数学建模spss.时间预测,心得总结和实例
数学建模心得体会6篇

数学建模心得体会6篇(经典版)编制人:__________________审核人:__________________审批人:__________________编制单位:__________________编制时间:____年____月____日序言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!并且,本店铺为大家提供各种类型的经典范文,如工作方案、工作总结、心得体会、演讲稿、合同协议、条据书信、规章制度、教学资料、作文大全、其他范文等等,想了解不同范文格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you!Moreover, our store provides various types of classic sample essays, such as work plans, work summaries, insights, speeches, contract agreements, policy letters, rules and regulations, teaching materials, complete essays, and other sample essays. If you want to learn about different sample formats and writing methods, please pay attention!数学建模心得体会6篇在写心得体会中促使大家明确自己的人生目标和追求,为我们的人生增添意义,通过心得体会,我们可以将自己的思考与感悟与他人分享,共同成长,本店铺今天就为您带来了数学建模心得体会6篇,相信一定会对你有所帮助。
spss实训心得体会范文

spss 实训心得体会范文【篇一: spss 实训个人总结表】数信系学生项目实训个人总结表数学与信息工程系年月日【篇二:实习总结spss 】实习总结这次实习使用的是spss17.0版本的软件,通过这次实习,我了解到 spss 具有完整的数据输入、编辑、统计分析、图形制作等功能。
平日课下进行统计调查技能培训的时候,分析数据所用的软件是excel 。
虽然使用excel 可以对数据进行透视、分类、筛选以及计算相关系数等,但是这些操作都需要自己每一步每一步的进行手动操作,而使用spss 软件在对数据进行整理时,只需对软件某选项内设置变量条件,系统便自动的进行整理。
通过这次spss 实习,我又入门了一项非常实用的软件,会为以后统计分析提供多一种的选择。
下面我会从以下四方面分别阐述这次实习的收获与总结。
做问卷调查根据指导老师的安排,我需要独自完成 6 份《广东高校在校大学生消费使用数码产品情况》的调查问卷。
去广工、广财听宣讲会并且在那里做了两份问卷调查,剩下的 4 份是以电子版的形式做的问卷调查。
在做问卷调查的过程中,为了保证问卷的有效性和准确性,我会认真审核每一份问卷是否填写完整以及前后是否合逻辑。
在我的六份问卷调查中,比较容易出现问题的主要在每天使用数码产品的时间,也是在做问卷调查中叮嘱最多的。
这都是值得的,因为保证问卷的客观和有效是后面做统计分析的基础。
这次实训是全班合作完成问卷,如果是一个人完成30 几份的问卷,那么真是一项不容小觑的任务。
spss 入门操作这一部分主要是根据老师编制的指导书展开。
spss 入门操作主要涉及到数据的输入、描述统计分析、假设检验、相关与回归分析。
针对每一项都有专门的案例以及相应的练习。
个人认为最难的是假设检验这一块,因为《统计学原理》是在之前的学期学习的,统计分析的原理基本上都记不起来,对于输出假设检验结果对问题进行分析方面问题比较大。
我自己也回去看了相应的统计学原理,有一定的了解后,进行实操也比较顺利。
spss课程学习的心得体会范文

spss课程学习的心得体会范文
在学习SPSS课程期间,我有了很多收获和体会。
首先,SPSS是一种功能强大的统计
分析软件,通过学习SPSS,我掌握了很多统计方法和技巧,能够更好地处理和分析数据。
这对于我的学术研究和数据分析能力的提升是非常有帮助的。
其次,学习SPSS让我对统计学有了更深入的理解。
在课程中,我学习了很多统计概念和方法,例如 t检验、方差分析和线性回归等。
通过实际操作和运用SPSS软件进行数据分析,我能够更好地理解这些概念和方法的实际应用,以及他们背后的原理和意义。
这让我对统计学的学习变得更加有趣和有意义。
此外,学习SPSS也培养了我数据处理和分析的能力。
在课程中,我学会了如何从原始数据中提取有用的信息,如何进行数据清洗和整理,以及如何运用不同的统计方法来
分析数据。
这些技能在我实际的研究项目中非常实用,帮助我更好地处理和解释数据,有效地支持我的研究成果。
最后,学习SPSS也提高了我的解决问题的能力。
在实际操作中,我经常会遇到一些数据分析中的问题,例如如何选择合适的统计方法,如何处理异常值等。
通过自学和与
同学、老师的讨论,我逐渐学会了解决这些问题的方法和技巧。
这让我在面对其他问
题时也能够更加冷静和有条理地思考和解决问题。
总之,学习SPSS课程给我带来了很多收获和体会。
通过学习SPSS,我不仅掌握了统
计方法和技巧,提高了数据分析能力,也对统计学有了更深入的理解。
同时,通过解
决问题的实践,我也提高了自己的解决问题的能力。
我相信这些收获和体会将会对我
的学习和研究产生积极的影响。
数学建模心得与体会[终稿]
![数学建模心得与体会[终稿]](https://img.taocdn.com/s3/m/cb0a2507f08583d049649b6648d7c1c708a10b05.png)
数学建模心得与体会数学建模心得与体会——陈保成自学校举行大学生首届数学建模比赛,我就积极参与,在比赛过程中我学的很多,也使我感觉自己所学知识有用,并体会了搞建模的艰辛,也意识到自己的知识匮乏,应该增深自己知识面。
与队友密切合作,培养了自己团队意识,并意识与他人合作重要性。
在通过学校选拔以后,接着就是‘痛苦’的培训。
在培训期间,正值高温期,有许多同学吃不下苦,而中途放弃了,现在想想都挺佩服自己的,不知是怎么坚持下来的。
既然在这样艰苦条件下都能坚持下来,以后还有什么坚持不下来呢!虽然培训是痛苦的,但也学到很多东西。
老师讲的内容都比较精彩生动,在课堂上,老师充分调动我们的积极性。
我们不仅学到了许多知识,也加强了动手能力和实践能力。
如在学习MATLAB过程中,通过自己动手操作,都能基本上掌握MATLAB,这对我来说,为了以后的后续课程打下基础。
还有图论、优化、聚类、统计等一些知识,增宽了我的知识面。
还有LINGO,SPSS 软件,如果没有参加建模的话,我也许一辈子都不会去接触这些东西。
这段时间的培训之后,会明显感觉自己的进步以及对问题的数学思维能力的加强,但个人认为要参加比赛,就要博览全书,仅仅把自己的知识局限于此是不够。
培训的过程是相当辛苦的,每天除了吃饭、睡觉,其余时间基本上都是在机房度过的,不断学习、练习,几天下来就会感觉相当疲劳,培训的过程也是对我们队员吃苦耐力的考验。
但是苦中有乐,每天大家过的都很充实,大家相互交流着想法,共同讨论,共同进步。
在参加全国赛的三天内,第一天,我们拿到题目,并结合自身的优点,选择题目,分析题目,指导老师给我们指导和建议,不过一天下来我们几乎毫无进展,我感觉很沮丧,多亏了队友的鼓励和帮助,我才能坚持下来。
第二天,我们又打起精神继续奋战接下来主要进行合理假设与参数说明,把题目转化成数学问题的形式,开始是肯定是建立初等模型,考虑的不全面,队友也有不同想法,这就需要队友相互交流,然后一起完善模型,这就体现团队重要性。
数学建模实战实践心得分享

数学建模实战实践心得分享在大学的学习生涯中,数学建模无疑是一项极具挑战性和趣味性的活动。
通过参与数学建模的实战实践,我不仅在数学知识和技能方面得到了显著的提升,还培养了自己解决实际问题的能力、团队协作精神以及创新思维。
在这里,我想和大家分享一下我在数学建模实战实践中的一些心得体会。
数学建模,简单来说,就是将实际问题转化为数学问题,并通过建立数学模型来求解。
它要求我们能够敏锐地洞察问题的本质,提取关键信息,运用所学的数学知识和方法构建合理的模型,然后利用计算机工具进行求解和分析。
这一过程充满了挑战和不确定性,需要我们具备扎实的数学基础、较强的逻辑思维能力和编程能力。
记得我第一次参加数学建模比赛时,面对一个复杂的实际问题,我感到无从下手。
题目是关于城市交通拥堵的优化问题,需要我们考虑道路容量、车辆流量、信号灯设置等多个因素,并提出有效的解决方案。
当时,我和我的队友们花费了大量的时间和精力来理解题目,查阅相关的资料和文献。
我们发现,这个问题可以用线性规划和图论的方法来解决。
于是,我们开始建立数学模型,将实际的交通网络抽象为一个图,将道路容量和车辆流量表示为图中的边权和节点流量,然后通过求解线性规划问题来确定最优的信号灯设置方案。
在这个过程中,我们遇到了很多困难,比如模型的求解速度太慢、结果不够准确等。
但是,我们并没有放弃,而是不断地尝试和改进。
最终,我们成功地建立了一个较为合理的数学模型,并得到了比较满意的结果。
通过这次经历,我深刻地认识到了数学建模的复杂性和挑战性。
首先,数学建模需要我们具备扎实的数学基础。
如果没有掌握线性代数、概率论、数理统计等数学知识,就很难建立有效的数学模型。
其次,数学建模需要我们具备较强的逻辑思维能力。
在建立模型的过程中,我们需要对问题进行深入的分析和思考,找出问题的内在规律和逻辑关系,然后用数学语言来描述和解决。
此外,数学建模还需要我们具备一定的编程能力。
在求解模型的过程中,我们往往需要使用计算机软件来进行数值计算和模拟,比如 MATLAB、Python 等。
spss学习心得体会学习心得体会

spss学习心得体会学习心得体会篇一:SPSS学习报告总结心得应用统计分析学习报告本科的时候有概率统计和数理分析的基础,但是从来没有接触过应用统计分析的东西,SPSS也只是听说过,从来没有学过。
一直以为这一块儿会比较难,这学期最初学的时候,因为没有认真看老师给的英文教材,课下也没有认真搜集相关资料,所以学起来有些吃力,总感觉听起来一头雾水。
老师说最后的考核是通过提交学习报告,然后我从图书馆里借了些教材查了些资料,发现很多问题都弄清楚了。
结合软件和书上的例子,实战一下,发现SPSS的功能相当强大。
最后总结出这篇报告,以巩固所学。
SPSS,全称是Statistical Product and Service Solutions,即“统计产品与服务解决方案”软件,是IBM公司推出的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称,也是世界上公认的三大数据分析软件之一。
SPSS具有统计分析功能强大、操作界1面友好、与其他软件交互性好等特点,被广泛应用于经济管理、医疗卫生、自然科学等各个领域。
具体到管理方面,SPSS也是一个进行数据分析和预测的强大工具。
这门课中也会用到AMOS软件。
关于SPSS的书,很多都是首先介绍软件的。
这个软件易于安装,我装的是19.0的,虽然20.0有一些改变和优化,但是主体都是一样的,而且都是可视化界面,用起来很方面且容易上手。
所以,我学习的重点是卡方检验和T检验、方差分析、相关分析、回归分析、因子分析、结构方程模型等方法的适用范围、应用价值、计算方式、结果的解释和表述。
首先是T检验这一部分。
由于参数检验的基础不牢固,这部分也是最初开始接触应用统计的东西,学起来很多东西拿不准,比如说原假设默认的是什么。
结果出来后依然分不清楚是接受原假设还是拒绝原假设。
不过现在弄懂了。
这部分很有用的是T检验。
T检验应用于当样本数较小时,且样本取自正态总体同时做两样本均数比较时,还要求两样本的总体方差相等时,已知一个总体均数u,可得到一个样本均数及该样本标准差,样本来自正态或近似正态总体。
基于SPSS的时间系列预测分析

福建农林渔牧业总产值的分析与预测图2-1 ARMA模型建模步骤3数据的采集、整理和分析3.1 数据的采集本文选取1978 年—2007 年福建农业经济产值时间序列数据,资料如下表3-1 所示:表3-1 福建省1978年—2007 农业经济产值时间序列数据(单位:亿)年份农业产值年份农业产值年份农业产值1978 36.33 1988 182.00 1998 973.371979 43.11 1989 209.92 1999 1010.821980 45.49 1990 227.12 2000 1037.271981 56.11 1991 253.51 2001 1061.611982 63.73 1992 295.24 2002 1125.291983 68.08 1993 386.34 2003 1170.541984 80.66 1994 574.05 2004 1315.101985 99.05 1995 738.63 2005 1373.011986 107.07 1996 850.67 2006 1449.781987 132.97 1997 925.56 2007 1692.16数据来源:福建经济与社会统计年鉴3.2 数据的分析处理利用17.0SPSS软件绘制原始数据的时间序列图,如图3-1所示:图3-1 原始数据时间序列图从图3-1可以看出福建省农林渔业总产值呈增长趋势,特别是在1993年以后,呈现出强劲的增长势头。
1992—2007年福建农林渔牧业总产值平均每年增长84.46亿元,平均年增长率为29.28%,呈现加快增长趋势。
从整个时间来看,福建农林渔牧业总产值时间序列呈现出指数增长的趋势,并且具有很强的非平稳性。
3.3 对数据进行零均值化和平稳化处理对含有指数趋势的时间序列,通常可以通过取对数将指数趋势转化为线性趋势,然后再对其进行差分来消除线性趋势[4]。
绘制取对数后的时间序列图3-2所示:图3-2:取对数后的时间序列图取对数后的序列图显示出了线性趋势,对该序列进行取差分运算,先进行一阶差分,绘制一阶差分后的时间序列图,如图3-3所示:图3-3 一阶差分时间序列从图3-3可以看到,一阶差分后,数据图前期波动较大,后期波动较小,且具有一定的非平稳性。
数学建模课实验报告心得(3篇)

第1篇一、前言数学建模是一门将数学理论与实际问题相结合的课程,旨在培养学生运用数学知识解决实际问题的能力。
通过参加数学建模课的实验,我对数学建模有了更深刻的认识,以下是我对实验的心得体会。
二、实验过程1. 理解实验目的在实验开始前,我明确了实验的目的:通过具体实例,掌握数学建模的基本思想和方法,提高自己的实际应用能力。
这使我更加有针对性地进行实验。
2. 实验步骤(1)选题:选择一个实际问题,明确问题的背景、目标和所需解决的问题。
(2)建立模型:运用数学知识,将实际问题转化为数学模型。
(3)求解模型:利用数学软件,对模型进行求解,得到最优解或近似解。
(4)分析结果:对求解结果进行分析,评估其合理性和可行性。
(5)撰写实验报告:总结实验过程、结果和分析,撰写实验报告。
3. 实验成果通过实验,我成功地将一个实际问题转化为数学模型,并利用数学软件求解得到最优解。
同时,我学会了如何分析结果,评估其合理性和可行性。
三、心得体会1. 数学建模的重要性数学建模是解决实际问题的有效途径。
通过数学建模,我们可以将复杂的问题简化为数学模型,从而提高解决问题的效率。
在实验过程中,我深刻体会到了数学建模在解决实际问题中的重要性。
2. 数学知识的运用数学建模实验使我更加深入地理解了所学数学知识,并将其应用于实际问题。
在实验过程中,我运用了线性规划、概率论、统计学等多种数学知识,提高了自己的综合运用能力。
3. 团队合作精神数学建模实验需要团队合作,共同完成实验任务。
在实验过程中,我与团队成员相互学习、相互帮助,共同攻克难题。
这使我认识到团队合作的重要性,培养了团队协作精神。
4. 实验技能的提升通过实验,我熟练掌握了数学建模的基本步骤,提高了自己的实验技能。
同时,我学会了使用数学软件进行求解和分析,为今后从事相关领域的工作打下了基础。
5. 分析问题的能力在实验过程中,我学会了如何分析问题,寻找问题的本质。
这使我具备了解决实际问题的能力,为今后的学习和工作奠定了基础。
spss心得体会5篇最新汇总

spss心得体会5篇最新汇总SPSS是统计产品与服务解决方案的简称,为IBM公司的一系列用于统计学分析运算、数据挖掘、预测分析和决策支持任务的软件产品及相关服务的总称。
下面给大家带来一些关于spss心得,希望对大家有所帮助。
spss心得1spss的许多菜单均可进行描述性统计分析,许多统计过程也都提供描述性统计指标的输出。
在独特样本T检验、方差分析、因子分析等许多分析过程中。
spss自定义表模块也可以产生大部分的描述性统计指标。
1.频率:该过程将产生频数表,也可以输出频数分布的条形图、饼图或者直方图。
2.描述:该过程进行一般性的统计描述。
它可以输出均值、均值的标准误、方差、标准差、范围、最大值、最小值、峰度和偏度。
3.探索:该过程用于对数据的探索性分析。
4.交叉表:该过程完成分类数据的统计描述和一般的统计检验。
5.比率:输出两个尺度变量比率的描述性统计量。
6.pp图:用于绘制尺度变量的pp图。
7.QQ图:用于绘制尺度变量的QQ图,以判断该变量是否服从正态分布。
在spss中选择【分析】—【描述统计】—【频率】在spss中选择【分析】—【描述统计】—【描述】在spss中选择【分析】—【描述统计】—【探索】在spss【设定表】菜单中也可以输出大部分的描述性统计分析指标。
选择【分析】—【表】—【设定表】。
描述性统计分析除了应用数量指标外,还可以应用条形图、饼图、帕累托图、直方图、箱图、茎叶图等统计图形。
在【分析】—【描述统计】—【频率】子菜单下的“图表”选项,可以选择绘制条形图、饼图和直方图。
(1)条形图给出相应每一类的频率,长方形的高度,与类的频率或者相对频率成比例。
(2)帕累托图是按照从高到底顺序排列条形图的长方形条后形成的一种特殊条形图,最高的长方形在左边。
(3)饼图把一个整圆分成几份,每一份代表一个类,每份中心角与类相对频率成比例。
直方图直方图和条形图十分类似,应用于连续型数据,表现在图形上直方图的各个正方形条之间没有任何间隔。
spss实验报告,心得体会

spss实验报告,心得体会目录一、内容概括(1) (2)1.1 实验目的与意义(1) (2)1.2 实验原理与方法(1) (3)1.3 报告结构安排(1) (4)二、实验准备与数据收集(2) (5)2.1 实验材料准备(2) (6)2.2 数据收集方法(2) (7)2.3 数据整理与预处理(2) (8)三、SPSS软件操作基础(3) (9)3.1 SPSS软件概述(3) (11)3.2 基本操作界面介绍(3) (12)3.3 数据编辑与导入(3) (14)四、实验设计与数据分析(4) (15)4.1 实验设计思路(4) (16)4.2 变量定义与赋值(4) (17)4.3 数据分析方法选择(4) (18)4.4 模型构建与评价(4) (19)五、实验结果解读与讨论(5) (20)5.1 实验结果展示(5) (21)5.2 结果分析讨论(5) (22)5.3 结果与预期对比分析(5) (23)5.4 结果的实际应用价值(5) (25)六、实验总结与反思(6) (26)6.1 实验收获总结(6) (27)6.2 实验不足之处分析(6) (28)6.3 对未来研究的建议(6) (29)一、内容概括(1)在本次SPSS实验报告中,我主要围绕实验目的、实验方法、数据处理和结果分析等方面进行了详细的阐述。
我明确了实验的目的,即通过使用SPSS软件对所给定的数据进行分析,以解决实际问题或支持研究。
我介绍了实验的基本方法,包括数据输入、变量定义、数据清洗和统计分析等步骤。
在此基础上,我详细描述了数据处理过程,包括数据的筛选、转换和归一化等操作。
我对实验结果进行了深入的分析,运用SPSS软件中的相关统计方法对数据进行了描述性统计、推断性统计和回归分析等。
通过本次实验,我对SPSS软件的使用有了更深入的了解,同时也提高了自己的数据分析能力。
1.1 实验目的与意义(1)本次SPSS实验旨在通过(具体实验主题)研究,运用SPSS软件进行数据分析,(详细说明实验目的,例如:探索变量之间的关系、检验假设、建立模型等)。
spss实验心得体会范文

spss实验心得体会范文篇一:spss心得体会学习SPSS在教育统计中的应用心得体会一、什么是SPSS,为什么要学习SPSS,新学期开始时,在信息化教育测量与评价的课程中第一次接触到SPSS这个软件,作为本科是计算机专业出身的我,当时只知道SPSS是一套统计软件,就是一套根据统计学原理所编写出来的统计分析软件,至于统计什么,分析什么,我一无所知,尤其是看到老师推荐的《SPSS在教育统计中的应用》这本书的时候,就简单的把它理解为用SPSS软件来统计、分析与教育相关的数据,最终得出想要的结论而已,而现在看来,我当初的想法未免有点简单与无知。
下面就来让我们了解一下SPSS。
SPSS软件是一组专业的、通用的统计软件包,同时它也是一个组合式软件包,兼有数据管理、统计分析、统计绘图和统计报表功能。
它广泛用于教育、心理、医学、市场、人口、保险等研究领域,也用于产品质量控制、人事档案管理和日常统计报表等。
SPSS软件对计算机硬件系统的要求较低;对运行的软件环境要求宽松,有各种版本可运行在WINDOWS XP、WIN7系统环境下, SPSS 统计软件采用电子表格的方式输入与管理数据,能方便地从其他数据库中读入数据(如Dbase,Excel,Lotus等)。
我为什么要学习SPSS呢,其实很简单,一方面,做为一名研究生,要具备一定的科研能力,如今量化研究的方法大行其道,一切要以事实说话、要以数据说话,有了数据支持的研究才能更容易被认可、被推论。
另一方面,根据对AECT94定义的理解,教育技术学研究的对象是学习过程和学习资源,包含大量的偶然现象和非精确现象。
因此,要深入研究教育技术现象及其规律,必须运用统计描述、统计分析方法和模糊数学分析方法,才可能使这门学科达到真正完善的地步。
教育技术学研究的现象多数是偶然的现象,其变化发展往往具有几种不同的可能性,究竟出现哪一种结果,那是带有偶然性的,是随机的。
这类偶然现象是遵循统计规律的,当随机现象是由大量的成份组成,或者随机现象出现大量的次数时,就能体现统计平均规律。
数学建模课后反思总结报告

数学建模课后反思总结报告1. 引言数学建模是一门应用数学的学科,它通过数学方法解决实际问题,具有广泛的应用价值。
在这门课程中,我了解了数学建模的基本概念、方法和技巧,并进行了一些小组项目实践。
通过课程的学习和实践,我对数学建模有了更深入的认识,并掌握了一些解决实际问题的具体方法。
2. 学习收获2.1 数学建模的思维方式在数学建模的学习中,我学会了运用数学方法思考和解决实际问题。
数学建模不仅仅是解决一个个孤立的问题,更重要的是从宏观的角度去分析问题,建立系统的数学模型,最终得到有意义的结论。
这种思维方式对于解决实际生活中的复杂问题具有重要的指导作用,同时也对我的数学思维能力产生了积极的影响。
2.2 数学建模的方法和技巧通过课程的学习,我掌握了数学建模的基本方法和技巧。
比如,如何进行问题分析和建模,如何选择合适的数学工具和模型,如何运用计算机进行模拟和优化,等等。
这些方法和技巧对于解决实际问题非常实用,使我能够更加高效地解决实际问题。
2.3 小组项目实践在课程中,我还参与了一些小组项目实践,这些项目涵盖了不同的领域和问题类型。
通过团队合作,我学会了与他人进行有效的沟通和协作,提高了解决问题的能力。
同时,在项目实践中,我还学到了很多新的知识和技能,不仅扩充了自己的专业知识面,还提高了自己的技术水平和综合能力。
3. 存在问题和不足3.1 对数学的理解不深在学习数学建模的过程中,我发现自己对于一些数学概念和方法的理解并不够深入。
虽然我能够熟练地运用一些基本的数学工具,但是在面对一些复杂的问题时,我并不能够完全理解其背后的数学原理,导致我在建模过程中缺乏一些创造性的想法和解决思路。
因此,我需要加强对数学知识的学习和理解,提高自己的数学素养。
3.2 缺乏实际问题解决的经验虽然在课程中有一些小组项目实践,但总所周知,实际问题的复杂程度往往要高于课堂上的问题模型。
因此,我在解决实际问题时,还缺乏一些实践经验和方法。
数学建模spss-时间预测-心得总结及实例汇编
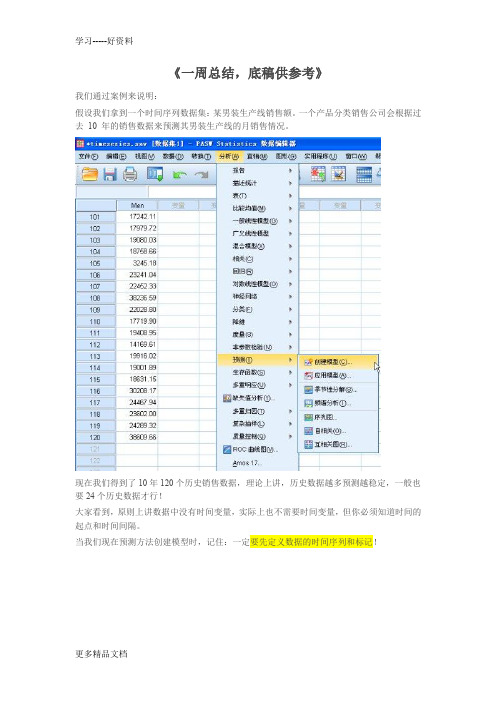
《一周总结,底稿供参考》我们通过案例来说明:假设我们拿到一个时间序列数据集:某男装生产线销售额。
一个产品分类销售公司会根据过去10 年的销售数据来预测其男装生产线的月销售情况。
现在我们得到了10年120个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也要24个历史数据才行!大家看到,原则上讲数据中没有时间变量,实际上也不需要时间变量,但你必须知道时间的起点和时间间隔。
当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标记!这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。
定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER、MONTH 和DATE(时间标签)。
接下来:为了帮我们找到适当的模型,最好先绘制时间序列。
时间序列的可视化检查通常可以很好地指导并帮助我们进行选择。
另外,我们需要弄清以下几点:•此序列是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝?•此序列是否显示季节变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?这时候我们就可以看到时间序列图了!我们看到:此序列显示整体上升趋势,即序列值随时间而增加。
上升趋势似乎将持续,即为线性趋势。
此序列还有一个明显的季节特征,即年度高点在十二月。
季节变化显示随上升序列而增长的趋势,表明是乘法季节模型而不是加法季节模型。
此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。
时间序列预测模型的建立是一个不断尝试和选择的过程。
spss提供了三大类预测方法:1-专家建模器,2-指数平滑法,3-ARIMA指数平滑法指数平滑法有助于预测存在趋势和/或季节的序列,此处数据同时体现上述两种特征。
创建最适当的指数平滑模型包括确定模型类型(此模型是否需要包含趋势和/或季节),然后获取最适合选定模型的参数。
SPSS学习心得(精选五篇)

SPSS学习心得(精选五篇)第一篇:SPSS学习心得SPSS学习心得本学期是我在大学学习的最后一个学期。
在这个学期里,学校根据我系专业特点开设了一些专业应用性课程,其中有一门课程便是SPSS。
SPSS的中文名称是社会科学统计软件包,是世界上最早的统计软件。
我们学期学习所使用的软件为英文版,起初接触时由于我英语水平问题,SPSS软件的操作让我很是头疼。
但是通过对这门课程的学习,我了解到SPSS具有完整的数据输入、编辑、统计分析、报表、图形制作等功能。
在日常的工作与学习中,我所接触到的数据比较多,但是我想从中获得有用的数据却很难,通过SPSS软件应用,使我处理数据的时间大幅度的缩短,另外也能客观直接的对我所需要的数据进行简单分析。
在我平日课下进行统计调查技能培训的时候,我起初分析数据所用的软件是Excel。
虽然使用Excel可以对数据进行透视、分类、筛选以及计算相关系数等,但是这些操作都需要自己每一步每一步的进行手动操作,而使用SPSS软件在对数据进行整理时,只需对软件某选项内设置变量条件,系统便自动的进行整理。
而且,在学习与应用SPSS 过程中,我了解到应用SPSS软件只要了解统计分析的原理无需知晓统计方法的各种算法就能得到自己所需要的统计分析结果。
另外对于常见的统计方法,SPSS的命令语句、子命令及选择项的选择绝大部分在软件内的对话框操作完成,我们无需花费大量的时间记忆大量的命令和选择项。
在这方面,SPSS软件的应用可以使我们节省大量时间,而且软件操作比较容易上手,在当今这个时间就是金钱的社会上,我们掌握SPSS软件的应用,也就是为自己赚取了不少金钱。
另外在与SPSS的接触中,我逐渐了解到SPSS软件的强大与方便。
SPSS提供了从简单的统计描述到复杂的多因素统计分析方法,其中有数据的统计分析、统计描述、交叉表分析、二维相关、方差分析、多元回归、因子分析、聚类分析、降维等分析方法。
利用这些方法可以得出计算数据和统计图形,看出数据的离散程度、集中趋势和分散程度,单变量的比重,还有对数据进行标准化处理。
SPSS数据-分析时间序列分析预测

时间序列分析预测——1961年至2008国民生产总值季度指标本文根据网上找的1961年至2008国民生产总值,利用SPSS软件对其进行一定的分析,得出一些结论和图像,进一步得到相关的指标。
一、基本概念在实际中的数据变量往往是受到大量随机因素的综合影响,曾现很强的随机性,因此这类变量关系不能用一个简单的函数来精确描述。
对于本文的数据问题,由于这类数据是由某一现象在不同时刻的状态所形成,通俗地讲,是某个数量指标在不同时间点上的数值,按照时间的先后顺序排列而成的数列,当其受到各种随机因素影响,从而表现出某种随机性。
时间序列数据的特点是按一定顺序排列,序列中的数据依赖于时间,其取值依赖于时间的变化,时间序列研究的系统是历史行为的客观记录,它包含了系统的结构特征及其运行规律。
本文时间序列分析的主要任务是:1、根据观察数据的特点为数据建立尽可能合理的统计模型。
2、利用模型的统计特性去解释数据来源系统的统计规律,以期达到预测或控制的目的。
这类模型的建模对象具有动态性(记忆性),即相邻观察值具有很强的依赖性,从统计的观点看,是指系统的现在行为与其历史的相关性。
下面就1961年至2008国民生产总值季度指标进行分析(不考虑数据中还包含的第一产业、第二产业和第三产业的GDP指标,因为与GDP总指标分析类同)。
在spss中的输入结果为:时间年限美国GDP1,961.00 5,296.001,961.00 5,483.001,962.00 5,897.001,963.00 6,222.001,964.00 6,686.001,965.00 7,244.001,966.00 7,928.001,967.00 8,378.001,968.00 9,159.001,969.00 9,905.001,970.00 10,447.001,971.00 11,344.001,972.00 12,464.001,973.00 13,949.001,974.00 15,150.001,975.00 16,507.001,976.00 18,414.001,977.00 20,504.001,978.00 23,153.001,979.00 25,945.001,980.00 28,225.001,981.00 31,598.001,982.00 32,897.001,983.00 35,747.001,984.00 39,658.001,985.00 42,440.001,986.00 44,777.001,987.00 47,540.001,988.00 51,238.001,989.00 55,081.001,990.00 58,350.001,991.00 60,220.001,992.00 63,714.001,993.00 66,985.001,994.00 71,092.001,995.00 74,444.001,996.00 78,701.001,997.00 83,558.001,998.00 88,100.001,999.00 93,817.002,000.00 99,898.002,001.00 103,381.002,002.00 106,914.002,003.00 112,108.002,004.00 119,590.002,005.00 127,355.002,006.00 134,712.002,007.00 141,933.002,008.00 145,833.00注:单位:万亿美元,数据表示一年中截止该季度时的国民生产总值。
数学建模实战实践经验总结

数学建模实战实践经验总结数学建模,对于许多人来说,可能是一个既神秘又充满挑战的领域。
在亲身经历了多次数学建模的实战实践后,我积累了不少宝贵的经验,也深刻体会到了其中的酸甜苦辣。
接下来,我将毫无保留地与大家分享这些经验。
首先,组队是数学建模实战中的关键一步。
一个优秀的团队应该具备不同的技能和优势。
一般来说,团队成员需要包括擅长数学理论的、精通编程的以及文字功底扎实的。
数学理论功底深厚的队员能够为模型的建立提供坚实的基础,确保模型的科学性和合理性;熟练掌握编程的队员则能将复杂的数学模型转化为可计算、可验证的程序,提高解决问题的效率;文字表达能力强的队员负责将团队的思路、方法和结果清晰准确地撰写出来,使最终的论文具有良好的可读性和说服力。
在组队过程中,不仅要考虑成员的专业能力,还要注重团队的协作精神和沟通能力。
一个和谐、默契的团队能够在面对困难和压力时保持冷静,共同攻克难题。
其次,选题是决定建模成败的重要因素之一。
在面对众多的题目时,我们不能盲目选择,而应该综合考虑多方面的因素。
一是要结合团队成员的专业背景和兴趣爱好。
如果对选题所涉及的领域有一定的了解和研究,那么在后续的建模过程中会更加得心应手。
二是要评估题目的难度和可行性。
过于简单的题目可能无法充分展现团队的实力,而过于复杂的题目则可能在有限的时间内无法完成。
三是要关注题目的现实意义和应用价值。
具有实际应用背景的题目往往更能激发团队的创新思维和积极性。
在确定好题目后,深入理解题目要求和背景信息是至关重要的。
我们需要仔细分析题目中给出的数据、条件和限制,明确问题的核心和目标。
同时,还要通过查阅相关的文献资料,了解该领域的研究现状和前沿成果,为建模提供更多的思路和方法。
在这个过程中,做好笔记和整理工作是非常有必要的,这样可以避免在后续的建模过程中出现遗漏和错误。
模型的建立是数学建模的核心环节。
在建立模型时,我们要遵循简洁、有效、合理的原则。
不要一开始就追求过于复杂和完美的模型,而是从简单的模型入手,逐步完善和优化。
学习数学建模心得体会3篇

学习数学建模心得体会3篇数学建模已成为国际、国内数学教育中稳定的内容和热点之一。
下面是店铺为大家准备的学习数学建模心得体会,希望大家喜欢!学习数学建模心得体会范文1自从大二下学期真正开了数学模型这一门课之后,我对数学认识又进一步加深。
虽然我是学纯数学即数学与应用数学,但是在我的认知中,数学最多的是单纯地证明一些定理抑或是反复的计算一些步骤比较多的题进而求解。
随着老师在课堂上一点一点的引导、介绍、讲解,我渐渐地发现数学真的是很万能啊(在我看来),任何实际问题只要运用数学建立模型都可以抽象成一个数学方面的问题,进而单纯的分析、计算、求解。
这只是我大体的认识。
首先,通过数学模型这一门课我解开了数学模型的神秘面纱,与数学模型紧密相连的就是数学建模,简而言之来说数学建模就是应用数学模型来解决各种实际问题的过程,也就是通过对实际问题的抽象、简化、确定变量和参数,并应用某些规律建立变量与参数之间的关系的数学问题(或称一个数学模型),在借用计算机求解该数学问题,并解释,检验,评价所得的解,从而确定能否将其用于解决实际问题的多次循环,不断深化的过程。
以下是我学习数学模型的一些心得:第一,数学模型是数学的一个分支,它还没有脱离数学,众所周知数学是一门比较抽象的课程,主要需要和训练的还是逻辑思维。
因此数学模型需要和训练的都基本是思维,但和纯数学区别的是数学模型只要抽象出数学问题的本质,进而建模,那之后不是非得自己一步步地演算、求解。
第二,数学模型最后的求解很多时候都不可避免地要用到计算机,比如像matlab,spss,linggo之类的数学软件。
因此在学习过程中我们也得对这些软件有一定的了解和认识。
这也就与平常的学习方式产生了区别,平常的数学方式因为其内容和讲授被限制在了平常的阶梯教室,但数学模型这一门课就必须通过自己的实践运用计算机来达到自己的目的。
因此我们的学习方式就多了一项(通过计算机进一步了解数学模型的魅力)。
时间序列预测实验心得

时间序列预测实验心得
时间序列预测是一种重要的数据分析方法,它可以帮助我们预测未来的趋势和模式。
在最近的一次时间序列预测实验中,我深刻体会到了这种方法的重要性和应用价值。
首先,在实验过程中,我发现时间序列预测需要对数据进行详细的分析和处理。
我们需要对时间序列数据进行平稳性检验、趋势性分析等,以确保数据的可靠性和准确性。
只有通过深入的数据分析,我们才能得到准确的预测结果。
其次,在选择预测模型时,我学会了根据数据的特点和趋势来选择不同的模型。
例如,对于具有明显周期性的数据,我们可以选择季节性时间序列模型;对于具有线性趋势的数据,我们可以选择ARIMA模型。
只有选择合适的模型,我们才能得到准确的预测结果。
最后,在实验中,我发现时间序列预测需要不断地调整和优化模型。
我们需要通过不断地对模型进行测试和评估,找到最佳的模型
参数和预测方法。
只有不断地优化模型,我们才能得到准确的预测结果。
通过这次时间序列预测实验,我对这种方法有了更深刻的了解。
我学会了如何对时间序列数据进行详细的分析和处理,如何选择合适的预测模型,以及如何不断地优化模型。
这些经验对我今后的数据分析工作将会有很大帮助。
总的来说,时间序列预测是一种重要的数据分析方法,它可以帮助我们预测未来的趋势和模式。
通过不断地实践和总结经验,我们可以不断地提高预测的准确性和可靠性。
希望在今后的工作中,我可以更好地运用时间序列预测方法,为企业的发展提供有力的数据支持。
数学建模spss时间预测,心得总结及实例
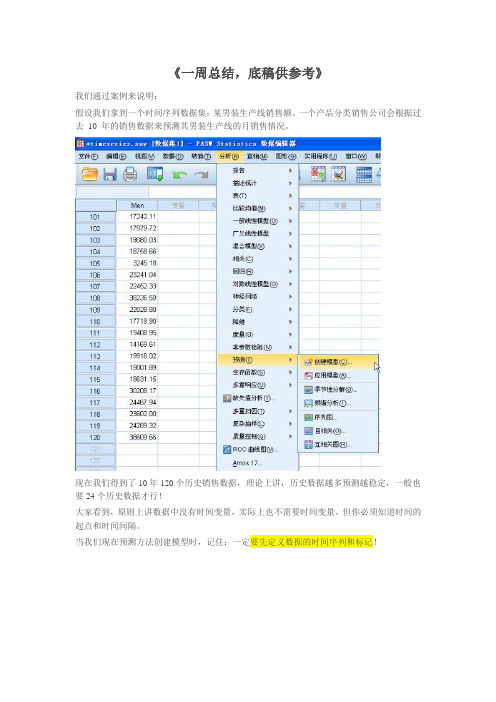
《一周总结,底稿供参考》我们通过案例来说明:假设我们拿到一个时间序列数据集:某男装生产线销售额。
一个产品分类销售公司会根据过去10 年的销售数据来预测其男装生产线的月销售情况。
现在我们得到了10年120个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也要24个历史数据才行!大家看到,原则上讲数据中没有时间变量,实际上也不需要时间变量,但你必须知道时间的起点和时间间隔。
当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标记!这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。
定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER、MONTH 和DATE(时间标签)。
接下来:为了帮我们找到适当的模型,最好先绘制时间序列。
时间序列的可视化检查通常可以很好地指导并帮助我们进行选择。
另外,我们需要弄清以下几点:•此序列是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝?•此序列是否显示季节变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?这时候我们就可以看到时间序列图了!我们看到:此序列显示整体上升趋势,即序列值随时间而增加。
上升趋势似乎将持续,即为线性趋势。
此序列还有一个明显的季节特征,即年度高点在十二月。
季节变化显示随上升序列而增长的趋势,表明是乘法季节模型而不是加法季节模型。
此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。
时间序列预测模型的建立是一个不断尝试和选择的过程。
spss提供了三大类预测方法:1-专家建模器,2-指数平滑法,3-ARIMA指数平滑法指数平滑法有助于预测存在趋势和/或季节的序列,此处数据同时体现上述两种特征。
创建最适当的指数平滑模型包括确定模型类型(此模型是否需要包含趋势和/或季节),然后获取最适合选定模型的参数。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
《一周总结,底稿供参考》
我们通过案例来说明:
假设我们拿到一个时间序列数据集:某男装生产线销售额。
一个产品分类销售公司会根据过去10 年的销售数据来预测其男装生产线的月销售情况。
现在我们得到了10年120个历史销售数据,理论上讲,历史数据越多预测越稳定,一般也要24个历史数据才行!
大家看到,原则上讲数据中没有时间变量,实际上也不需要时间变量,但你必须知道时间的起点和时间间隔。
当我们现在预测方法创建模型时,记住:一定要先定义数据的时间序列和标记!
这时候你要决定你的时间序列数据的开始时间,时间间隔,周期!在我们这个案例中,你要决定季度是否是你考虑周期性或季节性的影响因素,软件能够侦测到你的数据的季节性变化因子。
定义了时间序列的时间标记后,数据集自动生成四个新的变量:YEAR、QUARTER、MONTH 和DATE(时间标签)。
接下来:为了帮我们找到适当的模型,最好先绘制时间序列。
时间序列的可视化检查通常可以很好地指导并帮助我们进行选择。
另外,我们需要弄清以下几点:
•此序列是否存在整体趋势?如果是,趋势是显示持续存在还是显示将随时间而消逝?•此序列是否显示季节变化?如果是,那么这种季节的波动是随时间而加剧还是持续稳定存在?
这时候我们就可以看到时间序列图了!
我们看到:此序列显示整体上升趋势,即序列值随时间而增加。
上升趋势似乎将持续,即为线性趋势。
此序列还有一个明显的季节特征,即年度高点在十二月。
季节变化显示随上升序列而增长的趋势,表明是乘法季节模型而不是加法季节模型。
此时,我们对时间序列的特征有了大致的了解,便可以开始尝试构建预测模型。
时间序列预测模型的建立是一个不断尝试和选择的过程。
spss提供了三大类预测方法:1-专家建模器,2-指数平滑法,3-ARIMA
指数平滑法
指数平滑法有助于预测存在趋势和/或季节的序列,此处数据同时体现上述两种特征。
创建最适当的指数平滑模型包括确定模型类型(此模型是否需要包含趋势和/或季节),然后获取最适合选定模型的参数。
1-简单模型预测(即无趋势也无季节)
首先我们采用最为简单的建模方法,就是简单模型,这里我们不断尝试的目的是让大家熟悉各种预测模型,了解模型在什么时候不适合数据,这是成功构建模型的基本技巧。
我们先不讨论模型的检验,只是直观的看一下预测模型的拟合情况,最后我们确定了预测模型后我们再讨论检验和预测值。
从图中我们看到,虽然简单模型确实显示了渐进的上升趋势,但并不是我们期望的结果,既没有考虑季节性变化,也没有周期性呈现,直观的讲基本上与线性预测没有差异。
所以我们拒绝此模型。
2-Holt线性趋势预测
Holt线性指数平滑法,一般选择:针对等级的平滑系数lapha=0.1,针对趋势的平滑系数gamma=0.2;
从上面的拟合情况看,Holt预测模型更平滑了,也就是说Holt模型比简单模型显现了更强的平滑趋势,但未考虑季节因素,还是不理想,所以还应放弃此模型。
3-简单季节性模型
当我们考虑了季节性变化后,简单季节性预测模型基本上较好的拟合了数据的大趋势,也就是考虑了趋势和季节。
4-Winters相乘法预测模型
我们再次选择Winters预测模型
此时,在数据集的时间跨度为10年,并且包含10 个季节峰值(出现在每年十二月份)中,简单季节模型和Winters模型都扑捉到了这10个峰值与实际数据中的10个年度峰值完全匹配的预测结果。
此时,我们基本上可以得到了一个比较满意的预测结果。
此时也说明,无论采用指数平滑的什么模型,只要考虑了季节因素,都可以得到较好结果,不同的季节性指数平滑方法只是细微差异了。
但是,我们仔细看预测值和拟合值,还是有一些上升和下降的趋势和结构没有扑捉到。
预测还有改进的需求!
5-ARIMA预测模型ARIMA模型是自回归AR和移动平均MA加上差分考虑,
我们采用专家建模器,但指定仅限ARIMA模型,并考虑季节性因素。
此时,我们看到模型拟合并相比较简单季节性和Winters模型没有太大的优势,结果可接受,但是大家注意到没有,实际上我们一直没有考虑自变量的进入问题,假如我们有其它变量可能会影响到男装销售收入,情况又会发生什么变化呢?
时间序列预测技术之三——含自变量的ARIMA模型预测
下面的数据延续前两篇的案例,只是增加了自变量,(因为手头这个案例没有干预因素变量)
在我们增加了5个自变量后,采用预测建模方法,选择专家建模器,但限制只在ARIMA模型中选择。
确定后,得到分析结果,我们现在来看一下与原来的模型有什么不同。
从预测值看,比前一模型有了改进,至少这时候的模型捕捉了历史数据中的下降峰值,这可以认为是当前比较适合的拟合值了。
如果我们观察预测结果,可以发现模型选择了两个预测变量。
注意:使用专家建模器时,只有在自变量与因变量之间具有统计显著性关系时才会包括自变量。
如果选择ARIMA模型,“变量”选项卡上指定的所有自变量(预测变量)都包括在该模型中,这点与使用专家建模器相反;
当确定了最终选择的预测模型和方法后,我们就可以预测未来了,当然你要指定预测未来的时间点,这里我们时间包括年、季度和月份;假定我们预测未来半年的销售收入。
我们分别设定:预测值输出,95%置信度的上下限。
注意:SPSS中文环境有个小Bug,必须改一下名字!
在选项中,选择你的预测时间,预测期将根据你事先定义的数据时间格式填写。
(后面的模型为了让大家看清楚,实际上我预测了一年的数据,也就是2010年的4个季度的12个月)。
自变量的选择问题,在预测未来半年的销售收入中,ARIMA模型可以把其它预测变量纳入考虑,但如何确定未来这些预测变量的值呢?
主要方法可以考虑:1)选择最末期数据;2)选择近三期数据的平均;3)选择近三期的移动平均
这里我们选近三期移动平均作为预测自变量数值。
上面就是预测结果!于此同时,SPSS活动数据集中也存储了预测值!
最后,我们要解决时间序列预测的检验和统计问题!实际上我们可以通过软件得到各种统计检验指标和统计检验图表!
最后我们看一眼统计检验指标结果:
比如:Sig值越大越好,平稳得R方也是越大越好
∙Sig.列给出了Ljung-Box 统计量的显著性值,该检验是对模型中残差错误的随机检验;表示指定的模型是否正确。
显著性值小于0.05 表示残差误差不是随机的,则意味着所观测的序列中存在模型无法解释的结构。
∙平稳的R方:显示固定的R平方值。
此统计量是序列中由模型解释的总变异所占比例的估计值。
该值越高(最大值为1.0),则模型拟合会越好。
∙检查模型残差的自相关函数(ACF) 和偏自相关函数(PACF) 的值比只查看拟合优度统计量能更多地从量化角度来了解模型。
合理指定的时间模型将捕获所有非随机的变异,其中包括季节性、趋势、循环周期以及其他重要的因素。
如果是这种情况,则任何误差都不会随着时间的推移与其自身相关联(自关联)。
这两个自相关函数中的显著结构都可以表明基础模型不完整。