R语言上机实验
r语言实验报告

r语言实验报告R语言实验报告介绍•本文旨在对R语言实验报告进行相关介绍和指导。
准备工作•在开始编写R语言实验报告之前,需要进行一些准备工作:–安装R语言环境–确保安装必要的R包–理解实验要求和相关数据集实验报告结构•一个完整的R语言实验报告通常包含以下几个部分:1. 标题•实验报告的标题应简明扼要地描述实验内容。
2. 引言•引言部分应包含以下内容:–实验的背景和目的–实验所采用的数据集和方法的简要介绍3. 数据分析•数据分析部分是实验报告的重点,应包含以下内容:–数据的读取和预处理–数据的可视化–统计分析方法的应用–结果的解释和讨论4. 结论•结论部分应总结实验的结果,并对实验的目的和方法进行评价。
5. 参考文献•参考文献部分应列举实验报告中所引用的相关文献。
编写要点•在编写R语言实验报告时,需要遵守以下要点:1. 语法规范•使用清晰、准确的语法表达实验过程和结果。
2. 结果的解释•对于结果的解释,应该尽量采用简洁明了的语言,避免使用过于专业的术语或过于复杂的句子结构。
3. 图表的使用•图表是实验报告中常用的可视化工具,应合理使用图表来展示数据和结果,并配以简洁明了的图题和注解。
4. 逻辑性和连接性•实验报告应具有良好的逻辑性和连接性,各部分之间应有明确的联系和衔接,以确保整篇报告的连贯性。
结语•编写一份规范、完整的R语言实验报告需要系统的学习和实践,希望本文对您有所帮助。
参考文献•[参考文献1]•[参考文献2]继续编写一份更详细的R语言实验报告:R语言实验报告介绍•本文旨在对R语言实验报告进行相关介绍和指导。
准备工作•在开始编写R语言实验报告之前,需要进行一些准备工作:–安装R语言环境:确保在电脑上成功安装R语言的最新版本。
–确保安装必要的R包:根据实验需求,安装并加载所需的R包,例如ggplot2、dplyr等。
–理解实验要求和相关数据集:认真阅读实验要求,理解实验的目的和需求,并熟悉所使用的数据集。
R语言上机练习课第一章-2019

练习5:条形图
练习:对于数据集furness.csv,做出下列条形图
18
4
练习1:直方图
y<c(49.0,47.9,43.4,47.9,48.7,47.3,44.8,48.6,47.9,47.4,4 9.5,45.3,49.9,47.6,46.6,47.1,47.6,47.9,47.5,47.8,48.2, 49.3,50.2,51.3,52.6,48.7,49.2,49.9,49.6,50.3,51.8)
画出这组数据的箱线图,并解释异常值。
8. 两组数据的箱线图表示
> ward<-read.table("ward.csv", header=T, sep=",") > boxplot(EGGS~ZONE, data=ward, ylab="Number of eggs per capsule",
> set.seed(1) > VAR1 <- rlnorm(100,2,.5) > hist(VAR1, prob=T) > lines(density(VAR1))
7
5. Q-Q plots
通过将数据分位数与标准正态分布的数据进行比较, Q-Q正态图也可用于诊断偏离正态分布。
对这组数据画出Q-Q图,并判断这组数据是否满足正态分布。
6. 箱线图:Boxplots
对于较小的样本量,直方图和密度函数可能难以解释。 箱线图提供了描述数据分布的位置的替代方法。 > set.seed(6) > VAR2<-rlnorm(15,2,.5) > boxplot(VAR2)
> qqnorm(VAR1) > qqline(VAR1)
R语言 上机实验一 EXCEL的应用
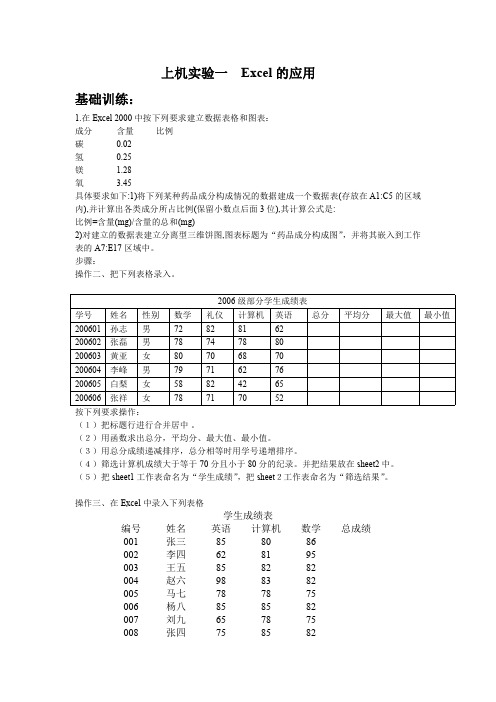
上机实验一Excel的应用基础训练:1.在Excel2000中按下列要求建立数据表格和图表:成分含量比例碳0.02氢0.25镁 1.28氧 3.45具体要求如下:1)将下列某种药品成分构成情况的数据建成一个数据表(存放在A1:C5的区域内),并计算出各类成分所占比例(保留小数点后面3位),其计算公式是:比例=含量(mg)/含量的总和(mg)2)对建立的数据表建立分离型三维饼图,图表标题为“药品成分构成图”,并将其嵌入到工作表的A7:E17区域中。
步骤:操作二、把下列表格录入。
2006级部分学生成绩表学号姓名性别数学礼仪计算机英语总分平均分最大值最小值200601孙志男72828162200602张磊男78747880200603黄亚女80706870200604李峰男79716276200605白梨女58824265200606张祥女78717052按下列要求操作:(1)把标题行进行合并居中。
(2)用函数求出总分,平均分、最大值、最小值。
(3)用总分成绩递减排序,总分相等时用学号递增排序。
(4)筛选计算机成绩大于等于70分且小于80分的纪录。
并把结果放在sheet2中。
(5)把sheet1工作表命名为“学生成绩”,把sheet2工作表命名为“筛选结果”。
操作三、在Excel中录入下列表格学生成绩表编号姓名英语计算机数学总成绩001张三858086002李四628195003王五858282004赵六988382005马七787875006杨八858582007刘九657875008张四758582009李十359565010王六755875平均分最高分按要求操作:1、设置工作表行、列:标题行:行高30;其余行高为20。
2、设置单元格:(1)标题格式:字体:楷书;字号:20;字体颜色为红色;跨列居中;底纹黄色。
(2)将成绩右对齐;其它各单元格内容居中。
3、设置表格边框:外边框为双线,深蓝色;内边框为细实心框,黑色。
R语言常用上机命令分功能整理 时间序列分析为主

第一讲 应用实例 • R 的基本界面是一个交互式命令窗口,命令提示符是一个大于号,命令的结果马上 显示在命令下面。 • S 命令主要有两种形式:表达式或赋值运算(用’<-’或者’=’表示) 。在命令提示符后 键入一个表达式表示计算此表达式并显示结果。赋值运算把赋值号右边的值计算出 来赋给左边的变量。 • 可以用向上光标键来找回以前运行的命令再次运行或修改后再运行。 • S 是区分大小写的,所以 x 和 X 是不同的名字。 我们用一些例子来看 R 软件的特点。假设我们已经进入了 R 的交互式窗口。如果没有打开 的图形窗口,在 R 中,用:> x11() 可以打开一个作图窗口。然后,输入以下语句: x1 = 0:100 x2 = x1*2*pi/100 y = sin(x2) plot(x2,y,type="l") 这些语句可以绘制正弦曲线图。其中,“=”是赋值运算符。0:100 表示一个从 0 到 100 的等 差数列向量。第二个语句可以看出,我们可以对向量直接进行四则运算,计算得到的 x2 是 向量 x1 的所有元素乘以常数 2*pi/100 的结果。 从第三个语句可看到函数可以以向量为输入, 并可以输出一个向量,结果向量 y 的每一个分量是自变量 x2 的每一个分量的正弦函数值。
#将未来 5 期预测值保存在 prop.fore 变量中 U = prop.fore$pred + 1.96* prop.fore$se L = prop.fore$pred – 1.96* prop.fore$se#算出 95%置信区间 ts.plot(prop, prop.fore$pred,col=1:2)#作时序图,含预测。 lines(U, col="blue", lty="dashed") lines(L, col="blue", lty="dashed")#在时序图中作出 95%置信区间 例题 3.9 d=scan("a1.22.txt") x=diff(d) arima(x, order = c(1,0,1),method="CSS") tsdiag(arima(x, order = c(1,0,1),method="CSS")) 第一点: 对于第三讲中的例 2.5,运行命令 arima(prop, order = c(1,0,0),method="ML")之后,显示: Call: arima(x = prop, order = c(1, 0, 0), method = "ML") Coefficients: ar1 intercept 0.6914 81.5509 s.e. 0.0989 1.7453 sigma^2 estimated as 15.51: log likelihood = -137.02, aic = 280.05 注意:intercept 下面的 81.5509 是均值,而不是截距!虽然 intercept 是截距的意思,这里如 果用 mean 会更好。 (the mean and the intercept are the same only when there is no AR term, 均值和截距是相同的,只有在没有 AR 项的时候) 如果想得到截距,利用公式计算。int=(1-0.6914)*81.5509= 25.16661。课本 P81 的例 2.5 续中 的截距 25.17 是正确的。
武汉理工大学R语言实验报告

第二部分:实验过程记录(可加页)(包括实验原始数据记录,实验现象
记录,实验过程发现的问题等)
原始数据(E:/fire.txt):
xy
3.4 26.2
1.8 17.8
4.6 31.3
2.3 23.1
3.1 27.5
5.5 36
0.7 14.1
3 22.3
2.6 19.6
4.3 31.3
2.1 24
1.1 17.3
6.1 43.2
4.8 36.4
3.8 26.1
打开 R 软件后依次按一下程序输入函数命令进行回归分析
1.数据准备
fire <- read.table('E:/fire.txt', head = T)
#读取数据
2.回归分析
plot(fire$y ~ fire$x)
#散点图:
fire.reg <- lm(fire$y ~ fire$x, data = fire)
summary(fire.reg)
#回归分析表:
#回归拟合
anova(fire.reg)
#方差分析表
abline(fire.reg, col = 2, lty = 2)
#拟合直线
3.残差分析 fire.res <- residuals(fire.reg) #残差 fire.sre <- rstandard(fire.reg) #学生化残差 plot(fire.sre) abline(h = 0) text(11, fire.sre[11], label = 11, adj = (-0.3), col = 2) #标注点
2. 一旦我们将时间序列读入 R,下一步通常是用这些数据绘制时间序列图,我 们可以使用 R 中的 plot.ts()函数。
R语言实验报告.

一、试验目的R是用于统计分析、绘图的语言和操作环境。
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
本次试验要求掌握了解R语言的各项功能和函数,能够通过完成试验内容对R语言有一定的了解,会运用软件对数据进行分析。
二、试验环境Windows系统,RGui(32-bit)三、试验内容模拟产生电商专业学生名单(学号区分),记录高数、英语、网站开发三科成绩,然后进行统计分析。
假设有的100 名学生,起始学号为210222001,各科成绩取整,高数成绩为均匀分布随机数,都在75分以上。
英语成绩为正态分布,平均成绩80,标准差为7。
网站开发成绩为正态分布,平均成绩83,标准差为18。
把正态分布中超过100分的成绩变成100分。
1 把上述信息组合成数据框,并写到文本文件中;2计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply 函数)3求总分最高的同学的学号4绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)5画星相图,解释其含义6画脸谱图,解释其含义,7画茎叶图、qq图四、试验实现(一)按要求随机生成学号,和对于的高数、英语、网站开发三科成绩。
A、生成学号B、生成高数成绩高数成绩要求:高数成绩为均匀分布随机数,都在75分以上均匀分布函数:runif(n,min=0,max=1)其中,n 为产生随机值个数(长度),min为最小值,max为最大值。
C、生成英语成绩英语成绩要求:正态分布,平均成绩80,标准差为7正态分布函数:rnorm(n, mean = 0, sd = 1)其中,n 为产生随机值个数(长度),mean 是平均数,sd 是标准差。
D、生成网站开发成绩网站开发成绩要求:网站开发成绩为正态分布,平均成绩83,标准差为18。
其中大于100的都记为100。
(二)把上述信息组合成数据框,并写到文本文件中; 计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply 函数)A、生成文本文件B、打开数据框C、在数据框中命名变量D、计算各种指标:平均分,每个人的总分,最高分,最低分平均分(x4):总分(x5):最低分(x6):最高分(x7):(三)将生成成绩写入文本文件中(四)求总分最高的同学的学号(五)绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)直方图散点图柱状图饼图箱尾图(要求指定颜色和缺口)(六)画星相图,解释其含义(七)画脸谱图,解释其含义(八)画茎叶图(九)qq图五、试验总结这次试验是我第一次接触R语言,刚开始遇到了很多困难,对于R语言一窍不通,后来经过老师的悉心指导,以及自己积极的去查找资料,对R语言有了进一步的了解。
R语言实验报告范文

R语言实验报告范文实验报告:基于R语言的数据分析摘要:本实验基于R语言进行数据分析,主要从数据类型、数据预处理、数据可视化以及数据分析四个方面进行了详细的探索和实践。
实验结果表明,R语言作为一种强大的数据分析工具,在数据处理和可视化方面具有较高的效率和灵活性。
一、引言数据分析在现代科学研究和商业决策中扮演着重要角色。
随着大数据时代的到来,数据分析的方法和工具也得到了极大发展。
R语言作为一种开源的数据分析工具,被广泛应用于数据科学领域。
本实验旨在通过使用R语言进行数据分析,展示R语言在数据处理和可视化方面的应用能力。
二、材料与方法1.数据集:本实验使用了一个包含学生身高、体重、年龄和成绩的数据集。
2.R语言版本:R语言版本为3.6.1三、结果与讨论1.数据类型处理在数据分析中,需要对数据进行适当的处理和转换。
R语言提供了丰富的数据类型和操作函数。
在本实验中,我们使用了R语言中的函数将数据从字符型转换为数值型,并进行了缺失值处理。
同时,我们还进行了数据类型的检查和转换。
2.数据预处理数据预处理是数据分析中的重要一步。
在本实验中,我们使用R语言中的函数处理了异常值、重复值和离群值。
通过计算均值、中位数和四分位数,我们对数据进行了描述性统计,并进行了异常值和离群值的检测和处理。
3.数据可视化数据可视化是数据分析的重要手段之一、R语言提供了丰富的绘图函数和包,可以用于生成各种类型的图表。
在本实验中,我们使用了ggplot2包绘制了散点图、直方图和箱线图等图表。
这些图表直观地展示了数据的分布情况和特点。
4.数据分析数据分析是数据分析的核心环节。
在本实验中,我们使用R语言中的函数进行了相关性分析和回归分析。
通过计算相关系数和回归系数,我们探索了数据之间的关系,并对学生成绩进行了预测。
四、结论本实验通过使用R语言进行数据分析,展示了R语言在数据处理和可视化方面的强大能力。
通过将数据从字符型转换为数值型、处理异常值和离群值,我们获取了可靠的数据集。
r语言实验报告

r语言实验报告R语言实验报告引言R语言是一种广泛应用于数据分析和统计建模的开源编程语言,具有丰富的包和函数库,适用于各种数据处理和可视化任务。
本实验旨在探讨R语言在数据处理和可视化方面的应用,通过实际案例展示其强大的功能和灵活性。
数据导入与处理我们需要导入数据集,并进行初步的处理。
在R语言中,可以使用read.csv()函数导入csv格式的数据文件,然后通过head()函数查看数据的前几行,以了解数据结构和内容。
接下来,可以使用subset()函数筛选出需要的数据列,并使用na.omit()函数删除缺失值,确保数据的完整性和准确性。
数据可视化数据可视化是数据分析的重要环节,可以帮助我们更直观地理解数据的分布和关系。
在R语言中,可以使用ggplot2包来绘制各种类型的图表,如散点图、折线图和直方图等。
通过设置不同的参数和颜色,可以定制化图表的样式,使其更具有美感和可读性。
统计分析除了数据可视化,R语言还提供了丰富的统计分析函数,可以帮助我们进行各种统计推断和建模分析。
例如,可以使用lm()函数进行线性回归分析,通过summary()函数查看回归模型的拟合效果和显著性检验结果。
此外,还可以使用t.test()函数进行假设检验,判断样本均值之间是否存在显著差异。
结果解释与总结我们需要对分析结果进行解释和总结。
在解释结果时,应该清晰地说明分析方法和推断过程,避免歧义和误导。
在总结部分,可以简要概括分析的主要发现和结论,指出数据分析对问题的解决和决策的重要性和价值。
结论通过本实验,我们深入探讨了R语言在数据处理和可视化方面的应用,展示了其强大的功能和灵活性。
R语言不仅可以帮助我们高效地处理和分析数据,还可以帮助我们更好地理解数据的特征和规律。
希望本实验可以帮助读者更好地掌握R语言的应用技巧,提升数据分析和统计建模的能力。
R语言回归分析和方差分析上机

Model 1: sbp ~ weight Model 2: sbp ~ weight + age Res.Df RSS Df Sum of Sq F Pr(>F) 3152 674389 3151 652430 1 21958 106.05 < 2.2e-16 *** -- Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘
2.残差分析 par(mfrow=c(2,2), pch=19) plot(M1,which=1) plot(M1,which=2) plot(M2,which=1) plot(M2,which=2)
anova(M1,M3) Analysis of Variance Table
by(sbp, agec, FUN=meansd) agec: 35-40 mean sd 125.22652 12.27492 --------------------------------------------------agec: 41-45 mean sd 127.04675 14.25961 --------------------------------------------------agec: 46-50 mean sd 129.6480 15.0121 --------------------------------------------------agec: 51-55 mean sd 132.32955 17.32263 --------------------------------------------------agec: 56-60 mean sd 132.21488 17.07062
r语言上级实验一

r语言上级实验一理学院实验报告班级:学号:姓名:实验编号:01实验一:初识R软件一、实验目的与要求:1、了解R软件的安装、启动和退出。
2、掌握软件包的安装和载入。
3、掌握R软件帮助功能。
4、会使用R的集成开发环境Tinn-R或Rstudio。
5、掌握用R进行基本的代数运算。
6、掌握用R生成向量、矩阵、数据框和列表的方法。
7、掌握提取数据子集的方法。
二、实验内容:1.按N的不同取值,计算∑=-Nii12)12(1,并求其与log(N)+1.0的距离,其中N=100,500,1000,1500.#计算其值> N<-c(100,500,1000,1500)> for(k in 1:length(N))+ {+ s=0+ for(i in 1:N[k]){+ s=s+1/(2*i-1)^2+ }+ print(s)+ }[1] 1.231201[1] 1.233201[1] 1.233451[1] 1.233534#求距离> y<-abs(s-(log(N)+1.0))> y[1] 4.371636 5.981074 6.674221 7.0796872.联合命令rep()和seq()生成(1,2,3,4,5,2,3,4,5,6,3,4,5,6,7,4,5,6,7,8,5,6,7,8,9). #用rep生成> rep(1:5,5)+rep(0:4,rep(5,5))[1] 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9 #用seq 生成> rep(seq(1,5),5)+rep(seq(0,4),rep(5,5))[1] 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 93. 利用命令matrix()将矩阵=4912011411435A 输入变量A ,并求A 的行列式、逆矩阵,T AA (转置命令为t())、A A T .#输入变量A> A<-matrix(c(35,14,1,4,11,0,12,9,4),nrow=3,ncol=3,byrow=T) > A [,1] [,2] [,3][1,] 35 14 1 [2,] 4 11 0 [3,] 12 9 4#计算A 值 > det(A) [1] 1220#计算A 逆> solve (A) %*%A[,1] [,2] [,3] [1,] 1.000000e+00 -5.551115e-17 0.000000e+00 [2,] -1.387779e-17 1.000000e+00 -1.734723e-18 [3,] -4.440892e-16 -4.440892e-16 1.000000e+00#计算AA T > A%*%t(A)[,1] [,2] [,3] [1,] 1422 294 550 [2,] 294 137 147 [3,] 550 147 241#计算A T A> t(A)%*%A[,1] [,2] [,3] [1,] 1385 642 83 [2,] 642 398 50[3,] 83 50 174. (1)利用命令data.frame()将下表数据读入变量sea,Season Salinity(盐度) Temperature winter 29.19 4 winter 27.37 6 spring24.997.3spring 28.79 8.2 spring 33.28 9.1 summer 32.69 18.1 summer31.9 17 summer NA 21 autumn 32.53 15.1 autumn32.53 13.8>Season<-c("winter","winter","spring","spring","spring","summer","summer ","summer","autu mn","autumn")> Salinity<-c(29.19,27.37,24.99,28.79,33.28,32.69,31.9,NA,32.53,32.53) > Temperature<-c(4,6,7.3,8.2,9.1,18.1,17,21,15.1,13.8) > sea<-data.frame(Season,Salinity,Temperature) > seaSeason Salinity Temperature 1 winter 29.19 4.0 2 winter 27.37 6.0 3 spring 24.99 7.3 4 spring 28.79 8.2 5 spring 33.28 9.1 6summer 32.69 18.1 7 summer 31.90 17.0 8 summer NA 21.0 9 autumn 32.53 15.1 10 autumn 32.53 13.8 > class(sea)[1] "data.frame"(2)将盐度的标准化变量加到这个数据框中;(标准化公式:ni s x x ,x 是样本均值,n s 是样本方差);#将标准化变量加入> sea<-data.frame(Season,Salinity,Temperature,scale(Salinity)) > seaSeason Salinity Temperature scale.Salinity.1 winter 29.19 4.0 -0.40437122 winter 27.37 6.0 -1.03160603 spring 24.99 7.3 -1.85183624 spring 28.79 8.2 -0.54222505 spring 33.28 9.1 1.00518406 summer 32.69 18.1 0.80184977 summer 31.90 17.0 0.52958848 summer NA 21.0 NA9 autumn 32.53 15.1 0.746708110 autumn 32.53 13.8 0.7467081(3)从数据框sea提取包含season和temperature变量的子数据框存入变量sea1,并计算温度的平均值和标准差;> sea1<-data.frame(sea$Season,sea$Temperature)> sea1Season Temperature1 winter 4.02 winter 6.03 spring 7.34 spring 8.25 spring 9.16 summer 18.17 summer 17.08 summer 21.09 autumn 15.110 autumn 13.8> mean(Temperature)[1] 11.96> sd(Temperature)[1] 5.782963(4) 从数据框sea提取包含season和salinity变量的子数据框存入变量sea2,并计算盐度的平均值和标准差(结果不能为NA);> sea2<-data.frame(sea$Season,sea$Salinity)> sea2sea.Season sea.Salinity1 winter 29.192 winter 27.373 spring 24.994 spring 28.795 spring 33.286 summer 32.697 summer 31.908 summer NA9 autumn 32.5310 autumn 32.53> mean(Salinity,na.rm=T)[1] 30.36333> sd(Salinity,na.rm=T)[1] 2.901625(5)利用命令list() 将上表读入变量sea.list, 再将盐度的标准化变量加入到这个列表中,并比较该方法与数据框方法的区别。
R语言实验报告4

R语言实验报告4
R语言实验报告4
本次实验的内容是利用R语言在数据分析的过程中,对数据进行可视
化分析,帮助用户更好地理解数据的分布及其特征。
一、实验环境准备
首先,我们需要准备实验环境,包括Rstudio的安装及R语言的安装,以及对R语言相关的统计分析和可视化工具包的安装。
二、实验数据的准备
其次,我们需要准备实验的数据,这里我们选择了一个世界各国GDP
数据集,包含了全球各个国家2000-2024年的GDP数据。
三、数据可视化分析
实验的思路是将数据以不同的图形进行可视化展示,以便更加直观地
查看各个国家的GDP变化和特征。
1.箱线图。
在R语言中,我们可以使用boxplot(函数来绘制箱线图,下面我们来实现:
```
boxplot(GDP ~ Country, data = world_gdp, col = "blue")
```
从箱线图中我们可以看出,在2024年,不同国家的GDP水平有很大的不同,印度和俄罗斯的GDP水平最高,而秘鲁和尼加拉瓜的GDP水平则相对较低。
2.柱状图。
下面我们使用barplot(函数来绘制柱状图,来更加清晰地看出每个国家在2000-2024年GDP的变化情况:
```
barplot(t(GDP), beside=TRUE, col=rainbow(20))
```
从柱状图中可以看出,在2000-2024年,不同国家的GDP变化幅度有很大的不同,主要有三种情况:美国和日本的GDP增长幅度较大。
r语言实验报告

r语言实验报告R语言实验报告一、引言R语言是一种广泛应用于数据分析、统计建模和可视化的编程语言。
本实验报告旨在介绍使用R语言进行数据分析的过程和结果。
二、实验设计本次实验的目标是分析某公司过去一年的销售数据,以了解销售业绩的情况。
实验设计包括以下步骤:1. 数据收集:从公司内部数据库中提取过去一年的销售数据,并将其导入R语言环境。
2. 数据清洗:对数据进行清理和预处理,包括处理缺失值、异常值和重复值等。
3. 数据探索:通过绘制统计图表和计算描述性统计指标,对销售数据进行探索性分析。
4. 模型建立:根据销售数据的特征和目标,选择适当的模型进行建立和训练。
5. 模型评估:使用交叉验证等方法对模型进行评估,并选择最佳模型。
6. 结果解释:根据模型的结果,对销售业绩进行解释和预测。
三、实验过程和结果1. 数据收集:从公司数据库中提取过去一年的销售数据,并导入R语言环境。
2. 数据清洗:对数据进行清理和预处理,包括处理缺失值、异常值和重复值等。
清洗后的数据包括销售额、销售数量、产品类别、销售时间等变量。
3. 数据探索:通过绘制统计图表和计算描述性统计指标,对销售数据进行探索性分析。
例如,绘制柱状图展示不同产品类别的销售额情况,计算销售数量的平均值和标准差等。
4. 模型建立:根据销售数据的特征和目标,选择适当的模型进行建立和训练。
例如,可以使用线性回归模型来预测销售额与销售数量之间的关系。
5. 模型评估:使用交叉验证等方法对模型进行评估,并选择最佳模型。
例如,可以计算模型的均方根误差(RMSE)来评估模型的预测精度。
6. 结果解释:根据模型的结果,对销售业绩进行解释和预测。
例如,可以通过模型预测某产品在未来一个月的销售额。
四、实验结论通过对过去一年销售数据的分析,我们得出以下结论:1. 不同产品类别的销售额存在差异,其中某些产品类别的销售额较高。
2. 销售数量与销售额呈正相关关系,即销售数量增加时,销售额也增加。
R语言上机实验三

R语⾔上机实验三理学院实验报告班级:学号:姓名:实验编号:实验三:概率和分布的R实现⼀、实验⽬的与要求:1、会⽤R给出常见分布的概率密度、概率、分位数和随机数。
2、会利⽤sample命令进⾏随机抽样,prod,choose命令计算概率。
3、会利⽤R绘制各类分布的图形。
4、会利⽤choose,prod命令计算古典概率。
⼆、实验内容:1.从⼀副扑克牌(52张)中随机抽5张,求下列概率(1) 抽到的是10,J,Q,K,A;> 4/choose(52,5)[1] 1.539077e-06(2) 抽到的是同花顺。
> 9*choose(4,1)/choose(52,5)[1] 1.385169e-05注:同花顺是指5张同⼀⾊牌能按从⼩到⼤连续排序,如2<3<4<5<6,3<4<5<6<7,…,10 2.模拟随机游动:(1)从两点分布中产⽣1000个随机数;> x<-rbinom(1000,1,0.5)> x(2)⽤函数ifelse( )将上⾯随机数中的0替换成-1;> ifelse(x==0,-1,1 )(3)⽤函数cumsum( )作出累积和; > y<-ifelse(x==0,-1,1 )> cumsum(y)(4)使⽤命令plot( ) 作出随机游动的⽰意图. > plot(cumsum(y))3.在同⼀个图形中画出统计的四⼤分布密度曲线(dnorm, dchisq, dt, df),注意不同分布有不同的线型、颜⾊和宽度,还有图形都要在同⼀⽅框中,最后⽤图例说明(legend)。
> curve(dnorm(x,0,1),xlim=c(-1,5),ylim=c(0,0.5),col=1,lwd=1,lty=1)> curve(dchisq(x,1),xlim=c(-1,5),ylim=c(0,0.5),lwd=2,lty=2,col=2,add=T)> curve(dt(x,1),xlim=c(0,8),ylim=c(0,0.5),lwd=3,lty=3,col=3,add=T)> curve(dt(x,1,1),xlim=c(0,8),ylim=c(0,0.5),lwd=4,lty=4,col=4,add=T)> legend('topright',c("dnorm","dchisp","dt","df"),lty=c(1,2,3,4),col=c(1,2,3,4),lwd=c(1,2,3,4))> curve(dnorm(x,0,1),xlim=c(-1,5),ylim=c(0,0.5),col=1,lwd=1,lty=1)> curve(dchisq(x,1),xlim=c(-1,5),ylim=c(0,0.5),lwd=2,lty=8,col=2,add=T)> curve(dt(x,1),xlim=c(0,8),ylim=c(0,0.5),lwd=5,lty=3,col=7,add=T)> curve(dt(x,1,1),xlim=c(0,8),ylim=c(0,0.5),lwd=4,lty=4,col=4,add=T)> legend('topright',c("dnorm","dchisp","dt","df"),lty=c(1,8,3,4),col=c(1,2,7,4),lwd=c(1,2,5,4))>4. 除本章给出的标准分布外, ⾮标准的随机变量X的抽样可通过格式点离散化⽅法实现.设p (x )为X 的密度函数, 其抽样步骤如下(1) 在X 的取值范围内等间隔地选取N 个点x 1, x 2,…, x N , 例如取N =1000; (2) 计算p (x i ); i = 1, 2, …, N ;(3) 正则化p (x i ); i =1, 2,…,N , 使其成为离散的分布律, 即每⼀项除以∑=Ni ix p 1)(;(4) 按离散分布抽样⽅法使⽤命令sample( )从x i , i = 1, 2, … ,N 有放回地抽取n 个数, 例如 n =1000.注:前⾯4⼩步是⽤来编⼀个函数,功能是对给定的概率密度产⽣随机数,形式应与rnorm差不多。
r语言实验报告(一)

r语言实验报告(一)R语言实验报告介绍•R语言是一种用于数据分析和统计建模的开源编程语言。
•本报告将介绍如何使用R语言进行实验分析及报告撰写。
实验设计•确定实验目的和假设。
•设计实验方案,包括样本选择、实验流程和数据收集方式。
数据预处理•导入实验数据,并进行数据清洗和整理。
•检查数据质量,包括缺失值处理、异常值处理等。
数据分析•运用统计学方法进行数据分析,包括描述统计、推断统计和回归分析等。
•可视化数据,通过绘制图表来展示分析结果。
•对实验结果进行解释,包括与初期假设的关联、统计显著性等。
•讨论实验结果的启示和限制。
结论•总结实验结果及其对研究问题的回答。
•提出未来研究的建议,探讨实验的局限性。
参考文献•在报告结尾列出参考文献,引用使用合适的引用格式。
通过以上步骤,可以使用R语言完成一份实验报告。
R语言具备丰富的数据处理和统计分析库,并支持生成高质量的图表,能够有效地帮助实验者进行数据分析和报告撰写。
注意在整个过程中保证数据的准确性和可靠性,以确保实验结果的可信度。
R语言实验报告介绍R语言是一种用于数据分析和统计建模的开源编程语言。
它的强大功能和丰富的数据处理、统计分析库使得它成为科学研究和实验分析的重要工具。
本报告将介绍如何使用R语言进行实验分析及报告撰写的基本步骤和规则。
•确定实验目的和假设。
在开始实验前,明确研究问题是什么,想要验证的假设是什么。
•设计实验方案。
根据实验目的和假设,选择合适的实验变量和控制变量,制定实验流程和数据收集方式。
数据预处理•导入实验数据。
在R语言中,可以使用read.table()或read.csv()等函数将数据导入到工作空间中。
•进行数据清洗和整理。
检查数据中是否存在缺失值、异常值等问题,并进行相应处理,如删除或填补缺失值,修正异常值等。
•数据质量检查。
使用summary()和str()等函数对数据进行初步的统计描述和结构检查,确保数据的正确性和一致性。
数据分析•描述统计。
R语言上机实验四

R语言上机实验四理学院实验报告班级:学号:姓名:实验编号:实验四:探索性数据分析的 R 实现(1) 一、实验目的与要求:1、直方图和核密度估计的 R 实现。
2、单组数据图形描述的 R 实现。
3、单组数据统计描述的 R 实现。
4、分组数据图形概括的 R 实现。
二、实验内容:1. 利用命令读取数据集 tinting, 并命名为 tinting(该数据在程序包DAAG 中), > library(DAAG) > setwd(“C:/Users/Administrator/Desktop”) > tinting names(tinting)[1] “X””case”“id”“age””sex””tint”“target”“it”[9] “csoa”“agegp”(1) 用 summary 查看该数据集的数据总括。
> summary(tinting)X case id age sex Min. : Min. : Min. : Min. : f:91 1st Qu.: 1st Qu.: 1st Qu.: 1st Qu.: m:91Median : Median : Median : Median : Mean : Mean : Mean : Mean : 3rd Qu.: 3rd Qu.: 3rd Qu.: 3rd Qu.: Max. : Max. : Max. : Max.:tint target it csoa agegp hi:52 hicon:104 Min. : Min. : older :91 lo:52 locon: 78 1st Qu.: 1st Qu.: younger:91 no:78 Median :Median :Mean: Mean:3rd Qu.:3rd Qu.: Max. : Max. : (2) 将变量 it 赋值给 obs,再查看其五数概括(fivenum); > obs fivenum(obs) [1] (3) 根据第(2)题得出obs 的取值范围,将其划分为8 个子区间,做直方图; > range(obs) [1]> hist(obs,breaks=17+(0:8)*25,freq=F,ylim=c(0,)) (4) 在第(3)题中画出的图中在画出obs 的核密度曲线,核函数取为“triangular”,窗口为5; > lines(density(obs,bw=5,kernel=“triangular”),col=“red”,l wd=3,lty=2)(5) 画出obs 的茎叶图; > stem(obs) The decimal point is 1 digit(s) to the right of the | 1 | 8 2 | 1122234444555566667777788999 3 | 00000111122222334444455555666777888888899 4 | 000011223333444455677788888889999 5 | 0111222234666777778899 6 | 0001115778 7 | #### 8 |000179 9 | 1139 10 | 025 11 | 338 12 | 001235 13 | 669 14 | 016 15 | 1 16 | 09 17 | 4 18 | 819 | 79 20 | 21 | 0 (6) 画出 obs 的框须图; > boxplot(obs,horizontal=T) (7) 画出 obs 的 QQ 图和 QQ 线,并判断其是否服从正态分布; > qqnorm(obs,main=“Normality Check via QQ Plot”) > qqline(obs,col=“red”,lwd=2)(8) 画出 obs 的经验分布图。
R语言上级实验二

理学院实验报告班级:学号:姓名:实验编号:实验二:R中数据的载入和处理、R编程和作图一、实验目的与要求:1、掌握数据的几种读取方法。
2、掌握数据子集的访问和处理方法。
3、掌握R的基本绘图方法(三大系统中的基本作图函数)。
4、掌握R的编程方法。
二、实验内容:1.用三种方法将数据集cherrytrs.xls读入到R中:(1)直接读入excel表格,并命名为cherry.xls。
> install.packages('readxl')--- 在此連線階段时请选用CRAN的鏡子---> library('readxl')> setwd("C:/Users/Administrator/Desktop")> cherry.xls <- read_excel("cherrytrs.xls",sheet=1)New names:* `` -> (1)> names(cherry.xls)[1] "...1" "Girth" "Height" "Volume" "Site"(2)用read.table读入制表分位符文件,并命名为cherry.txt。
> cherry.txt <- read.table("cherrytrs.txt",header=T,sep="\t")> names(cherry.txt)[1] "X" "Girth" "Height" "Volume" "Site"(3)用read.csv读入逗号分割符文件,并命名为cherry.csv.> cherry.csv<-read.csv("cherrytrs.csv",header=T,sep=",")> names(cherry.csv)[1] "X" "Girth" "Height" "Volume" "Site"2.编一个去掉某个向量中的缺失值的函数,输出结果为该变量的所以非缺失值,还要提示去掉几个缺失值。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
一、数据可视化
1.对于iris数据,用每类花(iris$Speciees)的样本数作为高度,制作条形图。
2.用每类花的Sepal.Length、Sepal.Width、Petal.Length、Petal.Width的平均值分别制作条形图,四图同显。
3.分别制作Sepal.Length、Sepal.Width、Petal.Length、Petal.Width的直方图(用密度值做代表,设置prob=T),添加拟合的密度曲线,四图同显。
二、中国地图:
(Note:首先从网上下载GIS数据,解压到GIS_data目录。
/wp-content/uploads/2009/07/chinaprovinceborderdata _tar_gz.zip)
setwd('F:/GIS_data') ### 设置工作目录
install.packages('maptools');
library(maptools)
china<- readShapePoly('bou2_4p.shp') ### 获得各省的边界信息
plot(china)
>> names(map_data)
[1] "AREA" "PERIMETER" "BOU2_4M_" "BOU2_4M_ID" "ADCODE93"
[6] "ADCODE99" "NAME"
可以看出map_data中有7列,对应的字段名如上面显示。
>> map_data$AREA #925个区域单元的面积
>> map_data$PERIMETER #925个区域单元的周长
>> map_data$BOU2_4M_ #没有重复的数字,2~926,可作为区域单元ID
>> map_data$BOU2_4M_ID #有重复数字,特定情况下可作为区域单元ID
>> map_data$ADCODE93 #93版ADCODE地理编码
>> map_data$ADCODE93 #99版ADCODE地理编码
>> map_data$NAME #各区域单元所隶属的省级行政单元的名称
>> unique(map_data$NAME) #查看各区域的名称是什么文本
[1] 黑龙江省内蒙古自治区新疆维吾尔自治区吉林省
[5] 辽宁省甘肃省河北省北京市
[9] 山西省天津市陕西省宁夏回族自治区[13] 青海省山东省西藏自治区河南省
[17] 江苏省安徽省四川省湖北省
[21] 重庆市上海市浙江省湖南省
[25] 江西省云南省贵州省福建省
[29] 广西壮族自治区台湾省广东省香港特别行政区
[33] 海南省<NA>
33 Levels: 安徽省北京市福建省甘肃省广东省广西壮族自治区 ...重庆市
provname=c("北京市","天津市","河北省","山西省","内蒙古自治区", "辽宁省","吉林省","黑龙江省","上海市","江苏省", "浙江省","安徽省","福建省","江西省","山东省", "河南省","湖北省","湖南省","广东省","广西壮族自治区","海南省","重庆市","四川省","贵州省", "云南省","西藏自治区","陕西省","甘肃省","青海省","宁夏回族自治区","新疆维吾尔自治区","台湾省", "香港特别行政区") ###省份向量
pop=c(1633,1115,6943,3393,2405,4298,2730,3824,1858,7625,5060,6118,3581 ,4368,9367,9360,5699,6355,9449,4768,845,2816,8127,3762,4514,284,3748,26 17,552,610,2095,2296,693) ###各省人口向量
根据各省人口数量给地图着色。
三、使用R语言的包Rwordseg和jiebaR 、wordcloud、tm对《2018年政府工作报告》画词云图。
2018年政府工作报告:
/18/0305/11/DC4MLN6100259A8F.html
test<-readLines('doc.txt')
seg<-worker()seg<=text
seg2<-worker("tag")
seg3<-worker(type="keywords",topn=3)
seg3<=text
for(i in text){a<-seg3<=i;print(a)}
text1<-gsub('[a-zA-Z]','',text) #去除所有英文字母
text2<-gsub("[的|和|了|来|与|到|由|等|从|以|一|为|在|上|各|去|对|侧|多|并|千|万|年|更|向|这是]","",text1)
seg<-worker()
seg<=text2
freq<-freq(segment(text2,seg))
index <- order(-freq[,2])
order2<-freq[index,]
install.packages("wordcloud2")
library(wordcloud2)
wordcloud2(order2,size = 1,minRotation = -pi/3, maxRotation = pi/3,rotateRatio = 0.8,fontFamily = "微软雅黑", color = "random-light")
实验报告电子版发送邮箱:******************
实验报告名称:班级-学号-姓名-实验二。