Stata命令大全-面板数据计量分析与软件实现
STATA面板数据模型操作命令讲解
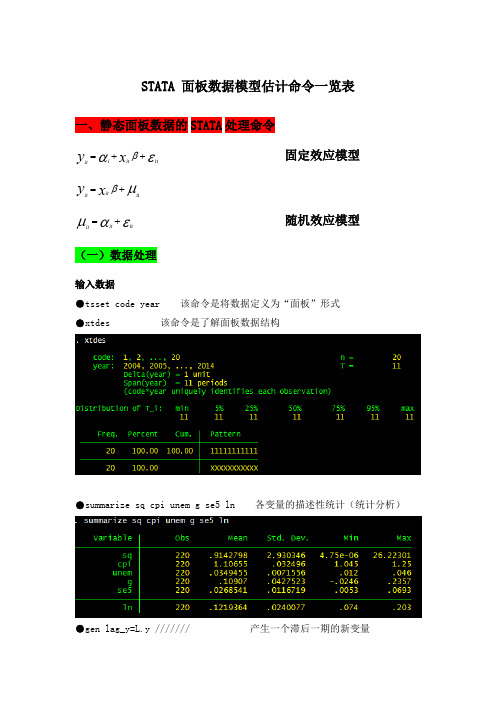
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令固定效应模型εαβit ++=x y it i it μβit +=x y it it随机效应模型εαμit +=it it (一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
Stata命令大全 面板数据计量分析与软件实现

Stata命令大全面板数据计量分析与软件实现说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
stata命令大全(全)

*
*-- F(4,373) = 855.93检验除常数项外其他解释变量的联合显著性
*-- corr(u_i, Xb)=-0.2347
*-- sigma_u, sigma_e, rho
* rho = sigma_uA2/(sigma_uA2+sigma_eA2)
*空间计量分析:SLM模型与SEM模型
*说明:STATA与Matlab结合使用。常应用于空间溢出效应(R&D)、财政 分权、地方政府公共行为等。
、常用的数据处理与作图
*指定面板格式
xtset id year(id为截面名称,year为时间名称)
xtdes /*数据特征*/
xtsum logy h /*数据统计特征*/
drop if id==2/*注意用==*/
*如何得到连续year或id编号(当完成上述操作时, 为形成panel格式,需要用egen命令)
ege n year_ new二group(year)
xtset id year_ new
**保留变量或保留观测值
keep inv /*删除变量*/
**或
keep if year==2000
dis e(sigma_u)A2/(e(sigma_u)A2+e(sigma_e)A2)
个体效应是否显著?
*F(28,373) =338.86 HO: al=a2 = a3 = a4 = a29
*Prob > F = 0.0000表明,固定效应高度显著
*---如何得到调整后的R2即adj-R2?
ereturn list
考虑中国29个省份的C-D生产函数
(完整word版)STATA面板数据模型操作命令讲解

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=xy itiit固定效应模型μβit +=xy ititεαμit+=itit随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量 gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0。
0000,检验结果表明固定效应模型优于混合OLS模型.●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui"之后第一幅图将不会呈现)xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型.●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
[实用参考]Stata命令大全
![[实用参考]Stata命令大全](https://img.taocdn.com/s3/m/8db05b2f650e52ea54189827.png)
GGGGGGGGG面板数据计量分析与软件实现GGGGGGGGG说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
G----------面板数据模型G1.静态面板模型:FE和REG2.模型选择:FEvsPOLS,REvsPOLS,FEvsRE(pols混合最小二乘估计)G3.异方差、序列相关和截面相关检验G4.动态面板模型(DID-GMM,SPS-GMM)G5.面板随机前沿模型G6.面板协整分析(FMOLS,DOLS)GGG说明:1-5均用STATA软件实现,6用GAUSS软件实现。
G生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)GGG说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI溢出效应(SpilloversEffect)、工业行业效率状况等。
G空间计量分析:SLM模型与SEM模型G说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
G---------------------------------G--------一、常用的数据处理与作图-----------G---------------------------------G指定面板格式GtsetidPear(id为截面名称,Pear为时间名称)Gtdes/G数据特征G/GtsumlogPh/G数据统计特征G/sumlogPh/G数据统计特征G/G添加标签或更改变量名labelvarh"人力资本"renamehhumG排序sortidPear/G是以STATA面板数据格式出现G/sortPearid/G是以DEA格式出现G/G删除个别年份或省份dropifPear<1992dropifid==2/G注意用==G/G如何得到连续Pear或id编号(当完成上述操作时,Pear或id就不连续,为形成panel 格式,需要用egen命令)egenPear_new=group(Pear)GtsetidPear_newGG保留变量或保留观测值keepinv/G删除变量G/GG或keepifPear==20PPGG排序sortidPear/G是以STATA面板数据格式出现sortPearid/G是以DEA格式出现GG长数据和宽数据的转换G长>>>宽数据reshapewidelogP,i(id)j(Pear)G宽>>>长数据reshapelogP,i(id)j(Pear)GG追加数据(用于面板数据和时间序列)GtsetidPearG或者Gtdestsappend,add(5)/表示在每个省份再追加5年,用于面板数据/tssetG或者tsdes.tsappend,add(8)/表示追加8年,用于时间序列/G方差分解,比如三个变量P,G,Z都是面板格式的数据,且满足P=G+Z,求方差var(P),协方差Cov(G,P)和Cov(Z,P)bPsortPear:corrPGZ,covGG生产虚拟变量G生成年份虚拟变量tabPear,gen(Pr)G生成省份虚拟变量tabid,gen(dum)GG生成滞后项和差分项GtsetidPeargenPlag=l.P/G产生一阶滞后项),同样可产生二阶滞后项G/genPlag2=L2.PgendP=D.P/G产生差分项G/G求出各省20PP年以前的openinv的平均增长率collapse(mean)openinvifPear<20PP,bP(id)变量排序,当变量太多,按规律排列。
stata命令大全(全)

********* 面板数据计量分析与软件实现 *********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
stata命令大全(全)

*********面板数据计量分析与软件实现*********说明:以下do文件相当一部分容来自于大学连玉君STATA教程,感他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计)* 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog 生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/ gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
(完整word版)STATA面板数据模型操作命令要点

STATA 面板数据模型预计命令一览表一、静态面板数据的STATA办理命令y it i x it it固定效应模型y it x it itit it it随机效应模型(一)数据办理输入数据●tsset code year该命令是将数据定义为“面板”形式●xtdes该命令是认识面板数据构造● summarize sq cpi unem g se5 ln各变量的描绘性统计(统计剖析)● gen lag_y=L.y ///////产生一个滞后一期的新变量gen F_y=F.y ///////产生一个超前项的新变量gen D_y=D.y ///////产生一个一阶差分的新变量gen D2_y=D2.y ///////产生一个二阶差分的新变量(二)模型的挑选和查验●1、查验个体效应(混淆效应仍是固定效应)(原假定:使用 OLS 混淆模型)●xtreg sq cpi unem g se5 ln,fe关于固定效应模型而言,回归纳果中最后一行报告的 F 统计量便在于查验所有的个体效应整体上明显。
在我们这个例子中发现 F 统计量的概率为 0.0000 ,查验结果表示固定效应模型优于混淆 OLS模型。
● 2、查验时间效应(混淆效应仍是随机效应)(查验方法:LM统计量)(原假定:使用OLS混淆模型)●qui xtreg sq cpi unem g se5( 加上“ qui ”以后第一幅图将不会体现) ln,re xttest0能够看出, LM查验获取的 P 值为 0.0000 ,表示随机效应特别明显。
可见,随机效应模型也优于混淆 OLS模型。
● 3、查验固定效应模型or 随机效应模型(查验方法:Hausman查验)原假定:使用随机效应模型(个体效应与解说变量没关)经过上边剖析,能够发现当模型加入了个体效应的时候,将明显优于截距项为常数假定条件下的混淆 OLS模型。
可是没法明确划分 FE or RE 的好坏,这需要进行接下来的查验,以下:Step1 :预计固定效应模型,储存预计结果Step2 :预计随机效应模型,储存预计结果Step3 :进行 Hausman查验●qui xtreg sq cpi unem g se5ln,fe est store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe(或许更优的是hausman fe,sigmamore/ sigmaless)能够看出, hausman查验的 P 值为 0.0000 ,拒绝了原假定,以为随机效应模型的基本假定得不到知足。
stata命令大全超实用(全)

表示追加 8年,用于时ห้องสมุดไป่ตู้序列 /
* 方差分解, 比如三个变量 Y,X,Z 都是面板格式的数据, 和Cov( Z,Y ) bysort year:corr Y X Z,cov
且满足 Y=X+Z,求方差 var(Y),
协方差 Cov(X,Y)
** 生产虚拟变量 * 生成年份虚拟变量 tab year,gen(yr) * 生成省份虚拟变量 tab id,gen(dum)
* ---------------------------------
* --------
固定效应模型 -----------
* ---------------------------------
* 实质上就是在传统的线性回归模型中加入
N-1 个虚拟变量,
* 使得每个截面都有自己的截距项 ,
* 截距项的不同反映了个体的某些不随时间改变的特征
*** 说明: DEA由DEAP2.1软件实现, SFA由 Frontier4.1 实现,尤其后者,侧重于比较 C-D与 Translog
生产函数,一步法与两步法的区别。常应用于地区经济差异、
FDI 溢出效应( Spillovers Effect )、
工业行业效率状况等。
* 空间计量分析: SLM模型与 SEM模型 * 说明: STATA与Matlab 结合使用 。常应用于空间溢出效应 ( R&D)、财政分权、 地方政府公共行为等。
* 散点图 +线性拟合直线 +置信区间 twoway (scatter logy h) (lfit logy h) (lfitci logy h)
* 按不同个体画出散点图和拟合线,可以以做出 twoway (scatter logy h if id<4) (lfit logy h if id<4) logy h if id==2) (lfit logy h if id==3)
(完整word版)STATA面板数据模型操作命令要点

STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板大数据模型操作命令要点

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=xy itiit固定效应模型μβit +=xy ititεαμit+=itit随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式 ●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
stata命令总结

stata命令总结.docStata命令总结引言Stata是一款强大的统计分析软件,广泛应用于经济学、社会学、医学等领域。
Stata命令是进行数据处理、统计分析、图形展示等操作的基础。
本文将对Stata中常用的命令进行总结,以帮助用户更高效地使用Stata进行数据分析。
Stata基础命令1. 数据管理导入数据:import excel, import delimited导出数据:export excel, export delimited数据集保存:save, saveold2. 变量管理创建变量:generate, egen修改变量:replace删除变量:drop3. 数据清洗数据类型转换:destring, encode, format缺失值处理:mvdecode, drop if missing()异常值检测:tabulate, summarize描述性统计分析1. 基本统计量描述性统计:summarize频率统计:tabulate相关系数:correlate2. 分组统计分组描述:bysort, xtsum 分组汇总:collapse3. 数据转换数据长格式:reshape long 数据宽格式:reshape wide 推断性统计分析1. 假设检验t检验:ttest方差分析:anova卡方检验:tabulate, chi2 2. 回归分析线性回归:regress逻辑回归:logit泊松回归:poisson3. 时间序列分析时间序列描述:tsreport自回归模型:arima高级统计分析1. 面板数据分析面板数据描述:xtset, xtsum固定效应模型:xtreg fe随机效应模型:xtreg re2. 多层次模型多层次线性模型:xtmelogit3. 结构方程模型结构方程模型:sem绘图与可视化1. 基本图形散点图:scatter线图:line柱状图:bar2. 高级图形箱线图:boxplot直方图:histogram核密度估计图:kdensity3. 交互式图形交互式图形:twoway, graph edit编程与自动化1. 循环与条件语句循环:foreach, forvalues条件语句:if, else2. 脚本与批处理脚本编写:do-file批处理:batch3. 宏与用户定义命令宏:macro用户定义命令:program define结语Stata命令的掌握是进行高效数据分析的前提。
stata命令大全(全)10491.pptx

4
aorder 或者 order fdi open insti
学海无 涯
*----------------* 二、静态面板模型 *-----------------
*--------- 简介 -----------
* 面板数据的结构(兼具截面资料和时间序列资料的特征) use product.dta, clear browse xtset id year xtdes
* 指定面板格式 xtset id year (id为截面名称,year为时间名称)
xtdes /*数据特征*/ xtsum logy h /*数据统计特征*/ sum logy h /*数据统计特征*/
*添加标签或更改变量名 label var h "人力资本" rename h hum
*排序 sort id year /*是以STATA面板数据格式出现*/ sort year id /*是以DEA格式出现*/
* 空间计量分析:SLM模型与SEM模型 *说明:STATA与Matlab结合使用。常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为 等。
* --------------------------------1
学海无 涯
* -------- 一、常用的数据处理与作图 ----------* ---------------------------------
*删除个别年份或省份 drop if year<1992 drop if id==2 /*注意用==*/
*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel格式,需要用 egen命令)
Stata软件操作教程

Stata软件操作教程第15章:面板数据分析面板数据是指在时间上具有一定连续性的多个个体观测值,例如不同地区连续多年的经济数据、同一个企业在多个时间点的财务数据等。
面板数据具有时间序列和截面两个维度,因此在分析面板数据时需要考虑个体间的相关性和时间序列的影响。
在Stata中,面板数据的操作和分析可以使用如下的一些命令:1. 导入面板数据:使用`use`命令导入面板数据文件,例如`use filename, clear`,其中filename为数据文件名。
2. 面板数据的描述性统计:使用`summarize`命令计算面板数据的平均值、标准差等描述性统计量。
例如,`summarize varname, detail`计算变量varname的描述性统计量。
3. 面板数据的时间序列图:使用`tsline`命令绘制面板数据的时间序列图。
例如,`tsline varname`绘制变量varname的时间序列图。
4. 固定效应模型(Fixed Effects Model):使用`xtreg`命令估计固定效应模型,该模型考虑了个体间的固定效应。
例如,`xtreg dependent var independent var, fe`估计固定效应模型。
5. 随机效应模型(Random Effects Model):使用`xtreg`命令估计随机效应模型,该模型考虑了个体间的随机效应。
例如,`xtreg dependent var independent var, re`估计随机效应模型。
6. 混合效应模型(Mixed Effects Model):使用`xtmixed`命令估计混合效应模型,该模型既考虑了个体间的固定效应,又考虑了个体间的随机效应。
例如,`xtmixed dependent var independent var ,groupvar:`估计混合效应模型。
7. 模型检验和诊断:使用`xttest0`命令进行固定效应模型的F检验;使用`xtserial`命令进行个体效应的序列相关性检验;使用`xtgee`命令进行广义估计方程的估计和推断。
stata命令大全(全)
********* 面板数据计量分析与软件实现 *********说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
STATA面板大数据模型操作命令

STATA 面板数据模型估计命令一览表 一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板数据模型操作命令讲解

STATA面板数据模型操作命令讲解STATA是一种常用的统计分析软件,可以用于面板数据模型的操作。
面板数据模型是一种用来分析涉及多个单位和多个时间点的数据的统计模型,其主要特点是能够考虑单位间和时间间的相关性。
在STATA中,可以使用一系列命令来进行面板数据模型的操作,包括数据导入、数据清洗、模型估计和结果展示等。
下面将详细介绍STATA中面板数据模型操作的常用命令。
首先,要进行面板数据模型的操作,首先需要将数据导入到STATA中。
STATA支持多种数据格式的导入,包括Excel、CSV和数据库等。
常用的导入命令包括:1. use命令:用于导入STATA格式的数据文件。
例如:use data.dta2. import命令:用于导入其他格式的数据文件。
例如:import excel data.xlsx, firstrow导入数据后,接下来需要进行数据清洗和变量定义。
可以使用一系列命令对数据进行操作,例如生成新变量、删除缺失值和标识变量等。
常用的数据清洗命令包括:1. generate命令:用于生成新变量。
例如:generate log_y = log(y)2. drop命令:用于删除变量。
例如:drop x3. replace命令:用于替换变量值。
例如:replace y = 0 if y < 0数据清洗完成后,就可以开始估计面板数据模型。
常用的估计命令包括固定效应模型(Fixed Effects Model)和随机效应模型(Random Effects Model)。
下面分别介绍这两种模型的估计命令。
1.固定效应模型的估计命令:xtreg y x1 x2, fe其中,xtreg表示面板数据的回归命令,y为因变量,x1和x2为自变量,fe为固定效应模型的选项。
2.随机效应模型的估计命令:xtreg y x1 x2, re其中,re表示随机效应模型的选项。
除了固定效应模型和随机效应模型,STATA还支持其他面板数据模型的估计方法,如差分估计(Difference-in-Differences)、合成控制法(Synthetic Control Method)等。
STATA面板数据模型操作命令
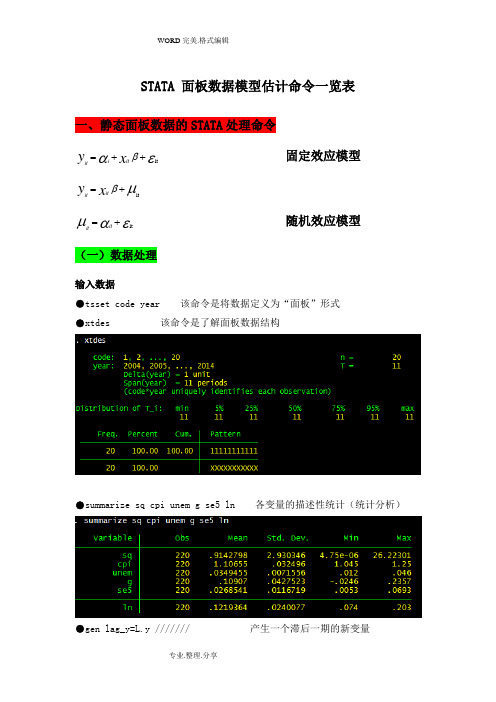
STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型(一)数据处理输入数据●tsset code year 该命令是将数据定义为“面板”形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计(统计分析)●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量(二)模型的筛选和检验●1、检验个体效应(混合效应还是固定效应)(原假设:使用OLS混合模型)●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果表明固定效应模型优于混合OLS模型。
●2、检验时间效应(混合效应还是随机效应)(检验方法:LM统计量)(原假设:使用OLS混合模型)●qui xtreg sq cpi unem g se5 ln,re (加上“qui”之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,表明随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型(检验方法:Hausman检验)原假设:使用随机效应模型(个体效应与解释变量无关)通过上面分析,可以发现当模型加入了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进行接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进行Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的基本假设得不到满足。
STATA面板大数据的模型操作命令

STATA 面板数据模型估计命令一览表一、静态面板数据的STATA 处理命令εαβit ++=x y it i it 固定效应模型μβit +=x y it itεαμit +=it it 随机效应模型〔一〕数据处理输入数据●tsset code year 该命令是将数据定义为“面板〞形式●xtdes 该命令是了解面板数据结构●summarize sq cpi unem g se5 ln 各变量的描述性统计〔统计分析〕●gen lag_y=L.y /////// 产生一个滞后一期的新变量gen F_y=F.y /////// 产生一个超前项的新变量gen D_y=D.y /////// 产生一个一阶差分的新变量gen D2_y=D2.y /////// 产生一个二阶差分的新变量〔二〕模型的筛选和检验●1、检验个体效应〔混合效应还是固定效应〕〔原假设:使用OLS混合模型〕●xtreg sq cpi unem g se5 ln,fe对于固定效应模型而言,回归结果中最后一行汇报的F统计量便在于检验所有的个体效应整体上显著。
在我们这个例子中发现F统计量的概率为0.0000,检验结果明确固定效应模型优于混合OLS模型。
●2、检验时间效应〔混合效应还是随机效应〕〔检验方法:LM统计量〕〔原假设:使用OLS混合模型〕●qui xtreg sq cpi unem g se5 ln,re (加上“qui〞之后第一幅图将不会呈现) xttest0可以看出,LM检验得到的P值为0.0000,明确随机效应非常显著。
可见,随机效应模型也优于混合OLS模型。
●3、检验固定效应模型or随机效应模型〔检验方法:Hausman检验〕原假设:使用随机效应模型〔个体效应与解释变量无关〕通过上面分析,可以发现当模型参加了个体效应的时候,将显著优于截距项为常数假设条件下的混合OLS模型。
但是无法明确区分FE or RE的优劣,这需要进展接下来的检验,如下:Step1:估计固定效应模型,存储估计结果Step2:估计随机效应模型,存储估计结果Step3:进展Hausman检验●qui xtreg sq cpi unem g se5 ln,feest store fequi xtreg sq cpi unem g se5 ln,reest store rehausman fe (或者更优的是hausman fe,sigmamore/ sigmaless)可以看出,hausman检验的P值为0.0000,拒绝了原假设,认为随机效应模型的根本假设得不到满足。
stata命令大全(全)之令狐采学创编

*********面板数据计量分析与软件实现*********欧阳家百(2021.03.07)说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE(pols混合最小二乘估计)* 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DIDGMM,SYSGMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:15均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较CD与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
** 一、常用的数据处理与作图** 指定面板格式xtset id year(id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/ tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/ gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
Stata命令大全面板数据计量分析与软件实现说明:以下do文件相当一部分内容来自于中山大学连玉君STATA教程,感谢他的贡献。
本人做了一定的修改与筛选。
*----------面板数据模型* 1.静态面板模型:FE 和RE* 2.模型选择:FE vs POLS, RE vs POLS, FE vs RE (pols混合最小二乘估计) * 3.异方差、序列相关和截面相关检验* 4.动态面板模型(DID-GMM,SYS-GMM)* 5.面板随机前沿模型* 6.面板协整分析(FMOLS,DOLS)*** 说明:1-5均用STATA软件实现, 6用GAUSS软件实现。
* 生产效率分析(尤其指TFP):数据包络分析(DEA)与随机前沿分析(SFA)*** 说明:DEA由DEAP2.1软件实现,SFA由Frontier4.1实现,尤其后者,侧重于比较C-D与Translog生产函数,一步法与两步法的区别。
常应用于地区经济差异、FDI 溢出效应(Spillovers Effect)、工业行业效率状况等。
* 空间计量分析:SLM模型与SEM模型*说明:STATA与Matlab结合使用。
常应用于空间溢出效应(R&D)、财政分权、地方政府公共行为等。
* ---------------------------------* --------一、常用的数据处理与作图-----------* ---------------------------------* 指定面板格式xtset id year (id为截面名称,year为时间名称)xtdes /*数据特征*/xtsum logy h /*数据统计特征*/sum logy h /*数据统计特征*/*添加标签或更改变量名label var h "人力资本"rename h hum*排序sort id year /*是以STATA面板数据格式出现*/sort year id /*是以DEA格式出现*/*删除个别年份或省份drop if year<1992drop if id==2 /*注意用==*/*如何得到连续year或id编号(当完成上述操作时,year或id就不连续,为形成panel 格式,需要用egen命令)egen year_new=group(year)xtset id year_new**保留变量或保留观测值keep inv /*删除变量*/**或keep if year==2000**排序sort id year /*是以STATA面板数据格式出现sort year id /*是以DEA格式出现**长数据和宽数据的转换*长>>>宽数据reshape wide logy,i(id) j(year)*宽>>>长数据reshape logy,i(id) j(year)**追加数据(用于面板数据和时间序列)xtset id year*或者xtdestsappend,add(5) /表示在每个省份再追加5年,用于面板数据/tsset*或者tsdes.tsappend,add(8) /表示追加8年,用于时间序列/*方差分解,比如三个变量Y,X,Z都是面板格式的数据,且满足Y=X+Z,求方差var(Y),协方差Cov(X,Y)和Cov(Z,Y)bysort year:corr Y X Z,cov**生产虚拟变量*生成年份虚拟变量tab year,gen(yr)*生成省份虚拟变量tab id,gen(dum)**生成滞后项和差分项xtset id yeargen ylag=l.y /*产生一阶滞后项),同样可产生二阶滞后项*/gen ylag2=L2.ygen dy=D.y /*产生差分项*/*求出各省2000年以前的open inv的平均增长率collapse (mean) open inv if year<2000,by(id)变量排序,当变量太多,按规律排列。
可用命令aorder或者order fdi open insti*-----------------* 二、静态面板模型*-----------------*--------- 简介 -----------* 面板数据的结构(兼具截面资料和时间序列资料的特征)use product.dta, clearbrowsextset id yearxtdes* ---------------------------------* -------- 固定效应模型 -----------* ---------------------------------* 实质上就是在传统的线性回归模型中加入 N-1 个虚拟变量,* 使得每个截面都有自己的截距项,* 截距项的不同反映了个体的某些不随时间改变的特征** 例如: lny = a_i + b1*lnK + b2*lnL + e_it* 考虑中国29个省份的C-D生产函数*******-------画图------**散点图+线性拟合直线twoway (scatter logy h) (lfit logy h)*散点图+二次拟合曲线twoway (scatter logy h) (qfit logy h)*散点图+线性拟合直线+置信区间twoway (scatter logy h) (lfit logy h) (lfitci logy h)*按不同个体画出散点图和拟合线,可以以做出fe vs re的初判断*twoway (scatter logy h if id<4) (lfit logy h if id<4) (lfit logy h if id==1) (lfit logy h if id==2) (lfit logy h if id==3)*按不同个体画散点图,so beautiful!!!*graph twoway scatter logy h if id==1 || scatter logy h ifid==2,msymbol(Sh) || scatter logy h if id==3,msymbol(T) || scatter logy h if id==4,msymbol(d) || , legend(position(11) ring(0) label(1 "北京") label(2 "天津") label(3 "河北") label(4 "山西"))**每个省份logy与h的散点图,并将各个图形合并twoway scatter logy h,by(id) ylabel(,format(%3.0f)) xlabel(,format(%3.0f))*每个个体的时间趋势图*xtline h if id<11,overlay legend(on)* 一个例子:中国29个省份的C-D生产函数的估计tab id, gen(dum)list* 回归分析reg logy logk logl dum*,est store m_olsxtreg logy logk logl, feest store m_feest table m_ols m_fe, b(%6.3f) star(0.1 0.05 0.01)* Wald 检验test logk=logl=0test logk=logl* stata的估计方法解析* 目的:如果截面的个数非常多,那么采用虚拟变量的方式运算量过大* 因此,要寻求合理的方式去除掉个体效应* 因为,我们关注的是 x 的系数,而非每个截面的截距项* 处理方法:** y_it = u_i + x_it*b + e_it (1)* ym_i = u_i + xm_i*b + em_i (2) 组内平均* ym = um + xm*b + em (3) 样本平均* (1) - (2), 可得:* (y_it - ym_i) = (x_it - xm_i)*b + (e_it - em_i) (4) /*within estimator*/ * (4)+(3), 可得:* (y_it-ym_i+ym) = um + (x_it-xm_i+xm)*b + (e_it-em_i+em)* 可重新表示为:* Y_it = a_0 + X_it*b + E_it* 对该模型执行 OLS 估计,即可得到 b 的无偏估计量**stata后台操作,揭开fe估计的神秘面纱!!!egen y_meanw = mean(logy), by(id) /*个体内部平均*/egen y_mean = mean(logy) /*样本平均*/egen k_meanw = mean(logk), by(id)egen k_mean = mean(logk)egen l_meanw = mean(logl), by(id)egen l_mean = mean(logl)gen dyw = logy - y_meanwgen dkw = logk - k_meanwgen dlw=logl-l_meanwreg dyw dkw dlw,noconsest store m_statagen dy = logy - y_meanw + y_meangen dk = logk - k_meanw +k_meangen dl=logl-l_meanw+l_meanreg dy dk dlest store m_stataest table m_*, b(%6.3f) star(0.1 0.05 0.01)* 解读 xtreg,fe 的估计结果xtreg logy h inv gov open,fe*-- R^2* y_it = a_0 + x_it*b_o + e_it (1) pooled OLS* y_it = u_i + x_it*b_w + e_it (2) within estimator* ym_i = a_0 + xm_i*b_b + em_i (3) between estimator** --> R-sq: within 模型(2)对应的R2,是一个真正意义上的R2* --> R-sq: between corr{xm_i*b_w,ym_i}^2* --> R-sq: overall corr{x_it*b_w,y_it}^2**-- F(4,373) = 855.93检验除常数项外其他解释变量的联合显著性***-- corr(u_i, Xb) = -0.2347**-- sigma_u, sigma_e, rho* rho = sigma_u^2 / (sigma_u^2 + sigma_e^2)dis e(sigma_u)^2 / (e(sigma_u)^2 + e(sigma_e)^2)** 个体效应是否显著?* F(28, 373) = 338.86 H0: a1 = a2 = a3 = a4 = a29* Prob > F = 0.0000 表明,固定效应高度显著*---如何得到调整后的 R2,即 adj-R2 ?ereturn listreg logy h inv gov open dum**---拟合值和残差* y_it = u_i + x_it*b + e_it* predict newvar, [option]/*xb xb, fitted values; the defaultstdp calculate standard error of the fitted values ue u_i + e_it, the combined residualxbu xb + u_i, prediction including effectu u_i, the fixed- or random-error component e e_it, the overall error component */xtreg logy logk logl, fepredict y_hatpredict a , upredict res,epredict cres, uegen ares = a + reslist ares cres in 1/10* ---------------------------------* ---------- 随机效应模型 ---------* ---------------------------------* y_it = x_it*b + (a_i + u_it)* = x_it*b + v_it* 基本思想:将随机干扰项分成两种* 一种是不随时间改变的,即个体效应 a_i* 另一种是随时间改变的,即通常意义上的干扰项 u_it * 估计方法:FGLS* Var(v_it) = sigma_a^2 + sigma_u^2* Cov(v_it,v_is) = sigma_a^2* Cov(v_it,v_js) = 0* 利用Pooled OLS,Within Estimator, Between Estimator* 可以估计出sigma_a^2和sigma_u^2,进而采用GLS或FGLS* Re估计量是Fe估计量和Be估计量的加权平均* yr_it = y_it - theta*ym_i* xr_it = x_it - theta*xm_i* theta = 1 - sigma_u / sqrt[(T*sigma_a^2 + sigma_u^2)]* 解读 xtreg,re 的估计结果use product.dta, clearxtreg logy logk logl, re*-- R2* --> R-sq: within corr{(x_it-xm_i)*b_r, y_it-ym_i}^2* --> R-sq: between corr{xm_i*b_r,ym_i}^2* --> R-sq: overall corr{x_it*b_r,y_it}^2* 上述R2都不是真正意义上的R2,因为Re模型采用的是GLS估计。