刘红杰关于异常下限的几种计算方法
背景值及异常下限

求区域背景值的方法就用黎彤的克拉克值就可以。
设:T=黎彤的克拉克值E=光谱分析的测试值E=2的(n-1)次方*T求出的n值就是改元素的丰度值。
n的大小就能反映他的富集程度。
新方法哦。
异常下限(threshold of anomaly)是根据背景值和标准离差按一定置信度所确定的异常起始值。
它是分辨地球化学背景与异常的一个量值界限。
从这个数值起,所有的高含量都可认为是地球化学异常,低于这个数值的所有含量则属于地球化学背景范围。
异常下限多用统计学方法求得,通常用背景平均值加上两倍或三倍标准差作为异常下限。
[1异常下限(threshold of anomaly)是根据背景值和标准离差按一定置信度所确定的异常起始值。
它是分辨地球化学背景与异常的一个量值界限。
从这个数值起,所有的高含量都可认为是地球化学异常,低于这个数值的所有含量则属于地球化学背景范围。
通常异常下限求得,即采用“迭代法”来求得,具体操作为:1、先计算背景平均值,及标准差。
2、背景平均值加上三倍标准差作为一个参照数,寻找分析数据中是否有大于这个参照数。
有的话,删除。
3、删除后的数据,又进行计算背景平均值,及标准差。
按背景平均值加上三倍标准差方法得出新的参照数,寻找分析数据中的大于这个参照数,有的话,删除。
4、循环执行第3步,直至数据不存在大于背景平均值加上三倍标准差的数时,才取这时的背景平均值加上三倍标准差的值为异常下限。
有时候可以用1.5,2 3倍标准差计算异常下限)也可通过LOG10()函数将原数据转为对,用上述方法进行计算。
近年来,随着分形理论的深入,采取分形技术也可求取一个拐点值,采取其中一个合适的值作为异常下限,从而圈定异常!楼主这个算法是通常的生产中的经验,一般的都这么算。
但楼主忽略了一个东西,那就是算出来的是理论异常下限,生产中的异常下限,我们通常都要进行校正。
校正主要是考虑该区域所处的大背景。
在excel中的计算方法1选择数据,进行升序排列在EXCEL中的公式中有计算标准离差的公式平均值:X=average键入:“=average(b2:b25)”[b2、b25.代表数据所在的行数和列数]计算出某元素的平均值。
数据挖掘中的异常检测算法与模式识别技巧

数据挖掘中的异常检测算法与模式识别技巧在数据挖掘领域,异常检测算法和模式识别技巧是非常重要的工具。
异常检测算法可以帮助我们识别数据中的异常值,而模式识别技巧可以帮助我们发现数据中的隐藏模式。
本文将介绍常用的数据挖掘中的异常检测算法和模式识别技巧,并讨论它们在实际应用中的作用和挑战。
一、异常检测算法1. 基于统计方法的异常检测算法基于统计方法的异常检测算法是最常见且基础的方法之一。
它基于数据的统计特性,通过计算数据点与整体数据分布之间的差异来判断数据点是否为异常值。
常见的统计方法包括Z得分、箱线图法和概率分布模型等。
2. 基于机器学习的异常检测算法基于机器学习的异常检测算法能够自动学习数据的模式和规律,并通过与已有模型的比较来判断数据点是否为异常。
常用的机器学习算法包括支持向量机、决策树和随机森林等。
3. 基于聚类分析的异常检测算法基于聚类分析的异常检测算法将数据点根据其相似性进行分组,然后通过计算数据点与其所属群集之间的距离来判断数据点是否为异常。
这种方法对于无监督学习的异常检测非常有效。
二、模式识别技巧1. 特征选择和降维在模式识别中,特征选择和降维是重要的技巧。
特征选择可以帮助我们选择最相关的特征,从而减少噪声的干扰和计算的复杂性。
降维可以将高维数据转化为低维表示,减少计算成本并提高模型的泛化能力。
2. 数据清洗和预处理数据清洗和预处理是模式识别中不可或缺的步骤。
数据清洗可以帮助我们去除无效或重复的数据,预处理可以对数据进行标准化、归一化和平滑处理,以便提高模型的性能和稳定性。
3. 特征提取和特征表示特征提取和特征表示是模式识别中的核心任务。
特征提取可以帮助我们从原始数据中提取最具有代表性和区分性的特征,特征表示可以将这些特征表示为机器学习算法所能理解的形式,如向量或矩阵。
三、异常检测算法与模式识别技巧的应用和挑战异常检测算法和模式识别技巧在各个领域都有广泛的应用,如金融欺诈检测、网络入侵检测和医学诊断等。
数据分析中的异常检测算法

数据分析中的异常检测算法在数据分析领域,异常检测算法是一项重要的技术,旨在发现数据集中与正常模式不符的异常值或异常行为。
异常值可能是由错误、噪声、欺诈、系统问题或其他未知因素引起的。
通过及时检测和处理这些异常值,可以有效提高数据分析的准确性和可靠性。
本文将介绍几种常用的数据分析中的异常检测算法。
一、统计方法统计方法是最常用的异常检测算法之一。
在统计方法中,可以使用均值、标准差、中位数等统计量来描述数据的分布情况,并利用这些统计量来判断数据是否偏离正常模式。
常用的统计方法包括Z-Score方法和箱线图法。
1. Z-Score方法Z-Score方法是一种常用的统计方法,用于检测数据集中的异常值。
该方法通过计算数据点与数据集均值之间的标准偏差的倍数,判断数据点是否偏离正常模式。
如果Z-Score的绝对值大于某个阈值(通常设为3),则认为该数据点为异常值。
2. 箱线图法箱线图法是另一种常用的统计方法,用于检测数据集中的异常值。
该方法通过绘制数据的箱线图,观察数据是否超出上下四分位之间的范围。
如果数据超过上下四分位的1.5倍的四分位距范围,那么被认为是异常值。
二、聚类方法聚类方法是一种基于数据挖掘的异常检测算法。
在聚类方法中,可以将数据点分为不同的簇或群组,然后通过计算数据点与所属簇的距离来判断数据是否异常。
常用的聚类方法包括K均值聚类和DBSCAN聚类。
1. K均值聚类K均值聚类是一种常用的聚类方法,用于将数据点分为K个簇。
在K均值聚类中,通过计算数据点与每个簇的距离,并将数据点分配给距离最近的簇。
如果某个数据点与所属簇的距离大于某个阈值,则认为该数据点为异常。
2. DBSCAN聚类DBSCAN聚类是一种密度聚类方法,用于将数据点分为簇。
在DBSCAN聚类中,通过定义邻域半径和最小邻域样本数量,来计算数据点的密度。
如果某个数据点的密度低于某个阈值,并且没有足够的邻居点,则认为该数据点为异常。
三、机器学习方法机器学习方法是一种基于模型的异常检测算法。
机器学习算法概览:异常检测算法常见算法深度学习

机器学习算法概览:异常检测算法常见算法深度学习本⽂是对机器学习算法的⼀个概览,以及个⼈的学习⼩结。
通过阅读本⽂,可以快速地对机器学习算法有⼀个⽐较清晰的了解。
本⽂承诺不会出现任何数学公式及推导,适合茶余饭后轻松阅读,希望能让读者⽐较舒适地获取到⼀点有⽤的东西。
本⽂主要分为三部分,第⼀部分为异常检测算法的介绍,个⼈感觉这类算法对监控类系统是很有借鉴意义的;第⼆部分为机器学习的⼏个常见算法简介;第三部分为深度学习及强化学习的介绍。
最后会有本⼈的⼀个⼩结1 异常检测算法异常检测,顾名思义就是检测异常的算法,⽐如⽹络质量异常、⽤户访问⾏为异常、服务器异常、交换机异常和系统异常等,都是可以通过异常检测算法来做监控的,个⼈认为这种算法很值得我们做监控的去借鉴引⽤,所以我会先单独介绍这⼀部分的内容。
异常定义为“容易被孤⽴的离群点 (more likely to be separated)”——可以理解为分布稀疏且离密度⾼的群体较远的点。
⽤统计学来解释,在数据空间⾥⾯,分布稀疏的区域表⽰数据发⽣在此区域的概率很低,因⽽可以认为落在这些区域⾥的数据是异常的。
图1-1离群点表现为远离密度⾼的正常点如图1-1所⽰,在蓝⾊圈内的数据属于该组数据的可能性较⾼,⽽越是偏远的数据,其属于该组数据的可能性就越低。
下⾯是⼏种异常检测算法的简介。
1.1 基于距离的异常检测算法图1-2 基于距离的异常检测思想:⼀个点如果⾝边没有多少⼩伙伴,那么就可以认为这是⼀个异常点。
步骤:给定⼀个半径r,计算以当前点为中⼼、半径为r的圆内的点的个数与总体个数的⽐值。
如果该⽐值⼩于⼀个阈值,那么就可以认为这是⼀个异常点。
1.2 基于深度的异常检测算法图1-3 基于深度的异常检测算法思想:异常点远离密度⼤的群体,往往处于群体的最边缘。
步骤:通过将最外层的点相连,并表⽰该层为深度值为1;然后将次外层的点相连,表⽰该层深度值为2,重复以上动作。
可以认为深度值⼩于某个数值k的为异常点,因为它们是距离中⼼群体最远的点。
异常检测算法综述

异常检测算法综述异常检测算法是用于在数据集中识别和捕获异常值或不寻常模式的方法。
这些异常可以是由错误或异常情况引起的,也可以是罕见但合法的数据点。
异常检测在许多领域都有应用,包括金融、网络安全、医疗诊断和工业制造等。
在异常检测算法中,常用的方法包括基于统计学的方法、基于机器学习的方法和基于局部离群因子的方法。
基于统计学的方法主要依赖于一些统计属性来判断一个数据点是否异常。
其中最简单的方法是使用均值和标准差来判断一个数据点是否位于正常范围内。
如果一个数据点的值超出了均值加减三倍标准差的范围,则可以认为它是异常的。
然而,这种方法在处理非高斯分布的数据时效果较差。
因此,还有一些其他的方法,如基于箱线图的方法、百分位数和离群值因子等。
基于机器学习的方法使用机器学习模型来对正常和异常数据进行建模和分类。
这些模型可以是有监督的或无监督的。
有监督的方法需要标记的训练数据,用于学习正常和异常样本的特征。
常见的有监督方法包括支持向量机、K最近邻和决策树等。
无监督的方法不需要标记的训练数据,而是通过学习数据本身的特征来识别异常值。
常见的无监督方法包括聚类、主成分分析和孤立森林等。
基于局部离群因子的方法是一种将异常检测问题转化为相对于其邻近点的密度的问题。
该方法可以通过计算每个数据点和其邻近点之间的距离来确定异常值。
如果一个数据点的邻近点相对较少或密度相对较低,则可以认为它是异常的。
此外,通过使用密度估计方法,如局部离群因子和K 最近邻法,还可以确定异常值的分数。
除了这些常见的异常检测方法,还有一些其他的方法,如基于聚类的方法、孤立子空间和演化算法等。
在实际应用中,异常检测算法的选择取决于具体的数据集和异常检测的要求。
没有一种方法适用于所有情况。
因此,根据数据的特点和问题的要求,选择最适合的异常检测算法是非常重要的。
总之,异常检测算法在数据分析中起着重要的作用。
通过使用基于统计学的方法、基于机器学习的方法和基于局部离群因子的方法,可以有效地识别和捕获异常值,提高数据分析的准确性和可靠性。
莱茵达法则检验异常值的步骤

莱茵达法则检验异常值的步骤摘要:1.莱茵达法则简介2.莱茵达法则检验异常值的步骤3.莱茵达法则在回弹法检测砼强度中的应用4.结论正文:一、莱茵达法则简介莱茵达法则,又称为3σ法则,是一种常用的检验数据异常值的方法。
该法则的基本思想是:在一个正常的数据分布中,约有99.7% 的数据会落在均值加减3 个标准差的范围内,而异常值就是那些不在这个范围内的数据。
因此,通过计算数据分布的均值和标准差,可以判断数据中是否存在异常值。
二、莱茵达法则检验异常值的步骤1.计算数据集的均值和标准差:首先,对给定的数据集进行求均值和标准差的操作。
标准差可以反映数据的离散程度,它越大表示数据的波动性越大,反之亦然。
2.确定3σ界限:根据正态分布的性质,我们知道在均值加减3 个标准差的范围内,包含了约99.7% 的数据。
因此,我们可以将这个范围作为判断异常值的界限。
3.判断异常值:将数据集中的每个数据点与3σ界限进行比较,如果某个数据点超出了这个范围,则可以判断它是一个异常值。
三、莱茵达法则在回弹法检测砼强度中的应用回弹法是一种常用的检测砼强度的方法,它通过对砼表面进行回弹测试,根据回弹的反弹程度来推断砼的强度。
然而,由于测试过程中受到各种因素的影响,测试数据中很可能存在异常值。
这时,我们可以使用莱茵达法则来判断和处理这些异常值。
具体操作步骤如下:1.对每批砼样本进行回弹测试,得到一组测试数据。
2.计算这组数据的均值和标准差。
3.根据3σ法则,确定异常值的界限。
4.将每个数据点与3σ界限进行比较,判断是否存在异常值。
如果存在异常值,可以采取相应的处理措施,如重新进行测试等。
通过以上步骤,可以有效提高回弹法检测砼强度的准确性,从而保证工程质量。
四、结论莱茵达法则是一种简单有效的检验数据异常值的方法,适用于各种数据集。
机器学习算法的异常检测与处理方法介绍

机器学习算法的异常检测与处理方法介绍在现代社会中,随着大数据时代的到来,机器学习算法成为了一种重要的技术工具。
机器学习算法的应用广泛,包括图像识别、自然语言处理、数据挖掘等领域。
然而,随着数据规模的不断增大,我们面临一个重要的问题:如何检测和处理异常数据?异常数据是指在数据集中与其他数据点具有明显差异的数据。
异常数据或离群点对于机器学习算法来说可能会产生严重的影响,因为它们可能导致模型的偏差。
因此,异常检测和处理对于保证机器学习算法的准确性和鲁棒性至关重要。
在机器学习中,我们经常使用的异常检测算法包括基于统计方法的异常检测和基于机器学习的异常检测。
下面我将分别介绍这两种方法。
基于统计方法的异常检测,是利用数据集的统计特性来寻找异常值。
其中最常用的方法是孤立森林算法。
孤立森林算法基于随机森林的思想,通过构建一棵由许多随机划分的二叉树来判断异常值。
该算法通过比较异常样本与正常样本在随机选择的特征上离根节点的远近来进行异常检测。
孤立森林算法的优点是可以处理多维数据和高维数据,并且不受数据分布的影响。
另一种基于统计方法的异常检测算法是离散概率检测算法。
该算法基于数据集中样本的分布情况来判断异常值。
具体的方法包括使用概率密度函数、直方图和K近邻算法等。
这些方法通过计算样本在概率分布曲线上的位置或与邻近样本的距离来确定异常值。
这些方法对于数据集的分布情况要求较高,对于非常规数据集可能效果不佳。
除了基于统计方法的异常检测,还有一种常用的方法是基于机器学习的异常检测。
这种方法使用训练集中的正常数据来构建一个正常模型,然后通过与新样本的比较来判断其是否为异常。
最常用的机器学习算法包括支持向量机、聚类算法和深度学习算法等。
支持向量机是一种常用的分类算法,可以通过最大化分类间距来找出异常值。
支持向量机通过将样本映射到高维空间,通过寻找分隔超平面来找到最大间隔。
在分类过程中,距离超平面较远的样本被认为是异常值。
支持向量机的优点是可以处理高维数据,但对于大规模的数据集计算复杂度较高。
异常数据处理常用技巧介绍

异常数据处理常用技巧介绍异常数据处理常用技巧介绍1. 异常数据的定义异常数据,也称为离群点或异常值,是指与数据集中的其他数据明显不同的数据点。
它们可能是由于测量误差、数据录入错误、设备故障、不完整数据或真实世界中的罕见事件而产生的。
处理异常数据是数据分析中的重要任务,因为它们可能对结果产生不良影响。
2. 异常数据处理的重要性处理异常数据的目的是识别和纠正异常值,以确保数据分析的准确性和可靠性,并提高模型的预测能力。
如果不对异常数据进行处理,它们可能导致错误的结论、不准确的预测或对模型的性能产生负面影响。
3. 异常数据处理的常用技巧以下是几种常用的技巧,可用于处理异常数据:3.1 识别异常数据需要识别数据集中的异常数据。
可以使用统计方法、可视化方法或机器学习算法来辅助确定异常数据。
统计方法包括使用均值和标准差来识别超出正常范围的数据点。
可视化方法可使用箱线图、直方图或散点图来可视化数据分布,从而帮助发现异常数据。
机器学习算法可以使用聚类或异常检测算法来自动识别异常数据。
3.2 删除异常数据删除异常数据是最简单和最常见的处理方法。
如果异常数据是由于数据录入错误或测量误差导致的,可以将其从数据集中删除。
然而,在删除异常数据之前,需要仔细考虑异常数据的原因以及删除它们对分析的影响。
3.3 替换异常数据替换异常数据是一种常见的方法,可以用数据集中的其他值来代替异常值。
替换异常数据的方法包括使用均值、中位数、众数或回归模型来估计异常值。
需要根据数据的性质和分布选择合适的替换方法,并进行仔细的评估和验证。
3.4 剔除异常数据剔除异常数据是一种更严格的处理方法,可以将异常数据视为干扰,完全从数据集中剔除。
这种方法适用于异常数据对分析结果造成极大影响的情况,但需要慎重使用,因为可能剔除了有用的信息。
3.5 分箱处理异常数据分箱处理异常数据是一种将异常数据放入合适的箱子或类别中的方法。
分箱可以根据数据的特点和分布进行划分,将异常值与普通值分开,从而提高模型的鲁棒性。
数据流中的异常检测算法选择比较分析

数据流中的异常检测算法选择比较分析引言:随着互联网和物联网的快速发展,大量的数据以高速流入系统中,对实时数据流中的异常进行检测变得尤为重要。
异常检测算法可以帮助我们快速识别数据流中的异常情况,从而及时采取措施。
本文将对常见的数据流中异常检测算法进行比较分析,以便为实际应用提供指导。
一、数据流中的异常检测算法概述数据流中的异常检测算法主要包括基于统计学的方法、基于聚类的方法、基于分类的方法和基于时间序列的方法。
以下将简要介绍这些方法。
1. 基于统计学的方法基于统计学的方法使用概率和统计分析来识别数据流中的异常。
常见的统计学异常检测算法包括Z-Score算法、箱线图算法和Grubbs' Test算法。
这些算法通过统计学方法计算数据点与均值之间的距离来判断异常情况。
2. 基于聚类的方法基于聚类的方法通过将数据分成不同的群集来识别异常。
常见的聚类算法包括K-Means算法和LOF(Local Outlier Factor)算法。
这些算法通过计算数据点之间的距离或相似度来确定异常点。
3. 基于分类的方法基于分类的方法利用已知的类别信息来判断数据是否异常。
常见的分类算法包括支持向量机(Support Vector Machine)算法和决策树算法。
这些算法使用已标记的数据对异常进行分类判断。
4. 基于时间序列的方法基于时间序列的方法通过对数据流进行时间分析来识别异常。
常见的时间序列异常检测算法包括孤立森林(Isolation Forest)算法和ARIMA(Autoregressive IntegratedMoving Average)算法。
这些算法在时间维度上分析数据,识别异常的频率和规律。
二、算法选择比较分析下面将对数据流中的异常检测算法进行比较分析,包括准确性、计算复杂度、鲁棒性以及适用性等方面。
1. 准确性准确性是衡量一个算法好坏的重要指标之一。
在实际应用中,我们希望异常检测算法能够尽可能准确地识别异常情况。
算异常下限的步骤

算异常下限的步骤打开异常下限→考入数据→点击打开→清空→D盘数据考入→保存→关闭→计算二(三)倍数→查看剖面制图方法电子表格(原始数据)→粘到记事本上→投影变换→形成属性点→空间分析→DTM →打开文件→打开数据文件(点文件)→属性点文件→处理点线→点数据高程点提取→点高程值→确定→模型应用→高程剖面分析→交互造成→确定(出现笔)→点击剖面起始点(可以输入)→确认→(用笔)找剖面终点(左击)→确认→右击→否→进入剖面线分析→参数设置→间距(第一行X=4,Y一般为50)→缩放比(X-1,Y-0.1)→步距值(插值间隔)10→选中转折点坐标→X轴线参数(自设)→Y 轴线参数(自设)→转折点轴线参数→仅处理剖面直方图数字填图→打开属性工程文件→综合数据处理→地球化学图(网格化数据)→选择图层(真值属性点)→选择等值线字段(单元素)→AU→点计算数字特征→点计浏览详细数字特征值→频数(真值,对数时用频率)→点击等间距分级→起点用最小值→点击分级数(9)→点击直方图→右击→保存图件→起名→保存文本统改属性点编辑→编辑点属性结构→加注释→回车→字符串→回车→字串长(20)→回车→OK→点编辑→注释赋为属性→OK→点编辑→根据属性赋参数→点击注释→(上行)注释后加“=.=”→在其后加“”号(双引号)→确定→注释确定→改替换结果条件→确定?统改属性打开要统改的属性文件→点编辑→编辑点属性结构→下拉到空格处→(打字)加“注释”→字符串→回车生成地球化学图数字填图→打开属性工程文件→综合数据处理→等值线图→选择图名(真值属性点) →选择等值线字段(单元素) →Au→(计算数字特征) →计算Log10对数数字特征→不点网格化方法选择→点击选中TIN方法→文件名→起名→OK→设置→选中等值线套区,光滑→等值层值→起始Z(负数第二位是3,正数第二位是7)包括段起始值→步长增为0.1→更新当前分段→确认→线参数→线宽0.1→颜色160→线参数下拉→注记参数→频度1→注记等值线线宽值0.1→注记格式(不管) →注记字体1.5→确定→确定→确定→删除点线面(已有) →重新进入综合数据处理→计算数字特征(真值) →TIN文件名Au1→OK→设置(点1行) →光滑(点1行) →起始Z用分区最小值→步长增默认(10) →改分区→线宽0.3(其它不变) →区改颜色→低值区用55→低背景区53→背区128→高背景区164→高值区173→注记参数→频度1→线宽0.3→注记格式(AU是一位,AG是3位) →字体(1.5) →注记颜色(区分对) →对数的颜色用3→确定→替换点参数→子图确定→条件1002(子图号)改为247→确定→是(全修) →保存→处理(替换参数高度是3) 改为10层→关所有图改10层→删掉10层→添加(第二次做)点线面→合并成图.生成地球化学图(mapgis)空间分析→DTM→文件→打开数据文件→点文件→属性点→处理点线→点数据高程点提取→各种元素→GRD模型→离散数据网格化→确定→GRD平面等值线绘制→开TWPCRD文件→等值线光滑处理→等值线定值层→起名Z???段起始值???更新当前分段→确定→线参数→线宽0.1→图层(?AU)→颜色→确定→注记参数→频度(1)→线宽0.1→字体1.5→确定→另存→保存点→保存线→GRD模型→平面等值线图绘制→(双击)打开→等值线套区→等值线光滑处理→等值层值→高低背景区数值→线参数→0.3→图层颜色→?→确定→制图检测设置→原始数据范围→区参数→频度→线宽0.3→字体→1.5→确定→保存→点→线→区地质图误差校正1、实用服务→误差校正→文件→打开文件→(打开被校正的文件,两种文件全打开)→1:1→对话框→选中需要校正的文件→确定→控制点→S设置控制点参数→实际值→采集搜索范围为4→E采集文件→添加→是???、2、正确标准图框→1:1→控制点→S设置控制点参数→理论值→4→确定→E采集文件→图框文件→添加→输入1.2.3.4各项分别确定→1:1→图框确定→数据校正→线文件(点文件。
浅析化探异常下限的确定方法

2016年 2月上 世界有色金属37C omprehensive综合浅析化探异常下限的确定方法王 峰,何 军(陕西地矿汉源玉业有限公司,陕西 汉中 723000)摘 要:化探,即勘查地球化学,数据处理中异常下限值的确定至关重要,它决定着异常区域范围的大小,关乎着化探工作的成败。
目前确定异常下限值的方法众多,而各种方法又有其自身的应用前提和不足之处,容易使人混淆不清,因此笔者将各种化探方法进行浅析,以期对化探工作者有所参考。
关键词:化探;异常下限;传统统计法;分形;趋势面;中图分类号:P632 文献标识码: A 文章编号:1002-5065(2016)03-0037-3The discussion on the methods of how todetermine the low limit of geochemical anomlyWANG Feng,HE Jun(HanYuan Jade Industry of Shanxi Provincial Bureau of Geological and mineral Resources,Hanzhong 723000,China)Abstract: The low limit of the geochemical anomaly is one of the most basic and important problems in geochemical work,and it decide success or fail.Now,The methods how to determine the limit of geochemical anomly are many;besides,every method has its own precondition and disadvantages that make people confused.So the writer discuss the methods and hope to have some benefit for geological workers. Keywords: geochemical exploration;threshold;traditional statistical method;fractal;trend surface;收稿日期:2016-01作者简介:王峰,生于1963年,男,陕西西安人,本科,工程师。
异常分析的方法与技巧课件

对异常检测和分类的结果进行解释和分析,将结 果以图表、报告等形式呈现给用户,为业务决策 提供数据支持和参考。
02
异常分析的基本流程
明确分析目的
确定分析的目标
在进行异常分析之前,需要明确分析的 目标,例如确定异常的类型、范围和程 度,以及分析的预期结果。
VS
分析目的与问题定义
根据分析目标,对异常问题进行定义和明 确,以便后续分析工作能够有的放矢。
在生产线上的异常分析中,通常需要收集包括生产效率、 良品率、原材料使用等数据。通过对这些数据的趋势分析 ,可以发现异常的生产数据。进一步的原因分析可能涉及 到生产流程、设备、工人操作等多个方面。在分析过程中 ,还需要与生产部门、质量部门等相关部门密切合作,共 同找出问题的根源并制定改进措施。
案例二:销售数据的异常分析
02
通过鱼骨图、因果图等方法,对异常进行根本原因分析,找出
问题的根源和关键因素。
模拟与预测分析
03
利用模拟和预测方法,对异常趋势和未来影响进行预测和分析
,以便制定相应的应对措施。
制定改进措施
问题解决方案制定
根据异常原因分析的结果,制定相应的解决方案和改 进措施。
实施改进方案
将制定的改进措施落实到实际生产和运营中,并对实 施过程进行监控和调整。
提炼经验教训
在异常分析实践过程中,总结了一些经验教训,如数据质量对异常检测结果的影响、异常定义的主观性 、异常检测算法的过度拟合等,为后续的异常分析提供了借鉴。
展望未来研究方向与价值
拓展应用领域
随着大数据、人工智能等技术的 不断发展,异常分析的应用领域 越来越广泛,例如金融、医疗、 安全等领域。未来可以进一步拓 展异常分析在这些领域的应用, 为这些领域的发展提供支持。
异常检测技术的使用教程

异常检测技术的使用教程异常检测是一个广泛应用于各种领域的技术,在金融、网络安全、工业制造等领域中起到重要的作用。
通过识别和检测数据中的异常模式,异常检测技术可以帮助我们发现潜在的问题或异常情况,从而及时采取相应的措施。
本文将介绍异常检测的基本原理和常用方法,并提供一些实际应用案例和使用教程。
一、异常检测的基本原理1. 异常定义首先,我们需要明确异常的定义。
异常是指与大多数数据或事件的规律不符,与预期模式明显不同的观测结果。
异常可以是单个数据点、一组数据点或者整个数据集中的某个子集。
2. 异常检测的目标异常检测的目标是从数据中找出异常行为或异常模式。
异常行为可能表现为明显的异常数据点,或者是在数据中不符合常见模式的子集。
3. 异常检测的挑战异常检测面临许多挑战,其中最主要的是依赖于异常的定义和数学统计模型。
另一个挑战是异常与正常数据的比例通常是极其不平衡的,因此在训练模型时需要采取有效的策略来解决这个问题。
二、常用的异常检测方法1. 基于统计的方法基于统计的异常检测方法假设数据的生成过程符合某种概率分布。
通过计算数据与该分布之间的距离或相似度,判断数据是否异常。
常用的统计方法包括均值-方差方法、箱线图、z-score等。
2. 基于机器学习的方法基于机器学习的异常检测方法使用训练数据来构建模型,然后使用该模型来预测新样本是否异常。
常用的机器学习方法包括支持向量机(SVM)、随机森林(Random Forest)、K近邻算法(k-Nearest Neighbors)等。
3. 基于聚类的方法基于聚类的异常检测方法将数据集划分为多个簇,在每个簇中寻找与其他簇分离较大的数据点。
聚类方法常用的有k-means算法、DBSCAN算法等。
三、异常检测的实际应用案例1. 金融领域在金融领域,异常检测技术可以用于检测欺诈交易、异常交易行为等。
通过分析客户的交易模式和行为特征,可以识别潜在的异常交易,并及时采取相应的措施。
地质化探资料整理及图件制作

聚类分析
根据需分类事物个体之间的关系疏密或相似程度用 聚合的办法将分类对象作出分类。
刘红杰作品
分布检验
检验数据是否符合正态分布
刘红杰作品
地球化学图件的编制
1、实际材料图(点位图) 2、原始数据图 3、异常剖析图 4、等值线图(地球化学图) 5、组合异常图(套地质底图) 6、综合异常及找矿远景图(地质、工程等等)
刘红杰作品
地球化学图的制作
1、等值线间隔的确定 数据集呈对数正态分布的一般使用0.1log含量间隔勾绘等值线成图, 部分宏量元素及数据变化范围较小的元素可采用0.05log含量间隔勾绘等 值线成图。图上等量线间隔不小于0.7mm。
刘红杰作品
2、色区划分 划分原则:
采用制作地球化学图的数据,剔除特异值后,求出 其算术平均值(X)及标准离差,采用如下图所示的间 隔划分色区。
刘红杰作品
直方图制作
直方图如果为双峰,说明数据来自两个不同 的母体 直方图不一致严格符合正态分布,大体符合 就可以了,微量元素为对数。 直方图数据统计(样品数≥30件) 金、汞单位为10-9,其余单位为10-6. 统计时保留所有的高值点。 直方图组距正直百分位为7,负值百分位为3.
刘红杰作品
刘红杰作品
变化系数(CV)
元素变化系数反映在地质体内的变异程度,变化系 数的大小亦可从侧面显示元素成矿希望的大小 前苏联学者对于变化系数的分析,变化系数低于 0.25的元素属均匀分布,0.25~0.50之间的元素属均匀分 异,0.50~0.75之间的元素属不均匀分异,大于0.75的属 极不均匀分布 变化系数( )采用S/X求取 变化系数(CV)采用 求取
化探资料整理
————内蒙古第三地质矿产勘查开发院 刘红杰
化探-异常下限-计算方法大全及详解

化探-异常下限-计算方法大全及详解谭亲平地球化学研究所目录1.传统方法,均值加标准差 (1)2.直方图解法 (2)3.概率格纸图解法.34.多重分形法。
(6)5.85%累计频率法。
(7)小结 (8)传统方法,均值加标准差在excel中用过函数,求均值,求标准差,先对数据中的极大/极小值进行剔除,大于/小于三倍标准差的剔除掉,直到无剔除点。
然后用均值加2倍标准差求异常下限。
图,D列中的函数,E列中的结果。
图一中的化探数据的异常下限114.86.。
直方图解法图2首先,做频率直方图,(图1的数据是某化探区数据)含量频率分布图上呈现双峰曲线,左边是背景部分,右边是异常部分,双峰间谷底处(0.7)为异常下限。
求真值得5.所以,异常下限位5。
图2另一个化探区的数据,是单峰曲线,在频率极大值的0.6倍处画一条平行直线,与曲线一侧相交,其横坐标长度即为σ。
用Ca=Co+2*σ=0.16+2*0.665=1.49,求得为真值为31。
概率格纸图解法.图3,图3是概率格纸。
发现纵坐标(累计频率)是不均匀的。
把样本值小于或等于某个样本ni的数据频率累加,即得到小于或等于ni的累积频率。
概率格纸用excel能轻松的做出来。
制造方法如下。
图4.图4显示了概率格纸的制造过程。
原理就是把标准正态分布曲线投影到纵坐标上。
首先确定纵坐标数值,如B列,0.1、1、5、10、20、30、40、50、60、70、80、90、95、99、99.9.。
如果想要纵坐标线密一点,也可以插入更多的数。
然后在C列中用NORMSINV 函数,求对应频率的分位数(如果把标准正态分布,正着放,分位数就是横坐标)。
这时的原点(0)在50%处,我们想要原点在0处,那么把C列的数统一加-03.090232(C5),---(处理化探数据的时候,加的也是相同的数)。
即输入公式”D5” =C5-$C$5…。
E列为x 值,根据实际化探数据,设定最大和最小值。
我们这里随便设为0、25。
化探单元素异常统计内容参数公式

化探单元素异常统计内容1、异常ID ID2、样品个数 N3、异常面积 S4、样品最大值 Max5、样品最小值 Min6、异常下限 T7、算术平均值 nXiX n∑=18、几何平均值 ∑=ng Xi n X 1log 19、标准离差 1)X X(n1i 2__0--∑=n S i=10、异常衬度 TX A c =11、异常规模 ()T X S A d -⨯= 12、异常NAP 值 S A NAP c ⨯=浓集克拉克值(C)计算公式: 某元素的克拉克值XC =变化系数(Cv)计算公式: XS Cv o=致矿系数(Z)计算公式:Z =Cv(全区)+10×Cv(剔高值后)+100×高值比例+C ,高值是大于3倍的标准离差。
化探背景分析 中位数:505050)50(f F H X Me -+=偏度:24)(1)(13231nX X f n X X f nR i i ii ∙⎪⎪⎭⎫ ⎝⎛--=∑∑ 峰度:963)(1)(14242n X X f n X X f nR i i i i ∙⎪⎪⎪⎪⎪⎪⎭⎫⎝⎛-⎪⎪⎭⎫ ⎝⎛--=∑∑正态检验: ∑∙-=ifx F x F |)()(|max 1λXi :组中值或含量值;f i :Xi 所对应的频数;H :组距;X50:包括累计频率50%在内的所在组的组下限;F 50:累计频率50%所在组之前的累计频率;f 50:包括累计频率50%所在组的组频率;F(X):为经验累计频率;F 1(X):为理论累计频率。
R 型聚类分析iiij ij S X X X -='其中:∑==nj ij X n X 11;1)(12--=∑=n X (XS nj i iji∑∑∑===-⋅---=⋅=ni ni k kij jik kini j jikkjj jk jk X (X X (X X (X X (XS S S r 11221)())()(式中:r kj 为第j 个变量和第k 个变量的相关系数;X ji 为第j 个变量第i 个样品的观测值; X j 与X k 为第j 个和第k 个变量的平均值。
异常下限计算
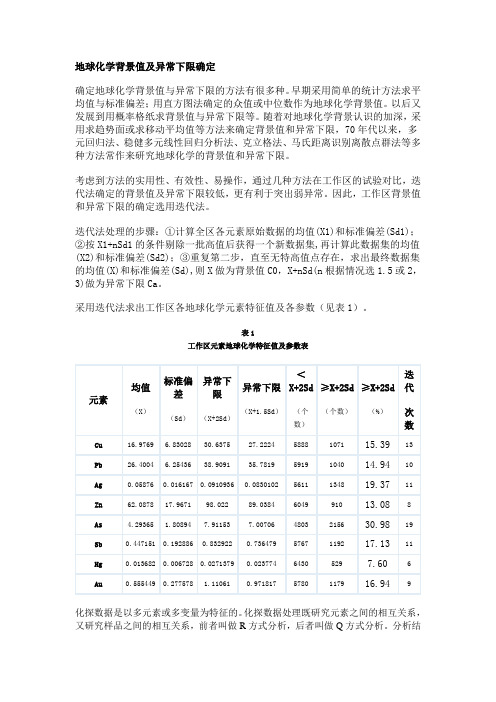
地球化学背景值及异常下限确定确定地球化学背景值与异常下限的方法有很多种。
早期采用简单的统计方法求平均值与标准偏差;用直方图法确定的众值或中位数作为地球化学背景值。
以后又发展到用概率格纸求背景值与异常下限等。
随着对地球化学背景认识的加深,采用求趋势面或求移动平均值等方法来确定背景值和异常下限,70年代以来,多元回归法、稳健多元线性回归分析法、克立格法、马氏距离识别离散点群法等多种方法常作来研究地球化学的背景值和异常下限。
考虑到方法的实用性、有效性、易操作,通过几种方法在工作区的试验对比,迭代法确定的背景值及异常下限较低,更有利于突出弱异常。
因此,工作区背景值和异常下限的确定选用迭代法。
迭代法处理的步骤:①计算全区各元素原始数据的均值(X1)和标准偏差(Sd1);②按X1+nSd1的条件剔除一批高值后获得一个新数据集,再计算此数据集的均值(X2)和标准偏差(Sd2);③重复第二步,直至无特高值点存在,求出最终数据集的均值(X)和标准偏差(Sd),则X做为背景值C0,X+nSd(n根据情况选1.5或2,3)做为异常下限Ca。
采用迭代法求出工作区各地球化学元素特征值及各参数(见表1)。
表1工作区元素地球化学特征值及参数表化探数据是以多元素或多变量为特征的。
化探数据处理既研究元素之间的相互关系,又研究样品之间的相互关系,前者叫做R方式分析,后者叫做Q方式分析。
分析结果是将数据按变量或按样品划分成若干类,使各类内部性质相似而各类之间性质相异。
如果参加分析的数据含有已知类别(如矿或非矿的作用)能起训练组作用时,数据处理的结果可给出明确的地质解释,否则所做的地质解释就含有较大程度的推测性。
在特定情况下地球化学数据可能只反映单一的地质过程,这样的化探数据是所谓“来自一个母体”的。
一般情况是几种地质过程作用在同一地区,他们相互重叠或部分重叠,这反映在地球化学数据上就具有“多个母体”的特征。
化探数据处理需要鉴别和分离这些母体,即对化探数据值进行分解,确定出不同母体的影响在数据中所产生的分量。
数组求异常度

数组求异常度全文共四篇示例,供读者参考第一篇示例:数组是在计算机科学中常用的数据结构,它可以存储多个相同类型的元素,并按照一定的顺序进行管理和访问。
在实际应用中,我们经常需要对数组中的元素进行一些统计和分析,比如求和、平均值等。
我们还经常会遇到一种情况,就是需要判断一个数组中是否存在异常值,即与其他元素差异较大的数值。
本文将介绍数组求异常度的概念及其应用。
一、什么是数组求异常度数组求异常度是指对一个数组中的元素进行异常值检测。
异常值是指与大多数元素差异较大的数值,它可能是由于数据采集错误、系统故障或者是真实的极端数值。
在数据分析和模型建设中,异常值会影响模型的准确性和稳定性,因此需要对其进行及时检测和处理。
为了求解数组中的异常度,我们可以根据一些统计学方法来进行判断。
常用的方法包括Z-score、箱线图等。
Z-score是一个统计方法,可以用来衡量一个数与平均值的差距,其数值偏离程度越大,则表明该数越可能是异常值。
箱线图则是一种可视化方法,可以直观地显示数据的分布情况,从而判断是否存在异常值。
对于一个给定的数组,我们可以通过以下步骤来求解其异常度:1.计算数组的平均值和标准差。
平均值是数组中所有元素的平均数值,标准差则是衡量数组元素离散程度的指标。
2.计算每个元素与平均值的差值。
对于每个元素,我们可以计算其与数组平均值的差值,即Z-score=(元素值-平均值)/标准差。
3.判断是否存在异常值。
根据Z-score的数值,我们可以判断一个元素是否是异常值。
一般来说,Z-score的绝对值大于3,则认为该元素是异常值。
4.可视化数据。
除了Z-score方法外,我们还可以利用箱线图等方法来可视化数据,直观地检测是否存在异常值。
通过以上步骤,我们可以初步判断一个数组中是否存在异常值,并对其进行进一步分析和处理。
数组求异常度在实际应用中有着广泛的用途,特别是在数据分析和模型建设中。
1.数据清洗。
在进行数据分析前,我们通常需要对数据进行清洗,包括异常值的检测和处理。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
地球化学元素含量的异常确定是勘查地球化学中最重要的工作之一,但迄今为止还没有找到一个完全令人满意的具有科学依据的方法。
长期以来,人们主要是使用经典的统计学方法,以样品数据呈正态分布为假设前提,通过计算数据的统计学参数(如均值、标准离差等)对异常进行筛选和评价。
一般是以平均值(X)与2倍(也有为1.5倍或3倍)的标准离差(δ)之和作为地球化学的异常下限值。
该方法仅适用于地球化学数据呈正态分布的情况,但实际上对于元素的地球化学分布而言正态分布并不是唯一的一种分布,人们已经发现许多元素,特别是微量元素并不遵循正态分布,而是呈明显的正向偏斜或表现为一种幂型的拖尾分布。
其他几种用来筛选和评价地球化学异常的方法,如移动平均法、趋势面法、克里格法以及概率格纸法等,除了概率格纸法仍是基于正态分布这一观点外,其他的几种方法虽然注意到了元素含量分布的空间信息,但都是以地球化学含量数据在空间上呈连续变化,且是一个光滑的连续曲面这一假设为基础建立的。
事实上,地球化学元素含量的空间分布是极其复杂、十分粗糙而并非处处可微的。
正如李长江等(1995)研究揭示的地球化学景观可能是一个具有低维(D=2.9)吸引子的混沌系统,是分形。
考虑到方法的实用性、有效性、易操作,通过几种方法在工作区的试验对比,叠代法确定的背景值及异常下限较低,更有利于突出弱异常。
因此,工作区背景值和异常下限的确定选用叠代法。
叠代法处理的步骤:①计算全区各元素原始数据的均值(X1)和标准偏差(S1);
②按X1+3S1的条件剔除一批高值后获得一个新数据集,再计算此数据集的均值(X2)和标准偏差(S2);③重复第二步,直至无特高值点存在,求出最终数据集的均值(X)和标准偏差(S),则X做为背景值C0,X+nS(n根据情况选1.5或2,3)做为异常下限Ca。