浅析大数据与统计新思维
浅谈大数据与统计新思维

浅谈大数据与统计新思维作者:李伟来源:《财经界·学术版》2016年第04期摘要:随着多媒体技术的发展,网络信息也渐渐丰富起来,大数据因其数据信息规模较大、结构复杂,受到各个国家广泛的关注。
并且大数据与统计工作之间存在多方面的联系大数据时代的出现给统计新思维也提出很多要求。
本文就大数据与统计新思维方式的进行分析,深入探讨统计思维的变化及创新大数据的收集方式,以期提升大数据分析数据的效率。
关键词:大数据统计新数据分析随着信息时代的发展,大数据发展的速度变得越来越快,渐渐改变着公众通过统计知识去探索世界的方法。
在以往的统计学分析中,所使用的数据一般都是样本数据,即现在的大数据。
大数据的数据规模非常广泛,数据的类型非常多,并且更新的速度较快。
大数据与样本数据相比,其数据量较广,因此,有利于研究人员从多方面统计及分析数据。
在统计学分析中,研究者所研究的对象没有更改,但数据的来源却有了相应的变化,比以往的更加完善,相关的统计思维方式也有很大的变化。
一、统计思维的变化(一)认识数据思维首先,从数据来源方面看,以往的样本数据是根据某种方式来进行收集,但大数据主要是来源于网络,数据库内的信息可被记录下来,不带有目的性。
因此,对于大数据的来源难以追溯。
其次,大部分的样本数据的类型都属于结构型,而大数据的类型属于半结构、非结构及异构型。
最后,以往的样本数据可依靠相关的理论基础,对一些结构型的数据实施量化处理,但大数据的数据类型较为复杂,量化的方式也需要有所更改。
(二)收集数据的思维要变化收集与统计数据的思维是确定数据统计分析的目的,之后再根据所需的数据进行收集,因此,要仔细分析相应的调查方案,严格按照规定来执行各个流程。
(三)分析数据的思维第一,以往的统计思维分析,主要是根据“定性--定量--再定性”的过程进行,定性的目的是为了确定进行定量分析的方向,根据相关经验来判断,这在数据缺失及运算受限的情况之下显得非常重要。
论大数据与统计新思维

的 样 本数 据 ,扩 充成 任意 类 型、没有上 限 、数字 化 数 据。大 数 据对 传 该结 合大 数据 的特 征 ,从 统计分 析过 程 、实证 分 析思路 、推 断分 析逻
统 统 计学 造 成 的 最大 影 响 就 是 :以大 数 据 的 大体 量 和 多样性 覆 盖 辑 、统 计分析评 价 的标 准等 角度作出相 应调 整。
借 助现 代 信息 技 术 和 计算 机 工具 ,对 所有 类 型的 数 据 进行 记 录 和 了“假设 —— 验 证 ”过 程 中的漏 洞 与不 合理 情况 ;同时 ,大 数 据 下 的
存 储 。大 数 据 将传 统 统 计 学 中刻 意 收集 的 、有一 定 限 度 的、结 构 化 样 本 即为总体 ,因此 在 推 断分析 过 程 不需 要依 据概 率 。新 的思 维应
大 数 据 是 一 个 整 体 概 念 ,它的 “大 ”指 的 不是 数 量 大 小 ,而 是 断总 体特 征 。然而 ,大 数据 时 代不 存在 数 据短 缺 和分 析 运算 手段有
意 味 着 “整 体 、全 体 ”。站在 统计 学 的 角度 ,大 数 据 是 以信息 为单位 , 限 的情况 ,因此 可以简化 定量 分析 过 程 ;并且 ,大 数据 的全 面 眭弥补
家战 略 、小到 民 间商业 ,尤 其是 电子商 务等 领 域 早 已率 先应 用 大 数 理 、提 炼 、汲 取 (删 除 )、分 配 和存 储 数据 的过 程 J。
据 技 术 。鉴于 此 ,以数 据 为研 究 对 象 、具 有 专业 严谨 特点 的统 计 学 , 2.3 分析 数 据 的思 维 变化
的优 势 进 行合 理 改 变而 形 成 。所 谓传 统 统 计思 维 是指 通 过 数 据 分 总 体 。另 外,传 统 思 维 下的 个 体 由于 符 号或 称 谓 的 重 叠异 位 ,导 致
数据分析与统计思维:培养学生的数据处理和解读能力

数据分析与统计思维:培养学生的数据处理和解读能力引言在当今信息爆炸的时代,数据已经成为我们日常生活中随处可见的一部分。
通过数据分析和统计思维,我们可以从大量的数据中提取有用的信息,并据此做出有效的决策。
因此,培养学生的数据处理和解读能力成为了非常重要的任务。
本文将探讨数据分析和统计思维的重要性,以及如何培养学生的相关能力。
数据分析的重要性解读复杂现象现实生活中的问题通常是复杂而多变的,而数据分析可以帮助我们更好地理解这些问题。
通过对大量数据的收集和分析,我们可以揭示事物之间的关联和趋势。
例如,在健康领域,通过分析大量的医疗数据,我们可以发现某种疾病的发病率与饮食习惯之间的关系,从而为预防和治疗提供科学依据。
支持决策制定数据分析为决策提供了有力的支持。
无论是在商业还是政府领域,决策都需要有可靠的数据支持。
通过分析历史数据和趋势,我们可以预测未来的发展,并据此做出相应的决策。
例如,在市场营销中,通过对消费者行为的分析,我们可以找到生产和销售的最佳策略。
促进创新发展数据分析也可以促进创新发展。
通过对市场和用户行为的深入了解,我们可以发现新的需求和机会,并据此提供创新的解决方案。
例如,在科技领域,通过分析用户数据,我们可以发现用户的痛点,并据此开发出更好的产品和服务。
统计思维的重要性逻辑思维的基础统计思维是逻辑思维的基础。
统计学是一门研究如何收集、分析和解释数据的学科,它强调逻辑思维的训练。
通过学习统计学,学生可以培养辨别事实和观念之间关联的能力,从而提升自己的逻辑思维水平。
提高问题解决能力统计思维培养了学生的问题解决能力。
在统计学中,学生需要通过收集和分析数据,得出结论,并据此解决实际问题。
这个过程中,学生需要运用逻辑思维和数学知识,同时也需要培养观察力和批判性思维。
通过这样的实践,学生可以提高自己的问题解决能力,并在面对各种问题时能够更加从容应对。
培养科学精神统计思维也培养了学生的科学精神。
在数据分析中,学生需要保持客观的态度,并进行合理的数据解释。
大数据与统计新思维

第31卷第1期2014年1月统计研究Statistical Research Vol.31,No.1Jan.2014大数据与统计新思维*李金昌内容提要:最近,《大数据时代》等几本书引起了广泛的关注,大数据正在改变着人们的行为与思维,那么以数据为研究对象的统计学该如何应对,本文基于对大数据的理解,认为统计思维需要发生三个方面的改变,即要改变认识数据的思维、收集数据的思维和分析数据的思维。
其中,数据分析思维又要在统计分析过程、实证分析思路、推断分析逻辑等方面发生变化,同时统计分析评价的标准也要有所调整。
围绕这些变化,本文提出需要从八个方面去积极应对大数据,以促使统计学科跟上时代的步伐。
关键词:大数据;统计思维;统计学中图分类号:C829.2文献标识码:A文章编号:1002-4565(2014)01-0010-06Big Data and New Mind on StatisticsLi JinchangAbstract :The latest publication of a book such as “Big Data :A Revolution That Will Transform How We Live ,Work ,and Think ”has captured the public attention.With the big data changing the way people think and behave ,how should the development of statistics ,a discipline that aims at data ,take its course ?Based on its understanding of the big data ,this paper puts forward three dimensions in which the mind on statistics need to be changed :the interpretation of data ,the idea of data collection and the view of data analysis ,where the process of statistical analysis ,the mode of empirical analysis and the logic of inferential analysis ,and also the evaluation standards of statistical analysis should be adjusted.According to those changes ,this paper suggests that the big data be actively dealt with from eight perspectives ,in order to keep the science of statistics to abreast of the times.Key words :Big Data ;Mind on Statistics ;Statistics*本文为浙江省高校人文社科重点研究基地(统计学)成果之一。
现代统计中新思维、新方法的应用

数 据 的 变 化 是 现 代 统 计 中最 明 显 , 也 是 最 关 键 的 变 化 。与 传
统数 据 相 比 , 互联 网 时代 的 数据 不仅 规 模 大 、变 化 快 , 而且 数 据 类 型多种多样 , 度量 口径 也各 不相 同 , 也就是说 , 目前 数 据 的 来 源 、 种 类和 量 化 方 式 都与 以往 大 不相 同 , 发生 了根 本 性 的变 化 。 首先 , 从 数据来源来 说 , 传 统 统 计 数 据 的 收 集 有 很 强 的 针 对
才培养 , 气 象 类 高 校 与培 训 机 构 在 相 关 专业 的 配 置 上 可 考 虑 将 知 识产权保护纳入 专业课学习 中, 培 养 能 胜 任 知 识 产 权 保 护 的高 级
管理 和保 护 的人 才 。
【 4 】 吴玲 . 气 象知 识 产 权 有 关 问 题 思 考 [ J ] . 气 象 与 减 灾 研
网络数据 也越 来越庞 大, 覆 盖 的 范 围也 越 来越 多 , 统 计 行 业 也 发 生 了 巨大 的 变化 , 已经 进 入 了大 数 据 时 代 。 而 网络 的发展 、大数据 时代 的到来 又与统 计工作存 在着一 定的联 系, 因此 大数据 时代 为统计工作提 出了新 的要 求 , 而现代 统 计的新 思维 、新 方法也 不断地应 用在各行 各业 中。 关键 词 : 统计行 业 ; 新 思维 ; 新 方 法; 大数据
究, 2 0 1 1 , ( 5 )
【 5 】何亮亮. 我 国 气象服 务产 品的 产权 界 定与 法律保 护 【 J 】 . 山
西省 政 法 管 理 干 部 学 院 学 报 , 2 0 1 0 , ( 5 ) 加 强 全 社 会 气 象 知 识 产 权 保 护 意 识 的培 养 , 只 有 明 白气 象 知 [ 6 ]邓 富 民, 王涛. 创新 与求 变: 我 国高新 企业知 识产权 管理新 识产权的重要性 , 居 民及 企 业 才 能 积 极 地 、 主 动 地 去 开 发 和 保 护 举措 【 J ] .现代 管理科 学 , 2 0 0 6 ( 6 ) 气象知识产权 , 自觉 地 尊 重 气 象 部 门 的智 力 劳 动 成 果 , 新 闻媒 体 [ 7 】 陶绪翔 . 论 企 业 知 识 产权 机 构 设 置一 从 法 经 济 学 的 角度 分 依法 刊播 气象 信 息 , 受 众 不 接 受 无序 传播 的气 象 信 息 , 以 达 到 维 护 析【 J 】 . 中南财经政 法 大学研 究生 学报 , 2 o o 6 ( 2 )
大数据统计思维新探

大数据统计思维新探1 对大数据的初步认识首先我们需要知道什么是大数据,它在不同的科学领域、不同的行业都有不同的解释。
相对于传统意义上的数据,大数据这里的含义有新的解释,不只是字面本身的意思,更为重要的是数据的内涵,可能“大”与“数据”的含义本就不能分开理解,只有把“大数据”这三个字放在一起才能更有意义。
从统计学的角度出发我们应该怎样来理解大数据呢?它是在现代信息技术、工具的基础上运用可自动记录、储存能力的所有类型的数据。
简单地说,大数据就是所有的可记录信息的集合。
可以这样来理解,把以前的统计研究数据比做是根据一定条件收集在一起的结构化的样本,那大数据就是所有可以记录、存储、超大容量的各种各样类型的数据总集合。
从统计学的角度出发,传统的样本数据与现今的大数据的区别在哪呢?区别就在于传统的样本数据是按特定的条件所产生的格式化数据,样本的数量是有限的,而且如果说统计设计过程偏离了方案,数据就失去意义。
一般都不可能同时满足各方面统计需求,如果出现了其事先未考虑到的情况,数据的不能扩展性就会导致数据的失效,那统计方案也就失效了。
而大数据是所有可能通过现代信息科技手段可获得的数据,其数据量巨大,并且不会受到一些条件的限制。
因此,大数据最大的优势就是非常宽的数据选择性,可进行多维度、多角度的数据分析方案。
更为重要的是因为大数据的样本选择面宽,样本如果不够说明情况还可以从大数据中选择扩大;样本中不能够发现的某些细小信息,在大数据也可以获得。
2 统计思维的新变化在大数据时代要想做好统计工作,需要改变统计思维,否则,统计工作很难发展,至少会被边缘化。
统计思维的变化应该从对数据的掌握与分析开始,下一步是揭示事物的本质与相互联系,直至揭示事物的发展规律。
也可以说统计工作的目的就是要还原事物的本来面目,从而达到还原真相的效果。
2.1 认识数据的思维要变化与传统样本数据相比,大数据不仅数量多和选择多,而且其来源和数据类型都发生了根本性的变化,数据既杂乱又多样。
大数据统计新思维分析

大数据统计新思维分析摘要:大数据时代,人们的思维与行为方式都在经受大数据的影响和改变。
信息化时代背景下,统计工作也受到了大数据新思维的冲击。
本文根据大数据的发展趋势,从理论和实践上针对统计新思维做出分析,根据统计思维发生的改变,提出相应的建议,促使统计思维紧跟科技和时代发展步伐。
关键词:大数据;统计新思维;信息化一、对大数据的基本认识传统统计工作的研究对象是有意收集的结构化样本数据。
而大数据时代,统计工作需要面临的是动态化发展、随时储存,具有无限容量的多种类型数据。
受信息化的冲击,传统统计工作中的各种缺陷也在不断暴露出来。
而大数据不仅指信息量大,还包括现代信息技术受到的条条框框限制较少,可以接纳各种各样的数据。
二、深化认识统计思维的变化大数据时代必然带来统计思维的变化。
当然统计的本质是指根据数据来还原事物本来的面目。
现在,我们可以借助大数据多角度无限空间地去实现这个目标。
相应地,统计思维也在发生着改变。
(一)认识数据的思维发生变化。
大数据相比于传统数据,在类型、量化方式和数据来源上都发成了巨大变化。
传统数据收集目的性强,可以确定数据来源,即数据提供者的信息和身份,在数据分析后还可以进行修改校对。
而大数据很难从微观层面追溯来源,因为大数据基本来源于互联网,数据产生并不以收集为目的。
传统数据的数据类型具有一定的结构性,基本上是定量和定性数据,标准和格式也是固定的,最终通过统计图标等方式呈现出来。
而大数据没有结构性或者具有半结构性特点,包括一切可以记录的符号。
传统数据在数据量化方面来说是非常成熟的。
量化之后,数据可以直接用来做分析和计算。
而大数据在数据量化方面则面临一个巨大的挑战。
因为大数据背景下,不同系统对数据的分析都是不同的。
因此,大数据的非结构性特征改变了传统的数据结构和数据量化方式。
(二)收集数据的思维发生变化。
传统统计是需要什么数据就去收集,收集数据后做好选择和比较就可以。
而大数据时代,数据来源多种多样,数据类型囊括万千,怎么去辨别数据真伪,怎样确定关联物,怎么适应数据快速的更新换代,都是摆在统计工作者面前的问题。
大数据与统计新思维

大数据与统计新思维 is e ■ s bi ffl rn m对大数据的初步认识到底什么是大数据,不同的学科领域、不同行业的从业人员肯定会有不同的理解。
与传统意义上的数据相比,大数据的“大”与“数据”都有了新的含义,绝不仅仅是体量的问题,更重要的是数据的内涵问题。
或许,“大”与“数据”根本就不能分开,只有把“大数据”当作一个整体概念来理解才有意义。
那么从统计学的角度,我们该如何来理解大数据?笔者认为大数据不是基于人工设计、借助传统方法而获得的有限、固定、不连续、不可扩充的结构型数据,而是基于现代信息技术与工具可以自动记录、储存和连续扩充的、大大超出传统统计记录与储存能力的一切类型的数据。
有人用4V(Volume,Variety、Velocity和Value)来形容大数据的特征,最根本之处就是数字化基础上的数据化。
通俗地说,大数据就是一切可记录信号的集合。
如果说,传统统计研究的数据是有意收集的结构化的样本数据,那么现在我们面对的数据则是一切可以记录和存储、源源不断扩充、超大容量的各种类型的数据。
样本数据与大数据的这种区别,具有什么样的统计学意义?我们知道,样本数据是按照特定研究目的、依据抽样方案获得的格式化的数据,不仅数据量有限,而且如果过程偏离方案,数据就不能满足要求。
基于样本数据所进行的分析,其空间十分有限———通常无法满足多层次、多角度的需要,若遇到抽样方案事先未曾考虑到的问题,数据的不可扩充性缺点就暴露无疑。
而大数据是一切可以通过现代信息技术记录和量化的数据,不仅所蕴含的信息量巨大,而且不受各种框框的限制———任何种类的数据都来者不拒、也无法抵拒。
不难发现,大数据相比于样本数据的最大优点是,具有巨大的数据选择空间,可以进行多维、多角度的数据分析。
更为重要的是,由于大数据的大体量与多样性,样本不足以呈现的某些规律,大数据可以体现;样本不足以捕捉的某些弱小信息,大数据可以覆盖;样本中被认为异常的值,大数据得以认可。
大数据背景下统计思维及统计应用能力提升的思考

大数据背景下统计思维及统计应用能力提升的思考汇报人:日期:•引言•大数据时代与统计思维•统计应用能力的提升•案例分析与应用实践•大数据与统计思维的未来发展目•结论与建议录01引言背景介绍统计思维是指运用统计学的理论和方法,分析和解决实际问题的思维方式。
统计应用能力则是将统计思维应用于实际工作中的能力,包括数据采集、数据处理、数据分析等方面。
随着大数据时代的到来,统计思维和统计应用能力在各个领域的重要性日益凸显。
研究目的与意义研究意义•有助于提高分析和解决实际问题的能力。
•有助于培养更多的统计学专业人才,满足社会需求。
•有助于推动大数据技术的深入应用和发展。
研究目的:探讨如何提升大数据背景下的统计思维及统计应用能力,为相关领域的发展提供理论支持和实践指导。
02大数据时代与统计思维大数据时代的特征大数据时代,数据量呈现出爆炸性增长,从TB级别跃升到PB级别。
数据量大速度快多样化价值密度低数据产生和处理的速率越来越快,对时效性要求也越来越高。
数据的来源和类型多样化,包括结构化数据、半结构化数据和非结构化数据等。
随着数据量的增加,有效信息相对较少,需要从大量数据中挖掘出有用的信息。
统计思维在大数据时代的地位与作用基础性地位统计思维是分析和处理大数据的基础性工具,为大数据的采集、整理、分析和挖掘提供支持。
决策支持作用通过统计思维,能够从海量数据中挖掘出有价值的信息,为决策提供科学依据。
预测性作用统计思维可以帮助我们理解和预测数据的未来趋势,为预测性决策提供支持。
010302统计思维的基本原则与方法在处理大数据时,应尽可能地消除随机性和不确定性,以准确反映数据的真实情况。
确定性原则将数据视为一个整体,从整体上把握数据的特征和规律,避免过度关注细节而忽略整体。
整体性原则通过比较不同数据之间的联系和差异,发现数据的内在规律和特征。
比较性原则在处理和分析数据时,应保证过程的可重复性和可再现性,以确保结果的准确性和可靠性。
浅谈大数据与统计新思维

浅谈大数据与统计新思维作者:刘霞来源:《商情》2018年第06期【摘要】随着信息技术的不断发展和进步,在当前这个时代,各项数据化信息呈现出了一个爆炸性的增长趋势,民众也迎来了“数据化时代”。
在当前,各个行业的发展,都和大数据的内容有所关联,所以,相关的研究人员需要对大数据与统计新思想进行全方位的认识,把握各项技术要点,尽可能分析数据背后所蕴藏的含义,这样才能为个人的发展、社会的进步做出贡献。
【关键词】大数据统计新思维探究要想对大数据的概念内容展开分析,需要根据不同行业、不同领域的区别展开较为深入的研究。
从传统意义上来分析,对于数据这一概念内容的理解,多是通过实验、统计、检验等方法获得相应的数值信息、记录信息等,这些内容具有固定、有限和不可扩充的特性。
而针对大数据,概念上却是不尽相同的。
从统计学的角度进行分析,大数据不仅仅是量大,同时也具备了多样、高速化的特征。
在当下的时代发展过程中,大数据已然成为了人们所共同关注的重要话题,本文通过对大数据和统计新思维的内容展开探究,希望能起到一些积极的参考作用。
1.大数据的统计学意义对于统计学而言,传统的数据主要是收集、分析、构建的结构化样本数据,但是对于大数据而言,统计学则是要进行自动化记录、存储、扩充的特性,传统数据统计过程中该出现的空间有限性和不可扩充性所带来的局限性也被打破,大数据由于其自身所包含的大量信息,以及现代技术的记录优势、量化优势和不受限制的特点,大大改变了传统的统计方法。
大数据上较大的选择空间,为统计学带来了多层次、多维度和多方法的数据分析优势:还有,大数据的多样性和大量性,对样本中的一些问题进行了有效的解决,帮助工作人员总结出了相应的数据规律,改善了决策者对重要信息的认知能力。
2.大数据背景下统计思维的变化2.1数据认识上的改变从数据来源的方面进行观察,可以发现以往样本数据是按照某种方法来进行收集的,但是大数据的内容主要是来源于网络,数据库内的信息记录不带有目的性,所以这也就导致大数据在来源上难以追溯。
大数据背景下中学生统计思维培养探讨

统计思维是一种基本的思维能力,在大数据时代特别重要。
统计思维能帮助中学生更好地理解、分析和应用数据,从而做出更明智的决策。
为了培养中学生的统计思维能力,教师可以采用以下方法:
让学生参与实际的数据收集和分析过程。
例如,可以让学生调查校园内的人口统计数据,并分析这些数据。
这样,学生就可以在实际操作中学习如何收集、清洗、分析和可视化数据。
使用可视化工具来帮助学生理解数据。
例如,可以使用图表、柱状图、饼图等工具来帮助学生更直观地理解数据。
教授基本的统计概念,如平均数、中位数、众数、极差等。
让学生学会如何使用这些概念来分析数据。
引导学生思考如何使用数据来回答问题。
例如,可以让学生思考如何使用数据来判断哪种销售策略更有效。
在课堂上经常讨论数据分析的例子,帮助学生更好地理解如何使用数据来解决实际问题。
提供实际的数据分析案例,让学生通过实际操作来学习如何使用数据解决问题。
使用模拟数据分析软件来帮助学生学习如何使用数据分析工具。
鼓励学生参加数据分析相关的竞赛或活动,以便让他们在实际的竞争环境中练习统计思维能力。
总的来说,培养中学生的统计思维能力需要综合运用多种方法,在实际的操作中练习,并通过不断的反馈来提升能力。
大数据时代的统计新思维

第二部分
相关关系还是因果关系
➢维克托·迈尔-舍恩伯格《大数据时代》 ➢要全体不要抽样 ➢要效率不要绝对精确 ➢要相关不要因果
第二部分
相关关系还是因果关系
➢译者周涛教授不认同“要相关不要因果” ➢要相关也要因果
➢数据的真实性
北京朝阳地税局:
网红主播3.9亿元 补缴了税款6000多万元
第一部分
基层统计工作的思考
➢数据的真实性 ➢四大工程 ✓调查单位名录库 ✓企业一套表制度 ✓数据采集管理软件平台 ✓联网直报系统 ➢数据的多渠道验证 ✓第三次农业普查采用无人机
第二部分
大数据时代的统计新思维
➢信息化平台的构建 ➢相关关系还是因果关系 ➢“大数据”与“小数据”的关系 ➢“开放数据”的相关问题
车、高端装备制造业、新材料
➢新型业态 ➢从“+互联网”到“互联网+”
➢新商业模式
✓产业转型升级(金融\商务) ✓智慧化管理(交通\环境) ✓优化统计工作的思考
➢数据的采集 ➢不能仅仅依靠上报 ➢从“四上”到“四下”
➢数据的分析 ➢仅仅采用描述性统计不够 ➢如何使用恰当的统计模型
大数据时代下科的技统幻计灯新片思模维板下载
主要内容 ➢背景篇: “三新”统计的新要求 ➢思考篇: 大数据时代的统计新思维 ➢实践篇: 统计工作的实例三则
➢不唯GDP论英雄vs年均增长底线是6.5%以上 ➢去产能、去库存、去杠杆、降成本、补短板
➢大众创业、万众创新 ➢众创、众包、众扶、众筹 ➢鲶鱼效应和蝴蝶效应 ✓余额宝 ✓摩拜单车
➢谷歌流感趋势预测:比美国疾控中心早两周预报流感发病率 ➢陈松蹊教授团队关于北京城区PM2.5污染状况的研究
大数据分析:数据科学的新思维

# 大数据分析:数据科学的新思维## 引言在大数据时代,数据科学成为了一门重要的学科,它通过对海量数据的收集、处理和分析,帮助我们从数据中挖掘出有价值的信息。
然而,随着数据规模的不断增长和数据类型的多样化,传统的思维方式已经无法应对这些挑战。
因此,数据科学需要新的思维方式来推动其发展和应用。
本文将探讨数据科学的新思维,并介绍如何利用这种思维方式开创数据科学的新时代。
## 数据科学的新思维### 1. 创造性思维传统的数据分析往往是基于已有的数据和方法进行分析和预测。
然而,在大数据时代,我们需要更具创造性的思维来发现新的问题、构建新的模型和解决方案。
数据科学家需要具备创造性思维,能够提出新的假设、采用新的算法,并勇于尝试和创新。
### 2. 联想思维大数据时代的数据源丰富多样,包括结构化数据、非结构化数据、传感器数据等。
传统的分析方法常常只关注单一数据源,而忽略了不同数据源之间的关联和影响。
因此,数据科学家需要运用联想思维,将不同数据源进行整合和关联分析,从中发现新的关联性和规律。
### 3. 敏捷思维在大数据时代,数据的变化速度快,对应的业务需求也在不断变化。
因此,数据科学家需要具备敏捷思维,能够快速适应和响应变化,及时调整分析方法和策略。
敏捷思维还要求数据科学家能够灵活应对挑战和问题,并能够迅速迭代和优化解决方案。
### 4. 综合思维数据科学是一门综合性的学科,需要跨越多个领域的知识和技术。
因此,数据科学家需要具备综合思维的能力,能够将不同学科的理论和方法结合起来,形成整体的解决方案。
综合思维还要求数据科学家能够从多个角度分析和解决问题,形成全面的视角和深入的洞察。
## 创造数据科学的新时代### 1. 开放数据和共享精神在大数据时代,数据的开放和共享是推动数据科学发展的重要驱动力。
政府、企业和研究机构应该共同努力,提供开放的数据集和共享的数据资源,为数据科学家提供更广阔的研究空间和数据来源。
大数据时代统计工作思考

大数据时代统计工作思考随着互联网技术与信息技术的飞速发展,大数据时代已经到来,数据处理、分析与应用已经成为当前社会发展的重头戏。
在这个时代中,统计工作的地位与作用也发生了很大变化。
本文将探讨大数据时代统计工作的新思路。
一、数据收集和清洗在大数据时代中,数据来源众多,包括传统的调查问卷、实验数据、统计报表、地理信息等,还有来自计算机、移动设备、传感器、互联网、社交网站等各种常规和非常规形式的海量数据。
统计工作者需要对这些数据进行筛选、合并、清洗、整合、去噪等处理,确保数据的准确性和一致性,保障数据的质量和可靠性。
二、数据分析和挖掘在大数据时代中,数据增长的速度之快,复杂性之大,远远超出传统统计方法的处理能力范围。
为了更好地发现数据中的价值信息,统计工作者需要掌握数据挖掘和机器学习等新技术,运用人工智能算法实现自动化和高效性,进行数据的拟合、分类、预测、聚类、关联规则挖掘等分析,得出有益的结论和决策建议。
三、可视化展示和沟通在大数据时代中,数据的结果往往需要反映到各种应用场景中,需要进行业务解释和应用设计。
为此,统计工作者需要学习数据可视化方面的技能,运用各种图表、地图、动画、交互式图像等,将数据转化为易懂的信息,帮助业务人员理解数据分析的含义和结果,达到有效沟通的目的。
四、数据保密和隐私保护在大数据时代中,数据的安全性和隐私性问题越来越受到重视。
统计工作者需要掌握数据保密和隐私保护方面的知识,运用加密技术、隐私保护技术、数据遮蔽和匿名化等手段,保障数据在传输和处理过程中的安全性和隐私性,防止数据泄露和非法使用。
综上所述,大数据时代对统计工作者提出了更高的要求,需要积极跟进新技术、新方法,不断提高自身的实战能力,同时还要充分发挥统计的核心优势,挖掘数据的潜力,为业务决策提供精准、有效的数据支持。
大数据时代下数据统计思维的转变及应对策略

目录
• 引言 • 数据统计思维的转变 • 应对策略 • 结论与展望
01
引言
背景介绍
进入大数据时代的标志
数据产生、流通和处理的规模不断扩大,同时数据处理技术 不断发展,使得大数据成为推动社会发展的重要力量。
大数据的定义
大数据是指在传统数据处理应用软件难以处理的大规模数据 集合。它包括数据的收集、存储、处理、分析等过程,具有 数据规模大、产生速度快、类型多样、价值密度低等特点。
03
应对策略
提高数据质量
1 2
数据清洗
对于异常值、缺失值和错误数据进行处理,提 高数据质量。
数据标准化
将数据进行标准化处理,以消除不同量纲对分 析结果的影响。
3
数据选择
选择与主题密切相关的数据进行分析,以避免 冗余和无关数据的干扰。
掌握大数据技术
学习大数据相关理论
01
了解大数据的概念、特征及发展趋势。
随机思维更注重数据的随机性,考虑数据之间的关联和相 互作用,更准确地反映数据的复杂性和不确定性。
从因果思维到关联思维
传统统计学注重探寻变量之间的因果关系 ,但在大数据时代,数据之间的关联关系 更加复杂和微妙。
关联思维更注重变量之间的关联性,通过 分析数据之间的相关性来揭示现象之间的 联系和规律。
数据匿名化
对敏感数据进行匿名化处理,以保护个人隐私和企业商业机密。
04
结论与展望
结论
大数据时代的到来使得数据统计思维 发生了重要的转变,从传统的统计思 维向现代化统计思维转变。
数据类型的多样化要求我们采取更为 复杂的数据处理和分析方法,以挖掘 出隐藏在数据中的有用信息。
大数据时代下对统计工作的思考

大数据时代下对统计工作的思考随着互联网、移动互联网、物联网等技术的快速发展,大数据时代已经到来。
在这个大数据时代下,各行各业的数据量呈指数级别的增长,数据的利用价值也变得更加重要。
统计学作为数据分析的一种重要方法,在大数据时代下的作用也显得特别重要。
对于统计工作的思考,需要在以下几个方面进行思考:一、统计方法的更新在大数据时代下,传统的统计方法是否还适用?这是需要思考的一个问题。
大数据的特点是数据量大、数据维度高、数据类型多样,传统的统计方法在应对大数据分析工作时可能存在局限性。
因此,需要及时更新统计方法,探索新的统计方法,以更好地应对大数据分析工作。
例如,深度学习、机器学习等新的分析方法和模型,可以更充分地挖掘数据的价值。
二、数据处理的优化在大数据时代下,数据处理变得更加困难,需要对数据进行清洗、处理、整合等工作。
因此,需要通过更加高效的数据处理方法来提高数据质量和分析精度。
例如,使用分布式计算架构、数据并行处理等方式,可以加快数据处理的速度,提高数据的处理效率。
三、交叉学科的合作大数据时代下,数据的应用范围变得更加广泛,需要各个领域的人员进行协作。
例如,医疗领域需要统计学家、医生、生物学家、工程师等人员进行交叉学科的合作。
这是因为,不同领域的人员对数据的理解、分析方法、实践经验等方面都存在差异。
因此,需要建立跨学科的交流平台,促进数据的共享和交流,实现不同领域人员的协作和合作。
四、数据隐私保护在大数据时代下,数据的隐私保护也变得更加重要。
在数据分析时,需要遵守隐私保护的法律法规,严格控制数据的使用权限,确保数据的安全。
例如,医疗领域的数据分析需要遵守 HIPAA(美国健康保险机构和可靠性法案)等法律法规。
总之,在大数据时代下,统计工作需要更加注重统计方法的更新、数据处理的优化、交叉学科的合作、数据隐私保护等方面。
通过多方面的思考和探索,可以更好地应对大数据的挑战,充分挖掘数据的价值。
大数据学习的思维原理

大数据学习的思维原理大数据学习的思维原理可以从以下几个方面来进行探讨:1. 数据驱动思维:大数据学习的核心是基于大规模的数据进行分析和推理,因此数据驱动思维是大数据学习的重要原则之一。
数据驱动思维要求我们从数据中寻找规律和趋势,通过对数据的分析和挖掘来做出决策和预测。
这种思维方式可以帮助我们更加客观地看待问题,减少主观偏见,提高决策的准确性和效率。
2. 统计思维:统计思维是大数据学习中必不可少的一种思维方式。
统计思维注重从大量的数据中获取概率和统计信息,通过对数据的整理和分析来揭示事物之间的关联和规律。
统计思维强调对数据的充分利用,通过合理的抽样和推断来对整体进行估计,从而使我们能够作出更准确的预测和决策。
3. 增量思维:大数据学习的一个重要特点是数据量庞大,而且还在不断增长。
增量思维要求我们在处理大数据时要能够快速适应和应对数据的增长。
这种思维方式要求我们具备快速的数据分析和处理能力,能够随时调整和更新我们的模型和算法,以适应不断变化的数据环境。
4. 开放思维:大数据学习的另一个重要原则是开放思维。
开放思维要求我们能够积极主动地和他人分享数据,合作共享并共同探索解决问题的方法和途径。
开放思维能够促使我们不断从他人的经验和观点中汲取营养,拓宽我们的视野,提高我们对问题的理解和解决能力。
5. 创新思维:大数据学习需要创新思维的支持。
创新思维要求我们能够深入分析问题的本质,寻找新颖的解决方案和方法。
创新思维注重对问题的重新定义和重新思考,通过打破传统的思维模式和束缚,发现新的规律和机会,从而实现更好的数据分析和决策。
6. 问题导向思维:大数据学习需要我们具备问题导向思维。
问题导向思维要求我们首先明确问题的关键点和目标,然后在这个目标的指导下进行大数据分析和挖掘。
问题导向思维能够帮助我们更好地理解问题的本质,更准确地找到解决问题的方法和途径。
综上所述,大数据学习的思维原理包括数据驱动思维、统计思维、增量思维、开放思维、创新思维和问题导向思维。
小议大数据与统计新思维
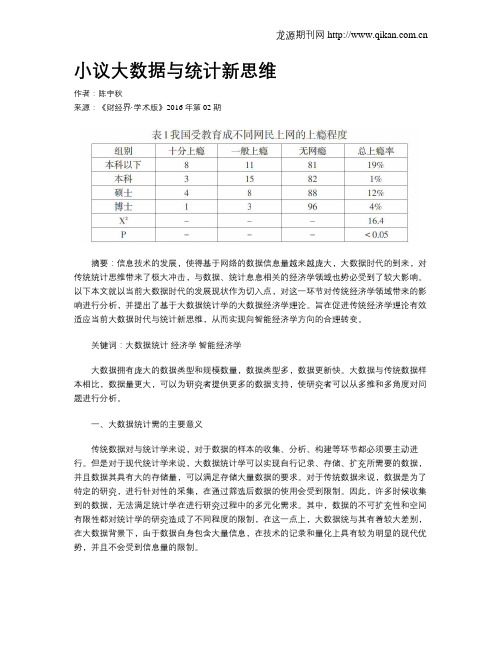
小议大数据与统计新思维作者:陈宇秋来源:《财经界·学术版》2016年第02期摘要:信息技术的发展,使得基于网络的数据信息量越来越庞大,大数据时代的到来,对传统统计思维带来了极大冲击,与数据、统计息息相关的经济学领域也势必受到了较大影响。
以下本文就以当前大数据时代的发展现状作为切入点,对这一环节对传统经济学领域带来的影响进行分析,并提出了基于大数据统计学的大数据经济学理论。
旨在促进传统经济学理论有效适应当前大数据时代与统计新思维,从而实现向智能经济学方向的合理转变。
关键词:大数据统计经济学智能经济学大数据拥有庞大的数据类型和规模数量,数据类型多,数据更新快。
大数据与传统数据样本相比,数据量更大,可以为研究者提供更多的数据支持,使研究者可以从多维和多角度对问题进行分析。
一、大数据统计需的主要意义传统数据对与统计学来说,对于数据的样本的收集、分析、构建等环节都必须要主动进行。
但是对于现代统计学来说,大数据统计学可以实现自行记录、存储、扩充所需要的数据,并且数据其具有大的存储量,可以满足存储大量数据的要求。
对于传统数据来说,数据是为了特定的研究,进行针对性的采集,在通过筛选后数据的使用会受到限制。
因此,许多时候收集到的数据,无法满足统计学在进行研究过程中的多元化需求。
其中,数据的不可扩充性和空间有限性都对统计学的研究造成了不同程度的限制,在这一点上,大数据统与其有着较大差别,在大数据背景下,由于数据自身包含大量信息,在技术的记录和量化上具有较为明显的现代优势,并且不会受到信息量的限制。
在研究统计学过程中,利用大数据为统计学提供了更多的层次和选择空间。
此外,在样本解决过程中,大数据的大量性和多样性对统计学来说意义重大,可以对样本中出现的各种问题进行合理解决,并且可以将数据中存在的规律进行总结。
在统计学中,对大数据进行应用,可以为决策者提供重要的数据支持,并且可以提高决策者的从多较角度对决策问题进行分析,提高其对问题的认知能力。
浅析大数据与统计新思维

浅析大数据与统计新思维发表时间:2016-10-28T16:00:05.143Z 来源:《基层建设》2016年12期作者:张晓秋[导读] 摘要:随着信息全球化的不断深入,国际社会成为了一个整体,信息技术的发展带动了整个国际社会的进步。
现阶段网络数据的信息量越来越庞大,大数据时代的到来对传统信息模式起到了相当大的冲击作用,其他领域必定受到大数据时代的影响产生一些相应的变化。
本文就以大数据时代下统计新思维对于其他领域的影响和发展进行了简单的分析,以促进传统统计学理论能够适应大数据时代的变化。
中国联合网络通信有限公司哈尔滨软件研究院黑龙江 150040摘要:随着信息全球化的不断深入,国际社会成为了一个整体,信息技术的发展带动了整个国际社会的进步。
现阶段网络数据的信息量越来越庞大,大数据时代的到来对传统信息模式起到了相当大的冲击作用,其他领域必定受到大数据时代的影响产生一些相应的变化。
本文就以大数据时代下统计新思维对于其他领域的影响和发展进行了简单的分析,以促进传统统计学理论能够适应大数据时代的变化。
关键词:大数据统计;统计思维 1、前言大数据时代是一个拥有庞大数据类型和规模数量的时代,同时它还有数据更新速度快等特点,这些特点对其他行业和国家经济的发展都有着重要影响。
为了使国家能够顺应大数据时代的发展,统计思维的创新十分有必要。
本文主要研究了大数据时代统计的发展,希望其他工作者可以通过本文的研究开阔视野,多个角度面对问题解决问题。
2、大数据的处理、抽样与分析 2.1 数据的预处理大数据的预处理包括数据清洗、不完全数据填补、数据纠偏与矫正。
利用随机抽样数据矫正杂乱的、非标准的数据源。
统计机构的数据是经过严格抽样设计获取的,具有总体的代表性和系统误差小的优势,但是数据获取和更新的周期长,尽管调查项目有代表性,但难以无所不包。
而互联网数据的获取速度快、量大、项目繁细,但是难以避免数据获取的偏倚性。
将统计机构的数据作为金标准和框架对互联网数据进行矫正,将互联网数据作为补充资源对统计机构的数据进行实时更新,也许是解决问题的一个思路。
大数据与统计新思维发展分析

大数据与统计新思维发展分析作者:汪辉来源:《青年时代》2016年第07期摘要:大数据正在改变着人们的行为与思维,而在全面深化改革背景下,我国正在加紧“四化同步”的协调,其中信息化的建设十分关键。
大数据的广泛应用使得统计对象的基础变了,统计思维也要跟着变化,本文基于对大数据的理解,在全面深化改革背景的特殊时期,分析统计思维发生的改变,围绕这些变化,本文提出相关政策建议应对大数据,以促使统计学科紧随时代步伐。
关键词:全面深化改革;大数据;统计新思维;新常态在近期召开的中央经济工作会议上,以习近平为总书记的党中央对我国经济发展做出了科学判断,当前所处的历史阶段做出的科学判断。
当前,我国发展仍处于重要战略机遇期,同时也正处于增速换档期、转型阵痛期和改革攻坚期三期叠加的关键历史阶段。
当前,信息快速发展,大数据以一种超乎想象的速度改变着整个商业形态与人民生活。
对于统计来说是不是也已进入新常态?在新的历史时期,我们应该要改变过去传统的统计思维,在全面深化改革背景下,结合大数据的特点来重新思考统计的新走向,运用新思维发挥统计的功能。
一、全面深化改革背景下对大数据的初步认识数据和统计工作存在着天然的、内在的、必然的联系,大数据作为各种数据源的变动趋势,改变了传统统计的思维。
同时大数据是未来企业创新、竞争和提高生产力的重要参考因素,“大”与“数据”根本就不能分开,我们该如何来理解大数据?尤其是在当前的宏观背景下,怎么结合大数据去改变统计思维。
二、全面深化改革背景下统计思维的变化改变统计思维,是大数据时代的必然要求,当然,统计思维的变化应该以一个永恒不变的主题为前提,也就是说,数据分析要以数据背后的数据去还原事物的本来面目,那么现在我们则可以在很多方面借助大数据去实现这个目的,而这又首先取决于我们统计思维能否适应大数据时代的变化。
统计思维应该发生怎样的变化?笔者认为:(1)认识数据的思维要变化。
与传统数据相比,大数据来源、类型和量化方式都发生了根本性的变化,因此数据的提供者大多是确定的,有的还可以进行事后核对,而是人们一切可记录的信号。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
浅析大数据与统计新思维发表时间:2016-10-28T16:00:05.143Z 来源:《基层建设》2016年12期作者:张晓秋[导读] 摘要:随着信息全球化的不断深入,国际社会成为了一个整体,信息技术的发展带动了整个国际社会的进步。
现阶段网络数据的信息量越来越庞大,大数据时代的到来对传统信息模式起到了相当大的冲击作用,其他领域必定受到大数据时代的影响产生一些相应的变化。
本文就以大数据时代下统计新思维对于其他领域的影响和发展进行了简单的分析,以促进传统统计学理论能够适应大数据时代的变化。
中国联合网络通信有限公司哈尔滨软件研究院黑龙江 150040摘要:随着信息全球化的不断深入,国际社会成为了一个整体,信息技术的发展带动了整个国际社会的进步。
现阶段网络数据的信息量越来越庞大,大数据时代的到来对传统信息模式起到了相当大的冲击作用,其他领域必定受到大数据时代的影响产生一些相应的变化。
本文就以大数据时代下统计新思维对于其他领域的影响和发展进行了简单的分析,以促进传统统计学理论能够适应大数据时代的变化。
关键词:大数据统计;统计思维 1、前言大数据时代是一个拥有庞大数据类型和规模数量的时代,同时它还有数据更新速度快等特点,这些特点对其他行业和国家经济的发展都有着重要影响。
为了使国家能够顺应大数据时代的发展,统计思维的创新十分有必要。
本文主要研究了大数据时代统计的发展,希望其他工作者可以通过本文的研究开阔视野,多个角度面对问题解决问题。
2、大数据的处理、抽样与分析 2.1 数据的预处理大数据的预处理包括数据清洗、不完全数据填补、数据纠偏与矫正。
利用随机抽样数据矫正杂乱的、非标准的数据源。
统计机构的数据是经过严格抽样设计获取的,具有总体的代表性和系统误差小的优势,但是数据获取和更新的周期长,尽管调查项目有代表性,但难以无所不包。
而互联网数据的获取速度快、量大、项目繁细,但是难以避免数据获取的偏倚性。
将统计机构的数据作为金标准和框架对互联网数据进行矫正,将互联网数据作为补充资源对统计机构的数据进行实时更新,也许是解决问题的一个思路。
研究利用多源数据的重叠关系整合多数据库资源的方法,多种专题(panels)的数据可以相互联合,实现单一专题数据不能完成的目标。
2.2 大数据环境的抽样大数据的抽样方法有待研究,“样本”不必使用所有“数据”,不管锅有多大,只要充分搅匀,品尝一小勺就知道其滋味。
针对大数据流环境,需要探索从源源不断的数据流中抽取足以满足统计目的和精度的样本。
需要研究新的适应性、序贯性和动态的抽样方法。
根据己获得的样本逐步调整感兴趣的调查项目和抽样对象,使得最近频繁出现的“热门”数据,也是感兴趣的数据进入样本。
建立数据流的缓冲区,记录新发生数据的频数,动态调整不在样本中的数据进入样本的概率。
2.3 大数据的分析与整合针对大数据的高维问题,需要研究降维和分解的方法。
探讨压缩大数据的方法,直接对压缩的数据核进行传输、运算和操作。
除了常规的统计分析方法,包括高维矩阵、降维方法、变量选择之外,需要研究大数据的实时分析、数据流算法(data stream computing)。
不用保存数据,仅扫描一遍数据的数据流算法,考虑计算机内存和外存的数据传送问题、分布数据和并行计算的方法。
如何无信息损失或无统计信息损失地分解大数据集,独立并行地在分布计算机环境进行推断,各个计算机的中间计算结果能相互联系沟通,构造全局统计结果。
2.4 网络图模型网络图模型用图的结构描述高维变量之间的相互关系,包括无向图概率模型、贝叶斯网络、因果网络等。
网络图模型是处理和分析高维大数据和多源数据库的有效工具,目前己经有丰富的图模型的软件系统,无向图模型利用有或无一条无方向边来描述变量之间的关联关系和条件独立性,可以将高维变量的统计推断问题分解为低维变量的统计推断问题。
在一个由众多变量作为结点的大网络中,当收集到一部分变量的信息后,不用计算高维联合概率,而是采用网络传播信息流的方法有效地计算目标变量的后验概率。
变量间的因果关系,利用数据学习网络结构,发现产生数据的机制和因果关系网络。
3、大数据与统计学分析方法的区别 3.1 基础数据不同在大数据时代,我们可以获得和分析更多的数据,有时候甚至可以处理和某个特别现象相关的所有数据,而不再依赖于随机抽样。
这意味着,与传统统计学数据相比,大数据不仅规模大,变化速度快,而且数据来源、类型、收集方法都有根本性变化。
①在数据来源方面,在大数据背景下,我们需要的纷繁多样的数据可以分布于全球多个服务器上,因此我们可以获得体量巨大的数据,甚至是关于总体的所有数据。
而统计学中的数据多是经由抽样调查而获得的局部数据,因此我们能够掌握的事“小数据量”。
这种情况下,因为需要分析的数据很少,所以必须尽可能精确的量化我们的数据。
综上,大数据情况下,分析人员可以拥有大量数据,因而不需要对一个现象刨根问底,只需要掌握事物大体的发展方向即可;然而传统的小数据情况下则需要十分注意所获得数据的精确度。
②在数据类型与收集方面,在既往模式下,数据的收集是耗时且耗力的,大数据时代所提出的“数据化”方式,将使得对所需数据的收集变得更加容易和高效。
除了传统的数字化数据,就连图像、方位、文本的字、词、句、段落等等,世间万物都可以成为大数据范畴下的数据。
届时,一切自然或者社会现象的事件都可以被转化为数据,我们会意识到本质上整个世界都是由信息构成的。
3.2 分析范式不同。
在小数据时代,我们往往是假想世界是如何运行的,然后通过收集和分析数据来验证这种假想。
也就是说,传统统计实证分析的基本范式为:(基于文献)提出理论假设-收集相关数据并进行统计分析-验证理论假设的真伪。
然而,在不久的将来,我们将会在大数据背景下探索世界,不再受限制于传统的思维模式和特定领域里隐含的固有偏见,我们对事物的研究始于数据,并可以发现以前不曾发现的联系。
换言之,大数据背景下,探索事物规律的范式可以概括为:数据观察与收集——数据分析——描述事物特征/关系。
3.3 数据分析方法不同传统统计学主要是基于样本的“推断分析”,而大数据环境下则是基于总体数据的“实际分析”,即直接得出总体特征,并可以分析出这些特征出现的概率。
3.4 分析视角不同传统的实证统计意在弄清事物之间的内在联系和作用机制,但大数据思维模式认为因果关系是没有办法验证的,因此需要关注的是事物之间的相关关系。
大数据并没有改变因果关系,但使因果关系变得意义不大,因而大数据的思维是告诉我们“是什么”而不是“为什么”。
换言之,大数据思维认为相关关系尽管不能准确地告知我们某事件为何会发生,但是它会提醒我们这件事情正在发生,因此相关关系的发现就可以产生经济和社会价值了。
4、大数据时代背景下统计工作的出路4.1 树立大数据意识方向问题是发展的根本问题。
确立发展方向的就是自身的意识,所以,统计工作必须根据时代的客观情况,树立正确的意识。
当前的大数据时代,是社会发展到一定阶段之后必然产生的过程,统计工作也要根据这一时代的需要,树立大数据意识。
树立大数据意识的根本目的是使全体统计人员意识到自身的危机,明确工作和时代的差距,同时也给整个统计部门一个明确的目标。
这样才能使整个统计工作的发展在有压力的情况下进行,促进其高速的发展。
同时,意识的树立可以使整个统计工作按部就班的进行,增强整个部门的凝聚力,把握整个部门的工作方向,细致的了解当代统计工作的特征,做好统计工作。
4.2 加强对统计专业认识的培养统计工作要进步,首要任务就是提高统计人员的工作素养,培养高素质的统计人员。
因为人是工作的主体,大数据时代对统计工作的更高要求就是变相的要求提升统计工作人员的专业素养。
传统的统计工作较为单一,统计工作人员的任务也比较简单,只是进行简单的劳动。
为了适应时代的发展,统计部门必须加强对专业统计人员的培养,一方面培养他们对于统计工作专业知识结构的了解,另一方面,培养他们对于新兴科技的应用,包括计算机的熟练掌握和相关统计软件的应用。
这需要专业的培训,在招收统计人员的时候就应该提高要求,然后系统的培训,只有合格以后才能真正的投入到统计工作当中,经过一段时间的磨合之后,由这批有知识、有能力的人来引导统计工作,然后不断的创新,逐步的提升统计工作的发展速度,最终使整体的统计工作向着精确、高速、高效的方向发展,提高统计的科学性和合理性。
同时,要间隔性的考核工作人员的业务能力,对于不合格要再培训,优秀的员工给予奖励,鼓励统计工作的创新,提升统计工作的速度。
结束语在过去传统小数据时代背景下,人们采用传统的方式进行分析和解决相关问题。
随着信息全球化的不断推进,大数据时代的到来给人们提出了更多的挑战。
在大数据时代背景下,我们必须要有新的统计创新思维方式,在面对现代高科技中常用积极的手段解决根本问题,做好相关统计的研究。
本文为笔者个人观点,如有不当之处希望大家批评指正。
参考文献[1]陈如明.大数据时代的挑战、价值与应对策略[J].中国国际信息通讯展专刊,2012 .[2]陈明奇,姜禾,张娟,廖方宇.大数据时代的美国信息网络安全新战略分析[J].全国计算机安全学术交流会,2012 .[3]孙立,杨军,潘坤友.基于大数据可用性的政府统计策略研究[J].科技管理研究,2014.[4]张雪.大数据时代的挑战[J].中国科技信息,2015.74.[5]张方宇.大数据时代的思维创新[J].计算机发展,2014.36.[6]孙友.大数据时代对我国发展的影响[J].科技发展,2012.。