语音信处理实验报告
语音信号处理实验报告.docx
在实验中,当P值增加到一定程度,预测平方误差的改善就不很明显了,而且会增加计算量,一般取为8~14,这里P取为10。
5.基音周期估计
①自互相关函数法
②短时平均幅度差法
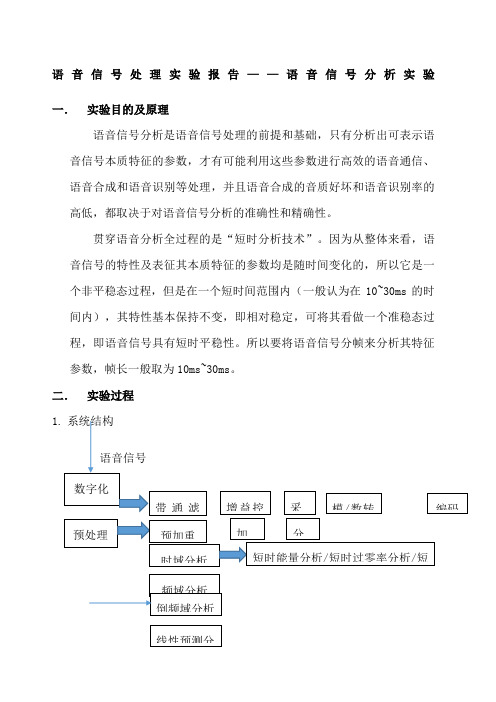
二.实验过程
1. 系统结构
2.仿真结果
(1)时域分析
男声及女声(蓝色为时域信号,红色为每一帧的能量,绿色为每一帧的过零率)
某一帧的自相关函数
3.频域分析
①一帧信号的倒谱分析和FFT及LPC分析
②男声和女声的倒谱分析
③浊音和清音的倒谱分析
④浊音和清音的FFT分析和LPC分析(红色为FFT图像,绿色为LPC图像)
从男声女声的时域信号对比图中可以看出,女音信号在高频率分布得更多,女声信号在高频段的能量分布更多,并且女声有较高的过零率,这是因为语音信号中的高频段有较高的过零率。
2.频域分析
这里对信号进行快速傅里叶变换(FFT),可以发现,当窗口函数不同,傅里叶变换的结果也不相同。根据信号的时宽带宽之积为一常数这一性质,可以知道窗口宽度与主瓣宽度成反比,N越大,主瓣越窄。汉明窗在频谱范围中的分辨率较高,而且旁瓣的衰减大,具有频谱泄露少的有点,所以在实验中采用的是具有较小上下冲的汉明窗。
三.实验结果分析
1.时域分析
实验中采用的是汉明窗,窗的长度对能否由短时能量反应语音信号的变化起着决定性影响。这里窗长合适,En能够反应语音信号幅度变化。同时,从图像可以看出,En可以作为区分浊音和清音的特征参数。
短时过零率表示一帧语音中语音信号波形穿过横轴(零电平)的次数。从图中可以看出,短时能量和过零率可以近似为互补的情况,短时能量大的地方过零率小,短时能量小的地方过零率较大。从浊音和清音的时域分析可以看出,清音过零率高,浊音过零率低。
语音信号处理实验报告实验二

语音信号处理实验报告实验二一、实验目的本次语音信号处理实验的目的是深入了解语音信号的特性,掌握语音信号处理的基本方法和技术,并通过实际操作和数据分析来验证和巩固所学的理论知识。
具体而言,本次实验旨在:1、熟悉语音信号的采集和预处理过程,包括录音设备的使用、音频格式的转换以及噪声去除等操作。
2、掌握语音信号的时域和频域分析方法,能够使用相关工具和算法计算语音信号的短时能量、短时过零率、频谱等特征参数。
3、研究语音信号的编码和解码技术,了解不同编码算法对语音质量和数据压缩率的影响。
4、通过实验,培养我们的动手能力、问题解决能力和团队协作精神,提高我们对语音信号处理领域的兴趣和探索欲望。
二、实验原理(一)语音信号的采集和预处理语音信号的采集通常使用麦克风等设备将声音转换为电信号,然后通过模数转换器(ADC)将模拟信号转换为数字信号。
在采集过程中,可能会引入噪声和干扰,因此需要进行预处理,如滤波、降噪等操作,以提高信号的质量。
(二)语音信号的时域分析时域分析是对语音信号在时间轴上的特征进行分析。
常用的时域参数包括短时能量、短时过零率等。
短时能量反映了语音信号在短时间内的能量分布情况,短时过零率则表示信号在单位时间内穿过零电平的次数,可用于区分清音和浊音。
(三)语音信号的频域分析频域分析是将语音信号从时域转换到频域进行分析。
通过快速傅里叶变换(FFT)可以得到语音信号的频谱,从而了解信号的频率成分和分布情况。
(四)语音信号的编码和解码语音编码的目的是在保证一定语音质量的前提下,尽可能降低编码比特率,以减少存储空间和传输带宽的需求。
常见的编码算法有脉冲编码调制(PCM)、自适应差分脉冲编码调制(ADPCM)等。
三、实验设备和软件1、计算机一台2、音频采集设备(如麦克风)3、音频处理软件(如 Audacity、Matlab 等)四、实验步骤(一)语音信号的采集使用麦克风和音频采集软件录制一段语音,保存为常见的音频格式(如 WAV)。
语音信号处理实验报告2
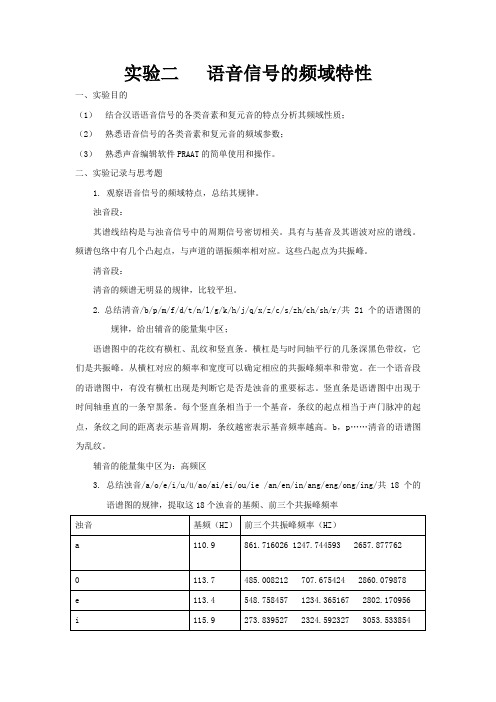
实验二语音信号的频域特性一、实验目的(1)结合汉语语音信号的各类音素和复元音的特点分析其频域性质;(2)熟悉语音信号的各类音素和复元音的频域参数;(3)熟悉声音编辑软件PRAAT的简单使用和操作。
二、实验记录与思考题1. 观察语音信号的频域特点,总结其规律。
浊音段:其谱线结构是与浊音信号中的周期信号密切相关。
具有与基音及其谐波对应的谱线。
频谱包络中有几个凸起点,与声道的谐振频率相对应。
这些凸起点为共振峰。
清音段:清音的频谱无明显的规律,比较平坦。
2.总结清音/b/p/m/f/d/t/n/l/g/k/h/j/q/x/z/c/s/zh/ch/sh/r/共21个的语谱图的规律,给出辅音的能量集中区;语谱图中的花纹有横杠、乱纹和竖直条。
横杠是与时间轴平行的几条深黑色带纹,它们是共振峰。
从横杠对应的频率和宽度可以确定相应的共振峰频率和带宽。
在一个语音段的语谱图中,有没有横杠出现是判断它是否是浊音的重要标志。
竖直条是语谱图中出现于时间轴垂直的一条窄黑条。
每个竖直条相当于一个基音,条纹的起点相当于声门脉冲的起点,条纹之间的距离表示基音周期,条纹越密表示基音频率越高。
b,p……清音的语谱图为乱纹。
辅音的能量集中区为:高频区3. 总结浊音/a/o/e/i/u/ü/ao/ai/ei/ou/ie /an/en/in/ang/eng/ong/ing/共18个的语谱图的规律,提取这18个浊音的基频、前三个共振峰频率4./r/、/m/、/n/、/l/ 从这几个音素的的基频、共振峰频率5.分析宽带语谱图和窄带语谱图的不同之处,请解释原因;语谱图中的花纹有横杠、乱纹和竖直条等。
横杠是与时间轴平行的几条深黑色带纹,它们是共振峰。
从横杠对应的频率和宽度可以确定相应的共振峰频率和带宽。
在一个语音段的语谱图中,有没有横杠出现是判断它是否是浊音的重要标志。
竖直条(又叫冲直条)是语谱图中出现与时间轴垂直的一条窄黑条。
每个竖直条相当于一个基音,条纹的起点相当于声门脉冲的起点,条纹之间的距离表示基音周期。
(完整word版)语音信号处理实验报告实验一

通信工程学院12级1班罗恒2012101032实验一语音信号的低通滤波和短时分析综合实验一、实验要求1、根据已有语音信号,设计一个低通滤波器,带宽为采样频率的四分之一,求输出信号;2、辨别原始语音信号与滤波器输出信号有何区别,说明原因;3、改变滤波器带宽,重复滤波实验,辨别语音信号的变化,说明原因;4、利用矩形窗和汉明窗对语音信号进行短时傅立叶分析,绘制语谱图并估计基音周期,分析两种窗函数对基音估计的影响;5、改变窗口长度,重复上一步,说明窗口长度对基音估计的影响。
二、实验目的1.在理论学习的基础上,进一步地理解和掌握语音信号低通滤波的意义,低通滤波分析的基本方法。
2.进一步理解和掌握语音信号不同的窗函数傅里叶变化对基音估计的影响。
三、实验设备1.PC机;2。
MATLAB软件环境;四、实验内容1。
上机前用Matlab语言完成程序编写工作.2。
程序应具有加窗(分帧)、绘制曲线等功能。
3.上机实验时先调试程序,通过后进行信号处理。
4.对录入的语音数据进行处理,并显示运行结果。
5。
改变滤波带宽,辨别与原始信号的区别。
6。
依据曲线对该语音段进行所需要的分析,并且作出结论。
7.改变窗的宽度(帧长),重复上面的分析内容。
五、实验原理及方法利用双线性变换设计IIR滤波器(巴特沃斯数字低通滤波器的设计),首先要设计出满足指标要求的模拟滤波器的传递函数Ha(s),然后由Ha(s)通过双线性变换可得所要设计的IIR滤波器的系统函数H(z)。
如果给定的指标为数字滤波器的指标,则首先要转换成模拟滤波器的技术指标,这里主要是边界频率Wp和Ws的转换,对ap和as指标不作变化。
边界频率的转换关系为∩=2/T tan(w/2).接着,按照模拟低通滤波器的技术指标根据相应设计公式求出滤波器的阶数N和3dB截止频率∩c ;根据阶数N查巴特沃斯归一化低通滤波器参数表,得到归一化传输函数Ha(p);最后,将p=s/ ∩c 代入Ha(p)去归一,得到实际的模拟滤波器传输函数Ha(s)。
语音信号处理实验报告

实验一 显示语音信号的语谱图一、实验目的综合信号频谱分析和滤波器功能,对语音信号的频谱进行 分析,并对信号含进行高通、低通滤波,实现信号特定处理 功能。
加深信号处理理论在语音信号中的应用;理解语谱图 与时频分辨率的关系。
二、实验原理语谱图分析语音又称语谱分析,语谱图中显示了大量的与语音的语句特性有关的信息,它总额了频谱图和时域波形的优点,明显地显示出语音频谱随时间的变化情况。
语谱图实际上是一种三维频谱,即同时在时间和频率上显示出语音的特性,或者说是一种动态的频谱。
窄带语谱图可以得到较好的频域分辨率,窗长通常为至少两个基音周期的“长窗”;而宽带语谱图可以给出较好的时域分辨率,窗长为小于一个基音周期的“短窗”。
三、实验内容实验数据为工作空间 ex3M2.mat 中数组 we_be10k 是单词“we ”和“be ”的语音波形(采样率为10000 点/秒) 。
1、 听一下 we_be10k (可用 sound )2、使用函数 specgram_ex3p19.显示语谱图和语音波形,如图一。
图一、参数窗长 20ms (200 点) 、帧间隔 1ms (10 点)0.511.5-2-1012Time (s)SPEECHTime (ms)F r e q u e n c y (H z )SPECTROGRAM00.51 1.5200040002、 对比调用参数窗长 20ms (200 点) 、帧间隔 1ms (10 点),(如图一)和参数窗长5ms (50点) 、帧间隔 1ms (10点)(如图二) ;图二、参数窗长5ms (50点) 、帧间隔 1ms (10点)图三、参数窗长30ms (300点) 、帧间隔 1ms (10点)0.511.5-2-1012Time (s)SPEECHTime (ms)F r e q u e n c y (H z )SPECTROGRAM00.51 1.5200040000.511.5-2-1012Time (s)SPEECHTime (ms)F r e q u e n c y (H z )SPECTROGRAM00.51 1.520004000图四、参数窗长20ms (200点) 、帧间隔 5ms (50点)3、 再对比窗长>20ms 或小于5ms ,以及帧间隔>1ms 时的语谱图说明宽带语谱图、窄带语谱图与时频分辨率的关系及如何得到时频折中。
《语音信号处理》实验5-DTW算法实现及语音模板匹配

华南理工大学《语音信号处理》实验报告实验名称:DTW算法实现及语音模板匹配姓名:学号:班级:10级电信5班日期:2013年6 月17日一、实验目的运用课堂上所学知识以及matlab工具,利用DTW(Dynamic Time Warping,动态时间规整)算法,进行说话者的语音识别。
二、实验原理1、语音识别系统概述一个完整特定人语音识别系统的方案框图如图1所示。
输入的模拟语音信号首先要进行预处理,包括预滤波、采样和量化、加窗、端点检测、预加重等,然后是参数特征量的提取。
提取的特征参数满足如下要求:(1)特征参数能有效地代表语音特征,具有很好的区分性;(2)参数间有良好的独立性;(3)特征参数要计算方便,要考虑到语音识别的实时实现。
图1 语音识别系统方案框图语音识别的过程可以被看作模式匹配的过程,模式匹配是指根据一定的准则,使未知模式与模型库中的某一个模型获得最佳匹配的过程。
模式匹配中需要用到的参考模板通过模板训练获得。
在训练阶段,将特征参数进行一定的处理后,为每个词条建立一个模型,保存为模板库。
在识别阶段,语音信号经过相同的通道得到语音特征参数,生成测试模板,与参考模板进行匹配,将匹配分数最高的参考模板作为识别结果。
2、语音信号的处理1、语音识别的DTW算法本设计中,采用DTW算法,该算法基于动态规划(DP)的思想解决了发音长短不一的模板匹配问题,在训练和建立模板以及识别阶段,都先采用端点检测算法确定语音的起点和终点。
在本设计当中,我们建立的参考模板,m为训练语音帧的时序标号,M为该模板所包含的语音帧总数,R(m)为第m帧的语音特征矢量。
所要识别的输入词条语音称为测试模板,n为测试语音帧的时序标号,N为该模板所包含的语音帧总数,T(n)为第n帧的语音特征矢量。
参考模板和测试模板一般都采用相同类型的特征矢量(如LPCC系数)、相同的帧长、相同的窗函数和相同的帧移。
考虑到语音中各段在不同的情况下持续时间会产生或长或短的变化,因而更多地是采用动态规划DP的方法。
语音信号处理实验报告 语音修正短时自相关

语音信号处理课程实验报告专业班级通信学号姓名指导教师实验名称 语音修正的短时自相关的实现 同组人 专业班级通信 学号 姓名 成绩 一、实验目的 熟悉语音修正自相关的意义。
充分理解取取不同窗长时的语音的修正自相关的变化情况。
熟悉Matlab 编程语言在语音信号处理中的作用。
能够实现对程序的重新编制。
二、实验原理 对于语音来说,采用短时分析方法,语音短时自相关函数为 ()()()[]()()[]∑--=+'++'+=k N m n m k w k m n x m w m n x k R 10 但是,在计算短时自相关时,窗选语音段为有限长度N ,而求和上限为N-1-k ,因此当k 增加时可用于计算的数据就越来越少了,从而导致k 增加时自相关函数的幅度减小。
为了解决这个问题,提出了语音修正的短时自相关。
修正的短时自相关函数,其定义如下: ()()()()() 2-m 1k m n w k m x m n w m x k R n --+-=∑+∞∞= 若令m n m '+=,代入上式得到 ()())(-)()(-ˆ21-k m w k m n x m w m n x k R m n '+'+''+=∑+∞-∞=' ()()()()1122ˆ ˆw m w m w m w m =-⎧⎪⎨=-⎪⎩定义……………………………………装………………………………………订…………………………………………线………………………………………()()() ˆˆ)()(ˆ 2-m 1k m w k m n x m w m n x k Rn ++++=∑+∞∞=则有()()121, 0n N-1ˆ0, 1, 0n N-1ˆ 0, w m K w m ≤≤⎧=⎨⎩≤≤+⎧=⎨⎩其它其它式中,K 为k 的最大值,即0≤k ≤K 。
由式(2-5)可知,要使)(ˆ2k m w +为非零值,必须使K N k m +1-≤+,考虑到K k ≤,可得1-≤N m ,故式(2-4)可以写成:∑1-0 )()()(ˆN m n k m n x m n x k R =+++= 三、实验要求1.实验前自己用Cool Edit 音频编辑软件录制声音,并把它保存为.txt 文件.2.编程实现不同矩形窗长N =320,160,70的短时修正自相关。
语音信号处理实验报告

通信与信息工程学院信息处理综合实验报告班级:电子信息工程1502班指导教师:设计时间:2018/10/22-2018/11/23评语:通信与信息工程学院二〇一八年实验题目:语音信号分析与处理一、实验内容1. 设计内容利用MATLAB对采集的原始语音信号及加入人为干扰后的信号进行频谱分析,使用窗函数法设计滤波器滤除噪声、并恢复信号。
2.设计任务与要求1. 基本部分(1)录制语音信号并对其进行采样;画出采样后语音信号的时域波形和频谱图。
(2)对所录制的语音信号加入干扰噪声,并对加入噪声的信号进行频谱分析;画出加噪后信号的时域波形和频谱图。
(3)分别利用矩形窗、三角形窗、Hanning窗、Hamming窗及Blackman 窗几种函数设计数字滤波器滤除噪声,并画出各种函数所设计的滤波器的频率响应。
(4)画出使用几种滤波器滤波后信号时域波形和频谱,对滤波前后的信号、几种滤波器滤波后的信号进行对比,分析信号处理前后及使用不同滤波器的变化;回放语音信号。
2. 提高部分(5)录制一段音乐信号并对其进行采样;画出采样后语音信号的时域波形和频谱图。
(6)利用MATLAB产生一个不同于以上频段的信号;画出信号频谱图。
(7)将上述两段信号叠加,并加入干扰噪声,尝试多次逐渐加大噪声功率,对加入噪声的信号进行频谱分析;画出加噪后信号的时域波形和频谱图。
(8)选用一种合适的窗函数设计数字滤波器,画出滤波后音乐信号时域波形和频谱,对滤波前后的信号进行对比,回放音乐信号。
二、实验原理1.设计原理分析本设计主要是对语音信号的时频进行分析,并对语音信号加噪后设计滤波器对其进行滤波处理,对语音信号加噪声前后的频谱进行比较分析,对合成语音信号滤波前后进行频谱的分析比较。
首先用PC机WINDOWS下的录音机录制一段语音信号,并保存入MATLAB软件的根目录下,再运行MATLAB仿真软件把录制好的语音信号用audioread函数加载入MATLAB仿真软件的工作环境中,输入命令对语音信号进行时域,频谱变换。
语音信号处理实验报告
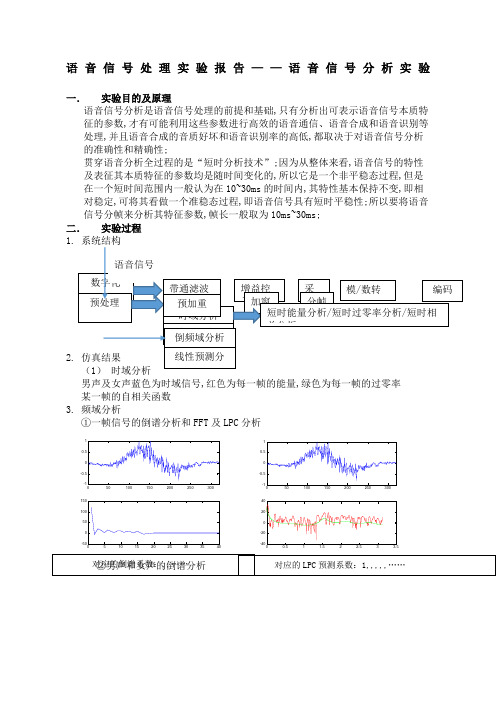
语音信号处理实验报告——语音信号分析实验一.实验目的及原理语音信号分析是语音信号处理的前提和基础,只有分析出可表示语音信号本质特征的参数,才有可能利用这些参数进行高效的语音通信、语音合成和语音识别等处理,并且语音合成的音质好坏和语音识别率的高低,都取决于对语音信号分析的准确性和精确性;贯穿语音分析全过程的是“短时分析技术”;因为从整体来看,语音信号的特性及表征其本质特征的参数均是随时间变化的,所以它是一个非平稳态过程,但是在一个短时间范围内一般认为在10~30ms的时间内,其特性基本保持不变,即相对稳定,可将其看做一个准稳态过程,即语音信号具有短时平稳性;所以要将语音信号分帧来分析其特征参数,帧长一般取为10ms~30ms;二.实验过程男声及女声蓝色为时域信号,红色为每一帧的能量,绿色为每一帧的过零率某一帧的自相关函数3.频域分析①一帧信号的倒谱分析和FFT及LPC分析②男声和女声的倒谱分析对应的倒谱系数:,,……对应的LPC预测系数:1,,,,,……原语音波形一帧语音波形一帧语音的倒谱③浊音和清音的倒谱分析④浊音和清音的FFT分析和LPC分析红色为FFT图像,绿色为LPC图像三.实验结果分析1.时域分析实验中采用的是汉明窗,窗的长度对能否由短时能量反应语音信号的变化起着决定性影响;这里窗长合适,En能够反应语音信号幅度变化;同时,从图像可以看出,En可以作为区分浊音和清音的特征参数;短时过零率表示一帧语音中语音信号波形穿过横轴零电平的次数;从图中可以看出,短时能量和过零率可以近似为互补的情况,短时能量大的地方过零率小,短时能量小的地方过零率较大;从浊音和清音的时域分析可以看出,清音过零率高,浊音过零率低;从男声女声的时域信号对比图中可以看出,女音信号在高频率分布得更多,女声信号在高频段的能量分布更多,并且女声有较高的过零率,这是因为语音信号中的高频段有较高的过零率;2.频域分析这里对信号进行快速傅里叶变换FFT,可以发现,当窗口函数不同,傅里叶变换的结果也不相同;根据信号的时宽带宽之积为一常数这一性质,可以知道窗口宽度与主瓣宽度成反比,N越大,主瓣越窄;汉明窗在频谱范围中的分辨率较高,而且旁瓣的衰减大,具有频谱泄露少的有点,所以在实验中采用的是具有较小上下冲的汉明窗;为了使频域信号的频率分辨率较高,所取的DFT及相应的FFT点数应该足够多,但时域信号的长度受到采样率和和短时性的限制,这里可以采用补零的办法,对补零后的序列进行FFT变换;从实验仿真图可以看出浊音的频率分布比清音高;3.倒谱分析通过实验可以发现,倒谱的基音检测与语音加窗的选择也是有关系的;如果窗函数选择矩形窗,在许多情况下倒谱中的基音峰将变得不清晰,窗函数选择汉明窗较为合理,可以发现,加汉明窗的倒谱基音峰较为突出;在典型的浊音清音倒谱对比中,理论上浊音倒谱基音峰应比较突出,而清音不出现这种尖峰,只是在倒谱的低时域部分包含关于声道冲激响应的信息;实验仿真的图形不是很理想;4.线性预测分析从实验中可以发现,LPC谱估计具有一个特点,在信号能量较大的区域即接近谱的峰值处,LPC谱和信号谱很接近;而在信号能量较低的区域即接近谱的谷底处,则相差比较大;在浊音清音对比中,可以发现,对呈现谐波特征的浊音语音谱来说这个特点很明显,就是在谐波成分处LPC谱匹配信号谱的效果要远比谐波之间好得多;在实验中,当P值增加到一定程度,预测平方误差的改善就不很明显了,而且会增加计算量,一般取为8~14,这里P取为10;5.基音周期估计①自互相关函数法②短时平均幅度差法③倒谱分析法共偏移92+32=124个偏移点16000/124=可以发现,上面三种方法计算得到的基音周期基本相同;。
最新语音信号处理实验报告实验二

最新语音信号处理实验报告实验二实验目的:本实验旨在通过实际操作加深对语音信号处理理论的理解,并掌握语音信号的基本处理技术。
通过实验,学习语音信号的采集、分析、滤波、特征提取等关键技术,并探索语音信号处理在实际应用中的潜力。
实验内容:1. 语音信号采集:使用语音采集设备录制一段时长约为10秒的语音样本,确保录音环境安静,语音清晰。
2. 语音信号预处理:对采集到的语音信号进行预处理,包括去噪、归一化等操作,以提高后续处理的准确性。
3. 语音信号分析:利用傅里叶变换等方法分析语音信号的频谱特性,观察并记录基频、谐波等特征。
4. 语音信号滤波:设计并实现一个带通滤波器,用于提取语音信号中的特定频率成分,去除噪声和非目标频率成分。
5. 特征提取:从处理后的语音信号中提取关键特征,如梅尔频率倒谱系数(MFCC)等,为后续的语音识别或分类任务做准备。
6. 实验总结:根据实验结果,撰写实验报告,总结语音信号处理的关键技术和实验中遇到的问题及其解决方案。
实验设备与工具:- 计算机一台,安装有语音信号处理相关软件(如Audacity、MATLAB 等)。
- 麦克风:用于采集语音信号。
- 耳机:用于监听和校正采集到的语音信号。
实验步骤:1. 打开语音采集软件,调整麦克风输入设置,确保录音质量。
2. 录制语音样本,注意控制语速和音量,避免过大或过小。
3. 使用语音分析软件打开录制的语音文件,进行频谱分析,记录观察结果。
4. 设计带通滤波器,设置合适的截止频率,对语音信号进行滤波处理。
5. 应用特征提取算法,获取语音信号的特征向量。
6. 分析滤波和特征提取后的结果,评估处理效果。
实验结果与讨论:- 描述语音信号在预处理、滤波和特征提取后的变化情况。
- 分析实验中遇到的问题,如噪声去除不彻底、频率成分丢失等,并提出可能的改进措施。
- 探讨实验结果对语音识别、语音合成等领域的潜在应用价值。
结论:通过本次实验,我们成功实现了语音信号的基本处理流程,包括采集、预处理、分析、滤波和特征提取。
语音信号处理实验报告一 ch

实验报告课程名称语音信号处理实验名称语音信号的时域特征与频域特征实验仪器系别光电学院专业电子信息工程班级电信0904 姓名陈为驰 2008010597 实验日期指导老师成绩实验一:语音信号的时域特征与频域特征实验项目:语音信号的时域特征与频域特征实验项目性质:验证性实验课程:《语音信号处理》计划学时:4学时一、实验目的使学生通过本实验观察语音信号在时域和频域的基本特征(语音波形、基音频率、过零数、共振峰),验证教材中关于语音信号在时域和频域的基本特征的概念与论述;通过采集语音数据与在实验中记录每个元音的基音周期、过零数、共振峰等环节熟悉这些语音的基本特征,为今后深入学习语音信号处理奠定基础。
二、实验内容学习音频编辑软件Cool Edit的使用方法及语音文件的建立;采集语音数据;观察语音波形;记录每个元音的基音周期(其倒数为基音频率)、过零数、共振峰;观察语音频域特征;分析不同元音的共振峰模式的特点(频率、相对振幅)。
三、实验原理元音与辅音在发音方法有如下基本区别:发元音时气流顺利通过声腔,声带颤动,形成的声波是周期性的;发辅音时气流暂时被阻不能通过或只能勉强挤出去。
元音具有基音与共振峰结构,辅音则不具有这两者。
基音由声带振动频率产生,决定语音的音高、音调。
在语音波形中表现为准周期峰值。
共振峰是语音频谱上的强频区,表现为频谱上呈峰状。
共振峰由声腔形状的变化决定,不同的声腔形状有不同的固有频率,产生不同的共振峰模式。
每个元音有特定的共振峰模式。
四、实验方法与实验步骤(一)音频编辑软件Cool Edit的使用方法及语音文件的建立①点击桌面上“cool edit”图标,选不同项可激活cool edit菜单中不同功能。
②点击“file”菜单中的“new”,设抽样频率为8KHz,单声道“mono”,“8 bit”。
②点击“Record”录音,将录音存成“.wav”文件。
③点击菜单中“View”中的“Spectral View”可观看语谱图。
语音信号处理实验报告

一、实验目的1. 理解语音信号处理的基本原理和流程。
2. 掌握语音信号的采集、预处理、特征提取和识别等关键技术。
3. 提高实际操作能力,运用所学知识解决实际问题。
二、实验原理语音信号处理是指对语音信号进行采集、预处理、特征提取、识别和合成等操作,使其能够应用于语音识别、语音合成、语音增强、语音编码等领域。
实验主要包括以下步骤:1. 语音信号的采集:使用麦克风等设备采集语音信号,并将其转换为数字信号。
2. 语音信号的预处理:对采集到的语音信号进行降噪、去噪、归一化等操作,提高信号质量。
3. 语音信号的特征提取:提取语音信号中的关键特征,如频率、幅度、倒谱等,为后续处理提供依据。
4. 语音信号的识别:根据提取的特征,使用语音识别算法对语音信号进行识别。
5. 语音信号的合成:根据识别结果,合成相应的语音信号。
三、实验步骤1. 语音信号的采集使用麦克风采集一段语音信号,并将其保存为.wav文件。
2. 语音信号的预处理使用MATLAB软件对采集到的语音信号进行预处理,包括:(1)降噪:使用谱减法、噪声抑制等算法对语音信号进行降噪。
(2)去噪:去除语音信号中的杂音、干扰等。
(3)归一化:将语音信号的幅度归一化到相同的水平。
3. 语音信号的特征提取使用MATLAB软件对预处理后的语音信号进行特征提取,包括:(1)频率分析:计算语音信号的频谱,提取频率特征。
(2)幅度分析:计算语音信号的幅度,提取幅度特征。
(3)倒谱分析:计算语音信号的倒谱,提取倒谱特征。
4. 语音信号的识别使用MATLAB软件中的语音识别工具箱,对提取的特征进行识别,识别结果如下:(1)将语音信号分为浊音和清音。
(2)识别语音信号的音素和音节。
5. 语音信号的合成根据识别结果,使用MATLAB软件中的语音合成工具箱,合成相应的语音信号。
四、实验结果与分析1. 语音信号的采集采集到的语音信号如图1所示。
图1 语音信号的波形图2. 语音信号的预处理预处理后的语音信号如图2所示。
语音信号处理实验报告

实验报告一、 实验目的、要求(1)掌握语音信号采集的方法(2)掌握一种语音信号基音周期提取方法(3)掌握短时过零率计算方法(4)了解Matlab 的编程方法二、 实验原理基本概念:(a )短时过零率:短时内, 信号跨越横轴的情况, 对于连续信号, 观察语音时域波形通过横轴的情况;对于离散信号, 相邻的采样值具有不同的代数符号, 也就是样点改变符号的次数。
对于语音信号, 是宽带非平稳信号, 应考察其短时平均过零率。
其中sgn[.]为符号函数⎪⎩⎪⎨⎧<=>=0 x(n)-1sgn(x(n))0 x(n)1sgn(x(n))短时平均过零的作用1.区分清/浊音:浊音平均过零率低, 集中在低频端;清音平均过零率高, 集中在高频端。
2.从背景噪声中找出是否有语音, 以及语音的起点。
(b )基音周期基音是发浊音时声带震动所引起的周期性, 而基音周期是指声带震动频率的倒数。
基音周期是语音信号的重要的参数之一, 它描述语音激励源的一个重要特征, 基音周期信息在多个领域有着广泛的应用, 如语音识别、说话人识别、语音分析与综合以及低码率语音编码, 发音系统疾病诊断、听觉残障者的语音指导等。
因为汉语是一种有调语言, 基音的变化模式称为声调, 它携带着非常重要的具有辨意作用的信息, 有区别意义的功能, 所以, 基音的提取和估计对汉语更是一个十分重要的问题。
由于人的声道的易变性及其声道持征的因人而异, 而基音周期的范围又很宽, 而同—个人在不同情态下发音的基音周期也不同, 加之基音周期还受到单词∑--=-=10)]1(sgn[)](sgn[21N m n n n m x m x Z发音音调的影响, 因而基音周期的精确检测实际上是一件比较困难的事情。
基音提取的主要困难反映在: ①声门激励信号并不是一个完全周期的序列, 在语音的头、尾部并不具有声带振动那样的周期性, 有些清音和浊音的过渡帧是很难准确地判断是周期性还是非周期性的。
语音信号_实验报告

一、实验目的1. 理解语音信号的基本特性及其在数字信号处理中的应用。
2. 掌握语音信号的采样、量化、编码等基本处理方法。
3. 学习语音信号的时域、频域分析技术。
4. 熟悉语音信号的增强、降噪等处理方法。
二、实验原理语音信号是一种非平稳信号,其特性随时间变化。
在数字信号处理中,我们通常采用采样、量化、编码等方法将语音信号转换为数字信号,以便于后续处理和分析。
三、实验内容1. 语音信号的采集与预处理- 使用麦克风采集一段语音信号。
- 对采集到的语音信号进行预加重处理,提高高频成分的幅度。
- 对预加重后的语音信号进行采样,采样频率为8kHz。
2. 语音信号的时域分析- 画出语音信号的时域波形图。
- 计算语音信号的短时能量和短时平均过零率,分析语音信号的时域特性。
3. 语音信号的频域分析- 对语音信号进行快速傅里叶变换(FFT)分析,得到其频谱图。
- 分析语音信号的频谱特性,提取关键频段。
4. 语音信号的增强与降噪- 在语音信号中加入噪声,模拟实际应用场景。
- 使用谱减法对加噪语音信号进行降噪处理。
- 对降噪后的语音信号进行主观评价,比较降噪效果。
5. 语音信号的回放与对比- 对原始语音信号和降噪后的语音信号进行回放。
- 对比分析两种语音信号的时域波形、频谱图和听觉效果。
四、实验步骤1. 采集语音信号- 使用麦克风采集一段时长为5秒的语音信号。
- 将采集到的语音信号保存为.wav格式。
2. 预处理- 使用Matlab中的preemphasis函数对采集到的语音信号进行预加重处理。
- 设置预加重系数为0.97。
3. 时域分析- 使用Matlab中的plot函数画出语音信号的时域波形图。
- 使用Matlab中的energy和zero crossing rate函数计算语音信号的短时能量和短时平均过零率。
4. 频域分析- 使用Matlab中的fft函数对语音信号进行FFT变换。
- 使用Matlab中的plot函数画出语音信号的频谱图。
语音信号处理实验报告.doc

语音信号处理实验班级:学号:姓名:实验一基于MATLAB的语音信号时域特征分析(2 学时)1)短时能量( 1)加矩形窗a=wavread('mike.wav');a=a(:,1);subplot(6,1,1),plot(a);N=32;for i=2:6h=linspace(1,1,2.^(i-2)*N);%形成一个矩形窗,长度为 2.^(i-2)*NEn=conv(h,a.*a);% 求短时能量函数Ensubplot(6,1,i),plot(En);if(i==2) ,legend('N=32' );elseif(i==3), legend('N=64' );elseif(i==4) ,legend('N=128' );elseif(i==5) ,legend('N=256' );elseif(i==6) ,legend('N=512' );endend1-10.5 1 1.5 2 2.54 x 102N=32 0 0.5 1 1.5 2 2.55 x 10N=64 0 0.5 1 1.5 2 2.510 x 1050.5 1 1.5 2 2.5 N=128 020 x 10100.5 1 1.5 2 2.5 N=256 040 x 1020N=5120 0.5 1 1.5 2 2.5x 10( 2)加汉明窗a=wavread('mike.wav');a=a(:,1);subplot(6,1,1),plot(a);N=32; 3 43 43 43 43 43 4for i=2:6h=hanning(2.^(i-2)*N);% 形成一个汉明窗,长度为 2.^(i-2)*NEn=conv(h,a.*a);% 求短时能量函数Ensubplot(6,1,i),plot(En);if(i==2), legend('N=32' );elseif(i==3), legend('N=64' );elseif(i==4) ,legend('N=128' );elseif(i==5) ,legend('N=256' );elseif(i==6) ,legend('N=512' );endend1-10.5 1 1.5 2 2.52 x 101N=32 0 0.5 1 1.5 2 2.54 x 102N=64 0 0.5 1 1.5 2 2.54 x 102N=128 0 0.5 1 1.5 2 2.510 x 105N=256 0 0.5 1 1.5 2 2.520 x 1010N=5120 0.5 1 1.5 2 2.5x 102)短时平均过零率a=wavread('mike.wav');a=a(:,1);n=length(a);N=320;subplot(3,1,1),plot(a);h=linspace(1,1,N);En=conv(h,a.*a); %求卷积得其短时能量函数Ensubplot(3,1,2),plot(En);for i=1:n-1if a(i)>=0 3 43 43 43 43 43 4elseb(i) = -1;endif a(i+1)>=0b(i+1)=1;elseb(i+1)= -1;endw(i)=abs(b(i+1)-b(i)); %求出每相邻两点符号的差值的绝对值endk=1;j=0;while (k+N-1)<nZm(k)=0;for i=0:N-1;Zm(k)=Zm(k)+w(k+i);endj=j+1;k=k+N/2; % 每次移动半个窗endfor w=1:jQ(w)=Zm(160*(w-1)+1)/(2*N); %短时平均过零率endsubplot(3,1,3),plot(Q),grid;1-100.51 1.52 2.5 34x 10201000.51 1.52 2.5 34x 100.50204060801001201401601803)自相关函数N=240y=wavread('mike.wav');y=y(:,1);x=y(13271:13510);x=x.*rectwin(240);R=zeros(1,240);for k=1:240for n=1:240-kR(k)=R(k)+x(n)*x(n+k);endendj=1:240;plot(j,R);grid;2.521.510.5-0.5-1-1.5050100150200250实验二基于 MATLAB 分析语音信号频域特征1)短时谱cleara=wavread('mike.wav');a=a(:,1);subplot(2,1,1),plot(a);title('original signal');gridN=256;h=hamming(N);for m=1:Nb(m)=a(m)*h(m)endy=20*log(abs(fft(b)))subplot(2,1,2)plot(y);title('短时谱 ');gridoriginal signal10.5-0.5-100.51 1.52 2.5 34x 10短时谱10.500.20.40.60.81 1.2 1.4 1.6 1.8 22)语谱图[x,fs,nbits]=wavread('mike.wav')x=x(:,1);specgram(x,512,fs,100);xlabel('时间 (s)');ylabel('频率 (Hz)' );title('语谱图 ');语谱图50004000)zH3000(率频200010000.51 1.5 2时间 (s) 3)倒谱和复倒谱(1)加矩形窗时的倒谱和复倒谱cleara=wavread('mike.wav',[4000,4350]);a=a(:,1);N=300;h=linspace(1,1,N);for m=1:Nb(m)=a(m)*h(m);endc=cceps(b);c=fftshift(c);d=rceps(b);d=fftshift(d);subplot(2,1,1)plot(d);title( '加矩形窗时的倒谱')subplot(2,1,2)plot(c);title( '加矩形窗时的复倒谱')加矩形窗时的倒谱1-1-2050100150200250300加矩形窗时的复倒谱105-5-10050100150200250300(2)加汉明窗时的倒谱和复倒谱 cleara=wavread('mike.wav',[4000,4350]);a=a(;,1);N=300;h=hamming(N);for m=1:Nb(m)=a(m)*h(m);endc=cceps(b);c=fftshift(c);d=rceps(b);d=fftshift(d);subplot(2,1,1)plot(d);title( '加汉明窗时的倒谱')subplot(2,1,2)plot(c);title( '加汉明窗时的复倒谱')加汉明窗时的倒谱1-1-2-3050100150200250300加汉明窗时的复倒谱105-5-10050100150200250300实验三基于 MATLAB 的 LPC 分析MusicSource = wavread('mike.wav');MusicSource=MusicSource(:,1);Music_source = MusicSource';N = 256; % window length, N = 100 -- 1000;Hamm = hamming(N); % create Hamming windowframe = input( '请键入想要处理的帧位置= ' );% origin is current frameorigin = Music_source(((frame - 1) * (N / 2) + 1):((frame - 1) * (N / 2) + N));Frame = origin .* Hamm';%%Short Time Fourier Transform%[s1,f1,t1] = specgram(MusicSource,N,N/2,N);[Xs1,Ys1] = size(s1);for i = 1:Xs1FTframe1(i) = s1(i,frame);endN1 = input( '请键入预测器阶数= ' ); % N1 is predictor's order[coef,gain] = lpc(Frame,N1); % LPC analysis using Levinson-Durbin recursionest_Frame = filter([0 -coef(2:end)],1,Frame); % estimate frame(LP)FFT_est = fft(est_Frame);err = Frame - est_Frame; % error% FFT_err = fft(err);subplot(2,1,1),plot(1:N,Frame,1:N,est_Frame,'-r');grid;title('原始语音帧 vs.预测后语音帧 ')subplot(2,1,2),plot(err);grid;title('误差 ');pause%subplot(2,1,2),plot(f',20*log(abs(FTframe2)));grid;title('短时谱 ')%%Gain solution using G^2 = Rn(0) - sum(ai*Rn(i)),i = 1,2,...,P%fLength(1 : 2 * N) = [origin,zeros(1,N)];Xm = fft(fLength,2 * N);X = Xm .* conj(Xm);Y = fft(X , 2 * N);Rk = Y(1 : N);PART = sum(coef(2 : N1 + 1) .* Rk(1 : N1));G = sqrt(sum(Frame.^2) - PART);A = (FTframe1 - FFT_est(1 : length(f1'))) ./ FTframe1 ; % inverse filter A(Z)subplot(2,1,1),plot(f1',20*log(abs(FTframe1)),f1',(20*log(abs(1 ./ A))),'-r');grid;title('短时谱 ');subplot(2,1,2),plot(f1',(20*log(abs(G ./ A))));grid;title( 'LPC谱 ');pause%plot(abs(ifft(FTframe1 ./ (G ./ A))));grid;title('excited')%plot(f1',20*log(abs(FFT_est(1 : length(f1')) .* A / G )));grid;%pause%%find_pitch%temp = FTframe1 - FFT_est(1 : length(f1'));%not move higher frequncepitch1 = log(abs(temp));pLength = length(pitch1);result1 = ifft(pitch1,N);% move higher frequncepitch1((pLength - 32) : pLength) = 0;result2 = ifft(pitch1,N);%direct do real cepstrum with errpitch = fftshift(rceps(err));origin_pitch = fftshift(rceps(Frame));subplot(211),plot(origin_pitch);grid;title( '原始语音帧倒谱 (直接调用函数 )');subplot(212),plot(pitch);grid;title( '预测误差倒谱 (直接调用函数 )');pausesubplot(211),plot(1:length(result1),fftshift(real(result1)));grid;title('预测误差倒谱 (根据定义编写,没有去除高频分量)');subplot(212),plot(1:length(result2),fftshift(real(result2)));grid;title('预测误差倒谱 (根据定义编写,去除高频分量 )');原始语音帧 vs. 预测后语音帧0.40.2-0.2-0.4050100150200250300误差0.20.1-0.1-0.2050100150200250300短时谱50-50-100010203040506070LPC 谱100806040010203040506070原始语音帧倒谱(直接调用函数)0.5-0.5-1050100150200250300预测误差倒谱(直接调用函数)0.5-0.5-1050100150200250300预测误差倒谱(根据定义编写,没有去除高频分量)0.2-0.2-0.4-0.6050100150200250300预测误差倒谱(根据定义编写,去除高频分量)0.1-0.1-0.2-0.3050100150200250300预测误差倒谱(根据定义编写,没有去除高频分量)0.2-0.2-0.4-0.6050100150200250300预测误差倒谱(根据定义编写,去除高频分量)0.1-0.1-0.2-0.3050100150200250300预测误差倒谱(根据定义编写,没有去除高频分量)0.2-0.2-0.4-0.6050100150200250300预测误差倒谱(根据定义编写,去除高频分量)0.1-0.1-0.2-0.3050100150200250300实验四基于 VQ 的特定人孤立词语音识别研究1、mfcc.mfunction ccc = mfcc(x)bank=melbankm(24,256,8000,0,0.5,'m' );bank=full(bank);bank=bank/max(bank(:));for k=1:12n=0:23;dctcoef(k,:)=cos((2*n+1)*k*pi/(2*24));endw = 1 + 6 * sin(pi * [1:12] ./ 12);w = w/max(w);xx=double(x);xx=filter([1 -0.9375],1,xx);xx=enframe(xx,256,80);for i=1:size(xx,1)y = xx(i,:);s = y' .* hamming(256);t = abs(fft(s));t = t.^2;c1=dctcoef * log(bank * t(1:129));c2 = c1.*w';m(i,:)=c2';enddtm = zeros(size(m));for i=3:size(m,1)-2dtm(i,:) = -2*m(i-2,:) - m(i-1,:) + m(i+1,:) + 2*m(i+2,:);enddtm = dtm / 3;ccc = [m dtm];ccc = ccc(3:size(m,1)-2,:);2、vad.mfunction [x1,x2] = vad(x)x = double(x);x = x / max(abs(x));FrameLen = 240;FrameInc = 80;amp1 = 10;amp2 = 2;zcr1 = 10;zcr2 = 5;maxsilence = 8; % 6*10ms = 30msminlen = 15; % 15*10ms = 150msstatus = 0;count = 0;silence = 0;tmp1 = enframe(x(1:end-1), FrameLen, FrameInc);tmp2 = enframe(x(2:end) , FrameLen, FrameInc);signs = (tmp1.*tmp2)<0;diffs = (tmp1 -tmp2)>0.02;zcr = sum(signs.*diffs, 2);amp = sum(abs(enframe(filter([1 -0.9375], 1, x), FrameLen, FrameInc)), 2); amp1 = min(amp1, max(amp)/4);amp2 = min(amp2, max(amp)/8);x1 = 0;x2 = 0;for n=1:length(zcr)goto = 0;switch statuscase {0,1}if amp(n) > amp1x1 = max(n-count-1,1);status = 2;silence = 0;count= count + 1;elseif amp(n) > amp2 | ...zcr(n) > zcr2status = 1;count = count + 1;elsestatus = 0;count= 0;endcase 2,if amp(n) > amp2 | ...zcr(n) > zcr2count = count + 1;elsesilence = silence+1;if silence < maxsilence count = count + 1;elseif count < minlenstatus = 0;silence = 0;count= 0;elsestatus = 3;endendcase 3,break;endendcount = count-silence/2;x2 = x1 + count -1;3、codebook.m%clear;function xchushi= codebook(m) [a,b]=size(m);[m1,m2]=szhixin(m);[m3,m4]=szhixin(m2);[m1,m2]=szhixin(m1);[m7,m8]=szhixin(m4);[m5,m6]=szhixin(m3);[m3,m4]=szhixin(m2);[m1,m2]=szhixin(m1);[m15,m16]=szhixin(m8);[m13,m14]=szhixin(m7);[m11,m12]=szhixin(m6);[m9,m10]=szhixin(m5);[m7,m8]=szhixin(m4);[m5,m6]=szhixin(m3);[m3,m4]=szhixin(m2);[m1,m2]=szhixin(m1);chushi(1,:)=zhixinf(m1);chushi(2,:)=zhixinf(m2);chushi(3,:)=zhixinf(m3);chushi(4,:)=zhixinf(m4);chushi(5,:)=zhixinf(m5);chushi(6,:)=zhixinf(m6);chushi(7,:)=zhixinf(m7);chushi(8,:)=zhixinf(m8);chushi(9,:)=zhixinf(m9);chushi(10,:)=zhixinf(m10);chushi(11,:)=zhixinf(m11);chushi(12,:)=zhixinf(m12);chushi(13,:)=zhixinf(m13);chushi(14,:)=zhixinf(m14);chushi(15,:)=zhixinf(m15);chushi(16,:)=zhixinf(m16);sumd=zeros(1,1000);k=1;dela=1;xchushi=chushi;while(k<=1000)sum=ones(1,16);for p=1:afor i=1:16d(i)=odistan(m(p,:),chushi(i,:));enddmin=min(d);sumd(k)=sumd(k)+dmin;for i=1:16if d(i)==dminxchushi(i,:)=xchushi(i,:)+m(p,:);sum(i)=sum(i)+1;endendendfor i=1:16xchushi(i,:)=xchushi(i,:)/sum(i); endif k>1dela=abs(sumd(k)-sumd(k-1))/sumd(k); endk=k+1;chushi=xchushi;endreturn4、 testvq.mclear;disp('这是一个简易语音识别系统,请保证已经将您的语音保存在相应文件夹中') disp('正在训练您的语音模版指令,请稍后...')for i=1:10fname = sprintf(海儿的声音\\%da.wav' ,i-1);x = wavread(fname);[x1 x2] = vad(x);m = mfcc(x);m = m(x1:x2-5,:);ref(i).code=codebook(m);enddisp('语音指令训练成功,恭喜!)?'disp('正在测试您的测试语音指令,请稍后...')for i=1:10fname = sprintf(海儿的声音\\%db.wav' ,i-1);x = wavread(fname);[x1 x2] = vad(x);mn = mfcc(x);mn = mn(x1:x2-5,:);%mn = mn(x1:x2,:)test(i).mfcc = mn;endsumsumdmax=0;sumsumdmin=0;disp('对训练过的语音进行测试')for w=1:10sumd=zeros(1,10);[a,b]=size(test(w).mfcc);for i=1:10for p=1:afor j=1:16d(j)=odistan(test(w).mfcc(p,:),ref(i).code(j,:));enddmin=min(d);sumd(i)=sumd(i)+dmin; %×üê§??endendsumdmin=min(sumd)/a;sumdmin1=min(sumd);sumdmax(w)=max(sumd)/a;sumsumdmin=sumdmin+sumsumdmax;sumsumdmax=sumdmax(w)+sumsumdmax;disp('正在匹配您的语音指令,请稍后...')for i=1:10if (sumd(i)==sumdmin1)switch (i)case 1fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'前 ', '前 ');case2fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'后 ', '后 ');case3fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'左 ', '左 ');case4fprintf( '您输入的语音指令为a:%s;识别结果为 %s\n' ,'右 ', '右 ');case5fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'东 ', '东 ');case6fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'南 ', '南 ');case7fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'西 ', '西 ');case8fprintf( '您输入的语音指令为:%s; 识别结果为 %s\n' ,'北 ', '北 ');case9fprintf( '您输入的语音指令为a:%s;识别结果为 %s\n' ,'上 ', '上 ');case10fprintf( '您输入的语音指令为a:%s;识别结果为 %s\n' ,'下 ', '下 ');otherwisefprintf( 'error');endendendenddelamin=sumsumdmin/10;delamax=sumsumdmax/10;disp('对没有训练过的语音进行测试')disp('正在测试你的语音,请稍后...')for i=1:10fname = sprintf(o£ ?ùμ ?éùò?\\%db.wav' ,i-1);x = wavread(fname);[x1 x2] = vad(x);mn = mfcc(x);mn = mn(x1:x2-5,:);%mn = mn(x1:x2,:)test(i).mfcc = mn;endfor w=1:10sumd=zeros(1,10);[a,b]=size(test(w).mfcc);for i=1:10for p=1:afor j=1:16d(j)=odistan(test(w).mfcc(p,:),ref(i).code(j,:));enddmin=min(d);sumd(i)=sumd(i)+dmin; %×üê§??endendsumdmin=min(sumd);z=0;for i=1:10if (((sumd(i))/a)>delamax)||z=z+1;endenddisp('正在匹配您的语音指令,请稍后...')if z<=3for i=1:10if (sumd(i)==sumdmin)switch (i)case 1fprintf( '您输入的语音指令为:%s; 识别结果为%s\n' ,'前 ', '前 ');case2fprintf( '您输入的语音指令为 :%s; 识别结果为 %s\n' ,'后 ', '后 ');case3fprintf( '您输入的语音指令为 :%s; 识别结果为 %s\n' ,'左 ', '左 ');case4fprintf( '您输入的语音指令为a:%s;识别结果为%s\n' ,'右 ', '右 ');case5fprintf( '您输入的语音指令为:%s; 识别结果为%s\n' ,'东 ', '东 ');case6fprintf( '您输入的语音指令为:%s; 识别结果为%s\n' ,'南 ', '南 ');case7fprintf( '您输入的语音指令为:%s; 识别结果为%s\n' ,'西 ', '西 ');case8fprintf( '您输入的语音指令为 :%s; 识别结果为 %s\n' ,'北 ', '北 ');case9fprintf( '您输入的语音指令为a:%s;识别结果为%s\n' ,'上 ', '上 ');case10fprintf( '您输入的语音指令为a:%s;识别结果为%s\n' ,'下 ', '下 ');otherwisefprintf( 'error');endendendelsefprintf( '您输入的语音无效?\n'£)?endend(此文档部分内容来源于网络,如有侵权请告知删除,文档可自行编辑修改内容,供参考,感谢您的配合和支持)。
语音信号处理实验报告

语音信号处理实验报告 The Standardization Office was revised on the afternoon of December 13, 2020语音信号处理实验报告——语音信号分析实验一.实验目的及原理语音信号分析是语音信号处理的前提和基础,只有分析出可表示语音信号本质特征的参数,才有可能利用这些参数进行高效的语音通信、语音合成和语音识别等处理,并且语音合成的音质好坏和语音识别率的高低,都取决于对语音信号分析的准确性和精确性。
贯穿语音分析全过程的是“短时分析技术”。
因为从整体来看,语音信号的特性及表征其本质特征的参数均是随时间变化的,所以它是一个非平稳态过程,但是在一个短时间范围内(一般认为在10~30ms的时间内),其特性基本保持不变,即相对稳定,可将其看做一个准稳态过程,即语音信号具有短时平稳性。
所以要将语音信号分帧来分析其特征参数,帧长一般取为10ms~30ms。
二.实验过程男声及女声(蓝色为时域信号,红色为每一帧的能量,绿色为每一帧的过零率)某一帧的自相关函数3.频域分析①一帧信号的倒谱分析和FFT及LPC分析②男声和女声的倒谱分析对应的倒谱系数:,,……对应的LPC预测系数:1,,,,,……原语音波形一帧语音波形一帧语音的倒谱③浊音和清音的倒谱分析④浊音和清音的FFT分析和LPC分析(红色为FFT图像,绿色为LPC图像)三.实验结果分析1.时域分析实验中采用的是汉明窗,窗的长度对能否由短时能量反应语音信号的变化起着决定性影响。
这里窗长合适,En能够反应语音信号幅度变化。
同时,从图像可以看出,En可以作为区分浊音和清音的特征参数。
短时过零率表示一帧语音中语音信号波形穿过横轴(零电平)的次数。
从图中可以看出,短时能量和过零率可以近似为互补的情况,短时能量大的地方过零率小,短时能量小的地方过零率较大。
从浊音和清音的时域分析可以看出,清音过零率高,浊音过零率低。
从男声女声的时域信号对比图中可以看出,女音信号在高频率分布得更多,女声信号在高频段的能量分布更多,并且女声有较高的过零率,这是因为语音信号中的高频段有较高的过零率。
语音信号实验报告

一、实验目的1. 理解语音信号的基本特性和处理方法。
2. 掌握语音信号的采样、量化、编码等基本过程。
3. 学习使用相关软件对语音信号进行时域和频域分析。
4. 了解语音信号的降噪、增强和合成技术。
二、实验原理语音信号是一种非平稳的、时变的信号,其频谱特性随时间变化。
语音信号处理的基本过程包括:信号采集、信号处理、信号分析和信号输出。
三、实验仪器与软件1. 仪器:计算机、麦克风、耳机。
2. 软件:Matlab、Audacity、Python。
四、实验步骤1. 信号采集使用麦克风采集一段语音信号,并将其存储为.wav格式。
2. 信号处理(1)使用Matlab读取.wav文件,提取语音信号的采样频率、采样长度和采样数据。
(2)将语音信号进行时域分析,包括绘制时域波形图、计算信号的能量和过零率等。
(3)将语音信号进行频域分析,包括绘制频谱图、计算信号的功率谱密度等。
3. 信号分析(1)观察时域波形图,分析语音信号的幅度、频率和相位特性。
(2)观察频谱图,分析语音信号的频谱分布和能量分布。
(3)计算语音信号的能量和过零率,分析语音信号的语音强度和语音质量。
4. 信号输出(1)使用Audacity软件对语音信号进行降噪处理,比较降噪前后的效果。
(2)使用Python软件对语音信号进行增强处理,比较增强前后的效果。
(3)使用Matlab软件对语音信号进行合成处理,比较合成前后的效果。
五、实验结果与分析1. 时域分析从时域波形图可以看出,语音信号的幅度、频率和相位特性随时间变化。
语音信号的幅度较大,频率范围一般在300Hz~3400Hz之间,相位变化较为复杂。
2. 频域分析从频谱图可以看出,语音信号的能量主要集中在300Hz~3400Hz范围内,频率成分较为丰富。
3. 信号处理(1)降噪处理:通过对比降噪前后的时域波形图和频谱图,可以看出降噪处理可以显著降低语音信号的噪声,提高语音质量。
(2)增强处理:通过对比增强前后的时域波形图和频谱图,可以看出增强处理可以显著提高语音信号的幅度和频率,改善语音清晰度。
语音信号处理实验报告

语音信号处理实验报告语音信号处理实验报告一、引言语音信号处理是一门研究如何对语音信号进行分析、合成和改善的学科。
在现代通信领域中,语音信号处理起着重要的作用。
本实验旨在探究语音信号处理的基本原理和方法,并通过实验验证其有效性。
二、实验目的1. 了解语音信号处理的基本概念和原理。
2. 学习使用MATLAB软件进行语音信号处理实验。
3. 掌握语音信号的分析、合成和改善方法。
三、实验设备和方法1. 设备:计算机、MATLAB软件。
2. 方法:通过MATLAB软件进行语音信号处理实验。
四、实验过程1. 语音信号的采集在实验开始前,我们首先需要采集一段语音信号作为实验的输入。
通过麦克风将语音信号输入计算机,并保存为.wav格式的文件。
2. 语音信号的预处理在进行语音信号处理之前,我们需要对采集到的语音信号进行预处理。
预处理包括去除噪声、归一化、去除静音等步骤,以提高后续处理的效果。
3. 语音信号的分析语音信号的分析是指对语音信号进行频谱分析、共振峰提取等操作。
通过分析语音信号的频谱特征,可以了解语音信号的频率分布情况,进而对语音信号进行进一步处理。
4. 语音信号的合成语音信号的合成是指根据分析得到的语音信号特征,通过合成算法生成新的语音信号。
合成算法可以基于传统的线性预测编码算法,也可以采用更先进的基于深度学习的合成方法。
5. 语音信号的改善语音信号的改善是指对语音信号进行降噪、增强等处理,以提高语音信号的质量和清晰度。
常用的语音信号改善方法包括时域滤波、频域滤波等。
六、实验结果与分析通过实验,我们得到了经过语音信号处理后的结果。
对于语音信号的分析,我们可以通过频谱图观察到不同频率成分的分布情况,从而了解语音信号的特点。
对于语音信号的合成,我们可以听到合成后的语音信号,并与原始语音信号进行对比。
对于语音信号的改善,我们可以通过降噪效果的评估来判断处理的效果。
七、实验总结通过本次实验,我们深入了解了语音信号处理的基本原理和方法,并通过实验验证了其有效性。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
语音信号处理实验报告——语音信号分析实验一.实验目的及原理
语音信号分析是语音信号处理的前提和基础,只有分析出可表示语音信号本质特征的参数,才有可能利用这些参数进行高效的语音通信、语音合成和语音识别等处理,并且语音合成的音质好坏和语音识别率的高低,都取决于对语音信号分析的准确性和精确性。
贯穿语音分析全过程的是“短时分析技术”。
因为从整体来看,语音信号的特性及表征其本质特征的参数均是随时间变化的,所以它是一个非平稳态过程,但是在一个短时间范围内(一般认为在10~30ms的时间内),其特性基本保持不变,即相对稳定,可将其看做一个准稳态过程,即语音信号具有短时平稳性。
所以要将语音信号分帧来分析其特征参数,帧长一般取为10ms~30ms。
二.实验过程
2.仿真结果
(1) 时域分析
男声及女声(蓝色为时域信号,红色为每一帧的能量,绿色为每一帧的过零率) 某一帧的自相关函数
3. 频域分析
①一帧信号的倒谱分析和FFT 及LPC 分析
-1
-0.500.51-50
050100150
-1
-0.500.51-40
-2002040
②男声和女声的倒谱分析
③浊音和清音的倒谱分析
④浊音和清音的FFT 分析和LPC 分析(红色为FFT 图像,绿色为LPC 图像)
三. 实验结果分析 1. 时域分析
实验中采用的是汉明窗,窗的长度对能否由短时能量反应语音信号的变
对应的倒谱系数:,,……
对应的LPC 预测系数:1,,,,,……
原语音
一帧语音波形
一帧语音的倒
化起着决定性影响。
这里窗长合适,En能够反应语音信号幅度变化。
同时,从图像可以看出,En可以作为区分浊音和清音的特征参数。
短时过零率表示一帧语音中语音信号波形穿过横轴(零电平)的次数。
从图中可以看出,短时能量和过零率可以近似为互补的情况,短时能量大的地方过零率小,短时能量小的地方过零率较大。
从浊音和清音的时域分析可以看出,清音过零率高,浊音过零率低。
从男声女声的时域信号对比图中可以看出,女音信号在高频率分布得更多,女声信号在高频段的能量分布更多,并且女声有较高的过零率,这是因为语音信号中的高频段有较高的过零率。
2.频域分析
这里对信号进行快速傅里叶变换(FFT),可以发现,当窗口函数不同,傅里叶变换的结果也不相同。
根据信号的时宽带宽之积为一常数这一性质,可以知道窗口宽度与主瓣宽度成反比,N越大,主瓣越窄。
汉明窗在频谱范围中的分辨率较高,而且旁瓣的衰减大,具有频谱泄露少的有点,所以在实验中采用的是具有较小上下冲的汉明窗。
为了使频域信号的频率分辨率较高,所取的DFT及相应的FFT点数应该足够多,但时域信号的长度受到采样率和和短时性的限制,这里可以采用补零的办法,对补零后的序列进行FFT变换。
从实验仿真图可以看出浊音的频率分布比清音高。
3.倒谱分析
通过实验可以发现,倒谱的基音检测与语音加窗的选择也是有关系的。
如果窗函数选择矩形窗,在许多情况下倒谱中的基音峰将变得不清晰,窗函
数选择汉明窗较为合理,可以发现,加汉明窗的倒谱基音峰较为突出。
在典型的浊音清音倒谱对比中,理论上浊音倒谱基音峰应比较突出,而清音不出现这种尖峰,只是在倒谱的低时域部分包含关于声道冲激响应的信息。
实验仿真的图形不是很理想。
4.线性预测分析
从实验中可以发现,LPC谱估计具有一个特点,在信号能量较大的区域即接近谱的峰值处,LPC谱和信号谱很接近;而在信号能量较低的区域即接近谱的谷底处,则相差比较大。
在浊音清音对比中,可以发现,对呈现谐波特征的浊音语音谱来说这个特点很明显,就是在谐波成分处LPC谱匹配信号谱的效果要远比谐波之间好得多。
在实验中,当P值增加到一定程度,预测平方误差的改善就不很明显了,而且会增加计算量,一般取为8~14,这里P取为10。
5.基音周期估计
①自互相关函数法
②短时平均幅度差法
③倒谱分析法
共偏移
92+32=124个偏移点
16000/124=
可以发现,上面三种方法计算得到的基音周期基本相同。