Prometheus-Grafana-监控服务器服务状态信息
普罗米修斯(Prometheus)监控操作系统

普罗⽶修斯(Prometheus)监控操作系统Prometheus(普罗⽶修斯)是⼀个应⽤⼗分⼴泛的⼀个性能监控平台监控的原理主要是:所以我们⾄少需要两台Linux系统、node_exporter、Grafana、Prometheus其中Grafana、Prometheus部署在⼀台机器上,node_exporter部署在你需要监控的系统机器上我们选择的运⾏环境为centos 7(64)部署前的准备:1、关闭所有机器上的防⽕墙,使⽤命令:systemctl stop firewalld.service2、保证所有的机器上的时间是准确的,可以使⽤date命令进⾏查询,如果不准确建议更改,可以使⽤ntp命令同步最新的⽹络时间yum install -y ntpntpdate 更新同步⽹络最新时间部署Linux操作系统的监控组件1、下载监控Linux的node_exporter官⽹下载地址:https://prometheus.io/download/进⼊下载页⾯后选择Operating system为Linux,Architecture为amd64后选择node_exporter进⾏下载2、下载完成后讲安装包上传到需要监控的Linux机器上的任意⽬录进⾏解压(tar -xzvf)3、解压完成之后进⼊到解压后的⽂件夹中使⽤nohup命令进⾏后台启动脚本nohup ./node_exporter &4、查看nohup.out ⽇志⽂件,出现下图的情况则认为启⽤成功部署Prometheus1、下载安装包找到Prometheus的Linux版本以及架构为amd64的进⾏下载2、下载完成之后上传到另外⼀台Linux中进⾏解压操作(tar -xvzf)3、进⼊到解压后的⽂件夹中,找到prometheus.yml ⽂件,进⼊修改在 scrape_configs 配置项下添加 Linux 监控的 job,其中IP 修改为上⾯部署 node_exporter 机器的 ip,端⼝号为 9100,注意缩进(yaml⽂件是严格按照缩进的)- job_name: 'node'static_configs:- targets: [192.168.75.129:9100]4、保存配置⽂件后运⾏ nohup ./prometheus & 进⾏启动prometheus检查nohup.out⽇志⽂件,如果有以下信息则说明启动成功6、点击菜单status中的Targets查看是否有node节点,并state是否为up部署grafana(注意:Grafana必须得和Prometheus部署在同⼀个机器上)1、下载安装包使⽤下图中的命令进⾏下载安装注意:Linux中⾃带没有wget命令,需要使⽤yum install -y wget 进⾏下载然后在使⽤以下命令进⾏下载安装2、安装完成之后使⽤命令:systemctl start grafana-server 进⾏启动grafana4、跳过修改密码后进⼊到主页按照下图顺序添加数据源点击左下⾓的save & Test按钮,如果提⽰success,就代表配置成功,然后点击Back返回5、导⼊监控模版进⼊到grafana到官⽹,查找官⽹提供到prometheus中到监控模版然后在 Date source选择Prometheus选择Linux服务监控到中⽂模版进⼊到详情中可以看到这个模版到ID为8919在Grafana中进⼊Import中进⾏操作这⾥填写ID(8919)然后点击Load按钮然后就可以看到监控到画⾯了。
普罗米修斯监控指标

普罗米修斯监控指标普罗米修斯(Prometheus)是一种开源的监控系统,它可以帮助我们监控服务器、容器、应用程序等等。
在使用普罗米修斯时,我们需要定义一些监控指标,这些监控指标可以告诉我们服务器的状态,并且还可以帮助我们分析问题。
本文将介绍一些在普罗米修斯中常见的监控指标以及它们的意义。
一、CPU 使用率CPU 使用率是监控系统中最常见的指标之一。
通过监控 CPU 使用率,我们可以了解系统的负载情况。
在普罗米修斯中,我们可以使用下面的指标来监控 CPU 使用率:1. node_cpu_seconds_total{mode="idle"}这个指标表示 CPU 空闲时间的总数,单位是秒。
我们可以通过给 mode 参数赋值为"user"、"system"、"nice" 等来监控不同的 CPU 使用类型。
2. node_load1这个指标表示系统的平均负载。
它的值通常应该小于 CPU 的数量,如果负载持续高于 CPU 数量的值,就说明系统需要更多的 CPU 资源。
二、内存使用率这个指标表示系统总共的内存大小,单位是字节。
2. node_memory_MemFree_bytes通过这些指标,我们可以计算出内存的使用率,例如:(node_memory_MemTotal_bytes - node_memory_MemFree_bytes -node_memory_Cached_bytes) / node_memory_MemTotal_bytes三、磁盘使用率磁盘使用率指的是磁盘空间占用的百分比。
在普罗米修斯中,我们可以使用下面的指标来监控磁盘使用率:四、网络流量irate(node_network_receive_bytes_total[5m])五、HTTP 请求HTTP 请求指的是服务器处理的 HTTP 请求数量和响应时间。
服务器监控工具比较PrometheusvsGrafana

服务器监控工具比较PrometheusvsGrafana 服务器监控工具比较:Prometheus vs. Grafana服务器监控工具是现代IT架构中不可或缺的一部分,其可以帮助我们实时跟踪服务器的运行状态和性能指标,及时发现并解决潜在的问题。
在众多的服务器监控工具中,Prometheus和Grafana是两个备受欢迎的选择。
本文将对这两个工具进行比较,并探讨它们各自的优势和特点。
一、基本介绍Prometheus是一种开源的系统监控和警报工具,最初由SoundCloud开发并开源。
它使用度量和告警规则来存储和检索时间序列数据,并提供丰富的查询语言PromQL,以对数据进行多维度的查询和聚合操作。
与之相对,Grafana是一个开源的数据可视化和监控报表工具,最初是为Graphite设计的,支持多种数据源,Prometheus是其中之一,用户可以通过可视化仪表盘和报表集中展示、分析和监控数据。
二、架构比较Prometheus的架构相对简单,由若干个核心组件组成,包括Prometheus Server、Pushgateway、Alertmanager等。
其中,Prometheus Server负责数据的抓取和存储,Pushgateway用于临时存储短期的指标数据,Alertmanager用于接收和处理告警通知。
而Grafana则是一个独立的软件,与Prometheus通过插件的方式进行集成。
Grafana的架构允许用户通过数据源插件来连接各种监控系统,如Prometheus、InfluxDB 等,同时还支持多用户、团队和权限管理。
三、特性比较1. 数据模型和查询语言Prometheus采用时间序列数据库来存储指标数据,即时序数据可以理解为以时间为索引的多维度数据,每个数据点由时间戳和相关标签组成。
而PromQL作为Prometheus的查询语言,支持以自由组合的方式查询和聚合数据。
与此不同,Grafana拥有更加灵活和强大的查询和过滤功能,用户可以通过自定义查询语句或者使用简单的UI界面来构建查询,同时还支持多种视图和图表类型,有助于更好地理解和展示数据。
服务器性能监控工具比较分析

服务器性能监控工具比较分析在今天的高度信息化和数字化的社会中,服务器作为计算机系统的核心组成部分,承担着重要的工作负载。
为了保证服务器的正常运行以及及时发现和解决潜在的问题,性能监控工具成为了必不可少的工具。
本文将对几种常见的服务器性能监控工具进行比较分析,以帮助人们选择最适合自己需求的工具。
一、工具一:ZabbixZabbix是一个开源的网络监控和性能管理解决方案,通过各种监控指标收集数据并提供报警功能。
它支持广泛的操作系统和网络设备,并具备分布式监控和故障转移功能。
Zabbix能够监控CPU负载、内存使用情况、磁盘空间、网络流量等关键性能指标。
它的优点是功能强大,具有良好的扩展性和自定义性。
二、工具二:NagiosNagios是一个用于监控系统、网络和基础设施的开源软件。
它提供了实时报警、事件处理、图形化界面等功能。
Nagios可以监控服务器的CPU负载、硬盘使用情况、网络流量等指标。
它的优点是稳定可靠、易于定制和扩展。
三、工具三:PrometheusPrometheus是一个开源的系统监控和告警工具集,特点是通过多维数据模型和灵活的查询语言提供实时监控和报警。
它支持多种数据源和多种监控方式,并提供了可视化的仪表板。
Prometheus可以监控服务器的CPU使用率、内存消耗、磁盘IO性能等关键指标。
它的优点是易于部署和配置,具有较低的资源消耗。
四、工具四:GrafanaGrafana是一个开源的可视化指标、分析和监控工具,通过仪表板展示各种数据源的监控指标。
它支持多种数据源,并提供丰富的插件和可视化图表。
Grafana可以与各种监控工具集成,如Prometheus、Zabbix等。
它的优点是界面友好,提供了丰富的可视化功能和个性化定制。
五、工具五:DatadogDatadog是一种云原生的监控和安全平台,为开发人员和运维团队提供实时的应用性能监控、日志管理和安全监控。
它支持多种云平台和部署方式,并提供了强大的API功能。
系统运行状态监控与异常报警:如何实时监控系统运行状态,设置异常报警机制

系统运行状态监控与异常报警:如何实时监控系统运行状态,设置异常报警机制引言无论是在个人生活还是工作领域,我们都希望能够及时了解系统的运行状态,以便及时发现异常并采取相应的措施。
特别是在信息技术领域,一个稳定可靠的系统是保障业务正常运行的重要因素之一。
因此,实时监控系统的运行状态并设置异常报警机制变得尤为关键。
本文将介绍如何通过监控系统运行状态和设置异常报警机制来提高系统的可靠性和稳定性。
监控系统运行状态的重要性提高系统可用性同样是一个系统,如果能够及时监控其运行状态,我们就能更早地发现潜在的问题,并在问题严重之前采取相应的措施。
例如,当系统出现性能瓶颈或资源紧张时,我们可以通过监控数据及时调整系统配置或增加资源,从而避免系统崩溃或影响业务正常运行。
因此,监控系统运行状态是提高系统可用性的关键一环。
预防潜在风险通过监控系统运行状态,我们还可以及早发现潜在的安全风险或漏洞。
例如,当系统的入侵检测系统发现可疑的网络流量时,可以及时采取措施来阻止攻击,保护系统和数据的安全。
此外,定期检查系统的运行状态还可以发现并修复潜在的软件漏洞,减少被恶意攻击的风险。
监控系统运行状态的方法和工具为了监控系统的运行状态,我们可以采取多种方法和工具。
以下是几种常用的方法和工具:网络监控通过监控网络流量和连接状态,我们可以了解系统在网络层面的运行状态。
例如,我们可以使用网络性能监控工具来监测系统的带宽利用率、丢包率、延迟等指标,以便及时发现网络故障或性能问题。
服务器监控服务器是系统的核心组件,监控服务器的运行状态对于保证系统稳定性至关重要。
我们可以通过监控服务器的资源利用率、服务可用性、负载情况等指标,及时发现服务器故障或资源不足的情况,并采取相应的措施。
常用的服务器监控工具包括Zabbix、Nagios等。
日志监控系统的日志包含了系统运行的各种信息,通过监控系统的日志,我们可以了解系统的运行状态、错误信息等。
可以通过设置日志监控系统,自动分析和报警系统的日志。
浪潮服务器故障问题报告分析

故障问题分析报告⼀、故障概述时间:2024年9⽉24⽇22:06主机:192.168.x.x 问题现象:存储池 A 和 B 未挂载,导致部分虚拟机⽆法访问其存储资源。
CPU 使⽤率 99.5%,内存占⽤率达到 84%。
⽆法通过 SSH 、KVM 和 BMC 远程连接节点。
其他 ⼏ 个节点运⾏正常,磁盘阵列⽆报警。
通过 ping 可以连接节点,但远程管理⼯具⽆法访问。
⼆、故障现象详细分析1. 存储池未挂载的连锁反应存储池 A 和 B 未能成功挂载,导致虚拟机进程⽆法访问磁盘数据。
虚拟机在尝试 I/O 操作时陷⼊阻塞状态,导致 CPU 和内存资源耗尽。
2. 系统⾼负载与 SSH/KVM 失效CPU 使⽤率 99.5%:表明系统中的⽤户进程或内核进程出现资源竞争。
内存使⽤率 84%:可能由于阻塞进程堆积,内存压⼒上升,触发 OOM (内存不⾜)⾏为。
系统在⾼负载下暂停 SSH 和 BMC 进程,使管理员⽆法通过远程访问登录系统排查问题。
3. dmesg 中的 BAR 13 分配失败关键⽇志信息如下:这条⽇志表明 PCI 资源分配不⾜,可能影响某些存储设备(如 HBA 卡或 RAID 控制器)正常⼯作。
4. crontab 任务过多导致系统资源耗尽通过⽇志分析,发现有⼤量 ⾃动任务被频繁触发,导致系统在短时间内创建⼤量会话:在 CPU 和内存接近饱和的情况下,这些任务进⼀步恶化了系统性能。
三、核⼼原因分析PCI: BAR 13: No available resource for PCI bridgesession_start: 400 sessions activeNo. 1 / 4三、核⼼原因分析1. 存储池挂载失败的具体原因PCI BAR 分配失败直接导致某些 PCI 设备(如 RAID/HBA 卡)⽆法正常注册资源,进⽽导致存储设备不可⽤:PCI: BAR 13: No available resource for PCI bridgeBAR(Base Address Register)是 PCI 设备⽤于内存映射的地址寄存器,分配失败意味着系统未能为该设备提供必要的地址空间,导致存储池不可访问。
服务器监控技巧如何实时监控服务器状态

服务器监控技巧如何实时监控服务器状态随着互联网的快速发展,服务器已经成为各种网站、应用程序以及企业的重要基础设施。
保证服务器的稳定运行对于保障业务的正常进行至关重要。
而实时监控服务器状态则是确保服务器运行稳定的重要手段之一。
本文将介绍一些服务器监控的技巧,帮助管理员实时监控服务器状态,及时发现和解决问题,确保服务器的正常运行。
一、选择合适的监控工具选择合适的监控工具是实时监控服务器状态的第一步。
目前市面上有许多优秀的监控工具,如Zabbix、Nagios、Prometheus等,这些工具都提供了丰富的监控功能,可以监控服务器的CPU、内存、磁盘、网络等各项指标。
管理员可以根据自己的需求和服务器环境选择合适的监控工具进行部署。
二、设置监控项和阈值在部署监控工具后,管理员需要设置监控项和相应的阈值。
监控项是指需要监控的服务器指标,如CPU利用率、内存使用率、磁盘空间等;而阈值则是指当监控项超过设定的数值时触发告警。
管理员可以根据服务器的实际情况设置监控项和阈值,以便及时发现问题并采取相应的措施。
三、配置告警机制监控工具一般都提供了告警功能,当监控项超过设定的阈值时会触发告警。
管理员需要配置告警机制,包括告警方式、告警接收人等。
告警方式可以选择邮件、短信、微信等多种方式,管理员可以根据自己的需求选择合适的告警方式。
同时,管理员还需要设置告警接收人,确保在服务器出现问题时能及时通知相关人员进行处理。
四、定期巡检和优化除了监控工具的部署和配置,定期巡检和优化也是保证服务器稳定运行的重要环节。
管理员可以定期检查服务器的运行状态,查看监控数据,及时发现潜在问题并进行处理。
同时,管理员还可以对服务器进行优化,如清理无用文件、优化数据库索引、调整系统参数等,提升服务器的性能和稳定性。
五、实时监控服务器状态在监控工具部署和配置完成后,管理员需要实时监控服务器状态,及时发现和解决问题。
通过监控工具的仪表盘可以直观地查看服务器各项指标的实时数据,管理员可以随时了解服务器的运行状态。
prometheus和grafana的工作原理

prometheus和grafana的工作原理Prometheus和Grafana是当今非常受欢迎的监控和可视化工具。
它们都具有重要的作用,用于实时监控和可视化系统的运行情况,以及支持故障排除和性能优化。
下面将详细讨论Prometheus和Grafana 的工作原理。
1. Prometheus工作原理:Prometheus是一个开源的监控系统,用于收集和存储各种系统指标数据,并提供强大的查询和报警功能。
它具有以下几个关键组件:1.1数据抓取(Data scraping):Prometheus使用展示层代理(exporter)来收集各种类型的指标数据。
这些代理可以是特定应用程序的客户端库,也可以是为特定系统或组件设计的中间件。
代理定期采样指标数据,并将其暴露给Prometheus的数据收集服务器。
1.2数据存储(Data storage):Prometheus使用时间序列数据库来存储指标数据。
每个指标由时间戳和单个或多个键值对组成。
Prometheus使用自定义的数据模型和压缩算法,以高效地存储和检索大量时间序列数据。
默认情况下,它存储数据为15天。
1.3数据查询(Data querying):Prometheus具有强大的查询功能,可以使用PromQL(Prometheus 查询语言)对存储的指标数据进行弹性和高效的查询。
PromQL支持各种运算符和函数,可以从时间序列数据中提取有用的信息、计算聚合值,并绘制图表。
1.4报警处理(Alerting):Prometheus还支持定义基于指标数据的警报规则。
这些规则基于用户定义的条件和阈值,定期将其计算以生成警报。
Prometheus可以通过电子邮件、Slack等方式发送警报通知。
2. Grafana工作原理:Grafana是一个开源的数据可视化和仪表盘工具,用于从多种数据源中收集、分析和监控数据,并实时展示给用户。
它具有以下几个关键组件:2.1数据源(Data sources):Grafana支持各种数据源,如Prometheus、InfluxDB、Elasticsearch等。
服务器监控工具实时查看服务器资源利用率

服务器监控工具实时查看服务器资源利用率服务器监控工具在现代信息技术领域扮演着至关重要的角色,它可以帮助管理员实时查看服务器资源的利用率。
这对于优化服务器性能、提高系统稳定性以及确保用户体验来说都是至关重要的。
本文将介绍一些常用的服务器监控工具以及它们的功能和使用方法。
一、ZabbixZabbix是一款功能强大的开源服务器监控工具,它可以实时监测服务器的CPU利用率、内存占用、磁盘空间以及网络流量等各项指标。
Zabbix提供了直观的图表和报表,方便管理员查看历史数据和趋势分析。
同时,Zabbix支持告警功能,当服务器资源利用率超过设定的阈值时,系统会自动发送邮件或短信通知管理员。
二、NagiosNagios是一款老牌的服务器监控工具,它可以监测服务器的网络状态、服务可用性以及性能指标等。
Nagios具有扩展性强的特点,用户可以自定义监控项和告警规则。
此外,Nagios还支持插件扩展,用户可以根据自己的需求选择合适的插件,以满足特定的监控需求。
三、PrometheusPrometheus是一款基于云原生架构的开源监控系统,它专注于时间序列数据的存储和查询。
Prometheus提供了灵活的数据模型和查询语言,用户可以根据需求自由地定义监控指标,并利用PromQL进行查询和分析。
此外,Prometheus还支持告警功能和可视化展示,可帮助管理员及时发现和解决潜在的问题。
四、GrafanaGrafana是一款流行的数据可视化工具,它可以与多种监控系统集成,包括Zabbix、Nagios和Prometheus等。
Grafana提供了丰富的图表和仪表盘展示,用户可以通过简单的配置实现对服务器资源利用率的实时可视化监控。
Grafana还支持报警功能和数据导出,方便管理员根据实际需要进行监控和分析。
综上所述,服务器监控工具是管理和维护服务器的重要工具,它可以帮助管理员实时查看服务器资源的利用率,及时发现问题并采取相应措施。
普罗米修斯进程监控指标

普罗米修斯进程监控指标普罗米修斯(Prometheus)是一款开源的系统监控和告警工具,被广泛应用于云原生和微服务架构中。
它具备强大的数据模型和查询语言,可以帮助用户实时监控系统的各项指标,并及时发现潜在的问题。
本文将以普罗米修斯进程监控指标为主题,介绍普罗米修斯的进程监控指标以及如何使用这些指标来监控系统的运行情况。
一、普罗米修斯进程监控指标的作用普罗米修斯通过采集和存储各种指标数据,并提供强大的查询和可视化功能,帮助用户全面掌握系统的运行情况。
进程监控是普罗米修斯的一项重要功能,它可以监控系统中的各个进程的运行状态、资源使用情况等指标,帮助用户发现并解决可能存在的问题,确保系统的稳定性和可靠性。
普罗米修斯的进程监控指标可以分为以下几类:1. 进程的基本信息指标:包括进程的ID、名称、状态等信息。
这些指标可以帮助用户了解系统中各个进程的基本情况。
2. 进程的资源使用情况指标:包括进程的CPU使用率、内存使用量、磁盘IO等指标。
这些指标可以帮助用户了解系统中各个进程的资源消耗情况,及时发现资源瓶颈和性能问题。
3. 进程的运行状态指标:包括进程的启动时间、运行时间、退出码等指标。
这些指标可以帮助用户了解系统中各个进程的运行情况,及时发现进程崩溃或异常退出的问题。
4. 进程的网络连接指标:包括进程的网络连接数、连接状态等指标。
这些指标可以帮助用户了解系统中各个进程的网络活动情况,及时发现网络故障和安全问题。
三、如何使用普罗米修斯监控进程使用普罗米修斯监控进程的步骤如下:1. 安装和配置普罗米修斯:首先需要下载并安装普罗米修斯,并进行基本的配置,如指定要监控的进程、指定数据存储路径等。
2. 采集进程监控指标:普罗米修斯提供了多种方式来采集进程监控指标,如通过Exporter、Agent等。
用户可以根据自己的需求选择合适的方式进行采集。
3. 配置告警规则:普罗米修斯可以根据用户定义的告警规则来实现实时的告警功能。
grafana prometheus counter当天的总量语法-概述说明以及解释

grafana prometheus counter当天的总量语法-概述说明以及解释1.引言1.1 概述概述:在当今互联网时代,监控系统数据对于企业和组织来说是至关重要的。
Grafana和Prometheus作为监控系统中的两大关键组件,扮演着不可或缺的角色。
在监控系统中,Counter当天的总量语法起着至关重要的作用,可以帮助用户实时了解系统当前的运行状态,及时发现问题并进行处理。
本文将重点介绍Grafana与Prometheus的基本概念,以及Counter当天总量语法的语法规则和使用方法,旨在帮助读者更好地了解和运用监控系统中的相关知识,提升系统的稳定性和可靠性。
1.2文章结构1.2 文章结构本文主要包括三个部分:引言、正文和结论。
在引言部分中,将会对Grafana和Prometheus进行简要介绍,并说明本文的目的和结构。
在正文部分,将详细介绍Counter当天的总量语法,包括语法的定义、用法和示例。
同时,还将探讨如何使用Grafana和Prometheus监控系统数据,以便更好地了解系统的运行情况。
最后,结论部分将总结Counter当天总量语法的重要性以及它在系统监控中的应用,同时展望未来的发展方向。
1.3 目的本文的主要目的是介绍和探讨Grafana和Prometheus在监控系统数据中的应用。
特别关注了Counter当天的总量语法,旨在帮助读者了解如何使用这一语法来获取当天的数据总量,以便更好地监控系统的运行状态和性能表现。
通过深入分析Counter当天的总量语法,读者能够更好地理解如何利用Grafana和Prometheus这两个监控工具来实时监控系统中的指标和数据变化。
同时,通过本文的阐述,读者也可以了解如何利用这些工具来及时发现潜在的问题,以便及时采取措施进行调整和优化。
总体而言,本文旨在帮助读者深入了解Grafana和Prometheus的基本原理和应用方法,从而提高他们在监控系统中的技术水平和应用能力。
使用prometheus+grafana监控MySQL监控Oracle

使⽤prometheus+grafana监控MySQL监控Oracle【环境介绍】系统环境:CentOS Linux release 7.6 + prometheus version 2.20.0 + Grafana CLI version 7.1.3 + mysql 5.7 + oracle 11.2.0.4.0【安装部署】1,安装prometheus下载安装包:https:///prometheus/prometheus/releases/download/v2.20.1/prometheus-2.20.1.linux-amd64.tar.gz创建安装⽬录(这⾥根据实际情况定义软件⽬录):mkdir -p /home/prometheus/prometheus解压⾄安装⽬录:tar xf prometheus-2.20.1.linux-amd64.tar.gz -C /home/prometheus/prometheus --strip-components=1⽬录说明,需要创建对应⽬录:安装软件⽬录:/home/prometheus/prometheus配置⽂件⽬录:/home/prometheus/prometheus/conf数据⽬录:/home/prometheus/prometheus/data⽇志⽬录:/home/prometheus/prometheus/logs2,修改配置⽂件cd /home/prometheus/prometheus/拷贝配置⽂件到conf⾃⼰定义的⽬录:cp prometheus.yml ./confcd /home/prometheus/prometheus/confvim prometheus.yml# my global configglobal:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configurationalerting:alertmanagers:- static_configs:- targets:# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files:# - "first_rules.yml"# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:# Here it's Prometheus itself.scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: 'prometheus'# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ['localhost:9090']- job_name: linuxstatic_configs:- targets: ['10.0.0.166:9100']labels:instance: linux_10.0.0.166后⾯红⾊部分为添加的内容3,配置启动脚本使⽤脚本进⾏启动服务,注意修改配置⽂件,后⾯参数指定配置⽂件,数据⽬录,⽇志⽬录,保留时间,pid路径cat >start_prometheus.sh#!/bin/bashBASEPATH=/home/prometheus/prometheusLOG=$BASEPATH/logsnohup $BASEPATH/prometheus --config.file=$BASEPATH/conf/prometheus.yml --web.listen-address=:9090 --storage.tsdb.path=$BASEPATH/data/ --storage.tsdb.retention=5d >> $LOG/prometheus.log 2>&1 & echo $! > $BASEPATH/run/prometheus.pidsleep 5PROC=`ps -ef |grep \`cat $BASEPATH/run/prometheus.pid\` |grep -v grep`if [ ! -n "$PROC" ] ;thenecho "##########################################"echo "Process not found, please check by yourself"echo "##########################################"elseecho "##########################################"echo "Prometheus is running"echo "##########################################"fi4,安装node_exporter,mysqld_exporter,oracledb_exportercd /home/prometheus/wget https:///prometheus/node_exporter/releases/download/v1.0.1/node_exporter-1.0.1.linux-amd64.tar.gzwget https:///prometheus/mysqld_exporter/releases/download/v0.10.0/mysqld_exporter-0.10.0.linux-amd64.tar.gzwget https:///iamseth/oracledb_exporter/releases/download/0.2.9/oracledb_exporter.0.2.9-ora18.5.linux-amd64.tar.gz解压到指定export⽬录:/home/prometheus/prometheus_exportercd /home/prometheus/tar xf node_exporter-1.0.1.linux-amd64.tar.gz -C prometheus_exporter/tar xf mysqld_exporter-0.12.1.linux-amd64.tar.gz -C prometheus_exporter/tar xf oracledb_exporter.0.2.9-ora18.5.linux-amd64.tar.gz -C prometheus_exporter/加载node_exportercd /home/prometheus/prometheus_exporter/node_exporter-1.0.1.linux-amd64nohup ./node_exporter &加载mysqld_exportercd prometheus_exporter/mysqld_exporter-0.12.1.linux-amd64创建MySQL数据库监控⽤户:create user mysql_monitor@'%' identified by 'Mysql_monitor123';GRANT REPLICATION CLIENT, PROCESS ON *.* TO mysql_monitor@'%';GRANT SELECT ON performance_schema.* TO mysql_monitor@'%';vim f[client]host=localhostport=3306user=mysql_monitorpassword=Mysql_monitor123后台运⾏服务nohup ./mysqld_exporter --config.my-cnf=f &加载oracle_exporter下载oracle客户端安装包,配置安装,需要19Chttps:///cn/database/technologies/instant-client/linux-x86-64-downloads.html这⾥使⽤root⽤安装19C的客户端rpm -ivh oracle-instantclient19.5-basic-19.5.0.0.0-1.x86_64.rpm[root@oracle21 prometheus_exporter]# rpm -ivh oracle-instantclient19.5-basic-19.5.0.0.0-1.x86_64.rpmPreparing... ################################# [100%]Updating / installing...1:oracle-instantclient19.5-basic-19################################# [100%][root@oracle21 prometheus_exporter]# cd /usr/lib/oracle/19.3/client64/network/admin-bash: cd: /usr/lib/oracle/19.3/client64/network/admin: No such file or directory[root@oracle21 prometheus_exporter]# cd /usr/lib/oracle/19.5/client64/[root@oracle21 client64]# ls -trltotal 4drwxr-xr-x 2 root root 33 Aug 13 09:54 bindrwxr-xr-x 3 root root 4096 Aug 13 09:54 lib[root@oracle21 client64]# mkdir -p network/admin/[root@oracle21 client64]# cd network/admin/[root@oracle21 admin]# cat >tnsnames.oraoratest =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = 10.0.0.166)(PORT = 1521))(CONNECT_DATA =(SERVER = DEDICATED)(SERVICE_NAME = oratest)))[root@oracle21 admin]#配置环境变量 vim ~/.bash_profile --根⽬录下为全局使⽤,为限制⽤户权限,可只修改某⼀⽤户的环境变量vim ~/.bash_profileexport ORACLE_HOME=/usr/lib/oracle/19.5/client64export TNS_ADMIN=$ORACLE_HOME/network/adminexport NLS_LANG='simplified chinese_china'.ZHS16GBKexport LD_LIBRARY_PATH=$ORACLE_HOME/libexport PATH=$ORACLE_HOME/bin:$PATHsource ~/.bash_profileOracle数据库创建⽤户create user oracle_monitor identified by Oracle_monitor123;grant connect,dba,select any table to oracle_monitor;[root@oracle21 prometheus_exporter]# cd oracledb_exporter.0.2.9-ora18.5.linux-amd64/[root@oracle21 oracledb_exporter.0.2.9-ora18.5.linux-amd64]# pwd/home/prometheus/prometheus_exporter/oracledb_exporter.0.2.9-ora18.5.linux-amd64[root@oracle21 oracledb_exporter.0.2.9-ora18.5.linux-amd64]# export DATA_SOURCE_NAME=oracle_monitor/Oracle_monitor123@oratest [root@oracle21 oracledb_exporter.0.2.9-ora18.5.linux-amd64]# nohup ./oracledb_exporter &[1] 2623[root@oracle21 oracledb_exporter.0.2.9-ora18.5.linux-amd64]# nohup: ignoring input and appending output to ‘nohup.out’[root@oracle21 oracledb_exporter.0.2.9-ora18.5.linux-amd64]# ps -ef |grep oracledb_exporterroot 2623 32023 0 10:01 pts/0 00:00:00 ./oracledb_exporterroot 2669 32023 0 10:01 pts/0 00:00:00 grep --color=auto oracledb_exporter[root@oracle21 oracledb_exporter.0.2.9-ora18.5.linux-amd64]#以上使⽤命令查看采集数据是否正常(修改对应的IP跟端⼝):curl http://IP:9161/metrics5,启动服务查看配置⽂件:cat prometheus.ymlstatic_configs:- targets: ['localhost:9090']- job_name: linuxstatic_configs:- targets: ['10.0.0.166:9100']labels:instance: linux_10.0.0.166- job_name: mysqlstatic_configs:- targets: ['10.0.0.166:9104']labels:instance: mysql_10.0.0.166- job_name: oracle_localstatic_configs:- targets: ['10.0.0.166:9161']instance: oracle_10.0.0.166直接运⾏脚本启动服务:[root@oracle21 prometheus]# sh start_prometheus.sh########################################## Prometheus is running##########################################[root@oracle21 prometheus]#查看⽹址是否监控正常:http://10.0.0.166:9090/targets5,安装grafana这⾥使⽤RPM安装wget https:///oss/release/grafana-7.1.3-1.x86_64.rpm yum install grafana-7.1.3-1.x86_64.rpm$ systemctl daemon-reload$ systemctl start grafana-server$ systemctl status grafana-server访问⽹址是否正常http://10.0.0.166:3000 ⽤户密码为admin admin6,导⼊对应的仪表盘效果如下下载对应的仪表盘:主机:MySQL:Oracle:7,遇到的问题使⽤之前查看的批量导⼊MySQL仪表盘显⽰需要安装插件,该插件本⾝⾃带,解决办法直接下载最新的仪表盘导⼊即可;Oracle数据库采集数据异常,查看为查询表空间耗时很久,在数据库层⾯清理回收站即可;Linux6安装监控异常,为需要安装Linux需要⽀持2.14 strings /lib64/libc.so.6 |grep GLIBC_ linux6需要升级下载glibc-2.14.tar.gz注意新的版本⼀定得⽤其他⽬录,防⽌覆盖原版本导致系统异常:mkdir -p /root/soft/glibcgunzip glibc-2.14.tar.gztar -xvf glibc-2.14.tarcd glibc-2.14mkdir buildcd build../configure --prefix=/root/soft/glibcmake -j4make installexport LD_LIBRARY_PATH=$ORACLE_HOME/lib:/root/soft/glibc/lib。
服务器监控工具ZabbixPrometheus和Grafana的选择与使用

服务器监控工具ZabbixPrometheus和Grafana的选择与使用服务器监控工具Zabbix、Prometheus和Grafana的选择与使用概述:服务器监控工具在现代 IT 系统中起着至关重要的作用,可帮助管理员实时监控服务器性能、运行状况以及资源利用率等重要指标。
本文将讨论两种常用的服务器监控工具:Zabbix、Prometheus和Grafana,并探讨它们的选择和使用。
一、ZabbixZabbix是一款功能强大的开源服务器监控工具,可用于监控服务器性能、网络设备、虚拟机等。
以下是Zabbix的主要特点与优势:1. 综合监控能力:Zabbix可以监控各种操作系统(如Windows、Linux、UNIX)、网络设备(如路由器、交换机)以及应用程序(如数据库、Web服务器等)的性能和状态。
2. 实时监测和警报:Zabbix能够以实时的方式监测服务器指标,并能够配置警报策略,及时通知管理员服务器出现问题。
3. 灵活的可扩展性:Zabbix支持自定义监控项和模板,可以根据不同的需求进行灵活配置和定制。
4. 直观的图表和报表:Zabbix提供了直观的图表和报表功能,可以帮助管理员更好地理解和分析监控数据。
5. 强大的告警功能:Zabbix支持多种告警方式,如邮件、短信、Slack等,可以根据不同的情况设置不同的告警策略。
二、PrometheusPrometheus是基于时间序列数据的开源服务器监控工具,被广泛用于云原生和容器化环境中。
以下是Prometheus的主要特点与优势:1. 高度可扩展:Prometheus具有出色的可扩展性,能够处理大规模的监控任务,并且具备持久化存储功能,可以长期保存监控数据。
2. 强大的查询和分析功能:Prometheus提供了灵活的查询语言,可以对监控数据进行实时查询和分析,方便管理员快速定位和解决问题。
3. 丰富的可视化特性:Prometheus内置了基本的图表和仪表盘功能,同时也方便与其他可视化工具(如Grafana)进行集成,提供更丰富的可视化效果。
服务器监控工具GrafanaZabbix和Prometheus的比较与选择

服务器监控工具GrafanaZabbix和Prometheus的比较与选择服务器监控工具Grafana、Zabbix和Prometheus的比较与选择概述:在当今云计算技术迅猛发展的背景下,服务器监控工具的选择显得尤为重要。
本文将对当前市场上比较常见的三种监控工具进行比较,分析其特点和适用场景,帮助读者做出明智的选择。
一、Grafana简介:Grafana是一款开源的数据可视化和监控平台。
它提供了丰富的图表和仪表盘,能够将监控指标以直观的方式展现出来。
Grafana的优点在于其简洁的界面设计、强大的图表定制功能和丰富的插件生态系统。
Grafana的核心特点包括:1. 支持多种数据源:Grafana可以与各种数据源集成,如Prometheus、Zabbix、InfluxDB等,使用户可以轻松获取各种监控指标。
2. 强大的图表和仪表盘功能:Grafana提供了多种图表类型和面板样式,用户可以自由自定义展示效果,并可以创建交互式的仪表盘。
3. 灵活的告警功能:Grafana支持基于监控指标的告警规则配置,当指标达到设定的阈值时,可以发送通知并执行相关操作。
4. 插件生态系统:Grafana的插件生态系统非常丰富,用户可以根据需求选择合适的插件进行扩展功能或增加数据源。
二、Zabbix简介:Zabbix是一款非常流行的企业级开源监控解决方案。
它提供了全面的监控功能,包括服务器性能监控、网络监控、应用程序监控等。
Zabbix的优点在于其丰富的功能和可靠的性能。
Zabbix的核心特点包括:1. 多种监控方式:Zabbix支持多种监控方式,包括Agent、SNMP、JMX等,可以满足不同场景下的监控需求。
2. 强大的告警功能:Zabbix提供了丰富的告警配置选项,可以根据监控指标的变化情况触发告警,并支持多种通知方式,如邮件、短信等。
3. 灵活的数据收集和分析:Zabbix可以对采集的监控数据进行存储和分析,支持多种数据图表和统计报表的展示。
Prometheus+Grafana+SpringBoot业务埋点可视化监控

Prometheus+Grafana+SpringBoot业务埋点可视化监控引⼊依赖<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId></dependency><dependency><groupId>io.micrometer</groupId><artifactId>micrometer-registry-prometheus</artifactId></dependency>application.yml⽂件server:port: 8010spring:application:name: spring-boot-prometheus-grafanamanagement:endpoints:web:exposure:include: "*"endpoint:health:show-details: alwayscontroller中埋点@RestController@RequestMapping("/api")public class MainController {@AutowiredMeterRegistry registry;private Counter counter;private Counter failCounter;@PostConstructprivate void init(){counter = registry.counter("requests_add_total","save","carson");failCounter= registry.counter("requests_add_fail_total","save","carson");}@GetMapping("/add")public String add(String name,Integer age) {counter.increment();if(RandomUtils.nextInt(0,1000)<185){failCounter.increment();return "error";}else{return "name="+name+" age="+age;}}}在prometheus.yml添加- job_name: 'spring_boot_8010'metrics_path: /actuator/prometheusstatic_configs:- targets: ['127.0.0.1:8010']在grafana中添加展⽰图表。
Grafana和prometheus监控服务器

Grafana和prometheus监控服务器Prometheus简介Prometheus 是⼀套开源的系统监控报警框架。
它启发于 Google 的 borgmon 监控系统,由⼯作在 SoundCloud 的 google 前员⼯在 2012 年创建,作为社区开源项⽬进⾏开发,并于 2015 年正式发布。
2016 年,Prometheus 正式加⼊ Cloud Native Computing Foundation,成为受欢迎度仅次于 Kubernetes 的项⽬。
安装Prometheus2.修改Prometheus服务器配置⽂件cd /opt/prometheuscat prometheus.yml# my global configglobal:scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.# scrape_timeout is set to the global default (10s).# Alertmanager configurationalerting:alertmanagers:- static_configs:- targets:# - alertmanager:9093# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.rule_files:# - "first_rules.yml"# - "second_rules.yml"# A scrape configuration containing exactly one endpoint to scrape:# Here it's Prometheus itself.scrape_configs:# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.- job_name: 'prometheus'# metrics_path defaults to '/metrics'# scheme defaults to 'http'.static_configs:- targets: ['localhost:9090'],详细请参考。
使用Prometheus+Grafana的方法监控Springboot应用教程详解

使⽤Prometheus+Grafana的⽅法监控Springboot应⽤教程详解1 简介项⽬越做越发觉得,任何⼀个系统上线,运维监控都太重要了。
关于Springboot微服务的监控,之前写过【,这个⽅案可以实时监控并提供告警提醒功能,但不能记录历史数据,⽆法查看过去1⼩时或过去1天等运维情况。
本⽂介绍Prometheus + Grafana的⽅法监控Springboot 2.X,实现美观漂亮的数据可视化。
2 PrometheusPrometheus是⼀套优秀的开源的监控、报警和时间序列数据库组合系统,在现在最常见的Kubernetes容器管理系统中,通常会搭配Prometheus进⾏监控。
2.1 引⼊到Springboot将Prometheus引⼊依赖如下:<dependency><groupId>io.micrometer</groupId><artifactId>micrometer-registry-prometheus</artifactId></dependency>对于Springboot,要开启Actuator,并打开对应的Endpoint:management.endpoints.web.exposure.include=*# 或者management.endpoints.web.exposure.include=prometheus启动Springboot后,可以通过下⾯URL看能不能正确获取到监控数据:localhost:8080/actuator/prometheus获取数据成功,说明Springboot能正常提供监控数据。
2.2 Docker⽅式使⽤为了⽅便,使⽤Docker启动Prometheus:# 拉取docker镜像docker pull prom/prometheus准备配置⽂件prometheus.yml:scrape_configs:# 可随意指定- job_name: 'spring'# 多久采集⼀次数据scrape_interval: 15s# 采集时的超时时间scrape_timeout: 10s# 采集的路径metrics_path: '/actuator/prometheus'# 采集服务的地址,设置成Springboot应⽤所在服务器的具体地址static_configs:- targets: ['hostname:9000','hostname:8080']启动docker实例:# 端⼝为9090,指定配置⽂件docker run -d -p 9090:9090 -v ~/temp/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus --config.file=/etc/prometheus/prometheus.yml2.3 测试与查看如上图所⽰,打开⽹页后,随便选取⼀个对应的监控指标与参数,点击Execute就可以查看了。
Prometheus+Grafana实用案例
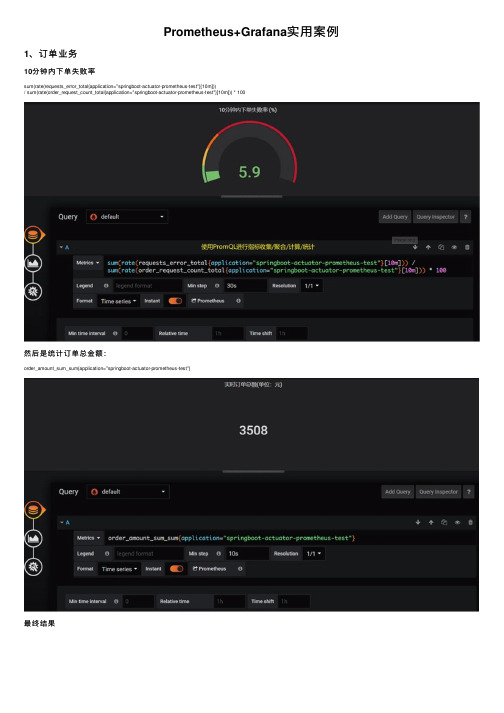
Prometheus+Grafana实⽤案例1、订单业务10分钟内下单失败率sum(rate(requests_error_total{application="springboot-actuator-prometheus-test"}[10m]))/ sum(rate(order_request_count_total{application="springboot-actuator-prometheus-test"}[10m])) * 100然后是统计订单总⾦额:order_amount_sum_sum{application="springboot-actuator-prometheus-test"}最终结果1、创建 Prometheus 监控管理类PrometheusCustomMonitor 这⾥⾯我们⾃定义了三个metrics:requests_error_total: 下单失败次数order_request_count:下单总次数order_amount_sum:下单⾦额统计@Componentpublic class PrometheusCustomMonitor {/*** 记录请求出错次数*/private Counter requestErrorCount;/*** 订单发起次数*/private Counter orderCount;/*** ⾦额统计*/private DistributionSummary amountSum;private final MeterRegistry registry;@Autowiredpublic PrometheusCustomMonitor(MeterRegistry registry) {this.registry = registry;}@PostConstructprivate void init() {requestErrorCount = registry.counter("requests_error_total", "status", "error");orderCount = registry.counter("order_request_count", "order", "test-svc");amountSum = registry.summary("order_amount_sum", "orderAmount", "test-svc");}public Counter getRequestErrorCount() {return requestErrorCount;}public Counter getOrderCount() {return orderCount;}public DistributionSummary getAmountSum() {return amountSum;}}2、新增/order接⼝当 flag="1"时,抛异常,模拟下单失败情况。
grafana的alert的3个状态描述

grafana的alert的3个状态描述Grafana是一款流行的开源数据可视化和监控工具,它提供了丰富的功能和灵活的配置选项,使用户能够轻松地创建仪表盘和报警规则。
在Grafana中,Alert是一种用于监控指标并在达到特定条件时触发通知的机制。
Alert的状态描述了当前监控指标的状态,帮助用户了解系统的健康状况。
本文将介绍Grafana的Alert的三个状态描述。
1. OK状态OK状态表示监控指标的数值在正常范围内,系统运行良好。
当Alert的条件未达到时,Grafana会将Alert的状态设置为OK。
例如,我们可以设置一个Alert规则,当CPU使用率低于80%时,将Alert状态设置为OK。
在OK状态下,Grafana不会触发任何通知,用户可以放心地知道系统正常运行。
2. Pending状态Pending状态表示Alert的条件已经达到,但在一段时间内未能持续达到。
当Alert的条件首次达到时,Grafana会将Alert的状态设置为Pending,并开始计时。
如果在一定时间内,Alert的条件持续达到,状态将会转变为Firing;如果在计时结束前,Alert的条件未能持续达到,状态将会转变为OK。
Pending状态的存在是为了避免短暂的波动或噪声对系统的影响,确保Alert的触发是有意义的。
3. Firing状态Firing状态表示Alert的条件已经达到并持续达到。
当Alert的条件持续达到时,Grafana会将Alert的状态设置为Firing,并触发相应的通知。
通知可以通过电子邮件、短信或其他方式发送给相关人员,提醒他们系统出现了异常情况。
例如,我们可以设置一个Alert规则,当磁盘使用率超过90%时,将Alert状态设置为Firing,并发送邮件给系统管理员。
Firing状态的存在是为了及时发现和解决系统问题,保障系统的稳定性和可靠性。
总结起来,Grafana的Alert的三个状态描述了监控指标的不同状态,帮助用户了解系统的健康状况。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Prometheus+Grafana 监控服务器服务状态信息监控哪些信息?
上文有提到Prometheus+Grafana如何去监控服务器的一些基础状态信息(CPU/内存/磁盘等) 本文将讲如何监控服务状态和数据库状态信息
监控服务进程状态
这里通过Process Exporter来实现目的
机器跟上文的一致,依然是30和31两台机器
为了偷懒,就直接监控上文部署的Node Exporter服务
同时为了实验效果,还装了个Mariadb
在31上部署Process Exporter
在30上配置Prometheus
到Grafana上导入模板
查看效果
监控数据库状态
通过Mysqld Exporter来实现目的
在31上部署Mysqld Exporter
在30上配置Prometheus
在30上配置Grafana
到Grafana web页面上导入模板
查看效果。