NLPIR-ICTCLAS分词系统开发手册2016版
nlpir分词法

nlpir分词法NLPIR(Natural Language Processing and Information Retrieval)分词法是一种基于自然语言处理和信息检索的文本分析方法。
它可以将自然语言文本切分成有意义的词语或词组,为后续的语义分析提供基础支持。
本文将介绍NLPIR分词法的原理、应用场景以及使用方法。
一、NLPIR分词法原理NLPIR分词法主要依赖于预先构建的字典和规则。
在分词过程中,NLPIR会根据字典中的单词和词组对文本进行切分,并根据规则对切分结果进行调整和修正,以得到更准确的分词结果。
NLPIR可以处理中文和英文文本,具有较好的鲁棒性和可靠性。
二、NLPIR分词法应用场景1. 信息检索:NLPIR分词法可以将文本切分成词语或词组,帮助搜索引擎更准确地理解用户的查询意图,提高搜索结果的相关性和准确性。
2. 文本挖掘:NLPIR分词法可以帮助提取文本中的关键词和关键短语,从而进行主题分析、情感分析、舆情监测等任务。
3. 自然语言处理:NLPIR分词法是自然语言处理的基础步骤,可以用于机器翻译、文本生成、问答系统等任务。
三、NLPIR分词法使用方法NLPIR分词法可以通过以下步骤进行使用:1. 安装NLPIR分词库:可以从官方网站下载并安装相应的分词库,支持多种编程语言和操作系统。
2. 导入分词库:在使用NLPIR分词法之前,需要在代码中导入分词库,并进行初始化设置。
3. 加载字典和规则:NLPIR分词法依赖于字典和规则进行分词,需要将相应的字典和规则加载到分词库中。
4. 分词处理:将待分词的文本输入分词库,调用相应的接口实现分词处理,并获取分词结果。
5. 分词结果处理:对分词结果进行后续处理,如去除停用词、提取关键词等。
总结:NLPIR分词法是一种基于自然语言处理和信息检索的文本分析方法,可以帮助将自然语言文本切分成有意义的词语或词组。
它在信息检索、文本挖掘和自然语言处理等领域有广泛的应用。
ICTCLAS分词系统研究(四)-初次切分

ICTCLAS分词系统研究(四)-初次切分
经过原子分词后,源字符串成了一个个独立的最小语素单位。
下面的初次切分,就是把原子之间所有可能的组合都先找出来。
算法是用两个循环来实现,第一层遍历整个原子单位,第二层是当找到一个原子时,不断把后面相邻的原子和该原子组合到一起,访问词典库看它能否构成一个有意义有词组。
用数学方法可以做如下描述:
有一个原子序列:A(n)(0<=n<m)(其中m为原子序列A的长度)。
当I=n时,判断AnAn+1..Ap 是否为一个词组,其中n<p<m.
用伪码表示:
for(int I=0;I<m;I++){
String s=A[I];
for(int j=I+1;j<m;j++){
s+=A[j];
if(s是一个词组){
把s加入到初次切分的列表中;
记录该词组的词性;
记录该词组所在表中的坐标位置及其它信息;
}
else
break;
}
}
分词用例”红跟病很多”经过初次切分后的数据结构及切分结果如下图所示:
用二维表来表示的表结构和队列结构如下图所示:
从上图可以看出,在二维表中,初次切分后的词组,第一次字相同的在同一行,最后一个字相同的在同一列,原来的原子在对称轴上.。
自然语言处理 操作手册

自然语言处理操作手册
自然语言处理(NLP)是一种人工智能技术,用于让计算机理解和生成人类语言。
以下是NLP的基本操作手册:
1. 数据收集:对于NLP任务来说,大量高质量的语料是基础。
可以通过直
接下载开源的语料库,如维基百科的语料库。
此外,也可以自己动手开发爬虫去抓取特定的内容。
2. 文本清洗:这个阶段主要涉及移除文本中的无关内容,例如标点符号。
可以使用Python的isalpha()函数将标点从文本中分离,同时创建一个新的
list存储不含标点的小写单词。
3. 分词:分词是将连续的文本切分为独立的单词或符号的过程。
中文分词是中文NLP预处理的重要步骤,常用的分词工具有jieba等。
4. 词性标注:给每个词分配一个词性标签,例如名词、动词、形容词等。
这有助于理解句子的结构和意义。
5. 命名实体识别(NER):识别文本中的特定实体,如人名、地名、组织等。
6. 去除停用词:停用词是那些对文本意义贡献不大的词,如“和”、“但是”、“所以”等。
去除停用词可以减少计算复杂度并提高模型的性能。
7. 特征提取:将文本转换为数值特征向量,以便机器学习算法使用。
常见的特征包括词袋模型、TF-IDF等。
8. 模型训练与评估:使用提取的特征训练NLP模型,如分类器、生成模型等。
然后使用测试数据评估模型的性能,根据评估结果调整模型参数或尝试其他算法。
9. 部署与优化:将训练好的模型部署到实际应用中,并根据实际使用情况进行优化和调整。
以上是NLP的基本操作流程,实际操作中可能需要根据具体任务和数据特点进行调整和优化。
几款开源的中文分词系统

⼏款开源的中⽂分词系统以下介绍4款开源中⽂分词系统python环境下,jieba也不错,实现词性分词性能据说不错。
1、ICTCLAS – 全球最受欢迎的汉语分词系统中⽂词法分析是中⽂信息处理的基础与关键。
中国科学院计算技术研究所在多年研究⼯作积累的基础上,研制出了汉语词法分析系统ICTCLAS(Institute of Computing Technology, Chinese Lexical Analysis System),主要功能包括中⽂分词;词性标注;命名实体识别;新词识别;同时⽀持⽤户词典;⽀持繁体中⽂;⽀持GBK、UTF-8、UTF-7、UNICODE等多种编码格式。
我们先后精⼼打造五年,内核升级6次,⽬前已经升级到了ICTCLAS3.0。
ICTCLAS3.0分词速度单机996KB/s,分词精度98.45%,API不超过200KB,各种词典数据压缩后不到3M,是当前世界上最好的汉语词法分析器。
系统平台:Windows开发语⾔:C/C++、Java、C#使⽤⽅式:dll调⽤晴枫附注:ICTCLAS有共享版、商业版、⾏业版,⽀持Linux平台,但不开源。
ICTCLAS已进⼊商⽤,且应⽤范围较⼴,相信分词效率出⾊。
2、HTTPCWS – 基于HTTP协议的开源中⽂分词系统HTTPCWS 是⼀款基于HTTP协议的开源中⽂分词系统,⽬前仅⽀持Linux系统。
HTTPCWS 使⽤“ICTCLAS 3.0 2009共享版中⽂分词算法”的API进⾏分词处理,得出分词结果。
ICTCLAS是中国科学院计算技术研究所在多年研究⼯作积累的基础上,基于多层隐马模型研制出的汉语词法分析系统,主要功能包括中⽂分词;词性标注;命名实体识别;新词识别;同时⽀持⽤户词典。
ICTCLAS经过五年精⼼打造,内核升级6次,⽬前已经升级到了ICTCLAS3.0,分词精度98.45%,各种词典数据压缩后不到3M。
ICTCLAS在国内973专家组组织的评测中活动获得了第⼀名,在第⼀届国际中⽂处理研究机构SigHan组织的评测中都获得了多项第⼀名,是当前世界上最好的汉语词法分析器。
自然语言处理技术手册

自然语言处理技术手册自然语言处理(Natural Language Processing,简称NLP)是计算机科学与人工智能领域中一门研究人机间如何进行自然语言交互的学科。
近年来,随着人工智能技术的不断发展和普及,自然语言处理在各个领域中都发挥着重要作用。
本手册将为您介绍自然语言处理的相关技术和方法。
一、自然语言处理概述1.1 自然语言处理的定义与应用范围1.2 自然语言处理的基本任务1.3 自然语言处理的挑战与机遇二、自然语言处理技术的关键步骤2.1 文本预处理2.1.1 文本清洗2.1.2 分词与词性标注2.1.3 停用词过滤2.1.4 词干化与词形还原2.2 文本表示与特征提取2.2.1 词袋模型2.2.3 Word2Vec与词嵌入2.2.4 文本分类与主题建模2.3 语法分析与句法树2.3.1 语法规则2.3.2 句法解析算法2.3.3 句法树的应用2.4 语义理解与语义角色标注2.4.1 语义角色标注的定义2.4.2 语义角色标注的方法2.4.3 语义角色标注的应用2.5 机器翻译与文本生成2.5.1 统计机器翻译2.5.2 神经机器翻译2.5.3 文本生成技术三、自然语言处理中的常用工具和资源3.1 Python自然语言处理库3.1.1 NLTK3.1.3 Gensim3.2 中文自然语言处理工具包3.2.1 jieba分词3.2.2 HanLP3.2.3 THULAC3.3 常用语料库与数据集3.3.1 Penn Treebank3.3.2 CoNLL3.3.3 Wikipedia语料库四、自然语言处理技术在各领域的应用4.1 信息抽取与知识图谱4.2 情感分析与舆情监测4.3 问答系统与智能助手4.4 文本摘要与文档自动化处理五、自然语言处理的发展趋势与展望5.1 深度学习在自然语言处理中的应用 5.2 多语言处理与跨语言情感分析5.3 知识图谱与语义搜索5.4 强化学习与自然语言交互结语自然语言处理技术作为人工智能领域的重要组成部分,正在不断发展和演进。
ICTCLAS 中科院分词系统 代码 注释 中文分词 词性标注

ICTCLAS 中科院分词系统代码注释中文分词词性标注(转)中科院分词系统概述这几天看完了中科院分词程序的代码,现在来做一个概述,并对一些关键的数据结构作出解释〇、总体流程考虑输入的一句话,sSentence="张华平欢迎您"总体流程:一、分词"张/华/平/欢迎/您"二、posTagging "张/q 华/j 平/j 欢迎/v 您/r"三、NE识别:人名识别,音译名识别,地名识别"张/q 华/j 平/j 欢迎/v 您/r" "张华平/nr"四、重新分词:"张华平/欢迎/您"五、重新posTagging: "张华平/nr 欢迎/v 您/r"技术细节一、分词分词程序首先在其头末添加开始符和结束符sSentence="始##始张华平欢迎您末##末"然后是分词,基本思想就是分词的得到的词的联合概率最大假设"张华平欢迎您" 分为"w_1/w_2/.../w_k" 则w_1/w_2/.../w_k=argmax_{w_1'/w_2'/.../w_k'}P(w_1',w_2',...,w_k')=argmax_{ w_1'/w_2'/.../w_k'}P(w_1')P(w_2')...P(w_k')细节:首先给原句按字划分,所有汉字一个一段,连续的字母,数字一段,比如"始##始张华平2006欢迎您asdf末##末"被划为"始##始/张/华/平/2006/欢/迎/您/asdf/末##末"接着找出这个句子中所有可能出现的词,比如"始##始张华平欢迎您末##末",出现的词有"始##始","张","华","平","欢","迎","您","末##末","欢迎"并查找这些词所有可能的词性和这些词出现的频率。
中文分词工具简介与安装教程(jieba、nlpir、hanlp、pkuseg、foolnl。。。

中⽂分词⼯具简介与安装教程(jieba、nlpir、hanlp、pkuseg、foolnl。
2.1 jieba2.1.1 jieba简介Jieba中⽂含义结巴,jieba库是⽬前做的最好的python分词组件。
⾸先它的安装⼗分便捷,只需要使⽤pip安装;其次,它不需要另外下载其它的数据包,在这⼀点上它⽐其余五款分词⼯具都要便捷。
另外,jieba库⽀持的⽂本编码⽅式为utf-8。
Jieba库包含许多功能,如分词、词性标注、⾃定义词典、关键词提取。
基于jieba的关键词提取有两种常⽤算法,⼀是TF-IDF算法;⼆是TextRank算法。
基于jieba库的分词,包含三种分词模式:精准模式:试图将句⼦最精确地切开,适合⽂本分析);全模式:把句⼦中所有的可以成词的词语都扫描出来, 速度⾮常快,但是不能解决歧义);搜索引擎模式:搜索引擎模式,在精确模式的基础上,对长词再次切分,提⾼召回率,适合⽤于搜索引擎分词。
Jieba官⽅⽂档:2.1.2 jieba安装Jieba库安装⽐较便捷,只需要在命令框中输⼊:pip install jieba;或者在pycharm中,通过setting-project安装。
2.2 thulac2.2.1 thulac简介THULAC(THU Lexical Analyzer for Chinese)由清华⼤学⾃然语⾔处理与社会⼈⽂计算实验室研制推出的⼀套中⽂词法分析⼯具包,具有中⽂分词和词性标注功能。
THULAC集成了⽬前世界上规模最⼤的⼈⼯分词和词性标注中⽂语料库(约含5800万字),模型标注能⼒强⼤。
该⼯具包在标准数据集Chinese Treebank(CTB5)上分词的F1值可达97.3%,词性标注的F1值可达到92.9%。
同时进⾏分词和词性标注速度为300KB/s,每秒可处理约15万字。
只进⾏分词速度可达到1.3MB/s。
总的来说,可以理解为thulac训练的分词、词性标注语料库很⼤,性能优良。
基于本体的小麦病虫害问答系统构建与实现

基于本体的小麦病虫害问答系统构建与实现郑颖;金松林;张自阳;王斌;茹振钢【摘要】为了能够及时、方便地解决农民在小麦种植过程中遇到的病虫害问题,研究并设计了一个关于小麦病虫害问题的自动问答系统.首先,将小麦的病虫害知识进行资源整合,在领域专家指导下构建小麦病虫害本体,将其作为问答系统的知识库.然后,利用自然语言处理相关技术对用户提出的问题进行分析并找到相应答案返回给用户.该系统操作方便,对小麦病虫害预防有重要作用.【期刊名称】《河南农业科学》【年(卷),期】2016(045)006【总页数】4页(P143-146)【关键词】小麦病虫害;本体;问句分析;问答系统【作者】郑颖;金松林;张自阳;王斌;茹振钢【作者单位】河南科技学院信息工程学院,河南新乡453003;河南科技学院信息工程学院,河南新乡453003;河南科技学院生命科技学院,河南新乡453003;河南科技学院生命科技学院,河南新乡453003;河南科技学院生命科技学院,河南新乡453003【正文语种】中文【中图分类】S126;S435.12小麦作为北方地区重要的粮食作物,其产量直接影响到我国经济发展和社会稳定[1]。
长期以来,病虫害一直是影响小麦产量的主要问题,有效预防和控制病虫害的发展对于提高小麦产量有着重要意义。
小麦种植过程中,农民会遇到许多难以解决的问题,这就需要有专门的技术人员进行指导,由于技术人员有限,又受制于时空因素,不可能实现一对一的指导。
随着互联网的发展,农村地区互联网也得到普及,很多农民开始通过搜索引擎搜索问题。
但是通过搜索引擎通常会搜索到许多与问题无关的答案,效果并不理想。
近几年国内也出现了许多与农业相关的网站,例如中国农业信息网、农林网等,这些网站虽然提供了专家在线服务,然而这种方式不仅时效性差,而且专家对于共通的问题逐一解答浪费了宝贵的时间。
问答系统是将人工智能、信息检索、自然语言处理等技术相结合的智能系统,它提供一个简单的接口供用户输入问题,通过分析问题自动返回答案,因其既克服了时空限制又能准确返回问题答案而备受关注。
Java自然语言处理NLP工具包

Java⾃然语⾔处理NLP⼯具包⾃然语⾔处理1. Java⾃然语⾔处理 LingPipeLingPipe是⼀个⾃然语⾔处理的Java开源⼯具包。
LingPipe⽬前已有很丰富的功能,包括主题分类(Top Classification)、命名实体识别(Named Entity Recognition)、词性标注(Part-of Speech Tagging)、句题检测(Sentence Detection)、查询拼写检查(Query Spell Checking)、兴趣短语检测(Interseting Phrase Detection)、聚类(Clustering)、字符语⾔建模(Character Language Modeling)、医学⽂献下载/解析/索引(MEDLINE Download, Parsing and Indexing)、数据库⽂本挖掘(Database Text Mining)、中⽂分词(Chinese Word Segmentation)、情感分析(Sentiment Analysis)、语⾔辨别(Language Identification)等API。
下载链接:2.中⽂⾃然语⾔处理⼯具包 FudanNLPFudanNLP主要是为中⽂⾃然语⾔处理⽽开发的⼯具包,也包含为实现这些任务的机器学习算法和数据集。
演⽰地址:FudanNLP⽬前实现的内容如下:1. 中⽂处理⼯具1. 中⽂分词2. 词性标注3. 实体名识别4. 句法分析5. 时间表达式识别2. 信息检索1. ⽂本分类2. 新闻聚类3.3. 机器学习1. Average Perceptron2. Passive-aggressive Algorithm3. K-means4. Exact Inference下载链接:3.⾃然语⾔处理⼯具Apache OpenNLPOpenNLP 是⼀个机器学习⼯具包,⽤于处理⾃然语⾔⽂本。
java中科院分词配置(ICTCLAS)
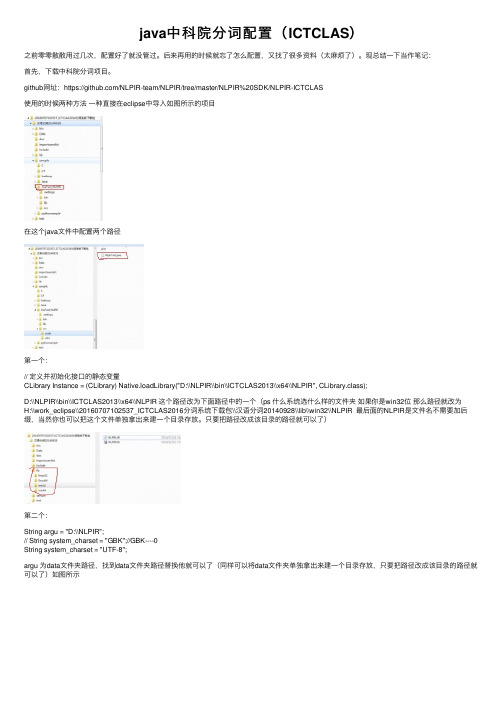
java中科院分词配置(ICTCLAS)之前零零散散⽤过⼏次,配置好了就没管过。
后来再⽤的时候就忘了怎么配置,⼜找了很多资料(太⿇烦了)。
现总结⼀下当作笔记:⾸先,下载中科院分词项⽬。
github⽹址:https:///NLPIR-team/NLPIR/tree/master/NLPIR%20SDK/NLPIR-ICTCLAS使⽤的时候两种⽅法⼀种直接在eclipse中导⼊如图所⽰的项⽬在这个java⽂件中配置两个路径第⼀个:// 定义并初始化接⼝的静态变量CLibrary Instance = (CLibrary) Native.loadLibrary("D:\\NLPIR\\bin\\ICTCLAS2013\\x64\\NLPIR", CLibrary.class);D:\\NLPIR\\bin\\ICTCLAS2013\\x64\\NLPIR 这个路径改为下⾯路径中的⼀个(ps 什么系统选什么样的⽂件夹如果你是win32位那么路径就改为H:\\work_eclipse\\20160707102537_ICTCLAS2016分词系统下载包\\汉语分词20140928\\lib\\win32\\NLPIR 最后⾯的NLPIR是⽂件名不需要加后缀,当然你也可以把这个⽂件单独拿出来建⼀个⽬录存放。
只要把路径改成该⽬录的路径就可以了)第⼆个:String argu = "D:\\NLPIR";// String system_charset = "GBK";//GBK----0String system_charset = "UTF-8";argu 为data⽂件夹路径,找到data⽂件夹路径替换他就可以了(同样可以将data⽂件夹单独拿出来建⼀个⽬录存放,只要把路径改成该⽬录的路径就可以了)如图所⽰路径就改为String argu = "H:\\work_eclipse\\20160707102537_ICTCLAS2016分词系统下载包\\汉语分词20140928";配置完成后运⾏NlpirTest 可能会出现Not valid license or your license expired 这个错误。
基于词典与CRF算法的中文生物医学实体自动标注平台建设

任雪菁,安新颖,范少萍,等.基于词典与CRF 算法的中文生物医学实体自动标注平台建设[J].中华医学图书情报杂志,2020,29(9):29-35DOI:10.3969/j.issn.1671-3982.2020.09.005㊃情报研究与方法㊃基于词典与CRF 算法的中文生物医学实体自动标注平台建设任雪菁1,安新颖1,范少萍1,张 飞2,黄裕翔1[摘要]目的:构建中文生物医学实体及关系的自动识别标注平台,为中文生物医学语料标注和精准医学语料积累及知识服务等提供参考㊂方法:基于词典和CRF 算法实现中文生物医学文本的自动实体识别,利用Python ㊁JavaScript ㊁CSS 等编程语言和Query 框架等相关工具构建中文生物医学实体自动标注平台㊂结果:构建了一个可以自动识别中文实体且具备上传㊁标注㊁审核文本并最终存储文本等功能的中文自动标注平台㊂该平台能高效㊁准确地识别文本内容,实现自动标注㊂结论:该平台具备了人工导入文献㊁标注㊁管理员审核结算的功能,可以为生物医学领域的研究者进行信息的数据挖掘㊁中文语料库的构建提供支持㊂[关键词]命名实体识别;语义关系;语义标注;知识图谱[中图分类号]P209;TP391.41 [文献标志码]A [文章编号]1671-3982(2020)09-0029-07Development of automatic annotation platform for Chinese biomedical entities based on dictionaries and CRF algorithmREN Xue -jing 1,AN Xin -ying 1,FAN Shao -ping 1,ZHANG Fei 2,HUANG Yu -xiang 1(1.Peking Union Medical College /Institute of Medical Information,Chinese Academy of Medical Sciences,Beijing 100020,China;2.Peking Union Medical College /Affiliated Fuwai Hospital of Chinese Academy of Medical Sciences,Beijing 100032,China)Corresponding author:AN Xin-ying[作者单位]1.北京协和医学院/中国医学科学院医学信息研究所,北京 100020;2.北京协和医学院/中国医学科学院阜外医院,北京 100032[作者简介]任雪菁(1995-),女,吉林通化人,在读硕士研究生㊂[通讯作者]安新颖(1978-),女,黑龙江大庆人,博士,研究员,硕士生导师,研究方向为医学信息分析与评价,发表论文40余篇㊂E -mail:an.xinying@imi⁃[Abstract ]Objective To develop the automatic identification and annotation platform for Chinese biomedical enti⁃ties and their relationship in order to provide reference for the annotation of Chinese biomedical corpora,accurate accumulation of medical corpora and knowledge service.Methods The automatic entity recognition of Chinese biomedical texts was achieved based on dictionaries and CRF algorithm.The automatic annotation platform forChinese biomedical entities was developed by making use of the programming languages such as Python,JavaScript,CSS and the related tools such as Query framework.Results The automatic annotation platform for Chinese biomedical entities was developed,which can upload,annotate,review and store the Chinese biomedical texts,effectively and accurately identify the contents in Chinese biomedical texts,and automatically annotate the Chinese biomedical texts.Conclusion The automatic identification and annotation platform for Chinese biomedical entities and theirrelationship is provided with the functions,such as artificial uploading and annotating the Chinese biomedical literature,verifying and final accounting for managing staff,supporting for those engaged in biomedical research to mine data and developing Chinese corpus repository.[Key words ]Named entity recognition;Semantic relation⁃ship;Semantic annotation;Knowledge graph 随着生物医学学科和相关生物医学技术的快速发展,生物医学领域的数据呈爆发式增长[1-2],生物医学实体识别工具㊁生物医学知识库㊁语料库等如雨后春笋般应运而生㊂它们包含丰富的生物医学信息资源,常以非结构化的形式进行存储与展示[3-5]㊂从海量数据中快速准确地抽取有用信息㊁挖掘生物医学知识,并建立精准的生物医学知识库是影响生物医学科研效率及临床实践应用指导的重要因素[6]㊂生物医学命名实体识别主要针对生物医学文本中不同种类的实体进行识别,包括疾病㊁基因㊁药物㊁蛋白质等[7],是开展其他知识抽取与数据挖掘的首要任务㊂通过识别这些实体,基于既定的知识库内容,深入挖掘实体之间和事件中的语义关系,对循证医学㊁精准化的个性医疗服务以及临床决策支持等均具有重要意义[8-9]㊂语料库是促进自然语言处理技术在生物医学领域应用的重要资源,对评测和提高该领域的文本挖掘技术性能起着重要作用㊂目前,国际上为了促进生物医学文本挖掘技术的发展组织了一系列的评测会议和比赛,同时提供了包括GENIA㊁GeneTag㊁BioInfer等在内的公开语料库[10]㊂采用机器自动识别结合人工标注的方法从生物医学文本中抽取大量的实体与实体之间关系的信息,对构建高质量的标注语料库具有现实意义,而构建高质量的标注语料库反过来也可以提高实体识别工具的性能[11]㊂有学者将一个小规模的生物医学标注语料库引入到一个大型的通用英语语料库中,使生物医学文本的词性标注的准确度从87%提高到了92%[12]㊂由此可见,利用人工精准标注的信息可以对机器学习等算法进行自身检验和评测计算,提高语义关系抽取性能㊂本文利用Python编程㊁自然语言处理㊁可视化等技术,融合生物医学词典㊁互联网健康信息㊁生物医学中文文献等数据,初步构建了中文生物医学实体及关系自动识别标注平台,为中文生物医学语料标注㊁精准医学语料积累及知识服务等提供参考㊂1 研究背景由于中文的语言特色㊁中文生物医学语料的爆炸式增长及生物医学命名实体本身固有的问题,中文医学命名实体识别难度增大,信息获取与知识挖掘的水平较低㊂命名实体识别主要存在两大难点:一是生物医学实体不断涌现,现有生物医学词典无法覆盖所有类型的实体,新实体的识别极大地影响生物医学命名实体识别的精确率和召回率[13];二是生物医学实体命名规则不统一㊁构词结构复杂,中文缩写歧义现象严重等㊂目前,国内外常用的命名实体识别工具主要有PubTator㊁Brat,以及中国科学院计算技术研究院开发的原名为ICTCLAS2013的NLPIR汉语分词系统等[14]㊂PubTator是美国国立医学图书馆开发的一个基于网络的生物医学文本挖掘工具,支持对PubMed 的检索结果进行标注,它所识别的生物医学实体类型包括基因㊁疾病㊁化学物质㊁物种㊁变异㊁细胞等,并支持对实体之间的语义关系进行标注[15]㊂PubTator 平台装配有多个文本挖掘算法及相应的算法评估,以保证其自动化标注结果的质量㊂以PubTator为主的英文生物医学文本标注平台暂时无法支持中文文本的实体识别工作,仅有少数平台可对中文生物医学文本进行实体标注与实体识别㊂而这些平台只是基于某领域范围内的科研需要进行构建的,缺乏统一性㊁持续性和开放性[16]㊂在标注过程中,标注方法和标注规则的选择同样面临着不统一㊁不规范等问题㊂Brat是一种人工实体标注工具,可应用于命名实体识别㊁事件抽取㊁语义关系抽取等文本挖掘技术㊂Co supporting task㊁Turku Dependency Treebank等多种语料库都采用Brat作为标注工具[17]㊂2 研究方法2.1 基于词典的方法基于词典的方法是通过字符串完全或模糊匹配的算法,在目标文本中查找与词典中收录词完全相同或非常相似的词并识别作实体,是早期生物医学命名实体识别研究中使用的方法[18]㊂在生物医学领域的命名实体识别方面,单一的㊁基于词典的方法效果不是很理想㊂但因为词典法具有一定的精确度且易于使用,在进行命名实体识别时,本文选择利用词典进行特征工程构建,同时把词典加入识别系统的后处理部分,用于提高识别的准确度和可操作性㊂2.2 基于统计机器学习的方法统计机器学习方法(statistical machine learningmethod)是目前生物医学命名实体识别领域的主流方法[19],是指在已标注好的一定规模的语料库中,人工提取数据特征并通过特定的算法进行训练形成机器学习的模型,再用该模型对未标注的数据进行训练和预测,完成命名实体识别㊂与基于词典的方法相比,该方法构建的模型具有鲁棒性好㊁更新换代速度快㊁可迁移性好等优点㊂常用的算法有最大熵模型(maximum entropy model,MEM)㊁隐马尔可夫模型(hidden markov model,HMM)㊁条件随机场(condi⁃tional random field,CRF)等[20]㊂2.3 基于词典结合机器学习的方法一些研究尝试将外部词典和机器学习的方法相结合,以提升模型整体的识别精度㊂如TaggerOne 方法,在训练和预测期间联合命名实体识别(named entity recognition,NER)和归一化模型,由半马尔可夫结构化线性分类器组成,可以克服级联错误,提高性能[21]㊂由于词典和机器学习相结合可以使两种方法取长补短,因此本文采取了词典和CRF算法相结合的方法㊂3 数据处理3.1 数据收集3.1.1 实体字典遴选目前内容完备㊁结构科学㊁获得业内认可的中文医学类词典主要有ICD-10中文版㊁医学系统术语表(Systematized Nomenclature of Medicine, SNOMED)和观测指标标识符逻辑命名与编码系统(Logical Observation Identifiers Names and Codes, LOINC)等㊂除上述词典外,本文还纳入了来自网络的㊁访问量高的字典,如WellMed公司的用户健康术语词典(the Consumer Health Terminology,CHT)等㊂各类实体的字典来源及数量的具体情况见表1㊂表1 各类实体的字典来源及数量实体类型字典来源实体数量/个疾病C-Mesh词表(/),国际疾病分类(第十版)(International Classification ofDiseases,ICD-10),WellMed公司的用户健康术语词典(the Consumer Health Terminology,CHT)4960症状C-Mesh词表(/),国际疾病分类(第十版)(International Classification ofDiseases,ICD-10),WellMed公司的用户健康术语词典(the Consumer Health Terminology,CHT)5055基因C-Mesh词表(/),Medportal数据库()63化学物质和药品C-Mesh词表(/),Medportal数据库()35989解剖部位C-Mesh词表(/),Medportal数据库()7471蛋白质C-Mesh词表(/),Medportal数据库()7213.1.2 标注文本收集系统模型的训练与展示所使用的文献均来自中国生物医学文献服务系统(SinoMed)㊂该系统由中国医学科学院医学信息研究所/图书馆研制,2008年首次上线服务,整合了中国生物医学文献数据库(CBM)㊁中国生物医学引文数据库(CBMCI)㊁西文生物医学文献数据库(WBM)㊁北京协和医学院博硕学位论文库(PUMCD)等多种资源,是集文献检索㊁引文检索㊁开放获取㊁原文传递及个性化服务于一体的生物医学中外文整合文献服务系统㊂在SinoMed中,以检索式 (("疾病"[常用字段]OR"疾病"[主题词])AND("治疗"[常用字段]OR"治疗"[主题词])AND("基因"[常用字段]OR"基因"[主题词]))AND2014-2019[日期]”进行检索,最终选择中华医学会期刊的1983篇文献中的200篇文献并将其纳入训练集㊂将训练集中的每一篇文献的摘要单独抽出,生成200个文档,用于后期标注㊂3.2 数据规范化处理为了使标注工具可以智能识别实体类型和标注实体关系,本文不仅使用了词表㊁编程算法进行关系抽取,而且对训练集中的200篇文献进行了人工背对背标注㊂标注人员为北京协和医学院/中国医学科学院医学信息研究所的教师和学生㊂两名标注人员先各自标注50篇,与相关领域的专家进行讨论后,形成一份较为完善的标注规范㊂3.3 数据存储将标注㊁审核后的文献由管理员统一上传至后台,以便在后续研究中作为训练集丰富语料库,完成精准医学中文语料库的构建㊂3.4 实体及关系类别的确定本文搭建的自动标注平台目前提供疾病㊁症状㊁基因㊁蛋白质㊁治疗方式㊁化学物质和药品㊁解剖部位七大类中文实体类型,以及 疾病-疾病”(并发关系)㊁ 疾病-治疗方式”(治疗关系)㊁ 基因-疾病”(基因影响)㊁ 疾病-症状”(出现症状)4种关系供标注用户选择㊂4 研究结果4.1 模型训练与测试4.1.1 训练集的构建利用本文搭建的自动标注平台,采用双人交叉标注的方式对200篇文献摘要进行标注,对有异议的标注进行讨论,最终得到200篇有标签文本㊂从中随机选取150篇作为训练集用于训练CRF实体识别模型,其余50篇作为测试集用于测试模型㊂各类实体标注数量如表2所示㊂表2 训练集和测试集中各类型实体出现次数实体类型训练集出现的次数测试集出现的次数疾病823173症状246119治疗方式2040解剖部位14788化学物质和药品9814蛋白质7549基因30从表2可以看出,治疗方式和基因实体在测试集中均未出现,所以不对其进行测试㊂模型测试过程一共分为3步:首先单纯基于实体字典进行识别,然后单纯使用CRF模型进行识别,最后基于实体字典和CRF算法模型进行联合识别㊂在联合识别出现冲突时,因为实体字典中出现的实体是明确和正确的,因此以实体字典为准㊂评价指标采用标注准确率(Precision)计算公式㊂准确率=TP TP+FN公式中,TP指被正确识别出的实体数量,FN指未被识别的实体数量㊂具体测试结果如表3所示㊂表3 3种方法进行实体识别的准确度实体类型基于实体字典的准确度基于CRF算法的准确度联合识别的准确度疾病 0.8380.2770.844症状 0.0420.0000.042解剖部位 0.2390.0110.239化学物质和药品0.8820.0000.882蛋白质 0.3880.0820.408由于标注的语料库较小,所以目前基于CRF算法的识别精度一般㊂但从疾病和蛋白质实体的识别结果可以看出,基于字典的识别效果优于基于CRF算法模型的识别效果,而当将两种方式联合使用时可进一步提升识别效果㊂随着标注语料的增加,系统将自动对CRF算法模型进行更新,进一步提升自动标注效果㊂症状实体字典和疾病实体字典的大小相当,但症状实体的识别效果却远低于疾病实体㊂这是因为症状实体字典主要采集自面向大众的医药网站,所以描述偏口语化,与文献中的描述差异较大,因此识别效果较差㊂综上所述,CRF算法模型可以识别某些未登录的实体,提升单纯基于实体字典库进行实体识别的效果㊂随着标注文献的增加,CRF算法模型对未登录词的识别效果将进一步提升,当标注数据量达到一定程度后可考虑提高模型的复杂度,以得到更加准确的实体识别模型㊂4.1.2 训练集标注结果统计根据管理员后台的数据统计,200篇人工标注的中文摘要共有实体为2039个,不重复实体总量为981个㊂其中,疾病实体出现的次数最多,一共有1039个;基因出现的次数最少,只有28个㊂4.2 具体实现4.2.1 总体框架设计中文生物医学实体自动标注平台的总体框架包括支撑层㊁数据层㊁功能层和表现层4个层次(图1)㊂图1 中文生物医学实体自动标注平台总体框架4.2.2 功能设计从实体标注流程及平台用户需求的角度,将平台所提供的功能分为实体标注㊁标注审核㊁前端可视化㊁数据管理和用户管理五大部分(图2)㊂图2 中文生物医学实体自动标注平台功能4.3 网站设计4.3.1 网站整体结构作为中文生物医学实体标注平台,本平台从用户易用性角度出发,设置了3层链接(图3)㊂第一层是身份认证与用户区别的入口,第二层包括用户中心㊁标注页面㊁审核页面㊁管理页面和标注结果,第三层仅包括关系标注页面和审核页面㊂根据标注的需求,平台主要实现了实体识别模型的构建与迭代更新㊁文本自动标注㊁前端可视化展示和用户标注功能(包括实体标注和关系标注),以及用户管理㊁文本数据库管理㊁标注结果下载等功能㊂图3 中文生物医学实体自动标注平台网站的整体设计4.3.2 命名实体识别模型构建首先构建CRF++模型语料库,从各医学文献㊁网站等收集预计标注的实体名称,构建各实体词典并合并;然后导入Python 的jieba 分词模型,采用精确模式进行以提高分词准确度㊂将分词结果在实体库进行匹配,根据实体词典自动标记文本中的实体,利用自动标注平台进行人工审核和再标注,利用脚本生成CRF++工具的输入语料㊂CRF++语料采用4-tag 标记集:第一列为文本;第二列为文本中实体对应的类型,如 disease_b”表示一个药物实体的开始字符, disease_m”表示一个药物实体的中间字符, disease_e”表示一个药物实体的尾关系目标实体, o”表示非实体字符,其他类型实体的标注类似㊂根据已有的实体词典库,利用jieba 分词器进行文本分词,采用字符匹配的方式识别文本中的实体,利用手工标记的语料训练CRF 实体识别模型发现实体词典库中没有的实体,二者结合即构成命名实体识别模型㊂随着人工审核后的标注文本的增加,可实时更新词典库,并在语料更新到一定数量时再次训练CRF 模型,实现对模型的迭代更新,以提升识别效果㊂4.3.3 自动标注模块实现利用训练好的CRF++模型进行文本标注时,首先用Python 脚本将文本处理为单列形式;然后由Python 脚本调用dos 命令:crf_test -m Model mytest.txt >>Result.txt,其中 Model”为上文训练的模型文件, mytest.txt”为待识别文件, Result”为识别结果文件;最后将文本处理为前端展示需要的格式并存入待标注数据库,形成自动标注模块㊂4.3.4 前端标注系统前端根据文本中每个实体所属的不同实体类型渲染为不同的颜色,以方便用户查看㊂当用户标注完毕并提交后,标注结果将传回后台进行处理和保存㊂图4为用户的标注界面示例㊂图4 中文生物医学实体自动标注平台标注界面示例5 结语本文利用词典和CRF 算法对文本内容和语义进行识别与分析,同时构建了一个具备人工导入文献㊁标注㊁管理员审核结算功能的中文生物医学命名实体自动识别平台,可以为生物医学领域的研究者进行信息的数据挖掘㊁中文语料库的构建提供支持㊂基于机器学习算法的中文生物医学命名实体自动识别在一定程度上提高了实体标注效率,但随着计算机技术的不断发展,算法编写与优化也不断向前发展㊂Bert+LSTM+CRF 等方法已应用于实体识别等领域,并取得较好效果㊂因此,未来可整合新的机器学习算法,提高机器自动识别的准确率㊂为提高用户满意度,今后将不断完善平台功能,美化平台设计,丰富可视化展示的图表,以多种可视化的表现形式展示数据的动态交互,提高平台的反应速度㊂【参考文献】[1] 刘洪涛.基于生物医学语料的神经机器翻译系统研究[D].长春:吉林大学,2020.[2] 杨锦锋,关 毅,何 彬,等.中文电子病历命名实体和实体关系语料库构建[J].软件学报,2016,27(11):2725-2746.[3] 李梦叶.医学文献中疾病与病症关系抽取研究与应用[D].大连:大连理工大学,2018.[4] 刘宏伟.基于生物医学文献挖掘的化合物与疾病关系识别[D].合肥:中国科学技术大学,2018.[5] 杨 希.面向海量生物医学文献的实体关系提取方法及其应用研究[D].长沙:国防科技大学,2017.[6] 周荣鹏.生物医学文献中命名实体的识别[D].大连:大连理工大学,2009.[7] 庹兵兵.中文用户健康词汇表构建研究[D].武汉:华中科技大学,2017.[8] Poulter G L,Rubin D L,Altman R B,et al .MScanner:a classifierfor retrieving medline citations [J].BMC Bioinfonnatics,2008,9:108.[9] Pyysalo S ,Ginter F,Heimonen J,et al .BioInfer:a corpus for infor⁃mation extraction in the biomedical domain [J ].BMC Bioinforma⁃tics,2007,8:50.[10] 晏归来,安新颖,范少萍,等.国外生物医学文本语料库分类及特点研究[J].医学信息学杂志,2018,39(10):74-80.[11] National Library of Medcine.PubTator [EB /OL].[2019-11-05].https:// /research /pubtator.[12] Coden AR,Pakhomov SV,Ando RK,et al .Domain-specific lan⁃guage models and lexicons for tagging[J].Journal of BiomedicalInformatics 2005,38(6):422-430.[13] Neves M.An analysis on the entity annotations in biologicalcorpo⁃ra[J].F1000Research,2014,3:96.[14] 杨 帅.肝癌精准医学语料标注[D].北京:军事科学院,2018.[15] Kim J D,Ohta L,Tateisi Y,et al .GENIA corpus-a semanticallyannotated corpus for bio-textmining [J].Bioinformatics(Oxford,England),2003,19(S1):i180-i182.[16] 徐 凯.面向医学命名实体识别的深度学习方法研究[D].广州:广东工业大学,2019.[17] 罗哲恒.精准医学知识库构建中的生物医学命名实体识别研究[D].北京:军事科学院,2019.[18] 翟菊叶,叶泽坤,杨 枢,等.基于生物医学文献挖掘的疾病-基因-药物关系抽取研究[J].新余学院学报,2018,23(2):1-5.[19] Fontaine J F,Barbosa-Silva A,Scgaefer M,et al .MedlineRanker:flexible ranking of biomedical literature[J].Nucleic Acids Re⁃search,2009,37(S2):Wl41-Wl46.[20] 刘胜宇.生物医学文本中药物信息抽取方法研究[D].哈尔滨:哈尔滨工业大学,2016.[21] 李世超.基于Hadoop 平台和隐马尔可夫模型的生物医学命名实体识别方法研究[D].咸阳:西北农林科技大学,2017.[收稿日期:2020-04-29][本文编辑:黄思敏]。
2------------NLPIR(ICTCLAS2016)分词系统添加用户词典功能

2------------NLPIR(ICTCLAS2016)分词系统添加⽤户词典功能备注:win7 64位系统,netbeans编程基本代码框架参见我的另⼀篇⽂章:代码实现:1. 1package cwordseg;23import java.io.UnsupportedEncodingException;4// import utils.SystemParas;5import com.sun.jna.Library;6import com.sun.jna.Native;78/**9 *10 * 功能:添加/删除⽤户⾃定义词汇/词典11 * 最后更新时间:2016年3⽉15⽇ 14:09:4912*/1314public class CWordSeg {15public interface CLibrary extends Library {16 CLibrary Instance = (CLibrary) Native.loadLibrary("D:\\NetBeansProjects\\CWordSeg\\file\\win64\\NLPIR",CLibrary.class);17public int NLPIR_Init(String sDataPath,int encoding,String sLicenceCode);18public String NLPIR_ParagraphProcess(String sSrc, int bPOSTagged);19// 添加⽤户词汇20public int NLPIR_AddUserWord(String sWord);21// 删除⽤户词汇22public int NLPIR_DelUsrWord(String sWord);23// 保存⽤户词汇到⽤户词典24public int NLPIR_SaveTheUsrDic();25// 导⼊⽤户⾃定义词典:⾃定义词典路径,bOverwrite=true表⽰替代当前的⾃定义词典,false表⽰添加到当前⾃定义词典后26public int NLPIR_ImportUserDict(String sFilename, boolean bOverwrite);27public String NLPIR_GetLastErrorMsg();28public void NLPIR_Exit();29 }3031public static String transString(String aidString,String ori_encoding,String new_encoding) {32try {33return new String(aidString.getBytes(ori_encoding),new_encoding);34 } catch (UnsupportedEncodingException e) {35 e.printStackTrace();36 }37return null;38 }3940public static void main(String[] args) throws Exception {41 String argu = "D:\\NetBeansProjects\\CWordSeg\\file";42// String system_charset = "UTF-8";43int charset_type = 1;44int init_flag = CLibrary.Instance.NLPIR_Init(argu, charset_type, "0");45 String nativeBytes;4647// 初始化失败提⽰48if (0 == init_flag) {49 nativeBytes = CLibrary.Instance.NLPIR_GetLastErrorMsg();50 System.err.println("初始化失败!原因:"+nativeBytes);51return;52 }5354 String sInput = "这是⼀本关于信息检索的书,作者是南京⼤学的。
自然语言处理技术手册

自然语言处理技术手册自然语言处理(Natural Language Processing,简称NLP)是人工智能领域的一个重要分支,旨在让计算机能够理解、处理和生成自然语言。
本手册旨在给读者提供一份详尽的自然语言处理技术介绍,涵盖了基本概念、常见任务和主要方法。
一、概述自然语言处理是研究计算机与人类语言之间交互的一门学科。
它涉及到语言的理解、生成、机器翻译、信息检索等多个任务。
NLP技术广泛应用于文本分析、机器翻译、情感分析、语音识别等领域。
二、文本处理1. 文本预处理文本预处理是自然语言处理的第一步,旨在将原始文本转化为计算机能够理解和处理的形式。
常见的文本预处理任务包括分词、去除停用词、词干提取等。
2. 词向量表示词向量是将词语表示为连续向量的方式,将离散的词语转化为计算机能够处理的数值形式。
常见的词向量表示方法包括词袋模型、word2vec、GloVe等。
三、语言模型语言模型是用来计算一个句子在语言中的概率的模型。
语言模型能够用于机器翻译、语音识别等任务。
常见的语言模型包括n-gram模型、循环神经网络语言模型(RNNLM)等。
四、文本分类与情感分析文本分类是自然语言处理中的一项重要任务,旨在将文本划分到不同的类别中。
情感分析是文本分类的一个应用,旨在分析文本中的情感倾向。
常见的文本分类方法包括朴素贝叶斯分类器、支持向量机(SVM)等。
五、机器翻译机器翻译是将一种语言的文本翻译成另一种语言的任务。
机器翻译技术分为统计机器翻译和神经网络机器翻译两种类型,常见的方法包括IBM模型、编码器-解码器模型(seq2seq)等。
六、信息检索信息检索是从大规模文本库中检索与用户查询相匹配的文档的任务。
常见的信息检索方法包括向量空间模型(VSM)、倒排索引等。
七、对话系统对话系统旨在实现与用户进行自然语言交互的人机对话。
常见的对话系统方法包括基于规则的对话系统、基于检索的对话系统、基于生成模型的对话系统等。
分词系统研究完整版(ICTCLAS)

分词系统研究完整版ICTClAS分词系统是由中科院计算所的张华平、刘群所开发的一套获得广泛好评的分词系统,难能可贵的是该版的Free版开放了源代码,为我们很多初学者提供了宝贵的学习材料。
但有一点不完美的是,该源代码没有配套的文档,阅读起来可能有一定的障碍,尤其是对C/C++不熟的人来说.本人就一直用Java/VB作为主要的开发语言,C/C++上大学时倒是学过,不过工作之后一直没有再使用过,语法什么的忘的几乎一干二净了.但语言这东西,基本的东西都相通的,况且Java也是在C/C++的基础上形成的,有一定的相似处.阅读一遍源代码,主要的语法都应该不成问题了.虽然在ICTCLAS的系统中没有完整的文档说明,但是我们可以通过查阅张华平和刘群发表的一些相关论文资料,还是可以窥探出主要的思路.该分词系统的主要是思想是先通过CHMM(层叠形马尔可夫模型)进行分词,通过分层,既增加了分词的准确性,又保证了分词的效率.共分五层,如下图一所示:基本思路:先进行原子切分,然后在此基础上进行N-最短路径粗切分,找出前N个最符合的切分结果,生成二元分词表,然后生成分词结果,接着进行词性标注并完成主要分词步骤.下面是对源代码的主要内容的研究:1.首先,ICTCLAS分词程序首先调用CICTCLAS_WinDlg::OnBtnRun()开始程序的执行.并且可以从看出它的处理方法是把源字符串分段处理。
并且在分词前,完成词典的加载过程,即生成m_ICTCLAS对象时调用构造函数完成词典库的加载。
关于词典结构的分析,请参加分词系统研究(二)。
void CICTCLAS_WinDlg::OnBtnRun(){......//在此处进行分词和词性标记if(!m_ICTCLAS.ParagraphProcessing((char *)(LPCTSTR)m_sSource,sResult)) m_sResult.Format("错误:程序初始化异常!");elsem_sResult.Format("%s",sResult);//输出最终分词结果......}2.在OnBtnRun()方法里面调用分段分词处理方法boolCResult::ParagraphProcessing(char *sParagraph,char *sResult)完成分词的整个处理过程,包括分词的词性标注.其中第一个参数为源字符串,第二个参数为分词后的字符串.在这两个方法中即完成了整个分词处理过程,下面需要了解的是在此方法中,如何调用其它方法一步步按照上图所示的分析框架完成分词过程.为了简单起见,我们先不做未登录词的分析。
集成NLPIR语义分析汇总
Java集成NLPIR语义分析系统1简介NLPIR是一套专门针对原始文本集进行处理和加工的软件,提供了中间件处理效果的可视化展示,也可以作为小规模数据的处理加工工具。
用户可以使用该软件对自己的数据进行处理。
NLPIR分词系统前身为2000年发布的ICTCLAS词法分析系统,从2009年开始,为了和以前工作进行大的区隔,并推广NLPIR自然语言处理与信息检索共享平台,调整命名为NLPIR分词系统。
NLPIR 系统支持多种编码(GBK 编码、UTF8 编码、BIG5 编码)、多种操作系统(Windows, Linux,FreeBSD 等所有主流操作系统)、多种开发语言与平台(包括:C/C++/C#,Java,Python,Hadoop 等)。
本文中,我们讨论NLPIR与Java Web项目的集成使用。
2源码下载https:///NLPIR-team/NLPIR,这个URL地址可以下载整个的NLPIR项目,如果要下载某一单独部分,比如summary(摘要),在下载时需要用TortoiseSVN工具,在check out里输入地址:https:///NLPIR-team/NLPIR/tree/master/NLPIR%20SDK/Summary,把tree/master换成trunk,下载。
3与web项目集成web项目的搭建与配置在这里不在累述。
NLPIR2016版本可以使用配置文件配置需要读取的dll路径使用配置文件时,代码中初始化接口时需要修改读取dll文件的路径。
如:图中的nlpirpathString需要读取dll_or_so_path来获得(避免又用配置文件,有放dll到tomcat bin目录下的问题)如果不用配置文件,则需要把用到的dll放到tomcat的bin目录下。
我们以提取文本摘要为例,讲一下集成NLPIR。
3.1加入jar包pom.xml里加入jna包的引用3.2拷贝Data和win64两个文件夹把下载的源码中Data和win64两个文件夹拷贝到tomcat的bin目录下3.3拷贝代码拷贝src下的文件到项目下,修改包路径3.4对方法进行简单封装3.5创建controller和service 返回jsp页面获取摘要的controller方法,content为文本字符串获取摘要的service方法3.6jsp页面textarea 文本输入域btn为功能按钮result为结果展现区域4测试在上一个输入框中输入文本,点击提取摘要,结果展现为下边输入框的内容。
NLPIR-ICTCLAS分词系统开发手册2016版

5.分词功能 C/C++接口............................................................................................................15
5.1 NLPIR_Init.....................................................................................................................15
Versio n
Author/Revie wer
Date
V1.0 Kevin Zhang 2011-8-21
V2.0 V3.0 V4.0 V5.0
Kevin Zhang Kevin Zhang Kevin Zhang Kevin Zhang
2012-8-21 2012-12-19 2013-12-19 2014-8-3
5.5 NLPIR_ParagraphProcessA...........................................................................................21 5.6 NLPIR_FileProcess.........................................................................................................22
Author
张华平
Publisher
/
Version Status Date Approved by
V4.0
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
3.
NLPIR/ICTCLAS2016 分词系统评测.............................................................................. 11
3.1 NLPIR/ICTCLAS 在 973 评测中的测试结果......................................................... 11 3.2 第一届国际分词大赛的评测结果..........................................................................12
5.16 NLPIR_GetFileNewWords ...........................................................................................36 5.17 NLPIR_FingerPrint .......................................................................................................37
5.2 NLPIR_Exit.....................................................................................................................16
5.3 NLPIR_ImportUserDict.................................................................................................17 5.4 NLPIR_ParagraphProcess.............................................................................................19
NLPIR Copyright © 2016 Kevin Zhang. All rights reserved.
2/56
NLPIR/ICTCLAS2016 分词系统开发文档
Document Information
Document ID NLPIR-ICTCLAS-2013-WHITEPAPER Security level Public 公开
1.
NLPIR/ICTCLAS2016 分词系统简介................................................................................5
2.
NLPIR/ICTCLAS2016 分词系统主要功能介绍................................................................6
Author
张华平
Publisher
/
Version Status Date Approved by
V4.0
Creation and first draft for comment Dec 19, 2013
Version History
Note:The first version is”v0.1”. Each subsequent version will add 0.1 to the exiting version. The version number should be updated only when there are significant changes, for example, changes made to reflect reviews. The first figure in the version 1.x denotes current review status by. 1. x denotes review process has passed round 1 etc .Anyone who create, review or modify the document should describe his action.
5.9 NLPIR_AddUserWord....................................................................................................27 5.10 NLPIR_SaveTheUsrDic................................................................................................28 5.11 NLPIR_DelUsrWord.....................................................................................................30 5.12 NLPIR_GetKeyWords ..................................................................................................31 5.13 NLPIR_GetFileKeyWords ............................................................................................33
目录 ..................................................................................................................................................4
5.分词功能 C/C++接口............................................................................................................15
5.1 NLPIR_Init.....................................................................................................................15
complete draft for comment.ICTCLAS2014
complete draft for comment.ICTCLAS2014 add some functions. complete draft for comment.ICTCLAS2014 add some functions. complete draft for comment.ICTCLAS2016 add some functions.
3.3 NLPIR/ICTCLAS 的评测结果 ................................................................................12
4.
NLPIR/ICTCLAS 大事记:..............................................................................................13
NLPIR/ICTCLAS2016 分词系统开发文档
NLPIR/ICTCLAS 2016 分词系统开发文档
/ @ICTCLAS 张华平博士
2016-2
NLPIR Copyright © 2016 Kevin Zhang. All rights reserved.
5.5 NLPIR_ParagraphProcessA...........................................................................................21 5.6 NLPIR_FileProcess.........................................................................................................22
NLPIR Copyright © 2016 Kevin Zhang. All rights reserved.
3/56
NLPIR/ICTCLAS2016 分词系统开发文档
目录
NLPIR/ICTCLAS 2016 分词系统开发文档 ..................................................................................1
Versio n
Author/Revie wer
Date
V1.0 Kevin Zhang 2011-8-21
V2.0 V3.0 V4.0 V5.0
Kevin Zhang Kevin Zhang Kevin Zhang Kevin Zhang
2012-8-21 2012-12-19 2013-12-19 2014-8-3
V6.0 Kevin Zhang 2014-12-25
V6.0 Kevin Zhang 2015omplete draft for comment. ICTCLAS2010 complete draft for comment.ICTCLAS2012