内核数据包处理
数据包处理过程

数据包处理过程来⾃链接:这篇⽂档是基于 x86 体系结构和转发 IP 分组的。
数据包在 Linux 内核链路层路径2 接收分组2.1 接收中断如果⽹卡收到⼀个和⾃⼰ MAC 地址匹配或链路层⼴播的以太⽹帧,它就会产⽣⼀个中断。
此⽹卡的驱动程序会处理此中断:从 DMA/PIO 或其他得到分组数据,写到内存⾥去;接着,会分配⼀个新的套接字缓冲区 skb ,并调⽤与协议⽆关的、⽹络设备均⽀持的通⽤⽹络接收处理函数netif_rx(skb) 。
netif_rx() 函数让内核准备进⼀步处理 skb 。
然后, skb 会进⼊到达队列以便 CPU 处理(对于多核 CPU ⽽⾔,每个 CPU 维护⼀个队列)。
如果 FIFO队列已满,就会丢弃此分组。
在 skb 排队后,调⽤ __cpu_raise_softirq() 标记 NET_RX_SOFTIRQ 软中断,等待 CPU 执⾏。
⾄此, netif_rx() 函数调⽤结束,返回调⽤者状况信息(成功还是失败等)。
此时,中断上下⽂进程完成任务,数据分组继续被上层协议栈处理。
2.2 softirq 和 bottom half内核 2.4 以后,整个协议栈不再使⽤ bottom half (下半⽂,没找到好的翻译),⽽是被软中断 softirq 取代。
软中断 softirq 优势明显,可以同时在多个 CPU 上执⾏;⽽ bottom half ⼀次只能在⼀个 CPU 上执⾏,即在多个 CPU执⾏时严格保持串⾏。
中断服务程序往往都是在 CPU 关中断的条件下执⾏的,以避免中断嵌套⽽使控制复杂化。
但是 CPU 关中断的时间不能太长,否则容易丢失中断信号。
为此, Linux 将中断服务程序⼀分为⼆,各称作“ Top Half ”和“ Bottom Half ”。
前者通常对时间要求较为严格,必须在中断请求发⽣后⽴即或⾄少在⼀定的时间限制内完成。
因此为了保证这种处理能原⼦地完成, Top Half 通常是在 CPU 关中断的条件下执⾏的。
linux gso机制

linux gso机制
Linux GSO机制是Linux内核中的一个重要特性,它可以提高数据包的传输效率。
GSO即Generic Segmentation Offload的缩写,它允许网络数据包在传输之前进行分段处理,从而减轻了网络协议栈的负担,提高了网络传输的效率。
GSO机制的实现原理是将较大的网络数据包分割成更小的片段,这样可以利用网络传输的并行性,提高数据传输的效率。
当数据包到达网络接口时,GSO会将数据包分割成合适的大小,并在传输过程中重新组装,最终将完整的数据包传输到目的地。
通过使用GSO机制,Linux系统可以在不降低网络传输速度的情况下,减少CPU的负载,提高网络传输的效率。
这对于网络密集型的应用程序来说尤为重要,可以显著提升系统的性能和响应速度。
GSO机制的应用非常广泛,特别是在虚拟化环境中。
虚拟机通常需要通过网络进行通信,而GSO机制可以帮助虚拟机提高网络传输效率,减少对物理主机的资源占用。
因此,GSO机制在云计算和数据中心等领域得到了广泛的应用。
Linux GSO机制是一项重要的网络优化技术,通过分段处理网络数据包,可以提高网络传输效率,减轻系统负载。
它在虚拟化环境中尤为重要,有助于提升系统性能和响应速度。
随着网络应用的不断发展,GSO机制的重要性将会越来越凸显。
希望通过不断的改进和
优化,能够进一步提高网络传输的效率,满足用户对高速、高效网络的需求。
内核 rps 原理

内核 rps 原理RPS(Receive Packet Steering)是一个在Linu某内核中使用的技术,用于自动分发网络数据包到不同的CPU核心处理。
它的目的是提高多核系统中网络处理的性能和伸缩性。
RPS通过在网络流量被处理时,将数据包分发到多个CPU核心上进行并行处理,从而减轻单个核心的负载,提高网络处理的吞吐量。
在传统的Linu某网络栈中,所有的网络流量都由内核通过协议栈处理。
内核将网络数据包接收到一个队列中,然后通过处理进程处理。
这种处理方式存在一个问题,即单个CPU核心负责处理所有的网络流量,如果流量很大,可能会导致CPU核心饱和,从而性能下降。
此外,由于网络流量被分散到不同的处理进程中,引起了多个进程之间的竞争条件和锁竞争。
RPS技术通过在网络接口上设置一个映射表,将接收到的数据包分发到不同的CPU核心上处理。
当数据包到达网卡驱动程序时,驱动程序会读取映射表,确定应该将数据包分发到哪个CPU核心进行处理。
这种分发的机制可以根据映射表中的规则来进行,如根据源IP地址、源端口、目的IP地址、目的端口等进行选择。
分发后,每个CPU核心都可以处理自己分配到的数据包,相互之间没有竞争条件,提高了并行处理的能力。
RPS的实现是通过一组内核线程来工作。
每个线程绑定到一个特定的CPU核心上,并通过等待网卡驱动程序中断的方式来触发数据包的接收和分发。
当驱动程序接收到一个数据包时,它会选择一个内核线程来处理,并在该线程的上下文中执行。
这样,数据包就可以在多个CPU核心上并行处理,提高了网络处理的性能。
RPS技术还能够在大规模的多核系统中提高负载均衡的能力。
通过将数据包分发到不同的CPU核心上处理,可以平均分配负载,避免某个核心负载过高,导致性能下降。
此外,RPS还可以减少多个核心之间对共享数据结构的竞争,提高系统的伸缩性。
总结来说,RPS是一个在Linu某内核中使用的技术,用于自动分发网络数据包到不同的CPU核心上处理。
Netfilter框架

Netfilter框架Netfilter是linux2.4内核实现数据包过滤/数据包处理/NAT等的功能框架。
该文讨论了linux 2.4内核的netfilter功能框架,还对基于netfilter 框架上的包过滤,NAT和数据包处理(packet mangling)进行了讨论。
阅读本文需要了解2.2内核中ipchains的原理和使用方法作为预备知识,若你没有这方面的知识,请阅读IPCHAINS-HOWTO。
第一部分:Netfilter基础和概念一、什么是NetfilterNetfilter比以前任何一版Linux内核的防火墙子系统都要完善强大。
Netfilter提供了一个抽象、通用化的框架,该框架定义的一个子功能的实现就是包过滤子系统。
因此不要在2.4中期望讨论诸如"如何在2.4中架设一个防火墙或者伪装网关"这样的话题,这些只是Netfilter功能的一部分。
Netfilter框架包含以下三部分:1 为每种网络协议(IPv4、IPv6等)定义一套钩子函数(IPv4定义了5个钩子函数),这些钩子函数在数据报流过协议栈的几个关键点被调用。
在这几个点中,协议栈将把数据报及钩子函数标号作为参数调用netfilter框架。
2 内核的任何模块可以对每种协议的一个或多个钩子进行注册,实现挂接,这样当某个数据包被传递给netfilter框架时,内核能检测是否有任何模块对该协议和钩子函数进行了注册。
若注册了,则调用该模块的注册时使用的回调函数,这样这些模块就有机会检查(可能还会修改)该数据包、丢弃该数据包及指示netfilter将该数据包传入用户空间的队列。
3 那些排队的数据包是被传递给用户空间的异步地进行处理。
一个用户进程能检查数据包,修改数据包,甚至可以重新将该数据包通过离开内核的同一个钩子函数中注入到内核中。
所有的包过滤/NAT等等都基于该框架。
内核网络代码中不再有到处都是的、混乱的修改数据包的代码了。
linux ebpf 用法

linux ebpf 用法eBPF(extended Berkeley Packet Filter)是一个在 Linux内核中执行的虚拟机,它可以用于高性能的网络分析、安全监控和性能调优等方面。
eBPF 提供了一种灵活的方式来扩展内核的功能,使得开发人员能够编写自定义的程序来处理网络数据包和系统调用。
以下是关于 Linux eBPF 用法的一些方面:1. 网络分析,eBPF 可以用于实时监控和分析网络流量,包括流量统计、协议分析、数据包过滤等。
通过编写 eBPF 程序,可以在内核空间对网络数据包进行处理,而无需将数据包传递到用户空间,从而获得更高的性能和更低的延迟。
2. 安全监控,eBPF 可以用于实现安全监控功能,例如检测恶意流量、拦截攻击、监控系统调用等。
借助 eBPF,可以在内核中实现复杂的安全策略,并且可以动态地更新这些策略,而无需重启系统。
3. 性能调优,eBPF 还可以用于性能调优,例如实时监控系统的 CPU 使用率、内存分配情况、磁盘 I/O 等,从而帮助开发人员识别和解决性能瓶颈问题。
4. 工具支持,许多开源工具和项目已经开始集成 eBPF 技术,例如 tcpdump、Wireshark、Prometheus 等,这些工具可以利用eBPF 来提供更强大的网络分析和监控功能。
5. 开发工具,针对 eBPF 的开发,可以使用 LLVM 编译器将 C 语言或者类似 C 语言的语言编写的程序编译成 eBPF 字节码。
此外,还有一些高级的工具和库,如 BCC(BPF Compiler Collection)和libbpf,可以帮助开发人员更轻松地编写和调试 eBPF 程序。
总的来说,eBPF 在 Linux 内核中的用法非常广泛,可以用于网络分析、安全监控、性能调优等多个方面,而且其灵活性和高性能使得它成为了许多开发人员和运维人员的首选工具之一。
希望这些信息能够帮助你更好地了解 Linux eBPF 的用法。
Linux内核Bridge模式数据处理流程

Linux内核Bridge模式数据处理流程1. 前言本文简要介绍数据包在进入桥网卡后在Linux网络协议栈的处理流程,并描述netfilter的hook点的挂接处理情况,具体各部分的详细处理待后续文章中说明。
以下内核代码版本为2.6.19.2.2. 函数处理流程bridge入口点handle_bridge()1./* net/core/dev.c */2.int netif_receive_skb(struct sk_buff *skb)3.{4.//......5.if(handle_bridge(&skb,&pt_prev,&ret, orig_dev))goto out;6.//......}bridge基本挂接点处理函数:br_handle_frame_hook()1.static__inline__int handle_bridge(struct sk_buff **pskb,2.struct packet_type **pt_prev,int*ret,3.struct net_device *orig_dev)4.{5.struct net_bridge_port *port;6.if((*pskb)->pkt_type == PACKET_LOOPBACK ||7.(port =rcu_dereference((*pskb)->dev->br_port))==NULL)8.return 0;9.if(*pt_prev){10.*ret = deliver_skb(*pskb,*pt_prev, orig_dev);11.*pt_prev =NULL;12.}13.14.return br_handle_frame_hook(port, pskb);15.}bridge_handle_frame_hook()的实际实现:1./* net/bridge/br.c */2.static int __init br_init(void)3.{4.//......5.br_handle_frame_hook = br_handle_frame;6.//......}br_handle_frame: PF_BEIDGE的prerouting点1./* net/bridge/br_input.c */2.int br_handle_frame(struct net_bridge_port *p,struct sk_buff **pskb)3.{4.struct sk_buff *skb =*pskb;5.const unsigned char*dest = eth_hdr(skb)->h_dest;6.if(!is_valid_ether_addr(eth_hdr(skb)->h_source))7.goto err;8.if(unlikely(is_link_local(dest))){9.// 自身包进入PF_BEIDGE的INPUT点, 一般处理的包数不多10.skb->pkt_type = PACKET_HOST;11.// 正常是返回1的, 然后就返回1, 表示桥模块全权处理该包了12.13.return NF_HOOK(PF_BRIDGE,NF_BR_LOCAL_IN,skb, skb->dev,14.NULL, br_handle_local_finish)!= 0;15.}16.if(p->state == BR_STATE_FORWARDING || p->state == BR_STATE_LEARNING){17.// br_should_route_hook函数一般没定义if(br_should_route_hook){18.if(br_should_route_hook(pskb))19.return 0;20.skb =*pskb;21.dest = eth_hdr(skb)->h_dest;22.}23.if(!compare_ether_addr(p->br->dev->dev_addr, dest))24.skb->pkt_type = PACKET_HOST;25.// PF_BRIDGE的prerouting处理结束后进入br_handle_frame_finish26.27.NF_HOOK(PF_BRIDGE,NF_BR_PRE_ROUTING,skb, skb->dev,NULL,28.br_handle_frame_finish);29.// 处理后始终返回1, 表示不再进行其他协议族处理,该数据包已经完全由bridge处理完毕30.31.return 1;32.}33.err:34.kfree_skb(skb);35.// 处理后始终返回1, 表示不再进行其他协议族处理,该数据包已经完全由bridge处理完毕36.37.return 1;38.}通过br_handle_frame_finish进入bridge的转发:1./* note: already called with rcu_read_lock (preempt_disabled) */2.int br_handle_frame_finish(struct sk_buff *skb)3.{4.const unsigned char*dest = eth_hdr(skb)->h_dest;5.struct net_bridge_port *p = rcu_dereference(skb->dev->br_port);6.struct net_bridge *br;7.struct net_bridge_fdb_entry *dst;8.int passedup = 0;9.if(!p || p->state == BR_STATE_DISABLED)10.goto drop;11./* insert into forwarding database after filtering to avoid spoofing */12.br = p->br;13.br_fdb_update(br, p, eth_hdr(skb)->h_source);14.if(p->state == BR_STATE_LEARNING)15.goto drop;16.if(br->dev->flags & IFF_PROMISC){17.struct sk_buff *skb2;18.skb2 = skb_clone(skb, GFP_ATOMIC);19.if(skb2 !=NULL){20.passedup = 1;21.br_pass_frame_up(br, skb2);22.}23.}24.if(is_multicast_ether_addr(dest)){25.// 多播转发,也是调用广播处理26.27.br->statistics.multicast++;28.br_flood_forward(br, skb,!passedup);29.if(!passedup)30.br_pass_frame_up(br, skb);31.goto out;32.}33.// 根据目的MAC找目的出口34.35.dst = __br_fdb_get(br, dest);36.if(dst !=NULL&& dst->is_local){37.if(!passedup)38.br_pass_frame_up(br, skb);39.else40.kfree_skb(skb);41.goto out;42.}43.if(dst !=NULL){44.// 单播转发br_forward(dst->dst, skb);45.goto out;46.}47.// 广播转发48.49.br_flood_forward(br, skb, 0);50.out:51.return 0;52.drop:53.kfree_skb(skb);54.goto out;55.}广播/多播转发: br_flood_forward/br_flood1./* called under bridge lock */2.void br_flood_forward(struct net_bridge *br,struct sk_buff *skb,int clone)3.{4.br_flood(br, skb, clone, __br_forward);5.}6./* called under bridge lock */7.static void br_flood(struct net_bridge *br,struct sk_buff *skb,int clone,8.void(*__packet_hook)(const struct net_bridge_port *p,9.struct sk_buff *skb))10.{11.struct net_bridge_port *p;12.struct net_bridge_port *prev;13.if(clone){14.struct sk_buff *skb2;15.if((skb2 = skb_clone(skb, GFP_ATOMIC))==NULL){16.br->statistics.tx_dropped++;17.return;18.}19.skb = skb2;20.}21.prev =NULL;22.list_for_each_entry_rcu(p,&br->port_list,list){23.if(should_deliver(p, skb)){24.if(prev !=NULL){25.struct sk_buff *skb2;26.if((skb2 = skb_clone(skb, GFP_ATOMIC))==NULL){27.br->statistics.tx_dropped++;28.kfree_skb(skb);29.return;30.}31.// 这里实际是__br_forward32.33.__packet_hook(prev, skb2);34.}35.prev = p;36.}37.}38.if(prev !=NULL){39.// 这里实际是__br_forward40.41.__packet_hook(prev, skb);42.return;43.}44.kfree_skb(skb);45.}单播转发: br_forward1./* net/bridge/br_forward.c */2./* called with rcu_read_lock */3.void br_forward(const struct net_bridge_port *to,structsk_buff *skb)4.{5.if(should_deliver(to, skb)){6.// 也是调用__br_forward7.8.__br_forward(to, skb);9.return;10.}11.kfree_skb(skb);12.}FORWARD点:1.static void __br_forward(const struct net_bridge_port *to, struct sk_buff *skb)2.{3.struct net_device *indev;4.indev = skb->dev;5.skb->dev = to->dev;6.skb->ip_summed = CHECKSUM_NONE;7.// 进入PF_BRIDGE的forward hook, 结束后进入br_forward_finish()8.9.NF_HOOK(PF_BRIDGE,NF_BR_FORWARD,skb,indev, skb->dev,10.br_forward_finish);11.}POSTROUTING点:1.// 从FORWARD点处理后直接进入POSTROUTING点处理2.3.int br_forward_finish(struct sk_buff *skb)4.{5.// 进入PF_BRIDGE的postrouting hook, 结束后进入br_dev_queue_push_xmit()6.7.return NF_HOOK(PF_BRIDGE, NF_BR_POST_ROUTING, skb, NULL, skb->dev,8.br_dev_queue_push_xmit);9.}数据包发出:1.int br_dev_queue_push_xmit(struct sk_buff *skb)2.{3./* drop mtu oversized packets except gso */4.if(packet_length(skb)>skb->dev->mtu &&!skb_is_gso(skb))5.kfree_skb(skb);6.else{7./* ip_refrag calls ip_fragment, doesn't copy the MAC header. */8.if(nf_bridge_maybe_copy_header(skb))9.kfree_skb(skb);10.else{11.skb_push(skb, ETH_HLEN);12.// 此处调用dev设备的hard_start_xmit()函数13.14.dev_queue_xmit(skb);15.}16.}17.return 0;18.}桥网卡设备的hard_start_xmit()函数定义为:1./* net/bridge/br_device.c */2.void br_dev_setup(struct net_device *dev)3.{4.//......5.6.dev->hard_start_xmit = br_dev_xmit;7.//......8.9.}10./* net device transmit always called with no BH (preempt_disabled) */11.int br_dev_xmit(struct sk_buff *skb,struct net_device *dev)12.{13.struct net_bridge *br = netdev_priv(dev);14.const unsigned char*dest = skb->data;15.struct net_bridge_fdb_entry *dst;16.br->statistics.tx_packets++;17.br->statistics.tx_bytes += skb->len;18.skb->mac.raw = skb->data;19.skb_pull(skb, ETH_HLEN);20.if(dest[0]& 1)21.// 多播发送22.23.br_flood_deliver(br, skb, 0);24.else if((dst = __br_fdb_get(br, dest))!=NULL)25.// 单播发送26.27.br_deliver(dst->dst, skb);28.else29.// 广播发送30.31.br_flood_deliver(br, skb, 0);32.// 这些发送函数最终都会调用__br_deliver()函数33.34.return 0;35.}36.37./* net/bridge/br_forward.c */38.static void __br_deliver(const struct net_bridge_port *to, struct sk_buff *skb)39.{40.skb->dev = to->dev;41.// 此处是PF_BRIDGE的OUTPUT点42.43.NF_HOOK(PF_BRIDGE,NF_BR_LOCAL_OUT,skb,NULL, skb->dev,44.br_forward_finish);45.}总结: PF_BRIDGE中的各个hook点和PF_INET不同, 可用下面的图表示:PREROUTING --+--FORWARD-----POSTROUTING------+----OUTPUT| || |INPUT3. BF_BRIDGE的hook点在net/bridge/br_netfilter.c中定义了以下hook点,注意这些hook点主要是PF_BRIDGE协议族的。
linux kernel回复tcp ack的机制

linux kernel回复tcp ack的机制标题:Linux内核回复TCP ACK的机制探究引言:TCP(Transmission Control Protocol)是一种面向连接的、可靠的协议,它负责确保数据的完整传输和有序交付。
在传输数据的过程中,TCP使用了一种称为确认机制(ACK mechanism)的方式来进行数据的确认和确认应答。
在Linux 内核中,实现了TCP ACK机制的一系列算法和流程,本文将一步一步地探索这个过程,从细节深入解析其实现原理。
第一部分:TCP ACK机制的简介1. TCP ACK机制的作用和重要性- 确保数据的可靠传输和有序交付- 提高网络连接的稳定性和性能2. TCP ACK机制的基本原理- 接收方返回ACK以确认接收到的数据- 发送方根据收到的ACK信息进行数据的发送和重传控制- 滑动窗口机制和拥塞控制算法的配合第二部分:Linux内核中TCP ACK的处理流程1. TCP ACK的基本数据结构和数据包格式- TCP数据包的头部结构和字段描述- TCP ACK报文的格式和字段含义2. 接收端的ACK处理流程- 接收方收到数据包后进行数据的处理- 判断是否需要发送ACK确认- 发送ACK确认报文的生成和发送3. 发送端的ACK处理流程- 发送方发送数据后等待ACK的到达- 接收到ACK后进行数据的确认处理- 更新发送窗口和进行重传控制第三部分:Linux内核中TCP ACK的优化和改进1. 延迟ACK的机制和优化- ACK的延迟发送和累积确认- Nagle算法对延迟ACK的影响2. SACK(Selective Acknowledgement)的使用- SACK的基本原理和算法- SACK对TCP连接性能的改进和提升3. 快速重传和快速恢复算法- 快速重传和快速恢复的流程和机制- 对丢包和拥塞事件的快速响应和调整第四部分:Linux内核中TCP ACK的调试和分析工具1. TCPDump和Wireshark的使用- 抓包工具的使用方法和基本原理- 分析ACK报文的内容和流向2. 通过/sys文件系统查看TCP ACK相关参数- 了解并调整系统中的ACK处理参数- sysctl命令和/proc文件系统的使用结论:Linux内核中的TCP ACK机制是保证数据传输可靠性和性能的关键因素之一。
netfilter 机制

netfilter 机制netfilter 是Linux 操作系统中用于实现网络数据包过滤和修改的核心机制。
本文将介绍netfilter 机制的基本原理和功能,以及它在网络安全和网络管理中的应用。
netfilter 是Linux 内核中的一个网络数据包处理框架,它允许用户空间程序通过注册钩子函数来拦截、过滤和修改网络数据包。
netfilter 的核心组件是iptables,它是一个用户空间的命令行工具,用于配置netfilter 规则。
iptables 可以根据网络数据包的源IP地址、目标IP地址、协议类型、端口等信息来过滤和处理数据包。
netfilter 的工作原理是将网络数据包交给注册的钩子函数进行处理。
钩子函数根据预先设定的规则来判断数据包的命运,可以选择将数据包丢弃、修改数据包的目标地址或端口,或者将数据包传递给下一个钩子函数。
钩子函数的执行顺序由netfilter 链决定,每个链都包含多个钩子函数,钩子函数按照预定的顺序执行。
netfilter 提供了多个预定义的链,包括INPUT、FORWARD 和OUTPUT 等链。
INPUT 链用于处理目标地址是本机的数据包,FORWARD 链用于处理转发的数据包,OUTPUT 链用于处理源地址是本机的数据包。
用户可以在这些链上注册自定义的钩子函数,实现特定的数据包处理逻辑。
netfilter 还支持使用扩展模块来增加更多的功能。
扩展模块可以提供额外的匹配条件和动作,使用户能够更灵活地配置netfilter 规则。
常用的扩展模块包括 conntrack、nat 和 mangle 等。
netfilter 在网络安全中扮演着重要的角色。
通过配置适当的规则,可以实现防火墙功能,对不符合规则的数据包进行过滤,从而保护网络安全。
例如,可以配置规则来禁止特定的IP地址访问某个端口,或者限制某个服务的连接数。
netfilter 还可以用于网络管理。
通过配置规则,可以实现网络地址转换(NAT)功能,将内部网络的私有IP地址映射为公共IP地址,从而实现内网和外网的通信。
linux内核收包流程

linux内核收包流程Linux内核是开源的,它的内核源代码可以被任何人查看、修改和分发。
内核是操作系统的核心,它负责管理和协调系统硬件和软件资源,为应用程序提供一致的接口。
在Linux内核中,收包是指当接收到网络数据包时,内核如何处理和分发这些数据包。
下面将详细介绍Linux内核收包的流程。
首先,当数据包到达网卡时,网卡会将这个数据包拷贝到内核的内存中。
然后,内核会通过网络设备驱动程序检查这个数据包的合法性,包括检查以太网帧头、校验和等。
如果数据包合法,那么内核会将其拷贝到内核的套接字缓冲区中。
接下来,内核会分析数据包的目标IP地址,以确定数据包是发给本地还是需要转发到其他主机。
如果目标IP地址是本地主机,那么内核会查找与目标IP地址对应的本地套接字,并将数据包传递给该套接字。
如果目标IP地址是其他主机,那么内核会将数据包传递给路由子系统进行进一步的处理。
在路由子系统中,内核会根据路由表来确定下一跳的IP地址,并将数据包传递给相应的网络设备驱动程序。
网络设备驱动程序将数据包发送到下一跳主机。
如果目标主机和当前主机在同一局域网中,那么内核会使用ARP协议获取对应目标IP地址的MAC地址,然后通过以太网帧发送数据包。
当数据包到达目标主机后,目标主机的网卡会将数据包拷贝到内存中。
然后,内核会根据数据包的协议字段来识别上层协议类型,如TCP、UDP或ICMP等。
然后,将数据包传递给相应的协议处理函数进行处理。
协议处理函数会对数据包进行相应的处理,如IP协议处理函数会进行IP分片重组、IP头校验等操作;TCP协议处理函数会对TCP连接进行状态管理、流量调整等操作;UDP协议处理函数会进行端口匹配和应用程序通信等操作。
最后,协议处理函数会将处理后的数据包传递给相应的套接字,并唤醒等待在该套接字上的应用程序。
应用程序可以通过调用系统调用来读取数据包或向其发送数据包。
总结起来,Linux内核收包的流程主要包括:数据包到达网卡、网卡拷贝数据包到内存、检查数据包合法性、目标IP地址分析、传递给本地套接字或路由子系统、路由子系统发送数据包到下一跳、目标主机网卡拷贝数据包到内存、协议处理函数对数据包进行处理、将处理后的数据包传递给套接字、应用程序读取或发送数据包。
LINUX内核网络协议栈

LINUX内核网络协议栈Linux内核网络协议栈是一个关键的软件组件,它实现了Linux操作系统的网络功能。
网络协议栈位于操作系统内核中,负责处理网络传输的各个层级。
Linux内核网络协议栈包括多个层级,从物理层到应用层。
每个层级都有特定的功能和协议。
下面是对每个层级的详细介绍:1.物理层:物理层是网络协议栈的最低层,负责传输数据的物理介质,如电缆、光纤等。
物理层由硬件设备支持,并通过设备驱动程序与内核进行通信。
2.数据链路层:数据链路层负责将数据转换为数据帧,并通过物理介质进行传输。
它包括两个子层:逻辑链路控制层和介质访问控制层。
逻辑链路控制层处理数据的流控制和错误检测,介质访问控制层则管理多个设备的访问冲突。
3.网络层:网络层处理数据包的路由和分组。
它使用IP协议进行路由和寻址,并通过路由表决定数据包的最佳路径。
网络层还可以处理一些附加功能,如分片和重新组装。
4.传输层:传输层负责在不同主机之间的进程之间提供可靠的数据传输。
它使用TCP协议和UDP协议来实现,TCP协议提供可靠的数据传输,而UDP协议提供不可靠但高效的传输。
5.会话层:会话层负责建立、管理和终止网络会话。
它处理会话标识符的生成和管理,并提供可靠的会话传输。
6.表示层:表示层负责数据的编码和解码,以确保数据在不同系统之间的互通。
它处理数据的格式、加密和压缩。
7.应用层:应用层是网络协议栈的最高层,提供用户与网络之间的接口。
它包括多个协议,如HTTP、FTP和SMTP,用于实现各种应用程序的网络功能。
Linux内核网络协议栈的功能包括数据传输、路由、安全、流量控制和错误检测。
内核通过各个层级的协议来实现这些功能。
内核还提供各种工具和接口,使用户可以配置网络设置、监控网络流量和诊断网络问题。
除了基本功能,Linux内核网络协议栈还支持各种高级功能,如多路复用、多队列和嵌入式系统。
它还可以通过加载额外的模块来支持特定的网络协议或功能。
linux prerouting 匹配规则

linux prerouting 匹配规则【Linux prerouting 匹配规则】是指在Linux网络处理中,针对数据包的预处理机制。
本文将逐步回答关于Linux prerouting匹配规则的相关问题,包括基本概念、实际应用和常见用例。
1. 什么是Linux prerouting匹配规则?Linux prerouting匹配规则是网络处理中的一环,位于数据包到达Linux内核之前,用于对数据包进行预处理和匹配操作。
它允许系统管理员定义一系列规则,以根据数据包的特征对其进行处理。
prerouting匹配规则主要用于网络地址转换(Network Address Translation,NAT)和防火墙功能。
2. 如何使用Linux prerouting匹配规则?要使用Linux prerouting匹配规则,需要使用iptables命令行工具。
该工具是Linux系统中用于管理数据包过滤规则和网络地址转换的工具。
通过iptables,可以对数据包进行各种操作,如丢弃、转发、修改等。
3. 在哪些情况下会使用Linux prerouting匹配规则?Linux prerouting匹配规则通常用于以下几种情况:- 网络地址转换(NAT):当数据包到达Linux系统时,需要将其目标地址修改为内部网络上的一个地址,以实现公网与私网之间的通信。
prerouting匹配规则可以用于识别并转发这些数据包。
- 防火墙规则:系统管理员可以使用prerouting匹配规则对数据包进行过滤和防火墙处理。
根据数据包的来源、目标、协议、端口等特征进行匹配并进行不同的操作,如允许、拒绝或重定向。
4. 如何创建Linux prerouting匹配规则?要创建Linux prerouting匹配规则,可以使用以下步骤:(1)打开终端或SSH连接到Linux系统。
(2)使用iptables命令行工具创建一个新的prerouting链,并指定它的表为nat表:shelliptables -t nat -N PREROUTING_RULE(3)为prerouting链添加匹配规则。
linux lro代码

// 内存分配失败 return; }
// 填充数据包内容
// 检查是否需要启用LRO if (netif_needs_gso(skb, features)) {
// 启用LRO功能 napi_gro_receive(&napi, skb); } else { // 不需要LRO,直接处理数据包 netif_receive_skb(skb); } ```
linux lro代码
3. 在网络发送路径中处理LRO功能:
```c struct sk_buff *skb;
// 发送合并后的数据包 netif_skb_features(skb); } else { // 不需要LRO,直接发送数据包 netdev_start_xmit(skb, netdev); } ```
linux lro代码
请注意,以上代码示例仅为了说明LRO功能的基本原理,实际的代码实现可能会涉及更多 的细节和处理逻辑,具体实现可能因Linux内核版本和网络适配器类型而有所不同。建议您参 考Linux内核源代码中与网络接口和协议相关的部分,以获取更详细和准确的LRO功能代码实 现。
// 启用LRO功能 skb_shinfo(skb)->gso_type = SKB_GSO_TCPV4; skb_shinfo(skb)->gso_size = LRO_SEGMENT_SIZE; skb_shinfo(skb)->gso_segs = LRO_SEGMENT_NUM; skb_shinfo(skb)->gso_size += skb->len;
内核构造skb数据包的实现总结

/macrossdzh/article/details/5438306一、IPv4、TCP和UDP的校验和计算校验和是网络协议用来识别传输错误的冗余域。
有些校验和不但能检测错误,还能自动修正某些类型的错误。
校验和的想法很简单。
在传输一个数据包之前,发送方计算出一个很小的、固定长度的域(校验和)包含数据的某种散列。
如果在传输过程中某几位数据被改变,很可能损坏的数据会产生一个不同的校验和。
取决于你用来产生校验和使用的函数,校验和提供不同级别的可靠性。
IP协议采用的校验和是简单的一个包括求和取反码,这个方法太弱了,不能被认为是可靠的。
对于更可靠的完整性检查,你必须依赖于L2 CRC或者SSL/IPSec消息认证码。
不同的协议可以使用不同的校验和算法。
IP协议校验和只覆盖IP头。
大多数L4协议的校验和均覆盖头和数据。
看起来在L2(比如,以太网)有校验和,L3(比如,IP)有另一个,L4(比如,TCP)还有一个的做法是冗余的,因为它们全都应用于数据的重叠部分,但是检查是有价值的。
错误不只在传输过程中发生,也会在层之间移动中发生。
而且,每个协议负责保证他自己的正确传输,不能假设高或低的层完成这个任务。
举一个可能发生的复杂情况的例子,想象LAN1上的PC A通过Internet发送数据给LAN2上的PC B。
假设LAN1中使用的L2协议使用校验和而LAN2上的不使用。
那么最少一个高层提供某种形式的校验和来减小接受损坏数据的可能性是很重要的。
每个协议的定义中都建议使用校验和,虽然它不是必须的。
然而,必须承认的是一个好的相关协议的设计可以去掉一些不同层协议之间的重叠特性带来的开销。
因为大多数L2和L4协议提供校验和,在L3中也有校验和就不是严格必须的。
正是由于这个原因,IPv6中去掉了这个校验和。
在IPv4中,IP校验和是一个16位域覆盖整个IP头,包括选项。
校验和最初由数据包源来计算,并在整个到目标的过程中一个跳跃一个跳跃的被更新以反映每个路由器带来的头部变化。
内核对icmp报文的处理流程

内核对icmp报文的处理流程icmp报文是互联网控制报文协议(Internet Control Message Protocol)的一种数据格式,主要用于网络设备之间的通信和错误报告。
在网络通信过程中,icmp报文起着非常重要的作用,它能够检测网络的可达性、传输速度以及错误处理等。
当源主机向目标主机发送icmp报文时,目标主机会先检查该报文的合法性,包括源主机的IP地址和数据校验和等。
如果报文合法,则目标主机会根据报文的类型进行相应的处理。
icmp报文的处理流程如下:1. 接收报文目标主机首先接收到icmp报文,并对报文进行解析和处理。
接收到的报文包括icmp报文的首部和数据部分。
2. 检查报文类型目标主机会检查icmp报文的类型字段,以确定该报文是响应报文还是请求报文。
常见的icmp报文类型包括回显请求和回显应答,路由器通告等。
3. 根据报文类型进行处理根据icmp报文的类型,目标主机会进行相应的处理。
以回显请求和回显应答为例,当目标主机接收到回显请求时,会立即向源主机发送一个回显应答,以确认源主机的可达性。
而当目标主机接收到回显应答时,会对源主机的可达性进行验证。
4. 生成错误报文如果目标主机在处理icmp报文时发现错误,比如目标不可达、超时等,它会生成一个错误报文,并将该报文发送给源主机。
错误报文中包含了错误信息和相关的网络信息,以便源主机进行错误处理。
5. 发送报文目标主机根据icmp报文的处理结果,生成相应的报文并发送给源主机。
报文中包含了处理结果、错误信息等。
6. 检查报文完整性源主机接收到目标主机发送的icmp报文后,会检查报文的完整性,包括首部和数据部分的校验和,以确保报文没有被篡改或损坏。
7. 处理报文源主机接收到icmp报文后,会根据报文的内容进行相应的处理。
比如,如果是回显应答报文,源主机会检查回显数据是否正确,并计算往返时间等。
总结起来,icmp报文的处理流程包括接收报文、检查报文类型、根据报文类型进行处理、生成错误报文、发送报文、检查报文完整性和处理报文等步骤。
linuxip透传总结

linuxip透传总结Linux IP透传是一种网络技术,它允许将网络流量在不同的网络接口之间进行传递,使得数据包可以直接在内核中进行处理,而无需经过用户空间的应用程序。
这种技术在网络通信中起到了重要的作用,本文将对Linux IP透传进行详细介绍和总结。
一、什么是Linux IP透传Linux IP透传是指将数据包在内核中进行处理和转发的技术。
传统上,网络流量需要经过用户空间的应用程序才能进行处理,而Linux IP透传则直接在内核中进行操作,提高了网络传输的效率和性能。
二、Linux IP透传的优势1. 提高网络传输性能:Linux IP透传可以直接在内核中进行操作,省去了数据包在用户空间的传输过程,提高了网络传输的效率和性能。
2. 简化网络架构:通过使用Linux IP透传技术,可以简化网络架构,减少了网络设备和传输路径的数量,降低了网络的复杂性。
3. 增强网络安全性:Linux IP透传可以在内核中对数据包进行处理,提供了更高的安全性和防护能力,可以有效防止网络攻击和数据泄露。
三、Linux IP透传的应用场景1. 虚拟化环境:在虚拟化环境中,Linux IP透传可以实现虚拟机之间的高性能网络通信,提高了虚拟化环境的网络效率和性能。
2. 高性能计算:在高性能计算领域,Linux IP透传可以提高数据传输的效率和性能,加快计算任务的执行速度。
3. 网络安全监控:通过使用Linux IP透传技术,可以在内核中对网络流量进行实时监控和分析,提供更高的网络安全防护能力。
四、Linux IP透传的实现方式1. 使用IPT ables:IPTables是Linux内核自带的一种过滤数据包的工具,可以通过配置IPTables规则来实现IP透传。
2. 使用Netfilter框架:Netfilter是Linux内核中的一个网络包过滤框架,可以通过在Netfilter中添加透传规则来实现IP透传。
3. 使用Linux网络设备驱动:通过在Linux网络设备驱动中添加透传功能,可以实现IP透传。
数据包处理流程
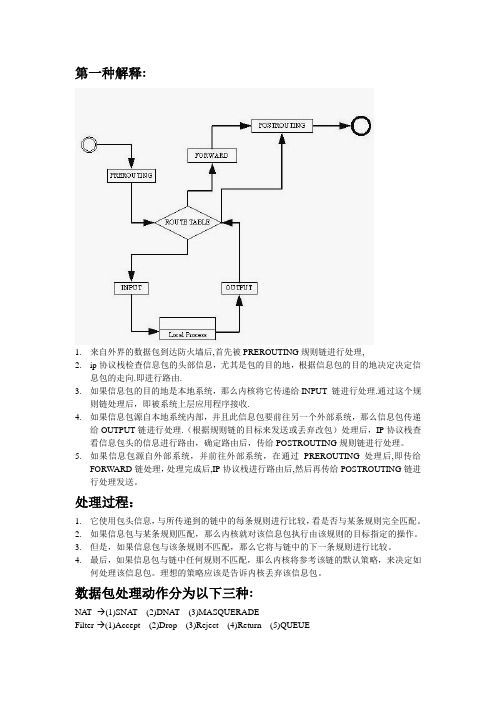
第一种解释:1.来自外界的数据包到达防火墙后,首先被PREROUTING规则链进行处理,2.ip协议栈检查信息包的头部信息,尤其是包的目的地,根据信息包的目的地决定决定信息包的走向.即进行路由.3.如果信息包的目的地是本地系统,那么内核将它传递给INPUT 链进行处理.通过这个规则链处理后,即被系统上层应用程序接收.4.如果信息包源自本地系统内部,并且此信息包要前往另一个外部系统,那么信息包传递给OUTPUT链进行处理.(根据规则链的目标来发送或丢弃改包)处理后,IP协议栈查看信息包头的信息进行路由,确定路由后,传给POSTROUTING规则链进行处理。
5.如果信息包源自外部系统,并前往外部系统,在通过PREROUTING处理后,即传给FORWARD链处理,处理完成后,IP协议栈进行路由后,然后再传给POSTROUTING链进行处理发送。
处理过程:1.它使用包头信息,与所传递到的链中的每条规则进行比较,看是否与某条规则完全匹配。
2.如果信息包与某条规则匹配,那么内核就对该信息包执行由该规则的目标指定的操作。
3.但是,如果信息包与该条规则不匹配,那么它将与链中的下一条规则进行比较。
4.最后,如果信息包与链中任何规则不匹配,那么内核将参考该链的默认策略,来决定如何处理该信息包。
理想的策略应该是告诉内核丢弃该信息包。
数据包处理动作分为以下三种:NA T--→(1)SNAT (2)DNA T (3)MASQUERADEFilter-→(1)Accept (2)Drop (3)Reject (4)Return (5)QUEUERouting- (1)本地系统(2)外部系统PREROUTING:SNATINPUT:FilterOUTPUT:(NAT) Filter FORWARD:Filter POSTROUTING: DNAT MASQUERADE。
Linux下一种高性能数据包收发机制与实现

Linux下一种高性能数据包收发机制与实现刘松涛;管鲍【摘要】The traditional Linux mainly sends and receives data packet in kernel space, so it has a memory copy process to protocol stack running in user space. This paper presents a mechanism of sending and receiving packet based on Datapath Acceleration Architecture, realizing the zero memory copy. Introduces each module of DPAA and the use schemes of USDPAA, analyses and realizes the design of USDPAA user space and kernel space. After testing, it is effective to sending and receiving data packet in user state.%传统上Linux主要在内核空间收发数据包,对于运行于用户空间的协议栈存在一次内存拷贝过程,文章提出基于数据通道加速架构(Datapath Acceleration Architecture,DPAA)的用户态收发包机制,实现内存零拷贝,介绍了DPAA各模块和USDPAA的使用方案,对USDPAA内核空间和用户空间的设计进行了分析和实现.经过测试,能够在用户态有效的收发数据包.【期刊名称】《价值工程》【年(卷),期】2012(031)015【总页数】2页(P187-188)【关键词】数据包;数据通道加速架构;内存拷贝【作者】刘松涛;管鲍【作者单位】武汉邮电科学研究院,武汉430074;武汉邮电科学研究院,武汉430074【正文语种】中文【中图分类】TP3920 引言传统的Linux在处理数据包时,主要采用在内核态收发包的模式,然后交给内核协议栈处理。
linux内核收包流程

linux内核收包流程摘要:I.引言- 介绍Linux 内核收包流程的重要性II.Linux 内核收包流程概述- 网卡接收数据包- 数据包处理流程III.网卡接收数据包- 硬件中断处理- 数据包接收和缓冲IV.数据包处理流程- 数据包的解析和分类- 数据包的过滤和处理- 数据包的发送和转发V.总结- 概括Linux 内核收包流程的关键步骤正文:I.引言Linux 内核收包流程是计算机网络中至关重要的一个环节。
它负责接收来自网络的数据包,并对数据包进行处理和转发。
了解Linux 内核收包流程对于理解计算机网络的工作机制以及优化网络性能有着重要的意义。
II.Linux 内核收包流程概述Linux 内核收包流程主要包括网卡接收数据包和数据包处理两个环节。
III.网卡接收数据包网卡接收数据包是整个收包流程的第一步。
在这一环节中,网卡通过硬件中断处理接收到的数据包。
当网卡接收到数据包时,会产生一个硬件中断,Linux 内核会通过中断处理程序来响应这个硬件中断。
接着,内核会从网卡的接收队列中取出数据包,并进行缓冲。
IV.数据包处理流程数据包处理流程是收包流程的第二步。
在这一环节中,内核会对数据包进行解析和分类,以确定数据包的类型和目的。
接着,内核会根据数据包的类型和目的进行相应的过滤和处理。
对于需要发送或转发的数据包,内核会将它们发送到相应的队列中,等待后续的发送和转发操作。
V.总结总的来说,Linux 内核收包流程包括网卡接收数据包和数据包处理两个主要环节。
其中,网卡接收数据包通过硬件中断处理和缓冲完成;数据包处理则涉及数据包的解析、分类、过滤和处理等操作。
AF_XDP发包原理

AF_XDP发包原理随着互联网的迅速发展,网络通信已经成为了人们生活中不可或缺的一部分。
而在网络通信中,数据包的传输是非常重要的一环节。
因此,对于数据包的处理和传输技术的研究也变得越来越重要。
AF_XDP是一种高性能网络数据包处理技术,它在处理数据包时能够实现零拷贝,从而提高了数据包的处理效率。
本文将详细介绍AF_XDP发包的原理。
一、AF_XDP简介AF_XDP是Linux内核中的一种高性能网络数据包处理技术,它可以实现数据包的高速处理和转发。
AF_XDP是通过使用XDP(eXpress Data Path)技术来实现的。
XDP技术是一种高性能的数据包处理技术,它可以在内核空间中处理数据包,从而避免了数据包在用户空间和内核空间之间的频繁拷贝和上下文切换。
AF_XDP是在XDP技术的基础上,通过使用AF_PACKET套接字来实现的。
AF_PACKET是Linux内核中的一个套接字类型,它可以用于数据包的捕获和发送。
AF_XDP可以通过AF_PACKET套接字来发送数据包,从而实现高速的数据包传输。
二、AF_XDP发包原理AF_XDP的发包原理可以分为以下几个步骤:1. 创建AF_PACKET套接字在使用AF_XDP发送数据包之前,需要先创建一个AF_PACKET套接字。
AF_PACKET套接字可以使用socket()函数来创建,创建时需要指定套接字类型为AF_PACKET。
2. 创建XDP程序在使用AF_XDP发送数据包之前,还需要创建一个XDP程序。
XDP 程序可以使用BPF(Berkeley Packet Filter)来实现,BPF是一种内核中的虚拟机,它可以用于过滤和处理数据包。
3. 绑定AF_XDP套接字和XDP程序在创建完AF_PACKET套接字和XDP程序之后,需要将它们进行绑定。
绑定时需要使用setsockopt()函数,将AF_PACKET套接字和XDP 程序进行关联。
4. 构造数据包在进行AF_XDP数据包发送之前,需要先构造数据包。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
ﻩ
ﻩ4)数据包操作
错误:
ﻩ陷阱:
无符号数的强制类型转换,u32类型永远都是大于等于0的,当payload_len小于512时,判断就会不生效。
改进:
或者
ﻩ5)
风险:
陷阱:
ﻩ可能是异常数据包,offset不是你想要的
ﻩ正确做法:
ﻩ
ﻩ
ﻩ综述:数据包处理要时刻保持警醒,它可能不是你想象的样子!
ﻩ内存分配
获取IP头部
ﻩ
1)__netif_receive_skb()在进入三层处理前就对network_header进行了设置。
2)ip_rcv()中详细的检查保证了IP头部到netfilter后是完整的。
ﻩ3)netfilter可以尽情使用ip头部。
ﻩ获取tcp头部
错误1:
陷阱:
netfilter的钩子点是属于TCP/IP协议栈的三层流程中,而四层的TCP头部此时还没有正确获取,只是初始化为IP头部的值,无法直接使用。
ﻩ模块卸载:
ﻩﻩ
2)每CPU变量
ﻩﻩ使用场景:
在钩子函数中使用的临时缓存区,不用每次申请释放,使用全局变量。
ﻩ方法:
ﻩhook函数:
模块加载:
ﻩﻩ模块卸载:
ﻩ
ﻩﻩ注意:
ﻩﻩalloc_percpu()上限32k
改进:
ﻩ2)查找数据包中的某个字符串
ﻩ风险:
ﻩ
陷阱:
可能会越界,数据包不一定是以'\0'结束。
ﻩ改进:
ﻩ
ﻩ一定要使用这一系列的函数:
strnchr
ﻩstrncpy
ﻩstrncat
strncmp
strnicmp
ﻩstrnlen
memcpy
3)移动指向数据包的指针
ﻩ风险:
ﻩ
陷阱:
ﻩ查找的字符串有可能是数据包的最后一部分。
ﻩﻩIPv6:%pI6%pi6
2)MAC地址
ﻩ%pM%pm
ﻩ3)字节序的转换
ﻩﻩntohs()ntohl()htons()htonl()
ﻩﻩ__const_ntohl()__const_ntohs()__const_htonl()__const_htons()
ﻩ区别:__const_*()是编译时处理的。
ﻩ错误2:
陷阱:
数据包可能是非线性的
ﻩ改进:
ﻩ
接口介绍:
ﻩ
计算三层头部相对于skb->data的偏移
ﻩ从skb的指定偏移取制定长度的数据,如果要取的数据位于线性区,直接返回其开始指针,否则,则拷贝到buffer中,并将buffer指针返回。
打印信息
注意要点:
ﻩ1) IP地址输出
ﻩﻩIpv4:%pI4%pi4
获取TCP负载
风险:
陷阱1:
数据包可能是非线性的,同TCP头部。
陷阱2:
TCP头部数据有可能是被篡改过的,tcph->doff如果很大怎么办?
改进1:
接口介绍:
ﻩ
判断skb的数据是否是非线性的
ﻩ改进2:
ﻩ
改进3:
ﻩ
接口介绍:
ﻩ
ﻩ
ﻩ将skb线性化
解析数据
ﻩ1)判断数据包内容
风险1:
风险2:
ﻩ
陷阱:
ﻩ如果payload的长度只有1个字节怎么办?
风险:
ﻩ陷阱1:
ﻩ如果需要申请的size是0会如何?
ﻩ陷阱2:
ﻩ多个cpu并发申请又会如何?
改进:
ﻩ问题:kmalloc(0,...)返回值是什么?
ﻩ建议:相同的内存反复申请释放的情况下,请使用kmem_cache_alloc
建议的同步与互斥方法
1)rcu锁
ﻩﻩ使用场景:进程上下文用来配置,软中断上下文只读配置的情况
内核数据包处理
———————————————————————————————— 作者:
———————————————————————————————— 日期:
数据包处理的一些建议
前言
我们大部分功能都需要解析数据,进行一系列的包匹配完成,但是目前,我们没有一个很好的框架来简化这个过程,大家处理数据包都是采用原生的linux内核接口,并且没有统一的规范要求如何使用这些接口,所以,存在大量的陷阱,一不留神就造成宕机。
ﻩ好处:性能高,接口简单
ﻩﻩ方法:
ﻩhook函数读取配置,中断上下文:
ﻩﻩ
ﻩﻩ基于proc文件等的配置下发,进程上下文:
ﻩ
ﻩ另一种方法:
注意1:synchronize_rcu()只能用于进程上下文,call_rcu()可以用于中断上下文。
ﻩﻩ注意2:data_free_rcu的调用是软中断上下文,不能使用vfree。