VF基础知识
VF笔记

一、基础知识:1、开机方法:先开显示器,再开主机。
2、关机方法:先关闭所有打开的窗口,“开始”-“关闭系统”-“关机”。
最后关闭显示器的电源按钮。
3、中英文切换:Ctrl+空格在拼音状态下: v+字母键4、窗口的切换:Alt+Tab5、输入法的切换:Ctrl+Shift6、大小写字母的切换:Caps Lock7、删除字符:Backspace:删除光标之前的字符Delete:删除光标之后的字符8、插入与改写:Insert二、Visual FoxPro的用途Visual FoxPro是目前微机上优秀的数据库管理系统之一,具有很强的查询功能。
同时还可以利用它开发出适合自己目的的各种管理系统,如图书管理系统,学生管理系统等。
三、表的模型表在日常生活中对应的是一张二维表格的形式。
下面是一张“学生表”:建表时,二维表标题栏的列标题称为表的字段名,表中的一列数据称为一个字段。
标题栏下方的内容输入到表中成为表的数据,每一行数据称为表的一条记录。
也就是说,表是由结构和数据两部分组成。
上面表中含有9个字段和10条记录,即表的数据共包括10条记录,其中每一条记录含有9个字段值。
建立表结构就是定义各个字段的属性,其中的字段属性可包括字段名、字段类型、字段宽度和小数位数等。
四、启动Visual Foxpro1、双击VF图标。
2、右击VF图标-打开。
3、选中VF图标,按回车键。
4、在“开始”菜单中打开。
五、Visual Foxpro界面显示、隐藏命令窗口的三种方式:p24(1)单击命令窗口右上角的关闭按钮可关闭它,通过“窗口”菜单下的“命令窗口”选项可重新打开。
(2)单击“常用”工具栏上的“命令窗口”按钮,按下则显示,弹起则隐藏命令窗口。
(3)按Ctrl+F4 组合键隐藏命令窗口,按Ctrl+F2组合键显示命令窗口。
六、Visual Foxpro的退出1、用鼠标单击标题栏右侧的关闭按钮。
2、从“文件”菜单下选择“退出”命令。
VF基础知识总结(1-8章)

11.MIN()函数字符函 Nhomakorabea:日期时间函数:
1.LEN()函数
1.DATE()函数
2.LOWER()函数
2.TIME()函数
3.UPPER()函数
3.DATETIME()函数
4.SPACE()函数
4.YEAR()函数
5.TRIM()函数
5.MONTH()函数
6.LTRIM()函数
6.DAY()函数
小结:排序与索引的区别
1、排序要执行两次,按关键字和记录号,要打开表;而索引只执行一次,按关 键字,不需要打开表;
2、排序生成一个新表,索引是针对原表生成一个指针文件 3、升降序的表示与书写方式不同:排序/a升序/d降序/c不区分大小写,索引 ascending和descending。 4、排序与索引的to的含义不同,排序的to 表示到一个新表,索引的to表示建立 单索引文件。
3、各类文件选项卡: ①“全部”选项卡(以下五项的全部内容) ②“数据”选项卡(数据库、自由表、查询、视图) ③“文档”选项卡(表单、报表、标签) ④“类”选项卡 ⑤“代码”选项卡 ⑥“其他”选项卡
第二章 数据与数据运算
1、字段数据类型(11种)
字符型
C
数值型
N
逻辑型
L(1)
日期型
D(8)
日期时间型 T(8)
****************************************************************** 小结:
1、用use 打开表时,记录号位于第一条记录 2、执行带all的命令,记录指针指向eof()=.T. 3、当为.T.时,bof的记录号总是为1,eof的记录号是记录数+1 4、空表的总记录是0,bof的记录号是1,eof的记录号是1
vf数据库基础知识习题与答案

第一章 VF 基础知识、选择题2. 数据库系统的核心是 ___ 。
A) 数据库管理系统C) 数据3. VFP 是一种 _____ 数据库管理系统A) 层次型 C) 关系型4. 支持数据库各种操作的软件系统是 _A) 数据库系统 B) 操作系统C) 数据库管理系统 D) 命令系统5. 在关系模型中,从表中选出满足条件的记录的操作称为A) 连接 B) 投影C) 联系 D) 选择6. 数据库系统与文件系统的主要区别是 __ 。
A) 文件系统只能管理程序文件,而数据库系统可以管理各种类型的文件B) 文件系统管理的数据较少,而数据库系统能管理大量数据C) 文件系统比较简单,数据库系统比较复杂D) 文件系统没有解决数据冗余和数据独立性问题,而数据库系统解决了 这些问题7. 在关系运算中,选择的操作对象是 __ ;投影的操作对象是 __ _;连接的操作对象是 __ 。
A) 一个表;一个表;两个表B) 一个表;两个表;两个表C) 一个表;一个表;一个表D) 两个表;一个表;两个表8. 在关系数据库中,基本的关系运算有三种,它们是 。
A) 选择、投影和统计 B) 选择、投影和连接C) 排序、索引和选择 D) 统计、查找和连接9. VFP 是一种关系型数据库管理系统,所谓关系是指 。
A) 表中各个记录之间的联系B) 数据模型满足一定条件的二维表格式C) 表中各个字段之间的联系D) 一个表与另一个表之间的联系10. 一个仓库里可以存放多个部件,一种部件可以存放于多个仓库,仓库与 部件之间是 的联系。
1. 在一个二维表中,行称为 A) 属性;元组 ,列称为 ____ 。
B) 元组;属性B) 数据库 D) 数据库应用系统 B) 网状型A) 一对一C) 一对多11. 自然连接要求被连接的两关系有若干相同的B) 多对一D) 多对多______12. 数据库类型是根据 A) 文件形式 C) 数据模型 13. 关系是指 ___ A) 元组的集合 C) 属性的集合 14. 对于关系 S (S1, S2, S3, S4),写一条规则,把其中 S2 的属性限制在10-20 之间,则这条规则属于 _ 。
VF复习资料课本复习知识汇总

2011年9月份全国计算机等级考试二级VF考试复习纲要目录第一章数据库基础知识 (2)第二章VF程序设计基础 (3)第一部分 (3)第二部分程序设计基础 (3)第三部分函数部分 (5)第三章数据库及其操作 (26)第四章关系数据库标准语言SQL (32)4.1概述 (32)4.2 查询功能 (33)4.3操作功能 (34)4.4 定义功能 (35)第五章查询与视图 (37)第六章表单设计与运用 (40)第七章菜单设计与应用 (46)第八章报表设计 (48)第一章数据库基础知识1、数据库管理系统:DBMS;数据库应用系统:DBAS;数据库系统:DBS;数据:DBDBS包括DBMS,DBAS,DB2、实体间的联系:一对一,一对多,多对多。
3、数据库中的数据模型:网状模型,层次模型,关系模型。
4、关系:一个关系就是一个二维表,每一个关系有一个关系名。
5、元组:二维表中的行称为元组。
6、属性:二维表中的列称为属性。
7、域:属性的取值范围。
8、关系→表;关系名→表名;属性→字段;元组→记录;行→记录,元组;列→字段,属性。
9、传统的集合运算:并,差,交。
10、专门的关系运算:选择(水平方向)for,while,where投影(垂直方向)fields,select联接(一对一,一对多,多对多)11、定义数组:dime/declare 数组名(3,4)第二章VF程序设计基础第一部分1、创建项目:①通过菜单创建②命令:creat project项目名2、打开项目管理器:①通过“文件→打开”菜单项②命令:modify project 项目名3、各类文件选项卡:①数据选项卡(数据库,自由表,查询,视图)②文档选项卡(表单,报表,标签)③类④代码⑤其他第二部分程序设计基础1、概念:是命令的集合,分行存储在磁盘上,按照人为的顺序依次输出的过程。
2、建立、修改:modify command 程序名3、运行:do 程序名4、基本输入语句:(以求圆的面积为例)①.input”请输入圆的半径”to r②.accept ”请输入圆的半径”to r③.@10.10 say “请输入圆的半径” get rread④.wait ”请等候……”window⑤. messagebox (“欢迎光临!”,48,“欢迎信息”)5、程序的结构:顺序结构选择结构(分支、判断)循环结构(条件循环、步长循环、扫描循环)6、程序的控制语、注释语①.exit 退出、终止②.loap 中止③.quit 关闭系统④.&& 同行注释⑤. * 换行注释⑥.error 不参与程序的执行6、程序模块7、变量的作用域①.公共变量(public):作用于程序运行的始终②.局部变量(local):只在本过程中使用,即不上传,也不接收③.私有变量(private):在程序运行过程中自动隐藏,成程序结束时显示本身第三部分函数部分1、字段数据类型(11种)* N包括Y,F,B,I2、变量:在程序运行过程中,其值可能发生变化的量。
学习VF基础理论知识

我VF课件一个完整的VF数据库系统(DBS)的基本组成部分:1数据库的集合 DB;872 数据库管理系统 DBMS系统软件;3 硬件;4 用户或管理员(应用程序)第二步:认识VF的开发界面界面的组成部分以及每部分的作用注意:(1)每次打开vf必须将输入法调到半角实心的状态(2)命令窗口中只能输入和执行单条命令语句第一讲 1.1数据库及其表操作一: 数据库的操作1:基本概念在VF中数据库是一个逻辑上的概念,通过一组系统文件将相互联系的表统一组织和管理。
(数据库和表之间的关系)文件数据库文件扩展名:DBC数据库备注文件: DCT数据库索引文件: DCXVF中的操作方式:界面操作:通过鼠标操作的过程命令操作:在命令窗口中输入命令完成相关功能的过程2:建立数据库a:通过“新建”对话框建立数据库b:使用命令交互建立数据库CREAT DATABASE [数据库文件名]3:使用数据库(打开、修改)OPEN DATABASE [数据库文件名]MODIFY DATABASE“ SET DATABASE TO 数据库文件名”指定一个打开的数据库为当前数据库。
4:删除数据库用命令删除VF 数据库文件并不真正含有表,只是在数据库文件中登录了表的相关条目信息,表是独立存放在磁盘上的。
所以删除数据库并没有删除数据库中的表等对象,要在删除数据库时同时删除表等对象,要用命令方式。
DELETE DATABASE 数据库文件名 [DELETETABLES]DELETE DATABASE <数据库名>只删除数据库文件DELETE DATABASE <数据库名> DELETETABLES删除数据库文件的同时并删除数据库对应的表二:表的操作概念: VF中操作的基本对象,将现实中的数据转换成VF所能识别的文件.与表相关的文件扩展名有:DBF 表文件FPT 表的备注文件BAK 表的备份文件表文件的创建不管是采用界面操作方式还是命令操作方式创建表文件都是首先进入表设计器,在表设计器中主要是完成对表结构的设计。
vf基础知识部分

第1章数据结构与算法经过对部分考生的调查以及对近年真题的总结分析,笔试部分经常考查的是算法复杂度、数据结构的概念、栈、二叉树的遍历、二分法查找,读者应对此部分进行重点学习。
详细重点学习知识点:1.算法的概念、算法时间复杂度及空间复杂度的概念2.数据结构的定义、数据逻辑结构及物理结构的定义3.栈的定义及其运算、线性链表的存储方式4.树与二叉树的概念、二叉树的基本性质、完全二叉树的概念、二叉树的遍历5.二分查找法6.冒泡排序法1.1算法考点1 算法的基本概念考试链接:考点1在笔试考试中考核的几率为30%,主要是以填空题的形式出现,分值为2分,此考点为识记内容,读者还应该了解算法中对数据的基本运算。
计算机解题的过程实际上是在实施某种算法,这种算法称为计算机算法。
1.算法的基本特征:可行性、确定性、有穷性、拥有足够的情报。
2.算法的基本要素:(1)算法中对数据的运算和操作一个算法由两种基本要素组成:一是对数据对象的运算和操作;二是算法的控制结构。
在一般的计算机系统中,基本的运算和操作有以下4类:算术运算、逻辑运算、关系运算和数据传输。
(2)算法的控制结构:算法中各操作之间的执行顺序称为算法的控制结构。
描述算法的工具通常有传统流程图、N-S结构化流程图、算法描述语言等。
一个算法一般都可以用顺序、选择、循环3种基本控制结构组合而成。
考点2 算法复杂度考试链接:考点2在笔试考试中,是一个经常考查的内容,在笔试考试中出现的几率为70%,主要是以选择的形式出现,分值为2分,此考点为重点识记内容,读者还应该识记算法时间复杂度及空间复杂度的概念。
1.算法的时间复杂度算法的时间复杂度是指执行算法所需要的计算工作量。
同一个算法用不同的语言实现,或者用不同的编译程序进行编译,或者在不同的计算机上运行,效率均不同。
这表明使用绝对的时间单位衡量算法的效率是不合适的。
撇开这些与计算机硬件、软件有关的因素,可以认为一个特定算法"运行工作量"的大小,只依赖于问题的规模(通常用整数n表示),它是问题规模的函数。
vf基础知识要点

#数值类型【科学记数法】格式:实数E整数。
如3.5E3,表示3.5*10^3。
E大小写均可,指数可以为负数。
【算术运算符】加法(+)、减法(-)、乘法(*)、除法(/)、乘法(**,^)【优先级】括号最高,然后乘方,然后乘除,然后加减【余数计算规则】1. 被除数=除数*商+余数2. 余数的绝对值必须小于除数的绝对值3. VFP规定余数和除数同号【精度】总原则:除非是整数,否则至少保留2位小数。
不存在计算结果只有1位小数的情况。
+,-:取两个操作数的小数位数多的一个作为计算结果的小数位数。
只有两个整数相加减结果才是整数。
*,/:将两个操作数的小数位数相加,作为计算结果的小数位数。
只有两个整数相乘除结果才是整数。
%:余数的计算结果,小数位数和被除数一致。
被除数为整数时,结果为整数。
**,^:计算结果至少保留2位小数。
无论任何情况,计算结果都不为整数。
货币类型1. 只要在数值类型前加上$符号即代表货币类型2. 小数位数永远保留4位#数值函数【绝对值和符号】ABS(数值表达式):求数值表达式的绝对值。
SIGN(数值表达式):求数值表达式的符号。
特别的,若用X表示某表达式,则ABS(X)*SIGN(X)=X【取整和四舍五入】INT(数值表达式):直接对数值表达式取整,直接舍去小数部分。
CEILING(数值表达式):天花板函数,返回大于该表达式的最小整数。
FLOOR(数值表达式):地板函数,返回小于该表达式的最大整数。
ROUND(数值表达式,精度):精度为正,表示保留几位小数;精度为0,表示保留整数;精度为负,表示将整数后几位置为0。
【其他】SQRT(数值表达式):求数值表达式的平方根。
其中,数值表达式必须是非负数,可以不是整数。
MOD(被除数,除数):求余数,规则和%运算符相同。
PI():求圆周率,返回值为3.14。
MAX(一组表达式):求这组表达式中的最大值。
MIN(一组表达式):求这组表达式中的最小值。
VF知识点总结
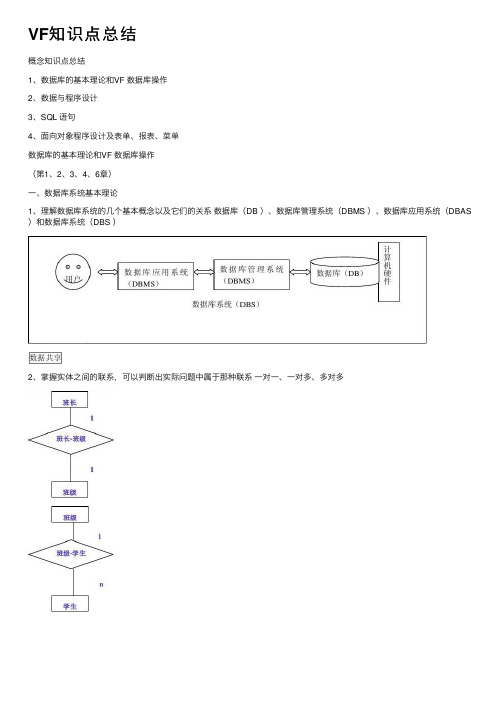
VF知识点总结概念知识点总结1、数据库的基本理论和VF 数据库操作2、数据与程序设计3、SQL 语句4、⾯向对象程序设计及表单、报表、菜单数据库的基本理论和VF 数据库操作(第1、2、3、4、6章)⼀、数据库系统基本理论1、理解数据库系统的⼏个基本概念以及它们的关系数据库(DB )、数据库管理系统(DBMS )、数据库应⽤系统(DBAS )和数据库系统(DBS )2、掌握实体之间的联系,可以判断出实际问题中属于那种联系⼀对⼀、⼀对多、多对多3、弄清三⼤数据模型的结构形式:层次模型、⽹状模型和关系模型我们现在所⽤到的数据库都是关系数据库(a )(b )(c )4、理解关系术语关系(就是⼆维表,记录的集合);元组(⾏、记录);属性(列、字段);域(⼀个字段的取值范围);关键字(关键的字段,唯⼀能标志⼀个元组的字段或字段的组合);外部关键字(不是本表的关键字,但是是其他表的关键字;⽤来建⽴表间的联系)5、关系运算理解传统的集合运算(并、交、差、笛卡尔积)和专门的关系运算(选择、投影、连接包括等值连接和⾃然连接)⼆、数据表操作1、了解表操作的⼀些命令,尤其以下⼏条:LIST显⽰记录:LIST | DISPLAY [FIELDS <字段名表>][<范围>] [FOR<条件表达式>]限定条件⽤FOR短语LOCATE条件定位:LOCATE FOR<条件表达式>本命令定位在满⾜条件的第⼀条记录,若想定为满⾜条件的下⼀条记录,必须⽤CONTINUE⽤FOUND()函数为T判断是否有满⾜条件的记录(也可⽤EOF()为F)APPEND为追加记录;INSERT为插⼊记录REPLACE修改记录:REPLACE <字段名1> WITH <表达式1> [FOR <条件表达式>]2、删除操作分两步⾛:DELETE与PACKDELETE是逻辑删除,也就是添加删除标记,PACK才是真正物理删除;逻辑删除的记录还可以恢复(RECALL)3、理解⼯作区的概念系统提供了32767个⼯作区,可以在不同的⼯作区同时打开多个表,使⽤⼯作区⽤其编号1~32767,或者别名,前⼗个⼯作区有别名:A~JSELECT 0表⽰使⽤最⼩未⽤过的⼯作区4、建⽴表之间的临时关联⼀个为主表,⼀个为⼦表,使⽤SET RELATION TO …INTO…语句要求两个表必须在不同的⼯作区打开可以使⽤SET RELATION TO解除关联三、数据库操作1、理解数据库⽂件它并不真正的存储数据,只是对存储数据的⽂件进⾏统⼀的管理建⽴数据库后,形成三个同名⽂件.dbc .dct .dcx2、理解⾃由表与数据库表的区别与联系区别:可以看⼀下“表设计器”⾃由表不能设置长表名、长字段名、标题、输⼊掩码、字段有效性规则、默认值、注释等内容⾃由表不能设置主索引⾃由表可以添加到数据库中形成数据库表(ADD TABLE…);数据库表可以移出形成⾃由表,相应的设置丢失,主索引变为候选索引(REMOVE TABLE…)3、掌握索引的概念索引就是排序,但它是逻辑排序,排列的不是实际记录,⽽是记录指针,排序的结果存放在索引⽂件中建⽴索引的主要⽬的是为了提⾼查询速度(在有序的集合中查询某个个体很显然⽐⽆序中查询快得多)A、建⽴索引可以通过命令实现:INDEX ON <索引关键字表达式> TO <独⽴索引⽂件名> | TAG <标识名> [ASCE | DESC] [UNIQUE] [CANDICATE]可以建普通索引(命令中不需表⽰)、候选索引(CANDICATE)、唯⼀索引(UNIQUE)B、可以以在表设计器中建⽴索引索引不是真正排序,表的排序命令为SORT,是对记录的排序,结果形成新的表⽂件.dbf 4、区别索引⽂件的类型索引⽂件分为独⽴索引⽂件(.idx 存放⼀条索引结果)和复合索引⽂件(.cdx 存放多条索引结果)复合索引⽂件⼜分为结构复合索引⽂件(与表同名)和⾮结构复合索引⽂件结构复合索引⽂件因其与表同名,随着表的打开⽽打开,表的关闭⽽关闭,在表被修改时⾃动同步修改,现在是主要应⽤的索引⽂件5、区别索引的类型主索引和候选索引意义相似,建⽴主索引和候选索引都要求关键字表达式的值唯⼀,没有重复。
vf程序设计教程知识点

vf程序设计教程知识点VF程序设计是一种广泛应用于计算机领域的编程语言,具有简单易学、可扩展性强等特点。
本文将介绍VF程序设计的一些重要知识点,帮助读者快速掌握VF程序设计的基础知识。
一、变量和数据类型1. 变量的定义和声明方法;2. 常用的数据类型,如整型、浮点型和字符型;3. 变量的赋值和运算;4. 变量的作用域和生命周期。
二、控制流程1. 条件语句的使用,如if语句和switch语句;2. 循环语句的运用,如for循环和while循环;3. 循环控制语句,如break和continue的使用。
三、函数和模块化编程1. 函数的定义和调用方式;2. 函数的参数传递和返回值;3. 模块化编程的概念和好处;4. VF中常用的内置函数。
四、数组和字符串1. 数组的定义和初始化方法;2. 多维数组的使用;3. 字符串的操作和常见函数。
五、指针和内存管理1. 指针的概念和基本用法;2. 动态内存分配与释放;3. 内存泄漏和内存溢出的预防。
六、面向对象编程1. 类和对象的概念;2. 成员变量和成员函数的定义和调用;3. 继承、封装和多态的实现方式。
七、异常处理1. 异常的定义和捕获方法;2. 异常的层次结构和处理方式。
八、文件处理1. 文件的打开和关闭;2. 文件的读写操作。
九、图形界面编程1. VF中的图形库和界面设计;2. 组件的创建和事件处理。
十、网络编程1. 网络编程的基本概念;2. VF中的网络函数和操作。
通过学习以上知识点,读者可以全面掌握VF程序设计的基础知识,为以后进行更复杂的程序开发奠定坚实的基础。
但要注意,单纯的理论学习远远不如实践操作来得有效,建议读者在学习的过程中多实践、多编写程序,加深对知识点的理解和应用能力。
祝愿大家在VF程序设计的学习中取得好成绩!。
VF基础讲义
第一章数据库基础知识一、数据:1、数据(DATA):存储在媒体上能够识别的物理符号。
其一,能够描述事物的特性,其二,能够存储在媒体上。
文字数据(数字,字母,文字)和多媒体数据(声音,图象,动画)2、数据处理:将数据转化成信息的过程。
3、数据管理发展三个阶段:人工管理阶段,文件系统阶段,数据库系统阶段。
数据库系统阶段特点:提高共享性,减少冗余度。
二、数据库系统:DATABASE SYSTEM1、数据库DATABASE (DB):存储在计算机上的结构化数据的集合。
2、数据库管理系统(DBMS):对数据库的建立、更新和维护所配置的软件。
是数据库系统的核心软件。
VISUAL FOXPRO 就是一个可以在计算机和服务器上运行的数据库管理系统。
3、数据库应用系统:系统开发人员利用数据库系统资源开发出来的、面向某一类实际应用的应用软件系统,例如以数据库为基础的财务管理系统、人事管理系统、图书管理系统、教学管理系统、生产管理系统。
4、数据库管理员(DBA):职责:●参与数据库的规划、设计和建立;●负责数据库管理系统的安装和升级;●规划和实施数据库的备份和恢复;5、数据库系统(DBS):由五部分组成:硬件系统,数据库集合,数据库管理系统,数据库管理员和用户。
6、数据库系统的核心软件:数据库管理系统(DBMS)。
7、DBS、DB、DBMS 三者之间的关系:DBS包含DB和DBMS三、数据模型:1、实体:客观存在的并且可以相互区分的事物称为实体。
2、属性:描述实体的特征和状态称为属性。
3、实体间联系:(1)一对一联系:学生和学号,公司和经理1:1(2)一对多联系:学校和学生,部门和职员1:M(3)多对多联系:学生和选课,图书和读者M:N4、数据模型:表示实体和实体间联系的方法的一种结构图。
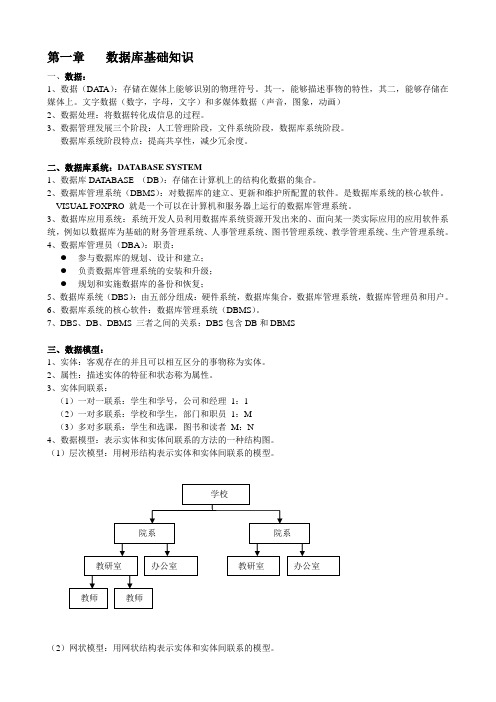
(1)层次模型:用树形结构表示实体和实体间联系的模型。
(2)网状模型:用网状结构表示实体和实体间联系的模型。
(3)关系模型:用二维表结构表示实体和实体间联系的模型。
vf的汇总知识

第一章vf的基础知识(1)人工文件数据库(2)关系运算传统:交并差专门:选择:行元组(记录) for where 行减少一个表投影:列属性(字段) fields 列减少一个表连接:多个表行列减少变多join on自然连接:多个表去掉重复属性的等值连接笛卡尔积:多个表3 * 3(3)关系的特点: 关系表二维表(.dbf)一个关系必须规范化元组不能重复属性不能重复属性的顺序没有要求记录顺序没有要求(4)项目(.pjx)建立项目:create project [项目名]修改项目:modify project [项目名]第二章函数常量数值表示方法:直接表示123 12.35 N货币常量表示:$123 默认4位小数$123 123.0000 8字节Y字符常量表示:"" '' [] sql Cthisform.grid1.recordsource="sele ..where 颜色='蓝' "日期常量{} 2005/05/02=>数值表示:{yyyy/mm/dd} 8字节D{yy/mm/dd}{mm/dd/yyyy} 传统严格:{^yyyy/mm/dd}set mark to ',' : set mark to :set date to ymd mdy dmy ...set cent on|offset stri to 0|1|2日期时间常量: {yyyy/mm/dd hh..} 8字节T逻辑型:m=5>6 .t. .T..y..Y. .F. .f..N..n. 1字节L表达(1)字符: + - 连接类型必须相同1+2=3"1"+"2"=12 1+"2" ×"1"-"2"=12"1 "+" 2 "=1口口2口"1 "-" 2 "=1口2口口(2)日期表达式:日期+日期×日期+数值√日期-数值√日期-日期(3)逻辑: and or not !.and. .or. .not. not>and>or(5)==:精确比较职工号=="z1" z1 z11 z12 z112日期越后的越大.t.>.f.$:包含left 左边right右边substr "...........""计算机" $ 商品名商品名like "%计算机%"like(商品名,"*计算机*")函数数值abs()sign()sqrt()int(3.456) =>3ceil(3.456)=>4floor(3.456)=>3round(3.456,2)=>3.46round(456.325,-2)=>500max("2","9","85")=>9min("计算机","电脑")=>电脑j d字符函数(1)len(字符型):结果数值len(sapce(0))=>0len(space(3)+space(5))=>8len(space(5)-space(3))=>8(2)space(数值):结果字符(3)trim() 后面结果字符ltrim() 前面allttrim() 前后into table allt(thisform.text1.value) (4)left(姓名,2) 左结果字符right(姓名,2) 右substr(姓名,2)任意位置截取一直到末尾substr(姓名,2,3):(5)at("..","..."):第一次结果数值at("..","...",n):第n次(6)stuff("abcdef",2,3,"11"):a11efstuff("abcdef",2,3,""):aefstuff("abcdef",2,0,"11"):a11bcdef(7)like(表达式1,表达式2):表达式可以出现通配符?*like("ab*","abcd") .t.like("abcd","ab*") .f.转换(1)str():数值转换为字符str(表达1,表达2,表达3) str(thisform.text1.value,8,2)(2)val():字符转数值(3)ctod():字符转日期(4)dtoc():日期转字符(5)year():截取年份n(6)month():月份n(7)day():天n(8)date():系统日期d(9)time():系统时间c(10)bof():表的首部(11)eof():表的末尾do while not eof()(12)&: &"123"=>123(13)vartype():(14)empty():"空值"测试0 .f. 空格空串 .t.empty(.null.)=> .f.(15)isnull():空值isnull(.null.) => .t.(16)iif(150>200,200,300)变量字段变量(表中的字段名)和内存变量(除表的字段名以外)当字段变量和内存变量同名,最终字段变量优先,要访问内存变量m.内存变量m->内存变量(1)假设表中的字段名姓名张三命令窗口输入:姓名=姓名-"你好"?姓名=>张三?m.姓名?m->姓名=>张三你好(2)假设表中的字段名商品名计算机命令窗口输入:m=商品名-"技术"?m => 计算机技术?商品名->计算机(3)x=3y=3store 3 to x,y(4)?:换行输出??:当前光标处输出一行(5)数组dime(1)数组的初值: .f.(2)数组的起始的小标(下标的下线):1(3)数组的个元素的类型可以不一样(4)vf变量的数据类型由变量的值决定,可以通过改变变量的值来改变变量的类型(5)对数组名赋值代表对所有元素赋值(6)可以用一维数组表示二维数组(6)scatter to :将表的当前记录赋值到数组gather from :将数组的值赋值到表的当前记录第三章数据库基本操作数据库(.dbc)数据库的命令(1)建立数据库:create database 数据库名(2)打开数据库:open database(3)修改数据库(打开数据数据库设计器):modify database(4)关闭数据库:close database(5)删除数据库:delete database(6)将自由表添加到数据库:add table(7)将数据库移除变为自由表:remove table(8)设置当前数据库:set database to 数据库名(9)取消当前数据库:set database to (所有的数据库都不是当前,不是关闭) 自由表:不属于任何一个数据库的表数据库表:放在库中(1)一个表只能属于一个数据(2)数据库表(1)字段有效性(域完整性):规则:逻辑表达式><信息:字符表达式""默认值:由字段的类型"" {} $ 123(2)索引:主候选普通唯一(3)联系:永久联系:表现为表与表之间的连线(1)必须在数据库设计器(2)建立永久联系必须先建索引:一个主一个普通(3) 一对一一对多主主(默认) 主普通(默认)候选候选主唯一主候选候选普通候选主候选唯一临时联系:指针的联动(1)先建立索引,一般主对普通(2)指针的联动:当父表的指针指向某条记录,子表的指针自动指向同一条记录(3)建立临时命令:set relation to 索引字段into 表名(4)取消临时联系:set relation to(4)参照完整性:更新插入删除步骤:(1)建立索引(2)建立永久联系(3)清理数据库:数据库->清理数据库(4)建立参照完整性更新:级联父子限制父子忽略删除:级联父子限制父子忽略插入:限制子父忽略自由表的特点:(1)自由表不能建立上面的操作(2)自由表不支持长表名into table allt(thisform.text1.value)(3)自由表:候选普通唯一(4)将数据库表删除后,原来是主索引->候选索引索引:逻辑顺序由指针构成的文件索引和表单独存放(1)主索引: 一个数据库表只能建立一个主索引建立主索引的字段值不能重复(2)候选索引:一个表可以建立多个候选候选索引和主索引的功能完全相同建立主索引的字段值不能重复(3)普通:一个表可以建立多个普通建立普通就是为了排序建立普通索引的字段值可以不重复,也可以重复(4)唯一:一个表可以建立多个唯一建立唯一就是为了排序建立唯一引的字段值可以不重复,也可以重复建立唯一索引,如果字段不重复,结果全部出现如果字段重复,重复字段结果只出现一个,默认出现第一个(5)建立单索引(.idx)index on 索引表达式to 索引名注意(1)一个单索引产生一个文件,多个单索引产生多个文件(2)单索引的文件名就是to后面的索引名(3)单索引只能升序,不能降序(4)单索引只能两种索引:普通(默认) 唯一(unique)(6)结构符合索引(.cdx)注意:(1)多个结构符合索引只产生一个文件(2)结构符合索引的文件名就是表名(3)结构可以升序,也可以降序默认:升序asce desc(4)建立三种:候选(candidate) 唯一(unique) 普通(默认)(5)index on 索引表达式tag 索引名(7)排序:物理顺序生成一个表文件和原来的表分开存储命令:sort on 排序字段to 表名(8)查找顺序查找:locate for 查找条件(1)locate for 无论执行多少次,最终只能找到符合条件的第一条记录(2)继续查找:continue(3)判断查找是否成功:found() .t. 找到.f. 未找到(4)如果找到则eof()=> .f.如果没有找到: 则eof()=>.t.索引查找:seek(1)要用seek,必须按查找的字段先建立索引(2)继续查找:skip(3)locate for 性别="男" seek "男"(9)设置当前索引(打开索引)(1)命令建立索引:index on tag 直接有效(2)设计器:不会直接有效set order to 索引名set order to :关闭有效索引第四章sql(1)简单sql公式sele 结果字段1,结果字段2,...from 表where 条件注意:(1)*:所有字段* from 表1 * from 表1,表2 表1.*(2)distinct:去掉重复记录张三女张三女(3)where 查询条件(2)连接查询(1)where 连接等价于[inner] join on 内连接wheresele 结果字段from 表1,表2,..where 表1.公共字段=表2.公共字段; and ..and 查询条件join on (2个表)sele 结果字段from 表1 join 表2 on 表1.公共字段=表2.公共字段; where 查询条件join on(3个表)sele 结果字段from 表1 join 表2 join 表3 ;on 表2.公共字段=表3.公共字段;on 表1.公共字段=表2.公共字段;where 查询条件(2)超级连接left join :左连接左的表如果不满足条件,结果也会出现,满足条件的也会出现right join:右连接full join:全连接join on:内连接只有满足的才会出现嵌套(1)in not in 在....里面sele 结果字段from 结果的表where 公共字段in;(sele 公共字段from 条件的表where 查询条件)(2) exists (真的条件) not exist (假的条件)sele 结果字段from 结果的表where exists;(sele * from 条件的表where 结果表.公共字段=条件表.公共字段; and 查询条件)计算查询(1)sum(参数) 求和(2)max (3)min (4)avg() (5)count()数数计数排序sele 结果字段from 表where 条件;order by 字段1 [asc|desc],排序字段2 [asc|desc],...注意:(1)order by 排的最终结果的顺序修正(2)排序可以更多个字段,从左到右的顺序(3)asc 升序desc 降序默认为升序分组sele 结果字段from 表where 条件;order by 排序[asc|desc];group by 分组字段1,分组字段2,...[having 分组的条]注意(1)as 重命名sele 原字段as 结果字段...(2)avg max sum min count:只能写在sele 或having(3)order by :结果排序只能跟结果字段(4)where :只能跟原字段(5)group by :可以跟原字段也可以是结果字段(6)条件:where having(7)having:必须跟在group by 的后面(8)having 和where 不矛盾先用where 限定元组,在用group by 分组,然后再用having去掉不满总条件的分组(9)嵌套查询sele ..(sele...)order by 不能用在子查询中查询去向(1)top n [perc] :前多少条:top必须和order by 同时使用(2)into array 数组名(3)into cursor 临时表(4)into table|dbf 永久表(5)to file 文本文件数据操纵(1)插入数据非sql:append insert append fromsql:insert into 表名values(字段值):插入全部字段insert into 表名(制定字段)values(字段值):插入部分字段insert into 表名from array 数组名insert into 表名from memvar 从同名的内存变量(2)更新数据非sql:replace 更新字段名with 字段值:只能当前一条replace 更新字段名with 字段值for :满足条件replace all 更新字段名with 字段值for : 满足条件replace all 更新字段名with 字段值:全部sql:update 表名set 字段名=字段值:默认全部update 表名set 字段名=字段值where :符合条件(3)删除记录非sql(1)逻辑删除:dele for 条件(2)恢复:recall for 条件(3)物理删除:pack 必须先逻辑后物理(4)彻底删除:zap 删除全部记录后,表依然存在sql:(1)逻辑删除:dele from 表名where 条件(2)物理:pack数据定义(1)建立表:create table|dbf 表名[name 长表名][free];(字段名1 字段类型[(字段宽度[,小数位数])] [null|not null] [check [error]] [default][primary key |unique ][refe 表2][,字段名2...])(2)修改表格式1:alter table 表名add|alter [column] 字段名字段类型[(字段宽度[,小数位数])] [null|not null][check [error]] [default][primary key |unique ][refe 表2][,字段名2...])格式2:alter table 表名alter [column] 字段名[null|not null] [set default] [set check][drop default] [droup check]格式3:alter table 表名drop 字段名alter table 表名renamen 原字段名to 新字段名alter table 表名add primary key |unique ..alter table 表名drop primary keyalter talbe 表名drop unqiue tag 索引名查询和视图查询的知识点(.qpr)(1)查询是预先定义好的sql sele 语句(2)是一个文本文件(3)建立查询(1)新建->查询(2)项目->数据->查询(3)create query 查询文件名(4)新建->文本文件->sql->保存->.qpr(4)修改查询:modify query 查询文件名(5)查询的选项卡: 字段->sele连接->join on筛选->where排序->order by分组->group by having杂项->top distinct运行查询:do 查询文件名.qpr视图(1)基于sql产生(2)视图保存在数据库中,磁盘上不存在,操作视图,必须先打开数据设计器(3)查询保存在磁盘上,就是叫查询文件,跟数据库无关(4)视图:字段连接筛选排序分组更新条件杂项(5)查询只能查表,但是不能更新表,视图既可以查询表,也可以更新表(6)建立视图:create view 视图名as sele ..(7)删除视图:drop view 视图名(8)修改视图:modify view表单(.scx)表单文件名:保存或关闭表单控件名(表单名):name表单标题:catpion背景色:backcolor自动居中:autocenter模式表单:windowtype不可移动:movable高:height宽:width左:left顶:top表单的退出命令:thisform.release方法:退出release 显示:show 隐藏:hide表单:load init destroy unload事件:click dblclick rightclick属性:caption backcolor name ...建立表单:create form 表单名修改表单:modify form 表单名运行表单:do form 表单名标签(label1)属性name:名字caption:标题fontsize:字体大小forecolor:字体颜色autosize:自动调整大小backcolorfontname:字体backstyle:是否透明文本框(text1)name:名字value:文本框的值inputmask:格式x:任意字符9:数字和+ - #:空格数字+- . , passwordchar:密码显示的字符表示文本框的值:thisform.text1.value将sql的结果放入文本框:(1)sele ..into array aa(2)thisform.text1.value=aa命令按钮(command1)属性default:默认按钮enter click .t. 一个cancel:取消escenabled:是否可用(黑色和灰色)visible:是否可见(显示和隐藏)caption:标题事件:click选项组:optiongroup1 option1 option2属性:value=n:第n 个按钮被选中if thisform.optiongroup1.value=n :选中第n个按钮.....elseendifdo casecase ....endcasebuttoncount:按钮的个数组合框(combo1)value:选中的值displayvalue:选中或输入的值displaycount:显示的最大数目字段名=bo1.displayvalue rowsourcetype:数据源的类型0-无additem 增加条目removeitem 删除条目1-值手动自己输计算机,电脑,...6-字段某个字段的值8-结构显示某个表的所有字段名3-sql 写sele 命令5-数组数组名7-文件*.doc *.xls 幻灯片pptrowsource:数据源列表框(list1)value:列表框中选中的值listcount:列表框中的条目总数rowsourcetype:数据源的类型rowsource:数据源list(i):代表第i个条目thisform.list1.value页框(pageframe1) page1 page 2..pagecount:页数activepage:激活某一页thisform.pageframe1.activepage=n:激活第n页表格(grid1)captionrecorsourcetype:数据源的类型0-表开关的状态无关1-别名表必须开4-sql sele 语句recordsource:数据源columncount:列数-1 :全部列N:只能有n列0-表thisform.grid1.recourdsource="表名"4-sqlthisform.grid1.recourdsource="sele .. into cursor "计时器(timer1)interval: 计时器时间间隔500复选框(check1)value=1 选中=0 为选中check1 check2 (一个check就是2个结果,二个check就是4个结果)菜单(.mnx .mpr)建立菜单(1)先建->菜单->(.mnx)->单击菜单->生成(.mpr)菜单文件菜单程序文件(2)运行:.mpr 程序文件(3)菜单表文件(书227页,本身并不能运行,必须要生成)(4)建立菜单/修改:modify menu 菜单名(5)退出菜单:set sysmenu to default(6)退出表单:thisform.release(7)菜单的显示位置:单击显示->常规选项->位置访问键: (\<字母)快捷键: 直接输(菜单设计器的选项打勾后,再按ctrl+某个键)分组线:\-运行菜单:do 菜单名.mpr(8)顶层表单(将菜单显示在表单上)菜单(1)建立菜单(2)单击显示->常规选项->勾上顶层表单表单(1)将表单的showwindow -2(2)给表单init (load):添加调用菜单的代码:do 菜单文件名.mpr with this注意:菜单中要用表单中的东西原来表单中:thisform.release菜单中:表单文件名.release快捷菜单(将菜单显示在表单上,右键才可以显示)菜单(1)先建->快捷菜单(2)单击显示->常规选型->设置-> para 形参名(是否设形参,关键是要看你的菜单是不要用表单,如果要就必须设,不要就不设)表单(1)在表单的rightclick 添加代码do 菜单名.mpr with this注意快捷菜单也可以用表单的东西原来在表单:thisform.release菜单中:形参名.release程序(.prg)注释*:&&:note :输入命令(1)input "输入提示" to 变量:输入任意类型数值:1213货币:$123字符型:"" '' []日期: {}(2)accetp "输入提示" to 变量:只能输入字符串字符:不用""(3)wait "输入提示" to 变量:只能输入单个字符程序结构(1)顺序结构(2)选择结构:if if do caseendif else case ..endif ..endcase (3)循环结构do while for scan for.. .. ..enddo endfor endscanloop:结束本次循环继续下一次exit:结束循环参数传递格式1: do 过程名(函数名) with 参数do aa with 5 (常量): 单向do aa with x+y (表达式):单向do aa with (x) (带括号的变量):单向do aa with x (变量):双向格式2:过程名(参数)set udfp to value:设置单向传递单向aa(5)aa(x+y)aa((x))aa(x)set udfp to refe :双向aa(5) :单向aa(x+y):单向aa((x)):单向aa(x) :双向变量的作用域公共变量:publicpublic 变量初值:.f.作用范围:全部都可以用私有变量:在他和他的下层可以使用直接定义的变量叫私有变量局部变量:local 变量名初值:.f.只能在本模块中使用建立和修改程序:modify command 运行程序:do 程序名do 查询.qprdo 菜单.mprdo form 表单报表(.frx)标签:显示文字表达式:域控件ole对象:图片建立报表:create report 报表名修改报表:modify report 报表名预览报表:report form 报表preview。
VF知识点总结

第一章 VF数据库基础1.4 vf系统简介Vf6.0是可运行于windows平台的 32位数据库开发系统1.5 项目管理器1.定义:指文件、数据、文档和visual foxpro对象的集合,是将一个应用程序的所有文件集合成一个有机的整体。
扩展名.pjx2.项目管理器包含的选项卡:●数据:数据库,自由表,查询●文档:表单,报表,标签●类:●代码:程序、函数库API,应用程序●其他:文本文件,菜单文件,其他文件●全部:包含以上各类文件3.在项目管理器中,可以:新建文件、添加文件、删除文件、修改文件,不可以重命名文件4.退出VF命令:quit1.6 数据库基础知识数据:是存储在某种媒体上能够识别的物理符号。
数据处理:将数据转化为信息的过程。
DBS(数据库系统)包括DB(数据库)、DBAS(数据库应用系统)、DBMS(数据库管理系统)数据库系统的组成:硬件系统、数据库集合、数据库管理系统及相关软件、数据库管理员和用户。
数据库系统的核心是:数据库管理系统(DBMS)数据模型:层次模型(用树型结构表示实体及其之间联系的模型称)网状模型(用网状结构表示实体及其之间联系的模型)关系模型(用二维表来表示实体以及实体之间联系的模型。
以关系数学理论为基础)1.7关系数据库“关系”指的是:表文件(.dbf文件)外部关键字:若表中的一个字段不是本表的主关键字或候选关键字而是另外一个表的主关键字或候选关键字,这个字段就称为外部关键字。
传统的集合运算并:两个关系的元组的集合。
差:属于一个关系而不属于另一个关系的元组的集合。
交:两个关系中的公共元组。
专门的关系运算:选择:从关系中找出满足给定条件的元组的操作称为选择。
投影:从关系中制定若干属性,组成新的关系。
投影是从列的角度进行的运算。
连接:把两个关系拼接成一个关系的运算。
第二章数据与数据运算2.1 常量与变量2.1.1 常量常量的数据类型:字符数值日期日期时间货币逻辑●字符常量:可以使用的定界符“”‘’ []●数值常量:1.23E-5 科学计数法●日期常量:分严格日期格式:{^yyyy-mm-dd}传统日期格式:{mm/dd/yy}Set strictdate to 0 可以使用传统日期格式Set strictdate to 1/2 必须使用严格日期格式默认情况下使用严格日期格式Set mark to “-”日期分隔符(”/”,”–““.”)默认 /Set date to mdy /dmy/ymd 设置日期顺序默认 mdySet century on 4位年份显示Set century off 2位年份显示(默认)Set century to 世纪值 rollover 年份参照值当输入两位的年份小于参照值,输出年份世纪值+1如: set century to 19 rollover 20R={10/21/13}?r 输出为: 2013年10月21日R={10/21/95}?r 输出为: 1995年10月21日●日期时间常量●逻辑常量:.t. .f.(.y. .n.)在主窗口口只显示 .t. 和 .f.货币型常量:使用$ ,保留4位小数2.1.2 变量1.变量三要素:变量名数据类型变量值2.变量分类:字段变量和内存变量当内存变量和字段变量同名时,字段变量优先使用,如果要使用内存变量M.变量名或 M->变量名3.内存变量赋值用= 或 storeStore 值 to 变量1,变量2,…Store 一次可以对多个变量赋相同的值。
VF基础知识

VF基础知识第⼀节课 VF ⼊门以及(⾃由表)表格的基本操作⼀、新建表(.dbf)1.菜单-⽂件-新建-表2.常⽤⼯具栏-新建-表3.命令 create [表名]默认⽬录的设置:菜单-⼯具-选项-⽂件位置-默认⽬录-双击-选择默认⽬录-找到驱动器-选择盘符⼆表格中的字段类型字段类型英⽂简称宽度定界符字符型 C 可改动 ' ' 或 " " 或[ ] "123"数值型 N 可改动⽆ 123⽇期型 D 8 {^yyyy-mm-dd} {^1989-02-16}逻辑型 L 1 .T. 或 .F.⽇期时间型 T 8 {^yyyy-mm-dd [hh[:mm[:ss]]]|[p|a]} 整型 I 4备注型 M 4 备注型的⽂件中.ftp通⽤型 G 41.打开表(1)菜单-⽂件-打开-选择⽂件类型中的表(2)常⽤⼯具栏-打开(3)命令 use <表名> use f:\董双双\学⽣信息表要在独占⽅式下(4)数据⼯作期窗⼝-打开2.关闭(当前表)(1)命令 use(2)数据⼯作期窗⼝-关闭3.进⼊当前表的表设计器(1)菜单-显⽰-表设计器(2)命令 modify structure4.浏览当前表的信息(1)数据⼯作期窗⼝-浏览(2)菜单-显⽰-浏览(3)命令 browse5.修改表中的记录(1)直接修改(2)插⼊ insert [blank][before] (当前记录之前)(3)追加 append [blank](4)replace 字段名 with 被修改的记录 [for 条件][范围]只能修改当前记录(没有限定范围的前提下)6.删除表中的记录(逻辑删除和物理删除)(1)逻辑删除不会真正删除表中的记录,可以恢复命令 delete [for 条件][范围]恢复 recall [for 条件][范围](2)物理删除会真正把表中打上逻辑删除标记记录删掉,不可恢复命令 pack(3)清空表中的记录 zap (物理删除不可恢复)第⼆课⾃由表的基本操作及数据库⼀⾃由表的简单命令1.显⽰表中的记录到VF屏幕上(1) list [for 条件][[fields] 字段][范围]默认显⽰表中所有的记录(滚屏显⽰)(2) display [for 条件][[fields] 字段][范围]默认只显⽰当前⼀条记录的信息(分屏显⽰)2.对表中的记录查询定位(1) 绝对定位 go 或 goto [n][top|bottom](2) 相对定位 skip [n](3) 在当前表中查找符合条件的记录,指针直接指向符合条件的第⼀条记录locate for 条件[continue] 若查找下⼀条符合条件的记录,⽤continue 连⽤⼆数据库 (.dbc) 1.新建(1)⽂件-新建-数据库(2)常⽤⼯具栏-新建-数据库(3)命令-create database [数据库名称]2.进⼊当前数据库设计器(1)显⽰-数据库设计器(2)命令-modify database3.关闭当前数据库close database4.打开数据库(1)菜单-⽂件-打开-⽂件类型-数据库名(2)open database 数据库名5.将打开的数据库设置为当前数据库(1)⿏标直接点(2)命令 set database to 数据库名6.添加⾃由表到当前数据库(1)⿏标操作(2)命令 add table ⾃由表名7.从当前数据库移去表(1)⿏标操作(2)命令 remove table 表名8.从当前数据库删除表(第四章的SQL语句)(1)⿏标操作(2)命令 drop table 表名9.删除数据库(被删除的数据库不能已经打开,必须关闭)delete database 数据库名10.在数据库中新建表(1)⽂件-新建(2)常⽤⼯具栏(3)简单命令 create(4)⽤数据库设计器的⼯具栏或在数据库中右单击或数据库的菜单下的⼦菜单(5)⽤(第四章)SQL语句(重点)create table 表名(字段名1 类型(宽度)[,字段名2 类型(宽度)..]) create table 学⽣(姓名 C(8),性别 C(2),出⽣⽇期 D,成绩 N(6,2))三、字段有效性(数据完整性中的域完整性)规则:是⼀个逻辑表达式信息:是⼀句话相当于字符串,要加字符型的定界符默认值:是跟本⾝字段类型匹配的记录,要加相应的定界符四、项⽬管理器(.pjx)第三课索引的建⽴应⽤及数据完整性⼀索引1.分类:简单索引和复合索引2.索引的作⽤:提⾼查询速度(但同时会降低更新速度)VF 中的索引是:指针构成的⽂件,这些指针逻辑上按照索引关键字进⾏排序,就叫做逻辑上的排序⼆简单索引(.idx)index on 索引关键字(字段名) to 索引⽂件名[.idx]例如:index on ⼯资 to gz打开索引⽂件set index to 索引⽂件名例如:set index to gz注意:简单索引⼀个索引只能建⽴⼀个索引项只能按照升序排序,不能按降序三复合索引(.cdx)1.分类:结构复合索引和⾮结构复合索引2.⾮结构复合索引index on 索引关键字(字段名) tag 索引名 of 索引⽂件名[.cdx]; [asce|desc]例如:index on ⼯资 tag ⼯资d of aa descindex on 地址 tag 地址a of aa打开索引⽂件set index to 索引⽂件名例如:set index to aa指定某个索引起作⽤set order to 索引标识例如:set order to ⼯资a或地址a3.结构复合索引(1)可以⽤命令建⽴index on 索引关键字(字段名) tag 索引名 [asce|desc]指定某个索引起作⽤set order to 索引标识(2)也可以⽤表设计器直接做(考试)注意:结构复合索引的⽂件直接放到当前表格中,随着表格的打开⽽打开关闭⽽关闭,⼀个表中可以有多个结构复合索引表设计器的复合索引类型:类型个数是否有重复值建⽴⽅式主索引⼀个不允许有重复值或空值表设计器候选索引多个不允许有重复值或空值命令 candidate 或设计器唯⼀索引多个允许有重复值或空值命令 unique 或设计器普通索引多个允许有重复值或空值命令或设计器4.删除索引(1)在表设计器中直接删除(2)命令 delete tag 索引名(索引标识) 或 delete tag all四数据完整性1.分类:实体完整性域完整性参照完整性2.实体完整性:就是指表中的主索引和候选索引所代表的记录的唯⼀性就理解为实体完整性3.域完整性:字段的有效性(规则信息默认值)4.参照完整性:(1)在数据库的表格之间设置永久性连接从同⼀个数据库的⼀个表的主索引的公共字段索引名拖向另⼀个表的公共字段的普通索引名就建⽴了两个表格之间的永久性连接(2)设置参照完整性⾸先把所有打开的表格都关闭,选择菜单-“数据库”-清理,然后在数据库空⽩地⽅单击⿏标右键选择编辑参照完整性五、⼯作区 1-32767⼯作区号最多有32767个,最⼩的⼯作区号是1选择⼯作区⽤命令 select(1)select 表格名称(2)select ⼯作区号(3)select A-J 代表1-10号use 表名 in ⼯作区号use 表名 in 0 :打开⼀个表放到没有使⽤的最⼩的⼯作区中select 0 :代表选中了没有使⽤的最⼩的⼯作区号六临时性连接(⼜叫指针的连动)1.⽤数据⼯作期窗⼝建⽴2.⽤命令建⽴例如:use 表1 in 1 order 公共字段索引名use 表2 in 2 order 公共字段索引名select 1 (⽗表)set relation to 公共字段索引名 into 表2 (⼦表)七使⽤索引快速定位 (⽤seek查找的记录所在的字段必须是当前索引)seek例如: seek "张三"seek "E1"⼋排序sort to 新表名 on 关键字(字段名) [/a|/d|/c]第四课常量和变量⼀常量1.固定不变的量称之为常量显⽰常量变量表达式和函数在屏幕上先换⾏再输出在屏幕上不换⾏直接输出2.分类:字符型货币型数值型⽇期型⽇期时间型逻辑型(1)字符型C例如:"张三 " "aabb" "1234" "" '' [](2)货币型 Y定界符:$ 例如:$24.6 $79 默认四位⼩数(3)数值型 N⽆定界符例如:123.456 70(4)⽇期型 D定界符 {^yyyy-mm-dd} 例如:{^1989-10-24}影响⽇期格式的命令set mark to "分隔符" 设置分隔符set date to ymd或mdy或dmy 设置显⽰格式set century on 或 off 设置显⽰4位还是2位年份默认2位set strictdate to 0或1或2 设置是否使⽤严格⽇期格式set century to 世纪值 rollover 年份参照值例如: set century to 19 rollover 50⽇期格式分为严格⽇期格式和传统⽇期格式严格⽇期格式:{^yyyy-mm-dd}传统⽇期格式:{mm/dd/yy}或{dd/mm/yy}或{yy/mm/dd}(5)⽇期时间型 T定界符 {^yyyy-mm-dd,[hh[:mm[:ss]]|[a|p]]}(6)逻辑型 L 定界符 .. 例如:.T. .y. .N. .f.⼆变量能随时变化的1.分类字段变量和内存变量内存变量的数据类型:字符型数值型货币型⽇期型⽇期时间型逻辑型(1)简单的内存变量的赋值> 内存变量名=表达式> store 表达式 to 内存变量名表注:"="⼀⾏命令只能⽤⼀个赋值,⽽store 可以把⼀个值赋给多个变量若在当前表中存在⼀个同名的字段变量,字段变量优先执⾏,如果想显⽰内存变量在内存变量名前加:m.内存变量名例如:m.职⼯号或m->职⼯号(2)数组 (array) 类型简称 A分类:⼀维数组和⼆维数组定义: dimension 数组名(下标上限[,下标上限2])declare 数组名(下标上限[,下标上限2])例如: dimension aa(10) aa(1)-aa(10)dimension bb(2,5) bb(1,1)-bb(2,5)显⽰内存变量:list memory [like 通配符] 例如:list memory like aa?display memory [like 通配符]注意:通配符"*"代表任意多个字符,"?"代表任意⼀个字符清除内存变量(1) clear memory(2) release 内存变量名表(3) release all(4) release all [like 通配符]|[except 通配符]将表中的数据与数组中的数据进⾏交换(1)将表的当前记录复制到数组中scatter to 数组名(2)将数组的数据复制到当前表的当前记录gather from 数组名第五课表达式和函数⼀、表达式表达式是由常量变量和函数通过特定的运算符连接起来的式⼦分类: 数值表达式字符表达式⽇期时间表达式关系表达式逻辑表达式1.数值表达式运算符:() **|^ * / % + -例如:被除数%除数2.字符表达式运算符:+ - 连接字符串3.⽇期时间表达式运算符:+ -4.关系表达式运算符:< 、> 、<>|#|!=、<=、>=、 =、==、$字符型的⽐较:空格运算符"="受命令 set exact off|on 命令的影响,当设置处于off状态时,指"="右侧的字符是否原样出现在在左侧字符的左边,如果出现就为.t.,否则.f.,当设置处于on 状态时,叫等长⽐较,指"="左右的两个字长度如果不相等,先在较短的末尾添加空格,直到两侧字符的长度相等再⼀个⼀个字符⽐较$ ⼦串包含字符串1$字符串2如果左侧字符串出现在右侧字符串的任意位置就返回.T.,否则 .F.5.逻辑表达式运算符: 逻辑⾮ not 或! 取右侧值的相反结果逻辑与 and 真真才为真逻辑或 or 假假才为假算术运算符>字符串运算符和⽇期时间运算符>关系运算符>逻辑运算符⼆、函数格式:函数名( )分类:数值函数字符处理函数⽇期类函数数据类型转换函数测试函数1.数值函数(1)abs(数值表达式) 求绝对值(2)sign(数值表达式) 求符号(3)sqrt(数值表达式) 求平⽅根(4)pi() 求圆周率(5)int(数值表达式) 取数值表达式的整数部分(6)ceiling(数值表达式)返回⼤于或等于数值表达式的最⼩整数(7)floor(数值表达式) 返回⼩于或等于数值表达式的最⼤整数(8)round(数值表达式1,数值表达式2) 四舍五⼊(9)mod(数值表达式1,数值表达式2) 求余数(10)max(数值表达式1,数值表达式2,数值表达式3)取最⼤值(11)min(数值表达式1,数值表达式2,数值表达式3)取最⼩值2.字符函数(1)len(字符表达式) 求字符串长度(2)lower(字符表达式)⼤写转为⼩写(3)upper(字符表达式)⼩写转为⼤写(4)space(数值表达式) 返回空格(5)trim(字符表达式)删除字符末尾的空格(6)ltrim(字符表达式) 删除字符左侧的空格(7)alltrim(字符表达式) 删除字符左侧和右侧的空格(中间的不删)第六课函数⼀、字符函数(8)left(字符表达式,长度) 取⼦串函数(9)right(字符表达式,长度)(10)substr(字符表达式,起始位置[,长度])(11)occurs(字符表达式1,字符表达式2) 返回第⼀个字符在第⼆个字符中出现的次数 ,返回数值型(12)at(字符表达式1,字符表达式2[,数值表达式])(区分⼤⼩写)求字符1在字符2中第⼏次出现的位置(13)atc(字符表达式1,字符表达式2[,数值表达式])(不区分⼤⼩写)(14)stuff(字符表达式1,起始位置,长度,字符表达式2) ⼦串替换函数 stuff("abcdef",2,3,"ttttt")(15)chrtran(字符表达式1,字符表达式2,字符表达式3) 字符替换函数(16)like(字符表达式1,字符表达式2) 字符串匹配函数左侧字符表达式1可以出现通配符 ?和 *⼆、⽇期和时间函数(1)date() 返回⽇期型 D(2)time() 返回字符型 C(3)datetime() 返回⽇期时间型 T(4)year(⽇期表达式或者⽇期时间表达式) 返回数值型 N(5)month(⽇期表达式或者⽇期时间表达式)(6)day(⽇期表达式或者⽇期时间表达式)(7)hour(⽇期时间表达式)(8)minute(⽇期时间表达式)(9)sec(⽇期时间表达式)三、数据类型转换函数(1)str(数值表达式[,长度[,⼩数位数]]) 数值->字符(2)val(字符表达式) 字符->数值(3)ctod(字符表达式) 字符->⽇期(4)ctot(字符表达式) 字符->⽇期时间(5)dtoc(⽇期表达式或⽇期时间表达式[,1]) ⽇期->字符(6)ttoc(⽇期时间表达式[,1]) ⽇期时间->字符(7)&字符型变量四、测试函数(1)between(表达式1,表达式2,表达式3)(2)isnull(表达式)(3)empty(表达式) 测试是否是空值(4)vartype(表达式[,逻辑表达式]) 测试数据类型返回英⽂简称(5)eof([⼯作区号或表别名]) 表中最后⼀条的后⾯(末尾)(6)bof([⼯作区号或表别名]) 表中第⼀条记录的前⾯(⾸位置)(7)recno([⼯作区号或表别名]) 返回当前表中的当前记录的记录号(8)reccount([⼯作区号或表别名]) 返回当前表中的记录条数(9)iif(逻辑表达式,表达式1,表达式2)(10)deleted([⼯作区号或表别名])第七课程序设计基础⼀、程序⽂件的建⽴与执⾏1.新建 (.prg)(1)⽂件-新建-程序(或常⽤⼯具栏上的新建)(2)命令 modify command [程序⽂件名]2.程序是需要建⽴完毕后保存并运⾏的⽂件运⾏⽅法:(1)菜单程序-运⾏(2)常⽤⼯具栏上的“叹号”或 ctrl+E(3)命令 do 程序⽂件名[.prg]3.程序中的注释语句* 和 note 打开头或者⽤ && 在程序的任意位置都可以是注释语句⼆、简单的输⼊输出命令1.输⼊命令input [字符表达式] to 内存变量默认只能输⼊数值型的数据,如果要输⼊其他类型,要加相应的定界符2.输⼊命令accept [字符表达式] to 内存变量只能输⼊字符类型的数据,不能加定界符3.输出命令wait [字符表达式] [window][timeout 秒数 ]三、程序的基本结构程序的结构分为:顺序结构选择结构和循环结构1.顺序结构正常情况下程序中的命令语句都是⼀句⼀句顺序执⾏的2.选择结构(1)条件语句 iif(条件,表达式1,表达式2)函数if 条件语句序列1[else语句序列2]endif(2)分⽀语句do casecase 条件1 2*x-1 x<0语句序列1 3*x+4 3>x>=0case 条件2 y= x+1 5>x>=3语句序列2 7*x+2 x>=5case 条件n语句序列n[otherwise语句序列]endcase3.循环结构⼀定要有使"条件"趋向于结束的语句存在否则死循环(1)do while 条件语句序列(循环体)enddo第⼋课多模块程序设计程序循环结构(2)for 变量=初值 to 终⽌值 [step 步长]语句序列(循环体)endfor(3)scan [for 条件][while 条件]语句序列(循环体)endscan注意:此循环结构只能在当前表中做操作,不能脱离表格在三种循环结构中都能⽤exit强制退出循环体和loop 返回条件⼀、模块的定义procedure 或 function 过程名命令序列[return [表达式]]endproc 或 endfunc⼆、模块的调⽤格式:1.do 过程名2.过程名()三、参数传递接收参数的命令parameters 形式参数1,形参2....lparameters 形式参数1,形参2....调⽤格式1.do 过程名 with 实际参数1,实参2....2.过程名(实际参数1,实参2....) 函数调⽤格式set udfparms to value 按值传递set udfparms to reference 按引⽤传递函数调⽤格式受命令的影响,按值传递形参变实参不变按引⽤传递形参变实参也变,"do "的调⽤格式不受影响,形参变实参都变四、程序中变量的作⽤范围1.程序中的变量分为三种:全局变量(公共变量),私有变量,局部变量2.全局变量public 变量名3.局部变量local 变量名4.私有变量除了⽤ public 和 local 定义的变量,直接使⽤的都叫私有变量5.private 变量名作⽤是隐藏同名的变量,使其暂时不起作⽤第九课关系数据库标准语⾔SQL⼀、SQL的核⼼内容叫查询 "select"⼆、查询语句基本格式 (不⽤打开表就可以操作)1.简单查询select 字段名... from 表名 [where 条件].....在 select 后查询 from 后表格的所有的字段⽤ "*"distinct 去掉查询结果的重复值 ,⼀个select 命令只能⽤⼀个2.简单连接查询select 字段名.. from 表1,表2... where 表1.公共字段=;表2.公共字段 [and 其他条件]3.嵌套查询最多分两层(外层和内层)select 字段 from 表1 where 公共字段 in|not in;(select 公共字段 from 表2 [where 条件])4.⼏种特殊的运算符(1)between ..and ..例如:⼯资 between 1220 and 1250(2)like可以出现通配符"%"代表任意字符 "_"代表⼀个字符5.排序短语 order by 字段1 [asc|desc][,字段2 [asc|desc]...] select -from- where- order by放在整个查询语句的末尾或 where 条件之后,对查询结果进⾏排序6.简单计算查询count() 统计计数sum() 求和值avg() 求平均max() 求最⼤值min() 求最⼩值这5个函数都是⽤在 select 后的字段上或 having 的条件⾥,不能直接出现在 where 条件⾥7.分组与计算查询 "每个,每..."短语 group by 字段名 [having 分组条件]位置:select -from-where-group by [having] order by8.利⽤空值查询is null 或 is not null9.别名(1)字段别名除了排序 order by 之外⼀般都不能⽤select 字段或表达式 as 新字段名 from ....select 字段或表达式空格新字段名 from ....(2)表别名表的别名是整句命令都必须使⽤表的新名select -from 表1 as 新表名select -from 表1 空格新表名第⼗课 SQL 语句⼀、查询1.使⽤量词和谓词查询量词: any some all(了解)谓词: exists 和 not exists (可以实现和嵌套相同的功能)select 字段 from 表1 where exists|not exists(select *; from 表2 where 表1.公共字段=表2.公共字段)[and 条件]select 字段 from 表1 where 公共字段 in|not in;(select 公共字段 from 表2 [where 条件])2.超链接格式(考上机题的改错)(了解)[inner] join 内连接left join 左连接right join 右连接full join 全连接join ...on 短语连⽤3.集合的并运算(了解)union4.查询去向(1)只显⽰前⼏条记录top n[percent] 必须和 order by 连⽤(2)将查询结果给数组into array 数组名select-from -[where][group by][order b]. into array 数组(3)将查询结果给永久表into table 表名或 into dbf 表名(4)将查询结果给临时表into cursor 表名(5)将查询结果给⽂本⽂件to file ⽂件名(6)将查询结果给打印机to printer⼆、操作功能1.插⼊记录(插⼊到指定表的末尾)insert into 表名 values(表中各记录的值)insert into 表名 (字段名...) values(各字段的记录值) insert into 表名 from array 数组名(数组中的值必须和表中的记录类型吻合) 2.更新记录(修改表中的记录)replace 字段 with "值" for 条件update 表名 set 字段名=值 [where 条件]3.逻辑删除delete from 表名 [where 条件]4.表结构的修改(了解)(表设计器中的内容)alter table 表名 ......例如:alter table 仓库 add ⼯资 N(4)alter table 仓库 drop ⼯资alter table 仓库 alter ⾯积 N(3)alter table 仓库 rename ⾯积 to mjalter table 仓库 add ⼯资 I check (⼯资>=0) ;error "⼯资的值必须⼤于等于零" default 0alter table 仓库 add unique 仓库号 tag 仓库号候选索引index on 表达式 tag 索引名 candidate 候选索引第⼗⼀课查询设计器与视图⼀、查询设计器(.qpr)1.新建(1)菜单-⽂件-新建-查询(或常⽤⼯具栏)(2)命令 create query [查询⽂件名]2.新建完查询之后⼀定要保存并运⾏运⾏⽅法:(1)在查询设计器打开的情况下⽤常⽤⼯具栏上的"!"(2)程序菜单-运⾏(3)命令 do 查询⽂件名.qpr3.查询设计器中各选项卡与 select 语句的对应(1)字段选项卡-select(2)联接选项卡-join on(3)筛选选项卡-where(4)排序依据-order by(5)分组依据-group by(6)杂项- distinct 和 * top n(7)查询去向-into table |cursor |to file|to printer查询设计器可以实现与select 语句相同的功能,但是做不了嵌套⼆、视图(相当于表)1.新建(1)⽂件-新建-视图(或常⽤⼯具栏)(2)⽤SQL 语句 create view 视图名 as select -from -where..... 2.视图必须依附于数据库存在,在建⽴视图的时候必须有⼀个当前数据库视图不占内存空间,随着数据库的打开⽽打开,关闭⽽关闭3.视图建⽴完毕后必须保存,并且⾃动保存到当前数据库中,并且不⽤运⾏选择题:视图⽐查询多了个“更新条件”少了个“查询去向”4.删除视图(1)在数据库中直接删除(2)命令 drop view 视图名第⼗⼆课表单设计与应⽤⼀、表单新建(.scx)1.⽂件-新建-表单(或常⽤⼯具栏)2.命令 create form [表单⽂件名]⼆、表单设计完成后要保存并运⾏运⾏⽅法:1.常⽤⼯具栏-"!"2.命令 do form 表单⽂件名三、表单设计器⼯具的使⽤四、对象属性访问及对象⽅法调⽤的基本格式对象引⽤.对象属性例如:thisform.caption="你好" 在command1的click 写对象引⽤.对象⽅法例如:thisform.release五、常⽤事件⽅法1.事件load init destroy unload error gotfocusclick dblclick rightclick interactivechange2.⽅法release refresh show hide setfocus六、常⽤控件对象的使⽤1.标签(label1) <- name 名称属性: caption :标题,指定标签中的⽂本内容alignment:指定标题⽂本在控件中显⽰的对齐⽅式2.命令按钮(command1)属性: default:该属性设为.t. 称为:"确认"cancel:该属性设为.t. 称为:"取消"enabled:指定对象能不能⽤visible:指定对象可不可见第⼗三课命令组⽂本框编辑框复选框选项组⼀、命令按钮组(commandgroup1)(了解)常⽤属性:1.buttoncount 指定命令按钮的个数2.buttons ⽤于存取命令组中各按钮的数组例如: /doc/d1b22756650e52ea5418983e.html mandgroup1.buttons(1).caption="第⼀个" /doc/d1b22756650e52ea5418983e.html mand1.caption="第⼀个"3.value 指定命令组当前的状态默认数值型,可以改成字符型⼆、⽂本框(text1)1.value 返回⽂本框的当前内容或赋值给⽂本框值,默认字符型2.passwordchar 指定⽂本框控件内是显⽰⽤户输⼊的字符还是占位符3.inputmask 指定在⼀个⽂本框中如何输⼊和显⽰数据X:代表任意⼀位字符#:代表任意的0-9数字,正负号和空格9:代表任意的0-9数字新建属性和⽅法程序在表单设计器设计的同时,选择菜单"表单"-新建属性和新建⽅法程序三、编辑框(edit1)(了解)1.allowtabs :指定编辑框能否使⽤tab键2.hideselection :当编辑框失去焦点时编辑框中选定的⽂本是否仍为选定状态3.readonly:指定是否只读4.scrollbars :是否具有垂直滚动条5.selstart:返回⽤户在编辑框中所选⽂本的起始点位置或插⼊位置6.sellength:返回⽤户在编辑框中所选⽂本的长度7.seltext:返回⽤户在编辑框中选定的⽂本内容四、复选框(check1)1.caption 指定显⽰在复选框右边的⽂字标题2.value 指定复选框的当前状态数值型: 1 代表选中 0 代表未选中逻辑型: .t. 代表选中 .f.代表未选中五、选项组(optiongroup1)1.buttoncount :指定选项按钮组中按钮的个数2.buttons : ⽤于存取选项组中各按钮的数组例如: thisform.optiongroup1.buttons(2).caption="第⼀个" thisform.optiongroup1.option1.caption="第⼀个"3.value 指定选项组当前的状态默认数值型,可以改成字符型第⼗四课列表框组合框表格⼀、列表框(list1)属性:1.rowsource 数据源2.rowsourcetype 数据源的类型 0-93.list :⽤以存取列表框中数据条⽬的字符串数组thisform.list1.list(1)4.listcount:指明列表框中数据条⽬的数⽬thisform.list1.listcount5.columncount:指定列表框的列数6.value:返回列表框中被选中的条⽬7.selected:指定列表框内某个条⽬是否处于选定状态if thisform.list1.selected(1)=.t.endif8.multiselect :指定⽤户能否在列表框内进⾏多重选定⼆、组合框(combo1)1.style:选择组合框的类型0-下拉组合框 :可以选择也可以输⼊值2-下拉列表框 :只能选择不能输⼊新值组合框的相关属性与列表框相同,但是组合框没有多选属性:multiselect,⽽且组合框要显⽰内容也必须修改 rowsource 和 rowsourcetype 0-9⼗种三、表格(grid1)1.recordsource 数据源2.recordsourcetype 数据源的类型 0-4 五种类型3.columncount: 表格的列数4.linkmaster :显⽰表的⽗表名称5.childorder:建⽴⼀对多关联的⼦表的索引名第⼗五课页框计时器微调控件类表单向导⼀、页框(pageframe1)1.pagecount: 指明⼀个页框对象所包含的页的个数2.pages:是⽤于存取页框中某个页对象的数组thisform.pageframe1.page1.caption="你好"thisform.pageframe1.pages(1).caption=""3.tabs:指定页框中是否显⽰页⾯标签栏4.tabstretch:若标题⽂本太长是否显⽰多重⾏5.activepage:返回页框中当前活动页的页号或使页框的指定页成为活动页⼆、计时器(timer1)1.interval :每间隔多少毫秒执⾏⼀次计时器timer1的timer事件三、微调控件(spinner1)1.spinnerhighvalue:最⼤值2.spinnerlowvalue:最⼩值3.value:默认值4.increment:增量四、类(.vcx)(了解)1.新建(1)⽂件-新建-类(或常⽤⼯具栏)(2)create class2.打开五、⽤表单向导新建表单分为:表单向导和⼀对多表单向导 13 1430 29第⼗六课菜单⼀、菜单(.mnx)1.新建(1)⽂件-新建-菜单(或常⽤⼯具栏)(2)命令 create menu [菜单名]2.分类:条形菜单和弹出式菜单3.菜单设计完成后⾸先保存 - 然后⽤"菜单"菜单下的“⽣成”,⽣成⼀个与本⾝菜单⽂件名同名但是扩展名为.mpr 的可执⾏菜单程序⽂件,最后运⾏该菜单.mpr ⽂件运⾏⽅法:(1)程序-运⾏-菜单⽂件名.mpr(2)命令 do 菜单⽂件名.mpr关闭菜单使之返回系统菜单: set sysmenu to default访问键:在菜单名称后⽤(\<字母)设置例如:⽂件(\⼦菜单中的间隔线直接在菜单名称⾥:\-快捷键:在菜单名称对应栏的“选项”中设置4.快捷菜单的设计5.表单调⽤快捷菜单步骤(1)新建或打开快捷菜单,设计好后保存,并⽣成扩展名.mpr的⽂件(2)新建或打开要调⽤菜单的表单,在表单的 rightclick 事件中编写代码:do 快捷菜单⽂件名.mpr可选项(3)如果题⽬有要求在关闭表单的同时清理菜单,就在菜单设计的同时选择显⽰-常规选项-清理 ,编写如下代码:release popups 快捷菜单名6.表单调⽤顶层菜单步骤(1)新建或打开菜单,设计完成后选择显⽰-常规选项-顶层表单,保存并⽣成.mpr 的菜单⽂件(2)新建或打开表单,将表单的 showwindow 属性设置为:2-作为顶层表单(3)在表单的 init 或 load 事件中调⽤菜单,命令如下:do 菜单⽂件名.mpr with this可选项(4)如果题⽬要求关闭表单的同时释放菜单,就在表单的 destroy 事件中编写: release menu 菜单名第⼗七课报表连编程序和 VF 基础⼀、报表(了解)1.新建(.frx)(1)⽂件-新建-报表(或常⽤⼯具栏)(2)命令 create report [报表⽂件名](3)报表向导 :报表向导和⼀对多报表向导(4)快速报表2.报表建⽴完成后要保存并预览预览的⽅法:(1)显⽰-预览(2)右单击-预览(3)命令: report form 报表⽂件名 preview⼆、连编程序1.在项⽬管理器中-连编2.命令build app 应⽤程序⽂件 from 项⽬名build exe 可执⾏程序⽂件名 from 项⽬名第⼗⼋课⼆级公共基础知识。
vf基础知识

第一章数据结构与算法知识要点:一、算法1、算法基本概念:算法是解决某个特定问题求解的一种描述,它是指令的有限序列。
算法不等于程序,也不等于计算机方法,程序的编制不可能优于算法的设计。
2、算法的基本特征:(1) 有穷性:一个算法总是在执行了有穷步的运算后终止,即该算法是可达的(2) 确定性:算法中每一步骤都必须有明确定义,不允许有模棱两可的解释,不允许有多义性(3) 可行性:要求算法中有待实现的运算都是基本的、能够实现的(4) 输入:一个算法有0个或多个输入,(5)输出:作为算法运算的结果,一个算法产生一个或多个输出3、算法设计的基本方法:(1) 列举法(2) 归纳法(3) 递推(4) 递归(5) 减半递推技术(6) 回溯法4、算法复杂度:算法时间复杂和算法空间复杂度。
(1) 算法时间复杂度是指执行算法所需要的计算工作量。
X=0;y=0;For(k=1;k<=n;k++)X++;For(i=1;i<=n;i++)For(j=1;j<=n;j++)y++;时间复杂度T(n)=O(n2)(2) 算法空间复杂度是指执行这个算法所需要的内存空间。
二、数据结构1、数据结构基本概念:数据结构是指相互有关联的数据元素的集合。
研究的三个方面:(1)数据集合中数据元素之间所固有的逻辑关系,即数据的逻辑结构;(2)在对数据进行处理时,各数据元素在计算机中的存储关系,即数据的存储结构;(3)对各种数据结构进行的运算。
2、数据的逻辑结构:是指反映数据元素之间逻辑关系的数据结构。
包含两方面(1)表示数据元素的信息;(2)表示各数据元素之间的前后件关系。
Eg:春---夏----秋----冬3、数据的存储结构:是指数据结构在计算机存储空间中的存放形式。
常见的存储结构(1) 顺序存储结构:特点是借助于数据元素的相对存储位置来表示数据元素之间的逻辑结构;(2) 链式存储结构:特点是借助于指示数据元素地址的指针表示数据元素之间的逻辑结构4、数据结构分类:线性结构和非线性结构(1)线性结构条件:有且只有一个根结点;每一个结点最多有一个前件,也最多有一个后件。
VF基础知识结构复习

.DBF
.DBC
.PRG
.SCX
.CDX
.IDX
.SCX
.FRX
.MNX
.MPR
.QPR
.TXT
4、VF工作方式
交互方式(命令方式):
程序方式:
菜单方式:
5、VF命令结构
1、命令格式:
命令动词【范围】【表达式】【FIELDS<字段表>】【FOR/WHILE <条件>】
要求:
命令动词:
使用空格:
4、列的次序可以随意交换
5、字段属性必须是不可分的数据项
6、每个关系都有一个关键字唯一标识它的各个记录
5、关系运算
选择
For/While
投影
Fields
链接
Set relation
6、完整性控制
数据完整性:使数据正确和有效
实体完整性
主属性不能取空(关键字)
学号
域完整性
属性取值范围
性别中“男”、“女”
参照完整性
减少数据冗余,多表参照
表间关联
VF基础知识结构二
1、VF启动
方法一:开始------程序------Visual Foxpro
方法二:桌面双击VF图标
方法三:开始------运行------输入VF路径
方法四:资源管理器中双击VF图标
2、VF窗口组成
标题栏
菜单栏
工具栏
工作区
命令窗口
3、VF文件类型
VF基础知识结构一
1、基本概念
数据(DATA)
信息(INformation)
数据处理
数据库(DB)
数据库系统(DBS)
数据库管理系统(DBMS)
vf程序设计基础教程知识点总结

vf程序设计基础教程知识点总结VF基础知识点总结第一章数据库基础知识1.基本概念:数据库、数据管理经历的五个阶段、数据库管理系统、数据库应用系统、数据库管理员。
2.数据库系统的组成:硬件系统、数据库集合、数据库管理系统及相关软件、数据库管理员和用户。
其中数据库管理系统是数据库系统的核心。
3.数据库系统的特点:(1)实现数据共享,减少数据冗余(2)采用特定的数据模型(3)具有较高的数据独立性(4)有统一的数据控制功能4.数据模型:实体间联系的种类:一对一、一对多、多对多。
5.数据模型的三种类型:层次模型、网状模型和关系模型。
6.关系数据库基本术语:关系、元组、属性、域、关键字、外部关键字。
关系的特点7.关系运算:传统的集合运算(并、差、交)另一类是专门的关系运算(选择、投影、连接、等值连接、自然连接)8.VF两种运行方式:菜单方式和交互式方式(命令方式和程序方式)9.所谓项目是指文件、数据、文档和对象的集合,其扩展名为 .pjx。
10.项目管理器包含的选项卡:全部、数据、文档、类、代码、其他11.项目管理器各选项卡所包含的文件有哪些?12.项目管理器可以完成对文件的新建、添加、移去、删除,但不包含重命名。
第二章常量、字符1.常量的种类:数值型、字符型、日期型、日期时间型和逻辑型在书写字符型、日期型、日期时间型和逻辑型需要加定界符2.变量是值能够随时改变的量。
变量名的命名规则:以字母、汉字和下划线开头,后接字母、数字、汉字和下划线构成,不包含有空格3.当内存变量与字段变量同名时,要访问内存变量需加前缀M.(或M-),例如M.姓名4.数组定义的格式 DIMENSION 数组名()、创建数组后,系统自动给每个数组元素赋以逻辑假.F.5.表达式的类型:数值表达式、字符表达式、日期时间表达式和逻辑表达式。
每个表达式的运算规则与结果。
6.运算符 $ 称为子串包含测试,格式字符表达式1 $ 字符表达式27.SET EXACT ON │OFF 的区别与含义。
VF知识点

第一章 Visual FoxPro 数据库基础Visual FoxPro 是计算机优秀的数据管理系统软件之一。
1.1数据库基础知识1.1.1计算机数据管理的发展1.数据与数据处理①数据是存储在某一种媒体上能够识别的物理符号。
被计算机存储和反应客观事物的符号。
存储在某一种媒体上能够被识别的符号。
描述事物的符号。
②数据处理是指将数据转换成信息的过程。
2.计算机数据管理数据管理经历了①人工和管理阶段②文件管理阶段③数据库管理阶段1.1.2数据库系统1.数据库①数据库:有组织,可共享的相关数据的集合数据库(DB Date Base)是存储在计算机存储设备上的结构化的相关数据集合。
数据库管理系统(DBMS Date Base Management System)2.数据库系统的特点数据路系统(DBS)是有五部分组成:硬件系统、数据库集合、数据库管理系统及相关软件、数据库管理员和用户。
其中数据库管理系统是数据库系统的核心。
DBS>DBMS>DB (DBS包含DBMS,DBMS包含DB)1.1.3数据模型1.实体的描述①实体:客观存在并且可以相互区别的事物称为实体。
②实体的属性:描述实体的特征称为属性。
③实体集和实体型:属性值的集合表示一个具体的实体,而属性的集合表示一个实体的类型,称为实体型(汗血宝马)。
同类型的实体集合称为实体集(马)2.实体间联系及联系的种类①一对一联系(唯一性)如:身份证和人②一对多联系(不可逆性)如:母亲和孩子,皇帝和臣子③多对多联系(胡逆性,可逆性)3.数据模型简介①层次数据模型(已淘汰)②网状模型(已淘汰)③关系数据模型:关系数据模型是以关系数学理论为基础的。
用二维表结构来表示实体以及实体之间联系的模型称为关系模型。
一张二维表就是一个关系,一个关系就是一张二维表。
1.2关系数据库1.2.1关系模型1.关系术语①关系:一个关系就是一张二维表,每个关系有一个关系名。
文件拓展名为.dbf 每个表都要有一个表名,表名的本质代表实体集,一个表存储为一个文件。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
第一章数据结构与算法1.1 算法算法:是指解题方案的准确而完整的描述。
算法不等于程序,也不等计算机方法,程序的编制不可能优于算法的设计。
算法的基本特征:是一组严谨地定义运算顺序的规则,每一个规则都是有效的,是明确的,此顺序将在有限的次数下终止。
特征包括:(1)可行性;(2)确定性,算法中每一步骤都必须有明确定义,不充许有模棱两可的解释,不允许有多义性;(3)有穷性,算法必须能在有限的时间内做完,即能在执行有限个步骤后终止,包括合理的执行时间的含义;(4)拥有足够的情报。
算法的基本要素:一是对数据对象的运算和操作;二是算法的控制结构。
指令系统:一个计算机系统能执行的所有指令的集合。
基本运算和操作包括:算术运算、逻辑运算、关系运算、数据传输。
算法的控制结构:顺序结构、选择结构、循环结构。
算法基本设计方法:列举法、归纳法、递推、递归、减斗递推技术、回溯法。
算法复杂度:算法时间复杂度和算法空间复杂度。
算法时间复杂度是指执行算法所需要的计算工作量。
算法空间复杂度是指执行这个算法所需要的内存空间。
1.2 数据结构的基本基本概念数据结构研究的三个方面:(1)数据集合中各数据元素之间所固有的逻辑关系,即数据的逻辑结构;(2)在对数据进行处理时,各数据元素在计算机中的存储关系,即数据的存储结构;(3)对各种数据结构进行的运算。
数据结构是指相互有关联的数据元素的集合。
数据的逻辑结构包含:(1)表示数据元素的信息;(2)表示各数据元素之间的前后件关系。
数据的存储结构有顺序、链接、索引等。
线性结构条件:(1)有且只有一个根结点;(2)每一个结点最多有一个前件,也最多有一个后件。
非线性结构:不满足线性结构条件的数据结构。
1.3 线性表及其顺序存储结构线性表由一组数据元素构成,数据元素的位置只取决于自己的序号,元素之间的相对位置是线性的。
在复杂线性表中,由若干项数据元素组成的数据元素称为记录,而由多个记录构成的线性表又称为文件。
非空线性表的结构特征:(1)且只有一个根结点a1,它无前件;(2)有且只有一个终端结点an,它无后件;(3)除根结点与终端结点外,其他所有结点有且只有一个前件,也有且只有一个后件。
结点个数n称为线性表的长度,当n=0时,称为空表。
线性表的顺序存储结构具有以下两个基本特点:(1)线性表中所有元素的所占的存储空间是连续的;(2)线性表中各数据元素在存储空间中是按逻辑顺序依次存放的。
ai的存储地址为:ADR(ai)=ADR(a1)+(i-1)k,,ADR(a1)为第一个元素的地址,k代表每个元素占的字节数。
顺序表的运算:插入、删除。
(详见14--16页)1.4 栈和队列栈是限定在一端进行插入与删除的线性表,允许插入与删除的一端称为栈顶,不允许插入与删除的另一端称为栈底。
栈按照“先进后出”(FILO)或“后进先出”(LIFO)组织数据,栈具有记忆作用。
用top表示栈顶位置,用bottom表示栈底。
栈的基本运算:(1)插入元素称为入栈运算;(2)删除元素称为退栈运算;(3)读栈顶元素是将栈顶元素赋给一个指定的变量,此时指针无变化。
队列是指允许在一端(队尾)进入插入,而在另一端(队头)进行删除的线性表。
Rear指针指向队尾,front指针指向队头。
队列是“先进行出”(FIFO)或“后进后出”(LILO)的线性表。
队列运算包括(1)入队运算:从队尾插入一个元素;(2)退队运算:从队头删除一个元素。
循环队列:s=0表示队列空,s=1且front=rear表示队列满1.5 线性链表数据结构中的每一个结点对应于一个存储单元,这种存储单元称为存储结点,简称结点。
结点由两部分组成:(1)用于存储数据元素值,称为数据域;(2)用于存放指针,称为指针域,用于指向前一个或后一个结点。
在链式存储结构中,存储数据结构的存储空间可以不连续,各数据结点的存储顺序与数据元素之间的逻辑关系可以不一致,而数据元素之间的逻辑关系是由指针域来确定的。
链式存储方式即可用于表示线性结构,也可用于表示非线性结构。
线性链表,HEAD称为头指针,HEAD=NULL(或0)称为空表,如果是两指针:左指针(Llink)指向前件结点,右指针(Rlink)指向后件结点。
线性链表的基本运算:查找、插入、删除。
1.6 树与二叉树树是一种简单的非线性结构,所有元素之间具有明显的层次特性。
在树结构中,每一个结点只有一个前件,称为父结点,没有前件的结点只有一个,称为树的根结点,简称树的根。
每一个结点可以有多个后件,称为该结点的子结点。
没有后件的结点称为叶子结点。
在树结构中,一个结点所拥有的后件的个数称为该结点的度,所有结点中最大的度称为树的度。
树的最大层次称为树的深度。
二叉树的特点:(1)非空二叉树只有一个根结点;(2)每一个结点最多有两棵子树,且分别称为该结点的左子树与右子树。
二叉树的基本性质:(1)在二叉树的第k层上,最多有2k-1(k≥1)个结点;(2)深度为m的二叉树最多有2m-1个结点;(3)度为0的结点(即叶子结点)总是比度为2的结点多一个;(4)具有n个结点的二叉树,其深度至少为[log2n]+1,其中[log2n]表示取log2n的整数部分;(5)具有n个结点的完全二叉树的深度为[log2n]+1;(6)设完全二叉树共有n个结点。
如果从根结点开始,按层序(每一层从左到右)用自然数1,2,….n给结点进行编号(k=1,2….n),有以下结论:①若k=1,则该结点为根结点,它没有父结点;若k>1,则该结点的父结点编号为INT(k/2);②若2k≤n,则编号为k的结点的左子结点编号为2k;否则该结点无左子结点(也无右子结点);③若2k+1≤n,则编号为k的结点的右子结点编号为2k+1;否则该结点无右子结点。
满二叉树是指除最后一层外,每一层上的所有结点有两个子结点,则k层上有2k-1个结点深度为m的满二叉树有2m-1个结点。
完全二叉树是指除最后一层外,每一层上的结点数均达到最大值,在最后一层上只缺少右边的若干结点。
二叉树存储结构采用链式存储结构,对于满二叉树与完全二叉树可以按层序进行顺序存储。
二叉树的遍历:(1)前序遍历(DLR),首先访问根结点,然后遍历左子树,最后遍历右子树;(2)中序遍历(LDR),首先遍历左子树,然后访问根结点,最后遍历右子树;(3)后序遍历(LRD)首先遍历左子树,然后访问遍历右子树,最后访问根结点。
1.7 查找技术顺序查找的使用情况:(1)线性表为无序表;(2)表采用链式存储结构。
二分法查找只适用于顺序存储的有序表,对于长度为n的有序线性表,最坏情况只需比较log2n次。
1.8 排序技术排序是指将一个无序序列整理成按值非递减顺序排列的有序序列。
交换类排序法:(1)冒泡排序法,需要比较的次数为n(n-1)/2;(2)快速排序法。
插入类排序法:(1)简单插入排序法,最坏情况需要n(n-1)/2次比较;(2)希尔排序法,最坏情况需要O(n1.5)次比较。
选择类排序法:(1)简单选择排序法,最坏情况需要n(n-1)/2次比较;(2)堆排序法,最坏情况需要O(nlog2n)次比较。
第二章程序设计基础2.1 程序设计设计方法和风格如何形成良好的程序设计风格1、源程序文档化;2、数据说明的方法;3、语句的结构;4、输入和输出。
注释分序言性注释和功能性注释,语句结构清晰第一、效率第二。
2.2 结构化程序设计结构化程序设计方法的四条原则是:1. 自顶向下;2. 逐步求精;3.模块化;4.限制使用goto 语句。
结构化程序的基本结构和特点:(1)顺序结构:一种简单的程序设计,最基本、最常用的结构;(2)选择结构:又称分支结构,包括简单选择和多分支选择结构,可根据条件,判断应该选择哪一条分支来执行相应的语句序列;(3)重复结构:又称循环结构,可根据给定条件,判断是否需要重复执行某一相同程序段。
2.3 面向对象的程序设计面向对象的程序设计:以60年代末挪威奥斯陆大学和挪威计算机中心研制的SIMULA语言面向对象方法的优点:(1)与人类习惯的思维方法一致;(2)稳定性好;(3)可重用性好;(4)易于开发大型软件产品;(5)可维护性好。
对象是面向对象方法中最基本的概念,可以用来表示客观世界中的任何实体,对象是实体的抽象。
面向对象的程序设计方法中的对象是系统中用来描述客观事物的一个实体,是构成系统的一个基本单位,由一组表示其静态特征的属性和它可执行的一组操作组成。
属性即对象所包含的信息,操作描述了对象执行的功能,操作也称为方法或服务。
对象的基本特点:(1)标识惟一性;(2)分类性;(3)多态性;(4)封装性;(5)模块独立性好。
类是指具有共同属性、共同方法的对象的集合。
所以类是对象的抽象,对象是对应类的一个实例。
消息是一个实例与另一个实例之间传递的信息。
消息的组成包括(1)接收消息的对象的名称;(2)消息标识符,也称消息名;(3)零个或多个参数。
继承是指能够直接获得已有的性质和特征,而不必重复定义他们。
继承分单继承和多重继承。
单继承指一个类只允许有一个父类,多重继承指一个类允许有多个父类。
多态性是指同样的消息被不同的对象接受时可导致完全不同的行动的现象。
第三章软件工程基础3.1 软件工程基本概念计算机软件是包括程序、数据及相关文档的完整集合。
软件的特点包括:(1)软件是一种逻辑实体;(2)软件的生产与硬件不同,它没有明显的制作过程;(3)软件在运行、使用期间不存在磨损、老化问题;(4)软件的开发、运行对计算机系统具有依赖性,受计算机系统的限制,这导致了软件移植的问题;(5)软件复杂性高,成本昂贵;(6)软件开发涉及诸多的社会因素。
软件按功能分为应用软件、系统软件、支撑软件(或工具软件)。
软件危机主要表现在成本、质量、生产率等问题。
软件工程是应用于计算机软件的定义、开发和维护的一整套方法、工具、文档、实践标准和软件工程包括3个要素:方法、工具和过程。
软件工程过程是把软件转化为输出的一组彼此相关的资源和活动,包含4种基本活动:(1)P——软件规格说明;(2)D——软件开发;(3)C——软件确认;(4)A——软件演进。
软件周期:软件产品从提出、实现、使用维护到停止使用退役的过程。
软件生命周期三个阶段:软件定义、软件开发、运行维护,主要活动阶段是:(1)可行性研究与计划制定;(2)需求分析;(3)软件设计;(4)软件实现;(5)软件测试;(6)运行和维护。
软件工程的目标和与原则:目标:在给定成本、进度的前提下,开发出具有有效性、可靠性、可理解性、可维护性、可重用性、可适应性、可移植性、可追踪性和可互操作性且满足用户需求的产品。
基本目标:付出较低的开发成本;达到要求的软件功能;取得较好的软件性能;开发软件易于移植;需要较低的费用;能按时完成开发,及时交付使用。