遗传算法 (2)
遗传算法遗传算法

(5)遗传算法在解空间进行高效启发式搜索,而非盲 目地穷举或完全随机搜索;
(6)遗传算法对于待寻优的函数基本无限制,它既不 要求函数连续,也不要求函数可微,既可以是数学解 析式所表示的显函数,又可以是映射矩阵甚至是神经 网络的隐函数,因而应用范围较广;
(7)遗传算法具有并行计算的特点,因而可通过大规 模并行计算来提高计算速度,适合大规模复杂问题的 优化。
26
(4)基本遗传算法的运行参数 有下述4个运行参数需要提前设定:
M:群体大小,即群体中所含个体的数量,一般取为 20~100; G:遗传算法的终止进化代数,一般取为100~500; Pc:交叉概率,一般取为0.4~0.99;
Pm:变异概率,一般取为0.0001~0.1。
27
10.4.2 遗传算法的应用步骤
遗传算法简称GA(Genetic Algorithms)是1962年 由美国Michigan大学的Holland教授提出的模拟自然 界遗传机制和生物进化论而成的一种并行随机搜索最 优化方法。
遗传算法是以达尔文的自然选择学说为基础发展起 来的。自然选择学说包括以下三个方面:
1
(1)遗传:这是生物的普遍特征,亲代把生物信息交 给子代,子代总是和亲代具有相同或相似的性状。生 物有了这个特征,物种才能稳定存在。
18
(3)生产调度问题 在很多情况下,采用建立数学模型的方法难以对生
产调度问题进行精确求解。在现实生产中多采用一些 经验进行调度。遗传算法是解决复杂调度问题的有效 工具,在单件生产车间调度、流水线生产车间调度、 生产规划、任务分配等方面遗传算法都得到了有效的 应用。
19
(4)自动控制。 在自动控制领域中有很多与优化相关的问题需要求
10
实验六:遗传算法求解TSP问题实验2篇

实验六:遗传算法求解TSP问题实验2篇第一篇:遗传算法的原理与实现1. 引言旅行商问题(TSP问题)是一个典型的组合优化问题,它要求在给定一组城市和每对城市之间的距离后,找到一条路径,使得旅行商能够在所有城市中恰好访问一次并回到起点,并且总旅行距离最短。
遗传算法作为一种生物启发式算法,在解决TSP问题中具有一定的优势。
本实验将运用遗传算法求解TSP问题,以此来探讨和研究遗传算法在优化问题上的应用。
2. 遗传算法的基本原理遗传算法是模拟自然界生物进化过程的一种优化算法。
其基本原理可以概括为:选择、交叉和变异。
(1)选择:根据问题的目标函数,以适应度函数来评估个体的优劣程度,并按照适应度值进行选择,优秀的个体被保留下来用于下一代。
(2)交叉:从选出的个体中随机选择两个个体,进行基因的交换,以产生新的个体。
交叉算子的选择及实现方式会对算法效果产生很大的影响。
(3)变异:对新生成的个体进行基因的变异操作,以保证算法的搜索能够足够广泛、全面。
通过选择、交叉和变异操作,不断迭代生成新一代的个体,遗传算法能够逐步优化解,并最终找到问题的全局最优解。
3. 实验设计与实施(1)问题定义:给定一组城市和每对城市之间的距离数据,要求找到一条路径,访问所有城市一次并回到起点,使得旅行距离最短。
(2)数据集准备:选择适当规模的城市数据集,包括城市坐标和每对城市之间的距离,用于验证遗传算法的性能。
(3)遗传算法的实现:根据遗传算法的基本原理,设计相应的选择、交叉和变异操作,确定适应度函数的定义,以及选择和优化参数的设置。
(4)实验流程:a. 初始化种群:随机生成初始种群,每个个体表示一种解(路径)。
b. 计算适应度:根据适应度函数,计算每个个体的适应度值。
c. 选择操作:根据适应度值选择一定数量的个体,作为下一代的父代。
d. 交叉操作:对父代进行交叉操作,生成新的个体。
e. 变异操作:对新生成的个体进行变异操作,以增加搜索的多样性。
遗传计算题的解题方法(二)

遗传计算题的解题方法(二)遗传计算(Genetic Algorithm)是一种基于生物进化原理的优化算法,已经被广泛应用于各种领域,包括工程、商业、金融等。
遗传计算题是指利用遗传计算算法来解决一些优化问题,例如旅行商问题、背包问题等。
遗传计算的基本思想遗传计算的基本思想是将问题转换成一个由二进制编码的染色体,并通过交叉、变异等操作来产生一代一代的后代,直到达到最优解或者算法收敛。
遗传计算主要包括下面几个步骤:1.初始化种群2.评估适应度3.选择优秀个体4.交叉与变异5.更新种群6.终止算法解决遗传计算题的方法方法一:遗传算法遗传算法是遗传计算的一种常见实现方式,它利用遗传算子(交叉和变异)来生成新的个体,并保留一定数量的优秀个体进入下一代。
遗传算法需要确定种群大小、交叉率、变异率等参数,同时也需要选择合适的适应度函数来评价个体的表现。
方法二:进化策略进化策略是一种基于遗传算法的改进版,它利用自适应进化策略(如选择适应度共享、自适应个体调整等)来提高算法的性能和收敛速度。
进化策略相比于遗传算法具有更强的寻优性能。
方法三:遗传规划遗传规划是一种利用遗传算法来实现规划任务的方法。
遗传规划通常包括问题建模(将决策变量编码成染色体)、适应度评价、遗传操作等步骤。
遗传规划在实际应用中已经被广泛应用于许多领域。
方法四:遗传表达式编程遗传表达式编程(Genetic Programming)是一种将遗传计算应用于自动编程的方法。
它将程序表示为一棵树状结构,并通过交叉和变异操作来生成新的程序,直到达到某种特定的效果。
遗传表达式编程适合于解决一些复杂的问题,例如图像识别、自动控制等。
总结遗传计算是一种强大的优化算法,它已经被成功应用于解决许多复杂的问题。
在实际应用中,要根据具体的问题选取合适的遗传计算方法,并合理设置各种参数,以达到最优的解决效果。
注意事项遗传计算虽然拥有很强的优化能力,但它也存在一些注意事项:1.初始种群的构建不能过于随意,需要按照一定的规则来生成。
遗传算法教程GA2

遗传算法教程GA2遗传算法教程GA2遗传算法(Genetic Algorithm,GA)是一种模拟自然进化过程的优化算法。
它模拟了自然界中的遗传和进化过程,通过适应度函数评价个体的优劣,通过选择、交叉和变异等操作,不断迭代最优解。
遗传算法的基本过程包括初始化种群、计算适应度、选择、交叉、变异和更新种群。
下面将详细介绍这些步骤。
首先是初始化种群。
种群是指问题的解空间中的一个个体集合,每个个体代表问题的一个可能解。
种群的初始化可以随机生成,也可以根据问题的特点进行设计。
通常情况下,种群的大小越大,空间越广,但计算量也会增加。
接下来是计算适应度。
适应度函数是用来评价个体优劣的指标,它根据问题的具体要求进行设计。
适应度函数应该能够对个体的解进行量化评价,并且能够反映个体与最优解之间的差距。
适应度越高,个体越好。
然后是选择操作。
选择是根据个体的适应度来决定哪些个体被选择作为下一代的父代。
选择操作通常采用轮盘赌算法或排名选择算法。
轮盘赌算法根据个体适应度的比例来决定个体被选中的概率,适应度越高的个体被选中的概率越大。
排名选择算法则根据个体适应度的等级来决定个体被选中的概率。
接下来是交叉操作。
交叉是指将两个父代个体的染色体进行配对,通过染色体上的其中一种操作(如交换、重组等),生成两个子代个体。
交叉操作可以增加种群的多样性,避免陷入局部最优解。
然后是变异操作。
变异是指对个体的染色体进行随机的变换,从而产生新的个体。
变异操作能够引入种群的新解,并且有助于跳出当前空间的局部最优解。
最后是更新种群。
通过选择、交叉和变异操作生成的新个体替代原来的个体,形成下一代的种群。
这样不断进行迭代,直到满足终止条件为止,终止条件可以是达到最大迭代次数、找到满意解或达到收敛条件等。
遗传算法在实际应用中有广泛的应用。
例如,在旅行商问题中,遗传算法可以用来寻找最短路径;在机器学习中,遗传算法可以用来优化神经网络的权重和偏差;在工程设计中,遗传算法可以用来优化系统的参数等。
遗传算法变异策略

遗传算法变异策略遗传算法是一种基于生物进化原理的优化算法,在解决复杂问题上具有很好的适应性和鲁棒性。
变异策略是遗传算法中的一个重要步骤,它通过引入随机扰动来增加搜索空间,使得算法能够更好地探索问题的解空间。
本文将重点讨论遗传算法中的变异策略。
一、遗传算法简介遗传算法是一种模拟生物进化过程的优化算法,它通过模拟自然界的选择、交叉和变异等过程,逐步优化问题的解。
遗传算法通常由三个基本操作组成:选择、交叉和变异。
其中,变异是遗传算法中的一个重要步骤,它通过引入随机扰动来增加搜索空间,以避免陷入局部最优解。
二、变异策略的意义在遗传算法中,变异策略的主要作用是引入随机扰动,使得算法能够更好地探索解空间。
如果只使用选择和交叉操作,那么算法可能会陷入局部最优解,无法找到全局最优解。
而变异操作能够通过改变个体的某些基因值,打破局部最优解,增加搜索的多样性,从而提高算法的全局搜索能力。
三、常用的变异策略在遗传算法中,常用的变异策略包括基本变异、非均匀变异和自适应变异等。
下面将分别介绍这三种变异策略。
1. 基本变异基本变异是最简单的一种变异策略,它通过随机改变个体的某个基因值来引入扰动。
具体步骤如下:(1) 随机选择一个个体;(2) 随机选择一个基因位进行变异;(3) 根据设定的变异概率,决定是否改变该基因位的值;(4) 如果改变了基因位的值,则将变异后的个体加入到下一代种群中。
2. 非均匀变异非均匀变异是一种根据适应度函数调整变异概率的策略,它可以使得变异概率随着进化过程的进行逐渐减小。
具体步骤如下:(1) 计算种群中每个个体的适应度值;(2) 根据适应度值计算每个个体的变异概率;(3) 对于每个个体,根据其变异概率进行基本变异操作;(4) 将变异后的个体加入到下一代种群中。
3. 自适应变异自适应变异是一种根据个体的适应度动态调整变异策略的方法,它能够根据问题的特点自适应地改变变异概率和变异方式。
具体步骤如下:(1) 计算种群中每个个体的适应度值;(2) 根据适应度值调整变异概率和变异方式;(3) 对于每个个体,根据调整后的变异概率和变异方式进行变异操作;(4) 将变异后的个体加入到下一代种群中。
nsga2拥挤度计算公式

nsga2拥挤度计算公式
【引言】
在多目标优化领域,遗传算法是一种广泛应用的求解方法。
其中,NSGA-II(Non-dominated Sorting Genetic Algorithm II)作为一种高效的遗传算法,具有较强的全局搜索能力。
在NSGA-II中,拥挤度计算公式起着关键作用,它决定了个体在下一代中的繁殖概率。
本文将详细介绍NSGA-II拥挤度计算公式及其应用。
【NSGA-II拥挤度计算公式原理】
SGA-II拥挤度计算公式主要基于两个核心思想:非支配排序和拥挤度计算。
首先,通过非支配排序将解集划分为不同层次,层次内解的排序依据是其目标函数值。
然后,在同一层次内,根据拥挤度计算公式对个体进行排序,确定其在下一代中的繁殖概率。
【公式具体实现】
SGA-II拥挤度计算公式如下:
1.计算个体i与同一层次内其他个体的目标函数差值的绝对值之和,记为Si。
2.计算所有个体目标函数差值的绝对值之和,记为S。
3.计算个体i的拥挤度:CI(i) = Si / S。
【公式应用示例】
假设一个多目标优化问题有三个目标函数,分别记为f1(x),f2(x)和
f3(x)。
当前代个体数为10,经过非支配排序后,得到两个非支配层。
03第三章 遗传算法

第三章遗传算法习题与答案1.填空题(1)遗传算法的缩写是,它模拟了自然界中过程而提出,可以解决问题。
在遗传算法中,主要的步骤是、、。
(2)遗传算法的三个算子是、、。
解释:本题考查遗传算法的基础知识。
具体内容请参考课堂视频“第3章遗传算法”及其课件。
答案:(1)GA,生物进化,全局优化,编码,计算适应度函数,遗传算子(2)选择,交叉,变异2.对于编码长度为7的二进制编码,判断以下编码的合法性。
(1)[1020110](2)[1011001](3)[0110010](4)[0000000](5)[2134576]解释:本题考查遗传算法的二进制编码的合法性。
具体内容请参考课堂视频“第3章遗传算法”及其课件。
答案:(1)[1020110]不合法,不能出现“2”(2)[1011001]合法(3)[0110010]合法(4)[0000000]合法(5)[2134576]不合法,不能出现0、1以外的数字3.下图能够基本反映生物学遗传与优胜劣汰的过程。
理解该图,联想计算类问题求解,回答下列问题。
(1)下列说法正确的是_____。
(多选)A)任何一个生物个体的性状是由其染色体确定的,染色体是由基因及其有规律的排列所构成的,因此生物个体可由染色体来代表。
B)生物的繁殖过程是通过将父代染色体的基因复制到子代染色体中完成的,在复制过程中会发生基因重组或基因突变。
基因重组是指同源的两个染色体之间基因的交叉组合,简称为“杂交/交配”。
基因突变是指复制过程中基因信息的变异,简称“突变”。
C)不同染色体会产生不同生物个体的性状,其适应环境的能力也不同。
D)自然界体现的是“优胜劣汰,适者生存”的丛林法则。
不适应环境的生物个体将被淘汰,自然界生物的生存能力会越来越强。
解释:本题考核对生物遗传观点以及所给图片的理解。
具体内容请参考课堂视频“第3章遗传算法”及其课件。
答案:A、B、C、D关于生物遗传进化的基本观点如下:(1)生物的所有遗传信息都包含在其染色体中,染色体决定了生物的性状。
遗传算法的C语言实现(二)-----以求解TSP问题为例

遗传算法的C语⾔实现(⼆)-----以求解TSP问题为例上⼀次我们使⽤遗传算法求解了⼀个较为复杂的多元⾮线性函数的极值问题,也基本了解了遗传算法的实现基本步骤。
这⼀次,我再以经典的TSP问题为例,更加深⼊地说明遗传算法中选择、交叉、变异等核⼼步骤的实现。
⽽且这⼀次解决的是离散型问题,上⼀次解决的是连续型问题,刚好形成对照。
⾸先介绍⼀下TSP问题。
TSP(traveling salesman problem,旅⾏商问题)是典型的NP完全问题,即其最坏情况下的时间复杂度随着问题规模的增⼤按指数⽅式增长,到⽬前为⽌还没有找到⼀个多项式时间的有效算法。
TSP问题可以描述为:已知n个城市之间的相互距离,某⼀旅⾏商从某⼀个城市出发,访问每个城市⼀次且仅⼀次,最后回到出发的城市,如何安排才能使其所⾛的路线最短。
换⾔之,就是寻找⼀条遍历n个城市的路径,或者说搜索⾃然⼦集X={1,2,...,n}(X的元素表⽰对n个城市的编号)的⼀个排列P(X)={V1,V2,....,Vn},使得Td=∑d(V i,V i+1)+d(V n,V1)取最⼩值,其中,d(V i,V i+1)表⽰城市V i到V i+1的距离。
TSP问题不仅仅是旅⾏商问题,其他许多NP完全问题也可以归结为TSP问题,如邮路问题,装配线上的螺母问题和产品的⽣产安排问题等等,也使得TSP问题的求解具有更加⼴泛的实际意义。
再来说针对TSP问题使⽤遗传算法的步骤。
(1)编码问题:由于这是⼀个离散型的问题,我们采⽤整数编码的⽅式,⽤1~n来表⽰n个城市,1~n的任意⼀个排列就构成了问题的⼀个解。
可以知道,对于n个城市的TSP问题,⼀共有n!种不同的路线。
(2)种群初始化:对于N个个体的种群,随机给出N个问题的解(相当于是染⾊体)作为初始种群。
这⾥具体采⽤的⽅法是:1,2,...,n作为第⼀个个体,然后2,3,..n分别与1交换位置得到n-1个解,从2开始,3,4,...,n分别与2交换位置得到n-2个解,依次类推。
nsga2算法通俗讲解

nsga2算法通俗讲解NSGA-II(Nondominated Sorting Genetic Algorithm II)是一种经典的多目标优化算法,是对遗传算法的一种改进和扩展。
它使用遗传算法的思想来解决求解多目标优化问题,可以同时优化多个目标函数。
NSGA-II通过遗传算子的选择、交叉、变异等操作对候选解进行搜索,然后使用非支配排序和拥挤度距离计算来选择较好的个体,最终得到Pareto最优解集。
NSGA-II的核心思想是模拟进化过程来搜索多目标优化问题的解空间。
它通过构建和维护一个种群来搜索解空间,每个个体都代表一个候选解。
首先,随机生成一组个体作为初始种群,然后通过迭代的方式进行优化。
在每一代演化中,NSGA-II从当前种群中选择父代个体,并使用交叉和变异操作来产生子代个体。
然后,将父代和子代合并为一组候选解,通过非支配排序和拥挤度距离计算筛选出优秀的个体,构成下一代种群。
重复迭代直到满足停止准则。
非支配排序(Non-dominated Sorting)是NSGA-II中的一个重要操作,用于根据个体的优劣程度进行排序。
首先,对种群中的所有个体进行两两比较,如果某个个体在所有目标函数上都优于另一个个体,则认为前者不被后者支配。
根据支配关系,将个体分为不同的等级,形成层次结构。
然后,在每个等级中按照拥挤度距离进行排序。
拥挤度距离用于衡量个体周围的密度,较大的值表示个体所在区域较为稀疏,较小的值表示个体所在区域较为密集。
通过综合考虑支配关系和拥挤度距离,可以选择出较优的个体。
NSGA-II采用了精英策略(Elitism)来保留种群中的优秀个体,避免遗忘最优解。
在选择下一代个体时,将精英个体直接复制到下一代,以保持种群的多样性和收敛性。
通过重复进行选择、交叉和变异操作,不断更新种群,使得算法能够逐渐搜索到Pareto最优解集。
NSGA-II是一种高效的多目标优化算法,它充分利用了种群中个体之间的关系,通过非支配排序和拥挤度距离计算来选择出Pareto最优解集。
生产计划排程优化方法(二)

生产计划排程优化方法(二)生产计划排程优化方法1. 介绍生产计划排程是制造业中至关重要的一个环节,它涉及生产任务的合理安排和资源的优化利用。
为了提高生产效率和响应速度,许多优化方法被提出并应用于生产计划排程中。
在本文中,我们将讨论几种常见的生产计划排程优化方法,并介绍它们的原理和应用场景。
2. 方法一:遗传算法遗传算法是一种模拟生物进化过程的优化算法。
它通过模拟遗传变异、交叉和选择的过程,不断优化生成的解决方案。
原理遗传算法基于适者生存的思想,将问题的解表示为一组基因,通过不断演化和迭代,逐步优化基因的适应性,找到最优解。
应用场景遗传算法适用于生产计划排程中的复杂问题,如多工厂、多道工序的排程问题。
它能够在整体和局部间找到平衡,得到较好的效果。
3. 方法二:模拟退火算法模拟退火算法是一种优化算法,模拟物质在高温慢冷过程中的有序转变过程。
它通过随机搜索和接受差解的策略,来寻求全局最优解。
原理模拟退火算法从一个初始解开始,通过随机改变解的位置,并按照一定的概率接受更差的解。
随着温度的下降,接受差解的概率逐渐降低,最终收敛于最优解。
应用场景模拟退火算法适用于需要全局搜索和接受差解的生产计划排程问题。
它能够在不陷入局部最优解的情况下,得到较优解。
4. 方法三:禁忌搜索算法禁忌搜索算法是一种基于局部搜索的优化算法,通过记录已搜索解的历史,避免陷入局部最优解。
原理禁忌搜索算法通过定义一个“禁忌表”,记录已搜索的解,并设置一定的规则来限制搜索空间。
它在局部搜索中,禁止访问已经搜索过的解,以避免陷入局部最优解。
应用场景禁忌搜索算法在生产计划排程中的效果较好,特别是对于存在耗时长的操作和临时限制条件的问题。
禁忌搜索能够快速找到较优解,并避免陷入局部最优解。
5. 方法四:蚁群算法蚁群算法是一种模拟蚂蚁觅食行为的优化算法,通过蚂蚁之间的信息交流和跟踪,找到最优解。
原理蚁群算法通过模拟蚂蚁在搜索食物过程中释放信息素和随机行走的行为,来寻找最优路径。
2遗传算法介绍

对控制参数的改进
Srinvivas等人提出自适应遗传算法,即PC和Pm 能够随适应度自动改变,当种群的各个个体适应度 趋于一致或趋于局部最优时,使二者增加,而当种 群适应度比较分散时,使二者减小,同时对适应值 高于群体平均适应值的个体,采用较低的PC和Pm, 使性能优良的个体进入下一代,而低于平均适应值 的个体,采用较高的PC和Pm,使性能较差的个体被 淘汰。
对遗传算子的改进
排序选择 均匀交叉 逆序变异
(1) 随机产生一个与个体编码长度 相同的二进制屏蔽字P = W1W2„Wn ; (2) 按下列规则从A、B两个父代个 体中产生两个新个体X、Y:若Wi = 0, 则X的第i个基因继承A的对应基因,Y 的第i个基因继承B的对应基因;若Wi = 1,则A、B的第i个基因相互交换,从 而生成X、Y的第i个基因。
模式阶用来反映不同模式间确定性的 差异,模式阶数越高,模式的确定性就越高,
所匹配的样本数就越少。在遗传操作中,即
使阶数相同的模式,也会有不同的性质,而
模式的定义距就反映了这种性质的差异。
模式定理
模式定理:具有低阶、短定义距以及平 均适应度高于种群平均适应度的模式在子代
中呈指数增长。
模式定理保证了较优的模式(遗传算法
的质量越好。适应度函数是遗传算法进化过
程的驱动力,也是进行自然选择的唯一标准,
它的设计应结合求解问题本身的要求而定。
选择算子
遗传算法使用选择运算来实现对群体中的个体 进行优胜劣汰操作:适应度高的个体被遗传到下一
代群体中的概率大;适应度低的个体,被遗传到下
一代群体中的概率小。选择操作的任务就是按某种 方法从父代群体中选取一些个体,遗传到下一代群
遗传算法应用于组合优化
遗传算法2

I. Basic Concepts of Multiple Objective Optimization
- Multiple Objective Optimization Problem with q objective functions and m nonlinear constraints can be represented: mo-OP:
I. Basic Concepts of Multiple Objective Optimization
2. Pareto (or Nondominated) Optimal Solutions
- In the single objective case, one attempts to obtain the best solution, which is absolutely superior to all other alternatives. - In the multiple objective case, there does not necessarily exist a solution that is best with respect to all objectives because of incommensurability and conflict among objectives. -There usually exist a set of solutions; nondominated or Pareto optimal solutions, for the multiple objective case which cannot simply be compared with each other. - For a given nondominated point in the criterion space Z, its image point in the decision space S is called efficient or noninferior. A point in S is efficient if and only if its image in Z is nondominated.
优化算法的分类

优化算法的分类优化算法是一种用于找到问题的最优解或近似最优解的方法。
在计算机科学和运筹学领域,优化算法被广泛应用于解决各种实际问题,例如机器学习、图像处理、网络设计等。
优化算法的分类可以根据其基本原理或应用领域进行划分。
本文将介绍一些常见的优化算法分类。
1. 传统优化算法传统优化算法是指早期开发的基于数学原理的算法。
这些算法通常基于确定性模型和数学规则来解决问题。
以下是一些常见的传统优化算法:(1) 穷举法穷举法是一种朴素的优化算法,它通过遍历所有可能的解空间来寻找最优解。
穷举法的优点是能够找到全局最优解(如果存在),缺点是搜索空间过大时会非常耗时。
(2) 贪婪算法贪婪算法是一种启发式算法,它通过每一步选择当前状态下最优的决策,从而逐步构建最优解。
贪婪算法的优势是简单快速,但它可能无法找到全局最优解,因为它只考虑了当前最优的选择。
(3) 动态规划动态规划是一种基于最优子结构和重叠子问题性质的优化算法。
它将原问题拆分为一系列子问题,并通过保存子问题的解来避免重复计算。
动态规划的优点是可以高效地求解复杂问题,例如最短路径问题和背包问题。
(4) 分支界限法分支界限法是一种搜索算法,它通过不断分割搜索空间并限制搜索范围,以找到最优解。
分支界限法可以解决一些组合优化问题,如旅行商问题和图着色问题。
2. 随机优化算法随机优化算法是基于概率和随机性的算法,通过引入随机扰动来逐步寻找最优解。
以下是一些常见的随机优化算法:(1) 模拟退火算法模拟退火算法模拟了固体物体冷却过程中的原子运动,通过逐步减小随机扰动的概率来搜索最优解。
模拟退火算法可以通过接受劣解来避免陷入局部最优解。
(2) 遗传算法遗传算法模拟了生物进化过程,通过遗传操作(如交叉和变异)来搜索最优解。
遗传算法通常包括种群初始化、选择、交叉和变异等步骤,能够自适应地搜索解空间。
(3) 蚁群算法蚁群算法模拟了蚂蚁在寻找食物时的行为,通过蚂蚁之间的信息交流和挥发性信息素来搜索最优解。
遗传算法例子2篇

遗传算法例子2篇遗传算法是一种受自然演化启发的优化算法,可以用来解决各种优化问题。
它通过模拟自然选择、遗传和突变等进化过程来不断搜索最优解。
在实际应用中,遗传算法可以被用于求解函数优化、组合优化、约束优化等问题。
下面我将为你介绍两个关于遗传算法的例子。
第一篇:基于遗传算法的旅行商问题求解旅行商问题(Traveling Salesman Problem, TSP)是计算机科学中经典的组合优化问题之一。
其目标是找到一条最短路径,使得一个旅行商可以经过所有城市,最终返回起始城市。
这个问题在实际应用中经常遇到,比如物流配送、电路布线等。
遗传算法可以用来求解旅行商问题。
首先,我们需要定义一种编码方式来表示旅行路径。
通常采用的是二进制编码,每个城市用一个二进制位来表示。
接下来,我们需要定义适应度函数,也就是评估每个个体的优劣程度,可以使用路径上所有城市之间的距离之和作为适应度值。
在遗传算法的执行过程中,首先创建一个初始种群,然后通过选择、交叉和变异等操作对种群进行迭代优化。
选择操作基于适应度值,较优秀的个体有更高的概率被选中。
交叉操作将两个个体的基因片段进行交换,以产生新的个体。
变异操作则在个体的基因中引入一些随机变动。
通过不断迭代,遗传算法能够逐渐找到一个接近最优解的解。
当然,由于旅行商问题属于NP-hard问题,在某些情况下,遗传算法可能无法找到全局最优解,但它通常能够找到质量较高的近似解。
第二篇:遗传算法在神经网络结构搜索中的应用神经网络是一种强大的机器学习模型,它具备非常大的拟合能力。
然而,在设计神经网络结构时,选择合适的网络层数、每层的神经元数量和连接方式等是一个非常复杂的问题。
传统的人工设计方法通常需要进行大量的尝试和实验。
遗传算法可以应用于神经网络结构搜索,以实现自动化的网络设计。
具体来说,遗传算法中的个体可以被看作是一种神经网络结构,通过遗传算法的进化过程可以不断优化网络结构。
在神经网络结构搜索的遗传算法中,个体的基因表示了网络的结构和参数。
遗传算法第二章实用详解
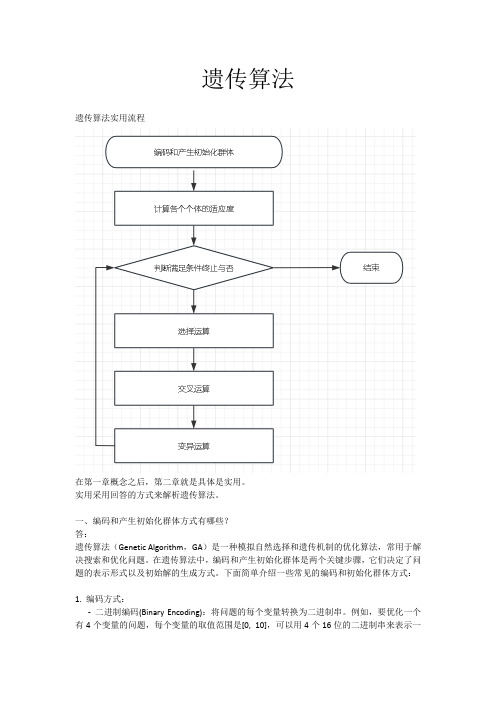
遗传算法遗传算法实用流程在第一章概念之后,第二章就是具体是实用。
实用采用回答的方式来解析遗传算法。
一、编码和产生初始化群体方式有哪些?答:遗传算法(Genetic Algorithm,GA)是一种模拟自然选择和遗传机制的优化算法,常用于解决搜索和优化问题。
在遗传算法中,编码和产生初始化群体是两个关键步骤,它们决定了问题的表示形式以及初始解的生成方式。
下面简单介绍一些常见的编码和初始化群体方式:1. 编码方式:-二进制编码(Binary Encoding):将问题的每个变量转换为二进制串。
例如,要优化一个有4个变量的问题,每个变量的取值范围是[0, 10],可以用4个16位的二进制串来表示一个解:1010010110111001。
在计算适应度函数时,需要将二进制串转换回对应的实际值。
-实数编码(Real-Valued Encoding):直接使用实数表示问题的变量。
例如,要优化一个有2个变量的问题,变量1的取值范围是[0, 5],变量2的取值范围是[-10, 10],一个解可以是(3.2, -5.7)。
适应度函数会直接使用实数值进行评估。
-整数编码(Integer Encoding):将问题的变量转换为整数值。
例如,要优化一个有3个变量的问题,变量1的取值范围是[1, 100],变量2的取值范围是[0, 50],变量3的取值范围是[10, 20],一个解可以是(50, 25, 15)。
2. 初始化群体方式:-随机初始化(Random Initialization):随机生成一组解作为初始群体。
在二进制编码中,可以随机生成一串0和1组成的二进制串。
在实数编码和整数编码中,可以随机生成变量的实数值或整数值。
-均匀初始化(Uniform Initialization):根据变量的取值范围,均匀地生成初始解。
在实数编码和整数编码中,可以根据变量范围使用均匀分布来生成初始解。
-根据问题特点初始化(Special Initialization):有时候根据问题的特点,可以使用一些启发式方法来生成初始解。
nsga2算法通俗讲解

nsga2算法通俗讲解(原创版)目录1.NSGA2 算法的概念与背景2.NSGA2 算法的基本原理3.NSGA2 算法的非支配排序与 crowding distance4.NSGA2 算法的优缺点5.NSGA2 算法的应用案例正文一、NSGA2 算法的概念与背景SGA2(Non-dominated Sorting Genetic Algorithm 2)算法是一种多目标的遗传算法。
在传统的遗传算法中,往往通过适应度函数对个体进行评估,选择优秀的个体进行繁殖。
然而,在多目标优化问题中,适应度函数的多样性使得传统的遗传算法难以应对。
因此,NSGA2 算法应运而生,它通过非支配排序和 crowding distance 等策略,有效地解决了多目标优化问题。
二、NSGA2 算法的基本原理SGA2 算法的基本原理主要包括以下三个方面:1.非支配排序:在选择父代个体之前,首先对所有个体进行非支配排序。
非支配排序的目的是确保选择的父代个体在当前种群中具有较高的适应度。
2.Crowding distance:在非支配排序的基础上,计算每个个体的crowding distance。
crowding distance 表示个体之间的拥挤程度,它反映了个体之间的差异。
选择父代个体时,应选择拥挤程度较大的个体,以增加种群的多样性。
3.父代选择:在计算 crowding distance 之后,根据非支配排序和crowding distance 的值,选择排名靠前且拥挤程度较大的个体作为父代。
三、NSGA2 算法的非支配排序与 crowding distance非支配排序是 NSGA2 算法的核心思想之一,它通过比较个体之间的适应度差异,选择具有较高适应度的个体。
非支配排序的步骤如下:1.对于每个个体,计算其与相邻个体之间的适应度差值。
2.根据适应度差值,将所有个体进行排序,得到非支配排序序列。
crowding distance 是另一个关键概念,它用于衡量个体之间的差异。
(第二讲)基本遗传算法

停止在未成熟阶段,引起未成熟收敛(premature convergence)现象。
从计算效率来看,群体规模越大,其适应度评价次数越多,计算量也就越 大,从而影响算法的效率。 在二进制编码的前提下,为了满足隐并行性,群体个体数只要设定为2L/2 即可,L为个体串长度。这个数比较大,实际应用中群体规模一般取几 十~几百。
陕师大 计算机科学学院 雷秀娟 4
(3) 遗传算子
基本遗传算法使用下述三种遗传算子: • 选择运算:使用比例选择算子; • 交叉运算:使用单点交叉算子; • 变异运算:使用基本位变异算子。
(4) 基本遗传算法的运行参数
基本遗传算法有下述4个运行参数需要提前设定: • M:群体大小,即群体中所含个体的数量,一般取为20 ~ 100 • T:遗传运算的终止进化代数,一般取为100 ~ 500 • pc:交叉概率,一般取为0.4 ~ 0.99 • pm:变异概率,一般取为 0.0001 ~ 0.1
陕师大 计算机科学学院 雷秀娟 9
问题编码一般应满足以下三个原则:
完备性(completeness):问题空间中的所有点都能成为GA编码空间 中的点的表现型。即编码应能覆盖整个问题空间。 健全性(soundness):GA编码空间中的染色体位串必须对应问题空 间中的某一潜在解。即每个编码必须是有意义的。 非冗余性(non-redundancy):染色体和潜在解必须一一对应。 在某些情况下,为了提高GA的运行效率,允许生成包含致死基因 的编码位串,它们对应于优化问题的非可行解。虽然会导致冗余或无 效的搜索,但可能有助于生成全局最优解所对应的个体,所需的总计 算量可能反而减少。
陕师大 计算机科学学院 雷秀娟
10
根据模式定理,De Jong 进一步提 出了较为客观明确的编码评估准则, 称之为编码原理。具体可以概括为两 条规则: 有意义积木块编码规则:编码应易 于生成与所求问题相关的短距和低 阶的积木块。 最小字符集编码规则:编码应采用 最小字符集,以使问题得到自然、 简单的表示和描述。
遗传算法

遗传算法一、遗传算法的简介及来源1、遗传算法简介遗传算法(Genetic Algorithm)是模拟达尔文生物进化论的自然选择和遗传学机理的生物进化过程的计算模型,是一种通过模拟自然进化过程搜索最优解的方法,它最初由美国Michigan大学J.Holland教授于1975年首先提出来的,并出版了颇有影响的专著《自然系统和人工系统的自适应》,GA这个名称才逐渐为人所知,J.Holland教授所提出的GA通常为简单遗传算法(SGA)。
遗传算法模仿了生物的遗传、进化原理, 并引用了随机统计理论。
在求解过程中, 遗传算法从一个初始变量群体开始, 一代一代地寻找问题的最优解, 直至满足收敛判据或预先设定的迭代次数为止。
它是一种迭代式算法。
2、遗传算法的基本原理遗传算法是一种基于自然选择和群体遗传机理的搜索算法, 它模拟了自然选择和自然遗传过程中发生的繁殖、杂交和突变现象。
在利用遗传算法求解问题时, 问题的每个可能的解都被编码成一个“染色体”,即个体, 若干个个体构成了群体( 所有可能解) 。
在遗传算法开始时, 总是随机地产生一些个体( 即初始解) , 根据预定的目标函数对每个个体进行评价, 给出了一个适应度值。
基于此适应度值, 选择个体用来繁殖下一代。
选择操作体现了“适者生存”原理, “好”的个体被选择用来繁殖, 而“坏”的个体则被淘汰。
然后选择出来的个体经过交叉和变异算子进行再组合生成新的一代。
这一群新个体由于继承了上一代的一些优良性状,因而在性能上要优于上一代, 这样逐步朝着更优解的方向进化。
因此, 遗传算法可以看作是一个由可行解组成的群体逐代进化的过程。
3、遗传算法的一般算法(1)创建一个随机的初始状态初始种群是从解中随机选择出来的,将这些解比喻为染色体或基因,该种群被称为第一代,这和符号人工智能系统的情况不一样,在那里问题的初始状态已经给定了。
(2)评估适应度对每一个解(染色体)指定一个适应度的值,根据问题求解的实际接近程度来指定(以便逼近求解问题的答案)。
算法(二)之遗传算法(SGA)

算法(⼆)之遗传算法(SGA)算法(⼆)之遗传算法(SGA)遗传算法(Genetic Algorithm)⼜叫基因进化算法或进化算法,是模拟达尔⽂的遗传选择和⾃然淘汰的⽣物进化过程的计算模型,属于启发式搜索算法⼀种。
下⾯通过下⾯例⼦的求解,来逐步认识遗传算法的操作过程。
我参考了博客(/b2b160/article/details/4680853/),这个博客没提供代码,为了新⼿更好的学习,我⽤java实现了程序例:求下述⼆元函数的最⼤值:(1) 个体编码遗传算法的运算对象是表⽰个体的符号串,所以必须把变量 x1, x2 编码为⼀种符号串。
本题中,⽤⽆符号⼆进制整数来表⽰。
因 x1, x2 为 0 ~ 7之间的整数,所以分别⽤3位⽆符号⼆进制整数来表⽰,将它们连接在⼀起所组成的6位⽆符号⼆进制数就形成了个体的基因型,表⽰⼀个可⾏解。
例如,基因型 X=101110 所对应的表现型是:x=[ 5,6 ]。
个体的表现型x和基因型X之间可通过编码和解码程序相互转换。
1/**2 *3*/4package com.math.algorithm;56/**7 * @author summer8 *9*/10public class Codec {1112static final int CODEC_LEN = 3;1314public static String encode(int x,int y){1516return MathUtils.toBinaryString(x,CODEC_LEN)+17 MathUtils.toBinaryString(y,CODEC_LEN);18 }1920public static double[] decode(String s){2122double[] r = new double[2];23 String s1 = s.substring(0, s.length()/2) ;24 String s2 = s.substring(s1.length());25 r[0] = MathUtils.toInt(s1);26 r[1] = MathUtils.toInt(s2);27return r;28 }2930public static void main(String[] args){3132 System.out.println(encode(5,6));33 System.out.println(encode(1,2));34double[] r =decode("101110");35 System.out.println("x="+r[0]+" y="+r[1]);36 r =decode("001010");37 System.out.println("x="+r[0]+" y="+r[1]);38 }3940 }View Code(2) 初始群体的产⽣遗传算法是对群体进⾏的进化操作,需要给其淮备⼀些表⽰起始搜索点的初始群体数据。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
用遗传算法优化BP神经网络的Matlab编程实例由于BP网络的权值优化是一个无约束优化问题,而且权值要采用实数编码,所以直接利用Matlab遗传算法工具箱。
以下贴出的代码是为一个19输入变量,1个输出变量情况下的非线性回归而设计的,如果要应用于其它情况,只需改动编解码函数即可。
程序一:GA训练BP权值的主函数function net=GABPNET(XX,YY)%--------------------------------------------------------------------------% GABPNET.m% 使用遗传算法对BP网络权值阈值进行优化,再用BP算法训练网络%--------------------------------------------------------------------------%数据归一化预处理nntwarn offXX=premn mx(XX);YY=premn mx(YY);%创建网络net=newff(minmax(XX),[19,25,1],{'tansig','tansig','purelin'},'trainlm');%下面使用遗传算法对网络进行优化P=XX;T=YY;R=size(P,1);S2=size(T,1);S1=25;%隐含层节点数S=R*S1+S1*S2+S1+S2;%遗传算法编码长度aa=ones(S,1)*[-1,1];popu=50;%种群规模initPpp=initializega(popu,aa,'gabpEval');%初始化种群gen=100;%遗传代数%下面调用gaot工具箱,其中目标函数定义为gabpEval[x,endPop,bPop,trace]=ga(aa,'gabpEval',[],initPpp,[1e-6 11],'maxGenTerm',gen,...'normGeomSelect',[0.09],['arithXover'],[2],'nonUnifMutation',[2 gen 3]);%绘收敛曲线图figure(1)plot(trace(:,1),1./trace(:,3),'r-');hold onplot(trace(:,1),1./trace(:,2),'b-');xlabel('Generation');ylabel('Sum-Squared Error');figure(2)plot(trace(:,1),trace(:,3),'r-');hold onplot(trace(:,1),trace(:,2),'b-');xlabel('Generation');ylabel('Fittness');%下面将初步得到的权值矩阵赋给尚未开始训练的BP网络[W1,B1,W2,B2,P,T,A1,A2,SE,val]=gadecod(x);net.LW{2,1}=W1;net.LW{3,2}=W2;net.b{2,1}=B1;net.b{3,1}=B2;XX=P;YY=T;%设置训练参数net.trainParam.show=1;net.trainParam.lr=1;net.trainParam.epochs=50;net.trainParam.goal=0.001;%训练网络net=train(net,XX,YY);程序二:适应值函数function [sol, val] = gabpEval(sol,options)% val - the fittness of this individual% sol - the individual, returned to allow for Lamarckian evolution % options - [current_generation]load data2nntwarn offXX=premn mx(XX);YY=premn mx(YY);P=XX;T=YY;R=size(P,1);S2=size(T,1);S1=25;%隐含层节点数S=R*S1+S1*S2+S1+S2;%遗传算法编码长度for i=1:S,x(i)=sol(i);end;[W1, B1, W2, B2, P, T, A1, A2, SE, val]=gadecod(x);程序三:编解码函数function [W1, B1, W2, B2, P, T, A1, A2, SE, val]=gadecod(x) load data2nntwarn offXX=premn mx(XX);YY=premn mx(YY);P=XX;T=YY;R=size(P,1);S2=size(T,1);S1=25;%隐含层节点数S=R*S1+S1*S2+S1+S2;%遗传算法编码长度% 前R*S1个编码为W1for i=1:S1,for k=1:R,W1(i,k)=x(R*(i-1)+k);endend% 接着的S1*S2个编码(即第R*S1个后的编码)为W2for i=1:S2,for k=1:S1,W2(i,k)=x(S1*(i-1)+k+R*S1);endend% 接着的S1个编码(即第R*S1+S1*S2个后的编码)为B1for i=1:S1,B1(i,1)=x((R*S1+S1*S2)+i);end% 接着的S2个编码(即第R*S1+S1*S2+S1个后的编码)为B2 for i=1:S2,B2(i,1)=x((R*S1+S1*S2+S1)+i);end% 计算S1与S2层的输出A1=tansig(W1*P,B1);A2=purelin(W2*A1,B2);% 计算误差平方和SE=sumsqr(T-A2);val=1/SE; % 遗传算法的适应值上述程序需要调用gaot工具箱,请从附件里下载!原创】蚁群算法最短路径通用Matlab程序(附图)下面的程序是蚁群算法在最短路中的应用,稍加扩展即可应用于机器人路径规划function [ROUTES,PL,Tau]=ACASP(G,Tau,K,M,S,E,Alpha,Beta,Rho,Q)%% ---------------------------------------------------------------% ACASP.m% 蚁群算法动态寻路算法% ChengAihua,PLA Information Engineering University,ZhengZhou,China % Email:aihuacheng@% All rights reserved%% ---------------------------------------------------------------% 输入参数列表% G 地形图为01矩阵,如果为1表示障碍物% Tau 初始信息素矩阵(认为前面的觅食活动中有残留的信息素)% K 迭代次数(指蚂蚁出动多少波)% M 蚂蚁个数(每一波蚂蚁有多少个)% S 起始点(最短路径的起始点)% E 终止点(最短路径的目的点)% Alpha 表征信息素重要程度的参数% Beta 表征启发式因子重要程度的参数% Rho 信息素蒸发系数% Q 信息素增加强度系数%% 输出参数列表% ROUTES 每一代的每一只蚂蚁的爬行路线% PL 每一代的每一只蚂蚁的爬行路线长度% Tau 输出动态修正过的信息素%% --------------------变量初始化----------------------------------%loadD=G2D(G);N=size(D,1);%N表示问题的规模(象素个数)MM=size(G,1);a=1;%小方格象素的边长Ex=a*(mod(E,MM)-0.5);%终止点横坐标if Ex==-0.5Ex=MM-0.5;endEy=a*(MM+0.5-ceil(E/MM));%终止点纵坐标Eta=zeros(1,N);%启发式信息,取为至目标点的直线距离的倒数%下面构造启发式信息矩阵for i=1:Nif ix==-0.5ix=MM-0.5;endiy=a*(MM+0.5-ceil(i/MM));if i~=EEta(1,i)=1/((ix-Ex)^2+(iy-Ey)^2)^0.5;elseEta(1,i)=100;endendROUTES=cell(K,M);%用细胞结构存储每一代的每一只蚂蚁的爬行路线PL=zeros(K,M);%用矩阵存储每一代的每一只蚂蚁的爬行路线长度%% -----------启动K轮蚂蚁觅食活动,每轮派出M只蚂蚁-------------------- for k=1:Kdisp(k);for m=1:M%% 第一步:状态初始化W=S;%当前节点初始化为起始点Path=S;%爬行路线初始化PLkm=0;%爬行路线长度初始化TABUkm=ones(1,N);%禁忌表初始化TABUkm(S)=0;%已经在初始点了,因此要排除DD=D;%邻接矩阵初始化%% 第二步:下一步可以前往的节点DW=DD(W,:);DW1=find(DWfor j=1:length(DW1)if TABUkm(DW1(j))==0DW(j)=inf;endendLJD=find(DWLen_LJD=length(LJD);%可选节点的个数%% 觅食停止条件:蚂蚁未遇到食物或者陷入死胡同while W~=E&&Len_LJD>=1%% 第三步:转轮赌法选择下一步怎么走PP=zeros(1,Len_LJD);for i=1:Len_LJDPP(i)=(Tau(W,LJD(i))^Alpha)*(Eta(LJD(i))^Beta);endPP=PP/(sum(PP));%建立概率分布Pcum=cumsum(PP);Select=find(Pcum>=rand);%% 第四步:状态更新和记录Path=[Path,to_visit];%路径增加PLkm=PLkm+DD(W,to_visit);%路径长度增加W=to_visit;%蚂蚁移到下一个节点for kk=1:N。