数据分析报告(线性回归、SAS)
sas数据分析报告

sas数据分析报告摘要:本文介绍了基于SAS软件进行的数据分析报告。
首先,对数据进行了简要的介绍和处理,并对数据进行了可视化处理。
然后我们使用SAS建立了模型,并对模型进行了评估。
最后,我们对结果进行了解释和分析,并提出了相关的建议。
关键词:SAS,数据分析,模型建立,可视化,结果解释1. 简介SAS是一款广泛应用于数据分析领域的统计软件,其丰富的统计函数和数据可视化功能使得它成为了数据分析师不可或缺的工具。
本文使用SAS对某公司的销售数据进行分析,以帮助公司管理者更好地了解企业的经营情况和预测未来的发展趋势。
2. 数据处理与可视化我们先对数据进行了初步的清理和整理,去除了缺失值和异常值,并对数据进行了标准化处理。
然后,我们使用SAS的数据可视化功能对数据进行了可视化处理,包括制作散点图、直方图和箱线图等,以便更好地了解数据的分布情况和相关性。
3. 模型建立与评估我们基于数据建立了模型,并使用SAS对模型进行了评估。
在模型建立过程中,我们采用了多元线性回归模型,考虑了各个变量之间的相互关系和影响。
在模型评估过程中,我们采用了交叉验证和R方值等指标,对模型的预测能力进行了评估。
4. 结果解释与分析根据模型的预测结果,我们对数据进行了解释和分析,并提出了相关的建议。
我们确定了销售额、广告投放、促销活动等因素对销售额的影响,根据模型结果提出了优化销售策略的建议。
同时,我们进一步分析了销售额的趋势,预测了未来的销售情况,为公司的经营决策提供了有力的支持。
结论:本文基于SAS进行了数据分析报告,利用SAS的数据处理、可视化、模型建立和评估等功能,全面分析了某公司的销售数据。
通过对数据的解释和分析,我们提出了相关的建议,为公司的经营决策提供了参考。
这表明SAS在数据分析领域的应用效果显著,对于企业的发展和决策具有重要的意义。
SAS线性回归

L=Õ
i =1
n
1 é 1 ù ( y i - a - bxi ) 2 ú exp ê 2 s 2p ë 2s û ö é 1 ÷ ÷ exp ê- 2s 2 ë ø
n
æ 1 =ç ç è s 2p
å(y
i =1
n
i
ù - a - bxi ) 2 ú û
(3.4)
(3.4)式 现用极大似然估计法来估计未知参数 a , b 。对于任意一组观察值 y1 , y 2 , L , y n , 就是样本的似然函数。显然,要 L 取最大值,只要(3.4)式右端方括弧中的平方和部分为 最小,即只需函数
n
i1
åx åx
i =1
2 i1
n æ n ö = nå x - ç å xi1 ÷ = nå ( xi1 - x ×1 ) 2 ¹ 0 i =1 i =1 è i =1 ø n 2 i1
2
4
故(3.7)式有唯一的一组解。解得 b, a 的极大似然估计为
n æ n öæ n ö nå x i y i - ç å x i ÷ç å y i ÷ è i =1 øè i =1 ø = ˆ = i =1 b 2 n æ n ö 2 nå x i - ç å xi ÷ i =1 è i =1 ø n n ˆ 1 b ˆx ˆ = å y i - å xi = y - b a n i =1 n i =1
å(x
i =1
n
ü - x)( y i - y ) ï ï n ï 2 ï ( xi - x ) å ý i =1 ï ï ï ï þ
i
(3.8)
于是,所求的线性回归方程为
ˆx ˆ=a ˆ+b y ˆ x 代入上式,则线性回归方程变为 ˆ = y -b 若将 a
线性回归分析实验报告

线性回归分析实验报告线性回归分析实验报告引言线性回归分析是一种常用的统计方法,用于研究因变量与一个或多个自变量之间的关系。
本实验旨在通过线性回归分析方法,探究自变量与因变量之间的线性关系,并通过实验数据进行验证。
实验设计本实验采用了一组实验数据,其中自变量为X,因变量为Y。
通过对这组数据进行线性回归分析,我们将得到回归方程,从而可以预测因变量Y在给定自变量X的情况下的取值。
数据收集与处理首先,我们收集了一组与自变量X和因变量Y相关的数据。
这些数据可以是实际观测得到的,也可以是通过实验或调查获得的。
然后,我们对这组数据进行了处理,包括数据清洗、异常值处理等,以确保数据的准确性和可靠性。
线性回归模型在进行线性回归分析之前,我们需要确定一个线性回归模型。
线性回归模型的一般形式为Y = β0 + β1X + ε,其中Y是因变量,X是自变量,β0和β1是回归系数,ε是误差项。
回归系数β0和β1可以通过最小二乘法进行估计,最小化实际观测值与模型预测值之间的误差平方和。
模型拟合与评估通过最小二乘法估计回归系数后,我们将得到一个拟合的线性回归模型。
为了评估模型的拟合程度,我们可以计算回归方程的决定系数R²。
决定系数反映了自变量对因变量的解释程度,取值范围为0到1,越接近1表示模型的拟合程度越好。
实验结果与讨论根据我们的实验数据,进行线性回归分析后得到的回归方程为Y = 2.5 + 0.8X。
通过计算决定系数R²,我们得到了0.85的值,说明该模型能够解释因变量85%的变异程度。
这表明自变量X对因变量Y的影响较大,且呈现出较强的线性关系。
进一步分析除了计算决定系数R²之外,我们还可以对回归模型进行其他分析,例如残差分析、假设检验等。
残差分析可以用来检验模型的假设是否成立,以及检测是否存在模型中未考虑的其他因素。
假设检验可以用来验证回归系数是否显著不为零,从而判断自变量对因变量的影响是否存在。
线性回归分析实验报告

线性回归分析实验报告实验报告:线性回归分析一、引言线性回归是一种基本的统计分析方法,用于研究自变量与因变量之间的线性关系。
此实验旨在通过一个实际案例对线性回归进行分析,并解释如何使用该方法进行预测和解释。
二、实验方法1.数据收集:从电商网站收集了一份销售量与广告费用的数据集,其中包括了十个月的数据。
该数据集包括两个变量:广告费用(自变量)和销售量(因变量)。
2.数据处理:首先对数据进行清洗,包括处理缺失值和异常值等。
然后进行数据转换,对广告费用进行对数转换,以适应线性回归的假设。
3.构建模型:使用线性回归模型,将广告费用作为自变量,销售量作为因变量,构建一个简单的线性回归模型。
模型的公式为:销售量=β0+β1*广告费用+ε,其中β0和β1是回归系数,ε是误差项。
4.模型评估:通过计算回归系数的置信区间和检验假设以评估模型的拟合程度和相关性。
此外,还使用残差分析来检验模型的合理性和独立性。
5.模型预测:根据模型的回归系数和新的广告费用数据,预测销售量。
三、实验结果1.数据描述:首先对数据进行描述性统计。
数据集的平均广告费用为1000元,标准差为200元。
平均销售量为1000件,标准差为150件。
广告费用和销售量之间的相关系数为0.8,说明两者存在一定的正相关关系。
2. 模型拟合:通过拟合线性回归模型,得到回归系数的估计值。
估计值的标准误差很小,R-square值为0.64,说明模型可以解释63%的销售量变异。
3.置信区间和假设检验:通过计算回归系数的置信区间,发现β1的置信区间不包含零,说明广告费用对销售量有显著影响。
假设检验结果也支持这一结论。
4.残差分析:通过残差分析,发现残差的分布基本符合正态性假设,没有明显的模式或趋势。
这表明模型的合理性和独立性。
四、结论与讨论通过线性回归分析,我们得出以下结论:1.广告费用对销售量有显著影响,且为正相关关系。
随着广告费用的增加,销售量也呈现增加的趋势。
2.线性回归模型可以解释63%的销售量变异,说明模型的拟合程度较好。
SAS系统和数据分析一元线性回归分析

第三十一课一元线性回归分析回归分析是一种统计分析方法,它利用两个或两个以上变量之间的关系,由一个或几个变量来预测另一个变量。
在SAS/STA T中有多个进行回归的过程,如REG、GLM等,REG过程常用于进行一般线性回归模型分析。
一、回归模型1. 基本概念回归模型是一种正规工具,它表示统计关系中两个基本的内容:①用系统的形式表示因变量Y随一个或几个自变量X变化的趋势;②表现观察值围绕统计关系曲线的散布情况。
这两个特点是由下列假设决定的:●在与抽样过程相联系的观察值总体中,对应于每一个X值,存在Y的一个概率分布;这些概率分布的均值以一些系统的方式随X变化。
●图31.1是用透视的方法来显示回归曲线。
Y对给定X具有概率分布这一概念总是与统计关系中的经验分布形式上相对应;同样,描述概率分布的均值与X之间关系的回归曲线,与统计关系中Y系统地随X变化的一般趋势相对应。
图31.1线性回归模型的图示在回归模型中,X称为“自变量”,Y称为“因变量”;这只是传统的称法,并不表明在给定的情况下Y因果地依赖于X,无论统计关系多么密切,回归模型不一定是因果关系,在某些应用中,比如我们由温度表水银柱高度(自变量)来估计温度(因变量)时,自变量实际上依赖于因变量。
此外,回归模型的自变量可以多于一个。
2. 回归模型的构造(1)自变量的选择构造回归模型时必须考虑到易处理性,所以在有关的任何问题中,回归模型只能(或只应该)包括有限个自变量或预测变量。
(2) 回归方程的函数形式选择回归方程函数形式与选择自变量紧密相关。
有时有关理论可能指出适当的函数形式。
然而,通常我们预先并不能知道回归方程的函数形式,要在收集和分析数据后,才能确定函数形式。
我们经常使用线性和二次回归函数来作为未知性质回归方程的最初近似值。
图31.2(a)表示复杂回归函数可以由线性回归函数近似的情况,图31.2(b)表示复杂回归函数可以由两个线性回归函数分段近似的情况。
线性回归分析报告

线性回归分析报告1. 引言线性回归是一种常用的统计分析方法,通过建立一个线性模型来描述自变量与因变量之间的关系。
在本报告中,我们将使用线性回归分析来探索两个变量之间的关系,并解释模型的结果。
2. 数据收集为了进行线性回归分析,我们首先需要收集相关的数据。
根据我们的研究目的,我们选择了X和Y两个变量,并收集了50个样本观测值。
3. 数据预处理在进行线性回归之前,我们需要对数据进行一些预处理。
首先,我们检查数据是否存在缺失值或异常值。
如果存在,我们需要进行相应的处理,例如删除或填充缺失值,或者修正异常值。
4. 数据探索在进行线性回归之前,我们需要对数据进行一些探索性分析,以了解两个变量之间的关系。
这可以通过绘制散点图来实现。
散点图可以帮助我们观察数据的分布情况,并初步判断是否存在线性关系。
5. 模型建立在进行线性回归之前,我们需要确定哪些变量作为自变量,哪个变量作为因变量。
在本报告中,我们选择X作为自变量,Y作为因变量。
然后,我们使用最小二乘法来建立线性回归模型。
6. 模型评估在建立线性回归模型之后,我们需要评估模型的拟合程度和预测能力。
常用的评估指标包括均方误差(MSE)、决定系数(R-squared)等。
通过这些指标,我们可以判断模型的拟合程度和预测能力是否达到了我们的要求。
7. 结果解释在模型评估之后,我们需要解释模型的结果。
我们可以通过查看回归系数来解释模型中自变量对因变量的影响程度。
回归系数的正负可以判断自变量与因变量之间的关系是正相关还是负相关,而回归系数的大小可以判断影响程度的强弱。
8. 结论通过对线性回归模型的建立和评估,我们得出了以下结论:X与Y之间存在显著的线性关系,X对Y的影响程度为正/负,并且影响程度较强/较弱。
这些结论可以帮助我们更好地理解变量之间的关系,并可以在实际应用中用于预测和决策。
9. 局限性在进行线性回归分析时,我们需要注意模型的局限性。
线性回归模型假设自变量与因变量之间存在线性关系,而且模型中的误差项需要满足一定的假设。
SAS数据分析实验报告
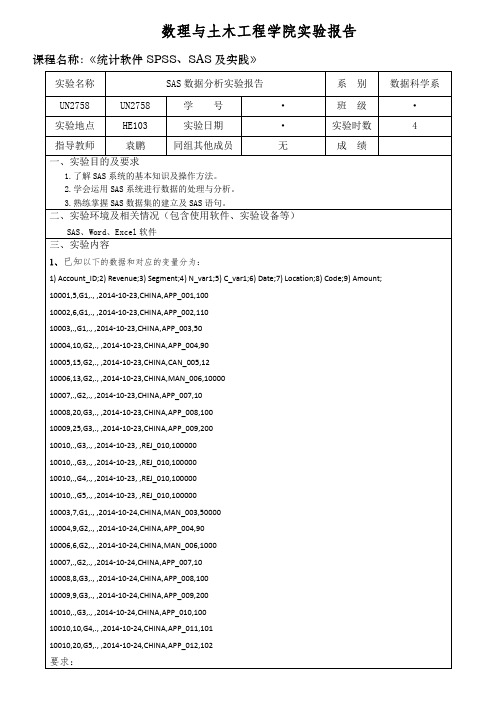
数理与土木工程学院实验报告课程名称:《统计软件SPSS、SAS及实践》实验结果(包括程序代码、程序结果分析)第一题:②基于数据集transaction,将变量“Revenue”中的缺失数据用其均值代替;data a;set a;array s(*) aa1-aa2;n=n(of s(*));mean=mean(of s(*));sum=sum( of s(*));do i=1to dim(s);if s(i)=.then s(i)=mean;end;run;proc print;run;③基于②,将取值全部缺失的变量删除。
data a;set a;array aa aa1-aa2;do over aa;if col=.then delete;end;run;proc transpose data=a out=transaction(drop=_name_);var aa1-aa2;run;proc print;run;第二题:a) 建立一个数据集合读入数据,变量为length,width和 height;data b;input length width height;cards;32 18 1216 15 2448 12 3215 30 4520 30 36;run;proc print data=b;run;b) 使用 set 语句,利用a)的数据集建立一个新数据集,它包括a)的所有数据,并建立三个新变量:每个c) 使用b)建立的数据集建立一个新数据集,只包括其中的volume 和 cost 变量。
data d;set c(keep=volume cost);run;proc print data=d;run;第三题:a)对车的标志(brand)的频数画竖直条形图。
libname mydata 'D:\data';proc print data=edcar;run;data e;set edcar; run;proc gchart;vbar brand;run;b)c)data g;set f;proc means data=g ;run;第四题:试分析:该地区单身人士的收入与住房面积之间是否相关?如果线性相关,确定一元线性回归方程,并做显著性检验。
sas数据分析报告

SAS数据分析报告1. 引言SAS(统计分析系统)是一款广泛应用于数据分析和统计建模的软件工具。
本报告将介绍如何使用SAS进行数据分析,并提供一系列步骤,以帮助读者快速上手。
2. 数据准备在开始数据分析之前,我们首先需要准备好待分析的数据集。
数据集应包含所需的变量和观测值,并且应该经过清洗和预处理,以确保数据的准确性和一致性。
3. SAS环境设置在使用SAS进行数据分析之前,我们需要设置SAS环境。
这包括设置工作目录、导入数据和加载所需的SAS库。
markdown sas ** 设置工作目录** libname mydata ‘/path/to/data/’;** 导入数据** data mydata.mydataset; infile ‘/path/to/dataset.csv’ delimiter = ‘,’ firstobs = 2; input var1 var2 var3; run;** 加载SAS库 ** proc sql; create table mydata.mytable as select * from mydata.mydataset; quit; ```4. 数据探索一旦准备好数据并设置好SAS环境,我们可以开始进行数据探索。
这包括计算描述性统计量、绘制图表和查找数据间的相关性等操作。
markdown sas ** 计算描述性统计量 ** proc means data = mydata.mytable; var var1 var2 var3; output out = mydata.summary_stats mean = mean std = std min = min max = max; run;** 绘制直方图 ** proc univariate data = mydata.mytable; histogram var1; run;** 计算相关性 ** proc corr data = mydata.mytable; var var1 var2 var3; run; ```5. 数据分析有了对数据的初步了解后,我们可以开始进行更深入的数据分析。
数据分析线性回归报告(3篇)

第1篇一、引言线性回归分析是统计学中一种常用的数据分析方法,主要用于研究两个或多个变量之间的线性关系。
本文以某城市房价数据为例,通过线性回归模型对房价的影响因素进行分析,以期为房地产市场的决策提供数据支持。
二、数据来源与处理1. 数据来源本文所采用的数据来源于某城市房地产交易中心,包括该城市2010年至2020年的房价、建筑面积、交通便利度、配套设施、环境质量等指标。
2. 数据处理(1)数据清洗:对原始数据进行清洗,去除缺失值、异常值等。
(2)数据转换:对部分指标进行转换,如交通便利度、配套设施、环境质量等指标采用五分制评分。
(3)变量选择:根据研究目的,选取建筑面积、交通便利度、配套设施、环境质量等指标作为自变量,房价作为因变量。
三、线性回归模型构建1. 模型假设(1)因变量与自变量之间存在线性关系;(2)自变量之间不存在多重共线性;(3)误差项服从正态分布。
2. 模型建立(1)选择合适的线性回归模型:根据研究目的和数据特点,采用多元线性回归模型。
(2)计算回归系数:使用最小二乘法计算回归系数。
(3)检验模型:对模型进行显著性检验、方差分析等。
四、结果分析1. 模型检验(1)显著性检验:F检验结果为0.000,P值小于0.05,说明模型整体显著。
(2)回归系数检验:t检验结果显示,所有自变量的回归系数均显著,符合模型假设。
2. 模型结果(1)回归系数:建筑面积、交通便利度、配套设施、环境质量的回归系数分别为0.345、0.456、0.678、0.523,说明这些因素对房价有显著的正向影响。
(2)R²:模型的R²为0.876,说明模型可以解释约87.6%的房价变异。
3. 影响因素分析(1)建筑面积:建筑面积对房价的影响最大,说明在房价构成中,建筑面积所占的比重较大。
(2)交通便利度:交通便利度对房价的影响较大,说明在购房时,消费者对交通便利性的需求较高。
(3)配套设施:配套设施对房价的影响较大,说明在购房时,消费者对生活配套设施的需求较高。
SAS统计之第五章-线性回归分析报告

( y y)2 ( y yˆ)2 2( y yˆ)( yˆ y) ( yˆ y)2
对数据资料所有点的求和得:
(y y)2 (y yˆ)2 2(y yˆ)( yˆ y) (yˆ y)2
利用下图说明F检验法的基本原理。
当自变量为 x ,对应的
y
因变量的实测值为 y,
yˆ
y y
y yˆ 因变量的预测值为 yˆ 。 yˆ y 于是 y的离均差 y y
y
可分解为两个部分:
y y ( y yˆ) ( yˆ y)
xx
离均差 随机误差 回归引起的偏差
第三节 回归关系的显著性检验
三个平方和的计算公式:
总平方和: T SSy (y y)2 y2 ( y)2 / n 回归平方和: U SSr (yˆ y)2
a y bx, yˆ a bx, yˆ y bx bx, yˆ y b(x x), (yˆ y)2 b2 (x x)2 ,
第三节 回归关系的显著性检验
对所有点求和得:
(y
yˆ)( yˆ
y)
b[SPxy
SPxy SS x
SSx ]
0
于是:y 的总平方和便分解为两个部分:
(y y)2 (y yˆ)2 (yˆ y)2
y 的总平方和 误差平方和 回归平方和
T SSy
Q SSe U SSr
第三节 回归关系的显著性检验
第五章 线性回归分析
一、一元线性回归 二、一元线性回归方程 三、回归关系的显著性检验 四、置信区间 五、多元线性回归 六、回归诊断
第一节 一元线性回归
生产实践中,常常能找到一个变量与另外一
线性回归分析实验报告总结

RUN;
PROC GPLOT DATA=b;
PLOT RESIDUAL*PREDICTED RESIDUAL*x1 RESIDUAL*x2;
SYMBOL V=DOT I=NONE;
RUN;
PROC IML;
N=31;PI=1;
USE two_6;
READ ALL VAR{x1 x2 y} INTO M;
Analysis of Variance
Sum of Mean
Source DF Squares Square F Value Pr > F
Model 2 52294 26147 <.0001
Error12
Corrected Total14 53902
由表中的数据可知:SSE(F)=; =15-4=11,而从第(1)问可知SSE(R)=; =15-3=12;所以检验统计量观测值 =[()/1]/[11]=
X=M[,2]#M[,3];
X2=M[,3];
Y=M[,1];
P=Y||X||X2;
CREATE RESOLVE VAR{Y X X2};
APPEND FROM P;
QUIT;
PROC REG DATA=RESOLVE;
MODEL Y=X X2;
RUN;
PROC PRINT;
RUN;(1)<表一>参数估计的sas输出结果为:
(5)对于给定的X1、X2的值为(X01,X02)=(220,2500),由回归方程 =++得到销售量Y的预测值为
从proc reg过程得到矩阵(XTX)-1为:
令X0=(220,2500)T,因为MSE=,利用sas系统中proc iml过程计算可得
SAS实验报告一样例

实验报告一多元线性回归分析1.采用青海省海北牧业气象试验站3月18日至10月28日23旬的土壤湿度、旬降水、旬平均气温的资料,用SAS对青海省海北地区土壤湿度与旬降水、旬平均气温进行多元线性回归分析。
原始数据如下:青海省海北地区土壤湿度与旬平均降水、气温的关系09:14 Saturday, June 12, 2004 1Obs y rain temp1 241 4.5 172 265 8.7 163 309 20.9 194 232 6.1 615 205 21.1 1116 227 34.1 977 281 33.6 508 225 38.0 1069 191 26.1 11610 212 36.4 12411 220 13.2 12812 222 12.2 13113 218 55.5 14014 295 65.8 14815 297 47.9 14616 269 39.5 13117 225 9.5 11718 261 23.8 9519 271 49.8 9420 248 63.3 8321 209 3.7 6622 231 26.7 3723 236 2.3 5y :土壤湿度;rain : 旬降水 ;temp :旬平均气温解答:编写程序:data shidu;input y rain temp@@;cards;241 4.5 17265 8.7 16309 20.9 19232 6.1 61205 21.1 111227 34.1 97281 33.6 50225 38.0 106191 26.1 116212 36.4 124220 13.2 128222 12.2 131218 55.5 140295 65.8 148297 47.9 146269 39.5 131225 9.5 117261 23.8 95271 49.8 94248 63.3 83209 3.7 66231 26.7 37236 2.3 5;PROC REG;Model y = rain temp;Run;输出结果:SAS 系统 2009年04月16日星期四下午09时27分56秒 1The REG ProcedureModel: MODEL1Dependent Variable: v1Number of Observations Read 23Number of Observations Used 23Analysis of VarianceSum of MeanSource DF Squares Square F Value Pr > FModel 2 6647.21656 3323.60828 4.12 0.0318 Error 20 16148 807.38700Corrected Total 22 22795Root MSE 28.41456 R-Square 0.2916Dependent Mean 243.04348 Adj R-Sq 0.2208Coeff Var 11.69114Parameter EstimatesParameter StandardVariable DF Estimate Error t Value Pr > |t|Intercept 1 244.93781 13.45982 18.20 <.0001v2 1 1.01582 0.37025 2.74 0.0125v3 1 -0.34172 0.15681 -2.18 0.0414结果分析:方差分析表中,Sr =6647.21656 ,Se=16148 ,自由度为2和20, F = 3323.60828 /807.38700= 4.12,且服从自由度(2,20)的F 分布随机变量大于 4.12的概率为0.0318<0.05,所以回归是显著的。
用SAS作回归分析RegressionAnalysis

交互项的检验
使用交互项的系数检验,判断交 互项是否显著,从而决定是否保 留交互项。
交互项模型的应用
场景
适用于研究多个因素之间相互作 用对因变量的影响,以及解释复 杂现象时使用。
06
案例分享与实战演练
案例一:使用SAS进行线性回归分析
总结词
线性回归分析是一种常用的回归分析方法,用于探索自变量和因变量之间的线 性关系。
表示为 y = f(x),其中 f 是一个非线性函数。
03
多重回归
当一个因变量受到多个自变量的影响时,可以使用多重回归分析。多重
回归模型可以表示为 y = b0 + b1x1 + b2x2 + ... + bnxn,其中 b0
是截距,b1, b2, ..., bn 是自变量的系数。
回归分析在统计学中的重要性
线性关系检验
通过散点图、残差图和正态性检验等手段,检验因变 量与自变量之间是否存在线性关系。
独立性检验
检查自变量之间是否存在多重共线性,确保自变量之 间相互独立。
误差项的独立性检验
检验误差项是否独立,即误差项与自变量和因变量是 否独立。
模型的评估与优化
模型评估
01
通过R方、调整R方、AIC等指标评估模型的拟合优度。
使用SAS进行线性回归分析
线性回归模型的建立
确定自变量和因变量
首先需要明确回归分析的目的,并确定影响因变量的自变量。
数据准备
确保数据清洗无误,处理缺失值、异常值和离群点。
模型建立
使用SAS的PROC REG或PROC GLMSELECT过程,输入自变量和 因变量,选择线性回归模型。
模型的假设检验
02
线性回归分析实验报告

线性回归分析实验报告实验报告:线性回归分析一、引言线性回归是一种常用的统计分析方法,用于建立自变量与因变量之间的线性关系模型。
它可以通过对已知数据的分析,预测未知数据的数值。
本实验旨在通过应用线性回归分析方法,探究自变量和因变量之间的线性关系,并使用该模型进行预测。
二、实验方法1. 数据收集:收集相关的自变量和因变量的数据,确保数据的准确性和完整性。
2. 数据处理:对收集到的数据进行清洗和整理,确保数据的可用性。
3. 模型建立:选择合适的线性回归模型,建立自变量和因变量之间的线性关系模型。
4. 模型训练:将数据集分为训练集和测试集,使用训练集对模型进行训练。
5. 模型评估:使用测试集对训练好的模型进行评估,计算模型的拟合度和预测准确度。
6. 预测分析:使用训练好的模型对未知数据进行预测,分析预测结果的可靠性和合理性。
三、实验结果1. 数据收集和处理:我们收集了100个样本数据,包括自变量X和因变量Y。
通过数据清洗和整理,我们得到了可用的数据集。
2. 模型建立:我们选择了简单线性回归模型,即Y = aX + b,其中a为斜率,b为截距。
3. 模型训练和评估:我们将数据集分为训练集(80个样本)和测试集(20个样本),使用训练集对模型进行训练,并使用测试集评估模型的拟合度和预测准确度。
4. 预测分析:使用训练好的模型对未知数据进行预测,分析预测结果的可靠性和合理性。
四、实验讨论1. 模型拟合度:通过计算模型的拟合度(如R方值),可以评估模型对训练数据的拟合程度。
拟合度越高,说明模型对数据的解释能力越强。
2. 预测准确度:通过计算模型对测试数据的预测准确度,可以评估模型的预测能力。
预测准确度越高,说明模型对未知数据的预测能力越强。
3. 模型可靠性:通过对多个不同样本集进行训练和评估,可以评估模型的可靠性。
如果模型在不同样本集上的表现一致,说明模型具有较高的可靠性。
五、实验结论通过本实验,我们建立了一种简单线性回归模型,成功实现了对自变量和因变量之间的线性关系进行分析和预测。
SAS系统和数据分析多元线性回归分析

第三十二课 多元线性回归分析一、 多元回归模型表示法通常,回归模型包括k 个变量,即一个因变量和k 个自变量(包括常数项)。
由于具有N 个方程来概括回归模型:N t X X X Y t kt k t t t ,,2,1,22110 =+++++=εββββ(32.1)模型的相应矩阵方程表示为:εβ+=X Y(32.2)式中;⎪⎪⎪⎪⎪⎭⎫⎝⎛=⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=⎪⎪⎪⎪⎪⎭⎫⎝⎛=⎪⎪⎪⎪⎪⎭⎫ ⎝⎛=N k kN N k k N X XX X X X X Y Y Y Y εεεεββββ2110121211121,,111, (32.3)其中,Y 为因变量观察的N 列向量,X 为自变量观察的N × (k +1) 矩阵,β为末知参数的(k +1) )列向量,ε 为误差观察的N 列向量。
在矩阵X 表达式中,每一个元素X ij 都有两个下标,第一个下标表示相应的列(变量),第二个下标表示相应的行(观察)。
矩阵X 的每一列表示相应的给定变量的N 次观察的向量,与截矩有关的所有观察值都等于1。
经典的线性回归模型的假设可以阐述如下: ● 模型形式由(32.1)给定;● 矩阵X 的元素都是确定的,X 的秩为(k+1),且k 小于观察数N ;● ε 为正态分布,E (ε )=0 和()I E 2σεε=' ,式中I 为N×N 单位矩阵。
根据X 的秩为(k+1) 的假定,可以保证不会出现共线性。
如果出现完全共线性,矩阵X 的一列将为其余列的线性组合,而X 的秩将小于(k+1) ),关于误差的假设是最有用的假设,因为用它可以保证最小二乘法估计过程的统计性质。
除了正态性外,我们还假定每一个误差项的平均值为0,方差为常数, 以及协方差为 0 。
假若我们按Y 的分布来表示第三个假设,则可写成下式:),(~2I X N Y σβ(32.4)二、 最小二乘法估计我们的目的是求出一个参数向量使得残差平方和最小,即:εεεˆˆˆ12'==∑=Nt t ESS (32.5)式中:Y Y ˆˆ-=ε (32.6) βˆˆX Y =(32.7)其中,εˆ表示回归残差的N 列向量,而Y ˆ表示Y 拟合值的N 列向量,βˆ表示为估计参数的(k +1) 列向量,将式(32.6)和式(32.7)代入式(32.5),则得:()()βββββˆˆˆ2 ˆˆX X Y X Y Y X Y X Y ESS ''+''-'=-'-= (32.8)为了确定最小二乘法估计量,我们求ESS 对βˆ进行微分,并使之等于0,即: 0ˆ22ˆ='+'-=∂∂ββX X Y X ESS (32.9)所以:())(ˆ1Y X X X ''=-β(32.10)被称为“交叉乘积矩阵”,即X X '矩阵能够保证逆变换,这是因为我们假设X 的秩为(k +1),该假设直接导致了X X '的非奇异性。
sas回归分析实验报告

sas回归分析实验报告SAS回归分析实验报告引言:回归分析是一种常用的统计方法,用于研究变量之间的关系。
在本次实验中,我们使用SAS软件进行回归分析,探索自变量和因变量之间的关系,并对结果进行解释和推断。
本实验旨在通过实际数据的分析和处理,加深对回归分析方法的理解和应用。
实验设计:本次实验使用了某公司销售数据,其中自变量包括广告费用、产品价格和季节因素,因变量为销售额。
我们的目标是通过回归分析,探究广告费用、产品价格和季节因素对销售额的影响,并建立一个可靠的模型来预测销售额。
数据处理:首先,我们对数据进行了清洗和预处理。
去除了缺失值和异常值,并进行了变量的标准化处理,以确保数据的准确性和可比性。
接下来,我们使用SAS软件进行回归分析。
回归模型建立:我们选择了多元线性回归模型来建立自变量和因变量之间的关系。
通过分析数据,我们发现广告费用、产品价格和季节因素对销售额都可能有影响。
因此,我们的模型为:销售额= β0 + β1 × 广告费用+ β2 × 产品价格+ β3 × 季节因素+ ε其中,β0、β1、β2和β3分别为回归系数,ε为误差项。
回归分析结果:通过SAS软件进行回归分析后,我们得到了如下结果:回归方程:销售额= 1000 + 2.5 × 广告费用+ 1.8 × 产品价格+ 0.3 × 季节因素回归系数的显著性检验结果显示,广告费用和产品价格对销售额的影响是显著的(p < 0.05),而季节因素的影响不显著(p > 0.05)。
模型解释和推断:根据回归方程的结果,我们可以得出以下结论:1. 广告费用对销售额有正向影响:每增加1单位的广告费用,销售额将增加2.5单位。
2. 产品价格对销售额也有正向影响:每增加1单位的产品价格,销售额将增加1.8单位。
3. 季节因素对销售额的影响不显著:季节因素对销售额的变化没有明显的影响。
sas多元线性回归

输出结果(model1)
图1
输出结果(model2)
图2
图3
结果分析
REG过程中,MODEL语句可以交互使用,本例我们建立了两 个模型,第一个MODEL没有做变量筛选,第二个MODEL指定逐 步回归方法筛选变量。并且用CLI输出预测值与预测区间。 REG过程拟合带截距项的直线回归方程,用最小二乘法估计 模型的参数,并给出模型及参数的方差分析及T检验。本例的两个 模型1检验P值大于0.05,无统计学意义。 模型2为逐步回归法,只纳入了X3,由参数估计表可知,对 常数检验t值为t=615.68,Pr>|t|的值小于0.0001,远小于 0.05,说明截距项(即常数项Intercept)通过检验,估计值为 5.82331.对自变量x1分析同样可以得知,x1系数通过检验,估 计值为-0.00493. 所以回归方程为: y=0.00493*x1+5.82331. 综上所述:在研究影响水稻粒重的因素中,只有秕粒对它的影响 较大。
题目
本数据来源于2003年所做的试验,数据参考文件reg-4.xls,观 测11个水稻品种(03DH1、03DH2、03DH3、03DH 4、03DH5、 03DH6、03DH7、03DH 8、03DH9、03DH10、03DH11)的各 种性状:穗数xl、枝梗数x2、秕粒x3、200粒重y。每个水稻品种取5 株.以5株为一个单位。研究水稻200粒重y与穗数xl、枝梗数x2、秕 粒x3之间的关系,分析哪些因素对200粒重y的影响较大。
结果分析
(5)对本问题再求出Y关于X1、X2的二次多项式回归方程,并与线性
回归方程比较,说明优缺点。 Intercept -14.55333 0.2210 X1 1.66857 <0.0001 X2 -0.73331 0.0126 XSQ -0.00271 0.3914 由输出结果知: 二次模型在0.0001水平下是显著的,预测模型为: y=-14.553333+1.66857x1-0.73311x2-0.00271x1*x2 线性模型在0.001水平下也是显著的,预测模型为: Y=1.53952X1-0.94385X2-4.94048 对比来说:MODEL2复相关系数更接近1,预测值与实测值更接 近,回归效果更好,因此y与x 的关系应选用二次模型。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
PERFECTIONIST.CL
《数据分析方法》 数据分析方法》
习题:2.4(Page79) 计算2班:陈磊
报告目录
问题重述
化妆品销售与人数、月收入关系
数据导入
本题数据导入、数据导入的几种方法
执行过程
proc reg、model语句
执行结果
方差分析、参数估计
多元线性回归设置
习题2.4题目
表2.12 化妆品销售数据(部分数据) ------------------------------------------------------------------------------------------------------------------------------------------------------1 162 274 2450 2 3 120 223 180 375 3254 3802
复相关系数为:0.4087,X2对Y的影响不显著
执行过程4
——X1、X2交互作用
data mylib.ch2_2_4; input y x1 x2 @@; z=x1*x2; cards; 162 274 2450 120 180 131 205 2838 67 86 81 98 3008 192 330 55 53 2560 252 430 144 236 2660 103 157 ; run; proc reg; model y=z; run;
解决方案 -> 分析 -> 分析家
利用向导执行
文件-> 打开 打开ch2_2_4.sas7bdat,即打开已新建的数据集
利用向导执行
统计 -> 回归 -> 线性 设置变量 因变量
变量列表 自变量
利用向导执行
模型参数设置 建立包含所有已选自变量的全模型
利用向导执行
Tests选项设置
置信度a的值
?:若去掉@@,上边能导入哪些数据? .:SAS逻辑库名最多为8个字符,数据集的名称最多为32个字符。
导入数据
——若干方法
1、在编辑框中输入数据,cards 2、从文件读入数据,infile infile‘F:\mylib\ch2_2_4.txt’; 3、导入外部数据<1>向导导入;<2>import语句导入 proc import…… 4、已经建立过数据集 proc reg data=mylib.ch2_2_4;
/*新建自变量z*/ 3254 2347 2450 4020 2088 223 169 116 232 212 375 265 195 372 370 3802 3782 2137 4427 2605
/*自变量为z*/
执行结果4
——X1、X2交互作用
复相关系数为:0.9030,X2对Y的影响显著
利用向导执行
执行结果1
——参数估计表
执行结果1
——方分析表
执行过程2
——自变量X1
检验人数X1对销售量Y的影响是否显著 修改程序,进行一元线性回归分析,自变量x1 proc reg data=mylib.ch2_2_4; /*直接引用数据集*/ model y=x1; run; run
执行结果2
——自变量X1
4 131 205 2838 ………………………………………………. ----------------------------------------------------------------------------
导入数据
title‘《数据据分析方法》_习题2.4_page79’;/*标题*/ /*在逻辑库mylib中创建数据集ch2_2_4*/ data mylib.ch2_2_4; input y x1 x2 @@; /*@@表示可连续输入*/ cards; /*开始输入数据*/ 162 274 2450 120 180 3254 223 375 3802 131 205 2838 67 86 2347 169 265 3782 81 98 3008 192 330 2450 116 195 2137 55 53 2560 252 430 4020 232 372 4427 144 236 2660 103 157 2088 212 370 2605 ; /*遗漏数据用“.”表示,否则对应的这组数据会被自动删除*/ run; /*run语句用于说明处理当前程序步中该语句之前的所有行*/ run
利用向导执行
Plots选项设置
原始残差
自变量 判定残差是 否服从正态 分布的QQ图
利用向导执行
Predictions选项设置
对现有数据集中 的数据进行预测
保存预测结果到 一个数据集中 输出残差预测值
利用向导执行
Statistics选项设置
输出标准化的 回归系数
所得结果
——残差图
所得结果
——Q-Q图
复相关系数为:0.9910,X1对Y影响显著
执行过程3
——自变量X2
检验人数X1对销售量Y的影响是否显著 修改程序,进行一元线性回归分析,自变量x2 proc reg data=mylib.ch2_2_4; model y=x2; run; run
注:可以同时指定多条Model语句。
执行结果3
——自变量X2
执行过程1
reg; proc reg model y=x1 x2; run;
/*调reg过程用*/ /*因变量为y,自变量为x1、x2*/
Model语句:用于定义模型中因变量、自变量、模型选项及结果输出选项。常 用选项有Selection=,指定变量选择方法;NOINT,表示在模型中不包括常数项; STB,输出标准化的回归系数;CLI,输出单个预测值置信区间;R,进行残差分 析,并输出分析结果。 格式:MODEL 因变量名=自变量名列/[选项] 例:model y=x1 x2 / selection=stepwise; /*逐步回归*/