R语言时间序列中文教程(可编辑)
时间序列分析R语言程序

#例2.1 绘制1964——1999年中国年纱产量序列时序图(数据见附录1.2)Data1.2=read.csv("C:\\Users\\Administrator\\De sktop\\附录1.2.csv",header=T)#如果有标题,用T;没有标题用Fplot(Data1.2,type='o')#例2.1续tdat1.2=Data1.2[,2]a1.2=acf(tdat1.2)#例2.2绘制1962年1月至1975年12月平均每头奶牛产奶量序列时序图(数据见附录1.3)Data1.3=read.csv("C:\\Users\\Administrator\\De sktop\\附录1.3.csv",header=F)tdat1.3=as.vector(t(as.matrix(Data1.3)))[1:168 ]#矩阵转置转向量plot(tdat1.3,type='l')#例2.2续acf(tdat1.3) #把字去掉pacf(tdat1.3)#例2.3绘制1949——1998年北京市每年最高气温序列时序图Data1.4=read.csv("C:\\Users\\Administrator\\De sktop\\附录1.4.csv",header=T)plot(Data1.4,type='o')##不会定义坐标轴#例2.3续tdat1.4=Data1.4[,2]a1.4=acf(tdat1.4)#例2.3续Box.test(tdat1.4,type="Ljung-Box",lag=6) Box.test(tdat1.4,type="Ljung-Box",lag=12)#例2.4随机产生1000个服从标准正态分布的白噪声序列观察值,并绘制时序图Data2.4=rnorm(1000,0,1)Data2.4plot(Data2.4,type='l')#例2.4续a2.4=acf(Data2.4)#例2.4续Box.test(Data2.4,type="Ljung-Box",lag=6) Box.test(Data2.4,type="Ljung-Box",lag=12) #例2.5对1950——1998年北京市城乡居民定期储蓄所占比例序列的平稳性与纯随机性进行检验Data1.5=read.csv("C:\\Users\\Administrator\\De sktop\\附录1.5.csv",header=T)plot(Data1.5,type='o',xlim=c(1950,2010),ylim=c (60,100))tdat1.5=Data1.5[,2]a1.5=acf(tdat1.5)#白噪声检验Box.test(tdat1.5,type="Ljung-Box",lag=6) Box.test(tdat1.5,type="Ljung-Box",lag=12)#例2.5续选择合适的ARMA模型拟合序列acf(tdat1.5)pacf(tdat1.5)#根据自相关系数图和偏自相关系数图可以判断为AR (1)模型#例2.5续 P81 口径的求法在文档上#P83arima(tdat1.5,order=c(1,0,0),method="ML")#极大似然估计ar1=arima(tdat1.5,order=c(1,0,0),method="ML") summary(ar1)ev=ar1$residualsacf(ev)pacf(ev)#参数的显著性检验t1=0.6914/0.0989p1=pt(t1,df=48,lower.tail=F)*2#ar1的显著性检验t2=81.5509/ 1.7453p2=pt(t2,df=48,lower.tail=F)*2#残差白噪声检验Box.test(ev,type="Ljung-Box",lag=6,fitdf=1) Box.test(ev,type="Ljung-Box",lag=12,fitdf=1) #例2.5续P94预测及置信区间predict(arima(tdat1.5,order=c(1,0,0)),n.ahead= 5)tdat1.5.fore=predict(arima(tdat1.5,order=c(1,0 ,0)),n.ahead=5)U=tdat1.5.fore$pred+1.96*tdat1.5.fore$seL=tdat1.5.fore$pred-1.96*tdat1.5.fore$seplot(c(tdat1.5,tdat1.5.fore$pred),type="l",col =1:2)lines(U,col="blue",lty="dashed")lines(L,col="blue",lty="dashed")#例3.1.1 例3.5 例3.5续#方法一plot.ts(arima.sim(n=100,list(ar=0.8))) #方法二x0=runif(1)x=rep(0,1500)x[1]=0.8*x0+rnorm(1)for(i in 2:length(x)){x[i]=0.8*x[i-1]+rnorm(1)}plot(x[1:100],type="l")acf(x)pacf(x)##拟合图没有画出来#例3.1.2x0=runif(1)x=rep(0,1500)x[1]=-1.1*x0+rnorm(1)for(i in 2:length(x)){x[i]=-1.1*x[i-1]+rnorm(1)}plot(x[1:100],type="l")acf(x)pacf(x)#例3.1.3方法一plot.ts(arima.sim(n=100,list(ar=c(1,-0.5)))) #方法二x0=runif(1)x1=runif(1)x=rep(0,1500)x[1]=x1x[2]=x1-0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=x[i-1]-0.5*x[i-2]+rnorm(1)}plot(x[1:100],type="l")acf(x)pacf(x)#例3.1.4x0=runif(1)x1=runif(1)x=rep(0,1500)x[1]=x1 x[2]=x1+0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=x[i-1]+0.5*x[i-2]+rnorm(1)}plot(x[1:100],type="l")acf(x)pacf(x)又一个式子x0=runif(1)x1=runif(1)x=rep(0,1500)x[1]=x1x[2]=-x1-0.5*x0+rnorm(1)for(i in 3:length(x)){x[i]=-x[i-1]-0.5*x[i-2]+rnorm(1)}plot(x[1:100],type="l")acf(x)pacf(x)#均值和方差smu=mean(x)svar=var(x)#例3.2求平稳AR(1)模型的方差例3.3mu=0mvar=1/(1-0.8^2) #书上51页#总体均值方差cat("population mean and var are",c(mu,mvar),"\n")#样本均值方差cat("sample mean and var are",c(mu,mvar),"\n")#例题3.4svar=(1+0.5)/((1-0.5)*(1-1-0.5)*(1+1-0.5))#例题3.6 MA模型自相关系数图截尾和偏自相关系数图拖尾#3.6.1法一:x=arima.sim(n=1000,list(ma=-2))plot.ts(x,type='l')acf(x)pacf(x)法二x=rep(0:1000)for(i in 1:1000){x[i]=rnorm[i]-2*rnorm[i-1]}plot(x,type='l')acf(x)pacf(x)#3.6.2法一:x=arima.sim(n=1000,list(ma=-0.5))plot.ts(x,type='l')acf(x)pacf(x)法二x=rep(0:1000)for(i in 1:1000){x[i]=rnorm[i]-0.5*rnorm[i-1]}plot(x,type='l')acf(x)pacf(x)##错误于rnorm[i] : 类别为'closure'的对象不可以取子集#3.6.3法一:x=arima.sim(n=1000,list(ma=c(-4/5,16/25))) plot.ts(x,type='l')acf(x)pacf(x)法二:x=rep(0:1000)for(i in 1:1000){x[i]=rnorm[i]-4/5*rnorm[i-1]+16/25*rnorm[i-2] }plot(x,type='l')acf(x)pacf(x)##错误于x[i] = rnorm[i] - 4/5 * rnorm[i - 1] + 16/25 * rnorm[i - 2] :##更换参数长度为零#例3.6续根据书上64页来判断#例 3.7拟合ARMA(1,1)模型,x(t)-0.5x(t-1)=u(t)-0.8*(u-1),并直观观察该模型自相关系数和偏自相关系数的拖尾性。
R语言时间序列中时间年、月、季、日的处理操作

R语⾔时间序列中时间年、⽉、季、⽇的处理操作1、年pt<-ts(p, freq = 1, start = 2011)2、⽉pt<-ts(p,frequency=12,start=c(2011,1))frequency=12表⽰以⽉份为单位,start 表⽰时间开始点,start=c(2011,1) 表⽰从2011年1⽉开始3、季度pt <- ts(p, frequency = 4, start = c(2011, 1))4、天pt<-ts(p,frequency=7,start=c(2011,1))⽤ts(p,frequency=365,start=(2011,1)) 也可以,但是这个是没有按星期对齐补充:R语⾔:ts() 时间序列的建⽴ts() 函数:通过⼀向量或者矩阵创建⼀个⼀元的或多元的时间序列(time series),为ts型对象。
调⽤格式:ts(data = NA, start = 1, end = numeric(0), frequency = 1, deltat = 1, ts.eps = getOption("ts.eps"), class, names)说明:data⼀个向量或者矩阵start第⼀个观测值的时间,为⼀个数字或者是⼀个由两个整数构成的向量end最后⼀个观测值的时间,指定⽅法和start相同frequency单位时间内观测值的频数(频率)deltat两个观测值间的时间间隔。
frequency和deltat必须并且只能给定其中⼀个ts.eps序列之间的误差限,如果序列之间的频率差异⼩于ts.eps,则认为这些序列的频率相等class对象的类型。
⼀元序列的缺省值是“ts”,多元序列的缺省值是c(“mts”,“ts”)names⼀个字符型向量,给出多元序列中每个⼀元序列的名称,缺省data中每列数据的名称或者Series 1,Series 2,。
R语言实现时间序列分析

R语言实现时间序列分析时间序列分析是一种用于分析时间序列数据的统计方法。
时间序列数据是一系列按照时间顺序排列的观测值,它们可以是连续的,例如每天的股票价格,也可以是间隔的,例如每个月的销售额。
R语言提供了丰富的时间序列分析功能,包括数据导入、可视化、模型建立和预测等。
下面将介绍在R语言中进行时间序列分析的常用步骤。
1.导入时间序列数据在R语言中,可以使用`ts(`函数导入时间序列数据。
该函数需要指定数据向量和时间间隔,并可选地指定起始时间。
例如,以下代码导入了一个月份和销售额的时间序列数据:```sales <- c(100, 120, 150, 130, 160, 180, 200)months <- c("Jan", "Feb", "Mar", "Apr", "May", "Jun", "Jul") ts_data <- ts(sales, start = c(2024, 1), frequency = 12)```这里的`start`参数指定了起始时间为2024年1月,`frequency`参数指定了数据的时间间隔为每年12个数据点。
2.可视化时间序列数据在进行时间序列分析之前,通常需要先可视化数据以了解其特征和模式。
R语言提供了多种绘图函数,例如`plot(`和`acf(`,用于绘制时间序列图和自相关图。
例如,以下代码绘制了销售额的时间序列图和自相关图:```plot(ts_data, main = "Sales Time Series")acf(ts_data)```时间序列图可以帮助我们观察数据的趋势、周期性和季节性。
自相关图可以用来检测数据是否存在自相关关系,即当前观测值与之前观测值之间的相关性。
3.模型建立和预测在时间序列分析中,常用的模型包括移动平均模型(MA)、自回归模型(AR)和自回归移动平均模型(ARMA)。
R语言时间序列中文教程

R语言时间序列中文教程R语言是一种广泛应用于统计分析和数据可视化的编程语言。
它提供了丰富的函数和包,使得处理时间序列数据变得非常方便。
本文将为大家介绍R语言中时间序列分析的基础知识和常用方法。
R语言中最常用的时间序列对象是`ts`对象。
通过将数据转换为`ts`对象,可以使用R语言提供的各种函数和方法来分析时间序列数据。
我们可以使用`ts`函数将数据转换为`ts`对象,并指定数据的时间间隔、起始时间等参数。
例如,对于按月份记录的时间序列数据,可以使用以下代码将数据转换为`ts`对象:```Rts_data <- ts(data, start = c(2000, 1), frequency = 12)```在时间序列分析中,常用的一个概念是平稳性。
平稳性表示时间序列的均值和方差在时间上不发生显著变化。
平稳时间序列的特点是,它的自相关函数(ACF)和偏自相关函数(PACF)衰减得很快。
判断时间序列是否平稳可以通过绘制序列的线图和计算序列的自相关函数来进行。
我们可以使用R语言中的`plot`函数和`acf`函数来实现。
例如,对于一个名为`ts_data`的时间序列数据,可以使用以下代码绘制序列的线图和自相关函数图:```Rplot(ts_data)acf(ts_data)```在进行时间序列分析时,经常需要进行模型拟合和预测。
R语言提供了一些常用的函数和包,用于时间序列的模型拟合和预测。
其中,最常用的方法是自回归移动平均模型(ARIMA)。
ARIMA模型是一种广泛应用于时间序列分析的统计模型,它可以描述时间序列数据中的长期趋势、季节性变动和随机波动等特征。
我们可以使用R语言中的`arima`函数来拟合ARIMA模型,并使用`forecast`函数来进行预测。
以下是一个使用ARIMA模型进行时间序列预测的示例代码:```Rmodel <- arima(ts_data, order = c(p, d, q))forecast_result <- forecast(model, h = 12)```以上代码中,`p`、`d`和`q`分别表示ARIMA模型的自回归阶数、差分阶数和移动平均阶数。
时间序列分析R语言代码

时间序列分析R语言代码时间序列分解分析的R语言操作如下:选取R语言自带的数据包UKgas,即1960-1986每月英国天然气消耗的数据,并将其赋值于n:n<-UKgassummary()函数提供了最小值、最大值、四分位数和数值型变量的均值: summary(n)画出UKgas的时序图:plot(n)时间序列分解分析方法一:基础包stats的decompose函数调用基础包stats:library("stats")利用基础包stats的decompose函数对时间序列进行分解分析,命名为fit1。
该函数基于移动平均方法,multiplicative表示使用乘法模型:fit1=decompose(n, type = c("multiplicative"))展示decompose函数的分解结果:fit1绘制方法一,即利用decompose函数分解的分解图:plot(fit1)`时间序列分解分析方法二:基础包stats的stl函数stl函数stl(x,s.window,s.degree=0,t.window = NULL, t.degree = 1, robust = FALSE,na.action = na.fail)x----待分解的变量s.window----提取季节性时的loess算法时间窗口宽度,可设为periodic,或者设为奇数并不能低于7s.degree -----提取季节性时局部拟合多项式的阶数,须为0或1 t.window----提取长期趋势性时的loess算法时间窗口宽度,缺省为NULL,或者奇数t.degree-----提取长期趋势性时的局部拟合多项式的阶数,须为0或1robust -----在loess过程中是否使用鲁棒拟合利用基础包stats的stl函数对时间序列进行分解分析,命名为fit2:fit2<-stl(n,s.window="periodic",s.degree = 0, t.window = NULL, t.degree = 1,robust= FALSE,na.action = na.fail)展示stl函数的分解结果:fit2绘制方法二的分解图: plot(fit2)。
时间序列建模的完整教程用R语言

时间序列建模的完整教程用R语言时间序列建模是一种分析和预测时间序列数据的方法。
R语言提供了丰富的时间序列建模函数和包,使得时间序列建模变得更加容易和高效。
本教程将向您介绍时间序列建模的基本概念和R语言的应用,以帮助您进行时间序列分析和预测。
Ⅰ.时间序列的基本概念时间序列是按照一定时间顺序排列的一系列观测值的集合。
它具有以下几个特点:1.时间依赖性:时间序列中的观测值之间存在着时间上的关联和依赖关系。
2.趋势性:时间序列在较长时间内可能会呈现出上升或下降的趋势。
3.季节性:时间序列中可能存在其中一种周期性的波动。
4.随机性:时间序列中可能存在一定的不规则波动或异常值。
Ⅱ.时间序列的建模步骤1.数据准备使用R语言读取时间序列数据,并将其转化为时间序列对象。
可以使用`ts(`函数来创建时间序列对象,指定时间序列的起始时间、观测间隔和数据值。
```R#读取时间序列数据data <- read.csv("data.csv")#创建时间序列对象ts_data <- ts(data$value, start = c(2000, 1), frequency = 12) ```2.模型选择和参数估计选择合适的时间序列模型对数据进行建模。
R语言提供了多种时间序列模型,如自回归移动平均模型(ARMA)、季节性自回归移动平均模型(SARIMA)和指数平滑模型(ES)等。
可以使用`auto.arima(`函数自动选择ARIMA模型的参数。
```R#自动选择ARIMA模型model <- auto.arima(ts_data)```3.模型检验根据所选择的模型,使用R语言提供的函数进行模型检验,判断模型是否符合数据的特征。
可以使用`checkresiduals(`函数对模型的残差进行检验。
```R#对模型的残差进行检验checkresiduals(model)```4.预测使用所选择的模型对未来的数据进行预测。
用R语言做时间序列分析

用R语言做时间序列分析时间序列(time series )是一系列有序的数据。
通常是等时间间隔的采样数据。
如果不是等间隔,则一般会标注每个数据点的时间刻度。
下面以time series 普遍使用的数据airline passenger 为例。
这是^一年的每月乘客数量,单位是千人次。
Time如果想尝试其他的数据集,可以访问这里:https:///data/list/?q=provider:tsdl可以很明显的看出,airli ne passe nger 的数据是很有规律的。
time series data mining 主要包括decompose (分析数据的各个成分,例如趋势,周期性),prediction (预测未来的值),classificatio n (对有序数据序列的feature 提取与分类),clusteri ng (相似数列聚类)等。
这篇文章主要讨论prediction (forecast,预测)问题。
即已知历史的数据,如何准确预测未来的数据。
先从简单的方法说起。
给定一个时间序列,要预测下一个的值是多少,最简单的思路是什么呢?(1)m ean (平均值):未来值是历史值的平均。
(2)exponential smoothing (指数衰减):当去平均值得时候,每个历史点的权值可以不一样。
最自然的就是越近的点赋予越大的权重。
= aX± + ct^X2 + a3X3+ …或者,更方便的写法,用变量头上加个尖角表示估计值X t+1 = aX t+ (1 - a)X t(3) sn aive :假设已知数据的周期,那么就用前一个周期对应的时刻作为下一个周期对应时刻的预测值(4)d rift :飘移,即用最后一个点的值加上数据的平均趋势tX t+h|t =禺+占2心-斗-丄= x t +占(罠-如Tt = •介绍完最简单的算法,下面开始介绍两个time series 里面最火的两个强大的算法:Holt-Winters 和ARIMA 。
R语言之数据分析高级方法「时间序列」

R语言之数据分析高级方法「时间序列」作者简介Introduction姚某某本节主要总结「数据分析」的「时间序列」相关模型的思路。
「时间序列」是一个变量在连续时点或连续时期上测量的观测值的序列,它与我们以前见过的数据有本质上的区别,这个区别在于之前的数据都在一个时间的横截面上去测量、计算数据,而「时间序列」给出了一种时间轴线上纵向的视角,将时间作为自变量,测量出一系列纵向数据。
关于「时间序列」的预测模型,我所了解的常用模型有三种:1. 移动平均 2. 指数预测模型 3. ARIMA 预测模型0. 时序的分解要研究时序如何预测,首先需要将复杂的时序数据进行分解,将复杂的时序数据分解为单一的分解成分,这样能利用统计方法进行拟合,然后个个击破,最后再合成为我们需要预测的未来时序数据。
前人在这一问题上已经得到很好的结论,通过对时序数据现实意义的理解,一般将时序数据分解为四个成分:1. 水平项2. 趋势项3. 季节效应(衍生出去为周期项)4. 随机波动•水平项,即剔除时序数据的趋势影响和季节影响后,时序数据所剩的成分,它代表着时序数据在时间轴上相对稳定的一个基础值。
就像一个原点一样,在这个原点上去考虑时间所带来的趋势影响和季节影响。
•趋势项,它用于捕捉时序数据的长期变化,是逐步增长还是逐步下降。
就像在二元空间中的一个单调函数。
•季节效应,衍生出去就是周期型,在一定时间内,时序数据所包含的周期型变化。
就像在二元空间中的三角函数,如y=sinx,其数值是周而复始的。
通常在分解以上各个成分时,有两种模式,一个是乘法模型,一个是加法模型。
其中,加法模型的季节效应被认为不依赖于时间序列,二乘法模型认为季节影响随着时间会发生改变。
不过两种模型在计算时可以相通,对乘法模型作对数处理即可。
1. 移动平均这一方法很简单,只做简单讲解•所谓移动平均,就是使用时间序列中最接近的 k 期数据值的平均值作为下一个时期的预测值。
即:较小的 k 值将更快速追踪时间序列的移动,而较大的 k 值将随着时间的推移更有效地消除随机波动。
如何使用R语言进行时间序列分析与预测

如何使用R语言进行时间序列分析与预测标题:使用R语言进行时间序列分析与预测导言:时间序列分析是一种用于研究随时间变化的数据模式和趋势的方法。
它在许多领域中都有广泛的应用,包括经济学、金融学、气象学等。
R语言是一种功能强大的统计分析软件,它提供了许多用于时间序列分析和预测的函数和包。
本文将介绍如何使用R语言进行时间序列分析和预测的步骤和方法。
一、准备数据1. 收集时间序列数据:首先需要收集相关的时间序列数据,例如每天的销售量、股票价格等。
这些数据可以通过调查、采样或从公开数据源中获取。
2. 数据清洗:对收集到的数据进行清洗,包括去除异常值、缺失值和重复值等。
确保数据的完整性和准确性。
3. 建立时间索引:将数据转换为时间序列对象,并建立时间索引。
R语言中常用的时间序列对象包括ts、xts和zoo等。
二、时间序列分析1. 可视化分析:使用R语言中的绘图函数,如plot()和ggplot2包,将时间序列数据可视化。
可以观察数据的趋势、季节性和周期性。
2. 平稳性检验:检验时间序列数据是否平稳,即均值、方差和自协方差不随时间变化。
常用的平稳性检验方法有ADF检验和KPSS检验。
3. 建立模型:根据时间序列数据的特点选择合适的模型。
常用的时间序列模型包括ARIMA模型、指数平滑模型和ARCH/GARCH模型等。
4. 模型识别:对建立的模型进行参数估计,并进行模型识别。
使用R语言中的函数,如auto.arima()和ets(),自动选择最佳的模型。
5. 模型诊断:对建立的模型进行诊断,检验模型的拟合优度。
常用的模型诊断方法有残差分析、Ljung-Box检验和AIC准则等。
三、时间序列预测1. 预测模型:基于建立的时间序列模型,使用R语言中的forecast包,预测未来一段时间内的数值。
可以使用函数,如forecast()和predict(),进行预测。
2. 模型评估:对时间序列预测结果进行评估。
使用预测准确度指标,如均方根误差(RMSE)和平均绝对百分误差(MAPE),评估预测模型的准确性。
时间序列分析R语言分析

时间序列分析R语言分析R语言是一个功能强大的统计分析软件,提供了丰富的包和函数用于时间序列分析。
本文将介绍R语言的时间序列分析方法,并以一个具体的案例来说明。
首先,我们需要导入与时间序列分析相关的包,其中最常用的包是`stats`和`forecast`。
我们可以使用`library(`函数导入这两个包:```Rlibrary(stats)library(forecast)```接下来,我们需要读取时间序列数据。
在R语言中,时间序列数据可以用`ts(`函数来创建。
`ts(`函数的参数包括数据向量、开始时间和时间间隔。
例如,以下代码将创建一个时间序列数据对象`tsdata`:```R```在创建时间序列对象后,我们可以使用`plot(`函数来可视化时间序列数据。
例如,以下代码将绘制时间序列数据的折线图:```Rplot(tsdata)```接下来,我们可以使用时间序列数据进行分析和建模。
一种常用的方法是拟合ARIMA模型。
ARIMA模型是一种常用的时间序列模型,可以用于预测未来的值。
我们可以使用`auto.arima(`函数自动选择ARIMA模型的参数。
例如,以下代码将拟合时间序列数据的ARIMA模型:```Rarima_model <- auto.arima(tsdata)````auto.arima(`函数将返回一个ARIMA模型对象`arima_model`。
我们可以使用`summary(`函数查看ARIMA模型的摘要信息。
例如,以下代码将输出ARIMA模型的参数估计值和统计检验结果:```Rsummary(arima_model)```对于已经拟合好的ARIMA模型,我们可以使用`forecast(`函数来进行预测。
例如,以下代码将使用拟合好的ARIMA模型对未来10个时间点的值进行预测并返回预测结果:```Rforecast_result <- forecast(arima_model, h = 10)````forecast(`函数将返回一个预测结果对象`forecast_result`。
【最新】r语言时间序列 PPT课件教案讲义(附代码数据)图文

15
Covariance tells us how two variables vary with each other. Are large values of X associated with large values of Y, or are large values of X associated with small values of Y? We have a population covariance between two variables and a sample covariance: 1 n Cov(x, y) E[(xi x)(yi y)] (xi x)(yi y) n 1 i1 WhatvalueforthesamplecovariancewouldwegetifXandYvaried together?(Largexiassociatedwithlargeyi) WhatvalueforthesamplecovariancewouldwegetifXandYvaried inversely?(Largexiassociatedwithsmallyi) Correlation is just standardised covariance, so the correlation between X and Y always lies between 1 and 1. 1 n xi x yi y Cor(x,y) r n 1 i1 sx s y Covariance and correlation tell us about the degree of association between 2 variables. Variance, Autocovariance and Autocorrelation :
时间序列完整教程R

时间序列完整教程(R)简介在商业应用中,时间是最重要的因素,能够提升成功率。
然而绝大多数公司很难跟上时间的脚步。
但是随着技术的发展,出现了很多有效的方法,能够让我们预测未来。
不要担心,本文并不会讨论时间机器,讨论的都是很实用的东西。
?本文将要讨论关于预测的方法。
有一种预测是跟时间相关的,而这种处理与时间相关数据的方法叫做时间序列模型。
这个模型能够在与时间相关的数据中,找到一些隐藏的信息来辅助决策。
?当我们处理时间序列数据的时候,时间序列模型是非常有用的模型。
大多数公司都是基于时间序列数据来分析第二年的销售量,网站流量,竞争地位和更多的东西。
然而很多人并不了解时间序列分析这个领域。
?所以,如果你不了解时间序列模型。
这篇文章将会向你介绍时间序列模型的处理步骤以及它的相关技术。
?本文包含的内容如下所示:?目录?* 1、时间序列模型介绍?* 2、使用R语言来探索时间序列数据?* 3、介绍ARMA时间序列模型?* 4、ARIMA时间序列模型的框架与应用1、时间序列模型介绍本节包括平稳序列,随机游走,Rho系数,Dickey Fuller检验平稳性。
如果这些知识你都不知道,不用担心-接下来这些概念本节都会进行详细的介绍,我敢打赌你很喜欢我的介绍的。
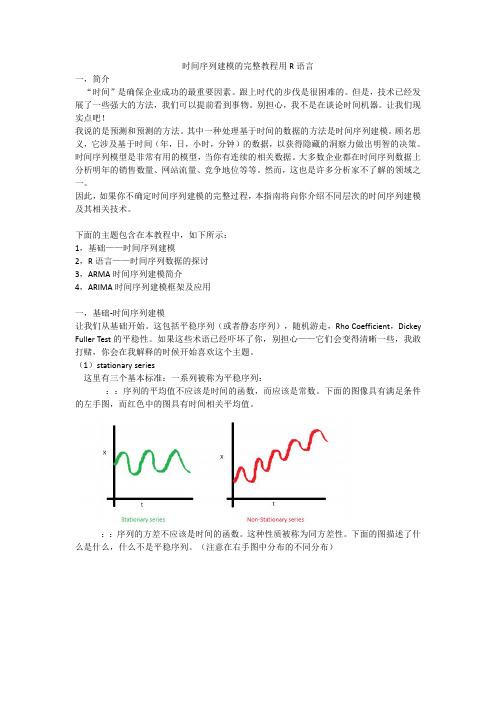
平稳序列判断一个序列是不是平稳序列有三个评判标准:?1. 均值,是与时间t 无关的常数。
下图(左)满足平稳序列的条件,下图(右)很明显具有时间依赖。
?1.方差,是与时间t 无关的常数。
这个特性叫做方差齐性。
下图显示了什么是方差对齐,什么不是方差对齐。
(注意右图的不同分布。
)?2.3.协方差,只与时期间隔k有关,与时间t 无关的常数。
如下图(右),可以注意到随着时间的增加,曲线变得越来越近。
因此红色序列的协方差并不是恒定的。
?4.我们为什么要关心平稳时间序列呢?除非你的时间序列是平稳的,否则不能建立一个时间序列模型。
在很多案例中时间平稳条件常常是不满足的,所以首先要做的就是让时间序列变得平稳,然后尝试使用随机模型预测这个时间序列。
使用R语言进行时间序列(arima,指数平滑)分析

使用R语言进行时间序列(arima,指数平滑)分析读时间序列数据您要分析时间序列数据的第一件事就是将其读入R,并绘制时间序列。
您可以使用scan()函数将数据读入R,该函数假定连续时间点的数据位于包含一列的简单文本文件中。
数据集如下所示:••••••••••••••••Age of Death of Successive Kings of England#starting with William the Conqueror#Source: McNeill, "Interactive Data Analysis"604367505642506568436534...仅显示了文件的前几行。
前三行包含对数据的一些注释,当我们将数据读入R时我们想要忽略它。
我们可以通过使用scan()函数的“skip”参数来使用它,它指定了多少行。
要忽略的文件顶部。
要将文件读入R,忽略前三行,我们键入:•••> kings[1] 60 43 67 50 56 42 50 65 68 43 65 34 47 34 49 41 13 35 53 56 16 43 69 59 48[26] 59 86 55 68 51 33 49 67 77 81 67 71 81 68 70 77 56在这种情况下,英国42位连续国王的死亡年龄已被读入变量“国王”。
一旦将时间序列数据读入R,下一步就是将数据存储在R中的时间序列对象中,这样就可以使用R的许多函数来分析时间序列数据。
要将数据存储在时间序列对象中,我们使用R中的ts()函数。
例如,要将数据存储在变量'kings'中作为R中的时间序列对象,我们键入:••••••Time Series:Start = 1End = 42Frequency = 1[1] 60 43 67 50 56 42 50 65 68 43 65 34 47 34 49 41 13 35 53 56 16 43 69 59 48[26] 59 86 55 68 51 33 49 67 77 81 67 71 81 68 70 77 56有时,您所拥有的时间序列数据集可能是以不到一年的固定间隔收集的,例如,每月或每季度。
时间序列建模的完整教程用R语言
如果我们尝试绘制这个图表,它会看起来像这样:
你注意到 MA 和 AR 模型的区别了吗?在 MA 模型中,噪声/冲击随时间迅速消失。AR 模型对冲击具有持久的影响。 AR 模型与 MA 模型的区别 AR 和 MA 模型之间的主要区别是基于~时间序列对象在不同时间点之间的相关性。 X (T) 和 X( T-N)之间的相关性,对于 n 阶的 MA 总是为零。这直接源于 MA 模型中 x( t)和 x
/WOP/RandomWalk.html
想象一下,你坐在另一个房间里,看不到那个女孩。你想预测女孩的位置随着时间的推移。 你会有多精确?当然,随着女孩的位置变化,你会变得越来越不准确。在 T=0,你完全知 道那个女孩在哪里。下一次,她只能移动到 8 个方格,因此你的概率下降到 1/8,而不是 1, 而且它一直在下降。现在让我们来尝试一下这个时间序列。
时间序列建模的完整教程用 R 语言 一,简介 “时间”是确保企业成功的最重要因素。跟上时代的步伐是很困难的。但是,技术已经发 展了一些强大的方法,我们可以提前看到事物。别担心,我不是在谈论时间机器。让我们现 实点吧! 我说的是预测和预测的方法。 其中一种处理基于时间的数据的方法是时间序列建模。 顾名思 义,它涉及基于时间(年,日,小时,分钟)的数据,以获得隐藏的洞察力做出明智的决策。 时间序列模型是非常有用的模型, 当你有连续的相关数据。 大多数企业都在时间序列数据上 分析明年的销售数量、网站流量、竞争地位等等。然而,这也是许多分析家不了解的领域之 一。 因此, 如果你不确定时间序列建模的完整过程, 本指南将向你介绍不同层次的时间序列建模 及其相关技术。 下面的主题包含在本教程中,如下所示: 1,基础——时间序列建模 2,R 语言——时间序列数据的探讨 3,ARMA 时间序列建模简介 4,ARIMA 时间序列建模框架及应用 一,基础-时间序列建模 让我们从基础开始。这包括平稳序列(或者静态序列),随机游走,Rho Coefficient,Dickey Fuller Test 的平稳性。如果这些术语已经吓坏了你,别担心——它们会变得清晰一些,我敢 打赌,你会在我解释的时候开始喜欢这个主题。 (1)stationary series 这里有三个基本标准:一系列被称为平稳序列: ::序列的平均值不应该是时间的函数,而应该是常数。下面的图像具有满足条件 的左手图,而红色中的图具有时间相关平均值。
R语言实现时间序列分析

R语言-时间序列时间序列:可以用来预测未来的参数,1.生成时间序列对象1 sales <- c(18, 33, 41, 7, 34, 35, 24, 25, 24, 21, 25, 20,2 22, 31, 40, 29, 25, 21, 22, 54, 31, 25, 26, 35)3# 1.生成时序对象4 tsales <- ts(sales,start = c(2003,1),frequency = 12)5 plot(tsales)6# 2.获得对象信息7 start(tsales)8 end(tsales)9 frequency(tsales)10# 3.对相同取子集11 tsales.subset <- window(tsales,start=c(2003,5),end=c(2004,6))12 tsales.subset 结论:手动生成的时序图2.简单移动平均案例:尼罗河流量和年份的关系1 library(forecast)2 opar <- par(no.readonly = T)3 par(mfrow=c(2,2))4 ylim <- c(min(Nile),max(Nile))5 plot(Nile,main='Raw time series')6 plot(ma(Nile,3),main = 'Simple Moving Averages (k=3)',ylim = ylim)7 plot(ma(Nile,7),main = 'Simple Moving Averages (k=3)',ylim = ylim)8 plot(ma(Nile,15),main = 'Simple Moving Averages (k=3)',ylim = ylim)9 par(opar) 结论:随着K值的增大,图像越来越平滑我们需要找到最能反映规律的K值3.使用stl做季节性分解案例:Arirpassengers年份和乘客的关系1# 1.画出时间序列2 plot(AirPassengers)3 lAirpassengers <- log(AirPassengers)4 plot(lAirpassengers,ylab = 'log(Airpassengers)')5# 2.分解时间序列6 fit <- stl(lAirpassengers,s.window = 'period')7 plot(fit)8 fit$time.series9 par(mfrow=c(2,1))10# 3.月度图可视化11 monthplot(AirPassengers,xlab='',ylab='')12# 4.季度图可视化13 seasonplot(AirPassengers,bels = T,main = '') 原始图 对数变换 总体趋势图 月度季度图4.指数预测模型 4.1单指数平滑 案例:预测康涅狄格州的气温变化# 1.拟合模型fit2 <- ets(nhtemp,model = 'ANN')fit2# 2.向前预测forecast(fit2,1)plot(forecast(fit2,1),xlab = 'Year',ylab = expression(paste("Temperature (",degree*F,")",)),main="New Haven Annual Mean Temperature")# 3.得到准确的度量accuracy(fit2) 结论:浅灰色是80%的置信区间,深灰色是95%的置信区间 4.2有水平项,斜率和季节项的指数模型 案例:预测5个月的乘客流量1# 1.光滑参数2 fit3 <- ets(log(AirPassengers),model = 'AAA')3 accuracy(fit3)4# 2.未来值预测5 pred <- forecast(fit3,5)6 pred7 plot(pred,main='Forecast for air Travel',ylab = 'Log(Airpassengers)',xlab = 'Time') 8# 3.使用原始尺度预测9 pred$mean <- exp(pred$mean)10 pred$lower <- exp(pred$lower)11 pred$upper <- exp(pred$upper)12 p <- cbind(pred$mean,pred$lower,pred$upper)13 dimnames(p)[[2]] <- c('mean','Lo 80','Lo 95','Hi 80','Hi 95')14 p 结论:从表格中可知3月份的将会有509200乘客,95%的置信区间是[454900,570000] 4.3ets自动预测 案例:自动预测JohnsonJohnson股票的趋势1 fit4 <- ets(JohnsonJohnson)2 fit43 plot(forecast(fit4),main='Johnson and Johnson Forecasts',4 ylab="Quarterly Earnings (Dollars)", xlab="Time") 结论:预测值使用蓝色线表示,浅灰色表示80%置信空间,深灰色表示95%置信空间5.ARIMA预测步骤: 1.确保时序是平稳的 2.找出合理的模型(选定可能的p值或者q值) 3.拟合模型 4.从统计假设和预测准确性等角度评估模型 5.预测library(tseries)plot(Nile)# 1.原始序列差分一次ndiffs(Nile)dNile <- diff(Nile)# 2.差分后的图形plot(dNile)adf.test(dNile)Acf(dNile)Pacf(dNile)# 3.拟合模型fit5 <- arima(Nile,order = c(0,1,1))fit5accuracy(fit5)# 4.评价模型qqnorm(fit5$residuals)qqline(fit5$residuals)Box.test(fit5$residuals,type = 'Ljung-Box')# 5.预测模型forecast(fit5,3)plot(forecast(fit5,3),xlab = 'Year',ylab = 'Annual Flow') 原始图 一次差分图形1 fit6 <- auto.arima(sunspots)2 fit63 forecast(fit6,3)4 accuracy(fit6)5 plot(forecast(fit6,3), xlab = "Year",6 ylab = "Monthly sunspot numbers")。
R语言时间序列中文教程共34页

R 语言时间序列中文教程2019特别声明:R 语言是免费语言,其代码不带任何质量保证,使用 R 语言所产生的后果由使用者负全责。
前言R 语言是一种数据分析语言,它是科学的免费的数据分析语言,是凝聚了众多研究 人员心血的成熟的使用范围广泛全面的语言,也是学习者能较快受益的语言。
在 R 语言出现之前,数据分析的编程语言是 SAS。
当时 SAS 的功能比较有限。
在贝尔 实验室里,有一群科学家讨论提到,他们研究过程中需要用到数据分析软件。
SAS 的局 限也限制了他们的研究。
于是他们想,我们贝尔实验室的研究历史要比 SAS 长好几倍, 技术力量也比 SAS 强好几倍,且贝尔实验室里并不缺乏训练有素的专业编程人员,那么, 我们贝尔实验室为什么不自己编写数据分析语言,来满足我们应用中所需要的特殊要求 呢?于是,贝尔实验室研究出了 S-PLUS 语言。
后来,新西兰奥克兰大学的两位教授非 常青睐 S-PLUS 的广泛性能。
他们决定重新编写与 S-PLUS 相似的语言,并且使之免费, 提供给全世界所有相关研究人员使用。
于是,在这两位教授努力下,一种叫做 R 的语言 在奥克兰大学诞生了。
R 基本上是 S-PLUS 的翻版,但 R 是免费的语言,所有编程研究人员都可以对 R 语 言做出贡献,且他们已经将大量研究成果写成了 R 命令或脚本,因而 R 语言的功能比较 强大,比较全面。
研究人员可免费使用 R 语言,可通过阅读 R 语言脚本源代码,学习其他人的研究成 果。
笔者曾有幸在奥克兰大学受过几年熏陶,曾经向一位统计系的老师提请教过一个数 据模拟方面的问题。
那位老师只用一行 R 语句就解答了。
R 语言的强大功能非常令人惊 讶。
为了进一步推广 R 语言,为了方便更多研究人员学习使用 R 语言,我们收集了 R 语言时间序列分析实例,以供大家了解和学习使用。
当然,这是非常简单的模仿练习, 具体操作是,用复制粘贴把本材料中 R 代码放入 R 的编程环境;材料中蓝色背景的内容 是相关代码和相应输出结果。
时间序列建模的完整教程用R语言
X( t ) X (t 1) Er (t )
这里的 Er 是在时间点 t 的误差。这是一个由女孩在时间上每个点产生的误差。 现在,如果我们递归地拟合所有的 XS,我们最终会得出下面的等式。
X (t ) X (0) Sum( Er (1), Er (2), Er (3),...Er (t ))
详细度量
这里还有几个操作可以做:
重要推论 1,年均趋势明显表明,客流量不断增加。 2,七月和八月的方差和平均值远高于其余月份。 , 3,即使每个月的平均值相差很大,它们的方差也很小。因此,我们具有较强的季节 效应,周期为 12 个月或更少。 在时间序列模型中, 探索数据是最重要的——没有这种探索, 你就不知道系列是静止的 还是不稳定的。在这种情况下,我们已经知道了我们正在寻找的模型的许多细节。 现在让我们来研究一些时间序列模型及其特性。 我们也将把这个问题提出来, 做一些预测。 三,ARMA 时间序列建模简介 ARMA 模型是时间序列建模中常用的模型。在 ARMA 模型中,AR 代表自回归,MA 代表 移动平均。 如果这些话听起来很吓人, 别担心, 我会在接下来的几分钟里为你简化这些概念。 现在我们将开发这些术语的诀窍并理解与这些模型相关的特性。 但在开始之前, 你应该 记住,AR 或 MA 不适用于非平稳序列。 如果你得到一个非平稳序列,你首先需要对这个系列进行平稳化(通过差分/变换), 然后从可用的时间序列模型中选择。 首先,我将分别解释这两个模型(AR 和 MA )中的每一个。接下来,我们将看看这些 模型的特点。 自动回归时间序列模型 让我们用下面的例子来理解 AR 模型: 一个国家的当前 GDP 称 X(t)依赖于去年的 GDP,即 X(t—1)。假设一个国家在一个 会计年度的产品和服务的总生产成本(称为 GDP)取决于前一年的制造工厂/服务的建立以 及本年度新设立的工业/工厂/服务。但 GDP 的主要组成部分是前一部分。 因此,我们可以将 GDP 的公式形式化为:
R语言实现时间序列分析

R语言实现时间序列分析时间序列分析是一种用于研究和预测时间序列数据的重要统计方法。
时间序列数据是一连串按照时间顺序排列的数据点,例如每月的销售数据、每日的股票价格等。
R语言提供了丰富的函数和包来进行时间序列分析,包括基本的数据导入和可视化、平稳性检验、模型拟合和预测等方面。
以下将介绍R语言中常用的时间序列分析方法和函数。
首先,导入时间序列数据是进行时间序列分析的第一步。
R语言提供了多种导入数据的函数,例如`read.csv(`、`read.table(`等。
对于时间序列数据,通常使用`ts(`函数将数据转换为时间序列对象。
例如,假设有一份包含每月销售数据的CSV文件,可以使用以下代码将其导入为时间序列对象:```Rsales <- read.csv("sales.csv")sales_ts <- ts(sales$amount, start = c(2024, 1), frequency = 12)```其中,`sales$amount`是CSV文件中的销售额列,`start`参数指定了时间序列的起始年份和月份,`frequency`参数指定了数据的采样频率。
在导入数据后,可以使用`plot(`函数对时间序列数据进行可视化。
例如,可以使用以下代码绘制销售数据的折线图:```Rplot(sales_ts, main = "Monthly Sales", xlab = "Year-Month", ylab = "Amount")```接下来,对时间序列数据进行平稳性检验是时间序列分析的重要步骤。
平稳性是指时间序列数据的均值和方差在时间上保持不变,是许多时间序列模型的基本假设。
R语言提供了多种平稳性检验函数,其中最常用的是`adf.test(`函数和`kpss.test(`函数。
例如,可以使用以下代码进行ADF单位根检验:```Rlibrary(urca)adf_test <- adf.test(sales_ts)adf_test```如果返回结果中的p-value小于显著性水平(通常为0.05),则认为时间序列数据是平稳的。
R语言时间序列中文教程

R语言时间序列中文教程2012特别声明:R语言是免费语言,其代码不带任何质量保证,使用R语言所产生的后果由使用者负全责。
前言R语言是一种数据分析语言,它是科学的免费的数据分析语言,是凝聚了众多研究人员心血的成熟的使用范围广泛全面的语言,也是学习者能较快受益的语言。
在R语言出现之前,数据分析的编程语言是SAS。
当时SAS的功能比较有限。
在贝尔实验室里,有一群科学家讨论提到,他们研究过程中需要用到数据分析软件。
SAS的局限也限制了他们的研究。
于是他们想,我们贝尔实验室的研究历史要比SAS长好几倍,技术力量也比SAS强好几倍,且贝尔实验室里并不缺乏训练有素的专业编程人员,那么,我们贝尔实验室为什么不自己编写数据分析语言,来满足我们应用中所需要的特殊要求呢?于是,贝尔实验室研究出了S-PLUS语言。
后来,新西兰奥克兰大学的两位教授非常青睐S-PLUS的广泛性能。
他们决定重新编写与S-PLUS相似的语言,并且使之免费,提供给全世界所有相关研究人员使用。
于是,在这两位教授努力下,一种叫做R的语言在奥克兰大学诞生了。
R基本上是S-PLUS的翻版,但R是免费的语言,所有编程研究人员都可以对R语言做出贡献,且他们已经将大量研究成果写成了R命令或脚本,因而R语言的功能比较强大,比较全面。
研究人员可免费使用R语言,可通过阅读R语言脚本源代码,学习其他人的研究成果。
笔者曾有幸在奥克兰大学受过几年熏陶,曾经向一位统计系的老师提请教过一个数据模拟方面的问题。
那位老师只用一行R语句就解答了。
R语言的强大功能非常令人惊讶。
为了进一步推广R语言,为了方便更多研究人员学习使用R语言,我们收集了R语言时间序列分析实例,以供大家了解和学习使用。
当然,这是非常简单的模仿练习,具体操作是,用复制粘贴把本材料中R代码放入R的编程环境;材料中蓝色背景的内容是相关代码和相应输出结果。
经过反复模仿,学习者便能熟悉和学会。
需要提醒学习者的是:建议学习者安装了R语言编程,再继续阅读本材料;执行R 命令时,请删除命令的中文注解,没使用过在命令中加入中文;如果学习者是初次接触R或者Splus,建议先阅读<<R语言样品比较应用举例>>,如果学习者比较熟悉R语言,还可以阅读优秀时间序列读物Ecomometrics in R,也可以上QuickR 网站。
单变量时间序列模型步骤 r语言

单变量时间序列模型步骤 r语言下载提示:该文档是本店铺精心编制而成的,希望大家下载后,能够帮助大家解决实际问题。
文档下载后可定制修改,请根据实际需要进行调整和使用,谢谢!本店铺为大家提供各种类型的实用资料,如教育随笔、日记赏析、句子摘抄、古诗大全、经典美文、话题作文、工作总结、词语解析、文案摘录、其他资料等等,想了解不同资料格式和写法,敬请关注!Download tips: This document is carefully compiled by this editor. I hope that after you download it, it can help you solve practical problems. The document can be customized and modified after downloading, please adjust and use it according to actual needs, thank you! In addition, this shop provides you with various types of practical materials, such as educational essays, diary appreciation, sentence excerpts, ancient poems, classic articles, topic composition, work summary, word parsing, copy excerpts, other materials and so on, want to know different data formats and writing methods, please pay attention!单变量时间序列模型是一种常用的统计方法,用于分析和预测时间序列数据中的趋势和模式。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
R语言时间序列中文教程(可编辑)R语言时间序列中文教程R语言时间序列中文教程李智在乔治梅森 2012特别声明:R语言是免费语言,其代码不带任何质量保证,使用R语言所产生的后果由使用者负全责。
前言R语言是一种数据分析语言,它是科学的免费的数据分析语言,是凝聚了众多研究人员心血的成熟的使用范围广泛全面的语言,也是学习者能较快受益的语言。
在R语言出现之前,数据分析的编程语言是SAS。
当时SAS的功能比较有限。
在贝尔实验室里,有一群科学家讨论提到,他们研究过程中需要用到数据分析软件。
SAS的局限也限制了他们的研究。
于是他们想,我们贝尔实验室的研究历史要比SAS长好几倍,技术力量也比SAS强好几倍,且贝尔实验室里并不缺乏训练有素的专业编程人员,那么,我们贝尔实验室为什么不自己编写数据分析语言,来满足我们应用中所需要的特殊要求呢,于是,贝尔实验室研究出了S-PLUS语言。
后来,新西兰奥克兰大学的两位教授非常青睐S-PLUS的广泛性能。
他们决定重新编写与S-PLUS相似的语言,并且使之免费,提供给全世界所有相关研究人员使用。
于是,在这两位教授努力下,一种叫做R的语言在奥克兰大学诞生了。
R基本上是S-PLUS的翻版,但R 是免费的语言,所有编程研究人员都可以对R语言做出贡献,且他们已经将大量研究成果写成了R命令或脚本,因而R语言的功能比较强大,比较全面。
研究人员可免费使用R语言,可通过阅读R语言脚本源代码,学习其他人的研究成果。
笔者曾有幸在奥克兰大学受过几年熏陶,曾经向一位统计系的老师提请教过一个数据模拟方面的问题。
那位老师只用一行R语句就解答了。
R语言的强大功能非常令人惊讶。
为了进一步推广R语言,为了方便更多研究人员学习使用R语言,我们收集了R 语言时间序列分析实例,以供大家了解和学习使用。
当然,这是非常简单的模仿练习,具体操作是,用复制粘贴把本材料中R代码放入R的编程环境;材料中蓝色背景的内容是相关代码和相应输出结果。
经过反复模仿,学习者便能熟悉和学会。
需要提醒学习者的是:建议学习者安装了R语言编程,再继续阅读本材料;执行R命令时,请删除命令的中文注解,没使用过在命令中加入中文;如果学习者是初次接触R或者Splus,建议先阅读,如果学习者比较熟悉R语言,还可以阅读优秀时间序列读物Ecomometrics in R,也可以上QuickR 网站。
目录R语言时间序列分析1前言1目录21.运用R语言研究JJ数据32.运用R语言研究空气污染193.运用R语言研究自动回归移动平均集成模型224.运用R语言研究全球变暖理论315.运用R语言研究非独立误差与线性回归326.运用R语言研究估计波动的频率367.运用R 语言研究厄尔尼诺频率398.运用R语言研究太阳黑子周期频率401.运用R语言研究JJ数据学习R言语时间序列分析程序操作,需要从最基础、最简单的学起,例如在命令窗口中,输入并执行2+2 等于4的R语言命令。
2+2 [1] 4 执行完2+2等于4的R语言命令后,我们可以开始时间序列,即学着把玩johnson & Johnson 数据。
下载jj.dat或执行下面语句。
这个数据已被人上传到因特网中。
R所需要做的只是将网址进行扫描就可以将数据读取进入R的编程环境中。
下面有3种不同读取数据的方法:jj scan "# read the data读取数据jj - scan " # read the data another way第二种方法读取数据scan " - jj # and another第三种方法读取数据使用R语言的人,有的喜欢使用[ -],有的喜欢使用[- ],大多数医疗系统的工作者喜欢用[ ],正因为如此才用了上面种不同读取数据的方法。
读取数据后,键入并执行jj,数据在窗口便会有如下显示:jj [1] 0.71 0.63 0.85 0.44 [5] 0.61 0.69 0.920.55 . . . . . . . . . . [77] 14.0412.96 14.85 9.99 [81] 16.20 14.67 16.02 11.61 jj中有84个数据被称作对象。
下面命令可以显示所有对象。
objects 如果使用matlab,你会认为jj 是一个84行1列的向量,但实际上不是这样。
jj有次序,有长度,但没维度,R称这些对象为向量,要小心区别。
在R里,矩阵有维度,但向量没维度。
这都是程序语言的一些概念。
jj[1] # the first element列中第一个数据 [1]0.71jj[84] # the last element列中最后一个数据 [1] 11.61jj[1:4] # the first 4 elements列中第一至第四个数据 [1] 0.71 0.63 0.85 0.44jj[- 1:80 ] # everything EXCEPT the first 80 elements列中除第80个以外的所有数据 [1] 16.20 14.67 16.02 11.61length jj # the number of elements 有多少个数据 [1] 84dim jj # but no dimensions ...但没维度 NULLnrowjj # ... no rows 没行 NULLncol jj # ... and no columns没列 NULL# 如果你要把jj转变为一个向量,执行如下操作后,维度为84行1列。
jj as.matrix jj dim jj [1] 84 1 然后把jj转变为一个时间序列对象。
jj ts jj, start 1960, frequency 4 #ts 命令这个数据是从1960年开始,个个季度的收入,frequency 4指四个季度。
R语言的优势在于可用一条命令做很多事,即可以把前面的命令放在一起打包执行。
其操作如下:jj ts scan " " ,start 1960, frequency 4 在上面命令里,scan可以被read.table替代。
用read.table读取数据可生成matrix对象,还可以给每列起名字。
下面学习一下read.table, data frames, 和时间序列对象。
输入命令后,窗口会有如下显示:jj tsread.table " , start 1960, frequency 4 help read.table help ts help data.frame 需要注意的是,Scan和read.table不一样。
Scan 生成的是有维度的向量,read.table生成的则是带有维度的数据架构。
读取jj数据的最后要领。
如果这个数据是从1960年第三个季度开始的,所需输入命令则为ts x,start c 1960,3 ,frequency 4 ;如果是一个每月每月的数据,例如数据是从1984年6月开始的,需要输入的命令则为ts x,start c 1984,6 ,frequency 12 。
输入命令后,转变后的时间序列对象为:jj Qtr1 Qtr2 Qtr3 Qtr4 1960 0.710.63 0.85 0.44 1961 0.61 0.69 0.920.55 . . . . . . . . . . 1979 14.04 12.96 14.85 9.99 1980 16.2014.67 16.02 11.61 注意到区别了吗,时间信息,也就是4个不同的季度的数据被加载到里面了。
进行时间数据分析后,窗口会有如下显示:time jj Qtr1 Qtr2 Qtr3 Qtr4 1960 1960.00 1960.25 1960.50 1960.75 1961 1961.00 1961.25 1961.501961.75 . . . . . . . . . . . . 1979 1979.00 1979.25 1979.50 1979.75 1980 1980.00 1980.25 1980.50 1980.75 接下来输入如下组合命令。
jj ts scan " , start 1960, frequency 4 然后进行对数据绘图:plot jj, ylab "Earnings per Share", main "J & J" 输入以上命令后,可以看到如下结果: 再输入下面的命令,看看区别。
plot jj, type"o", col "blue", lty "dashed" plot diff log jj , main "logged and diffed" 下面利用操作两个相关命令,显示区别。
x -5:5 #sequence of integers from -5 to 5y 5*cos x # guesspar mfrow c 3,2 # multifigure setup: 3 rows, 2 cols#--- plot:plotx, main "plot x " plot x, y, main "plot x,y " #--- plot.ts:plot.ts x, main "plot.ts x " plot.ts x, y, main "plot.ts x,y " #--- ts.plot:ts.plot x, main "ts.plot x " ts.plot ts x , ts y , col 1:2, main "ts.plot x,y " # note- x and y are ts objects #--- the help files [? and help are the same]:?plot.tshelp ts.plot ?par # might as well skim the graphical parameters help file while you're here从窗口中的显示可以看出,如果数据是时间序列对象,使用plot 命令就足够了;如果数据是平常序列,使用plot.ts 也可以做时间绘图。
不过,把jj数据放在一张图上,数据会随着时间的变化上上下下跳动,能从整体上反应上升或者下降的趋势。
上文中用红色光滑的曲线代表上升的趋势,简单明了。
这需要将过滤和光滑的技巧使用在jj数据上。
在这里,我们用对称的移动平均值来达到过滤和光滑的目的。