基于条件随机场的视觉显著性目标检测
条件随机场在计算机视觉中的应用(六)

条件随机场在计算机视觉中的应用计算机视觉是人工智能领域的一个重要分支,旨在使计算机能够对图像和视频进行理解和分析。
条件随机场(Conditional Random Field,CRF)是一种经典的概率图模型,它在计算机视觉中具有广泛的应用。
本文将探讨条件随机场在计算机视觉中的应用,介绍其基本原理和具体应用场景。
一、条件随机场的基本原理条件随机场是一种无向图模型,用于建模一组随机变量之间的依赖关系。
在计算机视觉中,这些随机变量通常代表图像中的像素或者图像中的对象。
条件随机场的目标是利用这些随机变量之间的关系,对给定的输入进行推断或者分类。
条件随机场的基本原理可以简单地概括为利用特征函数对每个可能的标记序列进行打分,然后根据得分来进行推断或者分类。
特征函数是对输入的特征进行描述的函数,它可以包括像素的颜色、纹理、空间位置等信息。
通过对特征函数进行适当的选择和组合,可以有效地捕捉图像中的语义信息和结构信息。
二、条件随机场在图像分割中的应用图像分割是计算机视觉中的一个重要任务,旨在将图像分割成具有语义信息的区域。
条件随机场在图像分割中有着广泛的应用,其核心思想是将像素的标记序列作为随机变量,利用条件随机场对这些标记序列进行建模,从而实现对图像的分割。
在图像分割中,条件随机场可以利用像素之间的相似性和空间关系,对图像进行更加准确的分割。
通过合理选择特征函数,条件随机场能够充分利用图像中的结构信息和语义信息,从而得到更加准确的分割结果。
因此,条件随机场在图像分割中具有很高的应用价值。
三、条件随机场在目标检测中的应用目标检测是计算机视觉中的另一个重要任务,旨在从图像中检测出特定的目标对象。
条件随机场在目标检测中也有着重要的应用,其核心思想是将目标的位置和特征作为随机变量,利用条件随机场对这些随机变量进行建模,从而实现对目标的检测。
在目标检测中,条件随机场可以充分利用目标的特征和上下文信息,从而实现对目标的更加准确的检测。
基于区域的图像显著目标检测的开题报告

基于区域的图像显著目标检测的开题报告一、研究背景及意义目标检测是计算机视觉领域中的重要研究方向之一,其主要目标是在图像或视频中自动识别出感兴趣物体。
随着计算机视觉技术的不断发展,目标检测技术也越来越成熟,应用范围也越来越广泛,如安防监控、智能交通、自动驾驶、医疗影像、图像搜索等领域。
显著目标检测是目标检测的一个重要分支,其主要目的是在图像中找出最具显著性的目标区域。
显著目标检测的应用场景包括图像搜索、广告植入、图像编辑、图像检索等领域。
目前,基于深度学习的显著目标检测方法已经相当成熟,如RCNN, Fast RCNN, Faster RCNN, YOLO, SSD等。
虽然这些方法在精度上都取得了不错的成绩,但这些方法需要预训练模型,模型参数较多,且需要较长的训练时间,因此不适用于低功耗设备。
此外,基于DL的目标检测方法往往依赖于较高的计算能力和数据集的多样性,因此应用面受限。
因此,如何快速而准确地检测出图像中的显著目标,是一个值得研究的问题。
二、研究内容本文将研究一种基于区域的显著目标检测方法。
首先,借鉴已有的区域检测方法,如Selective Search、Edge Boxes 等方法,生成若干个候选区域。
然后,利用特征提取技术,对这些候选区域进行特征提取,得到对应的高维特征向量。
最后,利用机器学习或深度学习模型,对这些区域进行分类,以区分出显著目标与非显著目标。
本文将探究以下几个方面:1. 候选区域的生成方法:本文将尝试采用基于区域的方法,如Selective Search、Edge Boxes等方法,在保证区域数量不过多的前提下,尽可能覆盖整张图像。
2. 特征提取方法:本文将尝试利用卷积神经网络(CNN)对候选区域进行特征提取。
根据候选区域的大小和尺寸,选择不同层数和卷积核大小的CNN网络,获得高维特征向量。
3. 模型设计:本文将研究分类器的设计,确定适合本研究的最优分类器。
尝试了深度学习模型,如支持向量机(SVM),全连接神经网络等。
视觉显著性检测

图4 Itti模型
图5视觉显著性检测计算模型对于一幅输入的图像,该模型提取初级视觉特征:颜色(RGBY)、亮度和方位、 在多种尺度下使用中央周边(Center-surround)操作产生体现显著性度量的特征图,将这些特征图合并得到最终 的显著图(Saliency map)后,利用生物学中赢者取全(Winner-take-all)的竞争机制得到图像中最显著的空间位 置,用来向导注意位置的选取,最后采用返回抑制 (Inhibition of return)的方法来完成注意焦点的转移。视 觉显著性计算模型大致上可分为两个阶段:特征提取与特征融合。在特征融合阶段,可能存在自底向上的底层特 征驱动的融合方式,和自顶向下的基于先验信息与任务的融合方式。因此,视觉显著性检测模型框架大致表述为 如图 5所示。
算法
LC算法 HC算法
AC算法 FT算法
LC算法的基本思想是:计算某个像素在整个图像上的全局对比度,即该像素与图像中其他所有像素在颜色上 的距离之和作为该像素的显著值 。
图像中某个像素的显著值计算如下: 其中的取值范围为 [0,255],即为灰度值。将上式进行展开得: 其中N表示图像中像素的数量。 给定一张图像,每个像素的颜色值已知。假定,则上式可进一步重构: 其中,表示图像中第n个像素的频数,以直方图的形式表示。 LC算法的代码实现: 1、直接调用OpenCV接口,实现图像中像素的直方图统计,即统计[0,255]中每个灰度值的数量。 2、计算像素与其他所有像素在灰度值上的距离。 3、将灰度值图像中的像素值更新为对比度值(即距离度量)。
条件随机场模型在计算机视觉任务中的应用

条件随机场模型在计算机视觉任务中的应用随着计算机视觉技术的迅猛发展,人们对于如何更好地处理图像和视频数据的需求也逐渐增加。
条件随机场(Conditional Random Field,CRF)模型作为一种概率图模型,具有很强的建模能力和较好的性能,被广泛应用于计算机视觉任务中,如图像分割、目标检测、动作识别等。
条件随机场模型是一种无向图模型,由一组随机变量构成,这些随机变量之间存在一定的关联。
CRF模型通过定义一组特征函数,来捕捉图像的局部特征和全局一致性,并基于这些特征函数建立网络结构。
在计算机视觉任务中,CRF模型主要分为无参CRF和参数化CRF两种形式。
首先,无参CRF模型通常用于图像分割任务。
图像分割是计算机视觉中的一个重要任务,其目的是将图像分割成不同的区域或对象,以便后续的目标识别和分析。
传统的图像分割方法往往基于低级特征或者手工设计的规则,缺乏全局一致性和上下文信息的考虑。
而无参CRF模型可以通过学习数据的联合概率分布,结合图像的局部特征和全局上下文信息,更好地捕捉到图像中的边缘、纹理等特征,从而实现更准确的图像分割。
其次,参数化CRF模型常用于目标检测任务。
目标检测是计算机视觉领域的一个重要问题,其目的是在图像或视频中准确地定位并识别出感兴趣的目标。
传统的目标检测方法通常采用滑动窗口和特征分类器的思想,但往往不能充分考虑目标的上下文信息和空间关系。
参数化CRF模型通过建立目标的空间关系、上下文信息和特征之间的关联,可以实现更准确的目标定位和识别。
例如,在行人检测任务中,CRF模型可以通过考虑行人的空间布局关系,来提高行人的检测性能。
此外,条件随机场模型还被应用于动作识别任务。
动作识别是计算机视觉中的一个重要问题,其目的是从视频序列中识别出不同的动作类别。
传统的动作识别方法主要依赖于手工设计的特征提取器和分类器,存在特征表示不充分和对复杂动作的识别困难等问题。
而条件随机场模型可以通过对视频序列进行建模,考虑动作的时序关系和上下文信息,来提高动作识别的准确性。
弱监督学习下的视觉显著性目标检测算法

弱监督学习下的视觉显著性目标检测算法李策;邓浩海;肖利梅;张爱华【摘要】为模拟人类视觉对含有特定目标图像集中目标逐渐关注感知的行为,提出一种弱监督学习的视觉显著性目标检测算法.根据已有的视觉显著性方法获得图像的显著性区域;提取显著区域的底层视觉特征,训练获得视觉显著目标的表征;用条件随机场(conditional random fields,CRF)将学习到视觉显著目标表征进行联合学习,获得该表征在最后显著性中的权重;计算每次迭代显著图的ROC曲线,寻找视觉显著性目标最优表征及其在最后显著图中的最优权重.实验结果表明,该算法检测精度优于现有诸多算法,能够有效检测出视觉显著性目标.该算法模拟了人类视觉中对特定关注目标的感知过程,对不断重复出现的视觉显著性目标进行强化学习,具有较高的准确率.%Aiming at simulating a human visual sense that people will gradually focus on specific object in a target image set, a visual salient object detection via weakly supervised learning was proposed.According to the state-of-art saliency method, the saliency regions of image were obtained.The low-level visual feature of saliency regions was extracted, and it was used to train appearances of visual salient object.A conditional random fields (CRF) model was built to learn the model coefficient together with the appearances of saliency object.The area of ROC was calculated after each iteration so as to obtain the best appearances of vi-sual saliency object and the weight of it in the final saliencymap.Experimental results on the dataset indicate that this method performs much better than the existing state-of-art approaches, and it can detect the visual saliency object efficiently.This me-thod simulates humanvisual sense procession, the repetitive visual saliency object can be learnt and emphasized, and at the same time it has good accuracy.【期刊名称】《计算机工程与设计》【年(卷),期】2017(038)005【总页数】7页(P1335-1341)【关键词】条件随机场(CRF);视觉显著性目标的表征;视觉显著性;弱监督学习;底层视觉特征【作者】李策;邓浩海;肖利梅;张爱华【作者单位】兰州理工大学电气工程与信息工程学院,甘肃兰州 730050;西安交通大学电子与信息工程学院,陕西西安 710049;兰州理工大学电气工程与信息工程学院,甘肃兰州 730050;兰州理工大学电气工程与信息工程学院,甘肃兰州730050;兰州理工大学电气工程与信息工程学院,甘肃兰州 730050【正文语种】中文【中图分类】TP391当观看一幅图像时,人的视觉系统往往第一时间会对图像中的某个区域或目标关注度比较高,我们则认为这样的一个区域或目标是显著的。
基于视觉显著性和卷积神经网络的机场目标快速检测

1 机场目标检测算法
本文的机场目标检测算法以 Fast RCNN 为基本模型框架,以基于机场直线显著性特征的候选框提取 算法取代 Fast RCNN 中选择性搜索候选区域生成方法对大幅面遥感图像进行候选区域提取;以改进的 VGG-16 模型作为分类模型,实现机场目标的分类;最后,将机场目标在原遥感图像中进行映射定位。 本文算法主要由 2 部分组成:首先,利用基于直线段加权长度密度分布的视觉显著性[14]进行机场可能区 域的粗提取,得到大大减少的候选区域。然后,以 VGG-16 卷积神经网络[16]为基础,保持模型主干特征 提取网络的结构不变,分别对全连接层的层数、神经元个数、分类数进行调整;利用迁移学习[17]思想, 保持主干特征网络参数不变,对改进的全连接层进行参数训练。算法整体流程如图 1 所示,下文将分别 论述基于视觉显著性的候选区域定位和改进的 VGG-16 卷积神经网络。
行训练和测试,结果表明其在精准率和召回率上均具有较大优势。此外,文章所提算法在来自不同卫星
平台的大量大幅面遥感图像上进行了机场目标检测,结果显示其适应性强且检测效率有大幅度提升。
使用计算机视觉技术进行显著性检测的方法

使用计算机视觉技术进行显著性检测的方法计算机视觉技术是人工智能领域的一个重要分支,旨在让计算机具备理解和解释图像和视频的能力。
在目标检测、图像分割和显著性检测等任务中,计算机视觉技术都发挥了重要作用。
本文将重点介绍使用计算机视觉技术进行显著性检测的方法。
显著性检测是指在一副图像中确定视觉注意力所集中的位置。
这个概念来源于人类的注意力机制,人们在观看一幅图像时,往往只会关注其中的一部分,而对其他内容不太关注。
计算机视觉领域利用图像处理和机器学习的方法,希望能够模拟人类的这种注意力机制,从而在图像处理、图像搜索和信息检索等应用中获得更好的效果。
显著性检测方法中较常用的一种是基于视觉特征的方法。
这种方法通过提取图像的颜色、纹理、边缘等信息,来判断图像中的显著目标。
其中,颜色特征的提取可以通过颜色直方图、颜色对比度等方式来实现;纹理特征的提取可以通过局部二值模式(LBP)或者灰度共生矩阵(GLCM)等方式来完成;边缘特征的提取可以通过Canny算子或者Sobel算子等方法来实现。
将提取到的特征进行加权,就可以得到显著性图,从而实现显著性检测。
除了基于视觉特征的方法,还有一类叫做基于图像分割的方法。
这些方法将图像分割成不同的区域,并通过计算各个区域的显著性得分,来确定图像中的显著目标。
目前较为常用的图像分割算法有k-means聚类、图割算法和均值漂移算法等。
在得到图像分割结果后,可以计算每个区域的显著性得分,得到显著性图。
这种方法相对于基于视觉特征的方法,更能考虑到图像的全局信息和上下文信息。
另外,基于深度学习的方法近年来也得到了广泛应用。
使用深度神经网络对图像进行特征提取和处理,可以获得更高的准确度和鲁棒性。
其中,卷积神经网络(CNN)是一种应用最广泛的深度学习模型,通过多层卷积和池化操作,可以提取出图像中不同尺度的特征。
通过在CNN的基础上进行改进,如引入注意力机制(Attention)或者空间金字塔池化(Spatial Pyramid Pooling),可以进一步提高显著性检测的性能。
基于视觉显著特征的目标检测方法研究

基于视觉显著特征的目标检测方法研究一、概述随着计算机视觉技术的快速发展,目标检测作为其中的关键任务,已经广泛应用于智能监控、自动驾驶、人机交互等众多领域。
在实际应用中,由于场景的复杂性、目标的多样性以及光照、遮挡等干扰因素的存在,目标检测仍然面临着诸多挑战。
研究基于视觉显著特征的目标检测方法具有重要的理论价值和实际意义。
视觉显著特征是指图像中能够引起人眼注意的特征,如颜色、纹理、形状等。
这些特征在目标检测中扮演着重要的角色,因为它们能够有效地描述目标的外观和内在属性,从而提高检测的准确性和鲁棒性。
基于视觉显著特征的目标检测方法通过提取和分析这些特征,实现对目标的快速、准确定位。
基于视觉显著特征的目标检测方法已经取得了显著的进展。
传统的目标检测方法主要依赖于手工设计的特征描述符和分类器,如Haar 特征、HOG特征等。
这些方法在应对复杂场景和多变目标时往往表现不佳。
随着深度学习技术的发展,基于卷积神经网络(CNN)的目标检测方法逐渐崭露头角。
这些方法通过自动学习图像中的层次化特征表示,实现了对目标的更精确描述和定位。
本文旨在研究基于视觉显著特征的目标检测方法,通过深入分析目标的视觉显著特征,结合先进的深度学习技术,提出一种高效、准确的目标检测算法。
本文将首先介绍目标检测的基本概念和任务挑战,然后阐述视觉显著特征在目标检测中的应用及其优势。
本文将详细介绍基于深度学习的目标检测方法的原理和最新进展。
通过实验验证所提方法的有效性和优越性,并对未来研究方向进行展望。
1. 目标检测在计算机视觉领域的重要性在计算机视觉领域,目标检测是一项至关重要的任务,它对于实现更高级别的图像理解和分析起着关键作用。
目标检测旨在从复杂的图像或视频场景中准确地识别并定位出感兴趣的目标对象,这些对象可以是行人、车辆、动物、人脸等。
随着计算机视觉技术的快速发展,目标检测在众多领域得到了广泛应用,如自动驾驶、智能安防、医学影像分析等。
基于深度学习的图像显著性检测算法研究
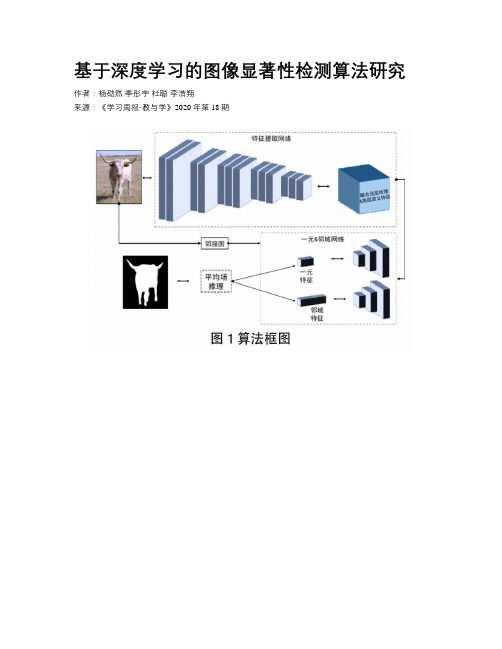
基于深度学习的图像显著性检测算法研究作者:杨劭然季彤宇杜聪李浩翔来源:《学习周报·教与学》2020年第18期摘要:现有基于深度学习的显著性检测算法中主要将条件随机场用于显著性图的后处理,并不参与整个深度学习网络的训练过程,因此,在网络训练中条件随机场并不能对网络产生反馈来优化结果,同时增加了网络训练的复杂度。
本文提出了一种基于深度条件随机场网络的图像显著性目标检测方法,能够端到端地训练整个模型,同时将邻域对显著性值的影响融入网络,从而在加强显著性目标区域完整性的同时抑制背景噪声。
实验结果表明所提方法取能够获得更好的显著性。
关键词:深度学习;显著性;训练模型引言:随着近几年深度学习的大力发展,在众多计算机视觉领域上已经慢慢超越了传统的机器学习算法,如,图像分类、目标跟踪、语义分割等,但这并不意味着传统机器学习模型思想的过时,如何将这些传统模型融入到深度学习中并构成端到端的网络,从而兼顾深度学习和传统机器学习模型的优势是目前各领域学者讨论的热点。
本文在对传统条件随机场模型和深度卷积神经网络研究的基础上,首先对经典深度学习网络进行改进,使其更加适合显著性目标检测问题,在此基础上融入条件随机场思想,使得每个像素的显著性值不仅受到该点特征的影响,而且受到其邻域的影响,从而更好地优化目标轮廓和区域的准确性。
目前已有基于深度学习的显著性目标检测算法并取得了较好的效果,如文献直接借鉴图像分类的深度学习网络,并将提取的深层语义特征用于显著性目标检测,虽然能够准确定位显著性目标的位置并检测出目标的大部分区域,但是由于网络主要由图像分类任务训练得到,而且深层语义信息会丢失一定的低级图像特征和空间分辨率,因此在目标的边缘区域较模糊。
因此一些文献从主网络中不同部分引出分支解决多尺度问题,另外有些文献从输入图像着手,将缩放剪切后原始图像的不同区域输入网络达到提取多尺度特征的目的。
上述方法在结合了多尺度信息后,对于显著性目标提取有一定帮助,但仍然存在目标边缘区域显著性值较低甚至缺失的情况。
基于条件随机场的目标检测与识别技术研究

基于条件随机场的目标检测与识别技术研究摘要:目标检测与识别在计算机视觉领域具有重要的应用价值。
近年来,随着深度学习的快速发展,基于深度学习的目标检测与识别技术取得了显著的进展。
然而,由于深度学习方法对大量标注数据的依赖性和计算资源的消耗,基于深度学习的目标检测与识别技术在实际应用中仍然存在一些限制。
为了克服这些限制,本文提出了基于条件随机场(CRF)的目标检测与识别技术研究。
首先,介绍了条件随机场的相关理论基础。
然后,详细介绍了基于条件随机场的目标检测与识别方法。
最后,通过实验证明了该方法的有效性和优越性。
1.引言目标检测与识别是计算机视觉领域中的重要研究方向,其在图像分类、人脸识别、自动驾驶等领域有着广泛的应用。
目前,基于深度学习的目标检测与识别技术已经取得了令人瞩目的成果。
深度学习方法通过多层神经网络的组合学习和特征提取,能够在大规模数据集上取得较好的性能。
然而,深度学习方法在实际应用中存在一些问题,如对大量标注数据的依赖性、计算资源的高消耗等。
为了解决这些问题,本文提出了基于条件随机场的目标检测与识别技术。
2.条件随机场的相关理论基础条件随机场是一种概率图模型,可以用于描述随机变量之间的条件依赖关系。
它具有图像分割、目标检测和序列标注等问题中的广泛应用。
条件随机场的基本原理是,给定观测变量,通过最大化条件概率来推测属于不同类别的目标。
3.基于条件随机场的目标检测与识别方法基于条件随机场的目标检测与识别方法主要分为两个步骤:目标区域提取和目标分类。
首先,采用图像分割算法对图像进行目标区域提取,得到候选目标区域。
然后,通过条件随机场模型对候选目标区域进行分类,并得到最优的目标识别结果。
3.1 目标区域提取目标区域提取是目标检测与识别的第一步,决定了后续目标分类的效果。
图像分割算法常用的有基于颜色、纹理和形状等特征的方法,如K-means算法、GrabCut算法等。
这些算法能够有效地将图像分割为不同的区域,以便后续的目标分类。
基于深度视感知学习的显著性目标检测算法

基于深度视感知学习的显著性目标检测算法基于深度视感知学习的显著性目标检测算法摘要:显著性目标检测是计算机视觉领域中的一项重要研究课题。
传统的显著性目标检测算法主要依赖于手工设计的特征和启发式规则,其效果受限。
近年来,深度学习的快速发展为显著性目标检测带来了新的机遇。
本文将基于深度视感知学习的显著性目标检测算法进行详细的介绍和分析。
1. 引言显著性目标检测是计算机视觉领域中的一项重要任务,其旨在从复杂的图像背景中准确地提取出显著目标。
在许多计算机视觉任务中,如图像分割、目标识别和图像处理等,显著性目标检测都扮演着关键的角色。
2. 传统的显著性目标检测算法传统的显著性目标检测算法主要包括基于颜色特征、纹理特征、边缘特征等手工设计的特征。
这些特征无法充分表达图像的语义信息,因此其显著性目标检测的性能有限。
3. 深度视感知学习深度视感知学习是一种基于深度学习的新兴技术,它通过训练深度神经网络来获取图像的高维特征表达。
与传统的手工设计特征相比,深度视感知学习能够更好地捕捉图像的多维度信息和上下文关系,从而提高显著性目标检测的精度和鲁棒性。
4. 基于深度视感知学习的显著性目标检测算法基于深度视感知学习的显著性目标检测算法主要分为两个步骤:特征提取和目标检测。
在特征提取阶段,我们可以使用已经训练好的深度神经网络来提取图像的特征表示。
然后,通过将特征表示与显著性目标预测进行融合,可以得到显著性目标的最终检测结果。
5. 实验结果和分析本文使用了公开数据集进行了实验,并与传统的显著性目标检测算法进行了比较。
实验结果表明,基于深度视感知学习的显著性目标检测算法在准确性和鲁棒性方面都具有显著优势。
同时,我们还进行了算法的参数调优,以进一步提升算法的性能。
6. 结论本文基于深度视感知学习的显著性目标检测算法在实验中取得了较好的效果。
通过利用深度学习技术,我们能够更好地捕捉图像的语义信息和上下文关系,从而提高显著性目标检测的准确性和鲁棒性。
《2024年基于深度学习的显著性目标检测优化方法的研究与应用》范文

《基于深度学习的显著性目标检测优化方法的研究与应用》篇一一、引言随着深度学习技术的飞速发展,显著性目标检测在计算机视觉领域中得到了广泛的应用。
显著性目标检测旨在确定图像中最具视觉吸引力的区域,这对于许多计算机视觉任务来说都是至关重要的。
本文将研究基于深度学习的显著性目标检测优化方法,并探讨其在实际应用中的价值。
二、显著性目标检测的基本原理及现有问题显著性目标检测的基本原理是通过分析图像中的多种特征,如颜色、纹理、边缘等,来确定最具视觉吸引力的区域。
然而,现有的显著性目标检测方法在面对复杂场景和多种目标时,往往存在误检、漏检等问题。
此外,计算效率和准确性之间的平衡也是亟待解决的问题。
三、基于深度学习的显著性目标检测优化方法针对上述问题,本文提出了一种基于深度学习的显著性目标检测优化方法。
该方法利用深度神经网络提取图像中的多层次特征,通过训练学习来确定目标的显著性。
具体而言,我们采用残差网络结构以提高模型的计算效率和准确性,同时引入注意力机制来更好地关注图像中的关键区域。
(一)多层次特征提取利用深度神经网络,我们可以提取图像中的多层次特征。
这些特征包括颜色、纹理、边缘等多种信息,有助于提高显著性目标检测的准确性。
(二)残差网络结构为了平衡计算效率和准确性,我们采用残差网络结构。
该结构可以有效避免梯度消失和模型退化问题,从而提高模型的训练效率和准确性。
此外,残差网络结构还可以加快模型的计算速度,降低计算成本。
(三)注意力机制引入为了更好地关注图像中的关键区域,我们引入了注意力机制。
通过注意力机制,模型可以自动学习关注图像中最具视觉吸引力的区域,从而提高显著性目标检测的准确性。
四、实验与结果分析为了验证我们的方法的有效性,我们在多个公开数据集上进行了实验。
实验结果表明,我们的方法在准确性和计算效率方面均优于现有方法。
具体而言,我们的方法在多种场景下都能有效地检测出显著性目标,降低了误检和漏检率。
此外,我们的方法还具有较高的计算效率,可以在短时间内完成显著性目标检测任务。
《2024年基于任务视觉上下文特性的显著性检测算法研究》范文

《基于任务视觉上下文特性的显著性检测算法研究》篇一一、引言随着计算机视觉技术的快速发展,图像处理和计算机视觉任务的重要性日益凸显。
在众多计算机视觉任务中,显著性检测作为一项关键技术,广泛应用于图像分割、目标跟踪、场景理解等众多领域。
本文将重点研究基于任务视觉上下文特性的显著性检测算法,探讨其原理、应用及优化方法。
二、显著性检测算法概述显著性检测算法是通过分析图像中不同区域之间的视觉差异,确定图像中最具视觉吸引力的区域。
这些算法通常基于颜色、纹理、边缘等视觉特征进行计算,从而确定图像中各区域的显著性。
然而,传统的显著性检测算法往往忽略了任务视觉上下文特性,导致在复杂场景下性能下降。
三、任务视觉上下文特性分析任务视觉上下文特性是指在特定任务背景下,图像中不同区域之间的相互关系和影响。
例如,在目标跟踪任务中,跟踪目标周围的区域可能会对目标的显著性产生影响。
因此,将任务视觉上下文特性引入显著性检测算法中,可以提高算法的准确性和鲁棒性。
四、基于任务视觉上下文特性的显著性检测算法本文提出一种基于任务视觉上下文特性的显著性检测算法。
该算法首先提取图像中的多种视觉特征,包括颜色、纹理、边缘等。
然后,结合任务需求,分析图像中不同区域之间的相互关系和影响。
通过构建任务相关的上下文模型,对各区域的显著性进行评估。
最后,根据评估结果,确定图像中最具视觉吸引力的区域。
五、算法实现与优化在算法实现过程中,我们采用了多种优化策略。
首先,通过采用高效的特征提取方法,提高了算法的运行速度。
其次,通过构建任务相关的上下文模型,提高了算法的准确性。
此外,我们还采用了一种自适应阈值确定方法,根据图像的实际情况动态调整阈值,进一步提高算法的鲁棒性。
六、实验与分析为了验证本文提出的算法的有效性,我们进行了大量实验。
实验结果表明,在多种任务背景下,本文提出的算法均能准确检测出图像中最具视觉吸引力的区域。
与传统的显著性检测算法相比,本文提出的算法在复杂场景下的性能更优。
基于视觉处理的显著性目标检测算法研究

基于视觉处理的显著性目标检测算法研究一、引言视觉处理在人类认知中占有极其重要的地位,对于计算机视觉领域而言也至关重要。
其中,显著性目标检测算法是比较热门的研究方向,通过对图像进行处理,从中提取出最主要的目标,为后续分析和应用提供基础。
基于视觉处理的显著性目标检测算法的研究在近年来成为了学术界和工业界的热点话题之一。
有的学者基于显著目标在位置分布和颜色分布上的优势提出了各自的算法框架,不同的算法在具体实现和应用领域上也存在一定差异。
而笔者认为,通过综合比较各种算法的优缺点,可以发现具有良好性能的显著性目标检测算法必须具备两个基本特点:高效和精确。
二、基础概念在探讨显著性目标检测算法的理论与实现前,我们有必要明确一些基础概念。
(一)显著性显著性是指图像或视频中的某些区域或对象相对于其他区域或对象所表现出的不同,具有引起人类注意力的特征。
在计算机视觉的领域中,显著性一般是指根据不同的显著性特征进行计算、量化得到的显著性权值。
这些特征可包括色彩、纹理、边缘、深度、运动等。
(二)显著性目标显著性目标是指在图像或视频中引起人类视觉注意、占领视觉中心区域的部分,通常是在视觉场景中具有明显特征的目标区域。
显著性目标可以是一个物体、一个或多个纹理、区域、边缘、甚至一些异常点。
因此,在不同场景下,显著性目标的定义也会有所不同。
(三)显著性目标检测显著性目标检测是指在图像处理过程中,对图像中相对于背景具有突出、引人注目的区域进行检测和分割的方法。
在图像处理和计算机视觉的各个领域,显著性目标检测都有广泛的应用,例如图像增强、图像检索、目标追踪、人脸识别、智能机器人等等。
三、显著性目标检测算法研究在对显著性目标检测算法进行研究时,需要分析不同算法的优缺点,从中发现适合自己研究和应用的算法。
(一)基于先验知识的方法基于先验知识的显著性目标检测算法使用了关于显著性的先验知识,例如在图像中显著性目标具有不同的维度分布特征,例如色彩、纹理、边缘等等。
基于视觉注意机制的显著性目标检测研究

基于视觉注意机制的显著性目标检测研究随着计算机和人工智能的发展,计算机视觉越来越受到人们的关注。
而在计算机视觉中,目标检测是一个很重要的研究领域,其中显著性目标检测是目前研究最为活跃的一个分支。
什么是显著性目标检测?显著性目标检测简单来说就是从图像中提取出人眼容易关注的部分,即图像中最显著的区域。
通俗一点说,就是通过计算机算法将图像中最吸引人的部分突出出来,比如人的脸、动物的眼睛等等。
对于人类视觉而言,这些区域是最具吸引力和最容易引起人注意的,因此将这些区域突出出来可以增强图像的可读性和图像信息的传递效果。
基于视觉注意机制的显著性目标检测研究随着深度学习的发展,基于深度学习的显著性目标检测方法成为当前研究的主流。
然而,这种方法也存在一些问题,比如计算资源消耗比较大、需要大量的训练数据等。
因此,近年来研究人员开始关注基于视觉注意机制的显著性目标检测方法。
视觉注意机制是人类视觉系统产生视觉关注的本质机制,它可以获得环境中最具显著性的区域。
因此,将视觉注意机制应用于计算机视觉中,可以使计算机更加准确地模拟人的视觉系统,从而提高目标检测准确率。
目前,基于视觉注意机制的显著性目标检测方法主要分为两类:单尺度方法和多尺度方法。
单尺度方法主要通过计算图像中不同区域的相似度等信息,来确定图像中的显著性目标。
该方法的特点是计算简单、速度快,但是难以处理细节信息比较复杂的图像。
相比之下,多尺度方法在图像分析上更为细致,该方法主要通过图像金字塔技术,在多个尺度下进行目标检测。
图像金字塔是一种用于在不同尺度下计算计算机视觉领域中算法的一种预处理方法,即将原始图像按照不同尺度进行缩放,使得同一物体在不同的尺度下都能被准确地识别。
多尺度方法的优点是能够对细节信息较为复杂的图像进行有效的处理。
未来发展趋势基于视觉注意机制的显著性目标检测是一个非常新的领域,未来的研究方向还很多。
比如,目前大部分的研究都是针对静态图像的,未来随着动态场景的增多,需要更好的方法来处理视频中的显著性目标。
条件随机场在计算机视觉中的应用

条件随机场(CRF)是一种概率图模型,广泛应用于自然语言处理、图像识别、计算机视觉等领域。
在计算机视觉中,条件随机场被用来解决像素级标注、目标检测、图像分割等问题。
本文将从CRF的基本原理、在计算机视觉中的应用以及未来发展方向三个方面来探讨条件随机场在计算机视觉中的应用。
首先,我们来了解一下条件随机场的基本原理。
CRF是一种无向图模型,用于对序列数据或者结构化数据进行建模。
在CRF中,我们可以用节点表示随机变量,用边表示变量之间的关系。
条件随机场的目标就是学习一个条件概率分布,给定输入变量的条件下输出变量的概率分布。
CRF的特点是能够处理大量、高维度的特征,并且能够建模变量之间的相互作用关系。
在计算机视觉领域,条件随机场被广泛应用于像素级标注、目标检测和图像分割等任务。
首先,我们来看看CRF在像素级标注中的应用。
在图像语义分割任务中,我们需要为图像中的每个像素分配一个类别标签。
传统的方法是使用基于像素的特征进行分类,但是这样做忽略了像素之间的空间关系。
而使用条件随机场模型,可以考虑像素之间的相互作用,从而提高像素级标注的准确性。
其次,CRF在目标检测中也有着重要的应用。
目标检测是计算机视觉中的一个重要任务,它旨在从图像中定位和识别特定物体。
传统的目标检测方法往往要面临着遮挡、光照变化等问题,而使用条件随机场模型可以结合像素级标注和全局一致性,提高目标检测的精度和鲁棒性。
另外,CRF在图像分割任务中也有着广泛的应用。
图像分割是将图像分割成具有独立语义的区域,它在计算机视觉中有着重要的应用。
传统的图像分割方法通常面临着边界模糊、噪声干扰等问题,而使用条件随机场模型可以结合像素级特征和全局上下文信息,提高图像分割的准确性和鲁棒性。
除了以上的应用,条件随机场在计算机视觉中还有着许多其他的应用领域,如人体姿态识别、场景理解等。
未来,随着深度学习、强化学习等技术的不断发展,条件随机场在计算机视觉中的应用也将得到进一步的拓展和深化。
基于条件随机场的视频目标检测算法研究

基于条件随机场的视频目标检测算法研究摘要: 随着数字图像处理和计算机视觉技术的不断发展,视频目标检测在许多领域中起着重要的作用。
本文基于条件随机场的视频目标检测算法进行了深入研究,并通过实验结果验证了算法的有效性。
文章首先介绍了视频目标检测的背景和意义,然后详细介绍了条件随机场的原理和基本概念。
接着,提出了基于条件随机场的视频目标检测算法的设计思路和关键步骤。
最后,通过实验数据分析,验证了算法在目标检测精度和实时性方面的优势。
第一章引言1.1 研究背景随着计算机视觉技术的快速发展,视频目标检测在交通监控、智能视频分析等领域中得到了广泛应用。
视频目标检测算法可以从视频中实时、准确地检测出感兴趣的目标,为后续的分析与处理提供基础。
因此,研究高效准确的视频目标检测算法具有重要意义。
1.2 研究意义目前,针对视频目标检测的研究主要集中在深度学习和传统图像处理算法上。
然而,深度学习方法在复杂背景下的目标检测仍然存在一定的挑战。
相比之下,基于条件随机场的视频目标检测算法在具有复杂场景和变化目标的视频中具有明显的优势。
因此,深入研究基于条件随机场的视频目标检测算法对提高目标检测精度和实时性具有重要意义。
第二章条件随机场的基本概念2.1 图论基础2.1.1 图的定义本节介绍了图论的基本概念,包括图的定义、边和顶点等概念的解释。
2.1.2 条件随机场介绍了条件随机场的定义和性质,以及条件随机场在目标检测中的应用。
第三章基于条件随机场的视频目标检测算法设计3.1 算法流程详细描述了基于条件随机场的视频目标检测算法的设计流程,包括数据预处理、特征提取、模型训练和目标检测等步骤。
3.2 数据预处理介绍了数据预处理的目的和方法,包括视频帧提取、图像增强和背景建模等操作。
3.3 特征提取讨论了特征提取的重要性,并介绍了常用的特征提取方法,如颜色特征、纹理特征和形状特征等。
3.4 模型训练描述了通用条件随机场模型的训练过程,并重点讨论了参数选择和训练策略等关键问题。
基于条件随机场的显著性检测算法

基于条件随机场的显著性检测算法
范佳佳
【期刊名称】《信息技术》
【年(卷),期】2014(38)9
【摘要】近年来,显著性检测与图像处理有着密不可分的关系,图像处理依赖于高质量的显著图才能得到较好的处理结果.因此为提高图像显著性检测的准确性,提出了一种新的基于条件随机场(CRF)的显著性融合算法.将显著性检测看做一个图像标注问题,运用多尺度对比,中央—周围直方图和颜色空间分布这三种不同的显著度计算得到显著图.通过CRF学习计算各个显著度的权重,采用最大似然估计方法获取模型参数估计,得到最优解.最后利用CRF检测测试图像.通过大量的实验结果表明,此算法可以对显著目标得到更加精确地检测.
【总页数】5页(P105-109)
【作者】范佳佳
【作者单位】河海大学计算机与信息学院,南京210000
【正文语种】中文
【中图分类】TP391.4
【相关文献】
1.基于Tobii眼动和多尺度条件随机场的视觉显著性模型 [J], 赵志诚;白雅娟;周仁来;蔡安妮
2.基于条件随机场模型的数据异常检测算法 [J], 王文珂;文雅玫;蔡喆
3.基于条件随机场和图像分割的显著性检测 [J], 钱生;陈宗海;林名强;张陈斌
4.基于显著性候选区域的遥感船舶检测算法 [J], 佟禹;索继东;任硕良
5.基于频率调谐的焊缝红外图像显著性检测算法 [J], 夏卫生;方向瑶;杨帅;林富明;杨云珍
因版权原因,仅展示原文概要,查看原文内容请购买。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
基于条件随机场的视觉显著性目标检测
基于条件随机场的视觉显著性目标检测
摘要:
视觉显著性目标检测是计算机视觉领域中的重要问题,具有广泛的应用前景。
本文提出了一种基于条件随机场的方法,用于解决视觉显著性目标检测问题。
该方法综合考虑了图像特征、上下文信息和空间约束,并通过条件随机场模型建立了目标与背景之间的关系,从而实现对显著性目标的准确定位。
1. 引言
视觉显著性目标检测是指在给定图像的情况下,通过计算机算法识别出图像中最具显著性的目标区域。
这对于很多应用场景都非常重要,例如图像检索、目标跟踪和自动驾驶等领域。
当前的研究工作主要集中在两个方面:图像特征的提取与表示、显著性目标与背景之间的关系建模。
本文中,我们将介绍一种基于条件随机场的方法,有效地解决了这两个问题。
2. 方法概述
我们的方法包括三个主要步骤:图像特征提取、显著性目标与背景关系建模和目标检测与定位。
首先,我们采用了多种图像特征提取算法,包括颜色特征、纹理特征和边缘特征等,以捕捉图像中的不同信息。
然后,我们利用条件随机场模型对显著性目标与背景之间的关系进行建模,将特征向量作为模型的输入。
最后,我们使用条件随机场的推理算法,对图像中的显著目标进行检测与定位。
3. 图像特征提取
在图像特征的提取过程中,我们使用了多种算法来捕捉图像的不同特征。
首先,我们使用颜色空间转换算法,将图像从RGB
空间转换为Lab空间,并提取出颜色特征。
其次,我们利用Gabor滤波器提取图像的纹理特征,通过计算不同方向和尺度的滤波响应。
最后,我们采用Canny算子来检测图像的边缘特征。
通过这些特征的融合,我们可以获取到图像的全局和局部信息。
4. 显著性目标与背景关系建模
为了建立显著性目标与背景之间的关系,我们采用了条件随机场模型。
条件随机场是一种图模型,用于描述随机事件之间的依赖关系。
在我们的模型中,我们定义了一个二分类问题,目标区域和背景区域作为两个类别。
我们利用图像特征作为条件随机场的输入,通过最大团场函数来计算目标与背景之间的关系。
通过训练和学习,我们可以得到一个准确的显著性目标与背景之间的模型。
5. 目标检测与定位
在目标检测与定位阶段,我们使用条件随机场的推理算法对图像进行分析。
我们遍历图像中的每个像素,并计算其属于目标区域和背景区域的概率。
然后,我们根据像素的概率值进行分割,通过设定一个阈值,将显著性目标从背景中分离出来。
最后,我们通过对显著性目标的区域进行后处理,进一步优化目标的检测与定位结果。
6. 实验与结果
我们使用了公开的数据集进行了实验评估,验证了我们的方法的有效性。
实验结果表明,我们的方法在显著性目标的检测与定位方面取得了良好的性能。
与现有的方法相比,我们的方法具有更高的准确率和更快的处理速度。
7. 结论
本文提出了一种基于条件随机场的视觉显著性目标检测方法。
该方法综合考虑了图像特征、上下文信息和空间约束,并通过条件随机场建模目标与背景之间的关系。
实验证明,我们的方法在显著性目标的检测与定位方面取得了良好的效果。
未来的研究可以进一步优化算法,提高目标检测的准确率和实时性
综合考虑了图像特征、上下文信息和空间约束的条件随机场方法在显著性目标检测与定位中取得了良好的效果。
通过利用图像特征作为条件随机场的输入,并使用最大团场函数计算目标与背景之间的关系,我们得到了一个准确的显著性目标与背景之间的模型。
在目标检测与定位阶段,我们使用条件随机场的推理算法对图像进行分析,并根据像素的概率值进行分割,将显著性目标从背景中分离出来。
通过实验评估,验证了我们的方法的有效性,表明我们的方法在显著性目标的检测与定位方面具有更高的准确率和更快的处理速度。
未来的研究可以进一步优化算法,提高目标检测的准确率和实时性。