hive规则及常用语法
hive的语法

hive的语法Hive是基于SQL语言的数据仓库和分析系统,其语法类似于传统的SQL语言,但是在细节上有所不同,下面列举一些常见的Hive 语法:1. 数据库操作创建数据库:CREATE DATABASE database_name;删除数据库:DROP DATABASE database_name;2. 表操作创建表:CREATE TABLE table_name (col1 data_type, col2data_type, ...);删除表:DROP TABLE table_name;3. 数据操作加载数据:LOAD DATA INPATH 'hdfs_path' INTO TABLE table_name;插入数据:INSERT INTO TABLE table_name VALUES (val1, val2, ...);查询数据:SELECT col1, col2, ... FROM table_name WHERE condition;更新数据:UPDATE table_name SET col1 = val1 WHERE condition;删除数据:DELETE FROM table_name WHERE condition;4. 函数和聚合操作常用函数:- COUNT- SUM- AVG- MIN- MAX- CONCAT- SUBSTR- TRIM- UPPER- LOWER聚合操作:SELECT col1, COUNT(*), SUM(col2), AVG(col3), MIN(col4), MAX(col5) FROM table_name GROUP BY col1;5. Join操作内连接:SELECT * FROM table1 INNER JOIN table2 ON table1.col1 = table2.col2;左连接:SELECT * FROM table1 LEFT OUTER JOIN table2 ONtable1.col1 = table2.col2;右连接:SELECT * FROM table1 RIGHT OUTER JOIN table2 ONtable1.col1 = table2.col2;全连接:SELECT * FROM table1 FULL OUTER JOIN table2 ONtable1.col1 = table2.col2;以上是Hive常用的一些语法,仅供参考。
HIVE常用正则函数(like、rlike、regexp、regexp_replace、r。。。

HIVE常⽤正则函数(like、rlike、regexp、regexp_replace、r。
Oralce中regex_like和hive的regexp对应LIKE语法1: A LIKE B语法2: LIKE(A, B)操作类型: strings返回类型: boolean或null描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合表达式B的正则语法,则为TRUE;否则为FALSE。
B中字符"_"表⽰任意单个字符,⽽字符"%"表⽰任意数量的字符。
hive> select 'football' like '%ba';OKfalsehive> select 'football' like '%ba%';OKtruehive> select 'football' like '__otba%';OKtruehive> select like('football', '__otba%');OKtrueRLIKE语法1: A RLIKE B语法2: RLIKE(A, B)操作类型: strings返回类型: boolean或null描述: 如果字符串A或者字符串B为NULL,则返回NULL;如果字符串A符合JAVA正则表达式B的正则语法,则为TRUE;否则为FALSE。
hive> select 'football' rlike 'ba';OKtruehive> select 'football' rlike '^footba';OKtruehive> select rlike('football', 'ba');OKtrueJava正则:"." 任意单个字符"*" 匹配前⾯的字符0次或多次"+" 匹配前⾯的字符1次或多次"?" 匹配前⾯的字符0次或1次"\d" 等于 [0-9],使⽤的时候写成'\d'"\D" 等于 [^0-9],使⽤的时候写成'\D'hive> select 'does' rlike 'do(es)?';OKtruehive> select '\\';OK\hive> select '2314' rlike '\\d+';OKtrueREGEXP语法1: A REGEXP B语法2: REGEXP(A, B)操作类型: strings返回类型: boolean或null描述: 功能与RLIKE相同hive> select 'football' regexp 'ba';OKtruehive> select 'football' regexp '^footba';OKtruehive> select regexp('football', 'ba');OKtrue语法: regexp_replace(string A, string B, string C)操作类型: strings返回值: string说明: 将字符串A中的符合java正则表达式B的部分替换为C。
hive基本语法

hive基本语法Hive基本语法Hive是一个开源的数据仓库系统,它提供了一种类似于SQL的查询语言,用于处理大规模数据集。
在Hive中,基本语法是进行数据操作的基础,掌握基本语法对于使用Hive进行数据处理是非常重要的。
一、创建表在Hive中,我们需要首先创建表来存储数据。
创建表的语法如下:CREATE TABLE table_name(column1 data_type,column2 data_type,...);其中,table_name为表名,column1、column2等为列名,data_type为列的数据类型。
通过这个语法,我们可以创建一个具有指定列的表。
二、加载数据创建表之后,我们需要加载数据到表中。
Hive支持从本地文件系统或HDFS中加载数据。
加载数据的语法如下:LOAD DATA [LOCAL] INPATH 'data_file_path' INTO TABLE table_name;其中,data_file_path为数据文件的路径,table_name为已经创建的表名。
通过这个语法,我们可以将数据加载到指定的表中。
三、查询数据在Hive中,我们可以使用类似于SQL的语法来查询数据。
查询数据的语法如下:SELECT column1, column2, ...FROM table_name[WHERE condition][GROUP BY column1, column2, ...][HAVING condition][ORDER BY column1, column2, ...][LIMIT n];其中,column1、column2等为需要查询的列名,table_name为需要查询的表名。
通过这个语法,我们可以从指定的表中查询出满足条件的数据。
四、更新数据在Hive中,我们可以使用UPDATE语句来更新表中的数据。
更新数据的语法如下:UPDATE table_nameSET column1 = value1, column2 = value2, ...[WHERE condition];其中,table_name为需要更新的表名,column1、column2等为需要更新的列名,value1、value2等为更新后的值。
hive正则表达式解析

hive正则表达式解析Hive是一个用于大数据处理的开源框架,它提供了SQL-like语言来处理各种数据源。
在Hive中,正则表达式是一种强大的工具,可用于解析和处理文本数据。
本文将介绍Hive正则表达式的基本语法、应用场景和解析技巧。
一、基本语法Hive的正则表达式由三个部分组成:正则表达式模式、替换文本和特殊字符集。
模式是用来匹配文本的规则,替换文本是当匹配成功后要替换的内容,特殊字符集是一些需要特殊处理的字符。
基本语法示例:* 匹配一个数字:\d+* 匹配一个单词:\w+* 匹配一个字符:.* 替换文本:替换成*二、应用场景1. 文本过滤:通过正则表达式过滤出符合特定规则的文本。
例如,过滤出包含特定关键词的文本。
2. 模式匹配:将文本按照特定模式进行匹配,提取出符合模式的文本或数据。
3. 替换文本:将匹配到的文本替换成指定的内容。
三、解析技巧1. 预编译正则表达式:使用预编译的正则表达式可以提高性能,因为它会将模式存储在内存中,避免重复编译。
2. 捕获组:使用捕获组可以提取匹配到的文本片段。
例如,匹配一个电话号码,可以将其分为号码和区号两个部分。
3. 忽略大小写:使用忽略大小写的模式可以匹配大小写不同的文本。
4. 多行模式:使用多行模式可以匹配跨越多行的文本。
5. 贪婪匹配:默认情况下,正则表达式使用贪婪匹配,即尽可能多地匹配字符。
可以通过在特殊字符前加上“?”来变为非贪婪匹配,即尽可能少地匹配字符。
四、示例解析假设有一组文本数据,其中包含一些数字和字母组成的字符串,现在需要提取出其中的数字和字母,可以使用正则表达式进行解析。
1. 使用正则表达式提取数字:\d+例如:提取字符串"abc123def456"中的数字"123"和"456"。
可以使用Hive SQL如下:SELECT REGEXP_extract('abc123def456', '\\d+', 1) AS extracted_numbers;输出结果为:"[123, 456]"2. 使用正则表达式提取字母:\w+例如:提取字符串"abc123def456"中的字母"abc"和"def"。
Hive(二)hive的基本操作

Hive(⼆)hive的基本操作⼀、DDL操作(定义操作)1、创建表(1)建表语法结构CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name[(col_name data_type [COMMENT col_comment], ...)] //字段注释[COMMENT table_comment] //表的注释[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] //分区,前⾯没有出现的字段[CLUSTERED BY (col_name, col_name, ...) //分桶,前⾯出现的字段[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS][ROW FORMAT row_format][STORED AS file_format][LOCATION hdfs_path]分区:不⽤关注数据的具体类型,放⼊每⼀个分区⾥;分桶:调⽤哈希函数取模的⽅式进⾏分桶(2)建表语句相关解释create table:创建⼀个指定名字的表。
如果相同名字的表已经存在,则抛出异常;⽤户可以⽤ IF NOT EXISTS 选项来忽略这个异常。
external :关键字可以让⽤户创建⼀个外部表,在建表的同时指定⼀个指向实际数据的路径( LOCATION), Hive 创建内部表时,会将数据移动到数据仓库指向的路径;若创建外部表,仅记录数据所在的路径,不对数据的位置做任何改变。
在删除表的时候,内部表的元数据和数据会被⼀起删除,⽽外部表只删除元数据,不删除数据。
(经典⾯试问题)partitioned :在 Hive Select 查询中⼀般会扫描整个表内容,会消耗很多时间做没必要的⼯作。
有时候只需要扫描表中关⼼的⼀部分数据,因此建表时引⼊了 partition 概念。
hive一级分区,二级分区 规则 -回复

hive一级分区,二级分区规则-回复Hive一级分区和二级分区规则Hive是一个基于Hadoop的数据仓库和分析工具,它可以让用户方便地使用SQL语言对大规模数据进行查询和分析。
在Hive中,数据存储是通过表的方式进行的,而分区则被用来对表中的数据进行划分和组织。
一级分区和二级分区是Hive中对分区的进一步划分。
一级分区是Hive中最基本的分区方式,可以将表的数据按照某个列的值进行划分。
常见的例子是按照日期进行分区,比如将一张销售表按照日期字段进行一级分区,每一天的数据存储在一个分区中。
通过一级分区,可以方便地对特定日期的数据进行查询和分析,提高查询效率和降低存储成本。
一级分区的语法规则如下:CREATE TABLE table_name (column1 data_type,column2 data_type,...)PARTITIONED BY (partition_column data_type);在上面的语法中,PARTITIONED BY子句指定了按照哪个列进行分区,该列的数据类型也需要在表的列定义中进行指定。
一级分区的数据存储形式是以各个分区为目录,每个目录中存储了该分区对应的数据文件。
二级分区是对一级分区的进一步划分,可以将数据按照两个或更多列的值进行划分。
二级分区的语法规则如下:CREATE TABLE table_name (column1 data_type,column2 data_type,...)PARTITIONED BY (partition_column1 data_type, partition_column2 data_type);在上面的语法中,PARTITIONED BY子句指定了按照哪些列进行分区,这些列的数据类型也需要在表的列定义中进行指定。
二级分区的数据存储形式是以各个分区组合为目录,每个目录中存储了该分区组合对应的数据文件。
通过二级分区,可以进一步提高数据查询和分析的效率,以及更灵活地组织数据。
Hive函数及语法说明

无线增值产品部Hive函数及语法说明版本:Hive 0.7.0.001eagooqi2011-7-19版本日期修订人描述V1.0 2010-07-20 eagooqi 初稿2012-1-4 Eagooqi ||、cube目录⏹函数说明 (2)⏹内置函数 (2)⏹增加oracle函数 (14)⏹增加业务函数 (17)⏹扩展函数开发规范 (19)⏹语法说明 (21)⏹内置语法 (21)⏹增加语法 (28)⏹扩展语法开发规范(语法转换) (29)⏹ORACLE sql 对应的hSQL语法支持 (29)⏹函数说明参考链接:https:///confluence/display/Hive/LanguageManualCLI下,使用以下命令显示最新系统函数说明SHOW FUNCTIONS;DESCRIBE FUNCTION <function_name>;DESCRIBE FUNCTION EXTENDED <function_name>;⏹内置函数数值函数Mathematical Functions集合函数Collection Functions类型转换函数Type Conversion Functions日期函数Date Functions条件判断函数Conditional Functions字符串函数String Functions其他函数Misc. FunctionsxpathThe following functions are described in [Hive-LanguageManual-XPathUDF]:∙xpath, xpath_short, xpath_int, xpath_long, xpath_float, xpath_double, xpath_number, xpath_stringget_json_objectA limited version of JSONPath is supported:∙$ : Root object∙. : Child operator∙[] : Subscript operator for array∙* : Wildcard for []Syntax not supported that's worth noticing:∙: Zero length string as key∙.. : Recursive descent∙@ : Current object/element∙() : Script expression∙?() : Filter (script) expression.∙[,] : Union operator∙[start:end.step] : array slice operatorExample: src_json table is a single column (json), single row table:json{"store":{"fruit":[{"weight":8,"type":"apple"},{"weight":9,"type":"pear"}], "bicycle":{"price":19.95,"color":"red"}},"email":"amy@only_for_json_udf_","owner":"amy"}The fields of the json object can be extracted using these queries:hive> SELECT get_json_object(src_json.json, '$.owner') FROM src_json; amyhive> SELECT get_json_object(src_json.json, '$.store.fruit[0]') FROM src_json;{"weight":8,"type":"apple"}hive> SELECT get_json_object(src_json.json, '$.non_exist_key') FROM src_json;NULL内置聚合函数Built-in Aggregate Functions (UDAF)增加oracle函数增加业务函数扩展函数开发规范提供以下两种实现方式:a继承org.apache.hadoop.hive.ql.exec.UDF类代码包为:package org.apache.hadoop.hive.ql.udf实现evaluate方法,根据输入参数和返回参数类型,系统自动转换到匹配的方法实现上。
hive函数大全

h i v e函数大全-CAL-FENGHAI.-(YICAI)-Company One1目录一、关系运算: ......................................................................................错误!未定义书签。
1. 等值比较: = .................................................................................错误!未定义书签。
2. 不等值比较: <>............................................................................错误!未定义书签。
3. 小于比较: < .................................................................................错误!未定义书签。
4. 小于等于比较: <=........................................................................错误!未定义书签。
5. 大于比较: > .................................................................................错误!未定义书签。
6. 大于等于比较: >=........................................................................错误!未定义书签。
7. 空值判断: IS NULL .......................................................................错误!未定义书签。
一脸懵逼学习Hive的使用以及常用语法(Hive语法即Hql语法)

⼀脸懵逼学习Hive的使⽤以及常⽤语法(Hive语法即Hql语法)Hive官⽹(HQL)语法⼿册(英⽂版):Hive的数据存储 1、Hive中所有的数据都存储在 HDFS 中,没有专门的数据存储格式(可⽀持Text,SequenceFile,ParquetFile,RCFILE等) 2、只需要在创建表的时候告诉 Hive 数据中的列分隔符和⾏分隔符,Hive 就可以解析数据。
3、Hive 中包含以下数据模型:DB、Table,External Table,Partition,Bucket。
(1):db:在hdfs中表现为${hive.metastore.warehouse.dir}⽬录下⼀个⽂件夹 (2):table:在hdfs中表现所属db⽬录下⼀个⽂件夹 (3):external table:外部表, 与table类似,不过其数据存放位置可以在任意指定路径 普通表: 删除表后, hdfs上的⽂件都删了 External外部表删除后, hdfs上的⽂件没有删除, 只是把⽂件删除了 (4): partition:在hdfs中表现为table⽬录下的⼦⽬录 (5):bucket:桶, 在hdfs中表现为同⼀个表⽬录下根据hash散列之后的多个⽂件, 会根据不同的⽂件把数据放到不同的⽂件中hive创建数据库操作:hive提供database的定义,database的主要作⽤是提供数据分割的作⽤,⽅便数据关闭,命令如下所⽰:#创建:create (DATABASE|SCHEMA) [IF NOT EXISTS] database_name [COMMENT database_comment] [LOCATION hdfs_path] [WITH DBPROPERTIES] (property_name=value,name=value...)#显⽰描述信息:describe DATABASE|SCHEMA [extended] database_name。
hive 常用正则

hive 常用正则Hive是一个数据仓库解决方案,它是建立在Hadoop之上的。
Hive 提供了一种类SQL的查询语言,用于将结构化数据映射到Hadoop中,这样就可以使用Hive来查询、分析和处理数据了。
在Hive中,正则表达式是非常重要的一部分,因为它可以帮助我们更加高效地处理数据。
在本文中,我们将介绍Hive中的常用正则表达式,以及它们的用法和示例。
1. 字符类字符类用于匹配某个字符集中的任意一个字符。
在Hive中,字符类用方括号[]表示。
例如,[abc]表示匹配a、b或c中的任意一个字符。
示例:SELECT * FROM table WHERE col REGEXP '[abc]';上述代码表示查询col列中包含a、b或c中的任意一个字符的行。
除了指定单个字符之外,字符类还可以使用范围指定多个字符。
例如,[a-z]表示匹配任何小写字母。
示例:SELECT * FROM table WHERE col REGEXP '[a-z]';上述代码表示查询col列中包含任何小写字母的行。
2. 量词量词用于指定匹配的次数。
在Hive中,常用的量词有*、+和?。
*表示匹配前面的字符0次或多次。
示例:SELECT * FROM table WHERE col REGEXP 'ab*c';上述代码表示查询col列中包含ab、acb、abbbbc等字符串的行。
+表示匹配前面的字符1次或多次。
示例:SELECT * FROM table WHERE col REGEXP 'ab+c';上述代码表示查询col列中包含ab、abbbbc等字符串的行,但不包含acb等字符串。
表示匹配前面的字符0次或1次。
示例:SELECT * FROM table WHERE col REGEXP 'ab?c';上述代码表示查询col列中包含ac或abc字符串的行。
hive 建表注释

hive 建表注释摘要:一、Hive 简介二、Hive 建表基本语法三、Hive 建表注释1.注释用途2.注释方法3.注释实例四、总结正文:Hive 是一个基于Hadoop 的数据仓库工具,可以用来存储、查询和分析大规模的结构化数据。
Hive 支持多种数据存储格式,如Parquet、ORC 等,并提供类SQL 查询语言HiveQL(HQL)进行数据操作。
在建表过程中,注释是一个重要的环节,可以帮助我们更好地理解和维护表结构。
Hive 建表基本语法如下:```CREATE TABLE table_name (column1 data_type,column2 data_type,...)COMMENT "注释内容"ROW FORMAT SERDE "serde_name"STORED AS storage_format;```其中,`table_name`为表名,`column1`、`column2`等为表的列名,`data_type`为列的数据类型,`serde_name`为序列化反序列化引擎名称,`storage_format`为数据存储格式。
在Hive 建表时,可以通过`COMMENT`关键字为表添加注释。
注释内容用单引号括起来,紧跟在`COMMENT`关键字后面。
例如:```CREATE TABLE student (id INT,name STRING,age INT)COMMENT "学生信息表";```Hive 建表注释有以下用途:1.描述表结构:通过注释可以简要说明表的结构、列的含义以及数据来源,方便其他开发人员快速了解表的信息。
2.记录建表时间:可以在注释中加入建表时间,方便追踪表的历史变更。
3.记录数据源:对于从外部数据源导入的数据表,可以在注释中说明数据源的详细信息,以便在数据异常时进行排查。
在实际应用中,可以通过以下方法为Hive 表添加注释:1.在建表语句中直接添加注释:在创建表时,使用`COMMENT`关键字添加注释。
hive中的正则表达式

hive中的正则表达式摘要:1.正则表达式的基本概念2.Hive中的正则表达式应用场景3.Hive正则表达式语法4.Hive正则表达式示例5.总结正文:正则表达式是一种强大的文本处理工具,它通过一系列特殊的字符和元字符来描述字符串的匹配模式。
Hive作为大数据处理领域的重要工具,也支持正则表达式的使用。
本文将详细介绍Hive中的正则表达式及其应用。
1.正则表达式的基本概念正则表达式(Regular Expression,简称:Regex)是一种用于描述字符串模式的字符集。
它通过一些特殊的字符和元字符来表示字符串的匹配模式,例如:字符集、字符类、量词、分组、选择等。
正则表达式广泛应用于文本处理、数据分析等领域。
2.Hive中的正则表达式应用场景在Hive中,正则表达式主要用于处理和匹配字符串数据。
以下是一些常见的应用场景:- 数据清洗:通过正则表达式匹配和替换,可以对数据进行预处理,如去除空格、转换数据类型等。
- 数据提取:从大量文本数据中提取特定格式的信息,如电话号码、邮件地址等。
- 数据验证:在数据入库时,通过正则表达式进行数据验证,确保数据的正确性。
3.Hive正则表达式语法Hive正则表达式的语法与Java中的正则表达式语法基本一致。
以下是一些常用的语法元素:- 字符集:用于匹配某一类字符,如:[a-z] 匹配小写字母。
- 字符类:用于匹配某一类字符集中的任意一个字符,如:[:alnum:] 匹配任意数字和字母。
- 量词:用于指定字符或字符类出现的次数,如:d{3} 匹配三位数字。
- 分组:用于将正则表达式的一部分组合起来,以便进行特定操作,如:(.*) 匹配任意字符(非换行符)组成的字符串。
- 选择:用于根据不同的匹配条件选择不同的匹配结果,如:(?i) 忽略大小写匹配。
4.Hive正则表达式示例以下是一些Hive正则表达式的示例:- 匹配所有数字:`d+`- 匹配所有字母:`[a-zA-Z]+`- 匹配所有小写字母:`[a-z]+`- 匹配所有大写字母:`[A-Z]+`- 匹配所有单词:`[a-zA-Z]+`- 匹配所有非单词字符:`[^a-zA-Z]+`- 匹配所有空白字符:`s+`- 匹配所有非空白字符:`[^ tf]+`5.总结Hive中的正则表达式是处理字符串数据的重要工具,可以广泛应用于数据清洗、数据提取、数据验证等场景。
hive regexp语法

hive regexp语法Hive是Hadoop生态系统中提供的一种大数据处理工具,支持使用正则表达式进行模式匹配,用于过滤、分割和提取数据。
Hive中的正则表达式语法基本上遵循了Java的正则表达式语法,其中一些关键字符和语法规则如下:1. "." 表示任何字符。
2. "^" 表示以指定字符或字符串开始。
3. "$" 表示以指定字符或字符串结尾。
4. "*" 表示前一个字符或表达式出现0或多次。
5. "+" 表示前一个字符或表达式出现1或多次。
6. "?" 表示前一个字符或表达式出现0或1次。
7. "|" 表示多个正则表达式的“或”操作。
8. "[]" 表示字符类,表示可以匹配其中任意一个字符。
9. "[^]" 表示否定字符类,表示不能匹配其中任何一个字符。
10. "\" 表示转义符,用于表示一些特殊字符的字面值,如 "." 表示匹配小数点。
下面是一些Hive中常用的正则表达式语法示例:1. 匹配字符串中以"Hello"开头的字符串:SELECT * FROM table_name WHERE column_name RLIKE '^Hello.*';2. 匹配邮件地址中的用户名称:SELECT SUBSTR(column_name, 1, INSTR(column_name, '@') - 1) AS user_name FROM table_name WHERE column_name RLIKE '@';3. 匹配指定日期格式的字符串:1/ 2SELECT * FROM table_name WHERE column_name RLIKE '^[0-9]{4}-[0-9]{2}-[0-9]{2}$';总之,Hive中的正则表达式基本上遵循了Java的正则表达式语法,仅有一些细微的差别,开发人员只需要了解Java的正则表达式语法,即可快速上手使用Hive的正则表达式功能。
简述hive基本查询语法规则中select、from和where谓词的涵义

简述hive基本查询语法规则中select、from和where谓词的涵义Hive是一个基于Hadoop的数据仓库工具,它可以简化数据提取、转换和加载过程。
在Hive中,基本查询语法包括SELECT、FROM和WHERE三个关键谓词。
以下将详细解释这三个谓词的涵义及其应用。
1.SELECT谓词SELECT谓词用于选择查询结果中的列。
在Hive查询中,可以使用以下格式:```SELECT column1, column2, ...FROM table_name;```例如,查询名为employees的表中,选择name和age两列的数据:```SELECT name, age FROM employees;```2.FROM谓词FROM谓词用于指定数据来源表名。
在Hive查询中,可以使用以下格式:```SELECT column1, column2, ...FROM table_name;```例如,从名为employees的表中查询数据:```SELECT name, age FROM employees;```3.WHERE谓词WHERE谓词用于添加查询条件,筛选出符合条件的数据。
在Hive查询中,可以使用以下格式:```SELECT column1, column2, ...FROM table_name WHERE condition;```例如,查询年龄大于等于30的员工信息:```SELECT name, age FROM employees WHERE age >= 30;```4.结合示例分析三者的用法以下是一个完整的Hive查询示例,展示了如何结合使用SELECT、FROM 和WHERE谓词:```SELECT name, age FROM employees WHERE age >= 30;```在这个示例中,我们从名为employees的表中查询年龄大于等于30的员工信息,并将结果显示为姓名和年龄两列。
hive 常用正则

hive 常用正则Hive是一个基于Hadoop的数据仓库工具,它提供了一个SQL-like查询语言,使得用户可以使用类SQL的语法来查询和分析大数据。
在Hive中,正则表达式是非常常用的工具,它可以帮助用户快速地处理和分析数据。
本文将介绍Hive中常用的正则表达式。
一、正则表达式的基本语法正则表达式是一种用来描述字符串模式的语言,它可以通过一些特定的符号来表示字符的匹配规则。
在Hive中,正则表达式包含了一些特殊字符和元字符,它们可以用来表示一些常见的字符或字符集合。
下面是一些常见的正则表达式语法:1. 字面值:表示一个具体的字符。
例如,正则表达式“hello”表示匹配一个字符串“hello”。
2. 字符集合:表示一组字符中的任意一个字符。
例如,正则表达式“[abc]”表示匹配一个字符“a”、“b”或“c”。
3. 范围:表示一组连续的字符中的任意一个字符。
例如,正则表达式“[a-z]”表示匹配一个小写字母。
4. 量词:表示一个字符或字符集合的出现次数。
例如,正则表达式“a{3}”表示匹配三个连续的字符“a”。
5. 通配符:表示任意一个字符。
例如,正则表达式“.”表示匹配任意一个字符。
二、常用的正则表达式函数在Hive中,常用的正则表达式函数包括REGEXP、RLIKE、REGEXP_REPLACE、REGEXP_EXTRACT等。
下面是这些函数的具体用法: 1. REGEXP函数REGEXP函数用来判断一个字符串是否匹配一个正则表达式。
它的语法如下:SELECT column1 FROM table1 WHERE column2 REGEXP 'pattern';其中,column2是要匹配的字符串,pattern是正则表达式。
例如,我们可以使用REGEXP函数来匹配所有以“a”开头的字符串:SELECT * FROM table1 WHERE column2 REGEXP '^a';2. RLIKE函数RLIKE函数和REGEXP函数类似,用来判断一个字符串是否匹配一个正则表达式。
hivesql语法规则

hivesql语法规则Hive SQL的语法规则主要包括以下部分:1. 创建数据库:使用`CREATE DATABASE`语句可以创建新的数据库。
语法为:`CREATE DATABASE [IF NOT EXISTS] db_name [LOCATION 'path'] [COMMENT database_comment];`。
其中,`IF NOT EXISTS`表示如果数据库已存在,则不执行任何操作;`LOCATION 'path'`用于自定义数据库的存储位置;`COMMENT database_comment`是可选的,用于添加数据库注释。
2. 删除数据库:使用`DROP DATABASE`语句可以删除数据库。
语法为:`DROP DATABASE [IF EXISTS] db_name [CASCADE];`。
其中,`IF EXISTS`表示如果数据库存在,则执行删除操作;`CASCADE`表示级联删除,如果数据库中存在表,则可以强制删除数据库。
3. 修改数据库位置:使用`ALTER DATABASE`语句可以修改数据库的位置。
语法为:`ALTER DATABASE database_name SET LOCATIONhdfs_path;`。
这不会在HDFS中对数据库所在目录进行改名,只是修改location后,新创建的表在新的路径,旧的不变。
4. 数据查询:使用`SELECT`语句可以从表中查询数据。
语法为:`SELECT [ALL DISTINCT] select_expr, select_expr, ... FROM tablename [WHERE where_condition] [GROUP BY col_list] [ORDER BY col_list] [CLUSTERBY col_list [DISTRIBUTE BY col_list] [SORT BY col_list] ] [LIMIT number];`。
hive语法和常用函数
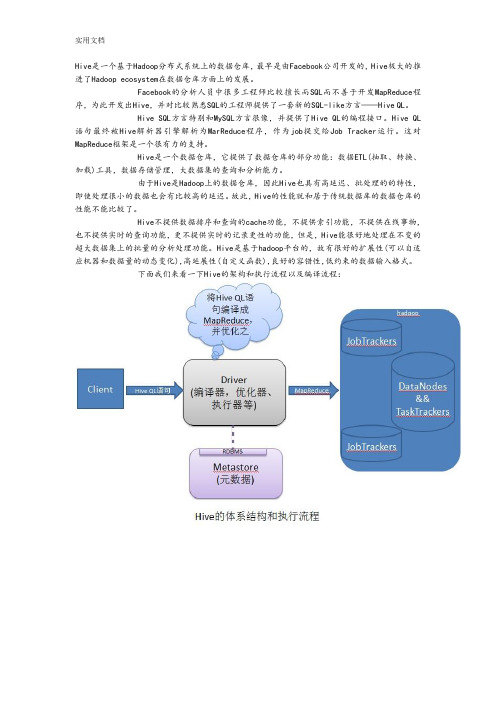
Hive是一个基于Hadoop分布式系统上的数据仓库,最早是由Facebook公司开发的,Hive极大的推进了Hadoop ecosystem在数据仓库方面上的发展。
Facebook的分析人员中很多工程师比较擅长而SQL而不善于开发MapReduce程序,为此开发出Hive,并对比较熟悉SQL的工程师提供了一套新的SQL-like方言——Hive QL。
Hive SQL方言特别和MySQL方言很像,并提供了Hive QL的编程接口。
Hive QL 语句最终被Hive解析器引擎解析为MarReduce程序,作为job提交给Job Tracker运行。
这对MapReduce框架是一个很有力的支持。
Hive是一个数据仓库,它提供了数据仓库的部分功能:数据ETL(抽取、转换、加载)工具,数据存储管理,大数据集的查询和分析能力。
由于Hive是Hadoop上的数据仓库,因此Hive也具有高延迟、批处理的的特性,即使处理很小的数据也会有比较高的延迟。
故此,Hive的性能就和居于传统数据库的数据仓库的性能不能比较了。
Hive不提供数据排序和查询的cache功能,不提供索引功能,不提供在线事物,也不提供实时的查询功能,更不提供实时的记录更性的功能,但是,Hive能很好地处理在不变的超大数据集上的批量的分析处理功能。
Hive是基于hadoop平台的,故有很好的扩展性(可以自适应机器和数据量的动态变化),高延展性(自定义函数),良好的容错性,低约束的数据输入格式。
下面我们来看一下Hive的架构和执行流程以及编译流程:用户提交的Hive QL语句最终被编译为MapReduce程序作为Job提交给Hadoop执行。
Hive的数据类型Hive的基本数据类型有:TINYINT,SAMLLINT,INT,BIGINT,BOOLEAN,FLOAT,DOUBLE,STRING,TIMESTAMP(V0.8.0+)和BINARY(V0.8.0+)。
hive查询语法

hive查询语法Hive查询语法详解一、Hive简介Hive是基于Hadoop的数据仓库基础设施,可以将结构化的数据文件映射为一张数据库表,并提供完整的SQL查询功能。
Hive查询语法是Hive的核心组成部分,本文将详细介绍Hive查询语法的使用方法和常见操作。
二、基本查询语句1. SELECT语句:用于选择需要查询的字段,可以使用通配符*选择所有字段或使用字段名指定需要查询的字段。
2. FROM语句:用于指定查询的数据源,可以是Hive表、Hive分区表或其他查询结果。
3. WHERE语句:用于指定查询的条件,可以使用逻辑运算符(AND、OR、NOT)和比较运算符(=、<、>)进行条件筛选。
4. GROUP BY语句:用于对查询结果进行分组,常与聚合函数(如SUM、COUNT、AVG)一起使用。
5. HAVING语句:用于对分组后的结果进行筛选,类似于WHERE语句,但作用于分组后的结果。
6. ORDER BY语句:用于对查询结果进行排序,默认按照升序排序,可以使用DESC关键字进行降序排序。
7. LIMIT语句:用于限制查询结果的返回行数,常用于分页查询。
三、高级查询语句1. JOIN语句:用于将多个表进行连接查询,常用的连接类型有内连接(INNER JOIN)、左连接(LEFT JOIN)和右连接(RIGHT JOIN)。
2. UNION语句:用于合并多个查询结果集,要求查询结果的字段数和类型必须一致。
3. SUBQUERY语句:用于嵌套查询,可以将查询结果作为另一个查询的输入。
4. CASE语句:用于条件判断,类似于其他编程语言的if-else语句,可以根据条件返回不同的结果。
5. DISTINCT关键字:用于去除查询结果中的重复记录。
6. LIKE关键字:用于模糊查询,可以使用通配符(%表示任意字符,_表示任意单个字符)进行匹配。
7. NULL关键字:用于判断字段是否为空,可以使用IS NULL或IS NOT NULL进行判断。
hive正则表达式

Hive正则表达式前段时间,在我们数据开发的过程中,因为没有现成的数据表,导致数据没有办法直接取,需要解析日志的内容,从日志里面拿到我们想要的数据,但是日志的内容并没有那么的规则,这个时候,正则表达式就展现出很大的优势,正好我也把正则表达式温习实践了一遍,正好整理下来。
hive支持的正则表达式有三种,分别是regexp、regexp_replace、regexp_extract一、regexp1,语法格式:A REGEXP B释义:A是需要匹配的字符串,B是正则表达式字符串返回结果:boolean或null示例SQL:select '四川办' regexp '川办';select '四川办' regexp '湖南';返回结果:truefalse二、regexp_replace1,语法格式:regexp_replace(string A, string B, string C)2,释义:将字符串A中的符合java正则表达式B的部分替换为C。
注意,在有些情况下要使用转义字符,类似oracle中的regexp_replace函数。
示例SQL:select regexp_replace('四川办第1名', '\\d+', '一');返回结果:三、regexp_extract1,语法格式:regexp_extract(string subject, string pattern, int index)2,释义:将字符串subject按照pattern正则表达式的规则拆分,返回index指定的字符,index 从1开始计。
示例SQL:select regexp_extract('四川办:第1名', '([0-9]+)', 1);返回结果:四、常用的正则表达式规则:1,元字符匹配(.) 表示匹配除换行符以外的任意字符。
hive中字符串生序规则

hive中字符串生序规则字符串长度函数:length语法: length(string A)返回值: int说明:返回字符串A的长度举例:hive> select length(‘abcedfg’) from lxw_dual;字符串反转函数:reverse语法: reverse(string A)返回值: string说明:返回字符串A的反转结果举例:hive> select reverse(abcedfg’) from lxw_dual; gfdecba字符串连接函数:concat语法: concat(string A, string B…)返回值: string说明:返回输入字符串连接后的结果,支持任意个输入字符串举例:hive> select concat(‘abc’,‘def’,‘gh’) from lxw_dual;abcdefgh带分隔符字符串连接函数:concat_ws语法: concat_ws(string SEP, string A, string B…)返回值: string说明:返回输入字符串连接后的结果,SEP表示各个字符串间的分隔符举例:hive> select concat_ws(’,’,‘abc’,‘def’,‘gh’) from lxw_dual;abc,def,gh字符串截取函数:substr,substring语法: substr(string A, int start),substring(string A, int start)返回值: string说明:返回字符串A从start位置到结尾的字符串举例:hive> select substr(‘abcde’,3) from lxw_dual;cdehive> select substring(‘abcde’,3) from lxw_dual;cdehive> selectsubstr(‘abcde’,-1) from lxw_dual; (和ORACLE 相同)字符串截取函数:substr,substring语法: substr(string A, int start, int len),substring(string A, intstart, int len)返回值: string说明:返回字符串A从start位置开始,长度为len的字符串举例:hive> select substr(‘abcde’,3,2) from lxw_dual;cdhive> select substring(‘abcde’,3,2) from lxw_dual;cdhive>select substring(‘abcde’,-2,2) from lxw_dual;de字符串转大写函数:upper,ucase语法: upper(string A) ucase(string A)返回值: string说明:返回字符串A的大写格式举例:hive> select upper(‘abSEd’) from lxw_dual;ABSEDhive> select ucase(‘abSEd’) from lxw_dual; ABSED字符串转小写函数:lower,lcase语法: lower(string A) lcase(string A)返回值: string说明:返回字符串A的小写格式举例:hive> select lower(‘abSEd’) from lxw_dual; absedhive> select lcase(‘abSEd’) from lxw_dual; absed去空格函数:trim语法: trim(string A)返回值: string说明:去除字符串两边的空格举例:hive> select trim(’ abc ') from lxw_dual; abc左边去空格函数:ltrim语法: ltrim(string A)返回值: string说明:去除字符串左边的空格举例:hive> select ltrim(’ abc ') from lxw_dual; abc右边去空格函数:rtrim语法: rtrim(string A)返回值: string说明:去除字符串右边的空格举例:hive> select rtrim(’ abc ') from lxw_dual;abc正则表达式替换函数:regexp_replace语法: regexp_replace(string A, string B, string C)返回值: string说明:将字符串A中的符合ja正则表达式B的部分替换为C。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Hive规则及常用语法一.hive介绍hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
其优点是学习成本低,可以通过类SQL语句快速实现简单的MapReduce统计,不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
二.Hive规则1.建表规则表名使用小写英文以字符串模块名称,项目以BI开头(数据集市以DM)以’_’分割主业务功能块名,然后详细业务名,最后以数据表类别结尾,数据表存放在相应的表空间例如:数据仓库层_业务大类_业务小类-***示例 dw_mobile_start_weekdw_mobile_start_mondw_mobile_start_day1)在建立长期使用的表时,需要给每个字段Column填写Comment栏,加上中文注释方便查看。
对于临时表在表名后加上temp;2)对运算过程中临时使用的表,用完后即使删除,以便及时的回收空间。
临时表如果只用来处理一天数据并且每天都要使用不要按时间建分区。
避免造成临时表数据越来越大。
3)字段名应使用英文创建,字段类型尽量使用string.避免多表关联时关联字段类型不一致。
4)多表中存在关联关系的字段,名称,字段类型保持一致。
方便直观看出关联关系及连接查询。
5)建表时能够划分分区的表尽量划分分区。
6)建表时为表指定表所在数据库中。
2.查询规则1.多表执行join操作时,用户需保证连续查询中的表的大小从左到右是依次增加的。
也可以使用/*+STREAMTABLES(表别名)*/来标记大表。
2. 对于join,在判断小表不大于1G的情况下,使用map join。
如/*+MAPJOIN(表别名) */来标示。
Map表一般选用key分散均匀的小表。
3、对于group by或distinct,设定 hive.groupby.skewindata=truehive.map.aggr = true。
4. 采用sum() group by的方式来替换count(distinct)完成计算。
5.多表关联时如果关联字段存在字段类型不同。
要使用cast把两边字段类型转换成一致,如把数字类型转换成字符串类型。
具体查询的示例可以看第四节hive数据倾斜的优化。
三.Hive基本语法1创建表:hive> CREATE TABLE pokes (foo INT, bar STRING);Creates a table called pokes with two columns, the first being an integer and the other a string创建一个新表,结构与其他一样hive> create table new_table like records;2创建分区表:hive> create table logs(ts bigint,line string) partitioned by (dt String,country String);3加载分区表数据:hive> load data local inpath '/home/Hadoop/input/hive/partitions/file1' into table logs partition (dt='2001-01-01',country='GB');4展示表中有多少分区:hive> show partitions logs;5.展示所有表:hive> SHOW TABLES;lists all the tableshive> SHOW TABLES '.*s';lists all the table that end with 's'. The pattern matching follows Java regularexpressions. Check out this link for documentation6.显示表的结构信息hive> DESCRIBE invites;shows the list of columns7.更新表的名称:hive> ALTER TABLE source RENAME TO target;8.添加新一列hive> ALTER TABLE invites ADD COLUMNS (new_col2 INT COMMENT 'a comment');9.删除表:hive> DROP TABLE records;10.删除表中数据,但要保持表的结构定义hive> dfs -rmr /user/hive/warehouse/records;11.从本地文件加载数据:hive> LOAD DATA LOCAL INPATH '/home/hadoop/input/ncdc/micro-tab/sample.txt' OVERWRITE INTO TABLE records;12.显示所有函数:hive> show functions;13.查看函数用法:hive> describe function substr;14.查看数组、map、结构hive> select col1[0],col2['b'],col3.c from complex;15.内连接:hive> SELECT sales.*, things.* FROM sales JOIN things ON (sales.id = things.id);16.查看hive为某个查询使用多少个MapReduce作业hive> Explain SELECT sales.*, things.* FROM sales JOIN things ON (sales.id = things.id);17.外连接:hive> SELECT sales.*, things.* FROM sales LEFT OUTER JOIN things ON (sales.id = things.id); hive> SELECT sales.*, things.* FROM sales RIGHT OUTER JOIN things ON (sales.id = things.id); hive> SELECT sales.*, things.* FROM sales FULL OUTER JOIN things ON (sales.id = things.id);18.in查询:Hive不支持,但可以使用LEFT SEMI JOINhive> SELECT * FROM things LEFT SEMI JOIN sales ON (sales.id = things.id);19.Map连接:Hive可以把较小的表放入每个Mapper的内存来执行连接操作hive> SELECT /*+ MAPJOIN(things) */ sales.*, things.* FROM sales JOIN things ON (sales.id = things.id);20创建视图:hive> CREATE VIEW valid_records AS SELECT * FROM records2 WHERE temperature !=9999;21.查看视图详细信息:hive> DESCRIBE EXTENDED valid_records;22.结果集输出1.将select的结果放到本地文件系统中INSERT OVERWRITE LOCAL DIRECTORY '/tmp/reg_3' SELECT a.* FROM events a;2.将select的结果放到hdfs文件系统中INSERT OVERWRITE DIRECTORY '/tmp/hdfs_out' SELECT a.* FROM invites a WHERE a.ds='<DATE>';23.hive不使用压缩设置set press.map.output=false;set press.output=false;24.当hive执行join内存溢出时set mapred.child.java.opts=-Xmx3072m25.insert into于insert overwrite的区别insert overwrite 会覆盖表里面的原有数据。
insert into 只是简单的copy插入,不做重复性校验;四.hive 查询1.select语法SELECT [ALL | DISTINCT] select_expr, select_expr, ...FROM table_reference[WHERE where_condition][GROUP BY col_list][CLUSTER BY col_list| [DISTRIBUTE BY col_list] [SORT BY col_list]][LIMIT number]注:select语句可以是union查询的一部分或者是另一个查询的子查询。
table_reference指示查询的输入。
它可以是普通的表,视图,join构造或者是子查询。
简单查询。
例如,下面的查询返回表t1所有的列和行。
SELECT * FROM t1where条件是一个boolean表达式。
例如,下面的查询,返回US地区,amount大于10的销售记录。
Hive 在where子句中不支持IN,EXISTS或子查询SELECT * FROM sales WHERE amount > 10 AND region = "US"2.ALL和DISTINCT子句ALL和DISTINCT选项,指定重复的行是否返回。
如果没有指定,默认是ALL(所有行会返回)。
DISTINCT 指定从结果集移除重复的行。
hive> SELECT col1, col2 FROM t11 31 31 42 5hive> SELECT DISTINCT col1, col2 FROM t11 31 42 5hive> SELECT DISTINCT col1 FROM t1123.基于分区的查询通常,一个SELECT查询扫描全部表(除了sampling)。