第二章 数据预处理
第二章 数据采集与预处理 (教案与习题)
2 of 42
2.1大数据采集架构
第二章 数据采集与预处理
2.1.2 常用大数据采集工具
数据采集最传统的方式是企业自己的生产系统产生的数据,除上述生产系统中的数据外, 企业的信息系统还充斥着大量的用户行为数据、日志式的活动数据、事件信息等,越来越 多的企业通过架设日志采集系统来保存这些数据,希望通过这些数据获取其商业或社会价 值。
$sudo apt-get update
Apache Kafka需要Java运行环境,这里使用apt-get命令安装default-jre包,然后安装Java运行环境:
$sudo apt-get install default-jre
通过下面的命令测试一下Java运行环境是否安装成功,并查看Java的版本信息:
第2章 数据预处理
(3)计算变量
• 改变原始数据的分布形态 • 产生新的变量、信息
练习1
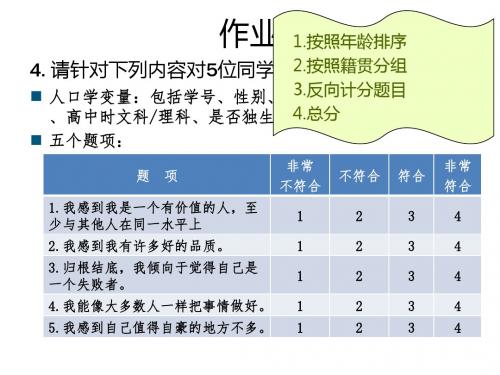
1.按照年龄排序 2.按照籍贯分组:省内/省外 4. 请针对下列内容对5位同学进行调查: 3.反向计分题目 人口学变量:包括学号、性别、年龄、籍贯(来自哪个省份) 4.总分 、高中时文科/理科、是否独生子女。
五个题项:
作业
2.基于表2-8(26页)完成2456题,简要写出完成 该操作的操作步骤。 3.简述变量重新编码的适用情况和保存方法。
2.1 数据菜单的预处理
• 选择个案
2.2 转换菜单的预处理
• 计算变量 • 变量重新编码 • 替换缺失值
(1)变量重新编码
• 反向计分题目 →具体数值的转换 • 分组次数分布 →数值范围的转换
(1)变量重新编码
• 重新编码为相同变量 • 重新编码为不同变量
(2)替换缺失值
• 替换缺失值是根据数据的分布类型和研究目的, 利用不同的方法将缺失的数据补充完整,使得原 始数据得到最大程度的利用。 • 默认“序列均值”
1
1 1 1 122 2 2233 3 3 3
4
4 4 4 4
第二章 SPSS的数据预处理
2.1 数据菜单的预处理 2.2 转换菜单的预处理
2.1 数据菜单的预处理
• 合并文件 • 排序个案 • 分类汇总 • 加权个案
2.1 数据菜单的预处理
• 排序个案
▫ 将已经录好的数据文件按照某个或某几个变量进行 排序。 ▫ 排序是对整个数据文件进行排序,排序完成保存后, 原有数据顺序被打乱,如果没有标识时间或顺序的 变量,很难恢复到原始数据状态。
题 项 非常 不符合 不符合 符合 非常 符合
1.我感到我是一个有价值的人,至 少与其他人在同一水平上 2.我感到我有许多好的品质。 3.归根结底,我倾向于觉得自己是 一个失败者。 4.我能像大多数人一样把事情做好。 5.我感到自己值得自豪的地方不多。
Microsoft Word - 第二章 数据预处理

由于数据库系统所获数据量的迅速膨胀(已达 或 数量级),从而导致了现实世界数据库中常常包含许多含有噪声、不完整( )、甚至是不一致( )的数据。
显然对数据挖掘所涉及的数据对象必须进行预处理。
那么如何对数据进行预处理以改善数据质量,并最终达到完善最终的数据挖掘结果之目的呢?数据预处理主要包括:数据清洗( )、数据集成( )、数据转换( )和数据消减( )。
本章将介绍这四种数据预处理的基本处理方法。
数据预处理是数据挖掘(知识发现)过程中的一个重要步骤,尤其是在对包含有噪声、不完整,甚至是不一致数据进行数据挖掘时,更需要进行数据的预处理,以提高数据挖掘对象的质量,并最终达到提高数据挖掘所获模式知识质量的目的。
例如:对于一个负责进行公司销售数据分析的商场主管,他会仔细检查公司数据库或数据仓库内容,精心挑选与挖掘任务相关数据对象的描述特征或数据仓库的维度( ),这包括:商品类型、价格、销售量等,但这时他或许会发现有数据库中有几条记录的一些特征值没有被记录下来;甚至数据库中的数据记录还存在着一些错误、不寻常( )、甚至是不一致情况,对于这样的数据对象进行数据挖掘,显然就首先必须进行数据的预处理,然后才能进行正式的数据挖掘工作。
所谓噪声数据是指数据中存在着错误、或异常(偏离期望值)的数据;不完整( )数据是指感兴趣的属性没有值;而不一致数据则是指数据内涵出现不一致情况(如:作为关键字的同一部门编码出现不同值)。
而数据清洗是指消除数据中所存在的噪声以及纠正其不一致的错误;数据集成则是指将来自多个数据源的数据合并到一起构成一个完整的数据集;数据转换是指将一种格式的数据转换为另一种格式的数据;最后数据消减是指通过删除冗余特征或聚类消除多余数据。
不完整、有噪声和不一致对大规模现实世界的数据库来讲是非常普遍的情况。
不完整数据的产生有以下几个原因:( )有些属性的内容有时没有,如:参与销售事务数据中的顾客信息;( )有些数据当时被认为是不必要的;( )由于误解或检测设备失灵导致相关数据没有记录下来;( )与其它记录内容不一致而被删除;( )历史记录或对数据的修改被忽略了。
数量生态学(第二版)第2章 数据处理

第二章数据的处理数据是数量生态学的基础,我们对数据的类型和特点应该有所了解。
在数量分析之前,根据需要对数据进行一些预处理,也是必要的。
本章将对数据的性质、特点、数据转化和标准化等做简要介绍。
第一节数据的类型根据不同的标准,数据可以分成不同的类型。
下面我们将介绍数据的基本类型,它是从数学的角度,根据数据的性质来划分的;然后叙述生态学数据,它是根据生态意义而定义的,不同的数据含有不同的生态信息。
一、数据的基本类型1、名称属性数据有的属性虽然也可以用数值表示,但是数值只代表属性的不同状态,并不代表其量值,这种数据称为名称属性数据,比如5个土壤类型可以用1、2、3、4、5表示。
这类数据在数量分析中各状态的地位是等同的,而且状态之间没有顺序性,根据状态的数目,名称属性数据可分成两类:二元数据和无序多状态数据。
(1)二元数据:是具有两个状态的名称属性数据。
如植物种在样方中存在与否,雌、雄同株的植物是雌还是雄,植物具刺与否等等,这种数据往往决定于某种性质的有无,因此也叫定性数据(qualitative data)。
对二元数据一般用1和0两个数码表示,1表示某性质的存在,而0表示不存在。
(2)无序多状态数据:是指含有两个以上状态的名称属性数据。
比如4个土壤母质的类型,它可以用数字表示为2、1、4、3,同时这种数据不能反映状态之间在量上的差异,只能表明状态不同,或者说类型不同。
比如不能说1与4之差在量上是1与2之差的3倍,这种数据在数量分析中用得很少,在分析结果表示上有时使用。
2.顺序性数据这类数据也是包含多个状态,不同的是各状态有大小顺序,也就是它一定程度上反映量的大小,比如将植物种覆盖度划为5级,1=0~20%,2=21%~40%,3=41%~60%,4=61%~80%,5=81%~100%。
这里1~5个状态有顺序性,而且表示盖度的大小关系。
比如5级的盖度就是明显大于1级的盖度,但是各级之间的差异又是不等的,比如盖度值分别为80%和81%的两个种,盖度仅差1%,但属于两个等级4和5;而另外两个盖度值分别为41%和60%,相差19%,但属于同一等级。
数据导入与预处理技术复习

数据导⼊与预处理技术复习数据导⼊与预处理技术复习笔记本⽂由本⼈学习过程中总结,难免有纰漏,欢迎交流学习第1章为什么需要数据处理本章内容将涵盖以下⼏个⽅⾯:为什么需要数据处理关于数据科学的六个简单处理步骤,包括数据清洗;与数据预处理相关的参考建议对数据清洗有帮助的⼯具⼀个关于如何将数据清洗融⼊整个数据科学过程的⼊门实例在数据分析、挖掘、机器学习或者是可视化之前,做好相关的数据预处理⼯作意义重⼤。
这个数据预处理的过程不是⼀成不变的,是⼀个迭代的过程,在实际的⼯作中,需要不⽌⼀次的执⾏数据预处理。
所采⽤的数据挖掘或分析⽅法会影响清洗⽅式的选取。
数据预处理包含了分析所需要的各种处理数据的任务:如交换⽂件的格式、字符编码的修改、数据提取的细节等。
数据导⼊、数据存储和数据清洗是数据预处理中密切相关的技术。
搜集原始数据->存储->数据清洗->存储->增量搜集数据->合并存储数据->数据挖掘(⼤数据、⼈⼯智能)->数据可视化;有三种处理⽅案可以选择:什么都不处理:忽略这些错误数据,直接开始构建线形图。
如果直接数据可视化,这样的结果是,有⽤的数据被掩盖了。
修正数据:算出错误消息的正确数据,采⽤修订后的数据集来可视化。
扔掉错误数据:放弃错误数据。
为了在选项⼆和三之间做个选择,计算错误数据实际上这些只占到了数据量的百分之⼀。
因此,选择选项三,扔掉这些数据。
利⽤Google的Spreadsheets能在初始数据中缺少⽇期的情况下,在x轴⾃动进⾏零值数据补齐,创建线性图或者条状图。
在以上的数据集中,需要补齐的零值就是所缺失的数据。
1.6 ⼩结从以上的实例看出,数据预处理占了整个过程的80%的⼯作量;数据预处理是数据科学过程的关键部分,不仅涉及对技术问题的理解,还需要做出相应的价值判断;第⼆章数据预处理为什么对数据进⾏预处理描述性数据汇总数据清理数据集成和变换数据归约离散化和概念分层⽣成脏数据不完整缺少数据值;缺乏某些重要属性;仅包含汇总数据;e.g., occupation=""有噪声包含错误或者孤⽴点e.g. Salary = -10数据不⼀致e.g., 在编码或者命名上存在差异e.g., 过去的等级: “1,2,3”, 现在的等级: “A, B, C”e.g., 重复记录间的不⼀致性e.g., Age=“42” Birthday=“03/07/1997”不完整数据的成因数据收集的时候就缺乏合适的值数据收集时和数据分析时的不同考虑因素⼈为/硬件/软件问题噪声数据(不正确的值)的成因数据收集⼯具的问题数据输⼊时的⼈为/计算机错误数据传输中产⽣的错误数据不⼀致性的成因不同的数据源违反了函数依赖性数据预处理为什么是重要的?没有⾼质量的数据,就没有⾼质量的挖掘结果⾼质量的决策必须依赖⾼质量的数据e.g. 重复值或者空缺值将会产⽣不正确的或者令⼈误导的统计数据仓库需要对⾼质量的数据进⾏⼀致地集成数据预处理将是构建数据仓库或者进⾏数据挖掘的⼯作中占⼯作量最⼤的⼀个步骤数据质量的多维度量⼀个⼴为认可的多维度量观点:精确度完整度⼀致性合乎时机可信度附加价值可解释性跟数据本⾝的含义相关的内在的、上下⽂的、表象的以及可访问性数据预处理的主要任务数据清理填写空缺的值,平滑噪声数据,识别、删除孤⽴点,解决不⼀致性数据集成集成多个数据库、数据⽴⽅体或⽂件数据变换规范化和聚集数据归约得到数据集的压缩表⽰,它⼩得多,但可以得到相同或相近的结果数据离散化数据归约的⼀部分,通过概念分层和数据的离散化来规约数据,对数字型数据特别重要基本统计类描述的图形显⽰常⽤的显⽰数据汇总和分布的⽅法:直⽅图、分位数图、q-q图、散布图和局部回归曲线直⽅图:⼀种单变量图形表⽰⽅法将数据分布划分成不相交的⼦集或桶,通常每个桶宽度⼀致并⽤⼀个矩形表⽰,其⾼度表⽰桶中数据在给定数据中出现的计数或频率数据清理任务填写空缺的值识别离群点和平滑噪声数据纠正不⼀致的数据解决数据集成造成的冗余空缺值数据并不总是完整的例如:数据库表中,很多条记录的对应字段没有相应值,⽐如销售表中的顾客收⼊引起空缺值的原因设备异常与其他已有数据不⼀致⽽被删除因为误解⽽没有被输⼊的数据在输⼊时,有些数据应为得不到重视⽽没有被输⼊对数据的改变没有进⾏⽇志记载空缺值要经过推断⽽补上如何处理空缺值忽略元组:当类标号缺少时通常这么做(假定挖掘任务设计分类或描述),当每个属性缺少值的百分⽐变化很⼤时,它的效果⾮常差。
Excel数据清洗与数据预处理教程

Excel数据清洗与数据预处理教程第一章:介绍Excel作为一款强大的数据处理工具,在数据分析和统计方面有着广泛的应用。
然而,原始数据通常存在各种问题,如重复数据、缺失值、错误数据等,这就需要对数据进行清洗和预处理,以保证数据的准确性和完整性。
本教程将介绍Excel数据清洗和数据预处理的基本技巧和方法,帮助读者更好地利用Excel进行数据处理。
第二章:去除重复值在数据清洗过程中,去除重复值是首要任务之一。
Excel提供了多种去除重复值的方式。
首先,可以使用“数据”菜单中的“删除重复项”功能来去除重复值。
其次,利用“排序”功能将数据按照一列或多列进行排序,并通过筛选功能选择非重复项。
此外,还可以使用Excel的公式函数和宏来实现自动去重,提高处理效率。
第三章:处理缺失值缺失值是数据中常见的问题之一。
Excel提供了多种方式来处理缺失值。
可以使用“查找与替换”功能,将缺失值替换为指定的数值或者删除包含缺失值的行或列。
此外,可以使用公式函数来识别和替换缺失值。
另外,利用数据透视表功能可以快速统计并填补缺失值,提高数据分析的准确性。
第四章:处理错误值错误值是数据清洗中需要处理的另一个问题。
Excel提供了多种处理错误值的方法。
首先,可以使用公式函数进行错误值的识别和替换。
例如,使用IF函数结合条件判断语句来判断错误值并替换或删除。
其次,可以使用数据透视表功能进行错误值的统计和处理,快速找出错误值所在的行或列。
此外,还可以使用条件格式设置对错误值进行标记,便于后续的处理和分析。
第五章:数据格式转换数据格式转换是数据预处理中一个重要环节。
Excel提供了丰富的数据格式转换功能。
通过选择单元格或选定一列,然后在“数据”菜单中选择“文本转列”功能,可以将数值格式转换为文本格式或者将文本格式转换为数值格式。
此外,还可以使用文本函数来进行数据格式转换,如将日期字符串转换为日期格式,将百分数字符串转换为数值格式等。
第六章:数据排序和筛选数据排序和筛选是数据清洗和预处理中常用的功能之一。
如何进行数据挖掘与分析

如何进行数据挖掘与分析数据挖掘与分析是指通过挖掘大量数据,发现其中的模式、关联、规律,并进行相应的分析和解释的过程。
这是一项涉及统计学、机器学习、数据库技术、数据可视化等多个领域的综合性工作。
本文将从数据获取、数据预处理、特征工程、模型选择和评估等方面介绍如何进行数据挖掘与分析。
## 第一章:数据获取数据获取是数据挖掘与分析的第一步,其质量和完整性直接影响后续分析的结果。
数据可以通过行业数据库、公共数据集、自主采集等方式获得。
在选择数据源时,需要考虑数据的可靠性、时效性和适用性。
同时,在获取数据之前,应详细了解数据的结构、格式和字段含义,为后续的预处理做好准备。
## 第二章:数据预处理数据预处理是对原始数据进行清洗、转换、集成和规约等操作,以减少数据的噪声、不一致性和冗余,提高后续分析的准确性和效率。
常用的数据预处理方法包括数据清洗、缺失值处理、异常值处理、数据变换等。
通过数据预处理,可以提高数据质量,并为数据挖掘和分析的进行打下基础。
## 第三章:特征工程特征工程是指通过对原始数据进行特征提取、降维和创造新特征等操作,以提取数据的有价值信息。
特征工程是数据挖掘与分析中的关键环节,直接影响模型的性能和结果的准确性。
常用的特征工程方法包括主成分分析(PCA)、线性判别分析(LDA)、特征选择、特征创造等。
通过特征工程,可以更好地表达数据,提高模型的泛化能力。
## 第四章:模型选择模型选择是在数据挖掘与分析中选择最合适的模型或算法。
常用的数据挖掘算法包括聚类算法、分类算法、回归算法等。
在模型选择过程中,需要根据具体的问题需求和数据特征来选择合适的模型。
同时,还需要考虑模型的复杂度、训练时间、解释性等因素。
通常可以通过交叉验证和评估指标来评估模型的性能和泛化能力。
## 第五章:模型评估模型评估是对数据挖掘与分析模型的性能进行评估和验证的过程。
常用的模型评估指标包括准确率、召回率、F1值、ROC曲线等。
数据清洗与整理软件的基本操作

数据清洗与整理软件的基本操作第一章:数据清洗的概念与意义数据清洗是指对原始数据进行处理,去除错误、重复、不完整和冗余等无效信息,保证数据的准确性和完整性,为后续的数据分析和建模提供可靠的基础。
数据清洗是数据科学中不可或缺的一部分,其重要性不言而喻。
第二章:数据清洗的流程与方法2.1 数据预处理:数据预处理是数据清洗的首要步骤,包括数据采集、数据清洗、数据集成和数据转换等。
在这一阶段,需要对数据进行正确的格式化和标准化,对缺失值进行处理,处理异常值等。
2.2 数据质量评估:数据质量评估是对清洗后的数据进行质量的评估和监控,以确保数据的准确性和一致性。
常见的数据质量评估方法包括数据可视化、数据统计和数据挖掘等。
2.3 数据清洗方法:数据清洗方法主要包括数据去重、数据变换、数据标准化和数据规范化等。
其中,数据去重是指去除数据集中的重复记录;数据变换是指对数据进行转换,以满足分析模型的需求;数据标准化是将数据按照一定的标准进行处理,以保证数据的一致性;数据规范化是对数据进行统一的格式标准化处理,以方便后续的数据分析和处理。
第三章:3.1 Excel:Excel是最常用的办公软件之一,也是数据清洗与整理的重要工具之一。
通过Excel可以进行数据筛选、排序、去重、替换、拆分、合并等操作,大大提高数据清洗与整理的效率和准确性。
3.2 OpenRefine:OpenRefine是一款免费的数据清洗工具,可以处理各种格式的数据,如CSV、Excel、JSON等。
OpenRefine提供了丰富的数据清洗函数,包括拆分列、合并列、转化数据类型、去除空格等,方便用户进行定制化的数据清洗操作。
3.3 Python:Python是一种通用的编程语言,在数据科学领域被广泛应用于数据清洗与整理。
通过Python中的pandas库和numpy 库,可以进行数据的读取、处理、清洗和整理等操作。
此外,Python还提供了丰富的数据可视化工具,如matplotlib和seaborn 等,方便用户对清洗后的数据进行可视化分析。
数据预处理ppt课件

用箱边界(去替换箱中的每个数 据)
28
分箱法光滑数据
Sorted data for price (in dollars): 4, 8, 9, 15, 21, 21, 24, 25, 26, 28, 29, 34
* Partition into equal-frequency (equi-depth) bins:
位数Q1 、中位数、上四分位数Q3和最大值
盒的长度等于IRQ 中位数用盒内的横线表示 盒外的两条线(胡须) 分别延伸到最小和
最大观测值。
盒图的功能 1.直观明了地识别数据集中的离群点 2.判断数据集的偏态和尾重 3.比较几批数据的形状
2.2.3 基本描述数据汇总的图形显示
直方图、 分位数图、分位数-分位数图(q-q图) 散布图、散布图矩阵 局部回归(Loess)曲线
不一致的
采用的编码或表示不同,如属性名称不同
冗余的
如属性之间可以相互导出
数据错误的不可避免性
数据输入和获得过程数据错误 数据集成所表现出来的错误 数据传输过程所引入的错误 据统计有错误的数据占总数据的5%左
右[Redmen],[Orr98]
3
数据错误的危害性
高昂的操作费用 糟糕的决策制定 组织的不信任 分散管理的注意力
四分位数
中位数是第50个百分位数,是第2个四分位 数
第1个是第25个百分位数,Q1 中间四分位数极差 IQR = Q3 – Q1
离群点outlier
与数据的一般行为或模型不一致的数据对象
盒图 方差、标准差
反映了每个数与均值相比平均相差的数值 15
度量数据的离散程度…
盒图boxplot,也称箱线图 从下到上五条线分别表示最小值、下四分
简述数据预处理的概念及预处理流程方法

数据预处理是指在进行数据挖掘和分析之前,对原始数据进行清洗、转换和集成的过程。
数据预处理的目的是为了提高数据的质量,使得数据更加适合进行后续的分析和挖掘工作。
数据预处理包括多个步骤和方法,下文将对数据预处理的概念和预处理流程方法进行简要介绍。
一、数据预处理概念数据预处理是指对原始数据进行清洗、转换和集成的过程,其目的是为了提高数据质量,使得数据更适合进行后续的挖掘和分析工作。
原始数据往往存在各种问题,如缺失值、噪声、不一致性等,需要通过数据预处理来解决这些问题,从而得到高质量、可靠的数据。
数据预处理是数据挖掘中非常重要的一个环节,其质量直接影响到后续挖掘和分析的结果。
如果原始数据存在较多的问题,直接进行挖掘和分析往往会导致结果的不准确性和不稳定性。
数据预处理是数据挖掘工作中必不可少的一个环节。
二、数据预处理流程方法1. 数据清洗数据清洗是数据预处理的第一步,其目的是去除原始数据中的错误、噪声和不一致性。
数据清洗包括以下几个方面的工作:(1)处理缺失值:对缺失值进行填充或者删除,以保证数据的完整性和准确性。
(2)处理异常值:对超出合理范围的数值进行修正或删除,以消除数据的噪声和干扰。
(3)处理重复值:去除重复的数据,以防止数据重复统计和分析。
2. 数据转换数据转换是数据预处理的第二步,其目的是将原始数据转换为适合挖掘和分析的形式。
数据转换包括以下几个方面的工作:(1)数据平滑:对数据进行平滑处理,以减少数据的波动和不稳定性。
(2)数据聚集:将数据进行聚集操作,以便进行更高效的分析和挖掘。
3. 数据集成数据集成是数据预处理的第三步,其目的是将多个数据源的数据进行集成,形成一个整体的数据集。
数据集成包括以下几个方面的工作:(1)数据合并:将多个数据表中的数据进行合并,形成一个完整的数据集。
(2)数据匹配:对不同数据源的数据进行匹配,以解决数据一致性和完整性的问题。
4. 数据变换数据变换是数据预处理的最后一步,其目的是将经过清洗、转换和集成的数据进行变换,使得数据更适合进行后续的挖掘和分析工作。
数据挖掘概念与技术课后答案第二版

数据挖掘概念与技术课后答案第二版第一章:数据挖掘概论1.什么是数据挖掘?数据挖掘是一种通过从大量数据中发现隐藏模式、关系和知识的方法。
它将统计学、机器学习和数据库技术结合起来,用于分析海量的数据,并从中提取出有用的信息。
2.数据挖掘的主要任务有哪些?数据挖掘的主要任务包括分类、回归、聚类、关联规则挖掘和异常检测等。
3.数据挖掘的流程有哪些步骤?数据挖掘的典型流程包括问题定义、数据收集、数据预处理、特征选择、模型构建、模型评估和模型应用等步骤。
4.数据挖掘的应用领域有哪些?数据挖掘的应用领域非常广泛,包括市场营销、金融分析、生物医学、社交网络分析等。
5.数据挖掘的风险和挑战有哪些?数据挖掘的风险和挑战包括隐私保护、数据质量、误差纠正、过拟合和模型解释等。
第二章:数据预处理1.数据预处理的主要任务有哪些?数据预处理的主要任务包括数据清洗、数据集成、数据转换和数据规约等。
2.数据清洗的方法有哪些?数据清洗的方法包括缺失值填补、噪声数据过滤、异常值检测和重复数据处理等。
3.数据集成的方法有哪些?数据集成的方法包括实体识别、属性冲突解决和数据转换等。
4.数据转换的方法有哪些?数据转换的方法包括属性构造、属性选择、规范化和离散化等。
5.数据规约的方法有哪些?数据规约的方法包括维度规约和数值规约等。
第三章:特征选择与数据降维1.什么是特征选择?特征选择是从原始特征集中选择出最具有代表性和区分性的特征子集的过程。
2.特征选择的方法有哪些?特征选择的方法包括过滤式特征选择、包裹式特征选择和嵌入式特征选择等。
3.什么是数据降维?数据降维是将高维数据映射到低维空间的过程,同时保留原始数据的主要信息。
4.数据降维的方法有哪些?数据降维的方法包括主成分分析、线性判别分析和非负矩阵分解等。
5.特征选择和数据降维的目的是什么?特征选择和数据降维的目的是减少数据维度、提高模型训练效果、降低计算复杂度和防止过拟合等。
第四章:分类与预测1.什么是分类?分类是通过训练数据集建立一个分类模型,并将未知数据对象分配到其中的某个类别的过程。
数据处理分析课后答案

化工数据分析与处理(课后作业)第一章 误差原理与概率分布1、某催化剂车间用一台包装机包装硅铝小球催化剂,额定标准为每包净重25公斤,设根据长期积累的统计资料,知道包装机称得的包重服从正态分布,又其标准差为σ=0.75公斤,某次开工后,为检验包装机的工作是否正常,随机抽取9包催化剂复核其净重分别为:试问包装机目前的工作状况如何? 解:先做原假设 假设H 0:μ=μ0构造统计量:Z =nx /σμ--~N(0,1)-x =∑x i /n=25.45σ=0.75μ=μ0=25 得:Z =1.8查表得:Φ ( 1.8 ) = 0.9641给出适当的α ,取α=0.05,1- α = 0.95 < 0.9641 落在大概率解范围内接受H 0则 μ=μ0 ,即包装机目前工作正常。
气总平均值的0.95置信区间。
解:因为P =1-α=0.95 所以α=1-0.95=0.05σ不知,所以只能用t 分布 即用S 代替σ S 2=1)(--∑-n x x i =0.048515789 S=0.220263-x =3.21令T =nS x /μ--~t(n-1,2α)则有:P(-At <T <At)=1-α=1-0.05n-1=20-1=192α=0.025 查表得:At (19,0.025)=2.0930估计区间为:P(-x -At(n-1, 2α)*n S <μ<-x +At(n-1, 2α)*nS =0.95所以:3.21-2.0930*200.220263<μ<3.21+2.0930*200.220263即:3.21-0.100425<μ<3.21+0.100425所以:3.109575<μ<3.3104253、某厂化验室用A,B 两种方法测定该厂冷却水中的含氯量(ppm ),每天取样一次,下面是试问:这两种方法测量的结果有无显著的差异?一般可取显著水平α=0.01. 解:因为是用两种方法来测同一个溶液,故把所测氯含量为母体。
地震数据处理第二章:预处理及真振幅恢复

j 2f
设补偿前数据为x(t),补偿后为y(t),即
y(t) x(t) * h(t, )
第三节 振幅平衡
浅层能量、深层能量弱,给显示带来困难,动平衡就 是为解决这类问题而提出的。
一、道内动平衡
设待平衡记录道长度为N个样点,将其分为K个时 窗,每时窗为2M+1个样点,则每时窗的平均振幅为:
A j
第二节 真振幅恢复 一、波前扩散能量补偿 二、地层吸收能量补偿
第一节 预处理
一、数据解编 (1)野外数据格式:
① SEG-D ② 时序 (2)解编:将时序变为道序
(3)解编后数据格式:SEG—Y 地震资料数字处理输入/输出均为SEG-Y
SEG_Y 格式: 卷头(4字节/字,共100字):
40行说名信息
2 卷内道序号 (字节5 ~ 8)
3 FFID & ILN (字节9 ~12)
4 道号
(字节13~16)
5 震源点号
(字节17~20)
6 CMP号 & XLN (字节21~24)
7 CMP集内道号 (字节25~28)
8 道识别码: (字节29~30) 1=地震数据;2=死道;3=空道 4 =爆炸信号;5 井口道;~
1
M
|
2M 1 mM
a jm
|
权系数:
w j
1 Aj
均衡处理: aj a j •w j
二、道间均衡
地震记录上反射能量随炮检距增大而衰减,也可能因 激发及接收条件的差异,使道与道之间的能量不均衡。 在共中心点叠加时,因能量不均衡会影响叠加效果,故 而进行道间均衡。
Q 2 E 2
A2 0
2
1
E
A2 0
《工程数据分析》-课程教学大纲

《工程数据分析》课程教学大纲英文: Engineering Data Analysis一、课程基本信息课程代码:112773课程名称:工程数据分析英文名称:Engineering Data Analysis课程类别:专业基础课学时:48学分:3适用对象: 计算机科学与技术本科考核方式:考试先修课程:《程序设计》、《高等数学》等二、课程简介中文简介数据是信息的重要载体,在当今信息化社会中扮演着重要角色。
工程数据分析研究利用数学和计算科学的基础理论和方法,运用现代电子计算机作为工具,对工程数据进行统计分析、从中获取有用的信息,以求解工程问题的理论和方法,是计算机科学与技术专业一门重要的专业基础课程。
英文简介The data is an important carrier of information, which plays an important role in today's information society. This course focus on the theories and methods which are used to analysis engineering data in order to capture the useful information. It lies on the intersection of mathematics and computer science, including statistical analysis, numerical methods, computer application and so on. It is an important professional basic course of undergraduate for the majors of computer science and technology, information and computation science as well as statistics.三、课程性质与教学目的通过本课程的学习,使学生对数据分析方法的基本理论有系统的了解,掌握常用数据分析方法的基本原理,熟练掌握利用专业软件进行数据分析的过程,培养学生应用计算机来分析问题和解决问题的能力,为后续课程的学习以及解决工程实际问题打下良好的基础。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2.4图像分幅裁剪
根据已经设Main-Date Preparation-Subset Image Image Viewer-select Viewer Type-Classic ViewerFile-Open-Raster Layer
2.4图像分幅裁剪
2.不规则分幅裁剪:指裁剪图像的边界范围是任 意多边形,而不是左上角和右下角两点坐标确 定,必须先设置好一个完整闭合多边形区域。 2.1.步骤:打开需要裁剪的图像。Viewer-AOI-应 用AOI工具绘制多边形-保存为*.Aoi-Main-Data Preparation-Subset Image
2.1图像校正
1.辐射校正:传感器的辐射校正、大气校正、照 度校正、条纹和斑点判定及消除。 2.几何校正:在校正过程中造成的各种几何畸变。 2.1几何粗校正:针对引起畸变的原因进行校正, 卫星遥感数据一般都经过几何粗校正处理。 2.2几何精校正:利用地面控制点进行校正,利 用数学模型来近似描述遥感图像几何畸变过程, 并利用标准图像与畸变图像之间对应点求得几 何畸变模型,利用模型进行几何畸变校正,这 种校正不考虑畸变的行程原因,只考虑如何利 用畸变模型校正图像。
2.1.1图像几何校正的一般步骤 采集地面控制点:在Viewer1中移动关联方框的位 置,寻找明显地物特征,Geometric Correction Tools对话框中的图标,进入控制点选取状态,点 击所选地物特征点;在Viewer2中移动关联方框的 位置,寻找对应的地物特 征点,同样点击,重复 以上步骤6次直至6个控制 点选择完毕,得到RMS Error,从中判断上一步所 选控制点的准确性。(一 般要求RMS Error小于15m)
2.2图像拼接
4.重叠区确定:无论色调,几何校正,都以重叠 区为基准进行,准确度直接影响拼接效果。
5.色调调整:即使几何位置很精确,色调调整不 均匀,不能满足应用。 6.图像拼接:相邻两幅图像重叠区内找到一条接 边线,进行色调调整、平滑处理。
2.2图像拼接
回顾: 图像拼接的前提条件: 1.输入图像必须经过几何校正处理。 2.图像相邻且波段数一致。
2.1.1图像几何校正的一般步骤 Viewer 1→Raster→Geometric Correction→SetGeom etric Model →选择多项式几何校正模型 →OK→ Geometric Correction Tools和Polynomial Model Properties→在PolynomialModel Properties定义多 项式次方为2,点击add/ Change projection、选择合 适的投影参数(采用高斯 克吕格投影,根据右表定 义)、设置完毕,点击 Apply、打开GCP Tool Reference Setup对话框
第二章 数据预处理
2.1 图像校正 2.2 图像拼接
2.3 图像投影变化
2.4 图像分幅裁剪
2.5 图像融合
2.6 图像命令基本功能 2.7 实例与练习
第二章 数据预处理
思考:为什么要做图像与处理?
遥感数据多平台、多实相、分幅特点,图像 处理时,原始数据不 能满足研究要求,为 更好充分利用原始观 测遥感数据,获得更 多信息,对图像做有 针对性的变换、增强 、分类工作。
2.2图像拼接
将具有地理参考的若干幅互为邻接的遥感数字 图像合并成新的一幅图。 要求:图像必须经过几何校正。 一般过程: 1.准备:挑选符合研究对象要求的遥感图像,尽 可能选择成像时间、条件接近的图像,减轻后 续色调工作。 2.预处理:辐射校正、去条带、几何校正。 3.确定实施方案:以标准相幅为中心,由中央向 四周逐步进行。
2.3图像投影变化
目的:将图像文件从一种投影类型转换到另一 种投影类型。 一般步骤:Main-Date Preparation-Reproject Image。
2.4图像分幅裁剪
两类裁剪方法:1.规则分幅裁剪;2.不规则分幅 裁剪 1.规则分幅裁剪:指裁剪图像边界范围是一个矩 形,取左上角和右下角两点坐标即可。 1.1.步骤: Main-Start Image Viewer-select Viewer Type-Classic Viewer-File-Open-Raster Layer
数 据 准 备
加载 图像 文件
启动 几何 校正 模块
采集 地面 控制 点
计算 转换 矩阵
图像 重采 样
检验 校正 结束
2.1.1图像几何校正的一般步骤
打开ERDAS图表面板菜单条:Session→Title Viewers 然后,在Viewer1中打开需要校正的图像,在 Viewer2中打开作为地理参考的校正过的图像。
2.1.1图像几何校正的一般步骤
几何校正的目的是改变原始影像的几何变形, 从而生成一幅所需求的新图像。
数 据 准 备
输入 显示 数字 图像
确立 校正 变换 模型
确定 输出 影像 范围
相元 空间 坐标 转换
相元 的灰 度重 采样
输出 校正 数字 图像
2.1.3多项式校正
优点:更直观灵活 缺点:不考虑畸变的具体形成,精度较低
2.1.1图像几何校正的一般步骤 计算转换模型:在控制点采集过程中,随着控制 点采集的完成,转换模型就自动生成,单击 Geometric Correction Tools对话框中的转换图标 →Transformation可以查阅多项式参数
2.1.1图像几何校正的一般步骤 图像重采样:指依据未校正图像的像元值,计算 生成一幅校正图像的过程.在Geometric Correction Tools中选择重采样图标→在弹出的Resample对话 框中输入重采样后的图像文件名→OK→在Viewer 中打开correct.img即可看到几何校正后的图像。
2.1.1图像几何校正的一般步骤 启动控制点工具:GCP Tool Reference Setup 对 话框中选择采点模式:选择Existing Viewer→OK→ 弹出如图对话框,提醒“点击某影像窗口”将其 设置为参考影像→在参考图像Viewer2中单击左键 →打开Reference Map Information 提示框→OK→ 弹出Approximate Statistics 提示框→OK→此时表明控 制点工具已启动,进入控 制点采点状态。