双向循环链表,最易读懂的插入,删除,查找,并且显示长度
循环链表--解决Josephus问题

用循环链表解决:
1. #include <iostream> 2. usingnamespace 3. typedefstruct 4. data; 5. struct Node *next; 6. }Node,*List; 7. List Creatlist( 8. List head,p; 9. head=(Node*)malloc(sizeof(Node));
19. return head;
20. Output(List head)ut<<p->data<<
23. p=p->next;
24. }while(p!=head);
25. cout<<endl;
26. Play(List head,//第一种方法
27. List p,q;
37. cout<<endl;
38. Josephus(List h,//第二种方法
39. Node* p=h,*pre=NULL;
40. (i=0;i<n-1;++i)
41. (j=1;j<m;++j)
42.
pre=p;
43.
p=p->next;
44. cout<<"出列的人是 "<<p->data<<endl;
28. p=head; c=1; k=n;
29. while(k>1)
30. (c==m-1)
31.
q=p->next; p->next=q->next;
32.
cout<<q->data<<
c语言双向链表的简单操作-创建、插入、删除

c语⾔双向链表的简单操作-创建、插⼊、删除数据结构-双向链表的创建、插⼊和删除双向链表是数据结构中重要的结构,也是线性结构中常⽤的数据结构,双向指针,⽅便⽤户从⾸结点开始沿指针链向后依次遍历每⼀个结点,结点的前驱和后继查找⽅便。
#include <stdio.h>#include <stdlib.h>//双向链表结点的定义typedef struct dbnode{int data;struct dbnode *prio, *next;}DbNode, linkdblist;//创建双向链表DbNode *creatlist(void){linkdblist *p, *q, *head;q = p = (linkdblist *)malloc(sizeof(linkdblist));p->next = NULL;head = q;p = (linkdblist *)malloc(sizeof(linkdblist));scanf("%d", &p->data);while (p->data != -1){q->next = p;p->prio = q;q = p;p = (linkdblist *)malloc(sizeof(linkdblist));scanf("%d", &p->data);}q->next = NULL;return head;}//输出双向链表void print(linkdblist *head){linkdblist *p;p = head->next;if (p == NULL)printf("空链表!\n");while (p != NULL){printf("%d ", p->data);p = p->next;}}//向双向链表中的第i个位置插⼊⼀个结点x void insertdblist(linkdblist *head, int x, int i) {linkdblist *p, *q = head;if (i == 1)q = head;else{q = q->next;int c = 1;while ((c<i - 1) && (q != NULL)){q = q->next;c++;}}if (q != NULL && q->next != NULL){p = (linkdblist *)malloc(sizeof(linkdblist)); p->data = x;p->prio = q;p->next = q->next;q->next = p;q->next->prio = p;}elseprintf("找不到插⼊的位置!");}//删除双向链表中指定位置上的⼀个结点void deletelinkdblist(linkdblist *head, int i) {linkdblist *p, *q = head;if (i == 1)q = head;else{q = q->next;int c = 1;while (c < i - 1 && q != NULL){q = q->next;c++;}}if (q != NULL && q->next != NULL){p = q->next;p->prio = q;p->prio->next = p->next;p->next->prio = p->prio;free(p);}else if (q->next == NULL){p = q;p->prio->next = NULL;free(p);}elseprintf("没有找到待删除的结点");}//双向链表的主函数void main(){linkdblist *head;head = creatlist();print(head);printf("\n\n====向双向链表的某位置插⼊⼀个值====\n"); int num, i;printf("输⼊插⼊的位置:");scanf("%d", &i);printf("\n输⼊插⼊的值:");scanf("%d", &num);insertdblist(head, num, i);print(head);printf("\n");printf("\n\n====删除双向链表的某位置上的⼀个值====\n"); int j;printf("输⼊删除的位置:");scanf("%d", &j);deletelinkdblist(head, j);print(head);system("pause");printf("\n");}。
纯C语言实现循环双向链表创建,插入和删除
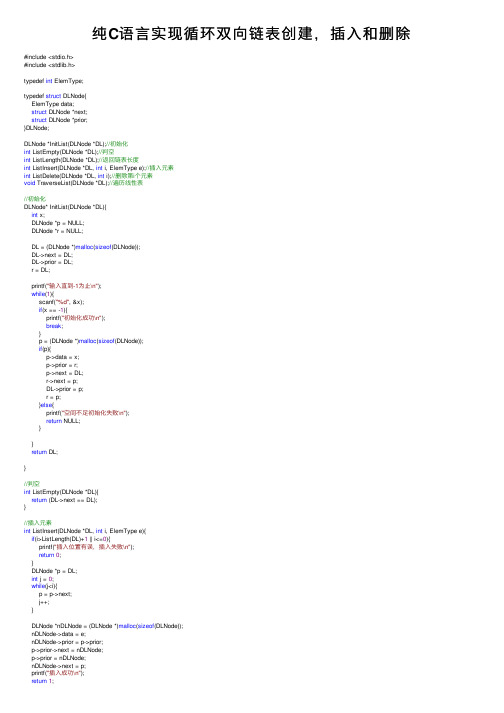
纯C语⾔实现循环双向链表创建,插⼊和删除#include <stdio.h>#include <stdlib.h>typedef int ElemType;typedef struct DLNode{ElemType data;struct DLNode *next;struct DLNode *prior;}DLNode;DLNode *InitList(DLNode *DL);//初始化int ListEmpty(DLNode *DL);//判空int ListLength(DLNode *DL);//返回链表长度int ListInsert(DLNode *DL, int i, ElemType e);//插⼊元素int ListDelete(DLNode *DL, int i);//删除第i个元素void TraverseList(DLNode *DL);//遍历线性表//初始化DLNode* InitList(DLNode *DL){int x;DLNode *p = NULL;DLNode *r = NULL;DL = (DLNode *)malloc(sizeof(DLNode));DL->next = DL;DL->prior = DL;r = DL;printf("输⼊直到-1为⽌\n");while(1){scanf("%d", &x);if(x == -1){printf("初始化成功\n");break;}p = (DLNode *)malloc(sizeof(DLNode));if(p){p->data = x;p->prior = r;p->next = DL;r->next = p;DL->prior = p;r = p;}else{printf("空间不⾜初始化失败\n");return NULL;}}return DL;}//判空int ListEmpty(DLNode *DL){return (DL->next == DL);}//插⼊元素int ListInsert(DLNode *DL, int i, ElemType e){if(i>ListLength(DL)+1 || i<=0){printf("插⼊位置有误,插⼊失败\n");return0;}DLNode *p = DL;int j = 0;while(j<i){p = p->next;j++;}DLNode *nDLNode = (DLNode *)malloc(sizeof(DLNode));nDLNode->data = e;nDLNode->prior = p->prior;p->prior->next = nDLNode;p->prior = nDLNode;nDLNode->next = p;printf("插⼊成功\n");return1;}//删除第i个元素int ListDelete(DLNode *DL, int i){if(i>ListLength(DL) || i<=0){printf("删除位置有误,插⼊失败\n");return0;}DLNode *p = DL;int j = 0;while(j<i){p = p->next;j++;}p->prior->next = p->next;p->next->prior = p->prior;free(p);printf("删除成功\n");return1;}//返回链表长度int ListLength(DLNode *DL){int len = 0;if(ListEmpty(DL)) return0;DLNode *p = DL->next;while(p->data!=DL->data){len++;p = p->next;}return len;}//遍历线性表void TraverseList(DLNode *DL){if(ListEmpty(DL)){printf("空链表");}DLNode *p = DL->next;//终⽌循环遍历while(p->data != DL->data){printf("%d ", p->data);p = p->next;}printf("\n");}int main(){ElemType e = NULL;DLNode *DL = NULL;//初始化测试DL = InitList(DL);////等价测试// DLNode *d = DL->next->next;// if(d->next->prior == d->prior->next){// printf("d->next->prior == d->prior->next\n");// }// if(d->next->prior == d){// printf("d->next->prior == d\n");// }// if(d == d->prior->next){// printf("d == d->prior->next\n");// }//遍历测试TraverseList(DL);//// printf("双向循环链表长度为%d\n",ListLength(DL));//插⼊元素测试printf("第3个位置插⼊999\n");ListInsert(DL, 3, 999);TraverseList(DL);//-----------------------------------------------------//⾮法操作?循环双向链表插⼊⼀个巨⼤的位置是否合法? //和⽼师讨论完,算不合法printf("第567位置插⼊999\n");ListInsert(DL, 567, 999);TraverseList(DL);//------------------------------------------------------//删除元素测试// printf("删除第1个位置\n");// ListDelete(DL, 1);// TraverseList(DL);//------------------------------------------------------//⾮法操作?同上//新问题,1,2,3,4,-1,删除第5个是头节点。
实现双向链表的基本操作

一、什么是双向链表双向链表,也称双向链式线性表,是一种常见的数据结构,它由多个节点组成,每个节点都包含指向前一个节点和后一个节点的指针。
与单向链表不同的是,双向链表的每个节点都有两个指针,这样可以在不遍历整个链表的情况下,方便地访问任何一个节点。
二、基本操作1. 初始化初始化双向链表需要定义一个头节点,该节点不存储实际数据,只用于标记链表的开始位置。
头节点的前驱指针和后继指针都指向NULL ,表示链表为空。
2. 插入节点插入节点是双向链表最常见的操作,它分为三种情况:在链表头部插入、在链表尾部插入和在链表中间插入。
头部插入:先创建一个新节点,并将该节点的后继指针指向当前头节点,将头节点的前驱指针指向新节点,再将链表的头节点指向新节点,完成插入。
尾部插入:先找到链表的尾节点,再创建一个新节点,并将新节点的前驱指针指向当前尾节点,将尾节点的后继指针指向新节点,再将新节点的后继指针指向 NULL ,完成插入。
中间插入:先找到要插入节点的位置,即该节点前一个节点的后继指针和后一个节点的前驱指针,分别指向新节点。
新节点的前驱指针指向前一个节点,后继指针指向后一个节点,完成插入。
3. 删除节点删除节点也分为三种情况:删除头节点、删除尾节点和删除中间节点。
头节点删除:将头节点的后继节点作为新的头节点,将新头节点的前驱指针指向 NULL ,完成删除。
尾节点删除:将尾节点的前驱节点作为新的尾节点,将新尾节点的后继指针指向 NULL ,完成删除。
中间节点删除:先找到要删除节点的位置,即该节点前一个节点的后继指针和后一个节点的前驱指针,分别指向该节点的前一个节点和后一个节点,完成删除。
4. 查找节点查找节点可以通过遍历链表来实现,在双向链表中,由于每个节点都有前驱和后继指针,因此可以从前向后或从后向前进行查找。
需要注意的是,由于双向链表的查找操作需要遍历整个链表,因此效率较低,不适用于大规模数据的查找。
5. 输出链表输出链表可以通过遍历链表来实现,从头节点开始,依次输出每个节点的数据。
循环链表与双向链表

线性链表结构因为具有方向性,所以一旦链表的开始指针被破坏,整个链表都会丢失。
如果将链表的最后一个结点的指针指向链表结构开始结点,经过这种处理的链表结构就称为单一的循环结构。
从循环链表中,从任意一个结点出发都可以到达链表内的其他各个结点。
而这种特性可以用来解决很多实际应用中的问题。
例如:计算机上处理内存工作区,或使用缓冲区输入输出时,通常就是用循环链表来重复使用各个结点。
这时各结点代表的是一块使用或闲置的内存空间。
建立循环链表结构只需要把建立基本链表的方式稍作修改即可。
其唯一的区别仅在于在建立完基本链表后,要将最后一个结点指向第一个结点。
1,循环链表内结点的插入:循环链表和单链表的结点插入稍有不同,在循环链表内每一个结点的指针都指向下一个结点。
所以将结点插入循环链表的情况就和将结点插入基本链表的中间结点是相同的。
(1)将新结点的指针指向结点P的下一个结点。
(2)将结点P的指针指向新结点。
2,删除循环链表内的结点。
删除步骤:(1)找到结点P的前一个结点。
(2)将前一个结点的指针指向结点P的下一个结点。
3,将两个循环链表首尾相结合并成一个循环链表。
循环链表的操作和线性链表基本一致,差别仅在于算法的循环条件不是P或p->next是否为空,而是它们是否等于头指针。
但有的时候,若在循环链表中设立尾指针而不设立头指针,可是某些操作简单化。
这样尾指针既起到了头指针的功能也起到了尾指针的功能。
所以在实际应用中,往往使用尾指针代替头指针进行某些操作。
例如:将两个循环链表首尾相接时采用尾指针可以简化操作,整个过程只需要修改两个指针。
双向链表:双向链表是一种数据结构中常用的链表结构。
因为链表是具有方向性的数据结构,在查找链表时,只能按照一个方向查找。
若要反过来查找就需要花费一些功夫,而解决的办法是可以运用链表的反转来达到人们想要的功能。
如此一来,可以往返查找此链表。
其实只要将两个链表结合起来,就可以建立一个无方向性的链表结构。
双循环链表算法描述

双循环链表算法描述双循环链表是一种特殊的链表结构,它有两个指针域,分别指向前一个节点和后一个节点,而最后一个节点指向头结点,头结点又指向第一个节点,形成了一个环形结构。
双循环链表可以用于实现队列和栈等数据结构,也可以用于解决某些问题。
双循环链表的基本操作包括插入、删除、查找和遍历等。
下面我们来详细介绍这些操作的算法描述。
1. 插入操作双循环链表的插入操作可以分为两种情况:在链表头部插入和在链表尾部插入。
具体算法描述如下:在链表头部插入:1. 创建一个新节点,并将其next指针指向头结点的next节点,将其prev指针指向头结点;2. 将头结点的next指针指向新节点,将新节点的next节点的prev 指针指向新节点。
在链表尾部插入:1. 创建一个新节点,并将其prev指针指向尾节点,将其next指针指向头结点;2. 将尾节点的next指针指向新节点,将头结点的prev指针指向新节点。
2. 删除操作双循环链表的删除操作也可以分为两种情况:删除头部节点和删除尾部节点。
具体算法描述如下:删除头部节点:1. 将头结点的next节点的prev指针指向头结点的prev节点;2. 将头结点的next指针指向头结点的next节点的next节点。
删除尾部节点:1. 将尾节点的prev节点的next指针指向尾节点的next节点;2. 将头结点的prev指针指向尾节点的prev节点。
3. 查找操作双循环链表的查找操作可以根据节点值或者节点位置进行。
具体算法描述如下:根据节点值查找:1. 从头结点的next节点开始遍历链表,直到找到节点值等于给定值的节点或者遍历到链表尾部;2. 如果找到了该节点,则返回该节点,否则返回NULL。
根据节点位置查找:1. 从头结点的next节点开始遍历链表,直到遍历到第i个节点或者遍历到链表尾部;2. 如果找到了该节点,则返回该节点,否则返回NULL。
4. 遍历操作双循环链表的遍历操作可以从头结点的next节点开始,依次访问每个节点。
双向链表排序、插入删除等基本操作
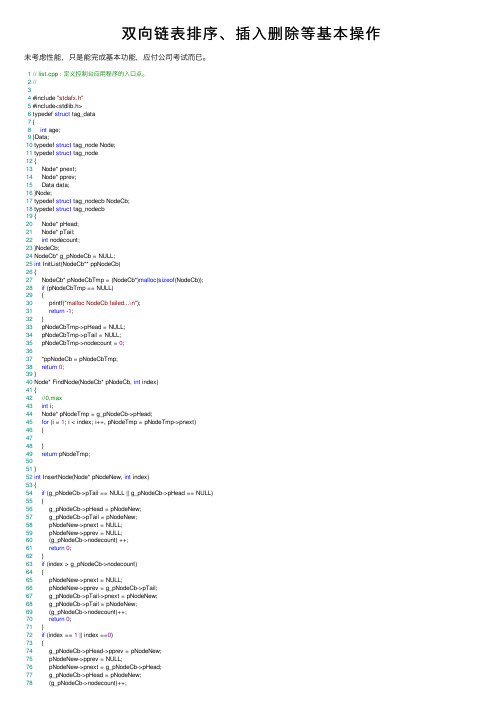
双向链表排序、插⼊删除等基本操作未考虑性能,只是能完成基本功能,应付公司考试⽽已。
1// list.cpp : 定义控制台应⽤程序的⼊⼝点。
2//34 #include "stdafx.h"5 #include<stdlib.h>6 typedef struct tag_data7 {8int age;9 }Data;10 typedef struct tag_node Node;11 typedef struct tag_node12 {13 Node* pnext;14 Node* pprev;15 Data data;16 }Node;17 typedef struct tag_nodecb NodeCb;18 typedef struct tag_nodecb19 {20 Node* pHead;21 Node* pTail;22int nodecount;23 }NodeCb;24 NodeCb* g_pNodeCb = NULL;25int InitList(NodeCb** ppNodeCb)26 {27 NodeCb* pNodeCbTmp = (NodeCb*)malloc(sizeof(NodeCb));28if (pNodeCbTmp == NULL)29 {30 printf("malloc NodeCb failed...\n");31return -1;32 }33 pNodeCbTmp->pHead = NULL;34 pNodeCbTmp->pTail = NULL;35 pNodeCbTmp->nodecount = 0;3637 *ppNodeCb = pNodeCbTmp;38return0;39 }40 Node* FindNode(NodeCb* pNodeCb, int index)41 {42//0,max43int i;44 Node* pNodeTmp = g_pNodeCb->pHead;45for (i = 1; i < index; i++, pNodeTmp = pNodeTmp->pnext)46 {4748 }49return pNodeTmp;5051 }52int InsertNode(Node* pNodeNew, int index)53 {54if (g_pNodeCb->pTail == NULL || g_pNodeCb->pHead == NULL)55 {56 g_pNodeCb->pHead = pNodeNew;57 g_pNodeCb->pTail = pNodeNew;58 pNodeNew->pnext = NULL;59 pNodeNew->pprev = NULL;60 (g_pNodeCb->nodecount) ++;61return0;62 }63if (index > g_pNodeCb->nodecount)64 {65 pNodeNew->pnext = NULL;66 pNodeNew->pprev = g_pNodeCb->pTail;67 g_pNodeCb->pTail->pnext = pNodeNew;68 g_pNodeCb->pTail = pNodeNew;69 (g_pNodeCb->nodecount)++;70return0;71 }72if (index == 1 || index ==0)73 {74 g_pNodeCb->pHead->pprev = pNodeNew;75 pNodeNew->pprev = NULL;76 pNodeNew->pnext = g_pNodeCb->pHead;77 g_pNodeCb->pHead = pNodeNew;78 (g_pNodeCb->nodecount)++;79return0;80 }8182 Node* pNodeTmp = FindNode(g_pNodeCb, index);83 pNodeNew->pnext = pNodeTmp;84 pNodeNew->pprev = pNodeTmp->pprev;85 pNodeTmp->pprev->pnext = pNodeNew;86 pNodeTmp->pprev = pNodeNew;87 (g_pNodeCb->nodecount)++;88return0;89 }90int DeleteNode(NodeCb* pNodeCb, int index)91 {92if (g_pNodeCb->pTail == NULL || g_pNodeCb->pHead == NULL)93 {94 printf("empty list...\n");95return -1;96 }97if (index == 0 || index == 1)98 {99 g_pNodeCb->pHead = g_pNodeCb->pHead->pnext;100 g_pNodeCb->pHead->pprev = NULL;101 (g_pNodeCb->nodecount)--;102//malloc的节点需要free103return0;104 }105if (index >= g_pNodeCb->nodecount)106 {107 g_pNodeCb->pTail = g_pNodeCb->pTail->pprev;108 g_pNodeCb->pTail->pnext = NULL;109 (g_pNodeCb->nodecount)--;110//malloc的节点需要free111return0;112 }113 Node* pNodeTmp = FindNode(g_pNodeCb, index);114115 pNodeTmp->pnext->pprev = pNodeTmp->pprev;116 pNodeTmp->pprev->pnext = pNodeTmp->pnext;117 (g_pNodeCb->nodecount)--;118//malloc的节点需要free119return0;120 }121int ShowList(NodeCb* pNodeCb)122 {123 Node* pNodeTmp = pNodeCb->pHead;124125for (int i = 0; i < pNodeCb->nodecount; i++, pNodeTmp = pNodeTmp->pnext) 126 printf("%d\n", pNodeTmp->data.age);127 printf("--------------------------\n");128return0;129 }130int SwapNode( Node* pNodeJ,Node* pNodeJ_1)131 {132if (pNodeJ->pprev == NULL)133 {134 pNodeJ->pnext = pNodeJ_1->pnext;135 pNodeJ_1->pnext->pprev = pNodeJ;136 pNodeJ_1->pnext = pNodeJ;137 pNodeJ->pprev = pNodeJ_1;138 g_pNodeCb->pHead = pNodeJ_1;139 pNodeJ_1->pprev = NULL;140return0;141 }142if (pNodeJ_1->pnext == NULL)143 {144 pNodeJ->pprev->pnext = pNodeJ_1;145 pNodeJ_1->pprev = pNodeJ->pprev;146 pNodeJ_1->pnext = pNodeJ;147 pNodeJ->pprev = pNodeJ_1;148 pNodeJ->pnext = NULL;149 g_pNodeCb->pTail = pNodeJ;150return0;151 }152153 pNodeJ->pprev->pnext = pNodeJ_1;154 pNodeJ_1->pprev = pNodeJ->pprev;155156 pNodeJ->pnext = pNodeJ_1->pnext;157 pNodeJ_1->pnext->pprev = pNodeJ;158 pNodeJ_1->pnext = pNodeJ;159 pNodeJ->pprev = pNodeJ_1;160return0;161162163 }164int BubbleSort(NodeCb* pNodeCb)165 {166 Node* pNodeJ = NULL;167 Node* pNodeJ_1 = NULL;168int i = 1, j = 2;169170for (i = pNodeCb->nodecount; i > 1; i--)171for (j = 1; j < i; j++)172//for (j = 1; j < pNodeCb->nodecount; j++) 173 {174 pNodeJ = FindNode(pNodeCb, j);175 pNodeJ_1 = FindNode(pNodeCb, j + 1); 176177if (pNodeJ->data.age>pNodeJ_1->data.age) 178 {179 SwapNode(pNodeJ, pNodeJ_1);180 }181 }182return0;183 }184int _tmain(int argc, _TCHAR* argv[])185 {186 Node a, b, c, d, e, f,g,h;187 a.data.age = 4;188 b.data.age = 8;189 c.data.age = 2;190 d.data.age = 5;191 e.data.age = 10;192 f.data.age = 6;193 g.data.age = 3;194 h.data.age = 1;195 InitList(&g_pNodeCb);196 InsertNode(&a, 1);197 InsertNode(&b, 10);198 InsertNode(&c, 10);199 InsertNode(&d, 2);200 InsertNode(&e, 4);201 InsertNode(&f, 10);202 InsertNode(&g, 5);203 InsertNode(&h, 6);204 ShowList(g_pNodeCb);205//DeleteNode(g_pNodeCb, 5);206//ShowList(g_pNodeCb);207 BubbleSort(g_pNodeCb);208 ShowList(g_pNodeCb);209return0;210 }。
双向循环链表的结构与定义

双向循环链表的结构与定义双向循环链表是一种常见的数据结构,它可以在链表中添加、删除、查找节点,并且可以在任意位置进行操作。
与单向链表不同的是,双向循环链表每个节点都有两个指针,一个指向前一个节点,一个指向后一个节点。
这种数据结构的优点是可以快速地在任意位置插入或删除节点。
双向循环链表的结构与定义如下:1. 结构双向循环链表由多个节点组成,每个节点包含三部分:数据域、前驱指针和后继指针。
其中,数据域存储节点的数据信息;前驱指针指向该节点的前一个节点;后继指针指向该节点的后一个节点。
2. 定义通常情况下,我们会定义一个双向循环链表类来实现这种数据结构。
类中包含以下几个基本元素:(1)头结点:头结点是一个特殊的哨兵节点,它不存储实际数据信息。
头结点的作用是方便对链表进行操作,并且可以避免处理空链表时出现异常情况。
(2)尾结点:尾结点也是一个特殊的哨兵节点,它与头结点类似,不存储实际数据信息。
尾结点的作用是方便对链表进行操作,并且可以避免处理空链表时出现异常情况。
(3)节点数目:节点数目表示当前链表中实际存储的节点数目。
当链表为空时,节点数目为0。
(4)构造函数:构造函数用于创建一个新的双向循环链表对象,并初始化头结点和尾结点。
(5)析构函数:析构函数用于销毁双向循环链表对象,并释放占用的内存资源。
(6)插入操作:插入操作可以在任意位置插入一个新的节点。
具体实现方式包括在头部插入、在尾部插入、在指定位置插入等。
(7)删除操作:删除操作可以删除任意位置的一个节点。
具体实现方式包括删除头部节点、删除尾部节点、删除指定位置的节点等。
(8)查找操作:查找操作可以根据指定条件查找符合要求的节点。
具体实现方式包括按照数据域查找、按照位置查找等。
总之,双向循环链表是一种非常重要的数据结构,它广泛应用于各种算法和程序设计中。
掌握双向循环链表的结构与定义,对于提高程序设计能力和算法水平都有很大帮助。
双向循环链表解释

双向循环链表解释
双向循环链表是一种特殊的链表结构,它与单向链表的区别在于,双向循环链表中的每个节点都有两个链接,一个指向前一个节点,另一个指向下一个节点。
这种结构使得双向循环链表在某些操作上更为高效,例如在查找中间节点或从链表两端插入或删除节点时。
在双向循环链表中,第一个节点的前一个节点是最后一个节点,最后一个节点的下一个节点是第一个节点,形成一个闭环。
这种结构使得在双向循环链表中的任何位置插入或删除节点变得简单,而无需像单向链表那样从头节点开始遍历。
双向循环链表通常使用四个字段来存储数据:两个链接字段用于存储指向前一个和下一个节点的链接,一个数据字段用于存储实际的数据,还有一个哨兵字段用于指示链表的开始和结束。
双向循环链表的主要操作包括插入节点、删除节点、查找节点等。
在插入节点时,需要更新前一个和后一个节点的链接,以使新节点成为正确的链表部分。
在删除节点时,需要更新前一个和后一个节点的链接,以移除被删除的节点。
在查找节点时,可以从任何位置开始遍历链表,直到找到所需的节点或到达链表的另一端。
双向循环链表的优点是操作效率高,可以在O(1)时间内完成插入、删除和查找等操作。
但是,与单向链表相比,双向循环链表需要更多的存储空间来存储额外的链接信息。
总之,双向循环链表是一种高效的链表结构,适用于需要在链表中频繁进行中间插入和删除操作的情况。
C语言类的双向链表详解

C语⾔类的双向链表详解⽬录前⾔双向链表的定义双向链表的创建节点的创建双向链表节点查找双向链表的插⼊双向链表的节点删除双向链表的删除总结前⾔链表(linked list)是⼀种这样的数据结构,其中的各对象按线性排列。
数组的线性顺序是由数组下标决定的,然⽽于数组不同的是,链表的各顺序是由链表中的指针决定的。
双向链表也叫双链表,是链表的⼀种,它的每个数据结点中都有两个指针,分别指向直接后继和直接前驱。
所以,从双向链表中的任意⼀个结点开始,都可以很⽅便地访问它的前驱结点和后继结点。
⼀般我们都构造双向循环链表。
双向链表的定义双链表(doubly linked list)的每⼀个元素都是⼀个对象,每⼀个对象都有⼀个数据域和两个指针front和tail。
对象中还可以包含其他辅助数据。
设L为链表的⼀个元素,L.front指向他在链表中的后继元素,L.tail指向他的前继元素。
我们可以定义⼀个结构体封装这些数据typedef struct Node{int data;struct Node* front;struct Node* tail;}NODE, * LPNODE;双向链表的创建在C++中,我们以类的形式封装了双向链表。
在类中,我们定义了两个指针,⼀个是指向链表的头部 frontNode,⼀个是指向了链表的尾部 tailNode,另外我们还加⼊了 curSize属性,记录节点的个数。
在对象创建的过程就是链表创建的过程,我们只需要在类的构造函数中初始化参数即可。
class duplexHead {public:duplexHead() {frontNode = NULL;tailNode = NULL;curSize = 0;}LPNODE createNode(int data);LPNODE seachNode(int data);void push_front(int data);void push_back(int data);void push_appoin(int posData, int data);void pop_front();void pop_back();void pop_appoin(int posData);void printByFront();void printByTail();protected:LPNODE frontNode;LPNODE tailNode;int curSize;};节点的创建在上⾯,我们已经知道双向链表的单体长啥样了,我们只需要给他的单体分配空间然后初始化他的参数即可。
双向链表上的插入和删除算法

编写程序,演示在双向链表上的插入和删除算法。
问题分析:1、在双向链表上操作首先要生成一个双向链表:1>节点定义struct DuLNode{ElemType data;DuLNode *prior;DuLNode *next;};2.> 创建双列表L=(DuLinkList)malloc(sizeof(DuLNode));L->next=L->prior=L;3>输入链表数据;2、3、对向链表进行插入操作算法:在节点p的前面加入一个新的节点q:q=(DuLinkList)malloc(sizeof(DuLNode));q->data=e;q->prior=p->prior;q->next=p;p->prior->next=q;p->prior=q;4、对双向链表进行删除操作算法删除给定节点p得到的代码如下:#include<iostream>#include<malloc.h>#define OK 1#define ERROR 0using namespace std;typedef int ElemType;typedef int status;struct DuLNode{ ElemType data;DuLNode *prior;DuLNode *next;};typedef DuLNode *DuLinkList;status DuListInsert_L(DuLinkList L,int i , ElemType e)//插入函数{DuLinkList p=L; //定义两个指向头节点的指针DuLinkList q=L;int j=0;while(p->next!=L&&j<i) //判断p是否到最后一个数据{p=p->next;j++;}if(p->next==L||j<i) //如果p是最后一个节点或者插入位置大于链表节点数{printf("无效的插入位置!\n");return ERROR;}//创建新节点q,数据为e,指针为nullq=(DuLinkList)malloc(sizeof(DuLNode));q->data=e;q->prior=p->prior;q->next=p;p->prior->next=q;p->prior=q;return OK;}status DuListDelete_L(DuLinkList L,int i , ElemType &e)//删除{DuLinkList p=L;int j=0;while(p->next!=L&&j<i){p=p->next;j++;}if(p->next==L||j<i){return ERROR;}p->prior->next=p->next;p->next->prior=p->prior;e=p->data;free(p);return OK;}int main(){ //初始化双向循环链表LDuLinkList L;L=(DuLinkList)malloc(sizeof(DuLNode)); //创建空双列表头结点L->next=L->prior=L;DuLNode *p,*q;ElemType e;//给L赋初始值p=L;q=L;while(cin>>e){p->next=(DuLNode*)malloc(sizeof(DuLNode));//分配新的节点q=p;p=p->next; //p指向新的节点p->data=e; //新结点的数据域为刚输入的ep->next=L; //新结点的指针域为头结点,表示这是单链表的最后一个结点p->prior=q;L->prior=p;}//p指向头指针,逐一输出链表的每个结点的值p=L;while(p->next!=L) //输出原列表{cout<<p->next->data<<' ';p=p->next;}cin.clear(); //清除上一个cin的错误信息cin.ignore(); //清空输入流int i;cout<<"输入待插入的元素e:";cin>>e;cout<<"输入待插入的位置i:";cin>>i;if(DuListInsert_L(L,i,e)){cout<<"插入后的双链为:";p=L;while(p->next!=L){cout<<p->next->data<<' ';p=p->next;}}printf("\n");p=L;while(p->next!=L) //输出列表{cout<<p->next->data<<' ';p=p->next;}int k;cin.clear(); //清除上一个cin的错误信息cin.ignore(); //清空输入流cout<<"要删除第几个节点k :";cin>>k;if(DuListDelete_L(L,k,e)){cout<<"被删除的元素为:"<<e<<endl;cout<<"删除后的元素为:";p=L;while(p->next!=L) //输出删除后的列表{cout<<p->next->data<<' ';p=p->next;}}elsecout<<"删除出错";return 0;}得到的结果如图罗达明电科一班学号2010301510028 2013、3、17。
便于插入和删除的数据结构,双链表,循环链表

便于插入和删除的数据结构:双链表、循环链表1.双链表双链表是一种常见的数据结构,它的每个节点包含两个指针,一个指向前一个节点,一个指向后一个节点。
相比于单链表,双链表能够更方便地进行插入和删除操作。
1.1双链表的节点结构双链表的节点结构可以定义如下:```m ar kd ow ns t ru ct No de{T d at a;//存储的数据N o de*p re v;//指向前一个节点的指针N o de*n ex t;//指向后一个节点的指针};```1.2双链表的插入操作在双链表中插入一个节点,需要将该节点的前后指针分别指向前一个节点和后一个节点,并将前一个节点的后指针和后一个节点的前指针分别指向待插入节点。
具体步骤如下:1.创建一个新节点,并给新节点赋值。
2.将新节点的前指针指向前一个节点,后指针指向后一个节点。
3.将前一个节点的后指针指向新节点,后一个节点的前指针指向新节点。
1.3双链表的删除操作在双链表中删除一个节点,需要将该节点的前后节点的指针重新连接起来,并释放待删除节点的内存空间。
具体步骤如下:1.找到待删除节点。
2.将待删除节点的前一个节点的后指针指向待删除节点的后一个节点。
3.将待删除节点的后一个节点的前指针指向待删除节点的前一个节点。
4.释放待删除节点的内存空间。
2.循环链表循环链表是一种特殊的链表,它的最后一个节点的后指针指向头节点,形成一个循环。
循环链表同样可以便于插入和删除操作。
2.1循环链表的节点结构循环链表的节点结构与单链表的节点结构相似,只是在最后一个节点的后指针处做了特殊处理:```m ar kd ow ns t ru ct No de{T d at a;//存储的数据N o de*n ex t;//指向下一个节点的指针};```2.2循环链表的插入操作循环链表的插入操作与单链表类似,只需要将插入节点的后指针指向下一个节点,并将上一个节点的后指针指向插入节点。
双向链表的增,删,改,查

双向链表的增,删,改,查由于单向链表只能从头遍历,那么在做增删改查操作时,必须从头结点开始遍历。
特别是在尾节点做追加操作时,需要将所有节点全部遍历⼀遍。
在时间上花费较多。
但是双向链表就不存在这个问题,在对双向链表做追加操作时只需要对头结点的先序节点进⾏⼀次遍历就到达了链表的尾部。
这样就⼤⼤的减少了时间上的开销。
以下是双向链表的结构⽰意图:可以看出,每个节点都有两个指针,⼀个指向前⾯,⼀个指向后⾯。
指向前⾯的叫先序节点,指向后⾯的叫后继结点。
我们通过这两个指针来访问所有节点,并通过他们来对链表进⾏操作。
双链表删除节点以下是对应代码:void DeleteNode(Node *head,int num) //删除⼀个节点{int i = 0;Node *temp = NULL;for(i=0;i<num;i++){head = head->next;}temp = head; //先暂存被删除节点head->prior->next = head->next;head->next->prior = head->prior;free(temp);printf("删除完毕\n");}双链表增加节点对应代码:void InsertNode(Node *head,int num,int data) //在第num个数后⾯插⼊⼀个节点{int i= 0;Node *temp = (Node*)malloc(sizeof(Node));Node *tp = head;temp->data = data;for(i=0;i<num&&(head->next!=tp);i++){head = head->next;}temp->next = head->next;temp->prior = head;head->next->prior = temp;head->next = temp;printf("插⼊成功\n");}为便于测试,我在这⾥贴上所有代码,如下:#define _CRT_SECURE_NO_WARNINGS#include <stdio.h>#include <string.h>#include <stdlib.h>typedef struct ListNode{int data;struct ListNode *prior; //前驱节点struct ListNode *next; //后驱节点}Node;int AddNode(Node *head,int data) //在链表尾部增加⼀个节点{Node *temp = (Node *)malloc(sizeof(Node));temp->data = data;temp->next = head;temp->prior = head->prior;head->prior->next = temp;head->prior = temp;}void PrintList(Node *head) //打印所有节点{Node *temp = head;while (head->next!=temp) //判断链表是否到了尾部{head = head->next;printf("%d ",head->data);}printf("\n");}void Reverse_PrintList(Node *head) //倒序打印所有节点{Node *temp = head;while (head->prior!=temp) //判断链表是否到了头部{head = head->prior;printf("%d ",head->data);}printf("\n");}void DeleteNode(Node *head,int num) //删除⼀个节点{int i = 0;Node *temp = NULL;for(i=0;i<num;i++){head = head->next;}temp = head; //先暂存被删除节点head->prior->next = head->next;head->next->prior = head->prior;free(temp);printf("删除完毕\n");}void InsertNode(Node *head,int num,int data) //在第num个数后⾯插⼊⼀个节点{int i= 0;Node *temp = (Node*)malloc(sizeof(Node));Node *tp = head;temp->data = data;for(i=0;i<num&&(head->next!=tp);i++){head = head->next;}temp->next = head->next;temp->prior = head;head->next->prior = temp;head->next = temp;printf("插⼊成功\n");}int main(int argc,char *argv[]){int i = 0;Node *head = (Node *)malloc(sizeof(Node));head->prior = head;head->next = head;for (i=0;i<5;i++){AddNode(head,i);}PrintList(head);AddNode(head,99);PrintList(head);InsertNode(head,6,66);PrintList(head);InsertNode(head,3,33);PrintList(head);Reverse_PrintList(head);//printf("Hello World!\r\n");system("pause");return 0;}还有些资料可以给学习的伙伴参考循环链表及线性表的应⽤单链表C语⾔编程基础C语⾔(系列“点标题下的开始学习就可以看了”)提升C编程能⼒。
双向循环链表

7 人 6 人 4 人
1
双向链表(Doubly Linked List)
如果在一个应用问题中经常要求检测指针向前驱和后继方向移动, 为保证移动的时间复杂度达到最小,就必须采用双向链表表示。
双向链表的结点结构:
左链指针 数据 右链指针
前驱结点
lLink
data
rLink
后继结点
template <class Type> class DblNode { private: Type data; DblNode <Type> * lLink, * rLink; }
2014-7-15 2
带头结点的双向循环链表 :
first
e0
e1
current
…
en-1
first 空表 游标结点: * current 游标结点的前驱结点: * ( current -> lLink ) 游标结点的后继结点: * ( current -> rLink )
2014-7-15 3
双向循环链表的类定义:
调查结果:
讲课进度: 偏快 27 人 适中 20 人 偏慢 2 人 课程难易: 太简单 1 人 偏难 9 人 太繁 1 人 讲解方法: 多讲理论、原理、方法,少讲具体程序 少讲理论,多讲程序和C++内容 多讲具体应用的完整实例 其他: 规定交作业时间,促进学生做作业; 作业太多,要少而精; 最好能现场编程、调试;
2014-7-15 4
2014-7-15
5
template <class Type> class DblList { public: DblList ( Type uniqueVal ); ~DblList ( ); int Length ( ) const; int IsEmpty ( ) { return first->rLink==first ;} int Find ( const Type & target ); Type getData ( ) const; void Firster ( ) { current = first; } int First ( ); int Next ( ); int ) { return current != NULL;} void Insert ( const Type & value ); void Remove ( ) ; private: DblNode <Type> * first, * current; }
c语言双向循环链表

c语言双向循环链表双向循环链表是一种特殊的链表结构,其中每个节点不仅包含下一个节点的指针,还包含上一个节点的指针。
它与单向链表的主要区别在于,循环链表中最后一个节点的指针指向第一个节点,而第一个节点的指针指向最后一个节点,形成了一个闭环。
在C语言中,我们可以使用结构体来定义双向循环链表中的节点。
下面是一个双向循环链表节点的定义示例:```ctypedef struct Node {int data;struct Node *prev;struct Node *next;} Node;```在上面的定义中,我们使用了一个名为`Node`的结构体来表示链表的节点。
每个节点包含一个整型数据`data`和两个指针`prev`和`next`,分别指向上一个节点和下一个节点。
接下来,我们需要定义一些用于操作双向循环链表的函数,包括插入、删除、搜索和遍历等。
首先是双向循环链表的创建函数。
该函数用于创建一个新的空链表,返回链表的头节点指针。
```cNode* createList() {Node *head = (Node*)malloc(sizeof(Node));if (head == NULL) {printf("Memory allocation failed!\n");return NULL;}head->prev = head;head->next = head;return head;}```在上述函数中,我们使用`malloc`函数动态分配了一个头节点的内存,并将头节点的`prev`和`next`指针都指向自己,形成一个空链表。
接下来,我们可以定义一个插入节点函数,用于在链表的指定位置插入一个新节点。
```cvoid insertNode(Node *head, int position, int data) {Node *newNode = (Node*)malloc(sizeof(Node));if (newNode == NULL) {printf("Memory allocation failed!\n");return;}newNode->data = data;Node *current = head->next; // 从第一个节点开始遍历int i;for (i = 1; i < position; i++) {current = current->next;if (current == head) {break; // 边界检查,防止遍历超出链表长度}}newNode->prev = current;newNode->next = current->next;current->next->prev = newNode;current->next = newNode;}```在上述函数中,我们首先创建了一个新节点`newNode`并为其分配内存。
数据结构之链表篇(单链表,循环链表,双向链表)C语言版

数据结构之链表篇(单链表,循环链表,双向链表)C语⾔版1.链表 链表是线性表的⼀种,由⼀系列节点(结点)组成,每个节点包含⼀个数据域和⼀个指向下⼀个节点的指针域。
链表结构可以克服数组需要预先知道数据⼤⼩的缺点,⽽且插⼊和删除元素很⽅便,但是失去数组随机读取的优点。
链表有很多种不同类型:单向链表,双向链表和循环链表。
在链表中第⼀个节点叫头节点(如果有头节点)头节点不存放有效信息,是为了⽅便链表的删除和插⼊操作,第⼀个有效节点叫⾸节点,最后⼀个节点叫尾节点。
2.单链表的操作 链表的操作⼀般有创建链表,插⼊节点,删除节点,遍历链表。
插⼊节点的⽅法有头插法和尾插法,头插法是在头部插⼊,尾插法是在尾部插⼊。
下⾯以⼀个带头节点,采⽤尾插法的链表说明链表的各种操作。
1 #include<stdio.h>2 #include<stdlib.h>3//单链表456//节点结构体7 typedef struct node8 {9int value;//数据域10struct node*next;//指针域11 }Node;1213 Node*createList();//创建链表并且返回头节点指针14void deleteNode(Node*head);//删除节点15void insertNode(Node*head);//插⼊节点16void travelList(Node*head);//遍历链表1718int main()19 {20 Node*head=createList();21 travelList(head);22 insertNode(head);23 travelList(head);24 deleteNode(head);25 travelList(head);26return0;27 }28//创建链表,返回头节点指针29 Node*createList()30 {31//采⽤尾插法32 Node*head;//头节点33 Node*tail;//尾节点34 Node*temp=NULL;35int i,value,size;36 head=(Node*)malloc(sizeof(Node));//头节点37 head->value=0;38 head->next=NULL;39 tail=head;40 printf("输⼊节点个数: ");41 scanf("%d",&size);42 printf("输⼊各个节点的值: ");4344for(i=0;i<size;i++)45 {46 scanf("%d",&value);47 temp=(Node*)malloc(sizeof(Node));48 temp->value=value;49 tail->next=temp;//让尾节点的指针域指向新创建的节点50 tail=temp;//尾节点改为新创建的节点51 tail->next=NULL;//让尾节点的指针域为空52 }53return head;54 }55//遍历链表56void travelList(Node*head)57 {58while(head->next!=NULL)59 {60 printf("%d\n",head->next->value);61 head=head->next;62 }63 }64//插⼊节点65void insertNode(Node*head)66 {67int value;68int position;69int pos=0;70 Node*pre=NULL;//⽤来保存要插⼊节点的前⼀个节点71 Node*newNode;72 printf("输⼊要插⼊节点的值: ");73 scanf("%d",&value);74 printf("要插⼊的位置: ");75 scanf("%d",&position);76while(head!=NULL)77 {78 pos++;79 pre=head;80 head=head->next;81if(pos==position)82 {83 newNode=(Node*)malloc(sizeof(Node));84 newNode->value=value;85 newNode->next=pre->next;86 pre->next=newNode;87 }88 }89 }90//删除节点91void deleteNode(Node*head)92 {93int value;94 Node*pre=head;95 Node*current=head->next;96 printf("输⼊要删除节点的值: ");97 scanf("%d",&value);98while(current!=NULL)99 {100if(current->value==value)101 {102 pre->next=current->next;103free(current);//释放空间104break;105 }106 pre=current;107 current=current->next;108 }109 }3.循环链表 循环链表就是让尾节点的指针域不再是NULL,⽽是指向头节点从⽽形成⼀个环。
双链表——精选推荐

双链表双向链表的定义双向链表也是链表的⼀种,它每个数据结点中都有两个结点,分别指向其直接前驱和直接后继。
所以我们从双向链表的任意⼀个结点开始都可以很⽅便的访问其前驱元素和后继元素。
第⼀就是头节点的前驱指针指向NULL空指针。
第⼆就是尾节点的后驱指针指向NULL指针。
双向链表的结构:双向链表的操作1. 创建双链表2. 新增节点(在链表尾插⼊)3. 从头遍历链表4. 判断链表是否为空5. 计算链表长度6. 从链表删除节点7. 删除整个链表8. 获取某个节点对象9. 从⼀个节点向前遍历10. 从⼀个节点向后遍历节点类型定义⼀个节点有⼀个前驱节点、⼀个后驱节点,和数据。
typedef struct doubleLink doubleLinkNode;struct doubleLink{int value ;doubleLinkNode *pre;doubleLinkNode *next;};创建双链表的头节点创建节点,必须使⽤malloc为节点分配内存,头节点不存储数据,且前驱指针为空,此时刚创建双链表,所以头指针的后驱指针也为空。
//创建双链表的头节点doubleLinkNode * create(){doubleLinkNode *head;head = (doubleLinkNode*)malloc(sizeof(doubleLinkNode));head->pre = NULL;head->next =NULL;return head;}新增节点,在链表尾插第⼀条判断语句是判断头指针为NULL时,返回-1,当链表被删除,头指针为NULL,然后新建node节点,它的后驱指针为NULL,它的前驱指针为原来的最后的节点,所以原来最后的节点的后驱指针变为它,它为双链表的最后⼀个节点。
int add(doubleLinkNode *head,int value){if(head == NULL)return -1;doubleLinkNode *t=head;doubleLinkNode *node;node = (doubleLinkNode*)malloc(sizeof(doubleLinkNode));//此节点的后驱指针为NULL,添加后,它为最后⼀个节点node->next =NULL;node->value =value;//找到最后⼀个节点,最后⼀个节点的后驱指针为空while(t->next!=NULL){t=t->next;}//此节点的前驱指针指向原本的最后⼀个节点,它成为最后⼀个节点node->pre = t;//原本最后节点的后驱指针此节点t->next = node;return1;}从头遍历链表最后⼀个指针的NULL为空,这是我们判断的依据,所以判断t->next,直⾄判断到最后⼀个节点,这⾥双链表的头指针是没有数据的,但是直接判断完t->next,然后对t赋值,是不会打印头指针的。
c语言双向循环表

c语言双向循环表各位编程小伙伴们!今天咱们要一起扒一扒C语言里一个挺有意思的家伙——双向循环表。
你可以把它想象成是一列超级灵活的小火车,每节车厢都知道自己前后都跟着谁,而且这火车还能循环跑,是不是感觉挺奇妙的?首先呢,咱们得搞清楚啥是双向循环表。
简单来说,它就是一种数据结构,里面的每个节点都有两个指针,一个指向前一个节点,就像是小火车车厢里有个小箭头指着前面那节车厢;另一个指针指向后一个节点,也就是还有个小箭头指着后面那节车厢。
而且啊,这列小火车的头和尾还连在一起,形成了一个循环,就好像小火车在一个环形轨道上跑,永远不会停下来(除非咱们让它停 )。
那为啥要有这么个双向循环表呢?这就好比你在一个大迷宫里,有了前后两个方向的指引,你就不容易迷路啦。
在编程里也是一样的道理,这种结构让我们在操作数据的时候更加方便。
比如说,你要查找某个节点,既可以从前往后找,也可以从后往前找,这可比单向链表灵活多了。
咱们来看看怎么创建一个双向循环表吧。
这就像是搭建小火车的车厢,首先得有个节点的结构体,里面除了要存放数据,还得有那两个指针。
然后呢,我们可以通过不断地创建新节点,把它们一个一个地连起来,就像把车厢一节一节地挂到小火车上。
在连接的时候,要注意把指针的方向设置对,不然这小火车可就乱套啦,说不定会朝着错误的方向跑出去 。
插入节点也是个有趣的操作。
想象一下,现在要在小火车中间加一节新车厢。
我们得先找到要插入的位置,然后把新节点的前后指针和周围的节点连接好,就好像小心翼翼地把新车厢挂到合适的位置,还要确保它和前后的车厢都连接牢固。
删除节点呢,就像是把某节车厢从火车上卸下来,要把它前后的车厢重新连接好,不能让小火车断成两截。
遍历双向循环表也有它的小窍门。
因为它是循环的,所以我们在遍历的时候得注意设置好结束条件,不然这小火车就会一圈一圈地跑个没完没了,就像陷入了一个无限循环的怪圈 。
可以通过记录已经遍历过的节点数量或者设置一个特殊的标记来判断什么时候该停下来。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
#include <stdio.h>
#include <stdlib.h>
typedef struct list
{
int data;
struct list *left,*next;
}List;
////*************** 建立空链表*******************/////
List * CreatList( void )
{
List * head=(List *)malloc(sizeof(List));
if(head==NULL)
{
printf("分配失败!\n");
return 0;
}
head->left=head->next=head; //双向链表结束标志为,尾到了头!
return head;
}
int InsertList(List * head,int value) //头结点是确定的,不需要每次都返回头结点了!!!{
List *newnode,*p;
if(head==NULL)
{
//你建立的是个带头结点的表,如果表是头是空,那么应该报错了!
printf("no head node!\n");
return -1;
}
newnode=(List *)malloc(sizeof(List));
if(newnode==NULL)
{
printf("分配失败!\n");
return -1;
}
newnode->data=value;
p=head ;
while(p->next!=head) //这里是为了找到表尾
{
p=p->next;
}
/**//**//**//**//**//**//**//**//**//**//**//**//**//**/
/***************将数据插入表尾位置*********************/ /**/ newnode->next=p->next ; /**/
/**/ p->next=newnode; /**/
/**/ newnode->left=p; /**/
/**//**//**//**//**//**//**//**//**//**//**//**//**//**/
////free(newnode); //这个结点(指针)你还要用,不能释放。
return 0;
}
void Find(List *head,int find)///查找并显示位置
{
List *p;
int i=0;
p=head;
while(p!=head)
{
p=p->next;
i+=1;
if(p->data==find)
{
printf("要查找的数%d 是第%d 个\n",find,i);
}
}
if(p->data!=find && p->next==head)
{
printf("连表里没有要查找的数%d!\n",find);
}
}
void print(List *head)//打印链表,并显示长度
{
//head=(List *)malloc(sizeof(List)); 遍历表不需要新分配空间!这样做会丢失掉原有的地址!!改成如下:
int i=0;
List *p=head->next ;
while(p!=head) //head一直要保证不变,这样,你才能正常转一圈
{
printf("%d ",p->data);
p=p->next;
i+=1;
}
printf("链表长度为%d \n",i);
printf("\n");
}
List * Delete(List *head ,int x)///删除数据操作
{
List *p;
int i=0;
p=head->next;
p=p->next;
while(p->next!=head)
{
p=p->next;
i+=1;
if(p->data!=x && p->next==head)
{
printf("没有要删除的数%d!\n",x);
}
else if(p->data==x)
{
/**//**//**//**//**//**//**//**//**//**//**//**//**//**/
/*************** 将数据删除操作*********************/
/**/ p->left->next=p->next; /**/
/**/ p->next->left=p->left; /**/
/**/ p=p->next; /**/
/**//**//**//**//**//**//**//**//**//**//**//**//**//**/
printf("要删除的数%d 是第%d 个\n",x,i);
}
}
return head;
}
int main()
{
List *head=NULL;
//CreatList(head); 这句带不回来指针值的!!!
head= CreatList();
InsertList(head,10);
print(head); //
Delete(head,10);
print(head);
Find(head,10);
return 0;
}。