R语言实验报告
大数定律和中心极限定理的r语言实验报告

大数定律和中心极限定理是概率论中的两个重要概念。
大数定律描述了在独立重复试验中,当试验次数趋于无穷时,某一事件发生的频率趋于其概率。
中心极限定理则指出,无论试验中的个体之间的差异有多大,当试验次数足够多时,试验结果的平均值将接近正态分布。
以下是一个简单的R语言实验报告,用于演示大数定律和中心极限定理。
大数定律和中心极限定理的R语言实验
实验目的:通过模拟实验,观察大数定律和中心极限定理的现象。
实验原理:
1.大数定律:在大量独立重复试验中,某一事件的相对频率趋近于该事件的概率。
2.中心极限定理:无论个体之间的差异有多大,当试验次数足够多时,试验结果的平均值将接近正态分布。
实验步骤:
1.生成1000个0到1之间的随机数,模拟1000次掷硬币试验(正面概率为0.5)。
2.计算正面朝上的频率。
3.使用R语言绘制频率直方图和正态分布曲线。
4.重复步骤1-3多次(例如100次),观察频率的稳定性。
5.计算100次试验中每次试验得分的平均值的频数分布,并绘制直方图和正态分布曲线。
实验结果:
1.正面朝上的频率逐渐稳定于0.5。
2.频率直方图接近正态分布。
3.平均值的频数分布也接近正态分布。
实验分析:
实验结果验证了大数定律和中心极限定理。
在大量独立重复试验中,正面朝上的频率趋近于0.5,符合大数定律。
同时,试验结果的平均值分布接近正态分布,符合中心极限定理。
结论:通过R语言模拟实验,我们观察到了大数定律和中心极限定理的现象,加深了对这两个定理的理解。
RStudioR语言与统计分析实验报告

RStudioR语言与统计分析实验报告1. 实验目的本实验旨在介绍RStudio软件和R语言在统计分析中的应用。
通过本实验,可以了解RStudio的基本功能和操作,掌握R语言的基本语法和常用函数,并在实际数据分析中应用所学知识。
2. 实验环境与工具本实验使用RStudio软件进行实验操作。
RStudio是一个集成开发环境(IDE),专门用于R语言编程和统计分析。
它提供了代码编辑器、调试器、数据可视化工具等一系列功能,便于用户进行数据处理和分析。
3. 实验步骤本实验分为以下几个步骤:3.1 安装R和RStudio在开始实验之前,需要先安装R语言和RStudio软件。
R语言是一种统计分析和数据挖掘的编程语言,而RStudio是R语言的集成开发环境。
3.2 RStudio界面介绍在打开RStudio后,可以看到主要分为四个区域:代码编辑器、控制台、环境和帮助。
代码编辑器用于编写R语言代码,控制台用于执行和查看代码运行结果,环境用于查看和管理数据对象,帮助用于查阅R语言文档和函数说明。
3.3 R语言基础研究R语言的基本语法和常用函数是使用RStudio进行统计分析的基础。
实验中将介绍R语言的数据类型、赋值操作、条件语句、循环语句等基本概念,并演示常用函数的使用方法。
3.4 实际数据分析应用通过实际数据分析案例,将R语言和RStudio运用到实际问题中。
根据给定的数据,使用R语言进行数据处理、探索性分析和统计模型建立,并通过可视化工具展示分析结果。
4. 实验总结通过完成本实验,我们了解了RStudio软件和R语言在统计分析中的应用。
掌握了RStudio的基本功能和操作,熟悉了R语言的基本语法和常用函数。
通过实际数据分析案例的应用,提高了数据处理和统计分析能力。
5. 参考资料。
R语言实验报告
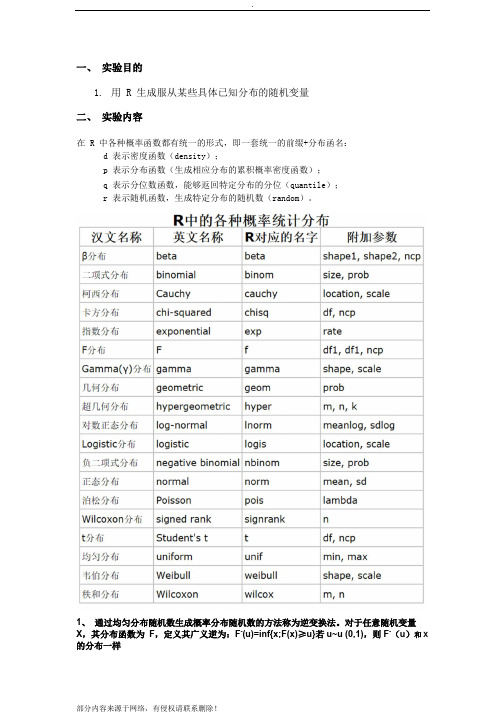
一、实验目的1.用 R 生成服从某些具体已知分布的随机变量二、实验内容在 R 中各种概率函数都有统一的形式,即一套统一的前缀+分布函名:d 表示密度函数(density);p 表示分布函数(生成相应分布的累积概率密度函数);q 表示分位数函数,能够返回特定分布的分位(quantile);r 表示随机函数,生成特定分布的随机数(random)。
1、通过均匀分布随机数生成概率分布随机数的方法称为逆变换法。
对于任意随机变量X,其分布函数为F,定义其广义逆为:F-(u)=inf{x;F(x)≥u}若u~u (0,1),则F-(u)和X 的分布一样Example 1 如果X~Exp(1)(服从参数为 1 的指数分布),F(x)=1-e-x。
若u=1-e-x并且u~u(0,1),则X=-logU~Exp(1)则可以解出x=-log(1-u)通过随机数生成产生的分布与本身的指数分布结果相一致R 代码如下:nsim = 10^4U = runif(nsim)X = -log(U)Y = rexp(nsim)X11(h=3.5)Xpar(mfrow=c(1,2),mar=c(2,2,2,2))hist(X,freq=F,main="Exp from Uniform",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)hist(Y,freq=F,main="Exp from R",ylab="",xlab="",ncl=150,col="grey",xlim=c(0,8))curve(dexp(x),add=T,col="sienna",lwd=2)2、某些随机变量可由指数分布生成。
报告R语言实验五..docx

实验五常见分布的相关计算、随机抽样与模拟【实验类型】验证性【实验学时】2 学时【实验目的】1、掌握常见分布的分布函数、密度函数(或分布列)及分位数的计算方法;2、掌握样本统计量的计算方法及所表达的意义;3、了解随机模拟的基本思想及其应用。
【实验内容】1、组合数与组合方案的生成、概率的计算,2、常见分布的分布函数、密度函数(或分布列)以及分位数的计算;3、随机数的生成与随机模拟(蒙特卡洛仿真) 。
【实验方法或步骤】第一部分、课件例题:1.#从1~5 个数中,随机取3个的全部组合combn(1:5,3) # 共10 种组合方案combn(1:5,3,FUN=mean) # 对每种组合方案求均值choose(5,3) # 从5 个数里面选3个的组合数目choose(50,3)factorial(10) # 计算10!3.#3. 从一副完全打乱的52张扑克中任取 4 张,计算下列事件的概率#(1) 抽取 4 张依次为红心A,方块A,黑桃A和梅花A的概率1/prod(49:52) #prod() 表示连乘积#(2) 抽取 4 张为红心A,方块A,黑桃A和梅花A的概率.1/choose(52,4)4.设在15 只同类型的零件中有2只是次品,一次任取3只,以X表示次品的只数,求X的分布律.x<-c(1,1,rep(0,13));x # 样本空间( 用1 表示次品, 0 为正品) X<-combn(x,3,FUN=sum) #从样本空间中任取 3 个元素的方案,并对每个方案求和,共455 个数(取值0,1,2 )p<-numeric(3) # 定义p 为数值型的 3 维向量,且初值为0for (i in 1:3)p[i]<-sum(X==i-1)/length(X) #sum(X==i-1) 表示对X 取值为i-1 的个数求和,X 的长度为455# 例5.3 :计算3σ 原则对应的概率x <- 1:3; p <- pnorm(x) - pnorm(-x); p# 例5.4 :令α=0.025 ,计算上α 分位点z α alpha <- 0.025; z <- qnorm(1-alpha); z6.#例5.5 :计算P{X≤160} ,其中X~U[150,200] 。
r语言编程实验报告总结

r语言编程实验报告总结
本次实验主要是对R语言编程的学习和掌握进行实践操作,通过实验了解R语言的基本语法和数据结构,掌握R语言的编程方法和数据分析技巧。
在实验中,我们学习了R语言的基础知识,如基本数据类型、变量、运算符、数据结构等。
同时,我们也学习了R语言的控制结构,如条件语句、循环语句等,这些控制结构可以帮助我们更好地控制程序的执行。
除此之外,我们还学习了R语言的函数和包的使用,在实验中我们使用了一些常用的包,如ggplot2包和dplyr包,这些包可以帮助我们更加方便地进行数据分析和绘图。
同时,我们也学习了如何自己编写函数,并且熟练掌握了函数的调用和参数传递。
通过实验,我们还学习了如何进行数据处理和数据分析,包括数据的读取和写入、数据的清洗和转换、数据的统计分析和可视化等等。
我们使用R语言对一些真实数据进行了处理和分析,这些数据包括房价、气温、人口等等。
在实验中,我们遇到了一些问题,如代码错误、数据异常等等,但是通过对问题的分析和解决,我们不断提升了自己的编程能力和数据分析技能。
综上所述,通过本次实验,我们深入了解了R语言的编程方法和数据分析技巧,掌握了一些常用的包和函数,并且在实践中熟悉了数据处理和分析的整个过程,这对我们今后的学习和工作都具有重要的
意义。
报告R语言实验五..docx

实验五常见分布的相关计算、随机抽样与模拟【实验类型】验证性【实验学时】2 学时【实验目的】1、掌握常见分布的分布函数、密度函数(或分布列)及分位数的计算方法;2、掌握样本统计量的计算方法及所表达的意义;3、了解随机模拟的基本思想及其应用。
【实验内容】1、组合数与组合方案的生成、概率的计算,2、常见分布的分布函数、密度函数(或分布列)以及分位数的计算;3、随机数的生成与随机模拟(蒙特卡洛仿真)。
【实验方法或步骤】第一部分、课件例题:1.#从1~5个数中,随机取3个的全部组合combn(1:5,3) #共10种组合方案combn(1:5,3,FUN=mean) #对每种组合方案求均值2.choose(5,3) #从5个数里面选3个的组合数目choose(50,3)factorial(10) #计算10!3.#3.从一副完全打乱的52张扑克中任取4张,计算下列事件的概率#(1)抽取4张依次为红心A,方块A,黑桃A和梅花A的概率1/prod(49:52) #prod()表示连乘积#(2)抽取4张为红心A,方块A,黑桃A和梅花A的概率.1/choose(52,4)4.设在15只同类型的零件中有2只是次品,一次任取3只,以X表示次品的只数,求X的分布律.x<-c(1,1,rep(0,13));x #样本空间(用1表示次品, 0为正品)X<-combn(x,3,FUN=sum) #从样本空间中任取3个元素的方案,并对每个方案求和,共455个数(取值0,1,2)p<-numeric(3) #定义p为数值型的3维向量,且初值为0for (i in 1:3)p[i]<-sum(X==i-1)/length(X) #sum(X==i-1)表示对X取值为i-1的个数求和,X的长度为455p5.# 例5.3 :计算3σ原则对应的概率x <- 1:3; p <- pnorm(x) - pnorm(-x); p# 例5.4 :令α=0.025,计算上α分位点z α .alpha <- 0.025; z <- qnorm(1-alpha); z6.#例5.5 :计算P{X≤160},其中X~U[150,200]。
R语言实验报告.

一、试验目的R是用于统计分析、绘图的语言和操作环境。
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具。
本次试验要求掌握了解R语言的各项功能和函数,能够通过完成试验内容对R语言有一定的了解,会运用软件对数据进行分析。
二、试验环境Windows系统,RGui(32-bit)三、试验内容模拟产生电商专业学生名单(学号区分),记录高数、英语、网站开发三科成绩,然后进行统计分析。
假设有的100 名学生,起始学号为210222001,各科成绩取整,高数成绩为均匀分布随机数,都在75分以上。
英语成绩为正态分布,平均成绩80,标准差为7。
网站开发成绩为正态分布,平均成绩83,标准差为18。
把正态分布中超过100分的成绩变成100分。
1 把上述信息组合成数据框,并写到文本文件中;2计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply 函数)3求总分最高的同学的学号4绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)5画星相图,解释其含义6画脸谱图,解释其含义,7画茎叶图、qq图四、试验实现(一)按要求随机生成学号,和对于的高数、英语、网站开发三科成绩。
A、生成学号B、生成高数成绩高数成绩要求:高数成绩为均匀分布随机数,都在75分以上均匀分布函数:runif(n,min=0,max=1)其中,n 为产生随机值个数(长度),min为最小值,max为最大值。
C、生成英语成绩英语成绩要求:正态分布,平均成绩80,标准差为7正态分布函数:rnorm(n, mean = 0, sd = 1)其中,n 为产生随机值个数(长度),mean 是平均数,sd 是标准差。
D、生成网站开发成绩网站开发成绩要求:网站开发成绩为正态分布,平均成绩83,标准差为18。
其中大于100的都记为100。
(二)把上述信息组合成数据框,并写到文本文件中; 计算各种指标:平均分,每个人的总分,最高分,最低分,(使用apply 函数)A、生成文本文件B、打开数据框C、在数据框中命名变量D、计算各种指标:平均分,每个人的总分,最高分,最低分平均分(x4):总分(x5):最低分(x6):最高分(x7):(三)将生成成绩写入文本文件中(四)求总分最高的同学的学号(五)绘各科成绩直方图、散点图、柱状图丶饼图丶箱尾图(要求指定颜色和缺口)直方图散点图柱状图饼图箱尾图(要求指定颜色和缺口)(六)画星相图,解释其含义(七)画脸谱图,解释其含义(八)画茎叶图(九)qq图五、试验总结这次试验是我第一次接触R语言,刚开始遇到了很多困难,对于R语言一窍不通,后来经过老师的悉心指导,以及自己积极的去查找资料,对R语言有了进一步的了解。
R语言实验报告范文

R语言实验报告范文实验报告:基于R语言的数据分析摘要:本实验基于R语言进行数据分析,主要从数据类型、数据预处理、数据可视化以及数据分析四个方面进行了详细的探索和实践。
实验结果表明,R语言作为一种强大的数据分析工具,在数据处理和可视化方面具有较高的效率和灵活性。
一、引言数据分析在现代科学研究和商业决策中扮演着重要角色。
随着大数据时代的到来,数据分析的方法和工具也得到了极大发展。
R语言作为一种开源的数据分析工具,被广泛应用于数据科学领域。
本实验旨在通过使用R语言进行数据分析,展示R语言在数据处理和可视化方面的应用能力。
二、材料与方法1.数据集:本实验使用了一个包含学生身高、体重、年龄和成绩的数据集。
2.R语言版本:R语言版本为3.6.1三、结果与讨论1.数据类型处理在数据分析中,需要对数据进行适当的处理和转换。
R语言提供了丰富的数据类型和操作函数。
在本实验中,我们使用了R语言中的函数将数据从字符型转换为数值型,并进行了缺失值处理。
同时,我们还进行了数据类型的检查和转换。
2.数据预处理数据预处理是数据分析中的重要一步。
在本实验中,我们使用R语言中的函数处理了异常值、重复值和离群值。
通过计算均值、中位数和四分位数,我们对数据进行了描述性统计,并进行了异常值和离群值的检测和处理。
3.数据可视化数据可视化是数据分析的重要手段之一、R语言提供了丰富的绘图函数和包,可以用于生成各种类型的图表。
在本实验中,我们使用了ggplot2包绘制了散点图、直方图和箱线图等图表。
这些图表直观地展示了数据的分布情况和特点。
4.数据分析数据分析是数据分析的核心环节。
在本实验中,我们使用R语言中的函数进行了相关性分析和回归分析。
通过计算相关系数和回归系数,我们探索了数据之间的关系,并对学生成绩进行了预测。
四、结论本实验通过使用R语言进行数据分析,展示了R语言在数据处理和可视化方面的强大能力。
通过将数据从字符型转换为数值型、处理异常值和离群值,我们获取了可靠的数据集。
r语言实验报告

r语言实验报告R语言实验报告引言R语言是一种广泛应用于数据分析和统计建模的开源编程语言,具有丰富的包和函数库,适用于各种数据处理和可视化任务。
本实验旨在探讨R语言在数据处理和可视化方面的应用,通过实际案例展示其强大的功能和灵活性。
数据导入与处理我们需要导入数据集,并进行初步的处理。
在R语言中,可以使用read.csv()函数导入csv格式的数据文件,然后通过head()函数查看数据的前几行,以了解数据结构和内容。
接下来,可以使用subset()函数筛选出需要的数据列,并使用na.omit()函数删除缺失值,确保数据的完整性和准确性。
数据可视化数据可视化是数据分析的重要环节,可以帮助我们更直观地理解数据的分布和关系。
在R语言中,可以使用ggplot2包来绘制各种类型的图表,如散点图、折线图和直方图等。
通过设置不同的参数和颜色,可以定制化图表的样式,使其更具有美感和可读性。
统计分析除了数据可视化,R语言还提供了丰富的统计分析函数,可以帮助我们进行各种统计推断和建模分析。
例如,可以使用lm()函数进行线性回归分析,通过summary()函数查看回归模型的拟合效果和显著性检验结果。
此外,还可以使用t.test()函数进行假设检验,判断样本均值之间是否存在显著差异。
结果解释与总结我们需要对分析结果进行解释和总结。
在解释结果时,应该清晰地说明分析方法和推断过程,避免歧义和误导。
在总结部分,可以简要概括分析的主要发现和结论,指出数据分析对问题的解决和决策的重要性和价值。
结论通过本实验,我们深入探讨了R语言在数据处理和可视化方面的应用,展示了其强大的功能和灵活性。
R语言不仅可以帮助我们高效地处理和分析数据,还可以帮助我们更好地理解数据的特征和规律。
希望本实验可以帮助读者更好地掌握R语言的应用技巧,提升数据分析和统计建模的能力。
《统计计算(R语言)》 随机模拟定积分实验报告一

《统计计算(R语言)》随机模拟定积分实验报告结论分析与心得体会:1、#重要抽样法模拟计算z1<-function(n){U<-runif(n)f<-function(x) exp(-x)g<-function(x) (2*(1-x))x<- 1-(sqrt(1-U))s=mean(f(x)/g(x))var<-1/n*var(f(x)/g(x))lis<-list(s,var)return(lis)}结果:#分层抽样法f1<-function(n,m){r1<-runif(n,min<-0,max<-0.5)r2<-runif(m,min<-0.5,max<-1)c<-1/2*mean(exp(-r1))+1/2*mean(exp(-r2))var<-var(exp(-r1))/(4*n)+var(exp(-r2))/(4*m) j<-list(c,var)return(j)}结果:#对立变量法d1<-function(n){f<-function(x) exp(-x)y<-function(x) exp(-(1-x))x<-runif(n)m<-sum(f(x))p<-sum(y(x))j<-(m/n+p/n)/2var<-1/4*(var(f(x))+var(y(x))+2*cov(f(x),y(x))) lis<-list(j,var)return(lis)}#控制变量法k2<-function(n){f<-function(x) exp(-x)r<-runif(n)X<-f(r)Y<-r-0.5b<-(-cov(X,Y))/var(Y)Z<-X+b*YI<-mean(Z)var<-(1-cor(X,Y)^2)*var(X) lst<-list(I,var)return(lst)}结果:#与精确值进行比较,以下是进行精确值计算f<-function(x){exp(-x)}integrate(f,0,1)重要抽样法模拟计算结果与精确值的误差:|0.6321206-0.632252|=0.0001314分层抽样法模拟计算结果与精确值的误差:|0.6321206-0.6112226|=0.020898对立变量法模拟计算结果与精确值的误差:|0.6321206-0.6245955|=0.0075251控制变量法模拟计算结果与精确值的误差:|0.6321206-0.6138306|=0.01829从上可以对比看出重要抽样法计算的结果误差最小,分层抽样法计算的结果最大。
R语言实验四

R语言编程技术实验报告
题目:数据的导入导出
院系:计算机科学与工程学院
班级:170408
姓名:刘馨雨
学号:20172693
【实验题目】
数据的导入导出。
【实验目的】
1.熟练掌握从一些包中读取数据。
2.熟练掌握csv文件的导入。
3.创建一个数据框,并导出为csv格式。
【实验内容与实现】
1.创建一个csv文件(内容自定),并用readtable函数导入该文件。
图1.1 vim命令,按shift+zz可保存退出。
图1.2 进入R语言环境
图1.3 读取文件
2.查看R语言自带的数据集airquality(纽约1973年5-9月每日空气质量)。
图2 截了前24行
3.列出airquality的前十列,并将这前十列保存到air中。
图3.1 列出前十列
图3.2 保存到air数据框中
图3.3 保存到air.csv中并读取4.任选三个列,查看airquality中列的对象类型。
图4 查看3、4、5行数据类型5.使用names查看airquality数据集中各列的名称
图5
6.将air这个数据框导出为csv格式文件。
(write.table (x, file ="", sep ="", s =TRUE, s =TRUE, quote =TRUE))
图6 导出为test.csv并查看当前目录文件
【实验心得】
1.第3题出现了三个错误。
2.第4题出现了两个错误。
3.第5题出错name改为names。
4.第6题出现的错误没太明白,准备上课询问老师。
r语言实验报告

r语言实验报告标题:R语言在数据分析中的应用及指导意义导语:R语言作为一种广泛应用于数据分析与统计建模的编程语言,在各个领域中发挥着重要的作用。
本文将对R语言在数据分析中的应用进行探讨,并总结出相关的指导意义,希望能够为数据分析初学者提供一定的参考和帮助。
一、R语言的基础概述R语言是一种开源的编程语言,具备灵活、高效、优雅的特点,被广泛应用于数据科学和统计学领域。
R语言拥有丰富的数据处理、数据可视化和数据分析库,能够满足不同层次的数据分析需求。
二、R语言在数据预处理中的应用1.数据清洗:R语言提供了丰富的数据清洗函数和技术,可以对数据中的缺失值、异常值和重复值进行处理,提高数据的质量。
2.数据转换:R语言能够通过函数和技术,对数据进行转换和重构,实现数据格式的统一和规整,为后续的分析提供基础。
三、R语言在数据分析中的应用1.统计分析:R语言提供了众多的统计分析函数和包,能够进行常见的统计分析,如描述性统计、假设检验、方差分析等。
2.数据建模:R语言拥有强大的建模功能,可以进行线性回归、逻辑回归、决策树、聚类等建模分析,为数据科学家提供了广泛的选择。
3.机器学习:R语言支持各种机器学习算法,如朴素贝叶斯、支持向量机、随机森林等,可以进行模式识别、预测和分类等任务。
四、R语言在数据可视化中的应用1.基础绘图:R语言提供了各类绘图函数,如散点图、柱状图、线图等,能够直观地展示数据的分布和趋势。
2.高级可视化:通过使用R语言的各种包,如ggplot2、plotly 等,可以制作专业、美观的可视化图表,提升数据分析的表达力。
3.交互式可视化:R语言可以与Shiny等工具结合,实现交互式可视化,使用户能够灵活地探索数据,在分析过程中进行实时调整和观察。
五、R语言在数据分析中的指导意义1.灵活性:R语言的灵活性使得分析人员能够根据需求进行自由创造和探索,满足不同场景下的分析需求。
2.社区支持:R语言拥有庞大的社区,用户可以在社区中获取丰富的资源、经验和技术支持,提高分析效率。
r语言上级实验一

r语言上级实验一理学院实验报告班级:学号:姓名:实验编号:01实验一:初识R软件一、实验目的与要求:1、了解R软件的安装、启动和退出。
2、掌握软件包的安装和载入。
3、掌握R软件帮助功能。
4、会使用R的集成开发环境Tinn-R或Rstudio。
5、掌握用R进行基本的代数运算。
6、掌握用R生成向量、矩阵、数据框和列表的方法。
7、掌握提取数据子集的方法。
二、实验内容:1.按N的不同取值,计算∑=-Nii12)12(1,并求其与log(N)+1.0的距离,其中N=100,500,1000,1500.#计算其值> N<-c(100,500,1000,1500)> for(k in 1:length(N))+ {+ s=0+ for(i in 1:N[k]){+ s=s+1/(2*i-1)^2+ }+ print(s)+ }[1] 1.231201[1] 1.233201[1] 1.233451[1] 1.233534#求距离> y<-abs(s-(log(N)+1.0))> y[1] 4.371636 5.981074 6.674221 7.0796872.联合命令rep()和seq()生成(1,2,3,4,5,2,3,4,5,6,3,4,5,6,7,4,5,6,7,8,5,6,7,8,9). #用rep生成> rep(1:5,5)+rep(0:4,rep(5,5))[1] 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 9 #用seq 生成> rep(seq(1,5),5)+rep(seq(0,4),rep(5,5))[1] 1 2 3 4 5 2 3 4 5 6 3 4 5 6 7 4 5 6 7 8 5 6 7 8 93. 利用命令matrix()将矩阵=4912011411435A 输入变量A ,并求A 的行列式、逆矩阵,T AA (转置命令为t())、A A T .#输入变量A> A<-matrix(c(35,14,1,4,11,0,12,9,4),nrow=3,ncol=3,byrow=T) > A [,1] [,2] [,3][1,] 35 14 1 [2,] 4 11 0 [3,] 12 9 4#计算A 值 > det(A) [1] 1220#计算A 逆> solve (A) %*%A[,1] [,2] [,3] [1,] 1.000000e+00 -5.551115e-17 0.000000e+00 [2,] -1.387779e-17 1.000000e+00 -1.734723e-18 [3,] -4.440892e-16 -4.440892e-16 1.000000e+00#计算AA T > A%*%t(A)[,1] [,2] [,3] [1,] 1422 294 550 [2,] 294 137 147 [3,] 550 147 241#计算A T A> t(A)%*%A[,1] [,2] [,3] [1,] 1385 642 83 [2,] 642 398 50[3,] 83 50 174. (1)利用命令data.frame()将下表数据读入变量sea,Season Salinity(盐度) Temperature winter 29.19 4 winter 27.37 6 spring24.997.3spring 28.79 8.2 spring 33.28 9.1 summer 32.69 18.1 summer31.9 17 summer NA 21 autumn 32.53 15.1 autumn32.53 13.8>Season<-c("winter","winter","spring","spring","spring","summer","summer ","summer","autu mn","autumn")> Salinity<-c(29.19,27.37,24.99,28.79,33.28,32.69,31.9,NA,32.53,32.53) > Temperature<-c(4,6,7.3,8.2,9.1,18.1,17,21,15.1,13.8) > sea<-data.frame(Season,Salinity,Temperature) > seaSeason Salinity Temperature 1 winter 29.19 4.0 2 winter 27.37 6.0 3 spring 24.99 7.3 4 spring 28.79 8.2 5 spring 33.28 9.1 6summer 32.69 18.1 7 summer 31.90 17.0 8 summer NA 21.0 9 autumn 32.53 15.1 10 autumn 32.53 13.8 > class(sea)[1] "data.frame"(2)将盐度的标准化变量加到这个数据框中;(标准化公式:ni s x x ,x 是样本均值,n s 是样本方差);#将标准化变量加入> sea<-data.frame(Season,Salinity,Temperature,scale(Salinity)) > seaSeason Salinity Temperature scale.Salinity.1 winter 29.19 4.0 -0.40437122 winter 27.37 6.0 -1.03160603 spring 24.99 7.3 -1.85183624 spring 28.79 8.2 -0.54222505 spring 33.28 9.1 1.00518406 summer 32.69 18.1 0.80184977 summer 31.90 17.0 0.52958848 summer NA 21.0 NA9 autumn 32.53 15.1 0.746708110 autumn 32.53 13.8 0.7467081(3)从数据框sea提取包含season和temperature变量的子数据框存入变量sea1,并计算温度的平均值和标准差;> sea1<-data.frame(sea$Season,sea$Temperature)> sea1Season Temperature1 winter 4.02 winter 6.03 spring 7.34 spring 8.25 spring 9.16 summer 18.17 summer 17.08 summer 21.09 autumn 15.110 autumn 13.8> mean(Temperature)[1] 11.96> sd(Temperature)[1] 5.782963(4) 从数据框sea提取包含season和salinity变量的子数据框存入变量sea2,并计算盐度的平均值和标准差(结果不能为NA);> sea2<-data.frame(sea$Season,sea$Salinity)> sea2sea.Season sea.Salinity1 winter 29.192 winter 27.373 spring 24.994 spring 28.795 spring 33.286 summer 32.697 summer 31.908 summer NA9 autumn 32.5310 autumn 32.53> mean(Salinity,na.rm=T)[1] 30.36333> sd(Salinity,na.rm=T)[1] 2.901625(5)利用命令list() 将上表读入变量sea.list, 再将盐度的标准化变量加入到这个列表中,并比较该方法与数据框方法的区别。
R语言实验报告—习题详解

R语言实验报告习题详解学院:班级:学号:姓名:导师:成绩:目录一、实验目的 (1)二、实验内容 (1)1.1问题叙述 (1)1.2问题求解 (1)1.2.1创建按列、行输入的4×5矩阵; (1)1.2.2编写程序求解 (1)1.3结果展示 (3)2.1问题叙述 (3)2.2问题求解 (4)2.2.1创建StudentData数据框 (4)2.2.2运行程序求解 (4)2.3结果展示 (4)3.1问题叙述 (4)3.2问题求解 (5)3.2.1运用hist函数绘制直方图; (5)3.2.2运用lines函数绘制密度估计曲线; (5)3.2.3运用plot函数绘制经验分布图; (5)3.2.4运用qqnorm函数绘制QQ图 (5)3.3结果展示 (5)4.1问题叙述 (8)4.2问题求解 (8)4.2.1创建x、y数据框 (8)4.2.2运用t.test函数求解 (8)4.3结果展示 (8)5.1问题叙述 (9)5.2问题求解 (9)5.2.1创建x、y数据框 (9)5.2.2运用t.test函数求解 (9)5.3结果展示 (9)6.1问题叙述 (9)6.2问题求解 (10)6.2.1创建x数据框 (10)6.2.2运用pnorm函数求解 (10)6.3结果展示 (10)三、实验总结 (10)一、实验目的R是用于统计分析、绘图的语言和操作环境。
R是属于GNU系统的一个自由、免费、源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具;本次试验要求掌握了解R语言的各项功能和函数,能够通过完成试验内容对R语言有一定的了解,会运用软件对数据进行分析;通过本实验加深对课本知识的理解以及熟练地运用R语言软件来解决一些复杂的问题。
二、实验内容1.1问题叙述将1,2,…,20构成两个4×5阶的矩阵,其中矩阵A是按列输入,矩阵B 是按行输入,并做如下运算.C=A+B;D=A*B;F是由A的前3行和前3列构成的矩阵;G是由矩阵B的各列构成的矩阵,但不含B的第3列.1.2问题求解1.2.1创建按列、行输入的4×5矩阵;1.2.2编写程序求解1.3结果展示2.1问题叙述已知有5名学生的数据,如下表所示.用数据框的形式读入数据.学生数据2.2问题求解2.2.1创建StudentData数据框2.2.2运行程序求解2.3结果展示3.1问题叙述某单位对100名女生测定血清总蛋白含量(g/L),数据如下:绘制上述数据的直方图、密度估计曲线、经验分布图和QQ图.3.2问题求解3.2.1运用hist函数绘制直方图;3.2.2运用lines函数绘制密度估计曲线;3.2.3运用plot函数绘制经验分布图;3.2.4运用qqnorm函数绘制QQ图3.3结果展示直方图密度估计曲线经验分布图the histogram of serumdataagef r e q u e n c y65707580850.000.020.040.060.080.1the histogram of serumdataagef r e q u e n c y65707580850.000.020.040.060.080.10QQ 图65707580850.00.20.40.60.81.0ecdf(serumdata)xF n (x)-2-10126570758085Normal Q-Q PlotTheoretical QuantilesS a m p l e Q u a n t i l e s4.1问题叙述甲、乙两种稻谷分别播种在10块试验田中,每块实验田甲乙稻谷各种一半.假设两稻谷产量X ,Y 均服从正态分布,且方差相等.收获后10块试验田的产量如下所示(单位:千克)求出两稻种产量的期望差12μμ- 的置信区间(0.05α= ).4.2问题求解4.2.1创建x 、y 数据框4.2.2运用t.test 函数求解4.3结果展示由以上程序运行得两稻种产量的期望差12μμ-的95%置信区间为 [ 7.53626, 20.06374].5.1问题叙述甲乙两组生产同种导线,现从甲组生产的导线中随机抽取4根,从乙组生产的导线中随机抽取5根,它们的电阻值(单位:Ω )分别为假设两组电阻值分别服从正态分布22212(,)(,)N N μσμσσ和, 未知.试求12μμ-的置信区间系数为0.95的区间估计.5.2问题求解5.2.1创建x 、y 数据框5.2.2运用t.test 函数求解5.3结果展示Two Sample t-testdata: x and yt = 1.198, df = 7, p-value = 0.2699alternative hypothesis: true difference in means is not equal to 095 percent confidence interval:-0.001996351 0.006096351sample estimates:mean of x mean of y0.14125 0.13920由以上程序运行甲乙两电阻的期望差12μμ-的95%置信区间为[-0.001996351, 0.006096351]. 6.1问题叙述已知某种灯泡寿命服从正态分布,在某星期所生产的该灯泡中随机抽取10只,测得其寿命(单位:小时)为1067 919 1196 785 1126 936 918 1156 920 948求这个星期生产出的灯泡能使用1000小时以上的概率.6.2问题求解6.2.1创建x数据框6.2.2运用pnorm函数求解6.3结果展示由以上程序运行得,x<=1000的概率为0.509,故x大于1000的概率为0.491.三、实验总结在R语言实验学习中,通过实验操作可使我们加深对理论知识的理解,学习和掌握R语言的基本方法,并能进一步熟悉和掌握R软件的操作方法,培养我们分析和解决实际问题的基本技能,提高我们的综合素质.。
r语言实验报告总结.doc

r语言实验报告总结.doc说明:本文是一个r语言实验报告的总结,共1000字。
主要内容包括实验目的和背景、实验设计和方法、实验结果和分析,以及实验结论和展望。
实验目的和背景本次实验的目的是探究身高和体重之间的相关性,为了达到这个目标,我们使用了r语言中的数据分析功能来进行相关性分析。
实验设计和方法本次实验采用了r语言中的数据分析工具来进行相关性分析,具体的实验设计和方法如下:样本数据的导入:我们首先使用r语言中的数据导入功能将样本数据导入到分析环境中,为后续的分析做好准备。
数据分析的可视化:为了更好地观察数据之间的相关性,我们使用r语言中的图形分析功能将样本数据制成散点图和箱线图等可视化图像。
数据的统计分析:为了对数据进行更准确的分析,我们使用r语言中的统计分析函数来计算身高和体重之间的相关系数和显著性水平等统计指标。
实验结果和分析通过对样本数据的分析,我们得出了以下结论:身高和体重之间存在着一定的相关性,相关系数为0.7,表明身高和体重之间具有较强的正相关关系。
身高和体重之间的差异较大,从箱线图的结果可以看出,身高和体重之间的差异较大,而且体重的分布范围也较为广泛。
身高和体重的分布形态较为正态,从散点图的结果可以看出,身高和体重的分布形态较为接近正态分布,符合正态分布的假设条件。
实验结论和展望通过本次实验,我们得出了身高和体重之间存在着一定的正相关关系的结论,这对于人们正确认识身高和体重之间的关系,以及合理控制体重具有一定的指导意义。
未来,我们可以考虑进一步拓展数据集,将年龄、性别、学历等因素纳入分析,以便更全面、深入地探究身高和体重之间的关系。
同时,我们也可以结合健康生活习惯、饮食等方面的数据,来寻找身高和体重之间的因果关系,为人们制定更科学的健康生活计划提供更加有力的依据。
R语言实验报告4

R语言实验报告4
R语言实验报告4
本次实验的内容是利用R语言在数据分析的过程中,对数据进行可视
化分析,帮助用户更好地理解数据的分布及其特征。
一、实验环境准备
首先,我们需要准备实验环境,包括Rstudio的安装及R语言的安装,以及对R语言相关的统计分析和可视化工具包的安装。
二、实验数据的准备
其次,我们需要准备实验的数据,这里我们选择了一个世界各国GDP
数据集,包含了全球各个国家2000-2024年的GDP数据。
三、数据可视化分析
实验的思路是将数据以不同的图形进行可视化展示,以便更加直观地
查看各个国家的GDP变化和特征。
1.箱线图。
在R语言中,我们可以使用boxplot(函数来绘制箱线图,下面我们来实现:
```
boxplot(GDP ~ Country, data = world_gdp, col = "blue")
```
从箱线图中我们可以看出,在2024年,不同国家的GDP水平有很大的不同,印度和俄罗斯的GDP水平最高,而秘鲁和尼加拉瓜的GDP水平则相对较低。
2.柱状图。
下面我们使用barplot(函数来绘制柱状图,来更加清晰地看出每个国家在2000-2024年GDP的变化情况:
```
barplot(t(GDP), beside=TRUE, col=rainbow(20))
```
从柱状图中可以看出,在2000-2024年,不同国家的GDP变化幅度有很大的不同,主要有三种情况:美国和日本的GDP增长幅度较大。
R语言实验报告—习题详解

R语言实验报告习题详解学院:班级:学号:姓名:导师:成绩:目录一、实验目的..................................................................二、实验内容..................................................................1.1问题叙述..............................................................1.2问题求解..........................................................................................................................................................................................................1.3结果展示..............................................................2.1问题叙述..............................................................2.2问题求解..........................................................................................................................................................................................................2.3结果展示..............................................................3.1问题叙述..............................................................3.2问题求解......................................................................................................................................................................................................................................................................................................................................................3.3结果展示..............................................................4.1问题叙述..............................................................4.2问题求解..........................................................................................................................................................................................................4.3结果展示..............................................................5.1问题叙述..............................................................5.2问题求解..........................................................................................................................................................................................................5.3结果展示..............................................................6.1问题叙述..............................................................6.2问题求解..........................................................................................................................................................................................................6.3结果展示..............................................................三、实验总结..................................................................一、实验目的R是用于统计分析、绘图的语言和操作环境。
R语言实验报告4

实验目的根据教科书上数据,作图,以及实现关于分布的假设检验,要求选择的数据除了服从正态分布外,还应选择一些其它类型的数据实验内容(一)根据教科书上数据,作图基本图形:直方图、条形图、点图和箱线图(参考书本例题mtcars)、饼图和扇形图(书本例题:国别数据)attach(mtcars)opar <- par(no.readonly=TRUE)par(mfrow=c(3,1))hist(wt)hist(mpg)hist(disp)par(opar)detach(mtcars)attach(mtcars)layout(matrix(c(1,1,2,3), 2, 2, byrow = TRUE))hist(wt)hist(mpg)hist(disp)detach(mtcars)attach(mtcars)plot(wt, mpg)abline(lm(mpg~wt))title("Regression of MPG on Weight")detach(mtcars)pdf("mygraph.pdf")attach(mtcars)plot(wt, mpg)abline(lm(mpg~wt))title("Regression of MPG on Weight")detach(mtcars)attach(mtcars)opar <- par(no.readonly=TRUE)par(mfrow=c(2,2))plot(wt,mpg, main="Scatterplot of wt vs. mpg") plot(wt,disp, main="Scatterplot of wt vs. disp") hist(wt, main="Histogram of wt")boxplot(wt, main="Boxplot of wt")par(opar)detach(mtcars)饼图和扇形图(书本例题:国别数据)par(mfrow=c(2,2))slices <- c(10, 12,4, 16, 8)lbls <- c("US", "UK", "Australia", "Germany", "France")pie(slices, labels = lbls,main="Simple Pie Chart")pct <- round(slices/sum(slices)*100)lbls <- paste(lbls, pct)lbls <- paste(lbls,"%",sep="")pie(slices,labels = lbls, col=rainbow(length(lbls)), main="Pie Chart with Percentages")library(plotrix)slices <- c(10, 12,4, 16, 8)lbls <- c("US", "UK", "Australia", "Germany", "France") fan.plot(slices, labels = lbls, main="Fan Plot")核密度图d <- density(mtcars$mpg) # returns the density dataplot(d) # plots the resultsd <- density(mtcars$mpg)plot(d, main="Kernel Density of Miles Per Gallon")polygon(d, col="red", border="blue")rug(mtcars$mpg, col="brown")(二)关于分布的假设检验(来自书本数据男女老少体重)> fit <- lm(weight ~ height, data=women)> summary(fit)Call:lm(formula = weight ~ height, data = women)Residuals:Min 1Q Median 3Q Max-1.7333 -1.1333 -0.3833 0.7417 3.1167Coefficients:Estimate Std. Error t value Pr(>|t|)(Intercept) -87.51667 5.93694 -14.74 1.71e-09 ***height 3.45000 0.09114 37.85 1.09e-14 ***---Signif. codes: 0 ‘***’0.001 ‘**’0.01 ‘*’0.05 ‘.’0.1 ‘’1Residual standard error: 1.525 on 13 degrees of freedomMultiple R-squared: 0.991, Adjusted R-squared: 0.9903F-statistic: 1433 on 1 and 13 DF, p-value: 1.091e-14> women$weight[1] 115 117 120 123 126 129 132 135 139 142 146 150 154 159 164> fitted(fit)1 2 3 4 5 6 7 8 112.5833 116.0333 119.4833 122.9333 126.3833 129.8333 133.2833 136.73339 10 11 12 13 14 15140.1833 143.6333 147.0833 150.5333 153.9833 157.4333 160.8833> residuals(fit)1 2 3 4 5 62.41666667 0.96666667 0.51666667 0.06666667 -0.38333333 -0.833333337 8 9 10 11 12 -1.28333333 -1.73333333 -1.18333333 -1.63333333 -1.08333333 -0.5333333313 14 150.01666667 1.56666667 3.11666667> plot(women$height,women$weight,+ main="Women Age 30-39",+ xlab="Height (in inches)",+ ylab="Weight (in pounds)")通过结果可知^y=-87.52+3.45x(^y为体重的估计量,x为身高)fit <- lm(weight ~ height, data=women)> par(mfrow=c(2,2))> plot(fit)> newfit <- lm(weight ~ height + I(height^2), data=women) > par(opar)> par(mfrow=c(2,2))> plot(newfit)线性模型的假设检验:由于global statp=0.0023251,因此不通过假设检验,从而我们考虑多项式线性模型:新的回归模型是^y=261.87818-7.35*x+0.083*x^2,且通过了ols回归模型所有的统计假设。
R语言判别分析实验报告

R语言判别分析实验报告判别分析是一种用于分类和预测的统计方法,广泛应用于各个领域,包括社会科学、医学、工程等。
本实验报告旨在介绍如何使用R语言进行判别分析,并分析实验结果。
一、实验目的本实验的目的是使用R语言进行判别分析,通过给定的数据集建立判别函数,并使用该函数对新样本进行分类预测。
二、实验方法本实验使用R语言中的“discrim”函数进行判别分析。
首先,读取实验所需的数据集,并进行数据预处理。
然后,划分训练集和测试集数据。
接下来,使用训练集数据建立判别函数,并使用该函数对测试集数据进行分类预测。
最后,评估分类的准确性。
三、实验步骤1. 数据读取和预处理:使用R语言中的“read.csv”函数读取数据集文件,查看数据的信息和结构,包括变量的名称、类型和缺失值情况。
对于有缺失值的数据,可以使用“na.omit”函数或者其他方法进行处理。
2. 划分训练集和测试集数据:将数据集分为训练集和测试集两部分,一般采用70%的数据作为训练集,30%的数据作为测试集。
可以使用“sample”函数进行随机抽样,将数据集按照指定的比例划分。
3. 建立判别函数:使用“discrim”函数建立判别函数。
该函数需要指定判别变量和预测变量,并可以选择判别方法和先验概率。
一般采用线性、二次和多项式判别方法。
可以使用“summary”函数查看判别分析模型的统计信息和结果。
4. 分类预测:使用建立好的判别函数对测试集数据进行分类预测。
可以使用“predict”函数,指定判别函数和测试集数据,得到预测结果。
5.分类准确性评估:计算分类预测的准确性,可以使用混淆矩阵、ROC曲线和AUC值等指标进行评估。
四、实验结果根据给定的判别变量和预测变量,我们建立了判别函数,并使用该函数对测试集数据进行分类预测。
最后,我们计算了分类预测的准确性指标。
五、实验结论判别分析是一种有效的分类和预测方法,可以应用于各个领域。
本实验使用R语言进行判别分析,并通过分类预测的准确性评估,验证了判别函数的有效性。
r语言实验报告(一)

r语言实验报告(一)R语言实验报告介绍•R语言是一种用于数据分析和统计建模的开源编程语言。
•本报告将介绍如何使用R语言进行实验分析及报告撰写。
实验设计•确定实验目的和假设。
•设计实验方案,包括样本选择、实验流程和数据收集方式。
数据预处理•导入实验数据,并进行数据清洗和整理。
•检查数据质量,包括缺失值处理、异常值处理等。
数据分析•运用统计学方法进行数据分析,包括描述统计、推断统计和回归分析等。
•可视化数据,通过绘制图表来展示分析结果。
•对实验结果进行解释,包括与初期假设的关联、统计显著性等。
•讨论实验结果的启示和限制。
结论•总结实验结果及其对研究问题的回答。
•提出未来研究的建议,探讨实验的局限性。
参考文献•在报告结尾列出参考文献,引用使用合适的引用格式。
通过以上步骤,可以使用R语言完成一份实验报告。
R语言具备丰富的数据处理和统计分析库,并支持生成高质量的图表,能够有效地帮助实验者进行数据分析和报告撰写。
注意在整个过程中保证数据的准确性和可靠性,以确保实验结果的可信度。
R语言实验报告介绍R语言是一种用于数据分析和统计建模的开源编程语言。
它的强大功能和丰富的数据处理、统计分析库使得它成为科学研究和实验分析的重要工具。
本报告将介绍如何使用R语言进行实验分析及报告撰写的基本步骤和规则。
•确定实验目的和假设。
在开始实验前,明确研究问题是什么,想要验证的假设是什么。
•设计实验方案。
根据实验目的和假设,选择合适的实验变量和控制变量,制定实验流程和数据收集方式。
数据预处理•导入实验数据。
在R语言中,可以使用read.table()或read.csv()等函数将数据导入到工作空间中。
•进行数据清洗和整理。
检查数据中是否存在缺失值、异常值等问题,并进行相应处理,如删除或填补缺失值,修正异常值等。
•数据质量检查。
使用summary()和str()等函数对数据进行初步的统计描述和结构检查,确保数据的正确性和一致性。
数据分析•描述统计。