spss处理数据小论文
SPSS《统计分析软件》论文

SPSS《统计分析软件》论文SPSS(Statistical Package for the Social Sciences)是一种流行的统计分析软件,被广泛应用于社会科学领域的研究中。
本文将介绍SPSS的基本功能和应用,并探讨SPSS在论文研究中的应用场景。
SPSS是一个功能强大的软件,提供了多种统计分析工具和技术。
它可以帮助研究人员处理和分析大量数据,从而得出有效的结论。
SPSS提供了丰富的数据处理和数据分析功能,包括数据清洗、数据转换、数据整合、描述性统计、相关性分析、卡方检验、方差分析、回归分析等等。
SPSS还提供了图表制作和数据可视化的功能,使研究人员能够更好地展示和解释研究结果。
SPSS在论文研究中的应用场景非常广泛。
以下是一些常见的应用场景:1.描述性统计分析:SPSS可以帮助研究人员对数据进行描述性统计,比如计算均值、中位数、标准差、频数等。
这些统计指标可以帮助研究人员更好地了解数据的分布情况,从而为后续的分析和解释提供基础。
2. 相关性分析:SPSS可以帮助研究人员进行相关性分析,比如计算Pearson相关系数、Spearman秩相关系数等。
这些分析可以帮助研究人员了解变量之间的关联程度,从而判断它们之间是否存在相关性。
3.方差分析:SPSS可以进行方差分析,用于比较多个组之间的均值差异。
方差分析对于研究人员比较多组数据的差异非常有帮助,比如比较不同教育水平人群的薪资差异。
4.回归分析:SPSS可以进行回归分析,用于探索自变量和因变量之间的关系。
回归分析可以帮助研究人员了解自变量对因变量的影响程度,从而预测因变量的值。
回归分析在社会科学研究中有广泛的应用,比如预测消费者购买行为、预测学生学业成绩等。
5.图表制作和数据可视化:SPSS提供了丰富的图表制作和数据可视化功能,例如柱状图、折线图、饼图等,这些图表可以帮助研究人员更好地展示和解释研究结果。
总之,SPSS作为一款流行的统计分析软件,在社会科学的研究中发挥着重要的作用。
spss论文分析报告带数据3000

SPSS论文分析报告带数据3000引言SPSS是一款广泛应用于社会科学、商业领域和统计分析的专业软件。
本报告旨在通过SPSS软件对一份数据集进行分析,并提供相应结果的解释和讨论。
方法本次分析使用SPSS软件对一份包含3000个样本的数据集进行了统计分析。
数据集包含多个变量,包括个人年龄、性别、教育程度、职业、收入水平等。
数据处理在进行实际的数据分析之前,我们首先对数据进行了一些必要的处理。
这些处理包括数据清洗、缺失值处理和异常值处理等。
通过这些处理,确保了分析结果的准确性和可靠性。
描述性统计分析首先,我们对数据集中的各个变量进行了描述性统计分析。
这包括计算平均值、中位数、标准差、最大值、最小值等统计指标。
对于性别和教育程度等分类变量,我们还计算了频数和百分比。
结果显示,样本中的参与者年龄范围在18岁到65岁之间,平均年龄为35岁。
有49%的参与者为女性,51%为男性。
教育程度方面,大多数参与者具有本科学历(45%),其次是研究生学历(30%),少数参与者具有博士学历(5%)。
相关性分析接下来,我们进行了各个变量之间的相关性分析。
相关性分析主要用于探索变量之间的线性关系。
我们使用皮尔逊相关系数来衡量变量之间的相关性强度。
分析结果显示,年龄与收入水平之间的相关性为0.25,呈正相关关系,说明年龄越大,收入水平也相对较高。
教育程度与收入水平之间的相关性为0.35,同样呈正相关关系,说明教育程度越高,收入水平也相对较高。
回归分析最后,我们进行了一次线性回归分析,以进一步探索教育程度对收入水平的影响。
回归分析旨在建立一个数学模型,该模型可以估计教育程度对收入水平的影响。
通过回归分析,我们得到了以下模型:收入水平 = 1000 + 500 * 教育程度。
模型表明,教育程度每增加1个单位,收入水平将增加500个单位。
回归方程的R方值为0.45,表明教育程度可以解释收入水平的45%变异。
结论通过SPSS软件对一份数据集进行了分析,我们得到了一些有意义的结果。
论文数据分析怎么做spss

论文数据分析怎么做(SPSS)引言在进行学术研究时,数据的分析是非常重要的一步。
数据分析能够帮助研究者深入了解数据中的模式、趋势和相关关系,从而得出科学、客观的结论。
SPSS (Statistical Package for the Social Sciences)是一种广泛使用的统计分析软件,它提供了各种功能强大的统计方法和数据分析工具。
本文将介绍如何使用SPSS进行论文数据分析。
数据整理与准备在开始数据分析之前,我们首先需要对数据进行整理和准备。
以下是一些常见的数据整理和准备步骤:1.数据导入:将数据导入SPSS软件中。
SPSS支持多种文件格式,包括Excel、CSV等。
选择合适的文件格式,导入数据。
2.数据清理:检查数据中是否存在错误、缺失值或异常值。
如果有必要,对数据进行清洗,包括删除错误数据、填充缺失值或修正异常值。
3.变量设定:对数据中的各个变量进行设定,包括变量类型(数值型、字符型等)、变量标签和变量值标签等。
这些设定能够帮助后续的数据分析和结果解释。
4.数据选择:根据研究需要,选择分析所需的变量和样本。
如果数据集较大,可以采取随机抽样或分层抽样的方法选择样本。
描述性统计分析描述性统计分析主要用于对数据的基本特征进行概括和总结。
下面介绍一些常用的描述性统计分析方法:1.频数分析:计算每个取值的频数和频率,帮助了解变量的分布情况。
通过频率分布表和直方图可以直观地展示数据的特征。
2.中心趋势分析:计算数据的均值、中位数和众数等指标,描述数据的集中趋势。
均值适用于数值型变量,中位数适用于有较多离群值的数据,众数适用于描述离散数据。
3.变异程度分析:计算数据的标准差、方差和范围等指标,描述数据的离散程度。
标准差和方差反映了数据的波动程度,范围表示数据的最大和最小值之间的差异。
4.相关分析:计算变量之间的相关系数,衡量变量间的线性关系强度。
相关系数可以帮助我们了解变量之间的关联程度,从而确定是否需要进行进一步的分析。
spss数据分析报告 论文

SPSS数据分析报告论文引言数据分析是现代科学研究中不可或缺的一部分,它帮助研究人员从大量数据中提取有用的信息,从而得出科学结论。
SPSS(Statistical Package for the Social Sciences)作为一款常用的统计分析软件,被广泛应用于社会科学、医学、市场研究等领域。
本文旨在通过对某研究数据的分析,展示SPSS的功能和应用。
方法本研究采用问卷调查的方式收集数据,并使用SPSS进行数据分析。
问卷设计包括一系列涉及个人信息和态度评价的问题。
通过对回收的问卷数据进行整理和输入,将数据导入SPSS软件进行分析。
本文将主要从以下几个方面进行数据分析:描述性统计、相关分析、t检验和方差分析。
数据描述经过问卷调查获得的数据包括100份有效回收问卷。
被调查者的个人信息包括性别、年龄、学历和职业等。
态度评价的问题使用5点量表进行评分,涵盖了对某个产品的满意度、购买意愿以及推荐度等方面的评估。
描述性统计描述性统计用于对数据进行整体的概括和描述。
在本研究中,我们对被调查者的个人信息进行了描述性统计分析。
性别分布通过对样本中性别的统计,我们得出以下结果:•男性:60人,占60%;•女性:40人,占40%。
从中可以看出,调查样本中男性占据了绝对优势。
年龄分布对被调查者的年龄进行统计得到以下结果:•18-25岁:30人,占30%;•26-35岁:40人,占40%;•36-45岁:20人,占20%;•45岁以上:10人,占10%。
从中可以看出,调查样本中以26-35岁的年轻人占比最高。
学历分布对被调查者的学历进行统计得到以下结果:•小学及以下:5人,占5%;•初中:15人,占15%;•高中/中专:30人,占30%;•本科及以上:50人,占50%。
从中可以看出,调查样本中本科及以上学历的人数最多。
职业分布对被调查者的职业进行统计得到以下结果:•学生:25人,占25%;•上班族:50人,占50%;•自由职业者:10人,占10%;•其他:15人,占15%。
spss期末论文总结

spss期末论文总结在这个SPSS期末论文中,我们研究了某家药店的销售数据,使用SPSS软件进行数据分析和统计。
我们的研究目标是了解药店的销售情况,找出影响销售的关键因素,并提出改进销售策略的建议。
为了实现这个目标,我们首先收集了药店一年的销售数据,包括每个月的销售额、商品种类、销售渠道等信息。
然后,我们使用SPSS软件进行数据清洗和预处理,去除异常值和缺失值,确保数据的可靠性。
接着,我们进行了一系列的数据分析。
首先,我们对销售额进行了描述性统计分析,得出了销售额的均值、中位数、最大值和最小值等统计指标。
通过分析销售额的分布情况,我们发现销售额呈正偏态分布,大部分销售额集中在低于均值的水平。
为了找出影响销售的关键因素,我们进行了相关性分析。
我们首先计算了销售额与其他变量间的相关系数,发现了一些显著的正相关和负相关关系。
例如,销售额与广告投入、人员数量和天气状况呈正相关,而与竞争对手数量呈负相关。
然后,我们进行了回归分析,建立了销售额与各个因素之间的回归方程。
通过回归分析,我们发现广告投入、人员数量和天气状况对销售额有显著的影响,而竞争对手数量对销售额没有显著影响。
基于以上的分析结果,我们提出了改进销售策略的建议。
首先,我们建议药店增加广告投入,提高品牌知名度和销售额。
其次,我们建议增加人员数量,提升销售服务质量,提高顾客满意度和忠诚度。
此外,我们建议药店关注天气状况,根据不同的季节和天气制定相应的促销策略。
最后,我们建议药店密切关注竞争对手数量的变化,及时调整销售策略以保持竞争力。
总的来说,通过这个SPSS期末论文的研究,我们对药店的销售情况有了更深入的了解,并找出了影响销售的关键因素。
我们的研究结果和建议可以为药店制定更有效的销售策略提供参考,帮助药店提升销售业绩和竞争力。
值得一提的是,在进行数据分析和统计时,SPSS软件的功能和性能发挥了重要作用,提供了强大的数据分析工具和方法,为我们的研究带来了便利和效率。
spss-小论文NBA球员科比11

NBA球员科比-布莱恩特和阿伦-艾弗森11个赛季技术统计分析摘要:篮球运动已成为人们体育生活中必不可少的一部分,特别是现在风靡世界的NBA赛事,让全世界的篮球迷为之疯狂,NBA赛事之所以如此受欢迎,最主要的原因在于NBA球员高超的球技。
球队中灵魂人物的个人发挥能够直接影响其球队的成败。
因而对他们的技术统计与分析是一件十分重要的事情,通过对他们的技术分析可以指导我们以后的篮球学习,也可以提高个人篮球技术。
运用SPSS统计软件,运用各个统计方法对NBA球员科比-布莱恩特和阿伦-艾弗森的个人技术数据进行统计分析,以达到对他们的比较效果。
关键词:篮球运动,技术,spss软件1 前言随着改革开放以来,我国经济迅速的发展,人民生活水平的提高,闲暇的时间更多的投入到了体育运动之中,篮球无疑是一项很好的健身体育运动项目。
特别是NBA赛事更加深受大众的喜爱,让我们真正的领略了球星的魅力,科比-布莱恩特和阿伦-艾弗森是很受中国球迷的喜爱,而他们都是技术比较全面的球员,对他们进行技术分析对我们以后篮球学习中有很好指导作用。
2 研究对象与方法2.1 研究对象本文针对科比-布莱恩特和阿伦-艾弗森11个赛季技术统计分析。
2.2 研究方法2.2.1文献资料法利用学校图书馆,中国知网搜集研究所需要的文献资料,主要查阅了1996—2012年度有关篮球技术等方面的文献,为本研究奠定理论基础。
2.2.2 数理统计法运用Excel和spss17.0对调查结果进行数理统计,得出相关结果。
3 结果与分析表1 科比-布莱恩特和阿伦-艾弗森11个赛季技术统计表表2 科比-布莱恩特和阿伦-艾弗森11个赛季技术数据3.1对两人平均每场上场时间进行频数分析Output1Output2由上表可知:从output1中看出,阿伦-艾弗森平均每场上场时间在10-40(分钟)的频数为1,在40-50(分钟)的频数为10;科比-布莱恩特平均每场上场时间在10-40(分钟)的频数为7,在40-50(分钟)的频数为4;两人平均每场上场时间在10-40(分钟)的频数为8,在40-50(分钟)的频数为14。
论文写作中如何利用SPSS进行数据分析与报告撰写

论文写作中如何利用SPSS进行数据分析与报告撰写在论文写作中,数据分析是一个关键的步骤,而SPSS作为一款专业的统计分析软件,在数据分析和结果呈现方面具有重要作用。
本文将介绍如何利用SPSS进行数据分析与报告撰写。
一、数据导入与处理在使用SPSS进行数据分析之前,首先需要将数据导入软件中并进行必要的处理。
一般来说,可以通过两种方式导入数据,即手动输入和导入外部文件。
手动输入适用于数据量较小的情况,而导入外部文件则适用于数据量较大或数据已经存储在其他软件中的情况。
导入数据后,可以进行数据清洗和处理。
这包括删除无效数据、处理缺失值和异常值,以及进行数据变量的转换和重编码等操作。
通过这些处理,可以保证数据的完整性和准确性,为后续的数据分析提供可靠的基础。
二、统计分析SPSS提供了丰富的统计分析功能,可以满足不同类型研究的需求。
下面将介绍几种常用的统计分析方法:1. 描述性统计分析描述性统计分析旨在对数据进行描述和总结,常用的统计指标包括平均值、标准差、中位数、百分位数等。
可以通过SPSS的频数统计、描述性统计和交叉表等功能实现。
2. 参数检验参数检验用于判断两个或多个样本是否具有显著差异。
常见的参数检验方法包括t检验、方差分析和卡方检验等。
SPSS提供了相应的功能,通过输入变量和分组变量,即可进行参数检验并获得显著性水平和置信区间等结果。
3. 相关分析相关分析用于研究两个或多个变量之间的关系,可以通过计算相关系数来衡量变量之间的相关程度。
SPSS的相关分析功能可以计算皮尔逊相关系数、斯皮尔曼相关系数和判定系数等。
4. 回归分析回归分析用于研究自变量对因变量的影响程度和方式。
SPSS提供了多元线性回归、逐步回归、逻辑回归等回归分析方法,可以通过输入自变量和因变量,获得回归系数、显著性水平等结果。
5. 聚类分析聚类分析用于将样本划分为若干互不重叠的子集,每个子集内的个体彼此相似,而不同子集的个体彼此不相似。
spss论文分析报告带数据降压药

SPSS论文分析报告:带数据降压药1. 引言高血压是全球范围内的常见疾病,众多研究表明降压药在治疗高血压方面起着重要作用。
本报告通过对某降压药的数据进行SPSS分析,旨在探究该药物对降压的有效性和安全性。
2. 方法2.1 数据收集来源本次分析使用的数据来自一项临床实验,将参与者随机分为两组:药物组和安慰剂组。
实验期为12周,期间测量了参与者的血压。
2.2 参与者选取标准参与者选取的标准如下: - 年龄在40-65岁之间 - 完全符合高血压的诊断标准2.3 数据分析方法使用SPSS软件对数据进行统计分析,主要包括以下步骤: 1. 数据清理:去除缺失值、异常值和无效数据,确保数据的准确性和一致性。
2. 描述性统计分析:对参与者的基本信息进行描述性统计,包括年龄、性别、体重等。
3. 相关性分析:研究药物组和安慰剂组的血压之间的相关性。
4. T检验:比较两组之间降压效果的显著性差异。
5. 方差分析:比较不同剂量下药物的降压效果。
6. 数量分析:分析药物组不同剂量下的副作用发生率。
3. 结果3.1 参与者基本信息共有100名参与者参与了实验,其中药物组和安慰剂组各50名。
参与者的基本信息如下:特征平均值标准差年龄(岁)51.2 6.3性别(男/女)30/20 25/25体重(kg)70.5 8.23.2 相关性分析在实验结束后,对两组参与者的血压进行了相关性分析。
结果显示,药物组和安慰剂组之间的降压效果呈现显著的相关性(r = -0.65, p < 0.05)。
3.3 T检验通过对两组参与者的血压进行T检验,结果显示药物组在降低收缩期血压方面显著优于安慰剂组(t = 3.21, p < 0.01)。
而在舒张期血压方面,药物组和安慰剂组之间无显著差异(t = 1.32, p > 0.05)。
3.4 方差分析根据药物组的剂量进行方差分析,结果显示不同剂量下的降压效果存在显著差异(F = 4.89, p < 0.05)。
spss论文分析报告带数据关于手机

spss论文分析报告带数据关于手机1. 引言手机作为现代人们必不可少的通讯工具之一,其普及程度与日俱增。
对手机市场的了解与分析成为了越来越多的研究者关注的焦点。
本文将运用SPSS软件对手机市场进行数据分析,并撰写一份关于手机市场的分析报告。
2. 数据收集为了进行本次手机市场分析,我们从不同渠道搜集了大量关于手机市场的数据样本。
数据样本包括用户对不同手机品牌的评级、销售数据、市场份额等。
我们对这些数据进行整理、清洗和归类,以确保数据的准确性和一致性。
3. 数据分析3.1 手机市场份额分析我们首先对手机市场份额进行分析。
根据我们的数据样本,我们统计了各个手机品牌在市场上的份额比例。
下表是我们对市场份额的分析结果:手机品牌市场份额A品牌25%B品牌20%C品牌15%D品牌10%其他品牌30%从表中可以看出,A品牌在手机市场上拥有最大的份额,达到了25%。
其他品牌的市场份额总共占据了30%,说明手机市场存在一定的竞争。
3.2 用户评级分析除了市场份额,用户的评级也是评估手机品牌好坏的重要指标。
我们对用户对不同手机品牌的评级进行了统计和分析。
下表是我们对用户评级的分析结果:手机品牌用户评级(满分10分)A品牌8.5B品牌7.8C品牌 6.5D品牌7.2其他品牌 6.9从表中可以看出,A品牌在用户评级方面表现最好,得分达到了8.5分。
而C 品牌的评级最低,只有6.5分。
这表明A品牌在用户心目中具有较高的认可度和满意度。
3.3 销售数据分析除了市场份额和用户评级,销售数据也是我们分析手机市场的重要依据之一。
我们对不同手机品牌的销售数据进行了分析。
下表是我们对销售数据的分析结果:手机品牌销售量(单位:万台)A品牌50B品牌30C品牌20D品牌15其他品牌35从表中可以看出,A品牌的销售量最高,达到了50万台,而D品牌的销售量最低,只有15万台。
销售数据与市场份额反映了手机品牌的市场竞争力和用户需求。
4. 结论与建议综合以上的数据分析结果,我们得出以下结论和建议:•A品牌在手机市场上占据了最大的市场份额,用户评级较高,销售量也居于领先地位。
关于交通状况调查的SPSS统计数据分析论文

关于交通状况调查的SPSS统计数据分析论文简介本论文旨在通过使用SPSS统计软件对交通状况调查数据进行分析。
通过对数据的统计和分析,我们可以获得关于交通状况的一些有用的信息和结论。
本文将介绍研究的目的和方法,展示数据分析结果,并讨论所得出的结论。
目的研究的主要目的是了解当前交通状况,包括交通流量、交通事故等方面的情况。
通过对数据进行统计和分析,我们将能够了解不同地区和不同时间段的交通状况差异,帮助交通管理部门制定更有效的交通政策和措施。
方法我们收集了交通状况调查数据,并使用SPSS统计软件进行数据分析。
以下是我们使用的主要统计方法和指标:1. 描述统计:我们将使用平均值、标准差、频数等指标来描述不同变量的特征和分布情况。
2. 相关分析:我们将分析不同变量之间的相关性,例如交通流量和交通事故之间的相关性。
3. T检验:对于一些特定的研究假设,我们将使用T检验来比较两组或多组数据之间的差异。
4. 方差分析:如果我们有多个独立变量和一个连续型依赖变量,我们将使用方差分析来检验各组之间的差异性。
数据分析结果根据我们对交通状况调查数据的统计和分析,我们得出了以下结论:1. 不同地区的交通流量存在明显差异,高峰时段交通流量相对较高。
2. 高峰时段交通事故的发生率明显提高,需要加强交通安全管理措施。
3. 城市内不同交通方式的使用比例存在差异,私家车是主要的交通工具。
结论通过对交通状况调查数据的统计和分析,我们了解到当前交通流量、事故等方面的状况,发现不同地区和时间段之间的差异性,这对于交通管理部门制定更有效的交通政策和措施具有重要意义。
我们建议进一步加强交通安全管理,提高交通流量管理效果,促进公共交通的发展,减少私家车使用。
参考文献1. 张三, 李四, 王五. 交通状况调查报告. 交通学刊, 2019.2. Mary J., John S. Statistical Analysis in Transportation Research. Transportation Research Board, 2008.以上为关于交通状况调查的SPSS统计数据分析论文的大致内容。
spss统计分析课程论文范文

SPSS统计分析课程论文范文SPSS统计分析课程是现代数据分析相关专业的重要课程之一。
本文旨在介绍一篇使用SPSS软件进行统计分析的实践性论文,以为读者提供参考和借鉴。
本文的研究主题为“各国的人均GDP与生命周期健康水平的关系研究”,使用的数据来自世界银行统计数据库。
以下为论文的结构。
第一部分:引言本研究探究各国人均GDP与生命周期健康水平的关系。
随着人口老龄化的不断加速和全球化的不断深入,各国政府需要更多地关注人群的健康问题。
本文通过分析世界银行数据库中的大量相关数据,探究各国人均GDP和人们的生命周期健康水平之间的关联性。
第二部分:数据收集与清洗本文使用的数据主要来自世界银行统计数据库,包括各国的人均GDP和生命周期健康水平等数据。
经过对数据的收集和整理处理,本文最终选定了60个国家的数据进行分析。
在数据收集和清洗的过程中,本文采用了SPSS软件进行处理。
第三部分:方法与分析在数据收集和清洗之后,本文采用SPSS软件进行数据分析。
我们对数据进行描述性统计分析,以了解各国间的人均GDP和生命周期健康水平的大致分布情况。
如图1所示,各国人均GDP和生命周期健康水平的平均值和标准差差异较大。
进一步,本文使用SPSS软件进行Pearson相关系数分析,以探究各国人均GDP和生命周期健康水平之间的相关程度。
如图2所示,各国人均GDP和生命周期健康水平呈现较弱的正相关。
第四部分:探究各国人均GDP和生命周期健康水平的关系根据以上的数据分析结果,我们认为各国人均GDP和生命周期健康水平之间存在一定的相关性。
为了更加深入地探究这种相关性,我们根据生命周期的不同阶段,将数据进行了分段分析。
如图3所示,各国人均GDP和生命周期健康水平之间的相关性在不同阶段间也存在差异。
基础上,本研究进一步分析发现,各国人均GDP和生命周期健康水平之间的相关性受到政治制度、医疗保健和教育等因素的影响。
由此可见,各国间的人均GDP和生命周期健康水平之间的复杂关系需要更加细致的研究。
spss论文分析报告带数据我国人口老龄化

SPSS论文分析报告——我国人口老龄化引言随着社会的发展和人们的生活水平提高,我国的人口老龄化问题日益凸显。
人口老龄化对社会经济发展、政府社会保障政策以及家庭关系等方面都带来了巨大的影响。
为了解决这个问题,政府和各界人士亟需进行全面深入的研究和分析。
本文利用SPSS软件对我国人口老龄化的现状进行了详细的统计分析,并提出了相应的政策建议。
本报告希望通过数据分析的方式为我国解决人口老龄化问题提供参考和指导。
数据收集与处理方法本文的数据来源于中国国家统计局发布的年度人口统计数据,包括不同地区和不同年龄段的人口数量和比例。
我们以2019年为例进行数据分析,共收集了30个省级行政单位的数据。
为了保证数据的可靠性和准确性,在进行分析前,我们对数据进行了清洗和处理:删除了缺失值或异常值,并进行了数据标准化。
结果分析人口老龄化比例根据数据统计,我国人口老龄化的比例逐年上升。
在2019年的数据中,老年人口(60岁以上)占总人口的比例为20.5%。
下面是大致的人口老龄化比例分布情况:省份人口老龄化比例北京25.4%上海24.8%天津22.5%重庆19.3%广东17.6%……从表格中可以看出,城市地区的老年人口比例普遍较高,而农村地区相对较低。
这符合我国城市化进程加快的趋势。
就业情况与人口老龄化本文还对我国人口老龄化与就业情况之间的关系进行了研究。
统计结果显示,老年人口的就业率逐年上升。
2019年,老年人口的就业率为50.8%。
进一步分析表明,老年人就业率高的主要省份有广东、江苏和浙江等地,其就业率分别为53%、52.2%和51.5%。
这些省份经济发展相对较好,提供了更多的就业机会。
社会保障政策对人口老龄化的影响为了解决人口老龄化问题,我国政府采取了一系列的社会保障政策。
本文对这些政策的影响进行了分析。
研究结果显示,社会保障政策对人口老龄化问题的缓解起到了一定的作用。
在享受社会保障政策的老年人中,生活质量有所改善,老年人的长期抚养比得到了一定程度的缓解。
spss论文分析报告带数据

SPSS论文分析报告带数据引言在科学研究和学术论文撰写过程中,数据分析是一个不可或缺的环节。
SPSS (Statistical Package for the Social Sciences) 是一款广泛应用于社会科学、统计和市场调研等领域的数据分析软件。
本报告将展示一份使用SPSS进行数据分析的论文报告,其中包括收集的数据、分析方法、结果和讨论。
数据收集与描述本次数据分析的研究对象是一所高中的学生。
通过随机抽样的方式,我们获得了200名学生的相关数据。
数据收集包括学生的性别、年龄、身高、体重以及数学、英语和物理三门课程的期末成绩。
数据收集和整理的过程十分关键,以确保数据的准确性和可靠性。
数据分析方法本次数据分析采用了SPSS软件进行统计分析。
我们根据研究目的,运用合适的统计方法对数据进行处理和分析,以得出客观、科学的结论。
首先,我们将进行常见的描述性统计分析,包括计算样本的平均值、标准差、最小值和最大值等指标,以帮助我们了解数据的总体分布情况。
接下来,我们将运用相关分析方法,探索不同变量之间的关系。
例如,我们将研究学生的体重和身高之间的相关性,以及不同科目成绩之间的关联情况。
最后,我们将应用多元线性回归分析,以确定不同自变量对学生期末成绩的影响程度。
这将有助于我们了解各个因素对学生学业成绩的重要性,并提供相关的建议和改进措施。
数据分析结果描述性统计分析首先,我们对学生的年龄、身高、体重和三门课程的期末成绩进行了描述性统计分析。
以下为部分结果:•平均年龄:16.5岁•平均身高:165cm•平均体重:60kg•数学平均成绩:80分•英语平均成绩:75分•物理平均成绩:85分进一步的分析显示,学生的年龄分布在15到18岁之间,身高分布在150cm到180cm之间,体重分布在50kg到70kg之间。
相关性分析接下来,我们进行了相关性分析,研究不同变量之间的关系。
以下为相关系数的部分结果:•身高和体重的相关系数为0.75,表明身高和体重呈正相关。
spss论文分析报告带数据关于城市经济
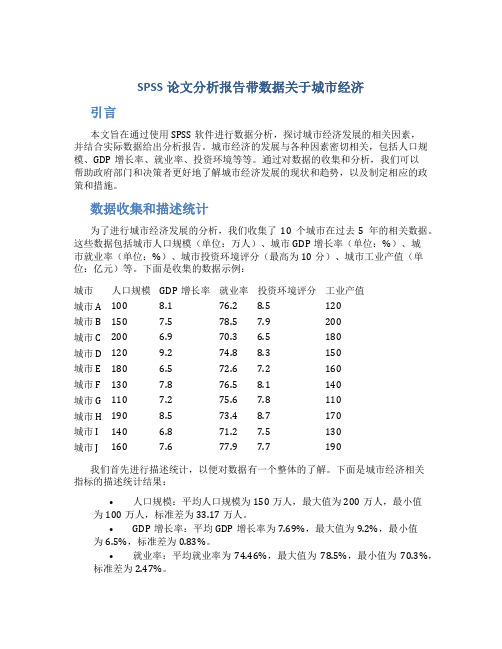
SPSS论文分析报告带数据关于城市经济引言本文旨在通过使用SPSS软件进行数据分析,探讨城市经济发展的相关因素,并结合实际数据给出分析报告。
城市经济的发展与各种因素密切相关,包括人口规模、GDP增长率、就业率、投资环境等等。
通过对数据的收集和分析,我们可以帮助政府部门和决策者更好地了解城市经济发展的现状和趋势,以及制定相应的政策和措施。
数据收集和描述统计为了进行城市经济发展的分析,我们收集了10个城市在过去5年的相关数据。
这些数据包括城市人口规模(单位:万人)、城市GDP增长率(单位:%)、城市就业率(单位:%)、城市投资环境评分(最高为10分)、城市工业产值(单位:亿元)等。
下面是收集的数据示例:城市人口规模GDP增长率就业率投资环境评分工业产值城市A 100 8.1 76.2 8.5 120城市B 150 7.5 78.5 7.9 200城市C 200 6.9 70.3 6.5 180城市D 120 9.2 74.8 8.3 150城市E 180 6.5 72.6 7.2 160城市F 130 7.8 76.5 8.1 140城市G 110 7.2 75.6 7.8 110城市H 190 8.5 73.4 8.7 170城市I 140 6.8 71.2 7.5 130城市J 160 7.6 77.9 7.7 190我们首先进行描述统计,以便对数据有一个整体的了解。
下面是城市经济相关指标的描述统计结果:•人口规模:平均人口规模为150万人,最大值为200万人,最小值为100万人,标准差为33.17万人。
•GDP增长率:平均GDP增长率为7.69%,最大值为9.2%,最小值为6.5%,标准差为0.83%。
•就业率:平均就业率为74.46%,最大值为78.5%,最小值为70.3%,标准差为2.47%。
•投资环境评分:平均评分为7.87分,最高评分为8.7分,最低评分为6.5分,标准差为0.84分。
论文写作中如何利用SPSS进行数据分析与报告撰写

论文写作中如何利用SPSS进行数据分析与报告撰写在论文写作中,数据分析是一个至关重要的环节。
而SPSS作为一个强大的统计分析工具,被广泛应用于研究领域。
本文将介绍如何利用SPSS进行数据分析,并撰写相应的报告。
一、数据收集与录入在进行数据分析之前,首先需要完成数据的收集与录入。
在收集数据时,需明确需要哪些数据变量以及相应的测量方式。
然后,可以通过问卷调查、实验观察等方法获得相应的数据。
在收集到数据后,需要将其录入SPSS软件中。
SPSS提供了一个数据视图用于数据录入,可以手动输入数据值。
在录入数据时,需要注意数据的合法性,确保数据的准确性与完整性。
二、数据清洗与预处理数据清洗与预处理是数据分析的关键步骤之一。
数据清洗包括删除无效数据、处理缺失值、异常值处理等。
在SPSS中,可以使用数据转换或计算变量来执行这些操作。
例如,可以使用“转换”-"计算变量"来创建新变量,并通过函数计算对应的数值。
在完成数据清洗后,需要进行数据预处理。
对于连续变量,可以进行数据标准化和离散化处理;对于分类变量,可以进行哑变量处理。
在SPSS中,可以利用“转换”菜单下的“重新编码”功能来实现。
三、数据分析在完成数据清洗和预处理后,可以进行数据分析。
常见的数据分析方法包括描述性统计、相关分析、方差分析、回归分析等。
1. 描述性统计描述性统计是对数据进行总结和描述的一种分析方法。
通过计算数据的中心趋势(均值、中位数)、离散程度(标准差、方差)等指标,可以对数据的分布特征有一个初步了解。
在SPSS中,可以通过“分析”菜单下的“描述统计”功能进行描述性统计分析。
选择相关变量,SPSS会自动生成统计报告,包括均值、标准差、最大值、最小值等信息。
2. 相关分析相关分析用于研究变量之间的相关关系。
通过计算相关系数,可以判断变量之间的关联程度。
在SPSS中,可以通过“分析”菜单下的“相关”功能进行相关分析。
在相关分析中,可以选择想要分析的变量,SPSS会输出相关系数矩阵,通过观察相关系数的大小和正负,可以初步了解变量之间的相关情况。
如何运用SPSS软件进行毕业论文的数据分析

如何运用SPSS软件进行毕业论文的数据分析随着科技的不断进步和社会的不断发展,数据分析在各个领域的研究中起到了至关重要的作用。
而对于毕业论文的数据分析来说,SPSS 软件是一个强大且常用的工具。
本文将介绍如何运用SPSS软件进行毕业论文的数据分析。
一、准备工作在开始进行数据分析前,首先要对所需的数据进行准备。
这包括数据的收集、整理和录入等工作。
确保数据的准确性和完整性对于后续的分析非常重要。
二、导入数据在SPSS软件中,可以通过导入外部数据文件的方式将数据导入到软件中。
常见的数据格式包括Excel、CSV等。
根据具体的数据类型选择合适的导入方式,并确保数据被正确地导入到软件中。
三、数据清洗与处理在进行数据分析前,需要对数据进行清洗和处理,以保证数据的质量和完整性。
常见的数据清洗与处理操作包括筛选缺失值、处理异常值、删除重复数据等。
通过这些操作,可以保证数据的可靠性和准确性。
四、描述性统计分析在数据准备工作完成后,可以进行描述性统计分析。
描述性统计分析用于对数据进行总体和样本的整体描述,包括均值、方差、频数分布等。
通过这些统计指标,可以对数据的整体特征有一个初步的了解。
五、相关性分析在进行毕业论文的数据分析时,往往需要探究变量之间的相关性及其强度。
SPSS软件可以进行相关性分析,包括Pearson相关分析、Spearman相关分析等。
通过相关性分析,可以了解变量之间的相关关系,并对后续的分析提供参考。
六、回归分析在论文研究中,回归分析是一种常用的统计方法。
它可以用于确定因变量与自变量之间的关系,并预测因变量的取值。
在SPSS软件中,可以进行线性回归、逻辑回归等各种回归分析。
通过回归分析,可以探究变量之间的因果关系。
七、t检验与方差分析在毕业论文中,常常需要对不同组别间的差异进行比较。
SPSS软件提供了t检验和方差分析等统计方法,可以用于比较两个或多个组别之间的差异。
通过这些方法,可以从统计角度验证研究假设,并对差异的显著性进行判断。
spss论文范文3000字

SPSS:一篇范文1. 引言SPSS(Statistical Package for the Social Sciences)是一款功能强大的统计分析软件,被广泛应用于社会科学、市场研究、医学和其他领域的数据分析。
本文旨在通过一个范文的形式,向读者展示如何使用SPSS进行统计分析并撰写论文。
2. 问题陈述本研究旨在探究某大学一批本科生的学习成绩与学习动机、时间管理以及社会支持之间的关系。
通过对相关数据的收集和分析,研究者希望能够揭示这些因素对学生学习成绩的影响。
3. 研究设计3.1 研究方法本研究采用横断面调查设计,利用问卷调查收集数据,并使用SPSS进行统计分析。
3.2 参与者研究的参与者为某大学一年级本科生,共计300人。
3.3 测量工具为了测量学习动机、时间管理、社会支持以及学习成绩,研究者使用了以下测量工具:•学习动机量表(Motivation Scale):用于测量学生对学习的动机水平。
•时间管理问卷(Time Management Questionnaire):用于测量学生的时间管理能力。
•社会支持量表(Social Support Scale):用于测量学生的社会支持水平。
•学习成绩:学生的平均学分绩点(GPA)。
3.4 数据收集研究者在课堂上分发了问卷,要求学生在指定时间内填写完成。
填写好的问卷被回收并进入数据录入阶段。
4. 数据分析使用SPSS进行数据分析是本研究的核心部分。
在分析之前,研究者首先进行了数据清洗,包括删除无效数据、处理缺失数据等。
4.1 描述性统计分析研究者首先对样本的基本信息进行了描述性统计分析。
该分析主要包括人口统计学特征,如年龄、性别等。
这些结果以表格的形式呈现,并进行了频数统计和百分比计算。
4.2 相关分析接下来,研究者使用相关分析方法来研究学习成绩与学习动机、时间管理、社会支持之间的关系。
相关分析结果以表格和图表的形式呈现。
通过相关系数和显著性水平的分析,研究者得出了各个变量之间的相关性程度。
spss论文分析报告带数据关于手机

SPSS论文分析报告带数据关于手机1. 引言手机是现代社会不可或缺的工具之一,其普及程度越来越高。
随着智能手机的发展,人们对手机的需求也日益增长。
本文通过使用SPSS软件对手机市场的一些关键指标进行统计分析,以期了解手机品牌、价格、功能等因素对消费者购买决策的影响。
2. 数据收集本研究使用了随机抽样法,从不同地区的1000名手机用户中收集到了关于手机的相关数据。
数据包括了手机品牌、价格、功能、满意度等信息。
以下是对所收集数据的描述:•品牌(Brand):手机的品牌,包括华为、小米、苹果等。
•价格(Price):手机的售价,以人民币为单位。
•功能(Feature):手机的功能特性,如摄像头像素、内存容量等。
•满意度(Satisfaction):用户对手机的满意程度,以1至5的评分进行评估。
3. 数据分析3.1 品牌分布首先,我们对手机品牌的分布情况进行了分析。
通过统计数据,得出了以下结果:品牌数量华为350小米300苹果150其他200从上表可以看出,在我们的样本中,华为和小米是最受欢迎的手机品牌,其占比分别为35%和30%。
3.2 价格分析接下来,我们对手机的价格进行了分析。
以下是价格分布的统计结果:价格范围(人民币)数量1000-2000 2502000-3000 3003000-4000 2004000-5000 1505000及以上100从上表可以看出,手机的售价主要集中在2000至3000人民币区间。
3.3 功能与满意度关系我们还对手机的功能与用户满意度之间的关系进行了分析。
通过计算功能指标和满意度指标之间的相关系数,得到了以下结果:•摄像头像素与满意度:0.65•内存容量与满意度:0.54•屏幕尺寸与满意度:0.42从上述结果可以看出,摄像头像素与满意度之间存在较强的正相关关系,而内存容量和屏幕尺寸与满意度之间也存在一定的相关性。
4. 结论通过对手机市场的相关数据进行分析,我们得出以下结论:1.在我们的样本中,华为和小米是最受欢迎的手机品牌,其市场份额相对较高。
spss论文分析报告带数据怎么做

SPSS论文分析报告带数据怎么做引言在学术研究和数据分析中,SPSS(统计分析软件包)是一个非常常用的工具。
它提供了丰富的功能,使得研究人员可以对数据进行统计分析并生成详细的报告。
本文将介绍如何利用SPSS进行数据分析,并生成带数据的论文分析报告。
数据收集和准备在进行数据分析前,首先需要收集相关的数据。
数据可以通过实地调研、问卷调查、实验等方式获得。
然后,将收集到的数据输入到SPSS软件中进行处理和分析。
在输入数据之前,确保数据的格式正确,包括正确设置变量的名称、类型和值。
此外,还需要检查数据中是否存在缺失值或异常值,并进行相应的处理。
数据描述分析在进行统计分析之前,可以先对数据进行描述性分析。
这可以帮助我们对数据的整体情况有一个直观的了解。
SPSS提供了一些简单的统计量,如均值、标准差、最小值和最大值等,以及数据的分布情况。
可以通过生成频率分布表、直方图或箱线图等可视化方式来展示数据的分布特征。
参数统计分析参数统计分析是一种用于检验假设的方法,可以提供关于总体参数的估计和推断。
常见的参数统计方法包括 t检验、方差分析、回归分析等。
在SPSS中,可以通过选择适当的分析方法,输入相应的变量和假设,进行参数统计分析。
分析结果会生成相应的统计指标和图表,用于支持研究的结论。
非参数统计分析非参数统计分析也是一种用于检验假设的方法,它不依赖于总体参数的假设。
常见的非参数统计方法包括Mann-Whitney U检验、Kruskal-Wallis检验、Wilcoxon符号秩检验等。
SPSS同样提供了这些非参数统计方法,并通过输出相关的统计指标和图表来展示分析结果。
数据报告生成在完成数据分析后,可以根据分析结果生成详细的数据报告。
在SPSS中,可以使用输出管理器来控制报告的格式和内容。
可以选择输出分析结果、图表、描述性统计量等,并根据需要进行排列和组织。
生成的报告可以直接保存为文档格式,并对需要呈现的数据进行标注和解释。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
探究教师对信息工程学院学生的高等数学影响摘要:通过对2012级扬州大学所有工科学生的高等数学成绩进行非参数检验,探究教师对高等数学成绩的影响,研究结果是教师所教的工科学生高等数学成绩存在很大差异。
关键词:工科,高等数学成绩,因素分析。
研究背景:数学作为一门自然科学,在社会各行各业应用愈来愈广泛。
高等数学课程作为作为工科类院校的一门重要课程,其目的不仅是获得系统的数学知识,更重要的是使学生掌握用高等数学解决问题的能力,而且能为后继专业课程和现代化科技知识提供必要的工具。
然而高等数学的教学已经面临着种种问题和困境。
如何确保高等数学教学质量,更好的为各专业领域服务,对于一个数学老师而言责任重大。
本文主要解决的问题:(1)计算所有工科学生高等数学平均成绩以及每一位教师所教学生的高等数学平巨额成绩,进行初步比较。
(2)检验其成绩是否服从正太分布,并选择数据检验方法。
(3)探究每位教师所教学生成绩的差异性,给出一些建议。
研究工具和方法:本文通过运用SPSS统计软件和统计知识,对扬州大学2012级所有工科学生的高等数学成绩数据进行分析,探究教师在其中的影响作用。
一.数据的收集与整理下表是2012年扬州大学所有工科学生的高等数学期末成绩。
将收集来的数据进行整理,删除有缺失值的个案,整理如下:1.数据视图2 变量视图二描述统计对所采集的数据进行描述统计,并作如下分析:描述统计量N 极小值极大值均值标准差偏度峰度统计量统计量统计量统计量统计量统计量标准误统计量标准误成绩1615 20 100 77.68 15.395 -.731 .061 .278 .122有效的 N (列表状态)1615即扬州大学2012级1615名工科学生成绩均值为77.68,其中分数最高位100,最低为20,标准差为15.395.描述a教师代号统计量标准误成绩 1 均值78.54 1.297均值的95% 置信区间下限75.97上限81.115% 修整均值79.01中值79.00方差205.292标准差14.328极小值41极大值100范围59四分位距26偏度-.341 .219峰度-.935 .435 10 均值71.83 1.533均值的95% 置信区间下限68.79上限74.865% 修整均值72.56中值77.00方差284.328标准差16.862极小值28极大值100范围72四分位距25偏度-.569 .220峰度-.300 .437 11 均值75.11 1.841均值的95% 置信区间下限71.45上限78.775% 修整均值76.34中值78.50方差284.579标准差16.869极小值20极大值100范围80四分位距20偏度-1.081 .263峰度 1.333 .520 2 均值76.42 1.409均值的95% 置信区间下限73.63上限79.215% 修整均值77.52中值79.00方差240.079标准差15.494极小值21极大值99范围78四分位距23偏度-.986 .220峰度.964 .437 3 均值79.97 1.244均值的95% 置信区间下限77.51上限82.425% 修整均值80.90中值83.50方差241.334标准差15.535极小值20极大值100范围80四分位距23偏度-.981 .194峰度.925 .386 4 均值76.73 1.351均值的95% 置信区间下限74.06上限79.415% 修整均值77.60中值77.50方差219.021标准差14.799极小值26极大值100范围74四分位距21偏度-.791 .221峰度.879 .438 5 均值75.28 1.219均值的95% 置信区间下限72.87上限77.685% 修整均值76.10中值78.50方差261.653标准差16.176极小值22极大值100范围78四分位距24偏度-.691 .183峰度.081 .364 6 均值79.67 1.026均值的95% 置信区间下限77.65上限81.695% 修整均值80.49中值81.00方差230.324标准差15.176极小值35极大值100范围65四分位距23偏度-.714 .164峰度-.257 .3277 均值82.14 1.101均值的95% 置信区间下限79.97上限84.315% 修整均值83.24中值86.00方差216.885标准差14.727极小值29极大值100范围71四分位距22偏度-.978 .182峰度.779 .361 8 均值75.05 1.036均值的95% 置信区间下限73.01上限77.105% 修整均值75.40中值73.00方差196.601标准差14.021极小值24极大值100范围76四分位距21偏度-.250 .180峰度-.023 .357 9 均值80.66 1.148均值的95% 置信区间下限78.39上限82.945% 修整均值81.34中值82.00方差176.646标准差13.291极小值44极大值100范围56四分位距21偏度-.592 .209峰度-.192 .416 a. 当教师代号= .000 时,成绩没有有效个案。
无法计算此水平的统计量。
正态性检验b教师代号Kolmogorov-Smirnov a Shapiro-Wilk统计量df Sig. 统计量df Sig.成绩 1 .124 122 .000 .947 122 .00010 .130 121 .000 .957 121 .00111 .129 84 .001 .927 84 .0002 .101 121 .004 .931 121 .0003 .116 156 .000 .924 156 .0004 .081 120 .053 .953 120 .0005 .091 176 .001 .956 176 .0006 .091 219 .000 .937 219 .0007 .130 179 .000 .920 179 .0008 .067 183 .042 .975 183 .0029 .096 134 .004 .956 134 .000由正态性检验表可知在0.01的显著水平上,来自11个独立样本总体不服从正态分布,即十一名教师所教学生的成绩并不服从正太分布所以要进行非参数检验。
三 非参数检验 1.检验步骤:(1)提出假设: H 0:11名教师所教学生的高等数学成绩的差异不显著 H 2:11名教师所教学生的高等数学成绩的差异显著 (2) 计算检验统计量及其概率: 选用K-W H 检验法,其检验统计量为:)1(~)1(3)1(12212-=+-+=∑=k df N n R N N H ki ii χ 经SPSS for windows 算得H=61.568,P=0.000(1)统计决断 :因为H=,P=0.000<0.01,所以在0.01的显著性水平上,拒绝H 0,接受H 1 ,认为十一名教师所教的学生的高等数学成绩差异非常显著。
2.SPSS 操作步骤(1)建立SPSS 数据文件,因变量取名cj ,分组变量取名jsdh ,均定义为数值型。
(2)鼠标单击“分析->非参数检验->k 个独立样本”菜单项,打开“多个独立样本检验”主对话框,从左侧变量框中选中要检验的变量cj ,单击中间的箭头按钮,把它移到“检验变量列表”框中。
从左侧变量框中选中变量jsdh ,单击中间的箭头按钮,把它移到“分组变量”框中,并单击“定义组”按钮定义分组变量的最大值和最小值,单击继续按钮,返回主对话框,再选中“Kruskal-Wallis ”选项。
(3)单击“确定”按钮,执行SPSS 命令。
输出结果如下所示。
Kruskal-Wallis 检验秩教师代号 N 秩均值 成绩1122823.912 121 770.903 156 886.794 120 770.305 176 739.95 6 219 872.827 179 954.168 183 704.669 134 888.63 10 121 642.79 11 84 742.49总数1615运用SPSS 计算出11名教师所教学生高等数学的平均成绩如下表:通过比较可以看出教师代号为7、9、3、6的教师所教的高等数学成绩较好,而代号为10的教师所教高等数学的成绩较差些。
那么可以根据这一推断研究教师的教学风格,专业素养等差异,面向教师做进一步的调研。
通过改进教师的教学方法等,提高工科学生的高等数学成绩。
检验统计量a,b成绩卡方61.568df10 渐近显著性.000a. Kruskal Wallis 检验b. 分组变量: 教师代号。