机器学习算法隐马尔可夫模型算法理论知识及算法实现代码实现最全整理汇总
5隐马尔可夫模型简介
算法
评估问题:向前算法
定义向前变量 采用动态规划算法,复杂度O(N2T)
解码问题:韦特比(Viterbi)算法
采用动态规划算法,复杂度O(N2T)
学习问题:向前向后算法
EM算法的一个特例,带隐变量的最大似然估计
算法:向前算法(一)
P (O | λ ) = ∑ P (O, X | λ ) = ∑ P ( X | λ ) P (O | X , λ )
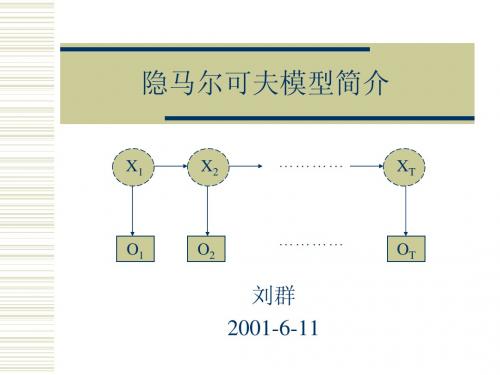
隐马尔可夫模型简介
X1 X2 ………… XT
O1
O2
…………
OT
刘群 2001-6-11
假设
对于一个随机事件,有一个观察值序列:O1,...,OT 该事件隐含着一个状态序列:X1,...,XT 假设1:马尔可夫假设(状态构成一阶马尔可夫链) p(Xi|Xi-1…X1) = p(Xi|Xi-1) 假设2:不动性假设(状态与具体时间无关) p(Xi+1|Xi) = p(Xj+1|Xj),对任意i,j成立 假设3:输出独立性假设(输出仅与当前状态有关) p(O1,...,OT | X1,...,XT) = Π p(Ot | Xt)
资源
Rabiner, L. R., A Tutorial on Hidden Markov Models and Selected Applications in Speech Recognition, Proceedings of the IEEE, vol. 77, no. 2, Feb. 1989, pgs 257 - 285. There is a lot of notation but verbose explanations accompany. 翁富良,王野翊,计算语言学导论,中国社会科学出版 社,1998 HTK:HMM Toolkit Hidden Markov Model (HMM) White Paper (GeneMatcher) ……
详细讲解隐马尔可夫模型配有实际例题

05
隐马尔可夫模型的优缺点
优点分析
能够处理序列数据,适用于 语音识别、自然语言处理等 领域
模型简单,易于理解和实现
具有较强的鲁棒性,能够适 应各种类型的数据
可以通过训练数据学习模型 的参数,提高模型的准确性
和泛化能力
缺点分析
计算复杂度高:隐马尔可夫模型的训练和预测需要大量的计算资源。
模型参数多:隐马尔可夫模型需要估计的状态转移概率和发射概率数量庞大,容易导致过拟合。
模型评估与调整
评估指标:准确率、召回率、F1值等 调整方法:调整模型参数、增加训练数据、调整模型结构等 评估工具:Python库(如sklern、pyrch等)、自定义评估函数等 调整策略:根据评估结果,选择合适的调整方法,以提高模型性能。
模型选择与决策
隐马尔可夫模型的定义和特点 隐马尔可夫模型的建立方法 隐马尔可夫模型的参数估计 隐马尔可夫模型的决策过程 隐马尔可夫模型的实际应用案例分析
04
隐马尔可夫模型的应用实例
语音识别
语音识别技术简介
隐马尔可夫模型在语音识 别中的应用
语音识别系统的组成和原 理
隐马尔可夫模型在语音识 别中的具体应用案例
自然语言处理
语音识别:将语音信号转化为文字 机器翻译:将一种语言的文本翻译成另一种语言 文本生成:根据输入生成连贯的文本 情感分析:分析文本中的情感倾向,如积极、消极、中性等
生物信息学
DN序列分析: 使用隐马尔可 夫模型预测DN 序列的进化关
系
RN结构预测: 利用隐马尔可 夫模型预测RN 的二级结构和
三级结构
蛋白质结构预 测:通过隐马 尔可夫模型预 测蛋白质的三 维结构和功能
基因调控网络 分析:使用隐 马尔可夫模型 分析基因调控 网络的动态变
隐马尔可夫模型算法及其在语音识别中的应用

隐马尔可夫模型算法及其在语音识别中的应用隐马尔可夫模型(Hidden Markov Model,HMM)算法是一种经典的统计模型,常被用于对序列数据的建模与分析。
目前,在语音识别、生物信息学、自然语言处理等领域中,HMM算法已经得到广泛的应用。
本文将阐述HMM算法的基本原理及其在语音识别中的应用。
一、HMM算法的基本原理1.概率有限状态自动机HMM算法是一种概率有限状态自动机(Probabilistic Finite State Automata,PFSA)。
PFSA是一种用于描述随机序列的有限状态自动机,在描述序列数据的时候可以考虑序列的概率分布。
PFSA主要包括以下几个部分:(1)一个有限状态的集合S={s_1,s_2,…,s_N},其中s_i表示第i个状态。
(2)一个有限的输出字母表A={a_1,a_2,…,a_K},其中a_i表示第i个输出字母。
(3)一个大小为N×N的转移概率矩阵Ψ={ψ_ij},其中ψ_ij表示在状态s_i的前提下,转移到状态s_j的概率。
(4)一个大小为N×K的输出概率矩阵Φ={φ_ik},其中φ_ik 表示在状态s_i的前提下,输出字母a_k的概率。
2. 隐藏状态在HMM中,序列的具体生成过程是由一个隐藏状态序列和一个观测序列组成的。
隐藏状态是指对于每个观测值而言,在每个时刻都存在一个对应的隐藏状态,但这个隐藏状态对于观测者来说是不可见的。
这就是所谓的“隐藏”状态。
隐藏状态和观测序列中的每个观测值都有一定的概率联系。
3. HMM模型在HMM模型中,隐藏状态和可观察到的输出状态是联合的,且它们都服从马尔可夫过程。
根据不同的模型,HMM模型可以划分为左-右模型、符合模型、环模型等。
其中最常见的是左-右模型。
在这种模型中,隐藏状态之间存在着马尔可夫链的转移。
在任何隐藏状态上,当前状态接下来可以转移到最多两个状态:向右移动一格或不变。
4. HMM的三个问题在HMM模型中,有三个基本问题:概率计算问题、状态路径问题和参数训练问题。
隐马尔可夫模型.pptx

第28页/共85页
学习问题
• Baum-Welch重估计公式
• 已知X和 的情况下,t时刻为状态i,t+1时刻为状态j的后验概率
θ
ij
(t
)
i
(t
1)aij P(XT
b |
jk
θ)
j
(t
)
向前
向后
T
jl (t)
t 1 l
bˆ v(t )vk
jk
T
jl (t)
t 1 l
第29页/共85页
例如:ML估计
第10页/共85页
估值问题
• 直接计算HMM模型产生可见长度为T的符号序列X的概率
其中,
表示状态 的初始概率
假设HMM中有c个隐状态,则计算复杂度为
!
例如:c=10,T=20,基本运算1021次!
(1)
第11页/共85页
O(cTT )
估值问题
• 解决方案
• 递归计算
t时刻的计算仅涉及上一步的结果,以及
x1和x3统计独立,而 其他特征对不独立
第32页/共85页
相关性例子
• 汽车的状态 • 发动机温度 • 油温 • 油压 • 轮胎内气压
• 相关性 • 油压与轮胎内气压相互独立 • 油温与发动机温度相关
第33页/共85页
贝叶斯置信网
• 用图的形式来表示特征之间的因果依赖性 • 贝叶斯置信网(Bayesian belief net) • 因果网(causal network) • 置信网(belief net)
P(θi )
P(θi | X)
θi P(X | θi )
第20页/共85页
解码问题
隐马尔科夫(HMM)模型详解及代码实现

机器学习之隐马尔科夫模型(HMM)机器学习之隐马尔科夫模型(HMM)1、隐马尔科夫模型介绍2、隐马尔科夫数学原理3、Python代码实现隐马尔科夫模型4、总结隐马尔可夫模型介绍马尔科夫模型(hidden Markov model,HMM)是关于时序的概率模型,描述由一个隐藏的马尔科夫随机生成不可观测的状态随机序列,再由各个状态生成一个观测从而产生观测随机序列的过程,属于一个生成模型。
下面我们来从概率学角度定义马尔科夫模型,从一个典型例子开始:假设有4个盒子,每个盒子里面有不同数量的红、白两种颜色的球,具体如下表:盒子编号1234红球数5368白球数5742现在从这些盒子中取出T个球,取样规则为每次选择一个盒子取出一个球,记录其颜色,放回。
在这个过程中,我们只能观测到球的颜色的序列,观测不到球是从哪个盒子中取出来的,即观测不到盒子的序列,这里有两个随机序列,一个是盒子的序列(状态序列),一个是球的颜色的观测序列(观测序列),前者是隐藏的,只有后者是可观测的。
这里就构成了一个马尔科夫的例子。
定义是所有的可能的状态集合,V是所有的可能的观测的集合:其中,N是可能的状态数,M是可能的观测数,例如上例中N=4,M=2。
是长度为T的状态序列,是对应的观测序列:A是状态转移概率矩阵:其中, 是指在时刻处于状态的条件下在时刻转移到状态的概率。
B是观测概率矩阵:其中, 是指在时刻处于状态的条件下生成观测的概率。
是初始状态概率向量:其中, 是指在时刻=1处于状态的概率。
由此可得到,隐马尔可夫模型的三元符号表示,即称为隐马尔可夫模型的三要素。
由定义可知隐马尔可夫模型做了两个基本假设:(1)齐次马尔科夫性假设,即假设隐藏的马尔科夫链在任意时刻的状态只和-1状态有关;(2)观测独立性假设,观测只和当前时刻状态有关;仍以上面的盒子取球为例,假设我们定义盒子和球模型:状态集合: = {盒子1,盒子2,盒子3,盒子4}, N=4观测集合: = {红球,白球} M=2初始化概率分布:状态转移矩阵:观测矩阵:(1)转移概率的估计:假设样本中时刻t处于状态i,时刻t+1转移到状态j 的频数为那么转台转移概率的估计是:(2)观测概率的估计:设样本中状态为j并观测为k的频数是那么状态j观测为k的概率, (3)初始状态概率的估计为S个样本中初始状态为的频率。
《隐马尔可夫模型》课件

隐马尔可夫模型在许多领域都有应用,如语音识 别、自然语言处理、生物信息学和金融预测等。
隐马尔可夫模型的应用领域
01
语音识别
用于将语音转换为文本,或识别说 话人的意图。
生物信息学
用于分析基因序列、蛋白质序列和 代谢物序列等。
03 隐马尔可夫模型的建立
观察概率矩阵的确定
总结词
观察概率矩阵描述了在给定状态下,观察到不同状态的概率 分布。
详细描述
观察概率矩阵是隐马尔可夫模型中的重要组成部分,它表示 了在给定状态下,观察到不同状态的概率分布。例如,在语 音识别中,观察概率矩阵可以表示在特定语音状态下发出不 同音素的概率。
状态转移概率矩阵的确定
VS
原理
通过动态规划找到最大概率的路径,该路 径对应于最可能的隐藏状态序列。
05 隐马尔可夫模型的优化与 改进
特征选择与模型参数优化
要点一
特征选择
选择与目标状态和观测结果相关的特征,提高模型预测准 确率。
要点二
模型参数优化
通过调整模型参数,如状态转移概率和观测概率,以改进 模型性能。
高阶隐马尔可夫模型
初始状态概率分布表示了隐马尔可夫模型在初始时刻处于各个状态的概率。这个概率分布是隐马尔可 夫模型的重要参数之一,它决定了模型在初始时刻所处的状态。在某些应用中,初始状态概率分布可 以根据具体问题来确定,也可以通过实验数据来估计。
04 隐马尔可夫模型的训练与 预测
前向-后向算法
前向算法
用于计算给定观察序列和模型参 数下,从初始状态到某个终止状 态的所有可能路径的概率。
《隐马尔可夫模型》 ppt课件
大数据分析中基于隐马尔可夫模型的聚类算法研究

大数据分析中基于隐马尔可夫模型的聚类算法研究一、引言近年来,人类社会逐渐向着信息化、智能化的方向发展,各种信息技术不断涌现。
在这其中,大数据技术是一项重要的技术,它的出现,极大地改变了数据处理的方式,大数据分析技术也因此得到了大力推广。
大数据分析涉及许多领域,而在聚类算法上,基于隐马尔可夫模型的算法在大数据分析中具有重要的应用价值。
二、基于隐马尔可夫模型的聚类算法隐马尔可夫模型是一种广泛应用于大数据分析中的概率模型。
隐马尔可夫模型是一种特殊的图模型,它由一个隐藏的马尔可夫链和一个观察序列组成。
这个模型假定在一定条件下,某个状态只与它之前的有限状态有关,即它有一个马尔可夫性。
假如我们已知在每个时刻系统处在哪个状态下观测到某些值,反过来就可以推理出系统的状态。
隐马尔可夫模型利用了不同状态下的特征,对大数据进行聚类处理,故隐马尔可夫模型也被称为混合模型。
在聚类算法中使用隐马尔可夫模型,主要分以下几个步骤:1. 设定初始值,将每一个样本通过随机数分到不同的簇中。
2. 通过条件概率密度函数,计算每一组数据是属于某一簇的概率,并根据概率将数据分配至对应的簇中。
3. 计算每个簇的类中心。
4. 计算每个簇各个成员与该簇中心点的距离,如果超过了预设的一定距离,视为离群点,将其从该簇中移除。
5. 重复进行第二步至第四步,直到满足一定的停止条件为止。
基于隐马尔可夫模型的聚类算法相较于其他聚类算法有一定的优势,其主要表现在:1. 当样本分布不是特别明显时,基于隐马尔可夫模型的聚类算法能够有效地识别出数据实现聚类分析。
2. 基于隐马尔可夫模型的聚类算法不依赖于样本数量,无选样偏差。
3. 隐马尔可夫模型很好地描述了样本数据的分布特点,可以有效地归纳数据的本质特征。
三、基于隐马尔可夫模型的聚类算法在实际应用中的应用隐马尔可夫模型聚类算法可以应用在许多的实际应用场景中,如新闻文本分类、足迹轨迹相似性分析、社交网络聚类、股票价格预测等。
自然语言处理技术中常用的机器学习算法介绍

自然语言处理技术中常用的机器学习算法介绍自然语言处理(Natural Language Processing,NLP)是人工智能领域中研究人类语言与计算机之间交互的一门学科。
在NLP领域中,机器学习算法被广泛应用于语言模型、文本分类、命名实体识别、情感分析等任务中。
本文将介绍NLP中常用的机器学习算法,包括支持向量机(Support Vector Machine,SVM)、朴素贝叶斯(Naive Bayes)、隐马尔可夫模型(Hidden Markov Model,HMM)和递归神经网络(Recurrent Neural Network,RNN)。
支持向量机(SVM)是一种常用的监督学习算法,广泛用于文本分类、情感分析等NLP任务中。
其核心思想是将数据映射到高维空间,通过构建一个最优的超平面,来实现数据的分类。
SVM在处理小样本、非线性和高维特征等问题上具有较好的性能。
朴素贝叶斯(Naive Bayes)是一种基于概率的分类算法,常用于文本分类任务。
它基于贝叶斯定理和特征间的条件独立性假设,可以在给定训练数据的条件下,通过计算后验概率来进行分类。
朴素贝叶斯算法简单、计算效率高,并且对输入数据的特征空间进行了较弱的假设,适用于处理大规模的文本分类问题。
隐马尔可夫模型(HMM)是一种统计模型,常用于语音识别、机器翻译等NLP任务中。
HMM假设系统是一个由不可观察的隐含状态和观测到的可见状态组成的过程,通过观察到的状态序列来估计最可能的隐含状态序列。
HMM广泛应用于词性标注、命名实体识别等任务中,具有较好的效果。
递归神经网络(RNN)是一种具有记忆能力的神经网络,适用于处理序列数据,如语言模型、机器翻译等NLP任务。
RNN通过引入循环结构,可以对序列中的上下文信息进行建模。
长短期记忆网络(Long Short-Term Memory,LSTM)是RNN的一种改进,通过引入门控机制解决了传统RNN存在的长期依赖问题,更适合处理长文本和复杂语义。
马尔可夫算法

马尔可夫算法
马尔可夫算法是一种基于统计的生成模型,用于对文本进行预测
和生成。
它的基本思想是,通过对已有文本的频率分析,从中获取规律,并用这些规律来生成新的文本。
在马尔可夫算法中,每一个词都有一个概率分布,表示它在文本
中出现的概率。
通过分析词之间的关系,可以得到一个状态转移矩阵,它表示了在给定一个词的情况下,下一个词出现的概率分布。
根据这
个矩阵,就可以通过一个简单的随机过程来生成新的文本。
马尔可夫算法有很多应用,比如自然语言处理、文本分析、机器
翻译等。
在自然语言处理领域,它可以用来生成新闻报道、评论、推
文等,大大提高了文本生成的效率和准确性。
然而,马尔可夫算法也存在一些局限性。
比如,它只能基于已有
的文本来生成新的语句,不能根据上下文来生成具有情感色彩的文本;它也存在词汇歧义和语法误用等问题,需要通过对生成结果进行筛选
和修正。
综上所述,马尔可夫算法虽然存在一定的局限性,但是在处理大
规模文本数据和生成基础语言文本方面具有重要的意义。
更多的研究
和应用可以进一步拓展其在自然语言处理领域中的应用。
基于OpenCL的隐马尔可夫模型的GPU并行实现

基于OpenCL的隐马尔可夫模型的GPU并行实现摘要:隐马尔可夫模型(HMM)是建立在马尔可夫链的基础上的统计模型。
虽然隐马尔可夫模型是一种计算高效的机器学习模型,但是当处理的数据集规模过于庞大时,分析的时间太长。
因此,我们有必要研究隐马尔可夫模型的并行化设计,以提高模型的运算速度。
近年来,开放计算语言(OpenCL)的出现,使得设计通用的并行程序成为可能。
该文,我们分析了隐马尔可夫模型三类算法的并行特性,并设计基于OpenCL的并行实现。
实验结果表明,隐马尔可夫模型在GPU上的并行化实现最高获得了640倍的加速比。
关键词:隐马尔可夫模型GPU通用计算OpenCL 并行计算隐马尔可夫模型作为一个时间序列的统计分析模型在语音识别、生物序列分析等领域中有着重要的应用。
虽然HMM是一种计算高效的机器学习模型,但是当处理数百万长度的序列或同时处理多个序列时,分析的时间往往需要几小时、几天。
因此,设计HMM的并行算法,提升模型的训练速度,具有重要的意义。
在该文,我们详细分析了HMM相关的三类关键算法的并行化设计,并在对三种关键算法深入研究的基础上,开发了基于开放式计算语言(OpenCL)的并行实现。
实验结果表明在各种情况下获得了良好的加速比性能。
1 隐马尔可夫模型隐马可夫模型实际上是一个双重的随机过程,由一个隐藏的具有有限状态的马尔可夫链和一个与马尔可夫链状态相关联的随机函数集组成。
本文只专注于离散时间系统。
为了方便讨论,根据文献[1],本文首先定义一些基本符号:(1)隐藏的状态集合记为对应于上述隐马尔可夫模型三个基本问题的求解,相应的解决方案分别为:前向(Forward)算法、Viterbi算法、Baum-Welch算法。
三种算法的具体描述均可在[1]一文找到。
2 OpenCL简介OpenCL是一个面向异构平台编程的开放性计算语言,其将各类计算设备抽象成为一个统一的平台。
OpenCL将并行设备看成为由一个或多个计算单元(CU)组成,而CU又由一个或多个处理单元(PE)组成,CU可以看成为一个单指多数据流处理器。
隐马尔科夫模型(HMM)详解

马尔科夫过程马尔科夫过程可以看做是一个自动机,以一定的概率在各个状态之间跳转。
考虑一个系统,在每个时刻都可能处于N个状态中的一个,N个状态集合是{S1,S2,S3,...S N}。
我们如今用q1,q2,q3,…q n来表示系统在t=1,2,3,…n时刻下的状态。
在t=1时,系统所在的状态q取决于一个初始概率分布PI,PI(S N)表示t=1时系统状态为S N的概率。
马尔科夫模型有两个假设:1. 系统在时刻t的状态只与时刻t-1处的状态相关;〔也称为无后效性〕2. 状态转移概率与时间无关;〔也称为齐次性或时齐性〕第一条详细可以用如下公式表示:P(q t=S j|q t-1=S i,q t-2=S k,…)= P(q t=S j|q t-1=S i)其中,t为大于1的任意数值,S k为任意状态第二个假设那么可以用如下公式表示:P(q t=S j|q t-1=S i)= P(q k=S j|q k-1=S i)其中,k为任意时刻。
下列图是一个马尔科夫过程的样例图:可以把状态转移概率用矩阵A表示,矩阵的行列长度均为状态数目,a ij表示P(S i|S i-1)。
隐马尔科夫过程与马尔科夫相比,隐马尔科夫模型那么是双重随机过程,不仅状态转移之间是个随机事件,状态和输出之间也是一个随机过程,如下列图所示:此图是从别处找来的,可能符号与我之前描绘马尔科夫时不同,相信大家也能理解。
该图分为上下两行,上面那行就是一个马尔科夫转移过程,下面这一行那么是输出,即我们可以观察到的值,如今,我们将上面那行的马尔科夫转移过程中的状态称为隐藏状态,下面的观察到的值称为观察状态,观察状态的集合表示为O={O1,O2,O3,…O M}。
相应的,隐马尔科夫也比马尔科夫多了一个假设,即输出仅与当前状态有关,可以用如下公式表示:P(O1,O2,…,O t|S1,S2,…,S t)=P(O1|S1)*P(O2|S2)*...*P(O t|S t) 其中,O1,O2,…,O t为从时刻1到时刻t的观测状态序列,S1,S2,…,S t那么为隐藏状态序列。
隐马尔科夫模型在人工智能中的应用方法(五)

隐马尔科夫模型在人工智能中的应用方法隐马尔科夫模型(Hidden Markov Model,HMM)是一种统计模型,主要用来描述一个含有隐藏状态的马尔科夫过程。
在人工智能领域,HMM被广泛应用于语音识别、自然语言处理、生物信息学等多个领域。
本文将从HMM的基本原理、在人工智能中的应用方法以及相关应用案例进行探讨。
HMM的基本原理HMM是一种双重随机过程模型,其中有一个隐含的马尔科夫链,以及一个依赖于状态的观察过程。
具体来说,HMM包括三个要素:状态空间、观察空间和状态转移概率。
其中,状态空间指的是系统可能处于的一组状态,观察空间指的是每个状态下可能观察到的输出。
状态转移概率则描述了系统从一个状态转移到另一个状态的概率。
在HMM中,状态和观察之间存在一个隐藏的马尔科夫链。
这意味着我们无法直接观察到系统的状态,只能通过系统的输出来推断其状态。
因此,HMM的核心问题就是根据观察序列来推断隐藏的状态序列,以及估计模型的参数。
HMM在人工智能中的应用方法在人工智能领域,HMM广泛应用于语音识别、自然语言处理、生物信息学等多个领域。
其中,语音识别是HMM最为经典的应用之一。
在语音识别中,语音信号被看作是一个隐含的马尔科夫链的输出,而语音的文本转换则是要找到对应的状态序列。
通过训练模型,可以利用HMM对语音信号进行建模,并从中识别出对应的文本。
此外,HMM还被广泛应用于自然语言处理领域。
在自然语言处理中,HMM可以用来建模文本序列,例如词性标注、命名实体识别等任务。
通过利用HMM对文本序列进行建模,可以更好地理解和处理自然语言。
在生物信息学领域,HMM也有着重要的应用。
例如,在基因组学中,HMM可以用来对生物序列(如DNA、RNA和蛋白质序列)进行建模和分析。
通过对生物序列的建模,可以发现其中的模式和结构,从而为生物信息学研究提供有力的工具。
相关应用案例HMM在人工智能领域有着丰富的应用案例。
以语音识别为例,HMM被广泛应用于商用语音识别系统中。
《隐马尔可夫模型》课件

C R F 常用在文本分类、句法分析、命名实体识别等 领域。
HMM的局限性和改进方法
1
截断、尾部效应
加入上下文信息,使用长短时记忆网络。
2
自适应马尔可夫链
使用观测序列预测假设的状态转移矩阵。
3
深度学习方法
使用神经网络建立序列到序列的映射关系,消除符号表示造成的信息损失。
总结
HMM模型的优缺点
HMM模型可以识别长时序列,具有较好的泛化 性,但是对许多情况会做出错误HMM将会在自然语言处理、语音识别、图像识 别等领域继续发挥重要作用。
参考文献
• 《统计学习方法》- 李航 • 《Python自然语言处理》- 谢益辉 • 《深度学习》- Goodfellow等
附录
最近,HMM被用于音乐生成,允许他们生成具有旋律的曲子,相信HMM会在越来越多的领域展现其重要性。
隐马尔可夫模型PPT课件
在本课件中,我们将一起了解隐马尔可夫模型的基本概念,算法和应用领域。 无论您是机器学习新手,还是专业人士,这份PPT都能帮助您了解隐马尔可夫 模型的关键要素。
隐马尔可夫模型概述
隐马尔可夫模型(Hidden Markov Model, HMM)是 一种用于描述动态系统的概率模型。
马尔可夫假设
HMM 假设未来的状态只与当前状态有关,与历史状态无关,即是一个马尔可夫过程。
HMM的基本问题
1 问题1:给出模型和观测序列,如何计算观测序列出现的 概率?
通过前向,后向算法,或者前向-后向算法计算观测序列出现的概率。
2 问题2:给出模型和观测序列,如何预测其中的状态序列?
通过维特比算法预测概率最大的状态序列。
3 问题3:给出模型和观测序列,如何调整模型数使其最优?
隐马尔可夫模型课件

隐马尔可夫模型课 件
目录
ቤተ መጻሕፍቲ ባይዱ
• 隐马尔可夫模型简介 • 隐马尔可夫模型的基本概念 • 隐马尔可夫模型的参数估计 • 隐马尔可夫模型的扩展 • 隐马尔可夫模型的应用实例 • 隐马尔可夫模型的前景与挑战
01
隐马尔可夫模型简介
定义与特点
定义
隐马尔可夫模型(Hidden Markov Model,简称HMM)是 一种统计模型,用于描述一个隐藏的马尔可夫链产生的观测 序列。
观测概率
定义
观测概率是指在给定隐藏状态下,观测到某一特定输出的概率。在隐马尔可夫 模型中,观测概率表示隐藏状态与观测结果之间的关系。
计算方法
观测概率通常通过训练数据集进行估计,使用最大似然估计或贝叶斯方法计算 。
初始状态概率
定义
初始状态概率是指在隐马尔可夫模型中,初始隐藏状态的概率分布。
计算方法
05
隐马尔可夫模型的应用实 例
语音识别
语音识别是利用隐马尔可夫模型来识别连续语音的技术。通过建立语音信号的时间序列与状态序列之 间的映射关系,实现对语音的自动识别。
在语音识别中,隐马尔可夫模型用于描述语音信号的动态特性,将连续的语音信号离散化为状态序列, 从而进行分类和识别。
隐马尔可夫模型在语音识别中具有较高的准确率和鲁棒性,广泛应用于语音输入、语音合成、语音导航 等领域。
Baum-Welch算法
总结词
Baum-Welch算法是一种用于隐马尔可夫模型参数估计的迭代算法,它通过最大化对数似然函数来估计模型参数 。
详细描述
Baum-Welch算法是一种基于期望最大化(EM)算法的参数估计方法,它通过对数似然函数作为优化目标,迭 代更新模型参数。在每次迭代中,算法首先使用前向-后向算法计算给定观测序列和当前参数值下的状态序列概 率,然后根据这些概率值更新模型参数。通过多次迭代,算法逐渐逼近模型参数的最优解。
隐马尔可夫模型与序列标注实验报告

自然语言处理实验报告课程:自然语言处理系别:软件工程专业:年级:学号:姓名:指导教师:实验一隐马尔可夫模型与序列标注实验一、实验目的1掌握隐马尔可夫模型原理和序列标注2使用隐马尔可夫模型预测序列标注二、实验原理1.隐马尔可夫模型隐马尔可夫模型是马尔可夫链的一种,它的状态不能直接观察到,但能通过观测向量序列观察到,每个观测向量都是通过某些概率密度分布表现为各种状态,每一个观测向量是由一个具有相应概率密度分布的状态序列产生。
所以,隐马尔可夫模型是一个双重随机过程----具有一定状态数的隐马尔可夫链和显示随机函数集。
2. 使用隐马尔可夫模型做预测需要的处理步骤收集数据:可以使用任何方法。
比如股票预测问题,我们可以收集股票的历史数据。
数据预处理:收集完的数据,我们要进行预处理,将这些所有收集的信息按照一定规则整理出来,从原始数据中提取有用的列,并做异常值处理操作。
样本生成:根据收集的数据生成样本。
训练模型:根据训练集,估计模型参数。
序列预测并分析结果:使用模型对测试集数据进行序列标注,计算准确率,进行误差分析,可以进行可视化。
三、实验数据收集1.训练数据由于训练数据需要进行大量标注工作,所以训练数据选择了现有的已标注的人民日报1998语料库。
所有文章都已分词完毕,如:1998,瞩目中华。
新的机遇和挑战,催人进取;新的目标和征途,催人奋发。
英雄的中国人民在以江泽民同志为核心的党中央坚强领导和党的十五大精神指引下,更高地举起邓小平理论的伟大旗帜,团结一致,扎实工作,奋勇前进,一定能够创造出更加辉煌的业绩!2.测试数据测试数据使用搜狗实验室的新闻数据集,由于该数据集也是没有标注的数据集,所以手动标注了少量用于测试。
四、实验环境1.Python3.7和JDK1.8五、实验步骤1.数据收集及数据预处理训练数据使用人民日报1998语料库,所以不需要进行太多预处理,主要是测试数据集,我们使用搜狗实验室的新闻数据集,以下是收集和处理过程。
hmm三个基本问题及相应算法

HMM三个基本问题及相应算法
HMM的三个基本问题
隐马尔科夫模型(Hidden Markov Model,简称HMM)是用于处理序列数据的统计模型,广泛应用于语音识别、自然语言处理、生物特征识别等领域。
HMM的三个基本问题是:
1. 概率计算问题:给定HMM模型和观测序列,如何计算在某个状态或状态转移下的概率?
2. 最优状态序列问题:给定HMM模型和观测序列,如何找到最优的状态序列,即最大概率的状态序列?
3. 参数学习问题:给定一组观测数据,如何估计HMM模型的参数,即状态转移概率、发射概率等?
相应算法
针对HMM的三个基本问题,有以下相应的算法:
1. 前向-后向算法:用于解决概率计算问题,可以计算在某个状态或状态转移下的概率。
算法基于动态规划的思想,通过递推计算前
向概率和后向概率,进而得到状态转移概率和发射概率的计算公式。
2. Viterbi算法:用于解决最优状态序列问题,可以找到最优的状态序列。
算法基于动态规划的思想,通过递推计算每个时刻的最优状态,并在每个时刻更新最优路径,最终得到最优状态序列。
Viterbi算法的时间复杂度为O(n*k^2),其中n为观测序列的长度,k为状态数。
以上是HMM三个基本问题及相应算法的简要介绍。
在实际应用中,需要根据具体问题选择合适的算法,并结合数据特点进行模型参数的学习和调整。
隐马尔可夫模型三个基本问题以及相应的算法

隐马尔可夫模型三个基本问题以及相应的算法一、隐马尔可夫模型(Hidden Markov Model, HMM)隐马尔可夫模型是一种统计模型,它描述由一个隐藏的马尔可夫链随机生成的不可观测的状态序列,再由各个状态生成一个观测而产生观测序列的过程。
HMM广泛应用于语音识别、自然语言处理、生物信息学等领域。
二、三个基本问题1. 概率计算问题(Forward-Backward算法)给定模型λ=(A,B,π)和观察序列O=(o1,o2,…,oT),计算在模型λ下观察序列O出现的概率P(O|λ)。
解法:前向-后向算法(Forward-Backward algorithm)。
前向算法计算从t=1到t=T时,状态为i且观察值为o1,o2,…,ot的概率;后向算法计算从t=T到t=1时,状态为i且观察值为ot+1,ot+2,…,oT的概率。
最终将两者相乘得到P(O|λ)。
2. 学习问题(Baum-Welch算法)给定观察序列O=(o1,o2,…,oT),估计模型参数λ=(A,B,π)。
解法:Baum-Welch算法(EM算法的一种特例)。
该算法分为两步:E 步计算在当前模型下,每个时刻处于每个状态的概率;M步根据E步计算出的概率,重新估计模型参数。
重复以上两步直至收敛。
3. 预测问题(Viterbi算法)给定模型λ=(A,B,π)和观察序列O=(o1,o2,…,oT),找到最可能的状态序列Q=(q1,q2,…,qT),使得P(Q|O,λ)最大。
解法:Viterbi算法。
该算法利用动态规划的思想,在t=1时初始化,逐步向后递推,找到在t=T时概率最大的状态序列Q。
具体实现中,使用一个矩阵delta记录当前时刻各个状态的最大概率值,以及一个矩阵psi记录当前时刻各个状态取得最大概率值时对应的前一时刻状态。
最终通过回溯找到最可能的状态序列Q。
三、相应的算法1. Forward-Backward算法输入:HMM模型λ=(A,B,π)和观察序列O=(o1,o2,…,oT)输出:观察序列O在模型λ下出现的概率P(O|λ)过程:1. 初始化:$$\alpha_1(i)=\pi_ib_i(o_1),i=1,2,…,N$$2. 递推:$$\alpha_t(i)=\left[\sum_{j=1}^N\alpha_{t-1}(j)a_{ji}\right]b_i(o_t),i=1,2,…,N,t=2,3,…,T$$3. 终止:$$P(O|λ)=\sum_{i=1}^N\alpha_T(i)$$4. 后向算法同理,只是从后往前递推。
HMM及其算法介绍

HMM及其算法介绍隐马尔可夫模型(Hidden Markov Model,HMM)是一种统计模型,用于描述具有潜在不可见状态的动态系统。
HMM主要用于序列数据的建模与分析,特别适用于语音识别、自然语言处理、语言模型、机器翻译等领域。
HMM是一种二层结构的概率图模型,包括状态序列和观测序列。
其中,状态序列代表系统内部的状态变化,而观测序列是根据系统状态产生的可见数据。
HMM的基本假设是系统状态满足马尔可夫性质,即当前状态只依赖于前一个状态。
HMM模型的核心是三个问题:评估问题、解码问题和学习问题。
评估问题是给定一个观测序列和模型参数,计算该观测序列出现的概率。
该问题可以使用前向算法和后向算法来解决。
前向算法从初始状态开始,计算每个时刻观测序列的概率;后向算法从最后一个状态开始,计算每个时刻观测序列的概率。
最后,两个算法的结果相乘得到观测序列的概率。
解码问题是给定一个观测序列和模型参数,找到最有可能的状态序列。
常用的解码算法有维特比算法和后向算法。
维特比算法通过动态规划的方式,计算每个时刻的最大概率状态,并在整个过程中维护一个路径矩阵,得到最有可能的状态序列。
学习问题是给定观测序列,估计模型参数。
通常使用的方法是极大似然估计,通过最大化观测序列的似然函数来估计模型参数。
Baum-Welch算法是HMM中常用的学习算法,它利用了前向算法和后向算法的结果,通过迭代优化模型参数,直到收敛。
HMM模型的应用之一是语音识别。
在语音识别中,观测序列是听到的声音,而状态序列代表对应的语音单元(如音素、词语)。
通过训练HMM模型,可以将声音与语音单元映射起来,从而实现语音的识别。
另一个常见的应用是自然语言处理中的词性标注。
词性标注是给每个词语标注上对应的词性,如名词、动词、形容词等。
通过训练HMM模型,可以将词语作为观测序列,词性作为状态序列,从而实现词性标注的任务。
总结来说,HMM是一种用于序列数据建模的统计模型,具有评估问题、解码问题和学习问题等核心问题。
隐马尔可夫模型三个基本问题及算法

隐马尔可夫模型三个基本问题及算法隐马尔可夫模型(Hien Markov Model, HMM)是一种用于建模具有隐藏状态和可观测状态序列的概率模型。
它在语音识别、自然语言处理、生物信息学等领域广泛应用,并且在机器学习和模式识别领域有着重要的地位。
隐马尔可夫模型有三个基本问题,分别是状态序列概率计算问题、参数学习问题和预测问题。
一、状态序列概率计算问题在隐马尔可夫模型中,给定模型参数和观测序列,计算观测序列出现的概率是一个关键问题。
这个问题通常由前向算法和后向算法来解决。
具体来说,前向算法用于计算给定观测序列下特定状态出现的概率,而后向算法则用于计算给定观测序列下前面状态的概率。
这两个算法相互协作,可以高效地解决状态序列概率计算问题。
二、参数学习问题参数学习问题是指在给定观测序列和状态序列的情况下,估计隐马尔可夫模型的参数。
通常采用的算法是Baum-Welch算法,它是一种迭代算法,通过不断更新模型参数来使观测序列出现的概率最大化。
这个问题的解决对于模型的训练和优化非常重要。
三、预测问题预测问题是指在给定观测序列和模型参数的情况下,求解最可能的状态序列。
这个问题通常由维特比算法来解决,它通过动态规划的方式来找到最可能的状态序列,并且在很多实际应用中都有着重要的作用。
以上就是隐马尔可夫模型的三个基本问题及相应的算法解决方法。
在实际应用中,隐马尔可夫模型可以用于许多领域,比如语音识别中的语音建模、自然语言处理中的词性标注和信息抽取、生物信息学中的基因预测等。
隐马尔可夫模型的强大表达能力和灵活性使得它成为了一个非常有价值的模型工具。
在撰写这篇文章的过程中,我对隐马尔可夫模型的三个基本问题有了更深入的理解。
通过对状态序列概率计算问题、参数学习问题和预测问题的深入探讨,我认识到隐马尔可夫模型在实际应用中的重要性和广泛适用性。
隐马尔可夫模型的算法解决了许多实际问题,并且在相关领域有着重要的意义。
隐马尔可夫模型是一种强大的概率模型,它的三个基本问题和相应的算法为实际应用提供了重要支持。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
机器学习算法隐马尔可夫模型算法理论知识及算法实现
代码实现最全整理汇总
HMM算法有三个核心问题:
1.评估问题:给定观测序列和模型参数,计算观测序列出现的概率。
2.解码问题:给定观测序列和模型参数,推测最可能的隐藏状态序列。
3.学习问题:给定观测序列,估计模型参数的最大似然估计。
下面是隐马尔可夫模型算法实现的代码示例(基于Python):
1.基本定义
```python
import numpy as np
#定义隐马尔可夫模型
class HMM(object):
def __init__(self, A, B, pi):
self.A = A # 状态转移概率矩阵
self.B = B # 观测概率矩阵
self.pi = pi # 初始状态概率向量
self.N = self.A.shape[0] # 状态数
self.M = self.B.shape[1] # 观测数
```
2.评估问题
```python
#前向算法
def forward(self, O):
T = len(O)
alpha = np.zeros((T, self.N))
alpha[0] = self.pi * self.B[:, O[0]]
for t in range(1, T):
for i in range(self.N):
alpha[t, i] = np.sum(alpha[t-1] * self.A[:, i]) * self.B[i, O[t]]
return alpha
#后向算法
def backward(self, O):
T = len(O)
beta = np.zeros((T, self.N))
beta[T-1] = 1
for t in range(T-2, -1, -1):
for i in range(self.N):
beta[t, i] = np.sum(beta[t+1] * self.A[i] * self.B[:, O[t+1]])
return beta
#前向后向算法,计算观测序列的概率
def evaluate(self, O):
alpha = self.forward(O)
return np.sum(alpha[-1])
```
3.解码问题
```python
#维特比算法
def viterbi(self, O):
T = len(O)
delta = np.zeros((T, self.N))
psi = np.zeros((T, self.N), dtype=int)
delta[0] = self.pi * self.B[:, O[0]]
for t in range(1, T):
for i in range(self.N):
delta[t, i] = np.max(delta[t-1] * self.A[:, i]) * self.B[i, O[t]]
psi[t, i] = np.argmax(delta[t-1] * self.A[:, i])
z = np.zeros(T, dtype=int)
z[-1] = np.argmax(delta[-1])
for t in range(T-2, -1, -1):
z[t] = psi[t+1, z[t+1]]
return z
```
4. 学习问题(Baum-Welch算法)
```python
def learn(self, O_list, max_iter=100):
P_O_list = [self.evaluate(O) for O in O_list]
for n in range(max_iter):
gamma_sum = np.zeros((self.N, self.N))
epsilon_sum = np.zeros((self.N, self.M))
pi_new = self.pi * 0
for O, P_O in zip(O_list, P_O_list):
alpha = self.forward(O)
beta = self.backward(O)
gamma = alpha * beta / P_O
T = len(O)
epsilon = np.zeros((self.N, self.N, T))
for t in range(T-1):
for i in range(self.N):
for j in range(self.N):
epsilon[i, j, t] = alpha[t, i] * self.A[i, j] * self.B[j, O[t+1]] * beta[t+1, j] / P_O
gamma_sum += np.sum(gamma[:T-1], axis=0)
epsilon_sum += np.sum(epsilon[:, :, :T-1], axis=2)
pi_new += gamma[0]
self.A = epsilon_sum / gamma_sum[:, np.newaxis]
self.B = np.zeros((self.N, self.M))
for k in range(self.M):
mask = np.array([o == k for O in O_list for o in O])
self.B[:, k] = np.sum(np.stack([gamma[mask, i] for i in range(self.N)]), axis=1) / np.sum(gamma, axis=0)
self.pi = pi_new / len(O_list)
P_O_list_new = [self.evaluate(O) for O in O_list]
if np.linalg.norm(np.array(P_O_list) -
np.array(P_O_list_new)) < 1e-6:
break
P_O_list = P_O_list_new
```
这些代码实现了隐马尔可夫模型的基本功能,包括评估问题、解码问题和学习问题。
根据具体需求,可以进一步进行优化和扩展。