ANSYS Maxwell HPC 高性能计算技术测试报告
高性能计算系统(HPC)软件实施方案

2:高性能计算平台——分系统组成
高性能计算平台——仿真计算分系统
双路计算服务器、双路GPU计算服务器、16路胖节点计算服务器组成。
硬件组成
软件配置
CAE高性能计算软件由于其计算方式的不同,对CPU、内存、IO等的要求也不同,具体分为三大类:IO密集型,通讯密集型和支持GPU加速类型。
考虑因素
应用软件兼容性Linux和Windows的互兼容性CPU兼容性厂家对操作系统的支持时间
操作系统
安装方式
Windows
图形服务器本地硬盘配置一块系统盘,全部空间都分配给c:盘。安装过程中选择带“图形界面的Windows Server”。
Linux
2路服务器本地配置一块系统盘。16路服务器本地多块配置一块系统盘。操作系统安装过程中选择“Desktop User”模式,安装完成后配置Yum,Yum源放置到/apps/rhel68下面,方便后续随时增减安装包。配置PAM动态认证插件,实现动态SSH配置,提升系统安全性。每台机器需要配置IB驱动和并行运行环境,保证并行计算可以通过IB口进行通信。并行运行环境需要配置MPICH、Open MPI和Intel MPI几种,并优先使用Intel MPI。
/opt/xcat
-
集群管理软件
/apps/<appname>
C:\(本地盘)
应用软件安装位置
计算数据区
/data
/data/<密级>/<user>
S:\(映射盘)
用户计算作业临时存储空间,不同密级的任务数据文件分开
存储规划
3:项目实施——集群时钟同步
高性能计算实验报告

高性能计算实验报告引言高性能计算是计算机科学领域的一个重要研究领域,在许多科学和工程领域有着广泛的应用。
本实验旨在通过使用并行计算技术,在一个实际问题上展示高性能计算的能力和优势。
实验背景在本实验中,我们选择了一个经典的问题:计算圆周率(π)的近似值。
计算圆周率是计算机科学中的一个重要问题,也是高性能计算的一个经典案例。
我们将使用蒙特卡罗方法来近似计算圆周率。
实验步骤1.生成随机点:首先,我们需要生成大量的随机点。
我们选择使用伪随机数生成器来生成这些点。
在本实验中,我们将使用Python的random库来生成均匀分布的随机点。
2.判断点的位置:对于生成的每个随机点,我们需要判断它是否在一个圆内。
为了做到这一点,我们可以计算点到圆心的距离,并检查是否小于等于圆的半径。
如果是,则该点在圆内。
3.统计在圆内的点数:我们需要记录下在圆内的点的数量,以便进行进一步的计算。
在本实验中,我们使用一个计数器来实现这一功能。
4.计算圆周率的近似值:通过统计在圆内的点的数量和总生成的点数,我们可以计算圆周率的近似值。
根据蒙特卡罗方法的原理,圆的面积与正方形的面积的比例等于在圆内的点的数量与总生成的点数的比例。
根据圆的面积公式,我们可以得到一个近似的圆周率值。
5.重复实验:为了提高准确性,我们需要进行多次实验。
每次实验,我们都会使用不同的随机种子来生成随机点。
通过取多次实验的平均值,我们可以得到更接近真实圆周率的近似值。
实验结果与分析我们进行了10次实验,每次实验生成了1000000个随机点。
下表显示了每次实验的圆周率近似值:实验次数圆周率近似值1 3.1418742 3.1424813 3.1416224 3.1417865 3.1420406 3.1420127 3.1413368 3.1418329 3.14184410 3.141643通过计算上述结果的平均值,我们得到圆周率的近似值为3.141772。
结论本实验通过使用蒙特卡罗方法来计算圆周率的近似值,展示了高性能计算的能力。
HPC集群测试实验报告

密级:受限公开版本号:V1.0HPC集群测试实验报告2019年4月18日目录为了方便,在电脑中安装了Xmanager,使用Xshell登陆虚拟机进行实验操作。
一、管理节点的环境配置1.配置主机名,内网IP查看主机名称:[root@centos ~]#hostname(通用的查看主机名称)[root@centos ~]#hostnamectl(CentOS7之后新增查看主机名称命令)修改主机名:我们修改主机名称话,不是“hostname 名字”临时的命令修改,我们要永久性的修改主机名称。
在CentOS7之后两种方法修改主机名称,一是特有的命令行修改:[root@centos ~]#hostnamectl set-hostname wangjinxi01二是修改系统配置文件:[root@centos ~]#vi /etc/hostname修改IP地址当前系统的IP地址是自动获取的,需要修改成静态IP地址。
原配置文件:修改配置文件,IP地址为:192.168.83.132[root@wangjinxi01 ~]#vi /etc/sysconfig/network-scripts/ifcfg-ens33[root@wangjinxi01 ~]#service network restart 重启网络服务或者[root@wangjinxi01 ~]#systemctl restart network最后修改/etc/hosts文件:[root@wangjinxi01 ~]# vi /etc/hosts,保存退出2. 关闭防火墙[root@wangjinxi01 ~]# systemctl status firewalld # 查看防火墙状态[root@wangjinxi01 ~]# systemctl stop firewalld # 关闭防火墙状态[root@wangjinxi01 ~]# systemctl disable firewalld # 防火墙开机不启动之后,我们可以重启操作系统验证一下,防火墙是否真的被彻底关闭了。
ANSYSMechanical结构并行计算(HPC)总结

ANSYSMechanical结构并行计算(HPC)总结ANSYS结构并行计算(HPC)一、概述HPC(High Performance Computing)高性能计算是一种融合了软件、硬件提高计算效率的计算,随着计算模型的精细化(更多的网格)、整体化(更多的结构)、精确化(动力学、多物理场)要求,高性能计算受到了越来越多的重视,甚至成为了决定项目桎梏的关键环节。
对于ANSYS的高性能计算,有三个重要的因素:计算机硬件、软件许可、操作设置。
二、计算机硬件随着计算机硬件的发展,CPU的计算能力逐年迭代,单CPU可以达到几十个核心,组成双路核心数可以轻松破百;如果组装集群,哪个成千上万也成为可能,这就为高性能计算提高了硬件保证。
三、软件许可软件许可也是高性能计算的必要保证,具有良好架构的软件,就可以调用更多的计算机核心参与计算,并且使得多核心CPU高度参与计算,整体提升运算效率。
ANSYS pack是ANSYS三种并行许可之一(其余两个是ANSYS HPC和ANSYS Workgroup),具有更高的多核心计算能力,一个Pack可以调用8核CPU参与计算,两个调用32核,三个就可以调用128核,目前有测试资料显示,ANSYS的具有千核CPU计算仍能保证线性效率的能力。
四、并行方式ANSYS 并行方式分为两种类型:SMP和DMP。
u SMP:即Shared-Memory Paraller。
该种方式适用于单个计算机具有多核心CPU进行高性能计算,单路和双路CPU都可以。
u DMP:即Distributer Computing。
该种方式适用于具有多个计算计算机(计算单元)的集群使用。
五、设置及相关1、经典界面启动设置HPC计算1)SMP计算除了在计算过程中调用多个CPU核心外,其余与单核无异。
2)DMP计算DMP的并行方式,由于采用多个计算节点进行计算,故计算完成后会生成多个部分结果,具体数量与设置的Number of Processors相对应;如计算完成后,生成的结果文件可能是***0.rst,***1.rst,***2.rst。
ansys实验分析报告

ANSYS 实验分析报告1. 引言在工程设计和科学研究中,计算机仿真技术的应用越来越广泛。
ANSYS是一种常用的工程仿真软件,它可以帮助工程师和科学家分析和解决各种复杂的问题。
本文将介绍我对ANSYS进行实验分析的过程和结果。
2. 实验目标本次实验的主要目标是使用ANSYS软件对一个特定的工程问题进行仿真分析。
通过这个实验,我希望能够了解ANSYS的基本操作和功能,并在解决工程问题方面获得一定的经验。
3. 实验步骤步骤一:导入模型首先,我需要将要分析的模型导入到ANSYS软件中。
通过ANSYS提供的导入功能,我可以将CAD模型或者其他文件格式的模型导入到软件中进行后续操作。
步骤二:设置边界条件在进行仿真分析之前,我需要设置边界条件。
这些边界条件可以包括约束条件、初始条件和加载条件等。
通过设置边界条件,我可以模拟出真实工程问题中的各种情况。
步骤三:选择分析类型ANSYS提供了多种不同的分析类型,包括结构分析、流体力学分析、热传导分析等。
根据实际情况,我需要选择适合的分析类型来解决我的工程问题。
步骤四:运行仿真设置好边界条件和选择好分析类型后,我可以开始运行仿真了。
ANSYS会根据我所设置的条件,在计算机中进行仿真计算,并生成相应的结果。
步骤五:分析结果仿真计算完成后,我可以对生成的结果进行分析。
通过对结果的分析,我可以得出一些关键的工程参数,如应力分布、温度分布等。
这些参数可以帮助我评估设计的合理性和性能。
4. 实验结果在本次实验中,我成功地使用ANSYS对一个特定的工程问题进行了仿真分析。
通过分析结果,我得出了一些有价值的结论和数据。
这些数据对于进一步改进设计和解决工程问题非常有帮助。
5. 总结与展望通过本次实验,我对ANSYS软件的使用有了更深入的了解,并且积累了一定的实践经验。
在未来的工程设计和科学研究中,我将更加灵活地应用ANSYS软件,以解决更加复杂和挑战性的问题。
同时,我也会继续学习和探索其他相关的仿真软件和工具,以提高自己的技术水平。
有限元ANSYS软件使用综合测试报告

ANSYS软件使用综合测试报告姓名:学号:2010-2011学年第1学期ANSYS 软件使用综合测试学号 姓名 得分一、 测试目的:1. 测试ANSYS 有限元分析软件基本使用方法掌握情况。
2. 测试使用ANSYS 有限元分析软件完成简单机械结构应力、变形和模态分析的能力。
二、 测试内容与要求:1. 使用ANSYS 软件完成一个机械结构的有限元建模。
2. 完成该机械结构的变形和应力分析。
3. 完成机械结构的固有频率和振型分析。
4. 比较有限元网格划分粗细不同(或单元类型不同)对计算结果的影响。
5.计算完成后,每人完成作业总结一份(用A4打印),与本试卷装订成册上交。
总结应包括以下内容:(1)封面(本试卷,填写学号和姓名) (2)题目(3)计算分析结果(应包括数据和图形)及计算的有关说明。
(4)有限元分析程序(log 文件)三、 测试题目:1. 两种薄板立柱结构弯曲、扭转变形和振动固有频率分析比较:薄板结构如图,材料为灰铸铁HT200。
板厚20毫米,其它尺寸见图。
立柱底面完全固定,顶部作用集中力F=10000N ,扭矩T=2000N-m 。
弹性模量E : 5100.2⨯ 波松比μ: 0.25-0.3 密度ρ: 9108.7-⨯四、 计算分析结果:本题目主要是比较两种模型结构不同所造成的弯曲、扭转变形和振动固有频率方面有何不同,其中分别用模型一(无加强筋板)与模型二(有加强筋板)来指代两模型。
本文着重从一下三方面展开论述:1、将两种薄板立柱结构在弯曲、扭转变形时整体变形及X 、Y 、Z 截面方向上的变形情况作对比;2、比较两种薄板立柱结构在前6阶模态下的不同;3、比较划分网格大小对分析结果的影响。
1、弯曲、扭转变形:首先对两个模型按照要求进行加载:立柱底面完全固定,顶部作用集中力F=10000N,扭矩T=2000N-m。
两模型变形趋势大体相同,最大变形量均集中在右上方,但模型二整体变形量较模型一要小。
高性能计算(HPC)资源管理和调度系统解决方案

网络安全:整个系统只需要在防火墙上针对特定服务器开放特定端口,就可以实现正常的访问和使用,保证了系统的安全性。数据安全性:通过设定ACL(访问控制列表)实现数据访问的严格控制,不同单位、项目、密级用户的数据区严格隔离,保证了数据访问的安全性。用户任务的安全性。排他性调度策略,虚拟机隔离用户账户的安全性。三员管理:系统管理员、安全管理员、审计管理员三个权限分离,互相监督制约,避免权限过大。审计系统。保证所有与系统安全性相关的事件,如:用户管理(添加、删除、修改等)、用户登录,任务运行,文件操作(上传,下载,拷贝,删除,重命名,修改属性)等都能被记录,并通过统计分析,审查出异常。密级管理。支持用户和作业的密级定义。
基于数据库的开放式调度接口
案例 用户自定义调度策略:需要根据用户余额来对其作业进行调度,如果用户余额不足,该用户的作业将不予调度。 解决方案: 针对上述需求可以自定义作业的准备阶段,在数据库中为该阶段定义一存储过程用来检测用户余额信息表,根据作业所对应的用户余额来返回结果,例如: Step 1. 根据数据库开放schema配置该自定义调度策略 表 POLICY_CONF:POLICY_NAME | POLICY_ENABLEmy_policy_01 | true Step 2. 为自定义调度策略my_policy_01自定义作业准备阶段 表JOB_PREPARE_PHASE: POLICY_NAME | READY_FUNC | REASON_IDX my_policy_01 | check_user_balance | 4 check_user_balance 为方案中所描述的存储过程,其接口需要满足作业准备阶段自定义的接口要求,其实现细节如下:
现有的LSF集群系统不用作任何改动,包括存储、操作系统、LSF、应用程序和二次开发的集成脚本等。大大降低了系统的整合的难度和工作量。也有利于保护现有的投资。同时考虑到了作业以及相关数据的转发。降低了跨集群作业管理的难度。数据传输支持文件压缩和断点续传,提高了作业远程投送的效率和稳定性。支持https加密传输,安全性更强。
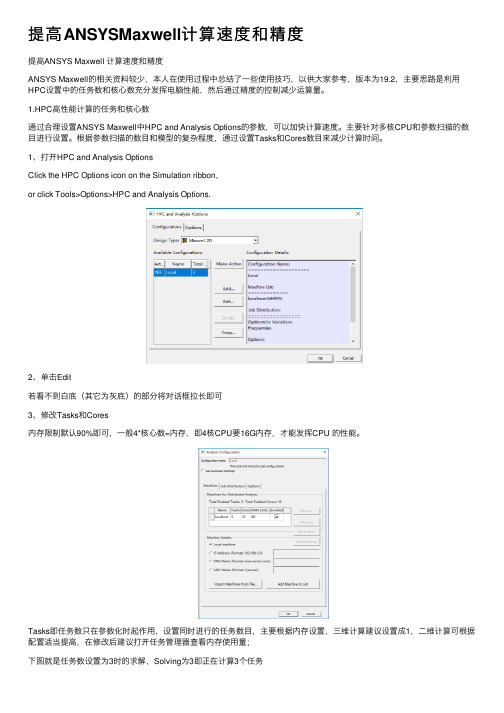
提高ANSYS Maxwell 计算速度和精度

提高ANSYS Maxwell 计算速度和精度ANSYS Maxwell的相关资料较少,本人在使用过程中总结了一些使用技巧,以供大家参考,版本为19.2,主要思路是利用HPC设置中的任务数和核心数充分发挥电脑性能,然后通过精度的控制减少运算量。
1.HPC高性能计算的任务和核心数通过合理设置ANSYS Maxwell中HPC and Analysis Options的参数,可以加快计算速度。
主要针对多核CPU和参数扫描的数目进行设置。
根据参数扫描的数目和模型的复杂程度,通过设置Tasks和Cores数目来减少计算时间。
1、打开HPC and Analysis OptionsClick the HPC Options icon on the Simulation ribbon,or click Tools>Options>HPC and Analysis Options.2、单击Edit若看不到白底(其它为灰底)的部分将对话框拉长即可3、修改Tasks和Cores内存限制默认90%即可,一般4*核心数=内存,即4核CPU要16G内存,才能发挥CPU 的性能。
Tasks即任务数只在参数化时起作用,设置同时进行的任务数目,主要根据内存设置,三维计算建议设置成1,二维计算可根据配置适当提高,在修改后建议打开任务管理器查看内存使用量;下图就是任务数设置为3时的求解,Solving为3即正在计算3个任务Cores即核心数无论是否参数化都起作用,设置同时进行计算的核心数目,主要根据CPU 设置,建议比CPU的线程数略小,当Cores和CPU的线程数相等时CPU占用率最高可达100%,若仿真同时开其它软件,建议小于最大线程。
2.自适应网格设置Maxwell中网格的设置较少,主要通过网格大小和网格数量控制,一般建议同时开启,避免网格大小不合理导致网格太多。
此外在Analysis下的Setup中也可以对网格进行设置,Maxwell采用自适应网格,即划分完网格后比较输入能量和现有网格所含能量,若误差达到设置要求就停止,否则在已有网格基础上继续划分。
ANSYS Maxwell时间分解法增强和HPC效率提升

Cluster: Cluster with 8 nodes Each node has 16cores/128 GB RAM
8kW BLDC 电动机 2000 rpm
226,000 网格 7 GB RAM
460,000 自由度 500 时间步
节点X处理器 总处理器 任务 子任务 DOFs/Subdiv.
数
数
求解时间
加速比
1X8
8
-
1
0.46Mil 26hours42min -
4X8
32
32
16
14.26Mil
3h09min
8.5
8X8
64
64
8
28.98Mil
2h03min
13
16X8
96
128 4
58.42Mil
1h32min
17.4
16X15
240
240
2
117.3Mil
1h17min
20.8
多级HPC加速和加大求解规模
k – 仿真时间步数 n – 并行求解任务数
Level 1 (MPI)
Distributed Time Steps
k
…
T1
Tk
Level 2 (MP)
Multi-Processing
n
Task求解任务
• 一个求解任务,表示一个单独的求解器。它可以计算单个或同时计算 多个时间点。
2D 大型发电机
200,000 网格 0.8 GB RAM
400,000 自由度 1700 时间步
12meters
节点X处理器 总处理器 任务 子任务 DOFs/Subdiv.
数
提高ANSYSMaxwell计算速度和精度
提⾼ANSYSMaxwell计算速度和精度提⾼ANSYS Maxwell 计算速度和精度ANSYS Maxwell的相关资料较少,本⼈在使⽤过程中总结了⼀些使⽤技巧,以供⼤家参考,版本为19.2,主要思路是利⽤HPC设置中的任务数和核⼼数充分发挥电脑性能,然后通过精度的控制减少运算量。
1.HPC⾼性能计算的任务和核⼼数通过合理设置ANSYS Maxwell中HPC and Analysis Options的参数,可以加快计算速度。
主要针对多核CPU和参数扫描的数⽬进⾏设置。
根据参数扫描的数⽬和模型的复杂程度,通过设置Tasks和Cores数⽬来减少计算时间。
1、打开HPC and Analysis OptionsClick the HPC Options icon on the Simulation ribbon,or click Tools>Options>HPC and Analysis Options.2、单击Edit若看不到⽩底(其它为灰底)的部分将对话框拉长即可3、修改Tasks和Cores内存限制默认90%即可,⼀般4*核⼼数=内存,即4核CPU要16G内存,才能发挥CPU 的性能。
Tasks即任务数只在参数化时起作⽤,设置同时进⾏的任务数⽬,主要根据内存设置,三维计算建议设置成1,⼆维计算可根据配置适当提⾼,在修改后建议打开任务管理器查看内存使⽤量;下图就是任务数设置为3时的求解,Solving为3即正在计算3个任务Cores即核⼼数⽆论是否参数化都起作⽤,设置同时进⾏计算的核⼼数⽬,主要根据CPU 设置,建议⽐CPU的线程数略⼩,当Cores和CPU的线程数相等时CPU占⽤率最⾼可达100%,若仿真同时开其它软件,建议⼩于最⼤线程。
2.⾃适应⽹格设置Maxwell中⽹格的设置较少,主要通过⽹格⼤⼩和⽹格数量控制,⼀般建议同时开启,避免⽹格⼤⼩不合理导致⽹格太多。
此外在Analysis下的Setup中也可以对⽹格进⾏设置,Maxwell采⽤⾃适应⽹格,即划分完⽹格后⽐较输⼊能量和现有⽹格所含能量,若误差达到设置要求就停⽌,否则在已有⽹格基础上继续划分。
HPC高性能计算项目IMB网络互联性能测试报告

HPC高性能计算项目IMB网络互联性能测试报告目录目录 .................................................................................................................................................. I I1 IMB简介 (1)2 HPC集群测试环境 (2)3 测试方案 (3)3.1 运行测试 (3)3.2 测试结果 (3)3.3 结果分析 (3)4 附录 (5)4.1 附录一Multi-Host网络卡内测试 (5)4.2 附录二Multi-Host网络跨卡测试 (7)4.3 附录三EDR网络测试 (8)1IMB简介IMB(Intel MPI benchmarks)用于测试集群网络互联性能,以及研究MPI/编译器组合,例如OpenMPI/GCC, IntelMPI/ICC, 对延迟和聚合带宽的影响。
IMB测试类型包含点对点、并行和群体通信测试,每一类测试都是基于MPI函数,例如MPI_Sendrecv、MPI_Reduce。
点对点:测试两个进程间的消息传递,包括Ping-Pong和Ping-Ping测试项目,通信吞吐量定义为throughput =X / 220* 106/ time = X / (1.048576 * time),X为发送消息长度,单位字节,time为等待时间,单位微秒。
并行发送:测试全局负载下消息收发效率,包括Sendrecv和Exchange两个方面的测试,MPI_Sendrecv创建一个周期性的消息收发链,第一个阶段每一个进程向右边进程发送一个消息,并接收左边进程发送的消息,第二个阶段每一个进程与左右两个进程进行数据交换。
通信吞吐量定义为throughput [Mbyte/sec] = ( (nmsg * X [bytes]) /220) * (106/ time) = (nmsg * X) / (1.048576 * time), time单位为微秒。
ansys高性能计算

– Preprocessing – Solution – Postprocessing
• This presentation aims to look at ways to reduce the time needed to obtain a solution
Focus:
FEA & CFD Simulation Software
and Services
Physical Testing Services
Objectives:
Technology Partner
Full Service Provider
Strong Commitment to Customer Satisfaction
– Memory management sometimes improves – Contact algorithms will often be faster – Solver output/feedback often improves
Solver Type
• Two main solver types for structural simulations
Parallel Processing
• Licensing
– Can run on two processors with any solver license – Need 1 HPC license per processor beyond the first
two – Processor : physical single core CPU or single core
ANSYS Maxwell时间分解法增强和HPC效率提升
• 如何激活 TDM、单机多机如何使用TDM
• 具体案例对比分析
• 案例分析、TDM 与 HPC的对比、TDM 中非线性残差的问题
TDM(Time Decomposition Method) 简介
TDM 功能始于 R17(V2016)
常规瞬态求解算法——按序求解所有的时间步:
t1
软磁滞材料
外电路
R18 Enhancements
分布式的 Expression Cache
瞬态-瞬态链接
退磁分析
La
K
Lb
B Br Br' Br''
a b
Worst-case demagnetization point
Hc
0H
TDM: 2D/3D的自动设置
• 自动调整参数:
✓ 任务书、子时间段数,内存占用
• TDM: 在没有子时间段的最后一点计算最恶劣工况点,而 不是在每个时间步
La
K
Lb
B Br Br' Br''
a b
最恶劣工作点
Hc
0H
周期性 TDM 模型
• 周期性 TDM 模型可以直接计算稳态工况
− 只需要求解一个电周期 − 支持涡流计算
• 模型要求
− 2D/3D 瞬态模型激励、涡流以及转速必须与时间具有相同的周期
t2
t3
t4
tn
TDM 瞬态求解算法——同时求解所有的时间步:
t0
t1
t2
t3
t4
…
tn
Sub-division 子时间段
时间轴
…. Sub-division1 Sub-division2
高性能计算实验报告

高性能计算实验报告高性能计算实验报告概述:高性能计算是一种利用超级计算机或者并行计算机集群来解决复杂问题的方法。
本实验旨在探索高性能计算在科学研究和工程应用中的作用,并通过实际操作和数据分析来评估其性能和效果。
实验一:并行计算与串行计算的对比在本实验中,我们选择了一个复杂的数值模型,使用串行计算和并行计算两种方法进行求解,并对比它们的效率和速度。
1. 实验设置为了保证实验的可靠性,我们选择了一个具有大规模计算需求的模型,并使用了相同的输入数据进行计算。
串行计算使用了一台普通的个人电脑,而并行计算使用了一个由多台计算机组成的集群。
2. 实验结果通过对比实验结果,我们发现并行计算在处理大规模计算问题时具有明显的优势。
它能够将任务分解成多个子任务,并同时进行计算,大大提高了计算速度和效率。
而串行计算则需要按顺序逐个计算,无法充分利用计算资源。
实验二:并行算法的设计与优化在本实验中,我们重点研究了并行算法的设计和优化方法,以提高并行计算的效果和性能。
1. 并行算法设计我们选择了一个经典的图像处理算法作为研究对象,通过将算法中的各个步骤并行化,将任务分配给不同的计算节点,并通过消息传递的方式进行数据交换,实现了并行计算。
2. 优化方法为了进一步提高并行计算的效果,我们采用了一系列优化方法。
例如,通过调整任务的划分方式,使得每个计算节点的计算负载均衡;通过减少数据传输的次数和量,降低了通信开销;通过使用高效的并行算法,减少了计算时间。
实验三:高性能计算在科学研究中的应用在本实验中,我们选择了一个真实的科学研究问题,探索了高性能计算在科学研究中的应用和效果。
1. 实验背景我们选择了一个天文学领域的问题,通过模拟和计算来研究宇宙中的星系形成和演化过程。
这个问题需要进行大规模的数值计算和模拟,对计算资源有很高的要求。
2. 实验结果通过使用高性能计算方法,我们成功地进行了大规模的数值计算和模拟,并得到了一系列有价值的科学结果。
ansys实验报告

引言概述:正文内容:大点一:ANSYS软件介绍1.ANSYS软件的背景和特点1.1ANSYS公司的历史和影响力1.2ANSYS软件的模块和功能2.ANSYS软件的安装和设置2.1安装步骤和要求2.2ANSYS的环境设置和优化3.ANSYS软件的界面和操作3.1ANSYS的用户界面和工作区域3.2ANSYS的常用工具和操作技巧大点二:ANSYS流体力学分析1.流体力学基础和原理1.1流体力学的定义和应用领域1.2流体力学方程和模型2.ANSYS流体力学分析的方法2.1流体网格的建立和划分2.2边界条件和求解器的设置3.ANSYS流体力学实验案例3.1空气动力学模拟实验3.2水流动分析实验大点三:ANSYS结构力学分析1.结构力学基础和原理1.1结构的定义和分类1.2结构力学方程和模型2.ANSYS结构力学分析的方法2.1结构的几何建模2.2边界条件和材料属性设置3.ANSYS结构力学实验案例3.1简支梁的应力分析3.2压力容器的变形分析大点四:ANSYS热传导分析1.热传导基础和原理1.1热传导的定义和描述1.2热传导方程和模型2.ANSYS热传导分析的方法2.1热传导模型的建立2.2边界条件和热源的设置3.ANSYS热传导实验案例3.1金属材料的热传导分析3.2电子设备的温度分布模拟大点五:ANSYS优化设计1.优化设计的基本概念和方法1.1优化设计的定义和分类1.2优化设计中的变量和目标函数2.ANSYS优化设计方法2.1ANSYS中的参数化建模技术2.2ANSYS中的优化算法和工具3.ANSYS优化设计案例3.1结构优化设计实验3.2流体优化设计实验总结:本文对ANSYS软件进行了全面的实验和分析,涵盖了流体力学分析、结构力学分析、热传导分析以及优化设计等领域。
通过实验案例的呈现和详细的解释,我们发现ANSYS软件在解决工程问题、优化设计和预测系统行为方面具有显著的优势。
希望本文能为读者提供一些关于ANSYS软件的基础知识和应用方法,并激发对工程领域中模拟和分析的兴趣。
ANSYS HPC高性能计算与Wiseteam高端图形工作站方案

ANSYS HPC高性能计算与Wiseteam高端图形工作站方案高性能计算(HPC)通过创建大型的、高可信度的模型(这些模型能为提议的设计方案的性能提供精确的细节洞察)为工程仿真增加了大量价值。
高可信度仿真能让工程团队满怀信心地进行创新,其产品将会满足客户期望,因为他们极其精确的仿真预测了真实条件下产品的真实性能。
作为高可信仿真技术的推动者,ANSYS HPC Packs允许任何所需级别的仿真能实现可扩展的高性能计算。
一组ANSYS HPC Packs能用来实现多个仿真任务的入门级并行,或者组合在一起为最具挑战的项目提供高度扩展的并行。
ANSYS HPC在一系列不同的计算平台上提供并行计算。
ANSYS HPC能被用于多核工作站,大幅地增加单个任务的计算能力。
对工作组或多任务,运行Linux® 或Microsoft Windows的集群会提供可扩展的性能提升。
ANSYS基于MPI的并行处理支持Gigabit以太网或不同厂商节点间的Infiniband®连接,并且MPI工具随ANSYS软件打包提供。
ANSYS软件也通过了Intel® Cluster Ready (ICR)认证,确保在ICR 厂商解决方案上提供顺利的部署和实施。
ANSYS HPC具有杰出的扩展性ANSYS流体软件中最大规模的标准测试案例表明,使用3072个核计算时,几乎呈线性化扩展,能把计算时间从几个小时或几天降低为只有几分钟。
结构仿真能在几百个处理器上实现每秒上万亿次的运算速度。
根据问题规模不同,ANSYS的客户一般对流体使用32到128核并行,而更复杂是结构仿真会用16到32个核。
ANSYS HPC Packs硬件采用Wiseteam 多核高端图形工作站/集群,工程团队不再是仅能分析一个设计方案,而是分析很多个设计方案。
同时仿真多个设计方案后,研发团队能在设计早期阶段,确定具有显著工程改进的方案,这比单独进行物理实验来得更早,也更有效。
HPC高性能计算项目Linpack性能测试报告

HPC高性能计算项目Linpack性能测试报告目录1 Linpack简介 (1)2 HPC集群测试环境 (2)3 单机Linpack测试 (3)3.1 测试方案 (3)3.2 测试结果 (4)3.3 结果分析 (5)4 整机Linpack测试 (6)4.1 测试方案 (6)4.2 测试结果 (7)4.3 结果分析 (7)5 附录 (8)5.1 HPL.dat修改说明 (8)5.2 附录1 单机测试原始输入文件 (10)5.3 附录2 单机测试输出文件 (11)5.4 附录3 整机测试输出文件 (15)1Linpack简介Linpack是国际上最流行的用于测试高性能计算机系统浮点性能的benchmark。
通过对高性能计算机采用高斯消元法求解一元N次稠密线性代数方程组的测试,评价高性能计算机的浮点性能。
Linpack 测试包括三类,Linpack100、Linpack1000和HPL。
Linpack100求解规模为100阶的稠密线性代数方程组,它只允许采用编译优化选项进行优化,不得更改代码,甚至代码中的注释也不得修改。
Linpack1000要求求解1000阶的线性代数方程组,达到指定的精度要求,可以在不改变计算量的前提下做算法和代码上做优化。
HPL即High Performance Linpack,也叫高度并行计算基准测试,它对数组大小N没有限制,求解问题的规模可以改变,除基本算法(计算量)不可改变外,可以采用其它任何优化方法。
前两种测试运行规模较小,已不是很适合现代计算机的发展。
HPL是针对现代并行计算机提出的测试方式。
用户在不修改任意测试程序的基础上,可以调节问题规模大小(矩阵大小)、使用CPU数目、使用各种优化方法等等来执行该测试程序,以获取最佳的性能。
HPL采用高斯消元法求解线性方程组。
求解问题规模为N时,浮点运算次数为(2/3 * N^3-2*N^2)。
因此,只要给出问题规模N,测得系统计算时间T,峰值=计算量(2/3 * N^3-2*N^2)/计算时间T,测试结果以浮点运算每秒(Flops)给出。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ANSYS 15.0 系列测试报告
ANSYS Maxwell HPC
测试人:李时伟ANSYS中国
测试时间:2013.12.01
Maxwell HPC介绍
美国ANSYS公司是世界最大的仿真技术公司,Maxwell软件来自于著名ANSOFT公司,作为ANSYS品牌的旗舰产品之一,领导着电磁场仿真行业的发展与潮流,在电机、变压器、传感器、作动器、高低压电气设备等电磁部件设计中得到广泛应用,备受业内的尊敬和推崇。
ANSYS一直致力于开发新一代的仿真技术,Maxwell软件在并行计算技术研发上取得了突破性的进展。
在ANSYS R15 中,Maxwell HPC结合了工程领域的需求及计算机硬件发展的趋势,基于有限元法的瞬态非线性问题矩阵求解,针对工程中常见电机结构和包含复杂结构和非线性材料的计算问题,实现磁场瞬态求解器支持高性能并行求解技术。
Maxwell 3D磁瞬态分析可通过采用多CPU(处理器)或者多核、共享存储的HPC功能实现加速计算。
由此,Maxwell HPC可提供优秀的多CPU或者多核并行计算加速比,大大提升大规模仿真模型磁瞬态求解效率,提高电机设计与仿真的速度,在计算电磁学领域具有里程碑式的意义。
测试案例介绍
测试案例1:中等规模混合励磁电机模型仿真,网格数量463.6k,仿真硬件平台为双CPU 计算机,共16核32线程,102 G共享内存
图:中等规模混合励磁电机模型和TAU网格规模
瞬态磁场求解器下,采用Maxwell HPC同时调用32核计算(超线程打开),仿真完成后的总求解时间(Total time)比单CPU单核计算速度提高了15.2倍。
在Maxwell整体计算过程中,矩阵求解时间占整个计算过程时间比例最大,单独监控非线性矩阵计算过程,则瞬态速度可以达到近30倍的加速,与参与求解的计算机核数相比,基本达到线性加速效果,加速效果非常明显。
说明Maxwell HPC 的可扩展性非常好,利用更多的CPU核能够达到更好的提速效果。
图:HPC并行求解加速效果
在Maxwell 3D 32核满核运算时,CPU使用率非常高,多数时间维持在高占用率90%左右,充分利用了现代计算机卓越的硬件计算资源,运算效率高。
图:高CPU占用率
测试案例2:新的ANSYS R15中,Maxwell v2014采用了新的HPC并行求解技术,与传统多处理器技术相比,在相同版本条件下加速性能更优秀,以这个磁滞电机仿真为例,采用ANSYS R14.5 中的MaxwellV16版本,相同计算机8核参与求解时,HPC技术加速是MP的1.5倍。
如果采用16核及以上效果则更明显,即HPC技术不会出现类似MP的饱和效应,当CPU或者核数量增加后,能够持续提升计算速率,充分体现了高性能的并行计算加速技术。
图:Maxwell HPC传统MP for Maxwell比较无饱和效应在ANSYS R15中,Maxwell v2014 HPC能够全面支持TAU体网格剖分、静磁计算、数据前后处理等并行技术,进一步加快软件的计算速度,提高计算能力。
测试案例3:Maxwell HPC结合OPT工具,支持DSO(Distributed Solve Option分布式求解)技术,将多变量和多参数优化仿真分布到局域网内的多台电脑上并行运行,大规模多变量问题可以得到线性的加速求解。
下图测试某IPM永磁电机在永磁材料几何尺寸寻优仿真案例中,将168个仿真参数分布到0~100台计算机上同时求解。
如图中表格统计数据显示:整个寻优计算的求解时间,几乎与参与计算机的数量成线性比例关系,且最多可以支持2000台以上计算机同时参与求解计算。
图:Maxwell HPC支持DSO线性加速
小结
ANSYS最新的R15版本中,Maxwellv2014 对高性能计算进行了重大改进,显著提高了计算速度和仿真规模,并且具有良好的可扩展性,仿真速度的提升基本上与参与计算的核数成正比,结合分布式并行计算与优化,能够很好地应对越来越复杂的设计,满足设计师对设计速度和仿真规模的要求,快速提交高性能的设计。