数据结构与算法分析习题及参考答案
数据结构与算法分析习题与参考答案
大学《数据结构与算法分析》课程习题及参考答案模拟试卷一一、单选题(每题 2 分,共20分)1.以下数据结构中哪一个是线性结构?( )A. 有向图B. 队列C. 线索二叉树D. B树2.在一个单链表HL中,若要在当前由指针p指向的结点后面插入一个由q指向的结点,则执行如下( )语句序列。
A. p=q; p->next=q;B. p->next=q; q->next=p;C. p->next=q->next; p=q;D. q->next=p->next; p->next=q;3.以下哪一个不是队列的基本运算?()A. 在队列第i个元素之后插入一个元素B. 从队头删除一个元素C. 判断一个队列是否为空D.读取队头元素的值4.字符A、B、C依次进入一个栈,按出栈的先后顺序组成不同的字符串,至多可以组成( )个不同的字符串?A.14B.5C.6D.85.由权值分别为3,8,6,2的叶子生成一棵哈夫曼树,它的带权路径长度为( )。
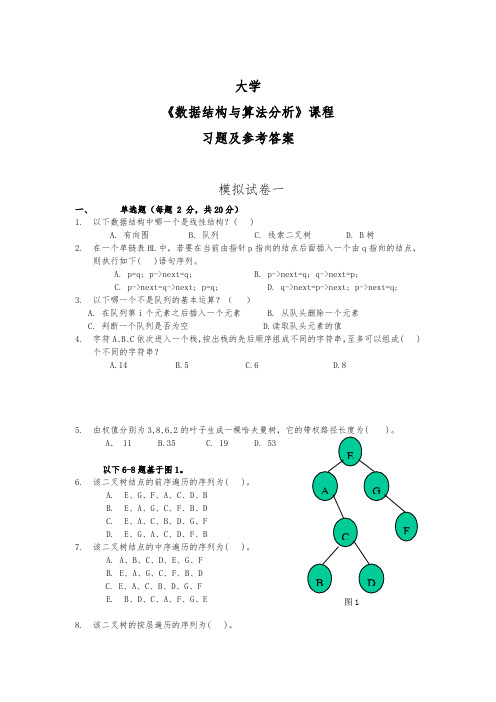
以下6-8题基于图1。
6.该二叉树结点的前序遍历的序列为( )。
A.E、G、F、A、C、D、BB.E、A、G、C、F、B、DC.E、A、C、B、D、G、FD.E、G、A、C、D、F、B7.该二叉树结点的中序遍历的序列为( )。
A. A、B、C、D、E、G、FB. E、A、G、C、F、B、DC. E、A、C、B、D、G、FE.B、D、C、A、F、G、E8.该二叉树的按层遍历的序列为( )。
A.E、G、F、A、C、D、B B. E、A、C、B、D、G、FC. E、A、G、C、F、B、DD. E、G、A、C、D、F、B9.下面关于图的存储的叙述中正确的是( )。
A.用邻接表法存储图,占用的存储空间大小只与图中边数有关,而与结点个数无关B.用邻接表法存储图,占用的存储空间大小与图中边数和结点个数都有关C. 用邻接矩阵法存储图,占用的存储空间大小与图中结点个数和边数都有关D.用邻接矩阵法存储图,占用的存储空间大小只与图中边数有关,而与结点个数无关10.设有关键码序列(q,g,m,z,a,n,p,x,h),下面哪一个序列是从上述序列出发建堆的结果?( )A. a,g,h,m,n,p,q,x,zB. a,g,m,h,q,n,p,x,zC. g,m,q,a,n,p,x,h,zD. h,g,m,p,a,n,q,x,z二、填空题(每空1分,共26分)1.数据的物理结构被分为_________、________、__________和___________四种。
算法与数据结构习题及参考答案

算法与数据结构习题及参考答案一、选择题1. 在算法分析中,时间复杂度表示的是:A. 算法执行的时间B. 算法的运行速度C. 算法执行所需的操作次数D. 算法的内存消耗答案:C2. 哪种数据结构可以在常数时间内完成插入和删除操作?A. 数组B. 栈C. 队列D. 链表答案:B3. 单链表的逆置可以使用哪种算法实现?A. 冒泡排序B. 归并排序C. 快速排序D. 双指针法答案:D4. 常用的查找算法中,哪种算法的时间复杂度始终为O(log n)?A. 顺序查找B. 二分查找C. 广度优先搜索D. 深度优先搜索答案:B5. 哪种排序算法的时间复杂度最坏情况下仍为O(n log n)?A. 冒泡排序B. 插入排序C. 快速排序D. 堆排序答案:C二、填空题1. 下面哪个数据结构先进先出?A. 栈B. 队列C. 堆D. 链表答案:B2. 在快速排序的基本步骤中,需要选取一个元素作为________。
答案:枢纽元素3. 广度优先搜索使用的数据结构是________。
答案:队列4. 二分查找是基于_________的。
答案:有序数组5. 哈希表的查找时间复杂度为_________。
答案:O(1)三、解答题1. 请简要说明冒泡排序算法的原理及时间复杂度。
答:冒泡排序是一种简单直观的排序算法。
它的基本思想是通过相邻元素之间的比较和交换来将最大(或最小)的元素逐渐“冒泡”到数列的一端。
冒泡排序的过程如下:1)比较相邻的元素,如果前面的元素大于后面的元素,则交换它们的位置;2)对每一对相邻元素重复进行比较和交换,直到最后一对元素;3)针对剩下的元素重复上述步骤,直到整个数列有序。
冒泡排序的时间复杂度为O(n^2),其中n为待排序数列的长度。
在最坏情况下,冒泡排序需要进行n-1次比较和交换操作,因此时间复杂度为O(n^2)。
在最好情况下,如果待排序数列已经有序,冒泡排序只需进行n-1次比较,没有交换操作,时间复杂度为O(n)。
《数据结构与算法分析》(C++第二版)【美】Clifford A.Shaffer著 课后习题答案 二

《数据结构与算法分析》(C++第二版)【美】Clifford A.Shaffer著课后习题答案二5Binary Trees5.1 Consider a non-full binary tree. By definition, this tree must have some internalnode X with only one non-empty child. If we modify the tree to removeX, replacing it with its child, the modified tree will have a higher fraction ofnon-empty nodes since one non-empty node and one empty node have been removed.5.2 Use as the base case the tree of one leaf node. The number of degree-2 nodesis 0, and the number of leaves is 1. Thus, the theorem holds.For the induction hypothesis, assume the theorem is true for any tree withn − 1 nodes.For the induction step, consider a tree T with n nodes. Remove from the treeany leaf node, and call the resulting tree T. By the induction hypothesis, Thas one more leaf node than it has nodes of degree 2.Now, restore the leaf node that was removed to form T. There are twopossible cases.(1) If this leaf node is the only child of its parent in T, then the number ofnodes of degree 2 has not changed, nor has the number of leaf nodes. Thus,the theorem holds.(2) If this leaf node is the child of a node in T with degree 2, then that nodehas degree 1 in T. Thus, by restoring the leaf node we are adding one newleaf node and one new node of degree 2. Thus, the theorem holds.By mathematical induction, the theorem is correct.32335.3 Base Case: For the tree of one leaf node, I = 0, E = 0, n = 0, so thetheorem holds.Induction Hypothesis: The theorem holds for the full binary tree containingn internal nodes.Induction Step: Take an arbitrary tree (call it T) of n internal nodes. Selectsome internal node x from T that has two leaves, and remove those twoleaves. Call the resulting tree T’. Tree T’ is full and has n−1 internal nodes,so by the Induction Hypothesis E = I + 2(n − 1).Call the depth of node x as d. Restore the two children of x, each at leveld+1. We have nowadded d to I since x is now once again an internal node.We have now added 2(d + 1) − d = d + 2 to E since we added the two leafnodes, but lost the contribution of x to E. Thus, if before the addition we had E = I + 2(n − 1) (by the induction hypothesis), then after the addition we have E + d = I + d + 2 + 2(n − 1) or E = I + 2n which is correct. Thus,by the principle of mathematical induction, the theorem is correct.5.4 (a) template <class Elem>void inorder(BinNode<Elem>* subroot) {if (subroot == NULL) return; // Empty, do nothingpreorder(subroot->left());visit(subroot); // Perform desired actionpreorder(subroot->right());}(b) template <class Elem>void postorder(BinNode<Elem>* subroot) {if (subroot == NULL) return; // Empty, do nothingpreorder(subroot->left());preorder(subroot->right());visit(subroot); // Perform desired action}5.5 The key is to search both subtrees, as necessary.template <class Key, class Elem, class KEComp>bool search(BinNode<Elem>* subroot, Key K);if (subroot == NULL) return false;if (subroot->value() == K) return true;if (search(subroot->right())) return true;return search(subroot->left());}34 Chap. 5 Binary Trees5.6 The key is to use a queue to store subtrees to be processed.template <class Elem>void level(BinNode<Elem>* subroot) {AQueue<BinNode<Elem>*> Q;Q.enqueue(subroot);while(!Q.isEmpty()) {BinNode<Elem>* temp;Q.dequeue(temp);if(temp != NULL) {Print(temp);Q.enqueue(temp->left());Q.enqueue(temp->right());}}}5.7 template <class Elem>int height(BinNode<Elem>* subroot) {if (subroot == NULL) return 0; // Empty subtreereturn 1 + max(height(subroot->left()),height(subroot->right()));}5.8 template <class Elem>int count(BinNode<Elem>* subroot) {if (subroot == NULL) return 0; // Empty subtreeif (subroot->isLeaf()) return 1; // A leafreturn 1 + count(subroot->left()) +count(subroot->right());}5.9 (a) Since every node stores 4 bytes of data and 12 bytes of pointers, the overhead fraction is 12/16 = 75%.(b) Since every node stores 16 bytes of data and 8 bytes of pointers, the overhead fraction is 8/24 ≈ 33%.(c) Leaf nodes store 8 bytes of data and 4 bytes of pointers; internal nodesstore 8 bytes of data and 12 bytes of pointers. Since the nodes havedifferent sizes, the total space needed for internal nodes is not the sameas for leaf nodes. Students must be careful to do the calculation correctly,taking the weighting into account. The correct formula looks asfollows, given that there are x internal nodes and x leaf nodes.4x + 12x12x + 20x= 16/32 = 50%.(d) Leaf nodes store 4 bytes of data; internal nodes store 4 bytes of pointers. The formula looks as follows, given that there are x internal nodes and35x leaf nodes:4x4x + 4x= 4/8 = 50%.5.10 If equal valued nodes were allowed to appear in either subtree, then during a search for all nodes of a given value, whenever we encounter a node of that value the search would be required to search in both directions.5.11 This tree is identical to the tree of Figure 5.20(a), except that a node with value 5 will be added as the right child of the node with value 2.5.12 This tree is identical to the tree of Figure 5.20(b), except that the value 24 replaces the value 7, and the leaf node that originally contained 24 is removed from the tree.5.13 template <class Key, class Elem, class KEComp>int smallcount(BinNode<Elem>* root, Key K);if (root == NULL) return 0;if (KEComp.gt(root->value(), K))return smallcount(root->leftchild(), K);elsereturn smallcount(root->leftchild(), K) +smallcount(root->rightchild(), K) + 1;5.14 template <class Key, class Elem, class KEComp>void printRange(BinNode<Elem>* root, int low,int high) {if (root == NULL) return;if (KEComp.lt(high, root->val()) // all to leftprintRange(root->left(), low, high);else if (KEComp.gt(low, root->val())) // all to rightprintRange(root->right(), low, high);else { // Must process both childrenprintRange(root->left(), low, high);PRINT(root->value());printRange(root->right(), low, high);}}5.15 The minimum number of elements is contained in the heap with a single node at depth h − 1, for a total of 2h−1 nodes.The maximum number of elements is contained in the heap that has completely filled up level h − 1, for a total of 2h − 1 nodes.5.16 The largest element could be at any leaf node.5.17 The corresponding array will be in the following order (equivalent to level order for the heap):12 9 10 5 4 1 8 7 3 236 Chap. 5 Binary Trees5.18 (a) The array will take on the following order:6 5 3 4 2 1The value 7 will be at the end of the array.(b) The array will take on the following order:7 4 6 3 2 1The value 5 will be at the end of the array.5.19 // Min-heap classtemplate <class Elem, class Comp> class minheap {private:Elem* Heap; // Pointer to the heap arrayint size; // Maximum size of the heapint n; // # of elements now in the heapvoid siftdown(int); // Put element in correct placepublic:minheap(Elem* h, int num, int max) // Constructor{ Heap = h; n = num; size = max; buildHeap(); }int heapsize() const // Return current size{ return n; }bool isLeaf(int pos) const // TRUE if pos a leaf{ return (pos >= n/2) && (pos < n); }int leftchild(int pos) const{ return 2*pos + 1; } // Return leftchild posint rightchild(int pos) const{ return 2*pos + 2; } // Return rightchild posint parent(int pos) const // Return parent position { return (pos-1)/2; }bool insert(const Elem&); // Insert value into heap bool removemin(Elem&); // Remove maximum value bool remove(int, Elem&); // Remove from given pos void buildHeap() // Heapify contents{ for (int i=n/2-1; i>=0; i--) siftdown(i); }};template <class Elem, class Comp>void minheap<Elem, Comp>::siftdown(int pos) { while (!isLeaf(pos)) { // Stop if pos is a leafint j = leftchild(pos); int rc = rightchild(pos);if ((rc < n) && Comp::gt(Heap[j], Heap[rc]))j = rc; // Set j to lesser child’s valueif (!Comp::gt(Heap[pos], Heap[j])) return; // Done37swap(Heap, pos, j);pos = j; // Move down}}template <class Elem, class Comp>bool minheap<Elem, Comp>::insert(const Elem& val) { if (n >= size) return false; // Heap is fullint curr = n++;Heap[curr] = val; // Start at end of heap// Now sift up until curr’s parent < currwhile ((curr!=0) &&(Comp::lt(Heap[curr], Heap[parent(curr)]))) {swap(Heap, curr, parent(curr));curr = parent(curr);}return true;}template <class Elem, class Comp>bool minheap<Elem, Comp>::removemin(Elem& it) { if (n == 0) return false; // Heap is emptyswap(Heap, 0, --n); // Swap max with last valueif (n != 0) siftdown(0); // Siftdown new root valit = Heap[n]; // Return deleted valuereturn true;}38 Chap. 5 Binary Trees// Remove value at specified positiontemplate <class Elem, class Comp>bool minheap<Elem, Comp>::remove(int pos, Elem& it) {if ((pos < 0) || (pos >= n)) return false; // Bad posswap(Heap, pos, --n); // Swap with last valuewhile ((pos != 0) &&(Comp::lt(Heap[pos], Heap[parent(pos)])))swap(Heap, pos, parent(pos)); // Push up if largesiftdown(pos); // Push down if small keyit = Heap[n];return true;}5.20 Note that this summation is similar to Equation 2.5. To solve the summation requires the shifting technique from Chapter 14, so this problem may be too advanced for many students at this time. Note that 2f(n) − f(n) = f(n),but also that:2f(n) − f(n) = n(24+48+616+ ··· +2(log n − 1)n) −n(14+28+316+ ··· +log n − 1n)logn−1i=112i− log n − 1n)= n(1 − 1n− log n − 1n)= n − log n.5.21 Here are the final codes, rather than a picture.l 00h 010i 011e 1000f 1001j 101d 11000a 1100100b 1100101c 110011g 1101k 11139The average code length is 3.234455.22 The set of sixteen characters with equal weight will create a Huffman coding tree that is complete with 16 leaf nodes all at depth 4. Thus, the average code length will be 4 bits. This is identical to the fixed length code. Thus, in this situation, the Huffman coding tree saves no space (and costs no space).5.23 (a) By the prefix property, there can be no character with codes 0, 00, or 001x where “x” stands for any binary string.(b) There must be at least one code with each form 1x, 01x, 000x where“x” could be any binary string (including the empty string).5.24 (a) Q and Z are at level 5, so any string of length n containing only Q’s and Z’s requires 5n bits.(b) O and E are at level 2, so any string of length n containing only O’s and E’s requires 2n bits.(c) The weighted average is5 ∗ 5 + 10 ∗ 4 + 35 ∗ 3 + 50 ∗ 2100bits per character5.25 This is a straightforward modification.// Build a Huffman tree from minheap h1template <class Elem>HuffTree<Elem>*buildHuff(minheap<HuffTree<Elem>*,HHCompare<Elem> >* hl) {HuffTree<Elem> *temp1, *temp2, *temp3;while(h1->heapsize() > 1) { // While at least 2 itemshl->removemin(temp1); // Pull first two treeshl->removemin(temp2); // off the heaptemp3 = new HuffTree<Elem>(temp1, temp2);hl->insert(temp3); // Put the new tree back on listdelete temp1; // Must delete the remnantsdelete temp2; // of the trees we created}return temp3;}6General Trees6.1 The following algorithm is linear on the size of the two trees. // Return TRUE iff t1 and t2 are roots of identical// general treestemplate <class Elem>bool Compare(GTNode<Elem>* t1, GTNode<Elem>* t2) { GTNode<Elem> *c1, *c2;if (((t1 == NULL) && (t2 != NULL)) ||((t2 == NULL) && (t1 != NULL)))return false;if ((t1 == NULL) && (t2 == NULL)) return true;if (t1->val() != t2->val()) return false;c1 = t1->leftmost_child();c2 = t2->leftmost_child();while(!((c1 == NULL) && (c2 == NULL))) {if (!Compare(c1, c2)) return false;if (c1 != NULL) c1 = c1->right_sibling();if (c2 != NULL) c2 = c2->right_sibling();}}6.2 The following algorithm is Θ(n2).// Return true iff t1 and t2 are roots of identical// binary treestemplate <class Elem>bool Compare2(BinNode<Elem>* t1, BinNode<Elem* t2) { BinNode<Elem> *c1, *c2;if (((t1 == NULL) && (t2 != NULL)) ||((t2 == NULL) && (t1 != NULL)))return false;if ((t1 == NULL) && (t2 == NULL)) return true;4041if (t1->val() != t2->val()) return false;if (Compare2(t1->leftchild(), t2->leftchild())if (Compare2(t1->rightchild(), t2->rightchild())return true;if (Compare2(t1->leftchild(), t2->rightchild())if (Compare2(t1->rightchild(), t2->leftchild))return true;return false;}6.3 template <class Elem> // Print, postorder traversalvoid postprint(GTNode<Elem>* subroot) {for (GTNode<Elem>* temp = subroot->leftmost_child();temp != NULL; temp = temp->right_sibling())postprint(temp);if (subroot->isLeaf()) cout << "Leaf: ";else cout << "Internal: ";cout << subroot->value() << "\n";}6.4 template <class Elem> // Count the number of nodesint gencount(GTNode<Elem>* subroot) {if (subroot == NULL) return 0int count = 1;GTNode<Elem>* temp = rt->leftmost_child();while (temp != NULL) {count += gencount(temp);temp = temp->right_sibling();}return count;}6.5 The Weighted Union Rule requires that when two parent-pointer trees are merged, the smaller one’s root becomes a child of the larger one’s root. Thus, we need to keep track of the number of nodes in a tree. To do so, modify the node array to store an integer value with each node. Initially, each node isin its own tree, so the weights for each node begin as 1. Whenever we wishto merge two trees, check the weights of the roots to determine which has more nodes. Then, add to the weight of the final root the weight of the new subtree.6.60 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15-1 0 0 0 0 0 0 6 0 0 0 9 0 0 12 06.7 The resulting tree should have the following structure:42 Chap. 6 General TreesNode 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15Parent 4 4 4 4 -1 4 4 0 0 4 9 9 9 12 9 -16.8 For eight nodes labeled 0 through 7, use the following series of equivalences: (0, 1) (2, 3) (4, 5) (6, 7) (4 6) (0, 2) (4 0)This requires checking fourteen parent pointers (two for each equivalence),but none are actually followed since these are all roots. It is possible todouble the number of parent pointers checked by choosing direct children ofroots in each case.6.9 For the “lists of Children” representation, every node stores a data value and a pointer to its list of children. Further, every child (every node except the root)has a record associated with it containing an index and a pointer. Indicatingthe size of the data value as D, the size of a pointer as P and the size of anindex as I, the overhead fraction is3P + ID + 3P + I.For the “Left Child/Right Sibling” representation, every node stores three pointers and a data value, for an overhead fraction of3PD + 3P.The first linked representation of Section 6.3.3 stores with each node a datavalue and a size field (denoted by S). Each child (every node except the root)also has a pointer pointing to it. The overhead fraction is thusS + PD + S + Pmaking it quite efficient.The second linked representation of Section 6.3.3 stores with each node adata value and a pointer to the list of children. Each child (every node exceptthe root) has two additional pointers associated with it to indicate its placeon the parent’s linked list. Thus, the overhead fraction is3PD + 3P.6.10 template <class Elem>BinNode<Elem>* convert(GTNode<Elem>* genroot) {if (genroot == NULL) return NULL;43GTNode<Elem>* gtemp = genroot->leftmost_child();btemp = new BinNode(genroot->val(), convert(gtemp),convert(genroot->right_sibling()));}6.11 • Parent(r) = (r − 1)/k if 0 < r < n.• Ith child(r) = kr + I if kr +I < n.• Left sibling(r) = r − 1 if r mod k = 1 0 < r < n.• Right sibling(r) = r + 1 if r mod k = 0 and r + 1 < n.6.12 (a) The overhead fraction is4(k + 1)4 + 4(k + 1).(b) The overhead fraction is4k16 + 4k.(c) The overhead fraction is4(k + 2)16 + 4(k + 2).(d) The overhead fraction is2k2k + 4.6.13 Base Case: The number of leaves in a non-empty tree of 0 internal nodes is (K − 1)0 + 1 = 1. Thus, the theorem is correct in the base case.Induction Hypothesis: Assume that the theorem is correct for any full Karytree containing n internal nodes.Induction Step: Add K children to an arbitrary leaf node of the tree withn internal nodes. This new tree now has 1 more internal node, and K − 1more leaf nodes, so theorem still holds. Thus, the theorem is correct, by the principle of Mathematical Induction.6.14 (a) CA/BG///FEDD///H/I//(b) CA/BG/FED/H/I6.15 X|P-----| | |C Q R---| |V M44 Chap. 6 General Trees6.16 (a) // Use a helper function with a pass-by-reference// variable to indicate current position in the// node list.template <class Elem>BinNode<Elem>* convert(char* inlist) {int curr = 0;return converthelp(inlist, curr);}// As converthelp processes the node list, curr is// incremented appropriately.template <class Elem>BinNode<Elem>* converthelp(char* inlist,int& curr) {if (inlist[curr] == ’/’) {curr++;return NULL;}BinNode<Elem>* temp = new BinNode(inlist[curr++], NULL, NULL);temp->left = converthelp(inlist, curr);temp->right = converthelp(inlist, curr);return temp;}(b) // Use a helper function with a pass-by-reference // variable to indicate current position in the// node list.template <class Elem>BinNode<Elem>* convert(char* inlist) {int curr = 0;return converthelp(inlist, curr);}// As converthelp processes the node list, curr is// incremented appropriately.template <class Elem>BinNode<Elem>* converthelp(char* inlist,int& curr) {if (inlist[curr] == ’/’) {curr++;return NULL;}BinNode<Elem>* temp =new BinNode<Elem>(inlist[curr++], NULL, NULL);if (inlist[curr] == ’\’’) return temp;45curr++ // Eat the internal node mark.temp->left = converthelp(inlist, curr);temp->right = converthelp(inlist, curr);return temp;}(c) // Use a helper function with a pass-by-reference// variable to indicate current position in the// node list.template <class Elem>GTNode<Elem>* convert(char* inlist) {int curr = 0;return converthelp(inlist, curr);}// As converthelp processes the node list, curr is// incremented appropriately.template <class Elem>GTNode<Elem>* converthelp(char* inlist,int& curr) {if (inlist[curr] == ’)’) {curr++;return NULL;}GTNode<Elem>* temp =new GTNode<Elem>(inlist[curr++]);if (curr == ’)’) {temp->insert_first(NULL);return temp;}temp->insert_first(converthelp(inlist, curr));while (curr != ’)’)temp->insert_next(converthelp(inlist, curr));curr++;return temp;}6.17 The Huffman tree is a full binary tree. To decode, we do not need to know the weights of nodes, only the letter values stored in the leaf nodes. Thus, we can use a coding much like that of Equation 6.2, storing only a bit mark for internal nodes, and a bit mark and letter value for leaf nodes.7Internal Sorting7.1 Base Case: For the list of one element, the double loop is not executed and the list is not processed. Thus, the list of one element remains unaltered and is sorted.Induction Hypothesis: Assume that the list of n elements is sorted correctlyby Insertion Sort.Induction Step: The list of n + 1 elements is processed by first sorting thetop n elements. By the induction hypothesis, this is done correctly. The final pass of the outer for loop will process the last element (call it X). This isdone by the inner for loop, which moves X up the list until a value smallerthan that of X is encountered. At this point, X has been properly insertedinto the sorted list, leaving the entire collection of n + 1 elements correctly sorted. Thus, by the principle of Mathematical Induction, the theorem is correct.7.2 void StackSort(AStack<int>& IN) {AStack<int> Temp1, Temp2;while (!IN.isEmpty()) // Transfer to another stackTemp1.push(IN.pop());IN.push(Temp1.pop()); // Put back one elementwhile (!Temp1.isEmpty()) { // Process rest of elemswhile (IN.top() > Temp1.top()) // Find elem’s placeTemp2.push(IN.pop());IN.push(Temp1.pop()); // Put the element inwhile (!Temp2.isEmpty()) // Put the rest backIN.push(Temp2.pop());}}46477.3 The revised algorithm will work correctly, and its asymptotic complexity will remain Θ(n2). However, it will do about twice as many comparisons, since it will compare adjacent elements within the portion of the list already knownto be sorted. These additional comparisons are unproductive.7.4 While binary search will find the proper place to locate the next element, it will still be necessary to move the intervening elements down one position in the array. This requires the same number of operations as a sequential search. However, it does reduce the number of element/element comparisons, and may be somewhat faster by a constant factor since shifting several elements may be more efficient than an equal number of swap operations.7.5 (a) template <class Elem, class Comp>void selsort(Elem A[], int n) { // Selection Sortfor (int i=0; i<n-1; i++) { // Select i’th recordint lowindex = i; // Remember its indexfor (int j=n-1; j>i; j--) // Find least valueif (Comp::lt(A[j], A[lowindex]))lowindex = j; // Put it in placeif (i != lowindex) // Add check for exerciseswap(A, i, lowindex);}}(b) There is unlikely to be much improvement; more likely the algorithmwill slow down. This is because the time spent checking (n times) isunlikely to save enough swaps to make up.(c) Try it and see!7.6 • Insertion Sort is stable. A swap is done only if the lower element’svalue is LESS.• Bubble Sort is stable. A swap is done only if the lower element’s valueis LESS.• Selection Sort is NOT stable. The new low value is set only if it isactually less than the previous one, but the direction of the search isfrom the bottom of the array. The algorithm will be stable if “less than”in the check becomes “less than or equal to” for selecting the low key position.• Shell Sort is NOT stable. The sublist sorts are done independently, andit is quite possible to swap an element in one sublist ahead of its equalvalue in another sublist. Once they are in the same sublist, they willretain this (incorrect) relationship.• Quick-sort is NOT stable. After selecting the pivot, it is swapped withthe last element. This action can easily put equal records out of place.48 Chap. 7 Internal Sorting• Conceptually (in particular, the linked list version) Mergesort is stable.The array implementations are NOT stable, since, given that the sublistsare stable, the merge operation will pick the element from the lower listbefore the upper list if they are equal. This is easily modified to replace“less than” with “less than or equal to.”• Heapsort is NOT stable. Elements in separate sides of the heap are processed independently, and could easily become out of relative order.• Binsort is stable. Equal values that come later are appended to the list.• Radix Sort is stable. While the processing is from bottom to top, thebins are also filled from bottom to top, preserving relative order.7.7 In the worst case, the stack can store n records. This can be cut to log n in the worst case by putting the larger partition on FIRST, followed by the smaller. Thus, the smaller will be processed first, cutting the size of the next stacked partition by at least half.7.8 Here is how I derived a permutation that will give the desired (worst-case) behavior:a b c 0 d e f g First, put 0 in pivot index (0+7/2),assign labels to the other positionsa b c g d e f 0 First swap0 b c g d e f a End of first partition pass0 b c g 1 e f a Set d = 1, it is in pivot index (1+7/2)0 b c g a e f 1 First swap0 1 c g a e f b End of partition pass0 1 c g 2 e f b Set a = 2, it is in pivot index (2+7/2)0 1 c g b e f 2 First swap0 1 2 g b e f c End of partition pass0 1 2 g b 3 f c Set e = 3, it is in pivot index (3+7/2)0 1 2 g b c f 3 First swap0 1 2 3 b c f g End of partition pass0 1 2 3 b 4 f g Set c = 4, it is in pivot index (4+7/2)0 1 2 3 b g f 4 First swap0 1 2 3 4 g f b End of partition pass0 1 2 3 4 g 5 b Set f = 5, it is in pivot index (5+7/2)0 1 2 3 4 g b 5 First swap0 1 2 3 4 5 b g End of partition pass0 1 2 3 4 5 6 g Set b = 6, it is in pivot index (6+7/2)0 1 2 3 4 5 g 6 First swap0 1 2 3 4 5 6 g End of parition pass0 1 2 3 4 5 6 7 Set g = 7.Plugging the variable assignments into the original permutation yields:492 6 4 0 13 5 77.9 (a) Each call to qsort costs Θ(i log i). Thus, the total cost isni=1i log i = Θ(n2 log n).(b) Each call to qsort costs Θ(n log n) for length(L) = n, so the totalcost is Θ(n2 log n).7.10 All that we need to do is redefine the comparison test to use strcmp. The quicksort algorithm itself need not change. This is the advantage of paramerizing the comparator.7.11 For n = 1000, n2 = 1, 000, 000, n1.5 = 1000 ∗√1000 ≈ 32, 000, andn log n ≈ 10, 000. So, the constant factor for Shellsort can be anything less than about 32 times that of Insertion Sort for Shellsort to be faster. The constant factor for Shellsort can be anything less than about 100 times thatof Insertion Sort for Quicksort to be faster.7.12 (a) The worst case occurs when all of the sublists are of size 1, except for one list of size i − k + 1. If this happens on each call to SPLITk, thenthe total cost of the algorithm will be Θ(n2).(b) In the average case, the lists are split into k sublists of roughly equal length. Thus, the total cost is Θ(n logk n).7.13 (This question comes from Rawlins.) Assume that all nuts and all bolts havea partner. We use two arrays N[1..n] and B[1..n] to represent nuts and bolts. Algorithm 1Using merge-sort to solve this problem.First, split the input into n/2 sub-lists such that each sub-list contains twonuts and two bolts. Then sort each sub-lists. We could well come up with apair of nuts that are both smaller than either of a pair of bolts. In that case,all you can know is something like:N1, N2。
《数据结构与算法》习题与答案

《数据结构与算法》习题与答案(解答仅供参考)一、名词解释:1. 数据结构:数据结构是计算机存储、组织数据的方式,它不仅包括数据的逻辑结构(如线性结构、树形结构、图状结构等),还包括物理结构(如顺序存储、链式存储等)。
它是算法设计与分析的基础,对程序的效率和功能实现有直接影响。
2. 栈:栈是一种特殊的线性表,其操作遵循“后进先出”(Last In First Out, LIFO)原则。
在栈中,允许进行的操作主要有两种:压栈(Push),将元素添加到栈顶;弹栈(Pop),将栈顶元素移除。
3. 队列:队列是一种先进先出(First In First Out, FIFO)的数据结构,允许在其一端插入元素(称为入队),而在另一端删除元素(称为出队)。
常见的实现方式有顺序队列和循环队列。
4. 二叉排序树(又称二叉查找树):二叉排序树是一种二叉树,其每个节点的左子树中的所有节点的值都小于该节点的值,而右子树中的所有节点的值都大于该节点的值。
这种特性使得能在O(log n)的时间复杂度内完成搜索、插入和删除操作。
5. 图:图是一种非线性数据结构,由顶点(Vertex)和边(Edge)组成,用于表示对象之间的多种关系。
根据边是否有方向,可分为有向图和无向图;根据是否存在环路,又可分为有环图和无环图。
二、填空题:1. 在一个长度为n的顺序表中,插入一个新元素平均需要移动______个元素。
答案:(n/2)2. 哈希表利用______函数来确定元素的存储位置,通过解决哈希冲突以达到快速查找的目的。
答案:哈希(Hash)3. ______是最小生成树的一种算法,采用贪心策略,每次都选择当前未加入生成树且连接两个未连通集合的最小权重边。
答案:Prim算法4. 在深度优先搜索(DFS)过程中,使用______数据结构来记录已经被访问过的顶点,防止重复访问。
答案:栈或标记数组5. 快速排序算法在最坏情况下的时间复杂度为______。
数据结构与算法分析课后习题答案

数据结构与算法分析课后习题答案【篇一:《数据结构与算法》课后习题答案】>2.3.2 判断题2.顺序存储的线性表可以按序号随机存取。
(√)4.线性表中的元素可以是各种各样的,但同一线性表中的数据元素具有相同的特性,因此属于同一数据对象。
(√)6.在线性表的链式存储结构中,逻辑上相邻的元素在物理位置上不一定相邻。
(√)8.在线性表的顺序存储结构中,插入和删除时移动元素的个数与该元素的位置有关。
(√)9.线性表的链式存储结构是用一组任意的存储单元来存储线性表中数据元素的。
(√)2.3.3 算法设计题1.设线性表存放在向量a[arrsize]的前elenum个分量中,且递增有序。
试写一算法,将x 插入到线性表的适当位置上,以保持线性表的有序性,并且分析算法的时间复杂度。
【提示】直接用题目中所给定的数据结构(顺序存储的思想是用物理上的相邻表示逻辑上的相邻,不一定将向量和表示线性表长度的变量封装成一个结构体),因为是顺序存储,分配的存储空间是固定大小的,所以首先确定是否还有存储空间,若有,则根据原线性表中元素的有序性,来确定插入元素的插入位置,后面的元素为它让出位置,(也可以从高下标端开始一边比较,一边移位)然后插入x ,最后修改表示表长的变量。
int insert (datatype a[],int *elenum,datatype x) /*设elenum为表的最大下标*/ {if (*elenum==arrsize-1) return 0; /*表已满,无法插入*/else {i=*elenum;while (i=0 a[i]x)/*边找位置边移动*/{a[i+1]=a[i];i--;}a[i+1]=x;/*找到的位置是插入位的下一位*/ (*elenum)++;return 1;/*插入成功*/}}时间复杂度为o(n)。
2.已知一顺序表a,其元素值非递减有序排列,编写一个算法删除顺序表中多余的值相同的元素。
数据结构与算法题库(附参考答案)

数据结构与算法题库(附参考答案)一、单选题(共86题,每题1分,共86分)1.在快速排序的一趟划分过程中,当遇到与基准数相等的元素时,如果左右指针都不停止移动,那么当所有元素都相等时,算法的时间复杂度是多少?A、O(NlogN)B、O(N)C、O(N2)D、O(logN)正确答案:C2.一棵有 1001 个结点的完全二叉树,其叶子结点数为▁▁▁▁▁ 。
A、254B、250C、501D、500正确答案:C3.对于一个具有N个顶点的无向图,若采用邻接矩阵表示,则该矩阵的大小是:A、(N−1)2B、NC、N2D、N−1正确答案:C4.在有n(>1)个元素的最大堆(大根堆)中,最小元的数组下标可以是:A、⌊n/2⌋−1B、⌊n/2⌋+2C、1D、⌊n/2⌋正确答案:B5.一棵非空二叉树,若先序遍历与中序遍历的序列相同,则该二叉树▁▁▁▁▁ 。
A、所有结点均无左孩子B、所有结点均无右孩子C、只有一个叶子结点D、为任意二叉树正确答案:A6.度量结果集相关性时,如果准确率很高而召回率很低,则说明:A、大部分检索出的文件都是相关的,但还有很多相关文件没有被检索出来B、大部分相关文件被检索到,但基准数据集不够大C、大部分检索出的文件都是相关的,但基准数据集不够大D、大部分相关文件被检索到,但很多不相关的文件也在检索结果里正确答案:A7.若某表最常用的操作是在最后一个结点之后插入一个结点或删除最后一个结点。
则采用哪种存储方式最节省运算时间?A、单循环链表B、带头结点的双循环链表C、单链表D、双链表正确答案:B8.设数组 S[ ]={93, 946, 372, 9, 146, 151, 301, 485, 236, 327, 43, 892},采用最低位优先(LSD)基数排序将 S 排列成升序序列。
第1 趟分配、收集后,元素 372 之前、之后紧邻的元素分别是:A、43,892B、236,301C、301,892D、485,301正确答案:C9.在快速排序的一趟划分过程中,当遇到与基准数相等的元素时,如果左指针停止移动,而右指针在同样情况下却不停止移动,那么当所有元素都相等时,算法的时间复杂度是多少?A、O(NlogN)B、O(N2)C、O(N)D、O(logN)正确答案:B10.在快速排序的一趟划分过程中,当遇到与基准数相等的元素时,如果左右指针都会停止移动,那么当所有元素都相等时,算法的时间复杂度是多少?A、O(NlogN)B、O(N)C、O(logN)D、O(N2)正确答案:A11.如果AVL树的深度为6(空树的深度定义为−1),则此树最少有多少个结点?A、12B、20C、33D、64正确答案:C12.已知指针ha和hb分别是两个单链表的头指针,下列算法将这两个链表首尾相连在一起,并形成一个循环链表(即ha的最后一个结点链接hb 的第一个结点,hb的最后一个结点指向ha),返回ha作为该循环链表的头指针。
数据结构与算法测试题+参考答案

数据结构与算法测试题+参考答案一、单选题(共80题,每题1分,共80分)1、某线性表中最常用的操作是在最后一个元素之后插入一个元素和删除第一个元素,则采用什么存储方式最节省运算时间?A、仅有头指针的单循环链表B、双链表C、仅有尾指针的单循环链表D、单链表正确答案:C2、数据结构研究的内容是()。
A、数据的逻辑结构B、数据的存储结构C、建立在相应逻辑结构和存储结构上的算法D、包括以上三个方面正确答案:D3、下列关于无向连通图特征的叙述中,正确的是:所有顶点的度之和为偶数边数大于顶点个数减1至少有一个顶点的度为1A、只有1B、1和2C、1和3D、只有2正确答案:A4、下面的程序段违反了算法的()原则。
void sam(){ int n=2;while (n%2==0) n+=2;printf(“%d”,n);}A、确定性B、可行性C、有穷性D、健壮性正确答案:C5、对任意给定的含 n (n>2) 个字符的有限集 S,用二叉树表示 S 的哈夫曼编码集和定长编码集,分别得到二叉树 T1 和 T2。
下列叙述中,正确的是:A、出现频次不同的字符在 T2 中处于相同的层B、出现频次不同的字符在 T1 中处于不同的层C、T1 的高度大于 T2 的高度D、T1 与 T2 的结点数相同正确答案:A6、数据序列{ 3,2,4,9,8,11,6,20 }只能是下列哪种排序算法的两趟排序结果?A、快速排序B、选择排序C、插入排序D、冒泡排序正确答案:A7、设散列表的地址区间为[0,16],散列函数为H(Key)=Key%17。
采用线性探测法处理冲突,并将关键字序列{ 26,25,72,38,8,18,59 }依次存储到散列表中。
元素59存放在散列表中的地址是:A、11B、9C、10D、8正确答案:A8、采用递归方式对顺序表进行快速排序,下列关于递归次数的叙述中,正确的是:A、每次划分后,先处理较短的分区可以减少递归次数B、递归次数与每次划分后得到的分区处理顺序无关C、递归次数与初始数据的排列次序无关D、每次划分后,先处理较长的分区可以减少递归次数正确答案:B9、以下数据结构中,()是非线性数据结构。
数据结构与算法题库(含参考答案)

数据结构与算法题库(含参考答案)一、单选题(共100题,每题1分,共100分)1、在一次校园活动中拍摄了很多数码照片,现需将这些照片整理到一个PowerPoint 演示文稿中,快速制作的最优操作方法是:A、创建一个 PowerPoint 相册文件。
B、创建一个 PowerPoint 演示文稿,然后批量插入图片。
C、创建一个 PowerPoint 演示文稿,然后在每页幻灯片中插入图片。
D、在文件夹中选中所有照片,然后单击鼠标右键直接发送到PowerPoint 演示文稿中。
正确答案:A2、下面对“对象”概念描述错误的是A、对象不具有封装性B、对象是属性和方法的封装体C、对象间的通信是靠消息传递D、一个对象是其对应类的实例正确答案:A3、设栈与队列初始状态为空。
首先A,B,C,D,E依次入栈,再F,G,H,I,J 依次入队;然后依次出队至队空,再依次出栈至栈空。
则输出序列为A、F,G,H,I,J,E,D,C,B,AB、E,D,C,B,A,J,I,H,G,FC、F,G,H,I,J,A,B,C,D,E,D、E,D,C,B,A,F,G,H,I,J正确答案:A4、设表的长度为 20。
则在最坏情况下,冒泡排序的比较次数为A、20B、19C、90D、190正确答案:D5、设二叉树的前序序列为 ABDEGHCFIJ,中序序列为 DBGEHACIFJ。
则后序序列为A、DGHEBIJFCAB、JIHGFEDCBAC、GHIJDEFBCAD、ABCDEFGHIJ正确答案:A6、Excel工作表B列保存了11位手机号码信息,为了保护个人隐私,需将手机号码的后 4 位均用“*”表示,以 B2 单元格为例,最优的操作方法是:A、=REPLACE(B2,7,4,"****")B、=REPLACE(B2,8,4,"****")C、=MID(B2,7,4,"****")D、=MID(B2,8,4,"****")第 10 组正确答案:B7、小金从网站上查到了最近一次全国人口普查的数据表格,他准备将这份表格中的数据引用到 Excel 中以便进一步分析,最优的操作方法是:A、通过 Excel 中的“自网站获取外部数据”功能,直接将网页上的表格导入到 Excel 工作表中。
数据结构与算法考试

数据结构与算法考试(答案见尾页)一、选择题1. 什么是数据结构?请列举几种常见的数据结构。
A. 数组B. 链表C. 栈D. 队列E. 图2. 算法的时间复杂度是如何表示的?请简述其计算方式。
A. 用大O符号表示B. 用大O符号表示C. 用大O符号表示D. 用大O符号表示3. 什么是递归?请举例说明递归在算法中的实现。
A. 一个函数调用自身B. 一个函数调用自身的过程C. 一个函数调用自身的过程D. 一个函数调用自身的过程4. 什么是排序算法?请列举几种常见的排序算法,并简要描述它们的特点。
A. 冒泡排序B. 选择排序C. 插入排序D. 快速排序E. 归并排序5. 什么是哈希表?请简述哈希表的原理和优点。
A. 一种数据结构,它通过将键映射到数组索引来存储和检索数据B. 一种数据结构,它通过将键映射到数组索引来存储和检索数据C. 一种数据结构,它通过将键映射到数组索引来存储和检索数据D. 一种数据结构,它通过将键映射到数组索引来存储和检索数据6. 什么是树形结构?请列举几种常见的树形结构,并简要描述它们的特点。
A. 二叉树B. 二叉树C. B树D. B+树E. 无7. 什么是图数据结构?请列举几种常见的图算法,并简要描述它们的特点。
A. 广度优先搜索B. 深度优先搜索C. 最短路径算法(Dijkstra算法)D. 最长路径算法(Floyd算法)E. 最小生成树算法(Kruskal算法,Prim算法)8. 什么是动态规划?请简述动态规划的基本思想和应用场景。
A. 一种通过分解问题为更小的子问题来求解的方法B. 一种通过分解问题为更小的子问题来求解的方法C. 一种通过分解问题为更小的子问题来求解的方法D. 一种通过分解问题为更小的子问题来求解的方法9. 请简述贪心算法的基本思想以及在哪些问题上可以应用贪心算法。
A. 一种通过局部最优解来达到全局最优解的策略B. 一种通过局部最优解来达到全局最优解的策略C. 一种通过局部最优解来达到全局最优解的策略D. 一种通过局部最优解来达到全局最优解的策略10. 什么是算法的时间复杂度和空间复杂度?请简述它们的含义以及如何计算它们。
数据结构与算法练习题库(含答案)

数据结构与算法练习题库(含答案)一、单选题(共80题,每题1分,共80分)1、对一棵二叉树的结点从 1 开始顺序编号。
要求每个结点的编号大于其左子树所有结点的编号、但小于右子树中所有结点的编号。
可采用▁▁▁▁▁ 实现编号。
A、中序遍历B、先序遍历C、层次遍历D、后序遍历正确答案:A2、设一段文本中包含4个对象{a,b,c,d},其出现次数相应为{4,2,5,1},则该段文本的哈夫曼编码比采用等长方式的编码节省了多少位数?A、5B、4C、2D、0正确答案:C3、两个有相同键值的元素具有不同的散列地址A、一定不会B、一定会C、可能会D、有万分之一的可能会正确答案:C4、将元素序列{18,23,11,20,2,7,27,33,42,15}按顺序插入一个初始为空的、大小为11的散列表中。
散列函数为:H(Key)=Key%11,采用线性探测法处理冲突。
问:当第一次发现有冲突时,散列表的装填因子大约是多少?A、0.73B、0.27C、0.64D、0.45正确答案:D5、对N个记录进行归并排序,归并趟数的数量级是:A、O(NlogN)B、O(logN)C、O(N)D、O(N2)正确答案:B6、下列说法不正确的是:A、图的遍历是从给定的源点出发每一个顶点仅被访问一次B、图的深度遍历不适用于有向图C、遍历的基本算法有两种:深度遍历和广度遍历D、图的深度遍历是一个递归过程正确答案:B7、二叉树的中序遍历也可以循环地完成。
给定循环中堆栈的操作序列如下(其中push为入栈,pop为出栈): push(1), push(2), push(3), pop(), push(4), pop(), pop(), push(5), pop(), pop(), push(6), pop()A、6是根结点B、2是4的父结点C、2和6是兄弟结点D、以上全不对正确答案:C8、设最小堆(小根堆)的层序遍历结果为{1, 3, 2, 5, 4, 7, 6}。
数据结构与算法练习题附答案

1、下面关于算法的说法错误的是()A、算法最终必须由计算机程序实现B、为解决某问题的算法同为该问题编写的程序含义是相同的C、算法的可行性是指指令不能有二义性D、以上几个都是错误的参考答案:D2、数据在计算机存储器内表示时,物理地址与逻辑地址不相同的,称为()A、存储结构B、逻辑结构C、链式存储结构D、顺序存储结构参考答案:C3、以下说法正确的是()(2分)A、数据元素是数据的最小单位B、数据项是数据的基本单位C、数据结构是带有结构的各数据项的集合D、数据结构是带有结构的数据元素的集合参考答案:D4、通常从正确性、易读性、健壮性、高效性等四个方面评价算法(包括程序)的质量。
以下解释错误的是()A、正确性算法应能正确地实现预定的功能(即处理要求)B、易读性算法应易于理解和阅读,以便于调试、修改和扩充C、健壮性当环境发生变化时,算法能适当地做出反应或进行处理,不会产生不需要的运行结果D、高效性即达到所需要的时间性能参考答案:C5、树形结构是数据元素之间存在一种()A、一对一关系B、多对多关系C、多对一关系D、一对多关系参考答案:D6、数据结构是指()A、数据元素的组织形式B、数据类型C、数据存储结构D、数据定义参考答案:A7、算法分析的目的是()A、找出数据结构的合理性3、研究算法中的输入和输出关系C、分析算法的效率以求改进D、分析算法的易懂性和文档性参考答案:C8、数据在计算机内有链式和顺序两种存储方式,在存储空间使用的灵活性上,链式存储比顺序存储要()A、低B、高C、相同D、以上都不正确参考答案:B9、算法的空间复杂度是指()A、执行算法程序所占的存储空间B、算法程序中的指令条数C、算法程序的长度D、算法执行过程中所需要的存储空间参考答案:D10、数据的存储结构是指()A、数据所占的存储空间量B、数据的逻辑结构在计算机中的表示C、数据在计算机中的顺序存储方式D、存数在外存中的数据参考答案:B11、线性表是()A、一个有限序列,可以为空B、一个有限序列,不能为空C、一个无限序列,可以为空D、一个无限序列,不能为空参考答案:A12、下列叙述正确的是()A、线性表是线性结构B、栈和队列是非线性结构C、线性链表是非线性结构D、二叉树是线性结构参考答案:A13、计算机内部数据处理的基本单位是()A、数据B、数据元素C、数据项D、数据库参考答案:B14、从逻辑上可以把数据结构分为()两大类A、动态结构、静态结构B、顺序结构、链式结构C、线性结构、非线性结构D、初等结构、构造型结构参考答案:C15、算法的时间复杂度取决于()A、问题的规模B、待处理数据的初态C、A 和B参考答案:C16、以下属于逻辑结构的是()(2分)A、顺序表B、哈希表C、有序表D、单链表参考答案:C17、下列数据结构中,()是非线性数据结构A、树B、字符串C、队D、栈参考答案:A18、设语句x++的时间是单位时间,则以下语句的时间复杂度为()for(i=1;i<=n;i++)for(j=|;j<=n;j++)x++;(2分)A、O(1)B、O(n2)C、O(n)D、O(n3)参考答案:B19、算法的计算量大小称为计算的()(2分)A、效率B、复杂性C、现实性D、难度参考答案:B20、数据结构只是研究数据的逻辑结构和物理结构,这种观点()A、正确B、错误C、前半句正确,后半句错误D、前半句错误,后半句正确参考答案:B21、计算机算法指的是(),它具有输入、输出、可行性、确定性和有穷性等五个特性。
数据结构与算法分析—期末复习题及答案

单选题(每题 2 分,共20分)1. 对一个算法的评价,不包括如下(B )方面的内容。
A.健壮性和可读性 B.并行性 C.正确性 D.时空复杂度2. 在带有头结点的单链表HL中,要向表头插入一个由指针p指向的结点,则执行( A )。
A. p->next=HL->next; HL->next=p;B. p->next=HL; HL=p;C. p->next=HL; p=HL;D. HL=p; p->next=HL;3. 对线性表,在下列哪种情况下应当采用链表表示?( B )A.经常需要随机地存取元素B.经常需要进行插入和删除操作C.表中元素需要占据一片连续的存储空间D.表中元素的个数不变4. 一个栈的输入序列为1 2 3,则下列序列中不可能是栈的输出序列的是( C )A. 2 3 1B. 3 2 1C. 3 1 2D. 1 2 36. 若需要利用形参直接访问实参时,应将形参变量说明为(D )参数。
A.值 B.函数 C.指针 D.引用8. 在稀疏矩阵的带行指针向量的链接存储中,每个单链表中的结点都具有相同的( A )。
A.行号 B.列号 C.元素值 D.非零元素个数10. 从二叉搜索树中查找一个元素时,其时间复杂度大致为(C )。
A. O(n)B. O(1)C. O(log2n)D. O(n2)二、运算题(每题 6 分,共24分)1. 数据结构是指数据及其相互之间的_联系。
当结点之间存在M对N(M:N)的联系时,称这种结构为__图__。
2. 队列的插入操作是在队列的___尾_进行,删除操作是在队列的_首_进行。
3. 当用长度为N的数组顺序存储一个栈时,假定用top==N表示栈空,则表示栈满的条件是___top==0___(要超出才为满)_______________。
4. 对于一个长度为n的单链存储的线性表,在表头插入元素的时间复杂度为___ O(1)__,在表尾插入元素的时间复杂度为___ O(n)___。
数据结构与算法分析c第三版答案

数据结构与算法分析c第三版答案【篇一:数据结构第三章习题答案】txt>#include iostream#include stringusing namespace std;bool huiwen(string s){int n=s.length();int i,j;i= 0;j=n-1;while(ij s[i]==s[j]){ i++;j--;}if(i=j) return true;else return false;}int main(){string s1;cins1;couthuiwen(s1);return 0;}=============(2)设从键盘输入一整数的序列:a1, a2, a3,…,an,试编写算法实现:用栈结构存储输入的整数,当ai≠-1时,将ai进栈;当ai=-1时,输出栈顶整数并出栈。
算法应对异常情况(入栈满等)给出相应的信息。
#include iostreamusing namespace std;#define overflow -2#define ok 1#define error 0typedef int selemtype;typedef int status;typedef struct{selemtype a[5];int top;} sqstack;status initstack(sqstack s){s.top=0;return ok;}status push(sqstack s,selemtype e){if (s.top4){coutoverlow!endl;return error;}else s.a[s.top++]=e;return ok;}status pop(sqstack s,selemtype e){if (s.top==0) {coutunderflowendl; return error;}e=s.a[--s.top];couteendl;return ok;}int main(){sqstack s;initstack(s);int n,x,e1;coutn=?endl;cinn;for(int i=0;in;i++){ cinx;if(x!=-1 )push(s,x);else pop(s,e1); }return 0;}============(3)假设以i和o分别表示入栈和出栈操作。
数据结构与算法分析 C++版答案

Data Structures and Algorithm 习题答案Preface ii1 Data Structures and Algorithms 12 Mathematical Preliminaries 53 Algorithm Analysis 174 Lists, Stacks, and Queues 235 Binary Trees 326 General Trees 407 Internal Sorting 468 File Processing and External Sorting 549Searching 5810 Indexing 6411 Graphs 6912 Lists and Arrays Revisited 7613 Advanced Tree Structures 82i14 Analysis Techniques 8815 Limits to Computation 94Contained herein are the solutions to all exercises from the textbook A Practical Introduction to Data Structures and Algorithm Analysis, 2nd edition.For most of the problems requiring an algorithm I have given actual code. Ina few cases I have presented pseudocode. Please be aware that the code presentedin this manual has not actually been compiled and tested. While I believe the algorithms to be essentially correct, there may be errors in syntax as well as semantics.Most importantly, these solutions provide a guide to the instructor as to the intended answer, rather than usable programs.1Data Structures and AlgorithmsInstructor’s note: Unlike the other chapters, many of the questions in this chapter are not really suitable for graded work. The questions are mainly intended to get students thinking about data structures issues.1.1This question does not have a specific right answer, provided the studentkeeps to the spirit of the question. Students may have trouble with the conceptof “operations.”1.2This exercise asks the student to expand on their concept of an integer representation.A good answer is described by Project 4.5, where a singly-linkedlist is suggested. The most straightforward implementation stores each digitin its own list node, with digits stored in reverse order. Addition and multiplication are implemented by what amounts to grade-school arithmetic. Foraddition, simply march down in parallel through the two lists representingthe operands, at each digit appending to a new list the appropriate partialsum and bringing forward a carry bit as necessary. For multiplication, combinethe addition function with a new function that multiplies a single digitby an integer. Exponentiation can be done either by repeated multiplication(not re ally practical) or by the traditional Θ(log n)-time algorithm based onthe binary representation of the exponent. Discovering this faster algorithmwill be beyond the reach of most students, so should not be required.1.3A sample ADT for character strings might look as follows (with the normal interpretation of the function names assumed).Chap. 1 Data Structures and Algorithms// Concatenate two stringsString strcat(String s1, String s2);// Return the length of a stringint length(String s1);// Extract a substring, starting at ‘start’,// and of length ‘length’String extract(String s1, int start, int length);// Get the first characterchar first(String s1);// Compare two strings: the normal C++ strcmp function.Some// convention should be indicated for how to interpretthe// return value. In C++, this is 1for s1<s2; 0 for s1=s2;// and 1 for s1>s2.int strcmp(String s1, String s2)// Copy a stringint strcpy(String source, String destination)1.4The answer to this question is provided by the ADT for lists given in Chapter4.1.5One’s compliment stores the binary representation of positive numbers, and stores the binary representation of a negative number with the bits inverted.Two’s compliment is the same, except that a negative number has its bits inverted and then one is added (for reasons of efficiency in hardware implementation). This representation is the physical implementation of an ADTdefined by the normal arithmetic operations, declarations, and other supportgiven by the programming language for integers.1.6An ADT for two-dimensional arrays might look as follows. Matrix add(Matrix M1, Matrix M2);Matrix multiply(Matrix M1, Matrix M2);Matrix transpose(Matrix M1);void setvalue(Matrix M1, int row, int col, int val);int getvalue(Matrix M1, int row, int col);List getrow(Matrix M1, int row);One implementation for the sparse matrix is described in Section 12.3 Another implementation is a hash table whose search key is a concatenation of the matrix coordinates.1.7Every problem certainly does not have an algorithm. As discussed in Chapter 15,there are a number of reasons why this might be the case. Some problems don’thave a sufficiently clear definition. Some problems, such as the halting problem,are non-computable. For some problems, such as one typically studied by artificial intelligence researchers, we simply don’t know a solution.1.8We must assume that by “algorithm” we mean something composed of steps areof a nature that they can be performed by a computer. If so, than any algorithmcan be expressed in C++. In particular, if an algorithm can be expressed in anyother computer programming language, then it can be expressed in C++, since all (sufficiently general) computer programming languages compute the same set of functions.1.9The primitive operations are (1) adding new words to the dictionary and (2) searchingthe dictionary for a given word. Typically, dictionary access involves some sortof pre-processing of the word to arrive at the “root” of the word.A twenty page document (single spaced) is likely to contain about 20,000 words. Auser may be willing to wait a few seconds between individual “hits” of mis-spelled words, or perhaps up to a minute for the whole document to be processed. Thismeans that a check for an individual word can take about 10-20 ms. Users willtypically insert individual words into the dictionary interactively, so this process cantake a couple of seconds. Thus, search must be much more efficient than insertion.1.10The user should be able to find a city based on a variety of attributes (name, location, perhaps characteristics such as population size). The user should also be able to insertand delete cities. These are the fundamental operations of any database system:search, insertion and deletion.A reasonable database has a time constraint that will satisfy the patience of a typicaluser. For an insert, delete, or exact match query, a few seconds is satisfactory. If the database is meant to support range queries and mass deletions, the entire operationmay be allowed to take longer, perhaps on the order of a minute. However, the timespent to process individual cities within the range must be appropriately reduced. In practice, the data representation will need to be such that it accommodates efficient processing to meet these time constraints. In particular, it may be necessary to support operations that process range queries efficiently by processing all cities in therange as a batch, rather than as a series of operations on individual cities.1.11Students at this level are likely already familiar with binary search. Thus, they should typically respond with sequential search and binary search. Binary search should be described as better since it typically needs to make fewer comparisons (and thus is likely to be much faster).1.12The answer to this question is discussed in Chapter 8. Typical measures of cost will be number of comparisons and number of swaps. Tests should include running timings on sorted, reverse sorted, and random lists of various sizes.Chap. 1 Data Structures and Algorithms1.13The first part is easy with the hint, but the second part is rather difficult to do without a stack.a) bool checkstring(string S) {int count = 0;for (int i=0; i<length(S); i++)if (S[i] == ’(’) count++;if (S[i] == ’)’) {if (count == 0) return FALSE;count--;}}if (count == 0) return TRUE;else return FALSE;}b) int checkstring(String Str) {Stack S;int count = 0;for (int i=0; i<length(S); i++)if (S[i] == ’(’)S.push(i);if (S[i] == ’)’) {if (S.isEmpty()) return i;S.pop();}}if (S.isEmpty()) return -1;else return S.pop();}1.14Answers to this question are discussed in Section 7.2.1.15This is somewhat different from writing sorting algorithms for a computer, since person’s “working space” is typically limited, as is their ability to physically manipulate the pieces of paper. Nonetheless, many of the common sorting algorithms havetheir analogs to solutions for this problem. Most typical answers will be insertionsort, variations on mergesort, and variations on binsort.1.16Answers to this question are discussed in Chapter 8.2Mathematical Preliminaries2.1(a) Not reflexive if the set has any members. One could argue it is symmetric, antisymmetric, and transitive, since no element violate any ofthe rules.(b)Not reflexive (for any female). Not symmetric (consider a brother and sister). Not antisymmetric (consider two brothers). Transitive (for any3 brothers).(c)Not reflexive. Not symmetric, and is antisymmetric. Not transitive(only goes one level).(d)Not reflexive (for nearly all numbers). Symmetric since a+ b= b+ a,so not antisymmetric. Transitive, but vacuously so (there can be no distinct a, b,and cwhere aRband bRc).(e)Reflexive. Symmetric, so not antisymmetric. Transitive (but sort of vacuous).(f)Reflexive – check all the cases. Since it is only true when x= y,itis technically symmetric and antisymmetric, but rather vacuous. Likewise,it is technically transitive, but vacuous.2.2In general, prove that something is an equivalence relation by proving that it is reflexive, symmetric, and transitive.(a)This is an equivalence that effectively splits the integers into odd andeven sets. It is reflexive (x+ xis even for any integer x), symmetric(since x+ y= y+ x) and transitive (since you are always adding twoodd or even numbers for any satisfactory a, b,and c).(b)This is not an equivalence. To begin with, it is not reflexive for any integer.(c)This is an equivalence that divides the non-zero rational numbers into positive and negative. It is reflexive since x˙x>0. It is symmetric sincexy˙= yx˙. It is transitive since any two members of the given class satisfy the relationship.5Chap. 2 Mathematical Preliminaries(d)This is not an equivalance relation since it is not symmetric. For example, a=1and b=2.(e)This is an eqivalance relation that divides the rationals based on their fractional values. It is reflexive since for all a, a.a=0. It is symmetricsince if a.b=xthen b.a=.x. It is transitive since any two rationalswith the same fractional value will yeild an integer.(f)This is not an equivalance relation since it is not transitive. For example, 4.2=2and 2.0=2,but 4.0=4.2.3A relation is a partial ordering if it is antisymmetric and transitive. (a)Not a partial ordering because it is not transitive.(b)Is a partial ordering bacause it is antisymmetric (if ais an ancestor ofb, then bcannot be an ancestor of a) and transitive (since the ancestorof an ancestor is an ancestor).(c)Is a partial ordering bacause it is antisymmetric (if ais older than b,then bcannot be older than a) and transitive (since if ais older than band bis older than c, ais older than c).(d)Not a partial ordering, since it is not antisymmetric for any pair of sisters.Not a partial ordering because it is not antisymmetric.(f)This is a partial ordering. It is antisymmetric (no violations exist) and transitive (no violations exist).2.4A total ordering can be viewed as a permuation of the elements. Since there are n!permuations of nelements, there must be n!total orderings.2.5This proposed ADT is inspired by the list ADT of Chapter 4.void clear();void insert(int);void remove(int);void sizeof();bool isEmpty();bool isInSet(int);2.6This proposed ADT is inspired by the list ADT of Chapter 4. Note that while it is similiar to the operations proposed for Question 2.5, the behaviour is somewhat different.void clear();void insert(int);void remove(int);void sizeof();bool isEmpty();// Return the number of elements with a given valueintcountInBag(int);2.7The list class ADT from Chapter 4 is a sequence.2.8long ifact(int n) { // make n <= 12 so n! for long intlong fact = 1;Assert((n >= 0) && (n <= 12), "Input out of range");for (int i=1; i<= n; i++)fact = fact * i;return fact;}2.9void rpermute(int *array, int n) {swap(array, n-1, Random(n));rpermute(array, n-1);}2.10(a) Most people will find the recursive form natural and easy to understand. The iterative version requires careful examination to understand whatit does, or to have confidence that it works as claimed.(b)Fibr is so much slower than Fibi because Fibr re-computes thebulk of the series twice to get the two values to add. What is much worse, the recursive calls to compute the subexpressions also re-compute the bulk of the series, and do so recursively. The result is an exponential explosion. In contrast, Fibicomputes each value in the seriesexactly once, and so its running time is proportional to n.2.11// Array curr[i] indicates current position of ring i.void GenTOH(int n, POLE goal, POLE t1, POLE t2,POLE* curr) {if (curr[n] == goal) // Get top n-1 rings set upGenTOH(n-1, goal, t1, t2, curr);else {if (curr[n] == t1) swap(t1, t2); // Get names right// Now, ring n is on pole t2. Put others on t1.GenTOH(n-1, t1, goal, t2, curr);move(t2, goal);GenTOH(n-1, goal, t1, t2, curr); // Move n-1 back}}2.12At each step of the way, the reduction toward the base case is only half asfar as the previous time. In theory, this series approaches, but never reaches, 0, so it will go on forever. In practice, the value should become computationally indistinguishable from zero, and terminate. However, this is terrible programming practice.Chap. 2 Mathematical Preliminaries2.13void allpermute(int array[], int n, int currpos) {if (currpos == (n-1)} {printout(array);return;}for (int i=currpos; i<n; i++) {swap(array, currpos, i);allpermute(array, n, currpos+1);swap(array, currpos, i); // Put back for next pass}}2.14In the following, function bitposition(n, i) returns the value (0 or1) at the ith bit position of integer value n. The idea is the print out the elements at the indicated bit positions within the set. If we do this for values in the range 0 to 2n.1, we will get the entire powerset.void powerset(int n) {for (int i=0; i<ipow(2, n); i++) {for (int j=0; j<n; j++)if (bitposition(n, j) == 1) cout << j << " ";cout << endl;}2.15 Proof: Assume that there is a largest prime number. Call it Pn,the nth largest prime number, and label all of the primes in order P1 =2, P2 =3, and so on. Now, consider the number Cformed by multiplying all of the nprime numbers together. The value C+1is not divisible by any of the nprime numbers. C+1is a prime number larger than Pn, a contradiction.Thus, we conclude that there is no largest prime number. .2.16Note: This problem is harder than most sophomore level students can handle. √Proof: The proof is by contradiction. Assume that 2is rational. By definition, there exist integers pand qsuch that√p2=,qwhere pand qhave no common factors (that is, the fraction p/qis in lowestterms). By squaring both sides and doing some simple algebraic manipulation, we get2p2=2q222qSince p2 must be even, p must be even. Thus,222q=4(p)222q=2(p)2This implies that q2 is also even. Thus, pand qare both even, which contra√dicts the requirement that pand qhave no common factors. Thus, 2mustbe irrational. .2.17The leftmost summation sums the integers from 1 to n. The second summation merely reverses this order, summing the numbers from n.1+1=ndown to n.n+1=1. The third summation has a variable substitution ofi.1for i, with a corresponding substitution in the summation bounds. Thus,it is also the summation of n.0=n.(n.1)=1.2.18 Proof:(a) Base case.For n=1, 12 = [2(1)3 +3(1)2 +1]/6=1. Thus, the formula is correct for the base case. (b) Induction Hypothesis.n.12(n.1)3 +3(n.1)2 +(n.1)i2 =.6i=1(c) Induction Step.nn.1i2 i2 +n2=i=1 i=12(n.1)3 +3(n.1)2 +(n.2=+n62n3 .6n2 +6n.2+3n2 .6n+3+n.1 2=+n62n3 +3n2 +n=.6Thus, the theorem is proved by mathematical induction. .2.19 Proof:(a) Base case.For n=1, 1/2=1.1/2=1/2. Thus, the formula iscorrect for the base case.(b) Induction Hypothesis.n.111=1.2in.1 2i=1Chap. 2 Mathematical Preliminaries(c) Induction Step.nn.11 11=+iin222i=1 i=111=1.+n.1 n221=1..n2Thus, the theorem is proved by mathematical induction. .2.20 Proof:(a) Base case. For n=0, 20 =21 .1=1. Thus, the formula is correctfor the base case.(b) Induction Hypothesis.n.12i=2n.1.i=0(c) Induction Step.nn.12i=2i+2ni=0 i=0n=2n.1+2n+1 .1=2.Thus, the theorem is proved by mathematical induction. .2.21 The closed form solution is 3n+1.3, which I deduced by noting that 3F (n).2n+1 .3F(n)=2F(n)=3. Now, to verify that this is correct, use mathematicalinduction as follows.For the base case, F(1)=3=32.3 .n.1The induction hypothesis is that =(3n.3)/2.i=1So,nn.13i=3i+3ni=1 i=13n.3n= +32n+1 .33= .2Thus, the theorem is proved by mathematical induction.n2.22 Theorem 2.1 (2i)=n2 +n.i=1(a) Proof: We know from Example 2.3 that the sum of the first n oddnumbers is n2.The ith even number is simply one greater than the ith odd number. Since we are adding nsuch numbers, the sum must be n greater, or n2 +n. .(b) Proof: Base case: n=1yields 2=12 +1, which is true.Induction Hypothesis:n.12i=(n.1)2 +(n.1).i=1Induction Step: The sum of the first neven numbers is simply the sum of the first n.1even numbers plus the nth even number.nn.12i=( 2i)+2ni=1 i=1=(n.1)2 +(n.1)+2n=(n2 .2n+1)+(n.1)+2n= n2 .n+2n= n2 +n.nThus, by mathematical induction, 2i=n2 +n. .i=12.23 Proof:52Base case. For n=1,Fib(1) = 1 <3.For n=2,Fib(2) = 1 <(5).3Thus, the formula is correct for the base case. Induction Hypothesis. For all positive integers i<n, 5 iFib(i)<().3Induction Step. Fib(n)=Fib(n.1)+Fib(n.2)and, by the InductionHypothesis, Fib(n.1)<(5)n.1 and Fib(n.2)<(5)n.2.So,. 3355 n.2Fib(n) <()n.1 +()3355 5 n.2<()n.2 +()333. Chap. 2 Mathematical Preliminaries85 n.2= ()3355 n.2<()2()33n5= .3Thus, the theorem is proved by mathematical induction. .2.24 Proof:12(1+1)23 =(a) Base case. For n=1, 1=1. Thus, the formula is correct4for the base case.(b) Induction Hypothesis.n.122(n1)ni3 = .4i=0(c) Induction Step. n2(n.1)n2i33=+n4i=02n4 .2n3 +n3=+n4n4 +2n3 +n2=4n2(n2 +2n+2)=2n2(n+1)=4Thus, the theorem is proved by mathematical induction..2.25(a) Proof: By contradiction. Assume that the theorem is false. Then, each pigeonhole contains at most 1 pigeon. Since there are nholes, there isroom for only npigeons. This contradicts the fact that a total of n+1pigeons are within the nholes. Thus, the theorem must be correct. .(b) Proof:i. Base case.For one pigeon hole and two pigeons, there must betwo pigeons in the hole.ii. Induction Hypothesis.For npigeons in n.1holes, some holemust contain at least two pigeons.iii. Induction Step. Consider the case where n+1pigeons are in nholes. Eliminate one hole at random. If it contains one pigeon, eliminate it as well, and by the induction hypothesis some other hole must contain at least two pigeons. If it contains no pigeons, then again by the induction hypothesis some other hole must contain at least two pigeons (with an extra pigeon yet to be placed). Ifit contains more than one pigeon, then it fits the requirements of the theorem directly..2.26 (a)When we add the nth line, we create nnew regions. But, we startwith one region even when there are no lines. Thus, the recurrence is F(n)=F(n.1)+n+1.(b) This is equivalent to the summation F(n)=1+ i=1 ni.(c) This is close to a summation we already know (equation 2.1).2.27 Base case: T(n.1)=1=1(1+1)/2.Induction hypothesis: T(n.1)=(n.1)(n)/2.Induction step:T(n)= T(n.1)+n=(n1)(n)/2+n= n(n+1)/2.Thus, the theorem is proved by mathematical induction.2.28 If we expand the recurrence, we getT(n)=2T(n.1)+1=2(2T(n.2)+1)+1)=4T(n.2+2+1.Expanding again yieldsT(n)=8T(n.3)+4+2+1.From this, we can deduce a pattern and hypothesize that the recurrence is equivalent tonT(n)= .12i=2n.1.i=0To prove this formula is in fact the proper closed form solution, we use mathematical induction.Base case: T(1)=21 .1=1.14Chap. 2 Mathematical PreliminariesInduction hypothesis: T(n.1)=2n.1 .1.Induction step:T(n)=2T(n.1)+1= 2(2n.1 .1) + 1=2n.1.Thus, as proved by mathematical induction, this formula is indeed the correct closed form solution for the recurrence.2.29 (a)The probability is 0.5 for each choice.(b)The average number of “1” bits is n/2, since each position has 0.5 probability of being “1.”(c)The leftmost “1” will be the leftmost bit (call it position 0) with probability 0.5; in position 1 with probability 0.25, and so on. The numberof positions we must examine is 1 in the case where the leftmost “1” isin position 0; 2 when it is in position 1, and so on. Thus, the expectedcost is the value of the summationni.2ii=1The closed form for this summation is 2 .n+2, or just less than two.2nThus, we expect to visit on average just less than two positions. (Students at this point will probably not be able to solve this summation,and it is not given in the book.)2.30There are at least two ways to approach this problem. One is to estimate the volume directly. The second is to generate volume as a function of weight. This is especially easy if using the metric system, assuming that the human body is roughly the density of water. So a 50 Kilo person has a volume slightly less than 50 liters; a 160 pound person has a volume slightly less than 20 gallons.2.31(a) Image representations vary considerably, so the answer will vary as a result. One example answer is: Consider VGA standard size, full-color (24 bit) images, which is 3 ×640 ×480, or just less than 1 Mbyte perimage. The full database requires some 30-35 CDs.(b)Since we needed 30-35 CDs before, compressing by a factor of 10 isnot sufficient to get the database onto one CD.[Note that if the student picked a smaller format, such as estimating the size of a “typical” gif image, the result might well fit onto a sin gle CD.](I saw this problem in John Bentley’s Programming Pearls.) Approach 1: The model is Depth X Width X Flow where Depth and Width are in miles and Flow is in miles/day. The Mississippi river at its mouth is about 1/4 mile wide and 100 feet (1/50 mile) deep, with a flow of around 15 miles/hour = 360 miles/day. Thus, the flow is about 2 cubic miles/day.Approach 2: What goes out must equal what goes in. The model is Area X Rainfall where Area is in square miles and Rainfall is in (linear) miles/day.The Mississipi watershed is about 1000 X 1000 miles, and the average rainfalis about 40 inches/year ≈.1 inches/day ≈.000002 miles/day (2 X 10.6).Thus, the flow is about 2 cubic miles/day.2.33Note that the student should NOT be providing answers that look like they were done using a calculator. This is supposed to be an exercise in estimation! The amount of the mortgage is irrelevant, since this is a question about rates. However, to give some numbers to help you visualize the problem, pick a $100,000 mortgage. The up-front charge would be $1,000, and the savings would be 1/4% each payment over the life of the mortgage. The monthly charge will be on the remaining principle, being the highest at first and gradually reducing over time. But, that has little effect for the first few years.At the grossest approximation, you paid 1% to start and will save 1/4% each year, requiring 4 years. To be more precise, 8% of $100,000 is $8,000, while7 3/4% is $7,750 (for the first year), with a little less interest paid (and therefore saved) in following years. This will require a payback period of slightlyover 4 years to save $1000. If the money had been invested, then in 5 yearsthe investment would be worth about $1300 (at 5would be close to 5 1/2 years.2.34Disk drive seek time is somewhere around 10 milliseconds or a little lessin 2000. RAM memory requires around 50 nanoseconds – much less thana microsecond. Given that there are about 30 million seconds in a year, a machine capable of executing at 100 MIPS would execute about 3 billion billion (3 .1018) instructions in a year.2.35Typical books have around 500 pages/inch of thickness, so one million pages requires 2000 inches or 150-200 feet of bookshelf. This would be in excess of 50 typical shelves, or 10-20 bookshelves. It is within the realm of possibility that an individual home has this many books, but it is rather unusual.A typical page has around 400 words (best way to derive this is to estimate the number of words/line and lines/page), and the book has around 500 pages, so the total is around 200,000 words.Chap. 2 Mathematical Preliminaries2.37An hour has 3600 seconds, so one million seconds is a bit less than 300 hours.A good estimater will notice that 3600 is about 10% greater than 3333, so the actual number of hours is about 10% less than 300, or close to 270. (The real value is just under 278). Of course, this is just over 11 days.2.38Well over 100,000, depending on what you wish to classify as a city or town. The real question is what technique the student uses.2.39(a) The time required is 1 minute for the first mile, then 60/59 minutesfor the second mile, and so on until the last mile requires 60/1=60 minutes. The result is the following summation.60 6060/i=60 1/i=60H60.i=1 i=1(b)This is actually quite easy. The man will never reach his destination,since his speed approaches zero as he approaches the end of the journey.。
数据结构与算法分析课后习题答案

数据结构与算法分析课后习题答案第一章:基本概念一、题目:什么是数据结构与算法?数据结构是指数据在计算机中存储和组织的方式,如栈、队列、链表、树等;而算法是一系列解决问题的清晰规范的指令步骤。
数据结构和算法是计算机科学的核心内容。
二、题目:数据结构的分类有哪些?数据结构可以分为以下几类:1. 线性结构:包括线性表、栈、队列等,数据元素之间存在一对一的关系。
2. 树形结构:包括二叉树、AVL树、B树等,数据元素之间存在一对多的关系。
3. 图形结构:包括有向图、无向图等,数据元素之间存在多对多的关系。
4. 文件结构:包括顺序文件、索引文件等,是硬件和软件相结合的数据组织形式。
第二章:算法分析一、题目:什么是时间复杂度?时间复杂度是描述算法执行时间与问题规模之间的增长关系,通常用大O记法表示。
例如,O(n)表示算法的执行时间与问题规模n成正比,O(n^2)表示算法的执行时间与问题规模n的平方成正比。
二、题目:主定理是什么?主定理(Master Theorem)是用于估计分治算法时间复杂度的定理。
它的公式为:T(n) = a * T(n/b) + f(n)其中,a是子问题的个数,n/b是每个子问题的规模,f(n)表示将一个问题分解成子问题和合并子问题的所需时间。
根据主定理的不同情况,可以得到算法的时间复杂度的上界。
第三章:基本数据结构一、题目:什么是数组?数组是一种线性数据结构,它由一系列具有相同数据类型的元素组成,通过索引访问。
数组具有随机访问、连续存储等特点,但插入和删除元素的效率较低。
二、题目:栈和队列有什么区别?栈和队列都是线性数据结构,栈的特点是“先进后出”,即最后压入栈的元素最先弹出;而队列的特点是“先进先出”,即最先入队列的元素最先出队列。
第四章:高级数据结构一、题目:什么是二叉树?二叉树是一种特殊的树形结构,每个节点最多有两个子节点。
二叉树具有左子树、右子树的区分,常见的有完全二叉树、平衡二叉树等。
数据结构与算法习题含参考答案

数据结构与算法习题含参考答案一、单选题(共100题,每题1分,共100分)1、要为 Word 2010 格式的论文添加索引,如果索引项已经以表格形式保存在另一个 Word文档中,最快捷的操作方法是:A、在 Word 格式论文中,逐一标记索引项,然后插入索引B、直接将以表格形式保存在另一个 Word 文档中的索引项复制到 Word 格式论文中C、在 Word 格式论文中,使用自动插入索引功能,从另外保存 Word 索引项的文件中插D、在 Word 格式论文中,使用自动标记功能批量标记索引项,然后插入索引正确答案:D2、下面不属于计算机软件构成要素的是A、文档B、程序C、数据D、开发方法正确答案:D3、JAVA 属于:A、操作系统B、办公软件C、数据库系统D、计算机语言正确答案:D4、在 PowerPoint 演示文稿中,不可以使用的对象是:A、图片B、超链接C、视频D、书签第 6 组正确答案:D5、下列叙述中正确的是A、软件过程是软件开发过程和软件维护过程B、软件过程是软件开发过程C、软件过程是把输入转化为输出的一组彼此相关的资源和活动D、软件过程是软件维护过程正确答案:C6、在 Word 中,不能作为文本转换为表格的分隔符的是:A、@B、制表符C、段落标记D、##正确答案:D7、某企业为了建设一个可供客户在互联网上浏览的网站,需要申请一个:A、密码B、门牌号C、域名D、邮编正确答案:C8、面向对象方法中,将数据和操作置于对象的统一体中的实现方式是A、隐藏第 42 组B、抽象C、结合D、封装正确答案:D9、下面属于整数类 I 实例的是A、-919B、0.919C、919E+3D、919D-2正确答案:A10、定义课程的关系模式如下:Course (C#, Cn, Cr,prC1#, prC2#)(其属性分别为课程号、课程名、学分、先修课程号 1和先修课程号 2),并且不同课程可以同名,则该关系最高是A、BCNFB、2NFC、1NFD、3NF正确答案:A11、循环队列的存储空间为 Q(1:100),初始状态为 front=rear=100。
数据结构与算法试题及

数据结构与算法试题及答案参考数据结构与算法试题及答案参考一、选择题1. 数据结构是研究什么的?A. 数据的结构和组织B. 数据的格式和排列C. 数据的读取和写入D. 数据的传输和存储正确答案:A2. 在数据结构中,栈(Stack)的特点是什么?A. 先进先出B. 先进后出C. 后进先出D. 后进后出正确答案:C3. 在链表中,结点的指针指向的是什么?A. 结点本身B. 结点的前一个结点C. 结点的后一个结点D. 结点的数据域正确答案:C4. 在二叉搜索树中,左子树的值都小于根节点,右子树的值都大于根节点。
这种特性被称为什么性质?A. 有序性B. 平衡性C. 完全性D. 二叉性正确答案:A二、填空题1. 算法的复杂度可以分为时间复杂度和________复杂度。
正确答案:空间2. 实现队列数据结构可以采用两个栈的方式,称为______队列。
正确答案:双栈3. 快速排序算法的时间复杂度为______。
正确答案:O(nlogn)三、编程题1. 请编写一个函数,实现对一个数组进行冒泡排序。
正确答案:```pythondef bubble_sort(arr):for i in range(len(arr) - 1):for j in range(len(arr) - 1 - i):if arr[j] > arr[j + 1]:arr[j], arr[j + 1] = arr[j + 1], arr[j]return arr```2. 请编写一个递归函数,计算斐波那契数列的第n项。
正确答案:```pythondef fibonacci(n):if n <= 1:return nelse:return fibonacci(n - 1) + fibonacci(n - 2)```四、简答题1. 请简单描述树和图的区别。
答:树是一种特殊的图,它是一个由节点和边组成的非线性数据结构,具有层级关系,且任意两个节点之间有且仅有一条路径相连。
数据结构与算法分析习题与参考答案
大学《数据结构与算法分析》课程习题及参考答案模拟试卷一一、单选题(每题 2 分,共20分)1.以下数据结构中哪一个是线性结构?( )A. 有向图B. 队列C. 线索二叉树D. B树2.在一个单链表HL中,若要在当前由指针p指向的结点后面插入一个由q指向的结点,则执行如下( )语句序列。
A. p=q; p->next=q;B. p->next=q; q->next=p;C. p->next=q->next; p=q;D. q->next=p->next; p->next=q;3.以下哪一个不是队列的基本运算?()A. 在队列第i个元素之后插入一个元素B. 从队头删除一个元素C. 判断一个队列是否为空D.读取队头元素的值4.字符A、B、C依次进入一个栈,按出栈的先后顺序组成不同的字符串,至多可以组成( )个不同的字符串?A.14B.5C.6D.85.由权值分别为3,8,6,2的叶子生成一棵哈夫曼树,它的带权路径长度为( )。
以下6-8题基于图1。
6.该二叉树结点的前序遍历的序列为( )。
A.E、G、F、A、C、D、BB.E、A、G、C、F、B、DC.E、A、C、B、D、G、FD.E、G、A、C、D、F、B7.该二叉树结点的中序遍历的序列为( )。
A. A、B、C、D、E、G、FB. E、A、G、C、F、B、DC. E、A、C、B、D、G、FE.B、D、C、A、F、G、E8.该二叉树的按层遍历的序列为( )。
A.E、G、F、A、C、D、B B. E、A、C、B、D、G、FC. E、A、G、C、F、B、DD. E、G、A、C、D、F、B9.下面关于图的存储的叙述中正确的是( )。
A.用邻接表法存储图,占用的存储空间大小只与图中边数有关,而与结点个数无关B.用邻接表法存储图,占用的存储空间大小与图中边数和结点个数都有关C. 用邻接矩阵法存储图,占用的存储空间大小与图中结点个数和边数都有关D.用邻接矩阵法存储图,占用的存储空间大小只与图中边数有关,而与结点个数无关10.设有关键码序列(q,g,m,z,a,n,p,x,h),下面哪一个序列是从上述序列出发建堆的结果?( )A. a,g,h,m,n,p,q,x,zB. a,g,m,h,q,n,p,x,zC. g,m,q,a,n,p,x,h,zD. h,g,m,p,a,n,q,x,z二、填空题(每空1分,共26分)1.数据的物理结构被分为_________、________、__________和___________四种。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
四川大学计算机学院《数据结构与算法分析》课程模拟试卷及参考答案模拟试卷一一、单选题(每题2 分,共20分)1.以下数据结构中哪一个是线性结构?( )A. 有向图B. 队列C. 线索二叉树D. B树2.在一个单链表HL中,若要在当前由指针p指向的结点后面插入一个由q指向的结点,则执行如下( )语句序列。
A. p=q; p->next=q;B. p->next=q; q->next=p;C. p->next=q->next; p=q;D. q->next=p->next; p->next=q;3.以下哪一个不是队列的基本运算?()A. 在队列第i个元素之后插入一个元素B. 从队头删除一个元素C. 判断一个队列是否为空D.读取队头元素的值4.字符A、B、C依次进入一个栈,按出栈的先后顺序组成不同的字符串,至多可以组成( )个不同的字符串?A.14B.5C.6D.85.由权值分别为3,8,6,2A. 11 B.35 C. 19 D. 53以下6-8题基于图1。
6.该二叉树结点的前序遍历的序列为( )。
A.E、G、F、A、C、D、BB.E、A、G、C、F、B、DC.E、A、C、B、D、G、FD.E、G、A、C、D、F、B7.该二叉树结点的中序遍历的序列为( )。
A. A、B、C、D、E、G、FB. E、A、G、C、F、B、DC. E、A、C、B、D、G、FE.B、D、C、A、F、G、E8.该二叉树的按层遍历的序列为( )。
A.E、G、F、A、C、D、B B. E、A、C、B、D、G、FC. E、A、G、C、F、B、DD. E、G、A、C、D、F、B9.下面关于图的存储的叙述中正确的是( )。
A.用邻接表法存储图,占用的存储空间大小只与图中边数有关,而与结点个数无关B.用邻接表法存储图,占用的存储空间大小与图中边数和结点个数都有关C. 用邻接矩阵法存储图,占用的存储空间大小与图中结点个数和边数都有关D.用邻接矩阵法存储图,占用的存储空间大小只与图中边数有关,而与结点个数无关10.设有关键码序列(q,g,m,z,a,n,p,x,h),下面哪一个序列是从上述序列出发建堆的结果?( )A. a,g,h,m,n,p,q,x,zB. a,g,m,h,q,n,p,x,zC. g,m,q,a,n,p,x,h,zD. h,g,m,p,a,n,q,x,z二、填空题(每空1分,共26分)1.数据的物理结构被分为_________、________、__________和___________四种。
2.对于一个长度为n的顺序存储的线性表,在表头插入元素的时间复杂度为_________,在表尾插入元素的时间复杂度为____________。
3.向一个由HS指向的链栈中插入一个结点时p时,需要执行的操作是________________;删除一个结点时,需要执行的操作是______________________________(假设栈不空而且无需回收被删除结点)。
4.对于一棵具有n个结点的二叉树,一个结点的编号为i(1≤i≤n),若它有左孩子则左孩子结点的编号为________,若它有右孩子,则右孩子结点的编号为________,若它有双亲,则双亲结点的编号为________。
5.当向一个大根堆插入一个具有最大值的元素时,需要逐层_________调整,直到被调整到____________位置为止。
6.以二分查找方法从长度为10的有序表中查找一个元素时,平均查找长度为________。
7.表示图的三种常用的存储结构为_____________、____________和_______________。
8.对于线性表(70,34,55,23,65,41,20)进行散列存储时,若选用H(K)=K %7作为散列函数,则散列地址为0的元素有________个,散列地址为6的有_______个。
9.在归并排序中,进行每趟归并的时间复杂度为______,整个排序过程的时间复杂度为____________,空间复杂度为___________。
10.在一棵m阶B_树上,每个非树根结点的关键字数目最少为________个,最多为________个,其子树数目最少为________,最多为________。
三、运算题(每题6 分,共24分)1.写出下列中缀表达式的后缀形式:(1)3X/(Y-2)+1(2)2+X*(Y+3)2.试对图2中的二叉树画出其:(1)顺序存储表示的示意图;(2)二叉链表存储表示的示意图。
3.判断以下序列是否是小根堆? 如果不是, 将它调图2 整为小根堆。
(1){ 12, 70, 33, 65, 24, 56, 48, 92, 86, 33 }(2){ 05, 23, 20, 28, 40, 38, 29, 61, 35, 76, 47, 100 }4.已知一个图的顶点集V和边集E分别为:V={1,2,3,4,5,6,7};E={(1,2)3,(1,3)5,(1,4)8,(2,5)10,(2,3)6,(3,4)15,(3,5)12,(3,6)9,(4,6)4,(4,7)20,(5,6)18,(6,7)25};按照普里姆算法从顶点1出发得到最小生成树,试写出在最小生成树中依次得到的各条边。
四、阅读算法(每题7分,共14分)1.void AE(Stack& S){InitStack(S);Push(S,3);Push(S,4);int x=Pop(S)+2*Pop(S);Push(S,x);int i,a[5]={1,5,8,12,15};for(i=0;i<5;i++) Push(S,2*a[i]);while(!StackEmpty(S)) cout<<Pop(S)<<' ';}该算法被调用后得到的输出结果为:2.void ABC (BTNode *BT,int &c1,int &c2) {if (BT !=NULL ) {ABC(BT->left,c1,c2);c1++;if (BT->left==NULL&&BT->right==NULL) c2++;ABC(BT->right,c1,c2);}//if}该函数执行的功能是什么?五、算法填空(共8分)向单链表的末尾添加一个元素的算法。
Void InsertRear(LNode*& HL,const ElemType& item){LNode* newptr;newptr=new LNode;If (______________________){cerr<<"Memory allocation failare!"<<endl;exit(1);}________________________=item;newptr->next=NULL;if (HL==NULL)HL=__________________________;else{LNode* P=HL;While (P->next!=NULL)____________________;p->next=newptr;}}六、编写算法(共8分)编写从类型为List的线性表L中将第i个元素删除的算法,(假定不需要对i的值进行有效性检查,也不用判别L是否为空表。
)void Delete(List& L, int i)模拟试卷一参考答案一、单选题(每题2分,共20分)1.B2.D3.A4.B5.B6.C7.A8.C9.B 10.B二、填空题(每空1分,共26分)1.顺序链表索引散列2.O(n) O(1)3.p->next=HS;HS=p HS=HS->next4.2i 2i+1 ⎣i/2⎦(或i/2)5.向上根6. 2.97.邻接矩阵邻接表边集数组8. 1 49.O(n) O(nlog2n) O(n)10.⎡m/2⎤-1 m-1 ⎡m/2⎤ m三、运算题(每题6分,共24分)1.(1) 3 X * Y 2 - / 1 +图3(2) 2 X Y 3 + * +2.(1)0 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 161 2 3 4 5 6 7 8 9(2)见图3所示:3.(1)不是小根堆。
调整为:{12,65,33,70,24,56,48,92,86,33}(2)是小根堆。
4.普里姆算法从顶点1出发得到最小生成树为:(1,2)3, (1,3)5, (1,4)8, (4,6)4, (2,5)10, (4,7)20四、阅读算法(每题7分,共14分)1.30 24 16 10 2 102.该函数的功能是:统计出BT所指向的二叉树的结点总数和叶子总数五、算法填空(共8分,每一空2分)newptr==NULL newptr->=data newptr p=p->next六、编写算法(8分)void Delete(List& L, int i){for(int j=i-1;j<L.size-1; j++)L.list[j]=L.list[j+1]; //第i个元素的下标为i-1 L.size--;}模拟试卷二一、单选题(每题2 分,共20分)1.在一个带有附加表头结点的单链表HL中,若要向表头插入一个由指针p指向的结点,则执行( )。
A. HL=p; p->next=HL;B. p->next=HL->next; HL->next=p;C. p->next=HL; p=HL;D. p->next=HL; HL=p;2.若顺序存储的循环队列的QueueMaxSize=n,则该队列最多可存储()个元素.A. nB.n-1C. n+1D.不确定3.下述哪一条是顺序存储方式的优点?()A.存储密度大 B.插入和删除运算方便C. 获取符合某种条件的元素方便D.查找运算速度快4.设有一个二维数组A[m][n],假设A[0][0]存放位置在600(10),A[3][3]存放位置在678(10),每个元素占一个空间,问A[2][3](10)存放在什么位置?(脚注(10)表示用10进制表示,m>3)A.658 B.648 C.633 D.6535.下列关于二叉树遍历的叙述中,正确的是( ) 。
A. 若一个树叶是某二叉树的中序遍历的最后一个结点,则它必是该二叉树的前序遍历最后一个结点B.若一个点是某二叉树的前序遍历最后一个结点,则它必是该二叉树的中序遍历的最后一个结点C.若一个结点是某二叉树的中序遍历的最后一个结点,则它必是该二叉树的前序最后一个结点D.若一个树叶是某二叉树的前序最后一个结点,则它必是该二叉树的中序遍历最后一个结点6.k层二叉树的结点总数最多为( ).A.2k-1 B.2K+1 C.2K-1 D. 2k-17.对线性表进行二分法查找,其前提条件是( ).A.线性表以链接方式存储,并且按关键码值排好序B.线性表以顺序方式存储,并且按关键码值的检索频率排好序C.线性表以顺序方式存储,并且按关键码值排好序D.线性表以链接方式存储,并且按关键码值的检索频率排好序8.对n个记录进行堆排序,所需要的辅助存储空间为A. O(1og2n)B. O(n)C. O(1)D. O(n2)9.对于线性表(7,34,77,25,64,49,20,14)进行散列存储时,若选用H(K)=K %7作为散列函数,则散列地址为0的元素有()个,A.1 B.2 C.3 D.410.下列关于数据结构的叙述中,正确的是( ).A.数组是不同类型值的集合B.递归算法的程序结构比迭代算法的程序结构更为精炼C.树是一种线性结构D.用一维数组存储一棵完全二叉树是有效的存储方法二、填空题(每空1分,共26分)1.数据的逻辑结构被分为_________、________、__________和___________四种。