20150831客户地图可视化使用说明书
365天酒店可视化管理操作手册

365天酒店可视化管理操作手册摘要:I.引言- 介绍365 天酒店可视化管理操作手册的目的和适用对象II.手册概述- 解释可视化管理操作手册的概念- 介绍手册的主要内容和结构III.酒店可视化管理基本理念- 阐述可视化管理的重要性- 描述可视化管理的五个核心理念IV.酒店可视化管理操作流程- 详述酒店可视化管理操作流程的步骤- 说明每个步骤的具体实施方法V.酒店可视化管理实践案例- 介绍几个成功的酒店可视化管理实践案例- 分析这些案例的成功因素VI.酒店可视化管理效果评估- 阐述可视化管理效果评估的方法和指标- 介绍如何根据评估结果优化管理策略VII.结论- 总结酒店可视化管理操作手册的重要性和价值- 提出未来可视化管理的发展趋势和挑战正文:【引言】365 天酒店可视化管理操作手册是一本为酒店管理人员和员工提供的实用指南,旨在帮助酒店实现高效、精确和可视化的管理。
该手册适用于各种类型的酒店,无论是豪华酒店还是经济型酒店,都可以通过可视化管理操作手册提升管理水平和客户满意度。
【手册概述】可视化管理操作手册是一本全面介绍酒店可视化管理理念和操作流程的指南。
手册共分为七个部分,分别是引言、手册概述、酒店可视化管理基本理念、酒店可视化管理操作流程、酒店可视化管理实践案例、酒店可视化管理效果评估和结论。
【酒店可视化管理基本理念】酒店可视化管理是一种以视觉为主要沟通手段的管理方式。
它通过将复杂的数据和信息以图表、图形等形式展示出来,使管理人员和员工能够更直观、更快速地了解和掌握酒店运营情况。
酒店可视化管理的核心理念包括:信息可视化、流程可视化、时间可视化、空间可视化和沟通可视化。
【酒店可视化管理操作流程】酒店可视化管理操作流程包括五个步骤:数据收集、数据处理、可视化设计、可视化展示和持续改进。
首先,需要收集酒店运营数据,包括客房入住率、餐饮销售额、酒店能耗等。
然后,对数据进行处理,将其转换为可供可视化的形式。
用户行为可视化分析指南模板

用户行为可视化分析指南模板一、背景介绍用户行为可视化分析是一种关键的数据分析技术,用于理解和解释用户在网站、移动应用程序或其他数字产品中的行为。
通过可视化的方式展示用户行为数据,我们可以更好地洞察用户的偏好、需求和行为模式,从而指导产品优化、市场推广和用户体验改进等方面的决策。
二、数据收集1. 选择合适的分析工具用户行为数据可以通过多种分析工具收集,如Google Analytics、Mixpanel、Hotjar等。
在选择工具时,应根据产品特点和需求综合考虑工具的功能、易用性、数据准确性等因素,并确保其兼容性和数据保护性能。
2. 设置数据收集目标在开始数据收集之前,明确需要收集哪些数据,如页面浏览量、用户访问路径、点击热点等。
此外,还应确定数据收集的时间范围和采样方式,以保证数据的全面性和有效性。
3. 数据标准化和分类为了便于后续的可视化分析,需要对收集到的数据进行标准化和分类处理。
例如,将访问时间、地理位置、用户属性等数据进行统一的格式转化和整理,并将用户行为归类为浏览、搜索、交互等类型。
三、可视化分析1. 选择合适的可视化工具可视化分析需要使用专业的可视化工具,如Tableau、Power BI、Google Data Studio等。
这些工具提供了丰富的可视化图表和交互功能,可以直观地展示用户行为数据,帮助用户更好地理解和分析数据。
2. 设计数据可视化图表根据分析需求和目标受众,设计合适的可视化图表来展示用户行为数据。
常用的图表类型包括柱状图、折线图、散点图、热力图等。
在设计时,要注重图表的简洁、清晰和易于理解,避免信息过载和视觉混乱。
3. 提取关键指标和洞察通过可视化分析,提取关键的指标和洞察帮助我们理解用户行为背后的规律和趋势。
例如,可以分析用户的转化率、留存率、流失率等指标,以及用户在不同渠道、设备上的行为差异;还可以通过路径分析、漏斗分析等方法挖掘用户在产品中的关键行为和瓶颈。
四、优化和改进1. 基于可视化分析结果,进行产品优化和改进。
客服可视化操作手册

客服可视化操作手册创建一个客服可视化操作手册可以帮助客服人员更好地了解和掌握客服工作的流程和技巧。
以下是一个可能的客服可视化操作手册的示例:1. 登录系统:- 打开客服系统的登录页面。
- 输入用户名和密码,点击登录按钮。
- 进入客服系统的主界面。
2. 接收新的客服请求:- 在主界面上,查看是否有新的客服请求。
- 如果有新的请求,点击接受按钮以接受该请求。
- 进入与客户的聊天界面。
3. 进行客服对话:- 在聊天界面上,欢迎客户并介绍自己的身份。
- 仔细阅读客户的问题或要求。
- 根据情况提供适当的解决方案或答案。
- 在对话过程中,尽量保持友好和礼貌。
- 如果需要,可以使用客服系统提供的内置工具(如文字模板、表情符号等)。
- 向客户解释任何必要的步骤或操作指导。
4. 处理投诉或问题:- 如果客户表达不满意或提出投诉,向其表示歉意并尽力解决问题。
- 记录客户的投诉或问题,并将其转达给上级或相关部门进行处理。
5. 结束对话:- 当客户的问题得到解决或请求被处理完毕时,向客户表示感谢。
- 如果客户有其他问题或需求,提供相应的建议或帮助。
- 确认是否还有其他待处理的请求,如无,则结束对话。
6. 客户信息管理:- 在客服系统中,记录客户的基本信息,如姓名、联系方式等。
- 维护客户信息的准确性和完整性。
- 根据需要,将客户信息导出或共享给相关部门。
7. 统计和分析工作:- 使用客服系统提供的统计和分析功能,了解自己的工作表现。
- 分析常见问题或投诉,提出改进意见和建议。
8. 保持沟通和学习:- 定期参加客服培训和会议,以不断提升自己的专业知识和技能。
- 与同事和上级保持沟通,分享经验和学习。
这只是一个简单的客服可视化操作手册示例,具体的内容和流程可以根据具体的公司和客服系统的要求进行调整和补充。
数据可视化软件使用方法

数据可视化软件使用方法一、数据可视化软件的介绍数据可视化软件是为了更好地展示数据而开发的工具,它可以将冗长枯燥的数据转化为直观、易懂的图表、图形等可视化形式,帮助用户更加直观地理解数据以及发现数据中隐藏的规律。
目前,市面上有许多出色的数据可视化软件,例如Tableau、Power BI、Google Data Studio等。
二、数据可视化软件的安装与设置在使用任何数据可视化软件之前,首先需要将该软件下载并安装在本地的计算机上。
下载安装完成后,根据软件界面的指引进行初始化设置和账号登陆。
不同软件的设置步骤可能会有所不同,但一般来说设置过程比较简单,只需按照提示输入相关信息即可。
三、数据导入与整理1. 数据源选择在进行数据可视化之前,首先需要将数据导入到软件中进行处理。
打开软件后,一般可见到“新建数据源”或“导入数据”等选项,用户可以选择从不同的源(如Excel、CSV文件、数据库等)导入数据。
2. 数据清洗与处理数据导入后,一般需要进行数据清洗与处理,以保证数据的准确性和完整性。
数据清洗可以包括去除重复值、填充缺失值、调整数据格式等操作,确保数据能够被准确地分析和可视化。
此外,还可以进行数据的聚合、筛选和排序等操作,以获得所需的数据集。
四、选择合适的可视化图表类型数据可视化软件提供了各种各样的图表类型,用户需要根据数据特征和表达需求选择合适的图表类型。
以下是常见的几种图表类型:1. 饼图和柱状图饼图适用于展示数据的相对比例,柱状图适用于展示数据的绝对数值以及多个数据的比较。
2. 折线图和面积图折线图适用于展示数据的趋势和变化,面积图在折线图的基础上填充了数据和坐标轴之间的区域。
3. 散点图和气泡图散点图适用于展示不同指标之间的关系,气泡图在散点图的基础上通过气泡大小显示第三个变量的值。
4. 地图和热力图地图和热力图适用于地理位置和区域的数据展示,可以更加直观地显示数据在不同区域之间的差异和分布。
北斗导航卫星可视化系统 用户手册说明书

北斗导航卫星可视化系统用户手册“北斗导航卫星可视化系统”是一个可在网络(局域网或国际互联网)上运行的网站,用户可通过支持WebGL的网络浏览器(如最新版本的Google Chrome, Firefox, Edge, Opera或Internet Explorer 11)访问这个网站,完成相应的操作、任务。
系统使用HTML、CSS以及JavaScript进行开发,系统架构在Linux操作系统上,可以在局域网或国际互联网环境下运行。
一、系统主界面1.1系统主界面系统正确安装以后,用户可在浏览器中输入系统所在的网址(如:http://39.98.197.60/LinuxBds_C/index.php),即可打开系统。
首先出现的是如下主界面,视图中间部分是数字地球以及卫星轨道显示,其中不同颜色表示不同类型的卫星。
右上角的图标分别对应着不同的功能模块,右下角显示的是比例尺和经纬度。
界面最下方是时间轴。
图1. 系统主界面二、系统菜单2.1 北斗卫星星座轨道可视化点击左侧的“展开”图标,可以对页面显示的卫星进行自定义设置。
选择“北斗卫星”栏,可对界面显示的卫星进行设置,数字表示卫星数量。
(1)针对不同的轨道类型,如GEO、IGSO或MEO,进行卫星轨道显示。
(2)根据不同的系列来选择,如“北斗二号“、”北斗三号“。
(3)根据卫星运行状态,如“正常”、“不正常”。
(4)设置“全部隐藏”或者“全部显示”。
图2. “北斗卫星”栏对于“北斗卫星”栏下方的单颗卫星,左侧显示的是卫星二维图标,右侧第一行显示的卫星名,轨道类型,运行状况,卫星所属系列;用户可分别对每颗卫星设置是否显示2D图标、3D模型、标注、轨迹、星下点、轨道设置(见2.2)。
图3. 单颗卫星显示设置选择“测控站”栏,可对测控站进行设置。
北斗卫星导航任务轨道可视化软件系统显示了喀什、佳木斯、三亚和圣地亚哥四个测控站。
用户可以对测控站的二维图标、文字标注和跟踪卫星连线的显示进行设置。
数据可视化工具的应用案例和操作说明

数据可视化工具的应用案例和操作说明在当今数字化的时代,数据如同海洋般浩瀚,如何从这海量的数据中快速获取有价值的信息并清晰地展示出来,成为了众多企业和个人面临的重要挑战。
数据可视化工具应运而生,它们以直观、生动的方式呈现数据,帮助我们更好地理解和分析数据背后的故事。
接下来,让我们一起走进数据可视化工具的世界,通过实际的应用案例来了解它们的强大功能,并学习一些基本的操作方法。
一、数据可视化工具的应用案例(一)销售数据分析假设我们是一家电商企业,每天都会产生大量的销售数据。
通过数据可视化工具,我们可以将这些复杂的数据转化为清晰易懂的图表。
例如,使用柱状图来展示不同产品类别的销售额,使用折线图来呈现销售额随时间的变化趋势,使用饼图来分析各个地区的销售占比。
这样一来,管理层可以迅速发现销售业绩的亮点和不足之处,从而制定更有针对性的营销策略。
(二)市场调研分析对于市场调研公司来说,收集和分析大量的消费者反馈数据是日常工作的重要部分。
数据可视化工具可以帮助他们将这些数据以直观的方式呈现出来。
比如,通过词云图展示消费者在评价中提到的高频词汇,从而快速了解消费者的关注点和需求;使用气泡图来比较不同品牌在各个维度上的表现,帮助企业了解自身的竞争优势和劣势。
(三)项目管理在项目管理中,进度、资源分配和任务完成情况等数据至关重要。
数据可视化工具可以创建甘特图来展示项目的时间进度和任务安排,使用资源负载图来监控资源的使用情况。
通过这些可视化图表,项目经理能够及时发现项目中的潜在问题,做出合理的调整和决策。
(四)财务数据分析企业的财务部门需要处理大量的财务数据,如收入、支出、利润等。
数据可视化工具可以将这些数据转化为财务报表、柱状图和趋势线等形式。
管理层可以直观地看到企业的财务状况,预测未来的财务趋势,为企业的发展制定合理的财务规划。
二、常见的数据可视化工具(一)TableauTableau 是一款功能强大的数据可视化工具,它支持多种数据源的连接,包括数据库、Excel 文件、CSV 文件等。
用户行为可视化分析指导手册模板

用户行为可视化分析指导手册模板一、引言在当今数字化时代,用户行为可视化分析成为了企业和组织中不可或缺的重要工具。
通过对用户行为数据进行收集、分析和可视化呈现,企业和组织可以更好地了解用户需求、优化产品和服务,并制定更有效的营销策略。
本文提供了一份用户行为可视化分析指导手册模板,旨在帮助读者轻松编写自己的指导手册,以实现更好的用户行为可视化分析。
二、用户行为可视化分析指导手册模板1. 背景和目标本章节旨在描述用户行为可视化分析的背景和目标。
请简要介绍所分析的业务领域和所追求的目标,并说明用户行为可视化分析在实现这些目标中的重要性。
2. 数据收集本章节应详细说明数据收集的方法和流程。
包括数据的来源、收集的频率和方式。
同时,还应提供常见的数据收集工具和技术,以及数据收集过程中需要注意的事项。
3. 数据预处理在本章节中,应详细介绍数据预处理的步骤和方法。
例如,数据清洗、数据过滤和缺失值处理等。
同时,还应提供数据预处理的代码示例和常见的数据预处理技术。
4. 数据分析本章节应重点介绍数据分析的方法和技术。
包括数据可视化、关联分析和聚类分析等。
同时,还应提供相关的数据分析工具和代码示例,以及数据分析结果的解读方法。
5. 结果呈现在本章节中,应介绍如何将数据分析结果进行可视化呈现。
请提供常用的数据可视化工具和技术,以及如何选择适合的可视化方式和布局。
同时,还应提供数据呈现的代码示例和制作可视化报告的注意事项。
6. 应用与优化本章节应说明如何将用户行为可视化分析的结果应用于产品优化和营销决策中。
请提供实际案例和经验分享,以及如何将用户行为数据与其他数据源进行综合分析,以获取更全面的洞察。
7. 最佳实践和注意事项本章节应总结用户行为可视化分析的最佳实践和注意事项。
包括数据隐私保护、数据可视化的设计原则和数据分析中的常见误区等。
同时,还应提供相关的参考资料和学习资源,帮助读者进一步提升用户行为可视化分析的能力。
8. 结论在本章节中,应总结用户行为可视化分析指导手册的主要内容和要点。
可视化的使用和流程

可视化的使用和流程一、什么是可视化?可视化是一种通过图形、图表、地图和其他视觉元素来展示数据的方式。
通过将数据转化为图形化的形式,可视化能够帮助我们更直观地理解数据的特征、趋势和关系。
可视化在数据分析、信息传达和决策支持等领域都有广泛的应用。
二、为什么使用可视化?1.更直观理解数据:可视化能够将复杂的数据转化为易于理解的图形,帮助我们更直观地理解数据的意义和特征。
2.发现隐藏的模式和关系:通过可视化,我们可以发现数据之间的隐藏模式和关系,以及突出的异常数据点。
3.传达信息:可视化可以通过清晰、简洁的图形将复杂的数据信息传达给他人,帮助他人更好地理解和使用数据。
三、可视化的流程为了正确、高效地使用可视化工具,我们需要按照一定的流程进行操作。
下面是一个通用的可视化流程:1.确定可视化目标:首先要明确可视化的目标是什么,我们希望通过可视化达到什么样的效果。
例如,是想要发现数据中的趋势还是比较不同数据之间的差异。
2.收集和整理数据:在进行可视化之前,我们需要收集和整理好需要展示的数据。
数据应该是准确、完整的,并且可以被可视化工具所接受。
3.选择合适的可视化工具:根据可视化的目标和数据的特征,选择适合的可视化工具。
常见的可视化工具有Tableau、Power BI、Python的Matplotlib库等。
4.设计可视化图形:根据可视化工具的要求,设计好需要展示的图形,包括图表类型、颜色、标签等。
5.创建可视化图形:使用选择的可视化工具来创建图形,根据数据的形式和工具的特性进行数据输入和设置。
6.调整和优化:根据需要,对可视化图形进行调整和优化,以便更好地展示数据,例如调整图形的尺寸、添加图例等。
7.解读和分析:对生成的可视化图形进行解读和分析,理解其中的趋势、关系和异常数据点。
8.分享和使用:根据可视化的目标,将生成的可视化图形分享给他人,并且将其应用于决策和分析过程中。
四、可视化的注意事项在进行可视化的过程中,需要注意以下几点:1.思考清楚可视化的目标:在进行可视化之前,要明确可视化的目标和所要传达的信息。
数据可视化系统说明书

数据可视化系统说明书一、引言数据可视化系统是一种利用图表、图形等视觉化形式展示数据的工具。
它可以帮助用户更直观地理解和分析数据,发现数据中的规律和趋势,从而支持决策和战略制定。
本文将详细介绍我们开发的数据可视化系统的功能和使用方法。
二、系统概述我们的数据可视化系统是基于云平台的在线工具,用户可以通过浏览器访问该系统进行数据可视化操作。
系统支持多种数据源导入,包括数据库、Excel文件、API接口等,用户可以自由选择数据源并进行数据加载。
三、系统功能1. 数据导入用户可以通过系统提供的数据导入功能,将需要进行可视化处理的数据导入到系统中。
系统支持常见的数据格式,包括CSV、Excel等。
用户只需选择数据源和相关参数,点击导入按钮,系统将自动完成数据导入工作。
2. 数据转换在导入数据后,用户可以对数据进行转换和清洗操作。
系统提供了多种数据转换功能,包括数据类型转换、缺失值处理、数据拆分和合并等。
用户可以根据需要对数据进行灵活的操作,以确保数据的准确性和一致性。
3. 数据可视化系统提供了丰富的数据可视化图表和图形,包括折线图、柱状图、饼图、散点图等。
用户可以根据数据类型和需求选择合适的图表进行展示。
同时,系统支持图表的自定义设置,用户可以调整图表的样式、颜色、标签等参数,以满足个性化的需求。
4. 数据分析除了数据展示功能,系统还提供了一些常用的数据分析功能,包括数据排序、数据筛选、数据聚合等。
用户可以通过这些功能对数据进行更深入的分析,发现数据中的规律和趋势,进而支持决策和战略制定。
5. 报表导出用户可以将生成的数据可视化图表导出为报表文件,包括PDF、Excel等格式。
这样可以方便用户在会议、报告等场合分享和展示数据信息。
同时,系统还支持生成动态交互式报表,用户可以通过鼠标悬停、点击等操作与报表进行交互,更好地理解和分析数据。
四、使用指南1. 注册和登录用户需要先注册一个账户,然后使用注册的账户登录系统。
ArcGIS Online数据可视化指南说明书
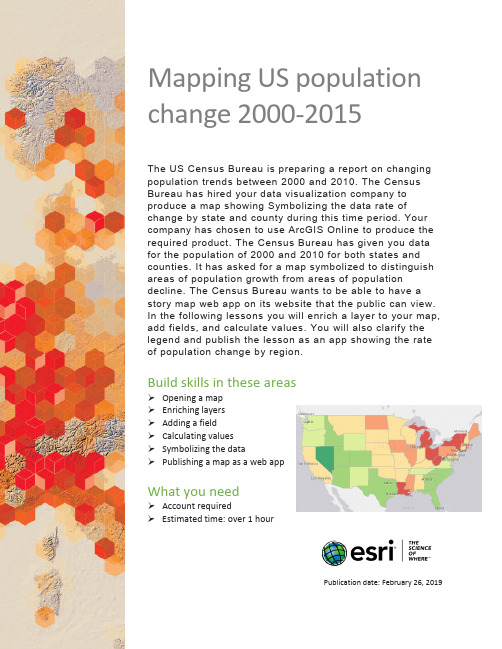
The US Census Bureau is preparing a report on changing population trends between 2000 and 2010. The Census Bureau has hired your data visualization company to produce a map showing Symbolizing the data rate of change by state and county during this time period. Your company has chosen to use ArcGIS Online to produce the required product. The Census Bureau has given you data for the population of 2000 and 2010 for both states and counties. It has asked for a map symbolized to distinguish areas of population growth from areas of population decline. The Census Bureau wants to be able to have a story map web app on its website that the public can view. In the following lessons you will enrich a layer to your map, add fields, and calculate values. You will also clarify the legend and publish the lesson as an app showing the rate of population change by region.Build skills in these areasOpening a mapEnriching layersCalculating valuesSymbolizing the dataPublishing a map as a web appWhat you needAccount requiredEstimated time: over 1 hourPublication date: February 26, 20191. Open the map1.Sign into your ArcGIS organizational account2.Open US Population Change 2000 to 2010.3.Click the Show Map Contents Button under Details.The map opens, showing the Topographic basemap, state, and countyboundaries. States are counties are political boundaries.2. Change basemapClick Basemap on the top menu and change the basemap to Light Gray Canvas.3. Save the map1. On the top of the page, click Save and choose Save As.2. In the Save Map window enter the following information:a. Title: US Population Change_yourinitials.b. Tags: Add individualized tags.c. Summary: Map indicates the annual rate of total population changefrom 2000 to 2010.3. Click SAVE MAP.4. Show table and examine attributesTo see information about features in a layer, you can display an interactive table at the bottom of the map.1. Click the Show Table icon for States.2. Examine the table. Notice the table shows only basic information.3. Close the table by clicking the X in the upper right corner.5. Enrich data for statesData enrichment produces an enriched layer that retrieves information about the people, places, and businesses in a specific area. Detailed demographic data is returned for your chosen area. You are interested in a layer that shows the total population of 2000 and 2010.1. Click States and Perform Analysis.The analysis icon can be activated by either clicking the analysis icon underState or by clicking Analysis on the top ribbon.2. Click Data Enrichment and Enrich Layer.3. Click Enrich Layer to activate the Enrich layer pane. States is the chosenlayer to enrich with new data.4. Click Select Variable to open Data Browser and browse for variables:a. Be sure the United States is chosen in the upper right corner.b. Click Population.c. Click the Arrow to go to the next page (2 times).d. Click Show all Population Variables.e. Click 2000 data in 2010 Geography (U.S. Census) to uncollapse the layerf. Check 2000 Total Population (U.S. Census).g. Click 2010 Population (U.S. Census).h. Check 2010 total Population (U.S. Census).5. Click Apply.6. Give Result layer a unique name such as enriched_states_yourinitials.7. Uncheck Use current map extent.8. Click Run Analysis.9. Click Save at the top of the menu.6. Add field and calculate: states1. Click Show Table on enriched_states. The interactive table appears at thebottom of your map.Notice that the table now shows 2000 Total Population and 2010 TotalPopulation. It also shows the Federal Information Processing Standard(FIPS) number developed by the US federal government for use incomputer systems.The information in the table that you need to calculate the annual rate ofchange from 2000 to2010 is State_Abbr, the 2000 Total Population, and the 2010 TotalPopulation.2. Click Table Options in the upper right corner of the table and chooseShow/Hide Columns.3. Uncheck all the fields except State_Abbr, 2000 Total Population and 2010Total Population. Close the table by clicking the X in the upper right.Your next step is to add a new field to the table to store the calculationthat you are going to make.4. Click Table Options in the right corner of the table and choose AddField.5. Add the following parameters to the Add Field menu.a. Name = rate_changeb. Alias = annual rate of change from 2000 to 2010c. Type = Doubled. Click Add New FieldYou can now see the new field added to the table.6. Click the column you have just created (Annual rate of change from 2000 to 2010) and choose Calculate. This opens the Expression Builder dialog box.You are trying to find the average rate of change per year from 2000 to 2010. If you subtract the population of 2000 from the population of 2010 and divide by the population of 2000, you will have the rate of change for 10 years; if you divide that number by 10, you will have the annual rate of change; and if you multiply that by 100, you will have a percentage. The formula is shown below.7. Click the Annual rate of change from 2000 to 2010 field and clickCalculate.8. Choose SQL.9. Type or copy the following formula in the Expressions Builder:( ( TOTPOP10 - TOTPOP00 ) / TOTPOP00 ) / 10 * 10010. Click Calculate. When you click Calculate, it populates the rows with the annual rate of change for each state.11. Close the table by clicking the X in the upper right corner.12. Click DONE.7. Symbolize and adjust legend statesYou want to distinguish your features based on the color gradient provided by the field you just calculated. The color gradient you should choose is Counts and Amounts (Color).1. Click Enriched States and click Change Style.2. In the Choose an attribute to show window, choose annual rate ofchange 2000 to 2010.3. Choose Counts and Amounts (Color).4. Click Options.5. Check Classify Data and choose Natural Breaks.6. Choose 6 classes.7. Click Symbols and choose Red to Green ramp.8. Click Legend.9. For Round classes choose 0.1.10. Click Legend and type percent symbols in the legend entries. You mightmust enlarge the style pane to see legend.11. Click OK.12. Click Done.13. Click States and the legend will show.14. Save map.Write a description of the spatial distribution of the US by state population 2000 to 2010.8. Enrich data by Counties for StatesFor this exercise counties of three states, Virginia, Nebraska, and Arizona, have been chosen.Virginia1. Click Counties and Filter.2. For the expressions, choose:3. Click Apply FilterOnly Virginia counties are shown on the map.4. Using previous knowledge, enrich counties for pop2000 and pop2010.5. Name the file.6. Run Analysis.7. Hide fields not needed, Keep checked Name, 2000 Total Population,and 2010 Total Population.8. Add field rate_change.9. Use the following expression when you calculate in the ExpressionBuilder.10. Symbolize and adjust legend.11. Save the map to use in your web app.Nebraska12. Remove the filter for Virginia.13. Filter for Nebraska.14. Repeat steps 4-11.15. Click Save.Arizona16. Remove the filter for Nebraska.17. Filter for Arizona.18. Repeat steps 4-11.19. Save.9. Create a web appYou can create a web app from your map using a configurable app template. Your client has asked that the population rate change map you have built be displayed as a web app. Your client has asked you to use the configurable Story Map Series Web App.1. Click Share.2. Click Create a web app.3. Select Build a Story Map.4. Select Story Map Series.5. Click CREATE WEB APP.6. Specify a title, tags, and summary for the new web app.7. Click Done.8. Select Tabbed on the Welcome to Map Series Builder.9. Click Start.10. Type Rate f Change Population 2000 to 2010 as the title for your TabbedMap Series.11. Click the arrow.12. Add State Change for the Add tab.13. Type US Population Change 2000 to 2010 for your map.14. Check Legend.15. Click Add.16. Write an analysis of the map in the text box.17. Add the map VA.18. Add the map NE.19. Add the map AZ.20. Click Save.21. Click Share on the top of the page. The Organization tab is highlighted.22. Click View live.Perform additional analysisThe enrichment tool gives you access to a vast amount of data. For an additional learning activity, choose a variable to study and, using the above exercise as a guide, repeat the process for the chosen variable. For example, you may be interested in calculating the change in density of the population older than age 65 in the past 10 years. You can do this analysis either by state or at the county level.Steps for this exercise:1. Enrich population over 65 in 2000.2. Enrich population over 65 in 2010.3. Calculate population density (2000 people over 65/area)4. Calculate population density (2010 people over 65/area)((Density 2010 -Density 2000)/Density 2000 * 100)/10Copyright © 2018 Esri. All rights reserved.https:///。
在线动态地图平台 用户手册说明书

在线动态地图平台用户手册二〇二〇年12月I 在线动态地图平台目录目录 (I)1 前言 (1)2 手册内容 (1)3 运行环境 (1)4 平台系统概述 (1)4.1 系统功能和技术特点 (2)4.2 数据资源模块 (2)4.3 制作地图模块 (3)4.4 出图打印模块 (4)5 系统操作指南 (4)5.1 数据资源操作说明 (4)5.1.1 公共数据管理 (5)5.1.1.1 公共数据查询 (6)5.1.1.2 公共数据预览 (6)5.1.2 我的数据管理 (7)5.1.2.1 我的数据上传 (7)5.1.2.2 我的数据预览 (8)5.2 制作地图操作说明 (8)5.2.1 自定义地图制作 (9)5.2.1.1 选择数据 (9)5.2.1.2 选择底图 (10)5.2.1.3 选择纸张 (11)5.2.1.4 地图编辑 (11)5.2.2 示例模板地图制作 (16)5.3 出图打印操作说明 (17)5.3.1 整幅导出 (17)5.3.2 分幅导出 (18)1 前言本手册为在线制图平台用户操作手册,手册将详细介绍平台所包括的上传数据、数据查看、制作地图、出图打印等的操作流程,旨在为用户熟悉系统功能、进行业务操作、提高工作效率提供帮助。
2 手册内容本手册内容主要为平台功能模块介绍及其操作流程。
3 运行环境支持IE、Google Chrome、360安全浏览器、Safari、Mozilla Firefox等主流浏览器浏览。
4 平台系统概述在线制图平台是为了克服弱GIS行业地图制图难、传统地图平台难以满足需求等问题所研发的,主要是具有数据改造发布、无极缩放、模板丰富、快速成图、不同尺寸纸张打印、分幅打印等功能的在线动态制图平台。
为方便用户操作、简化登录流程、本平台只需微信扫描二维码即可登录系统,如图4-1所示。
图4-1 在线制图平台入口页面4.1 系统功能和技术特点在线制图平台的硬件环境主要包括有服务器不低于2.3GHZ的4核Inter(R) Xeon(R) 处理器,不低于8G系统内存,不低于100GB存储容量。
可视化品类管理系统操作手册-全时

上海与智信息科技有限公司VCM系统操作手册VCM操作手册 (5)安装和使用 (5)后台 (5)前台 (5)登录 (6)主界面 (6)系统基本功能和用户 (8)用户分类 (8)用户组基本功能和权限 (8)门店组 (8)陈列业务组(简称陈列组) (8)监管组 (9)系统组 (9)VCM的两种登录模式 (9)用户管理 (9)陈列资料管理 (11)商品资料 (11)商品资料内容 (11)商品资料批量导入 (12)单个输入 (12)商品图像 (13)图像文件批量上传 (14)单个上传 (15)货架 (16)货架资料内容 (16)货架设置 (18)货架查询和删除 (19)可视化货架设置 (19)新品和促销商品 (24)新品和促销商品导入 (24)显示新品和促销品 (27)新品和促销品删除 (28)陈列图制作 (28)陈列规划 (29)陈列图类型 (29)标准陈列 (30)陈列数据 (30)新建陈列图套(空间) (31)陈列图更名 (32)陈列数据导入和导出 (33)陈列图调整 (34)保存陈列图 (40)打印陈列图 (40)比较不同版本的陈列图 (41)陈列图美化 (42)陈列图层 (42)非标准陈列图 (44)陈列数据 (44)新建非标陈列 (45)陈列数据导入导出 (46)商品调整 (46)保存 (46)导出全部陈列数据 (46)陈列图发布 (46)陈列图发布配置 (47)创建陈列图发布组 (47)配图 (48)选图 (49)门店陈列图配置调整查询 (50)门店平面管理 (50)陈列图发布 (52)查看陈列图使用用户 (52)陈列图发布单 (53)发布单审批 (54)陈列图查看和移交 (54)查看 (55)配置被查看用户 (55)如何查看 (55)移交 (56)移交单 (56)审核移交单 (57)门店 (57)门店平面图 (58)门店陈列图 (58)附件 (59)商品照片拍摄 (59)商品几何尺寸测量 (65)VCM操作手册VCM是上海与智信息科技有限公司所有的可视化陈列管理系统。
百度地图说明文档

1.企业客户分布图:
在地图上显示所有客户所在地理位置,并标记,左侧可选择缩放比例,如下图:
1-1:选择管理站地图中心则定位到此管理站,单击显示详细信息,如下图:
2.企业客户用量分布图:
根据客户地址,总用气量在地图标记(圆圈代表总用气量大小,红色标记代表客户所在位置),单击显示详细信息,如下图:
3.加气站分布图:
标注各加气站位置和压力情况及客户位置,并用圆圈表现客户的瞬时流量大小,
3-1:单击红色小标注显示客户信息和瞬时流量,如下图:
3-2:单击加气站显示加气站信息。
柱形图标内蓝色代表储罐内压力占额定最大压力的百分比情
况。
数据可视化设计软件操作指南

数据可视化设计软件操作指南第一章:简介数据可视化设计软件操作指南数据可视化设计软件是现代数据分析中的重要工具之一。
它能够将复杂的数据转化为易于理解和解释的图形和图表,可以帮助用户更好地理解和发现数据之间的关系。
本指南将详细介绍数据可视化设计软件的操作方法和技巧,助您快速上手和熟练运用该软件。
第二章:软件安装与基本设置在开始使用数据可视化设计软件之前,您需要先安装该软件。
打开软件安装包后,按照安装向导进行操作即可完成安装。
安装完成后,您可以根据自己的需求进行基本设置,例如界面语言、字体大小等。
这些设置可以根据个人习惯进行调整,以提高使用效率。
第三章:数据导入与导出数据可视化设计软件支持多种数据格式的导入和导出。
您可以通过拖拽文件到软件界面或者通过菜单中的“导入”选项来导入数据。
导出数据的方法也类似,您可以选择导出为图片、PDF、Excel等格式。
软件还支持从数据库中导入数据,以及与其他软件的数据共享,方便您进行数据分析和信息传递。
第四章:图形选择与编辑数据可视化设计软件提供了丰富的图形库,包括直方图、折线图、散点图等常见的图形类型。
您可以通过简单的拖拽和点击操作,选择合适的图形进行展示。
在选择图形后,您还可以对其进行进一步的修改和编辑,调整颜色、字体、坐标轴等属性,以满足自己的需求。
第五章:数据关系可视化数据可视化设计软件不仅可以展示单一数据的情况,还可以将多个数据之间的关系可视化展示。
您可以使用软件提供的连接功能,将不同的数据源进行关联,然后选择相应的图形展示数据之间的关系。
这可以帮助您发现数据中隐藏的规律和趋势,从而做出更准确的分析和决策。
第六章:交互式操作与动态效果数据可视化设计软件支持交互式操作和动态效果的展示。
您可以添加按钮、滑块等交互元素,使用户可以根据需要进行数据的筛选和查看。
同时,您还可以通过添加动画效果,使图形和图表更加生动和吸引人。
这样的交互和动态效果可以提高用户参与度和数据传达效果。
数据可视化工具使用技巧

数据可视化工具使用技巧第一章绪论数据可视化是指将数据以图形、图表、地图等形式展示出来,以便更好地理解和解读数据。
数据可视化工具是实现数据可视化的重要工具之一。
在本章中,我们将介绍数据可视化的概念和意义,并介绍几种常用的数据可视化工具。
1.1 数据可视化概念数据可视化是指通过图形、图表等形式将数据表达出来,以直观、易懂的方式传达数据的信息。
这能使人们更好地理解数据、发现数据之间的关联性,从而得出有效的结论。
1.2 数据可视化的意义数据可视化具有以下几个重要的意义:(1)更直观的表达:通过图形、图表等形式展示数据,能够更直观地表达数据的含义,使数据更易于理解。
(2)发现数据之间的关联性:数据可视化能够帮助人们发现数据之间的关联性和趋势,从而提供更有价值的信息。
(3)支持决策和预测:通过对数据进行可视化,可以更好地支持决策和预测,帮助企业和个人作出明智的选择。
1.3 常用的数据可视化工具目前,市场上有许多优秀的数据可视化工具,如Tableau、Power BI、Google 数据工作室等。
这些工具提供了丰富的图表和图形库,可以帮助用户创建独特的数据可视化作品。
第二章数据可视化工具的使用技巧在本章中,我们将详细介绍数据可视化工具的使用技巧,包括数据准备、图表选择、设计原则等方面。
2.1 数据准备在进行数据可视化之前,首先需要准备好要展示的数据。
数据准备的关键是保证数据的准确性和完整性,可以通过数据清洗、数据整合等方式来达到这一目的。
2.2 图表选择选择合适的图表类型是创建有效的数据可视化作品的关键。
在选择图表类型时,需要根据数据类型、数据结构和可视化目的来进行判断。
例如,如果要比较多个类别的数据,可以选择柱状图或饼图;如果要显示趋势和变化,可以选择折线图。
2.3 设计原则在进行数据可视化设计时,需要遵循一些基本的设计原则,以确保作品的可读性和可理解性。
以下是几个常见的设计原则:(1)简洁性:尽量避免冗余信息,保持作品简洁、清晰。
数据可视化操作指南

数据可视化操作指南数据可视化是一种以图表、图形等可视化形式展示数据信息的方式,可以帮助我们更好地理解数据背后的模式和关系。
本文将为大家介绍一些常见的数据可视化操作指南,旨在帮助读者更好地进行数据可视化分析。
1.选择合适的图表类型在进行数据可视化之前,首先需要选择适合数据类型和分析目的的图表类型。
常见的图表类型包括线图、柱状图、饼图、散点图等。
以下是几个常见的场景及其对应的图表类型:- 表示趋势:线图是最常见的用于表示趋势的图表类型,可以清晰地展示数据随时间变化的趋势。
- 比较数据:柱状图可以用于比较不同类别或组之间的数据。
- 部分与整体的关系:饼图可以直观地呈现不同类别的数据在整体中的比例。
- 相关性分析:散点图可以用于显示两个变量之间的相关性。
2.保持简洁明了的布局在进行数据可视化时,布局的简洁明了性是十分重要的。
以下是一些布局的注意事项:- 避免拥挤:确保图表元素之间有足够的间距,避免过于拥挤的布局造成视觉上的混乱。
- 合理分组:如果需要在同一图表中展示多组数据,可以使用颜色或者图例进行区分,避免混淆。
- 突出重点:可以使用颜色、标签、注释等方式突出图表中的重点信息,帮助读者更快地获取关键信息。
3.选择合适的颜色和字体颜色和字体的选择也对数据可视化的效果有很大影响。
以下是几个常见的建议:- 色彩搭配:选择有较好对比度的颜色,确保不同数据之间的区分度。
另外,在使用多个颜色表示不同类别时,尽量避免使用过多的颜色,以免造成视觉上的混乱。
- 字体选择:选择易读的字体,确保文字信息的清晰易懂。
注意字体的大小,避免文字过小导致阅读困难。
4.添加轴标签和标题在图表中添加轴标签和标题可以帮助读者更好地理解图表。
以下是一些建议:- 坐标轴标签:为横轴和纵轴添加标签,确保读者能够明确轴上所表示的数据内容。
- 图表标题:为图表添加一个简明扼要的标题,概括图表所展示的数据内容和分析结果。
5.添加图例和注释图例和注释是数据可视化中常用的辅助工具。
客户智能工具:迅速理解可视化客户分段说明书

Package‘citrus’October12,2022Type PackageTitle Customer Intelligence Tool for Rapid Understandable SegmentationVersion1.0.2Maintainer Dom Clarke<******************>Copyright See thefile COPYRIGHTSDescription A tool to easily run and visualise supervised and unsupervised state of the art cus-tomer segmentation.It is built like a pipeline covering the3main steps in a segmentation project:pre-processing,modelling,and plotting.Users can either run the pipeline as a whole,or choose to run any one of the three individual steps.It is equipped with a supervised option(tree optimisation)and an unsupervised option(k-clustering)as default models.License MIT+file LICENSESuggests testthatDepends R(>=3.5.0)Imports ggplot2(>=3.3.0),GGally(>=2.0.0),clustMixType(>=0.1-16),treeClust(>=1.1-7),rpart(>=4.1-15),tibble(>=3.0.0),rpart.plot(>=3.0.7),stringr(>=1.3.0),dplyr(>=1.0.6),RColorBrewer(>=1.1-2),rlang(>=0.4.9),methodsEncoding UTF-8LazyData trueRoxygenNote7.2.0NeedsCompilation noAuthor Dom Clarke[aut,cre],Cinzia Braglia[aut],Oskar Nummedal[aut],Leo McCarthy[aut],Rebekah Yates[aut],Stuart Davie[aut],Joash Alonso[aut],PEAK AI LIMITED[cph]Repository CRANDate/Publication2022-06-1715:50:02UTC12citrus_pair_plot R topics documented:citrus_pair_plot (2)k_clusters (3)model_management (3)output_table (4)preprocess (4)preprocessed_data (5)rpart.lists (6)rpart.plot_pretty (6)rpart.rules (7)rpart.rules.table (8)rpart.subrules.table (8)segment (9)transactional_data (10)tree_abstract (10)tree_segment (11)tree_segment_prettify (11)validate (12)Index13 citrus_pair_plot Creates pair plot from data tableDescriptionCreates pair plot from data tableUsagecitrus_pair_plot(model,vars=NULL)Argumentsmodel list,a citrus segmentation modelvars data.frame,the data to segmentValueGGally object displaying the segment feature pair plots.k_clusters3 k_clusters k-clusters modelDescriptionk-clusters method for segmentation.It can handle segmentation for both numerical data types only,by using k-means algorithm,and mixed data types(numerical and categorical)by using k-prototypes algorithmUsagek_clusters(data,hyperparameters,verbose=TRUE)Argumentsdata data.frame,the data to segmenthyperparameterslist of hyperparameters to pass.They include centers:number of clusters or a setof initial(distinct)cluster centers,or’auto’.When’auto’is chosen,the numberof clusters is optimised;iter_max:the maximum number of iterations allowed;n_start:how many ran-dom sets of cluster centers should be tried;max_centers:maximum number ofclusters when’auto’option is selected for the centers;segmentation_variables:the columns to use to segment on.standardize:whether to standardize numericcolumns.verbose logical whether information about the clustering procedure should be given.ValueA class called"k-clusters"containing a list of the model definition,the hyper-parameters,a table ofoutliers,the elbow plot(ggplot object)used to determine the optimal no.of clusters,and a lookup table containing segment predictions for customers.model_management Model management functionDescriptionSaves the model and its settings so that it can be recreatedUsagemodel_management(model,hyperparameters)4preprocess Argumentsmodel data.frame,the model to savehyperparameterslist,list of hyperparameters of the modelValueNo return value.Called to save model and settings locally.output_table Output TableDescriptionGenerates the output table for model and dataUsageoutput_table(data,model)Argumentsdata A dataframe generated from the pre-processing stepmodel A model object used to classify ids with,generated from the model selection layerValueA tibble providing high-level segment attributes such as mean and max(numeric)or mode(cate-gorical)for the segmentation features used.preprocess Preprocess FunctionDescriptionTransforms a transactional table into an id aggregated table with custom options for aggregation methods for numeric and categorical columns.preprocessed_data5Usagepreprocess(df,samplesize=NA,numeric_operation_list=c("mean"),categories=NULL,target=NA,target_agg="mean",verbose=TRUE)Argumentsdf data.frame,the data to preprocesssamplesize numeric,the fraction of ids used to create a sub-sample of the input dfnumeric_operation_listlist,a list of the aggregation functions to apply to numeric columns categories list,a list of the categorical columns to aggregatetarget character,the column to use as a response variable for supervised learning target_agg character,the aggregation function to use to aggregate the target columnverbose logical whether information about the preprocessing should be givenValueAn id attributes data frame,e.g.customer attributes if the id represents customer IDs.A single row per unique id.preprocessed_data Segmentation preprocessed dataDescriptionA sample customer dataset for the purpose of demonstrating the segmentation algorithm.Usagedata(preprocessed_data)FormatData frame on a customer level.Contains402rows and8columns.Examplesdata(preprocessed_data)6rpart.plot_pretty rpart.lists rpart.lists functionDescriptionTHIS HAS BEEN COPIED FROM THE ARCHIVED rpart.utils PACKAGE AND THIS CODE W AS WRITTEN BY THE AUTHORS OF THAT PACKAGE Creates lists of variable values(factor levels)associated with each rule in an rpart object.Usagerpart.lists(object)Argumentsobject an rpart objectValuea list of listsExampleslibrary(rpart)fit<-rpart(Reliability~.,data=car.test.frame)rpart.lists(fit)rpart.plot_pretty Plot a prettified rpart modelDescriptionPlot an rpart model and prettifies it.Wrap around the rpart.plot::prp functionUsagerpart.plot_pretty(model,main="",sub,caption,palettes,type=2,fontfamily="sans",...)rpart.rules7 Argumentsmodel an rpart model objectmain main titlesubfixing captions in linecaption character,caption to use in the plotpalettes list,list of colours to use in the plottype type of plot.Default is2.Possible values are:0Default.Draw a split label at each split and a node label at each leaf.1Label all nodes,not just leaves.2Like1but draw the split labels below the node labels.3Draw separate split labelsfor the left and right directions.4Like3but label all nodes,not just leaves.5Show the split variable name in the interior nodes.fontfamily Names of the font family to use for the text in the plots....Additional arguments.ValueAn rpart.plot object.This plot object can be plotted using the rpart::prp function.rpart.rules rpart.rules functionDescriptionTHIS HAS BEEN COPIED FROM THE ARCHIVED rpart.utils PACKAGE AND THIS CODE W AS WRITTEN BY THE AUTHORS OF THAT PACKAGE Returns a list of strings summarizing the branch path to each node.Usagerpart.rules(object)Argumentsobject an rpart objectExampleslibrary(rpart)fit<-rpart(Reliability~.,data=car.test.frame)rpart.rules(fit)8rpart.subrules.table rpart.rules.table rpart.rules.table functionDescriptionTHIS HAS BEEN COPIED FROM THE ARCHIVED rpart.utils PACKAGE AND THIS CODE W AS WRITTEN BY THE AUTHORS OF THAT PACKAGE Returns an unpivoted table of branch paths(subrules)associated with each node.Usagerpart.rules.table(object)Argumentsobject an rpart objectExampleslibrary(rpart)fit<-rpart(Reliability~.,data=car.test.frame)rpart.rules.table(fit)rpart.subrules.table rpart.subrules.table functionDescriptionTHIS HAS BEEN COPIED FROM THE ARCHIVED rpart.utils PACKAGE AND THIS CODE W AS WRITTEN BY THE AUTHORS OF THAT PACKAGE Returns an unpivoted table of variable values(factor levels)associated with each branch.Usagerpart.subrules.table(object)Argumentsobject an rpart objectExampleslibrary(rpart)fit<-rpart(Reliability~.,data=car.test.frame)rpart.subrules.table(fit)segment9 segment Segment FunctionDescriptionSegments the data by running all steps in the segmentation pipeline,including output tableUsagesegment(data,modeltype=c("tree","k-clusters"),FUN=NULL,FUN_preprocess=NULL,steps=c("preprocess","model"),prettify=FALSE,print_plot=FALSE,hyperparameters=NULL,force=FALSE,verbose=FALSE)Argumentsdata data.frame,the data to segmentmodeltype character,the type of model to use to segment choices are:’tree’,’k-clusters’FUN function,A user specified function to segment,if the standard methods are not wanting to be usedFUN_preprocess function,A user specified function to preprocess,if the standard methods are not wanting to be usedsteps list,names of the steps the user want to run the data on.Options are’preprocess’and’model’prettify logical,TRUE if want cleaned up outputs,FALSE for raw outputprint_plot logical,TRUE if want to print the plothyperparameterslist of hyperparameters to use in the model.force logical,TRUE to ignore errors in validation step and force model execution.verbose logical whether information about the segmentation pipeline should be given.ValueA list of three objects.A tibble providing high-level segment attributes,a lookup table(data frame)with the id and predicted segment number,and an rpart object defining the model.10tree_abstract transactional_data Segmentation transactional dataDescriptionA sample customer dataset for the purpose of demonstrating the segmentation algorithm.Usagedata(transactional_data)FormatData frame on a transactional level.Contains10,000rows and6columns.Examplesdata(transactional_data)tree_abstract Abstraction layer functionDescriptionOrganises the model outputs,predictions and settings in a general structureUsagetree_abstract(model)Argumentsmodel The model to organiseValueA structure with the class name"tree_model"which contains a list of all the relevant model data,including the rpart model object,hyper-parameters,segment table and the labelled customer lookup table.tree_segment11 tree_segment Tree Segment FunctionDescriptionRuns decision tree optimisation on the data to segment ids.Usagetree_segment(data,hyperparameters,verbose=TRUE)Argumentsdata data.frame,the data to segmenthyperparameterslist,list of hyperparameters to pass.They include segmentation_variables:avector or list with variable names that will be used as segmentation variables;dependent_variable:a string with the name of the dependent variable that is usedin the clustering;min_segmentation_fraction:integer,the minimum segmentsize as a proportion of the total data set;number_of_segments:integer,numberof leaves you want the decision tree to have.verbose logical whether information about the segmentation procedure should be given.ValueList of4objects.The rpart object defining the model,a data frame providing high-level segment attributes,a lookup table(data frame)with the id and predicted segment number,and a list of the hyperparameters used.Author(s)Stuart Davie,<********************>tree_segment_prettify Tree Segment Prettify FunctionDescriptionReturns a prettier version of the decision tree.Usagetree_segment_prettify(tree,char_length=20,print_plot=FALSE)12validateArgumentstree The decision tree model to prettifychar_length integer,the character limit before truncating categories and putting them into an "other"groupprint_plot logical,indicates whether to print the generated plot or notValueA formatted and"prettified"rpart.plot object.This plot object can be plotted using the rpart::prpfunction.validate Validation functionDescriptionValidates that the input data adheres to the expected format for modelling.Usagevalidate(df,supervised=TRUE,force,hyperparameters)Argumentsdf data.frame,the data to validatesupervised logical,TRUE for supervised learning,FALSE for k-clustersforce logical,TRUE to ignore error on categorical columnshyperparameterslist of hyperparameters used in the modelValue‘TRUE‘if all checks are passed.Otherwise an error is raised.Index∗datasetspreprocessed_data,5transactional_data,10citrus_pair_plot,2k_clusters,3model_management,3output_table,4preprocess,4preprocessed_data,5rpart.lists,6rpart.plot_pretty,6rpart.rules,7rpart.rules.table,8rpart.subrules.table,8segment,9transactional_data,10tree_abstract,10tree_segment,11tree_segment_prettify,11validate,1213。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
[东莞中原策略中心]
2015年4月10日
本报告仅供客户内部使用。在获得中原地产书面许可之前,本报告的任何部分都不可被擅自引用、复制和传播。 © Copyright Centaline Group, 2009
Code of this report | 1
• • • •
卖方市场向买方市场转变; 客户不冲动不主动,大宗花费偏保守; 客户和渠道资源的整合、拓客的精准定位和实效成为营销突破关键点! 坐销到行销的,这个是我本 人的,直接用也行。前 提是我不删除这个密匙。
"东莞市东城区东城中路422号", "东莞市茶山镇横江村", "东莞市茶山镇横江村环城路" ];
红色标注部分是客户地址数据,要把既 定格式的客户数据替换进去。后面会介 绍如何将excel的数据转成这样的格式。 如果是东莞的客户地图,只要改这里即 可,其他都不用改动。
<html> <head> <meta http-equiv="Content-Type" content="text/html; charset=utf8" /> <meta name="viewport" content="initial-scale=1.0, user-scalable=no" /> <title>批量地址</title> <style type="text/css"> body, html{width: 100%;height: 100%;margin:0;font-family:"微软雅黑";} #l-map{height:800px;width:100%;} #r-result{width:100%; font-size:14px;line-height:20px;} </style> <script type="text/javascript" src="/api?v=2.0&ak=QyzhknTS8gkORRRC0pGItHkP"></script> </head> <body> <div id="l-map"></div> <div id="r-result"> <input type="button" value="批量地址解析" onclick="bdGEO()" /> <div id="result"></div> </div> </body> </html> <script type="text/javw BMap.Map("l-map"); map.centerAndZoom(new BMap.Point(113.746572, 23.023252), 13); map.enableScrollWheelZoom(true); var index = 0; var myGeo = new BMap.Geocoder(); var adds = [
=CHAR(34)&A1&""&CHAR(34)&", "
2. 回车!一个地址就生成了。 3. 双击图二圈圈处,整个地址栏就出来了。
Step3——程序生成
1. 新建一个TXT文件,如左图 2. COPY以下整个网页代码到TXT文件中
红色标注部分是所在城市的经纬度数据, 现在这个是东莞市的,其他城市可以上 网查该城市的经纬度数据,保留小数点 后六位。
1. 打开刚才保存的TXT文件,如图一。 2. 我用公司电脑打开是个空白页面,点击提示栏——允许阻止的内容,见图二 3. 弹出安全警告对话框,选“是”。
Step7——地图生成
1. 出来是这样的!啥都没有!!别急!把右边滑动栏滑至最底。 2. 会看到左下角出现一个按钮“批量地址解析”,点击。
Step8——地图显示
Step4——程序生成
1. COPY后如下图一,找到其中的地址栏 2. 打开刚才制作的excel文件第二栏全部COPY到TXT文件的的地址部分。如图 三
Step5——程序生成
1. 直接Ctrl+S保存。记得把扩展名改为html;还有编码,改为第二个Unicode 选项。 2. 保存记
1. 打开 工具——标记,如图一所示 2. 鼠标放在地图上目标地点,并点击,如图二所示
Step3——填写标记
1. 填写标记名称——保存,备注 栏不必填 2. 0啦 3. 以上步骤循环复制便可以得到 图三了(那不得累死?!!!)
二、智能型(程序猿)
Step1——源数据处理
Wish you a good day!
红色标注部分这里修改为所在的城市, 这样在客户地址没有填城市名称时,也 会默认在定位到所在城市。
function geocodeSearch(add) { if (index < adds.length-1) { setTimeout(window.bdGEO, 400); } myGeo.getPoint(add, function (point) { if (point) { document.getElementById("result").innerHTML += index + "、" + add + ":" + point.lng + "," + t + "</br></br>"; var address = new BMap.Point(point.lng, t); addMarker(address,add); } }, "东莞市"); } // 编写自定义函数,创建标注 function addMarker(point, content) { var marker = new BMap.Marker(point); map.addOverlay(marker); addClickHandler(content, marker); // marker.setLabel(label); } </script>
var opts = { width: 250, // 信息窗口宽度 height: 50, // 信息窗口高度 // title: "信息窗口", // 信息窗口标题 enableMessage: false//设置允许信息窗发送短息 }; function bdGEO() { var add = adds[index]; geocodeSearch(add); index++; } function addClickHandler(content, marker) { marker.addEventListener("mouseover", function (e) { openInfo(content, e) } ); } function openInfo(content, e) { var p = e.target; var point = new BMap.Point(p.getPosition().lng, p.getPosition().lat); var infoWindow = new Window(content, opts); // 创建信息窗口对象 map.openInfoWindow(infoWindow, point); //开启信息窗口 }
1. 现在就是“等”!数据量太大的话,就要等待时间长些。标注会一个个显示 出来。 2. 根据自己需要,缩放显示,然后截图应用就OK啦!
应用
这个客户地图有什么用?
1. 客户分析
2. 客户定位 3. 渠道建议(媒介、覆射区域) 4. 拓展地图 5. 拓盘时显示我大中原客户量强盛
Thanks for your attention
1. 打开excel客户资料表(不是excel格式的,把地址COPY新建到excel) 2. 把客户地址栏放于第一栏,并在第二栏新建一个空白栏 3. 删除标题栏,即客户地址顶格。
Step2——数据转换
1. 这一步的目的是要把客户的地址转化成电脑能读懂的语言,因此,要利用一 个公式,在第二栏第一行输入公式,不用看明白,直接COPY就行!
•
• • • •
行销和拓客的前提是清楚的知道客户在哪里;
然后部署和制定相应的拓客兵团作战计划; 因此,客户地图成为了必不可少的有力工具; 而在大数据时代,面对海量的客户数据, 客户地图的可视化成为房地产营销的有力工具!
如何实现?
一、手工型(笨鸟)
圈可切换卫星地图显示 3. 把地图拖移至目标位置,选择合适的缩放显示