中英文对照的计算机论文.doc
计算机在现代生活中的过度使用英语作文

计算机在现代生活中的过度使用英语作文English:In modern life, computers play a crucial role in almost every aspect of our daily routines. From communication to entertainment, education to work, computers have become an indispensable tool for us. With the rapid development of technology, computer usage has become increasingly prevalent, leading to a phenomenon where we see over-dependence on computers in certain situations. One of the notable consequences of this overuse is the widespread adoption of the English language as the primary medium of communication in the digital realm. English has become the lingua franca of the internet, programming languages, software interfaces, and even social media platforms. As a result, individuals who are not proficient in English may find themselves at a disadvantage when navigating the digital landscape. This overreliance on English in the realm of computers not only poses challenges for non-English speakers but also raises concerns about the preservation of linguistic diversity and cultural identity.中文翻译:在现代生活中,计算机在我们日常生活的几乎每个方面都起着至关重要的作用。
软件工程毕业论文文献翻译中英文对照

软件工程毕业论文文献翻译中英文对照学生毕业设计(论文)外文译文学生姓名: 学号专业名称:软件工程译文标题(中英文):Qt Creator白皮书(Qt Creator Whitepaper)译文出处:Qt network 指导教师审阅签名: 外文译文正文:Qt Creator白皮书Qt Creator是一个完整的集成开发环境(IDE),用于创建Qt应用程序框架的应用。
Qt是专为应用程序和用户界面,一次开发和部署跨多个桌面和移动操作系统。
本文提供了一个推出的Qt Creator和提供Qt开发人员在应用开发生命周期的特点。
Qt Creator的简介Qt Creator的主要优点之一是它允许一个开发团队共享一个项目不同的开发平台(微软Windows?的Mac OS X?和Linux?)共同为开发和调试工具。
Qt Creator的主要目标是满足Qt开发人员正在寻找简单,易用性,生产力,可扩展性和开放的发展需要,而旨在降低进入新来乍到Qt的屏障。
Qt Creator 的主要功能,让开发商完成以下任务: , 快速,轻松地开始使用Qt应用开发项目向导,快速访问最近的项目和会议。
, 设计Qt物件为基础的应用与集成的编辑器的用户界面,Qt Designer中。
, 开发与应用的先进的C + +代码编辑器,提供新的强大的功能完成的代码片段,重构代码,查看文件的轮廓(即,象征着一个文件层次)。
, 建立,运行和部署Qt项目,目标多个桌面和移动平台,如微软Windows,Mac OS X中,Linux的,诺基亚的MeeGo,和Maemo。
, GNU和CDB使用Qt类结构的认识,增加了图形用户界面的调试器的调试。
, 使用代码分析工具,以检查你的应用程序中的内存管理问题。
, 应用程序部署到移动设备的MeeGo,为Symbian和Maemo设备创建应用程序安装包,可以在Ovi商店和其他渠道发布的。
, 轻松地访问信息集成的上下文敏感的Qt帮助系统。
可编程控制器本科毕业论文中英文翻译材料关于PLC外文翻译

可编程控制器本科毕业论文中英文翻译材料关于PLC外文翻译中文翻译可编程控制器技术可编程序控制器(Programmable Logic Controller,习惯上简称为PLC)是以微处理器为核心的通用工业自动化装置。
是20世纪60年代末在继电器控制系统的基础上开发出来的,它将传统的继电器控制技术与计算机技术和通信技术融为一体,具有结构简单、性能优越、可靠性高、灵活通用、易于编程、使用方便等优点。
具体来说,PLC的特点表现为以下几个方面:?硬件的可靠性高。
PLC专业在工业环境的恶劣条件下应用而设计。
一个设计良好的PLC能置于有很强电噪声、电磁干扰、机械振动、极端温度和湿度很大的环境中。
在硬件设计方面,首先是选用优质器件,再就是采用合理的系统结构,加固、简化安装,使它易于抗振冲击,对印刷电路板的设计、加工和焊接都采取了极为严格的工艺措施,而在电路、结构及工艺上采取了一些独特的方式。
由于PLC 本身具有很高的可靠性,所以在发生故障的部位大多集中在输入/输出的部位以及如传感器件、限位开关、光电开关、电磁阀、电机等外围装置上。
?编程简单,使用方便。
用微机实现自动控制,常使用汇编语言编程,难于掌握,要求使用者具有一定水平的计算机硬件和软件知识。
PLC采用面向控制过程、面向问题的编程方式,与目前微机控制常用的汇编语言相比,虽然在PLC内部增加了解释程序,增加了程序的执行时间,但对大多数的机电控制设备来说,这种损耗是微不足道的。
?接线简单,通用性好。
在电信号匹配的情况下,PLC的接线只需将输入信号的设备(按钮、开关等)与PLC输入端子连接,将接受输出信号执行控制任务的执行元件(接触器、电磁阀)与PLC输出端子连接。
接线简单、工作量少,省去了传统的继电器控制系统的接线和拆线的麻烦。
PLC的编程逻辑提供了能随要求而改变的逻辑关系,这样生产线的自动化过程就能随意改变。
这种性能使PLC具有很高的经济效益。
用于连接现场设备的硬件接口实际上已经设计成为PLC的组成部分,模块化的自诊断接口电路能指出故障,并易于排除故障与替换故障部件,这样的软硬件设计就使现场电气人员与技术人员易于使用。
论文中英文翻译(译文)

编号:桂林电子科技大学信息科技学院毕业设计(论文)外文翻译(译文)系别:电子工程系专业:电子信息工程学生姓名:韦骏学号:0852100329指导教师单位:桂林电子科技大学信息科技学院姓名:梁勇职称:讲师2012 年6 月5 日设计与实现基于Modbus 协议的嵌入式Linux 系统摘要:随着嵌入式计算机技术的飞速发展,新一代工业自动化数据采集和监测系统,采用核心的高性能嵌入式微处理器的,该系统很好地适应应用程序。
它符合消费等的严格要求的功能,如可靠性,成本,尺寸和功耗等。
在工业自动化应用系统,Modbus 通信协议的工业标准,广泛应用于大规模的工业设备系统,包括DCS,可编程控制器,RTU 及智能仪表等。
为了达到嵌入式数据监测的工业自动化应用软件的需求,本文设计了嵌入式数据采集监测平台下基于Modbus 协议的Linux 环境采集系统。
串行端口的Modbus 协议是实现主/从式,其中包括两种通信模式:ASCII 和RTU。
因此,各种药膏协议的设备能够满足串行的Modbus通信。
在Modbus 协议的嵌入式平台实现稳定和可靠。
它在嵌入式数据监测自动化应用系统的新收购的前景良好。
关键词:嵌入式系统,嵌入式Linux,Modbus 协议,数据采集,监测和控制。
1、绪论Modbus 是一种通讯协议,是一种由莫迪康公司推广。
它广泛应用于工业自动化,已成为实际的工业标准。
该控制装置或不同厂家的测量仪器可以链接到一个行业监控网络使用Modbus 协议。
Modbus 通信协议可以作为大量的工业设备的通讯标准,包括PLC,DCS 系统,RTU 的,聪明的智能仪表。
随着嵌入式计算机技术的飞速发展,嵌入式数据采集监测系统,使用了高性能的嵌入式微处理器为核心,是一个重要的发展方向。
在环境鉴于嵌入式Linux 的嵌入式工业自动化应用的数据,一个Modbus 主协议下的采集监测系统的设计和实现了这个文件。
因此,通信设备,各种药膏协议能够满足串行的Modbus。
单片机交通灯控制器论文中英文对照资料外文翻译文献

中英文对照资料外文翻译文献附件1:外文资料翻译译文基于单片机的十字路口交通灯控制器的设计由于我国经济的快速发展从而导致了汽车数量的猛增,大中型城市的城市交通,正面临着严峻的考验,从而导致交通问题日益严重,其主要表现如下:交通事故频发,对人类生命安全造成极大威胁;交通拥堵严重,导致出行时间增加,能源消耗加大;空气污染和噪声污染程度日益加深等。
日常的交通堵塞成为人们司空见惯而又不得不忍受的问题。
在这种背景下,结合我国城市道路交通的实际情况,开发出真正适合我们自身特点的智能信号灯控制系统已经成为当前的主要任务。
前言在实际应用上,根据对国内外实际交通信号控制应用的考察,平面独立交叉口信号控制基本采用定周期、多时段定周期、半感应、全感应等几种方式。
前两种控制方式完全是基于对平面交叉口既往交通流数据的统计调查,由于交通流存在的变化性和随机性,这两种方式都具有通行效率低、方案易老化的缺陷,而半感应式和全感应式这两种方式是在前两种方式的基础上增加了车辆检测器并根据其提供的信息来调整周期长和绿信比,它对车辆随机到达的适应性较大,可使车辆在停车线前尽可能少停车,达到交通流畅的效果。
在现代化的工业生产中,电流、电压、温度、压力、流量、流速和开关量都是常用的主要被控参数。
例如:在冶金工业、化工生产、电力工程、造纸行业、机械制造和食品加工等诸多领域中,人们都需要对交通进行有序的控制。
采用单片机来对交通进行控制,不仅具有控制方便、组态简单和灵活性大等优点,而且可以大幅度提高被控制量的技术指标,从而能够大大提高产品的质量和数量。
因此,单片机对交通灯的控制问题是一个工业生产中经常会遇到的问题。
在工业生产中,有很多行业有大量的交通灯设备,在现行系统中,大多数的交通控制信号都是用继电器来完成的,但继电器响应时间长,灵敏度低,长期使用之后,故障机会大大增加,而采用单片机控制,其精度远远大于继电器,响应时间短,软件可靠性高,不会因为工作时间缘故而降低其性能,相比而言,本方案具有很高的可行性。
计算机科学期刊投稿论文模板

文章标题(中文20字以内,两英文字符为一个汉字) 第一作者姓名,第二作者姓名(作者人数不能超过4个)(XXXX 学院,山东 青岛 266071)摘要:稿件摘要篇幅应在200至300字(5-6行),其中要包含有目的、方法、结果、结论四要素。
全文篇幅为五号字体(包括题目和文献)A4纸张4-5页左右。
………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………………关键词: XXX ;XXX ;XXX ;XXX (最少3个,最多6个,而且中文关键词中不能有外文) 中图分类号:(作者自己填写) 文献标识码:(作者自己填写) 分类号请参看:/ 栏目文 章 标 题(英文)ZHANG San ,FAN Yan-bin(College of Information Engineering, Qingdao University, Qingdao Shandong 266071, China)ABSTRACT :Large amount utility of digital data brings about much maladies for the multimedia inf ormation’s security. Digital watermark technology appearred under this circumstance. It is an effective measure for Copyright protection, distortion informing, unauthorized copy tracking etc. The adaptive algorithm based on wavelet packet and the feature of texture chooses the embedded position and computes embedded depth adaptively through the analysis of the texture to coordinate robustness and inperceptibility better. In the experiment, geometry crops, Gaussian noise, mosaic, etc. were applied as the attacks. The experimental results show that robustness of this scheme gets a large progress, especially for the attacks of geometry crops and mosaic.KEYWORDS :digital watermark; wavelet packet; adaptive; feature of texture1 引言 ………………………………………………………………………………………………………………2 XXXX …………………………………………………………………………………………………………………………… 2.1 XXXX ……………………………………………………………………………………………………………………… XXXXXXXX 如下方法: (),ij N i j T g B =-∑ (1)(),1ij N i j B g m m =⨯∑ (2) ()4k M M N N ⨯=⨯ (3)2.1.1 XXXXX…………………………………………………………………………………………………………………………………………………………………………………………如图1和图2。
计算机专业毕业设计论文外文文献中英文翻译——java对象

1 . Introduction To Objects1.1The progress of abstractionAll programming languages provide abstractions. It can be argued that the complexity of the problems you’re able to solve is directly related to the kind and quality of abstraction。
By “kind” I mean,“What is it that you are abstracting?” Assembly language is a small abstraction of the underlying machine. Many so—called “imperative” languages that followed (such as FORTRAN,BASIC, and C) were abstractions of assembly language。
These languages are big improvements over assembly language,but their primary abstraction still requires you to think in terms of the structure of the computer rather than the structure of the problem you are trying to solve。
The programmer must establish the association between the machine model (in the “solution space,” which is the place where you’re modeling that problem, such as a computer) and the model of the problem that is actually being solved (in the “problem space,” which is the place where the problem exists). The effort required to perform this mapping, and the fact that it is extrinsic to the programming language,produces programs that are difficult to write and expensive to maintain,and as a side effect created the entire “programming methods” industry.The alter native to modeling the machine is to model the problem you’re trying to solve。
智能控制系统毕业论文中英文资料对照外文翻译文献

智能控制系统中英文资料对照外文翻译文献附录一:外文摘要The development and application of Intelligence controlsystemModern electronic products change rapidly is increasingly profound impact on people's lives, to people's life and working way to bring more convenience to our daily lives, all aspects of electronic products in the shadow, single chip as one of the most important applications, in many ways it has the inestimable role. Intelligent control is a single chip, intelligent control of applications and prospects are very broad, the use of modern technology tools to develop an intelligent, relatively complete functional software to achieve intelligent control system has become an imminent task. Especially in today with MCU based intelligent control technology in the era, to establish their own practical control system has a far-reaching significance so well on the subject later more fully understanding of SCM are of great help to.The so-called intelligent monitoring technology is that:" the automatic analysis and processing of the information of the monitored device". If the monitored object as one's field of vision, and intelligent monitoring equipment can be regarded as the human brain. Intelligent monitoring with the aid of computer data processing capacity of the powerful, to get information in the mass data to carry on the analysis, some filtering of irrelevant information, only provide some key information. Intelligent control to digital, intelligent basis, timely detection system in the abnormal condition, and can be the fastest and best way to sound the alarm and provide usefulinformation, which can more effectively assist the security personnel to deal with the crisis, and minimize the damage and loss, it has great practical significance, some risk homework, or artificial unable to complete the operation, can be used to realize intelligent device, which solves a lot of artificial can not solve the problem, I think, with the development of the society, intelligent load in all aspects of social life play an important reuse.Single chip microcomputer as the core of control and monitoring systems, the system structure, design thought, design method and the traditional control system has essential distinction. In the traditional control or monitoring system, control or monitoring parameters of circuit, through the mechanical device directly to the monitored parameters to regulate and control, in the single-chip microcomputer as the core of the control system, the control parameters and controlled parameters are not directly change, but the control parameter is transformed into a digital signal input to the microcontroller, the microcontroller according to its output signal to control the controlled object, as intelligent load monitoring test, is the use of single-chip I / O port output signal of relay control, then the load to control or monitor, thus similar to any one single chip control system structure, often simplified to input part, an output part and an electronic control unit ( ECU )Intelligent monitoring system design principle function as follows: the power supply module is 0~220V AC voltage into a0 ~ 5V DC low voltage, as each module to provide normal working voltage, another set of ADC module work limit voltage of 5V, if the input voltage is greater than 5V, it can not work normally ( but the design is provided for the load voltage in the 0~ 5V, so it will not be considered ), at the same time transformer on load current is sampled on the accused, the load current into a voltage signal, and then through the current - voltage conversion, and passes through the bridge rectification into stable voltage value, will realize the load the current value is converted to a single chip can handle0 ~ 5V voltage value, then the D2diode cutoff, power supply module only plays the role of power supply. Signal to the analog-to-digital conversion module, through quantization, coding, the analog voltage value into8bits of the digital voltage value, repeatedly to the analog voltage16AD conversion, and the16the digital voltage value and, to calculate the average value, the average value through a data bus to send AT89C51P0, accepted AT89C51 read, AT89C51will read the digital signal and software setting load normal working voltage reference range [VMIN, VMAX] compared with the reference voltage range, if not consistent, then the P1.0 output low level, close the relay, cut off the load on the fault source, to stop its sampling, while P1.1 output high level fault light, i.e., P1.3 output low level, namely normal lights. The relay is disconnected after about 2minutes, theAT89C51P1.0outputs high level ( software design), automatic closing relay, then to load the current regular sampling, AD conversion, to accept the AT89C51read, comparison, if consistent, then the P1.1 output low level, namely fault lights out, while P1.3 output high level, i.e. normal lamp ( software set ); if you are still inconsistent, then the need to manually switch S1toss to" repair" the slip, disconnect the relay control, load adjusting the resistance value is: the load detection and repair, and then close the S1repeatedly to the load current sampling, until the normal lamp bright, repeated this process, constantly on the load testing to ensure the load problems timely repair, make it work.In the intelligent load monitoring system, using the monolithic integrated circuit to the load ( voltage too high or too small ) intelligent detection and control, is achieved by controlling the relay and transformer sampling to achieve, in fact direct control of single-chip is the working state of the relay and the alarm circuit working state, the system should achieve technical features of this thesis are as follows (1) according to the load current changes to control relays, the control parameter is the load current, is the control parameter is the relay switch on-off and led the state; (2) the set current reference voltage range ( load normal working voltage range ), by AT89C51 chip the design of the software section, provide a basis for comparison; (3) the use of single-chip microcomputer to control the light-emitting diode to display the current state of change ( normal / fault / repair ); specific summary: Transformer on load current is sampled, a current / voltage converter, filter, regulator, through the analog-digital conversion, to accept the AT89C51chip to read, AT89C51 to read data is compared with the reference voltage, if normal, the normal light, the output port P.0high level, the relay is closed, is provided to the load voltage fault light; otherwise, P1.0 output low level, The disconnecting relay to disconnect the load, the voltage on the sampling, stop. Two minutes after closing relay, timing sampling.System through the expansion of improved, can be used for temperature alarm circuit, alarm circuit, traffic monitoring, can also be used to monitor a system works, in the intelligent high-speed development today, the use of modern technology tools, the development of an intelligent, function relatively complete software to realize intelligent control system, has become an imminent task, establish their own practical control system has a far-reaching significance. Micro controller in the industry design and application, no industry like intelligent automation and control field develop so fast. Since China and the Asian region the main manufacturing plant intelligence to improve the degree of automation, new technology to improve efficiency, have important influence on the product cost. Although the centralized control can be improved in any particular manufacturing process of the overall visual, but not for those response and processingdelay caused by fault of some key application.Intelligent control technology as computer technology is an important technology, widely used in industrial control, intelligent control, instrument, household appliances, electronic toys and other fields, it has small, multiple functions, low price, convenient use, the advantages of a flexible system design. Therefore, more and more engineering staff of all ages, so this graduate design is of great significance to the design of various things, I have great interest in design, this has brought me a lot of things, let me from unsuspectingly to have a clear train of thought, since both design something, I will be there a how to design thinking, this is very important, I think this job will give me a lot of valuable things.中文翻译:智能控制系统的开发应用现代社会电子产品日新月异正在越来越深远的影响着人们的生活,给人们的生活和工作方式带来越来越大的方便,我们的日常生活各个方面都有电子产品的影子,单片机作为其中一个最重要的应用,在很多方面都有着不可估量的作用。
计算机病毒原理与防范文章英文文章

计算机病毒原理与防范文章英文文章English:Computer viruses are malicious software programs that can replicate themselves and spread to other computers, causing harm to the system or stealing sensitive data. They can infect computers through various means, such as email attachments, downloads from untrustworthy websites, or removable storage devices. Once a computer is infected, the virus can execute its malicious code, leading to a range of issues, from annoying pop-ups to complete system failure. To prevent computer viruses, users should always keep their operating system and security software up to date, avoid clicking on suspicious links or emails, and refrain from downloading software from unknown sources. Additionally, regularly backing up important data can help minimize the impact of a potential virus attack.中文翻译:计算机病毒是恶意软件程序,可以自我复制并传播到其他计算机,对系统造成危害或窃取敏感数据。
数学建模美赛论文标准格式参考--中英文对照

Your Paper's Title Starts Here: Please Centeruse Helvetica (Arial) 14论文的题目从这里开始:用Helvetica (Arial)14号FULL First Author1, a, FULL Second Author2,b and Last Author3,c第一第二第三作者的全名1Full address of first author, including country第一作者的地址全名,包括国家2Full address of second author, including country第二作者的地址全名,包括国家3List all distinct addresses in the same way第三作者同上a email,b email,c email第一第二第三作者的邮箱地址Keywords:List the keywords covered in your paper. These keywords will also be used by the publisher to produce a keyword index.关键字:列出你论文中的关键词。
这些关键词将会被出版者用作制作一个关键词索引。
For the rest of the paper, please use Times Roman (Times New Roman) 12论文的其他部分请用Times Roman (Times New Roman) 12号字Abstract. This template explains and demonstrates how to prepare your camera-ready paper for Trans Tech Publications. The best is to read these instructions and follow the outline of this text.Please make the page settings of your word processor to A4 format (21 x 29,7 cm or 8 x 11 inches); with the margins: bottom 1.5 cm (0.59 in) and top 2.5 cm (0.98 in), right/left margins must be 2 cm (0.78 in).摘要:这个模板解释和示范供稿技术刊物有限公司时,如何准备你的供相机使用文件。
论文的中英文译文

1, Electromechanical integration and the development of technology trends 一、机电一体化技术发展历程及其趋势Since an electronic technology birth of electronic technology and mechanical technology integration began, only a semiconductor integrated circuit, particularly in a microprocessor representative of thelarge-scale integrated circuits for the future, "mechatronics," a technical after significant progress, and has attracted widespread attention.自电子技术一问世,电子技术与机械技术的结合就开始了,只是出现了半导体集成电路,尤其是出现了以微处理器为代表的大规模集成电路以后,"机电一体化"技术之后有了明显进展,引起了人们的广泛注意.(1) mechanical-electrical integration, "the course of development(一)机电一体化"的发展历程1. CNC machine tools come out, wrote "mechatronics," the first page of history;1.数控机床的问世,写下了"机电一体化"历史的第一页;2. Microelectronic technology, "mechatronics''bring a great vitality;2.微电子技术为"机电一体化''带来勃勃生机;3. PLC, "Power Electronics" for the development of "mechatronics" providea firm foundation;3.可编程序控制器、"电力电子"等的发展为"机电一体化"提供了坚强基础;4. Laser technology, fuzzy technology, information technology and other new technologies to "mechanical and electrical integration," a new and higher level.4.激光技术、模糊技术、信息技术等新技术使"机电一体化"跃上新台阶.(2) mechanical-electrical integration, "the development trend(二)机电一体化"发展趋势1. Integration of optical and electrical machinery. General mechanical and electrical integration system by sensing systems, energy systems, information processing systems, machinery, and other components of the structure. Therefore, the introduction of optical technology, the realization of the inherent advantages of optical technology is effective Improved mechanical-electrical integration system sensing system, energy (power) systems and information processing system. optical and electrical machinery integration is the development of mechanical and electrical products trend.1.光机电一体化.一般的机电一体化系统是由传感系统、能源系统、信息处理系统、机械结构等部件组成的.因此,引进光学技术,实现光学技术的先天优点是能有效地改进机电一体化系统的传感系统、能源(动力)系统和信息处理系统.光机电一体化是机电产品发展的重要趋势.2. Systematic self-distribution - Flexible Future electromechanical integration products, and implementation of control systems are adequate "redundancy" and more "flexible" and can better deal with an emergency, is designed "self-distribution system." Self-discipline in thedistribution system, the various subsystems are independent of each other's work, the subsystem for system services, and has its own "self-discipline", according to different environmental conditions react differently. Its characteristics are subsystem can generate its own information and additional information given in the overall premise, specific "action" can be changed. In this way, significantly increase the system's ability to adapt (flexible), not because of the failure of a subsystem of the whole system.2.自律分配系统化——柔性化.未来的机电一体化产品,控制和执行系统有足够的“冗余度”,有较强的“柔性”,能较好地应付突发事件,被设计成“自律分配系统”。
毕业设计论文外文文献翻译计算机科学与技术微软VisualStudio中英文对照

外文文献翻译(2012届)学生姓名学号********专业班级计算机科学与技术08-5班指导教师微软Visual Studio1微软Visual StudioVisual Studio 是微软公司推出的开发环境,Visual Studio可以用来创建Windows平台下的Windows应用程序和网络应用程序,也可以用来创建网络服务、智能设备应用程序和Office 插件。
Visual Studio是一个来自微软的集成开发环境IDE(inteqrated development environment),它可以用来开发由微软视窗,视窗手机,Windows CE、.NET框架、.NET精简框架和微软的Silverlight支持的控制台和图形用户界面的应用程序以及Windows窗体应用程序,网站,Web应用程序和网络服务中的本地代码连同托管代码。
Visual Studio包含一个由智能感知和代码重构支持的代码编辑器。
集成的调试工作既作为一个源代码级调试器又可以作为一台机器级调试器。
其他内置工具包括一个窗体设计的GUI应用程序,网页设计师,类设计师,数据库架构设计师。
它有几乎各个层面的插件增强功能,包括增加对支持源代码控制系统(如Subversion和Visual SourceSafe)并添加新的工具集设计和可视化编辑器,如特定于域的语言或用于其他方面的软件开发生命周期的工具(例如Team Foundation Server的客户端:团队资源管理器)。
Visual Studio支持不同的编程语言的服务方式的语言,它允许代码编辑器和调试器(在不同程度上)支持几乎所有的编程语言,提供了一个语言特定服务的存在。
内置的语言中包括C/C + +中(通过Visual C++),(通过Visual ),C#中(通过Visual C#)和F#(作为Visual Studio 2010),为支持其他语言,如M,Python,和Ruby等,可通过安装单独的语言服务。
有关计算机网络的英文作文

有关计算机网络的英文作文English:Computer networks play a crucial role in our modern world, connecting devices and allowing for the exchange of information globally. The structure of a computer network typically consists of nodes, such as computers or servers, connected by communication links, enabling data to be transmitted efficiently. There are different types of computer networks, including LANs (Local Area Networks), MANs (Metropolitan Area Networks), and WANs (Wide Area Networks), with each designed to cater to specific needs and requirements. The advancements in networking technology have led to faster and more reliable connections, with the emergence of concepts such as cloud computing and the Internet of Things further expanding the capabilities of computer networks. Security concerns, however, remain a significant issue for networks, with measures such as firewalls, encryption, and authentication protocols being implemented to protect data and prevent unauthorized access. Overall, computer networks have revolutionized the way we communicate and access information, playing a vital role in our interconnected world.Translated content:计算机网络在我们现代世界中扮演着至关重要的角色,连接设备并允许在全球范围内交换信息。
中英文论文对照格式
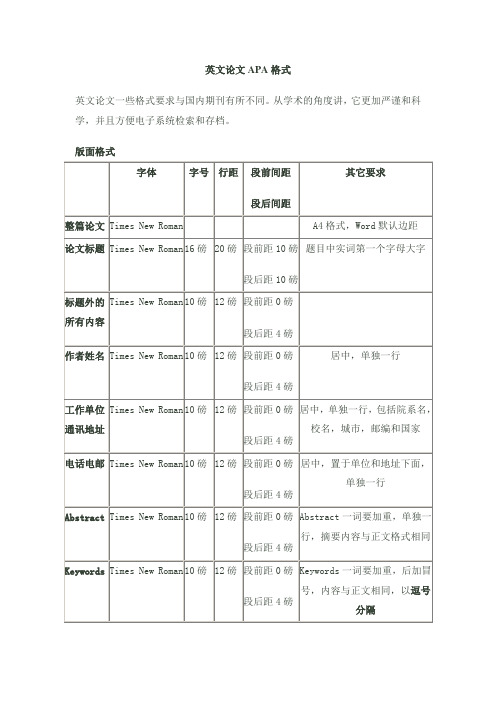
英文论文APA格式英文论文一些格式要求与国内期刊有所不同。
从学术的角度讲,它更加严谨和科学,并且方便电子系统检索和存档。
版面格式表格表格的题目格式与正文相同,靠左边,位于表格的上部。
题目前加Table后跟数字,表示此文的第几个表格。
表格主体居中,边框粗细采用0.5磅;表格内文字采用Times New Roman,10磅。
举例:Table 1. The capitals, assets and revenue in listed banks图表和图片图表和图片的题目格式与正文相同,位于图表和图片的下部。
题目前加Figure 后跟数字,表示此文的第几个图表。
图表及题目都居中。
只允许使用黑白图片和表格。
举例:Figure 1. The Trend of Economic Development注:Figure与Table都不要缩写。
引用格式与参考文献1. 在论文中的引用采取插入作者、年份和页数方式,如"Doe (2001, p.10) reported that …" or "This在论文中的引用采取作者和年份插入方式,如"Doe (2001, p.10) reported that …" or "This problem has been studied previously (Smith, 1958,pp.20-25)。
文中插入的引用应该与文末参考文献相对应。
举例:Frankly speaking, it is just a simulating one made by the government, or a fake competition, directly speaking. (Gao, 2003, p.220).2. 在文末参考文献中,姓前名后,姓与名之间以逗号分隔;如有两个作者,以and连接;如有三个或三个以上作者,前面的作者以逗号分隔,最后一个作者以and连接。
可编程控制器应用的发展支持软件论文中英文资料对照外文翻译文献综述

中英文资料对照外文翻译文献综述Support software for the development ofprogrammable logic1、IntroductionProgrammable Logic Controllers (PLC) class of real-time computers used extensively in industrial control applications. The development of a PLC application requires the configuration of the inputs and outputs of the PLC architecture, that is the selection of the number, type and addresses of the inputs and outputs of the PLC, and the writing and debugging of the application program. Programming these computers is usually done in specific graphical structured text languages [Bekkum93,Hughes 89,Jones 83] and the program debugging is carried out in a development environment. Most of the available environments [Square D 90, Taylor 90] allow program writing in more than one language, running it by step or in segments on the actual PLC and checking whether the assumed logical relationships between the inputs and the outputs at each program step or segment are satisfied. I addition, these environments offer engineering support, such as the preparation of input/output wiring diagrams and the generation of the executable code of the program. Recent versions of commercially available environments are supplied with a software emulator of one or more PLC units. This allows to perform program debugging without having access to the programmable controller itself. Also, the use of emulators makes easier and economically affordable the simulation of a large number of program operating conditions. By making sure that the program operates correcty under all the critical operating conditions, the risk of implementing aPLC-based system that does not meet the desired requirements is reduced. However, the ultimate goal of a development environment should be to verify the functional properties and behavior of the programs in all the possible states that thes programs and the plants they may enter.In the literature, various languages and graphical or mathematical formalisms are proposed for writing or specifying real-time programs .The timing and/or functional performance of these programs can be verified at compile time or mathematically. ADA[Ada83],RT-ASLAN[Auemheimer86], EUCLID[Kligerman86], PEARL [Halang 91], FLEX[Lin88] are some of the proposed and most widely known languages. Their graphical or mathematical formalisms are based on the use of finite state automata [Alford 77],Petri-Nets[Fedler 93], dataflow diagrams [Zave 82] and metric temporal logic [Koymans 90]. Although all these formal methods and languages represent significant advances to the problem of real-time program verification, still they have not reached the maturity required to deal with the complexities of large software systems . Until these methods reach a certain level of maturity we must rely on less formal methods, tuned to the needs of specific classes of real-time systems.In the case of PLC, we may continue to use simulation as a method to reveal logical errors in our programs and assess their behavior under an incomplete set of possible program states. In addition, we may include new facilities in the program development environments, the use of which will reduce the programming and engineering effort of an application. They may be editing and compilation facilities which support application programming in all the languages defined in the IEC 1131-3 standard. By using these languages our programming efficiency will be improved significantly, because each one of them can be used to program the part of the application for which it is appropriate, and yet the whole application can be linked into a single executable program. Other facilities which can reduce engineering effort are those whichcan make easier and more meaningful the declaration of the program input conditions. These facilities will allow us to study in a given timing period, a larger number of simulation cases than the ones we might have studied without these facilities. Furthermore, we may expand the scope of the simulation by including a simulator of the plant which interacts with the computer. Also, facilities can be added to assist in the better interpretation of the generated simulation results. Such facilities may allow us to configure the displays of the generated data the way we think appropriate, and animate the simulated operation of the application program.In this paper an architecture and language constructs are proposed for a software aid which ~an be used to declare input conditions to a PLC program, emulate the PLC operation and configure the display of the emulation results. The core of the architecture is the virtual machine, which is a software module which emulates the operation of a program written for a specific PLC in any application programming language. The virtual machine is linked with executable code generated from two other software modules which interpret instructions defining the input conditions to the application program and the configuration of the output display. Of course, the proposed facilities do not solve the problem of the complete verification of the timing behavior of an application program. However, when they are compared with the facilities offered by various commercially available aids, to our opinion they do significantly reduce the time taken to test the execution of a PLC program under a large number of possible input conditions, on different architectures and interpret the results. A scaled down experimental implementation of facilities for a specific PLC model is used to demonstrate the feasibility of the proposed concepts. The operation of the experimental set-up has been validated with data taken from the execution of sample program on a specific PLC.1、Principles of PLC Operation.The Programmable Logic Controller is a special purpose digital computer designed to control machine or process operations by means of a stored program and feedback from input/output field devices. It is composed primarily of two basic sections: the Central Processing Unit (PLC) and an Input/Output(I/O) interface. The CPU encompasses all the necessary elements that form the intelligence of the system. It is further subdivided to the Processor, Memory and Power supply. The CPU accepts input data from various input field devices, executes the stored program from the memory, and sends appropriate commands to output field devices. The Input/Output system forms the interface by which the field devices are connected to the controller. Its purpose is to condition the various signals received from or sent to field devices. Through this system the CPU can sense and measure physical quantities regarding a machine or process, such as proximity, position, motion, level temperature, pressure, current and voltage. Based on the status sensed or values measured, the CPU, through this interface system, issues commands that control various devices such as valves, motors, pumps and alarms. The most common type of I/O interface is the discrete one. This interface connects field input or output devices, which provide input signals or receive command signals of the Boolean type.Pushbuttons, limit switches and selector switches are some of the devices that provide incoming signals of this type,, whereas typical field devices that can be and position valves .The numerical I/O interface is another type of interface, provided in a PLC system. It can allow reading or writing a multi-bit digital or analog device. Multi-bit devices either generate or receive a group of bits which is the digital representation of a decimal number or an analogue quantity. This group of bits is handled as a unit by the CPU and can be in parallel form (BCD inputs or outputs) or in serial form (pulse inputs or outputs). Typical field devices providing multi-bit input to a PLC are thumbwheel switches, bar code readers and encoders ,whereas typical output devices are seven-segment and intelligent displays. The analogue field devices are the various sensors, motordrives, and process instruments used to monitor arid control physical variables such as temperature, pressure, humidity, flow, etc. The devices which monitor physical variables send to the I/O interface analogue voltages and currents which are converted by the A/D converter of the interface to a multi-bit digital code. On the other hand, an analogue device used to control the value of a physical variable, receives from the interface an analogue voltage or current as a result of the digital to analogue conversion of data produced by the CPU.The processor of the CPU performs all the mathematical operations, data handling and diagnostic routines by executing a collection , stored in the memory .This collection consists of supervisory programs ,that are permanently stored in the memory, and application programs . The supervisory programs, known as the executive, allow communication with the processor via a programming device or other peripheral memory management, monitoring of field devices, hardware fault diagnosis and execution of the application program written by the user. The memory organization and the way the application program is executed under the control of the executive are two features which distinguish a PLC from any other general purpose computer. In general, all PLC have memory allocated for executive programs, processor work area, data table and application program. The programmed instructions and any data that will be utilized by the processor to perform its control functions are stored in the Application Program Memory Area and Data Table Memory Area respectively. These two areas can be grouped into what is called application memory. Each controller has a maximum amount of application memory which is part of the total memory specified for the controller. The Data Table is functionally divided Into the Input Table, Internal Storage Area and Storage Registers Area. The Input Table is an array of bits that stores the status of the digital inputs which are connected to the I/O interface system.. The Output Table is an array of bits that control the status of the digital output devices, which are also connected. To the I/O system. The Internal Storage Bits Area is the memory area allocated for thestorage of the logic status of flags used by the application program. The Storage Registers Area is allocated for the storage of input registers, holding registers and output registers. The input registers are used to store numerical data received via digital of analogue input interfaces. The holding registers are used to store variable values that are generated by math, timer and counter instructions of a program. The output registers are used to provide storage for numerical or analogue values that control various output devices .Each virtual machine program is built according to a general computer model applicable to any PLC architecture. This model maps the usual functions performed by a PLC to machine language functions of a simple hypothetical computer. This computer consists of:(a) a Central Processing Unit (CPU)(b) a Memory unit(MU) where the application program is stored and(c) a number of Input and Output modules(I/O)At system start up, the execution of the executive program is initiated. During this program execution, the processor reads all the inputs, stores their values in the Input Storage Area and runs the application program. The results which are generated during the execution of the application program are saved in the Output Storage Area. The process of reading the inputs, executing the program, and updating the outdate all the outputs of the PLC by suing the data of the Output Storage Area. The process of reading the inputs, executing the program, and updating the outputs is known as scan. The time required to make a single scan is called scan time. A figure for the worst case time is usually provided by the manufacturers. Generally, they specify the maximum scan-time that corresponds to every 1K of programmed memory, i.e. 10msecs/1k. However, since the common method of monitoring the inputs at the end of each scan is inadequate for reading certain extremely fast inputs, some PLC provide software instructions that allow the interruption of the continuous program scan in order to receive an input or update an output immediately. Also, a newer approach inPLC design, which results to a significant reduction of the total processing time, is to divide the total system load to a number of tasks and assign their execution to several processors.The stack register is so designed that the execution of an instruction which reads discrete inputs shifts right by one bit the contents of the stack register and pushes the current state of the O.R flip flop into stack register. When this operation is completed, the O.R flip flop is loaded with the state of a discrete input. Instructions which perform logic operations shift left the contents of the stack register. Then, the leftmost bit of the stack register is loaded into the O.R flip flop. Then, the arithmetic, calculations and numerical handling are using the data registers DROO and DRO1 for byte and word operations respectively.可编程控制器应用的发展支持软件1、序可编程控制器(PLC)构成了工业的控制应用中被广泛地应用的即时计算器的一个类别。
计算机科学与技术Java垃圾收集器中英文对照外文翻译文献

中英文资料中英文资料外文翻译文献原文:How a garbage collector works of Java LanguageIf you come from a programming language where allocating objects on the heap is expensive, you may naturally assume that Java’s scheme of allocating everything (except primitives) on the heap is also expensive. However, it turns out that the garbage collector can have a significant impact on increasing the speed of object creation. This might sound a bit odd at first—that storage release affects storage allocation—but it’s the way some JVMs work, and it means that allocating storage for heap objects in Java can be nearly as fast as creating storage on the stack in other languages.For example, you can think of the C++ heap as a yard where each stakes out its own piece of turf object. This real estate can become abandoned sometime later and must be reused. In some JVMs, the Java heap is quite different; it’s more like a conveyor belt that moves forwardevery time you allocate a new object. This means that object storage allocation is remarkab ly rapid. The “heap pointer” is simply moved forward into virgin territory, so it’s effectively the same as C++’s stack allocation. (Of course, there’s a little extra overhead for bookkeeping, but it’s nothing like searching for storage.)You might observ e that the heap isn’t in fact a conveyor belt, and if you treat it that way, you’ll start paging memory—moving it on and off disk, so that you can appear to have more memory than you actually do. Paging significantly impacts performance. Eventually, after you create enough objects, you’ll run out of memory. The trick is that the garbage collector steps in, and while it collects the garbage it compacts all the objects in the heap so that you’ve effectively moved the “heap pointer” closer to the beginning of the conveyor belt and farther away from a page fault. The garbage collector rearranges things and makes it possible for the high-speed, infinite-free-heap model to be used while allocating storage.To understand garbage collection in Java, it’s helpful le arn how garbage-collection schemes work in other systems. A simple but slow garbage-collection technique is called reference counting. This means that each object contains a reference counter, and every time a reference is attached to that object, the reference count is increased. Every time a reference goes out of scope or is set to null, the reference count isdecreased. Thus, managing reference counts is a small but constant overhead that happens throughout the lifetime of your program. The garbage collector moves through the entire list of objects, and when it finds one with a reference count of zero it releases that storage (however, reference counting schemes often release an object as soon as the count goes to zero). The one drawback is that if objects circularly refer to each other they can have nonzero reference counts while still being garbage. Locating such self-referential groups requires significant extra work for the garbage collector. Reference counting is commonly used to explain one kind of g arbage collection, but it doesn’t seem to be used in any JVM implementations.In faster schemes, garbage collection is not based on reference counting. Instead, it is based on the idea that any non-dead object must ultimately be traceable back to a reference that lives either on the stack or in static storage. The chain might go through several layers of objects. Thus, if you start in the stack and in the static storage area and walk through all the references, you’ll find all the live objects. For each reference that you find, you must trace into the object that it points to and then follow all the references in that object, tracing into the objects they point to, etc., until you’ve moved through the entire Web that originated with the reference on the stack or in static storage. Each object that you move through must still be alive. Note that there is no problem withdetached self-referential groups—these are simply not found, and are therefore automatically garbage.In the approach described here, the JVM uses an adaptive garbage-collection scheme, and what it does with the live objects that it locates depends on the variant currently being used. One of these variants is stop-and-copy. This means that—for reasons that will become apparent—the program is first stopped (this is not a background collection scheme). Then, each live object is copied from one heap to another, leaving behind all the garbage. In addition, as the objects are copied into the new heap, they are packed end-to-end, thus compacting the new heap (and allowing new storage to simply be reeled off the end as previously described).Of course, when an object is moved from one place to another, all references that point at the object must be changed. The reference that goes from the heap or the static storage area to the object can be changed right away, but there can be other references pointing to this object Initialization & Cleanup that will be encountered later during the “walk.” These are fixed up as they are found (you could imagine a table that maps old addresses to new ones).There are two issues that make these so-called “copy collectors” inefficient. The first is the idea that you have two heaps and you slosh all the memory back and forth between these two separate heaps,maintaining twice as much memory as you actually need. Some JVMs deal with this by allocating the heap in chunks as needed and simply copying from one chunk to another.The second issue is the copying process itself. Once your program becomes stable, it might be generating little or no garbage. Despite that, a copy collector will still copy all the memory from one place to another, which is wasteful. To prevent this, some JVMs detect that no new garbage is being generated and switch to a different scheme (this is the “adaptive” part). This other scheme is called mark-and-sweep, and it’s what earlier versions of Sun’s JVM used all the time. For general use, mark-and-sweep is fairly slow, but when you know you’re generating little or no garbage, it’s fast. Mark-and-sweep follows the same logic of starting from the stack and static storage, and tracing through all the references to find live objects.However, each time it finds a live object, that object is marked by setting a flag in it, but the object isn’t collected yet.Only when the marking process is finished does the sweep occur. During the sweep, the dead objects are released. However, no copying happens, so if the collector chooses to compact a fragmented heap, it does so by shuffling objects around. “Stop-and-copy”refers to the idea that this type of garbage collection is not done in the background; Instead, the program is stopped while the garbage collection occurs. In the Sun literature you’llfind many references to garbage collection as a low-priority background process, but it turns out that the garbage collection was not implemented that way in earlier versions of the Sun JVM. Instead, the Sun garbage collector stopped the program when memory got low. Mark-and-sweep also requires that the program be stopped.As previously mentioned, in the JVM described here memory is allocated in big blocks. If you allocate a large object, it gets its own block. Strict stop-and-copy requires copying every live object from the source heap to a new heap before you can free the old one, which translates to lots of memory. With blocks, the garbage collection can typically copy objects to dead blocks as it collects. Each block has a generation count to keep track of whether it’s alive. In the normal case, only the blocks created since the last garbage collection are compacted; all other blocks get their generation count bumped if they have been referenced from somewhere. This handles the normal case of lots of short-lived temporary objects. Periodically, a full sweep is made—large objects are still not copied (they just get their generation count bumped), and blocks containing small objects are copied and compacted.The JVM monitors the efficiency of garbage collection and if it becomes a waste of time because all objects are long-lived, then it switches to mark-and sweep. Similarly, the JVM keeps track of how successful mark-and-sweep is, and if the heap starts to becomefragmented, it switches back to stop-and-copy. This is where the “adaptive” part comes in, so you end up with a mouthful: “Adaptive generational stop-and-copy mark-and sweep.”There are a number of additional speedups possible in a JVM. An especially important one involves the operation of the loader and what is called a just-in-time (JIT) compiler. A JIT compiler partially or fully converts a program into native machine code so that it doesn’t need to be interpreted by the JVM and thus runs much faster. When a class must be loaded (typically, the first time you want to create an object of that class), the .class file is located, and the byte codes for that class are brought into memory. At this point, one approach is to simply JIT compile all the code, but this has two drawbacks: It takes a little more time, which, compounded throughout the life of the program, can add up; and it increases the size of the executable (byte codes are significantly more compact than expanded JIT code), and this might cause paging, which definitely slows down a program. An alternative approach is lazy evaluation, which means that the code is not JIT compiled until necessary. Thus, code that never gets executed might never be JIT compiled. The Java Hotspot technologies in recent JDKs take a similar approach by increasingly optimizing a piece of code each time it is executed, so the more the code is executed, the faster it gets.译文:Java垃圾收集器的工作方式如果你学下过一种因为在堆里分配对象所以开销过大的编程语言,很自然你可能会假定Java 在堆里为每一样东西(除了primitives)分配内存资源的机制开销也会很大。
计算机科学说明文英语作文

计算机科学说明文英语作文英文回答:Computer science is the study of computation and information. It encompasses a wide range of topics, from theoretical foundations to practical applications. Computer scientists develop the algorithms, software, and hardware that power our modern world.There are two main branches of computer science: theoretical computer science and practical computer science. Theoretical computer science explores the fundamental principles of computation, such as the limits ofcomputation and the complexity of algorithms. Practical computer science focuses on the design and implementationof computer systems, including software engineering, operating systems, and computer architecture.Computer science is a rapidly evolving field, with new technologies and applications emerging all the time. Someof the most exciting recent advances in computer science include the development of artificial intelligence, machine learning, and quantum computing. These technologies have the potential to revolutionize many aspects of our lives, from the way we work and communicate to the way we learn and understand the world around us.Computer science is a challenging but rewarding field. It requires a strong foundation in mathematics and logical reasoning, as well as a passion for technology and problem-solving. Computer scientists are in high demand in today's job market, and they can work in a variety of industries, including technology, healthcare, finance, and government.If you are interested in a career in computer science, there are many resources available to help you get started. You can take classes at your local school or university, or you can find online courses and tutorials. There are also many clubs and organizations that support students and professionals in computer science.中文回答:计算机科学是计算和信息的研究。
计算机与人工智能专业重要性的英文作文

计算机与人工智能专业重要性的英文作文English:The importance of computer science and artificial intelligence has become increasingly apparent in today's world. With the rapid development of technology, these fields have not only revolutionized industries such as healthcare, finance, and transportation, but have also reshaped the way we live and work. Computer science provides the foundational knowledge and skills needed to navigate the digital landscape, from programming and software development to cybersecurity and data analysis. On the other hand, artificial intelligence empowers machines to perform tasks that traditionally required human intelligence, leading to advancements in automation, decision-making, and problem-solving. As we continue to rely on technology for everyday tasks and decision-making, the demand for skilled professionals in computer science and artificial intelligence will only continue to grow. From developing cutting-edge technologies to addressing ethical and societal implications, individuals in these fields play a crucial role in shaping the future of our world.中文翻译:计算机科学和人工智能在当今世界的重要性变得日益明显。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
DATA WAREHOUSEData warehousing provides architectures and tools for business executives to systematically organize, understand, and use their data to make strategic decisions. A large number of organizations have found that data warehouse systems are valuable tools in today's competitive, fast evolving world. In the last several years, many firms have spent millions of dollars in building enterprise-wide data warehouses. Many people feel that with competition mounting in every industry, data warehousing is the latestmust-have marketing weapon —— a way to keep customers by learning more about their needs.“So", you may ask, full of intrigue, “what exactly is a data warehouse?"Data warehouses have been defined in many ways, making it difficult to formulate a rigorous definition. Loosely speaking, a data warehouse refers to a database that is maintained separately from an organization's operational databases. Data warehouse systems allow for the integration of a variety of application systems. They support information processing by providing a solid platform of consolidated, historical data for analysis.According to W. H. Inmon, a leading architect in the construction of data warehouse systems, “a data warehouse is a subject-oriented, integrated, time-variant, and nonvolatile collection of data in support of management's decision making process." This short, but comprehensive definition presents the major features of a data warehouse. The four keywords, subject-oriented, integrated, time-variant, and nonvolatile, distinguish data warehouses from other data repository systems, such as relational database systems, transaction processing systems, and file systems. Let's take a closer look at each of these key features.(1).Subject-oriented: A data warehouse is organized around major subjects, such as customer, vendor, product, and sales. Rather than concentrating on the day-to-day operations and transaction processing of an organization, a data warehouse focuses on the modeling and analysis of data for decision makers. Hence, data warehouses typically provide a simple and concise view around particular subject issues by excluding data that are not useful in the decision support process.(2) Integrated: A data warehouse is usually constructed by integrating multiple heterogeneous sources, such as relational databases, flat files, and on-line transaction records. Data cleaning and data integration techniques are applied to ensure consistency in naming conventions, encoding structures, attribute measures, and so on.(3).Time-variant: Data are stored to provide information from a historical perspective(e.g., the past 5-10 years). Every key structure in the data warehouse contains, either implicitly or explicitly, an element of time.(4)Nonvolatile: A data warehouse is always a physically separate store of data transformed from the application data found in the operational environment. Due to this separation, a data warehouse does not require transaction processing, recovery, and concurrency control mechanisms. It usually requires only two operations in data accessing: initial loading of data and access of data.In sum, a data warehouse is a semantically consistent data store that serves as a physical implementation of a decision support data model and stores the information on which an enterprise needs to make strategic decisions. A data warehouse is also oftenviewed as an architecture, constructed by integrating data from multiple heterogeneous sources to support structured and/or ad hoc queries, analytical reporting, and decision making.“OK", you now ask, “what, then, is data warehousing?"Based on the above, we view data warehousing as the process of constructing and using data warehouses. The construction of a data warehouse requires data integration, data cleaning, and data consolidation. The utilization of a data warehouse often necessitates a collection of decision support technologies. This allows “knowledge workers" (e.g., managers, analysts, and executives) to use the warehouse to quickly and conveniently obtain an overview of the data, and to make sound decisions based on information in the warehouse. Some authors use the term “data warehousing" to refer only to the process of data warehouse construction, while the term warehouse DBMS is used to refer to the management and utilization of data warehouses. We will not make this distinction here.“How are organizations using the information from data warehouses?" Many organizations are using this information to support business decision making activities, including:(1) increasing customer focus, which includes the analysis of customer buying patterns (such as buying preference, buying time, budget cycles, and appetites for spending),(2) repositioning products and managing product portfolios by comparing the performance of sales by quarter, by year, and by geographic regions, in order to fine-tune production strategies,(3) analyzing operations and looking for sources of profit,(4) managing the customer relationships, making environmental corrections, and managing the cost of corporate assets.Data warehousing is also very useful from the point of view of heterogeneous database integration. Many organizations typically collect diverse kinds of data and maintain large databases from multiple, heterogeneous, autonomous, and distributed information sources. To integrate such data, and provide easy and efficient access to it is highly desirable, yet challenging. Much effort has been spent in the database industry and research community towards achieving this goal.The traditional database approach to heterogeneous database integration is to build wrappers and integrators (or mediators) on top of multiple, heterogeneous databases. A variety of data joiner and data blade products belong to this category. When a query is posed to a client site, a metadata dictionary is used to translate the query into queries appropriate for the individual heterogeneous sites involved. These queries are then mapped and sent to local query processors. The results returned from the different sites are integrated into a global answer set. This query-driven approach requires complex information filtering and integration processes, and competes for resources with processing at local sources. It is inefficient and potentially expensive for frequent queries, especially for queries requiring aggregations.Data warehousing provides an interesting alternative to the traditional approach of heterogeneous database integration described above. Rather than using a query-driven approach, data warehousing employs an update-driven approach in which information from multiple, heterogeneous sources is integrated in advance and stored in a warehousefor direct querying and analysis. Unlike on-line transaction processing databases, data warehouses do not contain the most current information. However, a data warehouse brings high performance to the integrated heterogeneous database system since data are copied, preprocessed, integrated, annotated, summarized, and restructured into one semantic data store. Furthermore, query processing in data warehouses does not interfere with the processing at local sources. Moreover, data warehouses can store and integrate historical information and support complex multidimensional queries. As a result, data warehousing has become very popular in industry.1.Differences between operational database systems and data warehousesSince most people are familiar with commercial relational database systems, it is easy to understand what a data warehouse is by comparing these two kinds of systems.The major task of on-line operational database systems is to perform on-line transaction and query processing. These systems are called on-line transaction processing (OLTP) systems. They cover most of the day-to-day operations of an organization, such as, purchasing, inventory, manufacturing, banking, payroll, registration, and accounting. Data warehouse systems, on the other hand, serve users or “knowledge workers" in the role of data analysis and decision making. Such systems can organize and present data in various formats in order to accommodate the diverse needs of the different users. These systems are known as on-line analytical processing (OLAP) systems.The major distinguishing features between OLTP and OLAP are summarized as follows.(1). Users and system orientation: An OLTP system is customer-oriented and is used for transaction and query processing by clerks, clients, and information technology professionals. An OLAP system is market-oriented and is used for data analysis by knowledge workers, including managers, executives, and analysts.(2). Data contents: An OLTP system manages current data that, typically, are too detailed to be easily used for decision making. An OLAP system manages large amounts of historical data, provides facilities for summarization and aggregation, and stores and manages information at different levels of granularity. These features make the data easier for use in informed decision making.(3). Database design: An OLTP system usually adopts an entity-relationship (ER) data model and an application -oriented database design. An OLAP system typically adopts either a star or snowflake model, and a subject-oriented database design.(4). View: An OLTP system focuses mainly on the current data within an enterprise or department, without referring to historical data or data in different organizations. In contrast, an OLAP system often spans multiple versions of a database schema, due to the evolutionary process of an organization. OLAP systems also deal with information that originates from different organizations, integrating information from many data stores. Because of their huge volume, OLAP data are stored on multiple storage media.(5). Access patterns: The access patterns of an OLTP system consist mainly of short, atomic transactions. Such a system requires concurrency control and recovery mechanisms. However, accesses to OLAP systems are mostly read-only operations (since most data warehouses store historical rather than up-to-date information), although many could be complex queries.Other features which distinguish between OLTP and OLAP systems include database size, frequency of operations, and performance metrics and so on.2.But, why have a separate data warehouse?“Since operational databases store huge amounts of data", you observe, “why not perform on-line analytical processing directly on such databases instead of spending additional time and resources to construct a separate data warehouse?"A major reason for such a separation is to help promote the high performance of both systems. An operational database is designed and tuned from known tasks and workloads, such as indexing and hashing using primary keys, searching for particular records, and optimizing “canned" queries. On the other hand, data warehouse queries are often complex. They involve the computation of large groups of data at summarized levels, and may require the use of special data organization, access, and implementation methods based on multidimensional views. Processing OLAP queries in operational databases would substantially degrade the performance of operational tasks.Moreover, an operational database supports the concurrent processing of several transactions. Concurrency control and recovery mechanisms, such as locking and logging, are required to ensure the consistency and robustness of transactions. An OLAP query often needs read-only access of data records for summarization and aggregation. Concurrency control and recovery mechanisms, if applied for such OLAP operations, may jeopardize the execution of concurrent transactions and thus substantially reduce the throughput of an OLTP system.Finally, the separation of operational databases from data warehouses is based on the different structures, contents, and uses of the data in these two systems. Decision support requires historical data, whereas operational databases do not typically maintain historical data. In this context, the data in operational databases, though abundant, is usually far from complete for decision making. Decision support requires consolidation (such as aggregation and summarization) of data from heterogeneous sources, resulting in high quality, cleansed and integrated data. In contrast, operational databases contain only detailed raw data, such as transactions, which need to be consolidated before analysis. Since the two systems provide quite different functionalities and require different kindsof data, it is necessary to maintain separate databases.数据仓库数据仓库为商务运作提供结构与工具,以便系统地组织、理解和使用数据进行决策。