外文文献-中文翻译-数据库
外文参考文献翻译-中文

外⽂参考⽂献翻译-中⽂基于4G LTE技术的⾼速铁路移动通信系统KS Solanki教授,Kratika ChouhanUjjain⼯程学院,印度Madhya Pradesh的Ujjain摘要:随着时间发展,⾼速铁路(HSR)要求可靠的,安全的列车运⾏和乘客通信。
为了实现这个⽬标,HSR的系统需要更⾼的带宽和更短的响应时间,⽽且HSR的旧技术需要进⾏发展,开发新技术,改进现有的架构和控制成本。
为了满⾜这⼀要求,HSR采⽤了GSM的演进GSM-R技术,但它并不能满⾜客户的需求。
因此采⽤了新技术LTE-R,它提供了更⾼的带宽,并且在⾼速下提供了更⾼的客户满意度。
本⽂介绍了LTE-R,给出GSM-R与LTE-R之间的⽐较结果,并描述了在⾼速下哪种铁路移动通信系统更好。
关键词:⾼速铁路,LTE,GSM,通信和信令系统⼀介绍⾼速铁路需要提⾼对移动通信系统的要求。
随着这种改进,其⽹络架构和硬件设备必须适应⾼达500公⾥/⼩时的列车速度。
HSR还需要快速切换功能。
因此,为了解决这些问题,HSR 需要⼀种名为LTE-R的新技术,基于LTE-R的HSR提供⾼数据传输速率,更⾼带宽和低延迟。
LTE-R能够处理⽇益增长的业务量,确保乘客安全并提供实时多媒体信息。
随着列车速度的不断提⾼,可靠的宽带通信系统对于⾼铁移动通信⾄关重要。
HSR的应⽤服务质量(QOS)测量,包括如数据速率,误码率(BER)和传输延迟。
为了实现HSR的运营需求,需要⼀个能够与 LTE保持⼀致的能⼒的新系统,提供新的业务,但仍能够与GSM-R长时间共存。
HSR系统选择合适的⽆线通信系统时,需要考虑性能,服务,属性,频段和⼯业⽀持等问题。
4G LTE系统与第三代(3G)系统相⽐,它具有简单的扁平架构,⾼数据速率和低延迟。
在LTE的性能和成熟度⽔平上,LTE- railway(LTE-R)将可能成为下⼀代HSR通信系统。
⼆ LTE-R系统描述考虑LTE-R的频率和频谱使⽤,对为⾼速铁路(HSR)通信提供更⾼效的数据传输⾮常重要。
大数据外文翻译参考文献综述

大数据外文翻译参考文献综述(文档含中英文对照即英文原文和中文翻译)原文:Data Mining and Data PublishingData mining is the extraction of vast interesting patterns or knowledge from huge amount of data. The initial idea of privacy-preserving data mining PPDM was to extend traditional data mining techniques to work with the data modified to mask sensitive information. The key issues were how to modify the data and how to recover the data mining result from the modified data. Privacy-preserving data mining considers the problem of running data mining algorithms on confidential data that is not supposed to be revealed even to the partyrunning the algorithm. In contrast, privacy-preserving data publishing (PPDP) may not necessarily be tied to a specific data mining task, and the data mining task may be unknown at the time of data publishing. PPDP studies how to transform raw data into a version that is immunized against privacy attacks but that still supports effective data mining tasks. Privacy-preserving for both data mining (PPDM) and data publishing (PPDP) has become increasingly popular because it allows sharing of privacy sensitive data for analysis purposes. One well studied approach is the k-anonymity model [1] which in turn led to other models such as confidence bounding, l-diversity, t-closeness, (α,k)-anonymity, etc. In particular, all known mechanisms try to minimize information loss and such an attempt provides a loophole for attacks. The aim of this paper is to present a survey for most of the common attacks techniques for anonymization-based PPDM & PPDP and explain their effects on Data Privacy.Although data mining is potentially useful, many data holders are reluctant to provide their data for data mining for the fear of violating individual privacy. In recent years, study has been made to ensure that the sensitive information of individuals cannot be identified easily.Anonymity Models, k-anonymization techniques have been the focus of intense research in the last few years. In order to ensure anonymization of data while at the same time minimizing the informationloss resulting from data modifications, everal extending models are proposed, which are discussed as follows.1.k-Anonymityk-anonymity is one of the most classic models, which technique that prevents joining attacks by generalizing and/or suppressing portions of the released microdata so that no individual can be uniquely distinguished from a group of size k. In the k-anonymous tables, a data set is k-anonymous (k ≥ 1) if each record in the data set is in- distinguishable from at least (k . 1) other records within the same data set. The larger the value of k, the better the privacy is protected. k-anonymity can ensure that individuals cannot be uniquely identified by linking attacks.2. Extending ModelsSince k-anonymity does not provide sufficient protection against attribute disclosure. The notion of l-diversity attempts to solve this problem by requiring that each equivalence class has at least l well-represented value for each sensitive attribute. The technology of l-diversity has some advantages than k-anonymity. Because k-anonymity dataset permits strong attacks due to lack of diversity in the sensitive attributes. In this model, an equivalence class is said to have l-diversity if there are at least l well-represented value for the sensitive attribute. Because there are semantic relationships among the attribute values, and different values have very different levels of sensitivity. Afteranonymization, in any equivalence class, the frequency (in fraction) of a sensitive value is no more than α.3. Related Research AreasSeveral polls show that the public has an in- creased sense of privacy loss. Since data mining is often a key component of information systems, homeland security systems, and monitoring and surveillance systems, it gives a wrong impression that data mining is a technique for privacy intrusion. This lack of trust has become an obstacle to the benefit of the technology. For example, the potentially beneficial data mining re- search project, Terrorism Information Awareness (TIA), was terminated by the US Congress due to its controversial procedures of collecting, sharing, and analyzing the trails left by individuals. Motivated by the privacy concerns on data mining tools, a research area called privacy-reserving data mining (PPDM) emerged in 2000. The initial idea of PPDM was to extend traditional data mining techniques to work with the data modified to mask sensitive information. The key issues were how to modify the data and how to recover the data mining result from the modified data. The solutions were often tightly coupled with the data mining algorithms under consideration. In contrast, privacy-preserving data publishing (PPDP) may not necessarily tie to a specific data mining task, and the data mining task is sometimes unknown at the time of data publishing. Furthermore, some PPDP solutions emphasize preserving the datatruthfulness at the record level, but PPDM solutions often do not preserve such property. PPDP Differs from PPDM in Several Major Ways as Follows :1) PPDP focuses on techniques for publishing data, not techniques for data mining. In fact, it is expected that standard data mining techniques are applied on the published data. In contrast, the data holder in PPDM needs to randomize the data in such a way that data mining results can be recovered from the randomized data. To do so, the data holder must understand the data mining tasks and algorithms involved. This level of involvement is not expected of the data holder in PPDP who usually is not an expert in data mining.2) Both randomization and encryption do not preserve the truthfulness of values at the record level; therefore, the released data are basically meaningless to the recipients. In such a case, the data holder in PPDM may consider releasing the data mining results rather than the scrambled data.3) PPDP primarily “anonymizes” the data by hiding the identity of record owners, whereas PPDM seeks to directly hide the sensitive data. Excellent surveys and books in randomization and cryptographic techniques for PPDM can be found in the existing literature. A family of research work called privacy-preserving distributed data mining (PPDDM) aims at performing some data mining task on a set of private databasesowned by different parties. It follows the principle of Secure Multiparty Computation (SMC), and prohibits any data sharing other than the final data mining result. Clifton et al. present a suite of SMC operations, like secure sum, secure set union, secure size of set intersection, and scalar product, that are useful for many data mining tasks. In contrast, PPDP does not perform the actual data mining task, but concerns with how to publish the data so that the anonymous data are useful for data mining. We can say that PPDP protects privacy at the data level while PPDDM protects privacy at the process level. They address different privacy models and data mining scenarios. In the field of statistical disclosure control (SDC), the research works focus on privacy-preserving publishing methods for statistical tables. SDC focuses on three types of disclosures, namely identity disclosure, attribute disclosure, and inferential disclosure. Identity disclosure occurs if an adversary can identify a respondent from the published data. Revealing that an individual is a respondent of a data collection may or may not violate confidentiality requirements. Attribute disclosure occurs when confidential information about a respondent is revealed and can be attributed to the respondent. Attribute disclosure is the primary concern of most statistical agencies in deciding whether to publish tabular data. Inferential disclosure occurs when individual information can be inferred with high confidence from statistical information of the published data.Some other works of SDC focus on the study of the non-interactive query model, in which the data recipients can submit one query to the system. This type of non-interactive query model may not fully address the information needs of data recipients because, in some cases, it is very difficult for a data recipient to accurately construct a query for a data mining task in one shot. Consequently, there are a series of studies on the interactive query model, in which the data recipients, including adversaries, can submit a sequence of queries based on previously received query results. The database server is responsible to keep track of all queries of each user and determine whether or not the currently received query has violated the privacy requirement with respect to all previous queries. One limitation of any interactive privacy-preserving query system is that it can only answer a sublinear number of queries in total; otherwise, an adversary (or a group of corrupted data recipients) will be able to reconstruct all but 1 . o(1) fraction of the original data, which is a very strong violation of privacy. When the maximum number of queries is reached, the query service must be closed to avoid privacy leak. In the case of the non-interactive query model, the adversary can issue only one query and, therefore, the non-interactive query model cannot achieve the same degree of privacy defined by Introduction the interactive model. One may consider that privacy-reserving data publishing is a special case of the non-interactivequery model.This paper presents a survey for most of the common attacks techniques for anonymization-based PPDM & PPDP and explains their effects on Data Privacy. k-anonymity is used for security of respondents identity and decreases linking attack in the case of homogeneity attack a simple k-anonymity model fails and we need a concept which prevent from this attack solution is l-diversity. All tuples are arranged in well represented form and adversary will divert to l places or on l sensitive attributes. l-diversity limits in case of background knowledge attack because no one predicts knowledge level of an adversary. It is observe that using generalization and suppression we also apply these techniques on those attributes which doesn’t need th is extent of privacy and this leads to reduce the precision of publishing table. e-NSTAM (extended Sensitive Tuples Anonymity Method) is applied on sensitive tuples only and reduces information loss, this method also fails in the case of multiple sensitive tuples.Generalization with suppression is also the causes of data lose because suppression emphasize on not releasing values which are not suited for k factor. Future works in this front can include defining a new privacy measure along with l-diversity for multiple sensitive attribute and we will focus to generalize attributes without suppression using other techniques which are used to achieve k-anonymity because suppression leads to reduce the precision ofpublishing table.译文:数据挖掘和数据发布数据挖掘中提取出大量有趣的模式从大量的数据或知识。
数据库中英文对照外文翻译文献

中英文对照外文翻译Database Management SystemsA database (sometimes spelled data base) is also called an electronic database , referring to any collection of data, or information, that is specially organized for rapid search and retrieval by a computer. Databases are structured to facilitate the storage, retrieval , modification, and deletion of data in conjunction with various data-processing operations .Databases can be stored on magnetic disk or tape, optical disk, or some other secondary storage device.A database consists of a file or a set of files. The information in these files may be broken down into records, each of which consists of one or more fields. Fields are the basic units of data storage , and each field typically contains information pertaining to one aspect or attribute of the entity described by the database . Using keywords and various sorting commands, users can rapidly search , rearrange, group, and select the fields in many records to retrieve or create reports on particular aggregate of data.Complex data relationships and linkages may be found in all but the simplest databases .The system software package that handles the difficult tasks associated with creating ,accessing, and maintaining database records is called a database management system(DBMS).The programs in a DBMS package establish an interface between the database itself and the users of the database.. (These users may be applications programmers, managers and others with information needs, and various OS programs.)A DBMS can organize, process, and present selected data elements form the database. This capability enables decision makers to search, probe, and query database contents in order to extract answers to nonrecurring and unplanned questions that aren’t available in regular reports. These questions might initially be vague and/or poorly defined ,but people can “browse” through the database until they have the needed information. In short, the DBMS will “manage” the stored data items and assemble the needed items from the common database in response to the queries of those who aren’t programmers.A database management system (DBMS) is composed of three major parts:(1)a storage subsystemthat stores and retrieves data in files;(2) a modeling and manipulation subsystem that provides the means with which to organize the data and to add , delete, maintain, and update the data;(3)and an interface between the DBMS and its users. Several major trends are emerging that enhance the value and usefulness of database management systems;Managers: who require more up-to-data information to make effective decisionCustomers: who demand increasingly sophisticated information services and more current information about the status of their orders, invoices, and accounts.Users: who find that they can develop custom applications with database systems in a fraction of the time it takes to use traditional programming languages.Organizations : that discover information has a strategic value; they utilize their database systems to gain an edge over their competitors.The Database ModelA data model describes a way to structure and manipulate the data in a database. The structural part of the model specifies how data should be represented(such as tree, tables, and so on ).The manipulative part of the model specifies the operation with which to add, delete, display, maintain, print, search, select, sort and update the data.Hierarchical ModelThe first database management systems used a hierarchical model-that is-they arranged records into a tree structure. Some records are root records and all others have unique parent records. The structure of the tree is designed to reflect the order in which the data will be used that is ,the record at the root of a tree will be accessed first, then records one level below the root ,and so on.The hierarchical model was developed because hierarchical relationships are commonly found in business applications. As you have known, an organization char often describes a hierarchical relationship: top management is at the highest level, middle management at lower levels, and operational employees at the lowest levels. Note that within a strict hierarchy, each level of management may have many employees or levels of employees beneath it, but each employee has only one manager. Hierarchical data are characterized by this one-to-many relationship among data.In the hierarchical approach, each relationship must be explicitly defined when the database is created. Each record in a hierarchical database can contain only one key field and only one relationship is allowed between any two fields. This can create a problem because data do not always conform to such a strict hierarchy.Relational ModelA major breakthrough in database research occurred in 1970 when E. F. Codd proposed a fundamentally different approach to database management called relational model ,which uses a table asits data structure.The relational database is the most widely used database structure. Data is organized into related tables. Each table is made up of rows called and columns called fields. Each record contains fields of data about some specific item. For example, in a table containing information on employees, a record would contain fields of data such as a person’s last name ,first name ,and street address.Structured query language(SQL)is a query language for manipulating data in a relational database .It is nonprocedural or declarative, in which the user need only specify an English-like description that specifies the operation and the described record or combination of records. A query optimizer translates the description into a procedure to perform the database manipulation.Network ModelThe network model creates relationships among data through a linked-list structure in which subordinate records can be linked to more than one parent record. This approach combines records with links, which are called pointers. The pointers are addresses that indicate the location of a record. With the network approach, a subordinate record can be linked to a key record and at the same time itself be a key record linked to other sets of subordinate records. The network mode historically has had a performance advantage over other database models. Today , such performance characteristics are only important in high-volume ,high-speed transaction processing such as automatic teller machine networks or airline reservation system.Both hierarchical and network databases are application specific. If a new application is developed ,maintaining the consistency of databases in different applications can be very difficult. For example, suppose a new pension application is developed .The data are the same, but a new database must be created.Object ModelThe newest approach to database management uses an object model , in which records are represented by entities called objects that can both store data and provide methods or procedures to perform specific tasks.The query language used for the object model is the same object-oriented programming language used to develop the database application .This can create problems because there is no simple , uniform query language such as SQL . The object model is relatively new, and only a few examples of object-oriented database exist. It has attracted attention because developers who choose an object-oriented programming language want a database based on an object-oriented model. Distributed DatabaseSimilarly , a distributed database is one in which different parts of the database reside on physically separated computers . One goal of distributed databases is the access of informationwithout regard to where the data might be stored. Keeping in mind that once the users and their data are separated , the communication and networking concepts come into play .Distributed databases require software that resides partially in the larger computer. This software bridges the gap between personal and large computers and resolves the problems of incompatible data formats. Ideally, it would make the mainframe databases appear to be large libraries of information, with most of the processing accomplished on the personal computer.A drawback to some distributed systems is that they are often based on what is called a mainframe-entire model , in which the larger host computer is seen as the master and the terminal or personal computer is seen as a slave. There are some advantages to this approach . With databases under centralized control , many of the problems of data integrity that we mentioned earlier are solved . But today’s personal computers, departmental computers, and distributed processing require computers and their applications to communicate with each other on a more equal or peer-to-peer basis. In a database, the client/server model provides the framework for distributing databases.One way to take advantage of many connected computers running database applications is to distribute the application into cooperating parts that are independent of one anther. A client is an end user or computer program that requests resources across a network. A server is a computer running software that fulfills those requests across a network . When the resources are data in a database ,the client/server model provides the framework for distributing database.A file serve is software that provides access to files across a network. A dedicated file server is a single computer dedicated to being a file server. This is useful ,for example ,if the files are large and require fast access .In such cases, a minicomputer or mainframe would be used as a file server. A distributed file server spreads the files around on individual computers instead of placing them on one dedicated computer.Advantages of the latter server include the ability to store and retrieve files on other computers and the elimination of duplicate files on each computer. A major disadvantage , however, is that individual read/write requests are being moved across the network and problems can arise when updating files. Suppose a user requests a record from a file and changes it while another user requests the same record and changes it too. The solution to this problems called record locking, which means that the first request makes others requests wait until the first request is satisfied . Other users may be able to read the record, but they will not be able to change it .A database server is software that services requests to a database across a network. For example, suppose a user types in a query for data on his or her personal computer . If the application is designed with the client/server model in mind ,the query language part on the personal computer simple sends the query across the network to the database server and requests to be notified when the data are found.Examples of distributed database systems can be found in the engineering world. Sun’s Network Filing System(NFS),for example, is used in computer-aided engineering applications to distribute data among the hard disks in a network of Sun workstation.Distributing databases is an evolutionary step because it is logical that data should exist at the location where they are being used . Departmental computers within a large corporation ,for example, should have data reside locally , yet those data should be accessible by authorized corporate management when they want to consolidate departmental data . DBMS software will protect the security and integrity of the database , and the distributed database will appear to its users as no different from the non-distributed database .In this information age, the data server has become the heart of a company. This one piece of software controls the rhythm of most organizations and is used to pump information lifeblood through the arteries of the network. Because of the critical nature of this application, the data server is also the one of the most popular targets for hackers. If a hacker owns this application, he can cause the company's "heart" to suffer a fatal arrest.Ironically, although most users are now aware of hackers, they still do not realize how susceptible their database servers are to hack attacks. Thus, this article presents a description of the primary methods of attacking database servers (also known as SQL servers) and shows you how to protect yourself from these attacks.You should note this information is not new. Many technical white papers go into great detail about how to perform SQL attacks, and numerous vulnerabilities have been posted to security lists that describe exactly how certain database applications can be exploited. This article was written for the curious non-SQL experts who do not care to know the details, and as a review to those who do use SQL regularly.What Is a SQL Server?A database application is a program that provides clients with access to data. There are many variations of this type of application, ranging from the expensive enterprise-level Microsoft SQL Server to the free and open source mySQL. Regardless of the flavor, most database server applications have several things in common.First, database applications use the same general programming language known as SQL, or Structured Query Language. This language, also known as a fourth-level language due to its simplistic syntax, is at the core of how a client communicates its requests to the server. Using SQL in its simplest form, a programmer can select, add, update, and delete information in a database. However, SQL can also be used to create and design entire databases, perform various functions on the returned information, and even execute other programs.To illustrate how SQL can be used, the following is an example of a simple standard SQL query and a more powerful SQL query:Simple: "Select * from dbFurniture.tblChair"This returns all information in the table tblChair from the database dbFurniture.Complex: "EXEC master..xp_cmdshell 'dir c:\'"This short SQL command returns to the client the list of files and folders under the c:\ directory of the SQL server. Note that this example uses an extended stored procedure that is exclusive to MS SQL Server.The second function that database server applications share is that they all require some form of authenticated connection between client and host. Although the SQL language is fairly easy to use, at least in its basic form, any client that wants to perform queries must first provide some form of credentials that will authorize the client; the client also must define the format of the request and response.This connection is defined by several attributes, depending on the relative location of the client and what operating systems are in use. We could spend a whole article discussing various technologies such as DSN connections, DSN-less connections, RDO, ADO, and more, but these subjects are outside the scope of this article. If you want to learn more about them, a little Google'ing will provide you with more than enough information. However, the following is a list of the more common items included in a connection request.Database sourceRequest typeDatabaseUser IDPasswordBefore any connection can be made, the client must define what type of database server it is connecting to. This is handled by a software component that provides the client with the instructions needed to create the request in the correct format. In addition to the type of database, the request type can be used to further define how the client's request will be handled by the server. Next comes the database name and finally the authentication information.All the connection information is important, but by far the weakest link is the authentication information—or lack thereof. In a properly managed server, each database has its own users with specifically designated permissions that control what type of activity they can perform. For example, a user account would be set up as read only for applications that need to only access information. Another account should be used for inserts or updates, and maybe even a third account would be used for deletes.This type of account control ensures that any compromised account is limited in functionality. Unfortunately, many database programs are set up with null or easy passwords, which leads to successful hack attacks.译文数据库管理系统介绍数据库(database,有时拼作data base)又称为电子数据库,是专门组织起来的一组数据或信息,其目的是为了便于计算机快速查询及检索。
文献检索 含中文数据库和外文数据库
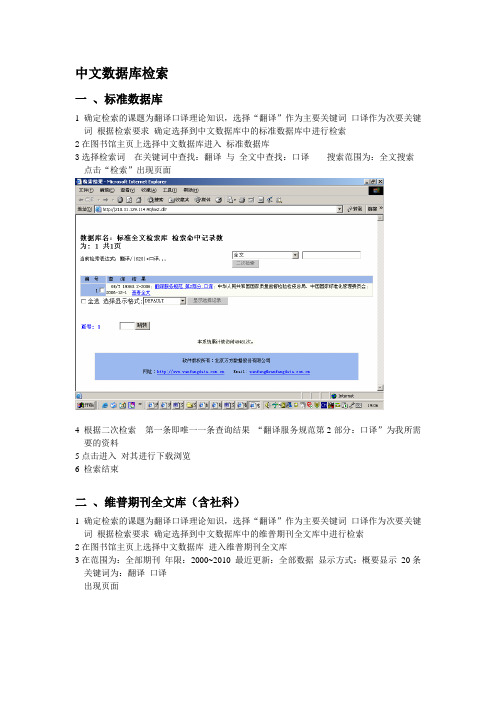
中文数据库检索一、标准数据库1确定检索的课题为翻译口译理论知识,选择“翻译”作为主要关键词口译作为次要关键词根据检索要求确定选择到中文数据库中的标准数据库中进行检索2在图书馆主页上选择中文数据库进入标准数据库3选择检索词在关键词中查找:翻译与全文中查找:口译搜索范围为:全文搜索点击“检索”出现页面4 根据二次检索第一条即唯一一条查询结果“翻译服务规范第2部分:口译”为我所需要的资料5点击进入对其进行下载浏览6 检索结束二、维普期刊全文库(含社科)1确定检索的课题为翻译口译理论知识,选择“翻译”作为主要关键词口译作为次要关键词根据检索要求确定选择到中文数据库中的维普期刊全文库中进行检索2在图书馆主页上选择中文数据库进入维普期刊全文库3在范围为:全部期刊年限:2000~2010 最近更新:全部数据显示方式:概要显示20条关键词为:翻译口译出现页面4 根据二次检索第6条搜索结果“谈如何做好英语口译”为我所需要的资料5点击进入对其进行下载浏览6 检索结束三、CNKI中国知网数据库1确定检索的课题为翻译口译理论知识,选择“翻译”作为主要关键词口译作为次要关键词根据检索要求确定选择到中文数据库中的CNKI中国知网数据库中进行检索2在图书馆主页上选择中文数据库进入CNKI中国知网数据库3 选择高级检索检索项:题名检索词翻译并且检索词:口译时间:2000~2009排序度:相关度匹配:模糊点击检索出现页面4 根据二次检索“第7条口译的文化功能及翻译策略”为我所需要的资料5点击进入对其进行下载浏览6 检索结束四、万方数据系统1确定检索的课题为翻译口译理论知识,选择“翻译”作为主要关键词口译作为次要关键词根据检索要求确定选择到中文数据库中的万方数据系统中进行检索2在图书馆主页上选择中文数据库进入万方数据系统3全部字段:翻译口译资源浏览范围:按数据库分类浏览点击检索出现页面4根据二次检索第3条检索结果“口译中的文化翻译策略初探”为我所需要的资料5点击进入对其进行下载浏览6 检索结束外文数据库一、spring link1确定检索的课题为翻译口译理论知识,选择“翻译”作为主要关键词口译作为次要关键词翻译:translating 口译:interpreting根据检索要求确定需要到外文数据库中的spring link中查找2进入工业大学图书馆主页选择外文数据库进入 spring link2首先输入检索词: ti:translating 出现页面出现页面4通过二次检索发现第四条记录Interpreting and considering the development of thegoal orientation in the transformation of Chinese normal universities为我所需要的5点击下载浏览6检索结束二、kluwer1确定检索的课题为翻译口译理论知识,选择“翻译”作为主要关键词口译作为次要关键词翻译:translating 口译:interpreting根据检索要求确定需要到外文数据库中的Kluwer中查找2进入工业大学图书馆主页选择外文数据库进入 Kluwer 选择复杂查询3输入检索条件检索条件:包含translating and interpreting点击检索发现没有符合条件的记录重新输入检索条件检索词:translating出版时间:2000年01月~2009年12月文件类型:全部其他设置不变点击检索出现页面4发现检索记录没有所需的再输入检索词 interpreting重新进行检索出现页面5根据观察发现第36条记录Re-interpreting some common objections to three transgenic applications: GM foods, xenotransplantation and germ line gene modification (GLGM)为我所需6点击进行下载浏览三、Ebssco1确定检索的课题为翻译口译理论知识,选择“翻译”作为主要关键词口译作为次要关键词翻译:translating 口译:interpreting根据检索要求确定需要到外文数据库中的spring link中查找2进入工业大学图书馆主页选择外文数据库进入 spring link 输入检索条件检索词:translating 位于 TX ALL TEXT 检索模式选择查找全部检索词语限制结果:全文出版日期:2000年01月~2009年12月其他设置不变点击检索3 根据观察发现第六条检索记录 Translator's adaptation in translating. (English) 为我所需4点击下载浏览5检索结束。
数据库外文文献翻译

Transact-SQL Cookbook第一章数据透视表1.1使用数据透视表1.1.1 问题支持一个元素序列往往需要解决各种问题。
例如,给定一个日期范围,你可能希望产生一行在每个日期的范围。
或者,您可能希望将一系列的返回值在单独的行成一系列单独的列值相同的行。
实现这种功能,你可以使用一个永久表中存储一系列的顺序号码。
这种表是称为一个数据透视表。
许多食谱书中使用数据透视表,然后,在所有情况下,表的名称是。
这个食谱告诉你如何创建表。
1.1.2 解决方案首先,创建数据透视表。
下一步,创建一个表名为富,将帮助你在透视表:CREATE TABLE Pivot (i INT,PRIMARY KEY(i))CREATE TABLE Foo(i CHAR(1))富表是一个简单的支持表,你应插入以下10行:INSERT INTO Foo VALUES('0')INSERT INTO Foo VALUES('1')INSERT INTO Foo VALUES('2')INSERT INTO Foo VALUES('3')INSERT INTO Foo VALUES('4')INSERT INTO Foo VALUES('5')INSERT INTO Foo VALUES('6')INSERT INTO Foo VALUES('7')INSERT INTO Foo VALUES('8')INSERT INTO Foo VALUES('9')利用10行在富表,你可以很容易地填充枢轴表1000行。
得到1000行10行,加入富本身三倍,创建一个笛卡尔积:INSERT INTO PivotSELECT f1.i+f2.i+f3.iFROM Foo f1, Foo F2, Foo f3如果你名单上的行数据透视表,你会看到它所需的数目的元素,他们将编号从0到999。
交通安全外文翻译文献中英文

外文文献翻译(含:英文原文及中文译文)英文原文POSSIBILITIES AND LIMITA TIONS OF ACCIDENT ANALYSISS.OppeAbstraetAccident statistics, especially collected at a national level are particularly useful for the description, monitoring and prognosis of accident developments, the detection of positive and negative safety developments, the definition of safety targets and the (product) evaluation of long term and large scale safety measures. The application of accident analysis is strongly limited for problem analysis, prospective and retrospective safety analysis on newly developed traffic systems or safety measures, as well as for (process) evaluation of special short term and small scale safety measures. There is an urgent need for the analysis of accidents in real time, in combination with background behavioural research. Automatic incident detection, combined with video recording of accidents may soon result in financially acceptable research. This type of research may eventually lead to a better understanding of the concept of risk in traffic and to well-established theories.Keyword: Consequences; purposes; describe; Limitations; concerned; Accident Analysis; possibilities1. Introduction.This paper is primarily based on personal experience concerning traffic safety, safety research and the role of accidents analysis in this research. These experiences resulted in rather philosophical opinions as well as more practical viewpoints on research methodology and statistical analysis. A number of these findings are published already elsewhere.From this lack of direct observation of accidents, a number of methodological problems arise, leading to continuous discussions about the interpretation of findings that cannot be tested directly. For a fruitful discussion of these methodological problems it is very informative to look at a real accident on video. It then turns out that most of the relevant information used to explain the accident will be missing in the accident record. In-depth studies also cannot recollect all the data that is necessary in order to test hypotheses about the occurrence of the accident. For a particular car-car accident, that was recorded on video at an urban intersection in the Netherlands, between a car coming from a minor road, colliding with a car on the major road, the following questions could be asked: Why did the driver of the car coming from the minor road, suddenly accelerate after coming almost to a stop and hit the side of the car from the left at the main road? Why was the approaching car not noticed? Was it because the driver was preoccupied with the two cars coming from the right and the gap before them that offered him thepossibility to cross? Did he look left before, but was his view possibly blocked by the green van parked at the corner? Certainly the traffic situation was not complicated. At the moment of the accident there were no bicyclists or pedestrians present to distract his attention at the regularly overcrowded intersection. The parked green van disappeared within five minutes, the two other cars that may have been important left without a trace. It is hardly possible to observe traffic behavior under the most relevant condition of an accident occurring, because accidents are very rare events, given the large number of trips. Given the new video equipment and the recent developments in automatic incident and accident detection, it becomes more and more realistic to collect such data at not too high costs. Additional to this type of data that is most essential for a good understanding of the risk increasing factors in traffic, it also important to look at normal traffic behavior as a reference base. The question about the possibilities and limitations of accident analysis is not lightly answered. We cannot speak unambiguously about accident analysis. Accident analysis covers a whole range of activities, each originating from a different background and based on different sources of information: national data banks, additional information from other sources, especially collected accident data, behavioral background data etc. To answer the question about the possibilities and limitations, we first have to look at the cycle of activities in the area of traffic safety. Some ofthese activities are mainly concerned with the safety management of the traffic system; some others are primarily research activities.The following steps should be distinguished:- detection of new or remaining safety problems;- description of the problem and its main characteristics;- the analysis of the problem, its causes and suggestions for improvement;- selection and implementation of safety measures;- evaluation of measures taken.Although this cycle can be carried out by the same person or group of persons, the problem has a different (political/managerial or scientific) background at each stage. We will describe the phases in which accident analysis is used. It is important to make this distinction. Many fruitless discussions about the method of analysis result from ignoring this distinction. Politicians, or road managers are not primarily interested in individual accidents. From their perspective accidents are often treated equally, because the total outcome is much more important than the whole chain of events leading to each individual accident. Therefore, each accident counts as one and they add up all together to a final safety result.Researchers are much more interested in the chain of events leading to an individual accident. They want to get detailed information abouteach accident, to detect its causes and the relevant conditions. The politician wants only those details that direct his actions. At the highest level this is the decrease in the total number of accidents. The main source of information is the national database and its statistical treatment. For him, accident analysis is looking at (subgroups of) accident numbers and their statistical fluctuations. This is the main stream of accident analysis as applied in the area of traffic safety. Therefore, we will first describe these aspects of accidents.2. The nature of accidents and their statistical characteristics.The basic notion is that accidents, whatever there cause, appear according to a chance process. Two simple assumptions are usually made to describe this process for (traffic) accidents:- the probability of an accident to occur is independent from the occurrence of previous accidents;-the occurrence of accidents is homogeneous in time.If these two assumptions hold, then accidents are Poisson distributed. The first assumption does not meet much criticism. Accidents are rare events and therefore not easily influenced by previous accidents. In some cases where there is a direct causal chain (e.g. , when a number of cars run into each other) the series of accidents may be regarded as one complicated accident with many cars involved.The assumption does not apply to casualties. Casualties are often related to the same accident andtherefore the independency assumption does not hold. The second assumption seems less obvious at first sight. The occurrence of accidents through time or on different locations are not equally likely. However, the assumption need not hold over long time periods. It is a rather theoretical assumption in its nature. If it holds for short periods of time, then it also holds for long periods, because the sum of Poisson distributed variables, even if their Poisson rates are different, is also Poisson distributed. The Poisson rate for the sum of these periods is then equal to the sum of the Poisson rates for these parts.The assumption that really counts for a comparison of (composite) situations, is whether two outcomes from an aggregation of situations in time and/or space, have a comparable mix of basic situations. E.g. , the comparison of the number of accidents on one particular day of the year, as compared to another day (the next day, or the same day of the next week etc.). If the conditions are assumed to be the same (same duration, same mix of traffic and situations, same weather conditions etc.) then the resulting numbers of accidents are the outcomes of the same Poisson process. This assumption can be tested by estimating the rate parameter on the basis of the two observed values (the estimate being the average of the two values). Probability theory can be used to compute the likelihood of the equality assumption, given the two observations and their mean.This statistical procedure is rather powerful. The Poisson assumptionis investigated many times and turns out to be supported by a vast body of empirical evidence. It has been applied in numerous situations to find out whether differences in observed numbers of accidents suggest real differences in safety. The main purpose of this procedure is to detect differences in safety. This may be a difference over time, or between different places or between different conditions. Such differences may guide the process of improvement. Because the main concern is to reduce the number of accidents, such an analysis may lead to the most promising areas for treatment. A necessary condition for the application of such a test is, that the numbers of accidents to be compared are large enough to show existing differences. In many local cases an application is not possible. Accident black-spot analysis is often hindered by this limitation, e.g., if such a test is applied to find out whether the number of accidents at a particular location is higher than average. The procedure described can also be used if the accidents are classified according to a number of characteristics to find promising safety targets. Not only with aggregation, but also with disaggregation the Poisson assumption holds, and the accident numbers can be tested against each other on the basis of the Poisson assumptions. Such a test is rather cumbersome, because for each particular case, i.e. for each different Poisson parameter, the probabilities for all possible outcomes must be computed to apply the test. In practice, this is not necessary when the numbers are large. Then the Poissondistribution can be approximated by a Normal distribution, with mean and variance equal to the Poisson parameter. Once the mean value and the variance of a Normal distribution are given, all tests can be rephrased in terms of the standard Normal distribution with zero mean and variance one. No computations are necessary any more, but test statistics can be drawn from tables.3. The use of accident statistics for traffic safety policy.The testing procedure described has its merits for those types of analysis that are based on the assumptions mentioned. The best example of such an application is the monitoring of safety for a country or region over a year, using the total number of accidents (eventually of a particular type, such as fatal accidents), in order to compare this number with the outcome of the year before. If sequences of accidents are given over several years, then trends in the developments can be detected and accident numbers predicted for following years. Once such a trend is established, then the value for the next year or years can be predicted, together with its error bounds. Deviations from a given trend can also be tested afterwards, and new actions planned. The most famous one is carried out by Smeed 1949. We will discuss this type of accident analysis in more detail later.(1). The application of the Chi-square test for interaction is generalised to higher order classifications. Foldvary and Lane (1974), inmeasuring the effect of compulsory wearing of seat belts, were among the first who applied the partitioning of the total Chi-square in values for the higher order interactions of four-way tables.(2). Tests are not restricted to overall effects, but Chi-square values can be decomposed regarding sub-hypotheses within the model. Also in the two-way table, the total Chisquare can be decomposed into interaction effects of part tables. The advantage of 1. and 2. over previous situations is, that large numbers of Chi-square tests on many interrelated (sub)tables and corresponding Chi-squares were replaced by one analysis with an exact portioning of one Chi-square.(3). More attention is put to parameter estimation. E.g., the partitioning of the Chi-square made it possible to test for linear or quadratic restraints on the row-parameters or for discontinuities in trends.(4). The unit of analysis is generalised from counts to weighted counts. This is especially advantageous for road safety analyses, where corrections for period of time, number of road users, number of locations or number of vehicle kilometres is often necessary. The last option is not found in many statistical packages. Andersen 1977 gives an example for road safety analysis in a two-way table. A computer programme WPM, developed for this type of analysis of multi-way tables, is available at SWOV (see: De Leeuw and Oppe 1976). The accident analysis at this level is not explanatory. It tries to detect safety problems that need specialattention. The basic information needed consists of accident numbers, to describe the total amount of unsafety, and exposure data to calculate risks and to find situations or (groups of) road users with a high level of risk. 4. Accident analysis for research purposes.Traffic safety research is concerned with the occurrence of accidents and their consequences. Therefore, one might say that the object of research is the accident. The researcher’s interest however is less focused at this final outcome itself, but much more at the process that results (or does not result) in accidents. Therefore, it is better to regard the critical event in traffic as his object of study. One of the major problems in the study of the traffic process that results in accidents is, that the actual occurrence is hardly ever observed by the researcher.Investigating a traffic accident, he will try to reconstruct the event from indirect sources such as the information given by the road users involved, or by eye-witnesses, about the circumstances, the characteristics of the vehicles, the road and the drivers. As such this is not unique in science, there are more examples of an indirect study of the object of research. However, a second difficulty is, that the object of research cannot be evoked. Systematic research by means of controlled experiments is only possible for aspects of the problem, not for the problem itself. The combination of indirect observation and lack of systematic control make it very difficult for the investigator to detectwhich factors, under what circumstances cause an accident. Although the researcher is primarily interested in the process leading to accidents, he has almost exclusively information about the consequences, the product of it, the accident. Furthermore, the context of accidents is complicated. Generally speaking, the following aspects can be distinguished: - Given the state of the traffic system, traffic volume and composition, the manoeuvres of the road users, their speeds, the weather conditions, the condition of the road, the vehicles, the road users and their interactions, accidents can or cannot be prevented.- Given an accident, also depending on a large number of factors, such as the speed and mass of vehicles, the collision angle, the protection of road users and their vulnerability, the location of impact etc., injuries are more or less severe or the material damage is more or less substantial. Although these aspects cannot be studied independently, from a theoretical point of view it has advantages to distinguish the number of situations in traffic that are potentially dangerous, from the probability of having an accident given such a potentially dangerous situation and also from the resulting outcome, given a particular accident.This conceptual framework is the general basis for the formulation of risk regarding the decisions of individual road users as well as the decisions of controllers at higher levels. In the mathematical formulation of risk we need an explicit description of our probability space, consistingof the elementary events (the situations) that may result in accidents, the probability for each type of event to end up in an accident, and finally the particular outcome, the loss, given that type of accident.A different approach is to look at combinations of accident characteristics, to find critical factors. This type of analysis may be carried out at the total group of accidents or at subgroups. The accident itself may be the unit of research, but also a road, a road location, a road design (e.g. a roundabout) etc.中文译文交通事故分析的可能性和局限性S.Oppe摘要交通事故的统计数字, 尤其国家一级的数据对监控和预测事故的发展, 积极或消极检测事故的发展, 以及对定义安全目标和评估工业安全特别有益。
SQL Server数据库管理外文翻译文献

SQL Server数据库管理外文翻译文献本文翻译了一篇关于SQL Server数据库管理的外文文献。
摘要该文献介绍了SQL Server数据库管理的基本原则和策略。
作者指出,重要的决策应该基于独立思考,避免过多依赖外部帮助。
对于非可确认的内容,不应进行引用。
文献还强调了以简单策略为主、避免法律复杂性的重要性。
内容概述本文详细介绍了SQL Server数据库管理的基本原则和策略。
其中包括:1. 独立决策:在数据库管理中,决策应该基于独立思考。
不过多依赖用户的帮助或指示,而是依靠数据库管理员的专业知识和经验进行决策。
独立决策:在数据库管理中,决策应该基于独立思考。
不过多依赖用户的帮助或指示,而是依靠数据库管理员的专业知识和经验进行决策。
2. 简单策略:为了避免法律复杂性和错误的决策,应采用简单策略。
这意味着避免引用无法确认的内容,只使用可靠和可验证的信息。
简单策略:为了避免法律复杂性和错误的决策,应采用简单策略。
这意味着避免引用无法确认的内容,只使用可靠和可验证的信息。
3. 数据库管理准则:文献提出了一些SQL Server数据库管理的准则,包括:规划和设计数据库结构、有效的数据备份和恢复策略、用户权限管理、性能优化等。
数据库管理准则:文献提出了一些SQL Server数据库管理的准则,包括:规划和设计数据库结构、有效的数据备份和恢复策略、用户权限管理、性能优化等。
结论文献通过介绍SQL Server数据库管理的基本原则和策略,强调了独立决策和简单策略的重要性。
数据库管理员应该依靠自己的知识和经验,避免过度依赖外部帮助,并采取简单策略来管理数据库。
此外,遵循数据库管理准则也是确保数据库安全和性能的重要手段。
以上是对于《SQL Server数据库管理外文翻译文献》的详细内容概述和总结。
如果需要更多详细信息,请阅读原文献。
土木工程外文文献及翻译

本科毕业设计外文文献及译文文献、资料题目:Designing Against Fire Of Building 文献、资料来源:国道数据库文献、资料发表(出版)日期:2008.3.25院(部):土木工程学院专业:土木工程班级:土木辅修091姓名:xxxx外文文献:Designing Against Fire Of BulidingxxxABSTRACT:This paper considers the design of buildings for fire safety. It is found that fire and the associ- ated effects on buildings is significantly different to other forms of loading such as gravity live loads, wind and earthquakes and their respective effects on the building structure. Fire events are derived from the human activities within buildings or from the malfunction of mechanical and electrical equipment provided within buildings to achieve a serviceable environment. It is therefore possible to directly influence the rate of fire starts within buildings by changing human behaviour, improved maintenance and improved design of mechanical and electrical systems. Furthermore, should a fire develops, it is possible to directly influence the resulting fire severity by the incorporation of fire safety systems such as sprinklers and to provide measures within the building to enable safer egress from the building. The ability to influence the rate of fire starts and the resulting fire severity is unique to the consideration of fire within buildings since other loads such as wind and earthquakes are directly a function of nature. The possible approaches for designing a building for fire safety are presented using an example of a multi-storey building constructed over a railway line. The design of both the transfer structure supporting the building over the railway and the levels above the transfer structure are considered in the context of current regulatory requirements. The principles and assumptions associ- ated with various approaches are discussed.1 INTRODUCTIONOther papers presented in this series consider the design of buildings for gravity loads, wind and earthquakes.The design of buildings against such load effects is to a large extent covered by engineering based standards referenced by the building regulations. This is not the case, to nearly the same extent, in the case of fire. Rather, it is building regulations such as the Building Code of Australia (BCA) that directly specify most of the requirements for fire safety of buildings with reference being made to Standards such as AS3600 or AS4100 for methods for determining the fire resistance of structural elements.The purpose of this paper is to consider the design of buildings for fire safety from an engineering perspective (as is currently done for other loads such as wind or earthquakes), whilst at the same time,putting such approaches in the context of the current regulatory requirements.At the outset,it needs to be noted that designing a building for fire safety is far morethan simply considering the building structure and whether it has sufficient structural adequacy.This is because fires can have a direct influence on occupants via smoke and heat and can grow in size and severity unlike other effects imposed on the building. Notwithstanding these comments, the focus of this paper will be largely on design issues associated with the building structure.Two situations associated with a building are used for the purpose of discussion. The multi-storey office building shown in Figure 1 is supported by a transfer structure that spans over a set of railway tracks. It is assumed that a wide range of rail traffic utilises these tracks including freight and diesel locomotives. The first situation to be considered from a fire safety perspective is the transfer structure.This is termed Situation 1 and the key questions are: what level of fire resistance is required for this transfer structure and how can this be determined? This situation has been chosen since it clearly falls outside the normal regulatory scope of most build- ing regulations. An engineering solution, rather than a prescriptive one is required. The second fire situation (termed Situation 2) corresponds to a fire within the office levels of the building and is covered by building regulations. This situation is chosen because it will enable a discussion of engineering approaches and how these interface with the building regulations–since both engineering and prescriptive solutions are possible.2 UNIQUENESS OF FIRE2.1 IntroductionWind and earthquakes can be considered to b e “natural” phenomena over which designers have no control except perhaps to choose the location of buildings more carefully on the basis of historical records and to design building to resist sufficiently high loads or accelerations for the particular location. Dead and live loads in buildings are the result of gravity. All of these loads are variable and it is possible (although generally unlikely) that the loads may exceed the resistance of the critical structural members resulting in structural failure.The nature and influence of fires in buildings are quite different to those associated with other“loads” to which a building may be subjected to. The essential differences are described in the following sections.2.2 Origin of FireIn most situations (ignoring bush fires), fire originates from human activities within the building or the malfunction of equipment placed within the building to provide a serviceable environment. It follows therefore that it is possible to influence the rate of fire starts by influencing human behaviour, limiting and monitoring human behaviour and improving thedesign of equipment and its maintenance. This is not the case for the usual loads applied to a building.2.3 Ability to InfluenceSince wind and earthquake are directly functions of nature, it is not possible to influence such events to any extent. One has to anticipate them and design accordingly. It may be possible to influence the level of live load in a building by conducting audits and placing restrictions on contents. However, in the case of a fire start, there are many factors that can be brought to bear to influence the ultimate size of the fire and its effect within the building. It is known that occupants within a building will often detect a fire and deal with it before it reaches a sig- nificant size. It is estimated that less than one fire in five (Favre, 1996) results in a call to the fire brigade and for fires reported to the fire brigade, the majority will be limited to the room of fire origin. In oc- cupied spaces, olfactory cues (smell) provide powerful evidence of the presence of even a small fire. The addition of a functional smoke detection system will further improve the likelihood of detection and of action being taken by the occupants.Fire fighting equipment, such as extinguishers and hose reels, is generally provided within buildings for the use of occupants and many organisations provide training for staff in respect of the use of such equipment.The growth of a fire can also be limited by automatic extinguishing systems such as sprinklers, which can be designed to have high levels of effectiveness.Fires can also be limited by the fire brigade depending on the size and location of the fire at the time of arrival. 2.4 Effects of FireThe structural elements in the vicinity of the fire will experience the effects of heat. The temperatures within the structural elements will increase with time of exposure to the fire, the rate of temperature rise being dictated by the thermal resistance of the structural element and the severity of the fire. The increase in temperatures within a member will result in both thermal expansion and,eventually,a reduction in the structural resistance of the member. Differential thermal expansion will lead to bowing of a member. Significant axial expansion will be accommodated in steel members by either overall or local buckling or yielding of local- ised regions. These effects will be detrimental for columns but for beams forming part of a floor system may assist in the development of other load resisting mechanisms (see Section 4.3.5).With the exception of the development of forces due to restraint of thermal expansion, fire does not impose loads on the structure but rather reduces stiffness and strength. Such effects are not instantaneous but are a function of time and this is different to the effects of loads such as earthquake and wind that are more or less instantaneous.Heating effects associated with a fire will not be significant or the rate of loss of capacity will be slowed if:(a) the fire is extinguished (e.g. an effective sprinkler system)(b) the fire is of insufficient severity – insufficient fuel, and/or(c)the structural elements have sufficient thermal mass and/or insulation to slow the rise in internal temperatureFire protection measures such as providing sufficient axis distance and dimensions for concrete elements, and sufficient insulation thickness for steel elements are examples of (c). These are illustrated in Figure 2.The two situations described in the introduction are now considered.3 FIRE WITHIN BUILDINGS3.1 Fire Safety ConsiderationsThe implications of fire within the occupied parts of the office building (Figure 1) (Situation 2) are now considered. Fire statistics for office buildings show that about one fatality is expected in an office building for every 1000 fires reported to the fire brigade. This is an order of magnitude less than the fatality rate associated with apartment buildings. More than two thirds of fires occur during occupied hours and this is due to the greater human activity and the greater use of services within the building. It is twice as likely that a fire that commences out of normal working hours will extend beyond the enclosure of fire origin.A relatively small fire can generate large quantities of smoke within the floor of fire origin. If the floor is of open-plan construction with few partitions, the presence of a fire during normal occupied hours is almost certain to be detected through the observation of smoke on the floor. The presence of full height partitions across the floor will slow the spread of smoke and possibly also the speed at which the occupants detect the fire. Any measures aimed at improving housekeeping, fire awareness and fire response will be beneficial in reducing thelikelihood of major fires during occupied hours.For multi-storey buildings, smoke detection systems and alarms are often provided to give “automatic” detection and warning to the occupants. An alarm signal is also transmitted to the fire brigade.Should the fire not be able to be controlled by the occupants on the fire floor, they will need to leave the floor of fire origin via the stairs. Stair enclosures may be designed to be fire-resistant but this may not be sufficient to keep the smoke out of the stairs. Many buildings incorporate stair pressurisation systems whereby positive airflow is introduced into the stairs upon detection of smoke within the building. However, this increases the forces required to open the stair doors and makes it increasingly difficult to access the stairs. It is quite likely that excessive door opening forces will exist(Fazio et al,2006)From a fire perspective, it is common to consider that a building consists of enclosures formed by the presence of walls and floors.An enclosure that has sufficiently fire-resistant boundaries (i.e. walls and floors) is considered to constitute a fire compartment and to be capable of limiting the spread of fire to an adjacent compartment. However, the ability of such boundaries to restrict the spread of fire can be severely limited by the need to provide natural lighting (windows)and access openings between the adjacent compartments (doors and stairs). Fire spread via the external openings (windows) is a distinct possibility given a fully developed fire. Limit- ing the window sizes and geometry can reduce but not eliminate the possibility of vertical fire spread.By far the most effective measure in limiting fire spread, other than the presence of occupants, is an effective sprinkler system that delivers water to a growing fire rapidly reducing the heat being generated and virtually extinguishing it.3.2 Estimating Fire SeverityIn the absence of measures to extinguish developing fires, or should such systems fail; severe fires can develop within buildings.In fire en gineering literature, the term “fire load” refers to the quantity of combustibles within an enclosure and not the loads (forces) applied to the structure during a fire. Similarly, fire load density refers to the quantity of fuel per unit area. It is normally expressed in terms of MJ/m2 or kg/m2 of wood equivalent. Surveys of combustibles for various occupancies (i.e offices, retail, hospitals, warehouses, etc)have been undertaken and a good summary of the available data is given in FCRC (1999). As would be expected, the fire load density is highly variable. Publications such as the International Fire Engineering Guidelines (2005) give fire load data in terms of the mean and 80th percentile.The latter level of fire load density is sometimes taken asthe characteristic fire load density and is sometimes taken as being distributed according to a Gumbel distribution (Schleich et al, 1999).The rate at which heat is released within an enclosure is termed the heat release rate (HRR) and normally expressed in megawatts (MW). The application of sufficient heat to a combustible material results in the generation of gases some of which are combustible. This process is called pyrolisation.Upon coming into contact with sufficient oxygen these gases ignite generating heat. The rate of burning(and therefore of heat generation) is therefore dependent on the flow of air to the gases generated by the pyrolising fuel.This flow is influenced by the shape of the enclosure (aspect ratio), and the position and size of any potential openings. It is found from experiments with single openings in approximately cubic enclosures that the rate of burning is directly proportional to A h where A is the area of the opening and h is the opening height. It is known that for deep enclosures with single openings that burning will occur initially closest to the opening moving back into the enclosure once the fuel closest to the opening is consumed (Thomas et al, 2005). Significant temperature variations throughout such enclosures can be expected.The use of the word ‘opening’ in relation to real building enclosures refers to any openings present around the walls including doors that are left open and any windows containing non fire-resistant glass.It is presumed that such glass breaks in the event of development of a significant fire. If the windows could be prevented from breaking and other sources of air to the enclosure limited, then the fire would be prevented from becoming a severe fire.Various methods have been developed for determining the potential severity of a fire within an enclosure.These are described in SFPE (2004). The predictions of these methods are variable and are mostly based on estimating a representative heat release rate (HRR) and the proportion of total fuel ςlikely to be consumed during the primary burning stage (Figure 4). Further studies of enclosure fires are required to assist with the development of improved models, as the behaviour is very complex.3.3 Role of the Building StructureIf the design objectives are to provide an adequate level of safety for the occupants and protection of adjacent properties from damage, then the structural adequacy of the building in fire need only be sufficient to allow the occupants to exit the building and for the building to ultimately deform in a way that does not lead to damage or fire spread to a building located on an adjacent site.These objectives are those associated with most building regulations includingthe Building Code of Australia (BCA). There could be other objectives including protection of the building against significant damage. In considering these various objectives, the following should be taken into account when considering the fire resistance of the building structure.3.3.1 Non-Structural ConsequencesSince fire can produce smoke and flame, it is important to ask whether these outcomes will threaten life safety within other parts of the building before the building is compromised by a loss of structural adequacy? Is search and rescue by the fire brigade not feasible given the likely extent of smoke? Will the loss of use of the building due to a severe fire result in major property and income loss? If the answer to these questions is in the affirmative, then it may be necessary to minimise the occurrence of a significant fire rather than simply assuming that the building structure needs to be designed for high levels of fire resistance. A low-rise shopping centre with levels interconnected by large voids is an example of such a situation.3.3.2 Other Fire Safety SystemsThe presence of other systems (e.g. sprinklers) within the building to minimise the occurrence of a serious fire can greatly reduce the need for the structural elements to have high levels of fire resistance. In this regard, the uncertainties of all fire-safety systems need to be considered. Irrespective of whether the fire safety system is the sprinkler system, stair pressurisation, compartmentation or the system giving the structure a fire-resistance level (e.g. concrete cover), there is an uncertainty of performance. Uncertainty data is available for sprinkler systems(because it is relatively easy to collect) but is not readily available for the other fire safety systems. This sometimes results in the designers and building regulators considering that only sprinkler systems are subject to uncertainty. In reality, it would appear that sprinklers systems have a high level of performance and can be designed to have very high levels of reliability.3.3.3 Height of BuildingIt takes longer for a tall building to be evacuated than a short building and therefore the structure of a tall building may need to have a higher level of fire resistance. The implications of collapse of tall buildings on adjacent properties are also greater than for buildings of only several storeys.3.3.4 Limited Extent of BurningIf the likely extent of burning is small in comparison with the plan area of the building, then the fire cannot have a significant impact on the overall stability of the building structure. Examples of situations where this is the case are open-deck carparks and very large area building such as shopping complexes where the fire-effected part is likely to be small in relation to area of the building floor plan.3.3.5 Behaviour of Floor ElementsThe effect of real fires on composite and concrete floors continues to be a subject of much research.Experimental testing at Cardington demonstrated that when parts of a composite floor are subject to heating, large displacement behaviour can develop that greatly assists the load carrying capacity of the floor beyond that which would predicted by considering only the behaviour of the beams and slabs in isolation.These situations have been analysed by both yield line methods that take into account the effects of membrane forces (Bailey, 2004) and finite element techniques. In essence, the methods illustrate that it is not necessary to insulate all structural steel elements in a composite floor to achieve high levels of fire resistance.This work also demonstrated that exposure of a composite floor having unprotected steel beams, to a localised fire, will not result in failure of the floor.A similar real fire test on a multistory reinforced concrete building demonstrated that the real structural behaviour in fire was significantly different to that expected using small displacement theory as for normal tempera- ture design (Bailey, 2002) with the performance being superior than that predicted by considering isolated member behaviour.3.4 Prescriptive Approach to DesignThe building regulations of most countries provide prescriptive requirements for the design of buildings for fire.These requirements are generally not subject to interpretation and compliance with them makes for simpler design approval–although not necessarily the most cost-effective designs.These provisions are often termed deemed-to-satisfy (DTS) provisions. All aspects of designing buildings for fire safety are covered–the provision of emergency exits, spacings between buildings, occupant fire fighting measures, detection and alarms, measures for automatic fire suppression, air and smoke handling requirements and last, but not least, requirements for compartmentation and fire resistance levels for structural members. However, there is little evidence that the requirements have been developed from a systematic evaluation of fire safety. Rather it would appear that many of the requirements have been added one to another to deal with another fire incident or to incorporate a new form of technology. There does not appear to have been any real attempt to determine which provision have the most significant influence on fire safety and whether some of the former provisions could be modified.The FRL requirements specified in the DTS provisions are traditionally considered to result in member resistances that will only rarely experience failure in the event of a fire.This is why it is acceptable to use the above arbitrary point in time load combination for assessing members in fire. There have been attempts to evaluate the various deemed-to-satisfy provisions (particularly the fire- resistance requirements)from a fire-engineering perspective taking intoaccount the possible variations in enclosure geometry, opening sizes and fire load (see FCRC, 1999).One of the outcomes of this evaluation was the recognition that deemed-to- satisfy provisions necessarily cover the broad range of buildings and thus must, on average, be quite onerous because of the magnitude of the above variations.It should be noted that the DTS provisions assume that compartmentation works and that fire is limited to a single compartment. This means that fire is normally only considered to exist at one level. Thus floors are assumed to be heated from below and columns only over one storey height.3.5 Performance-Based DesignAn approach that offers substantial benefits for individual buildings is the move towards performance-based regulations. This is permitted by regulations such as the BCA which state that a designer must demonstrate that the particular building will achieve the relevant performance requirements. The prescriptive provisions (i.e. the DTS provisions) are presumed to achieve these requirements. It is necessary to show that any building that does not conform to the DTS provisions will achieve the performance requirements.But what are the performance requirements? Most often the specified performance is simply a set of performance statements (such as with the Building Code of Australia)with no quantitative level given. Therefore, although these statements remind the designer of the key elements of design, they do not, in themselves, provide any measure against which to determine whether the design is adequately safe.Possible acceptance criteria are now considered.3.5.1 Acceptance CriteriaSome guidance as to the basis for acceptable designs is given in regulations such as the BCA. These and other possible bases are now considered in principle.(i)compare the levels of safety (with respect to achieving each of the design objectives) of the proposed alternative solution with those asso- ciated with a corresponding DTS solution for the building.This comparison may be done on either a qualitative or qualitative risk basis or perhaps a combination. In this case, the basis for comparison is an acceptable DTS solution. Such an approach requires a “holistic” approach to safety whereby all aspects relevant to safety, including the structure, are considered. This is, by far, the most common basis for acceptance.(ii)undertake a probabilistic risk assessment and show that the risk associated with the proposed design is less than that associated with common societal activities such as using pub lic transport. Undertaking a full probabilistic risk assessment can be very difficult for all but the simplest situations.Assuming that such an assessment is undertaken it will be necessary for the stakeholders to accept the nominated level of acceptable risk. Again, this requires a “holistic”approach to fire safety.(iii) a design is presented where it is demonstrated that all reasonable measures have been adopted to manage the risks and that any possible measures that have not been adopted will have negligible effect on the risk of not achieving the design objectives.(iv) as far as the building structure is concerned,benchmark the acceptable probability of failure in fire against that for normal temperature design. This is similar to the approach used when considering Building Situation 1 but only considers the building structure and not the effects of flame or smoke spread. It is not a holistic approach to fire safety.Finally, the questions of arson and terrorism must be considered. Deliberate acts of fire initiation range from relatively minor incidents to acts of mass destruction.Acts of arson are well within the accepted range of fire events experienced by build- ings(e.g. 8% of fire starts in offices are deemed "suspicious"). The simplest act is to use a small heat source to start a fire. The resulting fire will develop slowly in one location within the building and will most probably be controlled by the various fire- safety systems within the building. The outcome is likely to be the same even if an accelerant is used to assist fire spread.An important illustration of this occurred during the race riots in Los Angeles in 1992 (Hart 1992) when fires were started in many buildings often at multiple locations. In the case of buildings with sprinkler systems,the damage was limited and the fires significantly controlled.Although the intent was to destroy the buildings,the fire-safety systems were able to limit the resulting fires. Security measures are provided with systems such as sprinkler systems and include:- locking of valves- anti-tamper monitoring- location of valves in secure locationsFurthermore, access to significant buildings is often restricted by security measures.The very fact that the above steps have been taken demonstrates that acts of destruction within buildings are considered although most acts of arson do not involve any attempt to disable the fire-safety systems.At the one end of the spectrum is "simple" arson and at the other end, extremely rare acts where attempts are made to destroy the fire-safety systems along with substantial parts of the building.This can be only achieved through massive impact or the use of explosives. The latter may be achieved through explosives being introduced into the building or from outside by missile attack.The former could result from missile attack or from the collision of a large aircraft. The greater the destructiveness of the act,the greater the means and knowledge required. Conversely, the more extreme the act, the less confidence there can be in designing against suchan act. This is because the more extreme the event, the harder it is to predict precisely and the less understood will be its effects. The important point to recognise is that if sufficient means can be assembled, then it will always be possible to overcome a particular building design.Thus these acts are completely different to the other loadings to which a building is subjected such as wind,earthquake and gravity loading. This is because such acts of destruction are the work of intelligent beings and take into account the characteristics of the target.Should high-rise buildings be designed for given terrorist activities,then terrorists will simply use greater means to achieve the end result.For example, if buildings were designed to resist the impact effects from a certain size aircraft, then the use of a larger aircraft or more than one aircraft could still achieve destruction of the building. An appropriate strategy is therefore to minimise the likelihood of means of mass destruction getting into the hands of persons intent on such acts. This is not an engineering solution associated with the building structure.It should not be assumed that structural solutions are always the most appropriate, or indeed, possible.In the same way, aircrafts are not designed to survive a major fire or a crash landing but steps are taken to minimise the likelihood of either occurrence.The mobilization of large quantities of fire load (the normal combustibles on the floors) simultaneously on numerous levels throughout a building is well outside fire situations envisaged by current fire test standards and prescriptive regulations. Risk management measures to avoid such a possibility must be considered.4 CONCLUSIONSFire differs significantly from other “loads” such as wind, live load and earthquakes i n respect of its origin and its effects.Due to the fact that fire originates from human activities or equipment installed within buildings, it is possible to directly influence the potential effects on the building by reducing the rate of fire starts and providing measures to directly limit fire severity.The design of buildings for fire safety is mostly achieved by following the prescriptive requirements of building codes such as the BCA. For situations that fall outside of the scope of such regulations, or where proposed designs are not in accordance with the prescriptive requirements, it is possible to undertake performance-based fire engineering designs.However, there are no design codes or standards or detailed methodologies available for undertaking such designs.Building regulations require that such alternative designs satisfy performance requirements and give some guidance as to the basis for acceptance of these designs (i.e. acceptance criteria).This paper presents a number of possible acceptance criteria, all of which use the measure of risk level as the basis for comparison.Strictly, when considering the risks。
外文参考文献(带中文翻译)

外文资料原文涂敏之会计学 8051208076Title:Future of SME finance(c)Background – the environment for SME finance has changedFuture economic recovery will depend on the possibility of Crafts, Trades and SMEs to exploit their potential for growth and employment creation.SMEs make a major contribution to growth and employment in the EU and are at the heart of the Lisbon Strategy, whose main objective is to turn Europe into the most competitive and dynamic knowledge-based economy in the world. However, the ability of SMEs to grow depends highly on their potential to invest in restructuring, innovation and qualification. All of these investments need capital and therefore access to finance.Against this background the consistently repeated complaint of SMEs about their problems regarding access to finance is a highly relevant constraint that endangers the economic recovery of Europe.Changes in the finance sector influence the behavior of credit institutes towards Crafts, Trades and SMEs. Recent and ongoing developments in the banking sector add to the concerns of SMEs and will further endanger their access to finance. The main changes in the banking sector which influence SME finance are:•Globalization and internationalization have increased the competition and the profit orientation in the sector;•worsening of the economic situations in some institutes (burst of the ITC bubble, insolvencies) strengthen the focus on profitability further;•Mergers and restructuring created larger structures and many local branches, which had direct and personalized contacts with small enterprises, were closed;•up-coming implementation of new capital adequacy rules (Basel II) will also change SME business of the credit sector and will increase its administrative costs;•Stricter interpretation of State-Aide Rules by the European Commission eliminates the support of banks by public guarantees; many of the effected banks are very active in SME finance.All these changes result in a higher sensitivity for risks and profits in the financesector.The changes in the finance sector affect the accessibility of SMEs to finance.Higher risk awareness in the credit sector, a stronger focus on profitability and the ongoing restructuring in the finance sector change the framework for SME finance and influence the accessibility of SMEs to finance. The most important changes are: •In order to make the higher risk awareness operational, the credit sector introduces new rating systems and instruments for credit scoring;•Risk assessment of SMEs by banks will force the enterprises to present more and better quality information on their businesses;•Banks will try to pass through their additional costs for implementing and running the new capital regulations (Basel II) to their business clients;•due to the increase of competition on interest rates, the bank sector demands more and higher fees for its services (administration of accounts, payments systems, etc.), which are not only additional costs for SMEs but also limit their liquidity;•Small enterprises will lose their personal relationship with decision-makers in local branches –the credit application process will become more formal and anonymous and will probably lose longer;•the credit sector will lose more and more i ts “public function” to provide access to finance for a wide range of economic actors, which it has in a number of countries, in order to support and facilitate economic growth; the profitability of lending becomes the main focus of private credit institutions.All of these developments will make access to finance for SMEs even more difficult and / or will increase the cost of external finance. Business start-ups and SMEs, which want to enter new markets, may especially suffer from shortages regarding finance. A European Code of Conduct between Banks and SMEs would have allowed at least more transparency in the relations between Banks and SMEs and UEAPME regrets that the bank sector was not able to agree on such a commitment.Towards an encompassing policy approach to improve the access of Crafts, Trades and SMEs to financeAll analyses show that credits and loans will stay the main source of finance for the SME sector in Europe. Access to finance was always a main concern for SMEs, but the recent developments in the finance sector worsen the situation even more.Shortage of finance is already a relevant factor, which hinders economic recovery in Europe. Many SMEs are not able to finance their needs for investment.Therefore, UEAPME expects the new European Commission and the new European Parliament to strengthen their efforts to improve the framework conditions for SME finance. Europe’s Crafts, Trades and SMEs ask for an encompassing policy approach, which includes not only the conditions for SMEs’ access to l ending, but will also strengthen their capacity for internal finance and their access to external risk capital.From UEAPME’s point of view such an encompassing approach should be based on three guiding principles:•Risk-sharing between private investors, financial institutes, SMEs and public sector;•Increase of transparency of SMEs towards their external investors and lenders;•improving the regulatory environment for SME finance.Based on these principles and against the background of the changing environment for SME finance, UEAPME proposes policy measures in the following areas:1. New Capital Requirement Directive: SME friendly implementation of Basel IIDue to intensive lobbying activities, UEAPME, together with other Business Associations in Europe, has achieved some improvements in favour of SMEs regarding the new Basel Agreement on regulatory capital (Basel II). The final agreement from the Basel Committee contains a much more realistic approach toward the real risk situation of SME lending for the finance market and will allow the necessary room for adaptations, which respect the different regional traditions and institutional structures.However, the new regulatory system will influence the relations between Banks and SMEs and it will depend very much on the way it will be implemented into European law, whether Basel II becomes burdensome for SMEs and if it will reduce access to finance for them.The new Capital Accord form the Basel Committee gives the financial market authorities and herewith the European Institutions, a lot of flexibility. In about 70 areas they have room to adapt the Accord to their specific needs when implementing itinto EU law. Some of them will have important effects on the costs and the accessibility of finance for SMEs.UEAPME expects therefore from the new European Commission and the new European Parliament:•The implementation of the new Capital Requirement Directive will be costly for the Finance Sector (up to 30 Billion Euro till 2006) and its clients will have to pay for it. Therefore, the implementation – especially for smaller banks, which are often very active in SME finance –has to be carried out with as little administrative burdensome as possible (reporting obligations, statistics, etc.).•The European Regulators must recognize traditional instruments for collaterals (guarantees, etc.) as far as possible.•The European Commission and later the Member States should take over the recommendations from the European Parliament with regard to granularity, access to retail portfolio, maturity, partial use, adaptation of thresholds, etc., which will ease the burden on SME finance.2. SMEs need transparent rating proceduresDue to higher risk awareness of the finance sector and the needs of Basel II, many SMEs will be confronted for the first time with internal rating procedures or credit scoring systems by their banks. The bank will require more and better quality information from their clients and will assess them in a new way. Both up-coming developments are already causing increasing uncertainty amongst SMEs.In order to reduce this uncertainty and to allow SMEs to understand the principles of the new risk assessment, UEAPME demands transparent rating procedures –rating procedures may not become a “Black Box” for SMEs: •The bank should communicate the relevant criteria affecting the rating of SMEs.•The bank should inform SMEs about its assessment in order to allow SMEs to improve.The negotiations on a European Code of Conduct between Banks and SMEs , which would have included a self-commitment for transparent rating procedures by Banks, failed. Therefore, UEAPME expects from the new European Commission and the new European Parliament support for:•binding rules in the framework of the new Capital Adequacy Directive,which ensure the transparency of rating procedures and credit scoring systems for SMEs;•Elaboration of national Codes of Conduct in order to improve the relations between Banks and SMEs and to support the adaptation of SMEs to the new financial environment.3. SMEs need an extension of credit guarantee systems with a special focus on Micro-LendingBusiness start-ups, the transfer of businesses and innovative fast growth SMEs also depended in the past very often on public support to get access to finance. Increasing risk awareness by banks and the stricter interpretation of State Aid Rules will further increase the need for public support.Already now, there are credit guarantee schemes in many countries on the limit of their capacity and too many investment projects cannot be realized by SMEs.Experiences show that Public money, spent for supporting credit guarantees systems, is a very efficient instrument and has a much higher multiplying effect than other instruments. One Euro form the European Investment Funds can stimulate 30 Euro investments in SMEs (for venture capital funds the relation is only 1:2).Therefore, UEAPME expects the new European Commission and the new European Parliament to support:•The extension of funds for national credit guarantees schemes in the framework of the new Multi-Annual Programmed for Enterprises;•The development of new instruments for securitizations of SME portfolios;•The recognition of existing and well functioning credit guarantees schemes as collateral;•More flexibility within the European Instruments, because of national differences in the situation of SME finance;•The development of credit guarantees schemes in the new Member States;•The development of an SBIC-like scheme in the Member States to close the equity gap (0.2 – 2.5 Mio Euro, according to the expert meeting on PACE on April 27 in Luxemburg).•the development of a financial support scheme to encourage the internalizations of SMEs (currently there is no scheme available at EU level: termination of JOP, fading out of JEV).4. SMEs need company and income taxation systems, whichstrengthen their capacity for self-financingMany EU Member States have company and income taxation systems with negative incentives to build-up capital within the company by re-investing their profits. This is especially true for companies, which have to pay income taxes. Already in the past tax-regimes was one of the reasons for the higher dependence of Europe’s SMEs on bank lending. In future, the result of rating w ill also depend on the amount of capital in the company; the high dependence on lending will influence the access to lending. This is a vicious cycle, which has to be broken.Even though company and income taxation falls under the competence of Member States, UEAPME asks the new European Commission and the new European Parliament to publicly support tax-reforms, which will strengthen the capacity of Crafts, Trades and SME for self-financing. Thereby, a special focus on non-corporate companies is needed.5. Risk Capital – equity financingExternal equity financing does not have a real tradition in the SME sector. On the one hand, small enterprises and family business in general have traditionally not been very open towards external equity financing and are not used to informing transparently about their business.On the other hand, many investors of venture capital and similar forms of equity finance are very reluctant regarding investing their funds in smaller companies, which is more costly than investing bigger amounts in larger companies. Furthermore it is much more difficult to set out of such investments in smaller companies.Even though equity financing will never become the main source of financing for SMEs, it is an important instrument for highly innovative start-ups and fast growing companies and it has therefore to be further developed. UEAPME sees three pillars for such an approach where policy support is needed:Availability of venture capital•The Member States should review their taxation systems in order to create incentives to invest private money in all forms of venture capital.•Guarantee instruments for equity financing should be further developed.Improve the conditions for investing venture capital into SMEs•The development of secondary markets for venture capital investments in SMEs should be supported.•Accounting Standards for SMEs should be revised in order to easetransparent exchange of information between investor and owner-manager.Owner-managers must become more aware about the need for transparency towards investors•SME owners will have to realise that in future access to external finance (venture capital or lending) will depend much more on a transparent and open exchange of information about the situation and the perspectives of their companies.•In order to fulfil the new needs for transparency, SMEs will have to use new information instruments (business plans, financial reporting, etc.) and new management instruments (risk-management, financial management, etc.).外文资料翻译涂敏之会计学 8051208076题目:未来的中小企业融资背景:中小企业融资已经改变未来的经济复苏将取决于能否工艺品,贸易和中小企业利用其潜在的增长和创造就业。
数据库外文参考文献及翻译

数据库外文参考文献及翻译数据库外文参考文献及翻译SQL ALL-IN-ONE DESK REFERENCE FOR DUMMIESData Files and DatabasesI. Irreducible complexityAny software system that performs a useful function is going to be complex. The more valuable the function, the more complex its implementation will be. Regardless of how the data is stored, the complexity remains. The only question is where that complexity resides. Any non-trivial computer application has two major components: the program the data. Although an application’s level of complexity depends on the task to be performed, developers have some control over the location of that complexity. The complexity may reside primarily in the program part of the overall system, or it may reside in the data part.Operations on the data can be fast. Because the programinteracts directly with the data, with no DBMS in the middle, well-designed applications can run as fast as the hardware permits. What could be better? A data organization that minimizes storage requirements and at the same time maximizes speed of operation seems like the best of all possible worlds. But wait a minute . Flat file systems came into use in the 1940s. We have known about them for a long time, and yet today they have been almost entirely replaced by database s ystems. What’s up with that? Perhaps it is the not-so-beneficial consequences。
大数据挖掘外文翻译文献

文献信息:文献标题:A Study of Data Mining with Big Data(大数据挖掘研究)国外作者:VH Shastri,V Sreeprada文献出处:《International Journal of Emerging Trends and Technology in Computer Science》,2016,38(2):99-103字数统计:英文2291单词,12196字符;中文3868汉字外文文献:A Study of Data Mining with Big DataAbstract Data has become an important part of every economy, industry, organization, business, function and individual. Big Data is a term used to identify large data sets typically whose size is larger than the typical data base. Big data introduces unique computational and statistical challenges. Big Data are at present expanding in most of the domains of engineering and science. Data mining helps to extract useful data from the huge data sets due to its volume, variability and velocity. This article presents a HACE theorem that characterizes the features of the Big Data revolution, and proposes a Big Data processing model, from the data mining perspective.Keywords: Big Data, Data Mining, HACE theorem, structured and unstructured.I.IntroductionBig Data refers to enormous amount of structured data and unstructured data thatoverflow the organization. If this data is properly used, it can lead to meaningful information. Big data includes a large number of data which requires a lot of processing in real time. It provides a room to discover new values, to understand in-depth knowledge from hidden values and provide a space to manage the data effectively. A database is an organized collection of logically related data which can be easily managed, updated and accessed. Data mining is a process discovering interesting knowledge such as associations, patterns, changes, anomalies and significant structures from large amount of data stored in the databases or other repositories.Big Data includes 3 V’s as its characteristics. They are volume, velocity and variety. V olume means the amount of data generated every second. The data is in state of rest. It is also known for its scale characteristics. Velocity is the speed with which the data is generated. It should have high speed data. The data generated from social media is an example. Variety means different types of data can be taken such as audio, video or documents. It can be numerals, images, time series, arrays etc.Data Mining analyses the data from different perspectives and summarizing it into useful information that can be used for business solutions and predicting the future trends. Data mining (DM), also called Knowledge Discovery in Databases (KDD) or Knowledge Discovery and Data Mining, is the process of searching large volumes of data automatically for patterns such as association rules. It applies many computational techniques from statistics, information retrieval, machine learning and pattern recognition. Data mining extract only required patterns from the database in a short time span. Based on the type of patterns to be mined, data mining tasks can be classified into summarization, classification, clustering, association and trends analysis.Big Data is expanding in all domains including science and engineering fields including physical, biological and biomedical sciences.II.BIG DATA with DATA MININGGenerally big data refers to a collection of large volumes of data and these data are generated from various sources like internet, social-media, business organization, sensors etc. We can extract some useful information with the help of Data Mining. It is a technique for discovering patterns as well as descriptive, understandable, models from a large scale of data.V olume is the size of the data which is larger than petabytes and terabytes. The scale and rise of size makes it difficult to store and analyse using traditional tools. Big Data should be used to mine large amounts of data within the predefined period of time. Traditional database systems were designed to address small amounts of data which were structured and consistent, whereas Big Data includes wide variety of data such as geospatial data, audio, video, unstructured text and so on.Big Data mining refers to the activity of going through big data sets to look for relevant information. To process large volumes of data from different sources quickly, Hadoop is used. Hadoop is a free, Java-based programming framework that supports the processing of large data sets in a distributed computing environment. Its distributed supports fast data transfer rates among nodes and allows the system to continue operating uninterrupted at times of node failure. It runs Map Reduce for distributed data processing and is works with structured and unstructured data.III.BIG DATA characteristics- HACE THEOREM.We have large volume of heterogeneous data. There exists a complex relationship among the data. We need to discover useful information from this voluminous data.Let us imagine a scenario in which the blind people are asked to draw elephant. The information collected by each blind people may think the trunk as wall, leg as tree, body as wall and tail as rope. The blind men can exchange information with each other.Figure1: Blind men and the giant elephantSome of the characteristics that include are:i.Vast data with heterogeneous and diverse sources: One of the fundamental characteristics of big data is the large volume of data represented by heterogeneous and diverse dimensions. For example in the biomedical world, a single human being is represented as name, age, gender, family history etc., For X-ray and CT scan images and videos are used. Heterogeneity refers to the different types of representations of same individual and diverse refers to the variety of features to represent single information.ii.Autonomous with distributed and de-centralized control: the sources are autonomous, i.e., automatically generated; it generates information without any centralized control. We can compare it with World Wide Web (WWW) where each server provides a certain amount of information without depending on other servers.plex and evolving relationships: As the size of the data becomes infinitely large, the relationship that exists is also large. In early stages, when data is small, there is no complexity in relationships among the data. Data generated from social media and other sources have complex relationships.IV.TOOLS:OPEN SOURCE REVOLUTIONLarge companies such as Facebook, Yahoo, Twitter, LinkedIn benefit and contribute work on open source projects. In Big Data Mining, there are many open source initiatives. The most popular of them are:Apache Mahout:Scalable machine learning and data mining open source software based mainly in Hadoop. It has implementations of a wide range of machine learning and data mining algorithms: clustering, classification, collaborative filtering and frequent patternmining.R: open source programming language and software environment designed for statistical computing and visualization. R was designed by Ross Ihaka and Robert Gentleman at the University of Auckland, New Zealand beginning in 1993 and is used for statistical analysis of very large data sets.MOA: Stream data mining open source software to perform data mining in real time. It has implementations of classification, regression; clustering and frequent item set mining and frequent graph mining. It started as a project of the Machine Learning group of University of Waikato, New Zealand, famous for the WEKA software. The streams framework provides an environment for defining and running stream processes using simple XML based definitions and is able to use MOA, Android and Storm.SAMOA: It is a new upcoming software project for distributed stream mining that will combine S4 and Storm with MOA.Vow pal Wabbit: open source project started at Yahoo! Research and continuing at Microsoft Research to design a fast, scalable, useful learning algorithm. VW is able to learn from terafeature datasets. It can exceed the throughput of any single machine networkinterface when doing linear learning, via parallel learning.V.DATA MINING for BIG DATAData mining is the process by which data is analysed coming from different sources discovers useful information. Data Mining contains several algorithms which fall into 4 categories. They are:1.Association Rule2.Clustering3.Classification4.RegressionAssociation is used to search relationship between variables. It is applied in searching for frequently visited items. In short it establishes relationship among objects. Clustering discovers groups and structures in the data.Classification deals with associating an unknown structure to a known structure. Regression finds a function to model the data.The different data mining algorithms are:Table 1. Classification of AlgorithmsData Mining algorithms can be converted into big map reduce algorithm based on parallel computing basis.Table 2. Differences between Data Mining and Big DataVI.Challenges in BIG DATAMeeting the challenges with BIG Data is difficult. The volume is increasing every day. The velocity is increasing by the internet connected devices. The variety is also expanding and the organizations’ capability to capture and process the data is limited.The following are the challenges in area of Big Data when it is handled:1.Data capture and storage2.Data transmission3.Data curation4.Data analysis5.Data visualizationAccording to, challenges of big data mining are divided into 3 tiers.The first tier is the setup of data mining algorithms. The second tier includesrmation sharing and Data Privacy.2.Domain and Application Knowledge.The third one includes local learning and model fusion for multiple information sources.3.Mining from sparse, uncertain and incomplete data.4.Mining complex and dynamic data.Figure 2: Phases of Big Data ChallengesGenerally mining of data from different data sources is tedious as size of data is larger. Big data is stored at different places and collecting those data will be a tedious task and applying basic data mining algorithms will be an obstacle for it. Next we need to consider the privacy of data. The third case is mining algorithms. When we are applying data mining algorithms to these subsets of data the result may not be that much accurate.VII.Forecast of the futureThere are some challenges that researchers and practitioners will have to deal during the next years:Analytics Architecture:It is not clear yet how an optimal architecture of analytics systems should be to deal with historic data and with real-time data at the same time. An interesting proposal is the Lambda architecture of Nathan Marz. The Lambda Architecture solves the problem of computing arbitrary functions on arbitrary data in real time by decomposing the problem into three layers: the batch layer, theserving layer, and the speed layer. It combines in the same system Hadoop for the batch layer, and Storm for the speed layer. The properties of the system are: robust and fault tolerant, scalable, general, and extensible, allows ad hoc queries, minimal maintenance, and debuggable.Statistical significance: It is important to achieve significant statistical results, and not be fooled by randomness. As Efron explains in his book about Large Scale Inference, it is easy to go wrong with huge data sets and thousands of questions to answer at once.Distributed mining: Many data mining techniques are not trivial to paralyze. To have distributed versions of some methods, a lot of research is needed with practical and theoretical analysis to provide new methods.Time evolving data: Data may be evolving over time, so it is important that the Big Data mining techniques should be able to adapt and in some cases to detect change first. For example, the data stream mining field has very powerful techniques for this task.Compression: Dealing with Big Data, the quantity of space needed to store it is very relevant. There are two main approaches: compression where we don’t loose anything, or sampling where we choose what is thedata that is more representative. Using compression, we may take more time and less space, so we can consider it as a transformation from time to space. Using sampling, we are loosing information, but the gains inspace may be in orders of magnitude. For example Feldman et al use core sets to reduce the complexity of Big Data problems. Core sets are small sets that provably approximate the original data for a given problem. Using merge- reduce the small sets can then be used for solving hard machine learning problems in parallel.Visualization: A main task of Big Data analysis is how to visualize the results. As the data is so big, it is very difficult to find user-friendly visualizations. New techniques, and frameworks to tell and show stories will be needed, as for examplethe photographs, infographics and essays in the beautiful book ”The Human Face of Big Data”.Hidden Big Data: Large quantities of useful data are getting lost since new data is largely untagged and unstructured data. The 2012 IDC studyon Big Data explains that in 2012, 23% (643 exabytes) of the digital universe would be useful for Big Data if tagged and analyzed. However, currently only 3% of the potentially useful data is tagged, and even less is analyzed.VIII.CONCLUSIONThe amounts of data is growing exponentially due to social networking sites, search and retrieval engines, media sharing sites, stock trading sites, news sources and so on. Big Data is becoming the new area for scientific data research and for business applications.Data mining techniques can be applied on big data to acquire some useful information from large datasets. They can be used together to acquire some useful picture from the data.Big Data analysis tools like Map Reduce over Hadoop and HDFS helps organization.中文译文:大数据挖掘研究摘要数据已经成为各个经济、行业、组织、企业、职能和个人的重要组成部分。
公路线形设计外文文献翻译英文参考

外文文献翻译(含:英文原文及中文译文)文献出处:Y Hassan. Geometric Design of Highways[J] Advances in Transportation Studies, 2016, 6(1):31-41.英文原文Geometric Design of HighwaysY HassanA. Alignment DesignThe alignment of a road is shown on the plane view and is a series of straight lines called tangents connected by circular curves. In modern practice it is common to interpose transition or spiral curves between tangents and circular curves.The line shape should be continuous, sudden changes from flat line to small radius curve or sudden change of long line end connected to small radius curve should be avoided, otherwise a traffic accident may occur. Similarly, arcs with different radii end-to-end (complex curves) or short straight lines between two arcs with different radii are bad lines unless an easing curve is inserted between arcs. The long, smooth curve is always a good line because it is beautifully lined and will not be abandoned in the future. However, it is not ideal that the two-way road line shape is composed entirely of curves, because some drivers always hesitate to pass through curved road segments. The long and slow curve is used in thesmaller corners. If you use a short curve, you will see "kinks." In addition, the design of the flat and vertical sections of the line should be considered comprehensively and should not be only one. No matter which, for example, when the starting point of the flat curve is near the vertex of the vertical curve, serious traffic accidents will occur.V ehicles driving on curved sections are subjected to centrifugal force, and they need a force of the same magnitude in the opposite direction due to the height and lateral friction to offset it. From the viewpoint of highway design, the high or horizontal friction cannot exceed a certain value. The maximum, these control values for a certain design speed may limit the curvature of the curve. In general, the curvature of a circular curve is represented by its radius. For the linear design, the curvature is often described by the curvature, ie, the central angle corresponding to the 100-foot curve, which is inversely proportional to the radius of the curve.A normal road arch is set in a straight section of the road, and the curve section is set to a super high, and an excessively gradual road section must be set between the normal section and the super high section. The usual practice is to maintain the design elevation of each midline of the road unchanged. By raising the outer edge and lowering the inner edge to form a super high, for the line shape where the straight line is directly connected with the circle curve, the super high should never start on the straight line before reaching the curve. At the other end of the curve at acertain distance to reach all the ultra-high.If the vehicle is driving at a high speed on a restricted section of road, such as a straight line connected with a small radius circle curve, driving will be extremely uncomfortable. When the car enters the curve section, the super high starts and the vehicle tilts inward, but the passenger must maintain the body because it is not subjected to centrifugal force at this time. When the car reaches the curve section, centrifugal force suddenly occurs, forcing passengers to make further posture adjustments. When the car leaves the curve, the above process is just the opposite. After inserting the relaxation curve, the radius gradually transitions from infinity to a certain fixed value on the circle curve, the centrifugal force gradually increases, and ultra-high levels are carefully set along the relaxation curve, and the centrifugal force is gradually increased, thereby avoiding driving bumps.The easement curve has been used on railways for many years, but it has recently been applied on highways. This is understandable. The train must follow a precise orbit, and the uncomfortable feeling mentioned above can only be eliminated after the ease curve is used. However, the driver of a car can change the lateral position on the road at will, and he can provide a relaxation curve for himself by making a roundabout curve. But doing this in one lane (sometimes in other lanes) is very dangerous. A well-designed relaxation curve makes the above roundaboutnessunnecessary. Multi-cluster safety is a measure, and roads are widely used as transition curves.For a circular curve with the same radius, adding an easing curve at the end will change the relative positions of the curve and the straight line. Therefore, whether or not to use an easing curve should be determined before final alignment survey. The starting point of the general curve is labeled PC or BC and the end point is labeled PT or EC. For curves with transition curves, the usual marker configurations are: TC, SC, CS, and ST.For two-way roads, the road width should be increased at sharp bends. This is mainly based on the following factors: 1. The driver is afraid to get out of the edge of the road. 2. Due to the difference in the driving trajectory of the front and rear wheels of the vehicle, the effective lateral width of the vehicle increases; 3. The width of the front of the vehicle that is inclined relative to the centerline of the road. For roads that are 24 feet wide, the added width is negligible. Only if the design speed is 30 mil / h and the curvature is up to 2 ft. However, for narrow roads, widening is very important even on smooth curve sections. The recommended widening values and widened designs are shown in ". Highway linear design."B. Longitudinal slope lineThe vertical alignment of the highway and its impact on the safety andeconomy of vehicle operation constitute one of the most important elements in highway design. V ertical lines consist of straight lines and vertical parabolas or circular lines called vertical slope lines. When a grade line rises gradually from a horizontal line, it is called an uphill, and vice versa, it is called a downhill slope. In the analysis of slope and slope control, designers usually have to study the effect of changes in slope on the midline profile. In determining the slope, the ideal situation is the balance of excavation and filling, and there is no large amount of borrowers and abandoned parties. All the earth moving is carried down as far as possible and the distance is not long. The slope should change with the terrain and be consistent with the direction of ascent and descent of the existing drainage system. In the mountains, the slopes should be balanced to minimize the total cost. In the plain or grassland areas, the slope is approximately parallel to the surface, but higher than the surface at a sufficient height to facilitate drainage of the surface. If necessary, winds can be used to remove surface snow. If the road is approaching or running along a river, the current height of the slope is determined by the expected flood level. In any case, the gentle slope should be set at the excavation section compared to the short vertical section connecting the short vertical curve due to the upslope downslope, and the section from the downslope upslope should be set at the fill. Road section. Such a good linear design can often avoid the formation of a mound or depressionopposite to the current landscape. Other considerations are much more important when determining the vertical slope line than when filling the balance. Study and make more detailed adjustments to advanced issues. In general, the slope of the design that is consistent with the existing conditions is better, which can avoid some unnecessary costs.In slope analysis and control, the impact of slope on motor vehicle operating costs is one of the most important considerations. As the slope increases, the fuel consumption will obviously increase and the speed will slow down. A more economical solution can balance the annual increase in the annual cost of reducing the slope and increasing the annual cost of running the vehicle without increasing the slope. The exact solution to this problem depends on the understanding of traffic flow and traffic type, which can only be known through traffic investigations.In different states, where the maximum longitudinal gradient is also very different, AASHTO recommends that the maximum longitudinal slope be selected based on the time and terrain. The current design has a maximum longitudinal gradient of 5% at a design speed of 70 mil / h. At a design speed of 30 mil / h, the maximum longitudinal slope is generally 7% - 12% depending on the topography.When using longer sustained climbs, the slope length cannot exceed the critical slope length when no slow-moving vehicle is provided. The critical slope length can vary from 1700 ft in 3% grade to 500 ft in 8%grade. The slope of the continuous long slope must be less than the maximum slope of any end surface of the highway. Usually the long continuous single slope is disconnected and the lower part is designed as a steep slope, while approaching the top of the slope allows the slope to decrease. At the same time, it is necessary to avoid obstruction of the view due to the inclination of the longitudinal section.The maximum longitudinal gradient of the highway is 9%. Only when the drainage of the road is a problem, if the water must be drained to the side ditch or the drainage ditch, the minimum gradient criterion is of importance. In this case, AASHTO recommends a minimum gradient of0.35%.C. sight distanceIn order to ensure the safety of driving, the road must be designed to have a sufficient distance in front of the driver's line of sight, so that they can avoid obstacles other than the obstacles, or safely overtake. The line-of-sight is the length of the road visible to the driver of the vehicle. Two meanings: "parking distance" or "non-passing sight distance" or "overtaking sight distance."No matter what happens, reasonable design requires the driver to see this danger outside a certain distance, and brake the car before hitting it. In addition, it is not safe to think that the vehicle can avoid danger by leaving the driving lane. Because this can cause the vehicle to lose controlor to collide with another car.The parking distance is composed of two parts: The first part is the distance that the driver takes before the driver finds an obstacle and brakes. In this detection and reaction phase, the vehicle travels at its initial speed; the second part is the driver’s Part of the pa rking distance depends on the speed of the vehicle and the driver's visual time and braking time. The second part of the parking distance depends on the speed, the brakes, the tires, the conditions of the road surface, and the line shape and slope of the road.Otherwise, the capacity of the highway will be reduced, and the accident will increase, because the irritable driver would risk a collision and overtake the vehicle if he cannot safely overtake the vehicle. The minimum distance in front of which the driver can safely be seen is called the overtaking distance.When making a decision on whether to pass or not, the driver must compare the visibility distance ahead and the distance required to complete the overtaking movement. The factors that influence him to make a decision are the degree of caution in driving and the acceleration performance of the vehicle. Due to the significant differences between humans, the overtaking behavior, which is mainly determined by human judgments and actions rather than the mechanical theorem, varies greatly from driver to driver. In order to establish the line-of-sight value forovertaking, engineers observed many drivers’ overtaking behavior. Between 1938 and 1941, a basic survey was established to establish a standard of over- sight distance. Assume that the operating conditions are as follows:1. It is driven at a uniform speed by the overtaking vehicle.2. Overtaking When entering the overtaking area, decelerate after being overtaken.3. When arriving at the overtaking area, the driver needs to observe the passing area for a short time and start overtaking.4. In the face of the opposite vehicle, the overtaking is completed in a delayed start-up and a hurried turn. In the overtaking process, overtaking accelerates in the overtaking lane and the average speed is 10 mil / h faster than being overtaken.5. When overtaking returns to its original lane, there must be a safe distance between it and the opposite vehicle on the other lane.The sum of the above five items is the over sight distance.中文译文公路线形设计作者:Y HassanA. 平面设计道路的线形反映在平面图上是由一系列的直线和与直线相连的圆曲线构成的。
数据采集外文文献翻译中英文

数据采集外文文献翻译(含:英文原文及中文译文)文献出处:Txomin Nieva. DATA ACQUISITION SYSTEMS [J]. Computers in Industry, 2013, 4(2):215-237.英文原文DATA ACQUISITION SYSTEMSTxomin NievaData acquisition systems, as the name implies, are products and/or processes used to collect information to document or analyze some phenomenon. In the simplest form, a technician logging the temperature of an oven on a piece of paper is performing data acquisition. As technology has progressed, this type of process has been simplified and made more accurate, versatile, and reliable through electronic equipment. Equipment ranges from simple recorders to sophisticated computer systems. Data acquisition products serve as a focal point in a system, tying together a wide variety of products, such as sensors that indicate temperature, flow, level, or pressure. Some common data acquisition terms are shown below.Data collection technology has made great progress in the past 30 to 40 years. For example, 40 years ago, in a well-known college laboratory, the device used to track temperature rises in bronze made of helium was composed of thermocouples, relays, interrogators, a bundle of papers, anda pencil.Today's university students are likely to automatically process and analyze data on PCs. There are many ways you can choose to collect data. The choice of which method to use depends on many factors, including the complexity of the task, the speed and accuracy you need, the evidence you want, and more. Whether simple or complex, the data acquisition system can operate and play its role.The old way of using pencils and papers is still feasible for some situations, and it is cheap, easy to obtain, quick and easy to start. All you need is to capture multiple channels of digital information (DMM) and start recording data by hand.Unfortunately, this method is prone to errors, slower acquisition of data, and requires too much human analysis. In addition, it can only collect data in a single channel; but when you use a multi-channel DMM, the system will soon become very bulky and clumsy. Accuracy depends on the level of the writer, and you may need to scale it yourself. For example, if the DMM is not equipped with a sensor that handles temperature, the old one needs to start looking for a proportion. Given these limitations, it is an acceptable method only if you need to implement a rapid experiment.Modern versions of the strip chart recorder allow you to retrieve data from multiple inputs. They provide long-term paper records of databecause the data is in graphic format and they are easy to collect data on site. Once a bar chart recorder has been set up, most recorders have enough internal intelligence to operate without an operator or computer. The disadvantages are the lack of flexibility and the relative low precision, often limited to a percentage point. You can clearly feel that there is only a small change with the pen. In the long-term monitoring of the multi-channel, the recorders can play a very good role, in addition, their value is limited. For example, they cannot interact with other devices. Other concerns are the maintenance of pens and paper, the supply of paper and the storage of data. The most important is the abuse and waste of paper. However, recorders are fairly easy to set up and operate, providing a permanent record of data for quick and easy analysis.Some benchtop DMMs offer selectable scanning capabilities. The back of the instrument has a slot to receive a scanner card that can be multiplexed for more inputs, typically 8 to 10 channels of mux. This is inherently limited in the front panel of the instrument. Its flexibility is also limited because it cannot exceed the number of available channels. External PCs usually handle data acquisition and analysis.The PC plug-in card is a single-board measurement system that uses the ISA or PCI bus to expand the slot in the PC. They often have a reading rate of up to 1000 per second. 8 to 16 channels are common, and the collected data is stored directly in the computer and then analyzed.Because the card is essentially a part of the computer, it is easy to establish the test. PC-cards are also relatively inexpensive, partly because they have since been hosted by PCs to provide energy, mechanical accessories, and user interfaces. Data collection optionsOn the downside, the PC plug-in cards often have a 12-word capacity, so you can't detect small changes in the input signal. In addition, the electronic environment within the PC is often susceptible to noise, high clock rates, and bus noise. The electronic contacts limit the accuracy of the PC card. These plug-in cards also measure a range of voltages. To measure other input signals, such as voltage, temperature, and resistance, you may need some external signal monitoring devices. Other considerations include complex calibrations and overall system costs, especially if you need to purchase additional signal monitoring devices or adapt the PC card to the card. Take this into account. If your needs change within the capabilities and limitations of the card, the PC plug-in card provides an attractive method for data collection.Data electronic recorders are typical stand-alone instruments that, once equipped with them, enable the measurement, recording, and display of data without the involvement of an operator or computer. They can handle multiple signal inputs, sometimes up to 120 channels. Accuracy rivals unrivalled desktop DMMs because it operates within a 22 word, 0.004 percent accuracy range. Some data electronic automatic recordershave the ability to measure proportionally, the inspection result is not limited by the user's definition, and the output is a control signal.One of the advantages of using data electronic loggers is their internal monitoring signals. Most can directly measure several different input signals without the need for additional signal monitoring devices. One channel can monitor thermocouples, RTDs, and voltages.Thermocouples provide valuable compensation for accurate temperature measurements. They are typically equipped with multi-channel cards. Built-in intelligent electronic data recorder helps you set the measurement period and specify the parameters for each channel. Once you set it all up, the data electronic recorder will behave like an unbeatable device. The data they store is distributed in memory and can hold 500,000 or more readings.Connecting to a PC makes it easy to transfer data to a computer for further analysis. Most data electronic recorders can be designed to be flexible and simple to configure and operate, and most provide remote location operation options via battery packs or other methods. Thanks to the A/D conversion technology, certain data electronic recorders have a lower reading rate, especially when compared with PC plug-in cards. However, a reading rate of 250 per second is relatively rare. Keep in mind that many of the phenomena that are being measured are physical in nature, such as temperature, pressure, and flow, and there are generallyfewer changes. In addition, because of the monitoring accuracy of the data electron loggers, a large amount of average reading is not necessary, just as they are often stuck on PC plug-in cards.Front-end data acquisition is often done as a module and is typically connected to a PC or controller. They are used in automated tests to collect data, control and cycle detection signals for other test equipment. Send signal test equipment spare parts. The efficiency of the front-end operation is very high, and can match the speed and accuracy with the best stand-alone instrument. Front-end data acquisition works in many models, including VXI versions such as the Agilent E1419A multi-function measurement and VXI control model, as well as a proprietary card elevator. Although the cost of front-end units has been reduced, these systems can be very expensive unless you need to provide high levels of operation, and finding their prices is prohibited. On the other hand, they do provide considerable flexibility and measurement capabilities.Good, low-cost electronic data loggers have the right number of channels (20-60 channels) and scan rates are relatively low but are common enough for most engineers. Some of the key applications include:•product features•Hot die cutting of electronic products•Test of the environmentEnvironmental monitoring•Composition characteristics•Battery testBuilding and computer capacity monitoringA new system designThe conceptual model of a universal system can be applied to the analysis phase of a specific system to better understand the problem and to specify the best solution more easily based on the specific requirements of a particular system. The conceptual model of a universal system can also be used as a starting point for designing a specific system. Therefore, using a general-purpose conceptual model will save time and reduce the cost of specific system development. To test this hypothesis, we developed DAS for railway equipment based on our generic DAS concept model. In this section, we summarize the main results and conclusions of this DAS development.We analyzed the device model package. The result of this analysis is a partial conceptual model of a system consisting of a three-tier device model. We analyzed the equipment project package in the equipment environment. Based on this analysis, we have listed a three-level item hierarchy in the conceptual model of the system. Equipment projects are specialized for individual equipment projects.We analyzed the equipment model monitoring standard package in the equipment context. One of the requirements of this system is the ability to use a predefined set of data to record specific status monitoring reports. We analyzed the equipment project monitoring standard package in the equipment environment. The requirements of the system are: (i) the ability to record condition monitoring reports and event monitoring reports corresponding to the items, which can be triggered by time triggering conditions or event triggering conditions; (ii) the definition of private and public monitoring standards; (iii) Ability to define custom and predefined train data sets. Therefore, we have introduced the "monitoring standards for equipment projects", "public standards", "special standards", "equipment monitoring standards", "equipment condition monitoring standards", "equipment project status monitoring standards and equipment project event monitoring standards, respectively Training item triggering conditions, training item time triggering conditions and training item event triggering conditions are device equipment trigger conditions, equipment item time trigger conditions and device project event trigger condition specialization; and training item data sets, training custom data Sets and trains predefined data sets, which are device project data sets, custom data sets, and specialized sets of predefined data sets.Finally, we analyzed the observations and monitoring reports in the equipment environment. The system's requirement is to recordmeasurements and category observations. In addition, status and incident monitoring reports can be recorded. Therefore, we introduce the concept of observation, measurement, classification observation and monitoring report into the conceptual model of the system.Our generic DAS concept model plays an important role in the design of DAS equipment. We use this model to better organize the data that will be used by system components. Conceptual models also make it easier to design certain components in the system. Therefore, we have an implementation in which a large number of design classes represent the concepts specified in our generic DAS conceptual model. Through an industrial example, the development of this particular DAS demonstrates the usefulness of a generic system conceptual model for developing a particular system.中文译文数据采集系统Txomin Nieva数据采集系统, 正如名字所暗示的, 是一种用来采集信息成文件或分析一些现象的产品或过程。
儿童教育外文翻译文献

儿童教育外文翻译文献(文档含中英文对照即英文原文和中文翻译)原文:The Role of Parents and Community in the Educationof the Japanese ChildHeidi KnipprathAbstractIn Japan, there has been an increased concern about family and community participation in the child’s educat ion. Traditionally, the role of parents and community in Japan has been one of support and less one of active involvement in school learning. Since the government commenced education reforms in the last quarter of the 20th century, a more active role for parents and the community in education has been encouraged. These reforms have been inspired by the need to tackle various problems that had arisen, such as the perceived harmful elements of society’spreoccupation with academic achievement and the problematic behavior of young people. In this paper, the following issues are examined: (1) education policy and reform measures with regard to parent and community involvement in the child’s education; (2) the state of parent and community involvement at the eve of the 20th century.Key Words: active involvement, community, education reform, Japan, parents, partnership, schooling, supportIntroduction: The Discourse on the Achievement GapWhen western observers are tempted to explain why Japanese students attain high achievement scores in international comparative assessment studies, they are likely to address the role of parents and in particular of the mother in the education of the child. Education mom is a phrase often brought forth in the discourse on Japanese education to depict the Japanese mother as being a pushy, and demanding home-bound tutor, intensely involved in the child’s education due to severe academic competition. Although this image of the Japanese mother is a stereotype spread by the popular mass media in Japan and abroad, and the extent by which Japanese mothers are absorbed in their children is exaggerated (Benjamin, 1997, p. 16; Cummings, 1989, p. 297; Stevenson & Stigler, 1992, p. 82), Stevenson and Stigler (1992) argue that Japanese parents do play an indispensable role in the academic performance of their children. During their longitudinal and cross-national research project, they and their collaborators observed that Japanese first and fifth graders persistently achieved higher on math tests than American children. Besides reciting teacher’s teaching style, cultural beliefs, and organization of schooling, Stevenson and Stigler (1992) mention parent’s role in supporting the learning conditions of the child to explain differences in achievement between elementary school students of the United States and students of Japan. In Japan, children receive more help at home with schoolwork (Chen & Stevenson, 1989; Stevenson & Stigler, 1992), and tend to perform less household chores than children in the USA (Stevenson et al., 1990; Stevenson & Stigler, 1992). More Japanese parents than American parents provide space and a personal desk and purchase workbooks for their children to supplement their regular text-books at school (Stevenson et al., 1990; Stevenson & Stigler, 1992). Additionally, Stevenson and Stigler (1992) observed that American mothers are much more readily satisfied with their child’s performance than Asian parents are, have less realistic assessments of their child’s academic perform ance, intelligence, and other personality characteristics, and subsequently have lower standards. Based on their observation of Japanese, Chinese and American parents, children and teachers, Stevenson and Stigler (1992) conclude that American families can increase the academic achievement of their children by strengthening the link between school and home, creating a physical and psychological environment that is conducive to study, and by making realistic assessments and raising standards. Also Benjamin (1997), who performed ‘day-to-day ethnography’ to find out how differences in practice between American and Japanese schools affect differences in outcomes, discusses the relationship between home and school and how the Japanese mother is involved in the academic performance standards reached by Japanese children. She argues that Japanese parents are willing to pay noticeable amounts of money for tutoring in commercial establishments to improve the child’s performance on entrance examinations, to assist in ho mework assignments, to facilitate and support their children’s participation in school requirements and activities, and to check notebooks of teachers on the child’s progress and other school-related messages from the teacher. These booklets are read and written daily by teachers and parents. Teachers regularly provide advice and reminders to parents, and write about homework assignments of the child, special activities and the child’s behavior (Benjamin, 1997, p. 119, p. 1993–1995). Newsletters, parents’ v isits to school, school reports, home visits by the teacher and observation days sustain communication in later years at school. According toBenjamin (1997), schools also inform parents about how to coach their children on proper behavior at home. Shimahara (1986), Hess and Azuma (1991), Lynn (1988) and White (1987) also try to explain national differences in educational achievement. They argue that Japanese mothers succeed in internalizing into their children academic expectations and adaptive dispositions that facilitate an effective teaching strategy, and in socializing the child into a successful person devoted to hard work.Support, Support and SupportEpstein (1995) constructed a framework of six types of involvement of parents and the community in the school: (1) parenting: schools help all families establish home environments to support children as students; (2) communicating: effective forms of school-to-home and home-to-school communications about school programs and children’s progress; (3) volu nteering: schools recruit and organize parents help and support; (4) learning at home: schools provide information and ideas to families about how to help students at home with homework and other curriculum-related activities, decisions and planning; (5) decision making: schools include parents in school decisions, develop parent leaders and representatives; and (6) collaborating with the community: schools integrate resources and services from the community to strengthen school programs, family practices, and student learning and development. All types of involvement mentioned in studies of Japanese education and in the discourse on the roots of the achievement gap belong to one of Epstein’s first four types of involvement: the creation of a conducive learn ing environment (type 4), the expression of high expectations (type 4), assistance in homework (type 4), teachers’ notebooks (type 2), mother’s willingness to facilitate school activities (type3) teachers’ advice about the child’s behavior (type 1), observ ation days by which parents observe their child in the classroom (type 2), and home visits by the teachers (type 1). Thus, when one carefully reads Stevenson and Stigler’s, Benjamin’s and other’s writings about Japanese education and Japanese students’ high achievement level, one notices that parents’ role in the child’s school learning is in particular one of support, expected and solicited by the school. The fifth type (decision making) as well as the sixth type (community involvement) is hardly ever mentioned in the discourse on the achievement gap.In 1997, the OECD’s Center for Educational Research and Innovation conducted a cross-national study to report the actual state of parents as partners in schooling in nine countries, including Japan. In its report, OECD concludes that the involvement of Japanese parents in their schools is strictly limited, and that the basis on which it takes place tends to be controlled by the teacher (OECD, 1997, p. 167). According to OECD (1997), many countries are currently adopting policies to involve families closely in the education of their children because (1) governments are decentralizing their administrations; (2) parents want to be increasingly involved; and (3) because parental involvement is said to be associated with higher achievement in school (p. 9). However, parents in Japan, where students already score highly on international achievement tests, are hardly involved in governance at the national and local level, and communication between school and family tends to be one-way (Benjamin, 1997; Fujita, 1989; OECD, 1997). Also parent–teacher associations (PTA, fubo to kyoshi no kai ) are primarily presumed to be supportive of school learning and not to participate in school governance (cf. OECD, 2001, p. 121). On the directionsof the occupying forces after the second world war, PTA were established in Japanese schools and were considered with the elective education boards to provide parents and the community an opportunity to participate actively in school learning (Hiroki, 1996, p. 88; Nakata, 1996, p. 139). The establishment of PTA and elective education boards are only two examples of numerous reform measures the occupying forces took to decentralize the formal education system and to expand educational opportunities. But after they left the country, the Japanese government was quick to undo liberal education reform measures and reduced the community and parental role in education. The stipulation that PTA should not interfere with personnel and other administrative tasks of schools, and the replacement of elective education boards by appointed ones, let local education boards believe that parents should not get involved with school education at all (Hiroki, 1996, p. 88). Teachers were regarded to be the experts and the parents to be the laymen in education (Hiroki, 1996, p. 89).In sum, studies of Japanese education point into one direction: parental involvement means being supportive, and community involvement is hardly an issue at all. But what is the actual state of parent and community involvement in Japanese schools? Are these descriptions supported by quantitative data?Statistics on Parental and Community InvolvementTo date, statistics of parental and community involvement are rare. How-ever, the school questionnaire of the TIMSS-R study did include some interesting questions that give us a clue about the degree of involvement relatively compared to the degree of involvement in other industrialized countries. The TIMSS-R study measured science and math achievement of eighth graders in 38 countries. Additionally, a survey was held among principals, teachers and students. Principals answered questions relating to school management, school characteristics, and involvement. For convenience, the results of Japan are only compared with the results of those countries with a GNP of 20650 US dollars or higher according to World Bank’s indicators in 1999.Unfortunately, only a very few items on community involvement were measured. According to the data, Japanese principals spend on average almost eight hours per month on representing the school in the community (Table I). Australian and Belgian principals spend slightly more hours and Dutch and Singaporean principals spend slightly less on representing the school and sustaining communication with the community. But when it comes to participation from the community, Japanese schools report a nearly absence of involvement (Table II). Religious groups and the business community have hardly any influence on the curriculum of the school. In contrast, half of the principals report that parents do have an impact in Japan. On one hand, this seems a surprising result when one is reminded of the centralized control of the Ministry of Education. Moreover, this control and the resulting uniform curriculum are often cited as a potential explanation of the high achievement levels in Japan. On the other hand, this extent of parental impact on the curriculum might be an indicator of the pressure parents put on schools to prepare their children appropriately for the entrance exams of senior high schools.In Table III, data on the extent of other types of parental involvement in Japan and other countries are given. In Japan, parental involvement is most common in case of schools volunteering for school projects and programs, and schools expecting parents to make sure that thechild completes his or her homework. The former is together with patrolling the grounds of the school to monitor student behavior most likely materialized through the PTA. The kinds and degree of activities of PTA vary according to the school, but the activities of the most active and well-organized PTA’s of 395 elementary schools investigated by Sumida (2001)range from facilitating sport and recreation for children, teaching greetings, encouraging safe traffic, patrolling the neighborhood, publishing the PTA newspaper to cleaning the school grounds (pp. 289–350). Surprisingly, less Japanese principals expect from the parents to check one’s child’s completion of homework than principals of other countries. In the discourse on the achievement gap, western observers report that parents and families in Japan provide more assistance with their children’s homework than parents and families outside Japan. This apparent contradiction might be the result of the fact that these data are measured at the lower secondary level while investigations of the roots of Japanese students’ high achievement levels focus on childhood education and learning at primary schools. In fact, junior high school students are given less homework in Japan than their peers in other countries and less homework than elementary school students in Japan. Instead, Japanese junior high school students spend more time at cram schools. Finally, Japanese principals also report very low degrees of expectations toward parents with regard to serving as a teacher aid in the classroom, raising funds for the school, assisting teachers on trips, and serving on committees which select school personnel and review school finances. The latter two items measure participation in school governance.In other words, the data support by and large the descriptions of parental of community involvement in Japanese schooling. Parents are requested to be supportive, but not to mount the territory of the teacher nor to be actively involved in governance. Moreover, whilst Japanese principals spend a few hours per month on communication toward the community, involvement from the community with regard to the curriculum is nearly absent, reflecting the nearly absence of accounts of community involvement in studies on Japanese education. However, the reader needs to be reminded that these data are measured at the lower secondary educational level when participation by parents in schooling decreases (Epstein, 1995; OECD, 1997; Osakafu Kyoiku Iinkai, unpublished report). Additionally, the question remains what stakeholders think of the current state of involvement in schooling. Some interesting local data provided by the Osaka Prefecture Education Board shed a light on their opinion.ReferencesBenjamin, G. R. (1997). Japanese lessons. New York: New York University Press.Cave, P. (2003). Educational reform in Japan in the 1990s: ‘Individuality’ and other uncertainties. Comparative Education Review, 37(2), 173–191.Chen, C., & Stevenson, H. W. (1989). Homework: A cross-cultural examination. Child Development, 60(3), 551–561.Chuo Kyoiku Shingikai (1996). 21 seiki o tenbo shita wagakuni no kyoiku no arikata ni tsu-ite [First Report on the Model for Japanese Education in the Perspective of theCummings, W. K. (1989). The American perception of Japanese parative Education, 25(3), 293–302.Epstein, J. L. (1995). School/family/community partnerships. Phi Delta Kappan , 701–712.Fujita, M. (1989). It’s all mother’s fault: childcare and the socialization of working mothers in Japan. The Journal of Japanese Studies , 15(1), 67–91.Harnish, D. L. (1994). Supplemental education in Japan: juku schooling and its implication. Journal of Curriculum Studies , 26(3), 323–334.Hess, R. D., & Azuma, H. (1991). Cultural support for schooling, contrasts between Japanand the United States. Educational Researcher , 20(9), 2–8, 12.Hiroki, K. (1996). Kyoiku ni okeru kodomo, oya, kyoshi, kocho no kenri, gimukankei[Rights and duties of principals, teachers, parents and children in education. InT. Horio & T. Urano (Eds.), Soshiki toshite no gakko [School as an organization](pp. 79–100). Tokyo: Kashiwa Shobo. Ikeda, H. (2000). Chiiki no kyoiku kaikaku [Local education reform]. Osaka: Kaiho Shup-pansha.Kudomi, Y., Hosogane, T., & Inui, A. (1999). The participation of students, parents and the community in promoting school autonomy: case studies in Japan. International Studies in Sociology of Education, 9(3), 275–291.Lynn, R. (1988).Educational achievement in Japan. London: MacMillan Press.Martin, M. O., Mullis, I. V. S., Gonzalez, E. J., Gregory, K. D., Smith, T. A., Chrostowski,S. J., Garden, R. A., & O’Connor, K. M. (2000). TIMSS 1999 Intern ational science report, findings from IEA’s Repeat of the Third International Mathematics and ScienceStudy at the Eight Grade.Chestnut Hill: The International Study Center.Mullis, I. V. S., Martin, M. O., Gonzalez, E. J., Gregory, K. D., Garden, R. A., O’Connor, K. M.,Chrostowski, S. J., & Smith, T. A.. (2000). TIMSS 1999 International mathemat-ics report, findings from IEA’s Repeat of the Third International Mathematics and Science Study at the Eight Grade.Chestnut Hill: The International Study Center. Ministry of Education, Science, Sports and Culture (2000).Japanese government policies in education, science, sports and culture. 1999, educational reform in progress. Tokyo: PrintingBureau, Ministry of Finance.Monbusho Ed. (1999).Heisei 11 nendo, wagakuni no bunkyoshisaku : Susumu kaikaku [Japanese government policies in education, science, sports and culture 1999: Educational reform in progress]. Tokyo: Monbusho.Educational Research for Policy and Practice (2004) 3: 95–107 © Springer 2005DOI 10.1007/s10671-004-5557-6Heidi KnipprathDepartment of MethodologySchool of Business, Public Administration and TechnologyUniversity of Twente P.O. Box 2177500 AE Enschede, The Netherlands译文:家长和社区在日本儿童教育中的作用摘要在日本,人们越来越关心家庭和社区参与到儿童教育中。
ASP.NET2.0数据库外文文献及翻译和参考文献-英语论文

2.0数据库外文文献及翻译和参考文献-英语论文 2.0数据库外文文献及翻译和参考文献参考文献[1] Matthew 高级程序设计[M].人民邮电出版社,2009.[2] 张领项目开发全程实录[M].清华大学出版社,2008.[3] 陈季实例指南与高级应用[M].中国铁道出版社,2008.[4] 郑霞2.0编程技术与实例[M].人民邮电出版社,2009.[5] 李俊民.精通SQL(结构化查询语言详解)[M].人民邮电出版社,2009.[6] 刘辉 .零基础学SQL Server 2005[M].机械工业出版社,2007.[7] 齐文海.ASP与SQL Server站点开发实用教程[M].机械工业出版社,2008.[8] 唐学忠.原文请找SQL Server 2000数据库教程[M]. 电子工业出版社,2005.[9] 王珊、萨师煊.数据库系统概论(第四版)[M].北京:高等教育出版社,2006.[10] Mani work Management Principles and Practive. Higher Education Press,2005,12VS2005中开发 2.0数据库程序一、简介在2005年11月7日,微软正式发行了.NET 2.0(包括 2.0),Visual Studio 2005和SQL Server 2005。
所有这些部件均被设计为可并肩独立工作。
也就是说,版本1.x和版本2.0可以安装在同一台机器上;你可以既有Visual 2002/2003和Visual Studio 2005,同时又有SQL Server 2000和SQL Server 2005。
而且,微软还在发行Visual Studio 2005和SQL Server 2005的一个 Express式的SKU。
注意,该Express版并不拥有专业版所有的特征。
2.0除了支持1.x风格的数据存取外,自身也包括一些新的数据源控件-它们使得访问和修改数据库数据极为轻松。
数据库外文参考文献及翻译.

数据库外文参考文献及翻译数据库外文参考文献及翻译数据库管理系统——实施数据完整性一个数据库,只有用户对它特别有信心的时候。
这就是为什么服务器必须实施数据完整性规则和商业政策的原因。
执行SQL Server的数据完整性的数据库本身,保证了复杂的业务政策得以遵循,以及强制性数据元素之间的关系得到遵守。
因为SQL Server的客户机/服务器体系结构允许你使用各种不同的前端应用程序去操纵和从服务器上呈现同样的数据,这把一切必要的完整性约束,安全权限,业务规则编码成每个应用,是非常繁琐的。
如果企业的所有政策都在前端应用程序中被编码,那么各种应用程序都将随着每一次业务的政策的改变而改变。
即使您试图把业务规则编码为每个客户端应用程序,其应用程序失常的危险性也将依然存在。
大多数应用程序都是不能完全信任的,只有当服务器可以作为最后仲裁者,并且服务器不能为一个很差的书面或恶意程序去破坏其完整性而提供一个后门。
SQL Server使用了先进的数据完整性功能,如存储过程,声明引用完整性(DRI),数据类型,限制,规则,默认和触发器来执行数据的完整性。
所有这些功能在数据库里都有各自的用途;通过这些完整性功能的结合,可以实现您的数据库的灵活性和易于管理,而且还安全。
声明数据完整性声明数据完整原文请找腾讯3249114六,维-论'文.网 定义一个表时指定构成的主键的列。
这就是所谓的主键约束。
SQL Server使用主键约束以保证所有值的唯一性在指定的列从未侵犯。
通过确保这个表有一个主键来实现这个表的实体完整性。
有时,在一个表中一个以上的列(或列的组合)可以唯一标志一行,例如,雇员表可能有员工编号( emp_id )列和社会安全号码( soc_sec_num )列,两者的值都被认为是唯一的。
这种列经常被称为替代键或候选键。
这些项也必须是唯一的。
虽然一个表只能有一个主键,但是它可以有多个候选键。
SQL Server的支持多个候选键概念进入唯一性约束。
儿童教育外文翻译文献
儿童教育外文翻译文献(文档含中英文对照即英文原文和中文翻译)原文:The Role of Parents and Community in the Educationof the Japanese ChildHeidi KnipprathAbstractIn Japan, there has been an increased concern about family and community participation in the child’s educat ion. Traditionally, the role of parents and community in Japan has been one of support and less one of active involvement in school learning. Since the government commenced education reforms in the last quarter of the 20th century, a more active role for parents and the community in education has been encouraged. These reforms have been inspired by the need to tackle various problems that had arisen, such as the perceived harmful elements of society’spreoccupation with academic achievement and the problematic behavior of young people. In this paper, the following issues are examined: (1) education policy and reform measures with regard to parent and community involvement in the child’s education; (2) the state of parent and community involvement at the eve of the 20th century.Key Words: active involvement, community, education reform, Japan, parents, partnership, schooling, supportIntroduction: The Discourse on the Achievement GapWhen western observers are tempted to explain why Japanese students attain high achievement scores in international comparative assessment studies, they are likely to address the role of parents and in particular of the mother in the education of the child. Education mom is a phrase often brought forth in the discourse on Japanese education to depict the Japanese mother as being a pushy, and demanding home-bound tutor, intensely involved in the child’s education due to severe academic competition. Although this image of the Japanese mother is a stereotype spread by the popular mass media in Japan and abroad, and the extent by which Japanese mothers are absorbed in their children is exaggerated (Benjamin, 1997, p. 16; Cummings, 1989, p. 297; Stevenson & Stigler, 1992, p. 82), Stevenson and Stigler (1992) argue that Japanese parents do play an indispensable role in the academic performance of their children. During their longitudinal and cross-national research project, they and their collaborators observed that Japanese first and fifth graders persistently achieved higher on math tests than American children. Besides reciting teacher’s teaching style, cultural beliefs, and organization of schooling, Stevenson and Stigler (1992) mention parent’s role in supporting the learning conditions of the child to explain differences in achievement between elementary school students of the United States and students of Japan. In Japan, children receive more help at home with schoolwork (Chen & Stevenson, 1989; Stevenson & Stigler, 1992), and tend to perform less household chores than children in the USA (Stevenson et al., 1990; Stevenson & Stigler, 1992). More Japanese parents than American parents provide space and a personal desk and purchase workbooks for their children to supplement their regular text-books at school (Stevenson et al., 1990; Stevenson & Stigler, 1992). Additionally, Stevenson and Stigler (1992) observed that American mothers are much more readily satisfied with their child’s performance than Asian parents are, have less realistic assessments of their child’s academic perform ance, intelligence, and other personality characteristics, and subsequently have lower standards. Based on their observation of Japanese, Chinese and American parents, children and teachers, Stevenson and Stigler (1992) conclude that American families can increase the academic achievement of their children by strengthening the link between school and home, creating a physical and psychological environment that is conducive to study, and by making realistic assessments and raising standards. Also Benjamin (1997), who performed ‘day-to-day ethnography’ to find out how differences in practice between American and Japanese schools affect differences in outcomes, discusses the relationship between home and school and how the Japanese mother is involved in the academic performance standards reached by Japanese children. She argues that Japanese parents are willing to pay noticeable amounts of money for tutoring in commercial establishments to improve the child’s performance on entrance examinations, to assist in ho mework assignments, to facilitate and support their children’s participation in school requirements and activities, and to check notebooks of teachers on the child’s progress and other school-related messages from the teacher. These booklets are read and written daily by teachers and parents. Teachers regularly provide advice and reminders to parents, and write about homework assignments of the child, special activities and the child’s behavior (Benjamin, 1997, p. 119, p. 1993–1995). Newsletters, parents’ v isits to school, school reports, home visits by the teacher and observation days sustain communication in later years at school. According toBenjamin (1997), schools also inform parents about how to coach their children on proper behavior at home. Shimahara (1986), Hess and Azuma (1991), Lynn (1988) and White (1987) also try to explain national differences in educational achievement. They argue that Japanese mothers succeed in internalizing into their children academic expectations and adaptive dispositions that facilitate an effective teaching strategy, and in socializing the child into a successful person devoted to hard work.Support, Support and SupportEpstein (1995) constructed a framework of six types of involvement of parents and the community in the school: (1) parenting: schools help all families establish home environments to support children as students; (2) communicating: effective forms of school-to-home and home-to-school communications about school programs and children’s progress; (3) volu nteering: schools recruit and organize parents help and support; (4) learning at home: schools provide information and ideas to families about how to help students at home with homework and other curriculum-related activities, decisions and planning; (5) decision making: schools include parents in school decisions, develop parent leaders and representatives; and (6) collaborating with the community: schools integrate resources and services from the community to strengthen school programs, family practices, and student learning and development. All types of involvement mentioned in studies of Japanese education and in the discourse on the roots of the achievement gap belong to one of Epstein’s first four types of involvement: the creation of a conducive learn ing environment (type 4), the expression of high expectations (type 4), assistance in homework (type 4), teachers’ notebooks (type 2), mother’s willingness to facilitate school activities (type3) teachers’ advice about the child’s behavior (type 1), observ ation days by which parents observe their child in the classroom (type 2), and home visits by the teachers (type 1). Thus, when one carefully reads Stevenson and Stigler’s, Benjamin’s and other’s writings about Japanese education and Japanese students’ high achievement level, one notices that parents’ role in the child’s school learning is in particular one of support, expected and solicited by the school. The fifth type (decision making) as well as the sixth type (community involvement) is hardly ever mentioned in the discourse on the achievement gap.In 1997, the OECD’s Center for Educational Research and Innovation conducted a cross-national study to report the actual state of parents as partners in schooling in nine countries, including Japan. In its report, OECD concludes that the involvement of Japanese parents in their schools is strictly limited, and that the basis on which it takes place tends to be controlled by the teacher (OECD, 1997, p. 167). According to OECD (1997), many countries are currently adopting policies to involve families closely in the education of their children because (1) governments are decentralizing their administrations; (2) parents want to be increasingly involved; and (3) because parental involvement is said to be associated with higher achievement in school (p. 9). However, parents in Japan, where students already score highly on international achievement tests, are hardly involved in governance at the national and local level, and communication between school and family tends to be one-way (Benjamin, 1997; Fujita, 1989; OECD, 1997). Also parent–teacher associations (PTA, fubo to kyoshi no kai ) are primarily presumed to be supportive of school learning and not to participate in school governance (cf. OECD, 2001, p. 121). On the directionsof the occupying forces after the second world war, PTA were established in Japanese schools and were considered with the elective education boards to provide parents and the community an opportunity to participate actively in school learning (Hiroki, 1996, p. 88; Nakata, 1996, p. 139). The establishment of PTA and elective education boards are only two examples of numerous reform measures the occupying forces took to decentralize the formal education system and to expand educational opportunities. But after they left the country, the Japanese government was quick to undo liberal education reform measures and reduced the community and parental role in education. The stipulation that PTA should not interfere with personnel and other administrative tasks of schools, and the replacement of elective education boards by appointed ones, let local education boards believe that parents should not get involved with school education at all (Hiroki, 1996, p. 88). Teachers were regarded to be the experts and the parents to be the laymen in education (Hiroki, 1996, p. 89).In sum, studies of Japanese education point into one direction: parental involvement means being supportive, and community involvement is hardly an issue at all. But what is the actual state of parent and community involvement in Japanese schools? Are these descriptions supported by quantitative data?Statistics on Parental and Community InvolvementTo date, statistics of parental and community involvement are rare. How-ever, the school questionnaire of the TIMSS-R study did include some interesting questions that give us a clue about the degree of involvement relatively compared to the degree of involvement in other industrialized countries. The TIMSS-R study measured science and math achievement of eighth graders in 38 countries. Additionally, a survey was held among principals, teachers and students. Principals answered questions relating to school management, school characteristics, and involvement. For convenience, the results of Japan are only compared with the results of those countries with a GNP of 20650 US dollars or higher according to World Bank’s indicators in 1999.Unfortunately, only a very few items on community involvement were measured. According to the data, Japanese principals spend on average almost eight hours per month on representing the school in the community (Table I). Australian and Belgian principals spend slightly more hours and Dutch and Singaporean principals spend slightly less on representing the school and sustaining communication with the community. But when it comes to participation from the community, Japanese schools report a nearly absence of involvement (Table II). Religious groups and the business community have hardly any influence on the curriculum of the school. In contrast, half of the principals report that parents do have an impact in Japan. On one hand, this seems a surprising result when one is reminded of the centralized control of the Ministry of Education. Moreover, this control and the resulting uniform curriculum are often cited as a potential explanation of the high achievement levels in Japan. On the other hand, this extent of parental impact on the curriculum might be an indicator of the pressure parents put on schools to prepare their children appropriately for the entrance exams of senior high schools.In Table III, data on the extent of other types of parental involvement in Japan and other countries are given. In Japan, parental involvement is most common in case of schools volunteering for school projects and programs, and schools expecting parents to make sure that thechild completes his or her homework. The former is together with patrolling the grounds of the school to monitor student behavior most likely materialized through the PTA. The kinds and degree of activities of PTA vary according to the school, but the activities of the most active and well-organized PTA’s of 395 elementary schools investigated by Sumida (2001)range from facilitating sport and recreation for children, teaching greetings, encouraging safe traffic, patrolling the neighborhood, publishing the PTA newspaper to cleaning the school grounds (pp. 289–350). Surprisingly, less Japanese principals expect from the parents to check one’s child’s completion of homework than principals of other countries. In the discourse on the achievement gap, western observers report that parents and families in Japan provide more assistance with their children’s homework than parents and families outside Japan. This apparent contradiction might be the result of the fact that these data are measured at the lower secondary level while investigations of the roots of Japanese students’ high achievement levels focus on childhood education and learning at primary schools. In fact, junior high school students are given less homework in Japan than their peers in other countries and less homework than elementary school students in Japan. Instead, Japanese junior high school students spend more time at cram schools. Finally, Japanese principals also report very low degrees of expectations toward parents with regard to serving as a teacher aid in the classroom, raising funds for the school, assisting teachers on trips, and serving on committees which select school personnel and review school finances. The latter two items measure participation in school governance.In other words, the data support by and large the descriptions of parental of community involvement in Japanese schooling. Parents are requested to be supportive, but not to mount the territory of the teacher nor to be actively involved in governance. Moreover, whilst Japanese principals spend a few hours per month on communication toward the community, involvement from the community with regard to the curriculum is nearly absent, reflecting the nearly absence of accounts of community involvement in studies on Japanese education. However, the reader needs to be reminded that these data are measured at the lower secondary educational level when participation by parents in schooling decreases (Epstein, 1995; OECD, 1997; Osakafu Kyoiku Iinkai, unpublished report). Additionally, the question remains what stakeholders think of the current state of involvement in schooling. Some interesting local data provided by the Osaka Prefecture Education Board shed a light on their opinion.ReferencesBenjamin, G. R. (1997). Japanese lessons. New York: New York University Press.Cave, P. (2003). Educational reform in Japan in the 1990s: ‘Individuality’ and other uncertainties. Comparative Education Review, 37(2), 173–191.Chen, C., & Stevenson, H. W. (1989). Homework: A cross-cultural examination. Child Development, 60(3), 551–561.Chuo Kyoiku Shingikai (1996). 21 seiki o tenbo shita wagakuni no kyoiku no arikata ni tsu-ite [First Report on the Model for Japanese Education in the Perspective of theCummings, W. K. (1989). The American perception of Japanese parative Education, 25(3), 293–302.Epstein, J. L. (1995). School/family/community partnerships. Phi Delta Kappan , 701–712.Fujita, M. (1989). It’s all mother’s fault: childcare and the socialization of working mothers in Japan. The Journal of Japanese Studies , 15(1), 67–91.Harnish, D. L. (1994). Supplemental education in Japan: juku schooling and its implication. Journal of Curriculum Studies , 26(3), 323–334.Hess, R. D., & Azuma, H. (1991). Cultural support for schooling, contrasts between Japanand the United States. Educational Researcher , 20(9), 2–8, 12.Hiroki, K. (1996). Kyoiku ni okeru kodomo, oya, kyoshi, kocho no kenri, gimukankei[Rights and duties of principals, teachers, parents and children in education. InT. Horio & T. Urano (Eds.), Soshiki toshite no gakko [School as an organization](pp. 79–100). Tokyo: Kashiwa Shobo. Ikeda, H. (2000). Chiiki no kyoiku kaikaku [Local education reform]. Osaka: Kaiho Shup-pansha.Kudomi, Y., Hosogane, T., & Inui, A. (1999). The participation of students, parents and the community in promoting school autonomy: case studies in Japan. International Studies in Sociology of Education, 9(3), 275–291.Lynn, R. (1988).Educational achievement in Japan. London: MacMillan Press.Martin, M. O., Mullis, I. V. S., Gonzalez, E. J., Gregory, K. D., Smith, T. A., Chrostowski,S. J., Garden, R. A., & O’Connor, K. M. (2000). TIMSS 1999 Intern ational science report, findings from IEA’s Repeat of the Third International Mathematics and ScienceStudy at the Eight Grade.Chestnut Hill: The International Study Center.Mullis, I. V. S., Martin, M. O., Gonzalez, E. J., Gregory, K. D., Garden, R. A., O’Connor, K. M.,Chrostowski, S. J., & Smith, T. A.. (2000). TIMSS 1999 International mathemat-ics report, findings from IEA’s Repeat of the Third International Mathematics and Science Study at the Eight Grade.Chestnut Hill: The International Study Center. Ministry of Education, Science, Sports and Culture (2000).Japanese government policies in education, science, sports and culture. 1999, educational reform in progress. Tokyo: PrintingBureau, Ministry of Finance.Monbusho Ed. (1999).Heisei 11 nendo, wagakuni no bunkyoshisaku : Susumu kaikaku [Japanese government policies in education, science, sports and culture 1999: Educational reform in progress]. Tokyo: Monbusho.Educational Research for Policy and Practice (2004) 3: 95–107 © Springer 2005DOI 10.1007/s10671-004-5557-6Heidi KnipprathDepartment of MethodologySchool of Business, Public Administration and TechnologyUniversity of Twente P.O. Box 2177500 AE Enschede, The Netherlands译文:家长和社区在日本儿童教育中的作用摘要在日本,人们越来越关心家庭和社区参与到儿童教育中。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
英文原文2:《DBA Survivor: Become a Rock Star DBA》by Thomas LaRock,Published By Apress.2010You know that a database is a collection of logically related data elements that may be structured in various ways lo meet the multiple processing and retrieval needs of organizations and individuals. There’s nothing new about databases—early ones were chiseled in stone, penned on scrolls, and written on index cards. But now databases are commonly recorded on magnetizable media, and computer programs are required to perform the necessary storage and retrieval operations.Yo u’ll see in the following pages that complex data relationships and linkages may be found in all but the simplest databases. The system software package that handles the difficult tasks associated with creating, accessing, and maintaining database records is called a database management system (DBMS) .The programs in a DBMS package establish an interface between the database itself and the users of the database. (These users may be applications programmers, managers and others with information needs, and various OS programs.)A DBMS can organize, process, and present selected data elements from the database. This capability enables decision makers to search, probe, and query database contents in order to extract answers to nonrecurring and unplanned questions (hat aren't available in regular reports. These questions might initially be vague and / or poorly defined, but people can "browse” through the database until they have the needed information. In short, the DBMS will “m anage”the stored data items and assemble the needed items from the common database in response to the queries of those who aren’t10programmers. In a file-oriented system, users needing special information may communicate their needs to a programmer, who, when time permits, will write one or more programs to extract the data and prepare the information[4].The availability of a DBMS, however, offers users a much faster alternative communications path.If the DBMS provides a way to interactively and update the database, as well as interrogate it capability allows for managing personal data-Aces however, it does not automatically leave an audit trail of actions and docs not provide the kinds of control a necessary in a multiuser organization. These-controls arc only available when a set of application programs arc customized for each data entry and updating function.Software for personal computers which perform me of the DBMS functions have been very popular. Personal computers were intended for use by individuals for personal information storage and process- These machines have also been used extensively small enterprises, professionals like doctors, acrylics, engineers, lasers and so on .By the nature of intended usage, database systems on these machines except from several of the requirements of full doge database systems. Since data sharing is not tended, concurrent operations even less so. the fewer can be less complex. Security and integrity maintenance arc de-emphasized or absent. As data limes will be small, performance efficiency is also important. In fact, the only aspect of a database system that is important is data Independence. Data-dependence, as stated earlier, means that applicant programs and user queries need not recognizant physical organization of data on secondary storage. The importance of this aspect, particularly for the personal computer user, is that this greatly simplifies database usage. The user can store, access and manipulate data a( a high level (close to (he application) and be totally shielded from the10low level (close to the machine) details of data organization. We will not discuss details of specific PC DBMS software packages here. Let us summarize in the following the strengths and weaknesses of personal computer data-base software systems:The most obvious positive factor is the user friendliness of the software. A user with no prior computer background would be able to use the system to store personal and professional data, retrieve and perform relayed processing. The user should, of course, satiety himself about the quality of software and the freedom from errors (bugs) so that invest-merits in data arc protected.For the programmer implementing applications with them, the advantage lies in the support for applications development in terms of input screen generations, output report generation etc. offered by theses stems.The main negative point concerns absence of data protection features. Unless encrypted, data cane accessed by whoever has access to the machine Data can be destroyed through mistakes or malicious intent. The second weakness of many of the PC-based systems is that of performance. If data volumes grow up to a few thousands of records, performance could be a bottleneck.For organization where growth in data volumes is expected, availability of. the same or compatible software on large machines should be considered.This is one of the most common misconceptions about database management systems that are used in personal computers. Thoroughly comprehensive and sophisticated business systems can be developed in dBASE, Paradox and other DBMSs. However, they are created by experienced programmers using the DBMS's own programming language. Thai is not the same as users who create and manage personal10files that are not part of the mainstream company system.Transaction Management of DatabaseThe objective of long-duration transactions is to model long-duration, interactive Database access sessions in application environments. The fundamental assumption about short-duration of transactions that underlies the traditional model of transactions is inappropriate for long-duration transactions. The implementation of the traditional model of transactions may cause intolerably long waits when transactions aleph to acquire locks before accessing data, and may also cause a large amount of work to be lost when transactions are backed out in response to user-initiated aborts or system failure situations.The objective of a transaction model is to pro-vide a rigorous basis for automatically enforcing criterion for database consistency for a set of multiple concurrent read and write accesses to the database in the presence of potential system failure situations. The consistency criterion adopted for traditional transactions is the notion of scrializability. Scrializa-bility is enforced in conventional database systems through the use of locking for automatic concurrency control, and logging for automatic recovery from system failure situations. A “transaction’’ that doesn't provide a basis for automatically enforcing data-base consistency is not really a transaction. To be sure, a long-duration transaction need not adopt seri-alizability as its consistency criterion. However, there must be some consistency criterion.Version System Management of DatabaseDespite a large number of proposals on version support in the context of computer aided design and software engineering, the absence of a consensus on version semantics10has been a key impediment to version support in database systems. Because of the differences between files and databases, it is intuitively clear that the model of versions in database systems cannot be as simple as that adopted in file systems to support software engineering.For data-bases, it may be necessary to manage not only versions of single objects (e.g. a software module, document, but also versions of a collection of objects (e.g. a compound document, a user manual, etc. and perhaps even versions of the schema of database (c.g. a table or a class, a collection of tables or classes).Broadly, there arc three directions of research and development in versioning. First is the notion of a parameterized versioning", that is, designing and implementing a versioning system whose behavior may be tailored by adjusting system parameters This may be the only viable approach, in view of the fact that there are various plausible choices for virtually every single aspect of versioning.The second is to revisit these plausible choices for every aspect of versioning, with the view to discarding some of themes either impractical or flawed. The third is the investigation into the semantics and implementation of versioning collections of objects and of versioning the database.There is no consensus of the definition of the te rm “management information system”. Some writers prefer alternative terminology such as “information processing system”, "information and decision syste m, “organizational information syste m”, or simply “i nformat ion system” to refer to the computer-based information processing system which supports the operations, management, and decision-making functions of an organization. This text uses “MIS” because it is descriptive and generally understood; it also frequently uses "information system”instead of ''MIS” t o refer to an organizational information system.10A definition of a management information system, as the term is generally understood, is an integrated, user-machine system for providing information 丨o support operations, management, and decision-making functions in an organization. The system utilizes computer hardware and software; manual procedures: models for analysis planning, control and decision making; and a database. The fact that it is an integrated system does not mean that it is a single, monolithic structure: rather, ii means that the parts fit into an overall design. The elements of the definition arc highlighted below: Computer-based user-machine system.Conceptually, a management information can exist without computer, but it is the power of the computer which makes MIS feasible. The question is not whether computers should be used in management information system, but the extent to which information use should be computerized. The concept of a user-machine system implies that some (asks are best performed humans, while others are best done by machine. The user of an MIS is any person responsible for entering input da(a, instructing the system, or utilizing the information output of the system. For many problems, the user and the computer form a combined system with results obtained through a set of interactions between the computer and the user.User-machine interaction is facilitated by operation in which the user's input-output device (usually a visual display terminal) is connected lo the computer. The computer can be a personal computer serving only one user or a large computer that serves a number of users through terminals connected by communication lines. The user input-output device permits direct input of data and immediate output of results. For instance, a person using The computer interactively in financial planning poses 4t what10if* questions by entering input at the terminal keyboard; the results are displayed on the screen in a few second.The computer-based user-machine characteristics of an MIS affect the knowledge requirements of both system developer and system user, “computer-based” means that the designer of a management information system must have a knowledge of computers and of their use in processing. The “user-machine” concept means the system designer should also understand the capabilities of humans as system components (as information processors) and the behavior of humans as users of information.Information system applications should not require users Co be computer experts. However, users need to be able lo specify (heir information requirements; some understanding of computers, the nature of information, and its use in various management function aids users in this task.Management information system typically provide the basis for integration of organizational information processing. Individual applications within information systems arc developed for and by diverse sets of users. If there are no integrating processes and mechanisms, the individual applications may be inconsistent and incompatible. Data item may be specified differently and may not be compatible across applications that use the same data. There may be redundant development of separate applications when actually a single application could serve more than one need. A user wanting to perform analysis using data from two different applications may find the task very difficult and sometimes impossible.The first step in integration of information system applications is an overall information system plan. Even though application systems are implemented one at a10time, their design can be guided by the overall plan, which determines how they fit in with other functions. In essence, the information system is designed as a planed federation of small systems.Information system integration is also achieved through standards, guidelines, and procedures set by the MIS function. The enforcement of such standards and procedures permit diverse applications to share data, meet audit and control requirements, and be shares by multiple users. For instance, an application may be developed to run on a particular small computer. Standards for integration may dictate that the equipment selected be compatible with the centralized database. The trend in information system design is toward separate application processing form the data used to support it. The separate database is the mechanism by which data items are integrated across many applications and made consistently available to a variety of users. The need for a database in MIS is discussed below.The term “information” and “data” are frequently used interchangeably; However, information is generally defined as data that is meaningful or useful to The recipient. Data items are therefore the raw material for producing information.The underlying concept of a database is that data needs to be managed in order to be available for processing and have appropriate quality. This data management includes both software and organization. The software to create and manage a database is a database management system.When all access to any use of database is controlled through a database management system, all applications utilizing a particular data item access the same data item which is stored in only one place. A single updating of the data item updates it for10all uses. Integration through a database management system requires a central authority for the database. The data can be stored in one central computer or dispersed among several computers; the overriding requirement is that there be an organizational function to exercise control.It is usually insufficient for human recipients to receive only raw data or even summarized data. Data usually needs to be processed and presented in such a way that Che result is directed toward the decision to be made. To do this, processing of data items is based on a decision model.For example, an investment decision relative to new capital expenditures might be processed in terms of a capital expenditure decision model.Decision models can be used to support different stages in the decision-making process. “Intelligence’’ models can be used to search for problems and/or opportunities. Models can be used to identify and analyze possible solutions. Choice models such as optimization models maybe used to find the most desirable solution.In other words, multiple approaches are needed to meet a variety of decision situations. The following are examples and the type of model that might be included in an MIS to aid in analysis in support of decision-making; in a comprehensive information system, the decision maker has available a set of general models that can be applied to many analysis and decision situations plus a set of very specific models for unique decisions. Similar models are available tor planning and control. The set of models is the model base for the MIS.Models are generally most effective when the manager can use interactive dialog (o build a plan or to iterate through several decision choices under different conditions.10中文译文2:《数据库幸存者:成为一个摇滚名明星》众所周知,数据库是逻辑上相关的数据元的汇集.这些数据元可以按不同的结构组织起来,以满足单位和个人的多种处理和检索的需要。