nutch配置过程
nutch-1.0配置过程中文版

7.搜索页面上的部分中文出现乱码。该问题主要由jsp:include引起。
将被包含文件nutch\zh\include\header.html的乱码修改为简介和常见问题
8.搜索中文出现乱码。修改tomcat配置文件tomcat6\conf\server.xml。增加URIEncoding/useBodyEncodingForURI两项。
-dir dir names the directory to put the crawl in.
-threads threads determines the number of threads that will fetch in parallel.
-depth depth indicates the link depth from the root page that should be crawled.
每次重新修改nutch配置文件的时候,需要把crawl文件夹删掉
/nutch/tutorial8.html
/blog/382726
/category/41935
3.下载nutch-1.0
3.1在解压后的目录里面建urls文件夹
urls目录下面建url.txt
内容为: / 来自3.2修改解压目录下 conf/crawl-urlfilter.txt
# accept hosts in
#+^http://([a-z0-9]*\.)*/
内容为
<configuration>
<property>
<name></name>
<value>my nutch agent</value>
Nutch配置文档

Nutch配置文档目录1 JDK、Tomcat、Cygwin的配置 (2)2 Nutch1.0的基本配置 (2)2.1准备Nutch源码包 (2)2.2建立java项目 (2)2.3下载jid3lib-0.5.1.jar和rtf-parser.jar (2)2.4修改Nutch\conf (3)2.5动态网址的抓取 (3)3 Nutch1.0的优化配置 (4)3.1增加Summary长度 (4)3.2Nutch搜索高亮 (4)3.3提高Nutch抓取速度 (5)3.3.1 修改fetcher.threads.per.host: (5)这个值允许同一时刻访问一台主机的最大线程数,改成15 (5)3.3.2 修改fetcher.server.delay (5)修改conf/nutch-default.xml中的etcher.server.delay,改成1.0 在抓取时最高能到到3M/s (5)4 Nutch1.0中文分词IKAnalyzer的配置 (5)4.1准备工作 (5)4.2让Nutch支持中文分词 (5)4.3添加IKAnalyzer (6)4.4重新编译Nutch (6)5 运行Nutch1.0 (6)5.1配置好后,启动工程 (6)5.1.1 通过cygwin启动 (6)5.1.2 通过Myeclipse启动 (7)5.2Luke查看建立的索引 (7)6 Nutch1.0在Tomcat下的配置 (8)6.1解压nutch-1.0.war (8)6.2分页效果的实现 (8)6.3查询 (11)6.4乱码问题 (12)7 fetcher阶段之后,各个阶段的调用命令 (13)1JDK、Tomcat、Cygwin的配置2Nutch1.0的基本配置2.1准备Nutch源码包项目中使用的是nutch-1.0版本,到/下载nutch-1.0.tar.gz,下载后直接解压缩即可2.2建立java项目file->new->java project->从已有的项目导入点击next,将conf文件夹修改成Default output folder Browse选择nutch\conf确定即可,这时,一般确定以后会把conf中以前的文件清空掉,在重新把nutch压缩包里的conf下的所有文件复制到工程的conf下,千万不要把新生成的配置文件删掉2.3下载jid3lib-0.5.1.jar和rtf-parser.jar右键项目properties,添加外部jar,若在nutch-1.0下还要一般的工程都会有两个错误,nutch的official 1.0 release版本中,这两个问题因为licensing issues没有修复。
Nutch 的配置文件

Nutch 的配置Nutch的配置文件主要有三类:1.Hadoop的配置文件,Hadoop-default.xml和Hadoop-site.xml。
2.Nutch的配置文件,Nutch-default.xml和Nutch-site.xml。
3.Nutch的插件的配置文件,这些插件的配置文件在加载插件的时候由插件自行加载,如filter的配置文件。
配置文件的加载顺序决定了配置文件的优先级,先加载的配置文件优先级低,后加载的配置文件优先级高,优先级低的配置会被优先级高的配置覆盖。
因此,了解Nutch配置文件加载的顺序对学习使用Nutch是非常必要的。
下面我们通过对Nutch源代码的分析来看看Nutch加载配置文件的过程。
Nutch1.0使用入门(一)介绍了Nutch主要命令--crawl的使用,下面我们就从crawl的main类(org.apache.nutch.crawl.Crawl)的main方法开始分析:Crawl类main方法中加载配置文件的源码如下:Configuration conf = NutchConfiguration.create();conf.addResource("crawl-tool.xml");JobConf job = new NutchJob(conf);上面代码中,生成了一个NutchConfiguration类的对象,NutchConfiguration 是Nutch管理自己配置文件的类,Configuration是Hadoop管理自己配置文件的类。
下面我们进入NutchConfiguration类的create()方法。
/** Create a {@link Configuration} for Nutch. */public static Configuration create() {Configuration conf = new Configuration();addNutchResources(conf);return conf;}create()方法中,先生成了一个Configuration类的对象。
Nutch环境搭建

Nutch环境搭建1. 环境准备HOST:Ubuntu12.04LTSJDK: jdk-7u45-linux-i586.rpmNutch:apache-nutch-1.7-bin.tar.gzSolr:solr-4.6.0-src.tgz⼯作⽬录: /home/zephyr/1.1JDK安装为了下载快点,⼀下脑残下了rpm.可Ubuntu上没有rpm⼯具apt-get install rpm 后rpm -ivh jdk-7u45-linux-i586.rpm提⽰要使⽤alienapt-get install alien alien -i jdk-7u45-linux-i586.rpmalien -d jdk-7u45-linux-i586.rpm ⽣成deb⽂件不可⽤⽆奈,重新使⽤apt-get install oracle-java7-installer* 直接使⽤失败add-apt-repository ppa:webupd8team/javaapt-get updateapt-get install oracle-java7-installer到/etc/profile ⽂件的最后增加上以下⼏⾏export JAVA_HOME=/usr/java/jdk1.7.0_45export CLASSPATH=.:$JAVA_HOME/lib/tools.jar:$JAVA_HOME/lib/dt.jarexport NUTCH_HOME=/home/zephyr/apache-nutch-1.7export PATH=$JAVA_HOME/bin:$JAVA_HOME/jre/bin:$NUTCH_HOME/bin:$PATH1.2Tomcat安装apt-get install tomcat7 下载tomcat修改tomcat的端⼝使⽤情况为vi /etc/tomcat7/server.xml<Connector port="8088" protocol="HTTP/1.1"connectionTimeout="20000"URIEncoding="UTF-8"redirectPort="8443" />/etc/init.d/tomcat7 start1.3Nutch 安装⼯作⽬录下解压 tar xzvf apache-nutch-1.7-bin.tar.gz测试Nutch 是否能正常⼯作在urls⽬录touch⼀个seed.txt echo / >> seed.txt修改conf/regex-urlfilter.txt# accept anything else+.为+^http://([a-z0-9]*\.)*/编辑conf/nutch-site.xml<property><name></name><value>My Nutch Spider</value></property>.nutch crawl ../urls -dir ../test -depth 1 -topN 10报错java/lang/NoClassDefFoundError: java/lang/ObjectException in thread "main" ng.InternalError: internal error: SHA-1 not available修正JDKcd /usr/java/jdk1.7.0_45/lib 将pack结尾的⽂件都转成 jar 如:unpack200 tools.pack tools.jar/usr/java/jdk1.7.0_45/jre/lib 也做相同操作再操作成功。
nutch-index
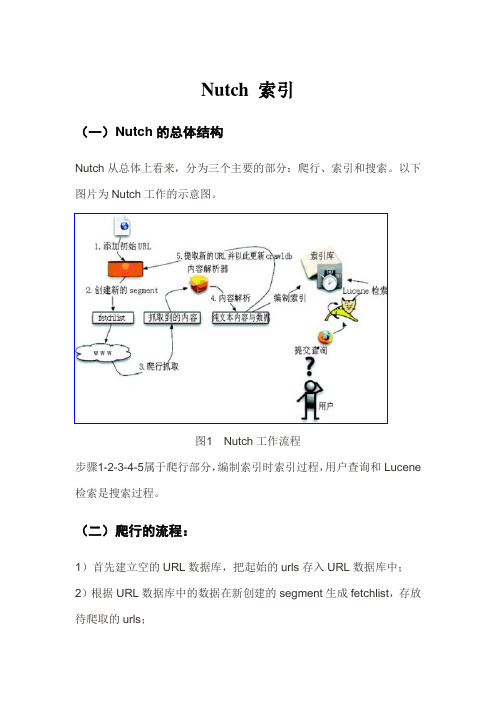
Nutch 索引(一)Nutch的总体结构Nutch从总体上看来,分为三个主要的部分:爬行、索引和搜索。
以下图片为Nutch工作的示意图。
图1 Nutch工作流程步骤1-2-3-4-5属于爬行部分,编制索引时索引过程,用户查询和Lucene 检索是搜索过程。
(二)爬行的流程:1)首先建立空的URL数据库,把起始的urls存入URL数据库中;2)根据URL数据库中的数据在新创建的segment生成fetchlist,存放待爬取的urls;3)根据fetchlist数据对internet中的相关网页爬行抓取;4)把步骤3抓取的数据解析成纯文本与数据;5)从步骤4中解析的数据中提取新的urls,更新URL数据库。
之后步骤2—5循环。
(三)Nutch索引部分:1)Nutch 是基于Lucene的。
Lucene为Nutch 提供了文本索引和搜索的API。
2)Nutch的索引是以增量的方式进行的。
新建去重合并新建:Nutch索引首先对本次抓取的数据进行索引(因为以前的数据被索引过,不需要再重新索引)。
每次抓取会在indexes中建立临时目录存放新创建的索引,indexes目录中存放的是本次的索引,index 目录中存放现有的索引。
新建程序结构:Indexer类的index()函数负责创建一个job,进行索引操作。
index函数调用IndexerMapReduce类的静态函数initMRJob()初始化该job,initMRJob负责将需要建立索引的数据通过FileInputFormat.addInputPath(job, p1)操作,加载到job的输入路径中,所以可以通过修改iniMRJob()函数来控制建立索引的输入数据,即只将本次爬取的数据作为输入来避免重复建立索引。
去重:对新的建立的索引和以前建立的索引进行去重操作,(其中如果新抓取的url已经存在索引,则去掉重复的)。
Indexes目录下有很多个索引,每个索引一个目录。
nutch核心流程分析

Nutch核心流程分析Crawl类的时序图流程如下:1. 建立初始URL 集2. 将URL 集注入crawldb 数据库---inject3. 根据crawldb 数据库创建抓取列表---generate4. 执行抓取,获取网页信息---fetch5. 更新数据库,把获取到的页面信息存入数据库中---updatedb6. 重复进行3 ~5 的步骤,直到预先设定的抓取深度。
--- 这个循环过程被称为“ 产生/ 抓取/ 更新” 循环7. 根据sengments 的内容更新linkdb 数据库---invertlinks8. 建立索引---index一、 org.apache.nutch.crawl.Injector:1,注入url.txt2,url标准化3,拦截url,进行正则校验(regex-urlfilter.txt)4,对符URL标准的url进行map对构造<url, CrawlDatum>,在构造过程中给CrawlDatum初始化得分,分数可影响url host的搜索排序,和采集优先级! 5,reduce只做一件事,判断url是不是在crawldb中已经存在,如果存在则直接读取原来CrawlDatum,如果是新host,则把相应状态存储到里边(STATUS_DB_UNFETCHED(状态意思为没有采集过))二、org.apache.nutch.crawl.Generator:1,过滤不及格url (使用url过滤插件)2,检测URL是否在有效更新时间里3,获取URL metaData,metaData记录了url上次更新时间4,对url进行打分5,将url载入相应任务组(以host为分组)6,计算url hash值7,收集url, 直至到达 topN 指定量三、 org.apache.nutch.crawl.Fetcher:1,从segment中读取<url, CrawlDatum>,将它放入相应的队列中,队列以queueId为分类,而queueId是由协议://ip 组成,在放入队列过程中,如果不存在队列则创建(比如javaeye的所有地址都属于这个队列:http://221.130.184.141) --> queues.addFetchItem(url, datum);2,检查机器人协议是否允许该url被爬行(robots.txt) -->protocol.getRobotRules(fit.url, fit.datum);3,检查url是否在有效的更新时间里 --> if (rules.getCrawlDelay() > 0) 4,针对不同协议采用不同的协议采用不同机器人,可以是http、ftp、file,这地方已经将内容保存下来(Content)。
nutch流程分析

1.创建一个新的WebDb (admin db -create);2.将抓取起始URLs写入WebDB中(inject);3.根据WebDB生成fetchlist并写入相应的segment(generate);4.根据fetchlist中的URL抓取网页(fetch).;5.根据抓取网页更新WebDb (updatedb).通过3—5这个循环就可以实现Nutch的深度抓取。
在nutch爬虫运行后在webdb文件夹下一共产生如下五个文件:linksByMD5 linksByURL pagesByMD5 pagesByURL statsStats文件用来存放爬虫爬行后的版本信息,处理网页数量,连接数量;pagesByURL等其余四个文件夹下均有两个文件――index和data,其中data文件用来存放有序的key/value对,排序是通过选择不同的key和comparator来改变的,当然里面会有一些其他信息,比如在pagesByURL中,就每隔一定长度的key /value对放入一个用来定位的信息(syn);index文件用来存放索引,但是这个索引文件也是一个有序的,这个里面存放的是key和位置信息,但是在data文件中出现的key在这个index中都能找到的,它为了节省空间,实施了每隔一段key/value 建立一条索引,这样在查找的时候,因为是有序的,所以采用2分查找,如果找不到,则返回最后时候的最小的位置信息,这个位置离我们要找的目标是相当近的,然后在data文件的这个位置向前找就可以很快找到了nutch维持这个webdb的方式是,在填加,删除网页或者连接时,并不是直接向这个webdb中填加网页或者连接,而是在WebDBWriter 中的内部类PageInstructionWriter或者LinkInstructionWriter中填加一条对网页操作的命令,然后最后对存放的命令进行排序去重,最后将这个命令与现有的webdb中存放的网页数据进行合并;Fetcher类是进行实际网页抓取时候运行的类,爬虫产生的文件或文件夹都是由这个类产生的,Nutch提供了选项―是否对抓回的网页进行parse(解析),如果这个选项设置为false,将没有parseddata和parsedtext这两个文件夹。
nutch_

Nutch实验过程与学习心得1.1安装Nutch1.1.1实验环境Linux操作系统,采用的是VMWare虚拟机下的Ubuntu 10.10系统。
1.1.2安装的必要软件1.JDK,本人采用的是JDK1.6版本,为了方便大家学习,给出软件的下载链接,在下载时,注意选择linux下的版本,不要选择windows的版本,此次实验下载的是jdk-6u13-linux-i586.bin。
/technetwork/java/javase/downloads/index.html2.Tomcat,采用的是apache-tomcat-6.0版本,此次实验选择的是apache-tomcat-6.0.32.tar.gz。
/3.Nutch, 采用的是apache-nutch-1.1版本,此次实验选择的是apache-nutch-1.1-bin.tar.gz。
/4.最后尽量采用较新的版本,否则,可能出现其他问题。
1.1.3软件的安装方法和安装过程1.安装JDK1)将下载好的jdk的bin文件放到虚拟机环境下,例如,可以放在/home目录下(虚拟机和主机之间的文件传递可以简单通过U盘或移动硬盘,当然还有其他很多种方法,可自行选择)。
2)到jdk的bin文件目录下,执行命令,安装jdk。
安装命令:[root@localhost -]#sh jdk-6u13-linux-i586.bin一直按Enter键,知道需要选择yes or no,选择也是即可。
(注意:如果对于linux不太熟悉,最简单的方法就是在操作界面中启动终端,应用程序->附件->终端,然后即可再次之下输入命令行了。
一般情况下,进入终端后的结果:andy是本人linux系统下用户名,每个人都不同。
先获取root权限,命令如下:andy@andy-virtual-machine:~$ sudo –sH并且需要输入password,输入的password是不会在终端中显示的,命令执行后的结果:此时,已获得root权限。
开发Nutch程序运行环境配置

程序运行环境配置1.开发环境配置将nutch-1.0.jar和nutch\lib下所有jar文件都配置在Referenced Libraries下即可其中c3p0-0.9.1是数据库池管理的jar,mysql-connector-java-5.1.6-bin.jar为mysql的jar。
2.运行中几个错误的解决Nutch1.0在eclipse中运行问题之解决文章分类:Java编程今天按照前面几篇文章所述之操作解决了程序中的报错,但是在调试运行过程中会出现如果错误.本问题主要针对windows操作系统.问题一:现贴出:2010-03-25 21:42:33,937 WARN fs.FileSystem (FileSystem.java:<init>(1440)) - uri=file:/// javax.security.auth.login.LoginException: Login failed: Cannot run program "whoami": CreateProcess error=2, ?????????atorg.apache.hadoop.security.UnixUserGroupInformation.login(UnixUserGroupInformation.java:25 0)atorg.apache.hadoop.security.UnixUserGroupInformation.login(UnixUserGroupInformation.java:27 5)atorg.apache.hadoop.security.UnixUserGroupInformation.login(UnixUserGroupInformation.java:25 7)at erGroupInformation.login(UserGroupInformation.java:67)at org.apache.hadoop.fs.FileSystem$Cache$Key.<init>(FileSystem.java:1438)at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:1376)at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:215)at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:120)at org.apache.nutch.crawl.Crawl.main(Crawl.java:84)2010-03-25 21:42:34,593 INFO crawl.Crawl (Crawl.java:main(87)) - crawl started in: crawl2010-03-25 21:42:34,593 INFO crawl.Crawl (Crawl.java:main(88)) - rootUrlDir = urls2010-03-25 21:42:34,593 INFO crawl.Crawl (Crawl.java:main(89)) - threads = 102010-03-25 21:42:34,593 INFO crawl.Crawl (Crawl.java:main(90)) - depth = 32010-03-25 21:42:34,593 INFO crawl.Crawl (Crawl.java:main(92)) - topN = 502010-03-25 21:42:34,609 WARN fs.FileSystem (FileSystem.java:<init>(1440)) - uri=file:/// javax.security.auth.login.LoginException: Login failed: Cannot run program "whoami": CreateProcess error=2, ?????????atorg.apache.hadoop.security.UnixUserGroupInformation.login(UnixUserGroupInformation.java:25 0)atorg.apache.hadoop.security.UnixUserGroupInformation.login(UnixUserGroupInformation.java:27 5)atorg.apache.hadoop.security.UnixUserGroupInformation.login(UnixUserGroupInformation.java:25 7)at erGroupInformation.login(UserGroupInformation.java:67)at org.apache.hadoop.fs.FileSystem$Cache$Key.<init>(FileSystem.java:1438)at org.apache.hadoop.fs.FileSystem$Cache.get(FileSystem.java:1376)at org.apache.hadoop.fs.FileSystem.get(FileSystem.java:215)at org.apache.hadoop.fs.FileSystem.getLocal(FileSystem.java:191)at org.apache.hadoop.conf.Configuration.getLocalPath(Configuration.java:787)at org.apache.hadoop.mapred.JobConf.getLocalPath(JobConf.java:232)at org.apache.nutch.crawl.Crawl.main(Crawl.java:101)2010-03-25 21:42:34,984 WARN fs.FileSystem (FileSystem.java:<init>(1440)) - uri=file:/// .................问题分析及解决:因为Nutch设计是在linux等系统下运行的,Windows系统是没有"whoami"这个命令的。
nutch(windows7环境下的配置)

经过好几天的尝试,终于成功在windows7的环境下将nutch成功运行出来了,下面将经验记下。
1、cygwin的安装:下载地址:/setup.exe(1)因为nutch自身的命令是要在linux环境下才能运行,所以先安装了cygwin,Cygwin 是一个在Windows下的模拟Linux系统程序。
Cygwin的安装:/cfree_ch/doc/help/UsingCF/CompilerSupport/Cygwin/Cygwin1 .htm这个网址对cygwin的安装步骤演示的很详细,对我们这些初步接触cygwin的人有很大的帮助。
(2)下面是我自己安装时的截图1)安装页面,点击下一步2)选择安装目录,可以根据默认,也可以根据自己需要换路径3)建立Downloads文件夹,接收下载包4)选择镜像地址,没有演示中说的:。
.cn代表中国的网站,下载会更快5)选择安装包6)安装完成2、下载安装apache-nutch-1.2-bin.zip并设置。
下载地址:/dist/nutch/(1)下载完成后将其解压到D盘,文件夹名为nutch-1.2(2)输入,打开到d盘目录下nutch-1.2文件夹,输入bin/nutch 进行nutch安装测试:出来一系列nutch的命令,证明nutch安装成功;(3)在Windows系统的环境变量设置中,添加NUTCH_JA V A_HOME环境变量:D:\jdk1.7.0_07。
并将其值设为JDK的安装目录。
(4)Nutch抓取网站页面前的预备工作1)在Nutch-1.2的安装目录下建立一个名为urls的文件夹,并在文件夹下建立url.text 文件,在文件中写入: (即要抓取网站的网址)2))修改网址过滤规则,编辑conf/crawl-urlfilter.txt文件,修改 部分:3)修改conf/nutch-site.xml代理信息,在<configuration>和</configuration>之间添加如下内容4)修改nutch-1.2\conf\nutch-default.xml文件,找<name></name> ,然后随便设置Value值注意:如果为空时,在爬行的时候可能出现空指针异常且在tomcat 中搜索时可能导致0条记录,所以务必加上。
nutch的基本工作流程理解

今天研究了Nutch,差不多已经好几个小时了,到现在还没有搞定,也这么晚了,先记录下来,明天继续吧。
一开始很多时间都浪费在了cygwin的安装上了,bs这个软件的开发者了,一个不伦不类的软件安装程序,安装的时候还要从网上下载东东。
不过最后终于装成功了,先下载到本地后,再安装的(建议下载站点中选 TW 的比较块)。
下面是我安装CYGWIN和NUTCH的过程,都块成功了,但最后卡在了用户查询界面,输入东西什么都查不出来,不知怎么回事。
NUTCH的大致原理如下:安装步骤参考了该文章一、环境:1.操作系统:windowsXp,windows2000+2.javaVM:java1.5.x,设置JAVA_HOME到环境变量3.cygwin,当然这个不是必需的,只是nutch提供的脚本只能在shell环境下使用,所以使用cygwin来虚拟shell命令。
4.nutch版本:0.85.tomcat:5.0二、cygwin的安装:cygwin的安装在Nutch在Windows中安装之细解一文中有较为详细的介绍,此处不再介绍安装步骤,只介绍安装后需要如何判断是否能够使用:在cygwin 的安装目录下,查找x:\cygwin\cygwin\bin\sh.exe,存在此命令即可使用。
cygwin在删除后会发现无法再次成功安装的问题,可以通过注册表内的查找功能,删除所有包含cygwin内容的键值即可。
三、nutch的安装和配置:1。
从/nutch/release/下载0.8或更高的版本,解压缩后,放置到cygwin的根目录下,如图:图中可以看到nutch目录在cygwin的根目录下。
2。
在nutch/bin下,建立urls目录,然后建立一个url.txt文件,在url.txt 文件内写入一个希望爬行的url,例如:,目录结构如图:3。
打开nutch\conf\crawl-urlfilter.txt文件,把字符替换为url.txt内的url的域名,其实更简单点,直接删除 这几个字就可以了,也就是说,只保存+^http://([a-z0-9]*\.)*这几个字就可以了,表示所有http的网站都同意爬行。
nutch_1.2

Nutch实验报告1.1安装Nutch1.1.1实验环境Linux操作系统,采用的是VMWare虚拟机下的Ubuntu 10.10系统。
1.1.2安装的必要软件1.JDK,采用的是JDK1.6版本,此次实验的版本是jdk-6u24-linux-i586.bin。
/technetwork/java/javase/downloads/index.html2.Tomcat,采用的是apache-tomcat-7.0版本,此次实验的版本是apache-tomcat-7.0.11.tar.gz。
/3.Nutch, 采用的是apache-nutch-1.2版本,此次实验的版本是apache-nutch-1.2-bin.tar.gz。
/1.1.3软件的安装方法和安装过程1.安装JDK1)将下载好的jdk的bin文件放到虚拟机环境下,例如,可以放在/home/root2)到jdk的bin文件目录下,执行命令,安装jdk。
安装命令:[root@ubuntu:/home/root]#sh jdk-6u24-linux-i586.bin3)修改环境变量编辑~/.bashrc文件[root@ubuntu:~]# vi ~/.bashrc在最后加入如下配置export JA V A_HOME=/home/root/jdk1.6.0_24export JA V A_BIN=/home/root/jdk1.6.0_24/binexport PATH=$PATH:$JA V A_HOME/binexport CLASSPATH=.:$JA V A_HOME/lib/dt.jar:$JA V A_HOME/lib/tools.jar 注意:在网上看其他资料是配置:/etc/environment但在配置后重启,出现无法进入系统的状况。
4)查看jdk是否安装成功命令如下:[root@ubuntu:~]# java –version如果出现下列结果,jdk安装成功。
nutch 1.4在windows下安装配置

Nutch1.4在windows下的安装配置0、介绍Apache Nutch是用java语言开发的开源网页爬虫程序。
使用Nutch可以自动获取网页中的超链接,在检查坏链接,创建遍历过的网页副本以便查询等方面,将会减少大量的维护工作。
也由此产生了Apache Solr。
Solr是一个开源的全文搜索框架,通过Solr我们可以搜索Nutch遍历过的网页。
而且Nutch和Solr的集成十分简易。
Apache Nutch框外支持Solr,这极大地简化了两者的集成。
Solr不再依附Apache Tomcat 来运行旧的Nutch Web应用,也不再依靠Apache Lucene来建立索引。
1、提前需要安装的工具和软件1)Jdk1.7下载地址:/javase/downloads/index.jspNutch是Java开发的所以需要下载安装Java JDK。
设置环境变量。
2)Cygwin下载地址:/Nutch的脚本都是用Linux的Shell写的,所以在Windows平台需要一个Shell解释程序。
C ygwin是一个在Windows下的模拟Linux系统程序。
我是下载的setup.exe,选择在线安装。
具体的安装过程网上有很多,可以参照。
3)Nutch1.4下载地址:/后缀名tar.gz为linux系统压缩包,zip为windows系统。
将下载的包,解压到一个盘的根目录下。
可修改名称(便于调试进入)。
4)Solr3.5下载地址:/solr/Solr作用相当于tomcat+webapp。
将下载的包,解压到一个盘的根目录下。
2、验证Nutch的安装打开cygwin,进入nutch-1.4/runtime/local,例如我把文件解压到d盘,文件名为apache-nutch-1.4,于是命令为:c d/cygdrive/d/apache-nutch-1.4/runtime/local,cygwin环境下,进入windows某个盘,加cygdrive,cd/cygdrive/d/就相当于进入d盘。
Cygwin+Nutch1.2网页爬虫配置运行

Cygwin+Nutch1.2网页爬虫配置运行一、搭建环境:电脑机型-ThinkpadT60;配置-1.83G/1G/500G/14.1XGA/ATI X1300-64M;操作系统-xp 32位;安装内存(RAM)-2.00GB。
二、所用软件包:jdk-1.7.0setup-x86(32-bit installation for cygwin)apache-nutch-1.2-bin.tar三、详细安装过程:1、JAVA安装a.运行jdk,比如安装到C:\jdk1.7.0;b.配置环境变量,通过“计算机-系统属性-高级系统设置-环境变量”进入环境变量修改环境,增加以下环境变量:环境变量名:Path,值:%JAVA_HOME%\bin;%JAVA_HOME%\jre\bin;环境变量名:CLASSPATH,值:.;%JAVA_HOME%\lib\tools.jar;%JAVA_HOME%\lib\dt.jar;%JAVA_HOME%\bin;c.环境变量配置好后,点击“WIN+R”组合键,输入cmd进入dos环境,运行“javac-version”,若显示出java版本相关信息,则java安装成功;2、Cygwin安装a.访问/,下载setup-x86(32-bit installation for cygwin);b.下载到本地后,点击setup-x86选择其中一种方式安装即可,假如安装在C:\Cygwin;c.配置环境变量,通过“计算机-系统属性-高级系统设置-环境变量”进入环境变量修改环境,增加以下环境变量:PATH后增加:C:\Cygwin\bin;d.检查Cygwin是否安装成功:打开C:\Cygwin\bin下的mintty,若能正常启动则表示安装成功。
3、Nutch安装a.解压apache-nutch-1.2-bin.tar至C:\Nutch1.2下,确保bin的母目录即为Nutch1.2;b.启动Cygwin,运行"df"指令,检查各盘使用情况,通过cd命令改变路径到E:\Nutch1.2;c.运行"bin/nutch"指令,若出现"Usage:Nutch [-core] COMMAND"相关提示命令,则表示Nutch安装成功,Cheers!四、网页抓取示例:1、Nutch1.2爬虫运行(以为例)1)打开E:\Nutch1.2\conf下的nutch-site.xml文件,这类似于对我要爬取的网站进行一下声明,不声明的话,会导致爬取失败。
Nutch-0.9在linux下的单机配置文档

Red hat linux 9下配置nutch-0.9詹坤林1.环境介绍 (1)2.配置前提 (1)2.1 安装jdk 1.6 (1)2.2 安装Tombact (1)3.配置和应用Nutch (2)3.1 配置Nutch (2)3.2 应用Nutch(无结果仍未解决) (6)1.环境介绍操作系统:Red hat linux 9Nutch版本:nutch-0.9,下载:/lucene/nutch/JDK版本:JDK 1.6Apache Tomcat版本:apache-tomcat-6.0.18/tomcat/tomcat-6/v6.0.18/bin/apache-tomcat-6.0.18.tar.gz 2.配置前提2.1 安装jdk 1.6首先下载jdk安装包jdk-1_6_0_13-linux-i586-rpm.bin第一步:# chmod +x jdk-1_6_0_13-linux-i586-rpm.bin (获得执行权限)第二步:# ./jdk-1_6_0_13-linux-i586-rpm.bin (生成rpm安装包)第三步:# rpm -ivh jdk-1_6_0_13-linux-i586.Rpm(安装JDK)安装完毕后,jdk默认安装在/usr/java/目录下。
第四步:配置JAVA环境变量。
在/etc/profile中设置环境变量[root@red-hat-9 root]# vi /etc/profile[root@red-hat-9 root]# chmod +x /etc/profile (执行权限)[root@red-hat-9 root]# source /etc/profile (此后设置有效)2.2 安装Tombact第一步:设置环境变量(不是必须的)[root@red-hat-9 program]# vi /etc/profileexport JDK_HOME=$JAVA_HOME[root@red-hat-9 program]# source /etc/profile第二步:安装tomnact,解压到某目录下即可tar xf apache-tomcat-6.0.18.tar.gzmv apache-tomcat-6.0.18 /zkl/progaram/第三步:如何使用Apache Tomcat①首先启动Tomcat,只需执行以下命令# /zkl/program/apache-tomcat-6.0.18/bin/startup.sh②Tomcat的网页主目录是/zkl/program/apache-tomcat-6.0.18/webapps/,只需在webapps目录中添加相应网页即可在浏览器访问,Tomcat默认目录是webapps下的ROOT目录。
NUTCH安装和配置

NUTCH安装和配置I.安装和配置jdk下载jdk-6u22-linux-i586.bin执行:chmod a+x jdk-6u22-linux-i586.bin在终端运行:./jdk-6u22-linux-i586.bin,产生文件夹jdk1.6.0_22在/usr/下创建目录java(这个自己随意:-) )将运行bin文件得到文件夹jdk1.6.0_22,全部移到/usr/java目录中编辑添加如下内容到/etc/profile中:export JAVA_HOME=/usr/java/jdk1.6.0_22export PATH=$PATH:$JAVA_HOME/binexportCLASSPATH=.:$JAVA_HOME/jre/lib:$JAVA_HOME/lib:$JAVA_ HOME/lib/tools.jar(在Centos中,首先要移除默认的java运行环境,即openjava,命令如下:yum remove java-1.4.2-gcj-compatyum remove java.顺便提下:解决yum被锁定的方法为:rm -f/var/run/yum.pid)II.安装和配置tomcat下载tomacat7:download from:/。
解压后得到apache-tomcat-7.0.4文件目录,将该文件目录移到想安装的目录中,例如/usr/local/tomcat/目录下配置tomcat:在/etc/profile中添加如下内容:exportTOMCAT_HOME=/usr/local/tomcat/apache-tomcat-7.0.4export PATH=$PATH:$TOMCAT_HOME/bin #not neccesary 运行TOMCAT:#cd 到tomcat所在的目录#执行:bin/startup.sh关闭TOMCAT:#cd 到tomcat所在的目录#执行:bin/shutdown.shIII.测试java运行环境和tomcat为了使修改后的配置文件生效, 需执行命令:source/etc/profile测试jdk, 在终端输入:#java –version得到:java version "1.6.0_22"Java(TM) SE Runtime Environment (build 1.6.0_22-b04)Java HotSpot(TM) Client VM (build 17.1-b03, mixed mode,sharing)测试tomcat:开启tomcat,然后再浏览器中输入:localhost:8080,又tomcat的网页出现。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Nutch搜索引擎数据获取1 基本原理:1.1 体系结构设计:网络蜘蛛一般都具有3模块:HTTP下载模块,链接分析模块,下载控制模块。
HTTP下载模块利用http网络协议下载,获取并存储内容。
链接分析模块能提取网页中的超链接,用来获得后续页面入口。
下载控制模块控制页面访问次序、更新策略、访问队列调度等工作。
工作流程:1、访问URL数据库,读取URL入口地址,生成内存访问队列。
2、寻找空闲的HTTP下载模块,分配URL,启动下载任务。
3、HTTP下载模块访问互联网,得到的网页内容放入结果队列。
4、定期保存到网页数据库,为后续索引做准备。
5、链接分析模块提取页面内的新连接,存入URL数据库等待下载。
6、重复上述过程直到全部下载完成,等待新的任务。
1.2 访问策略与算法:网络蜘蛛访问一个网站,一般入口页面为网站的首页或者sitemap页面。
从这个页面通过链接分析,寻找并访问后续页面地址。
网络蜘蛛对网站的访问有深度限制,一般在3~5层,遍历策略一般采用广度优先算法和深度优先算法。
从应用角度看,广度优先能尽可能的比较平均的获取不同网站的内容,比较适合于大型搜索引擎系统初期网页库的建立;深度优先在设计师比较容易,对垂直搜索或者站内搜索比较合适。
2 Nutch网络蜘蛛2.1 概述Nutch系统包含一个功能强大的网络蜘蛛。
这个网络蜘蛛的核心是Crawl工具。
这个工具根据事先设定的入口URL列表,不断地自动下载页面,知道满足系统预设的停止条件。
Crawl本身是另外一系列网页下载相关工具的组合。
Nutch主要的5个操作命令:Admin:用来创建一个新的WEB数据库,WEB数据库实际上就是URL数据库,存储了网络爬虫抓取的网页信息和网页之间的链接信息。
Inject:添加数据下载的入口链接。
首先读取给定的纯文本格式文件,获取URL列表,作为入口地址添加到已有的web数据库中。
Generate:生成待下载URL列表。
按照WEB数据库格式提取未下载的URL,以fetchlist形式给出,为下载做好准备。
Fetch:按照HTTP协议访问互联网,获取网页数据的具体内容。
下载过程有下载列表和操作参数控制,直到下载完毕。
Updatedb:用来添加网页下一层链接的URL。
从已经下载文件中获取URL 链接,更新web数据库,添加到已有的web数据库。
下载的数据存储主要以目录文件形式存放,具体内容包括WEB数据库、数据段(segments)和数据索引。
1、web数据库(web db)WEB数据库实际上就是URL数据库,存储了网络爬虫抓取的网页信息和网页之间的链接信息。
Web数据库之为网络爬虫服务,并不参与搜索引擎后面的检索和加载。
2、数据段(segments)数据段存放网络爬虫每一次抓取使用的待下载列表、以获得的网页内容和本次内容的索引。
数据段的具体内容会随着重新抓取更新。
数据段存储的数据内容主要饱和3中类型:待下载列表(fecthlist)是从web数据库中得到的,用来指定贮备抓取的网页地址。
已获得的网页内容(fetcher output)是下载的具体网页内容,网页内容采用索引方式存放的数据段中。
数据段索引(index)采用Lucene格式,是当前已经下载内容的索引。
3、数据索引数据索引时数据段索引的合并和汇集。
树荫的数据包含了系统所有的页面,以倒排索引的形式组织。
2.2 Nutch抓取模式分类目前使用比较多的搜索引擎可以划分为3类:全网搜索引擎,垂直搜索引擎和企业搜索引擎。
全网搜索引擎对海量信息的收录数量比较关注,希望尽可能的抓取网页,避免遗漏重要网站。
垂直搜索引擎对信息的实时性和内容的的精确性要求比较高,希望能尽快的针对性的下载信息,比较快的下载更新频率。
企业搜索引擎主要考虑如何以尽量小的代价,完成指定网站的信息下载,建立几乎没有遗漏的本地文档检索系统。
为满足不同类型的需要,nutch的网络蜘蛛提供了两种工作模式:局域网抓取和互联网全网抓取。
局域网抓取采用单一命令完成网页下载,是只对数量较少的网站或者某一个网站进行的网页下载方式。
互联网抓取使用命令组合完成网页下载,是针对网页数量比较多或者直接从开放目录终不过得到的海量网站的下载方式。
3 Nutch局域网抓取Nutch网络蜘蛛的工作机制非常清晰。
首先读取文本文件,增加待下载的URL列表,然后根据配置文和命令行参数,启动下载线程,从目标网站下载网页,得到网页信息保存到本地存储结构中。
3.1 本地测试下载检索1、启动tomcat服务。
2、打开nutch工作目录D:\nutch-0.9,创建weburls文件,文件中添加本次测试地址,作为网络蜘蛛抓取的网站入口地址,文件内容为:http://127.0.0.1:8888/examweb/index.htm(注:examweb文件存放在D:\Tomcat6.0\webapps\ROOT \examweb下,里面为本地测试准备的几个htm网页文件)。
3、打开nutch配置文件目录D:\nutch-0.9\conf,修改URL过滤规则文件crawl-urlfilter.txt。
该文件使用正则表达式来限定入口网站内那些URL需要下载。
过滤规则中以“+”表示允许下载,以“*”表明0或者任意多个字符。
具体修改如下:+^http://127.0.0.1:8888/表示允许下载当前站点内任何URL页面。
4、打开nutch配置文件目录D:\nutch-0.9\conf,修改nutch-site.xml文件。
修改如下:<configuration><property><name></name><value></value><description></description></property></configuration>Value值作为被抓取网站的名称。
本次抓取的网站名设置为.5、启动下载过程5.1、执行Cygwin。
5.2、在Cygwin命令行中输入cd /cygdrive/d/nutch-0.9,进入到Nutch目录5.3、输入命令:bin/nutch crawl weburls.txt –dir localweb –depth 3 –topN 100 –threads 1 回车执行。
命令行中参数指明了抓取行为。
含义如下:dir指定存放爬行结果的目录。
-depth 3 表明需要抓取的页面深度为3层内容。
-topN 100 表明只抓取每一层的前N个URL,本次为每层前100个。
-threads 1 指定crawl只采用一个下载线程进行下载。
本次完成后会在Nutch根目录中建立localweb目录,存放爬行的结果。
5.4修改D:\nutch-0.9\conf下的nutch-site.xml文件,增加检索目录属性指定器,读取数据的目录,修改后文件内容如下:<configuration><property><name></name><value></value><description></description></property><!-- file properties --><property><name>searcher.dir</name><value>D:\nutch-0.9\localweb</value><description></description></property></configuration>5.5、Cygwin命令窗口下执行命令:bin/nutch org.apache.nutch.searcher.NutchBean hat 命令含义即为检索包含hat的网页。
如上述步骤能顺利完成,表明本地测试完成。
3.2、下载多个网站多个网站下载和本地测试方式基本相同,需要修改个别规则。
1 在Nutch根目录中建立文本文件multiurls.txt文件,里面存放希望下载文件列表,自己测试的内容为://////////2修改URL过滤规则文件crawl-urlfilter.txt,允许下载任意站点。
修改后如下:#accept hosts in +^ //默认允许所有的网站# skip everything else-.3 启动Cygwin,进入Nurch目录,执行以下命令:bin/nutch crawl weburls.txt –dir multiweb –depth 2 –topN 100 –threads 5下载内容存放在multiweb目录中,同时建立索引。
4 修改检索规则,修改nutch-site.xml文件,修改后如下:<configuration><property><name></name><value>*</value><description></description></property><!-- file properties --><property><name>searcher.dir</name><value>D:\nutch-0.9\multiweb</value><description></description></property></configuration>5 执行检索命令bin/nutch org.apache.nutch.searcher.NutchBean 汽车结果如下:6 全部操作完成,退出Cygwin命令窗口。
4 Nutch互联网抓取Nutch的互联网抓取和局域网抓取模式有很大差别。
局域网下载模式使用Crawl命令,操作很简便,也有很多限制。
互联网抓取模式使用了更底层的一系列命令、更灵活的控制手段。
下载大量网站URL列表的获取,是真正实现全互联网抓取需要一个比较大的入口。
有两种方法:一是通过DmozParser工具提供了对开放式互联网DMOZ目录库的支持。
DMOZ目录库可以直接从网上下载使用。
使用DmozParser工具可以从文件中随机抽取部分数据,生成文件列表,命令如下:Bin/nutch org.apache.nutch.tools.DmozParser content.rdf.u8 –subset 3000 > dmozurls 命令执行结果是Nutch根目录生成一个dmozurls文本文件,该文件可以作为入口地址添加到下载库中。