NCBI使用方法
ncbi的使用方法

NCBI(美国国立生物技术信息中心)资源介绍及使用手册作者:未知来源:中科院上海生命科学研究院生物信息中心时间:2006-12-27NCBI 资源介绍本文目录:NCBI(美国国立生物技术信息中心) 简介NCBI 站点地图NCBI癌症基因组研究NCBI-Coffee BreakNCBI-基因和疾病NCBI-UniGeneCluster of Orthologous Groups of proteins(COG)介绍Gene Expression Omnibus (GEO)介绍LocusLink介绍关于RefSeq:NCBI参考序列NCBI(美国国立生物技术信息中心)简介介绍理解自然无声但精妙的关于生命细胞的语言是现代分子生物学的要求。
通过只有四个字母来代表DNA化学亚基的字母表,出现了生命过程的语法,其最复杂形式就是人类。
阐明和使用这些字母来组成新的“单词和短语”是分子生物学领域的中心焦点。
数目巨大的分子数据和这些数据的隐秘而精细的模式使得计算机化的数据库和分析方法成为绝对的必须。
挑战在于发现新的手段去处理这些数据的容量和复杂性,并且为研究人员提供更好的便利来获得分析和计算的工具,以便推动对我们遗传之物和其在健康和疾病中角色的理解。
国立中心的建立后来的参议员Claude Pepper意识到信息计算机化过程方法对指导生物医学研究的重要性,发起了在1988年11月4日建立国立生物技术信息中心(NCBI)的立法。
NCBI是在NIH的国立医学图书馆(NLM)的一个分支。
NLM是因为它在创立和维护生物信息学数据库方面的经验被选择的,而且这可以建立一个内部的关于计算分子生物学的研究计划。
NCBI的任务是发展新的信息学技术来帮助对那些控制健康和疾病的基本分子和遗传过程的理解。
它的使命包括四项任务:建立关于分子生物学,生物化学,和遗传学知识的存储和分析的自动系统实行关于用于分析生物学重要分子和复合物的结构和功能的基于计算机的信息处理的,先进方法的研究加速生物技术研究者和医药治疗人员对数据库和软件的使用。
ncbi使用方法

ncbi使用方法(原创版4篇)《ncbi使用方法》篇1CBI(National Center for Biotechnology Information)是美国国家生物技术信息中心的缩写,它提供了许多生物学和生命科学相关的数据库和工具。
以下是使用NCBI 的一些基本方法:1. 核酸序列数据库(Nucleotide Sequence Database):在NCBI 主页上,可以选择核酸序列数据库,输入序列名称或序列号,然后点击“Search”按钮即可查询序列信息。
2. 蛋白质序列数据库(Protein Sequence Database):在NCBI 主页上,可以选择蛋白质序列数据库,输入蛋白质名称或蛋白质号,然后点击“Search”按钮即可查询蛋白质信息。
3. 基因组数据库(Genome Database):在NCBI 主页上,可以选择基因组数据库,输入基因组名称或基因组号,然后点击“Search”按钮即可查询基因组信息。
4. 代谢通路数据库(Metabolic Pathway Database):在NCBI 主页上,可以选择代谢通路数据库,输入代谢通路名称或代谢通路号,然后点击“Search”按钮即可查询代谢通路信息。
5. 生物投影数据库(BioProject Database):在NCBI 主页上,可以选择生物投影数据库,输入生物投影名称或生物投影号,然后点击“Search”按钮即可查询生物投影信息。
6. 序列比对工具(Sequence Alignment Tool):NCBI 提供了一款名为“Clustal Omega”的序列比对工具,可以在NCBI 主页上使用该工具进行序列比对。
7. 基因表达数据库(Gene Expression Database):NCBI 提供了一款名为“GEO”的基因表达数据库,可以在NCBI 主页上查询基因表达数据。
8. 蛋白质结构数据库(Protein Structure Database):NCBI 提供了一款名为“RCSB PDB”的蛋白质结构数据库,可以在NCBI 主页上查询蛋白质结构信息。
NCBI序列提交方法

NCBI序列提交方法NCBI(National Center for Biotechnology Information)是一个提供生物学数据库和相关工具的国际性组织。
它托管并提供了大量的生物学和医学数据,包括基因组序列、蛋白质序列、文献数据、基因表达数据等。
NCBI数据库是生物学研究中重要的资源之一,而序列提交是将新的基因组或蛋白质序列添加到NCBI数据库的过程。
在本文中,我们将介绍如何使用NCBI的序列提交方法。
首先,要进行序列提交,您需要注册一个NCBI用户账号。
注册账号是免费的,并且可以让您获得进一步扩展和修改已提交序列的权限。
接下来,您需要准备您要提交的序列数据。
这可以是基因组序列、cDNA序列、蛋白质序列等。
在提交之前,请确保您的序列数据已经进行了适当的质量控制和整理,以确保数据的精确性和准确性。
一旦您准备好了序列数据,您可以使用NCBI的序列提交页面进行提交。
您可以通过以下步骤进行序列提交:2. 在主页上方的导航栏中,选择“Submit”。
3. 在下拉菜单中选择“Submissions”。
4. 选择适当的序列类型进行提交。
例如,如果您要提交基因组序列,选择“Genome”;如果是cDNA序列,选择“Transcriptome”;如果是蛋白质序列,选择“Protein”等。
6.将您的序列文件上传至NCBI的服务器。
通常,NCBI接受FASTA、GFF和GB格式的文件。
如果您的序列文件格式不符合要求,您可以通过本地软件进行格式转换,或者使用NCBI提供的工具进行转换。
7.在提交页面中进行进一步的设置,例如选择序列的性质、阅读朝向等。
此外,您还可以选择是否允许其他用户进行修改和扩展您的序列。
8. 最后,点击“Submit”按钮完成序列提交。
提交后,您的序列将被送至NCBI的审核队列。
NCBI的工作人员将对您的序列进行质检,并将其添加到相应的数据库中。
这个过程通常需要一些时间,所以请耐心等待。
ncbi使用指导

ncbi使用指导【原创版】目录1.NCBI 的概述2.NCBI 的使用方法3.NCBI 的数据库资源4.NCBI 的实用工具5.NCBI 的注意事项正文CBI(National Center for Biotechnology Information)是美国国家生物技术信息中心的缩写,是一个提供生物学和医学信息的数据库和工具的官方网站。
该网站由美国国家卫生研究院(NIH)建立,旨在为科学家、医生、研究人员和学生提供免费的生物学和医学信息。
以下是 NCBI 的使用指导:一、NCBI 的概述CBI 提供了多种数据库资源和实用工具,包括基因序列、蛋白质序列、基因组信息、生物学文献等。
这些资源对于生物学和医学研究非常重要。
二、NCBI 的使用方法1.访问 NCBI 的官方网站:https:///2.在主页上,你可以看到 NCBI 提供的各种数据库和工具的链接。
你可以点击链接进入相应的数据库或工具页面。
3.在数据库或工具页面,你可以使用各种搜索框和过滤器来查找你需要的信息。
例如,在基因序列数据库中,你可以输入基因名称或序列号来查找相关的基因序列信息。
三、NCBI 的数据库资源1.基因序列数据库(GenBank):提供了全球各种生物的基因序列信息。
2.蛋白质序列数据库(Protein Database):提供了全球各种生物的蛋白质序列信息。
3.基因组数据库(Genome Database):提供了全球各种生物的基因组信息。
4.生物学文献数据库(PubMed):提供了全球生物学和医学领域的文献信息。
四、NCBI 的实用工具1.BLAST(Basic Local Alignment Search Tool):用于比较基因序列或蛋白质序列的相似性。
2.Entrez:用于在 NCBI 的数据库中搜索和获取相关的生物学信息。
3.Coffee Break:用于查看和下载基因序列或蛋白质序列的图片。
五、NCBI 的注意事项1.在使用 NCBI 的数据库和工具时,请遵守相关的知识产权和版权规定。
NCBI Primer-BLAST使用方法

Primer-BLAST是NCBI的引物设计和特异性检验工具。
Primer-Blast介绍Primer-BLAST,在线设计用于聚合酶链反应(PCR)的特异性寡核苷酸引物。
Primer-BLAST可以直接从Blast主页(/)找到,或是直接用下面的链接进入:/tools/primer-blast/这个工具整合了目前流行的Primer3软件,再加上NCBI的 Blast进行引物特异性的验证。
Primer-BLAST免除了用另一个站点或工具设计引物的步骤,设计好的引物程序直接用Blast进行引物特异性验证。
并且,Primer-BLAST能设计出只扩增某一特定剪接变异体基因的引物–an important feature for PCR protocols measuring tissue specific expression(注:没办法准确的翻译,只好作罢,汗!)。
Primer-BLAST有许多改进的功能,这样在选择引物方面比单个的用 Primer3和NCBI BLAST更加准确。
Primer-BLAST的输入Primer-BLAST界面包括了Primer3和BLAST的功能。
提交的界面主要包括三个部分:target template(模板区), the primers(引物区), 和specificity check(特异性验证区)。
跟其它的BLAST一样,点击底部的“Advanced parameters”有更多的参数设置。
在“PCR Template”下面的文本框,输入目标模板的序列,FASTA格式或直接用Accession Number。
如果你在这里输入了序列,是用于引物的设计。
Primer-BLAST 就会根据你输入的序列设计特异性引物,并且在目标数据库(在specificity check区选择)是唯一的。
引物(Primers)如果你已经设计好了引物,要拿来验证引物的好坏。
可以在Primer Parameters 区填入你的一条或一对引物。
NCBI在线BLAST使用方法与结果详解

NCBI在线BLAST使用方法与结果详解BLAST(Basic Local Alignment Search Tool)是一套在蛋白质数据库或DNA数据库中进行相似性比较的分析工具。
BLAST程序能迅速与公开数据库进行相似性序列比较。
BLAST结果中的得分是对一种对相似性的统计说明。
BLAST 采用一种局部的算法获得两个序列中具有相似性的序列。
Blast中常用的程序介绍:1、BLASTP是蛋白序列到蛋白库中的一种查询。
库中存在的每条已知序列将逐一地同每条所查序列作一对一的序列比对。
2、BLASTX是核酸序列到蛋白库中的一种查询。
先将核酸序列翻译成蛋白序列(一条核酸序列会被翻译成可能的六条蛋白),再对每一条作一对一的蛋白序列比对。
3、BLASTN是核酸序列到核酸库中的一种查询。
库中存在的每条已知序列都将同所查序列作一对一地核酸序列比对。
4、TBLASTN是蛋白序列到核酸库中的一种查询。
与BLASTX相反,它是将库中的核酸序列翻译成蛋白序列,再同所查序列作蛋白与蛋白的比对。
5、TBLASTX是核酸序列到核酸库中的一种查询。
此种查询将库中的核酸序列和所查的核酸序列都翻译成蛋白(每条核酸序列会产生6条可能的蛋白序列),这样每次比对会产生36种比对阵列。
NCBI的在线BLAST:/Blast.cgi下面是具体操作方法1,进入在线BLAST界面,可以选择blast特定的物种(如人,小鼠,水稻等),也可以选择blast所有的核酸或蛋白序列。
不同的blast程序上面已经有了介绍。
这里以常用的核酸库作为例子。
2,粘贴fasta格式的序列。
选择一个要比对的数据库。
关于数据库的说明请看NCBI在线blast数据库的简要说明。
一般的话参数默认。
3,blast参数的设置。
注意显示的最大的结果数跟E值,E值是比较重要的。
筛选的标准。
最后会说明一下。
4,注意一下你输入的序列长度。
注意一下比对的数据库的说明。
5,blast结果的图形显示。
NCBI使用方法

NCBI使用方法NCBI (National Center for Biotechnology Information), 美国国家生物技术信息中心[url]/[/url]NCBI是NIH的国立医学图书馆(NLM)的一个分支。
NCBI提供检索的服务包括:1.GenBank(NIH遗传序列数据库):一个可以公开获得所有的DNA序列的注释过的收集。
GenBank是由NCBI受过分子生物学高级训练的工作人员通过来自各个实验室递交的序列和同国际核酸序列数据库(EMBL和DDBJ)交换数据建立起数据库的。
它同日本和欧洲分子生物学实验室的DNA数据库共同构成了国际核酸序列数据库合作。
这三个组织每天交换数据。
其中的数据以指数形式增长,最近的数据为它已经有来自47000个物种的30亿个碱基。
2.Molecular Databases(分子数据库):Nucleotide Sequence(核酸序列库):从NCBI其他如Genbank数据库中收集整理核酸序列,提供直接的检索。
Protein Sequence (蛋白质序列库):与核酸类似,也是从NCBI多个不同资源中编译整理的,方便研究者的直接查询。
Structure(结构)-——关于NCBI结构小组的一般信息和他们的研究计划,另外也可以访问三维蛋白质结构的分子模型数据库(MMDB)和用来搜索和显示结构的相关工具。
MMDB:分子模型数据库—一个关于三维生物分子结构的数据库,结构来自于X-ray晶体衍射和NMR色谱分析。
Taxonomy(分类学)——NCBI的分类数据库,包括大于7万余个物种的名字和种系,这些物种都至少在遗传数据库中有一条核酸或蛋白序列。
其目的是为序列数据库建立一个一致的种系发生分类学。
3.Literature Databases(文献数据库)(1)PubMed是NLM提供的一项服务,能够对MEDLINE上超过1200万条的上世纪六十年代中期至今的杂志引用和其他的生命科学期刊进行访问,并可以连接到参与的出版商网络站点的全文文章和其他相关资源。
ncbi的使用方法

ncbi的使用方法
1.功能:
-在NCBI网站的主页上,可以找到一个栏。
在栏中输入关键词,可以特定的基因、蛋白质、序列或文献等。
-在结果页面中,可以使用筛选器(过滤器)来缩小范围,例如按照物种、文章类型、出版日期等进行筛选。
2.数据库浏览:
- NCBI拥有多个数据库,包括GenBank、PubMed、Protein、Nucleotide等。
用户可以通过点击导航栏上的“主页”选择相应的数据库。
- 在每个数据库页面上,用户可以找到相关的方法和信息。
例如,在GenBank数据库页面上,用户可以和浏览基因序列的信息。
- NCBI 的PubMed数据库提供了数百万篇生物医学文献的摘要和全文信息。
用户可以通过在栏中输入关键词来特定的文献。
- 在结果页面上,用户可以点击文章标题来查看摘要,进一步点击“Full Text”或“PDF”链接来获取全文。
一些文章可能需要订阅或付费获取。
- 用户还可以使用PUBMED Central(PMC)数据库来获取免费的全文文章。
4.序列和分析:
- NCBI 的Nucleotide和Protein数据库提供了大量的基因和蛋白质序列。
用户可以通过在栏中输入基因或蛋白质的名称、序列号或其他相关信息来相应的序列。
- NCBI还提供了一些序列分析工具,例如BLAST(Basic Local Alignment Search Tool),可以对新序列进行比对和分析。
6.创建和保存历史:
7.利用NCBIAPI:。
NCBI(美国国立生物技术信息中心)使用方法

雨的印记乮潜伏系列乯NCBI(美国国立生物技术信息中心)资源介绍及使用手册 作者:未知 来源:中科院上海生命科学研究院生物信息中心 时间:2006-12-27 NCBI 资源介绍本文目录:NCBI(美国国立生物技术信息中心) 简介NCBI 站点地图NCBI 癌症基因组研究NCBI -Coffee BreakNCBI -基因和疾病NCBI -UniGeneCluster of Orthologous Groups of proteins(COG )介绍Gene Expression Omnibus (GEO )介绍 LocusLink 介绍 关于RefSeq :NCBI 参考序列 NCBI(美国国立生物技术信息中心)简介介绍理解自然无声但精妙的关于生命细胞的语言是现代分子生物学的要求。
通过只有四个字母来代表DNA 化学亚基的字母表,出现了生命过程的语法,其最复杂形式就是人类。
阐明和使用这些字母来组成新的“单词和短语”是分子生物学领域的中心焦点。
数目巨大的分子数据和这些数据的隐秘而精细的模式使得计算机化的数据库和分析方法成为绝对的必须。
挑战在于发现新的手段去处理这些数据的雨的印记乮潜伏系列乯容量和复杂性,并且为研究人员提供更好的便利来获得分析和计算的工具,以便推动对我们遗传之物和其在健康和疾病中角色的理解。
国立中心的建立后来的参议员Claude Pepper 意识到信息计算机化过程方法对指导生物医学研究的重要性,发起了在1988年11月4日建立国立生物技术信息中心(NCBI )的立法。
NCBI 是在NIH 的国立医学图书馆(NLM )的一个分支。
NLM 是因为它在创立和维护生物信息学数据库方面的经验被选择的,而且这可以建立一个内部的关于计算分子生物学的研究计划。
NCBI 的任务是发展新的信息学技术来帮助对那些控制健康和疾病的基本分子和遗传过程的理解。
它的使命包括四项任务: 建立关于分子生物学,生物化学,和遗传学知识的存储和分析的自动系统 实行关于用于分析生物学重要分子和复合物的结构和功能的基于计算机的信息处理的,先进方法的研究 加速生物技术研究者和医药治疗人员对数据库和软件的使用。
NCBI在线BLAST使用方法与结果详解

NCBI在线BLAST使用方法与结果详解NCBI在线BLAST(Basic Local Alignment Search Tool)是一种广泛使用的生物信息学工具,用于比对和分析DNA、RNA或蛋白质序列。
它可以对已知和未知序列进行,找到与查询序列相似的序列,并提供有关相似性和功能的信息。
使用NCBI在线BLAST可以分为四个主要步骤:选择BLAST程序,输入查询序列,选择目标数据库,解析和分析结果。
第一步:选择BLAST程序NCBI提供了多种BLAST程序可供选择,包括BLASTN(DNA对DNA的比对)、BLASTP(蛋白质对蛋白质的比对)、BLASTX(DNA对蛋白质的比对)等。
根据实际需求选择相应的BLAST程序。
第二步:输入查询序列在查询序列的文本框中输入待比对的序列。
可以输入单个序列,也可以上传包含多个序列的文件。
如果输入的序列是DNA或RNA序列,需要选择相应的序列类型。
此外,还可以选择是否使用掩码序列或低复杂性筛选来优化比对结果。
第三步:选择目标数据库用户可以选择目标数据库来与查询序列相似的序列。
NCBI提供了多个常用的数据库,如nr(非冗余蛋白质数据库)、nt(核酸数据库)等。
此外,还可以选择特定的物种数据库来限制比对范围。
第四步:解析和分析结果在BLAST运行完成后,会生成一个结果页面,其中包含了比对结果的详细信息。
结果页面包括比对统计信息、序列比对图、E值、分数等。
通过分析这些信息,可以了解查询序列与目标数据库中的序列之间的相似性和可能的功能。
此外,NCBI在线BLAST还提供了一些高级选项,例如使用特定的算法或参数来进行比对、设置比对阈值、选择比对输出格式等。
这些选项可以根据实际需求进行调整。
总结起来,使用NCBI在线BLAST可以通过选择BLAST程序、输入查询序列、选择目标数据库以及解析和分析结果来比对和分析序列。
通过权衡算法和参数选择,在特定数据库中找到与查询序列相似的序列,从而获得有关其相似性和功能的信息。
ncbi中查找基因序列的方法和三个号码
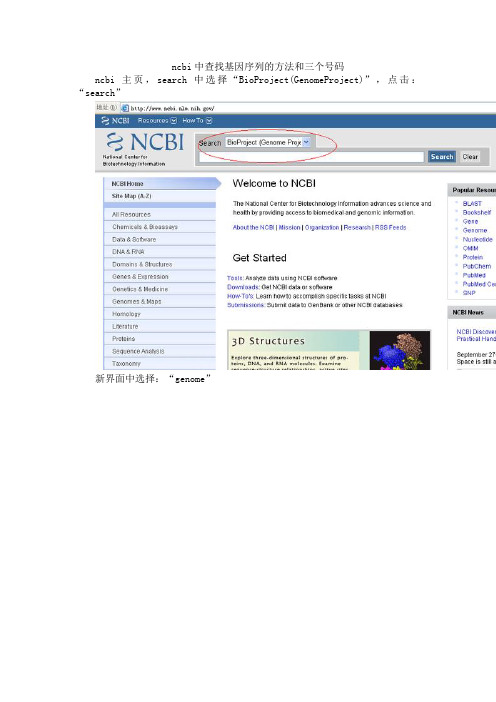
ncbi中查找基因序列的方法和三个号码
ncbi主页,search中选择“BioProject(GenomeProject)”,点击:“search”
新界面中选择:“genome”
新窗口中选择:“Prokaryotes”:
出现“genomeproject”选项,选择下拉框内的你要查找的菌的域名:例如:“Euryarchaeota(广古菌域)”
下拉滚动条,选择要下载基因组的菌株名,例如:MethanococcusvoltaeA3
点击对应的基因组号:
选择:NC_014222.1 进入MethanococcusvoltaeA3chromosome,completegenome
【注:若选择CP002057.1 可直接进入“MethanococcusvoltaeA3,completegenome”。
】
1.查找蛋白序列:
选择:Proteincoding: 1717 ,此界面上可以看到蛋白功能等方面的信息:
display选项中选择:“ProtienFASTA”,如果想下载序列,选择sendto 中的文件格式,保存即可。
2.查找核酸序列:
选择:GenBank: CP002057
然后选择页面右上角的sendto可以进行下载。
初步总结如上,NCBI的强大功能还要不断摸索!。
ncbi中查找基因序列的方法和三个登录号

ncbi 中查找基因序列的方法和三个号码中查找基因序列的方法和三个号码一.例子:查找酿酒酵母(Saccharomyces cerevisiae )里的海藻糖合成酶基因(tps1) 即可出现很多条目,找到Saccharomyces cerevisiae 的就是NC_001134了,点击后就进入该基因所在染色体的界面了,再在“编辑”中“查找” tps1就可以看该基因所在的位置,再点击CDS 或者GeneID:GeneID:852*********都可以出现相关链接!都可以出现相关链接!当然,如果你在文献查到目的蛋白的序列号如NP_009684.1或者GeneID:GeneID:852423852423,那分别在Search 后选择Protein 或者Gene 也可以出现相关链接!也可以出现相关链接!二.基因CDS 区界面的3个号码/entrez/viewer.fcgi?val=50593115&from=488899&to=490386&view=gbwithparts找到后,我发现该界面有3个标记,一个是NC_001134 ,其次是gi:50593115,最后是FEA TURES 中的gene 中的中的 /db_xref= “GeneID:GeneID:852423852423”,他们分别是什么号码,用在什么地方呢?尝试中,终于发现,地方呢?尝试中,终于发现,在Search “Nucleotide ”或者“Core Core NucleotideNucleotide ”时,for 后面是NC_001134,最终go 到该基因所在染色体全长序列的信息,所以NC_001134应该是该染色体的登录号吧?应该是该染色体的登录号吧?在Search “Nucleotide ”或者“Core Core NucleotideNucleotide ”时,for 后面是50593115,最终go 到该基因所在染色体全长序列的信息,所以50593115应该是该染色体的号吧?应该是该染色体的号吧?在Search “Gene ”时,for 后面是852423,最终go 到该基因的信息,所以852423应该是该基因的登录号吧?所以我们如果要记住目的基因在ncbi 中的位置就记住这个GeneID !其他像NP_009684当然是基因编码的蛋白质的登录号啦,不说了。
NCBI使用方法

。例为面画的入进个一第击点以面下 。击点� �个一只不能可�列序应相择选等置位的体色染在生学大州苏
IBC N 用使你教步一步一
21
0=ega&1=gpt&1=yts&3623259=di&76=dib?weiv/tsop/sbb/nc.yxd.www//:ptth 0=ega&1=gpt&1=yts&2977159=di&46=dib?weiv/tsop/sbb/nc.yxd.www//:ptth 。的发我是则个一另�习学得值很�富丰很容内�的起发 2002iyezuil 主版版本 是个一第�下一看家大给子帖个两荐推�了说多不就里这在我容内细详的计设物引。ogilO 和 5 remirP 用使议建 �吧计设己自就那 �话的物引的要需你到找能不都法方种两这果如 。强又性靠可�间时 省既��呢用不么什为们我物引的道报经已�文论关相阅查以可家大�物引找寻想果如 。了用使来过拿接直以可�物引的熟成很是都物引些这�你喜恭�话的段片的 P 想 你有好恰面里这果如但 �高很是不度程用实 �道味的巧取机投点有法方的物引找寻种这 。了掘发慢慢己自你要这过 不 �物引的用有己自对有会还能可的他其开打续继 �列序个一了开点只我面里二骤步在 。列序补互的 B remirP 和 列序原的 A remirP 是的 到找接直以可中列序在�增扩链双是 RCP�意注要过不 �的到找以可是�下一找中列序在 以可友朋的趣兴有。置位的中列序 AND 在们他了出给且并�列序物引后是则 B remirP�列 序物引前是 A remirP 中其�件条应反和系体应反有还�了前眼在现呈都物引后前�啊
分部 二第
IBC N 用使你教步一步一
7
取抓只(面页下以现出�字名的因基的目击点�面页的现出后之”oG“击点 1 骤步到回 列序白蛋、ANRm 找查 2.2
NCBI使用方法详解(中文)

一步一步教你使用NCBI 查找DNA、mRNA、cDNA、Protein、promoter、引物设计、BLAST序列比对等作者:urbest2007-8-1苏州大学生命科学学院最近看到很多战友在论坛上询问如何查询基因序列、如何进行引物设计、如何使用BLAST进行序列比对……,这些问题在NCBI上都可以方便的找到答案。
现在我就结合我自己使用NCBI的一些经历(经验)跟大家交流一下BCBI的使用。
希望大家都能发表自己的使用心得,让我们共同进步!我分以下几个部分说一下NCBI的使用:Part one 如何查找基因序列、mRNA、PromoterPart two 如何查找连续的mRNA、cDNA、蛋白序列Part three 运用STS查找已经公布的引物序列Part four 如何运用BLAST进行序列比对、检验引物特异性特别感谢本版版主,将这个帖子置顶!从发帖到现在,很多战友对该帖给与了积极的关注,在此向给我投票的(以及想给我投票却暂时不能投票的)各位战友表示真诚的感谢,谢谢各位战友!请大家对以下我发表的内容提出自己的意见。
关于NCBI其他方面的使用也请水平较高的战友给予补充First of all,还是让我们从查找基因序列开始。
第一部分 利用Map viewer查找基因序列、mRNA序列、启动子(Promoter)下面以人的IL6(白细胞介素6)为例讲述一下具体的操作步骤1.打开Map viewer页面,网址为:/mapview/index.html 在search的下拉菜单里选择物种,for后面填写你的目的基因。
操作完毕如图所示:2.点击“GO”出现如下页面:3.在步骤二图示的右下角有一个Quick Filter,下面是让你选择的几个复选框,在Gene 前面的小方框里打勾,然后点击Filter. 出现下图:说明一下:1、染色体的红色区域即为你的目的基因所处位置。
2、下面参考序列给出了三个,是不同的部门做出来的,经我验证,序列有微小的差异,但总体来说基本相同。
NCBI使用方法

NCBI使用方法NCBI(National Center for Biotechnology Information)是一个提供生物学数据库和工具的公共资源。
它提供了许多与生物学相关的数据库,如基因、蛋白质、序列、文献等。
这些数据库对于生物学研究者和生物信息学家来说是非常有用的。
本文将介绍如何使用NCBI进行常见的生物学研究。
另一个常用的NCBI数据库是GenBank,它是一个包含DNA序列、RNA序列和蛋白质序列的数据库。
要在GenBank中查找特定序列,可以在NCBI主页中的框中输入序列信息,如基因名称、序列碱基或蛋白质序列;还可以输入序列的GenBank号、Accession号或序列的FASTA格式。
点击后,系统会返回与查询相关的序列记录。
每个记录都包含序列信息、注释和相关文献等。
当找到感兴趣的序列后,可以查看其详细信息。
如果序列是基因,可以了解它的基因组位置、启动子区域、外显子和内含子等信息。
如果序列是蛋白质,可以了解其氨基酸序列、结构、功能等信息。
此外,在GenBank中还可以找到与特定序列关联的其他序列记录,如同一基因的多个转录本、同源基因等。
除了PubMed和GenBank外,NCBI还提供了许多其他有用的数据库和工具。
例如,BLAST(Basic Local Alignment Search Tool)是一个用于比较序列相似性的工具,可以帮助找到特定序列的同源序列。
通过输入查询序列,BLAST可以在NCBI的数据库中相似的序列,并对它们进行比对。
这对于鉴定未知序列的功能以及研究序列进化关系非常有用。
此外,NCBI还提供了一些用于序列分析和生物信息学研究的工具。
例如,COBALT(Constraint-Based Multiple Alignment Tool)可以用于多序列比对,Open Reading Frame Finder可以用于预测DNA序列中的开放阅读框,而RefSeq database则提供了高质量的基因组和蛋白质序列等。
ncbi使用指导

ncbi使用指导摘要:一、NCBI 简介1.NCBI 的定义和作用2.NCBI 的主要数据库二、NCBI 数据库使用方法1.基因数据库查询2.蛋白质数据库查询3.核酸序列数据库查询4.文献数据库查询三、NCBI 工具使用方法1.BLAST 工具2.ClustalW 工具3.Primer-BLAST 工具四、NCBI 的高级功能1.基因变异数据库查询2.基因表达数据库查询3.基因组数据库查询正文:一、NCBI 简介CBI(National Center for Biotechnology Information,美国国家生物技术信息中心)是一个提供生物科学和生物医学研究的公共资源网站。
它包含了大量的生物学和医学信息,为科研工作者提供了便捷的生物信息学资源。
NCBI 的主要数据库包括基因数据库、蛋白质数据库、核酸序列数据库和文献数据库等。
二、NCBI 数据库使用方法1.基因数据库查询基因数据库(Gene Database)是NCBI 的核心数据库之一,包含了大量已知的基因信息。
用户可以通过基因名称、序列标签、转录因子结合位点等信息进行查询。
查询结果包括基因的详细信息、基因序列、表达数据等。
2.蛋白质数据库查询蛋白质数据库(Protein Database)包含了大量已知的蛋白质信息,包括蛋白质序列、功能域、结构域等。
用户可以通过蛋白质名称、序列、功能等信息进行查询。
查询结果包括蛋白质的详细信息、序列、结构等。
3.核酸序列数据库查询核酸序列数据库(Nucleotide Database)包含了大量已知的核酸序列信息,包括基因组序列、cDNA 序列等。
用户可以通过序列名称、物种等信息进行查询。
查询结果包括核酸序列的详细信息、序列等。
4.文献数据库查询文献数据库(PubMed Database)是生物医学领域的文献摘要数据库,收录了大量的生物学和医学文献。
用户可以通过关键词、作者、杂志等信息进行查询。
查询结果包括文献的详细信息、摘要等。
NCBI使用方法详解

NCBI使用方法详解NCBI是美国国家图书馆国家医学院的生物信息学中心(National Center for Biotechnology Information)的缩写。
该中心为生物学研究提供了大量的数据库资源和工具,供科学家和研究人员使用。
NCBI的数据库涵盖了生物学、医学和生物化学等领域的各种数据,包括基因序列、蛋白质序列、文献数据等。
这些数据资源可以帮助研究人员进行基因和蛋白质的功能注释、序列比对、基因表达分析等生物信息学分析。
以下是NCBI的使用方法的详细介绍。
1.访问NCBI网站2.注册NCBI账号如果是第一次使用NCBI,建议注册一个账号。
点击页面右上方的“Sign In”按钮,再选择“Register for an NCBI Account”选项,根据指引填写必要的信息,完成注册。
3.和浏览数据库NCBI提供了多个数据库,如Pubmed(文献数据库)、GenBank(基因序列数据库)和Protein(蛋白质序列数据库)等。
在首页的框中输入关键词,即可相应的数据库。
4.进行基因和蛋白质的序列比对在NCBI中进行序列比对,可以使用BLAST(基本局部序列比对工具)或者BLAST+(改进版局部序列比对工具)工具。
点击首页的“BLAST”链接,选择相应的工具,输入查询序列,选择目标数据库和参数,点击“Submit”按钮开始比对。
5.获取文献信息NCBI的Pubmed数据库包含了大量的科学文献,可以通过关键词或是使用高级功能来获取所需的文献。
在结果页面,可以查看摘要、全文以及相关的引用文献。
6.分析基因表达数据NCBI提供了一系列工具,用于分析基因表达数据,如GEO(基因表达数据库)和SRA(短读测序存储库)等。
可以在首页的“Datasets”菜单中选择相应的工具,上传或所需的基因表达数据进行分析。
7.获取基因和蛋白质的注释信息NCBI的GenBank和Protein数据库中包含了大量的基因和蛋白质的序列和注释信息。
ncbi序列比对方法与操作实例

NCBI序列比对方法与操作实例一、序列比对方法概述1. 序列比对的概念序列比对是指通过对两个或多个生物序列进行比较分析,找到它们之间的相似性和差异性。
序列比对是生物信息学中的重要工具之一,可以帮助研究人员理解DNA、RNA、蛋白质等生物分子的结构和功能,进而推动生物医药和生物科学领域的发展。
2. 序列比对的意义在生物学研究中,通过对不同生物序列进行比对分析,可以揭示它们之间的进化关系、基因结构、功能和调控机制等重要信息,有助于揭示生物系统的内在规律。
序列比对还可以在分子生物学实验设计、基因工程、疾病诊断、新药开发等方面发挥重要作用。
3. 序列比对的方法常用的序列比对方法包括全局比对、局部比对和多序列比对等,其中全局比对适用于寻找整个序列间的相似段,局部比对适用于寻找两个序列中的部分匹配段,多序列比对则适用于比较多个序列之间的相似性和差异性。
二、NCBI序列比对工具介绍1. NCBI数据库NCBI(National Center for Biotechnology Information)是美国国家生物技术信息中心,是全球生物学信息资源的重要提供者之一。
NCBI数据库中包含大量生物信息数据,包括基因组序列、蛋白质序列、原始文献、生物信息学工具等。
2. NCBI序列比对工具NCBI提供了一系列用于序列比对的工具,其中包括BLAST(Basic Local Alignment Search Tool)、BLAT(BLAST-Like Alignment Tool)、ClustalW、MAFFT等。
这些工具可以帮助研究人员进行序列比对分析,找到感兴趣的生物序列在数据库中的同源序列或相似序列。
三、NCBI序列比对操作实例以BLAST工具为例,介绍NCBI序列比对的操作步骤。
1. 打开NCBI全球信息湾打开NCBI全球信息湾(),在全球信息湾首页的搜索栏中输入“BLAST”,进入BLAST工具的页面。
2. 输入查询序列在BLAST工具的页面中,选择适当的数据库,粘贴或上传待比对的查询序列,可以选择标准蛋白数据库、EST数据库、基因组数据库等作为比对的对象。
NCBI使用方法详解

NCBI使用方法详解NCBI(National Center for Biotechnology Information)是一个国际知名的生物技术信息中心,在生物信息学和生物医学研究领域起到重要的引领和支持作用。
在NCBI中,可以获取到海量的生物信息资源,同时也提供了一系列的工具和数据库,方便研究人员进行生物信息分析和研究。
本文将详细介绍NCBI的使用方法。
一、注册和登录在使用NCBI之前,首先需要注册一个账号。
在NCBI主页上,点击右上角的“Sign in to NCBI”按钮,然后选择“Register for an NCBI account”选项。
二、浏览和NCBI提供了海量的生物信息资源,可以通过浏览或者的方式来获取所需的信息。
1.浏览NCBI的主页上展示了许多重要的生物学数据库和工具,如Pubmed、Gene、BLAST等。
通过点击相应的链接,可以进入到对应的数据库或工具页面,进行浏览和。
2.NCBI提供了集中化的检索系统,可以通过关键词或者序列等信息进行。
在NCBI主页的框中输入关键词,然后点击“Search”按钮,即可进行。
结果中会显示相关资源的链接,点击链接即可进入具体的资源页面。
三、基因和序列NCBI提供了全面的基因和序列数据库,方便用户查找和获取相关信息。
1. Gene数据库Gene数据库是一个基因注释和浏览数据库,包含了所有已知的基因信息。
在NCBI主页的框中输入基因名或者ID,然后选择“Gene”选项,点击“Search”按钮即可进行。
结果中会显示与输入关键词相关的基因信息,点击链接即可进入基因信息页面,查看基因注释、对应的序列、蛋白质信息等。
2. Nucleotide数据库Nucleotide数据库是一个存储和管理核酸序列的数据库,包含了各种生物组织中的DNA和RNA序列信息。
在NCBI主页的框中输入序列的名称、ID或者序列本身,然后选择“Nucleotide”选项,点击“Search”按钮即可进行。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
NCBI使用方法NCBI (National Center for Biotechnology Information), 美国国家生物技术信息中心[url]/[/url]NCBI是NIH的国立医学图书馆(NLM)的一个分支。
NCBI提供检索的服务包括:1.GenBank(NIH遗传序列数据库):一个可以公开获得所有的DNA序列的注释过的收集。
GenBank是由NCBI受过分子生物学高级训练的工作人员通过来自各个实验室递交的序列和同国际核酸序列数据库(EMBL和DDBJ)交换数据建立起数据库的。
它同日本和欧洲分子生物学实验室的DNA数据库共同构成了国际核酸序列数据库合作。
这三个组织每天交换数据。
其中的数据以指数形式增长,最近的数据为它已经有来自47000个物种的30亿个碱基。
2.Molecular Databases(分子数据库):Nucleotide Sequence(核酸序列库):从NCBI其他如Genbank数据库中收集整理核酸序列,提供直接的检索。
Protein Sequence (蛋白质序列库):与核酸类似,也是从NCBI多个不同资源中编译整理的,方便研究者的直接查询。
Structure(结构)-——关于NCBI结构小组的一般信息和他们的研究计划,另外也可以访问三维蛋白质结构的分子模型数据库(MMDB)和用来搜索和显示结构的相关工具。
MMDB:分子模型数据库—一个关于三维生物分子结构的数据库,结构来自于X-ray晶体衍射和NMR色谱分析。
Taxonomy(分类学)——NCBI的分类数据库,包括大于7万余个物种的名字和种系,这些物种都至少在遗传数据库中有一条核酸或蛋白序列。
其目的是为序列数据库建立一个一致的种系发生分类学。
3.Literature Databases(文献数据库)(1)PubMed是NLM提供的一项服务,能够对MEDLINE上超过1200万条的上世纪六十年代中期至今的杂志引用和其他的生命科学期刊进行访问,并可以连接到参与的出版商网络站点的全文文章和其他相关资源。
(2)PMC/PubMed Center:也是NLM的生命科学期刊文献的数字化存储数据库,用户可以免费获取PMC的文章全文,除了部分期刊要求对近期的文章付费。
(3)OMIM(孟德尔人类遗传):有关人类基因和无序基因的目录数据库由Victor A.McKusick和他的同事共同创造和编辑的,由NCBI网站负责开发,其中也包括对MEDINE众多资源和Entrez系统的序列记录,以及NCBI中其他有关资源的链接。
(4)Books:NCBI的书库不断收集生物医学方面的书籍,提供这些书籍的出版信息、摘要、目录和全文的连接,用户可以直接在检索文本框内输入一个观念就可以查询。
4.NCBI提供的附加的软件工具有:开放阅读框寻觅器(ORF Finder),电子PCR,和序列提交工具Sequin和BankIt。
所有的NCBI数据库和软件工具可以从WWW或FTP来获得。
NCBI还有E-mail服务器,提供用文本搜索或序列相似搜索访问数据库一种可选方法。
NCBI网站上还提供了一些诸如研究热点问题、研究小组情况、教育培训、联系方式等信息,还提供了到NIH、NLM等的链接。
使用方法:用户可以免费登陆NCBI的网站,NCBI为使用者提供了方便的检索系统和检索方法:1.Entrez是NCBI为用户提供整合所有数据库的访问序列,定位,分类,和结构数据的搜索和检索工具系统,同时也提供序列和染色体图谱的图形视图。
用户进入系统或者进入任意一个数据库,都会看到简单检索的界面,选择数据库输入关键词即可进行查询。
Entrez 也提供条件限制和高级检索、布尔逻辑查询。
使用新的Linkout服务,外部资源可以被链接到Entrez记录。
2.BLAST是一个NCBI开发的序列相似搜索程序,还可作为鉴别基因和遗传特点的手段。
BLAST能够在小于15秒的时间内对整个DNA数据库执行序列搜索。
NCBI Education[url]/Education/index.html[/url]网址详情:这是NCBI在线教育资源的索引页,从这里出发你会找到NCBI提供的教学资源,这些教程不仅囊括了NCBI网站提供的最常用的工具和数据库(BLAST, Entrez, PubMed, NCBI News,Resource publications ,Map Viewer exercises,Structure ,NCBI Handbook)的使用方法和信息,还有一些相关的分子生物学的基础入门知识(NCBI science primer...)。
教程大多不仅有文字图片还有动画,直观易懂,目的就是一个让大家尽可能快而有效的掌握好NCBI的使用,在这个聚宝盆里淘到真金。
当然您如果想对所有NCBI的数据库和工具有更透彻深入的了解,请绝对不要错过共24章的NCBI手册(NCBI Handbook)[url]/books/bv.fcgi?rid=handbook[/url]小何 2007-9-7 09:20GenBank数据库简介[color=green][i]不错的内容,我来补充下[/i][/color][color=red]GenBank数据库简介[/color][b]基本信息:[/b]1. GenBank属于一个序列数据库的国际合作组织,包括EMBL和DDBJ。
是NIH遗传序列数据库,一个所有可以公开获得的DNA序列的注释过的收集。
GenBank同日本和欧洲分子生物学实验室的DNA数据库共同构成了国际核酸序列数据库合作。
唯一人类基因序列集合(UniGene),人类基因组基因图谱,分类学浏览器,同国立癌症研究所合作的癌症基因组剖析计划(CGAP)等数据库。
GenBank以指数形式增长,核酸碱基数目大概每14个月就翻一个倍。
2. 纪录样本 - 关于GenBank的各个字段的详细描述,以及同Entrez搜索字段的交叉索引。
3. 访问GenBank - 通过Entrez Nucleotides来查询。
用accession number,作者姓名,物种,基因/蛋白名字,还有许多其他的文本术语来查询。
关于Entrez更多的信息请看下文。
用BLAST来在GenBank和其他数据库中进行序列相似搜索。
用E-mail来访问Entrez 和BLAST可以通过Query和BLAST服务器。
另外一种选择是可以用FTP下载整个的GenBank和更新数据。
4. 增长统计 - 参见公布通知的2.2.6(每个分类的统计),2.2.7(每个物种的统计),2.2.8(GenBank增长)小节。
5. 公布通知,最新 - 最近和即将有的变化,GenBank的分类,数据增长统计,GenBank的引用。
6. 公布通知,旧 - 同上相同,是过去公布的统计。
7. 遗传密码 - 15个遗传密码的概要。
用来确保GenBank中纪录的编码序列被正确的翻译。
[b]向GenBank提交数据:[/b]1. 关于提交序列数据,收到accession number,和对纪录作更新的一般信息。
2. BankIt - 用于一条或者少数条提交的基于WWW的提交工具软件。
(请在提交前用VecScreen去除载体)3. Sequin - 提交软件程序,用于一条或者很多条的提交,长序列,完整基因组,alignments,人群/种系/突变研究的提交。
可以独立使用,或者用基于TCP/IP的“network aware”模式,可以链接到其他NCBI的资源和软件比如Entrez和PowerBLAST。
(请在提交前用VecScreen去除载体)4. ESTs - 表达序列标签,短的、单次(测序)阅读的cDNA序列。
也包括来自于差异显示和RACE实验的cDNA序列。
5. GSSs - 基因组调查序列,短的、单次(测序)阅读的cDNA序列,exon trap获得的序列,cosmid/BAC/YAC末端,及其他。
6. HTGs - 来自于大规模测序中心的高通量基因组序列,未完成的(阶段0,1,2)和完成的(阶段3)序列。
(注意:完成的人类的HTG序列可以同时在GenBank和Human GenomeSequencing页面上访问。
)7. STSs - 序列标签位点。
短的在基因组上可以被唯一操作的序列,用于产生作图位点。
8. 注:SNPs - 人类的和其他物种的遗传变异数据可以提交到NCBI数据库的单核苷酸多态性库中(dbSNP)。
[b]国际核苷酸序列数据库合作组织:[/b]1. GenBank,DDBJ,EMBL - 合作计划的概述,并链接到相应的主页。
GenBank,DDBJ (DNA Data Bank of Japan),and EMBL (European Molecular Biology Laboratory)数据库共享的数据是每天都交换的,因此他们是相等的。
数据纪录的格式和搜索方式可能会不一样,但是accession number,序列数据和注解都是一模一样的。
即,你可以用accession number U12345在GenBank,DDBJ或EMBL中查找相应纪录,得到的结果是完全一样的序列数据,参考内容等等2. DDBJ/EMBJ/GenBank特性表—特性表格式和标准被合作数据库用在序列记录的注释上,使得数据共享成为可能,包括详细的描述生物特性和特性限定语的附录,以及IUPAC规定的核苷酸和氨基酸的代号。
[b]FTP GenBank and Daily Updates:[/b]1. GenBank普通文件格式—参见GenBank记录样本和在GenBank公布通知中的详细描述,下载大多数最近的完全公告和日常积累或非积累更新数据。
2. ASN.1格式—摘要句法记号1,国际标准组织(ISO)数据表示格式,下载大多数最近的完全公告和日常积累或非积累更新数据。
3. FASTA格式—定义行号后只跟随序列数据(示例),参见描述数据库的readme 文件,包括nt.Z(每天更新的非冗余BLAST核酸数据库,包括GenBank+EMBL+DDBJ+PDB序列,但是不包括EST, STS, GSS, or HTGS序列),nr.Z(每日更新的非冗余蛋白质),est.Z,gss.Z, htg.Z, sts.Z,和其它文件。
[b]分子数据库:[/b]1. 核酸序列1、 Entrez核酸:用accession number,作者姓名,物种,基因/蛋白名字,以及很多其它的文本术语来搜索核酸序列记录(在GenBank + PDB中)。
更多的关于Entrez的信息见下。
如果要检索大量数据,也可使用Batch Entrez(批量Entrez)。