Sql 2008 数据库分文件组(指定磁盘),映射分区表使用不同的文件组详解
SQL Server 2008数据库类型.doc

SQ server 数据库mastermaster数据库是SQL Server中最重要的数据库,记录了SQL Server系统中所有的系统信息,包括登入账户、系统配置和设置、服务器中数据库的名称、相关信息和这些数据库文件的位置,以及SQL Server初始化信息等。
由于master数据库记录了如此多且重要的信息,一旦数据库文件损失或损毁,将对整个SQL Server系统的运行造成重大的影响,甚至是得整个系统瘫痪,因此,要经常对master数据库进行备份,以便在发生问题时,对数据库进行恢复。
tempdb数据库是存在于SQL Server会话期间的一个临时性的数据库。
一旦关闭SQL Server,tempdb数据库保存的内容将自动消失。
重启动SQL Server时,系统将重新创建新的、空的tempdb数据库。
tempdb保存的内容主要包括:显示创建临时对象,例如表、存储过程、表变量或游标。
所有版本的更新记录。
SQL Server创建的内部工作表。
创建或重新生成索引时,临时排序的结果。
modelmodel系统数据库是一个模板数据库,可以用作建立数据库的摸板。
它包含了建立新数据库时所需的基本对象,如系统表、查看表、登录信息等。
在系统执行建立新数据库操作时,它会复制这个模板数据库的内容到新的数据库上。
由于所有新建立的数据库都是继承这个model数据库而来的,因此,如果更改model数据库中得内容,如增加对象,则稍后建立的数据库也都会包含该变动。
model系统数据库是tempdb数据库的基础。
由于每次启动提供SQL Server时,系统都会创建tempdb数据库,所以model数据库必须始终存在于SQL Server系统中。
msdbmsdb系统数据库是提供提“SQL Server代理服务”调度警报、作业以及记录操作员时使用。
如果不使用这些SQL Server代理服务,就不会使用到该系统数据库。
SQL Server代理服务是SQL Server中的一个Windows服务,用于运行任何已创建的计划作业。
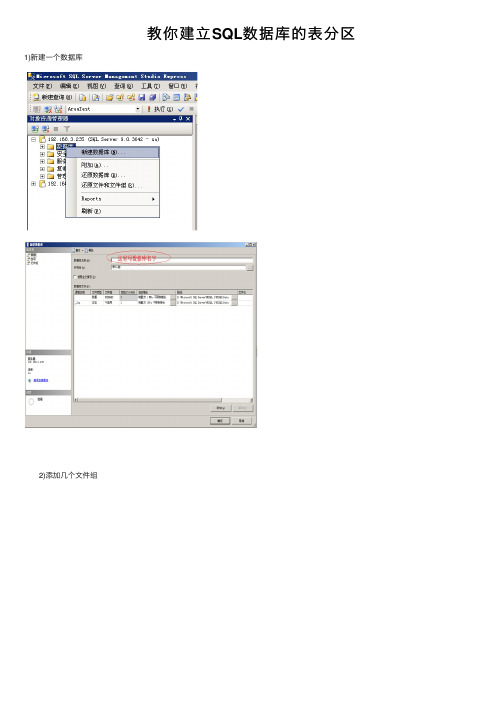
手把手教你建立SQL数据库的表分区

手把手教你建立SQL数据库的表分区1)新建一个数据库2)添加几个文件组3)回到“常规”选项卡,添加数据库文件看到用红色框框起来的地方没?上一步中建立的文件组在这里就用上了。
再看后面的路径,我把每一个文件都单独放在不同的磁盘上,而且最好都是单独的放在不同的物理盘上,这样会大大提高数据的性能。
点击“确定”数据库就算创建完成了。
4)接下来要做的是建立一个分区行数,SQL语句如下:大家学习的时候最好不要直接COPY,动手把它抄一遍也好。
create partition function PartFuncForExample(Datetime) as Range Right for Value('20000101','20010101','20020101','20030101')这里我准备用表中的某个时间字段作为分区的条件,当然你也可以用其他的,比如INT 之类,只要好分段的都可以。
这里注意 Right 关键字,意思就是当记录的时间(在下面会被指到表的某个字段)大于等于20000101的时候,数据会被分到下一个区间,比如2000年1月1号之前的数据会被分到一区,包含2000年1月1号和之后的数据会被分到二区,以此类推。
Right 也可以使用Left替代,意思同上类似。
另外,上面我定义了四个分割点,这四个分割点是根据我们刚刚创建的文件组来决定的。
四个分割点就能产生5个区间段,我们把每个区间段的数据存入一个文件组。
正确执行上述语句后你可以在数据里找到以“PartFuncForExample”命名的分区函数,如下图5)把分区函数建立好以后,我们再来建立分区方案。
目的是为了把分区函数产生的分区映射到文件数据组里。
分区函数是告诉数据库如何分区数据,而分区方案是告诉数据库如何把已分区的数据存到哪个文件组里。
下面我来创建分区方案。
Create Partition Scheme PartSchForExample //创建一个分区方案+分区方案名称 As Partition PartFuncForExample//目的为了分区函数PartFuncForExample To ( PRIMARY,//文件组名 Partition1, //文件组名 Partition2, //文件组名 Partition3, //文件组名Partition4 //文件组名 )正确执行后能在分区方案中看到,如下图6)马上就快要大公告成了,下面我们来建立要分区存储的表,该表的数据理论上应该是非常非常多的,百万级别的记录以上而且基本上是不更新的。
数据库的分区sql语句

数据库的分区sql语句数据库的分区是指将一个大的数据库表按照某种规则拆分成多个较小的子表,以提高查询性能和管理效率。
数据库的分区可以基于范围、列表或哈希等方式进行。
下面是数据库分区的SQL语句示例:1. 基于范围的分区:```sqlCREATE TABLE 表名(列1 数据类型,列2 数据类型,...) PARTITION BY RANGE(列名) (PARTITION 分区名1 VALUES LESS THAN (边界值1),PARTITION 分区名2 VALUES LESS THAN (边界值2),...);```2. 基于列表的分区:```sqlCREATE TABLE 表名(列1 数据类型,列2 数据类型,...) PARTITION BY LIST(列名) (PARTITION 分区名1 VALUES IN (值1, 值2),PARTITION 分区名2 VALUES IN (值3, 值4),...);```3. 基于哈希的分区:```sqlCREATE TABLE 表名(列1 数据类型,列2 数据类型,...) PARTITION BY HASH(列名) PARTITIONS 分区数量; ```这些示例中,`表名`为要进行分区的表的名称,`列名`为用于分区的列的名称,`分区名`为每个分区的名称,`边界值`为范围分区或列表分区的边界值,`值`为列表分区中的值,`分区数量`为哈希分区的数量。
需要注意的是,不同的数据库管理系统可能有不同的语法和规则来进行分区,上述示例是一般情况下的SQL语句,具体应根据所使用的数据库管理系统的文档进行调整和参考。
SQL Server 2008 数据库案例教程课后习题答案

《SQL Server 2008数据库案例教程》练习题及模拟试卷答案第1章一、判断题1. 数据库技术是是计算机数据处理与信息管理系统的核心。
(√)2. 数据是用于描述现实世界中具体事物或抽象概念,可存储的数字符号。
(×)3. 数据库是一个长期存储在计算机内的、有组织的、有共享的、统一管理的数据集合。
(√)4. 数据库管理系统是一个按数据结构来存储和管理数据的服务器管理系统。
(×)5. 关系数据库,是建立在关系模型基础上的数据库。
(√)二、单选题1. 数据(Data)是一些可存储并具有明确意义的(A)A. 符号B.图形C.文字D.数字2. 人工阶段计算机用于数值计算,没有操作系统及管理数据的软件。
这一阶段的年代是(C)A. 19世纪80年代B. 20世纪20年代C.20世纪50年代D. 20世纪80年代3. 在网页中常用的图像格式是(D)A..bmp和.jpgB..gif和.bmpC. .png和.bmpD. .gif和.jpg4.数据库系统的重要特征是什么?(D)A. 数据的独立性和动态性 B.数据的静态性和独立性C.数据的动态性和共享性 D.数据的独立性和共享性三、多选题1.与数据库技术密切相关的基本概念有(ABCD)A. 数据B. 数据库C. 数据库管理系统D. 数据库系统2.数据库可分为哪几种类型?(ABC)A. 关系型数据库B. 网状数据库C. 层次数据库D.树形数据库3. DBMS提供数据操作语言DML,为用户提供了哪些操作?(ABCD)A.数据的追加B.数据的删除C.数据的更新D.数据的查询4.DBMS要分类组织、存储和管理各种数据,包括哪些内容?(ABC)A. 数据字典B. 用户数据C. 存取路径D.服务器5. 目前,DBMS常见品牌有哪些公司?(ABC)A.微软公司的SQL Server B.IBM公司的DB2 C.甲骨文公司的ORACLE D.索尼公司的MySQL四、填空题1.数据库(管理)技术经历了人工管理阶段和文件管理阶段。
sql server 分区注意事项-概述说明以及解释

sql server 分区注意事项-概述说明以及解释1.引言1.1 概述SQL Server是一种关系型数据库管理系统,具有强大的数据处理和存储能力。
在处理大规模数据时,为了提高查询性能和维护数据的效率,我们可以使用分区技术来对数据库进行划分。
分区是将数据库表或索引按某种规则划分成多个逻辑上相互独立的部分,每个部分称为一个分区。
每个分区可以单独进行管理和维护,使得数据的访问和处理更加高效快速。
在使用SQL Server分区技术时,需要注意以下几点:首先,分区设计需要根据具体的业务需求进行合理的划分。
不同的业务场景可能需要不同的分区策略,如按照时间、地域或其他特定的业务属性进行分区。
合理的分区设计可以提高查询性能,并提供更好的数据管理能力。
其次,分区键的选择非常重要。
分区键是指用于划分分区的列或列集合,可以是表中的任意列。
选择一个适合的分区键可以提高查询性能和数据加载的效率。
通常,选择具有高选择性的列作为分区键会得到较好的效果。
另外,分区表的维护和管理也需要特别关注。
由于分区表的数据分布在不同的分区中,因此需要针对每个分区进行独立的维护工作,如备份、索引维护和数据迁移等。
同时,需要注意监控每个分区的使用情况,及时进行分区的调整或优化。
最后,使用分区功能可能涉及到一些限制和注意事项。
例如,分区表的设计需要遵循一些特定的规则和限制,如每个分区的大小应该合理控制,避免某个分区过大或过小。
此外,分区表的查询和删除操作也需要特别注意,以确保操作的正确性和效率。
总之,SQL Server分区技术可以提高数据库的性能和数据管理的灵活性,但在使用分区功能时需要注意以上几点,以确保分区设计的合理性和分区表的正常运行。
1.2 文章结构本文将按照以下结构进行讨论和介绍sql server 分区的注意事项:1. 引言:首先,我们会在引言部分简要介绍sql server 分区的概述,包括其定义、作用和应用场景。
同时,我们还会说明本文的目的,即为读者提供一些有关sql server 分区的注意事项,以帮助他们在使用和设计分区时避免一些常见的问题和错误。
sqlserver2008使用教程

sqlserver2008使用教程SQL Server 2008是由微软公司开发的一款关系型数据库管理系统(RDBMS),用于存储和管理大量结构化数据。
本教程将向您介绍SQL Server 2008的基本功能和使用方法。
首先,您需要安装SQL Server 2008软件。
您可以从微软官方网站下载并安装免费的Express版本,或者购买商业版本以获取更多高级功能。
安装完成后,您可以启动SQL Server Management Studio (SSMS),这是一个图形化界面工具,可用于管理和操作SQL Server数据库。
在SSMS中,您可以连接到本地或远程的SQL Server实例。
一旦连接成功,您将能够创建新的数据库,更改数据库设置,执行SQL查询和管理用户权限等。
要创建新的数据库,您可以右键单击数据库节点并选择“新建数据库”。
在弹出的对话框中,输入数据库名称和其他选项,然后单击“确定”。
新的数据库将出现在对象资源管理器窗口中。
要执行SQL查询,您可以在查询编辑器中编写SQL语句。
例如,要创建一个新的表,您可以使用“CREATE TABLE”语句,并在括号中定义表的列和数据类型。
将查询复制到查询窗口中,并单击“执行”按钮来执行查询。
除了执行基本的SQL查询外,SQL Server 2008还提供了许多高级功能,如存储过程、触发器、视图和索引等。
这些功能可以提高数据库的性能和安全性。
存储过程是预编译的SQL代码块,可以按需执行。
您可以使用存储过程来处理复杂的业务逻辑或执行重复的任务。
要创建存储过程,您可以使用“CREATE PROCEDURE”语句,并在大括号中定义存储过程的内容。
触发器是与表相关联的特殊存储过程,可以在表中插入、更新或删除数据时自动触发。
通过使用触发器,您可以实现数据的约束和验证。
视图是虚拟表,是对一个或多个基本表的查询结果进行封装。
视图可以简化复杂的查询,并提供安全性和数据隐藏。
SQL_Server_2008_创建数据库

第2章创建数据库数据库是用来存储数据的空间,它作为存储结构的最高层次是其他一切数据库操作的基础。
用户可以通过创建数据库来存储不同类别或者形式的数据。
因此,在本章用户将详细地学习针对数据库的基本操作和数据库的日常管理操作,即如何创建数据库、对数据/日志文件进行操作、生成数据库快照等日常操作。
本章学习目标:了解数据库对象及构成掌握创建数据库的两种方法掌握管理数据库的方法了解数据库快照2.1 SQL Server数据库概述SQL Server中的数据库是由数据表的集合组成的,每个数据表中包含数据以及其他数据库对象,这些对象包括视图、索引、存储过程和触发器等。
数据库系统使用一组操作系统文件来映射数据库管理系统中保存的数据库,数据库中的所有数据和对象都存储在其映射的操作系统文件中。
这些操作系统文件可以是数据文件或日志文件。
要熟练地理解和掌握数据库,必须对数据库的一些基本概念及构成有一个清楚的认识。
2.1.1 常见数据库对象数据库中存储了表、视图、索引、存储过程、触发器等数据库对象,这些数据库对象存储在系统数据库或用户数据库中,用来保存SQL Server数据库的基本信息及用户自定义的数据操作等。
1.表与记录表是数据库中实际存储数据的对象。
由于数据库中的其他所有对象都依赖于表,因此可以将表理解为数据库的基本组件。
一个数据库可以有多个行和列,并且每列包含特定类型的信息。
列和行也可以称为字段与记录。
字段是表中纵向元素,包含同一类型的信息,例如读者卡号(Rcert)、姓名(name)和性别(Sex)等;字段组成记录,记录是表中的横向元素,包含有单个表内所有字段所保存的信息,例如读者信息表中的一条记录可能包含一个读者的卡号、姓名和性别等。
如图2-1所示为【图书管理系统(BookDateBase)】数据库中【读者信息(Reader)】数据表的内容.图2-1 【读者信息(Reader)】数据表2.视图视图是从一个或多个基本(数据)表中导出的表,也被称为虚表。
SQL2008建立分区表

数据库结构和索引的是否合理在很大程度上影响了数据库的性能,但是随着数据库信息负载的增大,对数据库的性能也发生了很大的影响。
可能我们的数据库在一开始有着很高的性能,但是随着数据存储量的急速增长—例如订单数据—数据的性能也受到了极大的影响,一个很明显的结果就是查询的反应会非常慢。
在这个时候,除了你可以优化索引及查询外,你还可以做什么?建立分区表(Table Partition)可以在某些场合下提高数据库的性能,在SQL Server 2005中也可以通过SQL语句来创建表分区,但在SQL Server 2008中提供了向导形式来创建分区表。
本文介绍了如何来创建分区表。
什么是分区表?分区表是把数据按某种标准划分成区域存储在不同的文件组中,使用分区可以快速而有效地管理和访问数据子集,从而使大型表或索引更易于管理。
合理的使用分区会很大程度上提高数据库的性能。
已分区表和已分区索引的数据划分为分布于一个数据库中多个文件组的单元。
数据是按水平方式分区的,因此多组行映射到单个的分区。
已分区表和已分区索引支持与设计和查询标准表和索引相关的所有属性和功能,包括约束、默认值、标识和时间戳值以及触发器。
因为分区表的本质是把符合不同标准的数据子集存储在一个数据库的一个或多个文件组中,通过元数据来表述数据存储逻辑地址。
决定是否实现分区主要取决于表当前的大小或将来的大小、如何使用表以及对表执行用户查询和维护操作的完善程度。
通常,如果某个大型表同时满足下列两个条件,则可能适于进行分区:∙该表包含(或将包含)以多种不同方式使用的大量数据。
∙不能按预期对表执行查询或更新,或维护开销超过了预定义的维护期。
例如,如果对当前月份的数据主要执行INSERT、UPDATE、DELETE 和MERGE 操作,而对以前月份的数据主要执行SELECT 查询,则按月份对表进行分区可能会使表的管理工作更容易一些。
如果对表的常规维护操作只针对一个数据子集,那么此优点尤为明显。
第二章 sql server 2008 数据库的基本操作

/*日志文件逻辑文件名*/ /*日志文件物理文件名*/ /*日志文件初始大小*/ /*日志文件最大大小*/ /*日志文件自动增长*/
使用T-SQL语言为安易超市创建“supermarket”数据库
参数 参数值
数据库名称
数据文件逻辑文件名 数据文件物理文件名 数据文件的初始大小 数据文件的最大大小 数据文件增长量 日志文件逻辑文件名
在更改数据库名称之前,要确保以下三种条件: • 确保数据库被创建后没有被使用过 • 确保数据库的访问选项设置时单用户模式 • 确保数据库现在处于关闭状态
SQL Server 2000数据库的基本操作
【例】将数据库“学生信息管理”更名为“student”
1. 2.
ALTER DATABASE 学生信息管理 MODIFY NAME = student SP_RENAMEDB „student‟ , ‟学生信息管理’
CREATE DATABASE 教学管理 ON PRIMARY ( NAME = „教学管理_DATA1‟, FILENAME = „D:\教学管理\教学管理_DATA1.MDF‟. SIZE = 5, MAXSIZE = 100, FILEGROWTH = 10% ) FILEGROUP F_GROUP ( NAME = „教学管理_DATA2‟, FILENAME = „D:\教学管理\教学管理_DATA2.MDF‟. SIZE = 5, MAXSIZE = UNLIMITED, FILEGROWTH = 10% )
例: USE 教学管理 EXEC sp_helpfilegroup
SQL Server 2000数据库的基本操作
2、更改数据库名称
在查询分析器中使用T-SQL命令更改数据库名称。 语法一: SP_RENAMEDB „oldname‟ , ‟newname‟ 语法二: ALTER DATABASE dataname MODIFY NAME = newname 注意:
SqlServer数据库分区分表实例分享(有详细代码和解释)

SqlServer数据库分区分表实例分享(有详细代码和解释)数据库单表数据量太⼤可能会导致数据库的查询速度⼤⼤下降(感觉都是千万级以上的数据表了),可以采取分区分表将⼤表分为⼩表解决(当然这只是其中⼀种⽅法),⽐如数据按⽉、按年分表,最后可以使⽤视图将⼩表重新并为总的虚拟表,其实并不影响上层程序的使⽤(程序也许都不知道分表了)。
主要步骤:1、新建⽂件组,将数据表⽂件保存路径指向相应⽂件组(应将⽂件组和⽂件放⼊不同的磁盘中,甚⾄不同服务器形成分布式数据库,因为数据的读取瓶颈很⼤程度在于磁盘的的读写速度,多个磁盘存放⼀个表可以负载均衡)2、设置分区函数(声明分区的标准)3、设置分区⽅案(即哪些区域使⽤哪个分区函数,形成完整的分区⽅案)4、给新表或现有表设置分区⽅案5、建⽴视图详细步骤(看需求可选):⼀、数据库状态备份和恢复USE master-- 备份BACKUP DATABASE AdventureWorksTO DISK = 'AdventureWorks.bak'WITH FORMAT---- 恢复RESTORE DATABASE AdventureWorksFROM DISK = 'AdventureWorks.bak'WITH REPLACEGO⼆、⽂件组和⽂件操作添加⽂件组USE [master]GOALTER DATABASE ZHH ADD FILEGROUP [⽂件组名称]Go添加⽂件并把其指向指定⽂件组USE master;GOALTER DATABASE 数据库名ADD FILE(NAME=N'⽂件名',FILENAME='存放路径', //如:E:\201109.NDF(精确到⽂件名)⽂件组存放与不同磁盘可以提⾼IO读写效率(多个磁头并发)SIZE=3MB,MAXSIZE=100MB,FILEGROWTH=5MB)TO FILEGROUP [⽂件组名]Go修改⽂件(可选)USE master;GOALTER DATABASE 数据库名MODIFY FILE(NAME = ⽂件名,SIZE = 20MB); //可以修改所有属性,列举即可GO删除⽂件(可选)ALTER DATABASE 数据库名 REMOVE FILE [⽂件组名]三、分区函数和分区⽅案分区函数⽤于规范如何分区的标准,如已哪列进⾏为标准分区、分区的⽅式(按时间、ID等)、分区的具体界限(⼀般来说,界限指标数要⽐分区数少1,⼀⼑则有两段)USE 数据库名GOCREATE PARTITION FUNCTION 分区函数名 (指标列的数据类型) //如:datetime、intAS RANGE RIGHT //右边界切分,默认为LEFTFOR VALUES (划分界限) //如时间划分('2003/01/01', '2004/01/01'),两个时间界限可划分出三个分区GO分区⽅案⽤于将已经建⽴好的分区函数组织成完整的⽅案,为每个分区分配存储位置Use 数据库名gocreate partition scheme 分区⽅案名as partition 分区函数to(⽂件组1,⽂件组2,⽂件组3,...) //注意分区数要与实际分区⼀致go在原有的基础上添加分区(可选)use 数据库名goalter partition scheme ps_OrderDate next used [FG4] //修改分区⽅案ps_OrderDate,定义新新分区使⽤FG4⽂件组alter partition function pf_OrderDate() split range('2005/01/01') //修改分区函数pf_OrderDate,在末尾添加界限'2005/01/01'go为现有表设置分区⽅案(可选)//为AutoBench表的InsertTime列创建新聚集索引,并绑定Scheme_DateTime分区⽅案CREATE CLUSTERED INDEX IX_CreateDate ON AutoBench (InsertTime)ON Scheme_DateTime (InsertTime)注:如原来主键有聚众索引要将其改为⾮聚集索引,才可添加新聚众索引//删除原主键上的聚集索引PK_ProductALTER TABLE Product DROP CONSTRAINT PK_Product//重新创建主键⾮聚集索引PK_ProductALTER TABLE Product ADD CONSTRAINT PK_Product PRIMARY KEY NONCLUSTERED (ProductID ASC)上⾯语句也可直接在索引属性中将聚集改为⾮聚集为新建表设置分区⽅案(可选)//创建表格Order,并设置Scheme_DateTime分区⽅案,指标列为OrderDateCREATE TABLE [Order](OrderID INT IDENTITY(1,1) NOT NULL,UserID INT NOT NULL,TotalAmount DECIMAL(18,2) NULL,OrderDate DATETIME NOT NULL) ON Scheme_DateTime (OrderDate)查询分区数据四、其他操作查询分区数据$partition函数--为任何指定的分区函数返回分区号,⼀组分区列值将映射到该分区号中语法: [ database_name. ] $PARTITION.partition_function_name(expression)参数: database_name 包含分区函数的数据库的名称。
SQL2008问题+答案

1.请写出SQL Server 2005中系统数据库的名称及其作用master数据库:数据库服务器的核心,用户不能直接修改该数据库,若是损坏,整个SQL SERVER服务器将不能工作。
model数据库:创建数据库的模板。
如用户希望所创建的数据库有相同的初始化文件大小,可以在该数据库中保存文件大小的信息。
msdb数据库:提供运行SQL SERVER Agent工作的信息。
SQL SERVER Agent是一个Windows服务,用来运行制定的计划任务。
tempdb数据库:临时数据库,用于存放临时对象或者中间结果,SQL SERVER关闭后,被清空。
常用系统存储过程sp_addgroup:在当前的数据库中创建一个组。
sp_addlogin:创建新的Microsoft® SQL Server™ 登录sp_addrole:当前数据库创建新的Microsoft® SQL Server™ 角色。
sp_addtype:创建用户定义的数据类型。
sp_adduser:为当前数据库中的新用户添加安全帐户。
sp_bindefault:将默认值绑定到列或用户定义的数据类型。
sp_bindrule:将规则绑定到列或用户定义的数据类型。
sp_dbfixedrolepermission:显示每个固定数据库角色的权限。
sp_dropgroup:从当前数据库中删除角色。
sp_droprole:当前数据库删除Microsoft® SQL Server™ 角色。
sp_droptype:从 systypes 删除用户定义的数据类型。
sp_dropuser:从当前数据库中删除Microsoft® SQL Server™ 用户或 Microsoft Windows NT®用户。
sp_help:报告有关数据库对象(sysobjects 表中列出的任何对象)、用户定义数据类型或Microsoft® SQL Server™ 所提供的数据类型的信息。
sql-server-2008-数据库应用与开发教程--课后习题参考答案

sql-server-2008-数据库应用与开发教程--课后习题参考答案DServer的组成部分和这些组成部分之间的描述。
Microsoft SQL Server 2008系统由4个组件组成,这4个组件被称为4个服务,分别是数据库引擎、Analysis Services、Reporting Services和Integration Services。
数据库引擎是Microsoft SQL Server 2008系统的核心服务,负责完成数据的存储、处理、查询和安全管理等操作。
分析服务(SQL Server Analysis Services,简称为SSAS)的主要作用是提供多维分析和数据挖掘功能。
报表服务(SQL Server Reporting Services,简称为SSRS)为用户提供了支持Web方式的企业级报表功能。
集成服务(SQL Server Integration Services,简称SSIS)是一个数据集成平台,负责完成有关数据的提取、转换和加载等操作。
1.安装SQL Server 2008之前应该做什么准备工作?答:(1) 增强物理安全性(2) 使用防火墙(3) 隔离服务(4) 禁用NetBIOS和服务器消息块2.SQL Server 2008支持哪两种身份验证?答:Windows 身份验证或混合模式身份验证。
3.如何注册和启动SQL Server 服务器?答:1. 注册服务器使用Microsoft SQL Server Management Studio工具注册服务器的步骤如下:(1) 启动Microsoft SQL Server Management Studio工具,选择“视图”|“已注册”命令或者按下快捷键Ctrl+Alt+G,在打开的“已注册的服务器”窗口中选中“数据库引擎”图标。
(2) 在“数据库引擎”上单击鼠标右键,从弹出的快捷菜单中选择“新建”|“服务器注册”命令,即可打开如图1-20所示的“新建服务器注册”对话框。
教你建立SQL数据库的表分区
教你建⽴SQL数据库的表分区1)新建⼀个数据库 2)添加⼏个⽂件组 3)回到“常规”选项卡,添加数据库⽂件 看到⽤红⾊框框起来的地⽅没?上⼀步中建⽴的⽂件组在这⾥就⽤上了。
再看后⾯的路径,我把每⼀个⽂件都单独放在不同的磁盘上,⽽且最好都是单独的放在不同的物理盘上,这样会⼤⼤提⾼数据的性能。
点击“确定”数据库就算创建完成了。
4)接下来要做的是建⽴⼀个分区⾏数,SQL语句如下:⼤家学习的时候最好不要直接COPY,动⼿把它抄⼀遍也好。
以下是代码⽚段:create partition function PartFuncForExample(Datetime)as Range Right for Value('20000101','20010101','20020101','20030101') 这⾥我准备⽤表中的某个时间字段作为分区的条件,当然你也可以⽤其他的,⽐如INT之类,只要好分段的都可以。
这⾥注意 Right 关键字,意思就是当记录的时间(在下⾯会被指到表的某个字段)⼤于等于20000101的时候,数据会被分到下⼀个区间,⽐如2000年1⽉1号之前的数据会被分到⼀区,包含2000年1⽉1号和之后的数据会被分到⼆区,以此类推。
Right 也可以使⽤Left替代,意思同上类似。
另外,上⾯我定义了四个分割点,这四个分割点是根据我们刚刚创建的⽂件组来决定的。
四个分割点就能产⽣5个区间段,我们把每个区间段的数据存⼊⼀个⽂件组。
正确执⾏上述语句后你可以在数据⾥找到以“PartFuncForExample”命名的分区函数,如下图 5)把分区函数建⽴好以后,我们再来建⽴分区⽅案。
⽬的是为了把分区函数产⽣的分区映射到⽂件数据组⾥。
分区函数是告诉数据库如何分区数据,⽽分区⽅案是告诉数据库如何把已分区的数据存到哪个⽂件组⾥。
下⾯我来创建分区⽅案。
以下是代码⽚段:Create Partition Scheme PartSchForExample //创建⼀个分区⽅案+分区⽅案名称As Partition PartFuncForExample//⽬的为了分区函数PartFuncForExampleTo(PRIMARY, //⽂件组名Partition1, //⽂件组名Partition2, //⽂件组名Partition3, //⽂件组名Partition4 //⽂件组名) 正确执⾏后能在分区⽅案中看到,如下图 6)马上就快要⼤公告成了,下⾯我们来建⽴要分区存储的表,该表的数据理论上应该是⾮常⾮常多的,百万级别的记录以上⽽且基本上是不更新的。
SQLServer2008数据库分离和附加

SQLServer2008数据库分离和附加SQL Server 2008数据库分离和附加SQL Server 2008是一款常见的关系型数据库管理系统,具备良好的数据管理和数据存储能力。
在数据库管理中,数据库的分离和附加是一种常见的操作方式,用于将数据库从一个服务器迁移到另一个服务器,或者备份和恢复数据库。
本文将介绍SQL Server 2008数据库分离和附加的具体步骤和注意事项。
一、数据库分离数据库分离是指将数据库从一个服务器分离出来,使其成为一个独立的数据文件,方便进行备份和迁移。
下面是具体的操作步骤:1. 连接到SQL Server Management Studio(SSMS)。
2. 在对象资源管理器中,找到要分离的数据库,右键单击,并选择“任务”->“分离”。
3. 在分离数据库对话框中,选择要分离的数据库,确认所选数据库的文件路径和名称,并勾选“更新系统目录以反映更改”选项。
4. 单击“确定”按钮,数据库将会被分离,并将从服务器上移除。
需要注意的是,在分离数据库之前,应该确保没有其他用户正在使用该数据库,并且应该备份数据库以防止数据丢失。
二、数据库附加数据库附加是指将已经分离的数据库重新附加到SQL Server中,使其在新的服务器上可用。
下面是具体的操作步骤:1. 连接到SQL Server Management Studio(SSMS)。
2. 在对象资源管理器中,右键单击“数据库”节点,并选择“附加”。
3. 在附加数据库对话框中,单击“添加”按钮,并选择要附加的数据文件。
4. 确认数据库文件路径和名称正确无误。
5. 单击“确定”按钮,数据库将会被附加到服务器上,并在对象资源管理器中显示。
在附加数据库之前,应该确保附加的数据库文件没有被损坏,并且在附加过程中不会影响现有的数据库。
三、数据库分离和附加的注意事项1. 在分离数据库之前,应该备份数据库以防止数据丢失。
2. 在数据库附加之前,应该确保附加的数据库文件没有被损坏,并在附加过程中不会影响现有的数据库。
SQLServer2008数据库应用教程课后答案

SQLServer2008数据库应⽤教程课后答案第1章数据库基础⼀、单项选择题1.C 2.A 3.C 4.D 5.D6.B 7.A 8.B 9.B 10.D11.C 12.A 13.C 14.B 15.A16.B 17.A 18.D 19.B 20.B21.A; D 22.A 23.C 24.D 25.B26.B 27.B 28.D 29.B 30.B⼆、填空题1.概念;数据2.属性3.码4.⼀对⼀联系;⼀对多(或多对⼀)联系;多对多联系5.候选码6.候选码7.关系名(属性1,属性2,…,属性n)8.关系数据结构;关系操作集合;关系完整性约束9.实体;参照;⽤户定义的;实体;参照10.空植11.需求分析阶段;概念结构设计阶段;逻辑结构设计阶段;物理结构设计阶段;数据库实施阶段;数据库运⾏和维护阶段12.准确了解并分析⽤户对系统的要求,尤其是⽤户的信息要求、处理要求、安全性与完整性要求,确定所要开发的应⽤系统的⽬标,产⽣⽤户和设计者都能接受的需求说明书,做为下⼀步数据库概念结构设计的基础。
13.将需求分析得到的⽤户需求抽象为信息结构即概念模型。
14.将概念结构进⼀步转化为某⼀DBMS⽀持的数据模型,并对其进⾏优化。
15.为逻辑数据模型选取⼀个最适合应⽤环境的物理结构,包括数据库在物理设备上的存储结构和存取⽅法。
三、指出以下各缩写的英⽂意思和中⽂意思1.DB:DataBase2.DBMS:Database Management System3.RDBMS:4.DBS:DataBase System5.DBA:Relational Database Management System6.NF:Normal Form7.DDL:Data Definition Language四、按题⽬要求回答问题1.答:2.答:3.答:(1)关系R是2NF。
因为R的候选码为课程名,⽽课程名→教师名,教师名→教师地址,所以课程名→教师地址,即存在⾮主属性教师地址对候选码课程名的传递函数依赖,因此R不是3NF。
第5章 SQL Server 2008 数据库管理

昌吉学院计算机系
5.2.1 创建用户数据库
• 1.利用对象资源管理器创建用户数据库
在SQL Server Management Studio中,利用图形化
的方法可以非常方便地创建数据库。
பைடு நூலகம்
昌吉学院计算机系
2.利用T-SQL语句创建用户数据库
CREATE DATABASE database_name ON { [ PRIMARY ] ( NAME = logical_file_name , FILENAME = ‘os_file_name’ [ , SIZE = size] [ , MAXSIZE = { max_size | UNLIMITED } ] [ , FILEGROWTH = growth_increment ]) } [ ,...n ] LOG ON { [ PRIMARY ] ( NAME = logical_file_name , FILENAME = ‘os_file_name’ [ , SIZE = size] [ , MAXSIZE = { max_size | UNLIMITED } ] [ , FILEGROWTH = growth_increment ]) } [ ,...n ] 昌吉学院计算机系
昌吉学院计算机系
• SQL Server数据库内含的数据库对象包括数据表、
视图、约束、规则、默认、索引、存储过程、触发
器等。通过SQL Server 2008对象资源管理器,可 以查看当前数据库内的各种数据库对象。
昌吉学院计算机系
• 2.数据库的物理结构
数据库物理结构主要应用于面向计算机的数据组织
•
参数说明如下: database_name:新数据库的名称。 ON:指定显式定义用来存储数据库数据部分的磁盘文件(数据文 件)。 PRIMARY:在主文件组中指定文件。
第51章 SQL Server 2008备份和恢复概述

差异数据库备份
差异备份是指将从最近一次完全数据库备份以后发生改变的数据。如果在完整备份后将某个文件添加至数据库,则下一个差异备份会包括该新文件。这样可以方便地备份数据库,而无须了解各个文件。例如,如果在星期一执行了完整备份,并在星期二执行了差异备份,那么该差异备份将记录自星期一的完整备份以来已发生的所有修改。而星期三的另一个差异备份将记录自星期一的完整备份以来已发生的所有修改。差异备份每做一次就会变得更大一些,但仍然比完整备份小,因此差异备份比完整备份快。
第
用户使用数据库是因为要利用数据库来管理和操作数据,数据对于用户来说是非常宝贵的资产。数据存放在计算机上,但是即使是最可靠的硬件和软件也会出现系统故障或产品故障。所以,应该在意外发生之前做好充分的准备工作,以便在意外发生之后有相应的措施能快速地恢复数据库的运行,并使丢失的数据量减少到最小。
51.1
数据库备份就是创建完整数据库的副本,并将所有的数据项都复制到备份集,以便在数据库遭到破坏时能够恢复数据库。
文件组还可以用来加快数据访问的速度,因为文件组允许将表存放在一个文件上,而将对应的索引存放在另一个文件上。尽管这么做可以加快数据访问的速度,但也会减慢备份过程,因为必须将表和索引作为一个单元来备份。
为了使恢复的文件与数据库的其余部分保持一致,执行文件和文件组备份之后,必须执行事务日志备份。
51.3
SQL Server 2008包括3种恢复模型,其中每种恢复模型都能够在数据库发生故障的时候恢复相关的数据。不同的恢复模型在SQL Server备份、恢复的方式和性能方面存在差异,而且,采用不同的恢复模型对于避免数据损失的程度也不同。每个数据库必须选择三种恢复模型中的一种以确定备份数据库的备份方式。
SQLServer2008数据库—创建、建表、查询语句

SQLServer2008数据库—创建、建表、查询语句一、创建数据库1、利用对象资源管理器创建用户数据库:(1)选择“开始”—“程序”—MicrosoftSQLServer 2008—SQLServerManagementStudio命令,打开SQL ServerManagementStudio。
(2)使用“Windows身份验证”连接到SQLServer2008 数据库实例。
(3)展开SQLServer实例,右击“数据库”,然后人弹出的快捷菜单中选择“新建数据库存”命令,打开“新建数据库”对话框。
(4)在“新建数据库”对话框中,可以定义数据库的名称、数据库的所有者、是否使用全文索引、数据文件和日志文件的逻辑名称和路径、文件组、初始大小和增长方式等。
输入数据库名称student。
2、利用T-SQL语句创建用户数据库:在SQLServerManagementStudio中,单击标准工具栏的“新建查询”按钮,启动SQL编辑器窗口,在光标处输入T-SQL语句,单击“执行”按钮。
SQL编辑器就提交用户输入的T-SQL语句,然后发送到服务器执行,并返回执行结果。
创建数据库student的T-SQL语句如下:CreatedatabasestudentOnprimary(name=student_data,filename='E:\SQLServer2008SQLFULL_CHS\MicrosoftSQLstudent_data.mdf',size=3,maxsize=unlimited,filegrowth=1)Logon(name=student_log,filename='E:\SQLServer2008SQLFULL_CHS\MicrosoftSQLstudent_log.ldf',size=1,maxsize=20,filegrowth=10%)二、创建数据表1、利用表设计器创建数据表:o连接到SQL (1)启动SQLServerManagementStudi,Server2008数据库实例。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Sql 2008 : 数据库分文件组(指定磁盘), 映射分区表使用不同的文件组详解(阻止保存要求重新创建表的更改?)
Posted on 2011-01-25 11:09 且行且思阅读(2753) 评论(1) 编辑收藏
SQL Server 2008阻止保存要求重新创建表的更改
新建数据表以后,若再对该表进行更改,则会出现警告信息“不允许保存更改阻止保存要求重新创建表的更改”,
等等,需要进行一下设置:工具--->选项--->Designers--->表设计器和数据库设计器--->组织保存要求重新创建表的更改,去掉复选框。
分区请三思
1.虽然分区可以带来众多的好处,但是同进也增加了实现对象的管理费用和复杂性。
因此在进行分区之前要首先仔细的考虑以确定是否应为对象进行分区。
2.在确定了为对象进行分区后,下一步就要确定分区键和分区数。
要确定分区数据,应先评估您的数据中是否存在逻辑分组和模式。
3.确定是否应使用多个文件分组。
为了有助于优化性能和维护,应使用文件组分离数据。
文件组是数据库数据文件的逻辑组合,它可以对数据文件进行管理和分配,以便提高数据库文件的并发访问效率。
为了简化操作,SQL Server 2008中为表分区提供了相关的操作
操作的顺序:
1、先定义文件组
2、指定哪些辅助数据库文件属于这个文件组
3、将表放入到文件组中
数据库分文件组(指定磁盘):
数据实际上是依附于表来存在的,我们将表放入到文件组中,而文件组是一个逻辑的概念,其实体是辅助数据库文件(ndr),所以就等于将我们指定的数据放入到了指定的辅助数据库文件中,然后如果将这些辅助数据库文件放入在不同的磁盘分区中,就可以最终实现有针对性的对相应的数据实现性能的优化。
创建文件组时, 定义不同的文件组名称, 可以有序地进行下一步表分区的分区映射文件组, 如上图(选择数据库,右键查看属性图).
一个水平分区表中有多个分区,每个分区对应一个文件组,这样就产生了很多文件组,因此性能也会有所提升,包括I/O性能提升,因为所有分区可以驻扎在一个不同的磁盘上,另一个好处是可以通过备份文件组单独备份一个分区,此外,SQL Server数据库引擎可以智能判断哪个分区上存放了什么数据,如果不止一个分区被访问,那么还可以借助多处理器实现并行数据检索。
这种设计也充分利用了分区表的优势。
1,提高可伸缩性和可管理性:在SQL server 2005中建立分区, 改善大型表以及具有各种访问模式的表的可伸缩性和可管理性。
2,提高性能,
3,只有将数据分区分到不同的磁盘上,才会有较大的提升。
4. 因为在运行涉及表间联接的查询时,多个磁头可以同时读取数据
对SQL Server数据表进行分区的过程分为三个步骤:
1)建立分区函数
2)建立分区方案
3)对表格进行分区步骤如下:。