双链表的插入删除销毁
双向链表上的插入和删除算法

编写程序,演示在双向链表上的插入和删除算法。
问题分析:1、在双向链表上操作首先要生成一个双向链表:1>节点定义struct DuLNode{ElemType data;DuLNode *prior;DuLNode *next;};2.> 创建双列表L=(DuLinkList)malloc(sizeof(DuLNode));L->next=L->prior=L;3>输入链表数据;2、3、对向链表进行插入操作算法:在节点p的前面加入一个新的节点q:q=(DuLinkList)malloc(sizeof(DuLNode));q->data=e;q->prior=p->prior;q->next=p;p->prior->next=q;p->prior=q;4、对双向链表进行删除操作算法删除给定节点p得到的代码如下:#include<iostream>#include<malloc.h>#define OK 1#define ERROR 0using namespace std;typedef int ElemType;typedef int status;struct DuLNode{ ElemType data;DuLNode *prior;DuLNode *next;};typedef DuLNode *DuLinkList;status DuListInsert_L(DuLinkList L,int i , ElemType e)//插入函数{DuLinkList p=L; //定义两个指向头节点的指针DuLinkList q=L;int j=0;while(p->next!=L&&j<i) //判断p是否到最后一个数据{p=p->next;j++;}if(p->next==L||j<i) //如果p是最后一个节点或者插入位置大于链表节点数{printf("无效的插入位置!\n");return ERROR;}//创建新节点q,数据为e,指针为nullq=(DuLinkList)malloc(sizeof(DuLNode));q->data=e;q->prior=p->prior;q->next=p;p->prior->next=q;p->prior=q;return OK;}status DuListDelete_L(DuLinkList L,int i , ElemType &e)//删除{DuLinkList p=L;int j=0;while(p->next!=L&&j<i){p=p->next;j++;}if(p->next==L||j<i){return ERROR;}p->prior->next=p->next;p->next->prior=p->prior;e=p->data;free(p);return OK;}int main(){ //初始化双向循环链表LDuLinkList L;L=(DuLinkList)malloc(sizeof(DuLNode)); //创建空双列表头结点L->next=L->prior=L;DuLNode *p,*q;ElemType e;//给L赋初始值p=L;q=L;while(cin>>e){p->next=(DuLNode*)malloc(sizeof(DuLNode));//分配新的节点q=p;p=p->next; //p指向新的节点p->data=e; //新结点的数据域为刚输入的ep->next=L; //新结点的指针域为头结点,表示这是单链表的最后一个结点p->prior=q;L->prior=p;}//p指向头指针,逐一输出链表的每个结点的值p=L;while(p->next!=L) //输出原列表{cout<<p->next->data<<' ';p=p->next;}cin.clear(); //清除上一个cin的错误信息cin.ignore(); //清空输入流int i;cout<<"输入待插入的元素e:";cin>>e;cout<<"输入待插入的位置i:";cin>>i;if(DuListInsert_L(L,i,e)){cout<<"插入后的双链为:";p=L;while(p->next!=L){cout<<p->next->data<<' ';p=p->next;}}printf("\n");p=L;while(p->next!=L) //输出列表{cout<<p->next->data<<' ';p=p->next;}int k;cin.clear(); //清除上一个cin的错误信息cin.ignore(); //清空输入流cout<<"要删除第几个节点k :";cin>>k;if(DuListDelete_L(L,k,e)){cout<<"被删除的元素为:"<<e<<endl;cout<<"删除后的元素为:";p=L;while(p->next!=L) //输出删除后的列表{cout<<p->next->data<<' ';p=p->next;}}elsecout<<"删除出错";return 0;}得到的结果如图罗达明电科一班学号2010301510028 2013、3、17。
双链表的概念

双链表的概念双链表是一种常见的数据结构,它类似于链表,但每个节点除了包含指向下一个节点的指针之外,还包含指向前一个节点的指针。
这种额外的指针使得双链表可以在O(1)的时间复杂度内进行双向遍历,并且可以方便地在任意位置插入或删除节点。
双链表的节点通常由两个指针组成,一个指向前一个节点,另一个指向后一个节点。
第一个节点的前指针指向NULL,最后一个节点的后指针也指向NULL,这样可以方便地遍历整个链表。
在一些实现中,为了更好地表示空链表,还可以设置一个指针指向链表的头节点,即第一个节点的前指针为NULL。
双链表的插入和删除操作相对于单链表来说更加灵活。
对于插入操作,只需要改变需要插入节点的前后指针指向即可。
对于删除操作,只需要调整其前后节点的指针指向即可。
这样的操作不需要像单链表一样,需要先找到前一个节点,再进行插入或删除操作,从而减少了时间复杂度。
另外,双链表更方便地支持双向遍历。
可以通过当前节点的前指针快速地找到前一个节点,也可以通过当前节点的后指针快速地找到后一个节点。
这使得在某些情况下,从后往前遍历链表更加高效。
然而,相比于单链表,双链表需要更多的空间来存储额外的指针。
因此,在存储空间较为紧张的情况下,可能不适合使用双链表。
另外,在某些情况下,由于指针的存在,双链表的操作可能稍微复杂一些。
总之,双链表是一种能够在O(1)的时间复杂度内进行双向遍历,并且可以方便地在任意位置插入或删除节点的数据结构。
它相比于单链表需要更多的空间,但拥有更高的灵活性和遍历效率。
在实际应用中,根据具体情况选择适合的数据结构是非常重要的。
数据结构中的双向链表插入删除与查找的优化策略

数据结构中的双向链表插入删除与查找的优化策略在数据结构中,双向链表是一种常见且实用的数据结构,它具有节点中既包含前驱节点指针(prev),也包含后继节点指针(next)的特点。
双向链表的插入、删除和查找操作是常见的基本操作,为了提高这些操作的效率,我们可以采用一些优化策略。
本文将讨论双向链表插入、删除和查找操作的优化方法。
一、双向链表的插入优化策略双向链表的插入操作是将一个新节点插入到链表中的某个位置,一般情况下,我们可以通过以下步骤进行插入操作:1. 找到插入位置的前驱节点;2. 创建新节点,并将新节点的prev指针指向前驱节点,next指针指向前驱节点的后继节点;3. 将前驱节点的next指针指向新节点,后继节点的prev指针指向新节点。
然而,在实际应用中,我们可以通过一些优化策略来减少插入操作的时间复杂度。
1. 将链表按照特定顺序进行排序:通过维护一个有序的双向链表,可以使插入操作更加高效。
当需要插入新节点时,只需要遍历链表找到合适的位置进行插入,而不需要像无序链表那样遍历整个链表。
2. 使用“哨兵”节点:在链表头和尾部分别设置一个“哨兵”节点,可以简化插入操作。
当插入新节点时,不需要再对头节点和尾节点进行特殊处理,直接按照一般插入操作即可。
二、双向链表的删除优化策略双向链表的删除操作是将链表中的某个节点删除,一般情况下,我们可以通过以下步骤进行删除操作:1. 找到待删除的节点;2. 将待删除节点的前驱节点的next指针指向待删除节点的后继节点;3. 将待删除节点的后继节点的prev指针指向待删除节点的前驱节点;4. 删除待删除节点。
同样地,我们可以通过一些优化策略来提高删除操作的效率。
1. 使用“快速删除”策略:在实际应用中,我们可能需要经常删除某个特定值的节点。
为了提高删除效率,可以使用一个哈希表来存储节点的值和对应的指针,可以将删除操作的时间复杂度从O(n)降低到O(1)。
2. 批量删除操作:如果需要删除多个节点,可以先将待删除的节点标记,并在删除操作时一次性删除所有标记的节点。
双向链表的应用实例

双向链表的应⽤实例管理单向链表的缺点分析:1. 单向链表,查找的⽅向只能是⼀个⽅向,⽽双向链表可以向前或者向后查找。
2. 单向链表不能⾃我删除,需要靠辅助节点,⽽双向链表,则可以⾃我删除,所以前⾯我们单链表删除节点时,总是找到 temp,temp 是待删除节点的前⼀个节点。
双向链表如何完成遍历,添加,修改和删除的思路 1) 遍历:和单链表⼀样,只是可以向前,也可以向后查找 2) 添加 (默认添加到双向链表的最后) (1)先找到双向链表的最后这个节点 (2) temp.next = newNode; (3) newNode.pre = temp; 3) 修改思路和原来的单向链表⼀样 4) 删除 (1) 因为是双向链表,因此,我们可以实现⾃我删除某个节点 (2) 直接找到要删除的这个节点,⽐如 temp temp.pre.next = temp.next; temp.next.pre = temp.pre;//若删除的是最后⼀个节点,会有空指针异常代码实现1. class doublelinkedlist {2. //先初始化⼀个头节点,头节点不能动,不存放具体数据3. private hero head = new hero(-1, "", "");4.5. //添加节点6. public void add(hero h) {7. //因为head节点不能动,因此我们需要⼀个辅助变量temp8. hero temp = head;9. //遍历链表,找到最后⼀个节点10. while (true) {11. if (temp.getNext() == null) {12. break;13. }14. //如果没有到最后,将temp后移15. temp = temp.getNext();16. }17. //当退出while循环时,temp就指向了链表的最后18. //将链表的最后⼀个节点的next指向要添加的这个节点19. //将要添加的这个节点的pre指向链表的最后⼀个节点20. temp.setNext(h);21. h.setPre(temp);22. }23.24. //第⼆种⽅式在添加英雄时,根据排名将英雄插⼊到指定位置25. //(如果有这个排名,则添加失败,并给出提⽰)26. public void addByOrder(hero h) {27. //因为头节点不能动,因此我们仍然通过⼀个辅助指针(变量)来帮助找到添加的位置28. hero temp = head;29. boolean flag = false;// flag 标志添加的编号是否存在,默认为 false30. while (true) {31. if (temp.getNext() == null) {//说明 temp 已经在链表的最后32. break;33. } else if (temp.getNext().getNum() > h.getNum()) {//位置找到,就在 temp 的后⾯插⼊34. break;35. } else if (temp.getNext().getNum() == h.getNum()) {//说明希望添加的 heroNode 的编号已然存在36. flag = true;37. break;38. }39. temp = temp.getNext();//后移,遍历当前链表40. }41. if (flag) { //不能添加,说明编号存在42. System.out.println("添加的序号为" + h.getNum() + "的英雄序号已经存在,添加失败。
双向链表排序、插入删除等基本操作
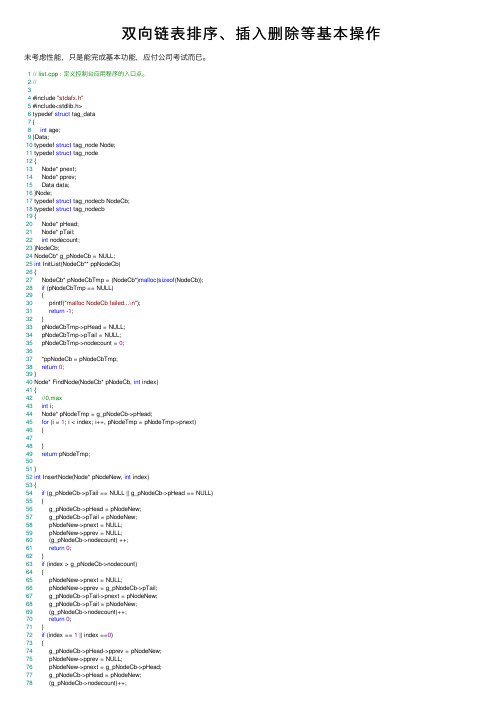
双向链表排序、插⼊删除等基本操作未考虑性能,只是能完成基本功能,应付公司考试⽽已。
1// list.cpp : 定义控制台应⽤程序的⼊⼝点。
2//34 #include "stdafx.h"5 #include<stdlib.h>6 typedef struct tag_data7 {8int age;9 }Data;10 typedef struct tag_node Node;11 typedef struct tag_node12 {13 Node* pnext;14 Node* pprev;15 Data data;16 }Node;17 typedef struct tag_nodecb NodeCb;18 typedef struct tag_nodecb19 {20 Node* pHead;21 Node* pTail;22int nodecount;23 }NodeCb;24 NodeCb* g_pNodeCb = NULL;25int InitList(NodeCb** ppNodeCb)26 {27 NodeCb* pNodeCbTmp = (NodeCb*)malloc(sizeof(NodeCb));28if (pNodeCbTmp == NULL)29 {30 printf("malloc NodeCb failed...\n");31return -1;32 }33 pNodeCbTmp->pHead = NULL;34 pNodeCbTmp->pTail = NULL;35 pNodeCbTmp->nodecount = 0;3637 *ppNodeCb = pNodeCbTmp;38return0;39 }40 Node* FindNode(NodeCb* pNodeCb, int index)41 {42//0,max43int i;44 Node* pNodeTmp = g_pNodeCb->pHead;45for (i = 1; i < index; i++, pNodeTmp = pNodeTmp->pnext)46 {4748 }49return pNodeTmp;5051 }52int InsertNode(Node* pNodeNew, int index)53 {54if (g_pNodeCb->pTail == NULL || g_pNodeCb->pHead == NULL)55 {56 g_pNodeCb->pHead = pNodeNew;57 g_pNodeCb->pTail = pNodeNew;58 pNodeNew->pnext = NULL;59 pNodeNew->pprev = NULL;60 (g_pNodeCb->nodecount) ++;61return0;62 }63if (index > g_pNodeCb->nodecount)64 {65 pNodeNew->pnext = NULL;66 pNodeNew->pprev = g_pNodeCb->pTail;67 g_pNodeCb->pTail->pnext = pNodeNew;68 g_pNodeCb->pTail = pNodeNew;69 (g_pNodeCb->nodecount)++;70return0;71 }72if (index == 1 || index ==0)73 {74 g_pNodeCb->pHead->pprev = pNodeNew;75 pNodeNew->pprev = NULL;76 pNodeNew->pnext = g_pNodeCb->pHead;77 g_pNodeCb->pHead = pNodeNew;78 (g_pNodeCb->nodecount)++;79return0;80 }8182 Node* pNodeTmp = FindNode(g_pNodeCb, index);83 pNodeNew->pnext = pNodeTmp;84 pNodeNew->pprev = pNodeTmp->pprev;85 pNodeTmp->pprev->pnext = pNodeNew;86 pNodeTmp->pprev = pNodeNew;87 (g_pNodeCb->nodecount)++;88return0;89 }90int DeleteNode(NodeCb* pNodeCb, int index)91 {92if (g_pNodeCb->pTail == NULL || g_pNodeCb->pHead == NULL)93 {94 printf("empty list...\n");95return -1;96 }97if (index == 0 || index == 1)98 {99 g_pNodeCb->pHead = g_pNodeCb->pHead->pnext;100 g_pNodeCb->pHead->pprev = NULL;101 (g_pNodeCb->nodecount)--;102//malloc的节点需要free103return0;104 }105if (index >= g_pNodeCb->nodecount)106 {107 g_pNodeCb->pTail = g_pNodeCb->pTail->pprev;108 g_pNodeCb->pTail->pnext = NULL;109 (g_pNodeCb->nodecount)--;110//malloc的节点需要free111return0;112 }113 Node* pNodeTmp = FindNode(g_pNodeCb, index);114115 pNodeTmp->pnext->pprev = pNodeTmp->pprev;116 pNodeTmp->pprev->pnext = pNodeTmp->pnext;117 (g_pNodeCb->nodecount)--;118//malloc的节点需要free119return0;120 }121int ShowList(NodeCb* pNodeCb)122 {123 Node* pNodeTmp = pNodeCb->pHead;124125for (int i = 0; i < pNodeCb->nodecount; i++, pNodeTmp = pNodeTmp->pnext) 126 printf("%d\n", pNodeTmp->data.age);127 printf("--------------------------\n");128return0;129 }130int SwapNode( Node* pNodeJ,Node* pNodeJ_1)131 {132if (pNodeJ->pprev == NULL)133 {134 pNodeJ->pnext = pNodeJ_1->pnext;135 pNodeJ_1->pnext->pprev = pNodeJ;136 pNodeJ_1->pnext = pNodeJ;137 pNodeJ->pprev = pNodeJ_1;138 g_pNodeCb->pHead = pNodeJ_1;139 pNodeJ_1->pprev = NULL;140return0;141 }142if (pNodeJ_1->pnext == NULL)143 {144 pNodeJ->pprev->pnext = pNodeJ_1;145 pNodeJ_1->pprev = pNodeJ->pprev;146 pNodeJ_1->pnext = pNodeJ;147 pNodeJ->pprev = pNodeJ_1;148 pNodeJ->pnext = NULL;149 g_pNodeCb->pTail = pNodeJ;150return0;151 }152153 pNodeJ->pprev->pnext = pNodeJ_1;154 pNodeJ_1->pprev = pNodeJ->pprev;155156 pNodeJ->pnext = pNodeJ_1->pnext;157 pNodeJ_1->pnext->pprev = pNodeJ;158 pNodeJ_1->pnext = pNodeJ;159 pNodeJ->pprev = pNodeJ_1;160return0;161162163 }164int BubbleSort(NodeCb* pNodeCb)165 {166 Node* pNodeJ = NULL;167 Node* pNodeJ_1 = NULL;168int i = 1, j = 2;169170for (i = pNodeCb->nodecount; i > 1; i--)171for (j = 1; j < i; j++)172//for (j = 1; j < pNodeCb->nodecount; j++) 173 {174 pNodeJ = FindNode(pNodeCb, j);175 pNodeJ_1 = FindNode(pNodeCb, j + 1); 176177if (pNodeJ->data.age>pNodeJ_1->data.age) 178 {179 SwapNode(pNodeJ, pNodeJ_1);180 }181 }182return0;183 }184int _tmain(int argc, _TCHAR* argv[])185 {186 Node a, b, c, d, e, f,g,h;187 a.data.age = 4;188 b.data.age = 8;189 c.data.age = 2;190 d.data.age = 5;191 e.data.age = 10;192 f.data.age = 6;193 g.data.age = 3;194 h.data.age = 1;195 InitList(&g_pNodeCb);196 InsertNode(&a, 1);197 InsertNode(&b, 10);198 InsertNode(&c, 10);199 InsertNode(&d, 2);200 InsertNode(&e, 4);201 InsertNode(&f, 10);202 InsertNode(&g, 5);203 InsertNode(&h, 6);204 ShowList(g_pNodeCb);205//DeleteNode(g_pNodeCb, 5);206//ShowList(g_pNodeCb);207 BubbleSort(g_pNodeCb);208 ShowList(g_pNodeCb);209return0;210 }。
c语言中链表进行增删查改的知识

c语言中链表进行增删查改的知识链表是一种常用的数据结构,可以用来存储一系列数据元素,并且可以实现对数据的增删查改操作。
在C语言中,链表的实现通常使用指针来进行。
我们来了解一下链表的基本概念。
链表由一个个节点组成,每个节点包含两部分:数据域和指针域。
数据域用来存储数据元素,而指针域则用来指向下一个节点。
链表的头节点是链表的第一个节点,而尾节点则指向NULL,表示链表的结束。
链表的插入操作可以在任意位置插入一个新节点。
具体步骤如下:1. 创建一个新节点,并为其分配内存空间。
2. 将新节点的数据域赋值为要插入的数据。
3. 将新节点的指针域指向当前节点的下一个节点。
4. 将当前节点的指针域指向新节点。
链表的删除操作可以删除链表中的一个节点。
具体步骤如下:1. 找到要删除的节点以及其前一个节点。
2. 将前一个节点的指针域指向要删除节点的下一个节点。
3. 释放要删除节点的内存空间。
链表的查找操作可以根据给定的数据值查找链表中对应的节点。
具体步骤如下:1. 从链表的头节点开始,依次遍历链表中的每个节点。
2. 判断当前节点的数据值是否与给定的数据值相等。
3. 如果相等,则找到了对应的节点,返回该节点;否则继续遍历下一个节点。
4. 如果遍历完整个链表仍未找到对应的节点,则返回NULL,表示未找到。
链表的修改操作可以修改链表中的一个节点的数据值。
具体步骤如下:1. 找到要修改的节点。
2. 将该节点的数据域修改为新的数据值。
通过上述的增删查改操作,我们可以实现对链表中数据的灵活操作。
链表可以动态地插入和删除节点,而不需要像数组那样需要提前定义大小。
链表的查找和修改操作的时间复杂度为O(n),其中n为链表的长度,而插入和删除操作的时间复杂度为O(1),即常数时间。
在实际应用中,链表常用于需要频繁进行插入和删除操作的场景,比如实现队列、栈、链表等数据结构。
链表也可以与其他数据结构相结合,例如与哈希表结合实现LRU缓存淘汰算法。
数据结构--数组、单链表和双链表介绍以及双向链表

数据结构--数组、单链表和双链表介绍以及双向链表数组:数组有上界和下界,数组的元素在上下界内是连续的。
数组的特点是:数据是连续的;随机访问速度快。
数组中稍微复杂⼀点的是多维数组和动态数组。
对于C语⾔⽽⾔,多维数组本质上也是通过⼀维数组实现的。
⾄于动态数组,是指数组的容量能动态增长的数组;对于C语⾔⽽⾔,若要提供动态数组,需要⼿动实现;⽽对于C++⽽⾔,STL提供了Vector。
单向链表:单向链表(单链表)是链表的⼀种,它由节点组成,每个节点都包含下⼀个节点的指针。
表头为空,表头的后继节点是"节点10"(数据为10的节点),"节点10"的后继节点是"节点20"(数据为10的节点),"节点20"的后继节点是"节点30"(数据为20的节点),"节点30"的后继节点是"节点40"(数据为10的节点),......删除"节点30"删除之前:"节点20" 的后继节点为"节点30",⽽"节点30" 的后继节点为"节点40"。
删除之后:"节点20" 的后继节点为"节点40"。
在"节点10"与"节点20"之间添加"节点15"添加之前:"节点10" 的后继节点为"节点20"。
添加之后:"节点10" 的后继节点为"节点15",⽽"节点15" 的后继节点为"节点20"。
单链表的特点是:节点的链接⽅向是单向的;相对于数组来说,单链表的的随机访问速度较慢,但是单链表删除/添加数据的效率很⾼。
「C语言」单链表双向链表的建立遍历插入删除

「C语⾔」单链表双向链表的建⽴遍历插⼊删除最近临近期末的C语⾔课程设计⽐平时练习作业⼀下难了不⽌⼀个档次,第⼀次接触到了C语⾔的框架开发,了解了View(界⾯层)、Service(业务逻辑层)、Persistence(持久化层)的分离和耦合,⼀种⾯向过程的MVC的感觉。
⽽这⼀切的基础就在于对链表的创建、删除、输出、写⼊⽂件、从⽂件读出......本篇⽂章在于巩固链表的基础知识(整理⾃《C语⾔程序设计教程--⼈民邮电出版社》第⼗章——指针与链表),只对链表的概念及增删改查作出探讨,欢迎指教。
⼀、链表结构和静态/动态链表⼆、单链表的建⽴与遍历三、单链表的插⼊与删除四、双向链表的概念五、双向链表的建⽴与遍历六、双向链表的元素查找七、循环链表的概念⼋、合并两个链表的实例九、链表实战拓展思维、拉到最后去看看 (•ᴗ•)و⼀、链表结构和静态/动态链表链表是⼀种常见的数据结构——与数组不同的是:1.数组⾸先需要在定义时声明数组⼤⼩,如果像这个数组中加⼊的元素个数超过了数组的长度时,便不能正确保存所有内容;链表可以根据⼤⼩需要进⾏拓展。
2.其次数组是同⼀数据类型的元素集合,在内存中是按⼀定顺序连续排列存放的;链表常⽤malloc等函数动态随机分配空间,⽤指针相连。
链表结构⽰意图如下所⽰:在链表中,每⼀个元素包含两个部分;数据部分和指针部分。
数据部分⽤来存放元素所包含的数据,指针部分⽤来指向下⼀个元素。
最后⼀个元素的指针指向NULL,表⽰指向的地址为空。
整体⽤结构体来定义,指针部分定义为指向本结构体类型的指针类型。
静态链表需要数组来实现,即把线性表的元素存放在数组中。
数组单元存放链表结点,结点的链域指向下⼀个元素的位置,即下⼀个元素所在数组单元的下标。
这些元素可能在物理上是连续存放的,也有可能是不连续的,它们之间通过逻辑关系来连接——这就要涉及到数组长度定义的问题,实现⽆法预知定义多⼤的数组,动态链表随即出现。
动态链表指在程序执⾏过程中从⽆到有地建⽴起⼀个链表,即⼀个⼀个地开辟结点和输⼊各结点的数据,并建⽴起前后相连的关系。
双链表的各种基本算法

双链表的各种基本算法双链表是一种常见的数据结构,它由节点组成,每个节点除了包含一个数据元素外,还有两个指针,分别指向前一个节点和后一个节点。
双链表具有插入、删除、遍历等基本操作,下面将介绍双链表的各种基本算法。
一、双链表的插入操作双链表的插入操作可以在指定位置插入一个新节点。
插入操作分为三种情况:在表头插入、在表尾插入和在指定位置插入。
1. 在表头插入:将新节点的next指针指向原表头节点,将原表头节点的prev指针指向新节点,更新表头指针为新节点。
2. 在表尾插入:将新节点的prev指针指向原表尾节点,将原表尾节点的next指针指向新节点,更新表尾指针为新节点。
3. 在指定位置插入:找到要插入位置的节点,将新节点的next指针指向该节点的next节点,将新节点的prev指针指向该节点,将该节点的next节点的prev指针指向新节点,将该节点的next指针指向新节点。
二、双链表的删除操作双链表的删除操作可以删除指定位置的节点。
删除操作分为三种情况:删除表头节点、删除表尾节点和删除指定位置节点。
1. 删除表头节点:将表头指针指向表头节点的next节点,将新的表头节点的prev指针置为空。
2. 删除表尾节点:将表尾指针指向表尾节点的prev节点,将新的表尾节点的next指针置为空。
3. 删除指定位置节点:找到要删除位置的节点,将该节点的prev 节点的next指针指向该节点的next节点,将该节点的next节点的prev指针指向该节点的prev节点。
三、双链表的查找操作双链表的查找操作可以根据给定的条件查找满足条件的节点。
查找操作分为两种:按值查找和按位置查找。
1. 按值查找:从表头开始遍历双链表,逐个比较节点的数据元素与给定值是否相等,直到找到满足条件的节点或遍历结束。
2. 按位置查找:从表头开始遍历双链表,遍历到指定位置的节点。
四、双链表的遍历操作双链表的遍历操作可以按顺序访问双链表中的每个节点。
便于插入和删除的数据结构,双链表,循环链表

便于插入和删除的数据结构:双链表、循环链表1.双链表双链表是一种常见的数据结构,它的每个节点包含两个指针,一个指向前一个节点,一个指向后一个节点。
相比于单链表,双链表能够更方便地进行插入和删除操作。
1.1双链表的节点结构双链表的节点结构可以定义如下:```m ar kd ow ns t ru ct No de{T d at a;//存储的数据N o de*p re v;//指向前一个节点的指针N o de*n ex t;//指向后一个节点的指针};```1.2双链表的插入操作在双链表中插入一个节点,需要将该节点的前后指针分别指向前一个节点和后一个节点,并将前一个节点的后指针和后一个节点的前指针分别指向待插入节点。
具体步骤如下:1.创建一个新节点,并给新节点赋值。
2.将新节点的前指针指向前一个节点,后指针指向后一个节点。
3.将前一个节点的后指针指向新节点,后一个节点的前指针指向新节点。
1.3双链表的删除操作在双链表中删除一个节点,需要将该节点的前后节点的指针重新连接起来,并释放待删除节点的内存空间。
具体步骤如下:1.找到待删除节点。
2.将待删除节点的前一个节点的后指针指向待删除节点的后一个节点。
3.将待删除节点的后一个节点的前指针指向待删除节点的前一个节点。
4.释放待删除节点的内存空间。
2.循环链表循环链表是一种特殊的链表,它的最后一个节点的后指针指向头节点,形成一个循环。
循环链表同样可以便于插入和删除操作。
2.1循环链表的节点结构循环链表的节点结构与单链表的节点结构相似,只是在最后一个节点的后指针处做了特殊处理:```m ar kd ow ns t ru ct No de{T d at a;//存储的数据N o de*n ex t;//指向下一个节点的指针};```2.2循环链表的插入操作循环链表的插入操作与单链表类似,只需要将插入节点的后指针指向下一个节点,并将上一个节点的后指针指向插入节点。
双链表的建立插入删除算法的实现

双链表的建立插入删除算法的实现摘要设计一个个人电话本,该电话本是基于双链表的具体功能实现,双链表的主要功能是查找、删除和插入。
其具体的实现过程:依次是建立空指针、构成双向链表、增加结点并给每个结点赋值,最后再通过所建链表进行插入,删除,查找等程序,从而实现了链表问题求解.可以用一般的指针来实现,但是数据库中着重强调了结构体,本题用结构体指针更容易理解和实现和初始化。
关键字:双链表;直接前驱;直接后继;节点;目录1 课程设计内容 (6)2 设计要求 (7)2.1 问题定义和任务分析 (7)2.2 逻辑设计 (7)2.3 详细设计 (8)2.4程序流程图 (11)2.5.程序编码 (12)2.6 程序的调试与测试 (15)总结 (18)参考文献 (19)1 课程设计内容用C/C++编写一个程序实现双向链表的建立、插入、删除算法。
要求建立的链表要有一定的应用价值,具体应用内容设计者自己确定。
建立双向链表必须运用结构体建立两个指针,先定义一个双链节点--但是,它的名字必须叫Node,当你派生双向链表时,这样写template <calss Type>class DblList : public List<newtype<Type >>,注意连续的两个">"之间要有空格。
或者根本不定义这样的结构,直接拿Node类型来做。
开发工具:visual C++6.02 设计要求本次设计是基于visual C++作为开发环境,采用双链表的插入删除查找等功能,来实现个人电话本的相应功能。
2.1 问题定义和任务分析通过题目要求本课题是用C/C++来实现双链表的插入删除查找的功能,具体应用于个人电话本,电话本中含有存储姓名和电话(电话号码使用整型,姓名使用字符型)。
双链表的节点中有两个指针域,其一指向直接后继,另一个指向直接前继。
和单链表的循环类似,双链表也可以有循环表。
在双向链表中,若d为指向表中某一结点的指针(即d为DuLinkList型变量),显然有d->next->prior=d->prior->next=d这个表示式恰当地反映了这种结构的特性。
链表的插入与删除

数组作为存放同类数据的集合,给我们在程序设计时带来很多的方便,增加了灵活性。
但数组也同样存在一些弊病。
如数组的大小在定义时要事先规定,不能在程序中进行调整,这样一来,在程序设计中针对不同问题有时需要3 0个大小的数组,有时需要5 0个数组的大小,难于统一。
我们只能够根据可能的最大需求来定义数组,经常会造成一定存储空间的浪费。
我们希望构造动态的数组,随时可以调整数组的大小,以满足不同问题的需要。
链表就是我们需要的动态数组。
它是在程序的执行过程中根据需要有数据存储就向系统要求申请存储空间,决不构成对存储区的浪费。
链表是一种复杂的数据结构,其数据之间的相互关系使链表分成三种:单链表、循环链表、双向链表,下面将逐一介绍。
7.4.1 单链表图7 - 3是单链表的结构。
单链表有一个头节点h e a d,指向链表在内存的首地址。
链表中的每一个节点的数据类型为结构体类型,节点有两个成员:整型成员(实际需要保存的数据)和指向下一个结构体类型节点的指针即下一个节点的地址(事实上,此单链表是用于存放整型数据的动态数组)。
链表按此结构对各节点的访问需从链表的头找起,后续节点的地址由当前节点给出。
无论在表中访问那一个节点,都需要从链表的头开始,顺序向后查找。
链表的尾节点由于无后续节点,其指针域为空,写作为N U L L。
图7 - 3还给出这样一层含义,链表中的各节点在内存的存储地址不是连续的,其各节点的地址是在需要时向系统申请分配的,系统根据内存的当前情况,既可以连续分配地址,也可以跳跃式分配地址。
看一下链表节点的数据结构定义:struct node{int num;struct node *p;} ;在链表节点的定义中,除一个整型的成员外,成员p是指向与节点类型完全相同的指针。
在链表节点的数据结构中,非常非凡的一点就是结构体内的指针域的数据类型使用了未定义成功的数据类型。
这是在C中唯一规定可以先使用后定义的数据结构。
•单链表的创建过程有以下几步:1 ) 定义链表的数据结构。
循环链表和双向链表

b.head->next = NULL; //此时,b中已只剩第一个结点(头), 为其置空表标志
return k; //返回结果链表中的元素个数
}
为了进一步说明上述程序,举一个程序运行的例子, 其各次循环的运行结果如图5-6所示
p
7 0 3 2 -9 3 1 5
^
(a)A(x)=p5(x)=7+3x2-9x3+x5,进入循环前
该程序不断比较A链和B链中的一对结点的指数值 (称其为当前结点)。开始时A链和B链中参加比较
的当前结点都是它们的第一个元素。
主循环while结束后,可能出现下列3种情况:①A
链和B链同时被处理完;②只有B链处理完;③只有A
链处理完。 对第一和第二种情况,不需要“善后”处理。对第 三种情况,B链中尚有未被处理完的结点,需将其挂 接在结果链的尾部。循环外的“if(q 不为空)将q
p = p->next; } // if (x==0) … else … q0 = q; q = q->next; delete q0; //将q所指结点从表中删除并释放,令q新指向原所 指的下一个 } // if (p->exp > q->exp ) … else … } //while if (q!=NULL) p0->next = q;
为处理方便,在具体存储多项式时,我们规定:
所存储的多项式已约简,即已合并同类项,不 保留0系数项,各项按指数的升序排列。 (二)多项式加法实现—直接操作链表 为操作方便,我采用带头结点的非循环链表,下面给 出一个例子说明多项式的这种表示法。
设有一个一元5次多项式: P5(x)=7+3x-9x3+x5
双链表的删除和插入的时间复杂度

双链表的删除和插⼊的时间复杂度
双向链表相⽐于单向链表,所谓的O(1)是指删除、插⼊操作。
单向链表要删除某⼀节点时,必须要先通过遍历的⽅式找到前驱节点(通过待删除节点序号或按值查找)。
若仅仅知道待删除节点,是不能知道前驱节点的,故单链表的增删操作复杂度为O(n)。
双链表(双向链表)知道要删除某⼀节点p时,获取其前驱节点q的⽅式为 q = p->prior,不必再进⾏遍历。
故时间复杂度为O(1)。
⽽若只知道待删除节点的序号,则依然要按序查找,时间复杂度仍为O(n)。
单、双链表的插⼊操作,若给定前驱节点,则时间复杂度均为O(1)。
否则只能按序或按值查找前驱节点,时间复杂度为O(n)。
⾄于查找,⼆者的时间复杂度均为O(n)。
对于最基本的CRUD操作,双链表优势在于删除给定节点。
但其劣势在于浪费存储空间(若从⼯程⾓度考量,则其维护性和可读性都更低)。
双链表本⾝的结构优势在于,可以O(1)地找到前驱节点,若算法需要对待操作节点的前驱节点做处理,则双链表相⽐单链表有更加便捷的优势。
数据结构C语言实现----销毁链表

数据结构C语⾔实现----销毁链表1.⾸先,将*list(头指针)赋值给p,这样p也指向链表的第⼀个结点,成为链表的表头2.然后判断只要p不为空,就将p指向下⼀个的指针赋值给q,再释放掉p3.之后再将q赋值给p,⽤来找到下⼀轮释放掉的结点的下⼀个结点代码如下:#include<stdio.h>#include<stdlib.h>typedef struct Node{char date;struct Node *next;}Node , *LinkList;//创建链表LinkList creat_linklist(int n){LinkList New_node,Tail_node;LinkList Head_node = NULL;char c;for (size_t i = 0; i < n; i++){printf("请输⼊在第%d个结点存⼊的数据:",i+1);scanf("%c",&c);fflush(stdin);New_node = (LinkList)malloc( sizeof(Node) );New_node->date = c;New_node->next = NULL;if (Head_node == NULL){Head_node = New_node;}else{Tail_node->next = New_node;}Tail_node = New_node;}return Head_node;}//销毁链表void destoryLinkList(LinkList *List){LinkList p,q;p = *List;while (p){q = p->next;free(p);p = q;}*List = NULL;}int main(){int n;char c;LinkList List , List2;//List⽤于第⼀次打印单链表,List2⽤于第⼆次打印单链表printf("请输⼊结点个数:");scanf("%d",&n);fflush(stdin);List = creat_linklist(n);List2 = List;//复制⼀遍链表,第⼀次打印链表后链表后头指针会直接指向NULL,导致第⼆次打印失败printf("打印单链表:");while ( List != NULL ){printf("%c" , List->date);List = List->next;}putchar('\n');printf("即将销毁链表,请按任意键确认!");getchar();destoryLinkList(&List2);if (List2 == NULL){printf("链表已被销毁!");}else{while ( List2 != NULL ){printf("%c" , List2->date); List2 = List2->next;}}return 0;}运⾏结果:。
双向链表插入删除基本操作演示 精选文档

return ERROR;
s->data=e;
① s->prior=p->prior;
② p->prior->next=s;
③ s->next=p;
p
④ p->prior=s;
return OK;
a
b
}
①
s
e
在双向链表中插入结点
Status ListInsert_Dul(DuLinklist &L,int i,ElemType e)
{
if(!(p=GetElem_DuL(L,i)))
return ERROR;
if(!(s=(DuLinkList)malloc(sizeof(DuLNode))))
return ERROR;
s->data=e;
① s->prior=p->prior;
② p->prior->next=s;
③ s->next=p;
return ERROR;
s->data=e;
① s->prior=p->prior;
② p->prior->next=s;
③ s->next=p;
p
④ p->prior=s;
return OK;
a
b
}
① ②④ ③
s
e
在双向链表中删除结点
Status ListDelete_Dul(DuLinklist &L,int i,ElemType &e)
return ERROR;
s->data=e;
① s->prior=p->prior;
链表的实现及应用实验原理与方法

链表的实现及应用实验原理与方法链表简介链表是一种数据结构,由一系列节点组成,每个节点包含数据和指向下一个节点的指针。
链表中的节点可以在内存中分散存储,相比于数组,链表更加灵活,动态插入和删除元素的效率更高。
链表的基本操作以下是链表的几个基本操作:1.创建链表:创建一个空链表,设置头节点为空。
2.插入节点:在链表的指定位置插入一个新节点,调整指针指向。
3.删除节点:根据给定值,在链表中找到并删除节点,调整指针指向。
4.查找节点:根据给定值,在链表中查找节点。
链表的实现方法链表可以通过不同的实现方法来实现,以下是两种常见的实现方法:单链表(Singly Linked List)单链表是最简单的链表形式,每个节点只包含一个指针指向下一个节点,最后一个节点指向空。
单链表的插入和删除操作效率高,但查找节点的效率较低。
双链表(Doubly Linked List)双链表在单链表的基础上增加了一个指向前一个节点的指针。
双链表的插入和删除操作相对复杂一些,但查找节点的效率更高,可以在双链表中前后遍历。
链表的应用链表作为一种常见的数据结构,在许多实际问题中都有广泛的应用,以下是几个常见的应用场景:1.链表用于实现栈和队列:链表可以轻松地实现栈和队列等数据结构,插入和删除操作效率高。
2.链表用于LRU缓存淘汰算法:链表可以按照访问顺序存储数据,当缓存容量不够时,可以通过删除链表尾部的节点来实现淘汰。
3.链表用于多项式求解:链表可以存储多项式的每一项,方便进行运算和求解。
链表的实验原理与方法链表的实验原理与方法可以包括以下几个方面:1.实验原理:了解链表的基本原理,包括节点结构、指针指向等。
2.实验设备:准备笔记本电脑和编程环境。
3.实验步骤:–步骤1:创建一个链表,设置头节点为空。
–步骤2:插入节点:根据需要在链表中插入节点,调整指针指向。
–步骤3:删除节点:根据需要在链表中删除节点,调整指针指向。
–步骤4:查找节点:根据给定值在链表中查找节点。
双链表(初始化,建立,插入,查找,删除)

双链表(初始化,建⽴,插⼊,查找,删除)双向链表和单向链表也是有很多相似的地⽅的,听名字可以猜到,每个节点都包含两个指针,⼀个指针指向上⼀个节点,⼀个指针指向下⼀个节点。
这⾥有两个特殊的地⽅,第⼀就是头节点的⼀个指针指向NULL空指针(没有前驱节点),第⼆就是尾节点的⼀个指针指向NULL指针(没有后继节点)。
#ifndef DOUBLY_LINKED_LIST_H#define DOUBLY_LINKED_LIST_Htypedef struct Node{int data;struct Node *pNext;struct Node *pPre;}NODE, *pNODE;//创建双向链表pNODE CreateDbLinkList(void);//打印链表void TraverseDbLinkList(pNODE pHead);//判断链表是否为空int IsEmptyDbLinkList(pNODE pHead);//计算链表长度int GetLengthDbLinkList(pNODE pHead);//向链表插⼊节点int InsertEleDbLinkList(pNODE pHead, int pos, int data);//从链表删除节点int DeleteEleDbLinkList(pNODE pHead, int pos);//删除整个链表,释放内存void FreeMemory(pNODE *ppHead);#endifDbLinkList.cpp 双向链表的源⽂件——包含了各种操作函数的定义。
(1)这部分是创建双向链表,和单向链表很相似,但是呢,有些地⽅还是得注意,就是每创建⼀个节点的时候都要注意初始化它的两个指针。
#include <stdio.h>#include <stdlib.h>#include "DbLinkList.h"//创建双向链表pNODE CreateDbLinkList(void){int i, length = 0, data = 0;pNODE pTail = NULL, p_new = NULL;pNODE pHead = (pNODE)malloc(sizeof(NODE));if (NULL == pHead){printf("内存分配失败!\n");exit(EXIT_FAILURE);}pHead->data = 0;pHead->pPre = NULL;pHead->pNext = NULL;pTail = pHead;printf("请输⼊想要创建链表的长度:");scanf("%d", &length);for (i=1; i<length+1; i++){p_new = (pNODE)malloc(sizeof(NODE));if (NULL == p_new){printf("内存分配失败!\n");exit(EXIT_FAILURE);}printf("请输⼊第%d个元素的值:", i);scanf("%d", &data);p_new->data = data;p_new->pNext = NULL;p_new->pPre = pTail;pTail->pNext = p_new;pTail = p_new;}return pHead;}(2)这部分是获得双向链表的信息,这⾥和单向链表基本⼀致,因为遍历的时候只⽤到了⼀个指针。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
case 1:
printf("建立双向链表");
head=chuangjian();
break;
case 2:
printf("输出双向链表");
print(head);
break;
case 3:
printf("双向链表插入");
{
printf("%d",p->date);
p=p->next;
}
printf("\n\n");
}
void insert(linknode *head)//建立函数向链表中某个位置插入指定元素//
{
int x,y;
linknode *h,*p,*q;
printf("输入想要插入的数和位置(中间用空格隔开):");
printf("******************************************************\n");
}
void main()
{
linknode *head;
int i;
head=NULL;
menu();
do
{
i=-1;
while(i<0||i>5)
printf(" 3.双向链表插入\n");
printf(" 4.双向链表查找\n");
printf(" 5.双向链表删除\n");
printf(" 0.退出\n");
s->prior=r;//令当前元素向前指的指针指向前一个元素地址//
r->next=s;
r=s;
}
printf("\n\n");
return h;
}
int ListLength(linknode *head)
{
int i=0;
linknode *p=head->next;//p指向第一个结点//
# include<stdio.h>
# include<stdlib.h>
# define ok 1
# define LEN sizeof(linknode)
typedef struct node{
int date;
node *next; ຫໍສະໝຸດ node *prior;
}linknode,*linklist;
return(ok);
}
void menu()
{
printf("*************** 双向链表的建立及操作 ***************\n");
printf(" 1.构建双向链表\n");
printf(" 2.输出双向链表\n");
insert(head);
print(head);
break;
case 4:
int m;
printf("双向链表查找");
m=find(head);
break;
case 5:
printf("双向链表删除");
delet(head);
{
int x;
printf("输入想要删除的数:");
scanf("%d",&x);
linknode *p,*q;
p=head->next;
while(p->date!=x&&p->next!=NULL)//查找指定删除的元素//
{
q=p;
p=p->next;
}
free(p);
}
}
int find(linknode*head)//建立函数查找某个元素前后两个元素值//
{
int x,j;
linknode *p;
printf("输入想要查找的数:");
scanf("%d",&x);
p=head->next;
for(j=0;j<ListLength(head);j++)
scanf("%d",&n);//输入想建链表的长度//
for(int i=0;i<n;i++)
{
printf("输入链表第%d个元素:",i+1);
s=(linknode*)malloc(LEN);
scanf("%d",&x);
s->date=x;
s->next=NULL;
}
if(p->date==x)
{
if(p==head->next)//如果指定删除元素为首元结点进行如下操作//
{
head->next=p->next;
p->next->prior=head;
}
else{
q->next=p->next;
p->next->prior=q;
scanf("%d%d",&x,&y);
h=(linknode*)malloc(LEN);
h->date=x;
p=head;
q=p->next;
for(int i=1;i<y;i++)//查找指定的位置//
{
p=p->next;
q=p->next;
}
if(q==NULL)
while(p!=NULL)//p没到表头//
{
i++;
p=p->next;
}
return i;
}
void print(linknode *h)//输出建立的双向链表//
{
linklist p=h->next;
printf("生成链表如下: \n");
while(p!=NULL)//如果当前元素不为空输出//
{
if(p->date==x)
{
printf("要查找的是第%d个元素\n",j+1);
break;
}
else
p=p->next;
}
if(j>=ListLength(head))//第i个元素不存在//
printf("\n不存在\n");
{
printf("请选择0到5的操作:");
scanf("%d",&i);
if(i>=6||i<=0)//判断i是否在0-5中间//
{
printf("你的输入有误!!");
exit(0);
}
printf("\n");
}
switch(i)
linknode* chuangjian(){//创建一个双链表//
linknode *h,*s,*r;
int n,x;
h=(linknode*)malloc(LEN);//设置头结点//
h->next=NULL;
h->prior=NULL;
r=h;
printf("输入想要建的链表的长度:");
{
p->next=h;
h->prior=p;
h->next=q;
}
else{
p->next=h;
h->prior=p;
h->next=q;
q->prior=h;
}//插入后调用函数输出//
print(head);
}
void delet(linknode *head)//建立函数删除指定元素//
print(head);
break;
default:
printf("退出");
exit(0);
}
}while(i!=0);
printf(" 谢谢使用!! ");
}