基于聚类分析的综合神经网络集成算法
基于人工神经网络的聚类算法优化研究

基于人工神经网络的聚类算法优化研究随着科技的不断发展,人工智能成为了当今社会一个备受关注的热点话题。
其中,人工神经网络作为一种重要的技术,受到了越来越多的关注和研究。
而在人工神经网络应用领域中,聚类算法优化也成为了一个重要的研究课题。
那么,本文便将基于人工神经网络的聚类算法优化进行深入探讨。
一、人工神经网络基础人工神经网络是一种由多个神经元相互连接组成的网络,其结构与生物神经系统相似。
通过学习与训练,人工神经网络可以模拟人类的智能行为,并对大量数据进行分类、预测、识别等操作。
而人工神经网络训练过程中使用的算法和方法,则对于聚类算法优化而言尤为重要。
二、聚类算法优化研究聚类算法是机器学习中的一个重要领域,它主要通过对样本进行分组或分簇,对数据进行分类和分析。
聚类算法优化则是针对现有聚类算法进行改进和优化,提升其运行效率和准确性。
传统的聚类算法中,K-means算法是一种著名的聚类算法。
它通过计算样本之间的欧几里得距离,将样本依据距离远近分组。
但是,K-means算法具有计算量大,对初始值敏感以及易陷入局部最小值等问题。
为此,研究人员提出了一系列基于人工神经网络的聚类算法。
例如,自组织特征映射(SOM)算法、基于ART神经网络的聚类算法等。
这些算法的出现,旨在优化传统聚类算法的问题,并提高聚类效果和精度。
具体来说,这些新算法能够通过不同的神经元之间的相互作用,学习样本的非线性特征,并能够自适应地调整分组结果。
三、优化研究案例为了更好的说明基于人工神经网络的聚类算法优化的具体应用,我们举一个实际的例子。
研究人员曾对美国著名的湾流飞机的大量数据进行聚类分析,探讨其工作状态下性能和健康状况的影响因子。
在传统聚类算法下,所得到的聚类结果效果不佳。
于是,研究人员采用基于单层神经网络和基于ART神经网络的聚类算法,并将两种算法结果进行比较。
实验结果表明,采用基于ART神经网络的方法所得到的分组结果比传统K-means算法更优,能够更好地揭示湾流飞机性能和健康状况的关联因素。
如何使用神经网络进行聚类分析

如何使用神经网络进行聚类分析神经网络在机器学习领域中扮演着重要的角色,可以用于各种任务,包括聚类分析。
聚类分析是一种将数据集中的对象划分为相似组的方法。
在本文中,我们将探讨如何使用神经网络进行聚类分析,并介绍一些常用的神经网络模型。
首先,让我们了解一下什么是神经网络。
神经网络是一种模仿人类神经系统的计算模型,由多个神经元(节点)组成的层级结构。
每个神经元都与其他神经元相连,并通过权重来传递信息。
神经网络通过学习权重和偏差的调整,从而能够对输入数据进行分类、回归或聚类等任务。
在聚类分析中,我们希望将数据集中的对象划分为不同的组,使得每个组内的对象相似,而不同组之间的对象差异较大。
神经网络可以通过学习数据集的特征和模式,自动将对象划分为不同的聚类。
下面介绍几种常用的神经网络模型用于聚类分析。
一种常用的神经网络模型是自组织映射(Self-Organizing Map,SOM)。
SOM 是一种无监督学习算法,可以将高维数据映射到一个低维的拓扑结构中。
SOM模型由输入层和竞争层组成,竞争层中的神经元代表聚类中心。
通过调整神经元之间的权重,SOM模型可以将输入数据映射到最相似的聚类中心。
另一种常用的神经网络模型是深度自编码器(Deep Autoencoder)。
深度自编码器是一种多层神经网络,由编码器和解码器组成。
编码器将输入数据压缩为低维表示,而解码器则将低维表示重构为原始数据。
通过训练深度自编码器,可以学习到数据的潜在特征,并用于聚类分析。
除了上述两种模型,还有许多其他的神经网络模型可用于聚类分析,如卷积神经网络(Convolutional Neural Network,CNN)和循环神经网络(Recurrent Neural Network,RNN)。
这些模型在不同的数据集和任务中表现出色,可以根据具体需求选择合适的模型。
在使用神经网络进行聚类分析时,还需要注意一些问题。
首先,数据的预处理非常重要。
神经网络对数据的分布和尺度敏感,因此需要对数据进行标准化或归一化处理。
基于聚类的神经网络规则抽取算法

中 图分 类 号 : P 8 T 13 文 献标 识 码 : A
Ru e ta t n fo Ari ca u a t r s d o u trn lsExr ci rm t ilNe r lNewo k Ba e n Cl sei g o i f
ta n d a r n d s c s f l r i e nd p u e uc e su l h cia in v l sa h d e i a ec u tr d i t ic ee v l e .I h y,t e a tv to aue tt ehid n unt r l se e n o d s r t au s n t e
cut h s , h ls r u e f e hs a eajs dd nmi l codn c vt nvle f h i ls r ae tecut mbr i t cn b dut y a c l acri t a t a o a so er ep en ow g e ay go i i u t
A b t a t W e p o o e a n v la g rt m o xr ci g r l sfo a t ca u a ewok. Afe he n t r s sr c : r p s o e lo ih fre ta t u e r m ri ilne r ln t r n i f tr t ewo k i
第2 8卷 第 5期 2 1 9月 0 0年
吉 林 大 学 学 报 ( 息 科 学 版) 信 Junl f inU i rt I om t nSi c d i ) o ra o l nv sy(n r ai ce e io Ji ei f o n E tn
聚类算法和分类算法总结

聚类算法和分类算法总结聚类算法总结原⽂:聚类算法的种类:基于划分聚类算法(partition clustering)k-means:是⼀种典型的划分聚类算法,它⽤⼀个聚类的中⼼来代表⼀个簇,即在迭代过程中选择的聚点不⼀定是聚类中的⼀个点,该算法只能处理数值型数据k-modes:K-Means算法的扩展,采⽤简单匹配⽅法来度量分类型数据的相似度k-prototypes:结合了K-Means和K-Modes两种算法,能够处理混合型数据k-medoids:在迭代过程中选择簇中的某点作为聚点,PAM是典型的k-medoids算法CLARA:CLARA算法在PAM的基础上采⽤了抽样技术,能够处理⼤规模数据CLARANS:CLARANS算法融合了PAM和CLARA两者的优点,是第⼀个⽤于空间数据库的聚类算法FocusedCLARAN:采⽤了空间索引技术提⾼了CLARANS算法的效率PCM:模糊集合理论引⼊聚类分析中并提出了PCM模糊聚类算法基于层次聚类算法:CURE:采⽤抽样技术先对数据集D随机抽取样本,再采⽤分区技术对样本进⾏分区,然后对每个分区局部聚类,最后对局部聚类进⾏全局聚类ROCK:也采⽤了随机抽样技术,该算法在计算两个对象的相似度时,同时考虑了周围对象的影响CHEMALOEN(变⾊龙算法):⾸先由数据集构造成⼀个K-最近邻图Gk ,再通过⼀个图的划分算法将图Gk 划分成⼤量的⼦图,每个⼦图代表⼀个初始⼦簇,最后⽤⼀个凝聚的层次聚类算法反复合并⼦簇,找到真正的结果簇SBAC:SBAC算法则在计算对象间相似度时,考虑了属性特征对于体现对象本质的重要程度,对于更能体现对象本质的属性赋予较⾼的权值BIRCH:BIRCH算法利⽤树结构对数据集进⾏处理,叶结点存储⼀个聚类,⽤中⼼和半径表⽰,顺序处理每⼀个对象,并把它划分到距离最近的结点,该算法也可以作为其他聚类算法的预处理过程BUBBLE:BUBBLE算法则把BIRCH算法的中⼼和半径概念推⼴到普通的距离空间BUBBLE-FM:BUBBLE-FM算法通过减少距离的计算次数,提⾼了BUBBLE算法的效率基于密度聚类算法:DBSCAN:DBSCAN算法是⼀种典型的基于密度的聚类算法,该算法采⽤空间索引技术来搜索对象的邻域,引⼊了“核⼼对象”和“密度可达”等概念,从核⼼对象出发,把所有密度可达的对象组成⼀个簇GDBSCAN:算法通过泛化DBSCAN算法中邻域的概念,以适应空间对象的特点DBLASD:OPTICS:OPTICS算法结合了聚类的⾃动性和交互性,先⽣成聚类的次序,可以对不同的聚类设置不同的参数,来得到⽤户满意的结果FDC:FDC算法通过构造k-d tree把整个数据空间划分成若⼲个矩形空间,当空间维数较少时可以⼤⼤提⾼DBSCAN的效率基于⽹格的聚类算法:STING:利⽤⽹格单元保存数据统计信息,从⽽实现多分辨率的聚类WaveCluster:在聚类分析中引⼊了⼩波变换的原理,主要应⽤于信号处理领域。
基于深度学习算法的聚类分析应用研究

基于深度学习算法的聚类分析应用研究随着互联网技术的日新月异,数据量的快速增长已经成为了当今社会的一个普遍现象。
为了更好地了解这些庞大的数据,我们可以通过数据分析的方式来寻找其中潜在的联系和规律。
其中的一个方法就是聚类分析。
聚类分析是一种数据分析方法,通过将数据划分成不同的群组,来挖掘出数据之间的内在联系。
这一方法也被广泛应用于人工智能领域之中。
基于深度学习算法的聚类分析,正是人工智能领域的一大创新。
一、深度学习算法的基本原理深度学习算法,是一种基于神经网络理论的学习方法。
其核心思想是借鉴生物神经系统中神经元之间信息传递的方式,构建出一个网络结构,利用输入数据与输出数据之间的关系,逐渐地训练出这个网络的参数,从而实现对于未知数据的预测。
在深度学习算法中,最为重要的是神经网络结构。
其中的主要构件是“神经元”,通过一定的权重间联系,形成了一个大规模的计算模型。
每一层的神经元都可以接受上一层的输入,并根据各自的函数进行计算,然后作为下一层神经元的输入进行传递。
而最后一层神经元的输出,则被认为是整个神经网络的预测结果。
二、深度学习算法在聚类分析中的应用深度学习算法因其优异的表现,被广泛应用于各种数据挖掘的应用场景之中。
其中包括了数据分类、目标检测、图像处理等领域。
而在聚类分析领域中,深度学习算法同样具有很大的优势。
基于深度学习算法的聚类分析,主要考虑到了数据内在的高阶规律性。
在网络训练的过程中,神经网络通过自适应策略来进行参数的调整,从而自动地发现数据内在的潜在联系。
相比于传统的聚类分析方法,这一方法所挖掘出的数据特征,更加准确、全面、以及具有实时性。
三、深度学习算法在聚类分析中的实例除了理论方面的研究外,深度学习算法在聚类分析领域中,也有着广泛的应用案例。
例如,在语音验证这一领域中,深度学习算法可以将许多声音特征归为一个群组。
这种方法可以帮助计算机提高对于语音信号的处理能力。
另一个实例,则是在图像处理方面的应用。
基于聚类算法的RBF神经网络设计综述

基于聚类算法的RBF神经网络设计综述张彬【期刊名称】《微型机与应用》【年(卷),期】2012(31)12【摘要】简要分析了径向基函数(RBF)神经网络。
在此基础上,介绍了K-均值聚类算法的神经网络、C-均值聚类算法的神经网络和PAM聚类算法的神经网络三种聚类算法的RBF神经网络。
展望了基于聚类的RBF神经网络设计的发展趋势。
%This paper briefly analyzed the mathematical model of RBF neural network. On this basis,three kinds of RBF net- work based on fuzzy clustering were introduced :K-means clustering algorithm, C-means clustering algorithm and PAM clustering algorithm. Finally, it was expected about the future trend of design of RBF Network based on fuzzy clustering.【总页数】4页(P1-3,7)【作者】张彬【作者单位】长沙理工大学电气与信息工程学院,湖南长沙410004【正文语种】中文【中图分类】TP18【相关文献】1.基于K-均值聚类算法RBF神经网络交通流预测 [J], 管硕;高军伟;张彬;刘新;冷子文2.基于蚁群聚类算法的RBF神经网络在压力传感器中的应用 [J], 孙艳梅;都文和;冯昌浩;刘道森;卢俊国;崔全领;苗凤娟;宋志章3.基于改进自适应聚类算法的RBF神经网络分类器设计与实现 [J], 郝晓丽;张靖4.基于K均值聚类算法与RBF神经网络的交通流预测方法 [J], 张天逸;孙毅然;刘凡琪;梁悦祺;林永杰;马明辉5.基于K均值聚类算法与RBF神经网络的交通流预测方法 [J], 张天逸;孙毅然;刘凡琪;梁悦祺;林永杰;马明辉因版权原因,仅展示原文概要,查看原文内容请购买。
基于聚类与梯度混合学习算法RBF神经网络的电液伺服系统建模及仿真

Ab tac : t S h r o g tt e e a tmo lo h l crhy rulc s r o s se usn is— i cpl eh d d e t he n n i a u ain s r t Asi’ a d t e h x c de fte e e to d a i e v y t m ig f tprn i e m t o u o t o lne rca s to s r s c ste i h r n ux— p e s e r lto u h a h n e e tf l r sur eainI RBF n u a ewok wa e o h o l n i lto ft e l cr h d a lc e r ln t r sus d f rt e m dei a d smu ain o h ee to y r ui ng s I y tm fam ie s e i gplu h i a n s se .Si e t urln t r a lw r i ngs e ndpo rc n e g nc , e ̄Os se o n we p n o g n awe po y tm nc hene a ewo k h d so tani pe da o o v r e e
,
W u xio io Ch n J i W a g L a xa e in l n i
( colfMe a i l n ier g, Sho o c n a gne n h c E i
n g
i c nea d Tc nl y N n n in s 10 4 hn ) t o i c n e o g , aj g J gu2 0 9 ,C ia y fS e h o i a
豢 遣 鞋
基于神经网络的聚类算法研究

基于神经网络的聚类算法研究近年来,随着人工智能技术的不断发展,基于神经网络的聚类算法也越来越受到研究者的关注。
此类算法能够根据数据的特征,将数据划分成不同的簇,从而方便后续的数据分析。
本文将探讨基于神经网络的聚类算法的研究现状、应用前景以及存在的问题。
一、研究现状随着数据量的不断增加,传统的聚类算法(例如k-means)已经不能满足现代数据的需求。
因此,基于神经网络的聚类算法应运而生。
这类算法结合了神经网络的非线性映射能力和聚类算法的分类能力,不仅能够处理大规模和高维的数据,还具有异构聚类的能力。
目前,基于神经网络的聚类算法主要可以分为两类:有监督学习和无监督学习。
有监督学习的算法需要先对数据标注,然后通过神经网络进行分类,这类算法的优点在于能够得到更准确的聚类结果。
无监督学习的算法则不需要数据标注,通常采用自组织映射网络(SOM)或高斯混合模型(GMM)进行计算,这类算法的优点在于不需要额外的标注信息。
二、应用前景基于神经网络的聚类算法在很多领域都有着广泛的应用前景。
其中,最为常见的应用领域就是图像分割和模式识别。
在图像分割领域,这类算法可以将一张图像分成若干个部分,每个部分代表一种物体或者纹理。
在模式识别领域,这类算法可以帮助我们检测文本和语言中的规律模式,从而方便我们进行分类和标注。
另外,基于神经网络的聚类算法还可以应用于网络安全领域。
例如,我们可以将用户的网络行为数据进行聚类,从而发现异常的网络行为,提供更加有效的安全防护。
三、存在的问题尽管基于神经网络的聚类算法具有许多优点,但也存在着一些问题和挑战。
首先,这类算法需要大量的计算资源才能进行有效的计算。
其次,由于神经网络模型的复杂性,这类算法可能存在过拟合的问题。
此外,由于神经网络的黑箱结构,这类算法可能难以解释计算的结果。
针对上述问题,目前研究者正在尝试寻找有效的解决方案。
例如,一些研究者提出了基于GPU加速的算法,可以显著减少计算时间。
基于聚类的RBF-LBF串联神经网络学习算法

K yw r s eeazt nait er e o s a i ai F nt n( B ) aenc s r g e od :gnr i i ly l ao b i;nua nt r ;R da B s uci R F ;pt r ut n l w k l s o t l e i
摘
要: 为提 高网络 的泛化 能 力 , 究 了单层 R F神 经 网络和 L F网络 组成 的 R FL F 串联神 研 B B B —B
经 网络 , 并提 出 了一种基 于模 式 聚类 的 R F L F串联 神 经 网络 的 学 习算 法。该 算法分 别对 单层 R F B —B B
网络 和 L F网络 的输入进 行模 式聚 类 , B 以确 定 网络 的初 始 结构 , 然后 通过 调 整错 分样 本 的类 别 , 使之
ajs di wogc s t oe a r r ekre fnf n xei et fw p a r lm p vsta t grh dut rn l so vr po g t enl uc o .E pr n o osi spo e r e hth a o tm e n a l me e h m t r l b o el i
s g — gr a i ai F nt n( B )a dLn a B i F nt n( B )ntok a rpsd n aenbsd i l l e da B s u co a E n ier a s uci L F e rsw pooe ,ada pt r—ae nea R l s i s o w s t
基于神经网络模型的聚类分析技术研究

维普资讯
第 2期
李大辉等 :基于神经 网络模 型的聚类分析技术研究
2 1 竞 争学 习神经 网络方 法 ( o e i eL a nn N ) . C mp ti e r i N t v g
竞争学习方法包含一个 由若干单元组成的层次结构… ,层与层之间的连接是有刺激 的,即一个给定层 上的单元接受来 自 低一层所有单元的输入 ,一个层上激活单元配置就构成了对高一层的输入模式.在一个 给定层上的聚类 中单元相互竞争 ,以响应来 自 低一层输 出的模式.层 内的连接是抑制的 ,以使得一个特定 聚类只有一个单元可被激活.获胜的单元调整与同一聚类 中其它单元 的连接,以使得之后可以对类似对象
反应更强烈.如果将一个权值定义为一个例证 ,那么新对象就赋给最近的例证.输入参数为聚类个数和每 个聚类的单元个数.在聚类过程结束时 , 每个簇被认为是一个新 的 “ 特征” 它检测对象 的某些规律.如此 ,
产生的结果簇可以看作一个低层特性向高层特性 的映射.
22 自组 织特征 图 S M 神 经 网络方 法 ( efOra in e tr p N ) . OF S l g nz gF aueMa sN — i
80年代初mchalski提出了概念聚类技术其要点是在划分对象时不仅考虑对象之间的距离还要求划分出的类具有某种内涵描述从而避免了传统技术的某些片面性聚类分析就是使用聚类算法来发现有意义的聚类它的主要依据是把相似的样本归为一类而把差异大的样本区分开来这样所生成的簇是一组数据对象的集合
维普资讯
在空间呈现这种结构 ,单元的组织形成一个特性映射 ,S F 被认 为类似于大脑的处理过程 ,对在二维或 OM 三维空间中可视化高维数据是很有用的. SF O M神经 网络结构是 由输入层和竞争层组成 , 输入层 由 个输入神经元组成,竞争层由 : X N个 输出神经元组成 ,且形成一个二维平面阵列.输入层各神经元与竞争层各神经元之间实现全互连接.该网 络根据其学习规则 ,通过对输入模式的反复学习 ,捕捉住各个输人模式 中所含的模式特征 ,并对其进行 自 组织 ,在竞争层将聚类结果表现出来 ,进行 自动聚类.竞争层的任何一个神经元都可以代表聚类结果. 2 引入可变学习速度的 S M神经网络训练算法 . 3 0F 设 网络 的输入 模 式 为 X , ,k …, ) k=l ,3 = , , ,2 ,… , P ;竞争 层 神 经 元 向量 为
第10章神经网络聚类方法

第10章神经网络聚类方法
神经网络聚类方法是一种以神经网络技术为根基,以聚类分析为基础
的分类算法,它可以检测出不同数据之间的相似性,从而将这些数据分类
组织起来。
它的出现主要是为了解决传统聚类方法结果效果不佳的问题。
神经网络聚类方法的基本思想是,将聚类分析问题转化为神经网络模
型的问题,用神经网络解决聚类问题,尤其是使用核函数来表示簇之间的
关系,使用反向传播算法来优化神经网络,得出最优聚类结果。
根据神经网络聚类方法的结构,可以将神经网络聚类方法分为两类:
一种是基于核映射的神经网络聚类,另一种是基于自组织映射的神经网络
聚类。
基于核映射的神经网络聚类的典型代表有核聚类神经网络,它是由一
个输入层、一个隐含层和一个输出层构成的神经网络,它的基本思想是使
用一种核函数来表示簇之间的关系,并用反向传播算法来优化该神经网络,使其能够得出较为精确的聚类结果。
基于自组织映射的神经网络聚类则由一个输入层、一个隐含层和一个
自组织映射(SOM)层构成的神经网络,其基本思想是使用一种自组织映射
函数来表示簇之间的关系,并用反向传播算法来优化该神经网络。
大数据的常用算法(分类、回归分析、聚类、关联规则、神经网络方法、web数据挖掘)

⼤数据的常⽤算法(分类、回归分析、聚类、关联规则、神经⽹络⽅法、web数据挖掘)在⼤数据时代,数据挖掘是最关键的⼯作。
⼤数据的挖掘是从海量、不完全的、有噪声的、模糊的、随机的⼤型数据库中发现隐含在其中有价值的、潜在有⽤的信息和知识的过程,也是⼀种决策⽀持过程。
其主要基于,,模式学习,统计学等。
通过对⼤数据⾼度⾃动化地分析,做出归纳性的推理,从中挖掘出潜在的模式,可以帮助企业、商家、⽤户调整市场政策、减少风险、理性⾯对市场,并做出正确的决策。
⽬前,在很多领域尤其是在商业领域如、电信、电商等,数据挖掘可以解决很多问题,包括市场营销策略制定、背景分析、危机等。
⼤数据的挖掘常⽤的⽅法有分类、回归分析、聚类、关联规则、⽅法、Web 数据挖掘等。
这些⽅法从不同的⾓度对数据进⾏挖掘。
数据准备的重要性:没有⾼质量的挖掘结果,数据准备⼯作占⽤的时间往往在60%以上。
(1)分类分类是找出数据库中的⼀组数据对象的共同特点并按照分类模式将其划分为不同的类,其⽬的是通过分类模型,将数据库中的数据项映射到摸个给定的类别中。
可以应⽤到涉及到应⽤分类、趋势预测中,如淘宝商铺将⽤户在⼀段时间内的购买情况划分成不同的类,根据情况向⽤户推荐关联类的商品,从⽽增加商铺的销售量。
分类的⽅法:决策树——是最流⾏的分类⽅法特点:a、它的每次划分都是基于最显著的特征的;b、所分析的数据样本被称作树根,算法从所有特征中选出⼀个最重要的,⽤这个特征把样本分割成若⼲⼦集;c、重复这个过程,直到所有的分⽀下⾯的实例都是“纯”的,即⼦集中各个实例都属于同⼀个类别,这样的分⽀即可确定为⼀个叶⼦节点。
在所有⼦集变成“纯”的之后,树就停⽌⽣长了。
决策树的剪枝:a、如果决策树建的过深,容易导致过度拟合问题(即所有的分类结果数量基本⼀样,没有代表性);b、剪枝通常采⽤⾃上⽽下的⽅式。
每次找出训练数据中对预测精度贡献最⼩的那个分⽀,剪掉它;c、简⾔之,先让决策树疯狂⽣长,然后再慢慢往回收缩。
基于模糊聚类算法的神经网络集成

论研究发现 ,组成神经 网络集 成的各 网络差 异性越 大 ,集 成 的效果越 好。B g ig5 B ot g 1 a gn 1和 o s n 1是最重要的生成集成个 1 i 6 体 网 络 技 术 , B g ig 的 基 础 是 可 重 复 取 样 (o tt p agn B os a r
S m l g,训练集 的选择是随机 的,其规模通常与原始训练 a pi ) n
“ … c“ l c n c ‘ ] l l 1
U U 2
,
集相 当,各轮训练集之 间相互独立 ,原始 训练集 中某 些示例 可能在 新的训练集 中出现 多次,而另外一 些示例 则可能一次 也不出现。B ot g方法可以产生一系列个体神 经 网络 ,各 o sn i
idvd a n ua ewok o stt nua nt oke smbeadte up t fh ne l ue jryv t gme o . h oei l n ls n n iiu l e rl t rs ntue erl ew r ne l n tu ee smbe ss o t oi t d T ert a ayia d n c i ho ot ma i n h c a s
用所抽得的数据作为 个体神 经网络的训练样本 ,多个个体神经 网络构成神经 网络集 成,集成 的输 出采 用相对 多数投票法。理论分析 和实验 结果表 明,该 方法对模 式分类能取得较好 的效果 。 关健词 :模糊 聚类 ;神经 网络集成 ;模 式分类
Ne a t r sEn e b eBa e n Fu z u t r n g r t m ur l Ne wo k s m l s d o z y Cl s e i gAl o ih
中 分 号; P8 图 类 T1
基于蚁群聚类的自适应神经网络算法

的参 数和 结构进 行优 化 . 达到 自适 应 调整 权值 参数 和 结构 的 目的。 最后 , 对 非线性 函数遥 近 问题 进行 了 针
验 证 通过 仿 真试验 证 明该 方 法取 得 了很 好 的结 果 . 系统 的逼 近精 度 明显提 高 , 而且 网络 的 自适应 能 力强 ,
并可 以将其 有效 地 用 于模 糊 建模 和控 制 问题 的 求解 【 键词 】 模 糊神 经 网络 ; 关 : 蚁群 聚类 ; 向传播 学 习; 反 结构优 化 的转 移概 率 , 是迹 的相 对 重要性 ( ≥O , 是 能见 度 的 )p 模 糊 神 经 网络 是 近 年 来 颇 受 关 注 的研 究 领 域 . 它 相 对 重 要 性 ( /o , 是 轨 迹 的 持 久性 ( ≤p 1, 一 为 p - )p _ 0 <)1 p 因此 , 态转移 概率 可根据 公式() 状 1来计 将神 经 网络低层 次学 习 和计 算 能力 与模糊 逻 辑 系统 高 轨 迹 的衰减 度 。
1 引 言 、
层次仿 人 思维和 推理 能力 相 结合 ,实 现 两者 的优 势互 算 。 补 。但 在发 展过 程 中 , 始终 存 在一 个 结构 辨识 难题 , 就 是如何 合适 地划 分输 入输 出空 间 .如 何从 观测 数 据 中 提取较 为简 化 的模糊 规则 库 聚类算 法作 为一 种 无监 督 的分类方 法 .它能按 照 一 定 的要求 和规 律对 事 物进
,
状 态转 移 规则 是 一 按 随 机 比例 决 定 蚂蚁 k 点选 目标 函数 , : 在i 即 择i 点作 为下 一访 问点 的概率 。 假设 m 蚂蚁个 数 , ; 是 1i 1 是
-
边 (j 能见 度 ,i 边 (j 轨 迹 程度 , 丁是 蚂 蚁k i) ,的 T是 j i) '的 △ 于
基于k-means聚类算法和BP神经网络的物资消耗预测模型的构建与测试
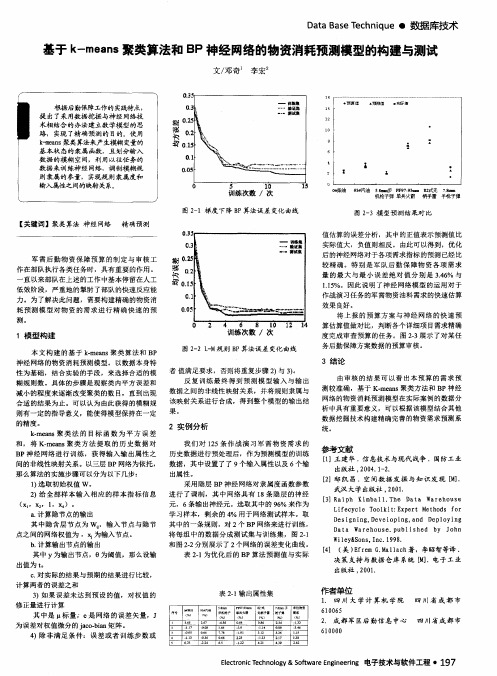
b . 计算输 出节 点的输 出 和 图2 — 2分别展示 了2个网络的误差变化 曲线。 其 中 Y为输 出节点,0为 阈值 ,那么设输 表2 . 1 为优 化后 的 B P算法 预测值与实 际 出值为 t 。 C . 对实际的结果与预期的结果进行 比较 , 计 算 两 者 的误 差 之 和 3 ) 如 果误差未 达到预 设的值,对权值 的 修正量进行计算 其 中是 标 量 e 是 网络 的误差矢 量,J 为误差对权值微分 的 i a c o . b i a n矩阵 。 4 )除非满 足条 件 :误 差或 者训练 步数 或 表2 - 1 输 出属性集
低效阶段 ,严重地 的掣肘了部队的快速反应能 力 。为 了解 决此 问题,需要构建精确的物资消 耗 预测模 型对 物 资 的需求进 行精 确快 速 的预
测。
作 战演 习任务 的军需物 资油料需求的快速 估算
效果良好 。 将 上报 的预 算方案 与神 经 网络 的快速 预 算估算值做对 比,判断各个详细项 目需求精确 度完成 审查预算的任务 。图 2 — 3展示 了对某任 务后勤保障方案数据 的预算审核。
a . Байду номын сангаас算 隐节点 的输 出 其 中隐含层 节点为 W , ,输 入节 点与隐节 点之 间的网络权值 为 , 为输入节点。
D es i g ni n g ,D e ve 1 o pi n g , an d D e p1 o yi n g D at a Wa re ho uS e .p ub1 i S hed b Y Jo hn
由审核 的结果 可 以看 出本 预算 的 需求预 测较准确 ,基 于 K. me a n s聚类方法和 B P神经 网络 的物 资消耗预测模 型在实 际案例 的数据分 析 中具有重要意义 ,可 以根据该模型结合其他 数据挖掘技术构建精确完善 的物资需求预测系
基于熵聚类的RBF神经网络学习算法

e t mey s n i v o t e n mb ra d i i a o ain f l se e tr ,i t e c oc sn t o d,t e n t o k p r xr e l e s ie t h u e nt llc t so u t rc n e t n i o c s f h h ie i o o g h ew r e -
g r m a h d a t g so s c n eg n p e d hg p r xmain a c rc . oi h t h st e a v n a e f a t o v re ts e d a ih a p o i t c u a y f n o
ABS RACT: h e on n t e d sg fRB ewok st p c f h u e n h o ai n o e c ne s T T e k y p i t h e in o F n t r si o s e i t e n mb ra d t e lc t ft e tr , i y o h a d t e mo tc mmo l s d meh d o p c y n e t rv co s k Me n l o t m. h — Me n g r h i n h s o n y u e t o fs e i i g c n e e tr i — f a s ag r h T e k i a s a o i m s l t
基于聚类分析和PSO优化的神经网络短期负荷预测研究

V o 1 . 1 6 N o . 2
象根 据其 与各 个簇 中心 的距 离 , 将 它赋予 给最 近 的
天最 高温度 ( ) 。相 应 的输 出量 为预测 日时刻 的预
簇, 并使 目标 数
=
m
i n
i 1 1 j E 11. 2 Z. 。 … } … }
l } 啦 一 l l 值减小。然
等 。然而 , 由于影 响短期 电力负 荷 的 因素大 都具 有 很 强 的非 线性 , 传 统 的拟线 性预 测 方法存 在 着 局 限
性, 一 些智 能 算法 凸显 出 了一定 的 优势 。但 同时 由 于大 量影 响负 荷 的随机 因素存 在 , 使得 负荷 波 动性
1 K — me a n s 聚 类算 法
想是 随 机选 择 k ( 聚 类 个数 ) 个对 象 , 每个 对 象 初始 地 代表 了一 个簇 的平 均值 或 中心 , 对剩 余 的每个 对
方 向为 电力 企 业 战 略 案 例 、 电 力市 场 技 术 、 技 术创 新理 论 。
;
2
基 于 聚类 分析 和P S O 优化 的神 经 网络短期 负荷 预测研究
未 来2 4 h 至 几 天 内的 电力负荷 需 求情 况 。短 期 负荷 预测 特别 是 日负荷 预测 曲线 为地 区 电力 余 缺调 度 、
度。 一些 新 的预i 贝 4 方法 也 显现 出不 足 。[ 1 - 4 ]
传 统 的短 期 负荷 预 测 方法 大 部 分 是针 对 未 来
S t u d y o n S h o r t - t e r m L o a d F o r e c a s t i n g Ba s e d o n Cl u s t e r i n g An a l y s i s a n d Op t i mi z e d N e u r a l Ne t wo r k b y P S O
基于深度学习的聚类分析算法研究

基于深度学习的聚类分析算法研究概述:聚类分析是数据挖掘领域中的一个重要任务,其目标是将具有相似特征的数据点聚集在一起。
传统的聚类算法通常依赖于人工选择的特征或距离度量,且在处理大规模数据时存在一定的局限性。
然而,随着深度学习的迅猛发展,基于深度学习的聚类分析算法逐渐展现出强大的潜力。
一、深度学习在聚类分析中的应用近年来,深度学习已成功应用于图像分类、自然语言处理等领域,其优越的表征学习能力和自动特征提取能力使其在聚类分析任务中得到广泛探索。
深度学习的聚类分析算法主要包括自编码器、生成对抗网络和变分自编码器等。
1. 自编码器:自编码器是一种无监督学习神经网络,主要由编码器和解码器两部分组成。
其核心目标是通过对输入数据的重新编码,学习到数据的低维表示。
自编码器在聚类分析中的应用主要包括降维和特征学习两个方面。
通过自编码器进行降维可以减少数据的维度,从而更好地可视化和理解数据聚类结构。
同时,自编码器可以通过重构损失函数对数据进行特征学习,从而发现数据的潜在结构和特征。
2. 生成对抗网络(GAN):生成对抗网络由生成器和判别器两个网络组成,通过对抗学习的方式来提高生成数据的质量。
在聚类分析中,GAN可以通过生成新的数据样本来拓展聚类样本集合,从而提高聚类的准确性和鲁棒性。
此外,GAN还可以学习到数据分布的隐式表示,将同一个聚类中的数据映射到更紧密的区域,从而增强聚类性能。
3. 变分自编码器(VAE):变分自编码器是一种生成模型,能够生成与原始数据具有相似分布的新样本。
在聚类分析中,VAE主要用于学习有效的低维表示,并通过重构损失函数来聚类数据。
与传统自编码器不同的是,VAE通过编码器学习数据的潜在分布,并通过解码器生成新的样本。
二、深度学习聚类分析算法的优势相比于传统的聚类算法,基于深度学习的聚类分析算法具有以下优势:1. 自动学习特征:传统的聚类算法通常需要人工选择合适的特征或距离度量,但这个过程可能存在主观性和不确定性。
一种基于多种神经网络集成的因果事理图谱构建方法[发明专利]
![一种基于多种神经网络集成的因果事理图谱构建方法[发明专利]](https://img.taocdn.com/s3/m/bc7a0c12dc36a32d7375a417866fb84ae45cc3a8.png)
(19)中华人民共和国国家知识产权局(12)发明专利申请(10)申请公布号 (43)申请公布日 (21)申请号 202010459865.X(22)申请日 2020.05.27(71)申请人 青岛大学地址 266000 山东省青岛市崂山区香港东路7号(72)发明人 云红艳 胡欢 云洋 李正民 (74)专利代理机构 青岛高晓专利事务所(普通合伙) 37104代理人 于正河(51)Int.Cl.G06F 16/36(2019.01)G06F 16/35(2019.01)G06F 40/211(2020.01)G06F 40/289(2020.01)G06F 40/30(2020.01)G06K 9/62(2006.01)G06N 3/04(2006.01)G06N 3/08(2006.01)(54)发明名称一种基于多种神经网络集成的因果事理图谱构建方法(57)摘要本发明属于网络信息技术领域,涉及一种基于多种神经网络集成的因果事理图谱构建方法,先将获取的语料库的获取采用BIO序列标注体系标注数据且分割数据,再用BERT+Bi ‑LSTM+Attention+CRF模型进行事件抽取,事件关系抽取时先基于事件抽取元素(<O ,V>)组合成事件并定义事件对及规则特征,再结合事件间规则特征与Bi ‑GRU模型抽取因果关系;然后基于事件对利用相似度计算,选取分数最高的两个事件组合成<事件i,相似,事件j>三元组,再基于事件关系抽取组合<原因事件,因果,结果事件>三元组,接着采用Neo4j图数据库持久化存储,搭建事理逻辑知识库构建出面向热点话题的因果事理图谱,构建的因果事理图谱能够深层次的提取语义信息,有利于相关监管部门及个人用户对热点事件的实时掌控。
权利要求书3页 说明书7页 附图3页CN 111767408 A 2020.10.13C N 111767408A1.一种基于多种神经网络集成的因果事理图谱构建方法,其特征在于包括以下步骤:步骤1:采用开源的Scrapy框架爬取互联网平台发布的数据,爬取的内容为标题、内容和时间,Spider向引擎发送请求,调度器接收到向调度器发送请求,通过URL向互联网发送请求,抓取的数据返回给Spider做处理,然后采用Xpath语句处理<h3 id=“title”>、<div class=“date”>、<span>标签,将获取的数据交给管道存储为以时间降序的CSV格式,形成以时间降序存储热点话题文本数据集;步骤2:根据步骤1将获取的热点话题文本数据集采用无监督学习kmeans算法进行文本聚类分析;步骤3:定义事件的组成元素,再利用步骤2获取的数据源采用BIO序列标注体系对文本数据标注;步骤4:根据步骤3标注的数据采用BERT模型空间向量化数据源,接着结合Bi-LSTM+ Attention+CRF模型抽取出事件元素;步骤5:根据步骤4事件抽取结果构建候选事件对;步骤6:定义事件间规则特征模板且结合Bi-GRU抽取模型识别因果关系;步骤7:根据步骤5获取<原因事件,因果,结果事件>三元组,再根据步骤4组成的事件对采用余弦相似度计算获取<事件i,相似,事件j>三元组,然后利用Neo4j图数据库存储事件逻辑知识;步骤8:根据步骤7存储的事理逻辑知识库采用HTML5、py2neo和VIS.JS相关技术将存储在Neo4j中的事件知识封装展现,实现因果事理图谱可视化。
基于神经网络和聚类的预测算法共45页PPT

基于神经网络和聚类的预测 算法
41、实际上,我们想要的不是针对犯 罪的法 律,而 是针对 疯狂的 法律。 ——马 克·吐温 42、法律的力量应当跟随着公民,就 像影子 跟随着 身体一 样。— —贝卡 利亚 43、法律和制度必须跟上人类思想进 步。— —杰弗 逊 44、人类受制于法律,法律受制于情 理。— —托·富 勒
45、法律的制定是为了保证每一个人 自由发 挥自己 的才能 ,而不 是为了 束缚他 的才能 。—— 罗财富 ❖ 丰富你的人生
71、既然我已经踏上这条道路,那么,任何东西都不应妨碍我沿着这条路走下去。——康德 72、家庭成为快乐的种子在外也不致成为障碍物但在旅行之际却是夜间的伴侣。——西塞罗 73、坚持意志伟大的事业需要始终不渝的精神。——伏尔泰 74、路漫漫其修道远,吾将上下而求索。——屈原 75、内外相应,言行相称。——韩非
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
计 算 机 仿 真
2010年 1月
基于聚类分析的综合神经网络集成算法
齐新战 1 ,刘丙杰 2 ,冀海燕 2
(1. 海军潜艇学院作战指挥系 ,山东 青岛 266071; 2. 海军潜艇学院导弹兵器系 ,山东 青岛 266071)
一 [10 ] 。但是 FCM 算法也有其自身的缺点 ,文献 [ 10 ]深入研
究了 FCM 算法的缺陷 ,主要是对噪声数据敏感 ,其主要原因
是聚类中心计算采用了最简单的均值计算 :
N
∑ x
=
1 N
xi
i =1
(1)
当有噪声或游离值时 , 聚类中心会发生改变 。由于中位
数对噪声和游离值的干扰不敏感 ,本文采用样本的中位数表
示聚类中心 。聚类算法采用 FCM 算法 。
假设待分类的样本集合为 X = { ( x1 , d1 ) , ( x2 , d2 ) , …, ( xn , dn ) } ,其中 xi表示输入 , di表示输出 , n为样本数量 。因为 神经网络处理的是输入数据 , 所以仅仅对样本的输入聚类 。
输入样本 的 每 个 元 素 由 一 组 特 征 表 示 xk = { xk1 , xk2 , …, xkm } , m 为特征数量 , 通常情况下 , m 和神经网络的输入层神 经元个数相同 。FCM 算法具体步骤如下 :
1) 数据的标准化 。有标准差标准化和极差标准化两种方
法 [11 ] ,本文采用极差标准化 :
xij
= xij - xj Rj
(2)
Xj (n
+ 1) , 2
n
is
odd
xj =
(3)
xj
= Xj (
n ), n 2
is even
Rj
=
m ax
0 < i≤n
(
xij
)
-
m in
0 < i≤n
(
xij
k
∑ d iff ( d, cj ) =
| di - cji | , 0 < j < m
(7)
i =1
集成权值为 :
Wj =
d iff ( d, cj )
m
,0 < j <m
(8)
∑d iff ( d, cj )
j=1
m
∑ 满足 : w i > 0, w j = 1。 j=1
假设网络 j的输出为 V j,则集成结果为 :
收稿日期 : 2008 - 10 - 01 修回日期 : 2008 - 10 - 30
— 166 —
经网络的方法进行改进 。李凯等 [2 ]以及李国正等 [3 ]提出基 于聚类技术的选择性 NNE算法 ,该算法通过计算个体神经 网络之间的差异度对神经网络进行聚类 ,剔除相关神经网 络 ,减小 NNE规模 ,实验表明这种算法是可行的 。M d. 等 [4 ] 提出一种新的集成算法 CNNE,该算法首先建立一个较小的 NN E,然后通过增加个体神经网络隐含层神经元及增加个体 神经网络来创建最优的网络结构 。W ang[5 ]通过增加一个偏 差对 Zhou[1 ]的算法进行了改进 ,在一定程度上提高了 NNE 的精度 。 Pitoyo[6 ]提出了一种从不完全样本中学习的自适应 NNE算法 ,该算法通过消除不正确样本达到提高神经网络精 度的目的 。 Yao[7 ]提出一种用进化计算方法调整权值的 NNE 算法 。
本文设计了一个综合神经网络集成算法 InNNE。该算 法首先利用聚类分析技术将样本分类 ,对不同类别的样本采 用不同的个体神经网络训练 ,个体神经网络的数目等于样本 类别数目 。这样可以达到不同的神经网络学习不同类的样 本 ,可以提高神经网络个体之间的差异性 [8 ] ,从而提高 NNE 的泛化能力 。NNE中的个体神经网络学习的样本不一样 ,对 一个问题的不同侧面的认识能力也不一样 ,所以对于不同的 输入数据 ,个体神经网络的处理能力是不同的 。固定的 NNE 权值可能会降低某些神经网络个体的性能 ,从而导致整体 NNE性能下降 。 InNNE根据输入数据与样本类别之间的相 关程度自适应调整集成权值 ,这样可以提高 NNE 的精度 。 文献 [ 2, 3 ]中也将聚类分析技术应用于 NNE,所不同的是 , 文献 [ 2, 3 ]用聚类技术对个体神经网络进行聚类 ,选择差异 度较大的神经网络作为集成网络的个体 ,网络集成权值还是 固定的 ,而且没有研究神经网络生成算法 。
An In tegra ted Neura l Net work En sem ble A lgor ithm Ba sed on C luster ing Technology
Q I X in - zhan1 , L IU B ing - jie2 , J I Hai - yan2
(1. Commd. Dep t. Navy Submarine Academy, Q ingdao Shandong 266071, China; 2. M issile Dep t. Navy Submarine Academy, Q ingdao Shandong 266071, China )
2 样本聚类
所谓聚类就是将物理或抽象的集合分组成相似对象组
成的多个类的过程 ,使得同一类中对象间的相似度最大化 , 不同类中的对象间的相似度最小化 [9 ] 。本文将利用模糊聚
类分析对样本分类 , FCM ( Fuzzy C - means) 算法是模糊聚类
分析中最主要的一个 ,其以被证明的最有效的聚类方法之
1 引言
由于神经网络集成 (Neural Network Ensemble, NNE) 在 泛化 能 力 上 的 优 良 性 能 以 及 精 度 的 大 幅 提 高 , NNE 自 从 1990年被提出以来 ,得到了众多学者的广泛研究 。NNE研 究主要集中在三个方面 :如何生成个体神经网络 ,如何集成 个体神经网络以及如何确定 NNE的结构 。 Zhou[1 ]提出了一 种基于遗传算法的选择性 NNE, GASEN , GASEN 利用遗传算 法选择差异度大的神经网络 ,而不是将所有的个体神经网络 都集成 。实验表明这种算法泛化能力和精度都高于普通算 法如 Boosting和 Bagging。但是该算法并没有对产生个体神
假设样本被分为 m 类 , 分别为 X1 , X2 , …, Xm , 其中心为 c1 , c2 , …cm ,每一个中心的特征为 ci1 , ci2 , …cik , 注意 , 这里使 用的中心特征值是同一类中对象各个特征的中位数 , 而不是 经过标准化以后的数据 ,这样可以减少游离数据对特征中心 的影响 。输入数据为 d = { d1 , d2 , …, dk } , d与各个每一类的 距离为 :
摘要 :研究神经网络集成是一种有效实用的分类方法 ,权值是影响神经网络集成性能的重要因素 。为了克服神经网络集成 固定权值的缺陷 ,提出一种基于聚类分析的综合神经网络集成算法 。算法首先将样本分类 ,每类样本中加入其他样本类一 定数量的中心样本 ,不同的神经网络学习不同类的样本 。根据输入数据与样本类别之间的相关程度自适应调整集成权值 。 算法不仅用于自适应调整集成权值 ,而且是一种产生个体神经网络的训练方法 。四个数据集上的仿真试验证实了算法的有 效性 。 关键词 :神经网络集成 ;聚类分析 ;泛化性能 中图分类号 : TP181 文献标识码 : A
)
(4)
2) 求样本之间的模糊相似矩阵 ,有相关系数法和距离表
示法等 ,本文采用后者产生相似矩阵 :
1 d12 … d1 n1… NhomakorabeaD=
(5)
1 dn - 1, 1
1
m
∑ dij =
~
~
| x ik - x jk |
(6)
k =1
D 为对称矩阵 ,其中 dij = dji , dii = 1。
3) 模糊相似矩阵 D ’的形成 。由于 D 仅仅满足自反性和
m
∑ V =
w jV i
(9)
j=1
算法的具体步骤如下 :
ABSTRACT:D ifferent component neural networks (NN s) in an ensemble in which different training sets have differ2 ent performance for the same input data. The weights of an ensemble impact greatly on the performance of ensemble. The fixed weights may weaken the performance of some component NN s which can have better performance and lower weights, An Integrated neural network ensemble ( InNNE) is p roposed in the paper, which is an integrated ensemble algorithm not only for dynam ically adjusting weights of an ensemble, but also for generating component NN s based on clustering technology. InNNE classifies the training set into different training subsets w ith clustering technology, which are used to train different component NN s. The weights of an ensemble are adjusted by the correlation of input data and the center of different training subsets. InNNE can increase the diversity of component NN s and decrease generalization error of ensemble. The paper p rovides both the analytical and experimental evidence to support the no2 vel algorithm. KEYW O RD S:Neural network ensemble; Clustering analysis; Generalization performance