数据库读写分离解决方案--DG实施方案
数据库读写分离方案与配置

数据库读写分离方案与配置在当今互联网时代,大多数互联网应用都离不开数据库的支持。
随着用户量的增加和数据量的急剧上升,数据库的读写压力也越来越大。
为了提高数据库的性能和稳定性,数据库读写分离成为了一种常用的解决方案。
数据库读写分离的原理是将数据库的读操作与写操作分离到不同的服务器上,以实现负载均衡和提升数据库的吞吐量。
一般来说,读操作占据数据库操作的大部分比例,而写操作则相对较少,因此将读写分离可以将读操作分摊到多个服务器上,从而减轻单台数据库服务器的负担。
下面我们将介绍一种常见的数据库读写分离方案与配置。
1. 主从复制主从复制是一种经典的数据库读写分离技术,在这种方案中,将一个数据库服务器作为主服务器(Master),其处理所有的写操作和一部分的读操作;而将多个数据库服务器作为从服务器(Slave),只处理读操作。
主服务器将自己的事务日志传输给从服务器,从服务器通过重放主服务器的事务日志实现数据复制。
在配置主从复制时,首先需要确保主服务器能够正常运行并持续写入数据。
接着,配置从服务器,使其能够连接到主服务器并获取数据。
通常,需要设置主从服务器之间的IP地址和端口,以及鉴权信息。
最后,启动主服务器和从服务器,监控数据库同步状态。
2. 读写分离中间件除了使用主从复制,还可以选择使用读写分离中间件来实现数据库的读写分离。
读写分离中间件底层使用了数据库主从复制的技术,但对外表现为一个数据库服务器,对应用程序透明。
读请求通过中间件转发到从服务器,而写请求则发送到主服务器。
在使用读写分离中间件之前,需要先配置从服务器,使其与主服务器实现数据同步。
然后,配置中间件的地址和端口,并将读请求通过中间件转发到从服务器。
最后,通过心跳等机制,保证中间件能够及时检测到主服务器和从服务器的状态变化。
3. 数据库连接池当数据库连接数较多时,频繁地创建和关闭连接会给数据库服务器带来较大的负担,降低数据库的性能。
使用连接池可以有效地管理和复用数据库连接,提高数据库的吞吐量和性能。
数据库读写分离方案

数据库读写分离方案数据库读写分离方案1. 概述数据库读写分离是一种常用的提升数据库性能和扩展能力的方案。
通过将读操作和写操作分离到不同的数据库服务器上,可以有效减轻数据库服务器的压力,提高系统的并发处理能力和响应速度。
2. 方案设计系统架构在数据库读写分离方案中,通常采用主备模式。
主数据库用于处理写操作,而备数据库则用于处理读操作。
数据同步为了保持主备数据库的数据一致性,需要进行数据同步。
可以采用以下两种方式进行数据同步:•基于二进制日志复制这种方式通过记录主数据库上的所有更新操作,并将其内容以二进制形式传输到备数据库,然后在备数据库上重新执行这些操作。
常见的基于二进制日志复制的工具有MySQL的主从复制和MariaDB的GTID复制。
•基于逻辑复制这种方式是通过将主数据库中的更新操作转换成对应的SQL语句,并将其传输到备数据库执行。
常见的基于逻辑复制的工具有MySQL的MGR复制和MySQL的Tungsten Replicator。
读写切换在数据库读写分离方案中,需要对读写操作进行切换。
•对于写操作,由应用程序直接连接到主数据库进行操作。
•对于读操作,可以通过以下两种方式进行切换:–应用层负载均衡在应用程序中引入负载均衡设备,通过设备层面的负载均衡算法,将读请求分发到多个备数据库中。
–数据库代理在主备数据库之间引入数据库代理,代理服务器可以屏蔽应用程序与具体数据库的直接交互,根据负载均衡算法将读请求转发到不同的备数据库上。
3. 实施步骤1.配置主备数据库服务器,并确保主备服务器之间网络连接正常。
2.配置主数据库的二进制日志复制或逻辑复制功能。
3.配置备数据库的可读权限,并确保备数据库能够接收到主数据库的数据同步请求。
4.配置应用程序,使其能够根据读写操作的类型进行切换。
5.配置应用层负载均衡设备或数据库代理,并确保其正常工作。
6.进行测试和验证,确保数据库读写分离方案正常运行。
4. 注意事项•配置数据库读写分离方案时,需要注意主备服务器之间的网络连接和数据同步的稳定性,以确保数据的一致性。
数据库读写分离解决方案--DG实施方案

数据库读写分离解决方案----oracle 11G ADG实施方案1.项目背景介绍1.1目的通过DG实现主库与备库同步,主库作为业务应用库,备库作为查询库,应用根据不同需求配置对应数据库;1.2测试环境在2台RedHat5.4上使用ORACLE 的DataGuard组件实现容灾。
设备配置(VMWare虚拟机环境)清单如下:2.Oracle DataGuard 介绍备用数据库(standby database)是ORACLE 推出的一种高可用性(HIGH AVAILABLE)数据库方案,在主节点与备用节点间通过日志同步来保证数据的同步,备用节点作为主节点的备份,可以实现快速切换与灾难性恢复。
●STANDBY DATABASE的类型:有两种类型的STANDBY:物理STANDBY和逻辑STANDBY两种类型的工作原理可通过如下图来说明:physical standby提供与主数据库完全一样的拷贝(块到块),数据库SCHEMA,包括索引都是一样的。
它是可以直接应用REDO实现同步的。
l ogical standby则不是这样,在logical standby中,逻辑信息是相同的,但物理组织和数据结构可以不同,它和主库保持同步的方法是将接收的REDO转换成SQL语句,然后在STANDBY上执行SQL语句。
逻辑STANDBY除灾难恢复外还有其它用途,比如用于用户进行查询和报表,但其数据库用户相关对象均需要有主键。
✧本次实施将选择物理STANDBY(physical standby)方式●对主库的保护模式可以有以下三种模式:–Maximum protection (最高保护)–Maximum availability (最高可用性)–Maximum performance (最高性能)✧基于项目应用的特征及需求,本项目比较适合采用Maximum availability (最高可用性)模式实施。
3.Dataguard 实施前提条件和注意事项:●灾备环境中的所有节点必须安装相同的操作系统,尽可能令详细补丁也保持相同。
读写分离实现方案

读写分离实现方案
读写分离是一种数据库优化策略,将读操作和写操作分别分配给不同的数据库实例处理,从而提高数据库的读写性能和容量。
实现读写分离可以采用以下方案:
1. 主从复制:将主数据库作为写操作的主要处理节点,而从数据库作为读操作的主要处理节点。
主数据库将写操作同步到从数据库,从数据库可在本地处理读操作。
这样可以减轻主数据库的读压力,提高读操作的性能。
2. 分布式数据库:将数据分散存储在多个数据库节点上,每个节点负责一部分数据的读写操作。
通过负载均衡的方式将读请求分发到各个数据库节点上,从而提高读操作的并发处理能力和性能。
3. 缓存系统:使用缓存系统缓存热点数据,将读操作请求优先从缓存系统中获取数据,减少对数据库的读操作需求。
常用的缓存系统有Redis、Memcached等。
4. 数据库中间件:使用数据库中间件作为代理,将读写请求分发到不同的数据库节点。
数据库中间件可以根据读写操作的特点,自动切换读写操作的目标节点,从而实现读写分离。
5. 垂直分表:将数据按照不同的业务逻辑分散存储在不同的数据库表中,读写操作分别针对不同的表进行。
通过垂直分表可以减少表的数据量和索引的大小,提高读取操作的性能。
需要注意的是,读写分离实现方案的选择应根据具体的业务需求和数据库架构进行调整,以达到最佳的性能和容量优化效果。
读写分离解决方案

第1篇
读写分离解决方案
一、背景
随着业务量的不断增长,数据库的压力日益增大,为提高数据库性能,降低数据查询延迟,提高数据处理效率,现对数据库进行读写分离改造。本方案旨在提供一套合法合规的读写分离解决方案,确保业务平稳运行,同时降低硬件成本,提高系统可用性。
二、目标
1.降低数据库读写压力,提高数据处理速度。
4.提升系统整体的伸缩性和可维护性。
四、方案设计
1.架构设计
本方案采用主-备-从(Master-Backup-Slave)架构模式,实现读写操作的分离。
-主数据库(Master):负责处理所有的写操作。
-备数据库(Backup):作为主数据库的冗余,用于故障转移。
-从数据库(Slave):负责处理所有的读操作。
主从库之间通过复制机制同步数据,确保数据一致性。
2.数据库选型
根据业务需求,选择合适的数据库产品。本方案推荐使用开源的MySQL数据库。
3.主从复制配置
在主库上开启二进制日志(Binary Log),用于记录所有修改数据的SQL语句。从库通过读取二进制日志,执行相应的SQL语句,实现数据同步。
配置步骤如下:5.逐步迁移业务到读写分离架构,监控性能变化。六、验收标准
1.数据一致性:通过比对主从数据库的数据,确保数据一致。
2.性能提升:通过性能测试,验证读写分离对系统性能的提升。
3.高可用性:模拟主数据库故障,验证故障转移的自动性和有效性。
七、后期维护
1.定期检查数据库同步状态,确保数据一致性。
2.监控数据库性能,根据业务增长调整分离策略。
-备数据库实时同步二进制日志,保持数据最新。
-从数据库定期(如每秒)拉取主数据库的最新数据。
数据库读写分离
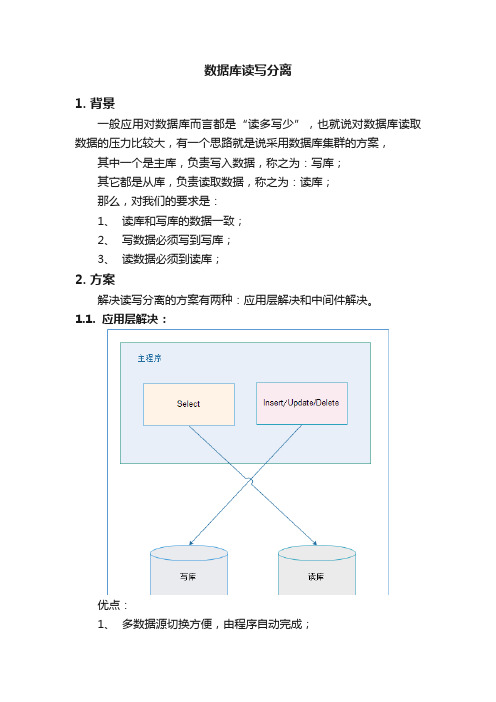
数据库读写分离1. 背景一般应用对数据库而言都是“读多写少”,也就说对数据库读取数据的压力比较大,有一个思路就是说采用数据库集群的方案,其中一个是主库,负责写入数据,称之为:写库;其它都是从库,负责读取数据,称之为:读库;那么,对我们的要求是:1、读库和写库的数据一致;2、写数据必须写到写库;3、读数据必须到读库;2. 方案解决读写分离的方案有两种:应用层解决和中间件解决。
1.1. 应用层解决:优点:1、多数据源切换方便,由程序自动完成;2、不需要引入中间件;3、理论上支持任何数据库;缺点:1、由程序员完成,运维参与不到;2、不能做到动态增加数据源;1.2. 中间件解决优缺点:优点:1、源程序不需要做任何改动就可以实现读写分离;2、动态添加数据源不需要重启程序;缺点:1、程序依赖于中间件,会导致切换数据库变得困难;2、由中间件做了中转代理,性能有所下降;中间件的产品有:mysql-proxy,Amoeba。
3. 使用Spring基于应用层实现3.1. 原理在进入Service之前,使用AOP来做出判断,是使用写库还是读库,判断依据可以根据方法名判断,比如说以query、find、get等开头的就走读库,其他的走写库。
3.2. DynamicDataSourceimportorg.springframework.jdbc.datasource.lookup.AbstractRoutingDa taSource;/*** 定义动态数据源,实现通过集成Spring提供的AbstractRoutingDataSource,只需要实现determineCurrentLookupKey方法即可* 由于DynamicDataSource是单例的,线程不安全的,所以采用ThreadLocal保证线程安全,由DynamicDataSourceHolder完成。
**/public class DynamicDataSource extends AbstractRoutingDataSource{@Overrideprotected Object determineCurrentLookupKey() {// 使用DynamicDataSourceHolder保证线程安全,并且得到当前线程中的数据源keyreturn DynamicDataSourceHolder.getDataSourceKey();}}3.3. DynamicDataSourceHolder/*** 使用ThreadLocal技术来记录当前线程中的数据源的key**/public class DynamicDataSourceHolder {//写库对应的数据源keyprivate static final String MASTER = "master";//读库对应的数据源keyprivate static final String SLAVE = "slave";//使用ThreadLocal记录当前线程的数据源keyprivate static final ThreadLocal<String> holder= new ThreadLocal<String>();/*** 设置数据源key* @param key*/public static void putDataSourceKey(String key) {holder.set(key);}/*** 获取数据源key* @return*/public static String getDataSourceKey() {return holder.get();}/*** 标记写库*/public static void markMaster(){putDataSourceKey(MASTER);}/*** 标记读库*/public static void markSlave(){putDataSourceKey(SLAVE);}}3.4. DataSourceAspectimport ng3.StringUtils;import ng.JoinPoint;/*** 定义数据源的AOP切面,通过该Service的方法名判断是应该走读库还是写库*/public class DataSourceAspect {/*** 在进入Service方法之前执行** @param point 切面对象*/public void before(JoinPoint point) {// 获取到当前执行的方法名String methodName = point.getSignature().getName();if (isSlave(methodName)) {// 标记为读库DynamicDataSourceHolder.markSlave();} else {// 标记为写库DynamicDataSourceHolder.markMaster();}}/*** 判断是否为读库** @param methodName* @return*/private Boolean isSlave(String methodName) {// 方法名以query、find、get开头的方法名走从库return StringUtils.startsWithAny(methodName, "query", "find", "get");}}3.5. 配置2个数据源3.5.1. jdbc.propertiesjdbc.master.driver=com.mysql.jdbc.Driverjdbc.master.url=jdbc:mysql://127.0.0.1:3306/mybatis_1128? useUnicode=true&characterEncoding=utf8&autoReconnect=tr ue&allowMultiQueries=trueername=rootjdbc.master.password=123456jdbc.slave01.driver=com.mysql.jdbc.Driverjdbc.slave01.url=jdbc:mysql://127.0.0.1:3307/mybatis_1128? useUnicode=true&characterEncoding=utf8&autoReconnect=tr ue&allowMultiQueries=trueername=rootjdbc.slave01.password=1234563.5.2. 定义连接池<!-- 配置连接池 --><bean id="masterDataSource" class="com.jolbox.bonecp.BoneCPDataSource"destroy-method="close"><!-- 数据库驱动 --><property name="driverClass" value="${jdbc.master.driver}" /><!-- 相应驱动的jdbcUrl --><property name="jdbcUrl" value="${jdbc.master.url}" /><!-- 数据库的用户名 --><property name="username" value="${ername}" /><!-- 数据库的密码 --><property name="password" value="${jdbc.master.password}" /><!-- 检查数据库连接池中空闲连接的间隔时间,单位是分,默认值:240,如果要取消则设置为0 --><property name="idleConnectionTestPeriod" value="60" /> <!-- 连接池中未使用的链接最大存活时间,单位是分,默认值:60,如果要永远存活设置为0 --><property name="idleMaxAge" value="30" /><!-- 每个分区最大的连接数 --><property name="maxConnectionsPerPartition" value="150" /><!-- 每个分区最小的连接数 --><property name="minConnectionsPerPartition" value="5" /> </bean><!-- 配置连接池 --><bean id="slave01DataSource" class="com.jolbox.bonecp.BoneCPDataSource"destroy-method="close"><!-- 数据库驱动 --><property name="driverClass" value="${jdbc.slave01.driver}" /><!-- 相应驱动的jdbcUrl --><property name="jdbcUrl" value="${jdbc.slave01.url}" /><!-- 数据库的用户名 --><property name="username" value="${ername}" /><!-- 数据库的密码 --><property name="password" value="${jdbc.slave01.password}" /><!-- 检查数据库连接池中空闲连接的间隔时间,单位是分,默认值:240,如果要取消则设置为0 --><property name="idleConnectionTestPeriod" value="60" /> <!-- 连接池中未使用的链接最大存活时间,单位是分,默认值:60,如果要永远存活设置为0 --><property name="idleMaxAge" value="30" /><!-- 每个分区最大的连接数 --><property name="maxConnectionsPerPartition" value="150" /><!-- 每个分区最小的连接数 --><property name="minConnectionsPerPartition" value="5" /> </bean>3.5.3. 定义DataSource<!-- 定义数据源,使用自己实现的数据源 --><bean id="dataSource" class="ermanage.spring.DynamicDataSource"> <!-- 设置多个数据源 --><property name="targetDataSources"><map key-type="ng.String"><!-- 这个key需要和程序中的key一致 --><entry key="master" value-ref="masterDataSource"/><entry key="slave" value-ref="slave01DataSource"/></map></property><!-- 设置默认的数据源,这里默认走写库 --><property name="defaultTargetDataSource" ref="masterDataSource"/></bean>3.6. 配置事务管理以及动态切换数据源切面3.6.1. 定义事务管理器<!-- 定义事务管理器 --><bean id="transactionManager"class="org.springframework.jdbc.datasource.DataSourceTra nsactionManager"><property name="dataSource" ref="dataSource" /></bean>3.6.2. 定义事务策略<!-- 定义事务策略 --><tx:advice id="txAdvice"transaction-manager="transactionManager"><tx:attributes><!--定义查询方法都是只读的 --><tx:method name="query*" read-only="true" /><tx:method name="find*" read-only="true" /><tx:method name="get*" read-only="true" /><!-- 主库执行操作,事务传播行为定义为默认行为 --><tx:method name="save*" propagation="REQUIRED" /><tx:method name="update*" propagation="REQUIRED" /> <tx:method name="delete*" propagation="REQUIRED" /><!--其他方法使用默认事务策略 --><tx:method name="*" /></tx:attributes></tx:advice>3.6.3. 定义切面<!-- 定义AOP切面处理器 --><beanclass="ermanage.spring.DataSourceAspect"id="dataSourceAspect" /><aop:config><!-- 定义切面,所有的service的所有方法 --><aop:pointcut id="txPointcut"expression="execution(* xx.xxx.xxxxxxx.service.*.*(..))" /><!-- 应用事务策略到Service切面 --><aop:advisor advice-ref="txAdvice"pointcut-ref="txPointcut"/><!-- 将切面应用到自定义的切面处理器上,-9999保证该切面优先级最高执行 --><aop:aspect ref="dataSourceAspect" order="-9999"><aop:before method="before" pointcut-ref="txPointcut" /> </aop:aspect></aop:config>4. 改进切面实现,使用事务策略规则匹配之前的实现我们是将通过方法名匹配,而不是使用事务策略中的定义,我们使用事务管理策略中的规则匹配。
MYSQL数据库的读写分离与主从同步实施方案

MYSQL数据库读写分离、主从同步的实施方案数据库读写分离对于大型系统或者访问量很高的云平台应用来说,是必不可少的一个重要功能。
对于MySQL来说,标准的读写分离是主从模式,一个写节点Master后面跟着多个读节点,读节点的数量取决于系统的压力,通常是1-3个或更多读节点的配置。
Mycat是实现数据库读写分离、主从同步的常用数据库中间件。
Mycat读写分离和自动切换机制,需要MySQL的主从复制机制配合。
1、主DB server和从DB server数据库的版本一致2、主DB server和从DB server数据库数据一致[这里就会可以把主的备份在从上还原,也可以直接将主的数据目录拷贝到从的相应数据目录]3、主DB server开启二进制日志,主DB server和从DB server的server_id 都必须唯一。
本方案是利用Mycat数据库中间件实现MySQL数据库读写分离与主从同步。
1.MYCAT的简介Mycat是一个彻底开源的,面向企业应用开发的大数据库集群,支持事务、ACID、可以替代MySQL的加强版数据库,一个可以视为MySQL集群的企业级数据库,用来替代昂贵的Oracle集群,一个融合内存缓存技术、NoSQL技术、HDFS大数据的新型SQL Server,结合传统数据库和新型分布式数据仓库的新一代企业级数据库产品,一个新颖的数据库中间件产品。
Mycat的目标:低成本的将现有的单机数据库和应用平滑迁移到“云”端,解决数据存储和业务规模迅速增长情况下的数据瓶颈问题。
Mycat的特点:-遵守Mysql原生协议,跨语言,跨数据库的通用中间件代理。
-基于心跳的自动故障切换,支持读写分离,支持MySQL一双主多从,以及一主多从-有效管理数据源连接,基于数据分库,而不是分表的模式。
-基于Nio实现,有效管理线程,高并发问题。
-支持数据的多片自动路由与聚合,支持sum,count,max等常用的聚合函数。
数据库读写分离方案

五、实施步骤
1.准备阶段
-对现有数据库进行评估,确定读写分离的必要性。
-选择合适的中间件,搭建测试环境。
2.实施阶段
-配置中间件,实现读写分离。
-部署从数据库,并配置数据同步。
3.迁移阶段
-分阶段迁移读请求到从数据库,观察性能变化。
-根据监控数据,调整读写分离策略。
(2)从库发生故障时,中间件自动剔除故障节点,并将请求分发到其他正常节点。
(3)采用双机热备或多机热备的方式,确保数据库的高可用性。
6.监控与优化
(1)部署数据库监控系统,实时监控数据库性能、连接数、同步状态等指标。
(2)根据监控数据,分析并优化数据库性能,调整中间件配置。
四、实施步骤
1.梳理现有业务,分析数据库压力来源。
2.中间件稳定性风险:选择成熟稳定的中间件,定期进行版本更新和性能优化。
3.性能瓶颈风险:通过监控和优化,及时调整中间件配置,提高数据库性能。
4.业务迁移风险:在迁移过程中,确保业务平滑过渡,减少对业务的影响。
六、总结
本方案通过实施数据库读写分离,提高系统整体性能,满足业务发展需求。在实施过程中,需注意数据一致性、中间件稳定性、性能瓶颈等问题,并采取相应的应对措施。通过不断优化和调整,确保数据库读写分离架构的高效稳定运行。
本方案旨在通过实施数据库读写分离,提升系统性能,保障数据一致性,并提高系统的扩展性和高可用性。在实施过程中,需密切关注数据同步状态、中间件稳定性以及系统性能,确保方案的成功实施和长期稳定运行。通过持续优化,本方案将为业务的快速发展提供强有力的支撑。
4.数据同步
-采用异步复制机制,将主数据库的变更同步到从数据库,保持数据一致性。
数据库读写分离解决方案

数据库读写分离解决方案目录一、概述 (3)二、架构设计 (4)1. 双主架构 (5)1.1 主数据库负责写操作 (6)1.2 从数据库负责读操作 (8)1.3 主从同步机制 (9)2. 主从复制 (10)2.1 基于语句的复制 (11)2.2 基于行的复制 (12)2.3 配置示例 (13)3. 读写分离策略 (14)3.1 垂直分库 (15)3.2 水平分库 (16)3.3 分库分表 (18)三、实施步骤 (20)1. 环境准备 (21)1.1 硬件资源准备 (22)1.2 软件环境准备 (23)1.3 人员分工与培训 (24)2. 数据库配置 (26)2.1 主数据库配置 (27)2.2 从数据库配置 (28)2.3 网络连接配置 (30)3. 数据迁移 (32)3.1 数据抽取 (32)3.2 数据转换 (34)3.3 数据加载 (35)4. 性能优化 (36)5.1 实时监控 (39)5.2 异常处理 (40)5.3 定期维护 (42)四、常见问题与解决方案 (43)1. 主从同步延迟 (44)1.1 原因分析 (45)1.2 解决方案 (47)2. 读写负载不均衡 (48)2.1 原因分析 (49)2.2 解决方案 (50)3. 数据一致性问题 (51)3.1 原因分析 (52)3.2 解决方案 (53)五、总结与展望 (54)1.1 提高了系统性能和可用性 (56)1.2 优化了资源分配和减少了成本 (58)1.3 增强了系统的可扩展性和稳定性 (59)2. 未来发展趋势 (60)2.1 更加智能化的读写分离策略 (61)2.2 更加高效的数据同步技术 (62)2.3 更加全面的监控和维护手段 (64)一、概述随着企业业务的不断扩展和数据量的急剧增长,数据库作为企业核心业务系统的重要组成部分,其性能和稳定性对于保障企业正常运行至关重要。
传统数据库在面临高并发访问和大量数据读写请求时,往往会出现性能瓶颈,影响企业运营效率。
oracle dg 方案

Oracle DG 方案1. 简介Oracle Data Guard(DG)是Oracle数据库提供的一种高可用性和灾难恢复解决方案。
它通过在主数据库和一个或多个辅助数据库之间建立物理或逻辑复制,实现数据的实时备份和同步,从而提供了数据的可用性和保护。
2. 物理复制2.1 主数据库配置在主数据库上配置DG,需要执行以下步骤:•创建物理复制所需的日志传输服务•配置主数据库的归档模式•启用日志传输和应用服务首先,我们需要创建一个可用于日志传输的网络服务,以便主数据库可以将归档日志传输到辅助数据库。
然后,将主数据库配置为归档模式,确保归档日志可以被传输和应用到辅助数据库上。
最后,需要启用日志传输和应用服务,以确保日志的实时传输和辅助数据库的数据同步。
2.2 辅助数据库配置在辅助数据库上配置DG,需要执行以下步骤:•创建辅助数据库实例•配置辅助数据库的连接和归档信息•启动辅助数据库实例•应用主数据库的归档日志首先,需要创建一个辅助数据库实例,该实例将用于接收和应用主数据库的归档日志。
然后,需要配置辅助数据库的连接信息,以确保它可以与主数据库进行通信,并获取归档日志。
接下来,启动辅助数据库实例,并配置归档日志的应用方式。
3. 逻辑复制逻辑复制是另一种Oracle DG的实现方式,它基于逻辑单位(如表或模式)的复制,而不是物理上的块复制。
逻辑复制可以在主数据库和辅助数据库之间实现数据的实时同步和备份。
3.1 主数据库配置在主数据库上配置逻辑复制,需要执行以下步骤:•创建逻辑复制所需的逻辑连接和组织形式•配置主数据库的归档模式(可选)•启用逻辑复制首先,我们需要创建逻辑复制所需的逻辑连接和组织形式。
逻辑连接是主数据库和辅助数据库之间的连接,它使得数据可以被传输和同步。
接下来,如果需要,我们可以将主数据库配置为归档模式,以便归档日志可以被传输和应用到辅助数据库上。
最后,启用逻辑复制,以确保数据的实时同步。
3.2 辅助数据库配置在辅助数据库上配置逻辑复制,需要执行以下步骤:•创建逻辑复制所需的逻辑连接和组织形式•启用逻辑复制服务首先,我们需要创建逻辑复制所需的逻辑连接和组织形式,以确保辅助数据库可以与主数据库进行通信,并接收和同步数据。
读写分离方案

读写分离方案在当今互联网应用开发中扮演着重要的角色。
它是一种通过将数据库的读和写操作分离到不同的节点上来提高系统性能和可伸缩性的技术方案。
本文将探讨读写分离的原理、实现方式以及其带来的好处。
一、读写分离的原理读写分离的核心原理是将数据库的读操作和写操作分别分配到不同的节点上。
传统的数据库架构中,读写操作都是由主数据库处理的,当并发读写操作增多时,主数据库的负载会变得非常大,导致性能下降。
而通过,可以将读操作分发到多个从数据库节点上,从而分担主数据库的负载压力,提高系统的并发处理能力。
二、读写分离的实现方式1. 基于代理模式基于代理模式的通过在应用服务器和数据库之间增加一个代理层来实现。
代理层负责接收应用服务器发送的数据库请求,并根据请求的类型将其分发到主数据库或从数据库上。
这种方式的优势在于对应用程序的透明性较高,应用程序无需修改即可实现读写分离。
2. 基于中间件基于中间件的通过引入中间件来实现,中间件负责对数据库请求进行监控和管理,并根据一定的策略将读请求分发到从数据库上。
这种方式需要对应用程序进行一定的修改,但灵活性较高,可以根据具体需求进行定制。
三、读写分离的好处1. 提高系统性能读写分离能够有效地分担主数据库的读负载,提高系统的并发处理能力。
通过将读操作分发到多个从数据库节点上,并行地处理请求,系统的响应速度会大大提升。
2. 提高系统可伸缩性通过,可以根据需求动态地增加从数据库节点,从而扩展系统的读能力。
当用户量增多时,可以通过增加从数据库节点来提供更好的服务,而无需对系统进行大规模的改造。
3. 提高数据安全性由于主数据库只负责写操作,从数据库只负责读操作,可以有效地防止因读操作而导致的数据损坏风险。
即使从数据库发生故障,主数据库上的数据仍然是完整的,可以通过其他备份手段进行恢复。
四、的应用场景适用于访问量较大、读写比例较高的应用场景,例如电商平台、新闻网站等。
在这些应用中,读操作通常占据大部分的数据库请求,通过可以提高系统的性能和可伸缩性,提供更好的用户体验。
数据库读写分离方案

数据库读写分离方案数据库读写分离是指将数据库的读操作和写操作分离到不同的数据库服务器上,以提高数据库的并发能力和性能。
在实际应用中,读操作的频率远远高于写操作,因此通过读写分离可以有效地减轻数据库服务器的压力,提高系统的稳定性和性能。
一、读写分离的原理。
数据库读写分离的原理是将数据库的读操作和写操作分别分配到不同的数据库服务器上。
读操作通常是指查询操作,而写操作则包括插入、更新和删除操作。
通过在不同的数据库服务器上部署主从数据库,可以实现读写分离的效果。
二、读写分离的优势。
1. 提高数据库的并发能力,通过将读操作和写操作分离到不同的数据库服务器上,可以有效地提高数据库的并发能力,满足高并发访问的需求。
2. 提升系统性能,由于读操作的频率远远高于写操作,通过读写分离可以减轻主数据库的压力,提升系统的整体性能。
3. 提高系统的稳定性,通过读写分离可以有效地分担数据库服务器的压力,降低系统崩溃的风险,提高系统的稳定性和可靠性。
三、读写分离的实现方案。
1. 基于数据库代理的读写分离方案,通过在应用程序和数据库之间增加一个数据库代理层,实现对数据库操作的拦截和分发,将读操作和写操作分别转发到不同的数据库服务器上。
2. 基于中间件的读写分离方案,通过在应用程序和数据库之间增加一个中间件层,实现对数据库操作的拦截和分发,将读操作和写操作分别转发到不同的数据库服务器上。
3. 基于数据库自身的读写分离方案,某些数据库产品本身支持读写分离功能,通过配置主从复制和负载均衡,实现数据库的读写分离。
四、读写分离的注意事项。
1. 数据一致性,由于主从数据库之间存在一定的延迟,需要注意主从数据库之间的数据一致性,避免出现数据同步的问题。
2. 业务逻辑处理,在进行读写分离的设计时,需要考虑业务逻辑的处理,确保写操作和相关的读操作能够在同一数据库上进行,避免数据不一致的情况发生。
3. 监控和管理,对于读写分离的架构,需要建立相应的监控和管理机制,及时发现和解决数据库的异常情况。
读写分离 解决方案

读写分离解决方案
《读写分离解决方案》
在现代社会,数据处理已经成为企业运营中极为重要的一部分。
随着数据量的增长和业务的扩张,如何高效地处理数据成为了企业发展中的一个重要问题。
读写分离解决方案应运而生,成为了许多企业解决数据处理问题的利器。
读写分离是一种数据库架构设计的方式,它将数据库的读和写操作分别放在不同的数据库服务器上进行,从而提高数据库的读写性能。
在传统的数据库架构中,读写操作都是在同一个数据库服务器上进行的,当读请求和写请求同时达到一定的规模时,会对数据库服务器的性能产生很大的压力,导致数据库性能下降。
而读写分离可以有效地缓解这个问题,提高数据库的读写性能。
读写分离解决方案不仅能提高数据库的读写性能,还能提高数据库的可用性和稳定性。
通过将读操作和写操作分别放在不同的数据库服务器上进行,当某一台数据库服务器出现故障时,不会对整个数据库系统产生影响,从而提高了数据库的可用性和稳定性。
在实际应用中,读写分离解决方案可以采用数据库复制的方式进行,即将写请求发送到主数据库服务器上进行,然后将读请求发送到从数据库服务器上进行。
这样既能保证数据的一致性,又能提高数据库的读写性能。
总的来说,读写分离解决方案是一种高效、稳定、可靠的数据库架构设计方式,它可以有效地提高数据库的读写性能,提高数据库的可用性和稳定性,是许多企业解决数据处理问题的利器。
因此,对于那些数据量大、业务复杂的企业来说,读写分离解决方案无疑是一个不错的选择。
MySQL读写分离的DAL层策略设计
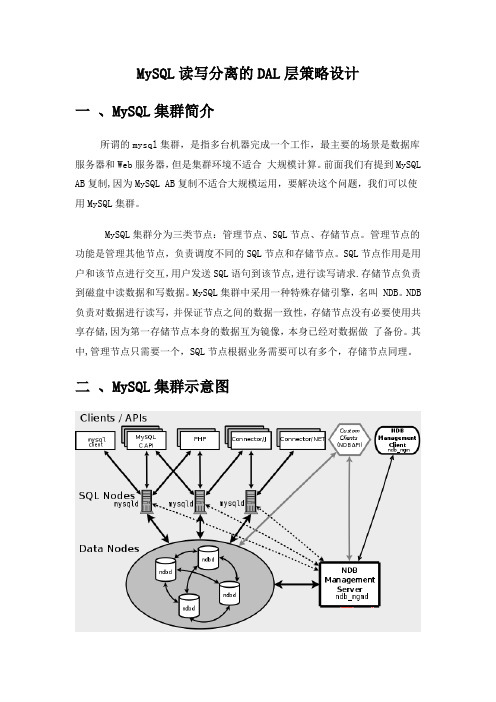
MySQL读写分离的DAL层策略设计一、MySQL集群简介所谓的mysql集群,是指多台机器完成一个工作,最主要的场景是数据库服务器和Web服务器,但是集群环境不适合大规模计算。
前面我们有提到MySQL AB复制,因为MySQL AB复制不适合大规模运用,要解决这个问题,我们可以使用MySQL集群。
MySQL集群分为三类节点:管理节点、SQL节点、存储节点。
管理节点的功能是管理其他节点,负责调度不同的SQL节点和存储节点。
SQL节点作用是用户和该节点进行交互,用户发送SQL语句到该节点,进行读写请求.存储节点负责到磁盘中读数据和写数据。
MySQL集群中采用一种特殊存储引擎,名叫 NDB。
NDB 负责对数据进行读写,并保证节点之间的数据一致性,存储节点没有必要使用共享存储,因为第一存储节点本身的数据互为镜像,本身已经对数据做了备份。
其中,管理节点只需要一个,SQL节点根据业务需要可以有多个,存储节点同理。
二、MySQL集群示意图三、使用MySQL集群的优劣3.1 优势1。
处理业务能力大幅提高;2.用户关注的点更集中于业务;3.数据不易丢失,因为存储节点对数据做备份。
当然不要完全依靠MySQL集群,制定合理的备份和恢复策略还是很有必要的;4.在SQL节点有多台的情况下,一台SQL节点宕机不影响,只需要开发人员手动判断该节点是否在线,不在线切换到另一台SQL节点上,保证了高可用性。
3。
2 劣势1.成本提高,因为MySQL集群至少需要五台服务器;2。
运维难度增强,因为服务器数量增加。
一、设计分析:MySQL Proxy最强大的一项功能是实现“读写分离(Read/Write Splitting)”。
基本的原理是让主数据库处理事务性查询,而从数据库处理SELECT查询。
数据库复制被用来把事务性查询导致的变更同步到集群中的从数据库。
当然,主服务器也可以提供查询服务.使用读写分离最大的作用无非是环境服务器压力。
oracle数据库读写分离方案

oracle数据库读写分离方案背景介绍:Oracle数据库是一种功能强大的关系型数据库管理系统,广泛应用于企业级应用和大型数据存储系统中。
在高并发的应用场景下,数据库读写性能经常成为瓶颈。
为了提升数据库的整体性能,读写分离方案应运而生。
本文将详细介绍Oracle数据库读写分离的原理和实施方法。
一、读写分离的原理读写分离是将数据库的读操作和写操作分离到不同的数据库实例上,实现负载均衡和提升系统性能的目的。
读操作通常占据数据库的大部分负载,而写操作则对数据进行更新和修改。
通过将读请求分发到多个副本数据库,可以有效减轻主数据库的负载压力。
二、Oracle数据库读写分离实施方法1. 配置主数据库和多个副本数据库首先,需要搭建一个主数据库和多个副本数据库的环境。
主数据库用于处理写操作,副本数据库用于处理读操作。
副本数据库可以通过物理复制或逻辑复制的方式实现数据的同步。
2. 配置数据库连接池在应用程序中,配置数据库连接池来实现数据库读写分离。
连接池的功能是管理数据库连接的创建和销毁,可以根据负载情况将读请求分发到副本数据库。
3. 实现读写分离的负载均衡通过在应用程序中配置负载均衡算法,实现读请求的分发和负载均衡。
常见的负载均衡算法有轮询、随机、权重等,可以根据实际需求选择合适的算法。
4. 监控和自动故障转移在读写分离方案中,需要设置监控机制来监测数据库的状态。
当主数据库发生故障时,应能自动将读请求切换到可用的副本数据库上,实现自动故障转移。
5. 数据一致性保证在读写分离方案中,主数据库和副本数据库之间的数据需要保持一致性。
可以通过同步机制和定期数据校验来实现数据的一致性。
三、读写分离方案的优势1. 提高系统性能和可用性通过将读操作分发到多个副本数据库,在保证数据一致性的前提下,提高数据库的整体性能和可用性。
2. 平衡负载压力将读请求分散到多个副本数据库上,减轻主数据库的负载压力,提高系统的整体并发能力。
3. 提升用户体验通过读写分离方案,可以更快地响应用户的读请求,提升用户的体验和满意度。
deld方案

deld方案摘要本文档介绍了deld方案的背景、目标、关键步骤以及预期效果。
deld方案是一个用于解决某个特定问题的方案,通过以下步骤来实现预期的效果。
背景在处理某个问题时,我们面临一个挑战:如何高效地处理大量的数据,并且保证数据的准确性和完整性。
传统的处理方式往往会面临运行时间过长、数据丢失或错误等问题。
因此,我们需要一个新的方案来解决这个问题。
目标deld方案的目标是通过优化数据处理流程,提高处理速度和数据质量。
具体而言,我们希望通过deld方案实现以下目标:1.减少数据处理时间:通过合理的算法设计和优化数据结构,减少数据处理的时间复杂度。
2.提高数据准确性:通过引入断言、数据校验等机制,确保数据的准确性,防止错误数据的污染。
3.保证数据完整性:在数据处理过程中采用事务管理机制,并确保数据的完整性和一致性。
关键步骤步骤1:数据预处理在使用deld方案处理数据之前,我们需要对原始数据进行预处理,以方便后续的数据处理操作。
数据预处理的关键步骤包括:1.数据清洗:去除重复数据、处理缺失值、格式化数据等。
2.数据转换:将数据从原始格式转换为可处理的格式,例如将文本数据转换为数值型数据。
步骤2:数据分析和处理在数据预处理完成后,利用deld方案进行数据分析和处理。
核心的数据分析和处理步骤如下:1.根据需求设计相应的数据模型:根据具体问题的需求,设计合适的数据模型,以便进行后续的数据处理操作。
可以采用关系型数据库、非关系型数据库或者其他数据存储方式。
2.数据清洗和过滤:根据定义好的规则和条件,对数据进行清洗和过滤,去除无效数据。
3.数据计算和统计分析:对清洗后的数据进行计算和统计分析,得到所需的统计结果或计算结果。
4.数据可视化:将计算和统计分析得到的结果进行可视化展示,以便更好地理解和分析数据。
步骤3:结果验证和优化在数据分析和处理完成后,需要对结果进行验证和优化,以确保结果的准确性和有效性。
具体要求如下:1.结果验证:使用其他方法或者数据进行结果的验证,确保结果的准确性。
数据库读写分离实现方案

数据库读写分离实现方案嘿,小伙伴们!今天咱们来唠唠数据库读写分离这个事儿。
咱这个方案就叫“数据库读写分离超棒方案”。
那咱先说说这方法流程啥的。
一、确定读写分离的架构模式这就好比盖房子先打地基,咱得先确定好整体的架构。
咱可以采用主从复制的模式来做读写分离。
主数据库负责处理所有的写操作,像什么插入数据、更新数据、删除数据这些。
从数据库呢,就专门负责读操作,就像你查询数据的时候就靠它啦。
二、选择合适的数据库管理系统(DBMS)这就像选鞋子,得合适才行。
对于读写分离来说,像MySQL这种流行的数据库就很合适。
它本身就有比较成熟的主从复制功能,可以方便地实现读写分离。
在选择的时候,咱得看看这个DBMS的性能、稳定性、可扩展性啥的。
比如说,如果咱们的业务量以后可能会变得很大,那就要选那种能轻松扩展的DBMS。
三、配置主数据库(1)安装好主数据库。
这就像把一个新的机器安装好,得按照步骤一步一步来,不能马虎。
(2)设置好相关的参数。
比如说,要配置好存储引擎,像InnoDB就很不错,它对事务的支持很好。
还有字符集的设置,要根据咱们的实际需求来,要是处理中文多的话,就设置成UTF - 8呗。
(3)开启二进制日志。
这就像给主数据库开个日记,它会记录所有的写操作,这样从数据库才能知道主数据库发生了啥变化。
四、创建从数据库(1)同样先安装好从数据库。
安装的时候要注意版本要和主数据库兼容哦。
(2)配置从数据库连接到主数据库。
这就像给从数据库装上一个眼睛,让它能看到主数据库的变化。
要设置好主数据库的IP地址、端口号、用户名、密码这些信息。
(3)启动从数据库的复制进程。
这个进程就像一个小跟班,会根据主数据库的二进制日志来更新自己的数据。
五、具体的实施步骤(1)在应用程序层面进行读写分离的设置。
比如说在代码里,当有写操作的时候,就把请求发送到主数据库;当有读操作的时候,就把请求发送到从数据库。
这就需要咱们修改程序里数据库连接的部分,把读写操作区分开来。
数据库读写分离方案的说明书

数据库读写分离方案的说明书一、概述数据库读写分离是一种将数据库的读操作和写操作分离的架构设计,通过将读操作和写操作分别分配到不同的数据库服务器上,可以提高数据库的读取性能和并发处理能力。
本文将介绍数据库读写分离的原理、实施方式以及优缺点。
二、原理数据库读写分离的原理是将数据库的读写操作分别分配到不同的服务器进行处理。
主服务器负责处理数据的写操作,而从服务器负责处理数据的读操作。
主服务器接收到写请求后,将数据写入主库,并将写操作同步到从服务器。
读请求则直接由从服务器处理,减轻主服务器的压力。
三、实施方式1. 主从复制主从复制是实现数据库读写分离的一种常用方式。
通过配置主数据库和多个从数据库,主数据库负责处理写操作,并将数据同步到从数据库。
读操作则由从数据库处理,从而实现读写分离。
2. 代理服务器代理服务器是另一种实现数据库读写分离的方式。
通过在应用程序和数据库之间增加一个代理服务器,代理服务器可以根据请求的类型将读请求和写请求分别转发到不同的数据库服务器上。
四、实施步骤1. 配置主服务器和从服务器首先,需要设置主服务器和从服务器。
主服务器负责接收写请求,而从服务器负责接收读请求。
主服务器将写操作同步到从服务器。
2. 配置代理服务器如果使用代理服务器来实现读写分离,需要配置代理服务器。
代理服务器可以根据请求类型将请求转发到不同的数据库服务器上。
3. 数据同步数据库读写分离要确保主服务器的写操作能够准确同步到从服务器。
可以使用数据库自带的主从复制功能或者第三方工具来实现数据的同步。
五、优点1. 提高读取性能:将读操作分配到从服务器,减轻了主服务器的负载,提高了读取性能。
2. 提高并发处理能力:通过将读操作和写操作分离,可以同时进行读写操作,提高并发处理能力。
3. 改善系统稳定性:当主服务器发生故障时,从服务器可以继续处理读请求,保证系统的稳定性。
六、缺点1. 数据同步延迟:由于数据同步需要一定的时间,从服务器上的数据可能与主服务器上的数据不完全一致,存在一定的延迟。
数据库读写分离及问题

数据库读写分离及问题简介 对于数据存储层⾼并发问题,最先想到的可能就是读写分离,在⽹站访问量⼤并且读写不平均的情况下,将存储分为master,slave两台,所有的写都路由到master上,所有的读都路由到slave上,然后master和slave同步。
如果⼀台salve不够,可以加多台,⽐如⼀台master,3台slave。
对于什么是读写分离,以及读写分离有什么好处,这⾥不再叙述,有兴趣的可以参考。
在设计读写分离的时候,有⼏种解决⽅案:1. 将读写分离放在dao层,在dao层,所有的insert/update/delete都访问master库,所有的select 都访问salve库,这样对于业务层是透明的。
2. 将读写分离放在ORM层,⽐如mybatis可以通过mybatis plus拦截sql语句,所有的insert/update/delete都访问master库,所有的select 都访问salve库,这样对于dao层都是透明。
3. 放在代理层,⽐如MySQL-Proxy,这样针对整个应⽤程序都是透明的。
对于绝⼤多数情景,读写分离都适⽤,但是读写分离有⼀个问题是master slave同步,这个同步是会有⼀定延迟,因此有⼏个场景还是要注意的:场景⼀考虑下⾯⼀个⽤户注册场景。
boolean addUserSuccess = userDao.addUser(registUser);if (addUserSuccess) {cachedThreadPool.execute(() -> {EmailService.SendActivateEmail(userId);});}public static void SendActivateEmail(int userId) {User user = userDao.getUser(userId);String userName = user.getUserName();String userEmail = user.getUserEmail();String subject = "...";String body = "...";//调⽤邮件服务发邮件}如上,当新⽤户注册,在注册完成后,会发⼀封激活邮件,新增⽤户是insert,发邮件获取⽤户是select ,如果master slave存在延迟,有可能在这个时候获取不到⽤户。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据库读写分离解决方案----oracle 11G ADG实施方案1.项目背景介绍1.1目的通过DG实现主库与备库同步,主库作为业务应用库,备库作为查询库,应用根据不同需求配置对应数据库;1.2测试环境在2台上使用ORACLE 的DataGuard组件实现容灾。
设备配置(VMWare虚拟机环境)清单如下:2. DataGuard 介绍备用数据库(standby database)是ORACLE 推出的一种高可用性(HIGH AVAILABLE)数据库方案,在主节点与备用节点间通过日志同步来保证数据的同步,备用节点作为主节点的备份,可以实现快速切换与灾难性恢复。
STANDBY DATABASE的类型:有两种类型的STANDBY:物理STANDBY和逻辑STANDBY两种类型的工作原理可通过如下图来说明:physical standby提供与主数据库完全一样的拷贝(块到块),数据库SCHEMA,包括索引都是一样的。
它是可以直接应用REDO实现同步的。
???logical standby则不是这样,在logical standby中,逻辑信息是相同的,但物理组织和数据结构可以不同,它和主库保持同步的方法是将接收的REDO转换成SQL语句,然后在STANDBY上执行SQL语句。
逻辑STANDBY除灾难恢复外还有其它用途,比如用于用户进行查询和报表,但其数据库用户相关对象均需要有主键。
本次实施将选择物理STANDBY(physical standby)方式对主库的保护模式可以有以下三种模式:–Maximum protection (最高保护)–Maximum availability (最高可用性)–Maximum performance (最高性能)保护模式数据丢失保护重做传输最高保护零数据丢失双重故障保护LGWR SYNC —将重做同步传输至两个站点,网络中断会导致主Database宕机最高可用性零数据丢失单重故障保护LGWR SYNC —重做同步传输最高性能最少的数据丢失LGWR ASYNC 或 ARCH —重做异步传输基于项目应用的特征及需求,本项目比较适合采用Maximum availability (最高可用性)模式实施。
3.Dataguard 实施前提条件和注意事项:灾备环境中的所有节点必须安装相同的操作系统,尽可能令详细补丁也保持相同。
灾备环境中的所有节点必须安装完全相同版本的Oracle数据库软件,包括版本号和发布号,比如必须都是Oracle主库必须处于归档(ARCHIVELOG)模式。
灾备环境中所有节点的硬件和操作系统架构必须相同主库可以是单实例,也可以是RAC。
主节点和备用节点之间的硬件配置可以不同,比如CPU数量,内存数量,存储的配置等等。
配置灾备环境的数据库用户必须具有SYSDBA权限。
4.Oracle软件安装1.要实施DataGurad的前,需要在主机RedHat-Primary和备机RedHat-Standby上进行ORACLE软件的基础安装。
2.备机基础软件的安装有两种方式供选择:1)源始安装介质安装采用ORACLE数据库安装介质进行软件安装。
2)“克隆”主站源数据库分别对主站源数据库进行tar压缩并FTP/rcp至备机上,然后展开压缩文件。
通常出于便捷的原因,备机的Oracle初始建立可采用上述的第二种方式。
测试环境中直接对虚拟机进行了拷贝,因此相当于采用了第二种方式。
现场环境下,如果主节点不是RAC环境,也可以采用第二种方式。
4.1环境配置RedHat5-Primary (primary , IP 以下简称主库Single Instance Primary说明IP单实例Instance ORCLData,Control File,Redo File$ORACLE_BASE/oradataRedHat5-Standby (standby, IP ,以下简称从库。
Single Instance Standby说明IP单实例Instance ORCLData,Control File,Redo File$ORACLE_BASE/oradata4.2系统硬件环境检查4.2.1检查内存相关项检查服务器的内存,可以通过下列命令:[root@localhost ~]# grep MemTotal /proc/meminfo另外与内存相关的swap 交换分区的设置也很重要,通常有下列的规则:实际内存建议swap 交换空间大小-------------- -----------------------------1G-2G 倍于内存2G-16G 与内存相同超过16G 设置为16G 即可查看当前服务器swap 交换分区大小,可以通过下列命令:[root@localhost ~]# grep SwapTotal /proc/meminfo查看系统当前共享内存,可以通过df 命令,例如:[root@localhost ~]# df -h /dev/shm4.2.2查看系统架构本步用来查看处理器的架构类型,需要确认ORACLE 安装包与处理器架构相符,不然安装时必然报错。
查看当前系统的处理器架构可以通过下列命令:[root@localhost ~]# uname –mi6864.2.3检查磁盘空闲空间首先/tmp 至少要有1g 的空闲空间,查看/tmp 的磁盘空间,也可以通过df 命令查看,例如:[root@localhost ~]# df -h /tmp在执行安装之前,建议执行df -h 命令,查看当前是否有充裕的空闲空间来安装和创建数据库。
[root@jssnode1 ~]# df –h4.3安装操作系统软件包(32位compat-libstdc++gcc-c++ksh-libstdc++libstdc++查看软件包是否已经安装:[root@localhost ~]# rpm -aq binutils compat-libstdc++-33[root@localhost ~]# rpm -aq | grep elfutils-libelf[root@localhost ~]# rpm -aq | grep gcc[root@localhost ~]# rpm -aq | grep glibc[root@localhost ~]# rpm -aq | grep ksh[root@localhost ~]# rpm -aq | grep libaio[root@localhost ~]# rpm -aq | grep libgcc[root@localhost ~]# rpm -aq | grep libgomp[root@localhost ~]# rpm -aq | grep libstdc++[root@localhost ~]# rpm -aq | grep make-3[root@localhost ~]# rpm -aq | grep sysstat[root@localhost ~]# rpm -aq | grep unixODBC通过以上命令来查看是否有未安装的软件包,可将未安装的软件包放到~/rpm下,因有些包会相互依赖,最简单的方式是将rpm包下的软件包一起安装:[root@localhost ~]#cd rpm[root@localhost rpm]#pwd/root/rpm[root@localhost rpm]#lscompat-libstdc++ rpm]#rpm –Uvh *64位需安装的操作系统软件包(32 bit)(32 bit)(32 bit)ksh-(32 bit)(32 bit)(32 bit)libstdc++ (32 bit)libstdc++-devel (32 bit)(32 bit)4.4修改内核参数下列将要进行配置的核心参数均拥有默认值(或者说最小值),需要对其进行配置的原因,是为了获得更好了性能,因此对于产品服务器来说,务必根据实际情况进行配置,不适当的值反倒可能适得其反。
使用vi 命令编辑/etc/ 文件,例如:[root@localhost ~]# vi /etc/将下列内容加入该文件:= 1048576= 6815744= 2097152= 2= 4096= 250 32000 100 128= 9000 65500= 262144= 4194304= 262144= 1048586注意,某些参数可能已经存在于该文件,注意修改参数值即可。
这里各参数所指定的值仅供参考,请根据实际情况进行修改,一般来说只需要对这个参数的参数值进行修改即可,该参数建议修改为物理内存的一半(以字节为单位)。
编辑完之后存盘退出,然后运行下列命令重新加载并验证参数是否正确:[root@jssnode1 ~]# sysctl -p4.5修改系统时间修改主机与备机的系统时间一致4.6创建用户和组及安装目录并配置环境变量创建用户和组:[root@localhost ~]# groupadd oinstall[root@localhost ~]#groupadd dba[root@localhost ~]#useradd -g oinstall -G dba oracle[root@localhost ~]#passwd oracle验证nobody用户:[root@localhost ~]#id nobody创建Oracle的安装目录:注: (因虚拟机环境安装Linux时没有手动分区,导致挂载点”/”空间不足,所以将oracle 安装到了/home/db下,现场环境下Oracle应安装到/opt或单独分区)[root@localhost ~]# cd /home[root@localhost home]#mkdir db改变文件系统/home/db的所有者为oracle,以便将Oracle安装到此目录[root@localhost home]#chown oracle:oinstall db切换到oracle用户,修改.bash_profile[oracle@localhost ~]$ vi .bash_profile# .bash_profile# Get the aliases and functionsif [ -f ~/.bashrc ]; then. ~/.bashrcfi# User specific environment and startup programsORACLE_SID=orclORACLE_BASE=/home/db/oracleORACLE_HOME=$ORACLE_BASE/product/export ORACLE_SID ORACLE_BASE ORACLE_HOMEexport LD_ASSUME_KERNEL= NLS_LANG=""umask 022PATH=$PATH:/$ORACLE_HOME/bin:$HOME/binexport PATH4.7安装Oracle数据库本节略5.配置DataGuard过程5.1备注“SQL>”:表示在sqlplus环境下执行,通常是以sysdba身份登录来执行命令“$”或” [oracle@localhost ~]$”:表示在命令行中执行的命令5.2判断DataGuard是否安装SQL>select * from v$option where parameter = 'Oracle Data Guard’;5.3网络配置5.4(orcl)监听配置主库[oracle@localhost ~]$ cd $ORACLE_HOME/network/admin[oracle@localhost admin]$ viLISTENER =(DESCRIPTION_LIST =(DESCRIPTION =(ADDRESS = (PROTOCOL = TCP)(HOST = = 1521))))SID_LIST_LISTENER =(SID_LIST =(SID_DESC =(GLOBAL_DBNAME = orcl)(SID_NAME = orcl)(ORACLE_HOME = /home/db/oracle/product/ ))注意:SID_LIST_LISTENER 配置的是静态注册,如果没有该参数,而且Data Guard 启动顺序又不正确,那么在主库可能会报 PING[ARC1]: Heartbeat failed to connect to standby 'orcl_st'. Error is 12514. 错误,导致归档无法完成。