数据挖掘导论第一二章_924
《数据挖掘导论》目录

《数据挖掘导论》⽬录⽬录什么是数据挖掘常见的相似度计算⽅法介绍决策树介绍基于规则的分类贝叶斯分类器⼈⼯神经⽹络介绍关联分析异常检测数据挖掘数据挖掘(英语:Data mining),⼜译为资料探勘、数据采矿。
它是数据库知识发现(英语:Knowledge-Discovery in Databases,简称:KDD)中的⼀个步骤。
数据挖掘⼀般是指从⼤量的数据中通过算法搜索隐藏于其中信息的过程。
数据挖掘通常与计算机科学有关,并通过统计、在线分析处理、情报检索、机器学习、专家系统(依靠过去的经验法则)和模式识别等诸多⽅法来实现上述⽬标。
常见的数据相似度计算汉密尔顿距离(r = 1)欧式距离(r = 2)上确界距离(r = max)⼆元数据相似性简单匹配系数(Simple Matching Coefficient,SMC):Jaccard 系数:余弦相似度:⼴义Jaccard系数:⽪尔逊相关系数(Pearson’s correlation):决策树(decision tree)(TODO)决策树是⼀个树结构(可以是⼆叉树或⾮⼆叉树)。
其每个⾮叶节点表⽰⼀个特征属性上的测试,每个分⽀代表这个特征属性在某个值域上的输出,⽽每个叶节点存放⼀个类别。
使⽤决策树进⾏决策的过程就是从根节点开始,测试待分类项中相应的特征属性,并按照其值选择输出分⽀,直到到达叶⼦节点,将叶⼦节点存放的类别作为决策结果。
构造决策树的关键步骤是分裂属性。
所谓分裂属性就是在某个节点处按照某⼀特征属性的不同划分构造不同的分⽀,其⽬标是让各个分裂⼦集尽可能地“纯”。
尽可能“纯”就是尽量让⼀个分裂⼦集中待分类项属于同⼀类别。
构造决策树的关键性内容是进⾏属性选择度量,属性选择度量是⼀种选择分裂准则,是将给定的类标记的训练集合的数据划分D“最好”地分成个体类的启发式⽅法,它决定了拓扑结构及分裂点split_point的选择。
属性选择度量算法有很多,⼀般使⽤⾃顶向下递归分治法,并采⽤不回溯的贪⼼策略。
数据挖掘导论

数据挖掘导论数据挖掘是一种通过从大量数据中发现模式、关联和趋势来提取实用信息的过程。
它涉及使用计算机技术和统计学方法来分析和解释数据,以便从中获取有关未来趋势和行为的洞察力。
在本文中,我们将介绍数据挖掘的基本概念、技术和应用。
1. 数据挖掘的基本概念数据挖掘是从大量数据中提取实用信息的过程。
它主要包括以下几个方面的内容:1.1 数据预处理数据预处理是数据挖掘的第一步,它涉及数据清洗、数据集成、数据变换和数据规约。
数据清洗是指处理数据中的噪声和缺失值,以确保数据的质量。
数据集成是将来自不同数据源的数据合并到一个统一的数据集中。
数据变换是将数据转换为适合进行挖掘的形式,例如将数据编码为数值型。
数据规约是通过减少数据集的大小来提高挖掘效率。
1.2 数据挖掘技术数据挖掘技术包括分类、聚类、关联规则挖掘和异常检测等。
分类是将数据分为不同的类别,例如将客户分为高价值和低价值客户。
聚类是将数据分为相似的组,例如将顾客分为不同的市场细分。
关联规则挖掘是发现数据中的相关关系,例如购买某种商品的人也会购买另一种商品。
异常检测是发现数据中的异常值,例如检测信用卡欺诈行为。
1.3 模型评估和选择在数据挖掘过程中,需要评估和选择不同的模型来解释数据。
常用的评估指标包括准确率、召回率和F1值等。
准确率是指分类模型预测正确的样本比例,召回率是指分类模型正确预测为正类的样本比例,F1值是准确率和召回率的调和平均值。
2. 数据挖掘的应用领域数据挖掘在各个领域都有广泛的应用,以下是一些常见的应用领域:2.1 金融领域在金融领域,数据挖掘可以用于信用评分、风险管理和欺诈检测等。
通过分析客户的历史交易数据和个人信息,可以预测客户的信用风险,并为银行和金融机构提供决策支持。
2.2 零售领域在零售领域,数据挖掘可以用于市场细分、商品推荐和销售预测等。
通过分析顾客的购买历史和偏好,可以将顾客分为不同的市场细分,并向他们推荐适合的商品。
同时,数据挖掘还可以预测销售量,匡助零售商合理安排库存和采购计划。
数据挖掘第一与第二章PPT课件

预测建模可以用来确定顾客对产品促销活 动的反应,预测地球生态系统的扰动,或根据 检查结果判断病人是否患有某种疾病。
14
数据挖掘任务
• 关联分析 用来描述数据中强关联特征的模式。 关联分析的应用包括找出具有相关功
能的基因组、识别用户一起访问的Web页面、 理解地球气候系统不同元素之间的联系等。
12
数据挖掘任务
• 预测vs.描述 • 预测(Prediction)
– 根据其他属性的值,预测特定属性的值 • 描述(Description)
– 导出概括数据中潜在联系的模式
2020年9月29日星期二
13
数据挖掘任务
• 预测建模 涉及以说明自变量函数的方式为目标变量
建立模型。 有两类预测建模任务:分类,用于预测离
– 使用抽样技术或开发并行和分布算法也可以提高可 伸缩程度
2020年9月29日星期二
7
挑战2
• 高维性
– 具有数以百计或数以千计属性的数据集
• 生物信息学:涉及数千特征的基因表达数据 • 不同地区温度测量:如果在一个相当长的时间周期内进
行测量,维度(特征数)的增长正比于测量的次数
– 为低维数据开发的数据分析技术不能很好地处理高 维数据
异常检测的应用包括检测欺诈、网络攻 击、疾病的不寻常模式、生态系统扰动等。
– Jiawei Han的定义
• 从大型数据集中提取有趣的 (非平凡的, 蕴涵的, 先前未知的并且是潜在有用的) 信息或模式
4
数据挖掘技术的定义
• 定义:数据挖掘就是从大量的、不完全的、有 噪声的、模糊的、随机的实际应用数据中,提 取隐含在其中的,人们事先不知道的、但又是 潜在有用的信息和知识的过程.
数据挖掘导论第章vppt课件

数据集类型(三大类)
记录数据 数据矩阵(Data Matrix) 文本数据(Document Data ):每篇文档可以表示成一个文档-词矩 阵 事务数据(Transaction Data)
基于图形(Graph)的数据 World Wide Web 分子结构(Molecular Structures)
有序(Ordered)数据 空间数据(Spatial Data) 时间数据(Temporal Data) 序列数据(Sequential Data )
11
数据集类型1:记录数据: 数据矩阵
数据矩阵: 如果一个数据集中的所有数据对象都具有相同的数值属性集,则数据对
数值的
区 间
新值 = a×旧值+ b, 其中a、b是常数
(定量的)
比 率
新值= a ×旧值
华氏和摄氏温度标度零度的位置和1度的 大小(单位)不同
长度可以用米或英尺度量
8
用值的个数描述属性:离散vs.连续属性
离散属性(Discrete Attribute) 有限或无限可数 (countable infinite )个值 例: 邮政编码, 计数, 文档集的词 常表示为整数变量. 注意: 二元属性(binary attributes)是离散属性的特例
6
表2-2 不同的属性类型
属性类型
标 称 分类的
(定性的) 序 数
区
数值的
间
(定量的)
比 率
描述
例子
操作
标称属性的值仅仅只是不 同的名字,即标称值只提供 足够的信息以区分对象
(=,)
序数属性的值提供足够的 信息确定对象的序
(<,>)
数据挖掘导论

数据挖掘导论数据挖掘是一种通过分析大量数据来发现隐藏在其中模式、关联和趋势的过程。
它结合了统计学、机器学习和数据库技术,旨在从大数据集合中提取有价值的信息。
在本文中,我们将介绍数据挖掘的基本概念、方法和应用,并探讨其在不同领域的应用。
一、数据挖掘的基本概念1.1 数据挖掘的定义数据挖掘是指从大量数据中发现、提取、分析和解释潜在的、有价值的模式、关联和趋势的过程。
它可以帮助人们发现隐藏在数据中的规律,从而做出更准确的预测和决策。
1.2 数据挖掘的过程数据挖掘的过程通常包括以下几个步骤:(1)问题定义:明确挖掘的目标和需求。
(2)数据采集:收集和获取相关数据。
(3)数据预处理:清洗、集成、转换和规范化数据。
(4)特征选择:从原始数据中选择最具代表性的特征。
(5)模型构建:选择合适的模型和算法进行建模。
(6)模型评估:评估模型的性能和准确度。
(7)模型优化:对模型进行调优和改进。
(8)模型应用:将模型应用于实际问题中,得出有价值的结论。
1.3 数据挖掘的方法数据挖掘的方法包括:(1)分类:将数据分为不同的类别或标签。
(2)聚类:将数据分为相似的组别。
(3)关联规则挖掘:发现数据中的关联关系。
(4)预测:根据已有数据预测未来的趋势和结果。
(5)异常检测:发现数据中的异常或离群值。
二、数据挖掘的应用2.1 金融领域数据挖掘在金融领域的应用非常广泛。
它可以帮助银行和金融机构进行信用评估、风险管理和欺诈检测。
通过分析客户的历史交易数据和个人信息,可以预测客户的信用风险,并及时采取相应的措施。
2.2 零售业数据挖掘在零售业中的应用也非常重要。
通过分析顾客的购买历史和行为模式,可以进行个性化推荐和定价策略。
此外,数据挖掘还可以帮助零售商预测销售趋势,优化库存管理和供应链。
2.3 健康医疗数据挖掘在健康医疗领域的应用越来越多。
通过分析患者的病历数据和基因组数据,可以预测疾病的风险和治疗效果。
此外,数据挖掘还可以帮助医院进行资源调配和病例分析。
数据挖掘-数据挖掘导论

2
数据
数据库 管理
数据仓库
数据挖掘
数据智能 分析
解决方案
图-- 数据到知识的演化过程示意描述
随着计算机硬件和软件的飞速发展,尤其是数据库技术与应用的日益普及,人 们面临着快速扩张的数据海洋,如何有效利用这一丰富数据海洋的宝藏为人类服务, 业已成为广大信息技术工作者的所重点关注的焦点之一。与日趋成熟的数据管理技 术与软件工具相比,人们所依赖的数据分析工具功能,却无法有效地为决策者提供 其决策支持所需要的相关知识,从而形成了一种独特的现象“丰富的数据,贫乏的 知识”。为有效解决这一问题,自二十世纪 9 年代开始,数据挖掘技术逐步发展起 来,数据挖掘技术的迅速发展,得益于目前全世界所拥有的巨大数据资源以及对将 这些数据资源转换为信息和知识资源的巨大需求,对信息和知识的需求来自各行各 业,从商业管理、生产控制、市场分析到工程设计、科学探索等。数据挖掘可以视 为是数据管理与分析技术的自然进化产物,如图-- 所示。
)。事实上, 一部人类文明发展史,就是在各种活动中,知识的创造、交流,再创造不断积累的 螺旋式上升的历史。
客观世界 客观世界
收集
数据 数据
分析
信息 信息
深入分析
知识 知识
决策与行动
图-- 人类活动所涉及数据与知识之间的关系描述
计算机与信息技术的发展,加速了人类知识创造与交流的这种进程,据德国《世 界报》的资料分析,如果说 ( 世纪时科学定律(包括新的化学分子式,新的物理关 系和新的医学认识)的认识数量一百年增长一倍,到本世纪 / 年代中期以后,每五 年就增加一倍。这其中知识起着关键的作用。当数据量极度增长时,如果没有有效 的方法,由计算机及信息技术来帮助从中提取有用的信息和知识,人类显然就会感 到像大海捞针一样束手无策。据估计,目前一个大型企业数据库中数据,约只有百 分之七得到很好应用。因此目前人类陷入了一个尴尬的境地,即“丰富的数据”( *)而“贫乏的知识0('
数据挖掘导论

本书的亮点之一在于对可视化分析的独到见解。作者指出,可视化是解决复杂 数据挖掘问题的有效手段,可以帮助我们直观地理解数据和发现隐藏在其中的 规律。书中详细讨论了可视化技术的种类、优缺点以及在数据挖掘过程中的作 用。还通过大量实例,让读者切实感受到可视化分析在数据挖掘中的强大威力。
除了可视化分析,本书还对关联规则挖掘、聚类分析等众多经典算法进行了深 入阐述。例如,在关联规则挖掘部分,作者首先介绍了Apriori算法的基本原 理和实现过程,然后提出了一系列改进措施,如基于哈希表的剪枝、基于密度 的剪枝等,有效提高了算法的效率和准确率。在聚类分析部分,不仅详细讨论 了K-Means、层次聚类等经典算法,还对如何评价聚类效果进行了深入探讨。
第4章:关联规则挖掘。讲解了关联规则的定义、算法和实际应用。
第5章:聚类分析。讨论了聚类算法的类型、原理和应用。
第6章:分类。介绍了分类算法的原理、应用及评估方法。
第7章:回归分析。讲解了回归分析的原理、方法和实际应用。
第8章:时间序列分析。探讨了时间序列的基本概念、模型和预测方法。
第9章:社交网络分析。讲解了社交网络的基本概念、测量指标和挖掘方法。
《数据挖掘导论》是一本非常优秀的书籍,全面介绍了数据挖掘领域的基本概 念、技术和应用。通过阅读这本书,我不仅对数据挖掘有了更深入的了解,还 从中获得了不少启示和收获。书中关键点和引人入胜的内容也让我进行了深入 思考。从个人角度来说,这本书给我带来了很多情感体验和思考。结合本书内 容简单探讨了数据挖掘在生活中的应用前景。
在阅读这本书的过程中,我最大的收获是关于数据挖掘技术的理解。书中详细 介绍了各种数据挖掘技术的原理、优缺点以及适用场景。尤其是关联规则挖掘、 聚类分析和分类算法等部分,让我对这些技术有了更深入的认识。通过这些技 术的学习,我明白了如何从大量数据中提取有用的信息和知识。
数据挖掘导论

人工神经网络的突破
1982年,美国加州理工学院物理学家Hopfield提出了HNN神经网 络模型,对神经网络理论的发展产生了深远的影响。他引入了“能量 函数”的概念,使得网络稳定性研究有了明确的判决。HNN的电子电 路物理实现为神经计算机的研究奠定了基础,并应用于一些计算复杂 度为NP完全型的问题,如著名的“巡回推销员问题(TSP)”。
人类神经网络
生物神经系统是一个有高度组织和相互作用的数量巨大的细胞组织群体。 人脑大约有10e11-10e13个左右的神经细胞(神经元)。 每个神经元都是独立的,均有自己的核和自己的分界线或原生质膜。 神经元之间的相互连接从而让信息传递的部位被称为突触(Synapase)。 当神经细胞受到外界一定强度信号的刺激时,会引起兴奋,并出现一次可 传导的动作电位(即神经冲动)。 单个神经元可以从别的细胞接受多个输入,由于输入分布于不同的部位, 对神经元影响的比例(权重)是不相同的。 多个神经元以突触联接形成了一个神经网络。
BP神经网络、径向基函数网络等模型均属于前向网络类型。
人工神经网络的互连模式
输出反馈的前向网络
输出层对输入层有信息反馈,即每一个输入节点都有可能接受来 自外部的输入和来自输出神经元的反馈,这种模式可用来存储某 种模式序列,如神经认知机即属于此类。
MP模型
MP模型属于一种阈值原件模型,由美国Mc Culloch和Pitts提出 的,是大多数神经网络模型的基础。
1984年,Hinton等人对Hopfield模型引入模拟退火方法,提出了 Boltzmann机模型。
1986年,Rumelhart提出了反向传播学习方法(BP算法),解决 了多层前向神经网络的学习问题,证明了多层前向网络具有很强的学 习能力。
数据挖掘导论完整版中文PPT

第 9章
聚类分析:附加的问题与算法
在各种领域,针对不同的应用类型,已经开发了大 量聚类算法。在这些算法中没有一种算法能够适应 所有的数据类型、簇和应用。 事实上,对于更加有效或者更适合特定数据类型、 簇和应用的新的聚类算法,看来总是有进一步的开 发空间。 我们只能说我们已经有了一些技术,对于某些情况 运行良好。其原因是,在许多情况下,对于什么是 一个好的簇集,仍然凭主观解释。此外,当使用客 观度量精确地定义簇时,发现最优聚类问题常常是 计算不可行的。
基于网格的聚类
网格是一种组织数据集的有效方法,至少在低维空 间中如此。
其基本思想是,将每个属性的可能值分割成许多相 邻的区间,创建网格单元的集合。每个对象落入一 个网格单元,网格单元对应的属性区间包含该对象 的值。
存在许多利用网格进行聚类的方法,大部分方法是 基于密度的。
例子
基于网格的算法
DBSCAN多次运行产生相同的结果,而k均值通常 使用随机初始化质心,不会产生相同的结果。 DBSCAN自动地确定簇个数;对于k均值,簇个数 需要作为参数指定。然而,DBSCAN必须指定另 外两个参数:Eps和Minpts K均值聚类可以看作优化问题,即最小化每个点到 最近的质心的误差的平方和,并且可以看作一种统 计聚类的特例。DBSCAN不基于任何形式化模型 。
FCM的结构类似于K均值。 K均值可以看作FCM的 特例。 K均值在初始化之后,交替地更新质心和指派每个 对象到最近的质心。具体地说,计算模糊伪划分等 价于指派步骤。 与k均值一样,FCM可以解释为试图最小化误差的 平方和(SSE),尽管FCM基于SSE的模糊版本 。
数据挖掘入门指南

数据挖掘入门指南第一章数据挖掘概述数据挖掘是一种从大量数据中发现有用模式和知识的过程。
它包括数据预处理、模型选择、模式发现和模型评估等步骤。
在当今信息化社会中,数据挖掘已经成为各个领域的热门技术,它为企业提供了利用数据进行决策和优化的有效手段。
第二章数据预处理数据挖掘的首要步骤是数据预处理。
数据预处理的目标是去除数据中的噪声、消除数据的冗余,以及解决缺失数据的问题。
常见的数据预处理技术包括数据清洗、数据集成、数据变换和数据降维。
数据预处理的好坏直接影响到后续模型选择和模式发现的结果。
第三章模型选择模型选择是数据挖掘过程中的关键步骤。
根据具体问题的特点选择合适的模型对于获得准确的挖掘结果至关重要。
常见的模型选择方法包括决策树、神经网络、支持向量机和朴素贝叶斯等。
不同的模型适用于不同类型的数据和问题,需要根据具体情况进行选择。
第四章模式发现模式发现是数据挖掘的核心任务之一。
模式发现旨在从数据中找出隐藏的、有用的模式和规律。
常用的模式发现方法包括关联规则挖掘、聚类分析和分类分析。
关联规则挖掘可以帮助人们找到数据中的关联关系,聚类分析可以将数据划分为不同的群组,而分类分析可以对数据进行分类和预测。
第五章模型评估模型评估是数据挖掘的最后一步。
模型评估的主要目的是评估所选择模型的准确性和可靠性。
常用的模型评估方法包括交叉验证、混淆矩阵和ROC曲线等。
通过进行模型评估,可以对模型的性能进行客观的评价,从而确定是否需要进一步优化或更换模型。
第六章数据挖掘应用数据挖掘在各个领域都有广泛的应用。
例如,在市场营销中,数据挖掘可以帮助企业发现潜在的消费者群体,优化产品定价和推广策略。
在医疗健康领域,数据挖掘可以辅助医生进行疾病诊断和治疗预测。
在金融领域,数据挖掘可以帮助银行识别风险,预测市场走势。
数据挖掘的应用正日益深入各行各业。
第七章数据挖掘工具为了实现数据挖掘的目标,需要借助各种数据挖掘工具。
常见的数据挖掘工具有WEKA、RapidMiner、KNIME和Python等。
数据挖掘导论--第1章-数据仓库基本理论

数据库:事务处理
数据仓库的数
据量是数据库 数据量的100倍 数据库:二维 数据仓库:多维 超立方
数据仓库:决策分
析需求
(3)数据库与数据仓库对比
可更新的
细节的 在存取时准确的 一次操作数据量小 面向应用 支持管理 不更新 综合或提炼的 代表过去的数据 一次操作数据量大 面向分析 支持决策
数据库
数据仓库
(2)联机分析处理(OLAP)
• OLAP软件,以它先进地分析功能和以多维 形式提供数据的能力,正作为一种支持企业
关键商业决策的解决方案而迅速崛起。
• OLAP的基本思想是决策者从多方面和多角
度以多维的形式来观察企业的状态和了解企
业的变化。
(2) OLTP与OLAP的对比
细节性数据
当前数据 经常更新 一次性处理的数据量小 对响应时间要求高 面向应用,事务驱动 综合性数据 历史数据 不更新,但周期性刷新 一次性处理的数据量大 响应时间合理 面向分析,分析驱动
析的概念,即联机分析处理(On Line
Analytical Processing,OLAP)概念。
• 关系数据库是二维数据(平面),多维数据库是
空间立体数据。
(2)联机分析处理(OLAP)
• OLAP专门用于支持复杂的决策分析操作,侧重 对分析人员和高层管理人员的决策支持。 • OLAP可以应分析人员的要求快速、灵活地进行 大数据量的复杂处理,并且以一种直观易懂地形 式将查询结果提供给决策制定人
(1)联机事务处理(OLTP)
• OLTP的特点在于事务处理量大,应用要求
多个并行处理,事务处理内容比较简单且
重复率高。
• 大量的数据操作主要涉及的是一些增加、 删除、修改、查询等操作。每次操作的数 据量不大且多为当前的数据。
数据挖掘导论第章_分类_其他技术ppt课件

规则评估(续)
考虑规则的支持度计数的评估度量 规则的支持度计数对应于它所覆盖的正例数 FOIL信息增益(First Order Inductive Leaner information gain) 设规则r : A→+覆盖p0个正例和n0个反例; 规则r’: A B→+覆盖p1个正例和n1个反例.扩展后规则的FOIL信息 增益定义为
规则的准确率(accuracy) : 在满足规则前件的记录中, 满足规则后件的记录所占的 比例
规则: (Status=Single) No
Coverage = 40%, Accuracy = 50%
Tid Refund Marital Taxable Status Income Class
1 Yes 2 No 3 No 4 Yes 5 No 6 No 7 Yes 8 No 9 No 10 No
10
Single 125K No
Married 100K No
Single 70K
No
Married 120K No
Divorced 95K
Yes
Married 60K
No
Divorced 220K No
22
规则评估:例
例: 60个正例和100个反例 规则r1:覆盖50个正例和5个反例(acc = 90.9%) 规则r2:覆盖2个正例和0个反例 (acc = 100%)
使用准确率, r2好 使用似然比
r1 : 正类的期望频度为e+ = 5560/160 = 20.625 负类的期望频度为e = 55100/160 = 34.375
如果规则集不是互斥的 一个记录可能被多个规则触发 如何处理? 有序规则集 基于规则的序 vs 基于类的序 无序规则集 – 使用投票策略
数据挖掘导论第四章_924
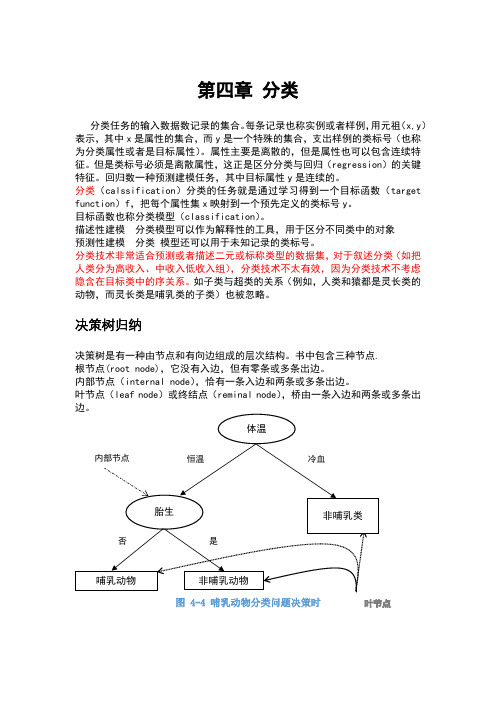
内部节点(internalnode),恰有一条入边和两条或多条出边。
叶节点(leafnode)或终结点(reminalnode),桥由一条入边和两条或多条出边。
图 4-4哺乳动物分类问题决策时
如何
Hunt算法
在Hunt算法中,通过训练记录相机划分成较纯的子集,以递归方式建立决策树。设 是与节点t相关联的训练记录集,而y={ }是类标号,Hunt算法的递归定义如下:
其中,k是决策树的结点数,e(T)是决策树的总训练误差, 是训练记录数, 是每个结点 对应的罚项。
最小描述长度原则:另一种结合模型复杂度的方法是基于称作最小描述长度(minimum description length, MDL)原则的信息论方法。为了解释说明该原则,考虑下图中的例子。在该例中,A和B都是已知属性x值得给定记录集。另外,A知道每个记录的确切类标号,而B却不知道这些信息。B可以通过要求A顺序传送类标号而获得每个记录的分类。一条消息需要θ(n)比特的信息,其中n是记录总数。
(1)如果 中所有的记录都属于同一个类 ,则t是叶节点,则用 标记。
(2)如果 中包含属于多个类的记录,则选择一个属性测试条件(attributetest condition),将记录划分成较小的子集。对于测试条件的每个输出,创建一个子女节点,并根据测试结果将 中的记录分布到子女节点中,然后,对于每个子女节点,递归的调用该算法。
建立决策树后,可以进行树剪枝(tree-pruning),以减小决策树的规模。决策树过大容易造成过分拟合(overfitting)。
算法特点
下面是对决策树归纳算法重要特点的总结。
1.决策树归纳是一种构建分类模型的非参数方法。它不需要任何先验假设,不假定类和其他属性服从一定的概率分布。
《数据挖掘导论》课件

详细描述
KNIME是一款基于可视化编程的数据挖掘工具,用户 可以通过拖拽和连接不同的数据流模块来构建数据挖掘 流程。它提供了丰富的数据挖掘和分析功能,包括分类 、聚类、关联规则挖掘、时间序列分析等,并支持多种 数据源和输出格式。
Microsoft Azure ML
总结词
云端的数据挖掘工具
详细描述
Microsoft Azure ML是微软Azure云平台上的数据挖掘工具,它提供了全面的数据挖掘和分析功能, 包括分类、聚类、关联规则挖掘、预测建模等。它支持多种数据源和输出格式,并提供了强大的可扩 展性和灵活性,方便用户在云端进行大规模的数据挖掘任务。
03
数据挖掘过程
数据准备
01
数据清洗
去除重复、错误或不完整的数据, 确保数据质量。
数据集成
将多个来源的数据整合到一个统一 的数据集。
03
02
数据转换
将数据从一种格式或结构转换为另 一种,以便于分析。
数据归一化
将数据缩放到特定范围,以消除规 模差异。
04
数据探索
数据可视化
通过图表、图形等展示数据的分布和关系。
序列模式挖掘
总结词
序列模式挖掘是一种无监督学习方法,用于 发现数据集中项之间具有时间顺序关系的有 趣模式。
详细描述
序列模式挖掘广泛应用于股票市场分析、气 候变化研究等领域。常见的序列模式挖掘算 法包括GSP、PrefixSpan等。这些算法通过 扫描数据集并找出项之间具有时间顺序关系 的模式,如“股票价格在某段时间内持续上
高维数据挖掘
高维数据的降维
高维数据的聚类和分类
利用降维技术如主成分分析、线性判 别分析等,将高维数据降维到低维空 间,以便更好地理解和分析数据。
《数据挖掘导论》教材配套教学PPT——第1章 认识数据挖掘

• 数据实例(Instance)
– 用于有指导学习的样本数据
• 训练实例(Training Instance)
– 用于训练的实例
• 检验实例(Test Instance)
– 分类模型建立完成后,经过检验实例进行检验,判断模型是否 能够很好地应用在未知实例的分类或预测中。
2022年3月23日星期三
第10页,共65页
Knowledge)
2022年3月23日星期三
第21页,共65页
1.4 专家系统
清华大学出版社
专家系统(Expert System)
• 一种具有“智能”的计算机软件系统。 • 能够模拟某个领域的人类专家的决策过程,解决那些需要人类专家
处理的复杂问题。 • 一般包含以规则形式表示的领域专家的知识和经验,系统就是利用
• 决策树有很多算法(第2章)
Sore-throat Yes Cooling-effect
Not good
Unknown Good
No
Cold Type=Viral (3/0)
Cold Type=Bacterial (4/1)
Cold Type=Viral (2/0)
Cold Type=Bacterial (1/0)
Sore-
throat 咽痛
Cooling-
effect 退热效果
Group 群体发病
Cold-type 感冒类型
1
Yes
2
No
3
Yes
4
Yes
5
No
6
No
7
No
8
Yes
9
Yes
10
Yes
No
Yes
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
2.3.4特征创建
常常可以由原来的属性创建新的属性集,更有效地捕获数据集中的重要信息。三种创建新属性的相关方法:特征提取、映射数据到新的空间和特征构造。
特征提取(feature extraction):由原始数据数据创建新的特征集称作特征提取。最常用的特征提取技术都是高度针对具体领域的。因此,一旦数据挖掘用于一个相对较新的领域,一个关键任务就是开发新的特征和特征提取方法。
首先定义测量误差和数据收集错误,然后进一步考虑涉及测量误差的各种问题:噪声、伪像、偏倚、精度和准确度。最后讨论可能同时涉及测量和数据收集的数据质量问题:离群点、遗漏和不一致值、重复数据。
测量误差(measurement error)指测量过程中导致的问题。
数据收集错误(data collection error)指诸如遗漏数据对象或属性值,或不当的包含了其他数据对象等错误。
过滤方法(filter approach):使用某种独立于数据挖掘任务的方法,在数据挖掘算法运行前进行特征选择。
包装方法(wrapper approach):这些方法将目标数据挖掘算法作为黑盒,使用类似于前面介绍的理想算法,但通常不枚举所有可能的子集来找出最佳属性子集。
过滤方法和包装方法唯一的不同是它们使用了不同的特征子集评估方法。对于包装方法,子集评估使用目标数据挖掘算法;对于过滤方法,子集评估技术不同于目标数据挖掘算法。搜索策略可以不同,但是计算花费应当较低,并且应当找到最优或近似最优的特征子集。通常不可能同时满足这两个要求,因此需要这种权衡。搜索的一个不可缺少的组成部分是评估步骤,根据已经考虑的子集评价当前的特征子集。这需要一种评估度量,针对诸如分类或聚类等数据挖掘任务,确定属性特征子集的质量。对于过滤方法,这种度量试图预测实际的数据挖掘算法在给定的属性集上执行的效果如何;对于包装方法,评估包括实际运行目标数据挖掘应用,子集评估函数就是通常用于度量数据挖掘结果的判断标准。
这些是去重复(deduplication)需要考虑的问题。
注意:在某些情况下,两个或多个对象在数据库的属性度量上是相同的,但是仍然代表不同的对象。这种重复是合法的。
2.2.2关于应用
2.3
这一节主要讲采用哪些预处理步骤,让数据更加适合挖掘。下面就是我们要谈到的一些主要的方法:
●聚集
●抽样
●维规约
●特征子集选择
3.基于图形的数据
4.有序数据
2.2
数据挖掘使用的数据常常是为其他用途收集的,或者在收集是未明确其目的。因此,数据挖掘常常不能“在数据源头控制质量”。所以,数据挖掘着眼于两个方面:
1.数据质量问题的纠正和检测和纠正,通常也称作数据清理(data cleaning)
2.使用可以容忍低质量数据的算法
2.2.1测量和
数据挖掘导论前两
第一章绪论
本章主要就是从全局的角度来介绍一下数据挖掘的概念、数据额挖掘要解决的问题、数据挖掘的起源、数据额挖掘的任务、以及数据挖掘的应用前景。
第二章数据
数据对数据挖掘的成败至关重要。本章就是主要讨论一些数据相关的问题。
1.数据类型——数据的类型决定我们应使用何种工具和技术分析数据。还有:数据挖掘研究常常是为了适应新的应用领域和新的数据类型的需要而展开的。
2.3.5离散化
有些数据挖掘算法,特别是某些分类算法,要求数据是分类属性形式。发现关联模式的算法要求数据是二元属性形式。这样,常常需要将连续属性变换成分类属性(离散化,discretization),并且连续和离散属性可能都需要变换成一个或多个二原属性(二元化,binarization)。另外,如果一个分类属性具有大量不同值(类别),或者某些值出现不频繁,则对于某些数据任务,通过合并某些值减少类别的数目可能是有益的。
用于分类的离散化方法之间的根本区别在于是否使用类信息。如果不适用类信息,我们称之为非监督(unsupervised)离散化,主要方法有:等宽(equal width)和等深(equal depth)或称等频率(equal frequency)。等宽将属性的值域划分成具有相同宽度的区间。等深和等频率将相同数量的对象放进每个区间。前者可能受离群点的影响而性能不佳。
注意:使用诸如K均值等聚类算法也是非监督离散化的另一种思路。目测检查数据有时也可能是一个有效的方法。
监督离散化:记住最终目的并使用附加的信息(类标号)常常能够产生更好的结果。因为未使用类标号知识所构造的区间常常包含混合的类标号。一种概念上简单的方法是以极大化区间纯度的方式确定分割点。但是,实践中这种方法可能需要人为确定区间的纯度和最小区间的大小。为了解决这一问题,一些基于统计学的方法用每个属性值来分隔区间,并通过合并类似于根据统计检验得出的相邻区间来创建较大的区间。另外,基于熵的方法是最有前途的离散方法之一。在此简单介绍一下。
映射数据到新的空间:使用一种完全不同的视角挖掘数据可能揭示出重要和有趣的特征。如对于时间序列和其他类型的数据,傅里叶变换(Fourier transform)和小波变换(wavelet transform)都非常有用。
特征构造:有时,原始数据集的特征具有必要的信息,但其形式不适合数据挖掘算法。在这种情况下,一个或多个由原特征构造的新特征可能比原特征更有用。比如:在区分材料时,密度(质量/体积)比质量和体积本身都有意义。
最佳的离散化和二元化方法是“对于用来分析数据的数据挖掘算法,产生最好结果”的方法。但直接使用这种标准是不实际的。离散化和二元化要满足的判别标准与所考虑的数据挖掘任务的性能好坏直接相关。
二元化:一种分类属性二元化的简单技术如下,如果有m个分类值,则将每个原始值唯一地赋予区间[0,m-1]中的一个整数。如果属性是有序的,则赋值必须保持序关系。(注意:即使属性原来用整数表示,但如果这些整数不在区间[0,m-1]中,则该过程也是必须的。)然后,将这m个整数的每一个都变换为二进制数。由于需要 个二进制位表示这些Байду номын сангаас数,因此需要使用n个二元属性表示这些二进制数。这样的变化可能导致复杂化,如无意中建立了转换后的属性之间的联系。
属性
1.什么是属性
数据集可以看作数据对象的集合。数据对象用一组刻画对象基本特性的属性来描述。属性是对象的性质或特性,它因对象而异,或随时间而变化。
2.属性类型
属性的类型:标称(nominal)、序数(ordinal)、区间(interval)和比率(ratio)。
3.用值的个性描述属性
离散的、连续的
噪声是测量误差的随机部分。
伪像(artifact)是数据错误造成的一种确定的现象的结果。(不是随机的)
精度(precision):(同一个量的)重复测量值之间的接近程度。通常以标准差度量。
偏倚(bias):测量值与被测量之间的系统的变差。通常以均值度量。
准确率(accuracy):被测量的测量值与实际值之间的接近程度。有效数字(significant digit)是准确率的一个重要方面。
4.非对称属性
只有非零值重要的属性才是非对称性的属性,我的理解就是属性的值的重要性不是对称。
数据集的
1.数据集的一般特性
维度(dimensionality)、稀疏性(sparsity)、分辨率(resolution)。
2.记录数据
许多数据挖掘的任务都假定数据集是记录(数据对象)的汇集,每个记录包含固定的数据字段(属性)集。
2.3.2抽样
1.抽样方法
1)无放回抽样
2)有放回抽样
2.渐进抽样
合适的样本容量可能很难确定,因此有时需要使用自适应抽样或者渐进抽样方法。这些方法从一个小样本开始然后增加样本容量直至得到足够容量的样本,尽管这种技术不需要在开始就确定样本容量,但是需要评估样本的方法,确定它是否足够大。
例如,假定使用渐进抽样来学习一个预测模型。尽管预测模型的准确率随着样本容量增加,但是在某一点的准确率的增加趋于稳定。我们希望在稳定点停止增加样本容量。通过掌握模型准确率岁样本增大的变化情况,并通过选取接近于当前样本容量的其他的样本,我们可以估计出于稳定点的接近程度,从而停止抽样。
2.数据质量——原始数据必须加以处理才能适合与分析。处理一方面是要提高数据的质量,另一方面要让数据更好地适应特定的数据挖掘技术或工具。
3.根据数据联系分析数据——数据分析的一种方法是找出数据对象之间的联系,之后使用这些联系而不是数据对象本身来进行其余的分析。有一点必须要强调的是在我们进行分析数据时,要深入了解数据,多观察数据,这个步骤在分析完数据得到实验结果之后更要回过头去观察数据,这一点特别重要!
不一致的值:无论造成不一致值得原因是什么,重要的是能检测出来,并且可能的话,纠正这种错误。
重复数据:数据集可能包含重复或几乎重复的数据对象。为了检测并删除这种重复,必须处理两个主要问题:
1.如果两个对象实际代表同一个对象,则对应的属性值必然不同(否则它们是完全相同的一条记录),必须解决不一致的值。
2.需要避免意外地将两个相似但并非重复的数据对象合并在一起。
2.3.3维规约
违规约有许多方面的好处。关键的好处是,如果维度(数据属性的个数)较低,许多数据挖掘算法的效果就会更好。这一部分是因为维规约可以删除不相关的特征并降低噪声,一部分是因为维规约可以删除不相关的特征并降低噪声,一部分是因为维灾难。
1.维灾难
随着数据维度的增加,许多数据分析变得非常困难。特别是随着维度增加,数据在它所占据的空间中越来越稀疏。对于分类,这可能意味没有足够的数据对象来常见模型,将所有可能的对象可靠的指派到一个类。对于聚类,点之间的密度和距离的定义失去了意义。结果是,对于高维数据,许多分类和聚类算法的结果都不理想(分类准确率降低,聚类质量下降)。
特征选择的理想方法是:将所有可能的特征子集作为感兴趣的数据挖掘算法的输入,然后选取产生最好结果的子集。但是,由于涉及n个属性子集多达 个。因此,需要其他策略。有三种标准的特征选择方法:嵌入、过滤和包装。