第三章时间序列挖掘相似性
相似性挖掘在时间序列数据中的应用研究

相似性挖掘在时间序列数据中的应用研究摘要:针对时间序列的数据挖掘首先需要将时间序列(Time Series)数据转换为离散的符号序列(Symbol Sequence)。
在前人的基础上,将界标模型和分段线性化进行了结合,以关键点作为分段依据,以最大似然函数和最小二乘法来拟合各分段线性拟合函数;此方法的优点在于符合人体生理实验结果,考虑了时间序列中的噪声。
关键词:时间序列;相似性挖掘;线性化分段;关键点0 引言时间序列是人们工作和生活中经常遇到的一类重要的数据形式.对时间序列进行分析,可以揭示事物运动变化和发展的内在规律,对于人们正确认识事物并据此作出科学的决策具有重要的现实意义。
数据挖掘(Data Mining)也称知识发现(Knowledge iscovery),是一种新兴的面向决策支持的数据处理手段。
针对时间序列的数据挖掘研究从大量时间序列历史数据中发掘有价值的规律性信息的算法及实现技术,也是一个新的、极具挑战性和有着重要应用前景的研究领域。
1 时间序列相似性的挖掘时间序列是指按时间变化的序列值或事件,时间序列数据库是指由随时间变化的序列值或事件组成的数据库。
这些值或事件通常是在等时间间隔测得的。
以股票每天的交易记录为例来说明上述定义,rj={600000,浦发银行,24.8,26.3,24.2,25.8,255105,62},其中600000是股票代码,浦发银行是股票名称,接下来的分别为当天的开盘价、最高价、最低价、收盘价、成交量以及第62个交易日。
前两个特性显然与时间无关,为静态特性,而其他特性值是与时间密切相关的,是动态特性。
很显然,对于静态特性研究的意义不大。
对于时间序列的相似性测量,不同的数据表达形式相似性测量的方法也不尽相同。
常用的测量方法主要有以下3种。
(1)欧几里德距离测量方法。
对于时间序列数据的相似性分析中,经常采用欧几里德距离作为相似计算的工具。
采用欧氏距离进行测量的优点是容易计算,易于理解,可以用于索引和聚类等数据挖掘。
时间序列相似性度量在水文数据挖掘中的应用研究

现等 。
2 水 文 时 间 序 列 相 似 性 挖 掘 及 其 模 型
20 0 2年 , 守 泽 和 夏 军 在 发 表 了 的 文 献 f1 认 叶 2中
为水 文科 学研 究 的 领域 面 临来 自许 多 方面 的不 确 定 性 和非确 知 问题 。 目前 国家水文数 据库 系统 和全 国防 汛 实时雨 水情 库 系统 已基 本建 成 .至 2 0 0 4年全 国水
关 键 词 :时 间 序 列 ;水 文 数 据 挖 掘 :相 似 性 度 量
0 引 言
时 间 序 列 的相 似 性 度 量 是 时 间 序 列 相 似 性 查 找 的关 键 环 节 之 一 。 在 实 际 应 用 中 . 同 领 域 的 时 间 序 不 列 各 有 不 同 的特 点 。采 样 方 法 和 度 量 手 段 都 不 一 样 .
时 间序 列相似 性度 量在水 文数 据挖 掘 中 的应 用 研 究
吴 德 . 叶 传 标
( 江学 院计 算机科 学 与工程 系 , 京 20 1) 三 南 102
摘
要 :相 似 性 度 量 方 法 是 时 间 序 列 相 似 性 研 究 的 重 要 课 题 , 同 时 也 是 水 文 时 问序 列 相 似 性 挖 掘 的 关 键 问 题 之 一 。充 分 分 析 目前 相 似 性 度 量 的 研 究成 果 , 合 水 文 时 间 序 列 相 似 性 挖 结 掘 模 型 , 过 实验 探 索 适 合 水 文 数 据 特 点 的相 似 性 度 量 方 法 。 通
—
() 2 比较 分 别 基 于 D W 和 D M 两 种 相 似 性 度 量 T P
方式 , 使用 中心点 聚类方法进行 聚类 的情况 。
时间序列分析相似性度量基本方法

时间序列分析相似性度量基本⽅法前⾔时间序列相似性度量是时间序列相似性检索、时间序列⽆监督聚类、时间序列分类以及其他时间序列分析的基础。
给定时间序列的模式表⽰之后,需要给出⼀个有效度量来衡量两个时间序列的相似性。
时间序列的相似性可以分为如下三种:1、时序相似性时序相似性是指时间序列点的增减变化模式相同,即在同⼀时间点增加或者减少,两个时间序列呈现⼀定程度的相互平⾏。
这个⼀般使⽤闵可夫斯基距离即可进⾏相似性度量。
2、形状相似性形状相似性是指时间序列中具有共同的形状,它通常包含在不同时间点发⽣的共同的趋势形状或者数据中独⽴于时间点相同的⼦模式。
两个时间序列整体上使⽤闵可夫斯基距离刻画可能不相似,但是他们具有共同相似的模式⼦序列,相似的模式⼦序列可能出现在不同的时间点。
这个⼀般使⽤DTW动态时间规整距离来进⾏相似性刻画。
3、变化相似性变化相似性指的是时间序列从⼀个时间点到下⼀个时间点的变化规律相同,两个时间序列在形状上可能并不⼀致,但是可能来⾃于同⼀个模型。
这个⼀般使⽤ARMA或者HMM等模型匹配⽅法进⾏评估。
时间序列相似性度量可能会受到如下因素影响:时间序列作为真实世界的系统输出或者测量结果,⼀般会夹杂着不同程度的噪声扰动;时间序列⼀般会呈现各种变形,如振幅平移振幅压缩时间轴伸缩线性漂移不连续点等时间序列之间可能存在不同程度的关联;以上因素在衡量时间序列相似性度量的时候要根据具体情况进⾏具体分析。
闵可夫斯基距离给定两条时间序列:P=(x_1,x_2,...x_n),\ \ Q(y_1,y_2,...y_n)闵可夫斯基距离的定义如下:dist(P,Q) = \left(\sum\limits_{i=1}^n|x_i-y_i|^p\right)^{\frac{1}{p}}注:1. 当p=1时,闵可夫斯基距离⼜称为曼哈顿距离:dist(P,Q)=\sum\limits_{i=1}^n |x_i-y_i|2.3. 当p=2时,闵可夫斯基距离⼜称为欧⽒距离:dist(P,Q) = \left(\sum\limits_{i=1}^n|x_i-y_i|^2\right)^{\frac{1}{2}}4. 当p\rightarrow\infty时,闵可夫斯基距离⼜称为切⽐雪夫距离:\lim\limits_{p\rightarrow\infty}\left(\sum\limits_{i=1}^n|x_i-y_i|^p\right)^{\frac{1}{p}} = \max\limits_{i}|x_i-y_i|5. 闵可夫斯基距离模型简单,运算速度快。
时间序列的结构复杂性及相似性研究

时间序列的结构复杂性及相似性探究关键词:时间序列;结构复杂性;相似性;长程相关性;动态时间规整1. 引言时间序列是指在不同时间点上观测到的数据序列,具有时间依存性和数据依存性。
随着数据采集技术和数据存储技术的不息提升,时间序列数据已经广泛应用于经济、金融、军事等领域。
在统计分析领域,时间序列分析一直是探究的重点之一,其主要探究内容包括时间序列的建模、时间序列的猜测、时间序列的变化和趋势分析等。
然而,时间序列的结构复杂性和相似性是影响时间序列分析效果的重要因素,因此,本文将从时间序列的结构复杂性及相似性两个方面进行探究。
2. 时间序列的结构复杂性2.1 长程相关性时间序列数据通常会出现长程相关性,即时间序列在不同时间点上观测到的数据呈现出相关性。
长程相关性可以通过时间序列的自相关函数进行刻画,自相关函数反映了时间序列中该点数据与其他时间点上数据之间的相关性。
依据自相关函数的特点,可以裁定时间序列的相关程度,从而进行时间序列的建模和猜测。
2.2 无序性时间序列的无序性指的是其在时间上的不行猜测性,即不同时间上的数据存在着无序性。
通过刻画时间序列的随机游走模型,可以发现时间序列数据呈现出平稳性和非平稳性的状态。
2.3 非线性时间序列中存在浩繁非线性因素,例如周期性、异方差性、非平稳性等。
对时间序列数据的建模、猜测和分析都会受到非线性因素的影响。
因此,在时间序列分析过程中,需要选择合适的非线性模型进行建模和猜测。
2.4 非正态性时间序列数据通常都不听从正态分布,而是存在着其他分布形式,例如泊松分布、伽马分布、指数分布等。
因此,在时间序列建模和分析中,需要选择合适的分布形式。
3. 时间序列的相似性时间序列的相似性是指不同时间序列之间存在的靠近程度和相似程度。
在时间序列分析中,需要对时间序列进行相似性器量,以便对不同时间序列之间的干系进行建模和分析。
时间序列相似性器量方法的主要分类如下:3.1 传统测度方法传统的时间序列相似性测度方法主要包括欧氏距离、Pearson相干系数、曼哈顿距离等。
时间序列的相似性的分层查询

将 时 间序 列 分 段 线 性 化 。 后 在这 些 子 段 上 抽 取 其 变 化特 然 征 . 样 不 仅 在 形 式 上 直 观 . 且 也 有 助 于对 时 间 序 列 数 据 的 这 而 挖 掘 。 实 现 序 列 分 段 线 性 化 的 常 见 方 法 是 采 用 最 小 误 差 方 法 n该 方 法 虽 然 能 达 到线 性 插 值 误 差 最 小 。 是 它 的计 算 量 。 但 比较 大 . 且还 有 可 能 造 成序 列 的某 些 重 要 特 征 的 丢 失 。 文献 而
fc ie. e tv
Ke wo d :t e i s i o r n i t , e d s q e c p t r th n y rs i me s r , e mp t t p n t n e u n e, at n mac i g a o s r e
l 引 言
相 似 性 问 题 是 时 间序 列数 据 挖 掘 中研 究 的 重 要 问 题 . 间 时 序 列 挖 掘 中的 其 它 问题 如 聚类 、 类 和规 则 发 现等 都 要 以 相似 分 性 问题 作 为 基 础 。 实 际 中 的 时 间序 列 数 据 大 都 是 海 量 的 , 统 传 的序 列 匹配 方 法 进行 相 似 性计 算 是 不 合 适 的 。 此 必 须从 时 间 因 序 列 数 据 中 提 取 有 效 的 特 征 。 缩原 始 数 据 . 而 高 效 地 计 算 压 从 数 据 , 出序 列相 似 性 。 文 献 『,1 出了 基 于 傅 里 叶 变换 的模 得 l2提 式 匹配 算 法 ; 献 【】 用 符 号影 射 法 、 文 3采 文献 【,】 用 小波 分 析 4 5采 等 方 法 、 献 『】 用 R 一re方 法 等 在 数据 约 简 和 序 列 匹 配 上 文 6采 t e 都 取 得 了一 定 的 成 果 , 也 存 在 缺 陷 , 对 噪 声 太 敏 感 、 觉 性 但 如 直 差 、 时 要精 心 选 择 参 数 等 。K o h 提 出用 分 段 表 示 序 列 O 有 eg 等 l
时间序列相似性查询的研究与应用

时间序列相似性查询的研究与应用随着大数据时代的到来,时间序列数据的重要性逐渐凸显。
时间序列数据是指按照时间顺序排列的一组数据,例如股票价格、气温变化、心电图等。
时间序列相似性查询作为一种重要的数据分析技术,旨在寻找与查询样本相似的时间序列数据,从而揭示隐藏在数据背后的规律和趋势。
在各个领域的实际应用中,时间序列相似性查询已经发挥了重要的作用。
时间序列相似性查询的研究主要包括两个方面:相似性度量和相似性查询算法。
相似性度量是衡量两个时间序列数据之间相似程度的方法,常用的度量方法包括欧氏距离、曼哈顿距离、动态时间规整等。
相似性查询算法是根据相似性度量方法,对大规模时间序列数据进行高效查询的方法,常用的算法包括基于索引的查询、基于哈希的查询、基于树结构的查询等。
这些研究成果为时间序列数据的分析和挖掘提供了基础。
时间序列相似性查询在实际应用中具有广泛的应用前景。
首先,在金融领域,通过对历史股票价格的相似性查询,可以预测未来股票价格的走势,为投资者提供决策依据。
其次,在气象领域,通过对历史气温变化的相似性查询,可以预测未来天气的变化,为气象预报提供支持。
再次,在医疗领域,通过对心电图的相似性查询,可以诊断心脏疾病,为医生提供治疗方案。
另外,在工业生产领域,通过对传感器数据的相似性查询,可以提前预测设备故障,进行维护和修复,提高生产效率。
然而,时间序列相似性查询也面临一些挑战。
首先,大规模时间序列数据的查询效率是一个问题,传统的查询算法无法满足实时查询的需求。
其次,相似性度量方法的选择也是一个难题,不同领域的数据可能需要采用不同的度量方法。
此外,在多维时间序列数据的查询中,如何考虑多个维度之间的相似性也是一个研究方向。
总之,时间序列相似性查询作为一种重要的数据分析技术,在各个领域的实际应用中发挥了重要作用。
未来,我们需要进一步研究相似性度量方法和查询算法,提高查询效率和准确性,以更好地应对大数据时代的挑战。
时间序列相似性度量方法综述

时间序列相似性度量方法综述作者:孙建乐廖清科来源:《数字化用户》2013年第27期【摘要】时间序列的相似性度量是时间序列数据挖掘的基础问题,针对时间序列相似性度量问题,综述了现有的时间序列相似性度量方法,重点介绍了各种度量方法的基本原理、优缺点,从而便于研究者对已有算法进行改进和研究新的时间序列相似性度量方法。
【关键词】时间序列数据挖掘相似性度量时间序列的相似性度量是时间序列数据挖掘的基础问题。
两条完全相同的时间序列几乎不存在,因此采用相似性(距离)度量来衡量时间序列之间的相似性。
由于时间序列数据的复杂性,经常发生振幅平移和伸缩、线性漂移、不连续性、时间轴伸缩和弯曲等形变,为了最大程度地支持上述形变,并尽量提高相似性度量的时间效率,有一系列时间序列距离度量方法被提出和引入。
一、明科夫斯基距离明科夫斯基(Minkowski)距离的优点在于简单直观,易于计算。
设两长度相等的序列和,把它们看成n维空间中的两个坐标点,则两者之间的明科夫斯基距离[2]定义为:当q=1时为曼哈顿(Manhattan)距离,当q=2时为欧几里德(Euclidean)距离,其中欧几里德距离是最常用也是应用最广泛的一种距离,其计算复杂度不高,与序列长度成线性关系,因而具有很好的伸缩性,序列长度的增加不会造成计算复杂度的迅速提高。
并且欧氏距离满足距离三角不等式,在基于索引的查询时,可以利用距离三角不等式快速过滤一些不符合条件的索引节点。
二、动态时间弯曲距离动态时间弯曲(DTW)距离在语音处理领域得到广泛的研究,Berndt和Clifford首次将DTW引入到数据挖掘领域[3]。
与欧几里德距离相比,动态时间弯曲距离不要求两条时间序列点与点之间一一对应,允许序列点自我复制在进行对齐匹配。
动态时间弯曲(DTW)距离:设时间序列和,则X和Y的DTW距离定义为:式中:表示序列点和之间的距离,可以根据情况选择不同的距离度量,通常使用明科夫斯基距离。
时间序列相似性度量方法

时间序列相似性度量方法王燕;安云杰【摘要】在时间序列相似性度量中,符号聚合近似(symbolic aggregate approximation,SAX)方法没有将符号化后的模式序列进一步处理,导致存在一定误差,为此提出将算术编码技术引用到SAX中,即将符号化序列转换为编码序列,实现时间序列在概率区间上的分析与度量;在计算序列间的相似度时采用分层欧式距离算法,综合考虑序列的统计距离和形态距离,由粗到细地进行筛选,达到序列整体趋势匹配以及细节拟合的目标.实验结果表明,该方法在不同的数据集上都有一定的可行性,具有较高的准确度和较好的鲁棒性.【期刊名称】《计算机工程与设计》【年(卷),期】2016(037)009【总页数】6页(P2520-2525)【关键词】时间序列;相似性度量;关键点对等;算术编码技术;符号化;分层欧式距离【作者】王燕;安云杰【作者单位】兰州理工大学计算机与通信学院,甘肃兰州730050;兰州理工大学计算机与通信学院,甘肃兰州730050【正文语种】中文【中图分类】TP311时间序列是对某一物理过程中的某一变量A(t)分别在时刻t1,t2,…,tn(t1<t2<…<tn)进行观察测量而得到的离散有序的数据集合,但由于时间序列数据的复杂,多种类、高维度等特性,为处理这些数据的分析带来了很大的困难,因此时间序列数据挖掘工作变得尤为重要[1]。
在整个时间序列数据挖掘过程中,相似性度量技术是许多其它工作(比如聚类、分类、关联规则等)的基础,吸引了大量学者的深入研究[2-6]。
其中,基于特征的符号聚合近似(SAX)[7]方法成为了最流行的相似性度量方法。
例如,Antonio Canelas等用SAX方法处理时间序列[8],具有简单易用、不依赖具体实验数据、并能准确表示时间序列统计特征的优点,但该方法弱化了序列的形态变化信息;张海涛等提出基于趋势的时间序列相似性度量[9],能够客观的描述序列形态变化,但由于选择的符号数太多,丧失了处理意义,使度量算法变的繁琐;肖瑞等提出了编码匹配算法在不确定时间序列相似性度量上的应用[10];Yan Wang将关键点提取和序列对等技术应用到了SAX算法中[11],为时间序列相似性度量提供了可以借鉴和参考的方向。
时间序列的快速相似性搜索改进算法

如高 频 噪声 、时 间轴上 伸缩 等 ,对 于这些 问题 已提 出很 多 算 法 .如 离 散 傅 立 叶 变 换 四 ,离 散 小 波 变 换 ,滑动平 均 聚集近 似方 法同 。笔者 引用 时 间序 等
列 分段 表示 思想 , 以某 省 电力公 司 E P系统业 务 量 R
时 间复 杂度 方 面作 了一 些研 究 ,提 出了一 种快 速 搜 索算法 。
111 欧式 类距 离 .。
给定两个时间序列 , ( l )Y I Im) I = , (l = ,当 ,
/- 的 ,它们之 问的 E cien距 离定义 为 .m t  ̄ ul a d
厂 —— —— 一
用 技 术
太 原科 技 文 章 编号 :0 6-87 2 1 )3 0 9 — 2 10 - 7 (0 0 0 — 0 0 0 4 21 0 0年 第 3期 可 0凹 阅 S@ 0 可匡@ 凰 —
|≯ 1 % 黪霉 餮 霉毒 毳 囊 囊 甏 赣 《 毫 毯 誊 罄 l 馥 § 罄 魏g毯 《 l |《 薯 一 薯≯ 臻 蕾 鍪 鞣豢 巷 囊鏊 穗 疆 繇 毽 囊 鼍 强 琵 l§ 毫 疆|鼋 强l 饕 繇 臻 鏊 。 l 。曩 l 魏 I
作者简介 : 刘利松 ( 9 5 , 陕西成 阳人 , 18 一) 男, 在读硕士 , 主要从事数据挖掘研 究 ,- i lo g l @1 3 o 。 E ma :sn_i 6 . r li u cn
9D・
・
应 用 技
太原 科技 2 1 0 0年第 3期 凰 凰 圆 0 匡 嗍 D @— @
EX Y =/ xy . (, ) 、∑(-) V ii
基于离散余弦变换的时间序列相似性检索

列 数 据相 似性 问题 的研究 成 果 已广 泛 应用 在 语音 处 理 、医学 、金 融 、传感 器 网络等领 域,产生 了巨大的
经济 和社会价值 .
以其简单 实用 被广泛采用 . 动态 时间弯 曲源于语音 识 别,其采用动态规划的思想递归定义, W 函数去掉 DT
ta so ma in meh d t ed s r t o i et n fI h s e n wi ey u e ef l f r p isa d i g r c s ig r n f r t t o , h ice ec sn a sc m a e d l s d i t ed o a h c n o r r b n h i g ma e o e s . p n
( olg f o ue c n e n eh oo yZ e agU iesyo T c lg, ng h u30 2 , hn) C l eo C mp t S i c d cn lg, hj n nv ri f el o Ha zo 10 3 C ia e r e a T i t mo y
其 中 时 间 序 列 长 度 为 组 成 的 实 数 值 个 数 ,记 为
l /n 给定一个查询序列O={l 2…, ) 但直接实现 D W 的算法的时间复杂度为 O mn ,相 I S=F , g, , , q T ( ) , 的时间复杂度 ,其计算 ? 个数据序列S=<l 2…,n , , , S) 如果序列9和序 对 计算 欧几里得 距离 的 D( ) S 列 S满足 as( , , i Q ) t 则认为时间序列 Q和 是 效率较低. 时间序列 的相似 性度量是衡量两个 时间序列 的相 相似 的.其中, 是时序相似阈值,ds( S 是一 i Q, ) t
时间的序列相似性度量

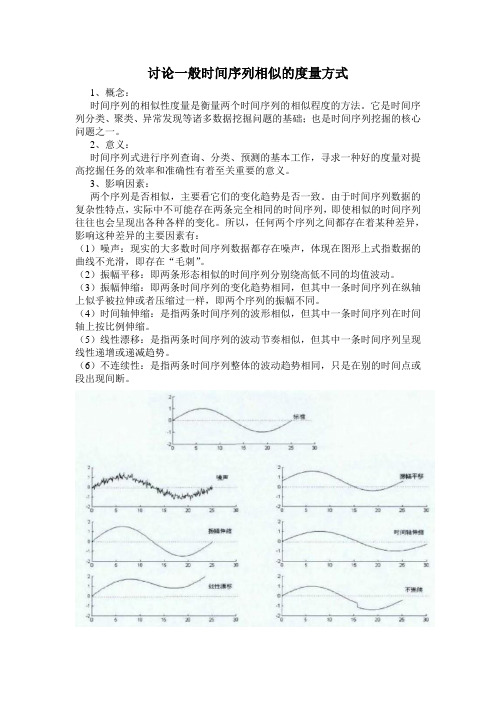
讨论一般时间序列相似的度量方式1、概念:时间序列的相似性度量是衡量两个时间序列的相似程度的方法。
它是时间序列分类、聚类、异常发现等诸多数据挖掘问题的基础;也是时间序列挖掘的核心问题之一。
2、意义:时间序列式进行序列查询、分类、预测的基本工作,寻求一种好的度量对提高挖掘任务的效率和准确性有着至关重要的意义。
3、影响因素:两个序列是否相似,主要看它们的变化趋势是否一致。
由于时间序列数据的复杂性特点,实际中不可能存在两条完全相同的时间序列,即使相似的时间序列往往也会呈现出各种各样的变化。
所以,任何两个序列之间都存在着某种差异,影响这种差异的主要因素有:(1)噪声:现实的大多数时间序列数据都存在噪声,体现在图形上式指数据的曲线不光滑,即存在“毛刺”。
(2)振幅平移:即两条形态相似的时间序列分别绕高低不同的均值波动。
(3)振幅伸缩:即两条时间序列的变化趋势相同,但其中一条时间序列在纵轴上似乎被拉伸或者压缩过一样,即两个序列的振幅不同。
(4)时间轴伸缩:是指两条时间序列的波形相似,但其中一条时间序列在时间轴上按比例伸缩。
(5)线性漂移:是指两条时间序列的波动节奏相似,但其中一条时间序列呈现线性递增或递减趋势。
(6)不连续性:是指两条时间序列整体的波动趋势相同,只是在别的时间点或段出现间断。
然而,在实际应用中情况要复杂得多,往往是以上多种因素交织在一起。
时间序列的相似性并没有一个客观的定义,具有一定的个人偏好性,也就是说,不同的人或不同的应用场合对各种差异影响的重视程度是不一样的。
给定两条时间序列 {}12,,....,n X x x x =和{}12=,,....m Y y y y ,相似性度量的问题就是在各种各样差异因素的影响下,寻求一个合适的相似性度量函数(),Sim X Y ,使得该函数能很好地反映时间序列数据的特点。
4、方法:目前时间序列相似性度量,最常用的有Minkowski 距离和动态时间弯曲。
时间序列相似性度量
讨论一般时间序列相似的度量方式1、概念:时间序列的相似性度量是衡量两个时间序列的相似程度的方法。
它是时间序列分类、聚类、异常发现等诸多数据挖掘问题的基础;也是时间序列挖掘的核心问题之一。
2、意义:时间序列式进行序列查询、分类、预测的基本工作,寻求一种好的度量对提高挖掘任务的效率和准确性有着至关重要的意义。
3、影响因素:两个序列是否相似,主要看它们的变化趋势是否一致。
由于时间序列数据的复杂性特点,实际中不可能存在两条完全相同的时间序列,即使相似的时间序列往往也会呈现出各种各样的变化。
所以,任何两个序列之间都存在着某种差异,影响这种差异的主要因素有:(1)噪声:现实的大多数时间序列数据都存在噪声,体现在图形上式指数据的曲线不光滑,即存在“毛刺”。
(2)振幅平移:即两条形态相似的时间序列分别绕高低不同的均值波动。
(3)振幅伸缩:即两条时间序列的变化趋势相同,但其中一条时间序列在纵轴上似乎被拉伸或者压缩过一样,即两个序列的振幅不同。
(4)时间轴伸缩:是指两条时间序列的波形相似,但其中一条时间序列在时间轴上按比例伸缩。
(5)线性漂移:是指两条时间序列的波动节奏相似,但其中一条时间序列呈现线性递增或递减趋势。
(6)不连续性:是指两条时间序列整体的波动趋势相同,只是在别的时间点或段出现间断。
然而,在实际应用中情况要复杂得多,往往是以上多种因素交织在一起。
时间序列的相似性并没有一个客观的定义,具有一定的个人偏好性,也就是说,不同的人或不同的应用场合对各种差异影响的重视程度是不一样的。
给定两条时间序列 {}12,,....,n X x x x =和{}12=,,....m Y y y y ,相似性度量的问题就是在各种各样差异因素的影响下,寻求一个合适的相似性度量函数(),Sim X Y ,使得该函数能很好地反映时间序列数据的特点。
4、方法:目前时间序列相似性度量,最常用的有Minkowski 距离和动态时间弯曲。
时间序列相似度

时间序列相似度
时间序列相似度是指比较两个或多个时间序列之间的相似程度。
时间序列是一系列按时间顺序排列的数据点,例如每小时的气温、每日的股票价格等。
时间序列相似度的应用非常广泛,如天气预测、金融预测、医疗诊断等领域。
常用的时间序列相似度计算方法有欧几里得距离、余弦相似度、皮尔逊相关系数等。
其中欧几里得距离是指在n维空间中两个点之间的距离,余弦相似度是指两个向量之间的夹角余弦值,皮尔逊相关系数是指两个变量之间的线性相关程度。
除了以上方法,还有一些新兴的时间序列相似度计算方法,如基于深度学习的方法、基于时间序列聚类的方法等。
这些方法在某些特定场景下可以取得更好的效果。
时间序列相似度的应用范围很广,但是在实际应用中也面临着一些挑战,如数据缺失、数据噪声等。
因此,需要针对不同的应用场景选择合适的相似度计算方法,并对数据进行预处理和清洗,以提高相似度计算的准确度和可靠性。
- 1 -。
关于时间序列相似性问题中间隔因子讨论
科技信息
O计算机 与信息技术0
S 皿 N E IF MA I C C N OR TON
20 07年
第 1 期 4
关于时问序列相似性问题中问隔因子讨论
李 峰 f 潭大 学信 息工程 学院 湖 南 湘
湘潭
4 10 ) 1 1 5
1序 言 .
时 间 序 列 (i eis, 通 常 指 的 是 每 隔 一 定 时 间 间 隔 (i TmeS r 1 e Tme
低ቤተ መጻሕፍቲ ባይዱ算复杂度。
It v1 ne a) r 所记录的变量数据。任何由数字组成的按时间顺序 的序 列都 可看作是一个时间序列 。而且时间间隔也不一定是规则的长度时间。 般 用 折 线 图来 直 观 地 表 示 时 间 序列 , 如 图 1 其 中 横 ( 轴 表 例 。 x) 示 时间 , 通常标注时刻 , 如年 、 、 时等 等; Y 轴表示 当前时刻变 月 日、 竖f) 量值 , 如某 时刻 的市场股价 、 河流水位 、 网站访问量、 地震震波 、 星方 恒 位等等。
一
0
0
图 2 图 1正 则 化 后 的表 示 。
3一 种 时 间间 隔 算法 . 不失一 般性 , 我们总 能把 时间序 列转 正则化 为 N01的随机分 (, )
布。
图 1 19 2 0 9 -0 6每 年 九月 份 的 澳 大 利 亚 全 国 失 业 率, 据编 号 6 0 、日 数 1 50 。
图 4 一 个 - f 后 时 间序 列的 被 上 述 分 割 线 ( I 划 分 的 例 子 。 , J v ̄ 化 N= O)
A,
维普资讯
科技信息
。计算机 与信息技术 o
时间序列数据挖掘中相似性和趋势预测的研究

时间序列数据挖掘中相似性和趋势预测的研究时间序列是指按照时间顺序进行排列的一组数据,具有非常广泛的应用,包括经济预测、环境监测、医疗诊断等领域。
时间序列数据挖掘是指通过机器学习、数据挖掘等方法,对于时间序列数据进行分析和处理,以达到对数据的深度理解、事件预测、系统优化等目的。
其中,相似性分析和趋势预测是时间序列数据挖掘中的两个重要方面,本文将着重对这两个方面进行综述和分析。
一、相似性分析相似性分析是对于时间序列中的不同数据进行比较和匹配,以寻找数据之间的相似性和相关性。
在时间序列数据挖掘中,相似性分析有非常广泛的应用,包括图像和声音识别、交通流量预测等。
下面我们将从数据表示、距离度量、相似性度量、采样率和插值等几个方面来讨论相似性分析的方法和技术。
1.数据表示对于时间序列数据的表示,常见的方式包括时间区间和时间点。
时间区间表示是指将时间序列数据分段表示,每一段代表一个时间区间的数据;时间点表示则是在时间轴上标注数据采集的时间戳,随着采集时间的增加,时间序列也在不断地增加。
时间区间表示的优点在于可以更好地处理时序数据的不确定性和噪声,但需要更多的计算资源;时间点表示则更直观和易于理解,但需要特殊处理不规则或不完整的数据。
根据具体应用场景和数据的特点,选择合适的数据表示方法非常重要。
2.距离度量距离度量是指对于两个时间序列的距离进行计算的方法。
常见的距离度量包括欧氏距离、曼哈顿距离、切比雪夫距离等,具体选择方法要根据数据特征进行处理。
例如,在处理具有线性关系的数据时可以使用欧氏距离;而在处理非线性数据时则可以使用切比雪夫距离。
3.相似性度量相似性度量是指对于两个时间序列相似性程度进行计算的方法。
常见的相似性分析方法包括最近邻方法、K-Means聚类和模式匹配等。
最近邻方法是指寻找与目标时间序列最相似的历史序列,并将其作为预测结果的依据。
K-Means聚类是指对于时间序列进行聚类分析,确定各个聚类中心,以此来寻找相似性更高的时间序列。
时间序列的相似 计算公式

时间序列的相似计算公式
时间序列的相似性计算是指通过一定的数学方法来衡量两个时间序列之间的相似程度。
常用的计算方法包括欧氏距离、曼哈顿距离、动态时间规整(Dynamic Time Warping, DTW)等。
首先,欧氏距离是最常见的相似性度量方法之一,它衡量的是两个时间序列在每个时间点上的差值的平方和的开方。
其计算公式为,\[ \sqrt{\sum_{i=1}^{n}(x_i y_i)^2} \] 其中 \( x_i \) 和 \( y_i \) 分别代表两个时间序列在第 \( i \) 个时间点上的取值。
其次,曼哈顿距离也是一种常用的相似性度量方法,它衡量的是两个时间序列在每个时间点上的差值的绝对值的和。
其计算公式为,\[ \sum_{i=1}^{n}|x_i y_i| \]
另外,动态时间规整(DTW)是一种考虑时间序列局部相似性的方法,它允许在比较序列时进行局部的时间拉伸或压缩。
DTW的计算过程复杂,但可以通过动态规划的方法来实现。
其计算公式需要通过动态规划算法来求解,不过可以简单描述为找到两个序列之间的最佳匹配路径,使得路径上的点之间的距离和最小。
除了上述方法,还有很多其他的时间序列相似性计算方法,比
如相关系数、余弦相似度等。
每种方法都有其适用的场景和局限性,选择合适的方法需要根据具体的应用需求和时间序列的特点来决定。
总的来说,时间序列的相似性计算是一个复杂而重要的问题,
需要根据具体情况选择合适的方法进行计算。
希望以上介绍能够对
你有所帮助。
时间序列数据挖掘中特征表示与相似性度量研究综述

L I Ha i . 1 i n , .GUO C h o n g . h u i
( 1 . C o l l e g e o fB u s i n e s s A d mi n i s t r a t i o n , H u a q i a o U n i v e r s i t y ,Q u a n z h o u F u j i a n 3 6 2 0 2 1 , C h i n a;2 . I n s t i t u t e fS o y s t e m s E n g i n e e r i n g, D a l i a n U n i — v e m i t y fT o e c h n o l o g y , D a l i a n L i a o n i n g 1 1 6 0 2 4, C h i n a )
d o i : 1 0 . 3 9 6 9 / j . i s s n . 1 0 0 1 — 3 6 9 5 . 2 0 1 3 . 0 5 . 0 0 2
S u r v e y o f f e a t u r e r e p r e s e n t a t i o n s a n d s i mi l a r i t y me a s u r e me n t s i n
Ab s t r a c t :T h i s p a p e r r e s p e c t i v e l y a n a l y z e d t h e f u n c t i o n a n d me a n i n g o f f e a t u r e r e p r e s e n t a t i o n s nd a s i m i l a it r y me a s u r e me n t s f o r t i me s e r i e s .I t a l s o s u mma r i z e d t h e e x i s t e d me t h o d s a n d na a ly z e d t h e me it r s nd a d e me i r t s .Me a n wh i l e ,b y d i s c u s s i n g t h e n o t e wo r — t h y p r o b l e ms , i t p r o v i d e d t h e f u r t h e r r e s e a r c h d i r e c t i o n o f f e a t u r e r e p r e s e n t a t i o n s a n d s i mi l a r i t y me a s u r e me n t s or f t i me s e i r e s . Ke y wo r d s :t i me s e ie r s ;d a t a mi n i n g;f e a t u r e r e p r e s e n t a t i o n; s i il m a it r y me a s u r e me n t
水文时间序列的相似性搜索研究

过程年 际 间的相 似性和 场 次洪水 的相 似性 只能是 某种 程度 上 的相似 , 而并 非完 全相 同 . 统水 文过 程 的相 似 传
性 研究 强调精 确 匹配 , 实际 的水文 过程 本身 很难 达到 如此要 求 , 而数据 挖 掘 中 , 一般 采用基 于 近似 匹配 的“ 近
D :0 3 7 / . s .0 018 .0 0 0 .0 OI1 .8 6 ji n 10 -9 0 2 1 .3 0 1 s
水 文 时 间序 列 的相 似 性 搜 索研 究
欧 阳如 琳 , 立 良 , 成 虎2 ,任 一 周
(. 1河海大学水文水资源与水利工程科学 国家重点实验室 , 江苏 南京 2 09 ; 108 100 ) 0 11 2 中国科学 院地 理科学 与资源研究所 资源与环境 信息系统 国家重点实验室 , . 北京
作者简介 : 阳如琳 (92 )女 , 欧 18 一 , 福建漳州人 , 博士研究生 , 主要从事 水文数据挖掘研究 . - i or h .d .n Ema :yl u eu c l @h
22 4
河 海 大 学 学 报 (自 然 科 学 版 )
第 3 8卷
( , , , ) l … ‰ 和一 个序 列 Y=( 1Y , ,m , 2 Y,2… Y )相似性 问题 就是 如何确定 和 y的相似度 s X, )这里 i m( Y . n和 m 的取 值可 以相 同也 可 以不 同 , n=m 时就 是这 两个 序列 完 全匹 配 ( hl s unem t i ) 问题 , 当 w o qec a h g的 ee cn 即从 具有 相同 长度 的序列 中查找 相似 的序列 ; 果 n≠m 就 是 子序 列 匹配 (us unem t i ) 如 sbe ec c n 问题 , q a hg 即从 Y( =12 … , i ,, m—n+1开始 , 出 y中与 最相 似 的子序列 ( ) 找 假定 n<m) .
时间序列相似性查询与索引方法研究

时间序列相似性查询与索引方法研究
邱均平;王菲菲
【期刊名称】《中国索引》
【年(卷),期】2009(007)004
【摘要】时间序列相似性查询从提出到现在已有10多年的历史,取得了大量的研究成果。
索引既是时间序列相似性查询实现的关键,也是信息技术领域的热点问题之一。
近年来,国内外学者为进一步提高查询的完备度而对时间序列索引方法进行了深入的研究。
本文在阐述时间序列查询原理的基础上,对各种索引方法进行了阐述和比较,以期对时间序列分析的研究和应用有所启发和帮助。
【总页数】5页(P4-8)
【作者】邱均平;王菲菲
【作者单位】武汉大学中国科学评价研究中心,430072;泉州市图书馆,福建泉州362000
【正文语种】中文
【中图分类】O211.61
【相关文献】
1.时间序列相似性查询与索引方法研究
2.基于线性散列索引的时间序列查询方法研究
3.IC-索引:一种支持时间序列反向查询的索引方法
4.基于线性散列索引的时间序列查询方法研究
5.水文时间序列相似性查询的分析与研究——以漯河站、何口站汛期降雨量相似性查询为例
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 定理:对于长度为 n 的任何两个时间序列 X 和 Y, 限定弯曲路径窗口为w,即对于 xi和 yj点的比较, 限定为 j-w i j+w,存在如下不等式: LB_ Hust(X,Y) Keogh(X,Y) 。 • 性质1:LB_Hust 距离是对称的。即 LB_Hust (X,Y) =LB_Hust (Y,X)。这可以减少距离计算的次数。 • 性质2:在 LB_Hust 距离计算方式下,时间复杂度 由传统的 DTW 距离计算的 O(nm)缩减到 O(n)。
时间序列常见距离定义
(6) Uniform Scaling距离
• time series – query, Q, length n – candidate, C, length m (m>n)
C
Q
0
100
200
300
400
Uniform Scaling
• time series – query, Q, length n – candidate, C, length m (m>n)
时间序列相似性应用场景
• 1.区别多个公司发展的相似性模型; • 2.在股票价格上寻找价格波动的相似运动; • 3.在乐谱版权问题上确认两份乐谱是否存在相似 性; • 4.对具有相似销售模式的商品进行聚类; • 5.查找具有相似病情的心电图; • 6.对网络的异常流量预警; • 7.对天气预报中灾害天气的模式提取等。
for i := 1 to n for j := 1 to m cost:= d(s[i], t[j]) DTW[i, j] := cost + minimum(DTW[i-1, j ], DTW[i , j-1], DTW[i-1, j-1])
} return DTW[n, m]
DTW的优缺点
• DTW 的优点在于:①克服了 Euclidean 距离 点对必须对应的问题,允许不同步的点对 应计算;②允许两时间序列具有不同长度; ③对时间序列的同步问题不敏感。
DTW的优缺点
• 缺点在于:①DTW 的计算复杂度较高,对于长度分别为 n和m 的时间序列,准确计算DTW 距离需要 O ( nm )的 时间复杂度;②DTW 并不满足距离的三角不等式(例如, DTW(111,111222)>DTW(111,112)+DTW(112,111222)),在 应用到依据索引的时间序列相似查询时剪枝过滤的程度 有限,在使用索引查询时则可能会产生漏查。 ③病态弯 曲问题,由于 DTW允许在比较的时候两个时间序列可进 行一定的非对应时刻匹配,即求取最小距离而忽略时间 上的差异,这容易形成时域差异过大的情况发生。 • 解决办法:对于①,对比较的时间序列数据进行降维处 理,进一步探索高压缩率和高效保真的降维方法;对于 ③,设定路径查找的带宽限制,即比较点不会超出参照 点的[ti-w,ti+w]的时间范围。这种方法同时 还可能降低 算法的时间复杂度。
• 对于时间序列 和 ,定 义距离矩阵:DM=(aij) m×n ,其中aij=(xi-yj)2, 或其它 度量。
在DM中寻找一条弯 曲路径W=w1,w2,…, wK, 其中wi=某个aij , 满足以下性质: 1、有界性: max{m , n}≤ K≤m+n-1; 2、边界性:w1=a11, wk=amn ; 3、单调性和连续性: 在弯曲路径中,相邻 两个元素wk=aij, wk+1=ast ,则0s-i 1, 0 t-j 1。
DTW与Uniform Scaling的不同
• Dynamic Time Warping (DTW) – Considers only local adjustments in time, to match two time series – However sometimes global adjustments are required
LB_Keogh的Matlab实现
LB_Keogh=sqrt(sum([[Q > U].* [Q-U]; [Q < L].* [L-Q]].^2));
LB_Hust 距离---对LB_Keogh距离的改进
• 针对 LB_Keogh距离计算的非对称性
• 其中,Lxi和 Uxi分别对应时间序列 X 的第 i 个元素在 2w 时间域内的最小值和最大值。Lyi和 Uyi同理。距 离产生方式如图 3-5 所示。
斜率距离---欧氏距离的一个变形
• 设 其中 X 和Y 分别 是原始时间序列数据转换而成的斜率组成的时间 序列,即:
时间序列常见距离定义
(3)编辑距离(Edit Distance) • Edit 距离是计算两字符串序列的距离一种度量,它 的定义是将一字符串转换为另一字符串所需的最 小编辑(插入、删除、改变)步数。 • 将时间序列进行不同的量化和编码后形成字符串, 采用编辑距离计算两字符串的距离。 • Edit 距离的优点是:①充分利用了字符串匹配等成 熟计算方法;②容易为人所理解; ③允许多对无。 • 缺点是:①需要将时间序列转化为相应的字符串, 精度不高;②对于不同步的时间序列效果较差。
时间序列常见距离定义
(4)最大公共子串 LCS(Longest Common Subseries)方法 • LCS是计算两时间序列间具有的公共长度子串,并 以该子串的长度与这两个时间序列中较长序列的 长度比值作为序列间的相似性度量。 • LCS 方法借用字符串匹配中的相似性度量,有其一 定的可取之处。其不足是:①公共长度子串的长 度可能偏小,两时间序列间可能非常相似,但是 由于数值并不能完全一致,细小的偏差都会导致 公共子串的长度偏小,从而影响到度量效果;② 公共长度子串的获取是一个问题,虽然可以采用 较为常见的动态规划的方法解决,但是由于时间 序列很可能是长度很长的序列,空间开销较大。
0 100
C
Q
200 300 400
• stretch Q to length p (n≤p≤m): Qp
– Qpj = Q┌j*n/p┐, 1 ≤ j ≤ p
Q
Qp
0 100 200 300 400
• scaling factor, sf = p/n
– max scaling factor, sfmax= m/n
例如:
• • • • a=1:10 b=1:13 如c=b*(10/13),则得 c=0.7692308 1.5384615 2.3076923 3.0769231 3.8461538 4.6153846 5.3846154 6.1538462 6.9230769 7.6923077 8.4615385 9.2307692 10.0000000 • 如 c=ceiling(b*(10/13)) • 则 c= 1 2 3 4 4 5 6 7 7 8 9 10 10
Given two time series Q = q1…qn and C = c1…cn their Euclidean distance is defined as:
Q
C
DQ, C qi ci
氏距离的优缺点
• Euclidean 距离的优点在于:①直观而计算简便, 有良好的数学背景和意义;②由于序列的一些常 用变换(如傅立叶变换等)的系数有欧氏距离保持 不变的性质,所以经常用于数据库的高效索引; ③无参。 • 缺点在于:①需要计算的两序列具有相同的长度; ②对于时间序列点的突变(e.g. noise)比较敏感; ③Euclidean 距离对序列按照时间轴进行点对点依 次计算,对时间序列的错位、移位(out of phase) 等比较敏感。
通常将w选为时间序列长度的10%。
LB_Keogh:一种考虑弯曲路径限制的DTW 计算 方法
• 对于弯曲路径限制为 w 的时间序列 DTW 距离计算, 定义两个序列 U 和 L,其中对于第 i 个元素我们 有如下的上下界定义:
• U 和 L 作为在 2w 时间窗内,对于原时间序列的 每个元素所对应的上下界,表现在图形上实际上是 形成了一个带状的域将原始时间序列包裹在这个域 中,如图 3-4 所示。
时间序列常见距离定义
• 时间序列间的距离可用来衡量时间序列之间的差 异性,以确定序列是否相似。 (1)Minkowski 距离(Minkowski Distance) • Minkowski 距离实际是一系列距离的集合,对于 两时间序列 和 其计算方法 为
其中p=1时为曼哈顿距离;p=2时为欧氏距离;
时间序列常见距离定义
(5)DTW 距离(Dynamic Time Warping Distance) • DTW 距离最先在语音数字处理领域得到诸多成功 的应用,由 Berndt 和 Clifford于 90 年代中旬 引入到时间序列挖掘中,并取得了巨大的成功。 • 在时间序列中,需要比较两段长度可能并不相等 的时间序列的相似性,在语音识别领域表现为不 同人的语速不同。而且同一个单词内的不同音素 的发音速度也不同,比如有的人会把‘A’这个音 拖得很长,或者把‘i’发的很短。另外,不同时 间序列可能仅仅存在时间轴上的位移,亦即在还 原位移的情况下,两个时间序列是一致的。在这 些复杂情况下,使用传统的欧几里得距离无法有 效地求得两个时间序列之间的距离(或者相似性)。
第三章
时间序列挖掘●相似性
山西财经大学信息管理学院常新功
目 录
• • • • 时间序列相似性定义 时间序列相似性应用场景 时间序列常见距离定义 时间序列相似性分类
时间序列相似性定义
• 反映两条时间序列相似程度的值刻划了这两条时间序 列的相似性,其概念和方法是时间序列挖掘的基础。 • 给定某个时间序列,要求从大型时间序列数据集合中 找出与之相似的序列---静态时间序列的相似性。 • 实际生活中有大量以动态序列形式存在的时间序列 (时间序列流)。 • 随着研究的深入,动态时间序列的相似性问题也日益 成为新时期时间序列相似性问题研究的重要组成部分。 • 与传统静态数据的精确相似不同,时间序列的相似性 会呈现多种变形,如振幅平移和伸缩、线性漂移、不 连续、噪声、时间轴伸縮等等。针对这些相似性变形, 研究者们提出了很多种相似性度量方法。