SPSS软件实例应用(计量地理学课后题详解)
《统计分析与SPSS的应用(第五版)》课后练习答案(第3章)

《统计分析与SPSS的应用(第五版)》课后练习答案(第3章)第三章:统计分析与SPSS的应用(第五版) 课后练习答案第一节:描述性统计在本章的课后习题中,我们将通过SPSS软件进行一系列的统计分析。
本节将提供第三章的课后习题答案,通过展示实际的数据和分析结果,帮助读者更好地理解统计分析的应用和SPSS软件的操作。
1. 描述性统计分析题目:使用某城市2019年1月至12月的气温数据,计算月平均气温、最高气温和最低气温的描述性统计指标。
答案:通过SPSS导入数据,选择变量"月份"和"气温",并进行描述性统计分析。
结果显示,2019年1月至12月的气温数据的月平均气温、最高气温和最低气温的描述性统计指标如下:月平均气温:- 平均值:20°C- 标准差:2°C- 最小值:15°C- 最大值:25°C最高气温:- 平均值:28°C- 标准差:3°C- 最小值:22°C- 最大值:35°C最低气温:- 平均值:12°C- 标准差:2°C- 最小值:8°C- 最大值:18°C根据以上结果,我们可以得出结论:2019年该城市的月平均气温在20°C左右,最高气温在28°C左右,最低气温在12°C左右。
气温的变化范围相对较小,波动性较小。
这些结果可以帮助我们对该城市的气候情况进行初步了解。
2. 相关性分析题目:使用某企业2018年1月至12月的销售额和广告投入数据,计算销售额和广告投入之间的相关性。
答案:通过SPSS导入数据,选择变量"销售额"和"广告投入",并进行相关性分析。
结果显示,2018年1月至12月的销售额和广告投入之间的Pearson 相关系数为0.85,表明二者呈现强正相关关系。
《统计分析与SPSS的应用》课后练习答案

《统计分析与SPSS的应用》课后练习答案在学习《统计分析与 SPSS 的应用》这门课程后,通过课后练习能够帮助我们更好地掌握所学知识,并将其应用到实际的数据分析中。
以下是针对部分课后练习的答案及解析。
一、选择题1、在 SPSS 中,用于描述数据集中变量分布特征的统计量是()A 均值B 标准差C 中位数D 众数答案:ABCD解析:均值、标准差、中位数和众数都是描述数据分布特征的常用统计量。
均值反映了数据的集中趋势;标准差反映了数据的离散程度;中位数是将数据排序后位于中间位置的数值;众数则是数据集中出现次数最多的数值。
2、进行独立样本 t 检验时,需要满足的前提条件是()A 样本来自正态分布总体B 两样本方差相等C 两样本相互独立D 以上都是答案:D解析:独立样本 t 检验要求样本来自正态分布总体、两样本方差相等以及两样本相互独立。
只有在这些条件满足的情况下,t 检验的结果才是可靠的。
3、以下哪种方法适用于多组数据的比较()A 单因素方差分析B 配对样本 t 检验C 相关分析D 回归分析答案:A解析:单因素方差分析用于比较三个或三个以上组别的数据是否存在显著差异。
配对样本 t 检验适用于配对数据的比较;相关分析用于研究变量之间的线性关系;回归分析用于建立变量之间的预测模型。
二、简答题1、请简述 SPSS 中数据录入的基本步骤。
答:SPSS 中数据录入的基本步骤如下:(1)打开 SPSS 软件,选择“新建数据文件”。
(2)在变量视图中定义变量的名称、类型、宽度、小数位数等属性。
(3)切换到数据视图,按照定义好的变量逐行录入数据。
(4)录入完成后,保存数据文件。
2、解释相关分析和回归分析的区别。
答:相关分析主要用于研究两个或多个变量之间的线性关系程度和方向,但它并不确定变量之间的因果关系。
相关分析的结果通常用相关系数来表示,如皮尔逊相关系数。
回归分析则不仅可以确定变量之间的关系,还可以建立数学模型来预测因变量的值。
计量地理学

相关分析目的:揭示地理要素之间相互关系的密切程度。
实际操作:第一步,我们应该主观列出一些影响Y的一些X,选择相关分析的方法,如果只是两个要素之间的关系,我们采用简单相关,秩相关的方法,如果要是想研究多个要素之间的关系,我们可以采用偏相关和复相关的方法。
第二步,绘制散点图判断是否线性相关,进行正态性检验(检验方法:选用SPSS中的正态性检验功能,样本数>50选用K-S,<50选用S-W,sig值<0.05非正态,>0.05正态)。
第三步,计算相关系数。
如果正态性检验通过,我们就可以进行简单相关的分析(使用SPSS计算其Person 相关系数,绝对值越接近1表示相关性越强),正态性检验没有通过,选用秩相关的方法(秩相关是将两要素的样本值按数据的大小顺序排列位次,以各要素样本值的位次代替实际数据而求得的一种统计量)(使用SPSS软件计算Spearman系数)。
第四步,对所求系数进行显著性检验。
(|r|>rα,p<α,拒绝零假设,表示他们相关性显著。
其中P在SPSS中是P值下的Sig值,小于0.05拒绝零假设,大于0.05承认零假设。
r(相关系数)在实际中可以用查表法进行检验,注意其中f=n-2,这里容易出错误!)偏相关检验方法:常使用t检验的方法。
(|t|> tα, p<α,拒绝零假设,表示他们相关性显著。
需要自己计算t=偏相关系数/根号下(1-偏相关系数的平方)*根号下(n-m-1),n是样本数,m是自变量个数。
)*复相关系数检验方法:常使用F检验的方法。
(f> fα, p<α,拒绝零假设,表示他们相关性显著。
)回归分析目的:找出影响Y的影响源X,对以后的发展进行预测。
实际操作:第一步,如果只是研究两个变量之间的相关关系,我们可以选用一元线性回归模型,绘制散点图,选择线形回归还是非线性回归,如果是非线性那么我们化为线性进行参数结算,线性直接进行计算。
《统计分析及SPSS的应用(第五版)》课后练习答案解析(第5章)

统计分析与SPSS 的应用(第五版)》(薛薇)课后练习答案第 5 章SPSS 的参数检验1、某公司经理宣称他的雇员英语水平很高,如果按照英语六级考试的话,一般平均得分为75分。
现从雇员中随机选出11人参加考试,得分如下:80, 81, 72, 60, 78, 65, 56, 79, 77,87, 76 请问该经理的宣称是否可信。
原假设:样本均值等于总体均值即u=u0=75步骤:生成spss 数据→ 分析→ 比较均值→ 单样本t 检验→ 相关设置→ 输出结果(Analyze->compare means->one-samples T test ;)采用单样本T 检验(原假设H0:u=u0=75, 总体均值与检验值之间不存在显著差异);单个样本统计量N均值标准差均值的标准误成绩1173.739.551 2.880单个样本检验检验值= 75tdf Sig.(双侧)均值差值差分的95% 置信区间下限上限成绩-.44210.668-1.273-7.69 5.14分析:指定检验值: 在test 后的框中输入检验值(填75),最后ok!分析:N=11人的平均值(mean )为73.7 ,标准差(std.deviation )为9.55 ,均值标准误差均值标准误差(std errormean )为2.87. t 统计量观测值统计量观测值为-4.22 ,t 统计量观测值的双尾概率p-值(sig.(2-tailed ))为0.668 ,六七列是总体均值与原假设值差的95%的置信区间,为(-7.68,5.14), 由此采用双尾检验比较a 和p 。
T 统计量观测值的双尾概率p-值(sig.(2-tailed ))为0.66 8>a=0.05 所以不能拒绝原假设;且总体均值的95%的置信区间为(67.31,80.14), 所以均值在67.31~80.14 内,75 包括在置信区间内, 所以经理的话是可信的。
实验一、计量地理学软件简介

实验一、软件基本操作实验名称:软件基本操作实验目的:熟悉常用数学软件的界面与基本操作1、EXCEL数据分析插件常用EXCEL软件作为计算工具,来进行数据的描述性分析。
大多数安装OFFICE 时,都没有把EXCEL的统计函数安装上。
首先,检查一下是否已安装,打开“工具”查看是否有“数据分析”选项。
若没有需要添加该函数。
安装完毕后,打开“工具-加载宏-分析工具库”,确定以完成分析工具库插件的安装。
2、SPSS软件简介SPSS是“社会科学统计软件包”(Statistical Package for the Social Science)的简称,是一种集成化的计算机数据处理应用软件。
1.SPSS的安装点击SETUP完全安装。
一、双击setup.exe安装英文原版(SPSS13.0有汉化包)二、将regedit.exe复制到SPSS安装目录,双击后点击patch it!完成注册三、双击cn.exe,选择SPSS安装目录,应用汉化补丁2.SPSS的主要窗口和菜单SPSS软件的主窗口,从上到下为:(1)10个主要的下拉菜单:①文件(File);②编辑(Edit);③视图(View);④数据(Data);⑤转换(Transform);⑥统计分析(Statistics);⑦作图(Graphs);⑧工具(Utilities);⑨窗口转换(Windows);⑩帮助(Help)(2)快捷工具栏:小图标表示常用操作,如:打开、存盘等(3)数据输入栏:二维数据表(每列为一个变量;每行为一个案例)(4)“数据视图”与“变量视图”转换按钮。
3.建立数据表(1)定义变量点击左下方的Variable View标签切换到定义新变量界面。
变量名变量类型:类型TYPE包括:1、Numeric:数值型,同时定义数值的宽度(Width),即整数部分+小数点+小数部分的位数,默认为8位;定义小数位数(Decimal Places),默认为2位。
计量地理课后题答案

计量地理课后题答案文档编制序号:[KKIDT-LLE0828-LLETD298-POI08]徐建华版计量地理学第二章答案1.地理数据有哪几种类型,各种类型地理数据之间的区别和联系是什么答:地理数据就是用一定的测度方式描述和衡量地理对象的有关量化指标。
按类型可分为:1)空间数据:点数据,线数据,面数据;2)属性数据:数量标志数据,品质标志数据地理数据之间的区别与联系:数据包括空间数据和属性数据,空间数据的表达可以采用栅格和矢量两种形式。
空间数据表现了地理空间实体的位置、大小、形状、方向以及几何拓扑关系。
属性数据表现了空间实体的空间属性以外的其他属性特征,属性数据主要是对空间数据的说明。
如一个城市点,它的属性数据有人口,GDP,绿化率等等描述指标。
它们有密切的关系,两者互相结合才能将一个地理试题表达清楚。
2. 各种类型的地理数据的测度方法分别是什么地理数据主要包括空间数据和属性数据:空间数据——对于空间数据的表达,可以将其归纳为点、线、面三种几何实体以及描述它们之间空间联系的拓扑关系;属性数据——对于属性数据的表达,需要从数量标志数据和品质标志数据两方面进行描述。
其测度方法主要有:(1) 数量标志数据①间隔尺度(Interval Scale)数据: 以有量纲的数据形式表示测度对象在某种单位(量纲)下的绝对量。
②比例尺度(Ratio Scale)数据: 以无量纲的数据形式表示测度对象的相对量。
这种数据要求事先规定一个基点,然后将其它同类数据与基点数据相比较,换算为基点数据的比例。
(2) 品质标志数据①有序(Ordinal)数据。
当测度标准不是连续的量,而是只表示其顺序关系的数据,这种数据并不表示量的多少,而只是给出一个等级或次序。
②二元数据。
即用0、1 两个数据表示地理事物、地理现象或地理事件的是非判断问题。
③名义尺度(Nominal Scale)数据。
即用数字表示地理实体、地理要素、地理现象或地理事件的状态类型。
《统计分析报告方案设计与SPSS地的应用(第五版)》课后练习答案详解(第4章的)
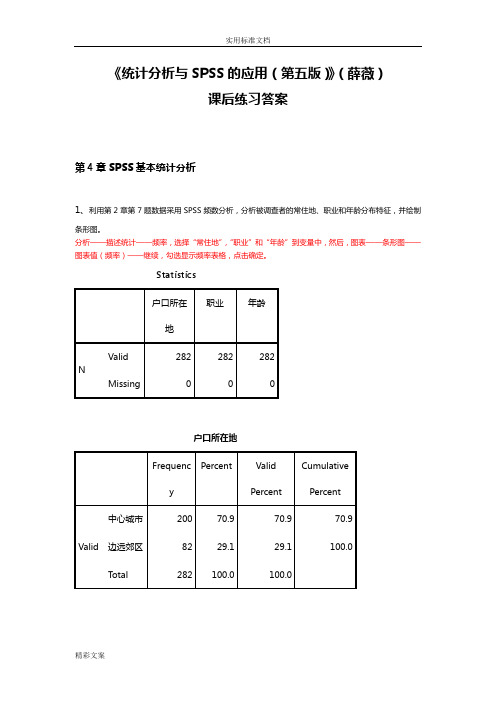
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第4章SPSS基本统计分析1、利用第2章第7题数据采用SPSS频数分析,分析被调查者的常住地、职业和年龄分布特征,并绘制条形图。
分析——描述统计——频率,选择“常住地”,“职业”和“年龄”到变量中,然后,图表——条形图——图表值(频率)——继续,勾选显示频率表格,点击确定。
Statistics户口所在地职业年龄NValid 282 282 282Missing 0 0 0户口所在地Frequency Percent ValidPercentCumulativePercentValid 中心城市200 70.9 70.9 70.9 边远郊区82 29.1 29.1 100.0 Total 282 100.0 100.0职业Frequency Percent ValidPercentCumulativePercentValid 国家机关24 8.5 8.5 8.5 商业服务业54 19.1 19.1 27.7 文教卫生18 6.4 6.4 34.0 公交建筑业15 5.3 5.3 39.4 经营性公司18 6.4 6.4 45.7 学校15 5.3 5.3 51.1 一般农户35 12.4 12.4 63.5 种粮棉专业户4 1.4 1.4 64.9 种果菜专业户10 3.5 3.5 68.4 工商运专业户34 12.1 12.1 80.5 退役人员17 6.0 6.0 86.5 金融机构35 12.4 12.4 98.9 现役军人 3 1.1 1.1 100.0 Total 282 100.0 100.0年龄Frequency Percent ValidPercentCumulativePercentValid 20岁以下4 1.4 1.4 1.4 20~35岁146 51.8 51.8 53.2 35~50岁91 32.3 32.3 85.5 50岁以上41 14.5 14.5 100.0 Total 282 100.0 100.0分析:本次调查的有效样本为282份。
《统计分析与SPSS的应用(第五版)》课后练习答案.doc(1)

《统计分析与SPSS的应用(第五版)》课后练习答案第一章练习题答案1、 SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是: Statistical Package for the SocialScience.(StatisticalProduct and Service Solutions)2、 SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、 SPSS的数据集:SPSS 运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
活动数据集:其中只有一个数据集为当前数据集。
SPSS 只对某时刻的当前数据集中的数据进行分析。
4、 SPSS的三种基本运行方式:完全窗口菜单方式、程序运行方式、混合运行方式。
完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
程序运行方式:是指在使用 SPSS的过程中,统计分析人员根据自己的需要,手工编写 SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
5、 .s av 混合运行方式:是前两者的综合。
是数据编辑器窗口中的SPSS数据文件的扩展名.spv 是结果查看器窗口中的SPSS分析结果文件的扩展名.sps 是语法窗口中的SPSS程序6、 SPSS 的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
7、概率抽样 (probability sampling) :也称随机抽样,是指按一定的概率以随机原则抽取样本,抽取样本时每个单位都有一定的机会被抽中,每个单位被抽中的概率是已知的,或是可以计算出来的。
计量地理学第6章作业题_参考答案

计量地理学第6章作业题_参考答案1. 证明题1)对于标准化的数据,任意两个长度为n 的向量x 和y 之间的相关系数可以表示为y x n r T1=. 任意两个m 列、n 行的矩阵X 和Y 之间的相关系数矩阵为Y X nR T1=, 式中R 为一个m *m 的方阵。
这里假定数据的排列都是从上到下为样品、从左到右为变量。
在因子分析中,因子模型可以表为如下矩阵方程形式EU FA Y +=,式中Y 为标准化的原始数据矩阵,F 为(标准化的)公因子得分矩阵,A 为公因子载荷,E 为单因子得分,U 为单因子载荷。
试证明公因子载荷矩阵为原始变量与公因子得分之间的相关系数矩阵。
2)已知主成分或者因子载荷为变量与主成分之间的相关系数。
对于长度为n 的两个变量而言,基于标准化数值的因子载荷矩阵可以表作⎥⎥⎥⎦⎤⎢⎢⎢⎣⎡=⎥⎦⎤⎢⎣⎡=22122111222112111111x f n xf n x f n x f n a a a a A T T T T. 将该矩阵转置,即得主成分载荷矩阵(SPSS 给出正是矩阵A 的转置形式)。
要求解决如下问题。
(1)已经证明2121221112122221121122221212212111111r a a a a r a a a a a a a a a a a a =+=+=+=+.这类r 为原始变量之间的相关系数。
试进一步证明R A A =T ,这里R 为原始变量的相关系数矩阵。
(2)已经证明22222212111212111112221121221221110λλ=+=+=+=+a a a a a a a a a a a a a a a a .这类λ为主成分得分的方差。
试进一步证明Λ=T AA ,这里Λ为相关系数矩阵R 的特征值构成的对角线矩阵,即主成分得分的方差形成的对角阵。
2. 计算-分析题1)美国统计学家Richard Stone于1947年开展的关于国民经济的主成分分析(PCA)比较著名,现在已经成为经典案例之一。
SPSS在计量地理学中的应用(精简)解析

SPSS FOR WINDOWS 在计量地理学中的应用二○○八年六月闽江学院地理科学系目录第一章SPSS概述 (3)第一节SPSS简介 (3)第二节SPSS的主界面 (3)第二章SPSS的数据管理 (5)第一节定义变量 (5)第二节数据的输入与编辑 (7)第三节数据转换 (8)第三章摘要性分析 (11)第一节Frequencies过程 (11)3.1.1 主要功能 (11)3.1.2 实例操作 (11)第二节Descriptives过程 (16)3.2.1 主要功能 (16)3.2.2 实例操作 (16)第四章相关分析 (19)第一节Bivariate过程 (19)4.1.1 主要功能 (19)4.1.2 实例操作 (19)第二节Partial过程 (22)4.2.1 主要功能 (22)4.2.2 实例操作 (22)第三节Distances过程 ........................................................................................ 错误!未定义书签。
4.3.1 主要功能............................................................................................. 错误!未定义书签。
4.3.2 实例操作............................................................................................. 错误!未定义书签。
第五章回归分析.. (26)第一节Linear过程 (26)5.1.1 主要功能 (26)5.1.2 实例操作 (26)第二节Curve Estimation过程............................................................................ 错误!未定义书签。
《统计分析和SPSS的应用(第五版)》课后练习答案与解析(第9章)
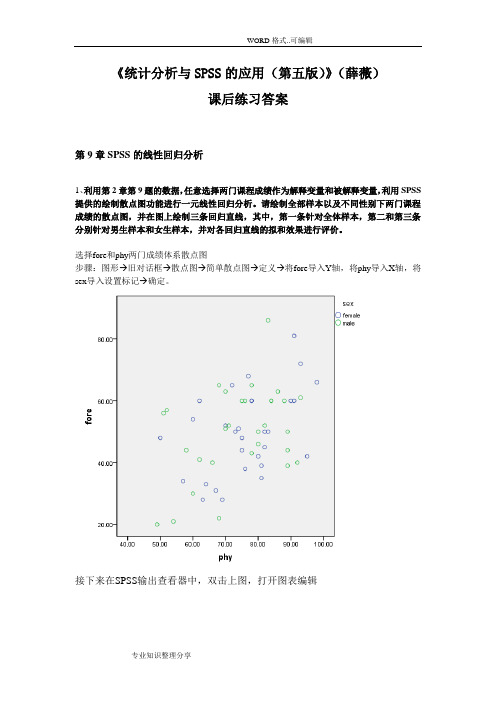
《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第9章SPSS的线性回归分析1、利用第2章第9题的数据,任意选择两门课程成绩作为解释变量和被解释变量,利用SPSS 提供的绘制散点图功能进行一元线性回归分析。
请绘制全部样本以及不同性别下两门课程成绩的散点图,并在图上绘制三条回归直线,其中,第一条针对全体样本,第二和第三条分别针对男生样本和女生样本,并对各回归直线的拟和效果进行评价。
选择fore和phy两门成绩体系散点图步骤:图形→旧对话框→散点图→简单散点图→定义→将fore导入Y轴,将phy导入X轴,将sex导入设置标记→确定。
接下来在SPSS输出查看器中,双击上图,打开图表编辑在图表编辑器中,选择“元素”菜单→选择总计拟合线→选择线性→应用→再选择元素菜单→点击子组拟合线→选择线性→应用。
分析:如上图所示,通过散点图,被解释变量y(即:fore)与解释变量phy有一定的线性关系。
但回归直线的拟合效果都不是很好。
2、请说明线性回归分析与相关分析的关系是怎样的?相关分析是回归分析的基础和前提,回归分析则是相关分析的深入和继续。
相关分析需要依靠回归分析来表现变量之间数量相关的具体形式,而回归分析则需要依靠相关分析来表现变量之间数量变化的相关程度。
只有当变量之间存在高度相关时,进行回归分析寻求其相关的具体形式才有意义。
如果在没有对变量之间是否相关以及相关方向和程度做出正确判断之前,就进行回归分析,很容易造成“虚假回归”。
与此同时,相关分析只研究变量之间相关的方向和程度,不能推断变量之间相互关系的具体形式,也无法从一个变量的变化来推测另一个变量的变化情况,因此,在具体应用过程中,只有把相关分析和回归分析结合起来,才能达到研究和分析的目的。
线性回归分析是相关性回归分析的一种,研究的是一个变量的增加或减少会不会引起另一个变量的增加或减少。
3、请说明为什么需要对线性回归方程进行统计检验?一般需要对哪些方面进行检验?检验其可信程度并找出哪些变量的影响显著、哪些不显著。
1,计量地理学spss

中位数是指将一组变量值从小到大排 列,位次居中的变量值。
107 54 73 65 68 71 97 80 76 84 79 88 94 62 49 61 98 79 57 98
66
62 74 92 75 65 81 83 78
62
116 86 78 90 81 62 70 66
79
65 73 88 80 77 89 62 83 81 94
90
96 66 68
78
75 86 72
71
64 96 77
101
76 89 60
78
72 81 87
43
77 71 84
59
74 85 75
67
65 99 77
61
82 59 51
71
86 92 45
85
83 74 73 73
67
68 91 77 63
87
72 76 79 63
80
67 83 94 89
68
64 68 103 71 94 93 77 77
74
79 78 88 71 71 61 72 63
61
78 89 63 74 85 65 84 66
82
79 72 68 70 84 62 67 75
65
77 58 88 74 83 92 59 68
98
86 69 81 76 63 65 58 76
连接两个四分(位)数画出箱子,再将两个极值 点与箱子相连接
–
X 最小值 QL 中位数
QU
X 最大值
4
6
8
简单箱线图
10
12
箱形图 (Boxplot)
统计分析与spss的应用第三版第章课后习题详细答案(docX页)

统计分析与spss的应用(第三版)第10章课后习题详细答案1、(1)聚类分析的第1步,1号样本(广西瑶族)和3号样本(广西侗族)聚为一小类,它们的个体距离(欧氏距离)是3.722,这个小类将在下面第2步用到。
聚类分析的第2步,8号个体(贵州苗族)与第1步聚成的小类(1号和3号聚成的小类)又聚成一小类,它们的距离(个体与小类的距离,采用组间平均链锁距离)是9.970,这个小类将在下面第4步用到。
聚类分析的第3步,5号样本和7号样本聚成小类,它们的距离(个体与个体的距离)是11.556,这个小类将在第5步用到。
聚类分析的第4步,6号与第2步形成的小类(1号3号8号聚成的小类)聚为小类,它们的距离(个体与小类的距离)为18.607,这个小类将在第6步用到。
聚类分析的第5步,4号样本与第3步聚成的小类聚为小类,它们的距离(个体与小类的距离)为20.337,这个小类将在第6步用到。
聚类分析的第6步,第4步聚成的小类与第5步聚成的小类聚成小类,它们的距离(小类与小类的距离,采用组间平均链锁距离)是22.262,这个小类将在下面第7步中用到。
聚类分析的第7步,2号样本与第6步中聚成的小类聚成小类。
它们的距离(个体与小类的距离)是31.020。
经过7步,8个样本最后聚成了一大类。
(2)(3) 广西瑶族与广西侗族、贵州苗族、基诺族为一类,土家族与崩龙族、白族为一类,湖南侗族自成一类2、(1)凝聚状态表随着类数目不断减少,类间距离在逐渐增大。
3类后,聚间距离迅速增大,形成极为平坦的碎石路。
所以考虑聚成3类。
(2)北京自成一类,江苏广东上海湖南湖北聚为一类,剩余的聚省为一类。
(3)(4)通过该表可以看出,,对应P值-小于0.005,所以各指数的均值在3类中的差异是显著的。
3、答:聚类分析是以各种距离来度量个体间的“亲疏”程度的。
从各种距离的定义来看,数量级将对距离产生较大的影响,并影响最终的聚类结果。
进行层次聚类分析时,为了避免上述问题,聚类分析之前应首先消除数量级对聚类的影响,对数据进行标准化就是最常用的方法。
地理学模型方法及应用spss

2.单因素方差分析基本原理 研究因素影响是否显著,就是检验如下假设: H0:μ1=μ2=…=μr 当p<0.05(系统默认的显著性概率值)时,推翻原假设, 认为这些因素的影响是显著的,说明这些因素造成的均值差 异有统计意义;否则认为影响是不显著的。 3.方法 Analyze→Compare Means→One-Way Analysis of Variance。 分别输入因变量Dependent List和因素变量Factor。 Significance leve确定显著性水平,一般选0.1,0.05,0.01, 系统默认的显著性概率为0.05。 4.结果分析 表中第一列为方差来源:①组间(由于因素不同水平或位级 所造成的差异);②组内(由于偶然或不可控制的随机因素 所造成的差异);③总平方和。 表中第一行:平方和;df为自由度;均方;F为组间均方除以组 内均方的商; Sig.为F分目的显著性概率。
表②为主效应方差分析表(Tests of BetweenSubjects Effects).表中第一行分别为:Source为方 差来源;Type Ⅲ Sume为按系统默认Ⅲ型草方和计算出 的离差平方和; df为自由度;Mean Square为均方,即 平方和与自由度之商;F为[Σ(xi-x均)2]1/2与[Σ随机误差 平方和]1/2之比;Sig.为接受原假设的显著性概率。表 中第一列分别为:修正模型;截距平方和(截距指线性 模型中的截距);因素1;因素2;因素1*因素2交互效应; 误差;因变量的总平方和;修正模型的总平方和。 三、相关分析 1.二元变量相关分析 方法:Analyze→Correlate→Bivariate(二元变量) , 选了Flags significante correlations项,显著水平 0.05以下显著相关的相关系数用*标记,显著水平0.01 以下显著相关的相关系数用**标记。 Pearson皮尔逊相关系数( |Rxy| ≤1): Rxy= Σ(xi-x均) (yi-y均)/[Σ(xi-x均)2 Σ(yi-y均)2]1/2
(完整版)《统计分析与SPSS的应用(第五版)》课后练习答案(第1章).docx

《统计分析与SPSS的应用(第五版)》(薛薇)课后练习答案第 1 章 SPSS统计分析软件概述1、 SPSS的中文全名和英文全名是什么?SPSS的中文全名是:社会科学统计软件包(后改名为:统计产品与服务解决方案)英文全名是: Statistical Package for the Social Science.(Statistical Productand Service Solutions)2、 SPSS 有哪两个主要窗口?它们的作用和特点各是什么?SPSS的两个主要窗口是数据编辑器窗口和结果查看器窗口。
数据编辑器窗口的主要功能是定义SPSS数据的结构、录入编辑和管理待分析的数据;结果查看器窗口的主要功能是现实管理SPSS统计分析结果、报表及图形。
3、什么是SPSS的数据集?什么是SPSS的活动数据集?SPSS的数据集:SPSS 运行时可同时打开多个数据编辑器窗口。
每个数据编辑器窗口分别显示不同的数据集合(简称数据集)。
活动数据集:其中只有一个数据集为当前数据集。
SPSS 只对某时刻的当前数据集中的数据进行分析。
4、 SPSS 有哪三种主要使用方式?各自的特点是什么?SPSS的三种基本运行方式:完全窗口菜单方式、程序运行方式、混合运行方式。
完全窗口菜单方式:是指在使用SPSS的过程中,所有的分析操作都通过菜单、按钮、输入对话框等方式来完成,是一种最常见和最普遍的使用方式,最大优点是简洁和直观。
程序运行方式:是指在使用 SPSS的过程中,统计分析人员根据自己的需要,手工编写 SPSS命令程序,然后将编写好的程序一次性提交给计算机执行。
该方式适用于大规模的统计分析工作。
混合运行方式:是前两者的综合。
5、 .sav、 .spo、 .sps 分别是 SPSS 哪类文件的扩展名?.sav 是数据编辑器窗口中的SPSS数据文件的扩展名.spv是结果查看器窗口中的SPSS分析结果文件的扩展名.sps是语法窗口中的SPSS程序6、SPSS 的数据加工和管理功能主要集中在哪些菜单中?统计绘图和分析功能主要集中在哪些菜单中?SPSS的数据加工和管理功能主要集中在编辑、数据等菜单中;统计分析和绘图功能主要集中在分析、图形等菜单中。
《统计分析与SPSS的应用》课后练习答案

《统计分析与SPSS的应用》课后练习答案在学习《统计分析与 SPSS 的应用》这门课程后,通过课后练习,我们对所学知识有了更深入的理解和掌握。
以下是针对课后练习的详细答案及相关解释。
一、单选题1、在 SPSS 中,用于描述数据集中变量分布特征的命令是()A FrequenciesB DescriptivesC ExploreD Crosstabs答案:B解释:Descriptives 命令可以提供变量的集中趋势、离散程度等分布特征的统计量。
2、进行独立样本 t 检验时,需要满足的前提条件是()A 样本来自正态分布总体B 两样本方差相等C 以上都是D 以上都不是答案:C解释:独立样本 t 检验要求样本来自正态分布总体,且两样本方差相等。
3、用于分析两个变量之间线性关系强度的统计量是()A 相关系数B 决定系数C 方差D 标准差答案:A解释:相关系数用于衡量两个变量之间线性关系的密切程度。
二、多选题1、以下哪些是 SPSS 中的数据类型()A 数值型B 字符型C 日期型D 以上都是答案:D解释:SPSS 中的数据类型包括数值型、字符型和日期型。
2、方差分析的基本假定包括()A 正态性B 方差齐性C 独立性D 以上都是答案:D解释:方差分析需要满足正态性、方差齐性和独立性这三个基本假定。
三、简答题1、请简述 SPSS 中数据录入的基本步骤。
答:首先打开 SPSS 软件,在变量视图中定义变量的名称、类型、宽度、小数位数等属性。
然后切换到数据视图,逐行录入数据。
在录入过程中,要注意数据的准确性和完整性。
2、解释均值、中位数和众数的含义及适用情况。
答:均值是所有数据的算术平均值,反映数据的集中趋势,但容易受极端值影响。
适用于数据分布较为对称、不存在极端值的情况。
中位数是将数据从小到大排序后位于中间位置的数值,不受极端值影响,适用于数据分布偏态或存在极端值的情况。
众数是数据中出现次数最多的数值,适用于描述数据的集中趋势,尤其在类别数据中常用。
SPSS软件实例应用(计量地理学课后题详解)

14
.080 13
0
1164
6
21
.150 0
0
16
15
8
18
.084 0
3
1165
5
22
.160 13
0
17
16
5
8
.085 14
15
1176
6
11
.166 14
0
27
17
5
16
.086 16
0
1187
5
8
.182 15
7
18
18
5
19
.093 17
12
1198
5
19
.190 17
0
20
19
5
32
0 0
28 8
第三列表示本步骤聚类中那两 6
5
17
.108 2
1
9
个样本或小类聚成一类;第四
7 8
8
18
.108 0
20
30
.115 0
0 5
17 10
列是相应的样本距离或小类距 9
5
16
.123 6
0
10
离;第五列、第六列表明本步
10 11
5 5
20
.127 9
8
32
.128 10
0
11 12
骤聚类中,参与聚类的是样本 12 5
a.软件操作
聚类表
聚类表
阶
群集组合
系数 首次出现阶群集 下阶一阶 群集组合
系数 首次出现阶群集 下一阶
a.数据结果与对比 群集 1 群集 2
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
·分析某地区35个城市20047项经
分 济统计指标数据
析
&
主 成
(1)试用最短距离法对35个城市综合 实力进行系统聚类分析,并画出聚类谱系图
分
分
析
a.软件操作及原理
实 例
b.数据结果及分析
a.软件操作及原理——操作
a.软件操作及原理——操作
a.软件操作及原理——标准差标准化原理
xij
xijminxi{j} maxij{}minxi{j}
( i1,2,.m .;.j,1,2,.n.) .
a.软件操作及原理——欧氏距离原理
dij
n
(xik xjk)2
k1
聚类表
阶
群集组合
系数 首次出现阶群集 下一阶
a.软件操作及原理——最短1 距离群17集聚1 类群25集法2 原.060理
群集 0
1
群集 2 0
6
2
5
29
.065 0
0
6
凝聚状态表的第一列表示 3
第2主成分与x1,x3呈现出较 强的正相关,x2呈现出较强的负 相关,因此可以认为第2主成分 是2014年农业经济的代表。
聚 类
·分析某地区35个城市2004年的7
分 项经济统计指标数据
析
&
主 成
(3)以第一、二、三主成分为变量, 进行聚类分析,结果又怎样呢?
分
分
析
a.软件操作
实 例
b.数据结果与对比
b.数据结果及分析——主成分因子
一般取累计贡献率达85%~95%的特征值所对应的第1、第 2、…、第m(m≤p)个主成分。
b.数据结果及分析——变量与因子联系系数
变量与某一因子联系系数 绝对值越大,则该因子与变量关 系越近。
将第一因子代替 x4,x5,x6,x7; 将 第 二 因 子 代 替 x1,x2,x3即可得到旋转矩阵,使 复杂的矩阵变得简洁。
5
10
9
5
20
.069 701905来自16.123 6
0
10
10
5
22
.070 9
0
1130
5
20
.127 9
8
11
11
32
33
.072 6
0
1191
5
32
.128 10
0
12
12
19
28
.076 0
0
1182
5
33
.129 11
3
13
13
5
12
.077 10
0
1143
5
14
.136 12
0
15
14
5
在不同的聚类标准(距离)下, 聚类结果不同,当距离标准逐渐 放大时,35个区域单元被依次聚 类。
当距离为0时,每个样本为单 独的一类;当距离为5,则35个区 域单元被聚为11类;当距离为10, 则35个区域单元被聚为7类;当距 离为15,则35个区域单元被聚为5 类;当距离为20,则35个区域单 元被聚为3类;最终,当聚类标准 (距离)扩大到25时,35个区域 单元被聚为1类。
10
离;第五列、第六列表明本步
10 11
5 5
20
.127 9
8
32
.128 10
0
11 12
骤聚类中,参与聚类的是样本 12 5
33
.129 11
3
13
13
5
14
.136 12
0
15
还是小类。0表示样本,数字 14 6
21
.150 0
0
16
n(非0)表示由第n部聚类产生的
15 16
5 6
22
.160 13
33
34
.085 0
0
12
聚类分析的第几步;第二列、
4 5
26
35
.089 0
30
31
.104 0
0 0
28 8
第三列表示本步骤聚类中那两 6
5
17
.108 2
1
9
个样本或小类聚成一类;第四
7 8
8
18
.108 0
20
30
.115 0
0 5
17 10
列是相应的样本距离或小类距 9
5
16
.123 6
0
3
18
31
.047 0
0
135
33
34
.085 0
0
12
4
5
29
.052 0
0
54
26
35
.089 0
0
28
5
5
17
.055 4
1
75
30
31
.104 0
0
8
6
32
34
.063 0
0
161
5
17
.108 2
1
9
7
5
30
.067 5
0
97
8
18
.108 0
0
17
8
6
21
.069 0
0
285
20
30
.115 0
a.软件操作
聚类表
聚类表
阶
群集组合
系数 首次出现阶群集 下阶一阶 群集组合
系数 首次出现阶群集 下一阶
a.数据结果与对比 群集 1 群集 2
群集 1 群集 2
1
17
25
.024 0
0
51
群集 1 群集 2
17
25
.060
群集 1 群集 2
0
0
6
2
26
35
.045 0
0
321
5
29
.065 0
0
6
聚 类
·分析某地区35个城市2004年的7
分 项经济统计指标数据
析
&
主
(2)试用主成份分析法对35个城市7项
成
经济指标进行主成分分析,并分析其综
分
合实力。
分
析
a.软件操作
实 例
b.数据结果及分析
a.软件操作
a.软件操作
b.数据结果及分析——Bartlett验证
因子分析前,首先进行KMO检验和巴特利球体检验。KMO检验用 于检查变量间的偏相关性,取值在0~1之前。KMO统计量越接近于1, 变量间的偏相关性越强,因子分析的效果越好。实际分析中,KMO统 计量在0.7以上时效果比较好;当KMO统计量在0.5以下,此时不适合应 用因子分析法,应考虑重新设计变量结构或者采用其他统计分析方法。
0
11
.166 14
0
17 27
小类参与本步骤聚类;第七列 17 5
8
.182 15
7
18
表示本步骤聚类的结果将在下
18 19
5 13
19 15
.190 17 .196 0
0 0
20 24
面聚类的第几部中用到。
20
5
7
.197 18
0
21
21
4
5
.198 0
20
22
22
4
28
.199 21
0
23
b.数据结果及分析
.096 18
11
2109
13
15
.196 0
0
24
20
5
7
.099 19
0
2210
5
7
.197 18
0
21
21
5
11
.107 20
0
2221
4
5
.198 0
20
22
22
5
15
.120 21
0
23
a.数据结果与对比
此课件下载可自行编辑修改,供参考! 感谢您的支持,我们努力做得更好!
b.数据结果及分析——变量与因子联系系数
变量与某一因子联系系数 绝对值越大,则该因子与变量关 系越近。
将第一因子代替 x4,x5,x6,x7; 将 第 二 因 子 代 替 x1,x2,x3即可得到旋转矩阵,使 复杂的矩阵变得简洁。
b.数据结果及分析——变量与因子联系系数
第1主成分与所有变量成正 相关,与x4,x5,x6,x7呈现出较强 的正相关,因此可以认为第1主 成分是2014年城市经济结构的代 表。
14
.080 13
0
1164
6
21
.150 0
0
16
15
8
18
.084 0
3
1165
5
22
.160 13
0
17
16
5
8
.085 14
15
1176
6
11
.166 14
0
27
17
5
16
.086 16
0
1187
5
8
.182 15
7
18
18
5
19
.093 17
12
1198
5
19
.190 17
0
20
19
5
32