LZW编码算法matlab实现
LZW-编码详解

待编码的数据序列为“dacab”,信源中各符号出现的概 率依次为P(a)=0.4,P(b)=0.2,P(c)=0.2, P(d)=0.2。
数据序列中的各数据符号在区间[0, 1]内的间隔(赋 值范围)设定为:
a=[0, 0.4) b=[0.4, 0.6) c=[0.6, 0.8) d=[0.8, 1.0 ]
8)读入code=3H,解码完毕。
解码过程
行号
1 2 3 4 5 6 7 8
输入数据 code 2H 0H 0H 1H 6H 4H 6H 3H
新串
aa ab bb bba aab
输出结果 oldcode 生成新字 符及索引
a
0H
a
0H aa<4H>
b
1H ab<5H>
bb
6H bb<6H>
aa
4H bba<7H>
输出S1=“aa”在字串表中的索引4H,并在字符串表末尾
为S1+S2=“aab”添加索引8H,且S1= S2=“b”
序号 输入数据 S1+S2 输出结果 S1
生成新字符及索引
S2
1 NULL
NULL 2H
NULL
2a
a
a
3a
aa
0H
a
aa<4H>
4b
ab
0H
b
ab<5H>
5b
bb
1H
b
bb<6H>
6b
4)读入code=1H,输出“b”,然后将 oldcode=0H所对应的字符串“a”加上 code=1H对应的字符串的第一个字符”b”, 即”ab”添加到字典中,其索引为5H,同 时oldcode=code=1H
LZW编码算法matlab实现

LZW编码算法,尝试使用matlab计算%encoder LZW for matlab%yu 20170503clc;clear;close all;%初始字典dic = cell(512,1);for i = 1:256dic{i} = {num2str(i)};end%输入字符串a,按空格拆分成A,注意加1对应范围1~256 a = input('input:','s');a = deblank(a);A = regexp(a,'\s+','split');L = length(A);for j=1:LA{j} = num2str(str2num(A{j})+1);endA_t = A{1};%可识别序列B_t = 'test';%待验证词条d = 256;%字典指针b = 1;%输出指针B = cell(L,1);%输出初始output = ' ';%输出初始j=1;for j = 2:Lm=1;B_t =deblank([A_t,' ',A{j}]);%合成待验证词条while(m <= d)if strcmp(dic{m},B_t)A_t = B_t;breakelsem=m+1;endendwhile(m == d+1)d = d+1;dic{d} = B_t;q=1;for q=1:dif strcmp(dic{q},A_t)B{b} = num2str(q);b = b+1;endendA_t = A{j};endendfor q=1:d%处理最后一个序列输出if strcmp(dic{q},A_t)B{b} = num2str(q);b = b+1;endendfor n = 1:(b-1)B{n} =num2str(str2num(B{n})-1);output=deblank([output,' ',B{n}]);endoutput运算结果计算结果为39 39 126 126 256 258 260 259 257 126LZW解码算法,使用matlab计算%decoder LZW for matlab%yu 20170503clc;clear;close all;%初始字典dic = cell(512,1);for i = 1:256dic{i} = {num2str(i)};end%输入字符串a,按空格拆分成A,注意加1对应范围1~256 a = input('input:','s');a = deblank(a);A = regexp(a,'\s+','split');L = length(A);for j=1:LA{j} = num2str(str2num(A{j})+1);endB_t = A{1};%待验证词条d = 256;%字典指针b = 1;%输出指针B = cell(L,1);%输出初始output = ' ';%输出初始j=1;B{b} = char(dic{str2num(A{j})});b = b+1;for j = 2:LBB = char(dic{str2num(A{j})});B_d = regexp(BB,'\s+','split');%按空格拆分L_B = length(B_d);p=1;for p=1:L_BB{(b+p-1)} = B_d{p};m=1;B_t =deblank([char(B_t),' ',char(B_d{p})]);%合成待验证词条while(m <= d)if strcmp(dic{m},B_t)B_t = B_t;breakelsem=m+1;endendwhile(m == d+1)d = d+1;dic{d} = B_t;B_t = B_d{p};endendb = b+L_B;endfor n = 1:(b-L_B)B{n} = num2str(str2num(B{n})-1);output=deblank([output,' ',B{n}]); endoutput运算结果运算结果为39 39 126 126 39 39 126 126 39 39 126 126 39 39 126 126。
LZW编码与译码编程实现
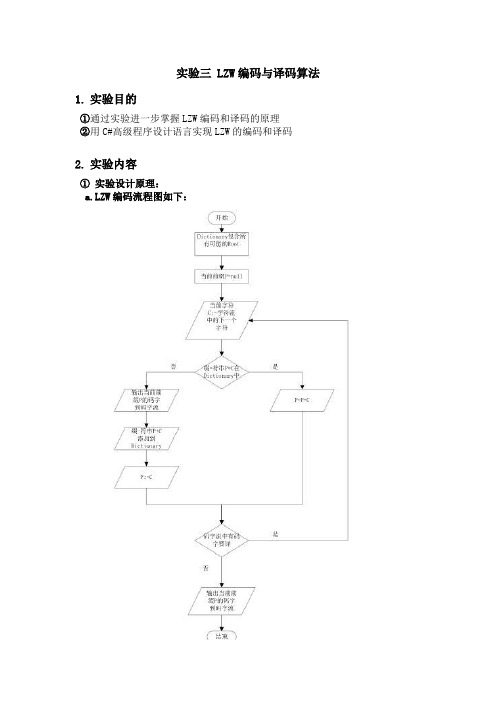
实验三 LZW编码与译码算法1.实验目的①通过实验进一步掌握LZW编码和译码的原理②用C#高级程序设计语言实现LZW的编码和译码2.实验内容①实验设计原理:a.LZW编码流程图如下:b.LZW译码流程图如下:②实验源代码:using System;using System.Collections.Generic; using System.Linq;using System.Text;using System.Threading.Tasks;namespace LZW{class Program{static void Main(string[] args){Encode();//编码Decode();//译码}public static void Encode()//编码函数{string Input = "ABBABABAC";//需要编码的字符流Console.WriteLine("编码前字符流:{0}",Input);Console.WriteLine();string P = null;//当前前缀P为空string X = null;int i = 0, j = 0, m = 3, n = 4, h = 0;string C = null;//当前字符Cstring[,] Dictionary=new string [9,2];//定义词典//词典初始化Dictionary[0,0]="1";Dictionary[0,1]="A";Dictionary[1,0]="2";Dictionary[1,1]="B";Dictionary[2,0]="3";Dictionary[2,1]="C";//LZW算法编码Console.Write("编码后码字流:");while (h<9){C = Input.ToCharArray()[h].ToString();X = P + C;for (i = 0; i < 9; i++){if (X.Equals(Dictionary[i, 1]))//缀-符串P+C在词典中{P = P + C;//P:=P+Cbreak;}}j = i;if (j >= 9)//缀-符串P+C不在词典中{for (i = 0; i < 9; i++){if (P.Equals(Dictionary[i, 1])){Console.Write(Dictionary[i, 0]);//把代表当前前缀P的码字输出到码字流Console.Write(" ");}}Dictionary[m, 0] = n.ToString();Dictionary[m, 1] = P + C;//把缀-符串P+C添加到词典P = C;//P:=Cm++;n++;}i = 0;j = 0;h++;}for (i = 0; i < 9; i++)//码字流中无码字要译{if (P.Equals(Dictionary[i, 1])){Console.Write(Dictionary[i, 0]);//把代表当前前缀P的码字输出到码字流Console.Write(" ");}}//输出DictionaryConsole.WriteLine();Console.WriteLine();Console.WriteLine("Dictionary如下:");for (i = 0; i < 9; i++, Console.WriteLine()){for (j = 0; j < 2; j++){Console.Write(Dictionary[i, j]);Console.Write(" ");}}}public static void Decode()//译码函数{string Output = "122473";//码字流string cW = null;//当前码字string pW = null;//先前码字string P = null;//当前前缀string C = null;//当前字符int i = 0, j = 0, h = 1, m = 3, n = 4;string[,] Dictionary = new string[20, 2];//定义词典//词典初始化Dictionary[0, 0] = "1";Dictionary[0, 1] = "A";Dictionary[1, 0] = "2";Dictionary[1, 1] = "B";Dictionary[2, 0] = "3";Dictionary[2, 1] = "C";Console.Write("解码后字符流:");cW = Output.ToCharArray()[0].ToString();//当前码字cW=码字流中的第一个码字Console.Write(Dictionary[int.Parse(cW) - 1, 1]);//输出当前缀-符串string.cW到字符流Console.Write(" ");while (h < 6){pW = cW;//先前码字=当前码字cW = Output.ToCharArray()[h].ToString();//当前码字递增for (i = 0; i < 9; i++){try{if (Dictionary[int.Parse(cW) - 1, 1].Equals(Dictionary[i, 1]))//当前缀-符串string.cW在词典中{Console.Write(Dictionary[int.Parse(cW) - 1, 1]);//当前缀-符串string.cW 输出到字符流Console.Write(" ");P = Dictionary[int.Parse(pW) - 1, 1];//当前前缀P:=先前缀-符串string.pWC = Dictionary[int.Parse(cW) - 1, 1].ToCharArray()[0].ToString();//当前字符C:=当前缀-符串string.cW的第一个字符Dictionary[m, 0] = n.ToString();Dictionary[m, 1] = P + C;//把缀-符串P+C添加到词典m++;n++;break;}}catch{continue;}}j = i;if (j >= 9)//当前缀-符串string.cW不在词典中{P = Dictionary[int.Parse(pW) - 1, 1];//当前前缀P:=先前缀-符串string.pWC = Dictionary[int.Parse(pW) - 1, 1].ToCharArray()[0].ToString();//当前字符C:=先前缀-符串string.pW的第一个字符Console.Write(P + C);//输出缀-符串P+C到字符流Console.Write(" ");Dictionary[m, 0] = n.ToString();Dictionary[m, 1] = P + C;//将缀-符串P+C添加到词典中m++;n++;}h++;i = 0;j = 0;}Console.WriteLine();Console.WriteLine();Console.WriteLine("Dictionary如下:");//输出词典for (i = 0; i < 9; i++,Console.WriteLine()){for (j = 0; j < 2; j++){Console.Write(Dictionary[i,j]);Console.Write(" ");}}}}}3.实验结果(截图)及分析①实验结果:②结果分析:由①中的实验结果可以看出,此次实验成功地对字符流ABBABABAC进行了编码和译码,并且在编码和译码过程中分别生成的Dictionary完全一致。
MATLAB中的数据的压缩与稀疏重建技术解析

MATLAB中的数据的压缩与稀疏重建技术解析引言随着数据量的快速增长和存储需求的提高,数据压缩和稀疏重建成为了一种非常重要的技术。
在MATLAB中,有许多强大的工具和技术可用于数据的压缩和稀疏重建。
本文将对MATLAB中的这些技术进行详细解析。
一、数据压缩1. 无损压缩无损压缩是指压缩后的数据可以完全恢复成原始数据,无任何失真。
MATLAB 中提供了多种无损压缩的方法,如Huffman编码、LZW压缩等。
这些方法通过统计数据中的频率分布来减少数据的冗余性,从而实现数据的压缩。
2. 有损压缩有损压缩是指在压缩数据的同时,对数据进行一定的损失,以减小数据的存储空间。
有损压缩在某些应用中具有重要的作用,如图像和音频压缩等。
在MATLAB中,我们可以使用一些经典的有损压缩算法,例如JPEG、MPEG等。
二、稀疏重建稀疏重建是指利用已知的部分采样数据,通过一定的算法或数学模型来估计原始信号的全部或部分。
在MATLAB中,有许多强大的稀疏重建技术可供使用。
1. 压缩感知压缩感知是一种新兴的稀疏重建技术,它基于信号的稀疏性假设,通过少量的测量来重建信号。
MATLAB中提供了一些方法来实现压缩感知,例如基于稀疏表示的信号重建算法。
2. 压缩采样匹配追踪压缩采样匹配追踪是另一种常用的稀疏重建方法。
它通过将信号表示为稀疏线性组合的方式,从而实现信号的重建。
在MATLAB中,我们可以使用OMP算法等方法来实现压缩采样匹配追踪。
3. 压缩感知重建的优化为了进一步提高压缩感知重建的性能,MATLAB中的优化方法也可以应用于该领域。
例如,我们可以使用凸优化算法,如最小二乘法、半正定规划等,来改进压缩感知重建的精度和速度。
三、案例研究为了进一步说明MATLAB中数据压缩与稀疏重建技术的应用,我们可以通过一个案例研究来进行分析。
假设我们有一个音频文件,需要对其进行压缩和稀疏重建。
我们可以使用MATLAB中的压缩感知算法来实现此目标。
Matlab函数实现哈夫曼编码算法

编写Matlab函数实现哈夫曼编码的算法一、设计目的和意义在当今信息化时代,数字信号充斥着各个角落。
在数字信号的处理和传输中,信源编码是首先遇到的问题,一个信源编码的好坏优劣直接影响到了后面的处理和传输。
如何无失真地编码,如何使编码的效率最高,成为了大家研究的对象。
哈夫曼编码就是其中的一种,哈夫曼编码是一种变长的编码方案。
它由最优二叉树既哈夫曼树得到编码,码元内容为到根结点的路径中与父结点的左右子树的标识。
所以哈夫曼在编码在数字通信中有着重要的意义。
可以根据信源符号的使用概率的高低来确定码元的长度。
既实现了信源的无失真地编码,又使得编码的效率最高。
二、设计原理哈夫曼编码(Huffman Coding)是一种编码方式,哈夫曼编码是可变字长编码(VLC)的一种。
uffman于1952年提出一种编码方法,该方法完全依据字符出现概率来构造异字头的平均长度最短的码字,有时称之为最佳编码,一般就叫作Huffman编码。
而哈夫曼编码的第一步工作就是构造哈夫曼树。
哈夫曼二叉树的构造方法原则如下,假设有n个权值,则构造出的哈夫曼树有n个叶子结点。
n 个权值分别设为w1、w2、…、wn,则哈夫曼树的构造规则为:(1) 将w1、w2、…,wn看成是有n 棵树的森林(每棵树仅有一个结点);(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;(3)从森林中删除选取的两棵树,并将新树加入森林;(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
具体过程如下图1产所示:(例)图1 哈夫曼树构建过程哈夫曼树构造成功后,就可以根据哈夫曼树对信源符号进行哈夫曼编码。
具体过程为先找到要编码符号在哈夫曼树中的位置,然后求该叶子节点到根节点的路径,其中节点的左孩子路径标识为0,右孩子路径标识为1,最后的表示路径的01编码既为该符号的哈夫曼编码。
LZ编码实验报告

信息论实验报告实验者:黎照益琛陈升富LZ编码一、实验目的1、通过实验进一步理解LZ编码原理和方法2、熟悉matlab编程和GUI界面的设计二、实验内容及步骤1、在“source.txt”文件中输入一段文字。
2、创建字典function [dictionary codelength]=LZcode(seq) l=length(seq);dictionary(1).sym=seq(1);k=2;index=0;str='';for i=2:lstr=[str seq(i)];for j=1:(k-1)index=0;if strcmp(dictionary(j).sym,str)index=1;break;endendif (index==0)dictionary(k).sym=str;k=k+1;str='';endendcodelength=fix(log2(k-1))+1;for i=1:(k-1)dictionary(i).code=dec2bin((i-1),codelength); endend3、进行编码function decode=LZdecode(dictionary)ld=length(dictionary);decode='';for i=1:lddecode=[decode dictionary(i).sym];endend4、进行解码function encode=LZencode(dictionary)ld=length(dictionary);encode='';for i=1:ldencode=[encode dictionary(i).code];endend5、建立GUI界面,将之前编好的函数与控件联系起来编码:display('Encoded Sequence : Look encode.txt.');enseq=LZencode(dictionary);fiden=fopen('encode.txt','w');en=fwrite(fiden,enseq);fclose(fiden);解码:display('Decoded Sequence : Look decode.txt.');deseq=LZdecode(dictionary);fidde=fopen('decode.txt','w');de=fwrite(fidde,deseq);fclose(fiden);三、实验结论1、GUI截图2、编码内容见decode.txt3、解码内容见encode.txt四.实验心得:通过本次试验,我掌握了LZ 编码的原理和方法,更重要的是掌握了MATLAB 图形界面GUI 的使用方法。
lzw编码实验报告

实验报告(一)——LZW编码的C++编程实现时间:2011.4.27一、实验目的及要求使用C++编程实现LZW编码、解码。
二、源程序设计思路1.编码程序:步骤一:开始时的词典包含所有可能的根,而当前前缀P是空的。
步骤二:当前字符C:=字符流中的下一个字符。
步骤三:判断P+C是否在词典中:(1)如果“是”,P:=P+C。
(2)如果“否”,则:①把代表当前前缀P的码字输出到码字流。
②把缀-符串P+C添加到词典中。
③令P:=C。
(3)判断字符流中是否还有字符需要编码:①如果“是”,返回到步骤二。
②如果“否”:输出相应于当前前缀P的码字。
结束编码。
2.译码程序:步骤一:在开始译码时,词典包含所有可能的前缀根。
步骤二:当前码字cW:=码字流中的第一个码字。
步骤三:输出当前缀-符串string.cW到字符流。
步骤四:先前码字pW:=当前码字cW。
步骤五:当前码字cW:=码字流中的下一个码字。
步骤六:判断当前缀-符串string.cW是否在词典中:(1)如果“是”,则:①当前缀-符串string.cW输出到字符流。
②当前前缀P:=先前缀-符串string.pW。
③当前字符C:=当前前缀-符串string.cW的第一个字符。
④把缀-符串P+C添加到词典。
(2)如果“否”,则:①当前前缀P:=先前缀-符串string.pW。
②当前字符C:=当前缀-符串string.pW的第一个字符。
③输出缀-符串P+C到字符流,然后把它添加到词典中。
步骤七:判断码字流中是否还有码字要译:(1)如果“是”,就返回到步骤四。
(2)如果“否”,结束。
三、程序框图词典初始化选择编码(1)或译码(2)?将第一个字符赋给前缀P结束是否有码字要译?字符串P+C 是否在词典中?是P :=P+C是输出代表当前前缀P 的码字否将P+C 添加到词典中P:=C 输出代表前缀P 的码字否C :=字符流中下一个字符 1 编码当前码字cW:=码字流中第一个码字输出对应字符string.cW先前码字pW:=当前码字cW;cW:=下一个码字是否有码字要译?否2 译码String.cW 是否在词典中?是输出string.cW是P :=string.pW C :=string.cW首字符将P+C 添加到词典P:=string.pW C:=string.pW 首字符输出P+C否四、程序设计代码及注释#include <iostream> #include <string> #include <iomanip> using namespace std;string dic[30]; int n;int find(string s) //字典中寻找,返回序号 { int temp=-1; for(int i=0;i<30;i++) { if(dic[i]==s) temp=i+1;}return temp;}void init() //字典初始化{dic[0]="a"; //开始时词典包含所有可能的根dic[1]="b";dic[2]="c";for(int i=3;i<30;i++) //其余为空{dic[i]="";}}void code(string str){init(); //初始化char temp[2];temp[0]=str[0]; //取第一个字符temp[1]='\0';string P=temp; //P为前缀int i=1;int j=3; //目前字典存储的最后一个位置cout<<"编码为:";while(1){char t[2];t[0]=str[i]; //取下一字符t[1]='\0';string C=t; //C为字符流中下一个字符if(C=="") //无码字要译,结束{cout<<" "<<find(P); //输出代表当前前缀的码字break; //退出循环,编码结束}if(find(P+C)>-1) //有码字要译,如果P+C在词典中,则用C扩展P,进行下一步:{P=P+C;i++;}else //如果P+C不在词典中,则将P+C添加到词典中,令P:=C{cout<<" "<<find(P);string PC=P+C;dic[j++]=PC;P=C;i++;}}cout<<endl;cout<<"生成的词典为:"<<endl;for(i=0;i<j;i++) //输出词典中的内容,j为词典的长度{cout<<setw(12)<<i+1<<setw(12)<<dic[i]<<endl;}cout<<endl;}void decode(int c[]){init(); //译码词典与编码词典相同,将a,b,c设为初始的前缀int pw,cw; //pw:先前码字,cw:当前码字cw=c[0]; //输入码字流的第一个码字,赋给当前码字int j=2,i;cout<<"译码为:";cout<<dic[cw-1]; //输出当前字符串到字符流for(int m=0;m<n-1;m++){pw=cw; //当前码字赋给先前码字cw=c[m+1];if(cw<=j+1) //若当前码字在词典中{cout<<dic[cw-1]; //输出当前码字锁代表的字符串char t[2];t[0]=dic[cw-1][0];t[1]='\0';string k=t;j++;dic[j]=dic[pw-1]+k; //将先前码字与当前码字所代表的字符串的首字符连接而成的字符串添加到词典中}else //若当前码字不在词典中{char t[2];t[0]=dic[pw-1][0];t[1]='\0';string k=t;j++;dic[j]=dic[pw-1]+k; //将先前码字与当前码字所代表的字符串的首字符连接而成的字符串添加到词典中cout<<dic[cw-1]; //输出该字符串}}cout<<endl;cout<<"生成的词典为:"<<endl;for(i=0;i<j;i++) //输出词典中的内容,j为词典的长度{cout<<setw(12)<<i+1<<setw(12)<<dic[i]<<endl;}cout<<endl;}int main() //主程序{string str;char choice;while(1){cout<<"\n\n\t"<<"1.编码"<<"\t"<<"2.译码\n\n";cout<<"请选择:";cin>>choice;if(choice=='1') //若选择a则编码{cout<<"\n输入要编码的字符串(由a、b、c组成):";cin>>str;code(str);}else if(choice=='2') //若选择b则译码{int c[30];cout<<"\n消息序列长度是:";cin>>n;cout<<"\n消息码字依次是:";for(int i=0;i<n;i++){cin>>c[i];}decode(c);}else return 0; //其他选择则退出程序}}五、程序运行结果。
Matlab函数实现哈夫曼编码算法讲解--实用.doc

编写 Matlab 函数实现哈夫曼编码的算法一、设计目的和意义在当今信息化代,数字信号充斥着各个角落。
在数字信号的理和中,信源是首先遇到的,一个信源的好坏劣直接影响到了后面的理和。
如何无失真地,如何使的效率最高,成了大家研究的象。
哈夫曼就是其中的一种,哈夫曼是一种的方案。
它由最二叉既哈夫曼得到,元内容到根点的路径中与父点的左右子的。
所以哈夫曼在在数字通信中有着重要的意。
可以根据信源符号的使用概率的高低来确定元的度。
既了信源的无失真地,又使得的效率最高。
二、设计原理哈夫曼 (Huffman Coding) 是一种方式,哈夫曼是可字 (VLC) 的一种。
uffman 于 1952 年提出一种方法,方法完全依据字符出概率来构造异字的平均度最短的字,有称之最佳,一般就叫作 Huffman 。
而哈夫曼的第一步工作就是构造哈夫曼。
哈夫曼二叉的构造方法原如下,假有 n 个,构造出的哈夫曼有 n 个叶子点。
n 个分 w1、 w2、⋯、wn,哈夫曼的构造:(1)将 w1、w2、⋯,wn 看成是有 n 棵的森林 (每棵有一个点 );(2)在森林中出两个根点的最小的合并,作一棵新的左、右子,且新的根点其左、右子根点之和;(3)从森林中除取的两棵,并将新加入森林;(4)重复 (2)、 (3)步,直到森林中只剩一棵树为止,该树即为所求得的哈夫曼树。
具体过程如下图 1 产所示:(例)图 1哈夫曼树构建过程哈夫曼树构造成功后,就可以根据哈夫曼树对信源符号进行哈夫曼编码。
具体过程为先找到要编码符号在哈夫曼树中的位置,然后求该叶子节点到根节点的路径,其中节点的左孩子路径标识为 0,右孩子路径标识为 1,最后的表示路径的 01 编码既为该符号的哈夫曼编码。
可以知道,一个符号在哈夫曼树中的不同位置就有不同的编码。
而且,不同符号的编码长度也可能不一样,它由该结点到父结点的路径长度决定,路径越长编码也就越长,这正是哈夫曼编码的优势和特点所在。
LZW编码算法详解

LZW编码算法详解LZW(Lempel-Ziv & Welch)编码又称字串表编码,是Welch将Lemple和Ziv所提出来的无损压缩技术改进后的压缩方法。
GIF图像文件采用的是一种改良的LZW 压缩算法,通常称为GIF-LZW压缩算法。
下面简要介绍GIF-LZW的编码与解码方程解:例现有来源于二色系统的图像数据源(假设数据以字符串表示):aabbbaabb,试对其进行LZW编码及解码。
1)根据图像中使用的颜色数初始化一个字串表(如表1),字串表中的每个颜色对应一个索引。
在初始字串表的LZW_CLEAR和LZW_EOI分别为字串表初始化标志和编码结束标志。
设置字符串变量S1、S2并初始化为空。
2)输出LZW_CLEAR在字串表中的索引3H(见表2第一行)。
3)从图像数据流中第一个字符开始,读取一个字符a,将其赋给字符串变量S2。
判断S1+S2=“a”在字符表中,则S1=S1+S2=“a”(见表2第二行)。
4)读取图像数据流中下一个字符a,将其赋给字符串变量S2。
判断S1+S2=“aa”不在字符串表中,输出S1=“a”在字串表中的索引0H,并在字串表末尾为S1+S2="aa"添加索引4H,且S1=S2=“a”(见表2第三行)。
5)读下一个字符b赋给S2。
判断S1+S2=“ab”不在字符串表中,输出S1=“a”在字串表中的索引0H,并在字串表末尾为S1+S2=“ab”添加索引5H,且S1=S2=“b”(见表2第四行)。
6)读下一个字符b赋给S2。
S1+S2=“bb”不在字串表中,输出S1=“b”在字串表中的索引1H,并在字串表末尾为S1+S2=“bb”添加索引6H,且S1=S2=“b”(见表2第五行)。
7)读字符b赋给S2。
S1+S2=“bb”在字串表中,则S1=S1+S2=“bb”(见表2第六行)。
8)读字符a赋给S2。
S1+S2=“bba”不在字串表中,输出S1=“bb”在字串表中的索引6H,并在字串表末尾为S1+S2=“bba”添加索引7H,且S1=S2=“a”(见表2第七行)。
matlab霍夫曼编码函数 -回复

matlab霍夫曼编码函数-回复Matlab是一个广泛应用于科学计算和工程领域的高级计算机语言和环境。
它提供了各种函数和工具箱,可用于解决各种数学问题和实现不同的算法。
霍夫曼编码是一种数据压缩算法,它通过将频率最高的字符编码为较短的比特串,从而实现对数据的有效压缩。
在本文中,我们将介绍如何在Matlab中实现霍夫曼编码函数。
首先,我们需要了解霍夫曼编码的基本原理。
该算法基于字符出现的频率构建一个霍夫曼树,其中出现频率较高的字符位于树的较低层,而出现频率较低的字符位于树的较高层。
然后,通过从根节点到每个字符的路径上的比特串表示字符的编码。
这样,频率较高的字符将使用较短的比特串编码,而频率较低的字符将使用较长的比特串编码。
在Matlab中实现霍夫曼编码,我们首先需要计算每个字符在给定数据中的出现频率。
我们可以使用Matlab提供的`histcounts`函数来实现这一点。
`histcounts`函数将数据分成一定数量的称为“bins”的区间,并计算每个区间中的数据的频数。
matlabdata = 'abcdefgh'; 给定的数据frequencies = histcounts(data, unique(data)); 计算每个字符的频数上述代码首先定义了一个包含字符的字符串,然后使用`unique`函数获取字符串中的唯一字符。
然后,`histcounts`函数基于这些唯一字符计算每个字符的频数,并将结果存储在名为“frequencies”的数组中。
下一步是构建霍夫曼树。
我们可以使用以下步骤来实现此操作:1. 创建一个含有所有字符频数的结点集合,并按照频率从低到高对结点排序。
2. 从频率最低的两个结点中创建一个新的父节点,并将这个父节点的频率设置为这两个结点的频率之和。
将这个新的父节点添加到结点集合中,并删除这两个被合并的结点。
3. 重复步骤2,直到只剩下一个节点为止。
这个节点将成为霍夫曼树的根节点。
LZW编码编程实现(C++版)

LZW编码的编程和实现一、实验目的编写源程序,实现LZW的编码和解码二、实验要求1.编码输入若干字母(如abbababac),输出相应的编码2.解码输入若干数字(如122473),输出相应的字母三、编程思想1.编码根缀表已知1 A2 B3 C编码分析字符串流,从词典中寻找最长匹配串,即字符串P在词典中,而字符串P+后一个字符C不在词典中此时,输出P对应的码字,将P+C放入词典中。
如第一步:输入A此时,A在表中,而AB不在表中,则输出A对应的码字1,同时将AB写入表中,此时表为1 A2 B3 C4 AB编码输出为1 (A已编码)第二步,输入B,B在词典中,而BB不在词典中,则输出2,将BB写入表中,此时表为1 A2 B3 C4 AB5 BB编码输出为12 (AB已经编码)....2.解码根缀表为1 A2 B3 C定义如下变量StringP :前一步码字流pW : StringP的第一个字符StringC :当前的码字流cW : StringC的第一个字符第一步输出StringC 并StringP = StringC如:1解码为A,则StringC = A那么输出A,并令StringP = A---------------------------------------------------------------------------第二步1.解码得到StringC,并输出StringC2.将StringP + cW放入词典(如果当前码字不在词典中,则将StringP + cP放入词典中)3.StringP = StringC如:第二步要解码为2,解码为B,则StringC=B,输出B (此时StringP = A)将StringP+cW放入表中,即将AB放入表中,此时表为1 A2 B3 C4 AB四、实验情况及分析编码解码错误提示附:源代码#include<iostream>#include<string>#include<iomanip>using namespace std;string dic[30];int n;int find(string s)//字典中寻找,返回序号{int temp=-1;for(int i=0;i<30;i++){if(dic[i]==s) temp=i+1;}return temp;}void init()//字典初始化{dic[0]="a";dic[1]="b";dic[2]="c";//字根为a,b,cfor(int i=3;i<30;i++)//其余为空{dic[i]="";}}void code(string str){init();//初始化char temp[2];temp[0]=str[0];//取第一个字符temp[1]='\0';string w=temp;int i=1;int j=3;//目前字典存储的最后一个位置cout<<"\n 编码为:";for(;;){char t[2];t[0]=str[i];//取下一字符t[1]='\0';string k=t;if(k=="") //为空,字符串结束{cout<<" "<<find(w);break;//退出for循环,编码结束if(find(w+k)>-1){w=w+k;i++;}else{cout<<" "<<find(w);string wk=w+k;dic[j++]=wk;w=k;i++;}}cout<<endl;for(i=0;i<j;i++){cout<<setw(45)<<i+1<<setw(12)<<dic[i]<<endl; }cout<<endl;}void decode(int c[]){init();int pw,cw;cw=c[0];int j=2;cout<<"\n 译码为:";cout<<dic[cw-1];for(int i=0;i<n-1;i++){pw=cw;cw=c[i+1];if(cw<=j+1){cout<<dic[cw-1];char t[2];t[0]=dic[cw-1][0];t[1]='\0';string k=t;j++;dic[j]=dic[pw-1]+k;}elsechar t[2];t[0]=dic[pw-1][0];t[1]='\0';string k=t;j++;dic[j]=dic[pw-1]+k;cout<<dic[cw-1];}}cout<<endl;for(i=0;i<j+1;i++){cout<<setw(45)<<i+1<<setw(12)<<dic[i]<<endl;}cout<<endl;}void main(){string str;while(1){cout<<"\n\n\ta.编码\tb.译码\n\n";cout<<"请选择:";char cha;cin>>cha;if(cha=='a'){cout<<"\n输入要编码的字符串(由a、b、c组成):"; cin>>str;code(str);}if(cha=='b'){int c[30];cout<<"\n消息序列长度是:";cin>>n;cout<<"\n消息码字依次是:";for(int i=0;i<n;i++){cin>>c[i];}decode(c);}else {cout<<"输入错误!"<<endl;} }。
实验二 LZW编码算法的实现

实验二LZW编码算法的实现一、实验目的1、学习Matlab软件的使用和编程2、进一步深入理解LZW编码算法的原理二、实验内容阅读Matlab代码,画原理图。
三、实验原理LZW算法中,首先建立一个字符串表,把每一个第一次出现的字符串放入串表中,并用一个数字来表示,这个数字与此字符串在串表中的位置有关,并将这个数字存入压缩文件中,如果这个字符串再次出现时,即可用表示它的数字来代替,并将这个数字存入文件中。
压缩完成后将串表丢弃。
如"print"字符串,如果在压缩时用266表示,只要再次出现,均用266表示,并将"print"字符串存入串表中,在图象解码时遇到数字266,即可从串表中查出266所代表的字符串"print",在解压缩时,串表可以根据压缩数据重新生成。
四、LZW编码的Matlab源程序及运行结果function lzw_test(binput)if(nargin<1)binput=false;elsebinput=true;end;if binputn=0;while(n==0)P=input('please input a string:','s')%提示输入界面n=length(P);end;else%Tests the special decoder caseP='Another problem on long files is that frequently the compression ratio begins...';end;lzwInput=uint8(P);[lzwOutput,lzwTable]=norm2lzw(lzwInput);[lzwOutput_decode,lzwTable_decode]=lzw2norm(lzwOutput);fprintf('\n');fprintf('Input:');%disp(P);%fprintf('%02x',lzwInput);fprintf('%s',num2str(lzwInput));fprintf('\n');fprintf('Output:');%fprintf('%02x',lzwOutput);fprintf('%s',num2str(lzwOutput));fprintf('\n');fprintf('Output_decode:');%fprintf('%02x',lzwOutput);fprintf('%s',num2str(lzwOutput_decode));fprintf('\n');fprintf('\n');for ii=257:length(lzwTable.codes)fprintf('Output_encode---Code:%s,LastCode%s+%s Length%3d\n',num2str(ii), num2str(lzwTable.codes(ii).lastCode),...num2str(lzwTable.codes(ii).c),lzwTable.codes(ii).codeLength)fprintf('Output_decode---Code:%s,LastCode%s+%s Length%3d\n',num2str(ii), num2str(lzwTable_decode.codes(ii).lastCode),...num2str(lzwTable_decode.codes(ii).c),lzwTable_decode.codes(ii).codeLength) end;function[output,table]=lzw2norm(vector,maxTableSize,restartTable)%LZW2NORM LZW Data Compression(decoder)%For vectors,LZW2NORM(X)is the uncompressed vector of X using the LZW algorithm. %[...,T]=LZW2NORM(X)returns also the table that the algorithm produces.%%For matrices,X(:)is used as input.%%maxTableSize can be used to set a maximum length of the table.Default%is4096entries,use Inf for ual sizes are12,14and16%bits.%%If restartTable is specified,then the table is flushed when it reaches%its maximum size and a new table is built.%%Input must be of uint16type,while the output is a uint8.%Table is a cell array,each element containig the corresponding code.%%This is an implementation of the algorithm presented in the article%%See also NORM2LZW%$Author:Giuseppe Ridino'$%$Revision:1.0$$Date:10-May-200414:16:08$%How it decodes:%%Read OLD_CODE%output OLD_CODE%CHARACTER=OLD_CODE%WHILE there are still input characters DO%Read NEW_CODE%IF NEW_CODE is not in the translation table THEN%STRING=get translation of OLD_CODE%STRING=STRING+CHARACTER%ELSE%STRING=get translation of NEW_CODE%END of IF%output STRING%CHARACTER=first character in STRING%add translation of OLD_CODE+CHARACTER to the translation table%OLD_CODE=NEW_CODE%END of WHILE%Ensure to handle uint8input vector and convert%to a rowif~isa(vector,'uint16'),error('input argument must be a uint16vector')Endvector=vector(:)';if(nargin<2)maxTableSize=4096;restartTable=0;end;if(nargin<3)restartTable=0;end;function code=findCode(lastCode,c)%Look up code value%if(isempty(lastCode))%fprintf('findCode:----+%02x=',c);%else%fprintf('findCode:%04x+%02x=',lastCode,c);%end;if(isempty(lastCode))code=c+1;%fprintf('%04x\n',code);return;Elseii=table.codes(lastCode).prefix;jj=find([table.codes(ii).c]==c);code=ii(jj);%if(isempty(code))%fprintf('----\n');%else%fprintf('%04x\n',code);%end;return;end;Endfunction[]=addCode(lastCode,c)%Add a new code to the tablee.c=c;%NB using variable in parent to avoid allocation coststCode=lastCode;e.prefix=[];e.codeLength=table.codes(lastCode).codeLength+1;table.codes(table.nextCode)=e;table.codes(lastCode).prefix=[table.codes(lastCode).prefix table.nextCode];table.nextCode=table.nextCode+1;%if(isempty(lastCode))%fprintf('addCode:----+%02x=%04x\n',c,table.nextCode-1);%else%fprintf('addCode:%04x+%02x=%04x\n',lastCode,c,table.nextCode-1);%end;Endfunction str=getCode(code)%Output the string for a codel=table.codes(code).codeLength;str=zeros(1,l);for ii=l:-1:1str(ii)=table.codes(code).c;code=table.codes(code).lastCode;end;Endfunction[]=newTable%Build the initial table consisting of all codes of length1.The strings%are stored as prefixCode+character,so that testing is very quick.To%speed up searching,we store a list of codes that each code is the prefix%for.e.c=0;stCode=-1;e.prefix=[];e.codeLength=1;table.nextCode=2;if(~isinf(maxTableSize))table.codes(1:maxTableSize)=e;%Pre-allocate for speedElsetable.codes(1:65536)=e;%Pre-allocate for speedend;for c=1:255e.c=c;stCode=-1;e.prefix=[];e.codeLength=1;table.codes(table.nextCode)=e;table.nextCode=table.nextCode+1;end;End%%Main loop%e.c=0;stCode=-1;e.prefix=[];e.codeLength=1;newTable;output=zeros(1,3*length(vector),'uint8');%assume compression of33%outputIndex=1;lastCode=vector(1);output(outputIndex)=table.codes(vector(1)).c;outputIndex=outputIndex+1;character= table.codes(vector(1)).c;、、tic;for vectorIndex=2:length(vector),%if mod(vectorIndex,1000)==0%fprintf('Index:%5d,Time%.1fs,Table Length%4d,Complete%.1f%%\n', outputIndex,toc,table.nextCode-1,vectorIndex/length(vector)*100);%*ceil(log2(size(table, 2)))/8);%tic;%end;element=vector(vectorIndex);if(element>=table.nextCode)%add codes not in table,a special case.str=[getCode(lastCode)character];else,str=getCode(element);Endoutput(outputIndex+(0:length(str)-1))=str;outputIndex=outputIndex+length(str);if((length(output)-outputIndex)<1.5*(length(vector)-vectorIndex))output=[output zeros(1,3*(length(vector)-vectorIndex),'uint8')];end;if(length(str)<1)keyboard;end;character=str(1);if(table.nextCode<=maxTableSize)addCode(lastCode,character);if(restartTable&&table.nextCode==maxTableSize+1)%fprintf('New table\n');newTable;end;end;lastCode=element;end;output=output(1:outputIndex-1);table.codes=table.codes(1:table.nextCode-1);Endfunction[output,table]=norm2lzw(vector,maxTableSize,restartTable)%NORM2LZW LZW Data Compression Encoder%For vectors,NORM2LZW(X)is the compressed vector of X using the LZW algorithm. %[...,T]=NORM2LZW(X)returns also the table that the algorithm produces.%For matrices,X(:)is used as input.%maxTableSize can be used to set a maximum length of the table.Default%is4096entries,use Inf for ual sizes are12,14and16%bits.%If restartTable is specified,then the table is flushed when it reaches%its maximum size and a new table is built.%Input must be of uint8type,while the output is a uint16.%Table is a cell array,each element containing the corresponding code.%This is an implementation of the algorithm presented in the article%See also LZW2NORM%$Author:Giuseppe Ridino'$%$Revision:1.0$$Date:10-May-200414:16:08$%Revision:%Change the code table structure to improve the performance.%date:22-Apr-2007%by:Haiyong Xu%Rework the code table completely to get reasonable performance.%date:24-Jun-2007%by:Duncan Barclay%How it encodes:%STRING=get input character%WHILE there are still input characters DO%CHARACTER=get input character%IF STRING+CHARACTER is in the string table then%STRING=STRING+character%ELSE%output the code for STRING%add STRING+CHARACTER to the string table%STRING=CHARACTER%END of IF%END of WHILE%output the code for STRING%Ensure to handle uint8input vector and convert%to a double row to make maths workif~isa(vector,'uint8'),error('input argument must be a uint8vector')Endvector=double(vector(:)');if(nargin<2)maxTableSize=4096;restartTable=0;end;if(nargin<3)restartTable=0;end;function code=findCode(lastCode,c)%Look up code value%if(isempty(lastCode))%fprintf('findCode:----+%02x=',c);%else%fprintf('findCode:%04x+%02x=',lastCode,c);%end;if(isempty(lastCode))code=c+1;%fprintf('%04x\n',code);return;Elseii=table.codes(lastCode).prefix;jj=find([table.codes(ii).c]==c);code=ii(jj);%if(isempty(code))%fprintf('----\n');%else%fprintf('%04x\n',code);%end;return;end;code=[];return;Endfunction[]=addCode(lastCode,c)%Add a new code to the tablee.c=c;%NB using variable in parent to avoid allocation coststCode=lastCode;e.prefix=[];e.codeLength=table.codes(lastCode).codeLength+1;table.codes(table.nextCode)=e;table.codes(lastCode).prefix=[table.codes(lastCode).prefix table.nextCode];table.nextCode=table.nextCode+1;%if(isempty(lastCode))%fprintf('addCode:----+%02x=%04x\n',c,table.nextCode-1);%else%fprintf('addCode:%04x+%02x=%04x\n',lastCode,c,table.nextCode-1);%end;Endfunction[]=newTable%Build the initial table consisting of all codes of length1.The strings%are stored as prefixCode+character,so that testing is very quick.To%speed up searching,we store a list of codes that each code is the prefix%for.e.c=0;stCode=-1;e.prefix=[];e.codeLength=1;table.nextCode=2;if(~isinf(maxTableSize))table.codes(1:maxTableSize)=e;%Pre-allocate for speedElsetable.codes(1:65536)=e;%Pre-allocate for speedend;for c=1:255e.c=c;stCode=-1;e.prefix=[];e.codeLength=1;table.codes(table.nextCode)=e;table.nextCode=table.nextCode+1;end;End%%Main loop%e.c=0;stCode=-1;e.prefix=[];e.codeLength=1;newTable;output=vector;outputIndex=1;lastCode=[];tic;for index=1:length(vector),%if mod(index,1000)==0%fprintf('Index:%5d,Time%.1fs,Table Length%4d,Ratio%.1f%%\n',index,toc, table.nextCode-1,outputIndex/index*100);%*ceil(log2(size(table,2)))/8);%tic;%end;code=findCode(lastCode,vector(index));if~isempty(code)lastCode=code;Elseoutput(outputIndex)=lastCode;outputIndex=outputIndex+1;%fprintf('output****:%04x\n',lastCode);if(table.nextCode<=maxTableSize)addCode(lastCode,vector(index));if(restartTable&&table.nextCode==maxTableSize+1)%fprintf('New table\n');newTable;end;end;lastCode=findCode([],vector(index));end;end;output(outputIndex)=lastCode;output((outputIndex+1):end)=[];output=uint16(output);table.codes=table.codes(1:table.nextCode-1);End五、运行结果1、请写下实验结果Input:111111111111111111111111111111111111111111111111111111111111111111111111111111 Output:?????????????????????????????Input:123123123123123123123123123123123123123123123123123123123123123123123 Output:?????????????????????????????2、请在实验代码中加入计算压缩比例的代码,并显示上述两种输入的不同压缩比。
使用Matlab进行图像压缩与编码的方法

使用Matlab进行图像压缩与编码的方法一、引言随着数字化时代的快速发展,图像的处理和传输已经成为了人们日常生活中不可或缺的一部分。
然而,图像的处理和传输过程中,数据量庞大往往是一个十分严重的问题。
为了解决这个问题,图像压缩与编码技术应运而生。
本文将介绍如何利用Matlab进行图像压缩与编码的方法,以实现高效的图像传输与存储。
二、图像压缩的原理与方法图像压缩是通过减少图像数据的冗余性,以达到减少数据量的目的。
常用的图像压缩方法包括无损压缩和有损压缩。
1. 无损压缩无损压缩技术可以完全恢复原始图像,但是压缩比较低。
其中,最常见的无损压缩方法是Huffman编码和LZW编码。
Huffman编码根据字符频率构建一颗Huffman树,使得频率高的字符编码短,频率低的字符编码长,从而实现编码的高效性。
而LZW编码则是利用字典来存储和恢复图像的编码信息。
2. 有损压缩有损压缩技术通过牺牲部分图像质量来获得更高的压缩比。
常见的有损压缩方法包括离散余弦变换(DCT)、小波变换(Wavelet Transform)以及预测编码等。
离散余弦变换是JPEG图像压缩标准所采用的一种技术,其将图像从空间域变换到频域,然后对频域信号进行量化和编码。
这种方法在保留图像主要特征的同时,实现了较高的压缩比。
小波变换是一种多尺度的信号分析方法,其能够将图像按照不同的频率组成进行分离,并对各个频率成分进行独立的处理。
小波变换不仅可以应用于图像压缩,还可以应用于图像增强和去噪等领域。
三、Matlab实现图像压缩与编码Matlab是一种强大的数学计算及可视化软件,其提供了丰富的函数和工具箱,便于进行图像处理和压缩编码。
1. 图像读取与显示首先,我们需要读取原始图像,并使用imshow函数来显示原始图像。
```matlabimg = imread('image.jpg');imshow(img);```2. 无损压缩对于无损压缩,在Matlab中可以使用imwrite函数来保存图像。
基于信号周期相似性和LZW编码的数据压缩方法

基于信号周期相似性和LZW编码的数据压缩方法马士强;郑常宝;曾野;杜杰成【期刊名称】《电测与仪表》【年(卷),期】2014(000)006【摘要】理想的电能质量信号呈现标准的正弦波形,具有周期性重复的特点。
实际的信号虽然可能会出现各种电能质量现象。
但是,在各个周期时间内的采样数据仍然具有很强的相似性。
根据电能质量信号的这一特点,可以提出一种简单有效的数据压缩方法。
首先提取某一个周期时间内的采样数据作为基准,然后将其他周期时间内的数据与该基准作减法处理,保存差值。
对差值采取相应的阈值处理,将较小的数值置零,最终结合LZW编码方法实现数据压缩。
文中详细地介绍了算法的实现过程和LZW编码的工作原理。
利用Matlab平台模拟了几种不同的电能质量现象,进行算法仿真。
经验证,该方法实现简单,处理速度快,并且可以取得较好的压缩效果。
【总页数】6页(P95-100)【作者】马士强;郑常宝;曾野;杜杰成【作者单位】安徽大学电气工程与自动化学院,合肥 230601; 安徽大学教育部电能质量工程研究中心,合肥230601;安徽大学电气工程与自动化学院,合肥230601; 安徽大学教育部电能质量工程研究中心,合肥230601;安徽大学电气工程与自动化学院,合肥 230601; 安徽大学教育部电能质量工程研究中心,合肥230601;上海大学通信与信息工程学院,上海200072【正文语种】中文【中图分类】TM714【相关文献】1.一种基于LZW算法的PDW数据压缩方法 [J], 彭德强;宋新超;王春芸2.基于模式相似度和LZW压缩编码的电能质量数据压缩方法 [J], 刘晓胜;王新库;黄南天;徐殿国3.基于LZW的海底声学探测数据压缩方法研究 [J], 晋松;裴彦良;阚光明;吴爱平;付青青4.基于LZW编码的卷积神经网络压缩方法 [J], 刘崇阳; 刘勤让5.基于LZW算法的高负荷光栅传感网络数据分块无损压缩方法 [J], 肖峰因版权原因,仅展示原文概要,查看原文内容请购买。
lzw和霍夫曼编码

lzw和霍夫曼编码LZW(Lempel-Ziv-Welch)编码和Huffman编码是常见的无损数据压缩算法。
它们可以将数据以更高效的方式表示,并减少数据所占用的存储空间。
虽然两种编码算法有一些相似之处,但它们的工作原理和实施方法略有不同。
1.LZW编码:LZW编码是一种基于字典的压缩算法,广泛应用于文本和图像等数据的压缩。
它的工作原理是根据已有的字典和输入数据,将连续出现的字符序列转换为对应的索引,从而减少数据的存储空间。
LZW编码的过程如下:•初始化字典,将所有可能的字符作为初始词条。
•从输入数据中读取字符序列,并检查字典中是否已有当前序列。
•如果字典中存在当前序列,则继续读取下一个字符,将该序列与下一个字符连接成一个长序列。
•如果字典中不存在当前序列,则将当前序列添加到字典中,并输出该序列在字典中的索引。
•重复以上步骤,直到输入数据全部编码完成。
LZW编码的优点是可以根据实际数据动态更新字典,适用于压缩包含重复模式的数据。
2.霍夫曼编码:霍夫曼编码是一种基于频率的前缀编码方法。
它根据字符出现的频率构建一个最优二叉树(霍夫曼树),将出现频率较高的字符用较短的二进制码表示,出现频率较低的字符用较长的二进制码表示。
霍夫曼编码的过程如下:•统计输入数据中各个字符的频率。
•使用字符频率构建霍夫曼树,频率较高的字符在树的较低层,频率较低的字符在树的较高层。
•根据霍夫曼树,为每个字符分配唯一的二进制码,保持没有一个字符的编码是另一个字符编码的前缀。
•将输入数据中的每个字符替换为相应的霍夫曼编码。
•输出霍夫曼编码后的数据。
霍夫曼编码的优点是可以根据字符频率进行编码,使高频字符的编码更短,适用于压缩频率差异较大的数据。
总的来说,LZW编码和霍夫曼编码都是常见的无损数据压缩算法,用于减少数据的存储空间。
它们的选择取决于具体的场景、数据特点和应用需求。
LZW编码算法详解

LZW编码算法详解LZW是一种字典压缩算法,用于无损数据压缩。
它是由Terry Welch在1977年提出的,主要用于无损压缩图像和文本数据。
LZW算法的特点是算法实现简单,压缩率高效。
LZW算法的基本原理是利用字典来存储已出现的文本片段,并使用字典中的索引来替代重复出现的片段。
初始时,字典中包含所有的单个字符。
算法从输入数据的第一个字符开始,不断扩充字典,直到处理完完整的数据流。
具体来说,LZW算法的编码流程如下:1.创建一个空字典,初始化字典中包含所有的单个字符。
2.读取输入数据流的第一个字符,将其作为当前字符。
3.从输入数据流中读取下一个字符,将其与当前字符进行拼接,得到当前字符串。
4.检查当前字符串是否在字典中,如果在字典中,则将当前字符串作为新的当前字符串,并继续读取下一个字符。
5.如果当前字符串不在字典中,将当前字符串的索引输出,并将当前字符串添加到字典中作为新的条目。
6.重复步骤3-5,直到处理完整的输入数据流。
LZW算法的解码流程与编码流程相似,但需要注意解码时字典的初始化方式。
解码时,初始字典只包含单个字符,不包含任何字符串。
解码算法的具体流程如下:1.创建一个空字典,初始化字典中包含所有的单个字符。
2.从输入编码流中读取第一个索引值,并将其作为上一个索引值。
3.在字典中找到当前索引值所对应的字符串,并输出。
4.如果已经读取完整个编码流,则解码结束。
5.否则,从输入编码流中读取下一个索引值,并将其作为当前索引值。
6.检查当前索引值是否在字典中,如果在字典中,则将上一个索引值和当前索引值对应的字符串进行拼接,得到新的解码字符串,并将其输出。
7.如果当前索引值不在字典中,将上一个索引值对应的字符串和上一个索引值拼接,得到新的解码字符串,并将其输出。
然后将新解码字符串添加到字典中作为新的条目。
8.将当前索引值作为上一个索引值,并继续重复步骤4-7,直到解码完成。
LZW算法的优点是能够在保持数据完整性的同时,显著减小数据的大小。
LZW编码算法

班级 __ __ 学号__姓名 __ ___评分__________1.实验名称LZW编码与解码算法2.实验目的2.1通过实验进一步掌握LZW编码的原理;2.2 用C/C++等高级程序设计语言实现LZW编码。
3.实验内容步骤或记录(包括源程序或流程和说明等)3.1 实验原理(1)在压缩过程中动态形成一个字符列表(字典)。
(2)每当压缩扫描图像发现一个词典中没有的字符序列,就把该字符序列存到字典中,并用字典的地址(编码)作为这个字符序列的代码,替换原图像中的字符序列,下次再碰到相同的字符序列,就用字典的地址代替字符序列3.2实验步骤LZW编码算法的具体执行步骤如下:步骤1:开始时的词典包含所有可能的根(Root),而当前前缀P是空的;步骤2:当前字符(C) :=字符流中的下一个字符;步骤3:判断缀-符串P+C是否在词典中(1) 如果“是”:P := P+C // (用C扩展P) ;(2) 如果“否”①把代表当前前缀P的码字输出到码字流;②把缀-符串P+C添加到词典;③令P := C //(现在的P仅包含一个字符C);步骤4:判断码字流中是否还有码字要译(1) 如果“是”,就返回到步骤2;(2) 如果“否”①把代表当前前缀P的码字输出到码字流;②结束。
3.3 源程序#include<iostream>#include<string>using namespace std;const int N=200;class LZW{private: string Dic[200];//存放词典int code[N];//存放编码过的码字public: LZW(){//设置词典根Dic[0]='a';Dic[1]='b';Dic[2]='c';string *p=Dic;//定义指针指向词典中的字符} void Bianma(string cs[N]);//进行编码int IsDic(string e);//判断是否在词典中int codeDic(string f);void display(int g);//显示结果};void LZW::Bianma(string cs[N]){string P,C,K;P=cs[0];int l=0;for(int i=1;i<N;i++){C=cs[i];//当前字符(C) :=字符流中的下一个字符 K=P+C;if(IsDic(K)) P=K;//P+C在词典中,用C扩展P else{//P+C不在词典中code[l]=codeDic(P);Dic[3+l]=K;//将P+C加入词典P=C;l++;}if(N-1==i)//如果字符流中没有字符需要编码code[l]=codeDic(P);}display(l);}int LZW::IsDic(string e){//如果字符流中还有字符需要编码for(int b=0; b<200; b++){ if(e==Dic[b]) return 1; }return 0;}int LZW::codeDic(string f){int w=0;for(int y=0;y<200;y++)if(f==Dic[y]){w=y+1;break;}return w;}void LZW::display(int g){cout<<"经过LZW编码后的码字如下:"<<endl;for(int i=0;i<=g;i++)cout<<code[i];cout<<endl;cout<<"经LZW编码后的词典如下:"<<endl;for(int r=0;r<g+3;r++)cout<<r+1<<Dic[r]<<endl;}int main(){LZW t;string CSstream[N];// 存放要进行LZW编码的字符序列int length;// 要进行LZW编码的字符序列长度cout<<"请输入所求码子序列的长度:";cin>>length;while(length>=N){cout<<"该长度太长,请重新输入:";cin>>length;}cout<<"请输入要进行LZW编码的字符序列:"<<endl; for(int a=0;a<length;a++)cin>>CSstream[a];t.Bianma(CSstream);return 0;}4.实验环境(包括软、硬件平台)硬件:装有32M以上内存MPC;软件:Windows XP操作系统、Visual C++高级语言环境。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
LZW编码算法,尝试使用matlab计算
%encoder LZW for matlab
%yu 20170503
clc;
clear;
close all;
%初始字典
dic = cell(512,1);
for i = 1:256
dic{i} = {num2str(i)};
end
%输入字符串a,按空格拆分成A,注意加1对应范围1~256 a = input('input:','s');
a = deblank(a);
A = regexp(a,'\s+','split');
L = length(A);
for j=1:L
A{j} = num2str(str2num(A{j})+1);
end
A_t = A{1};%可识别序列
B_t = 'test';%待验证词条
d = 256;%字典指针
b = 1;%输出指针
B = cell(L,1);%输出初始
output = ' ';%输出初始
j=1;
for j = 2:L
m=1;
B_t =deblank([A_t,' ',A{j}]);%合成待验证词条
while(m <= d)
if strcmp(dic{m},B_t)
A_t = B_t;
break
else
m=m+1;
end
end
while(m == d+1)
d = d+1;
dic{d} = B_t;
q=1;
for q=1:d
if strcmp(dic{q},A_t)
B{b} = num2str(q);
b = b+1;
end
end
A_t = A{j};
end
end
for q=1:d%处理最后一个序列输出
if strcmp(dic{q},A_t)
B{b} = num2str(q);
b = b+1;
end
end
for n = 1:(b-1)
B{n} =num2str(str2num(B{n})-1);
output=deblank([output,' ',B{n}]);
end
output
运算结果
计算结果为39 39 126 126 256 258 260 259 257 126
LZW解码算法,使用matlab计算
%decoder LZW for matlab
%yu 20170503
clc;
clear;
close all;
%初始字典
dic = cell(512,1);
for i = 1:256
dic{i} = {num2str(i)};
end
%输入字符串a,按空格拆分成A,注意加1对应范围1~256
a = input('input:','s');
a = deblank(a);
A = regexp(a,'\s+','split');
L = length(A);
for j=1:L
A{j} = num2str(str2num(A{j})+1);
end
B_t = A{1};%待验证词条
d = 256;%字典指针
b = 1;%输出指针
B = cell(L,1);%输出初始
output = ' ';%输出初始
j=1;
B{b} = char(dic{str2num(A{j})});
b = b+1;
for j = 2:L
BB = char(dic{str2num(A{j})});
B_d = regexp(BB,'\s+','split');%按空格拆分
L_B = length(B_d);
p=1;
for p=1:L_B
B{(b+p-1)} = B_d{p};
m=1;
B_t =deblank([char(B_t),' ',char(B_d{p})]);%合成待验证词条
while(m <= d)
if strcmp(dic{m},B_t)
B_t = B_t;
break
else
m=m+1;
end
end
while(m == d+1)
d = d+1;
dic{d} = B_t;
B_t = B_d{p};
end
end
b = b+L_B;
end
for n = 1:(b-L_B)
B{n} = num2str(str2num(B{n})-1);
output=deblank([output,' ',B{n}]);
end
output
运算结果
运算结果为39 39 126 126 39 39 126 126 39 39 126 126 39 39 126 126。