Hadoop集群规划
Hadoop集群配置详细

Linux系统配置
7安装JDK 将JDK文件解压,放到/usr/java目录下 cd /home/dhx/software/jdk mkdir /usr/java mv jdk1.6.0_45.zip /usr/java/
cd /usr/java
unzip jdk1.6.0_45.zip
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
从当前用户切换root用户的命令如下:
Linux系统配置
操作步骤需要在HadoopMaster和HadoopSlave节点
上分别完整操作,都是用root用户。 从当前用户切换root用户的命令如下:
su root
从当前用户切换root用户的命令如下:
Linux系统配置
1拷贝软件包和数据包 mv ~/Desktop/software ~/
环境变量文件中,只需要配置JDK的路径
gedit conf/hadoop-env.sh
从当前用户切换root用户的命令如下: 编辑主机名列表的命令
Hadoop配置部署
3配置核心组件core-site.xml
gedit conf/core-site.xml
<configuration> <property> <name></name> /*2.0后用 fs.defaultFS代替*/ <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/dhx/hadoopdata</value> </property> </configuration>
hadoop核心组件概述及hadoop集群的搭建

hadoop核⼼组件概述及hadoop集群的搭建什么是hadoop? Hadoop 是 Apache 旗下的⼀个⽤ java 语⾔实现开源软件框架,是⼀个开发和运⾏处理⼤规模数据的软件平台。
允许使⽤简单的编程模型在⼤量计算机集群上对⼤型数据集进⾏分布式处理。
hadoop提供的功能:利⽤服务器集群,根据⽤户的⾃定义业务逻辑,对海量数据进⾏分布式处理。
狭义上来说hadoop 指 Apache 这款开源框架,它的核⼼组件有:1. hdfs(分布式⽂件系统)(负责⽂件读写)2. yarn(运算资源调度系统)(负责为MapReduce程序分配运算硬件资源)3. MapReduce(分布式运算编程框架)扩展:关于hdfs集群: hdfs集群有⼀个name node(名称节点),类似zookeeper的leader(领导者),namenode记录了⽤户上传的⼀些⽂件分别在哪些DataNode上,记录了⽂件的源信息(就是记录了⽂件的名称和实际对应的物理地址),name node有⼀个公共端⼝默认是9000,这个端⼝是针对客户端访问的时候的,其他的⼩弟(跟随者)叫data node,namenode和datanode会通过rpc进⾏远程通讯。
Yarn集群: yarn集群⾥的⼩弟叫做node manager,MapReduce程序发给node manager来启动,MapReduce读数据的时候去找hdfs(datanode)去读。
(注:hdfs集群和yarn集群最好放在同⼀台机器⾥),yarn集群的⽼⼤主节点resource manager负责资源调度,应(最好)单独放在⼀台机器。
⼴义上来说,hadoop通常指更⼴泛的概念--------hadoop⽣态圈。
当下的 Hadoop 已经成长为⼀个庞⼤的体系,随着⽣态系统的成长,新出现的项⽬越来越多,其中不乏⼀些⾮ Apache 主管的项⽬,这些项⽬对 HADOOP 是很好的补充或者更⾼层的抽象。
hadoop集群部署之双虚拟机版

1、采用一台机器开两个虚拟机的方式构成两台电脑的环境,用root登录。
分别查看其IP地址:输入# ifconfig,可得主机IP:192.168.1.99;分机为:192.168.1.100。
2、在两台机器上的/etc/hosts均添加相应的主机名和IP地址:这里主机名命名为shenghao,分机名命名为slave:保存后重启网络:3、两台机器上均创立hadoop用户(注意是用root登陆)# useradd hadoop# passwd hadoop输入111111做为密码登录hadoop用户:注意,登录用户名为hadoop,而不是自己命名的shenghao。
4、ssh的配置进入centos的“系统→管理→服务器设置→服务,查看sshd服务是否运行。
在所有的机器上生成密码对:# ssh-keygen -t rsa这时hadoop目录下生成一个.ssh的文件夹,可以通过# ls .ssh/来查看里面产生的私钥和公钥:id_rsa和id_rsa.pub。
更改.ssh的读写权限:# chmod 755 .ssh在namenode上(即主机上)进入.ssh,将id_rsa.pub直接复制为authorized_keys(namenode的公钥):# cp id_rsa.pub authorized_keys更改authorized_keys的读写权限:# chmod 644 authorized_keys 【这个不必须,但保险起见,推荐使用】然后上传到datanode上(即分机上):# scp authorized_keys hadoop@slave:/home/hadoop/.ssh# cd .. 退出.ssh文件夹这样shenghao就可以免密码登录slave了:然后输入exit就可以退出去。
然后在datanode上(即分机上):将datanode上之前产生的公钥id_rsa.pub复制到namenode上的.ssh目录中,并重命名为slave.id_rsa.pub,这是为了区分从各个datanode上传过来的公钥,这里就一个datanode,简单标记下就可。
搭建hadoop集群的步骤

搭建hadoop集群的步骤Hadoop是一个开源的分布式计算平台,用于存储和处理大规模的数据集。
在大数据时代,Hadoop已经成为了处理海量数据的标准工具之一。
在本文中,我们将介绍如何搭建一个Hadoop集群。
步骤一:准备工作在开始搭建Hadoop集群之前,需要进行一些准备工作。
首先,需要选择适合的机器作为集群节点。
通常情况下,需要至少三台机器来搭建一个Hadoop集群。
其次,需要安装Java环境和SSH服务。
最后,需要下载Hadoop的二进制安装包。
步骤二:配置Hadoop环境在准备工作完成之后,需要对Hadoop环境进行配置。
首先,需要编辑Hadoop的配置文件,包括core-site.xml、hdfs-site.xml、mapred-site.xml和yarn-site.xml。
其中,core-site.xml用于配置Hadoop的核心参数,hdfs-site.xml用于配置Hadoop分布式文件系统的参数,mapred-site.xml用于配置Hadoop的MapReduce参数,yarn-site.xml用于配置Hadoop的资源管理器参数。
其次,需要在每个节点上创建一个hadoop用户,并设置其密码。
最后,需要在每个节点上配置SSH免密码登录,以便于节点之间的通信。
步骤三:启动Hadoop集群在完成Hadoop环境的配置之后,可以启动Hadoop集群。
首先,需要启动Hadoop的NameNode和DataNode服务。
NameNode是Hadoop分布式文件系统的管理节点,负责管理文件系统的元数据。
DataNode是Hadoop分布式文件系统的存储节点,负责实际存储数据。
其次,需要启动Hadoop的ResourceManager和NodeManager服务。
ResourceManager 是Hadoop的资源管理器,负责管理集群中的资源。
NodeManager是Hadoop的节点管理器,负责管理每个节点的资源。
Hadoop集群部署有几种模式?Hadoop集群部署方法介绍
Hadoop集群的部署分为三种,分别独立模式(Standalonemode)、伪分布式模式(Pseudo-Distributedmode)、完全分布式模式(Clustermode),具体介绍如下。
(1)独立模式:又称为单机模式,在该模式下,无需运行任何守护进程,所有的
程序都在单个JVM上执行。
独立模式下调试Hadoop集群的MapReduce程序非常
方便,所以一般情况下,该模式在学习或者发阶段调试使用。
(2)伪分布式模式:Hadoop程序的守护进程运行在一台节上,通常使用伪分布
式模式用来调试Hadoop分布式程序的代码,以及程序执行否正确,伪分布式模式完全分布式模式的一个特例。
(3)完全分布式模式:Hadoop的守护进程分别运行在由多个主机搭建的集群上,不同节担任不同的角色,在实际工作应用发中,通常使用该模式构建级Hadoop系统。
在Hadoop环境中,所有器节仅划分为两种角色,分别master(主节,1个)和slave(从节,多个)。
因此,伪分布模式集群模式的特例,只将主节和从节合二
为一罢了。
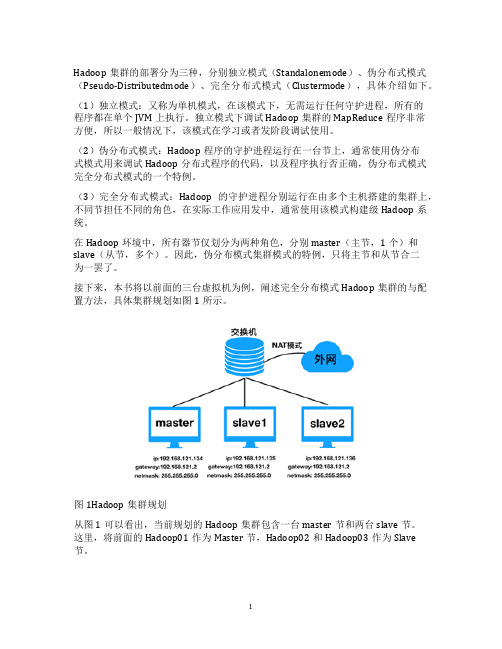
接下来,本书将以前面的三台虚拟机为例,阐述完全分布模式Hadoop集群的与配置方法,具体集群规划如图1所示。
图1Hadoop集群规划
从图1可以看出,当前规划的Hadoop集群包含一台master节和两台slave节。
这里,将前面的Hadoop01作为Master节,Hadoop02和Hadoop03作为Slave
节。
1。
大数据集群部署方案

八、风险与应对措施
1.技术风险:关注技术动态,及时更新和升级相关软件。
2.数据安全风险:加强数据安全防护措施,定期进行合规性检查。
3.人才短缺:加强团队培训,提高技能水平。
4.成本控制:合理规划项目预算,控制成本。
九、总结
本方案为企业提供了一套完整、科学的大数据集群部署方案,旨在实现高效、稳定的数据处理和分析。通过严谨的技术选型和部署架构设计,确保数据安全、合规性。同时,注重运维保障和人才培养,提高大数据应用能力。在项目实施过程中,积极应对各类风险,确保项目顺利推进,为企业创造持续的业务价值。
二、项目目标
1.搭建一套完整的大数据集群环境,满足业务部门对数据处理、分析、挖掘的需求。
2.确保集群系统的高可用性、高性能、易扩展性,降低运维成本。
3.遵循国家相关法律法规,确保数据安全与合规性。
三、技术选型
1.分布式存储:采用Hadoop分布式文件系统(HDFS)进行数据存储,确保数据的高可靠性和高可用性。
- Kafka集群:用于收集和传输实时数据,支持实时数据处理。
五、数据安全与合规性
1.数据加密:对存储在HDFS上的数据进行加密,防止数据泄露。
2.访问控制:采用Kerberos进行身份认证,结合HDFS权限管理,实现数据访问控制。
3.数据脱敏:对敏感数据进行脱敏处理,确保数据合规使用。
4.审计日志:开启Hadoop审计日志,记录用户操作行为,便于审计和监控。
- ZooKeeper集群:负责集群的分布式协调服务,确保集群的高可用性。
- Kafka集群:用于收集和传输实时数据,为实时数据处理提供支持。
五、数据安全与合规性
1.数据加密:对存储在HDFS上的数据进行加密处理,防止数据泄露。
Hadoop集群配置心得(低配置集群+自动同步配置)

Hadoop集群配置⼼得(低配置集群+⾃动同步配置)本⽂为本⼈原创,⾸发到炼数成⾦。
情况是这样的,我没有⼀个⾮常强劲的电脑来搞出⼀个性能⾮常NB的服务器集群,相信很多⼈也跟我差不多,所以现在把我的低配置集群经验拿出来写⼀下好了。
我的配备:1)五六年前的赛扬单核处理器2G内存笔记本 2)公司给配的ThinkpadT420,i5双核处理器4G内存(可⽤内存只有3.4G,是因为装的是32位系统的缘故吧。
)就算是⽤公司配置的电脑,做出来三台1G内存的虚拟机也显然是不现实的。
企业笔记本运⾏的软件多啊,什么都不做空余内存也才不到3G。
所以呢,我的想法就是:⽤我⾃⼰的笔记本(简称PC1)做Master节点,⽤来跑Jobtracker,Namenode 和SecondaryNamenode;⽤公司的笔记本跑两个虚拟机(简称VM1和VM2),⽤来做Slave节点,跑Tasktracker和Datanode。
这么做的话,就需要让PC1,VM1和VM2处于同⼀个⽹段⾥,保证他们之间可以互相连通。
⽹络环境:我的两台电脑都是通过⼀个⽆线路由上⽹。
构建跟外部的电脑同⼀⽹段的虚拟机配置过程:准备⼯作:构建⼀个集群,⾸先前提条件是每台服务器都要有⼀个固定的IP地址,然后才可能进⾏后续的操作。
所以呢,先把我的两台笔记本电脑全部设置成固定IP(注意,如果像我⼀样使⽤⽆线路由上⽹,那就要把⽆线⽹卡的IP设置成固定IP)。
⽤来做Master节点的PC1:192.168.33.150,⽤来跑虚拟机的宿主笔记本:192.168.33.157。
⽬标:VM1和VM2的IP地址分别设置成192.168.33.151和152。
步骤:1)新建VM1虚拟机。
2)打开VM1的⽹卡设置界⾯,连接⽅式选Bridge。
(桥接)关于桥接的具体信息,可以百度⼀下。
我们需要知道的,就是⽤桥接的⽅式,可以让虚拟机通过本机的⽹关来上⽹,所以就可以跟本机处于同⼀个⽹段,互相之间可以进⾏通信。
《hadoop基础》课件——第三章 Hadoop集群的搭建及配置

19
Hadoop集群—文件监控
http://master:50070
20
Hadoop集群—文件监控
http://master:50070
21
Hadoop集群—文件监控
http://master:50070
22
Hadoop集群—任务监控
http://master:8088
23
Hadoop集群—日志监控
http://master:19888
24
Hadoop集群—问题 1.集群节点相关服务没有启动?
1. 检查对应机器防火墙状态; 2. 检查对应机器的时间是否与主节点同步;
25
Hadoop集群—问题
2.集群状态不一致,clusterID不一致? 1. 删除/data.dir配置的目录; 2. 重新执行hadoop格式化;
准备工作:
1.Linux操作系统搭建完好。 2.PC机、服务器、环境正常。 3.搭建Hadoop需要的软件包(hadoop-2.7.6、jdk1.8.0_171)。 4.搭建三台虚拟机。(master、node1、node2)
存储采用分布式文件系统 HDFS,而且,HDFS的名称 节点和数据节点位于不同机 器上。
2、vim编辑core-site.xml,修改以下配置: <property>
<name>fs.defaultFS</name> <value>hdfs://master:9000</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/opt/soft/hadoop-2.7.6/tmp</value> </property> <property> <name>fs.trash.interval</name> <value>1440</value> </property>
Hadoop集群的搭建方法与步骤

Hadoop集群的搭建方法与步骤随着大数据时代的到来,Hadoop作为一种分布式计算框架,被广泛应用于数据处理和分析领域。
搭建一个高效稳定的Hadoop集群对于数据科学家和工程师来说至关重要。
本文将介绍Hadoop集群的搭建方法与步骤。
一、硬件准备在搭建Hadoop集群之前,首先要准备好适合的硬件设备。
Hadoop集群通常需要至少三台服务器,一台用于NameNode,两台用于DataNode。
每台服务器的配置应该具备足够的内存和存储空间,以及稳定的网络连接。
二、操作系统安装在选择操作系统时,通常推荐使用Linux发行版,如Ubuntu、CentOS等。
这些操作系统具有良好的稳定性和兼容性,并且有大量的Hadoop安装和配置文档可供参考。
安装操作系统后,确保所有服务器上的软件包都是最新的。
三、Java环境配置Hadoop是基于Java开发的,因此在搭建Hadoop集群之前,需要在所有服务器上配置Java环境。
下载最新版本的Java Development Kit(JDK),并按照官方文档的指引进行安装和配置。
确保JAVA_HOME环境变量已正确设置,并且可以在所有服务器上运行Java命令。
四、Hadoop安装与配置1. 下载Hadoop从Hadoop官方网站上下载最新的稳定版本,并将其解压到一个合适的目录下,例如/opt/hadoop。
2. 编辑配置文件进入Hadoop的安装目录,编辑conf目录下的hadoop-env.sh文件,设置JAVA_HOME环境变量为Java的安装路径。
然后,编辑core-site.xml文件,配置Hadoop的核心参数,如文件系统的默认URI和临时目录。
接下来,编辑hdfs-site.xml文件,配置Hadoop分布式文件系统(HDFS)的相关参数,如副本数量和数据块大小。
最后,编辑mapred-site.xml文件,配置MapReduce框架的相关参数,如任务调度器和本地任务运行模式。
1.Hadoop集群搭建(单机伪分布式)

1.Hadoop集群搭建(单机伪分布式)>>>加磁盘1)⾸先先将虚拟机关机2)选中需要加硬盘的虚拟机:右键-->设置-->选中硬盘,点击添加-->默认选中硬盘,点击下⼀步-->默认硬盘类型SCSI(S),下⼀步-->默认创建新虚拟磁盘(V),下⼀步-->根据实际需求,指定磁盘容量(单个或多个⽂件⽆所谓,选哪个都⾏),下⼀步。
-->指定磁盘⽂件,选择浏览,找到现有虚拟机的位置(第⼀次出现.vmdk⽂件的⽂件夹),放到⼀起,便于管理。
点击完成。
-->点击确定。
3) 可以看到现在选中的虚拟机有两块硬盘,点击开启虚拟机。
这个加硬盘只是在VMWare中,实际⼯作中直接买了硬盘加上就可以了。
4)对/dev/sdb进⾏分区df -h 查看当前已⽤磁盘分区fdisk -l 查看所有磁盘情况磁盘利⽤情况,依次对磁盘命名的规范为,第⼀块磁盘sda,第⼆块为sdb,第三块为sdc。
可以看到下图的Disk /dev/sda以第⼀块磁盘为例,磁盘分区的命名规范依次为sda1,sda2,sda3。
同理也会有sdb1,sdb2,sdb3。
可以参照下图的/dev/sda1。
下⾯的含义代表sda盘有53.7GB,共分为6527个磁柱,每个磁柱单元Units的⼤⼩为16065*512=8225280 bytes。
sda1分区为1-26号磁柱,sda2分区为26-287号磁柱,sda3为287-6528号磁柱下⾯的图⽚可以看到,还未对sdb磁盘进⾏分区fdisk /dev/sdb 分区命令可以选择m查看帮助,显⽰命令列表p 显⽰磁盘分区,同fdisk -ln 新增分区d 删除分区w 写⼊并退出选w直接将分区表写⼊保存,并退出。
mkfs -t ext4 /dev/sdb1 格式化分区,ext4是⼀种格式mkdir /newdisk 在根⽬录下创建⼀个⽤于挂载的⽂件mount /dev/sdb1 /newdisk 挂载sdb1到/newdisk⽂件(这只是临时挂载的解决⽅案,重启机器就会发现失去挂载)blkid /dev/sdb1 通过blkid命令⽣成UUIDvi /etc/fstab 编辑fstab挂载⽂件,新建⼀⾏挂载记录,将上⾯⽣成的UUID替换muount -a 执⾏后⽴即⽣效,不然的话是重启以后才⽣效。
hadoop集群建设方案

hadoop集群建设方案如何构建一个Hadoop集群。
Hadoop集群的构建是一个复杂的过程,涉及到硬件设备的选择、网络连接的配置、软件环境的搭建等诸多方面。
本文将从集群规模、硬件设备、操作系统、网络连接、Hadoop软件的安装与配置等方面,一步一步地介绍如何构建一个Hadoop集群。
一、集群规模的确定在构建Hadoop集群之前,首先需要确定集群规模,即集群中节点的数量。
集群规模的确定需要考虑到数据量的大小、负载的情况以及可承受的成本等因素。
一般来说,至少需要3个节点才能构建一个功能完善的Hadoop 集群,其中一个作为主节点(NameNode),其余为从节点(DataNode)。
二、硬件设备的选择在选择硬件设备时,需要考虑到节点的计算性能、存储容量以及网络带宽等因素。
对于主节点,需要选择一台计算性能较高、内存较大的服务器,通常选择多核CPU和大容量内存。
对于从节点,可以选择较为经济实惠的服务器或者PC机,存储容量要满足数据存储的需求,同时要保证网络带宽的充足。
三、操作系统的配置在构建Hadoop集群之前,需要在每个节点上安装操作系统,并设置网络连接。
一般推荐选择Linux 操作系统,如CentOS、Ubuntu 等。
安装完成后,需要配置每个节点的域名解析、主机名以及网络连接,确保各个节点之间能够相互通信。
四、网络连接的配置在构建Hadoop集群过程中,节点之间需要进行网络连接的配置。
可以使用以太网、局域网或者云服务器等方式进行连接。
在网络连接的配置过程中,需要设置IP地址、子网掩码、网关等参数,确保各个节点之间的通信畅通。
五、Hadoop软件的安装与配置Hadoop软件的安装与配置是构建Hadoop集群的关键步骤。
在每个节点上,需要安装并配置Hadoop软件,包括Hadoop的核心组件和相关工具。
安装Hadoop软件可以通过源码编译安装或者使用预编译的二进制包安装。
安装完成后,还需要进行相应的配置,包括修改配置文件、设置环境变量等。
hadoop学习笔记(一、hadoop集群环境搭建)

Hadoop集群环境搭建1、准备资料虚拟机、Redhat6.5、hadoop-1.0.3、jdk1.62、基础环境设置2.1配置机器时间同步#配置时间自动同步crontab -e#手动同步时间/usr/sbin/ntpdate 1、安装JDK安装cd /home/wzq/dev./jdk-*****.bin设置环境变量Vi /etc/profile/java.sh2.2配置机器网络环境#配置主机名(hostname)vi /etc/sysconfig/network#修第一台hostname 为masterhostname master#检测hostname#使用setup 命令配置系统环境setup#检查ip配置cat /etc/sysconfig/network-scripts/ifcfg-eth0#重新启动网络服务/sbin/service network restart#检查网络ip配置/sbin/ifconfig2.3关闭防火墙2.4配置集群hosts列表vi /etc/hosts#添加一下内容到vi 中2.5创建用户账号和Hadoop部署目录和数据目录#创建hadoop 用户/usr/sbin/groupadd hadoop#分配hadoop 到hadoop 组中/usr/sbin/useradd hadoop -g hadoop#修改hadoop用户密码Passwd hadoop#创建hadoop 代码目录结构mkdir -p /opt/modules/hadoop/#修改目录结构权限拥有者为为hadoopchown -R hadoop:hadoop /opt/modules/hadoop/2.6生成登陆密钥#切换到Hadoop 用户下su hadoopcd /home/hadoop/#在master、node1、node2三台机器上都执行下面命令,生成公钥和私钥ssh-keygen -q -t rsa -N "" -f /home/hadoop/.ssh/id_rsacd /home/hadoop/.ssh#把node1、node2上的公钥拷贝到master上scp /home/hadoop/.ssh/ id_rsa.pub hadoop@master:/home/hadoop/.ssh/node1_pubkey scp /home/hadoop/.ssh/ id_rsa.pub hadoop@master:/home/hadoop/.ssh/node2_pubkey#在master上生成三台机器的共钥cp id_rsa.pub authorized_keyscat node1_pubkey >> authorized_keyscat node2_pubkey >> authorized_keysrm node1_pubkey node2_pubkey#吧master上的共钥拷贝到其他两个节点上scp authorized_keys node1: /home/hadoop/.ssh/scp authorized_keys node1: /home/hadoop/.ssh/#验证ssh masterssh node1ssh node2没有要求输入密码登陆,表示免密码登陆成功3、伪分布式环境搭建3.1下载并安装JAVA JDK系统软件#下载jdkwget http://60.28.110.228/source/package/jdk-6u21-linux-i586-rpm.bin#安装jdkchmod +x jdk-6u21-linux-i586-rpm.bin./jdk-6u21-linux-i586-rpm.bin#配置环境变量vi /etc/profile.d/java.sh#手动立即生效source /etc/profile3.2 Hadoop 文件下载和安装#切到hadoop 安装路径下cd /opt/modules/hadoop/#从 下载Hadoop 安装文件wget /apache-mirror/hadoop/common/hadoop-1.0.3/hadoop-1.0.3.tar.gz#如果已经下载,请复制文件到安装hadoop 文件夹cp hadoop-1.0.3.tar.gz /opt/modules/hadoop/#解压hadoop-1.0.3.tar.gzcd /opt/modules/hadoop/tar -xvf hadoop-1.0.3.tar.gz#配置环境变量vi /etc/profile.d/java.sh#手动立即生效source /etc/profile3.3配置hadoop-env.sh 环境变量#配置jdk。
大数据--Hadoop集群环境搭建

⼤数据--Hadoop集群环境搭建⾸先我们来认识⼀下HDFS, HDFS(Hadoop Distributed File System )Hadoop分布式⽂件系统。
它其实是将⼀个⼤⽂件分成若⼲块保存在不同服务器的多个节点中。
通过联⽹让⽤户感觉像是在本地⼀样查看⽂件,为了降低⽂件丢失造成的错误,它会为每个⼩⽂件复制多个副本(默认为三个),以此来实现多机器上的多⽤户分享⽂件和存储空间。
Hadoop主要包含三个模块:HDFS模块:HDFS负责⼤数据的存储,通过将⼤⽂件分块后进⾏分布式存储⽅式,突破了服务器硬盘⼤⼩的限制,解决了单台机器⽆法存储⼤⽂件的问题,HDFS是个相对独⽴的模块,可以为YARN提供服务,也可以为HBase等其他模块提供服务。
YARN模块:YARN是⼀个通⽤的资源协同和任务调度框架,是为了解决Hadoop中MapReduce⾥NameNode负载太⼤和其他问题⽽创建的⼀个框架。
YARN是个通⽤框架,不⽌可以运⾏MapReduce,还可以运⾏Spark、Storm等其他计算框架。
MapReduce模块:MapReduce是⼀个计算框架,它给出了⼀种数据处理的⽅式,即通过Map阶段、Reduce阶段来分布式地流式处理数据。
它只适⽤于⼤数据的离线处理,对实时性要求很⾼的应⽤不适⽤。
多相关信息可以参考博客:。
本节将会介绍Hadoop集群的配置,⽬标主机我们可以选择虚拟机中的多台主机或者多台阿⾥云服务器。
注意:以下所有操作都是在root⽤户下执⾏的,因此基本不会出现权限错误问题。
⼀、Vmware安装VMware虚拟机有三种⽹络模式,分别是Bridged(桥接模式)、NAT(⽹络地址转换模式)、Host-only(主机模式):桥接:选择桥接模式的话虚拟机和宿主机在⽹络上就是平级的关系,相当于连接在同⼀交换机上;NAT:NAT模式就是虚拟机要联⽹得先通过宿主机才能和外⾯进⾏通信;仅主机:虚拟机与宿主机直接连起来。
Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐血整理)

Hadoop环境搭建--Docker完全分布式部署Hadoop环境(菜鸟采坑吐⾎整理)系统:Centos 7,内核版本3.10本⽂介绍如何从0利⽤Docker搭建Hadoop环境,制作的镜像⽂件已经分享,也可以直接使⽤制作好的镜像⽂件。
⼀、宿主机准备⼯作0、宿主机(Centos7)安装Java(⾮必须,这⾥是为了⽅便搭建⽤于调试的伪分布式环境)1、宿主机安装Docker并启动Docker服务安装:yum install -y docker启动:service docker start⼆、制作Hadoop镜像(本⽂制作的镜像⽂件已经上传,如果直接使⽤制作好的镜像,可以忽略本步,直接跳转⾄步骤三)1、从官⽅下载Centos镜像docker pull centos下载后查看镜像 docker images 可以看到刚刚拉取的Centos镜像2、为镜像安装Hadoop1)启动centos容器docker run -it centos2)容器内安装java下载java,根据需要选择合适版本,如果下载历史版本拉到页⾯底端,这⾥我安装了java8/usr下创建java⽂件夹,并将java安装包在java⽂件下解压tar -zxvf jdk-8u192-linux-x64.tar.gz解压后⽂件夹改名(⾮必需)mv jdk1.8.0_192 jdk1.8配置java环境变量vi ~/.bashrc ,添加内容,保存后退出export JAVA_HOME=/usr/java/jdk1.8export JRE_HOME=${JAVA_HOME}/jreexport CLASSPATH=.:${JAVA_HOME}/libexport PATH=$PATH:${JAVA_HOME}/bin使环境变量⽣效 source ~/.bashrc验证安装结果 java -version这⾥注意,因为是在容器中安装,修改的是~/.bashrc⽽⾮我们使⽤更多的/etc/profile,否则再次启动容器的时候会环境变量会失效。
Hadoop集群配置(最全面总结)

Hadoop集群配置(最全⾯总结)通常,集群⾥的⼀台机器被指定为 NameNode,另⼀台不同的机器被指定为JobTracker。
这些机器是masters。
余下的机器即作为DataNode也作为TaskTracker。
这些机器是slaves\1 先决条件1. 确保在你集群中的每个节点上都安装了所有软件:sun-JDK ,ssh,Hadoop2. Java TM1.5.x,必须安装,建议选择Sun公司发⾏的Java版本。
3. ssh 必须安装并且保证 sshd⼀直运⾏,以便⽤Hadoop 脚本管理远端Hadoop守护进程。
2 实验环境搭建2.1 准备⼯作操作系统:Ubuntu部署:Vmvare在vmvare安装好⼀台Ubuntu虚拟机后,可以导出或者克隆出另外两台虚拟机。
说明:保证虚拟机的ip和主机的ip在同⼀个ip段,这样⼏个虚拟机和主机之间可以相互通信。
为了保证虚拟机的ip和主机的ip在同⼀个ip段,虚拟机连接设置为桥连。
准备机器:⼀台master,若⼲台slave,配置每台机器的/etc/hosts保证各台机器之间通过机器名可以互访,例如:10.64.56.76 node1(master)10.64.56.77 node2 (slave1)10.64.56.78 node3 (slave2)主机信息:机器名 IP地址作⽤Node110.64.56.76NameNode、JobTrackerNode210.64.56.77DataNode、TaskTrackerNode310.64.56.78DataNode、TaskTracker为保证环境⼀致先安装好JDK和ssh:2.2 安装JDK#安装JDK$ sudo apt-get install sun-java6-jdk1.2.3这个安装,java执⾏⽂件⾃动添加到/usr/bin/⽬录。
验证 shell命令:java -version 看是否与你的版本号⼀致。
hadoop实施方案

hadoop实施方案Hadoop是一种开源的、可扩展的、可靠的分布式计算框架,可以存储和处理大规模数据集。
在实施Hadoop方案之前,关键是确定以下几个方面的内容:1.需求分析:明确项目的具体需求,包括数据量、数据类型、数据处理方式等。
根据需求,确定Hadoop集群需要的规模和配置。
2.基础设施准备:建立Hadoop集群所需的基础设施,包括物理服务器、网络设备、存储设备等。
确保集群的稳定性和可靠性。
3.节点规划:根据需求和集群规模,确定Hadoop集群的节点规划,包括主节点、从节点、辅助节点等。
合理规划节点数量和分布,最大限度地发挥集群的计算和存储能力。
4.数据准备:将需要处理的数据导入Hadoop集群,可以通过Hadoop的分布式文件系统HDFS进行数据的存储和管理。
确保数据的完整性和安全性。
5.任务分配:根据需求,将任务分配给Hadoop集群的各个节点进行并行处理。
可以使用Hadoop提供的编程模型MapReduce进行任务调度和执行。
6.结果输出:将处理结果输出到目标位置或存储介质,可以是数据库、文件、共享目录等。
保证结果的可访问性和安全性。
7.监控和优化:监控Hadoop集群的运行状态,及时发现和解决问题。
进行性能调优,提高集群的计算和存储效率。
8.安全管理:加强Hadoop集群的安全管理,保护数据的机密性和完整性。
实施用户身份验证、访问控制、数据加密等安全措施。
9.容灾和备份:建立Hadoop集群的容灾和备份机制,保障集群的高可用性和数据的可靠性。
可以进行数据备份、冗余部署、灾备恢复等操作。
10.培训和支持:为使用Hadoop集群的相关人员进行培训和支持,提高其对Hadoop的理解和应用能力。
及时解答和处理相关问题。
总之,实施Hadoop方案需要考虑到的方面很多,包括需求分析、基础设施准备、节点规划、数据准备、任务分配、结果输出、监控和优化、安全管理、容灾和备份、培训和支持等。
通过科学的规划和实施,可以充分发挥Hadoop的优势,提高数据处理效率和可靠性。
Hadoop大数据开发基础教案Hadoop集群的搭建及配置教案

Hadoop大数据开发基础教案-Hadoop集群的搭建及配置教案教案章节一:Hadoop简介1.1 课程目标:了解Hadoop的发展历程及其在大数据领域的应用理解Hadoop的核心组件及其工作原理1.2 教学内容:Hadoop的发展历程Hadoop的核心组件(HDFS、MapReduce、YARN)Hadoop的应用场景1.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节二:Hadoop环境搭建2.1 课程目标:学会使用VMware搭建Hadoop虚拟集群掌握Hadoop各节点的配置方法2.2 教学内容:VMware的安装与使用Hadoop节点的规划与创建Hadoop配置文件(hdfs-site.xml、core-site.xml、yarn-site.xml)的编写与配置2.3 教学方法:演示与实践相结合手把手教学,确保学生掌握每个步骤教案章节三:HDFS文件系统3.1 课程目标:理解HDFS的设计理念及其优势掌握HDFS的搭建与配置方法3.2 教学内容:HDFS的设计理念及其优势HDFS的架构与工作原理HDFS的搭建与配置方法3.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节四:MapReduce编程模型4.1 课程目标:理解MapReduce的设计理念及其优势学会使用MapReduce解决大数据问题4.2 教学内容:MapReduce的设计理念及其优势MapReduce的编程模型(Map、Shuffle、Reduce)MapReduce的实例分析4.3 教学方法:互动提问,巩固知识点教案章节五:YARN资源管理器5.1 课程目标:理解YARN的设计理念及其优势掌握YARN的搭建与配置方法5.2 教学内容:YARN的设计理念及其优势YARN的架构与工作原理YARN的搭建与配置方法5.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节六:Hadoop生态系统组件6.1 课程目标:理解Hadoop生态系统的概念及其重要性熟悉Hadoop生态系统中的常用组件6.2 教学内容:Hadoop生态系统的概念及其重要性Hadoop生态系统中的常用组件(如Hive, HBase, ZooKeeper等)各组件的作用及相互之间的关系6.3 教学方法:互动提问,巩固知识点教案章节七:Hadoop集群的调优与优化7.1 课程目标:学会对Hadoop集群进行调优与优化掌握Hadoop集群性能监控的方法7.2 教学内容:Hadoop集群调优与优化原则参数调整与优化方法(如内存、CPU、磁盘I/O等)Hadoop集群性能监控工具(如JMX、Nagios等)7.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点教案章节八:Hadoop安全与权限管理8.1 课程目标:理解Hadoop安全的重要性学会对Hadoop集群进行安全配置与权限管理8.2 教学内容:Hadoop安全概述Hadoop的认证与授权机制Hadoop安全配置与权限管理方法8.3 教学方法:互动提问,巩固知识点教案章节九:Hadoop实战项目案例分析9.1 课程目标:学会运用Hadoop解决实际问题掌握Hadoop项目开发流程与技巧9.2 教学内容:真实Hadoop项目案例介绍与分析Hadoop项目开发流程(需求分析、设计、开发、测试、部署等)Hadoop项目开发技巧与最佳实践9.3 教学方法:案例分析与讨论团队协作,完成项目任务教案章节十:Hadoop的未来与发展趋势10.1 课程目标:了解Hadoop的发展现状及其在行业中的应用掌握Hadoop的未来发展趋势10.2 教学内容:Hadoop的发展现状及其在行业中的应用Hadoop的未来发展趋势(如Big Data生态系统的演进、与大数据的结合等)10.3 教学方法:讲解与案例分析相结合互动提问,巩固知识点重点和难点解析:一、Hadoop生态系统的概念及其重要性重点:理解Hadoop生态系统的概念,掌握生态系统的组成及相互之间的关系。
标准hadoop集群配置

标准hadoop集群配置Hadoop是一个开源的分布式存储和计算框架,由Apache基金会开发。
它提供了一个可靠的、高性能的数据处理平台,可以在大规模的集群上进行数据存储和处理。
在实际应用中,搭建一个标准的Hadoop集群是非常重要的,本文将介绍如何进行标准的Hadoop集群配置。
1. 硬件要求。
在搭建Hadoop集群之前,首先需要考虑集群的硬件配置。
通常情况下,Hadoop集群包括主节点(NameNode、JobTracker)和从节点(DataNode、TaskTracker)。
对于主节点,建议配置至少16GB的内存和4核以上的CPU;对于从节点,建议配置至少8GB的内存和2核以上的CPU。
此外,建议使用至少3台服务器来搭建Hadoop集群,以确保高可用性和容错性。
2. 操作系统要求。
Hadoop可以在各种操作系统上运行,包括Linux、Windows和Mac OS。
然而,由于Hadoop是基于Java开发的,因此建议选择Linux作为Hadoop集群的操作系统。
在实际应用中,通常选择CentOS或者Ubuntu作为操作系统。
3. 网络配置。
在搭建Hadoop集群时,网络配置非常重要。
首先需要确保集群中的所有节点能够相互通信,建议使用静态IP地址来配置集群节点。
此外,还需要配置每台服务器的主机名和域名解析,以确保节点之间的通信畅通。
4. Hadoop安装和配置。
在硬件、操作系统和网络配置完成之后,接下来就是安装和配置Hadoop。
首先需要下载Hadoop的安装包,并解压到指定的目录。
然后,根据官方文档的指导,配置Hadoop的各项参数,包括HDFS、MapReduce、YARN等。
在配置完成后,需要对Hadoop集群进行测试,确保各项功能正常运行。
5. 高可用性和容错性配置。
为了确保Hadoop集群的高可用性和容错性,需要对Hadoop集群进行一些额外的配置。
例如,可以配置NameNode的热备份(Secondary NameNode)来确保NameNode的高可用性;可以配置JobTracker的热备份(JobTracker HA)来确保JobTracker的高可用性;可以配置DataNode和TaskTracker的故障转移(Failover)来确保从节点的容错性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 提高网络速度最直接的办法是通过端口绑定, 将服务器的多个端口绑定为一个
• •
–
IP ip
–
•
Linux
• •
• • 3 Hadoop HBase 10
10GBE
•
• InfiniBand 10G InifiBand 20G 40G
• InfiniBand
• 4~10个节点,解决较小规模问题
– NN:NameNode,2NN:SecondaryNameNode, JT:JobTracker, ZK: ZooKeeper, Hmaster: HBaseMaster, DN: DataNode, TT: TaskTracker, RS: HBase RegionServer
• 大规模生产需要高可用性,配置方案:
MapReduce实际计算 节点 Hive元数据以及驱动 程序
角色 ZooKeeper
描述 用以提供集群高可用性的 锁服务 HBase用以调度 RegionServer的主模块 HBase中用以管理数据的 模块 可能的集群监控管理节点
节点数目 3个或3个以上的奇数的独 立节点(小规模可以和其 它角色共享节点) 与其它角色共享节点的多 个节点 一般与DataNode运行与相 同的节点之上 一般为一个独立的节点, 如果小规模集群的话可以 与其它角色共享
角色
HDFS NameNode
描述
分布式文件系统用以 存储文件系统以及数 据块的元数据 NameNode的影子节 点 HDFS数据存储 MapReduce调度程序
节点数目
1个独立节点
HDFS Secondary NameNode HDFS DataNode MapReduce JobTracker
项目 处理器CPU 内存 磁盘接口 磁盘 指标 双路四核服务器处理器,2x4 2.6GHz 32G或者以上内存,DDR3,ECC SAS 6GB/s 6x或者12x SATA 1T 7200RPM监控级 硬盘
网络
两个以太网口
• 20+个节点,解决中等规模问题,实际上能够满足大多数中小企 业的需求
项目 处理器CPU 内存 磁盘接口 磁盘 指标 双路六核服务器处理器,处理器缓存 15MB,2x6 2.9GHz 64G或者以上内存,DDR3,ECC SAS 6GB/s 6x或者12x SATA 1T或者3T 7200RPM监 控级硬盘(依据数据规模而定)
确保用于构建集群的所有的服务 器满足集群节点要求 (包括硬件 要求、软件要求和网络要求。)
做好构造Hadoop集群的规划
进行系统安装
在集群中的所有 节点上安装需要 的操作系统
正确配置所有节 点的RAID
安装Hadoop
参数配置
• 在规划中,除了选取硬件之外,还需要进 行角色的规划 • 角色的规划即确定Hadoop的某一个运行角 色运行在哪个节点之上 • 与硬件推荐情况一致,首先需要确定集群 的本身负载,针对小规模,中规模以及大 规模集群有不同的集群规划方案
网络
两个以太网口
• 依据问题规模确定所需要的节点数目,解决大规模问题,使用 高端的内存,高速网络
项目 处理器CPU 指标 双路六核服务器处理器,处理器缓存 15MB,2x6 2.9GHz,依据应用可以选 用更高端的处理器 96G或者以上内存,DDR3,ECC 2xSAS 6GB/s 24x 1TB 告诉SAS硬盘 10Gb以太网口
– NN:NameNode,2NN:SecondaryNameNode, JT:JobTracker, ZK: ZooKeeper, Hmaster: HBaseMaster, DN: DataNode, TT: TaskTracker, RS: HBase RegionServer
• 小规模生产需要高可用性,配置方案:
•
• • •
+ +MapReduce
• 典型使用以太网络,为了使得系统能够正常运 行,最低使用千兆以太网连接,由于需要有数 据交换的需求,建议配置大容量的网络交换机 • 当一台机器上有多个网络适配器时,推荐使用 网络适配器绑定Linux的方法配置链路聚合,并 把工作模式设为6。在工作模式为6时,负载平 衡可以通过循环取得,并且这些网络适配器可 以在没有配置交换器的情况下正常工作
• 最常见的是使用服务器本身的万兆以太网络, 每一个机架使用一个交换机,在多个机架之间 进行带宽聚合。这种方式在总的节点数目较少 (少于40个)集群比较合适 • 如果应用(例如ETL的应用)的IO高负载,这 样的话,网络会成为性能瓶颈
– 12块以上的硬盘,每块以100MB/s速度运行,会很 快吃掉所有网络带宽 – 低端的交换器不能够支持线速,产生阻塞
• • • • •
标准的x86的服务器 以太网络 多机架数据中心 软件环境 硬件的选择 (处理器,硬盘,网络)
HDFS 客户端
MapReduce 客户端
HBase 客户端
……
Hive 客户端
Hadoop 集群
HDFS MapReduce HBase Hive
管理节点
……
节点2 节点3
节点1
…… 节点N
Hadoop
• 规划使用Hadoop的组件,这些组件包括HDFS, MapReduce,Hive,HA组件等 • 规划集群的硬件参数,包括服务器数量,物理 布局,机架数目以及服务器在机架上的分配 • 规划集群使用的网络,即决定使用网络的拓扑, 节点到交换机的连接,机柜之间的连接 • 规划节点的IP地址设置以及节点的角色,例如 用以各个逻辑角色管理的节点,用以存储元数 据的NameNode,MapReduce程序的JobTracker, 管理节点等
•
– HDFS HBase map
DataNode, MapReduce TaskTracker Region Server slot slots reduce slots 16 2GB + 2GB + 512MB*16 + 16GB = 28GB
• HBase
• JBOD vs. RAID
–
RAID – RAID RAID 0
内存 磁盘接口 磁盘 网络
高端网络可以考虑使用InifinBand网络
• 支持的操作系统为Linux,要求64位系统,版本 至少6以上。包括:
– RedHat Enterprise Linux – CentOS – Oracle Linux
• 软件依赖:
– Java 1.6 – openssh
» 在把服务器加入集群前,须要确保openssh-server在运行。如果 openssh-server没有在运行,在Hadoop集群中的所有节点中安装 openssh-server包。
• 千兆以太网接口是最基本的要求,更重要的是交换机的背板带宽,是 决定数据传输的关键因素 • 一个以太网交换机的接口是以太网交换机到主机的速度,这个速度决 定主机到交换机的速度级别,在Hadoop环境中,这个速度最少应该是 千兆以太网 • 接口速度即使达到了千兆以太网,实际的运行速度可能并不能真正达 到千兆以太网的速度,因为可能有数十个设备同时共享这个交换机 • 决定交换机的性能的关键因素是交换机的背板带宽,具有良好背板交 换能力的交换机能够使得任意两个接口之间的速度以及上行的速度都 能够达到千兆的速度,而通过总线进行共享的带宽往往不能达到理想 的速度 • 为了能够使得Hadoop的处理能力能够得到充分的释放,交换机对于系 统运行的性能起到了决定性的左右,建议在可能的情况下尽量选择高 端的交换机,使得每一个接口都能够达到线速(网线能够达到什么速 度,交换机就能够提供什么速度,没有性能损失)
– – – – – 单独的NameNode节点:NN 单独的JobTracker节点:JT+ZK+Hmaster NameNode的副本: backup NN+2NN+ZK+Hmaster JobTracker节点的副本:Backup JT+ZK+HMaster 数据节点Data Node:DN+TT+RS, 在一个数据节点中部 署ZK+HMaster – 保证ZK的数目为奇数 – NN:NameNode,2NN:SecondaryNameNode, JT:JobTracker, ZK: ZooKeeper, Hmaster: HBaseMaster, DN: DataNode, TT: TaskTracker, RS: HBase RegionServer
小规模集群可以和 NameNode共享节点,大规 模集群用独立节点 多个独立节点 1个独立节点,小规模集群 可以与NameNode共享,大 规模集群使用独立节点 与DataNode运行在相同的 节点之上 独立配置的话可以与 NameNode共享节点,或者 将元数据存放在客户端
MapReduce TaskTracker Hive
HBase HMaster
HBase RegionServer Management Node
ห้องสมุดไป่ตู้ •
Hadoop Hadoop
•
–
• •
– IO
• • •
• •
4
16GB
服务器角色及服务类型 MapReduce Job Tracker MapReduce Task Tracker MapReduce Slots on Task Tracker HDFS NameNode HDFS Secondary NameNode HDFS DataNode ZooKeeper HBase Master Server HBase Region Server Hive Server 客户端 内存要求 2GB 2GB 512MB * slot数量 16GB 16GB 2GB 4GB 2GB 16GB 2GB 8GB