《编译原理教程》习题解析与上机指导(第四版) 第十章
编译原理课后习题答案-清华大学-第二版

《编译原理》课后习题答案第一章
是哪种方式,其加工结果都是源程序的执行结果。目前很多解释程序采取上述两种方式的综 合实现方案,即先把源程序翻译成较容易解释执行的某种中间代码程序,然后集中解释执行 中间代码程序,最后得到运行结果。
广义上讲,编译程序和解释程序都属于翻译程序,但它们的翻译方式不同,解释程序是 边翻译(解释)边执行,不产生目标代码,输出源程序的运行结果。而编译程序只负责把源 程序翻译成目标程序,输出与源程序等价的目标程序,而目标程序的执行任务由操作系统来 完成,即只翻译不执行。
好似滚雪球一样,直到我们所要求的编译程序。 (4)移植:将 A 机器上的某高级语言的编译程序搬到 B 机器上运行。
《编译原理》课后习题答案第一章
第6题
计算机执行用高级语言编写的程序有哪些途径?它们之间的主要区别是什么?
答案: 计算机执行用高级语言编写的程序主要途径有两种,即解释与编译。 像 Basic 之类的语言,属于解释型的高级语言。它们的特点是计算机并不事先对高级语
第4题
对下列错误信息,请指出可能是编译的哪个阶段(词法分析、语法分析、语义分析、 代码生成)报告的。 (1) else 没有匹配的 if (2) 数组下标越界 (3) 使用的函数没有定义 (4) 在数中出现非数字字符
答案: (1) 语法分析 (2) 语义分析 (3) 语法分析 (4) 词法分析
第5题
b∶=10; end (q); procedure s; var c,d; procedure r;
var e,f; begin (r)
call q; end (r); begin (s) call r; end (s); begin (p) call s;
end (p); begin (main)
《编译原理教程》习题解析与上机指导(第四版) 第七章

(1) 试应用DAG进行优化; (2) 假定只有R、H在基本块出口是活跃的,写出优化后 的四元式序列; (3) 假定只有两个寄存器AX、BX,试写出上述优化后 的四元式序列的目标代码。 【解答】 (1) 根据DAG的构造算法构造基本块P的DAG 步骤如图7-1的(a)到(h)所示。
MOV MUL
R1, A R1, R0 该结果
//取一个空闲寄存器 R1 //运算结束后 R1 中为 T2 结果,内存中无
MOV R0, D
ADD R0, ?1? 该结果
/*此时 R0 中结果 T1 已经没有引用点, 且临时单元 T1 是非活跃的,所以,寄存 器 R0 可作为空闲寄存器使用*/ //运算结束后 R0 中为 T3 结果,内存中无
本块时,所有的寄存器被当成空闲的寄 存器使用,从而造成计算结果的丢失。
考虑到寄存器 R0 中的 T5和寄存器 R1 中 的 W,临时单元 T5 是非活跃的,因此 只要将结果 W 存回对应单元即可*/
7.4 对基本块 P:
S0=2 S1=3/S0 S2=T-C S3=T+C R=S0/S3 H=R S4=3/S1 S5=T+C S6=S4/S5 H=S6*S2
我们以四元式T=a+b为例来说明其翻译过程。 汇编语言的加法指令代码形式为
ADD R, X
其中,ADD为加法指令;R为第一操作数,第一操作数必须 为寄存器类型;X为第二操作数,它可以是寄存器类型,也 可以是内存型的变量。ADD R,X指令的含义是:将第一操 作数R与第二操作数相加后,再将累加结果存放到第一操作 数所在的寄存器中。要完整地翻译出四元式T=a+b,则可能 需要下面三条汇编指令:
MOV T2, R1
MOV R1, E SUB R1, F MUL R0, R1
《编译原理》课后习题答案

第7 题证明下述文法G[〈表达式〉]是二义的。
〈表达式〉∷=a|(〈表达式〉)|〈表达式〉〈运算符〉〈表达式〉〈运算符〉∷=+|-|*|/答案:可为句子a+a*a 构造两个不同的最右推导:最右推导1 〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉a=>〈表达式〉* a=>〈表达式〉〈运算符〉〈表达式〉* a=>〈表达式〉〈运算符〉a * a=>〈表达式〉+ a * a=>a + a * a最右推导2 〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉〈运算符〉〈表达式〉=>〈表达式〉〈运算符〉〈表达式〉〈运算符〉a=>〈表达式〉〈运算符〉〈表达式〉* a=>〈表达式〉〈运算符〉a * a=>〈表达式〉+ a * a=>a + a * a第8 题文法G[S]为:S→Ac|aB A→ab B→bc该文法是否为二义的?为什么?答案:对于串abc(1)S=>Ac=>abc (2)S=>aB=>abc即存在两不同的最右推导。
所以,该文法是二义的。
或者:对输入字符串abc,能构造两棵不同的语法树,所以它是二义的。
第9 题考虑下面上下文无关文法:S→SS*|SS+|a(1)表明通过此文法如何生成串aa+a*,并为该串构造语法树。
(2)G[S]的语言是什么?答案:(1)此文法生成串aa+a*的最右推导如下S=>SS*=>SS*=>Sa*=>SS+a*=>Sa+a*=>aa+a*(2)该文法生成的语言是:*和+的后缀表达式,即逆波兰式。
第10 题文法S→S(S)S|ε(1) 生成的语言是什么?(2) 该文法是二义的吗?说明理由。
答案:(1)嵌套的括号(2)是二义的,因为对于()()可以构造两棵不同的语法树。
第11 题令文法G[E]为:E→T|E+T|E-T T→F|T*F|T/F F→(E)|i证明E+T*F 是它的一个句型,指出这个句型的所有短语、直接短语和句柄。
《编译原理教程》习题解析与上机指导(第四版) 胡元义章 (4)

第六章 运行时存储空间组织 【解答】 按照嵌套过程语言栈式实现方法,ex调用PP(a)
前后活动记录的过程如图6-2所示。
图6-2 ex调用PP(a)前后的活动记录
第六章 运行时存储空间组织
6.5 类 PASCAL 结构(嵌套过程)的程序如下,该语言的编 译器采用栈式动态存储分配策略管理目标程序数据空间:
第六章 运行时存储空间组织 第六章 运行时存储空间组织
第六章 运行时存储空间组织
6.1 完成下列选择题:
(1) 分配目标程序数据空间的基本策略分为
。
A.栈式分配和堆式分配
B.局部分配和整体分配
C.静态分配和动态分配
D.程序运行之前分配
(2) 过程的DISPLAY表中记录了
。
A.过程的连接数据
B.过程的嵌套层次
第六章 运行时存储空间组织 图6-1 递归过程的活动记录
第六章 运行时存储空间组织
过程进入指令为
SP=TOP+1 1[SP]=返回地址
TOP=TOP+L 建立 DISPLAY 表 P; 返回指令为 TOP=SP-1
/*执行 P 过程*/
SP=0[SP]
X=2[TOP]
UJ 0[X]
(2) 对于 return 后的直接递归情况,可简化为
后放”和“后请先放”的原则,即申请和释放的顺序是任意的。 故选D。
第六章 运行时存储空间组织
(5) 栈式动态分配与管理在过程返回时应做的工作有:① 恢复老TOP;② 恢复老SP;③ 根据返回地址无条件返回。故 选B。
(6) 如果活动记录中没有DISPLAY表,则说明程序中不允 许有嵌套定义的过程。故选B。
编译原理 第10章(清华大学)

∶ ∶
(a) (a) 到 达 标 号 B1处 ;
BB 的 内 情 向 量 ZZ
BB11 的 TT OO P DISPLAY
形式单元 m,n 2
连接数据 A的TOP
∶ ∶ (b) (b)进 入 分 程 序 B1;
31
数 组B
B的 内 情 向 量 z
B1 的 T O P D I S P LAY
20
用Display表的方案
(1)主程序--->(2)P--->(3)Q--->(4)R
top
P的
display sp 活动记录
d[1]
主程序的
d[0]
活动记录
top display
主程序的
d[0]
sp 活动记录
(2)
(1)
21
用Display表的方案
• 主程序--->P--->Q--->R
d[2]displatyopsp
endmainmainqrmainqqtopr的活动记录q的活动记录spq的活动记录q的活动记录主程序全局主程序全局数据区数据区top临时工作单元局部简单变量局部数组的内情向量保存运行过程前的状态返回地址寄存器值??实参形式单元和参数个数sp控制链老sptop的数组区sp的活动记录q的活动记录主程序全局数据区嵌套过程语言的栈式分配方案l主要特点语言一个过程可以引用包围它的任一外层过程所定义的标识符如变量数组或过程等
地址 3 参数个数 4 形式单元
. . . d D ISP L A Y . 简单变量 . 数组内情向量 . 临时变量
• 当过程的层次为n, 它的 display为n+1个 值。 • 一个过程被调用时, 从调用过程的 DISPLAY表中自下向 上抄录n个SP值,再加 上本层的SP值。 •全局DISPLAY地址
编译原理课后习题解答

〈句子〉=>〈主语〉〈谓语〉
=>〈主语〉〈动词〉〈直接宾语〉
=>〈主语〉〈动词〉〈冠词〉〈名词〉
=>〈主语〉〈动词〉〈冠词〉peanut
=>〈主语〉〈动词〉the peanut
=>〈主语〉ate the peanut
=>〈冠词〉〈形容词〉〈名词〉ate the peanut
=>〈冠词〉〈形容词〉 elephant ate the peanut
=>〈冠词〉big elephant ate the peanut
=> the big elephant ate the peanut
(B) 〈句子〉=>〈主语〉〈谓语〉
=>〈主语〉〈动词〉〈直接宾语〉
=>〈冠词〉〈形容词〉〈名词〉〈动词〉〈直接宾语〉
=>〈冠词〉〈形容词〉〈名词〉〈动词〉〈冠词〉〈名词〉
〈偶数字〉::=0 | 2 | 4 | 6 | 8
3. 写一文法,使其语言是偶整数的集合,但不允许有以 0 开头的偶整数。
解:G[〈偶整数〉]:
〈偶整数〉::= 〈符号〉〈单偶数〉|〈符号〉〈首数字〉〈数字串〉〈尾偶数〉
〈符号〉::= + | — |ε
〈单偶数〉::=2 | 4 | 6 | 8
〈尾偶数〉::= 0 |〈单偶数〉
S::= a(B)a B::= bB |b|ε ( 2 ) 文法[G〈S〉]: S ::= (A)(B) A::= aA|a B::= bB|b 6. 文法 G3[〈表达式〉]: 〈表达式〉::=〈项〉|〈表达式〉+〈项〉|〈表达式〉—〈项〉 〈项〉::=〈因子〉|〈项〉*〈因子〉|〈项〉/〈因子〉 〈因子〉::=(〈表达式〉)| i 试给出下列符号串的推导: i, (i), i*i, i*i+i, i*(i+i) 解:(1)〈表达式〉=>〈项〉 =>〈因子〉
《编译原理教程》习题解析与上机指导-(3)

G[A]可进一步化简为G[S]:S→aS | bS | b(非终结符B对应的 产生式与A对应的产生式相同,故两非终结符等价,即可合 并为一个产生式)。
第二章 词法分析
2.8 构造一个DFA,它接收Σ={a, b}上所有不含子串abb 的字符串。
第二章 词法分析 图2-15 习题2.6的NFA
第二章 词法分析 用子集法将图2-15所示的NFA确定化,如图2-16所示。
图2-16 习题2.6的状态转换矩阵
第二章 词法分析 由图2-16可看出非终态2和4的下一状态相同,终态6和8
的下一状态相同,即得到最简状态为 {0} {1} {2,4} {3} {5} {6,8} {7}
状态转换矩阵。
图2-22 图2-21确定化后的状态转换矩阵
第二章 词法分析
比较图2-22与图2-19,重新命名后的转换矩阵是完全一 样的,也即正规式(a | b)*b可以同样得到化简后的DFA如图 2-20所示。因此,两个自动机完全一样,即两个正规文法等 价。
(2) 对图2-20,令A对应状态1,B对应状态2,则相应的 正规文法G[A]为
第二章 词法分析 图2-14 习题2.5的最简DFA'
第二章 词法分析
2.6 有语言L={w | w∈(0,1)+,并且w中至少有两个1, 又在任何两个1之间有偶数个0},试构造接受该语言的确定 有限状态自动机(DFA)。
【解答】 对于语言L,w中至少有两个1,且任意两个1 之间必须有偶数个0;也即在第一个1之前和最后一个1之后, 对0的个数没有要求。据此我们求出L的正规式为0*1 (00(00)*1)*00(00)*10*,画出与正规式对应的NFA,如图215所示。
《编译原理教程》习题解析与上机指导(第四版) 第四章

B.节省存储空间,不便于表的修改
C.便于优化处理,节省存储空间
D.节省存储空间,不便于优化处理
(4) 表达式(┐A∨B)∧(C∨D)的逆波兰表示为 。
A.┐AB∨∧CD∨
B.A┐B∨CD∨∧
C.AB∨┐CD∨∧
D.A┐B∨∧CD∨
(5) 后缀式________对应的中缀表达式是a-(-b)*c (注:
【解答】 此题只需要对说明语句进行语义分析而不需要
产生代码,但要求把每个标识符的类型填入符号表中。对 D、L、
T,为其设置综合属性 type,而过程 enter(name,type)用来把名字
name 填入到符号表中,并且给出此名字的类型 type。翻译方案
如下:
D→id L L→,id L(1)
图4-1 句子b(((aa)a)a)b对应的语法树
4.2 何谓“语法制导翻译”?试给出用语法制导翻译生 成中间代码的要点,并用一简例予以说明。
【解答】 语法制导翻译(SDTS)直观上说就是为每个产 生式配上一个翻译子程序(称语义动作或语义子程序),并且 在语法分析的同时执行这些子程序。也即在语法分析过程中, 当一个产生式获得匹配(对于自上而下分析)或用于归约(对于 自下而上分析)时,此产生式相应的语义子程序进入工作, 完成既定的翻译任务。
L.length:=2}
B→1 B→0
{B.val:=1} {B.val:=0}
4.4 下面的文法生成变量的类型说明: D→id L L→,id L | :T T→integer | real
试构造一个翻译 方案,仅使用综合属性,把每个 标识符的类型 填入符号表中(对所用到的过程,仅说明功能即可,不必具体写 出)。
@表示求负运算)。
编译原理教程课后习题答案

编译原理教程课后习题答案【篇一:编译原理教程课后习题答案——第一章】完成下列选择题:(1) 构造编译程序应掌握a. 源程序b. 目标语言c. 编译方法d. 以上三项都是(2) 编译程序绝大多数时间花在上。
a. 出错处理b. 词法分析c. 目标代码生成d. 表格管理(3) 编译程序是对。
a. 汇编程序的翻译b. 高级语言程序的解释执行c. 机器语言的执行d. 高级语言的翻译【解答】(1) d (2) d(3) d1.2 计算机执行用高级语言编写的程序有哪些途径?它们之间的主要区别是什么?【解答】计算机执行用高级语言编写的程序主要有两种途径:解释和编译。
在解释方式下,翻译程序事先并不采用将高级语言程序全部翻译成机器代码程序,然后执行这个机器代码程序的方法,而是每读入一条源程序的语句,就将其解释(翻译)成对应其功能的机器代码语句串并执行,而所翻译的机器代码语句串在该语句执行后并不保留,最后再读入下一条源程序语句,并解释执行。
这种方法是按源程序中语句的动态执行顺序逐句解释(翻译)执行的,如果一语句处于一循环体中,则每次循环执行到该语句时,都要将其翻译成机器代码后再执行。
在编译方式下,高级语言程序的执行是分两步进行的:第一步首先将高级语言程序全部翻译成机器代码程序,第二步才是执行这个机器代码程序。
因此,编译对源程序的处理是先翻译,后执行。
从执行速度上看,编译型的高级语言比解释型的高级语言要快,但解释方式下的人机界面比编译型好,便于程序调试。
这两种途径的主要区别在于:解释方式下不生成目标代码程序,而编译方式下生成目标代码程序。
1.3 请画出编译程序的总框图。
如果你是一个编译程序的总设计师,设计编译程序时应当考虑哪些问题?【解答】编译程序总框图如图1-1所示。
作为一个编译程序的总设计师,首先要深刻理解被编译的源语言其语法及语义;其次,要充分掌握目标指令的功能及特点,如果目标语言是机器指令,还要搞清楚机器的硬件结构以及操作系统的功能;第三,对编译的方法及使用的软件工具也必须准确化。
《编译原理》习题解答

《编译原理》习题解答:第一次作业:P14 2、何谓源程序、目标程序、翻译程序、汇编程序、编译程序和解释程序?它们之间可能有何种关系?答:被翻译的程序称为源程序;翻译出来的程序称为目标程序或目标代码;将汇编语言和高级语言编写的程序翻译成等价的机器语言,实现此功能的程序称为翻译程序;把汇编语言写的源程序翻译成机器语言的目标程序称为汇编程序;解释程序不是直接将高级语言的源程序翻译成目标程序后再执行,而是一个个语句读入源程序,即边解释边执行;编译程序是将高级语言写的源程序翻译成目标语言的程序。
关系:汇编程序、解释程序和编译程序都是翻译程序,具体见P4 图 1.3。
P14 3、编译程序是由哪些部分组成?试述各部分的功能?答:编译程序主要由8个部分组成:(1)词法分析程序;(2)语法分析程序;(3)语义分析程序;(4)中间代码生成;(5)代码优化程序;(6)目标代码生成程序;(7)错误检查和处理程序;(8)信息表管理程序。
具体功能见P7-9。
P14 4、语法分析和语义分析有什么不同?试举例说明。
答:语法分析是将单词流分析如何组成句子而句子又如何组成程序,看句子乃至程序是否符合语法规则,例如:对变量x:= y 符合语法规则就通过。
语义分析是对语句意义进行检查,如赋值语句中x与y类型要一致,否则语法分析正确,语义分析则错误。
P15 5、编译程序分遍由哪些因素决定?答:计算机存储容量大小;编译程序功能强弱;源语言繁简;目标程序优化程度;设计和实现编译程序时使用工具的先进程度以及参加人员多少和素质等等。
补充:1、为什么要对单词进行内部编码?其原则是什么?对标识符是如何进行内部编码的?答:内部编码从“源字符串”中识别单词并确定单词的类型和值;原则:长度统一,即刻画了单词本身,也刻画了它所具有的属性,以供其它部分分析使用。
对于标识符编码,先判断出该单词是标识符,然后在类别编码中写入相关信息,以表示为标识符,再根据具体标识符的含义编码该单词的值。
计算机编译原理课后习题及答案详细解析
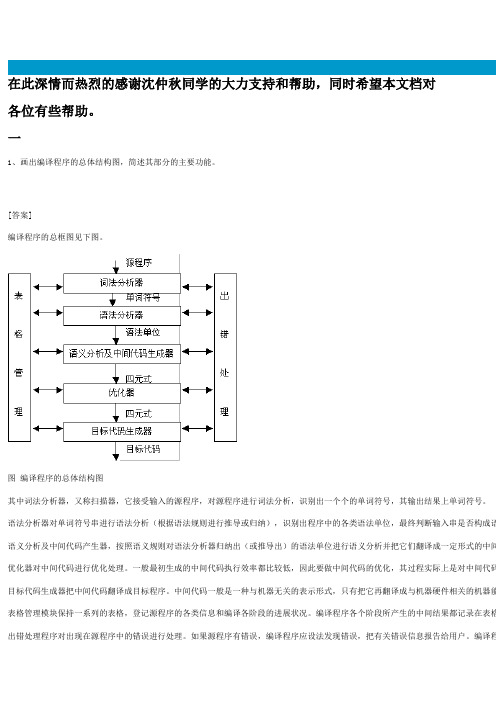
在此深情而热烈的感谢沈仲秋同学的大力支持和帮助,同时希望本文档对各位有些帮助。
一1、画出编译程序的总体结构图,简述其部分的主要功能。
[答案]编译程序的总框图见下图。
图编译程序的总体结构图其中词法分析器,又称扫描器,它接受输入的源程序,对源程序进行词法分析,识别出一个个的单词符号,其输出结果上单词符号。
语法分析器对单词符号串进行语法分析(根据语法规则进行推导或归纳),识别出程序中的各类语法单位,最终判断输入串是否构成语语义分析及中间代码产生器,按照语义规则对语法分析器归纳出(或推导出)的语法单位进行语义分析并把它们翻译成一定形式的中间优化器对中间代码进行优化处理。
一般最初生成的中间代码执行效率都比较低,因此要做中间代码的优化,其过程实际上是对中间代码目标代码生成器把中间代码翻译成目标程序。
中间代码一般是一种与机器无关的表示形式,只有把它再翻译成与机器硬件相关的机器能表格管理模块保持一系列的表格,登记源程序的各类信息和编译各阶段的进展状况。
编译程序各个阶段所产生的中间结果都记录在表格出错处理程序对出现在源程序中的错误进行处理。
如果源程序有错误,编译程序应设法发现错误,把有关错误信息报告给用户。
编译程2、计算机执行用高级语言编写的程序有哪些途径?它们之间的主要区别是什么?[答案]计算机执行用高级语言编写的程序主要途径有两种,即解释与编译。
像Basic之类的语言,属于解释型的高级语言。
它们的特点是计算机并不事先对高级语言进行全盘翻译,将其变为机器代码,而是每读总而言之,是边翻译边执行。
像C,Pascal之类的语言,属于编译型的高级语言。
它们的特点是计算机事先对高级语言进行全盘翻译,将其全部变为机器代码,再统1.文法G[S]为:S->Ac|aBA->abB->bc写出L(G[S])的全部元素。
[答案]S=>Ac=>abc或S=>aB=>abc所以L(G[S])={abc}2. 文法G[N]为:N->D|NDD->0|1|2|3|4|5|6|7|8|9G[N]的语言是什么?[答案]G[N]的语言是V+。
《编译原理教程》习题解析与上机指导(第四版) 胡元义章 (7)

典型的单操作数指令结构如图12-1所示。
第十二章 8086/8088小汇编的设计与实现
第十二章 8086/8088小汇编的设计与实现
的数和所需保存的结果,这就需要三个操作数,可以规定把加 得的结果存入到两个相加数的位置之一,从而使操作数减少为 两个,这两个操作数就分别称为源操作数和目的操作数。源操 作数与目的操作数相加的结果最终又送回到目的操作数,这意 味着原来目的操作数中存放的数据丢失了,但是这种情况无关 紧要,如果需要保留原来目的操作数的值,则可以在执行这条 指令之前将原目的操作数保存到其它寄存器或者存储器中。两 操作数指令的方法对于由许多指令组成的程序来说,所节省的 存储空间和送入CPU•的时间都是可观的。
第十二章 808பைடு நூலகம்/8088小汇编的设计与实现
第十二章 8086/8088小汇编的设计与实现
12.1 汇编指令系统的分析 12.2 8086/8088小汇编的设计实现 12.3 8086/8088小汇编实验 12.4 8086/8088小汇编程序
第十二章 8086/8088小汇编的设计与实现
12.1 汇编指令系统的分析 12.1.1 引言
(1) 能够满足CPU所寻址的最大地址空间,否则将存在 无法访问的地址。
第十二章 8086/8088小汇编的设计与实现
(2) 从速度和存储角度考虑,地址码不能占用太多的字 节。为减少地址码占用的字节数,就应采用多种寻址方式。
(3) 尽量满足高级语言中各种数据结构的寻址需要。以 数组元素A[I]为例,位移量对应数组A的开始地址,变址I(表 示数组A的第I个元素)的位距值存放在寄存器(如SI)中,则对 数组元素A[I]的访问地址应是“寄存器(SI)+位移”;有时位 移量是在基址寄存器(如BX)中,则A[I]的访问地址是“寄存器 (BX)+寄存器(SI)”;如果A[I]出现在递归子程序调用中,则 数据是以堆栈形式来逐层存储的,故访问数组元素A[I]时还需 由堆栈指针(如BP)来指示是哪一层子程序调用中的A[I],其地 址应为“寄存器(BP)+寄存器(SI)+位移”。由此可见,至少要 有如上所述的几种寻址方式才能满足程序语言的特殊使用(数 组、递归子程序)要求。
《编译原理教程》习题解析与上机指导(第四版) 第五章

(5) 可在基本块内实现合并已知量、删除无用赋值和删 除多余运算的优化。故选B。
(6) 在程序流图中,具有下列性质的结点序列为一个循 环:① 它们是强连通的;② 它们中间有一个且只有一个是 入口结点。故选D。
(7) 必经结点的二元关系包括:① 自反性;② 传递性; ③ 反对称性。故选D。
(8) 如果已知有向边n→d是一条回边,则由它组成的循 环就是由结点d、结点n以及有通路到达n但该通路不经过d的 所有结点组成的。故选B。
5.2 何谓局部优化、循环优化和全局优化?优化工作在 编译的哪个阶段进行?
【解答】 优化根据涉及的程序范围可分为三种。 (1) 局部优化是指局限于基本块范围内的一种优化。一 个基本块是指程序中一组顺序执行的语句序列(或四元式序 列),其中只有一个入口(第一个语句)和一个出口(最后一个 语句)。对于一个给定的程序,我们可以把它划分为一系列 的基本块,然后在各个基本块范围内分别进行优化。通常应 用DAG方法进行局部优化。
(6) 在程序流图中,我们称具有下述性质 的结点序列为 一个循环。
A.它们是非连通的且只有一个入口结点 B.它们是强连通的但有多个入口结点 C.它们是非连通的但有多个入口结点 D.它们是强连通的且只有一个入口结点
(7) 关于必经结点的二元关系,下列叙述中不正确的是 。
A.满足自反性
B.满足传递性
C.满足反对称性
(9) 对循环中各基本块的每个四元式,如果它的每个运 算对象为常数或者定值点在L外,则将此四元式标记为“不 变运算”。故选D。
(10) 对循环L中的不变运算S:A=B op C或A= op B或 A=B,要求满足下述条件(A在离开L后仍是活跃的)才可以外 提到前置结点中:① S所在的结点是L的所有出口结点的必 经结点;② A在L中其它地方未再定值;③ L中的所有A的 引用点只有S中A的定值才能到达。故选C。
编译原理教程第四版答案

编译原理教程第四版答案【篇一:编译原理教程课后习题答案——第三章】.1 完成下列选择题:(1) 文法g:s→xsx|y所识别的语言是a. xyxb. (xyx)*c. xnyxn(n≥0)d. x*yx*a. 最左推导和最右推导对应的语法树必定相同b. 最左推导和最右推导对应的语法树可能不同c. 最左推导和最右推导必定相同d. 可能存在两个不同的最左推导,但它们对应的语法树相同(3) 采用自上而下分析,必须。
a. 消除左递 a. 必有ac归b. 消除右递归c. 消除回溯d. 提取公共左因子(4) 设a、b、c是文法的终结符,且满足优先关系ab和bc,则。
b. 必有cac. 必有bad. a~c都不一定成立(5) 在规范归约中,用a. 直接短语b. 句柄c. 最左素短语d. 素短语a. 归约b. 移进c. 接受d. 待约a. lalr文法b. lr(0)文法c. lr(1)文法d. slr(1)文法(8) 同心集合并有可能产生新的冲突。
a. 归约b. “移进”/“移进”c.“移进”/“归约”d. “归约”/“归约”【解答】 (1) c (2) a (3) c (4) d (5) b (6) b (7) d (8) d3.2 令文法g[n]为g[n]: n→d|ndd→0|1|2|3|4|5|6|7|8|9(1) g[n]的语言l(g[n])是什么?(2) 给出句子0127、34和568的最左推导和最右推导。
【解答】(1) g[n]的语言l(g[n])是非负整数。
(2) 最左推导: nndnddnddddddd0ddd01dd012d0127nnddd3d34nndnddddd5dd56d568最右推导: nndn7nd7n27nd27n127d1270127nndn4d434nndn8nd8n68d685683.3 已知文法g[s]为s→asb|sb|b,试证明文法g[s]为二义文法。
【解答】由文法g[s]:s→asb|sb|b,对句子aabbbb可对应如图3-1所示的两棵语法树。
编译原理习题集与答案解析(整理后)

编译原理习题集与答案解析(整理后)第⼀章1、将编译程序分成若⼲个“遍”是为了。
a.提⾼程序的执⾏效率b.使程序的结构更加清晰c.利⽤有限的机器内存并提⾼机器的执⾏效率d.利⽤有限的机器内存但降低了机器的执⾏效率2、构造编译程序应掌握。
a.源程序b.⽬标语⾔c.编译⽅法d.以上三项都是3、变量应当。
a.持有左值b.持有右值c.既持有左值⼜持有右值d.既不持有左值也不持有右值4、编译程序绝⼤多数时间花在上。
a.出错处理b.词法分析c.⽬标代码⽣成d.管理表格5、不可能是⽬标代码。
a.汇编指令代码b.可重定位指令代码c.绝对指令代码d.中间代码6、使⽤可以定义⼀个程序的意义。
a.语义规则b.语法规则c.产⽣规则d.词法规则7、词法分析器的输⼊是。
a.单词符号串b.源程序c.语法单位d.⽬标程序8、中间代码⽣成时所遵循的是- 。
a.语法规则b.词法规则c.语义规则d.等价变换规则9、编译程序是对。
a.汇编程序的翻译b.⾼级语⾔程序的解释执⾏c.机器语⾔的执⾏d.⾼级语⾔的翻译10、语法分析应遵循。
a.语义规则b.语法规则c.构词规则d.等价变换规则⼆、多项选择题1、编译程序各阶段的⼯作都涉及到。
a.语法分析b.表格管理c.出错处理d.语义分析e.词法分析2、编译程序⼯作时,通常有阶段。
a.词法分析b.语法分析c.中间代码⽣成d.语义检查e.⽬标代码⽣成三、填空题1、解释程序和编译程序的区别在于。
2、编译过程通常可分为5个阶段,分别是、语法分析、代码优化和⽬标代码⽣成。
3、编译程序⼯作过程中,第⼀段输⼊是,最后阶段的输出为程序。
4、编译程序是指将程序翻译成程序的程序。
单选解答1、将编译程序分成若⼲个“遍”是为了使编译程序的结构更加清晰,故选b。
2、构造编译程序应掌握源程序、⽬标语⾔及编译⽅法等三⽅⾯的知识,故选d。
3、对编译⽽⾔,变量既持有左值⼜持有右值,故选c。
4、编译程序打交道最多的就是各种表格,因此选d。
《编译原理教程》习题解析与上机指导(第四版) 第十二章

由于计算机的主要工作是进行数据处理,故计算机指令 系统中的多数指令是与操作数有关的。这些操作数可以在寄 存器中,也可以在内存或I/O端口中,还可以隐含于指令码 中。对于不同的操作数有不同的方法来存取它们,特别是对 于存放于存储单元的操作数,可以采用多种不同的方式来寻 找地址以便进行数据存取。寻址方式越多,CPU的指令功能 就越强,灵活性也就越大。但是,寻址方式多也会造成指令 编码的复杂化。因此,在设计指令系统的寻址方式时主要考 虑以下问题:
典型的单操作数指令结构如图12-1所示。
图12-1 典型的单操作数指令结构 (a) 操作数在16位寄存器内;(b) 操作数在寄存器或存储器内
典型的双操作数指令结构如图12-2所示。 图12-2 典型的双操作数指令结构
由于双操作数指令只有一个w位,因此两个操作数要么 都是8位,要么都是16位。然而,对于值很小的立即数操作 来说,如果用16•位表示就显得有些浪费存储空间了。为了 减少这种情况下立即数所占用的字节数,8086/8088指令系 统对诸如加法、减法和比较的立即数操作指令设置了符号扩 展位s。s位只对16位操作数(w=1)有效,即:
的数和所需保存的结果,这就需要三个操作数,可以规定把 加得的结果存入到两个相加数的位置之一,从而使操作数减 少为两个,这两个操作数就分别称为源操作数和目的操作数。 源操作数与目的操作数相加的结果最终又送回到目的操作数, 这意味着原来目的操作数中存放的数据丢失了,但是这种情 况无关紧要,如果需要保留原来目的操作数的值,则可以在 执行这条指令之前将原目的操作数保存到其它寄存器或者存 储器中。两操作数指令的方法对于由许多指令组成的程序来 说,所节省的存储空间和送入CPU•的时间都是可观的。
(1) 能够满足CPU所寻址的最大地址空间,否则将存在 无法访问的地址。
编译原理-第十章习题答案

4
本章教学线索
1 概述 2 优化技术简介 3 局部优化 4 循环优化
上一页
下一页
5
1 概述
优化的目的是为了获得更高效的代码,必须遵循以下原则: (1)等价原则:优化后不能改变程序运行的结果 (2)有效原则:优化后所产生的目标代码运行时间更短、占 用的存储空间更小 (3)合算原则:尽可能以较低的代价获取较好的优化效果。 常用的优化技术: (1)删除公共子表达式 (2)复写传播 (3)删除无用代码 (4)代码外提 (5)强度削弱 (6)删除归纳变量
优化后: _tmp0 = 56 ; _tmp1 = _tmp0 – b ; a = _tmp1 ;
上一页 下一页
8
常数传播
_tmp4 = 0 ; f0 = _tmp4 ; _tmp5 = 1 ; f1 = _tmp5 ; _tmp6 = 2 ; i = _tmp6 ;
优化
f0 = 0 ; f1 = 1 ; i=2;
上一页 下一页
goto Lnext
L4:t2 = y - z x = t2 goto L1
21
3.2 基本块的DAG及其应用
基本块DAG图的概念: (1)图的叶子结点以一标识符或常数作为标志,表示该结点代表该变量或常数 的值; (2)图中的内部结点以一运算符作为标记,表示该结点代表应用该运算符对其 后继结点所代表的值进行运算的结果; (3)图中各个结点上可能附加一个或多个标识符,表示这些变量具有该结点所 代表的值。 基本块DAG图的构造算法: 假设代码形式为(0)A = B (1)A = op B (2)A = B op C 或 A = B[C]
例: L1: if a<b goto L2 goto Lnext L2: if c<d goto L3 goto L4 L3: t1 =y+z x =t1 goto L1 L4:t2 = y-z x =t2 goto L1 L1:if a<b goto L2 L2:if c<d goto L3 goto L4 L3:t1 = y + z x = t1 goto L1
编译原理考试习题及答案PPT课件

自底向上的语法分析是从输入的字符串出发,逐步将其归约为文法的起始符号。
自底向上的语法分析通常采用LR(0)、SLR(1)、LALR(2)等算法。
自底向上的语法分析可以检测出输入的字符串是否符合语言的语法规则,并生成相应的语法结构。
01
02
03
自底向上的语法分析
语法分析的算法和数据结构
语法分析的算法包括预测分析法、移位/归约法、LR(0)、SLR(1)、LALR(2)等。
三地址代码的生成
对三地址代码进行优化可以提高目标代码的执行效率,常见的优化技术包括常量折叠、死代码删除、循环展开等。
三地址代码的优化
循环优化
循环是程序中常见的结构之一,对循环进行优化可以提高程序的执行效率。常见的循环优化技术包括循环展开、循环合并、循环剪枝等。
要点一
要点二
死代码删除
死代码是指程序中永远不会被执行的代码,删除这些死代码可以减小目标代码的大小并提高程序的执行效率。
习题及答案解析
词法分析习题及答案解析
题目
给定一个字符串,判断它是否是合法的标识符。
答案解析
合法的标识符必须以字母或下划线开头,后面可以跟字母、数字或下划线。
题目
给定一个字符串,判断它是否是关键字。
答案解析
关键字是编程语言中预定义的保留字,不能用作标识符。例如,在C语言中,关键字包括`int`, `float`, `if`, `else`等。
答案解析
上下文无关文法是一种形式文法,它的产生式右部不依赖于左部的任何符号。这意味着产生式右部是一个终结符或一个非终结符的序列。
题目
给定一个抽象语法树,判断它是否是二叉树。
答案解析
抽象语法树是源代码的树形表示,每个节点表示源代码中的一个结构。如果一个抽象语法树中的每个节点最多有两个子节点,则它是二叉树。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
通过编译原理课程设计,应使学生达到下述能力: (1) 学会程序设计语言的词法分析程序的设计与实现; (2) 学会程序设计语言的语法分析程序的设计与实现; (3) 学会程序设计语言的语义分析程序的设计与实现; (4) 学会将程序设计语言的语句翻译为中间语言的完整 实现过程。
课程设计一
将PASCAL 语言程序语句文法改造为C 语言程序语句文法。 PASCAL 程序语句文法:
10.4 实验四 添加新的程序语句(二)
1. 实验目的 掌握另一种添加语句功能的方法。 2. 实验要求 通过深入了解语句的内在功能,利用等价变换的方法实 现语句的编译过程。 3. 实验内容 已知repeat语句与while语句的功能结构图如图10-1所示。
图10-1 条件循环语句结构图
通过等价变换用while语句实现repeat语句的格式如下: S; while not B do S;
begin i:=1; while i<=N do begin i:=i+1; if B=1 then begin j:=2; while i*j<=N do begin B:=0; j:=j+1 end end end
end#~
(2) 自行设计一程序进行正确性验证, 给出二元式序列的 注释及状态栈STACK加工分析对应的符号栈内容。
第十章 上机实验内容
10.1 实验一 编译程序的分析与验证 10.2 实验二 算术表达式的扩充 10.3 实验三 添加新的程序语句(一) 10.4 实验四 添加新的程序语句(二) 10.5 编译原理课程设计
10.1 实验一 编译程序的分析与验证
1. 实验目的 了解编译程序中LR分析表的作用以及语义加工程序的 功能。 2. 实验要求 通过编译程序PAS和COMPILER的运行,检验编译程序 输出结果的正确性。 3. 实验内容 (1) 验证下述程序输出结果的正确性:
S→if B then S else S∣while B do S∣begin L end∣a
L→S;L︱S 改造为
S→if (B) S else S∣while (B) S∣{ L }∣a L→S;L︱S;
课程设计二
将下面布尔表达式文法改造为 C 语言的布尔表达式文法: B→B and B∣B or B ∣not B∣(B) ∣i rop i∣i
试在编译程序中用等效的while语句实现repeat语句的功能。 4. 说明 可采用预处理方法先源程序中的repeat语句用等效的
while语句替换,但这种替换在嵌套语句中处理起来比较麻 烦。
10.5 编译原理课程设计
编译原理课程设计的目的是让学生在编译原理实验的基 础上,实际动手完成高级程序语言的词法、语法、语义及中 间代码生成程序的设计与实现,从而掌握高级程序语言编译 的基本能力,初步具备程序设计语言的词法分析、语法分析、 语义分析及中间代码生成等各环节的设计能力,能够设计并 完成一个高级程序设计语言语句的编译(由高级语言到中间 语言)。
4. 说明 (1) 实现时可对for语句的文法设计出一个LR分析表,然 后将该文法的开始符看做程序语句LR分析表中的一个终结 符,即像赋值语句一样处理(当然仍要重新设计程序语句的 LR分析表)。另一种方法就是直接将for语句的文法纳入到程 序语句文法中(即像if和while语句一样处理),并重新设计程 序语言的LR分析表。 (2) for语句中产生式的语义动作需要参考编译程序中对 if和while语句的处理部分做相应修改。
10.2 实验二 算术表达式的扩充
1. 实验目的 掌握LR分析表的设计方法和语义加工程序的扩充。 2. 实验要求 参照算术表达式LR分析表的设计方法,设计扩充后的 算术表达式LR分析表,并对原语义加工程序进行修改,加 入新添加的内容。 3. 实验内容 算术表达式文法扩充如下:
E→E+E∣E-E∣E*E∣E/E∣(E)∣i 试根据该文法重新设计LR分析表,并修改语义加工程序, 最后验证修改的结果。
F3→F2 until E(3) S→F3 do S(1)
{F3.quad:=F2.quad; q:=nxq; emit(j≤,F2.place,E(3).place,q+2); F3.chain:=nxq; emit(j,_,_,0)}
{先形成 S(1)相应的四元式序列;
emit(j,_,_,F3.quad); backpatch(S(1).chain,F3.quad); s.chain:=F3.chain}
F1→for i:=E(1) F2→F1 step E(2)
{emit(:=,E(1).place,_,entry(i); F1.place:=entry(i); F1.chain:=nxq; emit(j,_,_,0); F1.quad:=nxq}
{F2.quad:=F1.quad; F2.place:=F1.place; emit(+,F1.place,E(2).place,F1.place); backpatch(F1.chain,nxq)}
其中,rop 代表 6 种关系运算符:>, >=, =, <, <=, <>。 C 语言的布尔表达式文法: B→B && B∣B || B ∣! B∣(B) ∣i rop i∣i
课程设计三
添加新的程序语句:将 C 语言中的计数循环 for 语句的功能 添加到编译程序中。
课程设计四
实现将 C 语言程序语句 S→if (B) S;else S∣while (B) S∣{ L }∣a 经词法分析翻译为二元式的程序。
10.3 实验三 添加新的程序语句(一)
1. 实验目的 通过添加新的程序语句,全面了解一个语句的编译程序 设计过程。 2. 实验要求 对添加的语句设计LR分析表及相应的处理程序,并将 其添加到程序语义处理程序中。 3. 实验内容 将计数循环for语句的功能添加到编译程序中。for语句 的文法及每个产生式相应的语义子程序如下: