【黑马程序员】分布式缓存技术redis学习系列----深入理解Spring Redis的使用
黑马程序员Redis教程

黑马程序员Redis教程P1:Redis介绍1.mysql数据库,数据库以“文件形式存储在硬盘”里边。
一.Redis1. 什么是RedisRedis是远程数据服务,内存高速缓存数据库,支持丰富的数据结构,如String、list、hash、set、sorted set,可持久化,保证了数据安全。
Redis是做数据缓存的。
缓存有两种类型:数据缓存、页面缓存使用缓存减轻数据库的负载。
在开发的时候如果有一些数据在短时间之内不会发生变化,而他们还要被频繁的访问,为了提高用户的请求速度和降低网站的负载,就把这些数据放到一个读取速度更快的介质上(或者是通过较少的计算量就可以获得该数据),该行为就称作对该数据的缓存。
该介质可以是文件、数据库、内存,内存经常用于数据缓存。
缓存的两种形式:页面缓存经常用在CMS内存管理系统里边数据缓存经常用于页面的具体数据里边新闻页面(内容单一,集中)适合做页面缓存商品页面的组成部分根据业务特点,各个部分数据比较独立,适合给他们分别做数据缓存。
2. redis和memcache比较·Redis不仅仅支持简单的k/v类型的数据,同时还提供list,set,zset,hash等数据结构的存储。
·Redis支持master-slave(主从)模型应用·Redis支持数据的持久化,可以将内存中的数据保持在磁盘中,重启的时候可以再次加载进行使用·Redis单个value的最大限制是1GB,memcached只能保存1MB的数据。
二、具体使用1. key的操作在redis里边,除了“\n”和空格不能作为名字的组成部分,其他内容都可以作为key的名字部分。
名字长度不作要求。
2. String类型操作String是redis最基本的类型Redis的string可以包含任何数据。
包括jpg图片或者序列化对象单个value值最大上限是1G字节如果只用string类型,redis就可以被看做加上持久化特性的memcacheincr:increament增长该指令可以对key进行累加1操作,默认是累加1操作,类似i++操作该指令可以针对新key或已有key进行操作新key:创建该key并累加1,其值为1已有key:key的信息值类型要求必须为整型的decr的操作模式与incr一致,不过其是减1操作substr:对内容进行截取,包括start和end标记位置3. 数据类型List链表list类型其实就是一个双向链表。
redis分布式原理

redis分布式原理Redis分布式原理解析介绍Redis 是一款高性能的键值对存储数据库,常用于缓存、消息队列和排名等应用场景。
其分布式特性使得Redis在面对大规模数据和并发访问时表现出色。
本文将从浅入深地解释Redis分布式原理。
数据分片Redis采用数据分片(sharding)的方式实现分布式存储。
数据分片将键值对均匀地分散到多个节点上,每个节点只负责处理部分数据,从而提高整体的处理能力和存储容量。
一致性哈希算法一致性哈希算法(Consistent Hashing)是Redis中常用的数据分片策略。
该算法将节点和键之间形成一个环状结构,通过hash函数将键映射到相应的节点上。
在节点发生变动(如添加或删除)时,只需重新映射受影响的键,而不需要重新分配整个数据集。
虚拟节点为了解决节点负载不均的问题,Redis引入了虚拟节点的概念。
通过为每个节点分配多个虚拟节点,可以使数据在节点之间更加均匀地分布,提高整体的负载均衡性。
数据复制数据复制是Redis实现分布式的关键机制之一。
通过将数据复制到多个节点,即使某个节点发生故障,系统仍能继续提供服务。
主从复制主从复制(Master-Slave Replication)是Redis中常用的数据复制方式。
一个节点作为主节点(Master),负责处理读写请求,并将数据同步到一个或多个从节点(Slave)。
从节点只负责处理读请求,并通过异步复制将数据同步到自己的内存中。
双向复制双向复制是主从复制的一种改进方式。
在双向复制中,主节点既可以向从节点复制数据,也可以接收从节点的写请求。
这种方式提高了系统的可用性和容错性,并减少了主节点的负载压力。
故障切换故障切换(Failover)是Redis分布式系统中解决节点故障的一种机制。
SentinelRedis Sentinel是一个用于监控和管理Redis分布式系统的组件。
它会定期向所有节点发送心跳检测,一旦发现节点出现故障,会自动进行故障切换,将从节点提升为主节点,并将其他节点重新配置为新的从节点。
spring+redis实现数据的缓存

314<property name="locations">5<list>67<value>classpath*:/META-INF/config/redis.properties</value>8</list>9</property>10</bean>1112<import resource="spring-redis.xml"/>4)、web.xml设置spring的总配置⽂件在项⽬启动时加载1<context-param>2<param-name>contextConfigLocation</param-name>3<param-value>classpath*:/META-INF/applicationContext.xml</param-value><!----> 4</context-param>5)、redis缓存⼯具类ValueOperations ——基本数据类型和实体类的缓存ListOperations ——list的缓存SetOperations ——set的缓存HashOperations Map的缓存1import java.io.Serializable;2import java.util.ArrayList;3import java.util.HashMap;4import java.util.HashSet;5import java.util.Iterator;6import java.util.List;7import java.util.Map;8import java.util.Set;910import org.springframework.beans.factory.annotation.Autowired;11import org.springframework.beans.factory.annotation.Qualifier;12import org.springframework.context.support.ClassPathXmlApplicationContext;13import org.springframework.data.redis.core.BoundSetOperations;14import org.springframework.data.redis.core.HashOperations;15import org.springframework.data.redis.core.ListOperations;16import org.springframework.data.redis.core.RedisTemplate;17import org.springframework.data.redis.core.SetOperations;18import org.springframework.data.redis.core.ValueOperations;19import org.springframework.stereotype.Service;2021@Service22public class RedisCacheUtil<T>23{2425 @Autowired @Qualifier("jedisTemplate")26public RedisTemplate redisTemplate;2728/**29 * 缓存基本的对象,Integer、String、实体类等30 * @param key 缓存的键值31 * @param value 缓存的值32 * @return缓存的对象33*/34public <T> ValueOperations<String,T> setCacheObject(String key,T value)35 {3637 ValueOperations<String,T> operation = redisTemplate.opsForValue();38 operation.set(key,value);39return operation;40 }4142/**43 * 获得缓存的基本对象。
【黑马程序员】Spring Boot介绍和使用

【黑马程序员】Spring Boot介绍和使用简介:Spring Boot是由Pivotal团队提供的全新框架,其设计目的是用来简化新Spring应用的初始搭建以及开发过程。
该框架使用了特定的方式来进行配置,从而使开发人员不再需要定义样板化的配置。
通过这种方式,Spring Boot致力于在蓬勃发展的快速应用开发领域(rapid application development)成为领导者。
Spring Boot是一种简化原有Spring应用繁杂配置的微框架。
使开发者从繁杂的各种配置文件中解脱出来,通过Spring Boot能够很简单、很快速构建一个优秀的、产品级的Spring基础应用。
运行Spring Boot和运行普通的Java 类一样简单,仅仅run一下Spring Boot的入口main()方法即可开启应用;你也可以把Spring Boot应用打成jar,在命令行执行java -jar xxx.jar命令来运行;或者打成war包部署到服务器下运行服务器来开启应用。
Spring Boot微框架考虑到了Spring平台和第三方库的情况,所以你需要做的则是最少的操作或配置。
Spring Boot的特点:1. 创建独立的Spring应用程序2. 嵌入的Tomcat,无需部署WAR文件3. 简化Maven配置4. 自动配置Spring5. 绝对没有代码生成并且对XML也没有配置要求Spring boot的使用1.在ide中打开工程,这里使用的ide是idea,工程的目录结构为:2、maven配置文件<?xml version="1.0" encoding="UTF-8"?><project xmlns="/POM/4.0.0" xmlns:xsi="/2001/XMLSchema-instance"xsi:schemaLocation="/POM/4.0.0 /xsd /maven-4.0.0.xsd"><modelVersion>4.0.0</modelVersion><groupId>org.springboot.sample</groupId><artifactId>spring-boot-sample</artifactId><version>0.0.1-SNAPSHOT</version><packaging>war</packaging><name>spring-boot-sample</name><description>Spring Boot Sample Web Application</description><parent><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-parent</artifactId><version>1.3.2.RELEASE</version><relativePath /></parent><properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><java.version>1.8</java.version></properties><dependencies><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-web</artifactId></dependency><!-- MYSQL --><dependency><groupId>mysql</groupId><artifactId>mysql-connector-java</artifactId></dependency><!-- Spring Boot JDBC --><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-jdbc</artifactId></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-configuration-processor</artifactId><optional>true</optional></dependency></dependencies><build><plugins><plugin><groupId>org.springframework.boot</groupId><artifactId>spring-boot-maven-plugin</artifactId></plugin></plugins></build></project>3.配置好了pom后,我们一起看下自动生成的Application.java这个类相当于我们程序的main函数入口@SpringBootApplication@ServletComponentScanpublic class SpringBootApplication extends SpringBootServletInitializer {private static final Logger logger = LoggerFactory.getLogger(SpringBootSampleApplication.class);public static void main(String[] args) {SpringApplication.run(SpringBootSampleApplication.class, args);}}。
Redis缓存的分布式缓存

Redis缓存的分布式缓存缓存是计算机领域中常用的一种技术,它可以有效地提升系统的读取速度和性能。
而在大规模分布式系统中,为了进一步提升缓存效果并解决单点故障的问题,引入了分布式缓存的概念。
Redis作为一种流行的缓存方案,也可以用于构建分布式缓存系统。
1. 什么是Redis缓存?Redis是一种高性能的键值存储系统,它可以将数据存储在内存中,并提供多种数据结构的支持。
它的快速读取和写入速度使得它成为构建缓存系统的理想选择。
2. 为什么需要分布式缓存?在传统的缓存系统中,缓存数据通常存储在单个节点上。
当系统规模变大或并发访问量增加时,单个节点的容量和性能可能无法满足需求。
此外,如果单个节点发生故障,整个系统的缓存功能将受到影响。
因此,引入分布式缓存可以解决这些问题。
3. Redis如何支持分布式缓存?Redis提供了多个功能来支持分布式缓存。
其中包括:- Redis集群:Redis可以通过将数据分布在多个节点上来提供可扩展性和高可用性。
每个节点负责存储部分数据和处理请求,可以水平扩展以适应不断增长的需求。
- 数据分片:Redis可以根据键的哈希值将数据进行分片,并将不同的数据分布在不同的节点上。
这样可以确保数据均匀分布,避免节点负载不均衡。
- 主从复制:Redis支持主从复制,通过将数据从主节点同步到多个从节点,实现数据的冗余备份和读写分离。
这样可以提高系统的可用性和读取性能。
- 哨兵模式:Redis的哨兵模式可以监控节点的状态,并在主节点发生故障时自动切换到从节点。
这样可以减少系统的停机时间并提供高可用性。
4. Redis分布式缓存的优势引入Redis作为分布式缓存系统带来了以下优势:- 高性能:Redis的快速读写能力可以有效地提升系统的性能,特别是对于读密集型的应用场景。
- 高可用性:通过Redis的主从复制和哨兵模式,系统可以在主节点故障时自动切换到从节点,保证系统的可用性。
- 可扩展性:使用Redis集群可以实现系统的水平扩展,随着数据量和并发访问的增加,系统仍然能够保持高性能。
黑马程序员spring知识总结技术帖

S p r i n g框架一、技术说明(技术介绍,技术优势以及发展史等)1.1、什么是spring●Spring是分层的JavaSE/EE full-stack 轻量级开源框架分层:三层体系结构,为每一个层都提供解决方案web层:struts2、spring-mvcservice层:springdao层:hibernate、mybatis、jdbcTemplate(spring)轻量级:使用时占用资源少,依赖程序少。
比较:EJB1.2、spring由来Expert One-to-One J2EE Design and Development ,介绍EJB,使用,特点Expert One-to-One J2EE Development without EJB ,不使用EJB,spring思想1.3、spring核心●以IoC(Inverse of Control 反转控制)和AOP(Aspect Oriented Programming 面向切面编程为内核)1.5、spring体系结构●spring 核心功能:beans、core、context、expression二、环境搭建(技术开发环境)2.1、获取Spring framework jar 包1、spring官网下载下载完成后会发现三个目录,命名很明确。
Docs 目录相关文档。
包括一份API 和一份各种spring 的使用说明(reference),reference 提供了HTML.PDF 版本,非常详细。
2.spring包的核心包搭建第一个用到spring 依赖注册的程序直接用eclipse 建立一个JAVA 项目然后添加spring 的jar 包引入注:和hibernate 一起用时这个JAR 会冲突,解决方法删掉它就是了Caused by:除此之外,还有需要一个Apache common 的JAR 包3. 配置XMLSpring 的最大的作用就是提供bean 的管理功能,在spring 中bean 的管理是通过XML 实现的,要用此功能,需要把bean 配置到spring 的xml1. 新建立一个xml.名字任意,如applicationContext.xml,或者text.xml 都可以<xml version="1.0" encoding="utf-8">①②③"><bean> </bean> </beans>②schemaLoacation .用于绑定命名空间的schema 文件,通常是用URL 值对,中间用空格隔开,前面URL 是命名空间,后面URL 为schema 的文件地址③xsd 的存放地址,如果没有声明,eclipse 会去网上下载.在创建xml 时,在eclipse 编辑xml 配置没有提示。
黑马程序员:三大框架11天笔记全之Spring-day09笔记

黑马程序员:三大框架Spring-day09笔记Bean的属性注入在spring中bean的属性注入有两种1.1构造器注入1.2Setter方法注入关于ref属性作用使用ref来引入另一个bean对象,完成bean之间注入1.3集合属性的注入在spring中对于集合属性,可以使用专门的标签来完成注入例如:list set map properties等集合元素来完成集合属性注入.1.3.1List属性注入如果属性是数组类型也可以使用list完成注入1.3.2Set属性注入1.3.3Map属性注入1.3.4Properties属性注入Java.util.Properties是java.utilsMap的实现类,它的key与value都是String类型.1.4名称空间p和c的使用Spring2.0以后提供了xml命名空间。
P名称空间C名称空间首先它们不是真正的名称空间,是虚拟的。
它是嵌入到spring内核中的。
使用p名称空间可以解决我们setter注入时<property>简化使用c名称空间可以解决我们构造器注入时<constructor-arg>简化使用setter注入在applicationContext.xml文件中添加p名称空间简化setter注入使用c名称空间来解决构造器注入在applicationContext.xml文件中添加c名称空间注:如果c或p名称空间操作的属性后缀是”-ref”代表要引入另一个已经存在的bean,例如1.5SpElspring expression language 是在spring3.0以后的版本提供它类似于ognl或el表达式,它可以提供在程序运行时构造复杂表达式来完成对象属性存储及方法调用等。
Spel表达式的格式#{表达式}示例1:完成bean之间的注入示例2 支持属性调用及方法调用第2章Spring注解开发在spring中使用注解,我们必须在applicationContext.xml文件中添加一个标签<context:annotation-config/>作用是让spring中常用的一些注解生效。
【黑马程序员】JavaEE框架:spring(一)

【黑马程序员】JavaEE框架:spring(一)一、技术说明(技术介绍,技术优势以及发展史等)1.1、什么是springl Spring是分层的JavaSE/EE full-stack 轻量级开源框架分层:三层体系结构,为每一个层都提供解决方案web层:struts2、spring-mvcservice层:springdao层:hibernate、mybatis、jdbcTemplate(spring)轻量级:使用时占用资源少,依赖程序少。
比较:EJB1.2、spring由来Expert One-to-One J2EE Design and Development ,介绍EJB,使用,特点Expert One-to-One J2EE Development without EJB ,不使用EJB,spring思想1.3、spring核心l 以IoC(Inverse of Control 反转控制)和AOP(Aspect Oriented Programming 面向切面编程为内核)1.4、spring优点l 方便解耦,简化开发(易扩展,易维护)•Spring就是一个大工厂,可以将所有对象创建和依赖关系维护,交给Spring管理l AOP编程的支持•Spring提供面向切面编程,可以方便的实现对程序进行权限拦截、运行监控等功能l 声明式事务的支持•只需要通过配置就可以完成对事务的管理,而无需手动编程l 方便程序的测试•Spring对Junit4支持,可以通过注解方便的测试Spring程序l 方便集成各种优秀框架•Spring不排斥各种优秀的开源框架,其内部提供了对各种优秀框架(如:Struts、Hibernate、MyBatis、Quartz等)的直接支持l 降低JavaEE API的使用难度•Spring 对JavaEE开发中非常难用的一些API(JDBC、JavaMail、远程调用等),都提供了封装,使这些API应用难度大大降低1.5、spring体系结构l spring 核心功能:beans 、core 、context 、expression二、环境搭建(技术开发环境)2.1、获取 Spring framework jar 包 1、spring 官网下载从官网下载spring 最新的相关jar 包,官网download 地址/springcommunity-download下载完成后会发现三个目录,命名很明确。
分布式学习笔记redis二级缓存
13 14 15 16 17 18 19 20 21 22 23 24 25 }
context= applicationContext; }
//泛型方法 public static <T> T getBean(Class<T> aClass){
return context.getBean(aClass); }
26
redisTemplate.setValueSerializer(jackson2JsonRedisSerializer);
27
28
29
redisTemplate.setHashKeySerializer(new StringRedisSerializer());
30
redisTemplate.setHashValueSerializer(jackson2JsonRedisSerializer);
7
eviction="FIFO" :驱逐策略 清除册率
8
9 -->
10
<cache flushInterval=""/>
3、设置类实现序列化的接口
实现二级缓存的类要实现Cache接口,mybatis提供的有默认的实现
1 public interface Cache {
2
//id
3
String getId();
14
Dept dept = mapper.queryById(1);
15
System.out.println("查询:");
16
System.out.println(dept);
17
//session关闭才会将数据存入二级缓存
黑马程序员:为什么更要用redis,应该如何使用redis

为什么缓存数据库更要首选redis?如何使用redis?一、使用缓存数据库为什么首选用redis?我们都知道,把一些热数据存到缓存中可以极大的提高速度,那么问题来了,是用Redis 好还是Memcached好呢,以下是它们两者之间一些简单的区别与比较:1. Redis不仅支持简单的k/v类型的数据,同时还支持list、set、zset(sorted set)、hash等数据结构的存储,使得它拥有更广阔的应用场景。
2. Redis最大的亮点是支持数据持久化,它在运行的时候可以将数据备份在磁盘中,断电或重启后,缓存数据可以再次加载到内存中,只要Redis配置的合理,基本上不会丢失数据。
3. Redis支持主从模式的应用。
4. Redis单个value的最大限制是1GB,而Memcached则只能保存1MB内的数据。
5. Memcache在并发场景下,能用cas保证一致性,而Redis事务支持比较弱,只能保证事务中的每个操作连续执行。
6. 性能方面,根据网友提供的测试,Redis在读操作和写操作上是略领先Memcached的。
从上面这些看出,Redis的优势比Memcached大,不过Memcached也还是有它用武之地的。
要是只选择装其中一种的话,还是要首选Redis。
二、如何使用redis?你一定要知道的是:redis的key名要区分大小写,在redis中除了和空格外,其他的字符都可以做为key名,且长度不做限制,不过为了性能考虑,一般key名不要设置的太长。
redis 功能强大,支持数据类型丰富,以下是redis操作命令大全,基本上涵盖了redis所有的命令!1、redis命令基本篇1)、【set key value 】存入一个key和值。
如:set myname reson2)、【get key 】读取一个key的值。
3)、【del key 】删除一个key。
4)、【del key1 key2 ... keyN 】删除多个key。
【黑马程序员】Redis面试题及分布式集群

【黑马程序员】Redis面试题及分布式集群1.使用Redis有哪些好处?(1) 速度快,因为数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1)(2) 支持丰富数据类型,支持string,list,set,sorted set,hash(3) 支持事务,操作都是原子性,所谓的原子性就是对数据的更改要么全部执行,要么全部不执行(4) 丰富的特性:可用于缓存,消息,按key设置过期时间,过期后将会自动删除2. redis相比memcached有哪些优势?(1) memcached所有的值均是简单的字符串,redis作为其替代者,支持更为丰富的数据类型(2) redis的速度比memcached快很多(3) redis可以持久化其数据3.redis常见性能问题和解决方案:(1) Master最好不要做任何持久化工作,如RDB内存快照和AOF日志文件(2) 如果数据比较重要,某个Slave开启AOF备份数据,策略设置为每秒同步一次(3) 为了主从复制的速度和连接的稳定性,Master和Slave最好在同一个局域网内(4) 尽量避免在压力很大的主库上增加从库(5) 主从复制不要用图状结构,用单向链表结构更为稳定,即:Master <- Slave1 <- Slave2 <- Slave3…这样的结构方便解决单点故障问题,实现Slave对Master的替换。
如果Master挂了,可以立刻启用Slave1做Master,其他不变。
4.MySQL里有2000w数据,redis中只存20w的数据,如何保证redis中的数据都是热点数据相关知识:redis 内存数据集大小上升到一定大小的时候,就会施行数据淘汰策略。
redis 提供6种数据淘汰策略:voltile-lru:从已设置过期时间的数据集(server.db[i].expires)中挑选最近最少使用的数据淘汰volatile-ttl:从已设置过期时间的数据集(server.db[i].expires)中挑选将要过期的数据淘汰volatile-random:从已设置过期时间的数据集(server.db[i].expires)中任意选择数据淘汰allkeys-lru:从数据集(server.db[i].dict)中挑选最近最少使用的数据淘汰allkeys-random:从数据集(server.db[i].dict)中任意选择数据淘汰no-enviction(驱逐):禁止驱逐数据5.Memcache与Redis的区别都有哪些?1)、存储方式Memecache把数据全部存在内存之中,断电后会挂掉,数据不能超过内存大小。
黑马程序员redis笔记

黑马程序员redis笔记黑马程序员是一家知名的编程教育机构,提供了一系列优质的编程学习资源。
关于Redis的笔记,这里有一些关键点:1. Redis简介:Redis是一个开源的、内存中的数据结构存储系统,它可以用作数据库、缓存和消息代理。
Redis提供了许多高级的数据结构,如字符串、列表、集合、哈希表和有序集合。
2. 数据类型:Redis支持多种数据类型,如字符串、哈希、列表、集合和有序集合。
这些数据类型使得Redis能够适应各种应用场景,如缓存、消息队列和实时分析等。
3. 持久化:虽然Redis主要在内存中操作,但它也支持数据持久化。
通过RDB和AOF两种方式,Redis可以将数据保存到磁盘上,以防止数据丢失。
4. 事务:Redis支持事务处理,可以在一个原子操作中执行多个命令,并且可以在执行过程中使用WATCH、MULTI和EXEC等命令来保证操作的原子性。
5. 发布/订阅:Redis的发布/订阅模型允许用户通过频道和订阅者进行消息传递,这使得Redis可以用作消息代理或者实现实时系统。
6. 安全性和认证:Redis提供了密码保护功能,可以在运行时配置密码,以增加系统的安全性。
7. 内存管理和性能优化:Redis的内存管理和性能优化是关键的考虑因素。
了解Redis如何使用内存,以及如何优化性能对于高效使用Redis非常重要。
8. 应用场景:了解Redis的应用场景对于理解和使用Redis非常重要。
例如,Redis可以用作缓存、消息队列、排行榜、社交网络和购物车等。
以上就是一些关于Redis的黑马程序员笔记的关键点。
当然,为了深入理解和掌握Redis,还需要进行更多的实践和学习。
【黑马程序员】关于spring的面试和笔试题(一)的副本 5

【黑马程序员】关于spring的面试和笔试题(一)1. 什么是spring?Spring 是个java企业级应用的开源开发框架。
Spring主要用来开发Java应用,但是有些扩展是针对构建J2EE平台的web应用。
Spring 框架目标是简化Java企业级应用开发,并通过POJO为基础的编程模型促进良好的编程习惯。
2. 使用Spring框架的好处是什么?轻量:Spring 是轻量的,基本的版本大约2MB控制反转:Spring通过控制反转实现了松散耦合,对象们给出它们的依赖,而不是创建或查找依赖的对象们面向切面的编程(AOP):Spring支持面向切面的编程,并且把应用业务逻辑和系统服务分开容器:Spring 包含并管理应用中对象的生命周期和配置MVC框架:Spring的WEB框架是个精心设计的框架,是Web框架的一个很好的替代品事务管理:Spring 提供一个持续的事务管理接口,可以扩展到上至本地事务下至全局事务(JTA)异常处理:Spring 提供方便的API把具体技术相关的异常(比如由JDBC,Hibernate orJDO抛出的)转化为一致的unchecked 异常3. Spring由哪些模块组成?以下是Spring 框架的基本模块:Core moduleBean moduleContext moduleExpression Language moduleJDBC moduleORM moduleOXM moduleJava Messaging Service(JMS)moduleTransaction moduleWeb moduleWeb-Servlet moduleWeb-Struts moduleWeb-Portlet module4. 核心容器(应用上下文) 模块这是基本的Spring模块,提供spring 框架的基础功能,BeanFactory 是任何以spring为基础的应用的核心。
分布式缓存技术redis系列(一)——redis简介以及linux上的安装

分布式缓存技术redis系列(⼀)——redis简介以及linux上的安装redis简介redis是NoSQL(No Only SQL,⾮关系型数据库)的⼀种,NoSQL是以Key-Value的形式存储数据。
当前主流的分布式缓存技术有redis,memcached,ssdb,mongodb等。
既可以把redis理解为理解为缓存技术,因为它的数据都是缓存在内从中的;也可以理解为数据库,因为redis可以周期性的将数据写⼊磁盘或者把操作追加到记录⽂件中。
⽽我个⼈更倾向理解为缓存技术,因为当今互联⽹应⽤业务复杂、⾼并发、⼤数据的特性,正是各种缓存技术引⼊最终⽬的。
关于redis与传统关系型数据的对⽐、redis与memcached的对⽐、redis的优缺点,在此将不介绍,因为都各有各的好处,只有结合了具体的业务场景,才能深刻体会它们之间的差别和优缺点。
下⾯开始redis在linux上的安装。
linux下安装redis下载redis安装包编译源程序[root@localhost ftpuser]# tar zxvf redis-3.2.0.tar.gz[root@localhost ftpuser]# cd redis-3.2.0[root@localhost redis-3.2.0]# make[root@localhost redis-3.2.0]# cd src && make install创建⽬录存放redis命令和配置⽂件[root@localhost redis-3.2.0]# mkdir -p /usr/local/redis/bin[root@localhost redis-3.2.0]# mkdir -p /usr/local/redis/etc移动⽂件[root@localhost redis-3.2.0]# mv redis.conf /usr/local/redis/etc[root@localhost redis-3.2.0]# cd src[root@localhost src]# mv mkreleasehdr.sh redis-benchmark redis-check-aof redis-check-rdb redis-cli redis-server redis-sentinel redis-trib.rb /usr/local/redis/bin启动redis服务[root@localhost ~]# /usr/local/redis/bin/redis-server /usr/local/redis/etc/redis.conf如上,启动redis服务需要指定配置⽂件的,后台启动的话需要修改redis.conf⽂件,daemonize no ---- >daemonize yes。
黑马程序员redis讲义

黑马程序员redis讲义
《黑马程序员redis讲义》是一本详细介绍Redis的技术教材。
Redis是一款非关系型数据库,具有高性能、高可靠性、易扩展等优点,被广泛应用于Web应用、游戏、物联网等领域。
本书从Redis的基本概念、安装配置、数据类型、持久化、高级应用等方面全面深入地介绍了Redis的使用方法和技术要点。
其中,包括了Redis的五种基本数据类型,如字符串、哈希、列表、集合和有序集合的详细介绍,以及Redis的事务、发布订阅、Lua脚本等高级应用技术的讲解。
此外,本书还介绍了Redis的集群和哨兵监控等高级应用场景。
本书旨在为广大开发者提供一份Redis的实战指南。
- 1 -。
SpringCache分布式缓存的实现方法(规避redis解锁的问题)

SpringCache分布式缓存的实现⽅法(规避redis解锁的问题)简介spring 从3.1 开始定义org.springframework.cache.Cacheorg.springframework.cache.CacheManager来统⼀不同的缓存技术并⽀持使⽤JCache(JSR-107)注解简化我们的开发基础概念实战使⽤整合SpringCache简化缓存开发常⽤注解常⽤注解说明@CacheEvict触发将数据从缓存删除的操作(失效模式)@CachePut不影响⽅法执⾏更新缓存@Caching组合以上多个操作@CacheConfig在类级别共享缓存的相同配置@Cacheable触发将数据保存到缓存的操作⽅法1)、开启缓存功能 @EnableCaching2)、只需要使⽤注解就能完成缓存操作1、引⼊依赖spring-boot-starter-cache、spring-boot-starter-data-redis 配合redis使⽤<!-- 引⼊ redis--><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId><!-- 排除 lettuce --><exclusions><exclusion><groupId>io.lettuce</groupId><artifactId>lettuce-core</artifactId></exclusion></exclusions></dependency><dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-cache</artifactId></dependency>2、写配置在项⽬新建config⽂件夹,新建⼀个config类代码如下:@EnableConfigurationProperties(CacheProperties.class)//为configuration容器中放参数@EnableCaching@Configurationpublic class MyCacheConfig {/*** 配置⽂件中的内容不再⽣效(全部⾛⾃定义配置)* @param cacheProperties* @return*/@BeanRedisCacheConfiguration redisCacheConfiguration(CacheProperties cacheProperties){RedisCacheConfiguration config = RedisCacheConfiguration.defaultCacheConfig();config= config.serializeKeysWith(RedisSerializationContext.SerializationPair.fromSerializer(new StringRedisSerializer()));config = config.serializeValuesWith(RedisSerializationContext.SerializationPair.fromSerializer(new GenericJackson2JsonRedisSerializer())); CacheProperties.Redis redisProperties = cacheProperties.getRedis();if (redisProperties.getTimeToLive() != null) {config = config.entryTtl(redisProperties.getTimeToLive());}if (redisProperties.getKeyPrefix() != null) {config = config.prefixCacheNameWith(redisProperties.getKeyPrefix());}if (!redisProperties.isCacheNullValues()) {config = config.disableCachingNullValues();}if (!redisProperties.isUseKeyPrefix()) {config = config.disableKeyPrefix();}return config;}}(1)、⾃动配置写了哪些CacheAutoConfiguration 会导⼊ RedisAutoConfiguration⾃动配置好缓存管理器RedisCacheManager(2)、配置使⽤redis做为缓存spring.cache.typeredis3、修改pom 配置spring:cache:type: redisredis:# 缓存过期时间time-to-live: 60000# 如果制定了前缀,我们就是⽤指定的前缀,如果没有我们就默认使⽤缓存的名字作为前缀key-prefix: CACHE_# 是否使⽤前缀use-key-prefix: true# 是否把缓存空值,防⽌缓存穿透cache-null-values: true4、原理1、每⼀个要缓存的数据我们都来指定要放到那个名字的缓存【缓存的分区(按照业务类型)】2、@cacheable({"category"})代表当前⽅法的结果需要缓存,如果缓存中,⽅法不⽤调⽤如果缓存中没有,会调⽤⽅法,最后将⽅法的结果放⼊缓存3、默认⾏为1)、如果缓存中有,⽅法不⽤调⽤2)、key默认⾃动⽣成:缓存的名字::SimpleKey[] (⾃主⽣成的key值)3)、缓存的value的值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
【黑马程序员】分布式缓存技术redis学习系列----深入理解Spring Redis的使用关于spring redis框架的使用,网上的例子很多很多。
但是在自己最近一段时间的使用中,发现这些教程都是入门教程,包括很多的使用方法,与spring redis丰富的api大相径庭,真是浪费了这么优秀的一个框架。
Spring-data-redis为spring-data模块中对redis的支持部分,简称为“SDR”,提供了基于jedis 客户端API的高度封装以及与spring容器的整合,事实上jedis客户端已经足够简单和轻量级,而spring-data-redis反而具有“过度设计”的嫌疑。
jedis客户端在编程实施方面存在如下不足:1) connection管理缺乏自动化,connection-pool的设计缺少必要的容器支持。
2) 数据操作需要关注“序列化”/“反序列化”,因为jedis的客户端API接受的数据类型为string 和byte,对结构化数据(json,xml,pojo)操作需要额外的支持。
3) 事务操作纯粹为硬编码4) pub/sub功能,缺乏必要的设计模式支持,对于开发者而言需要关注的太多。
1. Redis使用场景Redis是一个开源的使用ANSI C语言编写、支持网络、可基于内存亦可持久化的日志型、Key-Value数据库,并提供多种语言的API。
我们都知道,在日常的应用中,数据库瓶颈是最容易出现的。
数据量太大和频繁的查询,由于磁盘IO 性能的局限性,导致项目的性能越来越低。
这时候,基于内存的缓存框架,就能解决我们很多问题。
例如Memcache ,Redis 等。
将一些频繁使用的数据放入缓存读取,大大降低了数据库的负担。
提升了系统的性能。
其实,对于hibernate 以及Mybatis 的二级缓存,是同样的道理。
利用内存高速的读写速度,来解决硬盘的瓶颈。
2. 配置使用redis项目的整体结构如下:在applicationContext-dao.xml 中配置如下:[AppleScript] 纯文本查看 复制代码?01 02 03 04 05 06 07 0<font size="3"><font color="#001000"><?xml version="1.0"encoding="UTF-8"?><beans xmlns="/schema/beans" xmlns:xsi="/2001/XMLSchema-instance" xmlns:context="/schema/context "xmlns:mongo="/schema/data/mong o"xmlns:aop="/schema/aop" xsi:schemaLocation="/schema/be ans[url=/schema/b eans/spring-beans-3.0.xsd]/schema/bean s/spring-beans-3.0.xsd[/url][url=/schema/d8 0 9 1 0 1 1 1 2 1 3 1 4 1 5 1 6 1 7 1 8 1 9 2 0 2 1 2 2 2 3 2 4 2 5 2 6 2 7 2 8 2 9 3ata/mongo]/schema/data/mongo[/url][url=/schema/d ata/mongo/spring-mongo.xsd]/schema/dat a/mongo/spring-mongo.xsd[/url][url=/schema/c ontext]/schema/context[/url][url=/schema/context/s pring-context-3.0.xsd]/s ...ing-context-3.0.xsd[/url][url=/schema/aop]http: ///schema/aop[/url][url=/schema/aop/sprin g-aop-3.0.xsd]/schema/aop/spring-aop-3 .0.xsd[/url]"><context:property-placeholderlocation="classpath:database.properties" /><bean id="poolConfig"class="redis.clients.jedis.JedisPoolConfig"><property name="maxIdle"value="${redis.maxIdle}" /><property name="maxTotal"value="${redis.maxActive}" /><property name="maxWaitMillis"value="${redis.maxWait}" /><property name="testOnBorrow"value="${redis.testOnBorrow}" /></bean><bean id="connectionFactory"class="org.springframework.data.redis.connection.jedis.JedisConnecti onFactory"><property name="hostName"value="${redis.host}"/><property name="port" value="${redis.port}"/><property name="password"value="${redis.pass}"/><property name="poolConfig" ref="poolConfig"/> </bean><bean id="stringSerializer"class="org.springframework.data.redis.serializer.StringRedisSerializ0 3 1 3 2 3 3 3 4 3 5 3 6 3 7 3 8 3 9 4 0 4 1 4 2 4 3 4 4er"/><bean id="hashSerializer"class="org.springframework.data.redis.serializer.JdkSerializationRed isSerializer"/><bean id="redisTemplate"class="org.springframework.data.redis.core.RedisTemplate"><property name="connectionFactory"ref="connectionFactory" /><property name="keySerializer"ref="stringSerializer"/><property name="valueSerializer"ref="stringSerializer"/><property name="hashKeySerializer"ref="stringSerializer" /><property name="hashValueSerializer"ref="hashSerializer"/></bean></beans> </font></font>database.properties配置文件如下:[AppleScript] 纯文本查看复制代码?1 2 3 4 5 6 7<font size="3"><font color="#001000">redis.maxIdle=10 redis.maxActive=20redis.maxWait=10000redis.testOnBorrow=trueredis.host=192.168.1.76redis.port=6379redis.pass=password1 </font></font>spring-data-redis提供了多种serializer策略,这对使用jedis的开发者而言,实在是非常便捷。
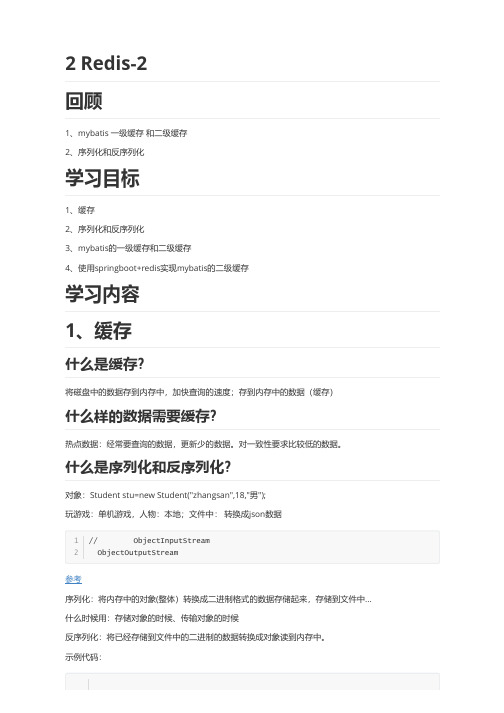
sdr提供了4种内置的serializer:∙JdkSerializationRedisSerializer:使用JDK的序列化手段(serializable接口,ObjectInputStrean,ObjectOutputStream),数据以字节流存储,POJO对象的存取场景,使用JDK本身序列化机制,将pojo类通过ObjectInputStream/ObjectOutputStream进行序列化操作,最终redis-server中将存储字节序列,是目前最常用的序列化策略。
∙StringRedisSerializer:字符串编码,数据以string存储,Key或者value 为字符串的场景,根据指定的charset对数据的字节序列编码成string,是“new String(bytes, charset)”和“string.getBytes(charset)”的直接封装。