ch10文件
CH10测试管理

常用白盒测试设计方法
条件覆盖:对条件判断型程序(典型的if语句)进行的测试,输入 相应条件,判定获得的结果是否正确,对嵌套条件语句中存在的条 件组合覆盖不到。 条件组合覆盖:对条件覆盖的补充,要求每个判定中条件的各种组 合至少出现一次。
因果图法
因果图法: 因果图法:
分析程序规格说明,引出原因(输入条件)和结果(输出条件), 并给每个原因各结果赋予一个标识符,分析程序规格说明的语义内容, 将其表示成连接各个原因各结果的“因果图”。通过跟踪因果图中的状 态条件,将因果图转换成有限项的判定表,再把判定表中的每一列都转 换成一个测试用例。 对于复杂逻辑程序,因果图法使用起来异常复杂,通常不采用。
边界值分析法
边界值分析: 边界值分析: 指南:
如果输入条件代表一组值,测试用例应当执行其中的最大值和最 小值,还应当测试略大于最小值和略小于最大值的值。 指南1也适用于输出条件。 如果程序数据结构有预定义的边界(如数组有100项),要测试其 边界的数据项。
错误猜测法
错误猜测法: 错误猜测法:
依据经验和直觉推测程序中可能存在的各种错误,从而有针对性地 编写检查这些错误地例子。 可以对历史缺陷数据进行分析总结,得出常见错误列表,运用于新 项目地错误猜测测试。
测试计划-提交
评审:同行评审;单人复审。 评审组的组成 -同行评审:3-7人。由项目经理、测 试经理、测试小组代表、开发小组代 表、设计小组代表组成。 -单人复审:测试部领导审批。 测试计划评审的Checklist
测试计划-checklist
PR检查单_测试计 划
3测试设计
软件的质量是设计出来的,同样测试的质量也是设计出来的。 一份好的测试设计大纲应涉及测试类型、被测对象特性、功能等,它必须明 确详尽地规定在测试中针对系统的每一项功能或特性所要完成的基本测试项 目和测试标准。测试设计必须体现测试计划,包括测试策略和测试资源的开 发。 无论是自动测试还是手动测试,都必须符合测试大纲的要求。 测试设计阶段输出《测试方案》,并要求对测试方案进行评审。
CH10.石基PMS:酒店信息管理典型软件介绍

10.5.1财务应收账的基本知识 10.5.2 财务应收账模块的工作流程 1.账户维护 (Account Maintenance) 2.数据转换(Transfer F/O Data) 3.过账(Postings) 4.交易搜索 (Transaction Search) 5.信用卡结账(Credit Card Payment) 6.催账函(Reminder Letters) 7.邮件历史(Mail History) 8.批处理(Batch Statements) 9.跟踪指示(Traces) 10.报表(Reports)
10.1.2 石基PMS的基本任务
石基PMS是整个物业管理的核心系统。以宾馆为例,其 收益主要来源于两大部分:一是客房收入;二是餐饮收 入。
10.2 预定模块介绍
10.2.1 预定相关的基本概念 1.预定的对象 宾馆预定的协议对象,可能是个人,也可 能是公司、旅行社或其它预定源,也可能 是旅行团队的团主。 2.预定的内容 预定包含的空间内容主要是特定房型的房 间或指定房间,以及房间数量。
1.变更房态(Housekeeping)
2.房态设置为OOO/OOS (Out Of Order/Service)
3.房间分配 (Room Assignment)
4.房间历史(Room History)
5.超额预定设置(OverBooking)
6.房间清洁员管理(Attendants)
7.排队房管理(Q-Room)
7.邮件历史(Mail History)
8.批处理(Batch Statements)
9.跟踪指示(Traces)
10.报表(Reports)
10.6 客房管理模块介绍
C++中Txt文件读取和写入

文件状态 我用过的唯一一个状态函数是 eof(), 它返回是否标志已经到了文件末尾。 我主要用在循பைடு நூலகம்中。 例如, 这个代码断统计小写‘e’ 在文件中出现的次数。
This is really awesome! 如果你想把整行读入一个 char 数组, 我们没办法用">>"?操作符,因为 每个单词之间的空格(空白字符)会中止文件的读取。为了验证:
char sentence[101]; fin >> sentence; 我们想包含整个句子, "This is really awesome!" 但是因 为空白, 现在它只包含了"This". 很明显, 肯定有读取整行的方法, 它就是 getline()。这就是我们 要做的。
fout.open("output.txt"); 你也可以把文件名作为构造参数来打开一个文件.
ofstream fout("output.txt"); 这是我们使用的方法, 因为这样创建和打开一个文件看起来更简单. 顺便说一句, 如果你要打开的文件不存在,它会为你创建一个, 所以不用担心文件创建的问题. 现在就输出到文件,看起来和"cout"的操作很像。对不了解控制台输出"cout"的人, 这里有个例 子。
int num = 150; char name[] = "John Doe"; fout << "Here is a number: " << num << "/n"; fout << "Now here is a string: " << name << "/n"; 现在保存文件,你必须关闭文件,或者回写 文件缓冲. 文件关闭之后就不能再操作了, 所以只有在你不再操作这个文件的时候才调用它,它 会自动保存文件。回写缓冲区会在保持文件打开的情况下保存文件, 所以只要有必要就使用它。 回写看起来像另一次输出, 然后调用方法关闭。像这样:
SEGY数据格式ch

SEG Y 修订版1 数据交换格式1SEG 技术标准委员会2版本1.0,2002年5月12001,勘探地球物理学家学会,版权所有2编者:Michael W. Norris 和Alan K. Faichney目录1.简介2.概述2.1. 不变的条目2.2. 修订版0到修订版1的变化2.3. 注释2.4. 监管机构2.5. 致谢3.SEG Y文件结构3.1. 记录介质3.2. 文件结构3.3. 数字格式3.4. 变道长3.5. 坐标4.原文文件头5.二进制文件头6.扩展原文文件头6.1. 扩展原文文件头结构6.2. 结尾文本段6.3. 文本段示例7.数据道7.1. 道头7.2. 道头数据附录A. 写SEG Y数据到磁盘文件附录B. SEG Y磁带标签附录C. 磁带上的SEG Y文件块附录D. 扩展原文文本段D-1. 位置数据D-1.1 位置数据文本段D-1.2 位置数据文本段示例D-2. 面元网格定义D-2.1 面元网格定义文本段D-2.2 面元网格定义文本段示例D-3. 资料地理范围和覆盖区域D-3.1 资料地理范围文本段D-3.2 资料地理范围文本段示例D-3.3 覆盖区域文本段D-3.4 覆盖区域文本段示例此例基于图3D-4. 数据取样测量单位D-4.1 数据取样测量单位文本段D-4.2 数据取样测量单位文本段示例D-5. 处理历史D-5.1 处理历史文本段D-5.2 处理历史文本段示例D-6. 震源类型/方位D-6.1 震源类型/方位文本段D-6.2 震源类型/方位文本段示例D-7. 震源测量单位D-7.1 震源测量单位文本段D-7.2 震源测量单位文本段示例附录E. 文字格式数据附录F. EBCDIC码和ASCII码附录G. 参考文献图片图1. 带N个扩展原文文件头记录和M道记录的SEGY文件字节流结构图2. 面元网格定义图3. 地震调查的数据范围和覆盖区域变化表格表1. 原文文件头表2. 二进制文件头表3. 道头表4. SEG Y磁带标签表5. 位置数据文本段表6. 面元网格定义文本段表7. 资料地理范围文本段表8. 覆盖区域文本段表9. 数据取样测量单位文本段表10. 处理历史文本段表11. 震源类型/方位文本段表12. 震源测量单位文本段表13. IBM 3270 字符集参考CH 10,GA27-2837-9,1987年4月1.简介最早的SEG Y数据交换格式(修订版0,参考第45页)自1975年出版以来在地球物理行业得到广泛的使用。
chap10(文件)
10.2 文件操作 在对文件读、写之前必须先打开该文件, 在对文件读 、 写之前必须先打开该文件 , 使用结束后 应关闭该文件。 应关闭该文件。 一、 文件打开函数 fopen 函数调用格式: 函数调用格式: FILE *fp; fp=fopen(“文件名”,“使用方式”); 文件名” 使用方式 使用方式” 文件名 打开指定的文件,以指定的使用方式进行访问。 打开指定的文件,以指定的使用方式进行访问。 说明: 说明: 指向打开的文件后, 就可以用它来访问该文件。 用 fp 指向打开的文件后 就可以用它来访问该文件。 文件名”为任何合法的DOS文件名。 文件名。 “文件名”为任何合法的 文件名 有的C 版本只用r、 、 ,或只用rw、 而不用r+、 有的 版本只用 、w、a,或只用 、ra 而不用 、 w+、a+ 、 在程序运行时, 系统自动打开三个标准文件stdin、 在程序运行时 , 系统自动打开三个标准文件 、 stdout、stderr。 、 。
第 10 章
10.1 文件操作库函数
文件
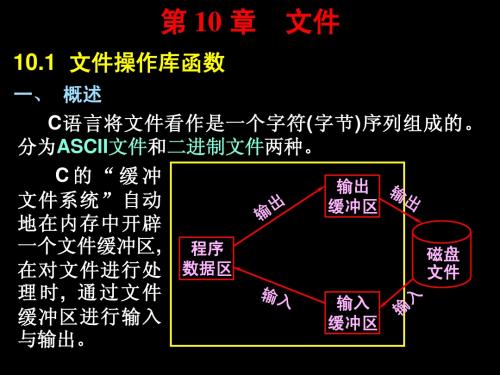
一、 概述 C语言将文件看作是一个字符 字节 序列组成的 。 语言将文件看作是一个字符(字节 序列组成的。 语言将文件看作是一个字符 字节)序列组成的 分为ASCII文件和二进制文件两种。 文件和 两种。 分为 文件 二进制文件两种 C的“缓冲 输出 文件系统” 文件系统 ” 自动 缓冲区 地在内存中开辟 一个文件缓冲区, 程序 一个文件缓冲区 磁盘 在对文件进行处 数据区 文件 理时, 通过文件 输入 缓冲区进行输入 缓冲区 与输出。 与输出。
文本文件中的回车换行符在输入时转换为一个换行符, 文本文件中的回车换行符在输入时转换为一个换行符, 在输出时又转换为回车换行符。 在输出时又转换为回车换行符。 为了可靠地打开指定的文件, 常用下列方法: 为了可靠地打开指定的文件 常用下列方法: if ((fp=fopen(“file1” , “ r ”))==NULL) { printf(“cannot open this file\n”); exit(0); } 二、 文件关闭函数 fclose 使用完一个文件后必须关闭它, 使用完一个文件后必须关闭它 , 以防数据丢失和 被其它操作误用。 被其它操作误用。 fclose函数的调用格式: 函数的调用格式: 函数的调用格式 fclose(文件指针 文件指针); 文件指针 关闭文件时的操作就是使指针与文件“脱钩” 关闭文件时的操作就是使指针与文件“脱钩”。正常 关闭时fclose函数返回 值,关闭有误时返回非 值。 函数返回0值 关闭有误时返回非0值 关闭时 函数返回
ch10[1]
![ch10[1]](https://img.taocdn.com/s3/m/3b3c6718a300a6c30c229f5d.png)
裘宗燕
从问题到程序(2003 年修订) ,第十章 程序开发 printf("Can't open file: %s\n", fn); else { commander(fp, fn); fclose(fp); } } while (next("file")); return 0;
}
这里的 getnstr 是第 8 章单词练习程序里开发的读取一个字符串的函数,这里将读入的字 符串用作文件名,设法打开该文件。commander 是程序里的一个主要函数。对一个打开的 文件,commander 首先将文件里的学生成绩记录读入,而后转入交互命令的处理:
除成绩统计和直方图外,这里还增加了一个成绩排序输出的函数 sortoutput。 上面两个函数都用到前面背单词程序定义的函数 next。此外这里还需定义一个取得用 户命令的函数 getcmd,它显示一个信息串,要求读入一定范围里的一个数。该函数的实现 应该参考 getnstr 和前面几次定义的 getnumber,读入一个数之后应该丢掉整个行中其 余的东西。下面是几个函数的原型:
#include #include #include #include <stdio.h> <stdlib.h> <math.h> <ctype.h>
enum { MAXNUM = 400, MIDDLE = 20, EXECISE = 30, FINAL = 50, /* 成绩比例 */ HISTLEN = 60, /* 最长行的长度(字符数)*/ SEGLEN = 5, /* 分段长度 */ SEGNUM = 100/SEGLEN+1 /* 分段数,根据分段长度自动算出 */ }; /* 公用类型的定义 */ typedef struct { unsigned long num; char name[20]; double mid, exe, final, score; } StuRec; /* 全局性数据对象的定义 */ StuRec students[MAXNUM];
ch10_Task

第
1b应用程序
学生上一章完成实验后的Web应用程序。
注:本章实验是上一章实验的继续。
10.2
报告书
名称
实验10-1配置全球化和本地化
姓名
指导教师
学号
日期
任务清单
场景
在本演示中,将在Web.config中配置AdventureWorks站点的全球化和本地化设置。
实验方法
场景
在本演示中,将通过创建本地资源文件实现AdventureWorks站点主页的全球化和本地化。
实验方法
1.首先打开Default.aspx页面,从VS 2005的“工具”菜单中选择“生成本地资源”以生成本地资源文件Default.aspx.resx,同时IDE自动为页面中控件隐式调用了本地资源。通过复制生成英文版本的本地资源文件Default.aspx.en-US.resx,并修改英文版本的资源项的值。
注意:可以修改配置文件中节点globalization的Culture和UICulture属性来测试本地化的结果,如将它们都设为en-US则显示英文的本地化。对于下面的各个实验也是如此。
实验预估时间
10分钟
实验结果
报告书
名称
实验10-3创建全局资源文件实现站点地图的全球化和本地化
姓名
指导教师
学号
日期
2.手动修改站点地图,包括设置siteMap元素的enableLocalization属性为true和各个节点的Title与Description,通过显示本地化方式引用全局资源。
实验预估时间
30分钟
实验结果
报告书
名称
实验10-4全球化和本地化AdventureWorks的主页
石盛林质量管理 ch10 群众性质量管理活动

(1)现场型课题。通常以稳定工序质量、改进产品质量,降 低消耗、改善生产环境为目的。一般选择的课题较小,难度 不大,活动周期较短,比较容易出成果,但经济效益不一定 大。
(2)服务型课题。通常以推动服务工作标准化、程序化、科 学化、提高服务质量和效益为目的。活动课题较小,活动时 间不长,见效较快。这类课题不一定取得显著的经济效益, 但社会效益往往比较明显。
5) 黑带。 六西格玛黑带是六西格玛管理中的“关键的场上队员”。他们 负有以下职责: ⑴领导六西格玛项目团队,实施并完成六西格玛项目。 ⑵向团队成员提供适用的工具与方法的培训 ⑶识别过程改进机会并选择最有效的工具和技术实现改进。 ⑷向团队传达六西格玛管理理念,建立对六西格玛管理的共识。 ⑸向倡导者或领航员以及管理层报告六西格玛项目的进展。 ⑹将通过项目实施获得的知识传递给企业的其他人员。 ⑺培训绿带并为绿带提供项目指导
3)六西格玛管理的特点 (1)以顾客为关注焦点 (2)用数据和事实说话 (3)聚焦于流程,消除变异 (4)持续改进 (5)跨职能、无边界合作 (6)注重观念转变,改变行为方式
10.1.2 六西格玛管理的组织
六西格玛管理是由企业的最高管理层推进的、由六西格玛倡导 者或领航员以及六西格玛资深黑带、黑带和绿带等关键角色领 导并带领全员参与实施的、以六西格玛项目的形式组织的围绕 企业经营绩效持续提升而开展的管理活动。 其中的关键角色与职责有:
C语言文件操作完全攻略

C语言文件操作完全攻略数据的输入和输出几乎伴随着每个C 语言程序,所谓输入就是从“源端”获取数据,所谓输出可以理解为向“终端”写入数据。
这里的源端可以是键盘、鼠标、硬盘、光盘、扫描仪等输入设备,终端可以是显示器、硬盘、打印机等输出设备。
在C 语言中,把这些输入和输出设备也看作“文件”。
文件及其分类计算机上的各种资源都是由操作系统管理和控制的,操作系统中的文件系统,是专门负责将外部存储设备中的信息组织方式进行统一管理规划,以便为程序访问数据提供统一的方式。
文件是操作系统管理数据的基本单位,文件一般是指存储在外部存储介质上的有名字的一系列相关数据的有序集合。
它是程序对数据进行读写操作的基本对象。
在C 语言中,把输入和输出设备都看作文件。
文件一般包括三要素:文件路径、文件名、后缀。
由于在C 语言中'\' 一般是转义字符的起始标志,故在路径中需要用两个'\' 表示路径中目录层次的间隔,也可以使用'/' 作为路径中的分隔符。
例如,"E:\\ch10.doc"或者"E:/ch10.doc",表示文件ch10.doc 保存在E 盘根目录下。
"f1.txt" 表示当前目录下的文件f1.txt。
文件路径:可以显式指出其绝对路径,如上面的”E:\\”或者”E:/”等;如果没有显式指出其路径,默认为当前路径。
C 语言不仅支持对当前目录和根目录文件的操作,也支持对多级目录文件的操作,例如:或者中的file_1.txt 均是C 语言可操作的多级目录文件。
文件名:标识文件名字的合法标识符,如ch10、file_1 等都是合法的文件名。
后缀:一般用于标明文件的类型,使用方式为:文件名.后缀,即文件名与后缀之间用'.' 隔开。
常见的后缀类型有:doc、txt、dat、c、cpp、obj、exe、bmp、jpg 等。
CH10ERP导入

企業藍圖
訂定組織架構 規劃並設計未來流程(select the
activity(all process requirement) 完成基本功能架構的討論 如果可以的話,用企業流程去配合系統
流程 確認外掛需求 企業藍圖確認研討會
Realization
專案準備(Project Preparation) 企業藍圖(Business Blueprint) 系統設計與開發( Realization) 系統上線準備(Final Preparation) 系統上線及後續支援(Go-Live and
接近,但關鍵在執行長(CEO’s)的決定
树 立 质 量 法 制观念 、提高 全员质 量意识 。20.12.1220.12.12Saturday, December 12, 2020
人 生 得 意 须 尽欢, 莫使金 樽空对 月。03:08:2303:08:2303:0812/12/2020 3:08:23 AM
系統上線準備(Final Preparation )
使用者測試系統並撰寫報告 種子教師撰寫使用者操作手冊 種子教師訓練終端使用者 支援站應該分三級
–種子教師Seeders –顧問 –軟體供應商(如sap)
轉檔及介面
是一很重要但經常被忘掉的子專案 IT 成員應視這個子專案為自己的責任
系統上線及後續支援
妥善處理變革
溝通 教育及訓練 提供資訊 工作調整 解僱
省思
成功因子
– 管理階層的視如己出 – 信賴的關係 – 簡單、清楚及可測量的目標 – 強而有效的專案管理 – ….
結論
審慎規劃是企業去配合軟體或軟體去配 合企業
變革管理關係者對員工對系統的接受度 很多 E-Business 系統和企業的流程很
数据挖掘导论-ch10

假定数据集D包含来自两个概率分布的混合的样本 :
– M (多数分布) – A (异常分布)
一般方法:
– 最初,假设所有数据点属于M – 令Lt(D)是D在时间t的对数似然性 – 对于属于M的每个点xt ,将其移动到A
令Lt+1 (D)为新的对数似然。
计算差值, = Lt(D) – Lt+1 (D)
如果异常值出现在数据的中间怎么办?
数据挖掘导论 2/27/2017 ‹#›
统计方法
假设描述数据分布的参数模型(例如,正态分布 ) 应用取决于的统计测试
– 数据分布 – 分布参数(例如,平均值,方差) – 预期异常值的数量(置信限制)
数据挖掘导论
2/27/2017
‹#›
格鲁布斯测试
检测单变量数据中的异常值 假设数据来自正态分布 一次检测一个异常值,删除异常值,然后重复
数据挖掘导论
2/27/2017
‹#›
基本利率下跌(Axelsson, 1999)
数据挖掘导论
2/27/2017
‹#›
基本利率下跌
即使测试是99%肯定,你的疾病的几率是1/100, 因为健康的人口比病人大得多
数据挖掘导论
2/27/2017
‹#›
入侵检测中的基本速率下降
I: 侵入行为 I: 非侵入行为 A: 报警 A: 无报警
数据挖掘 异常检测
第十章 数据挖掘简介
数据挖掘导论
2/27/2017
1
不规则/异常检测
什么是异常/离群值?
– 与其余数据相差很大的数据点集
异常/异常值检测问题的变体
c语言复习资料

c语⾔复习资料复习资料Ch2 数据类型、运算符与表达式1. C程序的结构:C程序是由⼀个或多个源⽂件组成,源⽂件是C程序的编译单位;源⽂件由函数组成的;⼀个程序有且仅有⼀个名字为main( )的函数;函数的定义不可嵌套,即,在⼀个函数内部不可定义另外⼀个函数;程序总是从main函数第⼀条可执⾏语句开始执⾏,在main函数结束;2.标识符合法的标识符的组成;如x1、a、max_int、_num等合法的,2x、x#等不合法,不能⽤关键字,如for、int等,最好不⽤函数名如 printf等。
关键字:查看附录B;如printf、define不是关键字;C语⾔区分⼤⼩写,故For、If等不是关键字3.常量的表⽰形式整型常量:⼗进制、⼋进制、⼗六进制。
如 028、0x2ah不合法;若整数是2个字节,则整数范围-32768-32767之间,32768(错) -037 0xaf均正确实型常量:3.0 2.3e3 2e-4正确,2e3.0错字符常量:注意转义字符,如\n、\72、\x23等均表⽰⼀个字符,如“\t\”name\\address\n”长度为15;’\38’错误字符串常量:变量定义及赋值:变量赋值时的类型应相同或兼容,如int a=3.5、float b=4、char c=97正确,但char ch=”abc”错误4.运算符及表达式运算符的功能、特点:如%要求两侧操作数均为整数;若 / 两侧操作数都是整数表⽰整除;运算符的优先级:复合运算符:如int a=3; 执⾏a+=a-=a*a; 后,a的值是-12;如:n=10,i=4,则赋值运算n%=i+1,n的值是逻辑运算符:掌握&& 和 || 的运算特点;如 i=2,j=3,k=4, if((i++) || (j++)) && k++) printf(“%d,%d,%d”,i,j,k);结果是?设a=3, b=4, c=5,表达式(1)‘a’ && ‘b’、 (2)a<=b 、a || b+c && b-c、(3)!((ab>a结果?如:c=0; 考虑,表达式c=b=a、(a=c)||(b=c)、(a=c)&&(b=c)、a=c=b能正确将c的值赋给变量a,b吗?为什么?关系运算符:注意= =与=的区别,如a=1,b=2 则if(a=3) b=0; 则b的值变化了吗?为什么?条件运算符:运算的特点如:i=1,j=2;执⾏语句n=i>j?i++:j++; 则i和j的值是5.⾃增⾃减:掌握前置与后置的运算特点;如:x=3,则表达式x++的结果是3,x的值变成4;⽽++x的结果是4,x的值也是4;-x++结果是-3,x的值变成4如:x=7,则(x++%3)结果是?6.表达式类型的转换:若char a; int b; float c; double d;则表达式 a*b+d-c 的值类型?7.逗号运算符:逗号表达式的值是最后⼀个表达式的值。
《中文版Project 2003实用教程》课件ch10

中文版Project 2003实用教程 中文版Project 2003实用教程
10.1.1 主/子项目和合并项目 10.1.1
合并项目文档就是将子项目文档插入到主项目文档中。主项目是指包含 其他项目(插入项目或子项目) 其他项目(插入项目或子项目)的项目,也称为合并项目。子项目是指插入到其 他项目中的项目,子项目可作为一种复杂项目分解为更多可管理部分的部分, 子项目也称为插入项目。每个子项目都可以被保存为一个单独的项目文档, 可以为每个子项目分配资源,建立链接和约束。当需要从宏观的角度跟踪整 个项目时,就可以把分离的多个子项目合并成为一个大型项目。子项目在合 并项目中显示为摘要任务,可以隐藏任何一个与子项目相关的任务。在合并 项目文档中,可以只对所关心的部分进行操作,可以查看、打印和修改任何 一个子项目的信息。 一个子项目的信息。
将子项目插入到主项目后,为了满足主项目文档的需要,还需对插入的项目 做进一步的编辑。例如,可以对子项目进行类似于摘要任务的处理,在大纲中通 过升级或降级的方法来更改任务层次中子项目的次序。 移动插入的项目:Project允许对插入的项目进行移动,从而适应不同情况下 移动插入的项目:Project允许对插入的项目进行移动,从而适应不同情况下 项目管理的需要。 升级或降级插入的项目: 升级或降级插入的项目:默认状态下,插入的子项目与上一行单元格中任务 的大纲级别相同,在插入一个项目之后,可以通过将其移到大纲中的某个级 别上来创建分层结构。如果其前面的任务也是一个插入项目的话,则不能够 升级或降级该插入项目。 计算多重关键路径:默认情况下,Project仅显示一条关键路径,即影响计划 计算多重关键路径:默认情况下,Project仅显示一条关键路径,即影响计划 完成日期的路径。但对于合并的项目,通常会有很多插入的子项目,而这些 子项目都有属于自己的一条关键路径。要想查看每个插入项目的关键路径, 使用计算多重关键路径的方法就可以很方便地达到目的。
CC++读写文本文件、二进制文件的方法

CC++读写⽂本⽂件、⼆进制⽂件的⽅法⼀:⽬的掌握C语⾔⽂本⽂件读写⽅式;掌握C语⾔⼆进制⽂件读写⽅式;掌握CPP⽂本⽂件读写⽅式;掌握CPP⼆进制⽂件读写⽅式;⼆:C语⾔⽂本⽂件读写1. ⽂本⽂件写⼊//采⽤C模式对Txt进⾏写出void TxtWrite_Cmode(){//准备数据int index[50] ;double x_pos[50], y_pos[50];for(int i = 0; i < 50; i ++ ){index[i] = i;x_pos[i] = rand()%1000 * 0.01 ;y_pos[i] = rand()%2000 * 0.01;}//写出txtFILE * fid = fopen("txt_out.txt","w");if(fid == NULL){printf("写出⽂件失败!\n");return;}for(int i = 0; i < 50; i ++ ){fprintf(fid,"%03d\t%4.6lf\t%4.6lf\n",index[i],x_pos[i],y_pos[i]);}fclose(fid);}2. ⽂本⽂件读取//采⽤C模式对Txt进⾏读取void TxtRead_Cmode(){FILE * fid = fopen("txt_out.txt","r");if(fid == NULL){printf("打开%s失败","txt_out.txt");return;}vector<int> index;vector<double> x_pos;vector<double> y_pos;int mode = 1;printf("mode为1,按字符读⼊并输出;mode为2,按⾏读⼊输出;mode为3,知道数据格式,按⾏读⼊并输出\n");scanf("%d",&mode);if(mode == 1){//按字符读⼊并直接输出char ch; //读取的字符,判断准则为ch不等于结束符EOF(end of file)while(EOF!=(ch= fgetc(fid)))printf("%c", ch);}else if(mode == 2){char line[1024];memset(line,0,1024);while(!feof(fid)){fgets(line,1024,fid);printf("%s\n", line); //输出}}else if(mode == 3){//知道数据格式,按⾏读⼊并存储输出int index_tmp;double x_tmp, y_tmp;while(!feof(fid)){fscanf(fid,"%d%lf%lf\n",&index_tmp, &x_tmp, &y_tmp);index.push_back(index_tmp);x_pos.push_back(x_tmp);y_pos.push_back(y_tmp);}for(int i = 0; i < index.size(); i++)printf("%04d\t%4.8lf\t%4.8lf\n",index[i], x_pos[i], y_pos[i]);}fclose(fid);}三:C语⾔⼆进制⽂件读写1. ⼆进制⽂件写⼊//采⽤C模式写⼆进制⽂件void DataWrite_CMode(){//准备数据double pos[200];for(int i = 0; i < 200; i ++ )pos[i] = i ;//写出数据FILE *fid;fid = fopen("binary.dat","wb");if(fid == NULL){printf("写出⽂件出错");return;}int mode = 1;printf("mode为1,逐个写⼊;mode为2,逐⾏写⼊\n");scanf("%d",&mode);if(1==mode){for(int i = 0; i < 200; i++)fwrite(&pos[i],sizeof(double),1,fid);}else if(2 == mode){fwrite(pos, sizeof(double), 200, fid);}fclose(fid);}2.⼆进制⽂件读取//采⽤C模式读⼆进制⽂件void DataRead_CMode(){FILE *fid;fid = fopen("binary.dat","rb");if(fid == NULL){printf("读取⽂件出错");return;}int mode = 1;printf("mode为1,知道pos有多少个;mode为2,不知道pos有多少个\n"); scanf("%d",&mode);if(1 == mode){double pos[200];fread(pos,sizeof(double),200,fid);for(int i = 0; i < 200; i++)printf("%lf\n", pos[i]);free(pos);}else if(2 == mode){//获取⽂件⼤⼩fseek (fid , 0 , SEEK_END);long lSize = ftell (fid);rewind (fid);//开辟存储空间int num = lSize/sizeof(double);double *pos = (double*) malloc (sizeof(double)*num);if (pos == NULL){printf("开辟空间出错");return;}fread(pos,sizeof(double),num,fid);for(int i = 0; i < num; i++)printf("%lf\n", pos[i]);free(pos); //释放内存}fclose(fid);}四:C++⽂本⽂件读写1. ⽂本⽂件写⼊//采⽤CPP模式写txtvoid TxtWrite_CPPmode(){//准备数据int index[50] ;double x_pos[50], y_pos[50];for(int i = 0; i < 50; i ++ ){index[i] = i;x_pos[i] = rand()%1000 * 0.01 ;y_pos[i] = rand()%2000 * 0.01;}//写出txtfstream f("txt_out.txt", ios::out);if(f.bad()){cout << "打开⽂件出错" << endl;return;}for(int i = 0; i < 50; i++)f << setw(5) << index[i] << "\t" << setw(10) << x_pos[i] <<"\t" <<setw(10)<< y_pos[i] << endl;f.close();}2.⽂本⽂件读取//采⽤CPP模式读取txtvoid TextRead_CPPmode(){fstream f;f.open("txt_out.txt",ios::in);//⽂件打开⽅式选项:// ios::in = 0x01, //供读,⽂件不存在则创建(ifstream默认的打开⽅式)// ios::out = 0x02, //供写,⽂件不存在则创建,若⽂件已存在则清空原内容(ofstream默认的打开⽅式)// ios::ate = 0x04, //⽂件打开时,指针在⽂件最后。
FLUENT udf中文资料ch10

第10章应用举例10.1 边界条件10.2源项10.3物理属性10.4反应速率(Reacting Rates)10.5 用户定义标量(User_Defined Scalars)10.1边界条件这部分包含了边界条件UDFs的两个应用。
两个在FLUENT中都是作为解释式UDFs被执行的。
10.1.1涡轮叶片的抛物线速度入口分布要考虑的涡轮叶片显示在Figure 10.1.1中。
非结构化网格用于模拟叶片周围的流场。
区域从底部周期性边界延伸到顶部周期性边界,左边是速度入口,右边是压力出口。
Figure 10.1.1: The Grid for the Turbine Vane Example常数x速度应用于入口的流场与抛物线x速度应用于入口的流场作了比较。
当采用分段线性分布的型线的应用是有效的对边界型线选择,多项式的详细说明只能通过用户定义函数来完成。
常数速度应用于流场入口的结果显示在Figure 10.1.2和Figure 10.1.3中。
当流动移动到涡轮叶片周围时初始常速度场被扭曲。
Figure 10.1.2: Velocity Magnitude Contours for a Constant Inlet x VelocityFigure 10.1.3: Velocity Vectors for a Constant Inlet x Velocity现在入口x速度将用以下型线描述:这里变量y在人口中心是0.0,在顶部和底部其值分别延伸到0745。
这样x速.0度在入口中心为20m/sec,在边缘为0。
UDF用于传入入口上的这个抛物线分布。
C源代码(vprofile.c)显示如下。
函数使用了Section 5.3中描述的Fluent提供的求解器函数。
/***********************************************************************//* vprofile.c *//* UDF for specifying steady-state velocity profile boundary condition *//***********************************************************************/#include "udf.h"DEFINE_PROFILE(inlet_x_velocity, thread, position){real x[ND_ND]; /* this will hold the position vector */real y;face_t f;begin_f_loop(f, thread){F_CENTROID(x,f,thread);y = x[1];F_PROFILE(f, thread, position) = 20. - y*y/(.0745*.0745)*20.;}end_f_loop(f, thread)}函数,被命名为inlet_x_velocity,使用了DEFINE_PROFILE定义并且有两个自变量:thread 和position。
ch10 数据库系统概念(第6版)第十章存储结构和文件结构

当一个磁盘发生故障,在系统得到修复之前镜像磁盘也发生故障,则 会发生数据丢失
文件组织 – 根据数据访问的方式来组织磁盘的块 ,以优化块访问时间
例如,在相同或者相邻的柱面存储相关信息. 文件可能随着时间推移变得 碎片化 例如,如果数据被插入文件中或者从文件中删除 或者磁盘上的空闲块是分散的, 以致新创建的文件 的块在磁盘上分散分布 顺序存取一个碎片化的文件导致磁盘臂移动距离增 加 有些文件系统提供了碎片整理工具, 以加速文件存取
物理存储介质(续)
光盘存储
非易失性, 数据从旋转的盘上通过激光器进行读取 CD-ROM (640 MB) 和 DVD (4.7 to 17 GB) 是最常见 的格式 蓝光光碟: 27 GB to 54 GB 一次写, 多次读 (WORM) 的光盘用于档案存储 (CD-R, DVD-R, DVD+R) 也有允许多次写的版本 (CD-RW, DVD-RW, DVD+RW, and DVD-RAM) 读写速度比磁盘慢 光盘机系统, 有大量可移动光盘, 几个驱动器, 和用于自 动加载/卸载光盘的机制以存储大量数据
磁盘块存取的优化
块 – 一个磁道上的连续扇区
数据在磁盘和主存储器中通过块传输 大小从 512 至几千字节 小块: 需要更多次传输 大块: 部分填充的块会造成更多空间浪费 如今常见的块大小为 4 至 16 千字节
磁盘臂调度 算法为磁道访问进行排序,以最小化磁盘臂 的移动距离
磁盘块存取的优化(续)
C++的File类文件操作

C++的File类⽂件操作语⾔⽂件系统称为流⽂件(Stream),正⽂流(正⽂⽂件),⼆进制流(⼆进制⽂件)缓冲与⾮缓冲⽂件顺序操作⽂件与随机操作⽂件顺序⽂件:读/写第K个数据块之前必须读/写第1⾄K-1个数据块;随机⽂件:可直接读/写第K个数据块;正⽂⽂件的操作⼀般是顺序⽂件;⼆进制⽂件的操作都是随机⽂件。
⼀、⽂件操作的⼀般过程定义⽂件指针 FILE *打开⽂件 fopen对⽂件进⾏读写< type="text/javascript"> < type="text/javascript" src="">⼆、系统已定义的与⽂件操作有关的数据结构全都在stdio.h中FILE 结构体FILE *fr,*fp,*fw;FILE* 指针作为⽂件句柄,是⽂件访问的唯⼀标识,它由fopen函数创建,fopen打开⽂件成功,则返回⼀个有效的FILE*指针,否则返回空指针NULL标准⽂件指针FILE *stdin,*stdout,*stderr,stdin 指键盘输⼊stdout 指显⽰器stderr 指出错输出设备,也指显⽰器这些变量已成功初始化,可直接使⽤.三、常⽤操作函数fopen格式:FILE *fopen(⽂件名字符串,打开⽅式串)例:FILE *fr; fr=fopen("c:\\user\\abc.txt","r");字符串操作:1)"r"或"rt":正⽂⽂件只读⽅式打开。
⽂件不存在,则打开失败(顺序读)"w"或"wt":正⽂⽂件只写⽅式打开。
若⽂件不存在,则建⽴⽂件;若⽂件存在,则删除⽂件内容,重建空⽂件(顺序写);(截取⽂件长度为0)2) "a"或"at":正⽂⽂件添加⽅式。
C++基础系列——文件操作

C++基础系列——⽂件操作⼀、C++⽂件类及⽤法C++ 标准库提供了 3 个类⽤于实现⽂件操作,它们统称为⽂件流类,这 3 个类分别为:ifstream:专⽤于从⽂件读取数据ofstream:专⽤于向⽂件写⼊数据fstream:可读可写这三个⽂件流类都位于 fstream 头⽂件中fstream 类拥有 istream、ostream 类的全部成员⽅法。
fstream 头⽂件中并没有定义可直接使⽤的 fstream、ifstream 和 ofstream 类对象fstream 类常⽤成员⽅法成员⽅法名适⽤类对象功能open()fstream打开指定⽂件,使其与⽂件流对象关联is_open()ifstream检查指定⽂件是否已打开。
close()ofstream关闭⽂件,切断和⽂件流对象的关联。
swap()ofstream交换 2 个⽂件流对象。
operator>>(i)fstream重载 >> 运算符,⽤于从指定⽂件中读取数据。
gcount()(i)fstream返回上次从⽂件流提取出的字符个数。
该函数常和 get()、getline()、ignore()、 peek()、read()、readsome()、putback() 和 unget() 联⽤。
get()(i)fstream从⽂件流中读取⼀个字符,同时该字符会从输⼊流中消失。
getline(str,n,ch)(i)fstream从⽂件流中接收 n-1 个字符给 str 变量,当遇到指定 ch 字符时会停⽌读取,默认情况下 ch 为 '\0'。
ignore(n,ch)(i)fstream从⽂件流中逐个提取字符,但提取出的字符被忽略,不被使⽤,直⾄提取出 n 个字符,或者当前读取的字符为 ch。
peek()(i)fstream返回⽂件流中的第⼀个字符,但并不是提取该字符。
putback(c)(i)fstream将字符 c 置⼊⽂件流(缓冲区)。