如,在自然语言处理领域,基于深度学习的方法在大规模数据集的训练下可以取得较好的效果,可以应用于机器翻译、文本分类等任务。
而基于词典的方法可以适用于某些特定领域的文本,如医药领
域或法律领域,因为这些领域往往有丰富的专业词汇和术语。
基于统计的方法则可以在较为通用的文本处理任务中使用,如情感分析、信息抽取等。
总之,中文分词方法的选择应根据具体任务和数据特点进行灵活调整,以期获得更好的处理效果。
中文分词工具对比

对比:LTP、NLPIR、THULAC和jieba (C++)
• 1、数据集:SIGHAN Bakeoff 2005 MSR, 560KB
对比:LTP、NLPIR、THULAC和jieba (C++)
• 2、数据集:SIGHAN Bakeoff 2005 PKU, 510KB
对比:LTP、NLPIR、THULAC和jieba (C++)
• Thulac4j在官方THULAC-Java基础上做了工程性优化
补充
• 测试数据集为搜狗新闻语料,65MB(少量噪声); • THULAC两种模式:SegOnly模式,只分词没有词性标注;SegPos模 式,分词兼有词性标注; • SegOnly分词速度快,但是准确率较SegPos模式低;而SegPos具有 更高的准确,但内存占用更多、分词速度较慢; • THULAC基于结构化感知器SP,CoreNLP基于CRF,Ansj与HanLP (其两种分词模式)是基于HMM; • 理论上讲,分词效果:CRF ≈≈ SP > HMM; • 从分词速率的测试结果上来看,THULAC是兼顾效果与速率。
几种中文分词工具简介
• NLPIR(ICTCLAS):中科院张华平博士,基于Bigram + HMM; • Ansj:孙健,ICTLAS的Java版本,做了一些工程上的优化; • Jieba:由fxsjy开源,基于Unigram + HMM; • LTP:哈工大2011年开源,采用结构化感知器(SP); • FNLP:复旦大学2014年开源,采用在线学习算法PassiveAggressive(PA),JAVA; • THULAC:清华大学2016年开源,采用结构化感知器(SP); • Standford CoreNLP, HanLP……
jieba分词的几种分词模式

jieba分词的几种分词模式
jieba分词是一种常用的中文分词工具,它支持多种分词模式,包括精确模式、全模式、搜索引擎模式和自定义词典模式。
1. 精确模式,精确模式是指尽可能将句子中的词语精确地切分
出来,适合做文本分析和语义分析。
在精确模式下,jieba分词会
将句子中的词语按照最大概率切分出来,以保证分词结果的准确性。
2. 全模式,全模式是指将句子中所有可能的词语都切分出来,
适合用于搜索引擎构建倒排索引或者快速匹配。
在全模式下,jieba
分词会将句子中的所有可能词语都切分出来,以保证句子中的所有
词语都能被检索到。
3. 搜索引擎模式,搜索引擎模式是介于精确模式和全模式之间
的一种模式,它会对长词再次进行切分,适合用于搜索引擎的查询
分词。
在搜索引擎模式下,jieba分词会对长词进行再次切分,以
保证更多的词语能够被搜索到。
4. 自定义词典模式,自定义词典模式是指用户可以自行添加自
定义的词典,以保证特定领域的专有名词或者新词能够被正确切分。
在自定义词典模式下,jieba分词会优先使用用户自定义的词典进行分词,以保证分词结果的准确性和完整性。
这些分词模式能够满足不同场景下的分词需求,用户可以根据具体的应用场景选择合适的分词模式来进行文本分词处理。
中文分词的三种方法(一)

中文分词的三种方法(一)中文分词的三种中文分词是指将一段中文文本划分为一个个有实际意义的词语的过程,是自然语言处理领域中的一项基本技术。
中文分词技术对于机器翻译、信息检索等任务非常重要。
本文介绍中文分词的三种方法。
基于词典的分词方法基于词典的分词方法是将一段文本中的每个字按照词典中的词语进行匹配,将匹配到的词作为分词结果。
这种方法的优点是分词速度快,但缺点是无法解决新词和歧义词的问题。
常见的基于词典的分词器有哈工大的LTP、清华大学的THULAC等。
基于统计的分词方法基于统计的分词方法是通过对大规模语料库的训练,学习每个字在不同位置上出现的概率来判断一个字是否为词语的一部分。
这种方法能够较好地解决新词和歧义词的问题,但对于生僻词和低频词表现不够理想。
常见的基于统计的分词器有结巴分词、斯坦福分词器等。
基于深度学习的分词方法基于深度学习的分词方法是通过神经网络对中文分词模型进行训练,来获取词语的内部表示。
这种方法的优点是对于生僻词和低频词的表现较好,但需要大量的标注数据和计算资源。
常见的基于深度学习的分词器有哈工大的BERT分词器、清华大学的BERT-wwm分词器等。
以上是中文分词的三种方法,选择哪种方法需要根据实际应用场景和需求进行评估。
接下来,我们将对三种方法进行进一步的详细说明。
基于词典的分词方法基于词典的分词方法是最简单的一种方法。
它主要针对的是已经存在于词典中的单词进行分词。
这种方法需要一个词典,并且在分词时将文本与词典进行匹配。
若匹配上,则将其作为一个完整的单词,否则就将该文本认为是单字成词。
由于它只需要匹配词典,所以速度也是比较快的。
在中文分词中,“哈工大LTP分词器”是基于词典的分词工具之一。
基于统计的分词方法基于统计的分词方法是一种基于自然语言处理技术的分词方法。
其主要思路是统计每个字在不同位置出现的概率以及不同字的组合出现的概率。
可以通过训练一个模型来预测哪些字符可以拼接成一个词语。
分词的用法

分词的用法分词(Segmentation)是自然语言处理(NLP)中一个重要的步骤,其主要目的是将一段连续的文本分割成一系列有意义的单词或短语。
在中文文本处理中,分词是必不可少的,因为中文是以字为基本单位而非以空格或标点符号,因此分词对于语言理解和文本处理非常关键。
本文将介绍分词的用法及其在不同应用场景中的重要性。
1. 分词的常用工具在中文文本处理中,有很多工具可用于分词,以下是一些常用的分词工具:•结巴分词:是目前广泛使用的中文分词工具之一,具有简单易用、效果较好的特点。
结巴分词采用基于词频和词汇概率的分词算法,可以实现精准的中文分词。
•THULAC:是由清华大学自然语言处理与社会人文计算实验室开发的一套中文词法分析工具。
THULAC不仅实现了分词功能,还包括词法分析、词性标注等功能。
•NLPIR:是由哈尔滨工业大学自然语言处理实验室开发的一套中文自然语言处理工具。
NLPIR提供了多种分词模式,可以根据不同的需求进行选择。
除了上述的工具之外,还有其他一些分词工具可供选择,根据具体的需求选择适合的分词工具非常重要。
2. 分词的应用场景分词在中文文本处理中有着广泛的应用场景,下面列举了一些常见的应用场景:2.1 机器翻译在机器翻译任务中,分词是必不可少的。
机器翻译将中文文本转化为其他语言的文本,而其他语言的单词之间是以空格进行分隔的,因此需要通过分词将中文文本划分成一个个有意义的单词,在翻译过程中进行对应的处理。
2.2 文本分类文本分类是根据文本的语义或主题将文本分成不同的类别。
分词在文本分类中扮演着至关重要的角色。
将文本分成单词后,可以提取每个单词的语义特征,然后通过机器学习算法对其进行分类。
2.3 搜索引擎在搜索引擎中,分词是非常重要的。
当用户输入关键词进行搜索时,搜索引擎需要将用户输入的关键词进行分词,然后在索引中查找相关的网页或文档。
分词的质量直接影响搜索结果的准确性和相关性。
2.4 情感分析情感分析是判断一段文本情感倾向的任务。
friso中文分词

friso中文分词
Friso是一个基于Java的中文分词工具,它可以帮助用户对中
文文本进行分词处理。
Friso使用了基于词典的分词算法,通过加
载中文词典来进行分词操作。
用户可以通过调用Friso的API来实
现中文分词的功能,从而对中文文本进行分词处理。
Friso的中文分词功能可以帮助用户实现对中文文本的分词操作,将连续的中文字符序列切分成有意义的词语。
这对于中文文本
的处理和分析非常重要,可以帮助用户理解文本的含义,进行文本
挖掘和信息检索等操作。
Friso中文分词工具的优点之一是它支持用户自定义词典,用
户可以根据自己的需求,添加特定领域的词汇到词典中,从而提高
分词的准确性和适用性。
此外,Friso还支持对未登录词的识别,
能够较好地处理一些新出现的词汇。
除此之外,Friso还提供了多种分词模式,包括最大匹配模式、最小匹配模式和搜索引擎模式等,用户可以根据具体需求选择合适
的分词模式。
这些模式的灵活性可以满足不同场景下的分词需求。
总的来说,Friso作为一个基于Java的中文分词工具,具有较高的准确性和灵活性,可以帮助用户实现对中文文本的有效分词处理。
它的特点包括支持用户自定义词典、对未登录词的识别以及多种分词模式选择,这些特性使得Friso在中文文本处理领域具有一定的竞争优势。
三种中文分词算法优劣比较
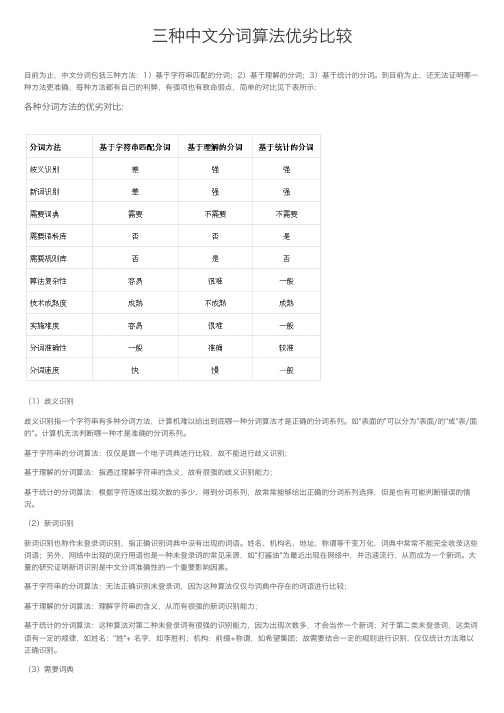
三种中⽂分词算法优劣⽐较⽬前为⽌,中⽂分词包括三种⽅法:1)基于字符串匹配的分词;2)基于理解的分词;3)基于统计的分词。
到⽬前为⽌,还⽆法证明哪⼀种⽅法更准确,每种⽅法都有⾃⼰的利弊,有强项也有致命弱点,简单的对⽐见下表所⽰:各种分词⽅法的优劣对⽐:(1)歧义识别歧义识别指⼀个字符串有多种分词⽅法,计算机难以给出到底哪⼀种分词算法才是正确的分词系列。
如"表⾯的"可以分为"表⾯/的"或"表/⾯的"。
计算机⽆法判断哪⼀种才是准确的分词系列。
基于字符串的分词算法:仅仅是跟⼀个电⼦词典进⾏⽐较,故不能进⾏歧义识别;基于理解的分词算法:指通过理解字符串的含义,故有很强的歧义识别能⼒;基于统计的分词算法:根据字符连续出现次数的多少,得到分词系列,故常常能够给出正确的分词系列选择,但是也有可能判断错误的情况。
(2)新词识别新词识别也称作未登录词识别,指正确识别词典中没有出现的词语。
姓名、机构名、地址、称谓等千变万化,词典中常常不能完全收录这些词语;另外,⽹络中出现的流⾏⽤语也是⼀种未登录词的常见来源,如"打酱油"为最近出现在⽹络中,并迅速流⾏,从⽽成为⼀个新词。
⼤量的研究证明新词识别是中⽂分词准确性的⼀个重要影响因素。
基于字符串的分词算法:⽆法正确识别未登录词,因为这种算法仅仅与词典中存在的词语进⾏⽐较;基于理解的分词算法:理解字符串的含义,从⽽有很强的新词识别能⼒;基于统计的分词算法:这种算法对第⼆种未登录词有很强的识别能⼒,因为出现次数多,才会当作⼀个新词;对于第⼆类未登录词,这类词语有⼀定的规律,如姓名:"姓"+ 名字,如李胜利;机构:前缀+称谓,如希望集团;故需要结合⼀定的规则进⾏识别,仅仅统计⽅法难以正确识别。
(3)需要词典基于字符串的分词算法:基本思路就是与电⼦词典进⾏⽐较,故电⼦词典是必须的。
并且词典越⼤,分词的正确率越⾼,因为词典越⼤,未登录词越少,从⽽可以⼤⼤减少未登录词识别的错误;基于理解的分词算法:理解字符串的含义,故不需要⼀个电⼦词典;基于统计的分词算法:仅仅根据统计得到最终的结果,故电⼦词典不是必须的。
自然语言处理工具

自然语言处理工具自然语言处理(Natural Language Processing,简称NLP)是人工智能领域的一个重要分支,它涉及计算机与人类自然语言的交互和理解。
随着科技的不断发展,各种自然语言处理工具应运而生,为人们的日常生活和工作提供了便利。
本文将介绍几种常见的自然语言处理工具,以及它们在不同领域的应用。
一、中文分词工具中文分词是将连续的汉字序列切分成有意义的词语。
中文分词对于中文文本的处理至关重要,它是许多其他自然语言处理任务的前置步骤。
常用的中文分词工具有结巴分词、哈工大LTP、清华大学THULAC等。
这些工具能够准确地进行中文分词,为后续的文本处理提供良好的基础。
二、词性标注工具词性标注是将每个词语赋予相应的词性标签,例如名词、动词、形容词等。
词性标注能够帮助我们更好地理解句子的语法结构和含义。
常用的词性标注工具有NLTK和斯坦福词性标注器等。
这些工具可以自动标注词语的词性,为文本分析和理解提供帮助。
三、命名实体识别工具命名实体识别是指从文本中识别出具有特定意义的实体,包括人名、地名、组织机构名等。
命名实体识别在信息提取、搜索引擎排名等领域有着重要的应用。
常用的命名实体识别工具有斯坦福NER(NamedEntity Recognition)工具、清华大学THU NER工具等。
这些工具可以对文本进行实体识别并进行分类标注。
四、情感分析工具情感分析是通过计算机自动分析文本中表达的情感倾向,判断文本的情感极性(正面、负面或中性)。
情感分析在舆情监测、产品评论等领域有着广泛的应用。
常用的情感分析工具有TextBlob、stanford-corenlp等。
这些工具可以对文本进行情感分类,为情感分析提供便利。
五、文本摘要工具文本摘要是将一篇较长的文本自动提炼为几句简洁的概括性语句。
文本摘要在新闻报道、学术论文等领域有着广泛的需求。
常用的文本摘要工具有Gensim、NLTK等。
这些工具可以根据文本的关键信息生成摘要,提高文本的可读性和信息获取效率。
中文分词工具jieba中的词性类型

中⽂分词⼯具jieba中的词性类型jieba为⾃然语⾔语⾔中常⽤⼯具包,jieba具有对分词的词性进⾏标注的功能,词性类别如下:Ag形语素形容词性语素。
形容词代码为 a,语素代码g前⾯置以A。
a形容词取英语形容词 adjective的第1个字母。
ad副形词直接作状语的形容词。
形容词代码 a和副词代码d并在⼀起。
an名形词具有名词功能的形容词。
形容词代码 a和名词代码n并在⼀起。
b区别词取汉字“别”的声母。
c连词取英语连词 conjunction的第1个字母。
dg副语素副词性语素。
副词代码为 d,语素代码g前⾯置以D。
d副词取 adverb的第2个字母,因其第1个字母已⽤于形容词。
e叹词取英语叹词 exclamation的第1个字母。
f⽅位词取汉字“⽅”g语素绝⼤多数语素都能作为合成词的“词根”,取汉字“根”的声母。
h前接成分取英语 head的第1个字母。
i成语取英语成语 idiom的第1个字母。
j简称略语取汉字“简”的声母。
k后接成分l习⽤语习⽤语尚未成为成语,有点“临时性”,取“临”的声母。
m数词取英语 numeral的第3个字母,n,u已有他⽤。
Ng名语素名词性语素。
名词代码为 n,语素代码g前⾯置以N。
n名词取英语名词 noun的第1个字母。
nr⼈名名词代码 n和“⼈(ren)”的声母并在⼀起。
ns地名名词代码 n和处所词代码s并在⼀起。
nt机构团体“团”的声母为 t,名词代码n和t并在⼀起。
nz其他专名“专”的声母的第 1个字母为z,名词代码n和z并在⼀起。
o拟声词取英语拟声词 onomatopoeia的第1个字母。
p介词取英语介词 prepositional的第1个字母。
q量词取英语 quantity的第1个字母。
r代词取英语代词 pronoun的第2个字母,因p已⽤于介词。
s处所词取英语 space的第1个字母。
tg时语素时间词性语素。
时间词代码为 t,在语素的代码g前⾯置以T。
t时间词取英语 time的第1个字母。
分词评测方法

分词评测方法我折腾了好久分词评测方法,总算找到点门道。
我一开始啊,真的是瞎摸索。
我就想着,分词嘛,那最简单的方法是不是看看分出来的词准不准就行了呢。
于是我就拿一些已经有标准分词结果的文本去做测试,就是像是老师给了正确答案,我来批改作业那样。
我先找了个简单的分词工具,把那些文本拿去处理,然后一个词一个词地看。
这时候我就发现问题了,有些词虽然看起来是分对了,但是在语义上不太对。
比如“中华人民共和国”,要是分成“中华人民共和国”,单个看词没错,可这在咱们正常理解里就是个完整的概念呀。
这就是我一开始碰到的失败教训,光看表面的词对不对是不够的。
后来我又想,那得结合语义来评测分词了。
但是语义这东西不好把握啊。
我就试着用一些简单的语义规则。
比如说,如果一个词后面加上某个字或者词后,在已有的词汇里有这个搭配,那也许就不该在这个地方把词分开。
这就好比搭积木,你不能把应该搭在一起的两块积木硬生生拆开。
不过这个方法也有问题,就是得定义太多的规则了,而且不同类型的文本规则还不一样。
像是科技类文本里的词汇搭配和生活类的就差别很大。
再后来,我又试了个新方法。
我在网上找了大量不同类型的文本,有新闻的、小说的、科技文章之类的,把它们当作一个大的样本库。
然后我用多种分词工具对这些文本进行分词处理。
然后对比不同分词工具的结果,看看哪个工具对于大多数文本都能比较好地分好词。
这个时候我就发现有些工具在小说类文本里分词很精准,但是到了科技文章就不行了。
这让我明白了,好的分词评测得针对不同文体有不同的标准。
我觉得吧,在做分词评测的时候,多找不同类型的文本是很重要的。
像我之前只找一种类型的文本,就很容易片面地得出结论。
还有就是不要只看形式,要多考虑语义。
而且呢,对比多个工具的表现可以在一定程度上让我们知道什么样的分词是比较好的。
不过我也不确定我现在的方法是不是就特别完美,感觉还能继续探索呢。
比如怎么更好地把语义融入到评测里,这个还需要更多的研究。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
对比:LTP、NLPIR、THULAC和jieba(C++)
• 2、数据集:SIGHAN Bakeoff 2005 PKU, 510KB
对比:LTP、NLPIR、THULAC和jieba(C++)
• 3、数据集:人民日报 2014, 65MB(只测试分词速度)
结论
• thulac和ltp都在各个数据集都有很不错的表现; • 分词速度上thulac和jieba表现的不错; • 真正想用分词工具来解决应用层面上的问题,需要借助于词库,
几种中文分词工具简介
• NLPIR(ICTCLAS):中科院张华平博士,基于Bigram + HMM; • Ansj:孙健,ICTLAS的Java版本,做了一些工程上的优化; • Jieba:由fxsjy开源,基于Unigram + HMM; • LTP:哈工大2011年开源,采用结构化感知器(SP); • FNLP:复旦大学2014年开源,采用在线学习算法Passive-
Aggressive(PA),JAVA; • THULAC:清华大学2016年开源,采用结构化感知器(SP); • Standford CoreNLP, HanLP……
对比:LTP、NLPIR、THULAC和jieba(C++)
• 1、数据集:SIGHAN Bakeoff 2005 MSR, 560KB
补充
• 测试数据集为搜狗新闻语料,65MB(少量噪声); • THULAC两种模式:SegOnly模式,只分词没有词性标注;SegPos模
式,分词兼有词性标注; • SegOnly分词速度快,但是准确率较SegPos模式低;而SegPos具有
更高的准确率,但内存占用更多、分词速度较慢; • THULAC基于结构化感知器SP,CoreNLP基于CRF,Ansj与HanLP
对比的4个工具均支持用户自定义词库; • 哈工大的ltp支持分词模型的在线训练,即在系统自带模型的基础
上可以不断地增加训练数据。
对比: Ansj、CoreNLP、HanLP和THULFra bibliotekC(Java)
分词器 thulac4j
THULAC-Java
Ansj
CoreNLP HanLP
SegOnly SegPos SegOnly SegPos ToAnalysis NlpAnalysis CRFClassifier StandardTokenizer NLPTokenizer
耗时(ms) 30,342 200,545 48,775 289,970 16,873 79,700 918,488 21,738 59,356
• Thulac4j在官方THULAC-Java基础上做了工程性优化
速率(Kb/s) 2102.1 318.1 1307.8 219.9 3780.2 800.3 69.4 2934.2 1074.6
(其两种分词模式)是基于HMM; • 理论上讲,分词效果:CRF ≈≈ SP > HMM; • 从分词速率的测试结果上来看,THULAC是兼顾效果与速率。