一个实例搞定libsvm分类(《Learn SVM Step by Step》by faruto2011系列视频-应用篇)
LIBSVM(二)参数实例详解

LIBSVM(⼆)参数实例详解1. ⼊门案例1.1 分类的⼩例⼦--根据⾝⾼体重进⾏性别预测%% 使⽤Libsvm进⾏分类的⼩例⼦%{⼀个班级⾥⾯有两个男⽣(男⽣1、男⽣2),两个⼥⽣(⼥⽣1、⼥⽣2),其中男⽣1 ⾝⾼:176cm 体重:70kg;男⽣2 ⾝⾼:180cm 体重:80kg;⼥⽣1 ⾝⾼:161cm 体重:45kg;⼥⽣2 ⾝⾼:163cm 体重:47kg;如果我们将男⽣定义为1,⼥⽣定义为-1,并将上⾯的数据放⼊矩阵data中,并在label中存⼊男⼥⽣类别标签(1、-1)%}train_data = [176 70;180 80;161 45;163 47];train_label = [1;1;-1;-1];%{这样上⾯的data矩阵就是⼀个属性矩阵,⾏数4代表有4个样本,列数2表⽰属性有两个,label就是标签(1、-1表⽰有两个类别:男⽣、⼥⽣)。
%}% 利⽤libsvm建⽴分类模型此处options参数为默认值model = svmtrain(train_label,train_data);%{此时该班级⼜转来⼀个新学⽣,其⾝⾼190cm,体重85kg我们想给出其标签(想知道其是男[1]还是⼥[-1])由于其标签我们不知道,我们假设其标签为-1(也可以假设为1)%}test_data = [190 85];test_label = -1;[predict_label,accuracy,dec_value] = svmpredict(test_label,test_data,model);predict_labelif 1 == predict_labeldisp('==该⽣为男⽣');endif -1 == predict_labeldisp('==该⽣为⼥⽣');end1.2 回归的⼩例⼦ y=x^2 利⽤训练集合已知的x,y来建⽴回归模型 model ,然后利⽤这个 model 去预测。
最新LibSVM分类的实用指南

L i b S V M分类的实用指南LibSVM分类的实用指南摘要SVM(support vector machine)是一项流行的分类技术。
然而,初学者由于不熟悉SVM,常常得不到满意的结果,原因在于丢失了一些简单但是非常必要的步骤。
在这篇文档中,我们给出了一个简单的操作流程,得到合理的结果。
(译者注:本文中大部分SVM实际指的是LibSVM)1入门知识SVM是一项非常实用的数据分类技术。
虽然SVM比起神经网络(Neural Networks)要相对容易一些,但对于不熟悉该方法的用户而言,开始阶段通常很难得到满意的结果。
这里,我们给出了一份指南,根据它可以得到合理结果。
需要注意,此指南不适用SVM的研究者,并且也不保证一定能够获得最高精度结果。
同时,我们也没有打算要解决有挑战性的或者非常复杂的问题。
我们的目的,仅在于给初学者提供快速获得可接受结果的秘诀。
虽然用户不是一定要深入理解SVM背后的理论,但为了后文解释操作过程,我们还是先给出必要的基础的介绍。
一项分类任务通常将数据划分成训练集和测试集。
训练集的每个实例,包含一个"目标值(target value)"(例如,分类标注)和一些"属性(attribute)"(例如,特征或者观测变量)。
SVM的目标是基于训练数据产出一个模型(model),用来预测只给出属性的测试数据的目标值。
给定一个训练集,"实例-标注"对,,支持向量机需要解决如下的优化问题:在这里,训练向量xi通过函数Φ被映射到一个更高维(甚至有可能无穷维)空间。
SVM在这个高维空间里寻找一个线性的最大间隔的超平面。
C 0是分错项的惩罚因子(penalty parameter of the error term)。
被称之为核函数(kernel function)。
新的核函数还在研究中,初学者可以在SVM书中找到如下四个最基本的核函数:(线性、多项式、径向基函数、S型)1.1实例表1是一些现实生活中的实例。
高光谱 libsvm 分类

高光谱libsvm 分类高光谱图像分类是指对高光谱图像中的每个像素点进行分类,将其归为不同的类别。
下面是一个简单的高光谱图像分类代码示例,使用的是支持向量机(SVM)分类器。
首先,需要导入必要的库和数据集:import numpy as npimport matplotlib.pyplot as pltfrom sklearn import svm, metricsfrom sklearn.model_selection import train_test_splitfrom sklearn.datasets import load_sample_image# 加载示例高光谱图像dataset = load_sample_image('data/flower.jpg')X = dataset.data.reshape(-1, 3)y = np.zeros(X.shape[0])# 选择前1000个像素点作为训练集X_train, X_test, y_train, y_test = train_test_split(X[:1000], y[:1000], test_size=0.2, random_state=42)接下来,使用支持向量机(SVM)分类器对高光谱图像进行分类:# 定义SVM分类器classifier = svm.SVC(gamma=0.001)# 训练模型classifier.fit(X_train, y_train)# 在测试集上进行预测y_pred = classifier.predict(X_test)# 计算准确率accuracy = metrics.accuracy_score(y_test, y_pred)print("Accuracy:", accuracy)最后,可以将分类结果可视化:# 可视化分类结果plt.figure(figsize=(8, 8))plt.subplot(211)plt.imshow(dataset)plt.title("Original Image")plt.axis("off")plt.subplot(212)plt.imshow(y_pred.reshape(dataset.shape[:2]))plt.title("Classified Image")plt.axis("off")plt.show()上述是简单的高光谱图像分类代码示例,可以根据需要进行修改和优化。
svm算法案例

svm算法案例SVM算法是一种支持向量机算法,被广泛应用于分类和回归问题。
下面我们将介绍一个使用SVM算法解决分类问题的案例。
假设我们有一个鸢尾花数据集,该数据集包含三个品种的鸢尾花(山鸢尾、变色鸢尾和维吉尼亚鸢尾)的测量数据,包括花萼和花瓣的长度和宽度。
我们的目标是根据这些测量值对鸢尾花进行分类。
我们将使用Python编程语言和Scikit-learn库来实现SVM算法。
首先,我们需要加载鸢尾花数据集,并将其拆分为训练集和测试集。
我们将使用70%的数据作为训练集,30%的数据作为测试集。
```from sklearn.datasets import load_irisfrom sklearn.model_selection import train_test_splitiris = load_iris()X_train, X_test, y_train, y_test =train_test_split(iris.data, iris.target, test_size=0.3, random_state=42)```接下来,我们将使用SVM算法进行分类。
我们将使用线性核函数,并设置正则化参数C为1。
我们还将拟合训练集并预测测试集。
```from sklearn.svm import SVC# Create SVM object with linear kernelsvm = SVC(kernel='linear', C=1)# Train SVM on training datasvm.fit(X_train, y_train)# Predict classes of test sety_pred = svm.predict(X_test)```最后,我们将评估模型的性能。
我们将使用混淆矩阵、准确率、召回率和F1得分来评估模型的性能。
```from sklearn.metrics import confusion_matrix,accuracy_score, recall_score, f1_score# Compute confusion matrixcm = confusion_matrix(y_test, y_pred)# Compute accuracy, recall, and F1 scoreaccuracy = accuracy_score(y_test, y_pred)recall = recall_score(y_test, y_pred, average='weighted') f1 = f1_score(y_test, y_pred, average='weighted')print('Confusion matrix:', cm)print('Accuracy: {:.2f}%'.format(accuracy * 100))print('Recall: {:.2f}%'.format(recall * 100))print('F1 score: {:.2f}%'.format(f1 * 100))```运行完整的程序后,我们将得到以下输出:```Confusion matrix:[[19 0 0][ 0 13 1][ 0 1 11]]Accuracy: 96.30%Recall: 96.30%F1 score: 96.30%```这表明我们的模型在测试集上表现良好,准确率为96.3%。
Libsvm分类实验报告

一、LIBSVM介绍LIBSVM是台湾大学林智仁(Chih-Jen Lin)副教授等开发设计的一个简单、易于使用和快速有效的SVM模式识别与回归的软件包,他不但提供了编译好的可在Windows系列系统的执行文件,还提供了源代码,方便改进、修改以及在其它操作系统上应用;该软件还有一个特点,就是对SVM所涉及的参数调节相对比较少,提供了很多的默认参数,利用这些默认参数就可以解决很多问题;并且提供了交互检验(Cross Validation)的功能。
二、准备工作2.1软件下载安装使用的平台是Windows XP,从命令列执行。
先把一些需要的东西装好,总共需要三个软件:libsvm, python, gnuplot。
这里我选择的版本是libsvm-2.88,python26。
Libsvm:到.tw/~cjlin/libsvm/下载libsvm,然后解压缩就好了。
Python:到/download/下载完直接安装就好了。
Gnuplot:下载ftp:///pub/gnuplot/gp400win32.zip解压缩。
这里全部解压安装在c盘c:\libsvm-2.88c:\python26c:\gnuplot2.2参数修改(1)把c:\libsvm-2.88\tools中的easy.py和grid.py复制到c:\libsvm-2.91\python中(2)在c:\libsvm-2.88\python中修改easy.py和grid.py的路径:①点中easy.py在右键中选Edit with IDLE打开,将else下面的路径修改如下:else:# example for windowssvmscale_exe = r"c:\libsvm-2.88\windows\svm-scale.exe"svmtrain_exe = r"c:\libsvm-2.88\windows\svm-train.exe"svmpredict_exe = r"c:\libsvm-2.88\windows\svm-predict.exe"gnuplot_exe = r"c:\gnuplot\bin\pgnuplot.exe"grid_py = r"c:\libsvm-2.88\python\grid.py"②点中grid.py在右键中选Edit with IDLE打开,将else下面的路径修改如下: else:# example for windowssvmtrain_exe = r"c:\libsvm-2.91\windows\svm-train.exe"gnuplot_exe = r"c:\gnuplot\bin\pgnuplot.exe"三、实验步骤(1)按照LIBSVM软件包所要求的格式准备数据集;(2)对数据进行缩放操作;(3)选用适当的核函数;(4)采用交叉验证选择惩罚系数C与g的最佳参数;(5)采用获得的最佳参数对整个训练集进行训练获取支持向量机模型;(6)利用获取的模型进行测试与预测。
支持向量机 libsvm python三分类问题实例

2:EXCEL下的数据处理
Libsvm所需的数据格式应该是 <lable_value> <index1>:<value1> <index2>:<value2>.....。 (lable_value,index,value变量的值全部为数值型,lable_value表示样本的类 型,在二分类其中,其值一般取-1和1或者0和1,当然取其他值也是可以的,只要能 区分就行。index可以理解为遥感影像中的波段序列或者特征序列。value可以理解 为对应的像元值或者特征值)。 也就是类似于 1 1:0.302000 2:0.67200 2 1:0.568000 2:0.668000 3 1:0.568000 2:0.668000 这样的,如果你的数据不是这样,请下载FormatDataLibsvmaa.xlsm这个自带宏 命令的表格来转换,其中标签向量根据分类的类别自己定义
注意,正确率为零是因为在TESTD文件中所有数据标签为均4,而train数据的三个标 签为1,2,3,肯定都是对不上的(在SVM-PREDICT中你需要分类的数据必须给出 任意一个标签数据)。
在C:\libsvm-3.21\windows下调用SVM-TRAIN,输入优化后的参数,ibsvm-3.21\windows下调用SVM-PREDICT,按照用法输入,可以得出
输出的最后结果储存在OUT222这个文件中。
4)最重要的是GRID.py 设置好各项参数进行参数寻优(预设值就是RBF核函数) 具体数值区间我是采用的默认值 根据README里面的用法,同时调用GNUPLOT和SVMTRAIN两个地址,可以得 出.out和.png两个结果 最后可以得出一个最好的G C两个参数的数值
svm分类 案例

svm分类案例
支持向量机(SVM)是一种强大的分类工具,在许多领域都有广泛的应用。
以下是一个使用SVM进行分类的案例:
案例背景:
假设我们正在处理一个二分类问题,其中有两个类别分别为正面和负面。
我们有一组数据,其中每个数据点都有一些特征,例如年龄、收入、教育程度等。
我们的目标是使用这些特征来预测每个数据点属于哪个类别。
案例步骤:
1. 数据预处理:首先,我们需要对数据进行预处理,包括缺失值填充、异常值处理、特征缩放等。
在这个案例中,我们假设数据已经进行了适当的预处理。
2. 特征选择:接下来,我们需要选择合适的特征来训练SVM分类器。
在这个案例中,我们选择年龄、收入和教育程度作为特征。
3. 训练SVM分类器:使用选择的特征和训练数据集,我们可以训练一个SVM分类器。
在训练过程中,SVM会找到一个超平面,使得两个类别的数据点尽可能分开。
4. 测试SVM分类器:使用测试数据集,我们可以评估SVM分类器的性能。
常见的评估指标包括准确率、精确率、召回率和F1分数等。
5. 优化SVM分类器:如果测试结果不理想,我们可以尝试调整SVM的参
数或使用其他优化方法来提高分类器的性能。
案例总结:
通过这个案例,我们可以看到SVM是一种强大的分类工具,可以用于处理
各种分类问题。
在实际应用中,我们需要注意数据预处理、特征选择和参数调整等方面,以确保分类器的性能和准确性。
SVM多分类问题libsvm在matlab中的应用

SVM多分类问题libsvm在matlab中的应⽤转载⾃对于⽀持向量机,其是⼀个⼆类分类器,但是对于多分类,SVM也可以实现。
主要⽅法就是训练多个⼆类分类器。
⼀、多分类⽅式1、⼀对所有(One-Versus-All OVA)给定m个类,需要训练m个⼆类分类器。
其中的分类器 i 是将 i 类数据设置为类1(正类),其它所有m-1个i类以外的类共同设置为类2(负类),这样,针对每⼀个类都需要训练⼀个⼆类分类器,最后,我们⼀共有 m 个分类器。
对于⼀个需要分类的数据 x,将使⽤投票的⽅式来确定x的类别。
⽐如分类器 i 对数据 x 进⾏预测,如果获得的是正类结果,就说明⽤分类器 i 对 x 进⾏分类的结果是: x 属于 i 类,那么,类i获得⼀票。
如果获得的是负类结果,那说明 x 属于 i 类以外的其他类,那么,除 i 以外的每个类都获得⼀票。
最后统计得票最多的类,将是x的类属性。
2、所有对所有(All-Versus-All AVA)给定m个类,对m个类中的每两个类都训练⼀个分类器,总共的⼆类分类器个数为 m(m-1)/2 .⽐如有三个类,1,2,3,那么需要有三个分类器,分别是针对:1和2类,1和3类,2和3类。
对于⼀个需要分类的数据x,它需要经过所有分类器的预测,也同样使⽤投票的⽅式来决定x最终的类属性。
但是,此⽅法与”⼀对所有”⽅法相⽐,需要的分类器较多,并且因为在分类预测时,可能存在多个类票数相同的情况,从⽽使得数据x属于多个类别,影响分类精度。
对于多分类在matlab中的实现来说,matlab⾃带的svm分类函数只能使⽤函数实现⼆分类,多分类问题不能直接解决,需要根据上⾯提到的多分类的⽅法,⾃⼰实现。
虽然matlab⾃带的函数不能直接解决多酚类问题,但是我们可以应⽤libsvm⼯具包。
libsvm⼯具包采⽤第⼆种“多对多”的⽅法来直接实现多分类,可以解决的分类问题(包括C- SVC、n - SVC )、回归问题(包括e - SVR、n - SVR )以及分布估计(one-class-SVM )等,并提供了线性、多项式、径向基和S形函数四种常⽤的核函数供选择。
Libsvm分类步骤

用svm(libsvm,lssvm、hssvm)等等进行分类预测,要进行三个步骤:1、训练2、测试3、预测
1、训练——大家都知道,就是用训练数据集,不管你采用那种寻优方式,得到相对的最优参数,训练模型。
2、测试——就是用刚刚得到的模型,对测试数据进行测试,此时测试数据集的label是已知的,这主要是用来对刚刚的模型的检测,或者是对参数的检测、或者是对模型的泛化能力的检测。
此时会得到一个准确率,这时的准确率是有用的,是有实际意义的,因为原来的label 是已知的。
3、预测——预测就是对未知类别的样本在测试确定了模型有好的泛化能力的情况下的预测分类,这步才是真的预测能力功能的实现。
此时数据的label随便给了,这样是为了满足libsvm对数据格式的要求。
此时也会得到一个准确率,但是这个是没有实际意义的,因为原始的label是随便给的,没有意义,我们只是关心的是最后得到的类别号——达到分类的目的。
机器学习算法掌握SVM分类器的关键步骤

机器学习算法掌握SVM分类器的关键步骤机器学习算法中,支持向量机(Support Vector Machine, SVM)是一种被广泛应用于分类和回归问题的方法。
它通过在特征空间中找到一个最优超平面来实现数据的划分。
本文将介绍掌握SVM分类器的关键步骤,帮助读者更好地理解和应用这个算法。
一、数据预处理在应用SVM分类器之前,需要对数据进行预处理。
这包括如下几个方面的步骤:1. 数据收集:收集与问题相关的数据,并将其整理为合适的格式,如矩阵或数据框。
2. 数据清洗:对数据进行清洗,处理缺失值、异常值等问题,确保数据的质量和可靠性。
3. 特征选择:根据问题的需求,选择与目标变量相关性高的特征,剔除对模型无意义或冗余的特征。
4. 特征缩放:对于特征值的范围差异较大的情况,使用特征缩放方法(如标准化或归一化)将其缩放到相同的范围内,以避免某些特征对模型训练的影响过大。
二、选择合适的SVM核函数SVM分类器的核心思想是通过一个超平面将数据划分为不同的类别。
在选择合适的核函数时,需要考虑问题的性质以及数据的分布情况。
1. 线性核函数:适用于线性可分的问题,即数据可以完全被一个超平面分割开。
2. 多项式核函数:适用于非线性问题,通过将数据映射到更高维的特征空间,将问题转化为线性可分的问题。
3. 高斯核函数(径向基函数):适用于非线性问题,可以处理数据在低维空间中呈现复杂结构的情况。
4. Sigmoid核函数:适用于二分类问题,但在一般情况下效果相对较差。
根据问题的特点选择合适的核函数,能够有效提高SVM分类器的性能。
三、模型训练与参数调优1. 模型训练:使用训练数据集对SVM分类器进行训练。
通过求解优化问题,找到能够使分隔超平面与不同类别的样本点之间的间隔最大化的超平面。
2. 超参数调优:SVM分类器中存在一些关键的超参数,如正则化参数C、核函数的参数等。
通过交叉验证等方法,寻找最优的超参数组合,以提高模型的泛化能力和分类性能。
SVM分类器实现实例
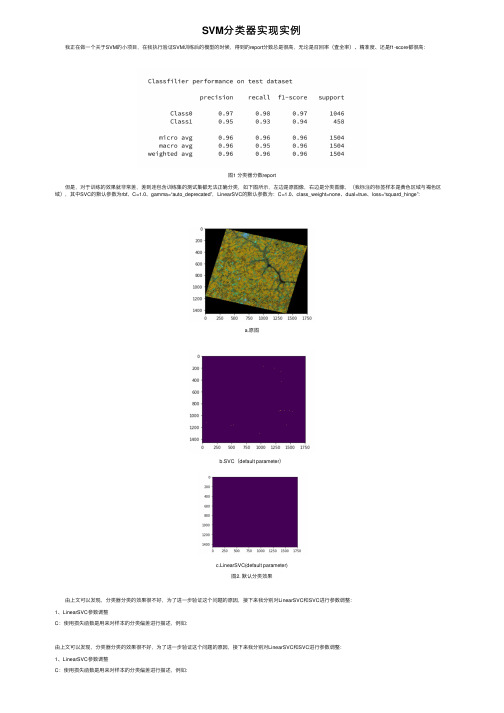
SVM分类器实现实例 我正在做⼀个关于SVM的⼩项⽬,在我执⾏验证SVM训练后的模型的时候,得到的report分数总是很⾼,⽆论是召回率(查全率)、精准度、还是f1-score都很⾼:图1 分类器分数report 但是,对于训练的效果就⾮常差,差到连包含训练集的测试集都⽆法正确分类,如下图所⽰,左边是原图像,右边是分类图像,(我标注的标签样本是黄⾊区域与褐⾊区域),其中SVC的默认参数为rbf、C=1.0、gamma=“auto_deprecated”,LinearSVC的默认参数为:C=1.0、class_weight=none、dual=true、loss=“squard_hinge”:a.原图b.SVC(default parameter)c.LinearSVC(default parameter)图2. 默认分类效果 由上⽂可以发现,分类器分类的效果很不好,为了进⼀步验证这个问题的原因,接下来我分别对LinearSVC和SVC进⾏参数调整:1、LinearSVC参数调整C:使⽤损失函数是⽤来对样本的分类偏差进⾏描述,例如:由上⽂可以发现,分类器分类的效果很不好,为了进⼀步验证这个问题的原因,接下来我分别对LinearSVC和SVC进⾏参数调整:1、LinearSVC参数调整C:使⽤损失函数是⽤来对样本的分类偏差进⾏描述,例如:引⼊松弛变量后,优化问题可以写为:约束条件为:对于不同的C值对于本实例中的分类影响为,如图3所⽰:图3. LinearSVC在不同惩罚系数C下的表现由此可以看出SVC在惩罚系数为0.3、4.0、300时能够较准确根据颜⾊对图像进⾏分类。
但是作者发现,惩罚系数相同,重新训练时,会有不同的效果展⽰,才疏学浅,尚未能解释,如果有知道为什么的⼤神,敬请指点迷津。
2、SVC参数调整SVC模型中有两个⾮常重要的参数,即C与gamma,其中C是惩罚系数,这⾥的惩罚系数同LinearSVC中的惩罚系数意义相同,表⽰对误差的宽容度,C越⾼,说明越是不能容忍误差的出现,C越⼩,表⽰越容易⽋拟合,泛化能⼒变差。
libsvm详细训练步骤

1、正样本的大小一定要与检测窗口大小保持一致。
2、Dalal的训练可以分为3步:a 、正样本图像若干(窗口大小),负样本图像若干,负样本图像的尺寸任意。
从负样本图像的随机位置抽取窗口大小的图像,作为真正参与训练的负样本。
然后从所有样本图像中提取特征(对每一个64*128的图像Dalal提取一个3780维的特征向量),然后用svm训练,得到一个初始的分类器。
b、这一步要在前面的负样本图像中抽取大量的具有窗口尺寸的负样本。
对每一个负样本图像,可以经过若干次缩放处理得到不同层次上的金字塔图像(pyramid),不过要保证其大于等于窗口尺寸。
(这里面就用到了-startscale, -endscale, -scaleratio这三个参数。
)检测窗也可以在这些金字塔图像上平移滑动,每一个位置都对应了一个窗口大小的负样本。
用初始分类器检测这些负样本,记录所有分类错误的负样本,这就是所谓的(hard samples)c、把分类错误的负样本集加入到初始的训练集中,重新训练,生成最终的分类器。
We selected 1239 of the images as positivetraining examples, together with their left-right reflections(2478 images in all). A xed set of 12180 patches sampledrandomly from 1218 person-free training photos providedthe initial negative set. For each detector and parameter combinationa preliminary detector is trained and the 1218 negativetraining photos are searched exhaustively for false positives(`hard examples'). The method is then re-trained usingthis augmented set (initial 12180 + hard examples) to producethe nal detector. The set of hard examples is subsampledif necessary, so that the descriptors of the nal trainingset it into 1.7 Gb of RAM for SVM training.1. 程序介绍和环境设置windows下的libsvm是在命令行运行的Console Program。
libsvm多分类

libsvm多分类关于使用libsvm进行分类的几个问题在使用libsvm进行分类时,碰到以下几个问题,求高手指点:(1)在进行多类分类时,由于libsvm用的是1-v-1方法,但是一般一个样本有很多属性,就拿葡萄酒的样本来说,它是一个三类问题,每个样本有13个属性,那么其训练预测过程是什么呢?训练过程是先对样本的同一属性使用1-v-1方法,进行训练,得到一组支持向量和相应模型,然后呢?其它的12个属性是怎么加入训练过程的?预测时,也是先对所有样本的第一个属性使用训练好的1-v-1模型进行投票决策,接下来呢?其他的12个属性也是使用同样的方法吗?最终的决策是怎样得出的?(2)有没有函数命令直接求得对每类的投票所得的票数?(3)在使用葡萄酒数据分类时,使用预测函数[predicted_label, accuracy, decision_values/prob_estimates] = svmpredict(test_label, test_matrix, model, ['libsvm_options']);,其中的decision_values/prob_estimates是决策函数f(x)=(w,x)+b的值吗?对于两分类问题,它是nx1维的矩阵,对于红酒的三类问题,它为什么是89x3维的矩阵?(4)对于葡萄酒数据,训练出的model是:Parameters: [5x1 double]nr_class: 3totalSV: 89rho: [3x1 double]Label: [3x1 double]ProbA: []ProbB: []nSV: [3x1 double]sv_coef: [89x2 double]SVs: [89x13 double]系数w,也就是model中的sv_coef怎么成了89x2 维的矩阵了,这个怎么理解?还有SVs到底代表什么?(5)如果想使用Platt模型p=1/(1+exp(Af+B)) 求模型的概率输出,其中的参数A和B怎么求得?[本帖最后由 xffxff 于 2010-4-28 11:24 编辑]SVM视频:。
傻瓜攻略(十九)——MATLAB实现SVM多分类

傻瓜攻略(十九)——MATLAB实现SVM多分类SVM (Support Vector Machine) 是一种常用的机器学习算法,广泛应用于分类问题。
原始的 SVM 算法只适用于二分类问题,但是有时我们需要解决多分类问题。
本文将介绍如何使用 MATLAB 实现 SVM 多分类。
首先,我们需要明确一些基本概念。
在 SVM 中,我们需要对每个类别建立一个分类器,然后将未知样本进行分类。
这涉及到两个主要步骤:一对一(One-vs-One)分类和一对其他(One-vs-Rest)分类。
在一对一分类中,我们需要对每两个类别都建立一个分类器。
例如,如果有三个类别 A、B 和 C,那么我们需要建立三个分类器:A vs B, A vs C 和 B vs C。
然后,我们将未知样本进行分类,看它属于哪个类别。
在一对其他分类中,我们将一个类别看作是“正例”,而其他所有类别看作是“负例”。
例如,如果有三个类别 A、B 和 C,那么我们需要建立三个分类器:A vs rest, B vs rest 和 C vs rest。
然后,我们将未知样本进行分类,看它属于哪个类别。
接下来,我们将使用一个示例数据集来演示如何使用MATLAB实现SVM多分类。
我们将使用鸢尾花数据集,该数据集包含了三个类别的鸢尾花样本。
首先,我们需要加载数据集。
在 MATLAB 中,我们可以使用`load`函数加载内置的鸢尾花数据集。
代码如下所示:```load fisheriris```数据集加载完成后,我们可以查看数据集的结构。
在 MATLAB 中,我们可以使用`whos`函数查看当前工作空间中的变量。
代码如下所示:```whos``````X = meas;Y = species;```然后,我们可以使用`fitcecoc`函数构建一个多分类 SVM 模型。
`fitcecoc`函数可以自动选择最佳的核函数,并训练多个二分类器来实现多分类。
代码如下所示:```SVMModel = fitcecoc(X, Y);```训练完成后,我们可以使用`predict`函数对未知样本进行分类。
如何使用libsvm进行分类

这帖子就是初步教教刚接触libsvm(svm)的同学如何利用libsvm进行分类预测,关于参数寻优的问题在这里姑且不谈,另有帖子详述。
其实使用libsvm进行分类很简单,只需要有属性矩阵和标签,然后就可以建立分类模型(model),然后利用得到的这个model进行分类预测了。
那神马是属性矩阵?神马又是标签呢?我举一个直白的不能在直白的例子:说一个班级里面有两个男生(男生1、男生2),两个女生(女生1、女生2),其中男生1 身高:176cm 体重:70kg;男生2 身高:180cm 体重:80kg;女生1 身高:161cm 体重:45kg;女生2 身高:163cm 体重:47kg;如果我们将男生定义为1,女生定义为-1,并将上面的数据放入矩阵data中,即1.data = [176 70;2.180 80;3.161 45;4.163 47];复制代码在label中存入男女生类别标签(1、-1),即bel = [1;1;-1;-1];复制代码这样上面的data矩阵就是一个属性矩阵,行数4代表有4个样本,列数2表示属性有两个,label就是标签(1、-1表示有两个类别:男生、女生)。
Remark:这里有一点废话一些(因为我看到不止一个朋友问我这个相关的问题):上面我们将男生定义为1,女生定义为-1,那定义成别的有影响吗?这个肯定没有影响啊!(用脚趾头都能想出来,我不知道为什么也会有人问),这里面的标签定义就是区分开男生和女生,怎么定义都可以的,只要定义成数值型的就可以。
比如我可将将男生定义为2,女生定义为5;后面的label相应为label=[2;2;5;5];比如我可将将男生定义为18,女生定义为22;后面的label相应为label=[18;18;22;22];为什么我说这个用脚趾头都能想怎么定义都可以呢?学过数学的应该都会明白,将男生定义为1,女生定义为-1和将男生定义为2,女生定义为5本质是一样的,应为可以找到一个映射将(2,5)转换成(1,-1),so所以本质都是一样的,后面的18、22本质也是一样的。
libSVM使用手册

3.3 svmtrain 的用法
svmtrain实现对训练数据集的训练,获得SVM模型。 用法: svmtrain [options] training_set_file [model_file] 其中, options(操作参数) :可用的选项即表示的涵义如下所示 -s svm 类型:设置 SVM 类型,默认值为 0,可选类型有: 0 -- C SVC 1 -- n SVC 2 -- one class SVM
3.4 svmpredict 的用法
svmpredict 是根据训练获得的模型,对数据集合进行预测。 用法:svmpredict [options] test_file model_file output_file options(操作参数) : -b probability_estimates:是否需要进行概率估计预测,可选值为0 或者1,默认值为 0。 model_file 是由 svmtrain 产生的模型文件; test_file 是要进行预测的数据 文 件;output_file 是svmpredict 的输出文件,表示预测的结果值。svmpredict 没有其它 的选项。
3.2 svmscale 的用法
对数据集进行缩放的目的在于:1)避免一些特征值范围过大而另一些特征 值范围过小;2)避免在训练时为了计算核函数而计算内积的时候引起数值计算 的困难。 因此,通常将数据缩放到[-1,1]或者是[0,1]之间。 用法: svmscale [-l lower] [-u upper] [-y y_lower y_upper] [-s save_filename] [-r restore_filename] filename (缺省值: lower = -1,upper = 1,没有对y进行缩放) 其中, -l:数据下限标记;lower:缩放后数据下限; -u:数据上限标记;upper:缩放后数据上限; -y:是否对目标值同时进行缩放;y_lower为下限值,y_upper为上限值; -s save_filename:表示将缩放的规则保存为文件save_filename; -r restore_filename:表示将缩放规则文件restore_filename载入后按此缩放; filename:待缩放的数据文件(要求满足前面所述的格式) 。 缩放规则文件可以用文本浏览器打开,看到其格式为: lower upper <index1> lval1 uval1 <index2> lval2 uval2 其中的lower 与upper 与使用时所设置的lower 与upper 含义相同;index 表 示特征序号;lval 为该特征对应转换后下限lower 的特征值;uval 为对应于转换 后上限upper 的特征值。 数据集的缩放结果在此情况下通过DOS窗口输出,当然也可以通过DOS的 文件重定向符号“>”将结果另存为指定的文件。 使用实例: 1) svmscale –s train.range train3>train.scale 表示采用缺省值(即对属性值缩放到[-1,1]的范围,对目标值不进行缩放) 对数据集train3 进行缩放操作,其结果缩放规则文件保存为train3.range,缩放集 的缩放结果保存为train.scale。 2) svmscale –r train.range test>test.scale 表示载入缩放规则train.range 后按照其上下限对应的特征值和上下限值线 性的地对数据集 test 进行缩放,结果保存为 test.scale。
高光谱 libsvm 分类

高光谱libsvm 分类全文共四篇示例,供读者参考第一篇示例:高光谱图像是一种具有连续且密集的光谱信息的遥感影像类型,具有丰富的光谱特征,可以提供大量反映地物表面特征的信息。
在高光谱图像应用中,分类和识别是一个重要的研究内容,而支持向量机(Support Vector Machine,简称SVM)是一种常用的分类方法之一。
本文将介绍高光谱图像分类中使用libsvm工具进行分类的方法及其应用。
一、高光谱图像分类概述高光谱图像是通过遥感技术获取的一种具有丰富光谱信息的影像,其可以捕捉地物表面的特定光谱特征,有助于对地物进行精准分类和识别。
高光谱数据拥有数百个波段,使得在分类过程中可以更加精细地区分不同的地物类型。
在高光谱图像分类中,传统的分类方法通常会面临维度灾难和过拟合等问题,而支持向量机能够有效应对这些问题,是一种被广泛应用的分类方法之一。
二、支持向量机分类算法介绍支持向量机是一种基于统计学习理论的二元分类方法,其核心思想是通过建立一个最优的超平面来完成分类任务。
在支持向量机分类中,训练数据被映射到高维空间中,找到能够最大化间隔的超平面,并通过支持向量来确定分类决策边界。
支持向量机具有良好的泛化能力和鲁棒性,在分类问题中表现出色,特别适用于高维数据和小样本数据的分类任务。
三、libsvm工具介绍libsvm是一种快速且高效的支持向量机库,由台湾国立大学林智仁博士团队开发,支持向量机的分类和回归等任务。
libsvm具有简洁的代码结构和友好的接口,使得用户可以方便地进行模型训练和预测。
libsvm还提供了多种核函数的选择,可以根据不同任务需求进行灵活的设置。
在高光谱图像分类任务中,libsvm可以帮助研究者高效地进行地物分类和识别。
四、高光谱图像分类中libsvm的应用在高光谱图像分类中,libsvm可以用于对高光谱数据进行地物分类和识别。
需要将高光谱数据进行预处理,包括数据校正、特征提取等步骤。
然后,将处理后的数据输入到libsvm中进行模型训练,通过调整参数和选择合适的核函数对模型进行优化。
python libsvm 实例

python libsvm 实例Pythonlibsvm是一个基于C++编写的支持向量机(SVM)库,可以在Python中调用。
它提供了各种不同的内核函数、参数优化方式和模型选择工具,使得使用者可以灵活地进行SVM的分类、回归和异常检测等任务。
本文将通过实例介绍Python libsvm的使用方法。
1. 安装Python libsvmPython libsvm可以通过pip安装:```pip install -U libsvm```2. 导入数据在本例中,我们将使用UCI Machine Learning Repository的Iris Dataset作为样本数据。
该数据集包含3种不同的鸢尾花,每种花有50个样本,共计150个样本。
每个样本包含4个特征:花萼长度、花萼宽度、花瓣长度和花瓣宽度。
我们将使用这些特征来预测鸢尾花的种类。
首先,我们需要导入数据。
在本例中,我们将使用pandas库来加载CSV文件,并将其转换为NumPy数组。
代码如下:```import pandas as pdimport numpy as np# 加载数据data = pd.read_csv('iris.csv')# 将数据转换为NumPy数组x = np.array(data.iloc[:, :-1])y = np.array(data.iloc[:, -1])```在上面的代码中,我们首先使用pandas库加载Iris Dataset的CSV文件。
然后,我们将数据转换为NumPy数组。
x数组包含所有样本的特征,y数组包含所有样本的类别标签。
3. 数据预处理在使用SVM进行分类任务之前,我们需要对数据进行一些预处理。
首先,我们将使用sklearn库的train_test_split函数将数据分为训练集和测试集。
我们将70%的数据用于训练,30%的数据用于测试。
代码如下:```from sklearn.model_selection import train_test_split# 将数据分为训练集和测试集x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.3)```其次,我们需要对数据进行标准化处理。
一个实例搞定libsvm回归(《Learn SVM Step by Step》by faruto2011系列视频-应用篇)
——打造最优秀、专业和权威的MATLAB技术交流平台! MATLAB技术论坛| Simulink仿真论坛| 专业MATLAB技术交流平台!网址:邮箱:matlabsky@客服:1341692017(QQ)技术论坛:函数百科:电子期刊:官方博客:读书频道:视频教程:有偿编程:软件汉化:——打造最优秀、专业和权威的MATLAB技术交流平台!MATLAB技术论坛视频教学内容:《Learn SVM Step by Step 》系列视频作者:faruto时间:2011.6-9版权:All Rights Preserved By 声明:严厉谴责和鄙夷一切利用本论坛资源进行任何牟利或盗版的行为!更多MATLAB精彩视频详见/forum-5-1.html——打造最优秀、专业和权威的MATLAB技术交流平台!《Learn SVM Step by Step 》系列视频目录•《Learn SVM Step by Step 》应用篇•Libsvm的下载、安装和使用•Libsvm参数实例详解•一个实例搞定libsvm分类•一个实例搞定libsvm回归•Libsvm分类参数优化•Libsvm回归参数优化•Libsvm-FarutoUltimate版本介绍与使用•Libsvm-FarutoGUI版本介绍与使用•使用libsvm分类&回归的整体过程•……•Lssvm的下载、安装和使用•一个实例搞定lssvm分类•一个实例搞定lssvm回归•……•《Learn SVM Step by Step 》理论篇•具体内容待定。
——打造最优秀、专业和权威的MATLAB技术交流平台!MATLAB技术论坛视频教学内容:一个实例搞定libsvm回归《Learn SVM Step by Step 》系列视频——应用篇作者:faruto时间:2011.7版权:All Rights Preserved By 声明:严厉谴责和鄙夷一切利用本论坛资源进行任何牟利或盗版的行为!更多MATLAB精彩视频详见/forum-5-1.html——打造最优秀、专业和权威的MATLAB技术交流平台!本讲视频内容目录•一个实例搞定libsvm回归–观看此视频前建议您先观看–《Learn SVM Step by Step》系列视频-应用篇:一个实例搞定libsvm分类/thread-18521-1-1.html•关于测试集目标变量的注意事项•如何保存训练好的回归模型•回归模型model参数解密•本讲涉及到的MATLAB使用技巧总结——打造最优秀、专业和权威的MATLAB技术交流平台!本讲视频内容目录•一个实例搞定libsvm回归–观看此视频前建议您先观看–《Learn SVM Step by Step》系列视频-应用篇:一个实例搞定libsvm分类/thread-18521-1-1.html•关于测试集目标变量的注意事项•如何保存训练好的回归模型•回归模型model参数解密•本讲涉及到的MATLAB使用技巧总结——打造最优秀、专业和权威的MATLAB技术交流平台!一个实例搞定libsvm回归(1)•使用libsvm进行回归过程很简单,回归和分类本质都是一样,就是有一个输入(属性矩阵或者自变量)然后有输出(分类是分类标签,回归是因变量或目标变量),也就是相当于一个函数:Y = f(x)•利用训练集合已知的x,y来建立回归模型model,然后用这个model去预测。
libSVM分类小例C++

使用libSVM求解分类问题的C++小例1.libSVM简介训练模型的结构体struct svm_problem//储存参加计算的所有样本{int l; //记录样本总数double *y; //指向样本类别的组数struct svm_node **x;//数据样本};当样本类别事先已经被告知时,可以通过数字来给样本数据进行标识(如果是两类通常以1与-1来表示)。
如果不清楚样本类别可以用样本个数编号来设置,这时候分类的准确率也就无法判定了。
数据样本是一个二维数组,其中每个单元格储存的是一个svm_node,y与样本数据的对应关系为:数据节点的结构体struct svm_node//储存单一向量的单个特征{int index; //索引double value; //值};如果需要储存向量,就可以使用6个svm_node来保存,内存映像为:index 1 2 3 4 5 -1value 1 121 12321 121 1 NULLSVM模型类型枚举enum { C_SVC, NU_SVC, ONE_CLASS, EPSILON_SVR, NU_SVR };◆C_SVC:C表示惩罚因子,C越大表示对错误分类的惩罚越大◆NU_SVC:和C_SVC相同。
◆ONE_CLASS:不需要类标号,用于支持向量的密度估计和聚类.◆EPSILON_SVR:-不敏感损失函数,对样本点来说,存在着一个不为目标函数提供任何损失值的区域,即-带。
◆NU_SVR:由于EPSILON_SVR需要事先确定参数,然而在某些情况下选择合适的参数却不是一件容易的事情。
而NU_SVR能够自动计算参数。
注意:C_SVC与NU_SVC其实采用的模型相同,但是它们的参数C的范围不同C_SVC采用的是0到正无穷,NU_SVC是[0,1]。
核函数类型枚举enum { LINEAR, POLY, RBF, SIGMOID, PRECOMPUTED };◆LINEAR:线性核函数(linear kernel)◆POLY:多项式核函数(ploynomial kernel)◆RBF:径向机核函数(radical basis function)◆SIGMOID:神经元的非线性作用函数核函数(Sigmoid tanh)◆PRECOMPUTED:用户自定义核函数计算模型参数结构体struct svm_parameter{int svm_type; //支持向量机模型类型int kernel_type; //核函数类型int degree; /* 使用于POLY模型*/double gamma; /* for poly/rbf/sigmoid */double coef0; /* for poly/sigmoid *//* these are for training only */double cache_size; /* 缓存块大小(MB) */double eps; /* 终止条件(默认0.001) */double C; /*惩罚因子for C_SVC, EPSILON_SVR and NU_SVR */int nr_weight; /*权重的数目for C_SVC */int *weight_label; /* for C_SVC */double* weight; /* for C_SVC */double nu; /* for NU_SVC, ONE_CLASS, and NU_SVR */double p; /* for EPSILON_SVR */int shrinking; /*指明训练过程是否使用压缩*/int probability; /*指明是否要做概率估计*/};结构体svm_mod el用于保存训练后的训练模型,当然原来的训练参数也必须保留。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
• 利用svmtrain来建立模型
• 利用svmpredict来进行预测
《Learn SVM Step by Step 》by faruto
一个实例搞定libsvm分类
7
——打造最优秀、专业和权威的MATLAB技术交流平台!
一个实例搞定libsvm分类(2)
– model svmtrain训练得到的模型
• 输出
– predict_label预测的测试集的标签,大小N*1,N表示样本数,数据类型double; – accuracy/mse 一个3*1的列向量,第一个数表示分类准确率(分类问题使用),第二个数表示
mse(回归问题使用),第三个数表示平方相关系数(回归问题使用);
更多MATLAB精彩视频详见/forum-5-1.html
《Learn SVM Step by Step 》faruto
一个实例搞定libsvm分类
2
——打造最优秀、专业和权威的MATLAB技术交流平台!
• model = svmtrain(label,data,'-s 0 -t 2 -c 1 -g 0.1'); • 有了model我们就可以做分类预测,比如此时该班级又转来两个新学生:
• 身高190cm,体重85kg • 身高161cm,体重50kg
• 通过上面建立的model给出其标签(想知道其是男【1】还是女【-1】) • 令 testdata = [190 85;161 50] • 由于新来的同学的标签,我们并不知道,假设其全为1(也可以假设全为-1) • 令testdatalabel = [1;1] • 然后利用libsvm来预测新来的学生是男生还是女生
• 本讲涉及到的MATLAB使用技巧总结
《Learn SVM Step by Step 》by faruto
一个实例搞定libsvm分类
13
——打造最优秀、专业和权威的MATLAB技术交流平台!
关于数据标签的注意事项(1)
• 上面我们将男生定义为1,女生定义为-1,那定义成别的有影响吗?
• 输入
– test_data测试集属性矩阵,大小N*m,N表示测试集样本数,m表示属性数目(维数),数据类 型double;
– test_label测试集标签,大小N*1,N表示样本数,数据类型double ;
» 注意:如果没有测试集标签,可以用任意的N*1的列向量代替即可,此时的输出accuracy/mse,就 没有参考价值。
• …… • Lssvm的下载、安装和使用 • 一个实例搞定lssvm分类 • 一个实例搞定lssvm回归
• ……
• 《Learn SVM Step by Step 》理论篇 • 具体内容待定。
《Learn SVM Step by Step 》by faruto
一个实例搞定libsvm分类
3
——打造最优秀、专业和权威的MATLAB技术交流平台!
MATLAB技术论坛 | Simulink仿真论坛 | 专业MATLAB技术交流平台! 网址: 邮箱:matlabsky@ 客服:1341692017(QQ)
更多MATLAB精彩视频详见/forum-5-1.html
《Learn SVM Step by Step 》by faruto
一个实例搞定libsvm分类
4
本讲视频内容目录
——打造最优秀、专业和权威的MATLAB技术交流平台!
《Learn SVM Step by Step 》系列视频目录
• 《Learn SVM Step by Step 》应用篇
• Libsvm的下载、安装和使用 • Libsvm参数实例详解 • 一个实例搞定libsvm分类 • 一个实例搞定libsvm回归 • Libsvm分类参数优化 • Libsvm回归参数优化 • Libsvm-FarutoUltimate版本介绍与使用 • Libsvm-FarutoGUI版本介绍与使用 • 使用libsvm分类&回归的整体过程
• 一个分类例子 • 一个班级里面有两个男生(男生1、男生2),两个女生(女生1、女生2)
• 男生1 身高:176cm 体重:70kg; 男生2 身高:180cm 体重:80kg;
女生1 身高:161cm 体重:45kg; 女生2 身高:163cm 体重:47kg;
• 将男生定义为1,女生定义为-1,并将上面的数据放入矩阵data中
• data = [176 70; 180 80; 161 45; 163 47];
• 在label中存入男女生类别标签(1、-1)
• label = [1;1;-1;-1];
• 上面的data矩阵就是一个属性矩阵,行数4代表有4个样本,列数2表示属性有 两个,label就是标签(1、-1表示有两个类别:男生、女生)。
技术论坛: 函数百科: 电子期刊: 官方博客: 读书频道: 视频教程: 有偿编程: 软件汉化:
一个实例搞定libsvm分类(1)
• 使用libsvm进行分类过程很简单,只需要有属性矩阵和标签,然后就可以建 立分类模型(model),然后利用得到的这个model进行分类预测了。
• 难点在libsvm的参数调节,关于参数寻优的问题在这里姑且不谈,重点是讲 解会用libsvm进行分类,效果好坏暂且不论。
《Learn SVM Step by Step 》by faruto
一个实例搞定libsvm分类
8
——打造最优秀、专业和权威的MATLAB技术交流平台!
一个实例搞定libsvm分类(3)
• svmpredict的调用格式
• [predict_label, accuracy/mse, dec_value] = svmpredict(test_label, test_data,model);
《Learn SVM Step by Step 》by faruto
一个实例搞定libsvm分类
1
——打造最优秀、专业和权威的MATLAB技术交流平台!
MATLAB技术论坛视频教学
内容:《Learn SVM Step by Step 》系列视频 作者:faruto 时间:2011.6-9 版权:All Rights Preserved By 声明:严厉谴责和鄙夷一切利用本论坛资源进行任何牟利或盗版的行为!
• svmtrain的调用格式
• model = svmtrain(train_label, train_data, ‘options’);
• 输入
– train_data训练集属性矩阵,大小n*m,n表示样本数,m表示属性数目(维数),数据类型 double;
– train_label训练集标签,大小n*1,n表示样本数,数据类型double ; – options参数选项,比如‘-c 1 –g 0.1’,详见视频 《Learn SVM Step by Step》系列视频-应用
《Learn SVM Step by Step 》by faruto
一个实例搞定libsvm分类
10
——打造最优秀、专业和权威的MATLAB技术交流平台!
一个实例搞定libsvm分类(5)
• 有了上面的属性矩阵data,和标签label就可以利用libsvm建立分类模型了。
• 一个实例搞定libsvm分类
• 关于数据标签的注意事项
• 分类模型model参数解密
• 本讲涉及到的MATLAB使用技巧总结
《Learn SVM Step by Step 》by faruto
一个实例搞定libsvm分类
6
——打造最优秀、专业和权威的MATLAB技术交流平台!
• 一个实例搞定libsvm分类
• 关于数据标签的注意事项
• 分类模型model参数解密
• 本讲涉及到的MATLAB使用技巧总结
《Learn SVM Step by Step 》by faruto
一个实例搞定libsvm分类
5
本讲视频内容目录
——打造最优秀、专业和权威的MATLAB技术交流平台!
– 答曰:没有影响,但标签必须是数值类型的,不可以是字符类型的。
– 这里面的标签定义就是区分开男生和女生,怎么定义都可以的,只要定义成数值 型的就可以。 比如我可将将男生定义为2,女生定义为5;
– 后面的label相应为label=[2;2;5;5]; 比如我可将将男生定义为18,女生定义为22;
– 后面的label相应为label=[18;18;22;22];
篇:Libsvm参数实例详解/thread-18457-1-1.html
• 输出
– model训练得到的模型,是一个结构体。
» 注意:当使用-v参数时,返回的model不再是一个结构体,分类问题返回的是交叉验证下的平均分 类准确率;回归问题返回的是交叉检验下的平均mse(均方根误差)。
» 注意:如果测试集的真实标签事先无法得知,此返回值没有参考意义。
– dec_value决策值
《Learn SVM Step by Step 》by faruto
一个实例搞定libsvm分类
9
——打造最优秀、专业和权威的MATLAB技术交流平台!
一个实例搞定libsvm分类(4)
——打造最优秀、专业和权威的MATLAB技术交流平台!
一个实例搞定libsvm分类(6)
– data = – 176 70 – 180 80 – 161 45 – 163 47 – label = –1 –1 – -1 – -1 – testdata = – 190 85 – 161 50 – testdatalabel = –1 –1 – Accuracy = 50% (1/2) (classification) 此时这个指标没有参考价值 – predictlabel = –1 – -1