哈夫曼树
哈夫曼树定义

哈夫曼树定义
哈夫曼树是一种二叉树,它用来表示一组符号权值的最优编码。
它应用于编码论,通常用来代表数据权值的树。
哈夫曼树是指一种最短带宽传输时能够有效工作的最优编码树。
哈夫曼树是每个节点都包含一个权值的二叉树。
它的定义如下:每一个权值所构成的数据集合,其最优树形式是每一个数据项的权值都比它的子节点的权值大,最终形成一个哈夫曼树。
哈夫曼树的构建一般是以权值的大小为基础进行的,权值越大,在哈夫曼树上就越靠近根节点,在结点之间的路径越短,这样便可以减少树的总长度,可以加快数据的传输速度。
此外,哈夫曼树还可以用于实现多种额外的功能。
哈夫曼树的构建有一种特别的方法,叫做“哈夫曼编码”,它采用“编码”和“解码”的方法来把一个数据集分成不同的组,这些组就是哈夫曼树的节点。
每组的数据都含有一个权值,当这些组被组合到一起时,它们就构成了一棵哈夫曼树。
哈夫曼树的建立是低耗时的,最优建立方式是将权值数组排序,然后依次添加,添加过程为:先将最小的两个数字添加到根节点,再将它们的和也添加到根节点,重复此过程,直到所有数字都被添加完为止。
哈夫曼树在编码的时候,如果一个字符出现的次数越多,它的权值就越大,它就越接近根节点。
数据结构哈夫曼树和哈夫曼编码权值

数据结构哈夫曼树和哈夫曼编码权值一、引言在计算机领域,数据结构是非常重要的一部分,而哈夫曼树和哈夫曼编码是数据结构中非常经典的部分之一。
本文将对哈夫曼树和哈夫曼编码的权值进行全面评估,并探讨其深度和广度。
通过逐步分析和讨论,以期让读者更深入地理解哈夫曼树和哈夫曼编码的权值。
二、哈夫曼树和哈夫曼编码的基本概念1. 哈夫曼树哈夫曼树,又称最优二叉树,是一种带权路径长度最短的二叉树。
它的概念来源于一种数据压缩算法,可以有效地减少数据的存储空间和传输时间。
哈夫曼树的构建过程是基于给定的权值序列,通过反复选择两个最小权值的节点构建出来。
在构建过程中,需要不断地重排权值序列,直到构建出一个满足条件的哈夫曼树。
2. 哈夫曼编码哈夫曼编码是一种变长编码方式,它利用了哈夫曼树的特点,对不同的字符赋予不同长度的编码。
通过构建哈夫曼树,可以得到一套满足最优存储空间的编码规则。
在实际应用中,哈夫曼编码经常用于数据压缩和加密传输,能够有效地提高数据的传输效率和安全性。
三、哈夫曼树和哈夫曼编码的权值评估1. 深度评估哈夫曼树和哈夫曼编码的权值深度值得我们深入探究。
从构建哈夫曼树的角度来看,权值决定了节点在树中的位置和层次。
权值越大的节点往往位于树的底层,而权值较小的节点则位于树的高层。
这种特性使得哈夫曼树在数据搜索和遍历过程中能够更快地找到目标节点,提高了数据的处理效率。
而从哈夫曼编码的角度来看,权值的大小直接决定了编码的长度。
权值越大的字符被赋予的编码越短,可以有效地减少数据传输的长度,提高了数据的压缩率。
2. 广度评估另哈夫曼树和哈夫曼编码的权值也需要进行广度评估。
在构建哈夫曼树的过程中,权值的大小直接影响了树的结构和形状。
当权值序列较为分散时,哈夫曼树的结构会更加平衡,节点的深度差异较小。
然而,当权值序列的差异较大时,哈夫曼树的结构也会更不平衡,而且可能出现退化现象。
这会导致数据的处理效率降低,需要进行额外的平衡调整。
简述哈夫曼树的定义

简述哈夫曼树的定义哈夫曼树是一种重要的二叉树,它有着广泛的应用,是许多计算机系统中常用的数据结构。
哈夫曼树是一种完全二叉树,其中任意一个结点都有左右子树,叶子结点只有左子树或者右子树。
它是根据“最优化原则”建立的,目的是使总代价最低。
它是一种最高效率、最具有利用价值的数据结构,因此深受广大科学家和技术工作者的喜爱。
简而言之,哈夫曼树是一种带权路径长度最小的二叉树,即它的任一非叶子结点的权值之和等于所有叶子结点的权值之和。
它的定义如下:将n个权值不同的叶子结点组成的n棵二叉树,它们的带权路径长度之和最小称为哈夫曼树。
哈夫曼树的带权路径长度指的是从根节点到叶子节点的路径上结点权值的乘积之和,它是求解最优二叉树的重要参数。
哈夫曼树可分为正哈夫曼树和负哈夫曼树,它们的不同之处在于哈夫曼树的根节点权值是正数或者负数,而负哈夫曼树的根节点权值总是负数。
哈夫曼树的构造方法是从叶子结点开始,依次将权值较小的两棵二叉树合并,然后将这两棵子树的权值之和作为新的父母亲结点,新的子树的根节点的权值就是这两个结点的权值之和。
构造方法至将所有的n个结点合并为一棵树,最后得到的哈夫曼树即为最优二叉树。
哈夫曼树是最优二叉树,在许多需要使用最优二叉树的算法中均可运用,如字符编码算法、矩阵乘法算法、最短路径算法等,它的应用非常广泛。
哈夫曼树的设计既可以给出解决问题的最佳答案,又能将数据结构设计得非常有效。
哈夫曼树可以帮助计算机系统显著提高性能,在网络通信、数据压缩、资源分配等方面均有用处。
总而言之,哈夫曼树是一种完全二叉树,其中每一个结点都有左右子树,根据“最优化原则”建立,其带权路径长度最小,广泛应用于计算机系统中。
它可以有效地解决许多计算机系统中的性能瓶颈问题,无论是在数据组织方面还是在计算机系统性能提升方面都有重要的意义。
哈夫曼树

哈夫曼树及其应用一、基本术语1.路径和路径长度在一棵树中,从一个结点往下可以达到的孩子或子孙结点之间的通路,称为路径。
通路中分支的数目称为路径长度。
若规定根结点的层数为1,则从根结点到第L层结点的路径长度为L-1。
2.结点的权及带权路径长度若将树中结点赋给一个有着某种含义的数值,则这个数值称为该结点的权。
结点的带权路径长度为:从根结点到该结点之间的路径长度与该结点的权的乘积。
3.树的带权路径长度树的带权路径长度(Weighted Path Length of Tree):也称为树的代价,定义为树中所有叶结点的带权路径长度之和,通常记为:其中:n表示叶子结点的数目wi和li分别表示叶结点ki的权值和根到结点ki之间的路径长度。
二、哈夫曼树构造1.哈夫曼树的定义在权为w l,w2,…,w n的n个叶子所构成的所有二叉树中,带权路径长度最小(即代价最小)的二叉树称为最优二叉树或哈夫曼树。
【例】给定4个叶子结点a,b,c和d,分别带权7,5,2和4。
构造如下图所示的三棵二叉树(还有许多棵),它们的带权路径长度分别为:(a)WPL=7*2+5*2+2*2+4*2=36(b)WPL=7*3+5*3+2*1+4*2=46(c)WPL=7*1+5*2+2*3+4*3=35其中(c)树的WPL最小,可以验证,它就是哈夫曼树。
2.哈夫曼树的构造假设有n个权值,则构造出的哈夫曼树有n个叶子结点。
n 个权值分别设为w1,w2,…,wn,则哈夫曼树的构造规则为:(1) 将w1,w2,…,wn看成是有n 棵树的森林(每棵树仅有一个结点);(2) 在森林中选出两个根结点的权值最小的树合并,作为一棵新树的左、右子树,且新树的根结点权值为其左、右子树根结点权值之和;(3)从森林中删除选取的两棵树,并将新树加入森林;(4)重复(2)、(3)步,直到森林中只剩一棵树为止,该树即为我们所求得的哈夫曼树。
下面给出哈夫曼树的构造过程,假设给定的叶子结点的权分别为1,5,7,3,则构造哈夫曼树过程如下图所示。
数据结构第六章 哈夫曼树
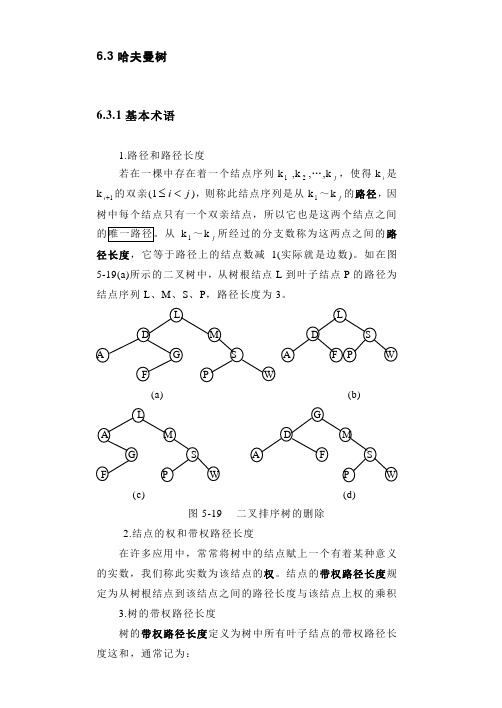
6.3哈夫曼树6.3.1基本术语1.路径和路径长度若在一棵中存在着一个结点序列k1 ,k2,…,kj,使得ki是k1+i 的双亲(1ji<≤),则称此结点序列是从k1~kj的路径,因树中每个结点只有一个双亲结点,所以它也是这两个结点之间k 1~kj所经过的分支数称为这两点之间的路径长度,它等于路径上的结点数减1(实际就是边数)。
如在图5-19(a)所示的二叉树中,从树根结点L到叶子结点P的路径为结点序列L、M、S、P,路径长度为3。
(a) (b)(c) (d)图5-19 二叉排序树的删除2.结点的权和带权路径长度在许多应用中,常常将树中的结点赋上一个有着某种意义的实数,我们称此实数为该结点的权。
结点的带权路径长度规定为从树根结点到该结点之间的路径长度与该结点上权的乘积3.树的带权路径长度树的带权路径长度定义为树中所有叶子结点的带权路径长度这和,通常记为:2 WPL = ∑=n i i i lw 1其中n 表示叶子结点的数目,i w 和i l 分别表示叶子结点i k 的权值和根到i k 之间的路径长度 。
4.哈夫曼树哈夫曼(Huffman)树又称最优二叉树。
它是n 个带权叶子结点构成的所有二叉树中,带权路径长度 WPL 最小的二叉树。
因为构造这种树的算法是最早由哈夫曼于1952年提出的,所以被称之为哈夫曼树。
例如,有四个叶子结点a 、b 、c 、d ,分别带权为9、4、5、2,由它们构成的三棵不同的二叉树(当然还有其它许多种)分别如图5-20(a)到图5-20(c)所示。
b ac a b cd d c a b d(a) (b) (c)图5-20 由四个叶子结点构成的三棵不同的带权二叉树 每一棵二叉树的带权路径长度WPL 分别为:(a) WPL = 9×2 + 4×2 + 5×2 + 2×2 = 40(b) WPL = 4×1 + 2×2 + 5×3 + 9×3 = 50(c) WPL = 9×1 + 5×2 + 4×3 + 2×3 = 37其中图5-20(c)树的WPL 最小,稍后便知,此树就是哈夫曼树。
哈夫曼树的实际应用

哈夫曼树的实际应用
哈夫曼树(Huffman Tree)是一种重要的数据结构,它在信息编码和压缩、数据传输和存储、图像处理等领域有广泛应用。
1. 数据压缩:哈夫曼树是一种无损压缩的方法,能够有效地减小数据的存储空间。
在进行数据压缩时,可以使用哈夫曼树构建字符编码表,将出现频率较高的字符用较短的编码表示,而出现频率较低的字符用较长的编码表示,从而减小数据的存储空间。
2. 文件压缩:在文件压缩领域,哈夫曼树被广泛应用于压缩算法中。
通过构建哈夫曼树,可以根据字符出现的频率来生成不同长度的编码,从而减小文件的大小。
常见的文件压缩格式如ZIP、GZIP等都使用了哈夫曼树。
3. 图像压缩:在图像处理中,哈夫曼树被用于图像压缩算法中。
通过将图像中的像素值映射为不同长度的编码,可以减小图像的存储空间,提高图像传输和存储的效率。
常见的图像压缩格式如JPEG、PNG等都使用了哈夫曼树。
4. 文件传输:在数据传输中,哈夫曼树被用于数据压缩和传输。
通过对数据进行压缩,可以减小数据的传输时间和带宽占用。
在传输过程中,接收方可以通过哈夫曼树解码接收到的数据。
5. 数据加密:在数据加密中,哈夫曼树可以用于生成密钥,从而实现数据的加密和解密。
通过将字符映射为不同长度的编码,可以实
现对数据的加密和解密操作。
哈夫曼树在信息编码和压缩、数据传输和存储、图像处理等领域有广泛应用,能够有效地减小数据的存储空间、提高数据传输效率、实现数据加密等功能。
名词解释哈夫曼树

名词解释哈夫曼树哈夫曼树是最早的陆地植物之一,它能很快适应各种不同的生活环境,还能改变自己。
由于陆地变化快,各种动物如食草类、肉食类等,都被迫来到了陆地上,为了适应这些环境,有一些动物就发生了很大的变化,如熊从熊变成了能走路的猿,就是因为长期没在水中生活,他的后腿已经完全退化了;长臂猿的前肢已经退化了;海龟和海豹能爬到陆地上,就是因为生活环境发生了改变。
人们可以用种子繁殖也可以进行无性繁殖。
种子有翅膀的属于子叶植物,像杨、柳、榆树,它们的种子都是靠风力来传播的,因此它们是不需要嫁接的。
种子外面都包着果皮,而且种子外面还有一层厚厚的果肉。
吃过苹果的人都知道,苹果的表皮就像小刀一样会刮得手很疼。
这就是种子的作用。
种子的里面还有胚芽,胚芽才是种子的主体,它决定了种子以后是长出幼苗还是发育成一棵树。
有些植物的种子没有胚芽,有些植物的种子有胚芽。
像竹子的种子就没有胚芽。
而松树的种子有胚芽。
在野外的时候,可以见到许多树木的种子,如松树、红豆杉等。
它们看起来好像没有什么区别,其实它们是有区别的,你仔细观察一下就会发现,松树种子外面有一层薄薄的膜,把种子紧紧的裹住,红豆杉的种子也是用一层薄薄的膜包着的,而竹子的种子没有这层膜。
竹子的种子是要在水中才能发芽的,所以在竹林里你几乎看不到竹笋,但有一些植物的种子可以在干燥的土壤里也可以发芽,例如玉米的种子。
玉米的种子虽然在干燥的土壤里也能发芽,但它要经过一个漫长的过程。
这个过程叫做“吐丝”,种子在慢慢长大的过程中,要不断的吸收营养物质来壮大自己。
哈夫曼树不仅仅分布在北美洲,在世界各地都有。
其中松柏类的常青树比较多,如松树、柏树等,它们的树冠特别庞大,覆盖面积也很广。
其次是阔叶林,有很多乔木树种,如桉树、樟树等,它们的叶子非常茂盛。
再次是针叶林,有很多常绿的针叶树,如山茶、油茶、梧桐等。
灌木、藤本和草本植物更是数不胜数。
还有些落叶林,常绿树种比较少,以竹类居多。
但每种树都有自己的特点,就像人的特点各有不同一样,这样才能构成了这美丽的大千世界!其中松、柏、杉都是我国比较常见的乔木树种。
哈夫曼树经典例题

哈夫曼树经典例题哈夫曼树是一种经典的缩小数据存储空间的算法。
它是由David Huffman在1952年提出的,被广泛应用于数据压缩、编码和解码等领域。
本文将介绍哈夫曼树的定义、构建算法和常见的应用示例。
一、哈夫曼树的定义哈夫曼树是一种特殊的二叉树,它的构建基于一组给定的权值集合。
每个权值都与二叉树中的一个叶子节点相关联。
哈夫曼树的特点是权值较大的节点越接近于根节点,权值较小的节点越接近于叶子节点。
这种结构使得较高频率的字符具有较短的编码,而较低频率的字符具有较长的编码,从而达到压缩数据的目的。
二、哈夫曼树的构建算法哈夫曼树的构建算法主要分为以下几个步骤:1. 创建一个权值表,记录每个字符的权值。
2. 将权值表按照权值从小到大进行排序。
3. 选择权值最小的两个字符,创建一个新的内部节点,将这两个字符作为其子节点,并将其权值设为这两个字符的权值之和。
4. 将新创建的节点插入到排序后的权值表中,并删除原先两个节点。
5. 重复步骤3和步骤4,直到只剩下一个节点,即根节点为止。
三、哈夫曼树的应用示例:数据压缩数据压缩是哈夫曼树最常见的应用之一。
在压缩数据时,哈夫曼树根据字符出现的频率进行构建,将频率较高的字符用较短的编码表示,而频率较低的字符用较长的编码表示,从而达到压缩数据的目的。
举个例子,假设我们要压缩一个文本文件,其中包含6个不同的字符:A: 2次B: 3次C: 4次D: 4次E: 5次F: 6次首先,我们根据字符频率构建哈夫曼树。
按照步骤2,我们将字符按照频率从小到大排序,得到以下顺序:A, B, C, D, E, F然后,按照步骤3和步骤4,我们构建哈夫曼树的过程如下:1. 构造A和B的新节点AB,权值为2+3=5,得到新权值表:AB, C, D, E, F2. 构造AB和C的新节点ABC,权值为5+4=9,得到新权值表:ABC, D, E, F3. 构造D和E的新节点DE,权值为4+5=9,得到新权值表:ABC, DE, F4. 构造ABC和DE的新节点ABCDE,权值为9+9=18,得到新权值表:ABCDE, F5. 构造ABCDE和F的新节点全集,权值为18+6=24,得到最终的哈夫曼树。
数据结构哈夫曼树课件

总结词
优化、提升
详细描述
基于哈夫曼树的网络流量分类算法的优化策 略主要从以下几个方面进行优化和提升:一 是优化哈夫曼树的构造算法,提高树的构造 效率和准确性;二是利用多级哈夫曼编码技 术,降低编码和解码的时间复杂度;三是引 入机器学习算法,对网络流量特征进行自动
提取和分类,进一步提升分类准确率。
THANKS
基于堆排序的构造算法
总结词:堆排序是一 种基于比较的排序算 法,它利用了堆这种 数据结构的特点,能 够在O(nlogn)的时间 内完成排序。在哈夫 曼树的构造中,堆排 序可以用来找到每个 节点的父节点,从而 构建出哈夫曼树。
详细描述:基于堆排 序的构造算法步骤如 下
1. 定义一个最大堆, 并将每个节点作为一 个独立的元素插入到 堆中。每个元素包含 了一个节点及其权值 。
哈夫曼编码的基本概念
哈夫曼编码是一种用于无损数据压缩的熵编码算法,具有较高的编码效率和较低的 编码复杂度。
它利用了数据本身存在的冗余和相关性,通过构建最优的前缀编码来实现高效的数 据压缩。
哈夫曼编码是一种可变长编码,其中每个符号的编码长度取决于它在输入序列中出 现的频率。
哈夫曼编码的实现方法
构建哈夫曼树
节ቤተ መጻሕፍቲ ባይዱ。
优化编码长度
在分配码字时,通过一些策略优化 编码长度,例如给高频符号更短的 码字。
可变长度编码
为了提高压缩比,可以使用可变长 度编码,即对于高频符号赋予更短 的码字,对于低频符号赋予更长的 码字。
04
哈夫曼树在数据压 缩中的应用
基于哈夫曼编码的数据压缩算法
哈夫曼编码是一种可变长度的 编码方式,通过统计数据的出 现频率来构建哈夫曼树,实现 数据压缩。
哈夫曼树度为m

哈夫曼树度为m1. 哈夫曼树的概念哈夫曼树(Huffman Tree)是一种特殊的二叉树,它的每个非叶子节点都有度为m (m>=2)的子节点。
哈夫曼树是一种用来构建哈夫曼编码的数据结构,它能够有效地压缩数据,减少存储空间的占用。
2. 哈夫曼编码的原理哈夫曼编码是一种变长编码方式,将频率较高的字符用较短的编码表示,频率较低的字符用较长的编码表示,从而实现对数据的压缩。
而哈夫曼树是构建哈夫曼编码的关键。
哈夫曼编码的构建过程如下:1.统计字符的频率:对待编码的数据进行扫描,统计每个字符出现的频率。
2.构建哈夫曼树:根据字符的频率构建哈夫曼树。
频率较低的字符位于树的较低层,频率较高的字符位于树的较高层。
3.生成哈夫曼编码:从哈夫曼树的根节点开始,沿着左子树路径走为0,沿着右子树路径走为1,直到叶子节点。
叶子节点的路径即为字符的哈夫曼编码。
3. 构建哈夫曼树度为m的方法构建哈夫曼树度为m的方法与构建普通哈夫曼树的方法类似,只是在构建过程中需要考虑节点的度数。
下面以度为3的哈夫曼树为例进行说明。
1.统计字符的频率:对待编码的数据进行扫描,统计每个字符出现的频率。
2.构建哈夫曼树:首先将所有字符的频率作为权值,构建一个初始的度为3的哈夫曼树。
然后,从频率最小的节点开始,逐渐合并节点,直到只剩下一个根节点。
–合并节点的方法:每次选择权值最小的m个节点,将它们合并为一个新的父节点,并将新节点的权值设置为这m个节点权值之和。
–合并节点的顺序:由于要构建度为3的哈夫曼树,所以每次合并节点时,需要选择m个节点。
可以采用贪心算法,每次选择权值最小的m个节点进行合并。
3.生成哈夫曼编码:从哈夫曼树的根节点开始,沿着左子树路径走为0,沿着右子树路径走为1,直到叶子节点。
叶子节点的路径即为字符的哈夫曼编码。
4. 哈夫曼编码的优缺点优点1.哈夫曼编码是一种无损压缩算法,可以完全还原原始数据。
2.哈夫曼编码能够根据字符的频率进行编码,使得频率较高的字符用较短的编码表示,从而实现对数据的有效压缩。
哈夫曼树的实际应用

哈夫曼树的实际应用
哈夫曼树在实际中有许多应用,以下是一些例子:
1. 数据压缩:哈夫曼树常用于数据压缩算法,如哈夫曼编码。
哈夫曼编码是一种前缀编码,它可以将数据中的字符编码为二进制字符串,使得平均编码长度最短,从而达到数据压缩的效果。
2. 文件存储:在文件存储中,哈夫曼树可以用于数据存储和检索。
例如,可以使用哈夫曼树来存储文件索引,以便快速找到文件。
3. 图像处理:在图像处理中,哈夫曼树可以用于图像压缩和编码。
例如,可以使用哈夫曼树来编码图像中的像素值,从而减小图像文件的大小。
4. 通信网络:在通信网络中,哈夫曼树可以用于数据传输和调度。
例如,可以使用哈夫曼树来优化数据的传输路径和顺序,以提高网络传输的效率和可靠性。
5. 数据库优化:在数据库优化中,哈夫曼树可以用于索引和查询处理。
例如,可以使用哈夫曼树来构建索引,以便快速检索数据库中的数据。
总的来说,哈夫曼树在许多领域中都有广泛的应用,特别是在需要数据压缩、文件存储、图像处理、通信网络和数据库优化的领域中。
名词解释哈夫曼树

名词解释哈夫曼树哈夫曼树哈夫曼树是一种常绿乔木,可高达25米,树冠圆形或卵形。
单叶互生,全缘,革质,掌状3- 5裂,两面无毛,有长柄,深绿色,侧脉在两面隆起,网脉细密。
聚伞花序顶生,花小,白色;萼5深裂;花瓣5,分离,长椭圆形,早落;雄蕊与花瓣同数而对生;子房上位,心皮2,合生, 2室,每室1胚珠。
核果倒卵形,具短柄,内果皮薄骨质。
分类地位:种。
形态特征:常绿乔木,树冠呈圆形。
叶为奇数羽状复叶,具有长柄,基部膨大成鞘状。
叶片呈三角形,分裂为两半,在两半之间又成V字形向上裂开。
叶肉呈楔形,背面呈暗绿色,叶的边缘光滑无锯齿,腹面叶脉明显突出。
花白色,花期3月。
果实球形,外果皮厚,光滑。
6。
星芒鼠尾草星芒鼠尾草的一个变种。
多年生草本,株高30厘米至50厘米。
根茎肥厚,紫红色。
茎直立,基部木质化。
叶簇生于茎端,剑形,长约40厘米,宽1厘米至2厘米,先端尖锐,两面无毛,边缘波状,背面具龙骨,中脉明显。
轮伞花序有花2朵;花梗长3毫米,被短柔毛;苞片卵状披针形,长5毫米;花萼钟状,长约2毫米,外面被短柔毛,裂片4,三角形,长1毫米,先端渐尖;花冠钟形,淡黄色,长约2.5厘米,花冠筒隐于花萼内,长约5毫米,冠檐二唇形,上唇短,直伸, 2裂,下唇3裂,中裂片最大;能育雄蕊2,着生于花冠筒上,花丝长1毫米,药隔长约5毫米,弯曲,上臂长2毫米,下臂长3毫米,分离,药室2,并行,顶端联合;退化雄蕊短小,顶端不明显2裂。
花盘前方略膨大。
小坚果长圆形,褐色,光滑。
花期4月。
7。
华西紫茉莉华西紫茉莉的一个变种。
多年生草本,具匍匐茎,茎细长,有棱,无毛,带紫色,高约70厘米。
叶对生,膜质,卵圆形,长约8毫米,宽5毫米,先端钝,基部圆形或近截形,叶脉3条,顶端连接;茎生叶对生,同形。
顶生总状花序长7厘米,直径3厘米;苞片及小苞片线形,长3毫米,早落;花小,花冠淡紫色,长2.5毫米,花冠筒隐于萼内,长约1毫米;花萼管状,长3毫米,外面被毛,萼齿三角形,长0.5毫米,边缘具纤毛;花冠长5毫米,花冠筒隐于萼内,长约2毫米,冠檐二唇形,上唇长圆形,长1毫米,下唇比上唇稍长, 3裂,中裂片最大,先端微缺,侧裂片短小, 2裂,极不明显。
哈弗曼树实验报告(3篇)

一、实验目的1. 理解并掌握哈弗曼树的构建原理。
2. 学会使用哈弗曼树进行数据编码和解码。
3. 了解哈弗曼编码在数据压缩中的应用。
二、实验原理哈弗曼树(Huffman Tree)是一种带权路径长度最短的二叉树,用于数据压缩。
其基本原理是:将待编码的字符集合按照出现频率从高到低排序,构造一棵二叉树,使得叶子节点代表字符,内部节点代表编码,权值代表字符出现的频率。
通过这棵树,可以生成每个字符的编码,使得编码的平均长度最小。
三、实验环境1. 操作系统:Windows 102. 编程语言:C++3. 开发工具:Visual Studio 2019四、实验步骤1. 构建哈弗曼树(1)创建一个结构体`HuffmanNode`,包含字符、权值、左子树和右子树指针。
```cppstruct HuffmanNode {char data;int weight;HuffmanNode left;HuffmanNode right;};(2)定义一个函数`HuffmanTree()`,用于创建哈弗曼树。
```cppHuffmanNode HuffmanTree(std::vector<char>& chars, std::vector<int>& weights) {// 创建初始二叉树std::vector<HuffmanNode> trees;for (int i = 0; i < chars.size(); ++i) {trees.push_back(new HuffmanNode{chars[i], weights[i], nullptr, nullptr});}// 构建哈弗曼树while (trees.size() > 1) {// 选择两个权值最小的节点auto it1 = std::min_element(trees.begin(), trees.end(),[](HuffmanNode a, HuffmanNode b) {return a->weight < b->weight;});auto it2 = std::next(it1);HuffmanNode parent = new HuffmanNode{0, it1->weight + it2->weight, it1, it2};// 删除两个子节点trees.erase(it1);trees.erase(it2);// 将父节点添加到二叉树集合中trees.push_back(parent);}// 返回哈弗曼树根节点return trees[0];}```2. 生成哈弗曼编码(1)定义一个函数`GenerateCodes()`,用于生成哈弗曼编码。
哈夫曼树

比如,发送一段编码:0000011011010010, 接收方可以准确地通过译码得到:⑥⑥⑦⑤②⑧。
<
<80
<90 good
very good
图 5-
首先,将各分数段的比例数值作为权值构造一 棵哈夫曼树。 70≤...≤79
general
good
80≤...≤89
60≤...≤69 pass
...<59
图 5-30
bad
very good
<80 <70 <60 general good <90
4 8
图5-27 叶子结点带权值的二叉树
5
下面我们讨论一下权值、树形与带权的路径长 度之间的关系。假设有6个权值分别为{3,6,9,10, 7,11},以这6个权值作为叶子结点的权值可以构造 出下面三棵二叉树。
10
11
3
(a)
6
7
9
3 6 7
9
7
9
11 10
(b)
6
3
11
图 528
10
(c)
到这段电文后无法进行译码,因为无法断定前面4个0
是4个A,1个B、2个A,还是2个B,即译码不唯一, 因此这种编码方法不可使用。
(1)利用字符集中每个字符的使用频率作为权 值构造一个哈夫曼树; (2)从根结点开始,为到每个叶子结点路径上 的左分支赋予0,右分支赋予1,并从根到叶子方向形 成该叶子结点的编码。 假设有一个电文字符集中有8个字符,每个字 符的使用频率分别为 {0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11},现 以此为例设计哈夫曼编码。 哈夫曼编码设计过程为: (1)为方便计算,将所有字符的频度乘以 100,使其转换成整型数值集合,得到 {5,29,7,8,14,23,3,11}; (2)以此集合中的数值作为叶子结点的权值 构造一棵哈夫曼树,如图5-27所示;
哈夫曼树度为m

哈夫曼树度为m
(原创版)
目录
1.哈夫曼树的概念和基本性质
2.哈夫曼树的度为 m 的含义
3.哈夫曼树的构造方法
4.哈夫曼树在数据压缩和编码中的应用
正文
哈夫曼树(Huffman Tree)是一种带权路径长度最短的二叉树,主要用于数据压缩和编码。
它是由美国计算机科学家 David A.Huffman 在1952 年提出的,具有唯一解的性质。
哈夫曼树的度为 m 是指树的每个节点最多有 m 个子节点。
哈夫曼树的构造方法如下:
1.根据输入数据(字符)的出现频率构建一个哈夫曼树。
首先将输入数据中的每个字符作为叶子节点,将其出现的频率作为权值。
2.在所有节点中选择权值最小的两个节点,将它们作为一棵新二叉树的左右子节点,且它们的权值之和作为新节点的权值。
3.将这两个节点从原节点集合中移除,将新节点加入集合。
4.重复步骤 2 和 3,直到只剩下一个节点,这个节点就是哈夫曼树
的根节点。
哈夫曼树在数据压缩和编码中的应用十分广泛。
由于哈夫曼树是带权路径长度最短的二叉树,因此可以实现对原始数据的压缩。
在压缩过程中,将每个字符映射到哈夫曼树中的一个路径,这个路径代表一个编码。
在解压缩时,根据编码沿着哈夫曼树进行路径还原,即可得到原始数据。
哈夫曼编码是一种前缀编码,即任何字符的编码都不是另一个字符编码的前缀,
这保证了解压缩的唯一性。
综上所述,哈夫曼树度为 m,具有唯一解的性质,通过构造哈夫曼树,可以实现数据压缩和编码。
哈夫曼树

(a) WPL=2×2+2×3+2×4+2×7=32 (b) WPL=1×2+2×3+3×4+3×7=41 × + × × × × + × × ×
7 4 3 2
(c) WPL=1×7+2×4+3×3+3×2=30 × + × × ×
2. 构造哈夫曼树 哈夫曼树又叫最优二叉树,它是由 个带权叶子结点构成的所有二 哈夫曼树又叫最优二叉树,它是由n个带权叶子结点构成的所有二 又叫最优二叉树 叉树中带权路径长度 带权路径长度WPL最短的二叉树。 最短的二叉树 叉树中带权路径长度 最短的二叉树。 构造哈夫曼算法的步骤如下: 构造哈夫曼算法的步骤如下: (1)用给定的n个权值{w1,w2, … ,wn}对应的n个结点构成n棵二叉树的森林 用给定的n个权值{w1,w2, ,wn}对应的 个结点构成n 对应的n 用给定的 ,Tn}, F={T1,T2, …,Tn},其中每一棵二叉树Ti (1≤i≤n)都只有一个权值 ,Tn} 其中每一棵二叉树Ti (1≤i≤n)都只有一个权值 wi的根结点 其左、右子树为空。 的根结点, 为wi的根结点,其左、右子树为空。 (2)在森林F中选择两棵根结点权值最小的二叉树,作为一棵新二叉树的左、 (2)在森林F中选择两棵根结点权值最小的二叉树,作为一棵新二叉树的左、 在森林 右子树,标记新二叉树的根结点权值为其左右子树的根结点权值之和。 右子树,标记新二叉树的根结点权值为其左右子树的根结点权值之和。 (3)从 中删除被选中的那两棵二叉树, (3)从F中删除被选中的那两棵二叉树,同时把新构成的二叉树加入到森林 F 中。 (4)重复( )、(3 操作,直到森林中只含有一棵二叉树为止, (4)重复(2)、(3)操作,直到森林中只含有一棵二叉树为止,此时得 重复 到的这棵二叉树就是哈夫曼树。 到的这棵二叉树就是哈夫曼树。
哈夫曼树hufferman构成原理应用及其数学证明

哈夫曼树hufferman构成原理应用及其数学证明哈夫曼树(Huffman Tree),又称最优树,它是一种常用的编码技术,它是一种十分高效的字符编码技术, 它主要是通过对字符按照出现频率高低进行分组,从而构成一颗树;每个字符的编码由树的层次顺序确定,字符越靠近根节点,编码越短,且编码长度与概率成正比,最后得出最优(最短)编码。
哈夫曼树构成原理:哈夫曼树构成原理是通过将信源字符重新按照概率顺序构成一棵有序树来实现的,即带有权值的叶子节点的树。
例如,某信源由四种字符A,B,C,D组成,出现的概率分别为p1,p2,p3,p4。
则可以构成一棵哈夫曼树。
首先,将四个字符依据概率从大到小重新排列,得到ABCD,依据概率大小选择A和B两个字符,以他们为叶子节点构成根节点,这样就分出了两颗子树。
接着将C和D两个字符以此作为叶子节点构成另外两棵子树,将他们与上面的根节点联接在一起,当初始树建立完毕,就得到了一棵哈夫曼树。
哈夫曼树数学证明:证明哈夫曼树是最优树:假设一棵信源树的叶子节点有n个,则此树的权重之和为:w1+w2+…+wn,其中wi是叶子节点i的权重,建立该信源树的目标是将其权重之和最小化,而在没有违反信源编码原理的前提下,树的最小权重之和也就是最优树的权重之和。
假设w1~wn分别为叶子节点1~n的权重,从大到小排列为w1,w2,…,wn,一棵以w1,w2,…,wn为叶子节点的最优树的权重之和为:T(w1,w2,…,wn)=w1+w2+…+wn+2(w1+w2)+2(w1+w2+w3)+……+2(w1+w2+…+wn-1)=2(w1+w2+…+wn-1)+wn =2T(w1,w2,…,wn-1)+wn由上式可知,最优树的权重之和T(w1,w2,…,wn)是由T (w1,w2,…,wn-1)和wn组成的,也就是说,每次取出w1,w2,…,wn中的最大者wn作为树的一个节点,其余的作为树的另一个节点,而每一次节点的选取都是满足最优化条件的,因此一棵满足最优树条件的树就是哈夫曼树,而此树的权重之和也就是最优树的权重之和.从上述可以看出,哈夫曼树构成原理和哈夫曼树数学证明都支持哈夫曼树是最优树的观点,因此哈夫曼树是一种有效的编码技术。
哈夫曼树 密码故事

哈夫曼树密码故事摘要:1.哈夫曼树的简介2.哈夫曼编码的原理3.哈夫曼树在信息编码中的应用4.哈夫曼编码的优点和局限性5.哈夫曼编码在现代通信技术中的应用正文:哈夫曼树,又称哈夫曼编码树,是一种用于数据压缩的树形结构。
它是由美国计算机科学家David A.Huffman于1952年提出的。
哈夫曼树的构建过程是基于信息论的概念,其主要目的是降低数据的传输成本和提高通信效率。
哈夫曼编码的原理是根据信息论中的熵概念,将信息源产生的比特流编码为对应的码字,使得码字的长度最短,从而达到压缩信息的目的。
在哈夫曼编码中,字符的出现频率作为构建哈夫曼树的基础,频率高的字符被分配较短的码字,频率低的字符被分配较长的码字。
通过这种方式,哈夫曼树保证了编码的平均码字长度最短,从而实现了数据的高效压缩。
哈夫曼编码在信息编码领域具有广泛的应用。
在现代通信技术中,如光纤通信、无线通信等,哈夫曼编码被广泛应用于数据传输和存储。
通过哈夫曼编码,可以降低传输成本,提高通信速率,提高数据存储的密度。
此外,哈夫曼编码在数据压缩领域也取得了显著的成果,如图像压缩、音频压缩等。
尽管哈夫曼编码在信息编码领域具有明显的优点,但它也存在一定的局限性。
首先,哈夫曼编码适用于定长数据,对于不定长数据,如自然语言处理中的文本数据,编码效果较差。
其次,哈夫曼编码依赖于字符的出现频率,当字符的分布发生变化时,编码效果可能会受到影响。
总之,哈夫曼树和哈夫曼编码是一种高效的数据压缩方法,它在信息编码和通信领域具有广泛的应用。
然而,它也存在一定的局限性,适用于定长数据和字符分布稳定的场景。
在实际应用中,我们需要根据具体需求选择合适的编码方法,以实现最优的数据压缩和通信效果。
哈夫曼树 加权平均长度 全称 缩写

哈夫曼树加权平均长度全称缩写哈夫曼树(Huffman Tree)是一种经典的树形数据结构,常用于编码和解码过程中的最优算法。
它是由一系列权重不同的叶子节点构建而成的,以此来实现对数据进行有效压缩和解压。
在信息论和通信领域,哈夫曼树被广泛应用于数据压缩算法中,通过构建一棵最优的哈夫曼树来实现数据的高效编码和解码。
在哈夫曼树中,每个叶子节点都代表一个字符,并且具有一个权重值,该权重值通常是该字符在待压缩数据中出现的频率。
通过构建哈夫曼树,并以不同的路径编码每个字符,使得出现频率高的字符拥有较短的编码,从而实现对数据的高效压缩。
哈夫曼树的构建过程也可以用于实现最优的前缀编码,从而避免编码歧义,提高了数据的传输效率。
在实际应用中,哈夫曼树的加权平均长度(Weighted Average Length)是评估数据压缩效果的重要指标之一。
通过计算每个字符的编码长度与其出现概率的乘积,并将所有字符的乘积之和作为数据的平均编码长度,可以评估哈夫曼编码的效率。
在理想情况下,哈夫曼树的加权平均长度应该尽可能接近信息熵,以达到最优的压缩效果。
哈夫曼树是一种重要且高效的数据结构,它在数据压缩和编码领域发挥着重要作用。
通过构建最优的哈夫曼树,并实现对数据的高效编码和解码,可以有效地提高数据的传输效率和存储空间利用率。
加权平均长度作为评估数据压缩效果的指标,对于优化哈夫曼编码方案具有重要意义。
在个人观点上,我认为哈夫曼树的应用不仅局限于数据压缩领域,还可以在其他领域发挥重要作用。
在网络通信中,通过使用哈夫曼编码来优化数据传输过程,可以提高网络传输效率,减少数据传输的时间和成本。
在大数据分析和存储领域,哈夫曼编码也可以用于优化数据的存储和处理,从而实现对数据的高效管理和利用。
总结而言,哈夫曼树作为一种重要的数据结构,在信息论和通信领域发挥着重要作用。
通过构建最优的哈夫曼树,并实现数据的高效编码和解码,可以实现对数据的高效压缩和传输。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
1 107 1 65 0
L 42
0
C 32
1
33
F
0
F 24
1 9 0
Z 2
K
1
K 7
L U Z
哈夫曼编码的效率。 我们定义该编码方案的平均编码长度为: B(T)=(c1p1+ c2p2 +…+ cnpn)/pt 其中: ci和pi是字符集中第i个字符的代码长度及 其相对频率,pt是字符集的总频率。对本例计算平 均编码长度≈2.565 若采用固定长度编码,每个字母需log28=3位, 而哈夫曼编码只需2.565位,节省空间约12%。 哈夫曼编码对于典型的文本文件将比ASCII编 码节省约40%的空间。
下面给出的是某个文献中其中8个英文字母的使用 频率: 字母:C D E F K L U Z 频率:32 42 120 24 7 42 37 2 若采用ASCII编码,单词“DEED”和“FUZZ”占 用等长的空间。但若给出现频率高的字符以较短的编 码,给出现频率低的字符以较长的编码,即使用不等 长编码,也许可以缩短文件的总的码长——总的存储 空间减少了。这个概念就是今天使用的文件压缩技术 的核心。 那么,如何给上述8个字母编码,以保证实际数 据文件的总码长最短呢? 考虑:1.出现频率高的字符用短编码 2.译码时不会出现错误 解决方法:哈夫曼树
考虑这样一棵带权二叉树,即给定一组 权值: W={w1,w2,…,wn} 使得二叉树的每个叶结点有一个权值,定义二 叉树的带权路径长度为:
WPL =
n
∑wl
k =1
k k
lk为根到叶结点wk的路径长度。则其中带 权路径长度最小的二叉树称作哈夫曼树或长是最短的。
前缀编码
任一个字符的编码都不是另一个字符的编码的前 缀。 假如有A,BC,D四个字符,设计的前缀编码分别为 0,10,110,111,任一个的编码都不是另一个编码的 前缀. 哈夫曼编码
哈夫曼编码的构造方法
(1)利用字符集中每个字符的使用频率作为权 值构造一个哈夫曼树; (2)从根结点开始,为到每个叶子结点路径上 0 1 的左分支赋予0,右分支赋予1,并从根到叶子方向 形成该叶子结点的编码。
练习: 假设有一组权值{5,29,7,8,14,23,3,11},利 用这组权值构造哈夫曼树。
5
29
7
8
14
23
3
11
哈夫曼树的应用
一、判定问题
将学生的百分制成绩表转换为五分制成绩,大于 或等于90分者表为“A”,80~90分为“B”, 70~79分为“C”,60~69为“D”,小于60分为 “E”。 程序实现很简单:
用途:用于通信和数据传送中字符的二进制编码,可以 用途 使文件编码总长度最短。 F K L U Z 例字符集: C D E 频 率:32 42 120 24 7 42 37 2
306
0
1 186
C D E
1110 101 0 11110 111111 110 100 111110
E 79 0 1 120 0 U D 37 42
其中wi为叶子i的权,li为根结点到叶子i之间路 径长度,在权w1,w2,w3,…,wn的二叉树中, WTL最小的二叉树称为哈夫曼树或最优树。
基本术语
结点的权: 结点的权:树中的结点上赋予的一定意义的数值。 结点的带权路径长度:从树根结点到该结点之间 结点的带权路径长度 的路径长度与该结点上权的乘积。 树的带权路径长度:树中所有叶子结点的带权路 树的带权路径长度 径长度之和。通常记作
if (socre<60) printf(“bad”); else if (socre<70) printf(“pass”); else if (score<80) printf(“general”); else if (score<90) printf(“good”); esle printf(“very good”);
10000(5%+2×15%+3×40%+4×40%)=31500次
也即按如上图所示的分支结构与程序段,则 10000个数据需执行判断31500次。
下面我们就利用哈夫曼树寻找一棵最佳判定树, 即总的比较次数最少的判定树。
<80 <70 <60 C D B <90 A
E
需比较的次数应为10000(3×20%+2×80%) =22000次,很明显,两种方法的效率是不一样的。
在实际应用中,往往各个分数段的分布并不是均匀 的。下面就是在一次考试中某门课程的各分数段的分布情 况:
分数 比例 0~59 0.05 60~69 0.15 70~79 0.40 80~89 0.30 90~100 0.10
判定过程如图所示:
学生的成绩数据共10000个,5%的数据需1次比 较,15%的数据需2次比较,40%的数据需3次比较, 40%的数据需4次比较,因此10000个数据比较的次 数为
练习:假设有一个电文字符集中有8个字符,每个字 符的使用频率分别为 {0.05,0.29,0.07,0.08,0.14,0.23,0.03,0.11},设计哈 夫曼编码。
字符 ① ② ③ ④ ⑤ ⑥ ⑦ ⑧
字符的使用频率 0.05 0.29 0.07 0.08 0.14 0.23 0.03 0.11
① 将给定的n个权值W={w1,w2,…,wn}构成n棵 二叉树的集合即森林F={T1,T2,…,Tn},其中每棵树Ti 的初值为只有一个权值wi 的根结点,其左右子树为 空; ② 在F中选取两棵根结点之权值为最小的树作 为左、右子树构成一棵新的二叉树,该新二叉树的根 结点的权值为其左、右子树的根结点权值之和。 ③ 从F中删除这两棵树,同时将新得到的二叉 树加到F中。 ④ 重复②和③,直到F中只有一棵树。这棵树 就是哈夫曼树。 哈夫曼树。
基本思想:使权大的结点靠近根。 基本思想
例1:{ : 5 10 12 13 30 }
15 第一步 5 第二步 15 5 10 10
12
13
30
25 12 13
30
第三步
40 30 5 10 70 30 12 13
第四步
5
10
12
13
WPL=5×3+10×3+12×3+13×3+30×1=150 由图可以看出,哈夫曼树的结点的度数为0 或2,没有度为1的结点
哈夫曼编码是不等长编码 哈夫曼编码是前缀编码,即任一字符的编码都 不是另一字符编码的前缀 哈夫曼编码树中没有度为1的结点。若叶子结点 的个数为n,则哈夫曼编码树的结点总数为 2n-1 发送过程:根据由哈夫曼树得到的编码表送出 字符数据 接收过程:按左0、右1的规定,从根结点走到 一个叶结点,完成一个字符的译码。反复此过 程,直到接收数据结束
哈夫曼树及其应用 1.问题的提出 问题的提出
在程序设计中,常用一个代码来表示一个 元素,标准ASCII码就是一个例子。它用log2128 即7位提供了128个不同的代码来表示ASCII表中 的128个字符。假设所有代码都等长,则表示n 个不同的代码需要log2n位,称为固定长度编码 (如ASCII码)。如果每个字符的使用频率相等, 则固定长度编码的空间效率最高。但事实上,每 个字符的使用频率并非一样。
编码 0110 10 1110 1111 110 00 0111 010
以上的①∼⑧分别代表 8 个字符。
发送一段编码:0000011011010010,
接收方译码:⑥⑥①⑤②⑧
二、前缀编码
在电文传输中,需要将电文中出现的每个字符 进行二进制编码。在设计编码时遵守两个原则: (1)发送方传输的二进制编码,到接收方解 码后必须具有唯一性,即解码结果与发送方发送的 电文完全一样; (2)发送的二进制编码尽可能地短。 编码方法: 1. 等长编码:译码简单且具有唯一性,但编 码长度不是最短; 2. 不等长编码:译码可能不唯一 解决方法:前缀编码
树的路径长度是从树的根结点到树的各个结点 的路径长度之和,记作TL,例如上图所示的三棵二 叉树的路径长度分别为: TL(a)=0+1+1+2+2+3+3+4+4=20 TL(b)=0+1+1+2+2+2+2+3+3=16 TL(c)=0+1+1+2+2+2+2+3+3=16
将上述概念推广到一般情况,考虑带权的结点, 则某结点的带权路径长度是指该结点的路径长度与 该结点上权的乘积,二叉树的带权路径长度是指所 有带权叶子结点的带权路径长度之和。 假定一个有n个权值的集合{w1,w2,…,wn}, 其中wi≥0(1≤i≤n),若T是一个有n个叶子的二叉 树,而且将权w1,w2,…,wn分别赋给树的n个叶 子,则n个叶子的二叉树带权路径长度定义为:
WPL =
n
k =1 其中n为叶子结点数,lk为根到叶结点wk的 路径长度。 最优二叉树(哈夫曼树 哈夫曼树): 最优二叉树 哈夫曼树 :n个带权叶子结点构成的 所有二叉树中,带权路径长度WPL最小的二叉 树。
∑wl
k k
2. 建立哈夫曼树(最优二叉树)的方法 建立哈夫曼树(最优二叉树) 1952年由 年由D.A.Huffman提出的哈夫曼算法: 提出的哈夫曼算法: 年由 提出的哈夫曼算法
预备知识
先介绍二叉树路径长度的概念。 树中一个结点到另一个结点之间的路径长度是 这两个结点之间的分支所构成的路径上的分支数。 由树的定义可知,从根结点到达树的每个结点 有且仅有一种路径。我们规定根的层数为1,如果 树中某个结点的层次为k,则从根到该结点的路径长 度为(k-1)。
如下图为三棵二叉树,其中图(a)所示的二叉 树中,从根A到B,C,D,E,F,G,H,I的路径长 度分别为1,1,2,2,3,3,4,4。