数据分析算法与模型(一)(附答案)
python数据分析课后习题精选全文完整版

python数据分析课后习题B. 数据合并按照合并轴⽅向主要分为左连接、右连接、内连接和外连接C. 预处理过程主要包括数据清洗、数据合并、数据标准化和数据转换,它们之间存在交叉,没有严格的先后关系D. 数据标准化的主要对象是类别型的特征3. (单选题)以下关于缺失值检测的说法中,正确的是(B)。
A. null 和 notnull 可以对缺失值进⾏处理B. dropna⽅法既可以删除观测记录,亦可以删除特征C. fillna⽅法中⽤来替换缺失值的值只能是数据框D. pandas 库中的interpolate 模块包含了多种插值⽅法4. (单选题)关于标准差标准化,下列说法中错误的是(B)。
A. 经过该⽅法处理后的数据均值为0,标准差为1B. 可能会改变数据的分布情况C.Python中可⾃定义该⽅法实现函数:def StandardScaler(data):data=(data-data.mean())/data.std()return dataD. 计算公式为X*=(X-`X)/σ5. (单选题)以下关于pandas数据预处理说法正确的是(D)。
A. pandas没有做哑变量的函数B. 在不导⼈其他库的情况下,仅仅使⽤pandas 就可实现聚类分析离散化C. pandas 可以实现所有的数据预处理操作D. cut 函数默认情况下做的是等宽法离散化6. (单选题)以下关于异常值检测的说法中错误的是(D)。
A. 3σ原则利⽤了统计学中⼩概率事件的原理B. 使⽤箱线图⽅法时要求数据服从或近似服从正态分布C. 基于聚类的⽅法可以进⾏离群点检测D. 基于分类的⽅法可以进⾏离群点检测7. (单选题)有⼀份数据,需要查看数据的类型,并将部分数据做强制类型转换,以及对数值型数据做基本的描述性分析。
下列的步骤和⽅法正确的是(A)。
A. dtypes 查看类型,astype 转换类别,describe 描述性统计B. astype 查看类型,dtypes转换类别,describe描述性统计C. describe查看类型,astype转换类别,dtypes描述性统计D. dtypes 查看类型,describe 转换类别,astype 描述性统计8. (单选题)下列与标准化⽅法有关的说法中错误的是(A)。
算法设计与分析历年期末试题整理_含答案_

《算法设计与分析》历年期末试题整理(含答案)(1)用计算机求解问题的步骤:1、问题分析2、数学模型建立3、算法设计与选择4、算法指标5、算法分析6、算法实现7、程序调试8、结果整理文档编制(2)算法定义:算法是指在解决问题时,按照某种机械步骤一定可以得到问题结果的处理过程(3)算法的三要素1、操作2、控制结构3、数据结构算法具有以下5 个属性:有穷性:一个算法必须总是在执行有穷步之后结束,且每一步都在有穷时间内完成。
确定性:算法中每一条指令必须有确切的含义。
不存在二义性。
只有一个入口和一个出口可行性:一个算法是可行的就是算法描述的操作是可以通过已经实现的基本运算执行有限次来实现的。
输入:一个算法有零个或多个输入,这些输入取自于某个特定对象的集合。
输出:一个算法有一个或多个输出,这些输出同输入有着某些特定关系的量。
算法设计的质量指标:正确性:算法应满足具体问题的需求;可读性:算法应该好读,以有利于读者对程序的理解;健壮性:算法应具有容错处理,当输入为非法数据时,算法应对其作出反应,而不是产生莫名其妙的输出结果。
效率与存储量需求:效率指的是算法执行的时间;存储量需求指算法执行过程中所需要的最大存储空间。
一般这两者与问题的规模有关。
经常采用的算法主要有迭代法、分而治之法、贪婪法、动态规划法、回溯法、分支限界法迭代法也称“辗转法”,是一种不断用变量的旧值递推出新值的解决问题的方法。
利用迭代算法解决问题,需要做好以下三个方面的工作:一、确定迭代模型。
在可以用迭代算法解决的问题中,至少存在一个直接或间接地不断由旧值递推出新值的变量,这个变量就是迭代变量。
二、建立迭代关系式。
所谓迭代关系式,指如何从变量的前一个值推出其下一个值的公式(或关系)。
迭代关系式的建立是解决迭代问题的关键,通常可以使用递推或倒推的方法来完成。
三、对迭代过程进行控制。
在什么时候结束迭代过程?这是编写迭代程序必须考虑的问题。
不能让迭代过程无休止地重复执行下去。
北语网院20春《算法与数据分析》作业_1答案

(单选)1:下列随机算法中运行时有时候成功有时候失败的是A:数值概率算法
B:舍伍德算法
C:拉斯维加斯算法
D:蒙特卡罗算法
正确答案:C
(单选)2:最长公共子序列算法利用的算法是
A:分支界限法
B:动态规划法
C:贪心法
D:回溯法
正确答案:B
(单选)3:矩阵连乘问题的算法可由什么设计实现
A:分支界限算法
B:动态规划算法
C:贪心算法
D:回溯算法
正确答案:B
(单选)4:下列哪一种算法不是随机化算法
A:蒙特卡罗算法
B:.拉斯维加斯算法
C:.动态规划算法
D:.舍伍德算法
正确答案:C
(单选)5:贪心算法与动态规划算法的共同点是
A:重叠子问题
B:构造最优解
C:贪心选择性质
D:最优子结构性质
正确答案:D
(单选)6:下面哪种函数是回溯法中为避免无效搜索采取的策略A:递归函数
B:.剪枝函数
C:。
随机数函数
D:.搜索函数
正确答案:B
(单选)7:采用最大效益优先搜索方式的算法是
A:分支界限法。
全球数据分析一级考试Python试题及答案

全球数据分析一级考试Python试题及答案本文档包含了全球数据分析一级考试的Python试题及其答案,旨在帮助考生进行复习和自测。
试题请根据以下试题要求,编写Python代码。
试题1编写一个Python函数,实现求两个数的最大公约数(GCD)。
试题2使用Python实现一个冒泡排序算法。
试题3编写一个Python函数,读取一个CSV文件,并返回文件中数值型列的平均值、中位数和标准差。
试题4使用Python和Pandas库对以下数据集进行操作:1. 计算每个人的工资增长率。
2. 将工资从低到高进行排序。
3. 删除年龄小于30岁的数据。
答案答案1def gcd(a, b):while b:a, b = b, a % breturn a答案2def bubble_sort(arr):n = len(arr)for i in range(n):for j in range(0, n-i-1):if arr[j] > arr[j+1]:arr[j], arr[j+1] = arr[j+1], arr[j] return arr答案3import csvimport numpy as npdef read_csv_and_calculate(file_path):with open(file_path, 'r') as f:reader = csv.DictReader(f)data = [row for row in reader]numeric_cols = [col for col in data[0].keys() if data[0][col].isdigit()] numeric_data = [list(row.values()) for row in data]avg = np.mean([float(row[col]) for row in numeric_data for col in numeric_cols])median = np.median([float(row[col]) for row in numeric_data for col in numeric_cols])std_dev = np.std([float(row[col]) for row in numeric_data for col in numeric_cols])return avg, median, std_dev答案4import pandas as pddata = {'Name': ['Alice', 'Bob', 'Carol', 'Dave'],'Age': [24, 30, 28, 35],'Salary': [70000, 80000, 90000, 100000]}df = pd.DataFrame(data)计算每个人的工资增长率df['Salary Growth Rate'] = df['Salary'] / df['Salary'].shift(1) - 1将工资从低到高进行排序df = df.sort_values(by='Salary', ascending=False)删除年龄小于30岁的数据df = df[df['Age'] >= 30]print(df)。
数据结构与算法分析课后习题解答
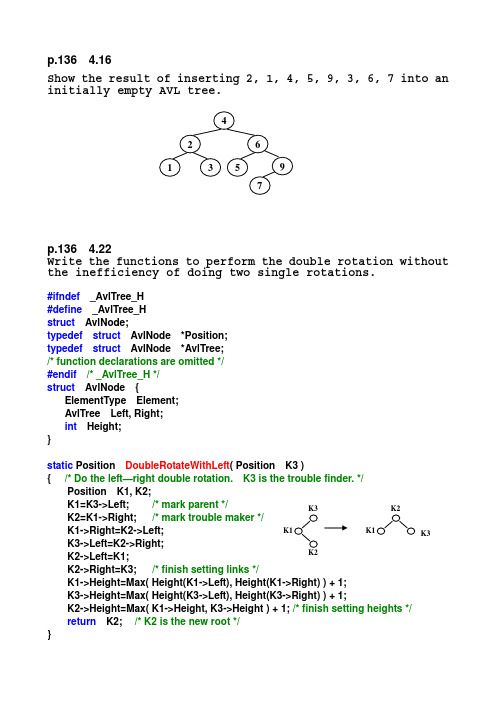
p.136 4.16Show the result of inserting 2, 1, 4, 5, 9, 3, 6, 7 into an initially empty AVL tree.p.136 4.22Write the functions to perform the double rotation without the inefficiency of doing two single rotations.#ifndef _AvlTree_H #define _AvlTree_H struct AvlNode;typedef struct AvlNode *Position; typedef struct AvlNode *AvlTree; /* function declarations are omitted */ #endif /* _AvlTree_H */ struct AvlNode { ElementType Element; AvlTree Left, Right; int Height; }static Position DoubleRotateWithLeft ( Position K3 ){ /* Do the left—right double rotation. K3 is the trouble finder. */ Position K1, K2;K1=K3->Left; /* mark parent */ K2=K1->Right; /* mark trouble maker */K1->Right=K2->Left;K3->Left=K2->Right;K2->Left=K1;K2->Right=K3; /* finish setting links */ K1->Height=Max( Height(K1->Left), Height(K1->Right) ) + 1; K3->Height=Max( Height(K3->Left), Height(K3->Right) ) + 1; K2->Height=Max( K1->Height, K3->Height ) + 1; /* finish setting heights */ return K2; /* K2 is the new root */ }K3static Position DoubleRotateWithRight( Position K1 ){ /* Do the right--left double rotation. K1 is the trouble finder. */Position K2, K3; /* Similar to the above function */K3=K1->Right;K2=K3->Left;K1->Right=K2->Left;K3->Left=K2->Right;K2->Left=K1;K2->Right=K3;K1->Height=Max( Height(K1->Left), Height(K1->Right) ) + 1;K3->Height=Max( Height(K3->Left), Height(K3->Right) ) + 1;K2->Height=Max( K1->Height, K3->Height ) + 1;return K2;}p.136 4.23Show the result of accessing the keys 3, 9, 1, 5 in order in the splay tree in Figure 4.61.Figure 4.61Result for 3:Result for 9:Result for 1:Result for 5:。
教科版( )信息技术必修一第5章 数据分析与人工智能单元知识点总结+检测(含部分答案)

第五单元数据分析与人工智能5.1走近数据分析一、学习目标:课本P1181、了解数据分析的几种常用方法2、体验对比分析和平均分析的一般分析过程3、了解大数据的含义,认识大数据分析在信息社会的重要作用。
二、知识梳理:1.数据分析:课本P119数据分析是指用恰当的统计分析方法对收集来的大量数据进行分析,提取有用信息,并形成结论的过程。
2.数据分析的方法:课本P119对比分析:指将两个或两个以上的数据进行比较,分析它们的差异,从而揭示这些数据所代表的事物发展变化情况和规律。
对比分为横向对比和纵向对比。
平均分析:是运用计算平均值的方法,来反映总体在一定时间、地点条件下某一数量特征的一般水平。
3.数据可视化表达:课本P120以图形、图像和动画等方式更加直观生动地呈现数据及数据分析结果,揭示数据之间的关系、趋势和规律等的表达方式称为数据可视化表达图表是最常用的数据可视化表达方式之一。
基本的图表类型有:柱形图、饼图和折线图.常用图表制作方法:选定表格的数据区域——插入图表——应用“图表向导”工具,根据需要选择不同类型的图表4.数据分析报告:数据分析报告是项目研究结果的展示,也是数据分析结论的有效承载形式. 课本P121数据分析报告的一般结构:分析报告标题分析目的、背景和来源分析思路、方法和模型分析过程、结论和建议5.大数据:课本P122大数据的特点:容量大、类型多、存取速度快、应用价值高大数据的意义:大数据的意义在于,我们有可能从如此庞大的数据中挖掘出有价值的数据,并运用于管理、农业、金融、医疗和教育等各个社会领域,为社会发展服务。
课本P123三、例题分析:选择题:1、某公司根据对上一年各个季度原材料供应商A 送货量及时率的分析及建模,预测本季度该供应商的订单履约率下降2%。
该过程最有可能用到的数据分析方法有?( )A.平均分析B.纵向对比分析C.横向对比分析D.一般分析2、要直观地展示某同学高二学年连续几次考试成绩的变化的情况,最合适的图表类型是(C)A.条形图B.柱状图C.饼图D.折线图3、数据分析的过程不包括()A.首先要根据分析的目标提出假设B.然后选择恰当的分析方法进行分析C.验证假设是否正确D.根据分析直接得出相应的结论填空题:4.大数据是以① 大、② 多、③快、④高为主要特征的数据集合,它正快速发展为对数量巨大、来源分散、格式多样的数据进行⑤、⑥和⑦,从中发现新知识,创造新价值、提升新能力的新一代信息技术和服务业态。
数据结构与算法分析课后习题答案

数据结构与算法分析课后习题答案【篇一:《数据结构与算法》课后习题答案】>2.3.2 判断题2.顺序存储的线性表可以按序号随机存取。
(√)4.线性表中的元素可以是各种各样的,但同一线性表中的数据元素具有相同的特性,因此属于同一数据对象。
(√)6.在线性表的链式存储结构中,逻辑上相邻的元素在物理位置上不一定相邻。
(√)8.在线性表的顺序存储结构中,插入和删除时移动元素的个数与该元素的位置有关。
(√)9.线性表的链式存储结构是用一组任意的存储单元来存储线性表中数据元素的。
(√)2.3.3 算法设计题1.设线性表存放在向量a[arrsize]的前elenum个分量中,且递增有序。
试写一算法,将x 插入到线性表的适当位置上,以保持线性表的有序性,并且分析算法的时间复杂度。
【提示】直接用题目中所给定的数据结构(顺序存储的思想是用物理上的相邻表示逻辑上的相邻,不一定将向量和表示线性表长度的变量封装成一个结构体),因为是顺序存储,分配的存储空间是固定大小的,所以首先确定是否还有存储空间,若有,则根据原线性表中元素的有序性,来确定插入元素的插入位置,后面的元素为它让出位置,(也可以从高下标端开始一边比较,一边移位)然后插入x ,最后修改表示表长的变量。
int insert (datatype a[],int *elenum,datatype x) /*设elenum为表的最大下标*/ {if (*elenum==arrsize-1) return 0; /*表已满,无法插入*/else {i=*elenum;while (i=0 a[i]x)/*边找位置边移动*/{a[i+1]=a[i];i--;}a[i+1]=x;/*找到的位置是插入位的下一位*/ (*elenum)++;return 1;/*插入成功*/}}时间复杂度为o(n)。
2.已知一顺序表a,其元素值非递减有序排列,编写一个算法删除顺序表中多余的值相同的元素。
大数据CPDA考试模拟样题—数据分析算法与模型

⼤数据CPDA考试模拟样题—数据分析算法与模型考试模拟样题—数据分析算法与模型⼀.计算题 (共4题,100.0分)1.下⾯是7个地区2000年的⼈均国内⽣产总值(GDP)和⼈均消费⽔平的统计数据:⼀元线性回归.xlsx⼀元线性回归预测.xlsx要求:(1)绘制散点图,并计算相关系数,说明⼆者之间的关系;(2)⼈均GDP作⾃变量,⼈均消费⽔平作因变量,利⽤最⼩⼆乘法求出估计的回归⽅程,并解释回归系数的实际意义;(3)计算判定系数,并解释其意义;(4)检验回归⽅程线性关系的显著性(a=0.05);(5)如果某地区的⼈均GDP为5000元,预测其⼈均消费⽔平;(6)求⼈均GDP为5000元时,⼈均消费⽔平95%的置信区间和预测区间。
(所有结果均保留三位⼩数)正确答案:(1)以⼈均GDP为x,⼈均消费⽔平为y绘制散点图,如下:⽤相关系数矩阵分析可求得相关系数为0.9981。
从图和相关系数都可以看出⼈均消费⽔平和⼈均国内⽣产总值(GDP)有⽐较强的正相关关系。
(2)以⼈均GDP作⾃变量,⼈均消费⽔平作因变量,做线性回归分析,得到回归⽅程如下:y = 0.3087x + 734.6928回归系数0.3087表⽰⼈均GDP每增加⼀个单位,⼈均消费⽔平⼤致增加0.3087个单位,⼈均GDP对⼈均消费⽔平的影响是正向的,⼈均GDP越⾼⼈均消费⽔平也越⾼。
(3)判定系数R⽅为0.9963,说明模型拟合效果很好。
(4)T检验和F检验的P值都⼩于0.05,线性关系显著。
(5)做预测分析可得,如果某地区的⼈均GDP为5000元,则其⼈均消费⽔平为2278.1066元。
(6)⼈均GDP为5000元时,由预测分析的结果可知,⼈均消费⽔平95%的置信区间为[1990.7491,2565.4640],预测区间为[1580.4632,2975.7500]。
2.根据以下给出的数据进⾏分析,本次给出鸢尾花数据,其中包含萼⽚长、萼⽚宽、花瓣长、花瓣宽、以及花的类型数据,请根据以下问题进⾏回答。
数据结构与算法题库(含参考答案)

数据结构与算法题库(含参考答案)一、单选题(共100题,每题1分,共100分)1、在一次校园活动中拍摄了很多数码照片,现需将这些照片整理到一个PowerPoint 演示文稿中,快速制作的最优操作方法是:A、创建一个 PowerPoint 相册文件。
B、创建一个 PowerPoint 演示文稿,然后批量插入图片。
C、创建一个 PowerPoint 演示文稿,然后在每页幻灯片中插入图片。
D、在文件夹中选中所有照片,然后单击鼠标右键直接发送到PowerPoint 演示文稿中。
正确答案:A2、下面对“对象”概念描述错误的是A、对象不具有封装性B、对象是属性和方法的封装体C、对象间的通信是靠消息传递D、一个对象是其对应类的实例正确答案:A3、设栈与队列初始状态为空。
首先A,B,C,D,E依次入栈,再F,G,H,I,J 依次入队;然后依次出队至队空,再依次出栈至栈空。
则输出序列为A、F,G,H,I,J,E,D,C,B,AB、E,D,C,B,A,J,I,H,G,FC、F,G,H,I,J,A,B,C,D,E,D、E,D,C,B,A,F,G,H,I,J正确答案:A4、设表的长度为 20。
则在最坏情况下,冒泡排序的比较次数为A、20B、19C、90D、190正确答案:D5、设二叉树的前序序列为 ABDEGHCFIJ,中序序列为 DBGEHACIFJ。
则后序序列为A、DGHEBIJFCAB、JIHGFEDCBAC、GHIJDEFBCAD、ABCDEFGHIJ正确答案:A6、Excel工作表B列保存了11位手机号码信息,为了保护个人隐私,需将手机号码的后 4 位均用“*”表示,以 B2 单元格为例,最优的操作方法是:A、=REPLACE(B2,7,4,"****")B、=REPLACE(B2,8,4,"****")C、=MID(B2,7,4,"****")D、=MID(B2,8,4,"****")第 10 组正确答案:B7、小金从网站上查到了最近一次全国人口普查的数据表格,他准备将这份表格中的数据引用到 Excel 中以便进一步分析,最优的操作方法是:A、通过 Excel 中的“自网站获取外部数据”功能,直接将网页上的表格导入到 Excel 工作表中。
《算法与数据结构》练习一(答案)

习题一一、选择题1、数据结构是一门研究非数值计算的程序设计问题中的操作对象以及它们之间的(B)和运算的学科。
A.结构B.关系C.运算D.算法2、在数据结构中,从逻辑上可以把数据结构分成(C)。
A.动态结构和静态结构B.紧凑结构和非紧凑结构C.线性结构和非线性结构D.逻辑结构和存储结构3、线性表的逻辑顺序和存储顺序总是一致的,这种说法(B)。
A.正确B.不正确C.无法确定D.以上答案都不对4、算法分析的目的是(C)。
A.找出算法的合理性B.研究算法的输人与输出关系C.分析算法的有效性以求改进D.分析算法的易懂性二、填空题1、数据是信息的载体,是对客观事物的符号表示,它能够被计算机识别、存储、加工和处理,数据是对能够有效的输人到计算机中并且能够被计算机处理的符号的总称。
例如,数学中所用到的整数和实数,文本编辑所用到的字符串等。
2、数据元素是数据的基本单位,有些情况下也称为元素、结点、顶点、记录等。
3、数据项是数据不可分割的最小单元,是具有独立含义的最小标识单位。
例如构成一个数据元素的字段、域、属性等都可称之为_数据项。
4、简而言之,数据结构是数据之间的相互关系,即数据的组织形式。
5、数据的逻辑结构是指数据之间的逻辑关系。
逻辑结构是从逻辑关系上描述数据,它与具体存储无关,是独立于计算机的。
因此逻辑结构可以看作是从具体问题抽象出来的数学模型。
6、数据的存储结构指数据元素及其关系在计算机存储器内的表示。
存储结构是逻辑结构在计算机里的实现,也称之为映像。
7、数据的运算是指对数据施加的操作。
它定义在数据的逻辑结构之上,每种逻辑结构都有一个数据的运算。
常用的有:查找、排序、插人、删除、更新等操作。
8、数据逻辑结构可以分为四种基本的类型,集合结构中的元素除了仅仅只是同属于一个集合_,不存在什么关系。
9、数据逻辑结构的四种基本类型中,线性结构_中的元素是一种一对一的关系,这种结构的特征是:若结构是非空集,则有且只有一个开始结点和一个终端结点,并且所有结点最多只能有一个直接前驱和一个直接后继。
数据分析及应用试题库与答案

数据分析及应用试题库与答案一、单选题(共30题,每题1分,共30分)1、python源程序执行的方式A、A 编译执行B、B 解析执行C、C 直接执行D、D 边编译边执行正确答案:B2、实现最长公共子序列利用的算法是()A、A 分治策略B、B 动态规划法C、C 贪心法D、D 回溯法正确答案:B3、以下哪些选项为真?A、A O(log(n))B、B O(n)C、C O(nlog(n))D、D O(n^2)正确答案:B4、for i in range(10,-1,)循环如果自然结束将执行循环内语句(?)次。
A、A 10B、B 9C、C 1D、D 0正确答案:D5、在结构化方法中,用数据流程图(DFD)作为描述工具的软件开发阶段是______。
A、A 可行性分析B、B 需求分析C、C 详细设计D、D 程序编码正确答案:B6、已知df为DataFrame对象,提取Pulse列中值大于100并且Calories列中值小于400的行,代码是:()A、A print(df[df( Calories )>300] & (df[ Calories ]B、B print(df[(df[ Pulse ]>100) &&(df[ Calories ]C、C print(df[(df[ Pulse ]>100) and (df[ Calories ]D、D print(df[(df[ Pulse ]>100) &(df[ Calories ]正确答案:D7、pow(2,2,3)返回值为()。
A、A 64B、B 64.0C、C 1D、D 1.0正确答案:C8、下列哪种说法是错误的A、A 除字典类型外,所有标准对象均可以用于布尔测试B、B 空字符串的布尔值是FalseC、C 空列表对象的布尔值是FalseD、D 值为0的任何数字对象的布尔值是False正确答案:A9、时间复杂度不受数据初始状态影响而恒为的是()。
数据分析方法与技术作业及答案

数据分析⽅法与技术作业及答案⼀、填写题(抄题,写答案)1.数据分析“六步曲”按顺序依次是:明确分析⽬的和内容、数据收集、数据处理、数据分析、数据展现、报告撰写。
2.定量数据⼀般可分为计量的、计数的、⼆种类型。
定性数据⼀般可分为有序的、名义的、⼆种类型。
3.数据收集⽅法总的可分为⼀⼿数据、⼆⼿数据、两⼤类。
前⼀类⽅法常⽤的具体⽅法有调查法、观察法、实验法;后⼀类⽅法常⽤的具体⽅法有机构查询、书刊查询、⽹络查询。
4.SPSS中有三种主要的⼯作窗⼝,它们是:数据编辑窗⼝、结果浏览窗⼝、程序编辑窗⼝;在进⾏数据表编辑时,有⼆种主要视图,它们是:数据视图、变量视图。
5.SPSS中对变量属性进⾏定义时,对变量的命名在Name 栏中设置,定义变量值标签在Values 栏中设置。
6.根据数据的计量性质,可以将数据分为定量的数据和定性的数据;根据数据获得的直接性,可以将数据分为⼀⼿数据和⼆⼿数据。
7.统计检验的⼀种思路是:设定原假设H0,构造相应的统计判断量,当根据实验数据或样本数据计算出的统计判断量落在拒绝区域,则拒绝原假设;反之,则落在接受区域,接受原假设。
在SPSS软件的统计操作中,通过计算样本数据的实际显著性概率Sig.,并将其与给定的显著性概率⽔平α⽐较,当Sig. < α时(填“>” 或“<” ),则拒绝原假设。
8.⽅差分析主要⽤来判断样本数据之间的差异是由不可控的随机因素造成的还是由研究中施加的对结果形成影响的可控因素造成的。
9.因⼦分析法是多元统计分析中处理降维的⼀种,其最主要的⼯作是降维,即将具有错综复杂关系的变量或者样品综合为数量较少的⼏个因⼦,以再现原始变量与因⼦之间的相互关系。
10.下图所⽰因⼦分析结果中,数值6.845的含义是第⼀主成分特征根,数值84.421的含义是前三个主成分的累计贡献率;在Extraction Sums块中,有三⾏数据,其含义是根据提取因⼦条件----特征值⼤于1,共选出了三个公共因⼦。
数据分析中的时间序列模型与预测算法

数据分析中的时间序列模型与预测算法随着互联网的发展,现代社会正呈现出一个数字化的趋势,海量的数据如雨后春笋一般涌现而来。
在这个背景下,数据分析成为了一种前所未有的重要工具,为我们揭示了很多之前未曾发现的规律和趋势。
而其中比较基础而且应用广泛的就是时间序列模型,并且还伴随着一系列广泛而深入的预测算法。
本文旨在探讨时间序列模型以及在其基础上的几种预测算法。
一、时间序列模型时间序列模型是一种描述一系列时间上的随机变量的模型。
例如可以表示成一个时间序列的有气温、股票价格、生产量等。
我们可以从这些数据中分析出长期趋势、季节性变化以及周期性变化等规律。
一般地,时间序列分析的步骤包括:观察数据、描述性统计、绘制图形、模型识别、参数估计和模型检验等。
其中比较常用的模型有AR、MA、ARMA、ARIMA等。
下面我们来简单介绍一下ARIMA模型。
1. ARIMA模型ARIMA模型(Autoregressive Integrated Moving Average model)是一种时间序列模型,广泛地应用于时间序列的分析与预测。
ARIMA模型是由三个过程组成的,即自回归过程(AR)、线性趋势过程(I)和移动平均过程(MA)。
其中,自回归过程 AR(p)是描述序列自身的特征,意味着当前时刻的序列值会受到p个前面时刻的值的影响,其中p代表使用几个前面的时刻。
移动平均过程 MA(q) 是描述序列的噪声,即与预测变量无关的随机误差,意味着当前时刻的序列值会受到最近q 个前面时刻噪声的影响,其中q代表使用几个前面的噪声误差。
而线性趋势过程 I(d) 是描述序列的非稳定性和趋势项,需要经过差分处理来得到平稳时间序列。
其中,d代表差分的次数。
ARIMA模型在使用时需要确定以下参数:p:自回归项的阶数;d:时间序列需要几次差分才能变为平稳;q:移动平均项的阶数。
确定了这些参数后,我们就可以对时序数据进行建模和预测。
二、预测算法在时间序列模型的基础上,我们还可以运用各种预测算法来预测未来的趋势和变化。
南开24年秋季《数据分析》作业参考一

24秋学期《数据分析》作业参考1.评价分类器效果时,表示正确分类的样本数与总样本数之比的指标是()。
选项A:准确率选项B:精确率选项C:召回率选项D:F1值参考答案:A2.并行算法包括()选项A:MapRedce选项B:关联分析选项C:KNN选项D:Kmeans参考答案:A3.文本中所有单词的出现情况表示了文本的()选项A:种类选项B:特征选项C:语义内容选项D:语义结构参考答案:C4.模型参数估计变为以()为目标函数的最优化问题选项A:交叉熵损失函数选项B:合页损失函数选项C:对数似然函数选项D:KL散度参考答案:C5.话题向量空间模型中,用()的一个向量表示该文本。
选项A:特征词选项B:话题空间选项C:语义空间选项D:词向量空间参考答案:B6.经典的Apriori算法是逐层扫描的,也就是说它是()优先的选项A:宽度选项B:深度参考答案:A7.为了计算中介度,必须计算所有边上()的数目。
选项A:所有路径选项B:最短路径选项C:结点入度选项D:节点出度参考答案:B8.数据产生方式变革中数据产生方式是被动的主要是来自哪个阶段()。
选项A:运营式系统阶段选项B:用户原创内容阶段选项C:感知式系统阶段参考答案:A9.向量空间模型中,用一个()表示语义选项A:向量选项B:特征选项C:数字选项D:距离参考答案:A10.逻辑斯谛函数是一条()曲线选项A:抛物线。
数据结构与算法(一)时间复杂度、空间复杂度计算

数据结构与算法(⼀)时间复杂度、空间复杂度计算⼀、时间复杂度计算1、时间复杂度的意义复杂度分析是整个算法学习的精髓,只要掌握了它,数据结构和算法的内容基本上就掌握了⼀半1. 测试结果⾮常依赖测试环境2. 测试结果受数据规模的影响很⼤所以,我们需要⼀个不⽤具体的测试数据来测试,就可以粗略地估计算法的执⾏效率的⽅法,即时间、空间复杂度分析⽅法。
2、⼤ O 复杂度表⽰法1)、可以将计算时间复杂度的⽅式和计算代码执⾏次数来进⾏类别int cal(int n) {int sum = 0;int i = 1;for (; i <= n; ++i) {sum = sum + i;}return sum;}第 2、3 ⾏代码分别需要 1 个 unit_time 的执⾏时间,第 4、5 ⾏都运⾏了 n 遍,所以需要 2n * unit_time 的执⾏时间,所以这段代码总的执⾏时间就是(2n+2) * unit_time。
可以看出来,所有代码的执⾏时间 T(n) 与每⾏代码的执⾏次数成正⽐。
2)、复杂⼀点的计算int cal(int n) { ----1int sum = 0; ----2int i = 1; ----3int j = 1; ----4for (; i <= n; ++i) { ----5j = 1; ----6for (; j <= n; ++j) { ----7sum = sum + i * j; ----8} ----9} ----10} ----11T(n) = (2n^2+2n+3)unit_timeT(n)=O(f(n))⼤ O 时间复杂度实际上并不具体表⽰代码真正的执⾏时间,⽽是表⽰代码执⾏时间随数据规模增长的变化趋势,所以,也叫作渐进时间复杂度(asymptotic time complexity),简称时间复杂度2、时间复杂度计算法则1. 只关注循环执⾏次数最多的⼀段代码2. 加法法则:总复杂度等于量级最⼤的那段代码的复杂度如果 T1(n)=O(f(n)),T2(n)=O(g(n));那么 T(n)=T1(n)+T2(n)=max(O(f(n)), O(g(n))) =O(max(f(n), g(n))).3. 乘法法则:嵌套代码的复杂度等于嵌套内外代码复杂度的乘积T(n) = T1(n) * T2(n) = O(n*n) = O(n2)3、常见的是时间复杂度复杂度量级(递增)排列公式常量阶O(1)对数阶O(logn)线性阶O(n)线性对数阶O(nlogn)平⽅阶、⽴⽅阶...K次⽅阶O(n2),O(n3),O(n^k)指数阶O(2^n)阶乘阶O(n!)①. O(1):代码的执⾏时间和n没有关系,⼀般情况下,只要算法中不存在循环语句、递归语句,即使有成千上万⾏的代码,其时间复杂度也是Ο(1);②. O(logn)、O(nlogn)i=1;while (i <= n) {i = i * 2;}通过 2x=n 求解 x 这个问题我们想⾼中应该就学过了,我就不多说了。
数据分析及应用试题库及答案

数据分析及应用试题库及答案一、单选题(共40题,每题1分,共40分)1、Matplotlib中的绘制散点图scatter()方法,表示点的透明度的参数是()A、A markerB、B sC、C cD、D alpha正确答案:D2、某算法的时间复杂度为,表明该算法的A、A 问题规模是n^2B、B 执行时间等于n^2C、C 执行时间与n^2成正相关D、D 问题规模与n^2成正比正确答案:C3、求解斐波那契数列第n项的算法最小的时间复杂度为()。
A、A O(N!)B、B O(N^N)C、C O(N)D、D O(LogN)正确答案:D4、神经网络模型训练时,依赖于以下哪一种法则进行参数计算?A、A 最大值法则B、B 最小值法则C、C 链式求导法则D、D 平均求导法则正确答案:C5、np.array([[1,2],[3]]).tolist()=(?)A、A [1 2 3]B、B [[1,2],[3]]C、C [[1 2],[3]]D、D 程序报错正确答案:D6、一所大学内的各年纪人数分别为:一年级200人,二年级160人,三年级130人,四年级110人。
则年级属性的众数是: ()A、A 一年级B、B 二年级C、C 三年级D、D 四年级正确答案:A7、直接插入排序在最好情况下的时间复杂度为A、A 问题规模是n2B、B 执⾏时间等于n2C、C 执⾏时间与n2成正⾏D、D 问题规模与n2成正⾏正确答案:C8、Python文件的后缀名是()。
A、A .docB、B .vbpC、C .pyD、D .exe正确答案:C9、软件按功能可以分为应用软件、系统软件和支撑软件(或工具软件)。
下面属于应用软件的是______。
A、A 学生成绩管理系统B、B C语言编译程序C、C UNIX操作系统D、D 数据库管理系统正确答案:A10、假设在今日头条里面,有很多工作人员检查新闻是不是属于虚假新闻,所有新闻真实率到达了98%,工作人员在检验一个真实的新闻把它检验为一个虚假的新闻的概率为2%,而一个虚假的新闻被检验为真实的新闻的概率为5%.那么,一个被检验为真实的新闻确实是真实的新闻的概率是多大?A、A 0.9991B、B 0.9989C、C 0.9855D、D 0.96正确答案:B11、设某汽车站在某一时间区间内的候车人数服从参数为5的泊松分布,候车人数多于10人的概率A、A 0.2B、B 0.05C、C 0.013695D、D 0.28正确答案:C12、循环队列的存储空间为Q(1:100),初始状态为front=rear=100。
数据结构与算法习题含参考答案

数据结构与算法习题含参考答案一、单选题(共100题,每题1分,共100分)1、要为 Word 2010 格式的论文添加索引,如果索引项已经以表格形式保存在另一个 Word文档中,最快捷的操作方法是:A、在 Word 格式论文中,逐一标记索引项,然后插入索引B、直接将以表格形式保存在另一个 Word 文档中的索引项复制到 Word 格式论文中C、在 Word 格式论文中,使用自动插入索引功能,从另外保存 Word 索引项的文件中插D、在 Word 格式论文中,使用自动标记功能批量标记索引项,然后插入索引正确答案:D2、下面不属于计算机软件构成要素的是A、文档B、程序C、数据D、开发方法正确答案:D3、JAVA 属于:A、操作系统B、办公软件C、数据库系统D、计算机语言正确答案:D4、在 PowerPoint 演示文稿中,不可以使用的对象是:A、图片B、超链接C、视频D、书签第 6 组正确答案:D5、下列叙述中正确的是A、软件过程是软件开发过程和软件维护过程B、软件过程是软件开发过程C、软件过程是把输入转化为输出的一组彼此相关的资源和活动D、软件过程是软件维护过程正确答案:C6、在 Word 中,不能作为文本转换为表格的分隔符的是:A、@B、制表符C、段落标记D、##正确答案:D7、某企业为了建设一个可供客户在互联网上浏览的网站,需要申请一个:A、密码B、门牌号C、域名D、邮编正确答案:C8、面向对象方法中,将数据和操作置于对象的统一体中的实现方式是A、隐藏第 42 组B、抽象C、结合D、封装正确答案:D9、下面属于整数类 I 实例的是A、-919B、0.919C、919E+3D、919D-2正确答案:A10、定义课程的关系模式如下:Course (C#, Cn, Cr,prC1#, prC2#)(其属性分别为课程号、课程名、学分、先修课程号 1和先修课程号 2),并且不同课程可以同名,则该关系最高是A、BCNFB、2NFC、1NFD、3NF正确答案:A11、循环队列的存储空间为 Q(1:100),初始状态为 front=rear=100。
数据结构与算法分析习题及参考答案

四川大学计算机学院《数据结构与算法分析》课程模拟试卷及参考答案模拟试卷一一、单选题(每题2 分,共20分)1.以下数据结构中哪一个是线性结构?( )A. 有向图B. 队列C. 线索二叉树D. B树2.在一个单链表HL中,若要在当前由指针p指向的结点后面插入一个由q指向的结点,则执行如下( )语句序列。
A. p=q; p->next=q;B. p->next=q; q->next=p;C. p->next=q->next; p=q;D. q->next=p->next; p->next=q;3.以下哪一个不是队列的基本运算?()A. 在队列第i个元素之后插入一个元素B. 从队头删除一个元素C. 判断一个队列是否为空D.读取队头元素的值4.字符A、B、C依次进入一个栈,按出栈的先后顺序组成不同的字符串,至多可以组成( )个不同的字符串?A.14B.5C.6D.85.由权值分别为3,8,6,2A. 11 B.35 C. 19 D. 53以下6-8题基于图1。
6.该二叉树结点的前序遍历的序列为( )。
A.E、G、F、A、C、D、BB.E、A、G、C、F、B、DC.E、A、C、B、D、G、FD.E、G、A、C、D、F、B7.该二叉树结点的中序遍历的序列为( )。
A. A、B、C、D、E、G、FB. E、A、G、C、F、B、DC. E、A、C、B、D、G、FE.B、D、C、A、F、G、E8.该二叉树的按层遍历的序列为( )。
A.E、G、F、A、C、D、B B. E、A、C、B、D、G、FC. E、A、G、C、F、B、DD. E、G、A、C、D、F、B9.下面关于图的存储的叙述中正确的是( )。
A.用邻接表法存储图,占用的存储空间大小只与图中边数有关,而与结点个数无关B.用邻接表法存储图,占用的存储空间大小与图中边数和结点个数都有关C. 用邻接矩阵法存储图,占用的存储空间大小与图中结点个数和边数都有关D.用邻接矩阵法存储图,占用的存储空间大小只与图中边数有关,而与结点个数无关10.设有关键码序列(q,g,m,z,a,n,p,x,h),下面哪一个序列是从上述序列出发建堆的结果?( )A. a,g,h,m,n,p,q,x,zB. a,g,m,h,q,n,p,x,zC. g,m,q,a,n,p,x,h,zD. h,g,m,p,a,n,q,x,z二、填空题(每空1分,共26分)1.数据的物理结构被分为_________、________、__________和___________四种。
数据分析本科试题及答案

数据分析本科试题及答案一、单项选择题(每题2分,共20分)1. 数据分析中,用于描述数据集中趋势的统计量是()。
A. 方差B. 标准差C. 平均值D. 极差答案:C2. 以下哪个选项不是数据清洗的目的()。
A. 去除重复数据B. 纠正错误数据C. 增加数据量D. 识别并处理缺失值答案:C3. 在数据分析中,相关系数的取值范围是()。
A. -1到1之间B. 0到1之间C. -1到0之间D. 0到正无穷答案:A4. 以下哪个算法不是监督学习算法()。
A. 决策树B. 支持向量机C. K-均值聚类D. 逻辑回归答案:C5. 数据可视化中,用于展示数据分布情况的图表是()。
A. 散点图B. 折线图C. 柱状图D. 直方图答案:D6. 以下哪个选项是时间序列分析中常用的模型()。
A. 线性回归模型B. 逻辑回归模型C. ARIMA模型D. 神经网络模型答案:C7. 在数据分析中,用于识别异常值的方法是()。
A. 箱线图B. 相关系数C. 回归分析D. 聚类分析答案:A8. 以下哪个选项是描述性统计分析的内容()。
A. 预测未来趋势B. 识别数据模式C. 建立因果关系D. 计算数据的平均值答案:D9. 在数据分析中,用于评估分类模型性能的指标是()。
A. 均方误差B. 精确率C. 召回率D. 以上都是答案:D10. 以下哪个选项不是数据预处理的步骤()。
A. 数据清洗B. 特征选择C. 数据转换D. 模型训练答案:D二、多项选择题(每题3分,共15分)11. 数据分析中,以下哪些是数据转换的常见方法()。
A. 归一化B. 标准化C. 离散化D. 数据清洗答案:ABC12. 在数据分析中,以下哪些是特征选择的目的()。
A. 提高模型的准确性B. 减少计算复杂度C. 降低模型过拟合的风险D. 增加数据量答案:ABC13. 以下哪些是数据可视化中常用的图表类型()。
A. 散点图B. 热力图C. 树状图D. 饼图答案:ABCD14. 在数据分析中,以下哪些是数据挖掘的常见任务()。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
数据分析算法与模型模拟题(一)
一、计算题(共4题,100分)
1、影响中国人口自然增长率的因素有很多,据分析主要因素可能有:(1)从宏观经济上看,经济整体增长是人口自然增长的基本源泉;(2)居民消费水平,它的高低可能会间接影响人口增长率。
(3)文化程度,由于教育年限的高低,相应会转变人的传统观念,可能会间接影响人口自然增长率(4)人口分布,非农业与农业人口的比率也会对人口增长率有相应的影响。
为了全面反映中国“人口自然增长率”的全貌,选择人口增长率作为被解释变量,以反映中国人口的增长;选择“国名收入”及“人均GDP”作为经济整体增长的代表;选择“居民消费价格指数增长率”作为居民消费水平的代表。
暂不考虑文化程度及人口分布的影响。
从《中国统计年鉴》收集到以下数据(见表1):
表1 中国人口增长率及相关数据
年份人口自然增长率
(%。
)
国民总收入
(亿元)
居民消费价格指数增长
率(CPI)%
人均GDP
(元)
1988 15.73 15037 18.8 1366 1989 15.04 17001 18 1519 1990 14.39 18718 3.1 1644 1991 12.98 21826 3.4 1893 1992 11.6 26937 6.4 2311 1993 11.45 35260 14.7 2998 1994 11.21 48108 24.1 4044 1995 10.55 59811 17.1 5046 1996 10.42 70142 8.3 5846 1997 10.06 78061 2.8 6420 1998 9.14 83024 -0.8 6796 1999 8.18 88479 -1.4 7159 2000 7.58 98000 0.4 7858 2001 6.95 108068 0.7 8622 2002 6.45 119096 -0.8 9398 2003 6.01 135174 1.2 10542 2004 5.87 159587 3.9 12336 2005 5.89 184089 1.8 14040
2006 5.38 213132 1.5 16024 设定的线性回归模型为:
算法1多元线性回归.xlsx
(1)求出模型中的各个参数,试从多个角度评价此线性回归模型,并检验模型的经济意义;
(2)检验模型中是否存在多重共线性问题(逐步回归),若有,试消除多重共线性。
解:
(1)首先进行数据预处理,数据经检查,无缺失值,接着将数据导入dataHoop平台中,进行异常值检验等分析,数据基本正常,但是数据存在多重共线性,多重共线性将在第二问中详述。
然后对数据进行多元线性回归拟合,以人口自然增长率(Y)作为因变量,国民总收入(X1)、居民消费价格指数增长率(X2)和人均GDP(X3)作为自变量,得到拟合结果为:
Y = 14.7236 + 0.0003X1 + 0.0644X2 - 0.0052X3
调整R方为0.8831,F检验的p值为0,(常数项)t检验的p值为0,国民总收入t检验的p值为0.0427,居民消费价格指数增长率t检验的p值为0.1359,人均GDPt检验的p值为0.0243。
该模型解释为在其他变量不变的情况下,国民收入每增长1亿元,则人口增长率随之增长0.0003%;在其他变量不变的情况下,居民消费价格指数增长率每增长1%,则人口增长率随之增长0.0644%;在其他变量不变的情况下,人均GDP每增长1元,则人口增长率随之降低
0.0052%。
居民消费价格指数增长率CPI与人口增长率呈正增长与现实情况不符,说明模型反映出的统计学意义与实际情况不完全相符,可能是因为自变量之间存在共线性。
(2)发现国民收入与人均GDP相关系数高达0.9996,两个变量间极高度相关,因此得到回归方程存在多重共线性。
变量间的多重共性对基于最小二乘法的回归模型模拟结果有非常严重的影响,导致回归结果不准确。
采用“逐步回归法”对模型进行优化消除变量间的多重共线性。
分别对单个变量进行分析:
国民总收入(X1):
居民消费价格指数增长率(X2):
人均GDP(X3):
通过对比,X3的调整R方更高,且均通过检验,所以采用X3为基础变量;人均GDP(X3)和国民总收入(X1):
人均GDP(X3)和居民消费价格指数增长率(X2):
显然X1和X3的组合的调整R方更大,且均通过了检验。
人均GDP(X3)、国民总收入(X1)和居民消费价格指数增长率(X2):
当加入X2后,虽然调整R方有了一定的增加,但是X2的假设检验并没有通过,所以采用X1和X3两个变量的方程。
方程为:
Y = 15.7418 + 0.0004X1 – 0.0058X3
2、对近期上映的10部电影进行调查研究,抽取290人对这10部电影的评分(分值0~10分),结果如下表所示。
(1)根据表中数据对这10部电影的评分进行因子分析,并解析各个因子的含义;
(2)可否利用电影的评分数据对这290名观影者进行聚类分析?给出你的理由。
算法2因子分析.xlsx
解:(1)首先计算所有变量的相关系数矩阵,从结果可以看出,大部分的相关系数均大于0.3,所以,此数据适合做因子分析。
按因子为4个进行分析,结果得到第四个因子比例仅占比3%左右,所以该数据隐含因子设定为3个。
载荷矩阵如下:
所以,容易看出,第一因子为动作片,第二因子为爱情片,第三因子为动画片。
(2)同观众可能会偏好不同类型的电影,体现在对不同类型电影的评分不同。
因此可以利用电影评分数据对观众进行聚类分析。
3、某超市为了优化商品摆放结构,对近期顾客购买的商品类型进行了统计,如附表所示。
(1)写出所有有效强关联规则(minsupport=10%,minconfidence=50%);(2)结合实际情况分析顾客喜欢的商品搭配,并对该超市提出合理的建议。
算法3关联分析.xlsx
(1)支持度大于1的均为有效强关联规则。
数据无缺失值,几个变量(商品)的值为T/F,在DATEHOOP的关联分析中可被识别,故直接将数据导入datehoop对变量果蔬、鲜肉、奶制品、蔬菜制品、肉制品、冷冻食品、啤酒、红酒、软饮料、鱼类、糖果进行关联分析。
设置最小支持度为0.1、最小置信度为0.5,得到的强关联规则中提升度大于1的有效强关联规则如下所示:{冷冻食品}->{蔬菜制品},{蔬菜制品}->{冷冻食品},{啤酒}->{冷冻食品},{冷冻食品}->{啤酒},{啤酒}->{蔬菜制品},{蔬菜制品}->{啤酒},{鲜肉}->{红酒},{红酒}->{鲜肉},{冷冻食品,啤酒}->{蔬菜制品},{蔬菜制品,啤酒}->{冷冻食品},{蔬菜制品,冷冻食品}->{啤酒}
(2)由(1)可见,蔬菜制品、冷冻食品、啤酒之前存在较高的关联性,故建议将三类商品陈列区域互相临近;另,红酒与鲜肉之前存在较高的关联性,故建议将两类商品陈列区域互相临近。
4、某市为调查驾驶员视力情况(“1”表示视力正常,“0”表示有视力缺陷)、年龄、是否有驾驶教育经历(“1”表示有,“0”表示没有),这三个因素对是否曾引起交通事故(“1”表示发生过,“0”表示未发生过)的影响,随机抽样调查了45名驾驶员,得到数据如下:
(1)建立模型分析驾驶员视力情况、年龄、是否有驾驶教育经历对是否曾引起交通事故的影响,写出详细的思路过程。
(2)若要应用此模型预测某批驾驶员中可能会引起过交通事故的人都有哪些,则还需要进行的研究步骤有哪些?请说明。
算法4逻辑回归.xlsx
(1)数据类型是数值型的不需要数值化,而且不存在缺失值。
逻辑回归要考虑异常值的影响,以及变量是否存在共线性,因此我们进行异常值分析和相关性分析。
异常值分析发现异常值较多,猜测可能是分类的影响,因此不做处理。
由相关矩阵可看出变量之间虽然也有相关,但不是很强,因此可以进行逻辑回归。
以accident为因变量,视力状况、age、drive为自变量进行逻辑回归分析,分析结果如下:
得到逻辑回归方程ln(P(Yi)/(1-P(Yi))=-0.0819+-0.7412 x1+0.032x2-
1.4972x3
可以看到Accuracy、AUC、准确率召回率等都较大,模型拟合效果较好,训练误差不大。
(2)若想用此模型优化成为可以用来预测哪些人可能会引起过交通事故,则一方面需进一步丰富样本量(本题只有45个样本),在大样本量的基本上继续使用训练数据集、测试数据集训练模型的拟合度,直到泛化误差小到可接受的范围内,再进一步应用到预测中来。