粒子群算法(C++版)
粒子群算法以及应用原理

粒子群算法介绍优化问题是工业设计中经常遇到的问题,许多问题最后都可以归结为优化问题. 为了解决各种各样的优化问题,人们提出了许多优化算法,比较著名的有爬山法、遗传算法等.优化问题有两个主要问题:一是要求寻找全局最小点,二是要求有较高的收敛速度. 爬山法精度较高,但是易于陷入局部极小. 遗传算法属于进化算法( Evolutionary Algorithms) 的一种,它通过模仿自然界的选择与遗传的机理来寻找最优解. 遗传算法有三个基本算子:选择、交叉和变异. 但是遗传算法的编程实现比较复杂,首先需要对问题进行编码,找到最优解之后还需要对问题进行解码,另外三个算子的实现也有许多参数,如交叉率和变异率,并且这些参数的选择严重影响解的品质,而目前这些参数的选择大部分是依靠经验.1995 年Eberhart 博士和kennedy 博士提出了一种新的算法;粒子群优化(Partical Swarm Optimization -PSO) 算法 . 这种算法以其实现容易、精度高、收敛快等优点引起了学术界的重视,并且在解决实际问题中展示了其优越性.粒子群优化(Partical Swarm Optimization - PSO) 算法是近年来发展起来的一种新的进化算法( Evolu2tionary Algorithm - EA) .PSO 算法属于进化算法的一种,和遗传算法相似,它也是从随机解出发,通过迭代寻找最优解,它也是通过适应度来评价解的品质. 但是它比遗传算法规则更为简单,它没有遗传算法的“交叉”(Crossover) 和“变异”(Mutation) 操作. 它通过追随当前搜索到的最优值来寻找全局最优 .粒子群算法1. 引言粒子群优化算法(PSO)是一种进化计算技术(evolutionary computation),有Eberhart博士和kennedy博士发明。
源于对鸟群捕食的行为研究PSO同遗传算法类似,是一种基于叠代的优化工具。
粒子群算法

粒子群算法原理及简单案例[ python ]介绍粒子群算法(Particle swarm optimization,PSO)是模拟群体智能所建立起来的一种优化算法,主要用于解决最优化问题(optimization problems)。
1995年由 Eberhart和Kennedy 提出,是基于对鸟群觅食行为的研究和模拟而来的。
假设一群鸟在觅食,在觅食范围内,只在一个地方有食物,所有鸟儿都看不到食物(即不知道食物的具体位置。
当然不知道了,知道了就不用觅食了),但是能闻到食物的味道(即能知道食物距离自己是远是近。
鸟的嗅觉是很灵敏的)。
假设鸟与鸟之间能共享信息(即互相知道每个鸟离食物多远。
这个是人工假定,实际上鸟们肯定不会也不愿意),那么最好的策略就是结合自己离食物最近的位置和鸟群中其他鸟距离食物最近的位置这2个因素综合考虑找到最好的搜索位置。
粒子群算法与《遗传算法》等进化算法有很多相似之处。
也需要初始化种群,计算适应度值,通过进化进行迭代等。
但是与遗传算法不同,它没有交叉,变异等进化操作。
与遗传算法比较,PSO的优势在于很容易编码,需要调整的参数也很少。
一、基本概念与遗传算法类似,PSO也有几个核心概念。
粒子(particle):一只鸟。
类似于遗传算法中的个体。
1.种群(population):一群鸟。
类似于遗传算法中的种群。
2.位置(position):一个粒子(鸟)当前所在的位置。
3.经验(best):一个粒子(鸟)自身曾经离食物最近的位置。
4.速度(velocity ):一个粒子(鸟)飞行的速度。
5.适应度(fitness):一个粒子(鸟)距离食物的远近。
与遗传算法中的适应度类似。
二、粒子群算法的过程可以看出,粒子群算法的过程比遗传算法还要简单。
1)根据问题需要,随机生成粒子,粒子的数量可自行控制。
2)将粒子组成一个种群。
这前2个过程一般合并在一起。
3)计算粒子适应度值。
4)更新种群中每个粒子的位置和速度。
粒子群算法求解最小值

粒子群算法求解最小值
(实用版)
目录
一、粒子群算法概述
二、粒子群算法求解最小值的原理
三、粒子群算法在 MATLAB 中的实现
四、粒子群算法求解最小值的应用实例
五、总结
正文
一、粒子群算法概述
粒子群算法(Particle Swarm Optimization, PSO)是一种基于群体智能的优化算法,于 1995 年由美国社会心理学家 James Kennedy 和电气工程师 Russell Eberhart 共同提出。
该算法的提出是受对鸟类群体行为进行建模与仿真的研究结果的启发。
粒子群优化算法通过个体间的协作与竞争,实现复杂空间最优解的搜索。
将群体中的个体视为 d 维空间中的粒子,该粒子以一定的速度在解空间运动,并向自身历史最优解和全局最优解靠拢。
二、粒子群算法求解最小值的原理
粒子群算法求解最小值主要通过以下步骤实现:
1.初始化粒子群:在解空间中随机分布一定数量的粒子,每个粒子包含四个变量(x, y, z, w),表示粒子在解空间中的位置。
2.评估适应度:根据粒子位置计算目标函数值,得到每个粒子的适应度。
3.更新个体最优解和全局最优解:比较当前粒子的适应度与其历史最
优解的适应度,如果当前适应度更优,则更新个体最优解。
同时,比较全局最优解与当前粒子的适应度,如果当前适应度更优,则更新全局最优解。
4.更新粒子速度和位置:根据个体最优解、全局最优解和当前位置,计算每个粒子的新速度和新位置。
5.检查停止条件:如果达到预设的最大迭代次数或全局最优解的适应度变化小于设定阈值,则停止迭代。
6.返回全局最优解:输出全局最优解及其对应的最小值。
用c语言或matlab语言求解墨西哥草帽函数最小值的粒子群算法程序

用c语言或matlab语言求解墨西哥草帽函数最小值的粒子群算法程序以下是一种用C语言实现的基本粒子群算法程序,用于求解墨西哥草帽函数的最小值。
#include <stdio.h>#include <stdlib.h>#include <math.h>#define SWARM_SIZE 50 // 粒子群规模#define MAX_ITERATION 1000 // 最大迭代次数#define DIMENSION 2 // 问题维度#define INERTIA_WEIGHT 0.7 // 惯性权重#define COGNITIVE_WEIGHT 1.4 // 认知权重#define SOCIAL_WEIGHT 1.4 // 社会权重#define LOWER_BOUND -10.0 // 自变量下界#define UPPER_BOUND 10.0 // 自变量上界void evaluateFitness(double* positions, double* fitness);double mexicanHatFunction(double* x);double randDouble(double min, double max);int randInt(int min, int max);int maindouble swarm[SWARM_SIZE][DIMENSION]; // 粒子群位置double velocity[SWARM_SIZE][DIMENSION]; // 粒子群速度double bestPosition[DIMENSION]; // 全局最优位置double bestFitness = __DBL_MAX__; // 全局最优适应度double fitness[SWARM_SIZE]; // 粒子适应度//初始化粒子群for (int i = 0; i < SWARM_SIZE; i++)for (int j = 0; j < DIMENSION; j++)swarm[i][j] = randDouble(LOWER_BOUND, UPPER_BOUND);velocity[i][j] = 0.0;}evaluateFitness(swarm[i], &fitness[i]);if (fitness[i] < bestFitness)bestFitness = fitness[i];for (int k = 0; k < DIMENSION; k++)bestPosition[k] = swarm[i][k];}}//迭代求解for (int iter = 0; iter < MAX_ITERATION; iter++)for (int i = 0; i < SWARM_SIZE; i++)for (int j = 0; j < DIMENSION; j++)double r1 = randDouble(0.0, 1.0);double r2 = randDouble(0.0, 1.0);velocity[i][j] = INERTIA_WEIGHT * velocity[i][j] + COGNITIVE_WEIGHT * r1 * (bestPosition[j] - swarm[i][j]) + SOCIAL_WEIGHT * r2 * (bestPosition[j] - swarm[i][j]); swarm[i][j] += velocity[i][j];if (swarm[i][j] < LOWER_BOUND)swarm[i][j] = LOWER_BOUND;else if (swarm[i][j] > UPPER_BOUND)swarm[i][j] = UPPER_BOUND;}evaluateFitness(swarm[i], &fitness[i]);if (fitness[i] < bestFitness)bestFitness = fitness[i];for (int k = 0; k < DIMENSION; k++)bestPosition[k] = swarm[i][k];}}}printf("Best position: ");for (int i = 0; i < DIMENSION; i++)printf("%.4f ", bestPosition[i]);printf("\n");printf("Best fitness: %f\n", bestFitness);return 0;void evaluateFitness(double* positions, double* fitness)*fitness = mexicanHatFunction(positions);double mexicanHatFunction(double* x)double result = 0.0;result = -(pow(x[0], 2) + pow(x[1], 2)) + 2 * exp(-(pow(x[0], 2) + pow(x[1], 2)) / 2);return result;double randDouble(double min, double max)return min + ((double)rand( / RAND_MAX) * (max - min);int randInt(int min, int max)return min + rand( % (max - min + 1);这个程序使用经典的粒子群算法来求解墨西哥草帽函数的最小值。
粒子群算法介绍

1.介绍:粒子群算法(Particle Swarm Optimization, PSO)最早是由Eberhart 和Kennedy于1995年提出,它的基本概念源于对鸟群觅食行为的研究。
设想这样一个场景:一群鸟在随机搜寻食物,在这个区域里只有一块食物,所有的鸟都不知道食物在哪里,但是它们知道当前的位置离食物还有多远。
那么找到食物的最优策略是什么呢?最简单有效的就是搜寻目前离食物最近的鸟的周围区域。
经过实践证明:全局版本的粒子群算法收敛速度快,但是容易陷入局部最优。
局部版本的粒子群算法收敛速度慢,但是很难陷入局部最优。
现在的粒子群算法大都在收敛速度与摆脱局部最优这两个方面下功夫。
其实这两个方面是矛盾的。
看如何更好的折中了。
粒子群算法主要分为4个大的分支:(1)标准粒子群算法的变形在这个分支中,主要是对标准粒子群算法的惯性因子、收敛因子(约束因子)、“认知”部分的c1,“社会”部分的c2进行变化与调节,希望获得好的效果。
惯性因子的原始版本是保持不变的,后来有人提出随着算法迭代的进行,惯性因子需要逐渐减小的思想。
算法开始阶段,大的惯性因子可以是算法不容易陷入局部最优,到算法的后期,小的惯性因子可以使收敛速度加快,使收敛更加平稳,不至于出现振荡现象。
经过本人测试,动态的减小惯性因子w,的确可以使算法更加稳定,效果比较好。
但是递减惯性因子采用什么样的方法呢?人们首先想到的是线型递减,这种策略的确很好,但是是不是最优的呢?于是有人对递减的策略作了研究,研究结果指出:线型函数的递减优于凸函数的递减策略,但是凹函数的递减策略又优于线型的递减,经过本人测试,实验结果基本符合这个结论,但是效果不是很明显。
对于收敛因子,经过证明如果收敛因子取0.729,可以确保算法的收敛,但是不能保证算法收敛到全局最优,经过本人测试,取收敛因子为0.729效果较好。
对于社会与认知的系数c2,c1也有人提出:c1先大后小,而c2先小后大的思想,因为在算法运行初期,每个鸟要有大的自己的认知部分而又比较小的社会部分,这个与我们自己一群人找东西的情形比较接近,因为在我们找东西的初期,我们基本依靠自己的知识取寻找,而后来,我们积累的经验越来越丰富,于是大家开始逐渐达成共识(社会知识),这样我们就开始依靠社会知识来寻找东西了。
群体智能与优化算法

群体智能与优化算法群体智能(Swarm Intelligence)是一种模拟自然界群体行为的计算方法,借鉴了群体动物或昆虫在协作中展现出来的智能。
在群体智能中,个体之间相互通信、相互协作,通过简单的规则和局部信息交流来实现整体上的智能行为。
而优化算法则是一类用于解决最优化问题的数学方法,能够在大量搜索空间中找到最优解。
在现代计算领域,群体智能和优化算法常常结合使用,通过模拟自然界群体行为,寻找最佳解决方案。
接下来将分析几种典型的群体智能优化算法。
1. 蚁群算法(Ant Colony Optimization):蚁群算法源于对蚂蚁寻找食物路径行为的模拟。
蚁群算法通过模拟蚁群在环境中的寻找和选择过程,来寻找最优解。
算法中蚂蚁在搜索过程中会释放信息素,其他蚂蚁则根据信息素浓度选择路径,最终形成一条最佳路径。
2. 粒子群算法(Particle Swarm Optimization):粒子群算法源于对鸟群觅食过程的模拟。
在算法中,每个“粒子”代表一个潜在的解,粒子根据自身经验和周围最优解的经验进行位置调整,最终寻找最优解。
3. 遗传算法(Genetic Algorithm):遗传算法源于对生物进化过程的模拟。
通过模拟自然选择、交叉和变异等操作,来搜索最优解。
遗传算法在优化问题中有着广泛的应用,能够在复杂的搜索空间中找到较好的解决方案。
4. 蜂群算法(Artificial Bee Colony Algorithm):蜂群算法源于对蜜蜂群食物搜寻行为的模拟。
在算法中,蜜蜂根据花粉的量和距离选择食物来源,通过不断地试探和挑选来找到最佳解。
总体来说,群体智能与优化算法的结合,提供了一种高效且鲁棒性强的求解方法,特别适用于在大规模、高维度的优化问题中。
通过模拟生物群体的智能行为,这类算法能够在短时间内找到全局最优解或者较好的近似解,应用领域覆盖机器学习、数据挖掘、智能优化等多个领域。
群体智能与优化算法的不断发展,将进一步推动计算领域的发展,为解决实际问题提供更加有效的方法和技术。
粒子群算法粒子群算法简介
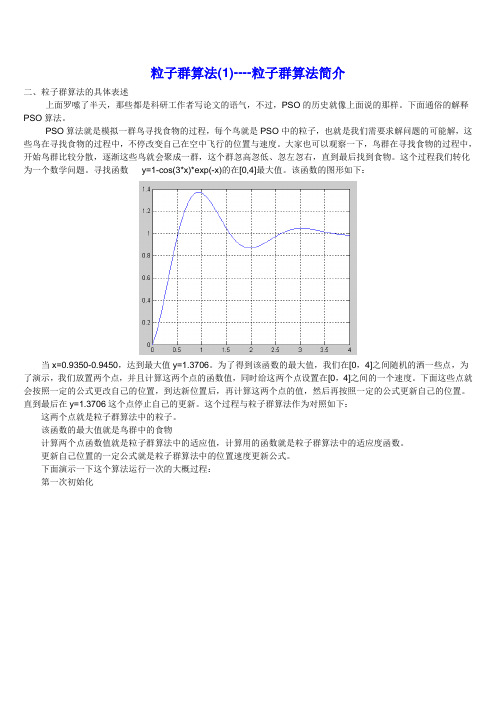
粒子群算法(1)----粒子群算法简介二、粒子群算法的具体表述上面罗嗦了半天,那些都是科研工作者写论文的语气,不过,PSO的历史就像上面说的那样。
下面通俗的解释PSO算法。
PSO算法就是模拟一群鸟寻找食物的过程,每个鸟就是PSO中的粒子,也就是我们需要求解问题的可能解,这些鸟在寻找食物的过程中,不停改变自己在空中飞行的位置与速度。
大家也可以观察一下,鸟群在寻找食物的过程中,开始鸟群比较分散,逐渐这些鸟就会聚成一群,这个群忽高忽低、忽左忽右,直到最后找到食物。
这个过程我们转化为一个数学问题。
寻找函数y=1-cos(3*x)*exp(-x)的在[0,4]最大值。
该函数的图形如下:当x=0.9350-0.9450,达到最大值y=1.3706。
为了得到该函数的最大值,我们在[0,4]之间随机的洒一些点,为了演示,我们放置两个点,并且计算这两个点的函数值,同时给这两个点设置在[0,4]之间的一个速度。
下面这些点就会按照一定的公式更改自己的位置,到达新位置后,再计算这两个点的值,然后再按照一定的公式更新自己的位置。
直到最后在y=1.3706这个点停止自己的更新。
这个过程与粒子群算法作为对照如下:这两个点就是粒子群算法中的粒子。
该函数的最大值就是鸟群中的食物计算两个点函数值就是粒子群算法中的适应值,计算用的函数就是粒子群算法中的适应度函数。
更新自己位置的一定公式就是粒子群算法中的位置速度更新公式。
下面演示一下这个算法运行一次的大概过程:第一次初始化第一次更新位置第二次更新位置第21次更新最后的结果(30次迭代)最后所有的点都集中在最大值的地方。
粒子群算法(2)----标准的粒子群算法在上一节的叙述中,唯一没有给大家介绍的就是函数的这些随机的点(粒子)是如何运动的,只是说按照一定的公式更新。
这个公式就是粒子群算法中的位置速度更新公式。
下面就介绍这个公式是什么。
在上一节中我们求取函数y=1-cos(3*x)*exp(-x)的在[0,4]最大值。
多目标最优化的粒子群算法

多目标最优化的粒子群算法多目标最优化问题是指在一个问题中同时优化多个目标函数,这些目标函数通常是相互冲突的,无法通过改变一个目标而不影响其他目标。
粒子群优化算法(Particle Swarm Optimization, PSO)是一种基于群体智能的优化算法,它受到鸟群觅食行为的启发,通过模拟鸟群中的个体在解空间中的和信息交流来寻找问题的最优解。
在多目标最优化问题中,粒子群优化算法也可以被扩展为多目标优化版本,即多目标粒子群优化算法(Multi-Objective Particle Swarm Optimization, MOPSO)。
多目标粒子群优化算法的核心思想是利用非支配排序将种群中的个体划分为多个不同的前沿(Pareto Front),每个前沿上的解都是最优解的候选。
根据个体之间的支配关系和拥挤度,确定前沿上的个体,并通过粒子群算法进行和优化。
为了保持种群的多样性,采用了一个外部存档来存储过去迭代中的非支配解,以避免陷入局部最优。
多目标粒子群优化算法的步骤如下:1.初始化种群:设定种群规模、粒子的初始位置和速度,以及其他算法参数。
2.非支配排序:根据个体之间的支配关系对种群中的解进行排序。
3.拥挤度计算:计算种群中个体的拥挤度,通过衡量个体周围解的密度来保持前沿上的均匀分布。
4.外部存档更新:根据非支配排序和拥挤度计算结果,更新外部存档中的非支配解。
5.速度和位置更新:根据粒子群算法的速度和位置更新规则,更新每个粒子的速度和位置。
6.达到停止条件:判断是否满足停止条件,如达到最大迭代次数或找到满意的近似解。
7.重复步骤2至6,直到满足停止条件。
多目标粒子群优化算法相比单目标版本有以下几个特点:1.非支配排序:非支配排序用于划分种群中的解为多个前沿。
支配关系的判断通常使用帕累托支配方法。
2.拥挤度计算:拥挤度计算用于保持前沿上的均匀分布,避免解集中在其中一区域。
3.外部存档更新:外部存档用于存储过去迭代中的非支配解,保证多样性。
c语言实现的粒子群算法代码及解释

//粒子群PSO算法#include<stdio.h>#include<math.h>#include<time.h>#include<stdlib.h>#define PI 3.141592653589 /* */#define P_num 200 //粒子数目#define dim 50#define low -100 //搜索域范围#define high 100#define iter_num 1000#define V_max 20 //速度范围#define c1 2#define c2 2#define w 0.5#define alp 1double particle[P_num][dim]; //个体集合double particle_loc_best[P_num][dim]; //每个个体局部最优向量double particle_loc_fit[P_num]; //个体的局部最优适应度,有局部最优向量计算而来double particle_glo_best[dim]; //全局最优向量double gfit; //全局最优适应度,有全局最优向量计算而来double particle_v[P_num][dim]; //记录每个个体的当前代速度向量double particle_fit[P_num]; //记录每个粒子的当前代适应度double Sphere(double a[]){int i;double sum=0.0;for(i=0; i<dim; i++){sum+=a[i]*a[i];}return sum;}double Rosenbrock(double a[]){int i;double sum=0.0;for(i=0;i<dim-1; i++){sum+= 100*(a[i+1]-a[i]*a[i])*(a[i+1]-a[i]*a[i])+(a[i]-1)*(a[i]-1);return sum;}double Rastrigin(double a[]){int i;double sum=0.0;for(i=0;i<dim;i++){sum+=a[i]*a[i]-10.0*cos(2*PI*a[i])+10.0;}return sum;}double fitness(double a[]) //适应度函数{return Rastrigin(a);}void initial(){int i,j;for(i=0; i<P_num; i++) //随即生成粒子{for(j=0; j<dim; j++){particle[i][j] = low+(high-low)*1.0*rand()/RAND_MAX; //初始化群体particle_loc_best[i][j] = particle[i][j]; //将当前最优结果写入局部最优集合particle_v[i][j] = -V_max+2*V_max*1.0*rand()/RAND_MAX; //速度}}for(i=0; i<P_num; i++) //计算每个粒子的适应度{particle_fit[i] = fitness(particle[i]);particle_loc_fit[i] = particle_fit[i];}gfit = particle_loc_fit[0]; //找出全局最优j=0;for(i=1; i<P_num; i++){if(particle_loc_fit[i]<gfit){gfit = particle_loc_fit[i];j = i;}for(i=0; i<dim; i++) //更新全局最优向量{particle_glo_best[i] = particle_loc_best[j][i];}}void renew_particle(){int i,j;for(i=0; i<P_num; i++) //更新个体位置生成位置{for(j=0; j<dim; j++){particle[i][j] += alp*particle_v[i][j];if(particle[i][j] > high){parti cle[i][j] = high;}if(particle[i][j] < low){particle[i][j] = low;}}}}void renew_var(){int i, j;for(i=0; i<P_num; i++) //计算每个粒子的适应度{particle_fit[i] = fitness(particle[i]);if(particle_fit[i] < particle_loc_fit[i]) //更新个体局部最优值{particle_loc_fit[i] = particle_fit[i];for(j=0; j<dim; j++) // 更新局部最优向量{particle_loc_best[i][j] = particle[i][j];}}}for(i=0,j=-1; i<P_num; i++) //更新全局变量{if(particle_loc_fit[i]<gfit){gfit = particle_loc_fit[i];j = i;}}if(j != -1){for(i=0; i<dim; i++) //更新全局最优向量{particle_glo_best[i] = particle_loc_best[j][i];}}for(i=0; i<P_num; i++) //更新个体速度{for(j=0; j<dim; j++){particle_v[i][j]=w*particle_v[i][j]+c1*1.0*rand()/RAND_MAX*(particle_loc_best[i][j]-particle[i][j])+c2*1.0*rand()/RAND_MAX*(particle_glo_best[j]-particle[i][j]);if(particle_v[i][j] > V_max){particle_v[i][j] = V_max;}if(particle_v[i][j] < -V_max){particle_v[i][j] = -V_max;}}}}int main(){freopen("result.txt","a+",stdout);int i=0;srand((unsigned)time(NULL));initial();while(i < iter_num){renew_particle();renew_var();i++;}printf("粒子个数:%d\n",P_num);printf("维度为:%d\n",dim);printf("最优值为%.10lf\n", gfit);return 0; }。
粒子群算法在武器装备保障资源优化中的应用

配置 ,对 提 高装备 战 斗 力有重要 的军 事价值 。
关键 词 : 资源约 束项 目调 度 问题 ;粒 子群优 化 算法 ; 资源优 化 中图 分类 号:T 3 16 O2 4 文 献标 识码 :A P 0 .: 2
Ap lc to fPSO n W e p u p e a e a d Re o r e Op i i a i n p i ai n o i a onEq i m ntS f gu r s u c tm z to
a t ii s s q e c t e a i n c n ta n ,t e s l t n s a e o c i t e u n e wi r l t o s r i t h o u i p c f RCP P a d t e r p i ta e y a d t e c l u a i n o v e h o o S n h e a r sr t g n h a c l to f
Ke wod : C S R s uc— n t ie rjc S h d l gPo lm) P O ( at l S r Opi zt n ; eo re y r s R P P( eo reCo sr n dP oe t c e ui rbe ; S P r ce wam t a n i miai ) R suc o
A src: o s l ywep ne up n ae u r eo repoet pi zt n p ril s r o t z t n( S b t t T i i a o q imetsfg adrsuc rjc t ai , at e wam pi ai P O) a mp f o mi o c mi o ag r h wa h sn t ov h eo rec n t ie rjc c e uig p o lm ( C S ) T e d tr n t n f loi m s c oe o sle te rsuc ・o s an d poetsh d l rbe t r n R P P . h eemiai so o
粒子群算法求解最小值

粒子群算法求解最小值摘要:I.粒子群算法简介A.粒子群算法的发展历史B.粒子群算法的原理II.粒子群算法求解最小值A.求解最小值的问题描述B.粒子群算法的求解流程C.粒子群算法的参数设置D.粒子群算法求解最小值的实例III.粒子群算法的优点与局限性A.优点1.全局搜索能力2.快速收敛3.适用于多种问题类型B.局限性1.算法复杂度较高2.可能会陷入局部最优解正文:粒子群算法(Particle Swarm Optimization, PSO)是一种启发式全局优化算法,由美国社会心理学家James Kennedy 和电气工程师RussellEberhart 于1995 年提出。
该算法受到对鸟类群体行为进行建模与仿真的研究结果的启发,通过模拟鸟群觅食行为,实现对复杂问题最优解的搜索。
粒子群算法已经在多个领域得到广泛应用,如信号处理、机器学习、工程设计等。
在求解最小值问题方面,粒子群算法具有较好的性能。
问题描述如下:给定一个目标函数f(x),要求在搜索空间中找到一个最小值xmin。
其中,x 通常是一个n 维向量,表示问题的各个变量。
粒子群算法求解最小值的流程如下:1.初始化粒子群:随机生成一组粒子,每个粒子包含一个当前位置xi 和一个速度vi。
同时,初始化个体最优解pbest 和全局最优解gbest。
2.评估目标函数:计算每个粒子xi 对应的目标函数值f(xi)。
3.更新个体最优解:对于每个粒子xi,如果f(xi) < pbest[i],则更新pbest[i] = f(xi)。
4.更新全局最优解:如果f(xi) < gbest,则更新gbest = f(xi)。
5.更新粒子的速度和位置:根据以下公式更新粒子的速度和位置:vi = w * vi + c1 * r1 * (pbest[i] - xi) + c2 * r2 * (gbest - xi)xi = xi + vi其中,w 表示惯性权重,c1 和c2 分别表示加速常数,r1 和r2 分别表示随机数生成器产生的随机数。
举例说明粒子群算法的搜索原理

举例说明粒子群算法的搜索原理粒子群算法(Particle Swarm Optimization, PSO)是一种进化计算方法,它通过模拟鸟群或鱼群的群体行为实现优化问题的搜索。
粒子群算法由于其简单性和高效性,在解决各种优化问题中得到了广泛应用。
本文将通过举例说明粒子群算法的搜索原理。
粒子群算法的搜索原理基于两个基本概念:粒子和适应度。
每个粒子代表解决方案的一个候选解,并拥有一个速度和位置。
适应度则表示该粒子解决方案的优劣程度。
假设我们要用粒子群算法来优化一个简单的函数,例如$f(x)=x^2$,其中$x$的取值范围在$[-5,5]$之间。
我们可以将每个粒子的位置表示为$x$的值,每个粒子的速度表示为$x$的变化率。
为了简化问题,我们假设粒子的速度范围在$[-1,1]$之间,即每个粒子在每个迭代中最大可以改变一个单位。
首先,我们需要初始化一批粒子。
假设我们初始化10个粒子,它们的位置和速度可以随机选择或者均匀分布在取值范围内。
在每次迭代中,粒子根据其位置和速度更新自己的解决方案。
具体来说,每个粒子根据当前的位置和速度计算下一个位置。
例如,假设粒子i的当前位置为$x_i$,速度为$v_i$,则下一个位置可以计算为$x_i^{'}=x_i+v_i$。
然后,根据新的位置计算粒子的适应度,并与个体最佳适应度比较。
如果粒子的适应度优于其个体最佳适应度(即$f(x_i^{'})<f(x_i)$),则更新个体最佳适应度和个体最佳位置。
否则,粒子保持当前的个体最佳适应度和位置。
接下来,粒子需要根据群体的最佳适应度和位置进行更新。
群体的最佳适应度是所有粒子的个体最佳适应度中的最优解,而群体的最佳位置是对应于最佳适应度的粒子的位置。
粒子根据群体最佳位置与当前位置的差异来调整自己的速度。
这个调整过程可以由以下公式表示:$v_i^{'} = w \cdot v_i + c_1 \cdot r_1 \cdot (p_i - x_i) + c_2\cdot r_2 \cdot (g - x_i)$其中,$v_i^{'}$是粒子的新速度,$w$是惯性权重,$p_i$是粒子的个体最佳位置,$g$是群体最佳位置,$c_1$和$c_2$是加速度常数,$r_1$和$r_2$是在$[0,1]$范围内的随机数。
粒子群算法

粒子群算法粒子群算法(Particle Swarm Optimization,PSO)是一种群体智能优化算法,它模拟了鸟群觅食行为中个体在信息交流、合作与竞争中寻找最优解的过程。
粒子群算法在解决优化问题中具有较好的效果,尤其适用于连续优化问题。
粒子群算法的基本思想是模拟粒子在解空间中的移动过程,每个粒子代表一个候选解,粒子的位置表示解的一组参数。
每个粒子都有一个速度向量,表示粒子在解空间中的移动方向和速率。
算法的核心是通过更新粒子的位置和速度来搜索目标函数的最优解。
具体来说,粒子的位置和速度更新通过以下公式计算:$$v_i^{t+1} = w\cdot v_i^{t} + c_1 \cdot rand() \cdot (p_i^{best}-x_i^{t}) + c_2 \cdot rand() \cdot (p_g^{best}-x_i^{t})$$$$x_i^{t+1} = x_i^{t} + v_i^{t+1}$$其中,$v_i^{t}$是粒子$i$在时间$t$的速度,$x_i^{t}$是粒子$i$在时间$t$的位置,$p_i^{best}$是粒子$i$自身经历过的最好位置,$p_g^{best}$是整个种群中经历过的最好位置,$w$是惯性权重,$c_1$和$c_2$是加速度因子,$rand()$是一个0到1的随机数。
粒子群算法的优点在于简单、易于理解和实现,同时具有较好的全局搜索能力。
其收敛速度较快,可以处理多维、非线性和非光滑的优化问题。
另外,粒子群算法有较少的参数需要调节,因此适用于许多实际应用中的优化问题。
粒子群算法的应用领域非常广泛,包括机器学习、数据挖掘、图像处理、模式识别、人工智能等。
例如,在机器学习中,粒子群算法可以应用于神经网络的训练和参数优化;在数据挖掘中,粒子群算法可以用于聚类、分类和关联规则挖掘等任务;在图像处理中,粒子群算法可以用于图像分割、边缘检测和特征提取等;在模式识别中,粒子群算法可以用于目标检测和模式匹配等。
群体智能优化算法-粒子群优化算法

第二章粒子群优化算法粒子群优化(PSO)是一种基于群体智能的数值优化算法,由社会心理学家James Kennedy和电气工程师Russell Eberhart于1995年提出。
自PSO诞生以来,它在许多方面都得到了改进,这一部分将介绍基本的粒子群优化算法原理和过程。
2.1粒子群优化粒子群优化(PSO)是一种群智能算法,其灵感来自于鸟类的群集或鱼群学习,用于解决许多科学和工程领域中出现的非线性、非凸性或组合优化问题。
图1 Russel Eberhart和James Kennedy2.1.1算法思想许多鸟类都是群居性的,并由各种原因形成不同的鸟群。
鸟群可能大小不同,出现在不同的季节,甚至可能由群体中可以很好合作的不同物种组成。
更多的眼睛和耳朵意味着有更多的及时发现食物和捕食者的机会。
鸟群在许多方面对其成员的生存总是有益的:觅食:社会生物学家E.O. Wilson说,至少在理论上,群体中的个体成员可以从其他成员在寻找食物过程中的发现和先前的经验中获益[1]。
如果一群鸟的食物来源是相同的,那么某些种类的鸟就会以一种非竞争的方式聚集在一起。
这样,更多的鸟类就能利用其他鸟类对食物位置的发现。
抵御捕食者:鸟群在保护自己免受捕食者侵害方面有很多优势。
◆更多的耳朵和眼睛意味着更多的机会发现捕食者或任何其他潜在的危险;◆一群鸟可能会通过围攻或敏捷的飞行来迷惑或压制捕食者;◆在群体中,互相间的警告可以减少任何一只鸟的危险。
空气动力学:当鸟类成群飞行时,它们经常把自己排成特定的形状或队形。
鸟群中鸟的数量不同,每只鸟煽动翅膀时产生不同的气流,这都会导致变化的风型,这些队形会充分利用不同的分型,从而使得飞行中的鸟类能够以最节能的方式利用周围的空气。
粒子群算法的发展需要模拟鸟群的一些优点,然而,为了了解群体智能和粒子群优化的一个重要性质,值得提一下是鸟群的一些缺点。
当鸟类成群结队时,也会给它们带来一些风险。
更多的耳朵和眼睛意味着更多的翅膀和嘴,这导致更多的噪音和运动。
粒子群算法基本原理

粒子群算法基本原理粒子群算法(Particle Swarm Optimization, PSO)是一种基于群集智能的优化算法,灵感来源于鸟类或鱼群等群体的行为。
其基本原理是通过模拟粒子在搜索空间中的移动和信息交流,以寻找问题的最优解。
在粒子群算法中,问题的解被表示为粒子在搜索空间中的一个位置,每个粒子都有自己的速度和位置。
算法的初始化阶段,粒子随机分布在搜索空间中,每个粒子根据自身当前位置评估其适应度(目标函数值)。
在每一代迭代中,粒子根据自身的局部最优解和整个群体的全局最优解进行移动。
粒子通过不断调整自身速度和位置来实现优化过程。
它会根据自身经验和群体的经验,调整速度和位置,试图找到更优的解。
粒子的速度更新公式如下:\[v_i^{k+1} = w \cdot v_i^k + c_1 \cdot rand() \cdot (pbest_i^k -x_i^k) + c_2 \cdot rand() \cdot (gbest^k - x_i^k)\]其中,- \(v_i^{k+1}\) 是粒子在第 \(k+1\) 代的速度- \(w\) 是惯性权重- \(c_1\) 和 \(c_2\) 是加速常数- \(rand()\) 是一个生成随机数的函数- \(pbest_i^k\) 是粒子历史最优位置- \(gbest^k\) 是群体历史最优位置- \(x_i^k\) 是粒子的当前位置粒子的位置更新公式如下:\[x_i^{k+1} = x_i^k + v_i^{k+1}\]在迭代的过程中,粒子群算法会不断更新粒子的速度和位置,并记录群体中的历史最优解。
当达到预定的终止条件时,算法输出全局最优解作为问题的解。
粒子群算法具有很好的全局搜索能力和并行计算能力,广泛应用于函数优化、机器学习、图像处理等领域。
其优势在于简单易实现,但可能存在收敛速度慢和陷入局部最优的问题。
因此,研究者们提出了各种改进的粒子群算法,如自适应粒子群算法、混沌粒子群算法等,以提高算法的性能。
标准粒子群算法速度更新公式

标准粒子群算法速度更新公式标准粒子群算法速度更新公式是粒子群优化算法中的一个关键组成部分。
这玩意儿就像是给一群小粒子指明奔跑方向和速度的神秘指令。
先来说说这个公式到底是啥。
它一般长这样:$v_{id}^{k+1} =wv_{id}^{k} + c_{1}r_{1}(p_{id}^{k} - x_{id}^{k}) +c_{2}r_{2}(p_{gd}^{k} - x_{id}^{k})$ 。
这里面的字母和符号都有它们特定的含义。
$v_{id}^{k}$ 表示第 $i$ 个粒子在第 $d$ 维上第 $k$ 次迭代的速度,$w$ 是惯性权重,$c_{1}$ 和 $c_{2}$ 是学习因子,$r_{1}$ 和 $r_{2}$ 是在 [0,1] 区间内的随机数,$p_{id}^{k}$ 是第$i$ 个粒子在第 $d$ 维上经历过的最好位置,$p_{gd}^{k}$ 是整个粒子群在第 $d$ 维上经历过的最好位置,$x_{id}^{k}$ 是第 $i$ 个粒子在第$d$ 维上第 $k$ 次迭代的当前位置。
我给您打个比方哈,就好像我们有一群小朋友在操场上玩“寻宝游戏”。
每个小朋友就是一个粒子,他们要在操场上找到藏起来的宝贝。
这个速度更新公式就像是老师给小朋友们的提示,告诉他们该往哪个方向跑多快才能更快地找到宝贝。
惯性权重 $w$ 呢,就像是小朋友自己的惯性思维。
如果 $w$ 比较大,小朋友就更倾向于按照自己之前跑的方向和速度继续跑;要是$w$ 比较小,小朋友就更容易改变自己的方向和速度。
学习因子 $c_{1}$ 和 $c_{2}$ 就像是两个不同的小伙伴给的建议。
$c_{1}r_{1}(p_{id}^{k} - x_{id}^{k})$ 这部分,就像是自己好朋友说的“你上次在这边找到过好东西,这次也往这边试试”;$c_{2}r_{2}(p_{gd}^{k} - x_{id}^{k})$ 这部分呢,就像是班里最聪明的那个同学告诉大家“咱们班之前在那边发现过宝贝,大家都去那边看看”。
第6章粒子群算法基本理论

PSO算法作为一种新兴智能仿生算法,目前还没有完备 的数学理论基础,但作为新兴优化算法已在诸多领域得到广 泛应用。
6.1 粒子群算法的概述
6.1.3 粒子群算法的特点
粒子群算法的优点 ① 粒子群算法依靠粒子速度完成搜索,在迭代进化中只 有最优的粒子将信息传递给其他粒子,搜索速度快。 ② 粒子群算法具有记忆性,粒子群体的历史最好位置可 以记忆,并传递给其他粒子。 ③ 需调整的参数较少,结构简单,易于工程实现。 ④ 采用实数编码,直接由问题的解决定,问题解的变量 数直接作为粒子的维数。
[2] Eberhart R,Kennedy J,A new optimizer using particle swarm theory,Proceeding of the 6th International Symposium on Micro-Machine and Human Science, 1995,39~43
粒子群算法的基本思想是通过群体中个体之间的协作和 信息共享来寻找最优解。
6.1 粒子群算法的概述
6.1.2 粒子群算法的发展
萌芽阶段
1986年,人工生命、计算机图形 学专家 Craig Reynolds提出了简单的 人工生命系统——boid模型(解释为 bird like object),模拟了鸟类在飞行 过程中分离、列队和聚集三种聚群飞 行行为,并能感知到周围一定范围内 其他boid的飞行信息。boid根据该信 息,结合当前自身的飞行状态,在三 条简单行为规则的指导下,做出下一 步的飞行决策。
Step2:评价每个微粒的适应度值。 Step3:将每个微粒的适应度值与其经过的最好位置 pbest进行比较,如果较好则将其作为当前的最好位置pbest。 Step4:将每个微粒的适应度值与种群的最好位置gbest 进行比较,如果较好则将其作为种群的最好位置gbest。 Step5:根据速度和位置公式调整粒子的飞行速度和所 处位置。 Step6:判断是否达到结束条件,若未达到转到Step2。
粒子群优化算法(详细易懂-很多例子)讲解学习

粒子群算法的构成要素 -停止准则
停止准则一般有如下两种: 最大迭代步数 可接受的满意解
v i k d = w v i k d - 1 c 1 r 1 ( p b e s t i d x i k d 1 ) c 2 r 2 ( g b e s t d x i k d 1 )
粒子速度更新公式包含三部分: 第一部分为粒子先前的速度 第二部分为“认知”部分,表示粒子本身的思考,可理解为 粒子i当前位置与自己最好位置之间的距离。 第三部分为“社会”部分,表示粒子间的信息共享与合作, 可理解为粒子i当前位置与群体最好位置之间的距离。
惯性因子
基本粒子群算法
失去对粒子本身
的速度的记忆
粒子群算法的构成要素-权重因子 权重因子:惯性因子 、学习因子
v i k d = w v i k d - 1 c 1 r 1 ( p b e s t i d x i k d 1 ) c 2 r 2 ( g b e s t d x i k d 1 )
Xik=Xik1+Vik1
V i =V i1,V i2,...,V iN X i= X i1,X i2,...,X iN
算法流程
1. Initial:
初始化粒子群体(群体规模为n),包括随机位置和速度。
2. Evaluation:
根据fitness function ,评价每个粒子的适应度。
3. Find the Pbest:
粒子群优化算法(PS0)
粒子群优化算法概述

计算机辅助工艺课程作业学生:赵华琳学号: s308070072时间:09年6月粒子群优化算法概述0.前言优化是科学研究、工程技术和经济管理等领域的重要研究工具。
它所研究的问题是讨论在众多的方案中寻找最优方案。
例如,工程设计中怎样选择设计参数,使设计方案既满足设计要求又能降低成本;资源分配中,怎样分配有限资源,使分配方案既能满足各方面的基本要求,又能获得好的经济效益。
在人类活动的各个领域中,诸如此类,不胜枚举。
优化这一技术,正是为这些问题的解决,提供理论基础和求解方法,它是一门应用广泛、实用性很强的科学。
近十余年来,粒子群优化算法作为群体智能算法的一个重要分支得到了广泛深入的研究,在路径规划等许多领域都有应用。
本文主要结合现阶段的研究概况对粒子群优化算法进行初步介绍。
1.粒子群优化算法的基本原理1.1 粒子群优化算法的起源粒子群优化(PSO)算法是由Kennedy和Eberhart于1995年用计算机模拟鸟群觅食这一简单的社会行为时,受到启发,简化之后而提出的[1][2]。
设想这样一个场景:一群鸟随机的分布在一个区域中,在这个区域里只有一块食物。
所有的鸟都不知道食物在哪里。
但是他们知道当前的位置离食物还有多远。
那么找到食物的最优策略是什么呢。
最简单有效的方法就是追寻自己视野中目前离食物最近的鸟。
如果把食物当作最优点,而把鸟离食物的距离当作函数的适应度,那么鸟寻觅食物的过程就可以当作一个函数寻优的过程。
鱼群和鸟群的社会行为一直引起科学家的兴趣。
他们以特殊的方式移动、同步,不会相互碰撞,整体行为看上去非常优美。
生物学家CargiReynolds提出了一个非常有影响的鸟群聚集模型。
在他的模拟模型boids中,每一个个体遵循:避免与邻域个体相冲撞、匹配邻域个体的速度、试图飞向感知到的鸟群中心这三条规则形成简单的非集中控制算法驱动鸟群的聚集,在一系列模拟实验中突现出了非常接近现实鸟群聚集行为的现象。
该结果显示了在空中回旋的鸟组成轮廓清晰的群体,以及遇到障碍物时鸟群的分裂和再度汇合过程。
粒子群算法公式

粒子群算法公式
粒子群算法(ParticleSwarmOptimization,PSO)是一种基于社会化行为的优化算法,它被广泛应用于解决复杂问题。
本文将介绍粒子群算法的公式。
PSO的核心公式如下:
$$
v_{i,j} = w * v_{i,j} + c_1 * rand() * (pbest_{i,j} - x_{i,j}) + c_2 * rand() * (gbest_j - x_{i,j})
$$
其中,$v_{i,j}$表示粒子$i$在第$j$维上的速度,$x_{i,j}$表示粒子$i$在第$j$维上的位置,$pbest_{i,j}$表示粒子$i$历史最好的位置,$gbest_j$表示整个群体历史最好的位置,$w$表示惯性权重,$c_1$和$c_2$分别表示粒子自身和群体的学习因子,$rand()$表示在$[0,1]$范围内随机生成的数。
在PSO算法中,每个粒子都代表一个解,它的位置和速度随着迭代的进行而不断更新。
粒子通过与$pbest$和$gbest$进行比较来确定自己的运动方向和速度,不断搜索最优解。
除了核心公式外,PSO算法还有其他重要的公式,如惯性权重更新公式、学习因子更新公式等。
这些公式的具体形式根据不同的PSO 变体有所不同,但都基于核心公式。
总之,粒子群算法是一种优秀的全局优化算法,它通过模拟粒子群的行为来搜索最优解。
熟悉PSO的公式是深入理解和应用这种算法
的重要基础。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
//#pragma comment (linker, "/STACK:16777216")
//HEAD
#include <cstdio>
#include <ctime>
#include <cstdlib>
#include <cstring>
}
getFitness();
UpdateVal();
}
}
void solve()
{
init();
evolution();
printf("answer %lf:\n", vPgd);
printf("solution \n");
for (int i = 0; i < cityNum; i++)
{
if (i) printf(" ");
{
int j = 0;
double vj = fitness[0];
for (int i = 0; i < scale; i++)
{
if (vPd[i] > fitness[i])
{
vPd[i] = fitness[i];
copyArray(Pd[i], oPop[i], cityNum);///???
copyArray(Pd[i], oPop[i], cityNum);
}
bestNum = 0;
vPgd = fitness[0];
bestGen = 0;
for (int i = 0; i < scale; i++) if (vPgd > fitness[i])
{
vPgd = fitness[i];
}
if (vj > fitness[i])
{
vj = fitness[i];
j = i;
}
}
if (vj < vPgd)
{
bestGen = nowGen;///
bestNum = j;///
vPgd = vj;
copyArray(Pgd, oPop[j], cityNum);
}
}
void changeTo(int a[], vector<SO> v)///
{
int cn = pv.size();
for (int i = 0; i < cn; i++)
for (int j = i + 1; j < cn; j++)
{
d[i][j] = d[j][i] = getDist(pv[i], pv[j]);
}
}
int main ()
{
srand((unsigned long)time(0)); ///设置时间种子
vector<SO> v;
v.clear();
int lvn = w * listV[is].size();
addTo(v, listV[is], lvn);
vector<SO> a = minus(Pd[is], oPop[is]);
int an = randomD() * a.size();
addTo(v, a, an);
{
int vn = v.size();
for (int i = 0; i < vn; i++)
{
int x = v[i].x, y = v[i].y;
swap(a[x], a[y]);
}
}
vector<SO> minus(int a[], int b[])///
{
int c[MAX_CITY], d[MAX_CITY];
#include <cstdlib>
using namespace std;
typedef long long LL;
const double MAX_VAL = (double)1e18;
const int MAX_GEN = 30;///最大迭代次数
const int MAX_SCALE = 3000;///最大种群规模
inline double getDist(Point a, Point b)
{
return sqrt((a.x - b.x) * (a.x - b.x) + (a.y - b.y) * (a.y - b.y));
}
struct PSO{
double w;
int scale;
int cityNum;
{
s.x = i, s.y = c[a[i]];
swap(d[s.x], d[s.y]);
v.push_back(s);
}
}
return v;
}
void addTo(vector<SO> &v, vector<SO> a, int vn)
{
for (int i = 0; i < vn; i++)
v.push_back(a[i]);
for (int i = 0; i < cityNum; i++) d[i] = b[i];
for (int i = 0; i < cityNum; i++) c[a[i]] = i;
vector<SO> v;
SO s;
for (int i = 0; i < cityNum; i++)
{
if (d[i] != a[i])
SO so(x, y);
listV[i].push_back(so);
// cout << so.x << "*" << so.y << ' ';
}
// cout <<endl;
}
getFitness();
for (int i = 0; i < scale; i++)
{
vPd[i] = fitness[i];
vector<SO> listV[MAX_SCALE];///每科粒子的初始交换序列
int Pd[MAX_SCALE][MAX_CITY];///一颗粒子历代中出现最好的解,
double vPd[MAX_SCALE];///解的评价值
int Pgd[MAX_CITY];///整个粒子群经历过的的最好的解,每个粒子都能记住自己搜索到的最好解
printf("%d\n", Pgd[i]);
}
cout << bestGen << ' ' << bestNum << endl;
puts("");
}
};
int cn;
vector<Point> pv;
double d[MAX_CITY][MAX_CITY];
void pre(vector<Point> pv)
for (int j = 0; j < cityNum; j++)
dist[i][j] = d[i][j];
}
void copyArray(double a[], double b[], int n)
{
for (int i = 0; i < n; i++) a[i] = b[i];
}
void copyArray(int a[], int b[], int n)
{
// cout << i << " :" << endl;
int vn = randomI(cityNum) + 1;
for (int j = 0; j < vn; j++)
{
int x = randomI(cityNum);
int y = randomI(cityNum);
while (x == y) y = randomI(cityNum);
while (cin >> cn)
{
pv.clear();
for (int i = 0; i < cn; i++)
{
Point p;
p.read();
pv.push_back(p);
}
pre(pv);
PSO solver(MAX_SCALE, cn, MAX_GEN, W_VAL, d);
cout << "***************************************************" << endl;
vector<SO> b = minus(Pgd, oPop[is]);
int bn = randomD() * b.size();
addTo(v, b, bn);
listV[is] = v;changeTo(oPo源自[is], listV[is]);
// cout << listV[is].size() << endl;
#include <queue>
#include <string>