7第七讲——名空间和RTTI
计算机名人

安德斯· 海尔斯伯格
安德斯· 海尔斯伯格(Anders Hejlsberg, 1960.12~),丹麦人,Turbo Pascal编 译器的主要作者,Delphi和C#之父,同 时也是· NET创立者。
C++之父
1982年,美国AT&T公司贝尔实验室的Bjarne Stroustrup博士在c语言的基础上引 入并扩充了面向对象的概念,发明了—种新的程序语言。为了表达该语言与c语言 的渊源关系,它被命名为C++。而Bjarne Stroustrup(本贾尼· 斯特劳斯特卢普) 博士被尊称为C++语言之父。后C++语言历经了不断地完善,例如1990年c++语 言引入模板和异常处理的概念,1993年引入运行时类型识别(RTTI)和名字空间 (Name Space)的概念。1997年,c++语言成为美国国家标准(ANSI)。1998年, c++语言又成为了国际标准(ISO)。目前,c++语言已成为使用最广泛的面向对象 程序设计语言之一。
计算机名人
C语言之父
丹尼斯· 里奇,C语言之父,UNIX之父。曾担任朗讯科技公 司贝尔实验室下属的计算机科学研究中心系统软件研究部的主 任一职。1978年与布莱恩· 科尔尼干(Brian W. Kernighan)一 起出版了名著《C程序设计语言(The C Programming Language)》C语言是使用最广泛的语言之一,可以说,C语 言的诞生是现代程序语言革命的起点,是程序设计语言发展史 中的一个里程碑。自C语言出现后,以C语言为根基的C++、 Java和C#等面向对象语言相继诞生,并在各自领域大获成功。 但今天C语言依旧在系统编程、嵌入式编程等领域占据着统治 地位。
RTTI的介绍和使用

RTTI的介绍和使⽤RTTI介绍及使⽤什么是RTTI?RTTI是[运⾏阶段类型识别](Runtime Type Identification) 。
RTTI旨在为程序在运⾏阶段确定对象的类型提供⼀种标准的⽅式。
很多类库已经为其对象提供了实现这种功能的⽅式,但由于c++内部不⽀持,因此各个⼚商的机制通常互不兼容。
RTTI的⽤途为何需要知道类型。
可能希望调⽤类⽅法的正确版本,在这种情况下,只要该函数是类层次结构中所有成员都有的虚函数,则并不真正需要知道对象的类型。
但派⽣对象可能包含不是继承⽽来的⽅法,在这种情况下,只有某些类型的对象可以使⽤该⽅法。
也可能是出于调试的⽬的,想跟踪⽣成的对象的类型。
对于后两种情况,RTTI提供解决⽅案。
RTTI的⼯作原理C++有3个⽀持RTTI的元素。
如果可能的话,dynamic_cast 运算符将使⽤⼀个指向基类的指针来⽣成⼀个指向派⽣类的指针:否则,该运算符将返回0——空指针。
typeid 运算符返回⼀个指出对象的类型的值。
type_info 结构存储了有关特定类型的信息。
警告:RTTI只适⽤于包含虚函数的类1.dynamic_cast 运算符dynamic_cast 不能回答“指针指向的是哪类对象”这样的问题,但能回答“是否可以安全地将对象的地址赋给特定的指针”这样的问题。
#include "stdafx.h"#include <iostream>#include <cstdlib>#include <ctime>using std::cout;class Grand{private:int hold;public:Grand(int h = 0):hold(h){}virtual void Speak() const { cout << "I am a grand class!\n"; }virtual int value() const { return hold; }};class Superb :public Grand{public:Superb(int h = 0) :Grand(h){}void Speak() const { cout << "I am a Superb class!\n"; }virtual void Say() const { cout << "I hold the superb value of " << value() << "!\n"; }};class Magnificent :public Superb{private:char ch;public:Magnificent(int h = 0, char c = 'A') :Superb(h), ch(c) {}void Speak() const { cout << "I am a magnificent class !\n"; }void Say() const { cout << "I hold the character " << ch << " and the integer " << value() << "!\n"; }};Grand *GetOne();Grand *GetOne(){Grand *p = nullptr;switch (std::rand() % 3){case 0:p = new Grand(std::rand() % 100);break;case 1:p = new Superb(std::rand() % 100);break;case 2:p = new Magnificent(std::rand() % 100, 'A' + std::rand() % 26);break;default:break;}return p;}int _tmain(int argc, _TCHAR* argv[]){std::srand(std::time(0));Grand *pg;Superb *ps;for (int i = 0; i < 5; i++){pg = GetOne();pg->Speak();if (ps = dynamic_cast<Superb *>(pg))ps->Say();}return 0;}2.typeid 运算符和type_info类typeid 运算符使得能够确定两个对象是否为同种类型。
Thinking in C

Thinking in C++1.private与protect关键字的区别。
子类能访问基类的protect成员而不能访问private成员。
2.友元,friend如何声明一个友元。
3.缺省构造函数。
当类声明了一个带参数的构造函数后而没有声明无参数构造函数,编译器还会为它生成一个默认的缺省构造函数吗?分析下例的错误:class A{public:A(int i){cout<<i<<endl;}};void main(){A a;}4.构造函数有没有返回值?析构函数有没有返回值?析构函数可不可以带参数?5.解释一下重载函数重载允许两个或更多个函数使用同一个名字限制条件是它们的参数表必须不同参数类型不同或参数的数目不同。
6.重载函数如何来区分彼此?7.解释缺省参数函数8.下例能编译通过吗?为什么。
重载的缺省参数函数不能与其它函数产生二义。
void s(int i){cout<<i<<endl;}void s(int i, int j=0){cout<<i<<endl;}void main(){s(5);}9.能否用返回值来区分重载函数?10.看下例回答以下问题:a.常量必须初始化,下面的代码又和问题:const int i;i=20;b.常量有没有存储控件,或者只是编译时的符号而已?不一定c.常量一定是在编译时就确定其值的吗?const int i=100;const int j=i+100;long address=(long)&j;//强迫编译器为常量分配存储空间char buf[j+10];void main(){const char c=cin.get();const char c2=c-'a'+'A';cout<<c<<" "<<c2<<endl;}11.看下例回答以下问题:a.能否将一个非常量对象的地址赋给一个常量指针?b.能否将一个常量对象的抵制赋给一个非常量指针?若确要如此,该如何做?void main(){const int i=5;int *j=const_cast<int *>(&i);}const int* x;//常量指针int* const x=&d; //指针常量int const* x; //常量指针const int* const x=&d; //常量指针常量12.函数调用中值传递使用常量定义无甚意义:void f(const int i);但函数返回值的常量定义有特殊作用,看下例:class X{int i;public:void modify(){cout<<"haha"<<endl;}};const X fun(){return X();}void main(){//! fun().modify(); 常量不能为左值,所以下例也不成立://! const X g;//! g.modify();//!!! 常量一定不能为左值吗?看16题}13.常量的典型应用:void u(const int* p);const char* v();14.分析下例说出错误的原因:class X{};X f(){return X();}void g1(X&){}void g2(const X&){}void main(){//! g1(f()); 临时变量都是常量g2(f());}15.如何使用类常量成员,如何初始化?class Y{public:const size;Y();};Y::Y():size(100){}class X{enum{i=100};};//! class X{//! const int i;//! X(){};//! };16.将一个成员函数声明为常量函数有什么作用?a. 编译器保证该函数不得修改成员变量的值b. 允许一个常量对象调用此函数class X{public:void f() const{cout<<"haha..."<<endl;}};void main(){const X cs;cs.f();}17.volatile关键字有什么作用?volatile告诉编译器不要对其做任何自作多情的假设与优化。
c++PRIMER中文版

前言C++ Primer的第二版和第三版之间的变化非常大。
最引人注意的是,C++已经被国际标准化,这不但为语言增加了新的特性,比如异常处理、运行时刻类型识别(RTTI)、名字空间、内置布尔数据类型、新的强制转换方式,而且还大量修改并扩展了现有的特性,比如模板、支持面向对象(object-oriented)和基于对象(object-based)程序设计所需要的类(class)机制、嵌套类型、以及重载函数的解析机制。
也许更重要的是,一个覆盖面非常广阔的库现在成了标准C++的一部分,其中包括以前的标准模板库或STL。
新的string类型、一组顺序和关联容器类型——比如vector、list、map和set——以及在这些类型上进行操作的一组可扩展的泛型算法(generic algorithms),都是这个新标准库的特性。
本书不但包括了许多新的资料,而且还涵盖了怎样在C++中进行程序设计的新的思考方法。
简而言之,实际上,不但C++已经被重新创造,它的C++ Primer,第三版,也有了很大的变化。
在此第三版中,不但对语言的处理方式发生了根本的变化,而且作者本身也发生了变化:首先,我们的人数已经加倍。
而且,我们的写作过程也已经被国际化了(尽管我们还牢牢扎根于北美大陆):Stan是美国人,Josée是加拿大人。
最后,这个双作者关系也反映了C++团体的两类主要活动:Stan现在正在华特迪思尼动画公司(Walt Disney Feature Animation)致力于以C++为基础的3D计算机图形和动画应用,而Josée正专心于C++的定义与实现,同时她也是C++标准的核心语言小组的主席,以及IBM加拿大实验室的C++编译器组的成员。
Stan是Bell实验室中与Bjarne Stroustrup(C++的发明人)一起工作的早期成员之一,从1984年开始一直从事C++方面的工作。
Stan曾经致力于cfront的各种实现,从1986年的版本1.1到版本3.0,并领导了2.1和3.0版本的开发组。
RTTI、虚函数和虚基类的实现方式、开销分析及使用指导
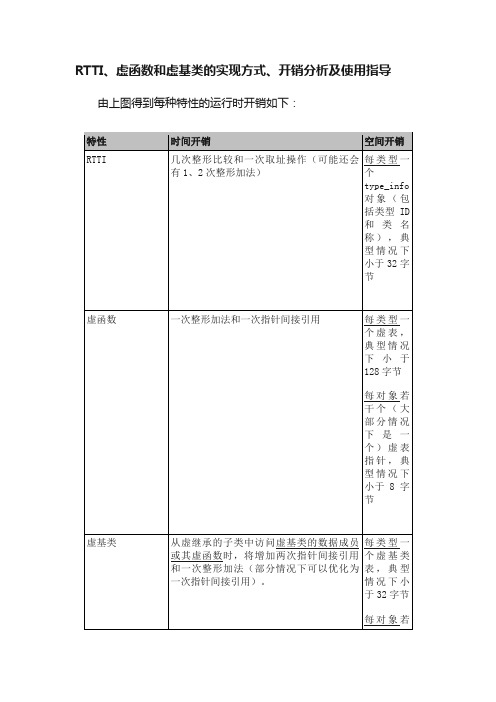
RTTI、虚函数和虚基类的实现方式、开销分析及使用指导由上图得到每种特性的运行时开销如下:可见,关于老天“饿时掉馅饼、睡时掉老婆”等美好传说纯属谣言。
但凡人工制品必不完美,总有设计上的取舍,有其适应的场合也有其不适用的地方。
C++中的每个特性,都是从程序员平时的生产生活中逐渐精化而来的。
在不正确的场合使用它们必然会引起逻辑、行为和性能上的问题。
对于上述特性,应该只在必要、合理的前提下才使用。
"dynamic_cast" 用于在类层次结构中漫游,对指针或引用进行自由的向上、向下或交叉强制。
"typeid" 则用于获取一个对象或引用的确切类型,与 "dynamic_cast" 不同,将 "typeid" 作用于指针通常是一个错误,要得到一个指针指向之对象的type_info,应当先将其解引用(例如:"typeid(*p);")。
一般地讲,能用虚函数解决的问题就不要用"dynamic_cast",能够用 "dynamic_cast" 解决的就不要用 "typeid"。
比如:voidrotate(IN const CShape& iS){if (typeid(iS) == typeid(CCircle)){// ...}else if (typeid(iS) == typeid(CTriangle)){// ...}else if (typeid(iS) == typeid(CSqucre)){// ...}// ...}以上代码用 "dynamic_cast" 写会稍好一点,当然最好的方式还是在CShape里定义名为 "rotate" 的虚函数。
虚函数是C++众多运行时多态特性中开销最小,也最常用的机制。
ASP.NET常见面试题及答案(130题)

常见⾯试题及答案(130题)1. 简述 private、 protected、 public、 internal 修饰符的访问权限。
答 . private : 私有成员, 在类的内部才可以访问。
protected : 保护成员,该类内部和继承类中可以访问。
public : 公共成员,完全公开,没有访问限制。
internal: 在同⼀命名空间内可以访问。
2 .列举 页⾯之间传递值的⼏种⽅式。
答. 1.使⽤QueryString, 如....?id=1; response. Redirect()....2 .使⽤Session变量3.使⽤Server.Transfer4.C#中的委托是什么?事件是不是⼀种委托?答:委托可以把⼀个⽅法作为参数代⼊另⼀个⽅法。
委托可以理解为指向⼀个函数的引⽤。
是,是⼀种特殊的委托5.override与重载的区别答:重载是⽅法的名称相同。
参数或参数类型不同,进⾏多次重载以适应不同的需要Override 是进⾏基类中函数的重写。
为了适应需要。
6.如果在⼀个B/S结构的系统中需要传递变量值,但是⼜不能使⽤Session、Cookie、Application,您有⼏种⽅法进⾏处理?答: this.Server.TransferResponse. Redirect()---QueryString9.描述⼀下C#中索引器的实现过程,是否只能根据数字进⾏索引?答:不是。
可以⽤任意类型。
11.⽤.net做B/S结构的系统,您是⽤⼏层结构来开发,每⼀层之间的关系以及为什么要这样分层?答:⼀般为3层:数据访问层,业务层,表⽰层。
数据访问层对数据库进⾏增删查改。
业务层⼀般分为⼆层,业务表观层实现与表⽰层的沟通,业务规则层实现⽤户密码的安全等。
表⽰层为了与⽤户交互例如⽤户添加表单。
优点:分⼯明确,条理清晰,易于调试,⽽且具有可扩展性。
缺点:增加成本。
13.什么叫应⽤程序域?答:应⽤程序域可以理解为⼀种轻量级进程。
c++ 第2章-2.4指针与名字空间

指针型变量的定义
“先定义后使用”
一般格式:
类型描述符* 指针变量名表; 例: int* ptr; float* array;
char *s1,*s2;
例:int *p;
*p=3;
随机内容 1000H 随机内容 随机内容
p 编译可能通过,但危险!!!
定义一个指针后,必须先给它赋值后才能引用,否则将
const修饰符的用法 格式1:普通常量 const 类型 常量名 = 值;
const double PI = 3.1415;
格式2:引用 const 类型 &引用名 = 变量名;
说明:不能通过常引用修改所引用的对象。
int i = 0; const int &refi = i; i++; // refi++; //
OK
Error!
const修饰符的用法
格式3: 修饰指针变量指向的变量,放在类型前面
const 类型 *指针变量;
int a = 6, b = 7; const int *p = &a //表示不能通过p改变p指向的内存的内容 *p=19
//错误
//正确
a = 19;
p = &b;
//正确
array
//*(a+i) = rand();
{ int array[3]; init( array, 3 ); return 0; }
4.3
void和const类型的指针
void指针
void在作为函数类型和参数类型时为空类型,表示没有返 回值或参数。 void修饰指针时称为“无类型指针”,表示该指针可以指 向任意类型的变量。 虽然void指针可以指向任意类型的数据,但是在使用void
第六讲 空间数据索引技术与空间查询语言(2)ppt课件

⑤查询:求出河流在流经的各国境内的长度 ⑥查询:按其邻国数目的多少列出所有国家。
四、空间查询处理
过滤筛选步骤(Filter): 细化步骤(Refine): 用一个不精确的大致范围来进行查询,产生
一个满足条件的较小候选集合。对候选集合 中的对象进行精确的筛选,产生最终的查询 结果。
点四叉树的每个结点存储了一个空间点的信 息及孩子结点的指针。
(0,100) D (30,90)
B (10,75)
(100,100) N WN E
A
SWSE
F(80,70)
F BC E
A (45,45)
C (25,15) E(70,20)
D
(0,0)
(100,0)
(a)平面图
(b)结构图
图5-22 一颗二维的点四叉树结构
本讲重点内容
➢ 空间索引的定义 ➢ 各种空间索引方法 ➢ 主要的空间操作算子 ➢ 空间查询的处理步骤
此课件下载可自行编辑修改,此课件供参考! 部分内容来源于网络,如有侵权请与我联系删除!感谢你的观看!
Disjoint(anotherGeometry ) Intersects(anotherGeometry ) Touches(anotherGeometry ) 空间 Crosses(anotherGeometry) 关系 Within(anotherGeometry) 运算
Contains(anotherGeometry)
PR四叉树叶子结点可能不在树的同一层次;叶子结 点的黑结点或空结点分别表示数据空间某一位置空 间点的存在与否。
H
G
B F I
7第七讲——名空间和RTTI

模块3
m1
模块1
文件2
g1 g2 g3 g1,g2,g3
g1 g2 g3 g1,g2,g3
文件4
n1 n2
h2 n1 h3 n2
文件3
h1 h1 h1
模块2
// file1.h namespace f1 { void f1(); void f2(); void f3(); void f4(); } // file2.h namespace f2 { void g1(); void g2(); void g3(); }
namspace B { class File; void Fun (); namspace C //名空间可以嵌套。 { class File; void Fun (); } }
匿名空间
“匿名空间”:设定一个无名的命名空间,将标识符 集合其内,由于无名,本文件的域外可以无限制地 使用该空间的标识符,省却了定义时的static,使用 时也节省了空间名前缀。但别的文件不可使用。因 此匿名空间的作用相当于C时代的静态全局变量 。 如: namspace { class File; void Fun (); } 匿名空间也可以跨文件追加。 一个编译单元只可有一个匿名空间。
1规则的示例:
在名字空间之外使用时要时刻带空间名: namespace Parser { double prim( bool);
double term( bool);
} double Parser::prim( bool get) {} double Parser::term( bool get) {}
然后,在源程序开发时,就可以将这三个模块 文件作为资源使用。当然,要对各头文件中所 涉及的函数予以实现。
第五章空间查询与空间分析PPT课件

可编辑课件PPT
返回 9
第五章 空间查询与空间分析 §5-1 空间查询
二、空间数据查询种类
3、空间关系查询 7)边沿匹配检索 空间查询在多幅地图的数据文件之间进行,这时需应用 边沿匹配处理技术。
可编辑课件PPT
返回 10
第五章 空间查询与空间分析 §5-1 空间查询
二、空间数据查询种类
4、属性查询
二、空间数据查询种类
4、属性查询
1) 查找
可编辑课件PPT
12
第五章 空间查询与空间分析 §5-1 空间查询
二、空间数据查询种类
4、属性查询 2)SQL查询
实现:交互式选择各项,输入后,系统再转换为标准的 SQL,由数据库系统执行或ODBC C语言执行,得到结果,提 取目标标识,在图形文件中找到空间对象,并显示。
二、空间数据查询种类
3、空间关系查询
4)穿越查询
采用空间运算的方法执行,根据一个线目标的空间坐标,计算哪些面或线 与之相交。
5)落入查询
一个空间对象落入哪个空间对象之内。--空间运算
6)缓冲区查询
根据用户给定的一个点、线、面缓冲的距离,从而形成一个缓冲区的多边 形,再根据多边形检索原理,检索该缓冲区内的空间实体。
实现:根据空间索引,检索哪些对象可能位于该窗口,然后根据点、 线、面在查询开窗内的判别计算,检索到目标。--空间运算方法
可编辑课件PPT
5
第五章 空间查询与空间分析 §5-1 空间查询
二、空间数据查询种类
3、空间关系查询
1)相邻分析检索---通过检索拓扑关系
面—面: A、 从多边形与弧段关联表中,检索该多边形关联的所有弧段; B、 从弧段关联的左右多边形表中,检索出这些弧段关联的多 边形。 线—线: A、 从线状地物表中,查找组成A的所有弧段及关联的结点; B、 从结点表中,查询与这些结点关联的弧段; 点—点: (A与B是否相通)等。
codewarrior的pathentry编译问题

codewarrior的pathentry编译问题第一步:理解编译阶段我们的前面的课程中已经学到,源程序输入完之后的工作就是要编译它。
编译源程序就是计算机把你所写(通常是用C 或 C++编写的)的源代码进行分解、分析,然后转化为机器语言。
机器语言是一种计算机能够理解阿语言,而且它运行起来比 C 或 C++ 也要快得多。
编译的大致过程如下:1. 用C或C++ 编写代码:2. 进行编译。
CodeWarrior 编译上述代码并把它翻译成机器语言,结果如下:上述机器代码难于阅读,不要去管它。
机器代码相比 C 或 C++ 而言,要难理解多了。
但是,计算机只能理解机器语言。
只有将你的程序编译—或翻译—成机器代码,然后再执行它,这样运行起来才能快一些,而不是每次运行时才去翻译它,那样运行速度就很慢了。
你只需选定一个源文件,然后从工程菜单中选择反汇编项,你就能看到该文件的机器语言清单。
实际上上面我们看到的机器语言清单就是这样得到的。
如果你仔细地对照阅读一下你的 C 或 C++ 源代码和它编译后的机器代码,不难发现它们之间的关系。
CodeWarrior 中编译选项的详细设置在正式开始编译源代码之前,CodeWarrior 还要对其做预处理。
在这个阶段,是对 C 或 C++ 代码进行编译前的一些准备工作。
在编写程序的过程中,往往会有很多相同的P代码输入,于是程序员使用一些快捷方式,比如所谓的宏(macros)来代替这些相同的输入。
例如,你可以使用 APPNAME 作为一个宏,来表示“Metrowerks CodeWarrior”,以此来减少输入的工作量。
预处理就是要把这些宏转换为它们实际表示的代码,此外还要替换一些定义符号(比如#define THREE 3)为实际的源代码。
为了更好地理解预处理所做的工作,你可以查看一下预处理结果的清单。
首先在工程窗口中选中一个源文件,然后从工程菜单中选择预处理项,你就可以看到源代码进行了预处理之后,编译之前的结果清单了。
Google C++ 编程规范

1. 现有不统一代码(Existing Non-conformant Code)52
2. Windows代码(Windows Code)52
十、团队合作.........................53
一、头文件
通常,每一个.cc 文件(C++的源文件)都有一个对应的.h 文件(头文件),也有一些例
外,如单元测试代码和只包含main()的.cc 文件。
正确使用头文件可令代码在可读性、文件大小和性能上大为改观。
下面的规则将引导你规避使用头文件时的各种麻烦。
1. #define的保护
所有头文件都应该使用#define 防止头文件被多重包含(multiple inclusion),命名格式
些包含了你的头文件的代码重新编译。因此,我们宁可尽量少包含头文件,尤其是那些包含
在其他头文件中的。
使用前置声明可以显著减少需要包含的头文件数量。举例说明:头文件中用到类File,但不
需要访问File 的声明,则头文件中只需前置声明class File;无需#include
"file/base/file.h"。
之包含头文件。
有时,使用指针成员(pointer members,如果是scoped_ptr 更好)替代对象成员(object
members)的确更有意义。然而,这样的做法会降低代码可读性及执行效率。如果仅仅为
在头文件如何做到使用类Foo 而无需访问类的定义?
1) 将数据成员类型声明为Foo *或Foo &;
2) 参数、返回值类型为Foo 的函数只是声明(但不定义实现);
RTTI介绍

名称空间namespaceC++名字空间主要就是用来避免类名的冲突,尤其是在大项目中,它的作用体现非常明显。
#include <cstdlib>#include <iostream>using namespace std;float float1 = 88.8f; //全局变量::namespace//未命名名字空间{float unnamespacefloat = 99.9f;}namespace ns1//名字空间ns1{const int integer1 = 100;const double double1 = 100.5;float float1 = 99.9f;void printValue();namespace Inner//内嵌名字空间{double innerdouble = 55.5;}}void main(void){cout<<"全局变量”<< ::float1 <<endl;cout << "未命名名字空间变量" << unnamespacefloat << endl;cout << "ns1::integer1 = " <<ns1::integer1 << endl;cout << "ns1::double1 = " << ns1::double1 << endl;cout << "ns1::float1 = " << ns1::float1 << endl;cout << "ns1::Inner::innerdouble = " << ns1::Inner::innerdouble <<endl;ns1::printValue();}void ns1::printValue()//ns1中输出函数的实现{cout <<::float1 << endl;cout <<unnamespacefloat << endl;cout << "integer1 = " << integer1 << endl;cout << "double1 = " << double1 << endl;cout << "float1 = " << float1 << endl;cout << "Inner::innerdouble = " << Inner::innerdouble << endl;}RTTI介绍runtime typeinfo多态RTTI提供了以下两个非常有用的操作符:(1)typeid操作符,返回指针和引用所指的实际类型;(2)dynamic_cast操作符,将基类类型的指针或引用安全地转换为派生类型的指针或引用。
异常

异常处理-命名空间-RTTI异常处理-命名空间-RTTI (1)1. 异常处理一般性概念 (1)2. C++标准异常处理 (6)2.1. C++异常处理 (6)2.2. 多个异常的组织 (13)2.3. 异常接口说明 (20)3. MFC异常处理 (21)4. Win32结构化异常处理(SEH) (26)4.1. __try{}__finally{}结构 (27)4.2. __try{}__except(){}结构 (29)4.3. SEH到标准C++异常处理的转换 (34)5. 命名空间 (36)5.1. C语言的命名控制 (36)5.2. 命名空间的目标和定义 (37)5.3. 未命名的命名空间--命名空间后没有定义名字 (39)5.4. 命名空间的使用 (39)6. RTTI运行时类型信息 (41)6.1. RTTI的两种使用方法 (41)1.异常处理一般性概念修复技术是提高代码健壮性的最有效方法之一。
C语言中实现错误处理的方法是将函数调用与错误处理程序紧密结合起来,这使得错误处理的使用很不方便。
在传统的C 语言程序设计中,一个函数的出错信息往往是通过函数的返回值获得,这就要求函数的使用者在每次的函数调用时都要进行相应的错误判断,有时,返回值所包含的错误信息较为复杂时,对出错信息的判断和处理也变的非常复杂,而且对同一函数的重复调用往往要伴随着对错误信息的重复判断和处理。
这样的异常处理方式使得程序代码既累赘,可读性又差。
而且往往因为缺乏条理而遗漏对某个错误的处理。
异常处理通过把异常的检查和异常的处理分开,使得程序的代码简洁、清晰、可读性强。
例:假设有一个初始化数据库的函数InitDb(),它需要调用创建数据库的函数CreateDb(),创建用户及授权函数CreateUser(),创建表函数CreateTable(),CreateTable()又调用创建索引的函数CreateIndex():每个函数都以返回值表示处理的结果,在InitDb()的返回值中,如果既要包含最终的错误信息,又要包含那一层次调用出错的信息,一种代码的形式为:int CreateUser(){//...}int CreateIndex(){//...}int CreateTable(){//....if((iRet=CreateIndex())<0)//错误处理}int CreateDb(){//...}int InitDb(){if((iRet=CreateDb())==0){if((iRet=CreateUser())==0){if((iRet=CreateTable()==0)){//...return 0;}else{//错误处理return ??;}}else{//错误处理return ??}}else{//错误处理return ??}}//或者int InitDb(){if((iRet=CreateDb())<0){//错误处理//return ??}if((iRet=CreateUser())<0){//错误处理//return ??}if((iRet=CreateTable()<0)){//错误处理//return ??}return 0;}代码变得复杂而难以维护,而如果使用异常处理,可简化为如下形式void CallFunc(){try{InitDb();}catch(???){//异常处理}}void InitDb(){CreateDb(); //在CreateDb()内部如果执行失败,抛出异常CreateUser(); //在CreateUser()内部如果执行失败,抛出异常CreateTable(); //在CreateTable()函数内部如果执行失败,抛出异常}例子:写一个程序计算公式值n!+|a|+∑n(n等负数时出错处理,a=0时出错处理,a,n可以从键盘输入也可以给定)2.C++标准异常处理2.1.C++异常处理C++的异常处理分为两部分,第一部分是检查程序处理情况,如果处理结果非期望的结果,则生成一个异常,并将异常抛出,抛出后,由异常的接收者处理这个异常,异常抛出的语法形式为:throw 异常对象throw是C++关键字,表示要抛出异常。
C++简介

c++简介C++是一种使用非常广泛的电脑程序设计语言。
它是一种静态数据类型检查的,支持多范型的通用程序设计语言。
C++支持过程化程序设计、数据抽象化、面向对象程序设计、泛型程序设计、基于原则设计等多种程序设计风格。
贝尔实验室的比雅尼·斯特劳斯特鲁普博士在20世纪80年代发明并实现了C++。
起初,这种语言被称作“C with Classes”(“包含类的C语言”),作为C 语言的增强版出现。
随后,C++不断增加新特性。
虚函数(virtual function)、操作符重载(operator overloading)、多重继承(multiple inheritance)、模板(template)、异常处理(exception)、RTTI(Runtime type information)、命名空间(namespace)逐渐纳入标准。
1998年国际标准组织(ISO)颁布了C++程序设计语言的国际标准ISO/IEC 14882-1998。
另外,就目前学习C++而言,可以认为它是一门独立的语言;它并不依赖C语言,我们可以完全不学C 语言,而直接学习C++。
根据《C++编程思想》(Thinking in C++)一书所评述的,C++与C的效率往往相差在正负5%之间。
所以有人认为在大多数场合中,C++完全可以取代C语言。
C++语言发展大概可以分为三个阶段:第一阶段从80年代到1995年。
这一阶段C++语言基本上是传统类型上的面向对象语言,并且凭借着接近C语言的效率,在工业界使用的开发语言中占据了相当大份额;第二阶段从1995年到2000年,这一阶段由于标准模板库(STL)和后来的Boost等程序库的出现,泛型程序设计在C++中占据了越来越多的比重性。
当然,同时由于Java、C#等语言的出现和硬件价格的大规模下降,C++受到了一定的冲击;第三阶段从200 0年至今,由于以Loki、MPL等程序库为代表的产生式编程和模板元编程的出现,C++出现了发展历史上又一个新的高峰,这些新技术的出现以及和原有技术的融合,使C++已经成为当今主流程序设计语言中最复杂的一员。
C++学习笔记

回用户定义类型的根本所在。 它可以被用来从现有的类创建新类。当用传值方式传递或返回一个
对象时,编译器调用这个拷贝构造函数。因为 C+编译器默认是进行位拷贝(bitcopy)的,位拷贝方
式在类中存在指针时通常是危险的,因为这将使多个对象指向同一片内存区域。因为缺省构造函数
1 直接引自文献【3】,原文引用。
第 4 页 共 19 页
1.4 语言技术规则
C++学习笔记
Language-technical rules No implicit violations of the static type system. Provide as good support for user-defined types as for built-in types. Locality is good. Avoid order dependencies. If in doubt, pick the variant of a feature that is easiest to teach. Syntax matters(often in perverse ways). Preprocessor usage should be eliminated.
3ɽ对 ࢀߟจݙత评 လ………………………………………………19 4ɽ总 结 ………………………………………………………………19 5ɽࢀߟจ…………………………………………………………ݙ19
第 1 页 共 19 页
C++学习笔记
0.问题
已经有 C,为什么要发明 C++? C++的设计遵循哪些原则? C++的特征? C++与面对对象编程有何关系? C++设计时在操作系统方面有什么考虑? C++与 C 有什么重要差别?试比较 C 与 C++。 C++对 C 的改进主要体现在哪些方面? C++的 class 与 C 的 struct 的区别是什么? 没有定义析构函数的类会如何?会自己清除吗?如果会,什么时候清除? 如 X:X (int I):i(I) {},构造函数初始化表达式有什么作用?在什么时候必须使用? 什么是引用?它与指针有什么区别? 使用关键字 const 的好处是什么? 何时需要使用 const ? 引进 const 的原因? volatile 关键字与 const 关键字有何区别? C 中的常量与 C++中的常量有什么区别? const int f(const int& a) const ,如此定义的函数有什么特别之处? 三个 const 各起什么作用? const 指针和指向 const 的指针有什么区别?如何使用? f(const X& x), f(X& x), f(X x)的三种引用方式有什么区别?分别在什么时候使用? 在 const 成员函数中改变数据成员有什么方法? const 与 volatile 的区别? 在类中使用 const 与使用 enum 有什么区别? 为什么要引进输入输出流? 原来 C 的标准 I/O 的不足? endl 操纵算子起什么作用? 它与 flush 算子有什么不同? 输入输出流的类层次结构? 有哪些头文件?分别处理哪些事务? 如何在输入输出流中寻找? C 和 C++中的库函数 printf 和 cout 等是如何与计算机硬件打交道的?为什么可以从屏幕产生输出? 什么是内联函数?内联函数与非内联函数有什么区别? 变量用 static 修饰与不用 static 修饰有什么区别。static, extern, auto, register 指定符号的
DELPHI RTTI 探索

问题:Delphi 的RTTI机制浅探( 积分:100, 回复:21, 阅读:352 )分类:Object Pascal ( 版主:menxin, cAkk )来自:savetime, 时间:2004-1-21 0:48:00, ID:2420610 [显示:小字体| 大字体] Delphi 的RTTI机制浅探savetime2k@ 2004.1.20目录===============================================================================⊙RTTI 简介⊙类(class) 和VMT 的关系⊙类(class)、类的类(class of class)、类变量(class variable) 的关系⊙TObject.ClassType 和TObject.ClassInfo⊙is 和as 运算符的原理⊙TTypeInfo –RTTI 信息的结构⊙获取类(class)的属性(property)信息⊙获取方法(method)的类型信息⊙获取有序类型(ordinal)、集合(set)类型的RTTI 信息⊙获取其它数据类型的RTTI 信息===============================================================================本文排版格式为:正文由窗口自动换行;所有代码以80 字符为边界;中英文字符以空格符分隔。
(作者保留对本文的所有权利,未经作者同意请勿在在任何公共媒体转载。
)正文=============================================================================== ⊙RTTI 简介===============================================================================RTTI(Run-Time Type Information) 翻译过来的名称是“运行期类型信息”,也就是说可以在运行期获得数据类型或类(class)的信息。
头文件与名字空间的概念

头文件与名字空间的概念
头文件和名字空间是编程中两个重要的概念。
头文件通常用于对函数进行声明,在一个程序中,一般是命名空间包含类,类中包含函数,函数是某个功能的实现,而头文件是函数的声明。
库则是一些标准函数(经常重复使用的函数)的实现。
在新的C++标准中,标准库文件(函数的实现)和我们写的程序开头include的头文件(函数的声明)都是包含在命名空间std中,所以要使用头文件中声明的函数的话,还应该加上:using namespace std。
名字空间是一种逻辑概念,类似于贴标签,其目的是为了避免同名歧义。
例如,在计算机网络中,各种设备可能会有相同的名字,如果没有名字空间,就难以区分不同的设备。
库则是物理概念,类似于工具箱,一个库含有多个同类工具。
库的目的是为了将不通用途的工具分别装在不同的箱子里,实现解耦。
总的来说,头文件和名字空间都是为了使编程更高效、更易读、更易管理。
名字空间

感谢观看
内部引用
名字空间的名字也可以省略,称之为“无名名字空间”,无名名字空间经常被使用,其作用是“内部可以引 用,而外部不能引用”。
#include <iostream> using namespace std; namespace na { namespace { //无名名字空间 int sum(int a, int b) { return a + b; } } int calc(int x, int y) { return sum(x, y); //内部可以调用无名名字空间的变量或函数
#include <iostream> using namespace std; namespace na { void print(int a) { cout << "na::print: " << a << endl; } } namespace nb {
别名
名字空间可以一层层嵌套,指定时也得一层层地指定,这样很不方便,一般用别名代替就方便多了。 #include <iostream> using namespace std; namespace na { namespace nb { namespace nc { int sum(int a, int b) { return a + b; } } }
名字空间
计算机术语
01 定义
03 别名
目录
02 引用 04 内部引用
名字空间除了系统定义的名字空间之外,还可以自己定义,定义名字空间用关键字“namespace”,使用名 字空间时用符号“::”指定。
定义
名字空间除了系统定义的名字空间之外,还可以自己定义,定义名字空间用关键字“namespace”,使用名 字空间tream> using namespace std; namespace na { void print(int n) { //与名字空间nb的函数名相同 cout << "na::print: " << n << endl; }
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
void main () { G(); using namespace A; F(); B::F(); B::C::F(); G():from global namespace A::G(); F():from namespace A } F():from namespace B
F():from namespace C
include 与 using namespace 的区别和联系: 前者是将某文件搬到本地来,搬来了未必好用,是否 能用全在后者。 using ... 只是告诉编译器,扫描源代码时,凡遇到非 本作用域的标识符该到哪去找。
#include <iostream.h> namspace A { void F () { cout<<“F():from namespace A”<<endl; } void G () { cout<<“G():from namespace A”<<endl; } namspace B { void F () { cout<<“F():from namespace B”<<endl; } namspace C { void F () { cout<<“F():from namespace C”<<endl; } } } } void G () { cout<<“G():from global namespace”<<endl; }
使用名空间的方法:
1. 将使用的标识符前加名空间名——凡用就加: NS:: File obj; NS:: Fun (); 这属于“单个一次性开放”,且每次使用都得加。 尽管繁琐,但小巧灵活。此法用于使用的名空间 标识符个数、次数较少时。 2. 用using声明,一劳永逸地指定,免去了每次必须指 定的繁琐。属于“单个一劳永逸开放”,: 例如,经过以下声明: using NS::File; 在当前作用域中就可以不再加标识地直接引用File。 此法用于使用的名空间标识符次数频繁时。
G():from namespace A
VC6.0的名空间不成熟
1. 在VC6.0中,名空间与友元冲突,编译器会报错。 只好舍弃其中的一个。 2. 名空间还会与模板冲突。
这只是VC不成熟的表现,到后来的VC7.0、8.0 就完全解决了。但这时你只能忍疼割爱,放 弃其中的一个。
名空间设计规范
首先,根据问题,分析分解产生“函数调用关 系图”。该图应标明三个层次的模块划分(程 序级、文件级、函数级)。注意要按调用关系 而非依赖关系划分。 按规则转换为“文件组模块”。 按模块从宏到微的次序,将个模块的输出归纳 于各头文件中,并以各名空间命名。 再以模块(最外层)为单位,归纳为上一级名空 间,产生更抽象的头文件。 最后分别实现这些资源。
// file3.h namespace f3 { void h1(); }
// file4.h namespace f4 { void n1(); void n2(); }
k4
k2
文件5
k1 h1 k1
k5
k3
m2
文件6
m1 m1 m1
m3
模块3
// module1.h namespace m1 { #include “file1.h” } //using namespace f1; // module2.h namespace m2 { #include “file2.h” #include “file3.h” } //using namespace f2; //using namespace f3;
namspace B { class File; void Fun (); namspace C //名空间可以嵌套。 { class File; void Fun (); } }
匿名空间
“匿名空间”:设定一个无名的命名空间,将标识符 集合其内,由于无名,本文件的域外可以无限制地 使用该空间的标识符,省却了定义时的static,使用 时也节省了空间名前缀。但别的文件不可使用。因 此匿名空间的作用相当于C时代的静态全局变量 。 如: namspace { class File; void Fun (); } 匿名空间也可以跨文件追加。 一个编译单元只可有一个匿名空间。
然后,在源程序开发时,就可以将这三个模块 文件作为资源使用。当然,要对各头文件中所 涉及的函数予以实现。
名空间尽管发源于模块的划分和隔离,服务于 模块设计的开发模式,但从中受益的不仅是模 块,还有数据的使用。当然数据要求更细致的 服务,名空间就显粗糙了些,更精细的是类。
四个强制转换运算符 RTTI的概念 RTTI的两种使用方法 合理使用RTTI
新增的四个强制类型转换符
“强制”的含义: 在告诉编译器: “我知道你不愿意这样做,可是你必须做。尽管 执行吧,后果由我负责!”
const_cast
对象自身.
static_cast
除去对象的常属性。转换的是表达式而非 形式:const_cast < type > ( object )
欲引进多个名空间时,可在当前区域内使用如下语句: using namespace 空间名1; using namespace 空间名2; 当前区域是指using指令所在的位 臵,如函数内、文件内等等 此时在两个名空间有同名标识符时会产生二义性。区分 的方法同上。
主函数不可放入任何名空间中。
ቤተ መጻሕፍቲ ባይዱ
在新的C++标准程序库中,系统所用的标识符都声明 在命名空间std中,而未使用名空间的程序,都使用 带.h的头文件,则意味着其标识符都是全局的。
1规则的示例:
在名字空间之外使用时要时刻带空间名: namespace Parser { double prim( bool);
double term( bool);
} double Parser::prim( bool get) {} double Parser::term( bool get) {}
3. “全面开放,一劳永逸”
用指示符using:
using namespace std;语句后,名空间std中的所有 标识符都在本作用域中开放,可直接使用。此法将引 起标识符的“全面冲突”。 此法用于使用的名空间标识符个数、次数都很多时。 此法将因别的名空间的引进而产生“名冲突”。编 译器的仲裁准则是“外来服从本层”。它的在外层, 你的在内层,内层屏蔽外层。被屏蔽的同名者可用空 间名::标识符 来区分。 用2方法打开时可能发生的“个别冲突”,也用此 法解决。
C/C++的命名原则
C/C++/C#/Java等语言都遵循的命名原则:在同一 作用域内,不得命名相同名称的同种类标识符,否 则视为“名冲突”语法错误。 “命名冲突”:在不同文件模块中使用了相同的名 字来表示不同的事物,当这些模块一旦由头文件导 入凑到了一起,则会引起名称的混乱。 名空间如同磁盘的子目录,标识符如同各子目录下 的文件。名空间如同子目录一样可以嵌套。使用名 空间如同使用文件时要加路径,不过那是用于文件 的,名空间不能用,名空间有特定的使用方式。
C++语言程序设计
命名空间和RTTI
本章主要内容
命名空间 RTTI的概念 RTTI的两种使用方法 合理使用RTTI
在无“命名空间“的年代
记得在五六十年代,火车站的候车室(还有 候船厅)里都有块“旅客留言板”。人们在上 面留下自己的纸条。“小李,我已乘xx次列车 走了。”、“老王,我已抵连,现住在xx旅 馆。” ... 开始,旅客较少时很方便。但随着 旅客的增多,由于简称、同名等造成的误解, 带来的不是方便,而是混乱。 可见公共资源的是不可滥用的,必须加以限 制。
使用using namespace std;语句的同时要求标准库 的头文件都不得使用扩展名.h ,但用户自定义的头 文件可以带.h 。
//用using namespace std;打开标准库的标识符 #include <set> #include <iostream> void main() { using namespace std; //一劳永逸地打开 using std::set<int>::iterator; // 永久打开了iterator int a[100] = {10}; set<int> iSet(a,a+99); iterator it = iSet.find(25); cout<<" "<<*it<<endl; }
命名空间(namespace)
“命名空间”:为语言再设定一个命名的作用域 (named scope)——又加了一层隔离带,将所用 的标识符集合其内,域外使用时便多了一层名称来 标明归属。“名空间”在UML 中统称为“包”。 声明一个命名空间NS: namspace NS { class File; void Fun (); ... // 所有空间成员的声明必须写在名空间内 }
namespace U{ void f(); void s(); } namespace V{ void f(); //可以有多个f,它们是重载关系 void s(); 将引进重载的所有的f() } void func() { using namespace U; using V::f; // 注意,只写f,不写参数和返回类型 f(); // 必然是V空间的f() U::f(); // 这才是U空间的f() }
名空间的性质
“名空间”是跨越文件的。它不是简单的包含了文件, 而是更灵活的超越了文件。是个逻辑概念,就如同活动 在校内外的学生依然从属于某系某班级一样。