SPSS统计分析分析案例
spss的数据分析案例

- -关于某公司474名职工综合状况的统计分析报告一、数据介绍:本次分析的数据为某公司474名职工状况统计表,其中共包含十一变量,分别是:id(职工编号),gender(性别),bdate(出生日期),edcu(受教育水平程度),jobcat(职务等级),salbegin(起始工资),salary(现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)。
通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。
二、数据分析1、频数分析。
基本的统计分析往往从频数分析开始。
通过频数分析能够了解变量的取值状况,对把握数据的分布特征非常有用。
此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu(受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。
Statistics首先,对该公司的男女性别分布进行频数分析,结果如下:上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。
其次对原有数据中的受教育程度进行频数分析,结果如下表:Educational Level (years)上表及其直方图说明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。
且接受过高于20年的教育的人数只有1人,比例很低。
2、描述统计分析。
再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。
spss综合案例分析国家统计局

spss综合案例分析国家统计局
(一)实验目的
近年来随着现代化和工业化的进程,我国大气污染状况十分严重,主要呈现煤烟型污染特征,城市大气环境中总悬浮颗粒浓度普遍超标、二氧化硫污染保持在较高水平、机动车尾气污染物排放总量迅速增加、氮氧化物污染趋势加重、全国形成多个酸雨区等,危害生态环境、影响人民群众身体健康。
从污染物构成来看,我国大气污染来源主要有三个方面:一是生活污染源,包括饮食或取暖时燃料向大气排放有害气体和烟雾;二是工业污染源,包括火力发电、钢铁和有色金属冶炼,各种化学工业给大气造成的污染;三是交通污染源,包括汽车、飞机、火车、船舶等交通工具的煤烟、尾气排放。
本文通过聚类分析和主成分分析法,研究我国主要城市的空气质量,以及各参数对空气质量好坏的影响以及最主要的影响因素。
并据此提出科学合理的对策建议。
(二)问题描述
在2013年之前,大部分人对于雾霾天气的认知都会自然而然觉
得是的事。
然而,12月伊始,我国遭受了入冬以来最大围雾霾天气,今年12月伊始,我国中东部地区迎来了严重雾霾事件,几乎涉及中
东部所有地区。
天津等多地空气质量指数达到六级严重污染级别,使得京津冀与长三角雾霾连成片。
由于能见度过低,导致多处高速公路封道关
闭,给车辆出行带来了不便,也严重影响了市民的正常工作与生活。
(三)数据来源
通过查询“中华人民国国家统计局官方”的“国家统计数据库”,《中国统计年鉴》获得。
(四)案例中使用的SPSS方法
1.描述性分析
2.相关分析
3.聚类分析
4.主成分分析。
spss案例分析报告(精选)

spss案例分析报告(精选)本文通过分析一份 SPSS 数据,展示 SPSS 在统计分析中的应用。
数据概述本数据为一家咖啡馆的销售数据,共有 200 条记录,包括 7 个变量:日期、时间、收银员、商品名、销售价格、数量和总价。
SPSS 分析1. 描述性统计使用 SPSS 的描述性统计功能,可以获取数据的基本信息,如均值、标准偏差、最大值、最小值等。
其中,销售价格的均值为 44.71 元,标准偏差为 13.29 元,最小值为 23 元,最大值为 78 元。
数量的均值为 1.62 个,标准偏差为 0.51 个,最小值为 1 个,最大值为3 个。
总价的均值为 73.25 元,标准偏差为 21.89 元,最小值为 23 元,最大值为 156 元。
2. 单样本 t 检验假设一杯咖啡的平均售价为 50 元,我们可以使用单样本 t 检验对这个假设进行检验。
首先,我们需要用 SPSS 的数据透视表功能,计算出每杯咖啡的平均售价。
然后,使用单样本 t 检验功能,输入样本均值、假设的总体均值(50 元)、样本标准差、样本大小以及置信度水平。
在这个数据集中,单样本 t 检验得出的 t 值为 -2.36,P 值为 0.019,显著性水平为 0.05,因此我们可以拒绝原假设,认为该咖啡馆的咖啡售价不是 50 元。
4. 相关分析假设我们想要了解商品数量和销售额之间的关系,我们可以使用 SPSS 的相关分析功能来进行分析。
首先,我们需要使用数据透视表功能,计算出每个订单的总价和数量。
然后,使用相关分析功能,输入这两个变量的值,得出相关系数和显著性水平。
在这个数据集中,商品数量和销售额之间的相关系数为 0.749,P 值为 0,显著性水平非常显著。
因此,我们可以认为商品数量和销售额之间存在极强的正相关关系。
结论本文通过 SPSS 对一份咖啡馆销售数据进行分析,展示了 SPSS 在统计分析中的应用。
通过描述性统计、单样本 t 检验、双样本 t 检验和相关分析等功能,我们可以获得数据的基本信息,检验假设,分析变量之间的关系,从而帮助企业更好地决策和管理。
spss案例统计分析大学生收支分析

spss案例统计分析大学生收支分析标题:SPSS案例统计分析——大学生收支分析随着社会经济的发展和科技的进步,大学生作为未来社会的中坚力量,他们的收支情况日益受到社会各界的。
本文通过SPSS软件对大学生的收支情况进行案例统计分析,以揭示他们的经济生活状况。
一、数据来源与处理本文选取了某高校500名大学生作为研究对象,通过问卷调查的方式收集他们的收支数据。
数据包括每个学生的基本信息(如性别、年级、专业等)、月收入、月支出以及主要支出项目等。
在数据处理阶段,我们利用SPSS软件对数据进行清洗、整理和分类,以确保数据的质量和可用性。
二、大学生收支情况的描述性统计分析通过SPSS软件的描述性统计分析功能,我们可以得到大学生月收入和月支出的平均值、中位数、标准差等统计指标。
结果显示,大学生的月收入平均值为1500元,月支出平均值为1200元,收支差额平均为300元。
男生的月支出略高于女生,高年级学生的月支出略高于低年级学生。
三、大学生收支情况的交叉统计分析为了进一步探究大学生收支情况的影响因素,我们采用交叉统计分析方法,将学生的收支情况与他们的性别、年级、专业等因素进行关联分析。
结果显示,不同性别、年级和专业的大学生在收支情况上存在一定差异。
例如,女生的月支出普遍较低,而男生的月支出普遍较高;高年级学生的月支出普遍较高,低年级学生的月支出普遍较低;人文社科类专业的月支出普遍较低,理工科类专业的月支出普遍较高。
四、大学生主要支出项目的频数分析为了了解大学生主要支出项目的分布情况,我们采用频数分析方法,对收集到的数据进行统计。
结果显示,大学生的主要支出项目包括生活必需品(如食品、衣物等)、学习用品(如书本、文具等)、娱乐社交(如电影、聚餐等)以及交通费用等。
其中,生活必需品和学习用品的支出占据较大比例。
五、结论与建议通过以上统计分析,我们可以得出以下目前大学生收支状况整体稳定,但存在一定差异。
男生、高年级和理工科类专业的学生月支出相对较高,而女生、低年级和人文社科类专业的学生月支出相对较低。
大学生spss数据分析案例

大学生spss数据分析案例大学生SPSS数据分析案例。
在大学教育中,数据分析是一个非常重要的环节,尤其是对于社会科学和商业管理专业的学生来说。
SPSS(Statistical Package for the Social Sciences)是一个专业的统计分析软件,广泛应用于学术研究和商业决策中。
本文将以一个大学生SPSS数据分析案例为例,介绍如何使用SPSS进行数据分析。
案例背景:某大学社会科学专业的学生对大学生活满意度进行了调查,并收集了相关数据,包括学生的性别、年级、专业、宿舍类型、课程质量、宿舍环境、社交活动等方面的信息。
现在需要对这些数据进行分析,以了解不同因素对大学生活满意度的影响。
数据准备:首先,需要将调查所得的数据录入SPSS软件中,确保数据的准确性和完整性。
在录入数据时,要注意将不同的变量分别录入不同的列中,以便后续的分析和处理。
数据分析:1. 描述统计分析。
首先,可以对各个变量进行描述统计分析,包括计算均值、标准差、频数分布等。
通过描述统计分析,可以直观地了解各个变量的分布情况,为后续的分析提供基础。
2. 相关性分析。
接下来,可以进行各个变量之间的相关性分析,通过相关系数的计算来了解不同变量之间的关联程度。
例如,可以分析学生的性别、年级、专业与大学生活满意度之间的相关性,以及宿舍类型、课程质量、社交活动等因素对大学生活满意度的影响程度。
3. 方差分析。
针对分类变量,可以进行方差分析,比较不同组别之间的均值差异是否显著。
例如,可以分析不同年级、不同专业的学生对大学生活满意度的差异情况,以及不同宿舍类型对大学生活满意度的影响是否显著。
4. 回归分析。
最后,可以利用回归分析来探讨不同因素对大学生活满意度的影响程度。
通过建立回归模型,可以了解各个自变量对因变量的影响情况,以及它们之间的关系强度和方向。
结论与建议:通过以上的数据分析,可以得出不同因素对大学生活满意度的影响程度,为学校和相关部门提供决策建议。
统计学课SPSS数据分析实战案例

统计学课SPSS数据分析实战案例SPSS(统计分析系统)是一款常用的统计软件,被广泛应用于社会科学、商业、医学等领域的数据分析工作中。
通过这个案例,我们将运用SPSS软件进行数据分析,以展示统计学课的实战应用。
案例背景假设你是一位市场研究员,你的公司正在调查消费者对某产品的满意度。
你已经收集了一份随机抽样的数据集,包含了消费者的满意度评分以及他们的一些个人信息。
你的任务是对这些数据进行分析,以了解消费者满意度与个人信息之间是否存在关联。
数据集说明数据集包括了500个消费者的信息,具体变量如下:1. 变量1:满意度评分(连续变量,取值范围从1到10);2. 变量2:性别(分类变量,取值为男性和女性);3. 变量3:年龄(连续变量);4. 变量4:收入水平(分类变量,取值为低、中、高三个层次);5. 变量5:购买次数(连续变量,表示过去一年内购买该产品的次数)。
数据分析步骤以下是对这份数据集进行分析的步骤:1. 数据清洗和准备首先,我们需要检查数据集中是否存在缺失值或异常值,并进行数据清洗。
在SPSS中,我们可以使用数据查看和数据清洗的功能来完成这一步骤。
确保数据集中的每一列都没有缺失值,并且所有的异常值已经得到恰当的处理。
2. 描述性统计分析接下来,我们可以使用SPSS的描述性统计分析功能,对数据集进行描述性统计分析。
我们可以计算满意度评分、年龄和购买次数的平均值、标准差、最小值、最大值,并生成频数分布表和柱状图。
3. 相关性分析为了确定满意度评分与其他个人信息变量之间的关联性,我们可以使用SPSS的相关性分析功能。
通过计算满意度评分与性别、年龄、收入水平和购买次数之间的相关系数,我们可以评估它们之间的相关性。
4. 单因素方差分析我们可以使用SPSS进行单因素方差分析,以了解不同收入水平的消费者在满意度评分上是否存在显著差异。
通过观察方差分析表和显著性水平,我们可以得出初步结论。
5. 多元线性回归分析最后,我们可以使用SPSS的多元线性回归分析功能来建立一个回归模型,以预测满意度评分。
spss数据分析报告案例

SPSS数据分析报告案例1. 研究背景本研究旨在调查大学生是否存在晚睡现象,并探究晚睡与健康问题之间的关系。
通过采集大学生的睡眠时间、就寝时间以及健康状况等数据,利用SPSS软件进行数据分析,进一步了解大学生的睡眠状况与健康问题的关联。
2. 数据概况本研究共收集了200名大学生的数据,其中包括性别、年级、每晚睡眠时间、平均就寝时间、是否存在健康问题等变量。
下面是对数据的描述统计分析结果:•性别分布:男性占50%,女性占50%。
•年级分布:大一占25%,大二占30%,大三占25%,大四占20%。
•每晚睡眠时间:平均睡眠时间为7.8小时,标准差为1.2小时。
最小值为5小时,最大值为10小时。
•平均就寝时间:平均就寝时间为23:30,标准差为0.5小时。
最早就寝时间为22:00,最晚就寝时间为01:00。
•健康问题:共有45%的大学生存在健康问题。
3. 数据分析结果3.1 性别与睡眠时间的关系首先,我们探究性别与睡眠时间之间的关系。
利用独立样本T检验,得出以下的结果:•假设检验:男性和女性的睡眠时间是否存在显著差异?•结果:独立样本T检验显示,男性平均睡眠时间为7.6小时,女性平均睡眠时间为8.0小时。
T值为-2.14,P值为0.034,意味着男性和女性的睡眠时间存在显著差异。
3.2 年级与睡眠时间的关系我们进一步探究年级与睡眠时间的关系。
使用单因素方差分析(ANOVA),得出以下结果:•假设检验:各年级的睡眠时间是否存在显著差异?•结果:单因素方差分析显示,大一、大二、大三和大四的平均睡眠时间分别为7.7小时、7.9小时、8.1小时和7.6小时。
F值为2.75,P值为0.043,说明各年级之间的睡眠时间存在显著差异。
3.3 睡眠时间与健康问题的关系最后,我们分析睡眠时间与健康问题之间的关系。
利用相关分析,得出以下结果:•假设检验:睡眠时间与健康问题之间是否存在相关性?•结果:相关分析结果显示,睡眠时间和健康问题之间存在显著负相关(r = -0.25,P值 = 0.001),即睡眠时间越少,存在健康问题的可能性越大。
spss案例大数据分析报告

spss案例大数据分析报告SPSS 案例大数据分析报告在当今数字化时代,数据已成为企业和组织决策的重要依据。
通过对大量数据的分析,可以揭示隐藏在其中的规律和趋势,为决策提供有力支持。
本报告将以一个具体的案例为例,展示如何使用 SPSS 进行大数据分析。
一、案例背景本次分析的对象是一家电商企业的销售数据。
该企业在过去一年中积累了大量的销售记录,包括商品信息、客户信息、订单金额、购买时间等。
企业希望通过对这些数据的分析,了解客户的购买行为和偏好,优化商品推荐和营销策略,提高销售业绩。
二、数据收集与整理首先,从企业的数据库中提取了相关数据,并进行了初步的清理和整理。
删除了重复记录和缺失值较多的字段,对数据进行了标准化处理,使其具有统一的格式和单位。
在整理数据的过程中,发现了一些问题。
例如,部分客户的地址信息不完整,部分商品的分类存在错误。
通过与相关部门沟通和核实,对这些问题进行了修正和补充。
三、数据分析方法本次分析主要采用了以下几种方法:1、描述性统计分析计算了数据的均值、中位数、标准差、最大值、最小值等统计指标,以了解数据的集中趋势和离散程度。
2、相关性分析分析了不同变量之间的相关性,例如商品价格与销量之间的关系,客户年龄与购买金额之间的关系。
3、聚类分析将客户按照购买行为和偏好进行聚类,以便更好地了解客户群体的特征。
4、因子分析提取了影响客户购买行为的主要因素,为进一步的分析和建模提供基础。
四、数据分析结果1、描述性统计分析结果商品的平均价格为_____元,中位数为_____元,标准差为_____元。
销量的最大值为_____件,最小值为_____件,均值为_____件。
客户的平均年龄为_____岁,中位数为_____岁,标准差为_____岁。
购买金额的最大值为_____元,最小值为_____元,均值为_____元。
2、相关性分析结果商品价格与销量之间呈现负相关关系,相关系数为_____。
这表明价格越高,销量越低。
spss案例分析报告精选文档

s p s s案例分析报告精选文档TTMS system office room 【TTMS16H-TTMS2A-TTMS8Q8-S p s s分析身高与体重的相互影响一、案例介绍:这是某幼儿园学生的身高体重数据,数据中主要包括编号,学生姓名,性别,学生年龄,每个学生的体重以及身高数值。
主要是看下幼儿园学生体重与身高的相互关系。
二、研究案例的目的:分析幼儿园学生身高体重的相互关系和影响。
三、下面是数据来源:四、研究的方法:主要是使用spss中的描述统计分析和线性回归分析;在描述统计分析中主要是分析出身高体重的最大值和最小值、均值,在图表中可以看出身高的最大值;在线性回归分析中主要是采用身高为自变量,体重为因变量来进行分析的。
五、研究的结果:1)描述分析:打开文件“某班23名同学的身高、体重、年龄数据”,通过菜单兰中的分析选项,进行描述性分析,选择体重和身高,求最大值最小值和均值,得到如下结果:从结果看出,该班学生样本数为23,体重最小值为13.7kg,最大值为23kg,平均体重为17.7167kg。
身高最小值为105cm,最大值为116cm,平均身高为108.85cm。
以身高为例子,选择描述中的频率选项可以得出分布,在频率对话框的图形选项中,选择条形图,即可用图形直观看到结果。
从图形中可以很直观的看出不同身高段的人数分布情况,其中108cm左右的人数最多。
从表格中则可以清楚地看到具体数目。
2)线性回归分析:选择分析——回归——线性,在弹出的对话框中,以身高作为自变量,体重作为因变量,结果如下:从表中可以得出。
R=0.223,即两者具有弱相关性。
从图表中,可以看出它们之间的线性关系大概可以表示为y=-0.139x+2.617 六、研究结论:从描述分析和回归分析可以身高和体重的相关性是相对比较弱的,也就是弱相关性。
spss数据分析案例

spss数据分析案例SPSS数据分析案例。
在实际的数据分析工作中,SPSS(Statistical Product and Service Solutions)是一个非常常用的统计分析软件。
它提供了强大的数据处理和分析功能,可以帮助研究人员快速、准确地进行数据处理和分析。
本文将通过一个实际的案例,介绍如何使用SPSS进行数据分析,并展示分析结果。
案例背景:某公司想要了解员工满意度与工作绩效之间的关系,为了达到这个目的,他们进行了一项调查,收集了员工的满意度评分和绩效评分数据。
现在,他们希望通过这些数据,利用SPSS进行分析,找出员工满意度和工作绩效之间的关系。
数据收集:首先,我们收集了100名员工的满意度评分和绩效评分数据。
满意度评分采用了1-5的五级评分制,绩效评分采用了1-100的百分制评分。
数据导入:将收集到的数据导入SPSS软件中,创建一个新的数据集,并将员工的满意度评分和绩效评分数据分别录入到不同的变量中。
数据描述统计分析:首先,我们对数据进行描述性统计分析,包括计算满意度评分和绩效评分的均值、标准差、最大值、最小值等。
这些统计量可以帮助我们更好地了解数据的分布情况。
相关性分析:接下来,我们使用SPSS进行相关性分析,探索员工满意度评分和绩效评分之间的相关关系。
通过相关性分析,我们可以计算出两个变量之间的相关系数,进而判断它们之间是否存在显著的相关性。
回归分析:在确定了员工满意度评分和绩效评分之间存在相关性的基础上,我们可以进一步进行回归分析,建立员工满意度评分对绩效评分的预测模型。
通过回归分析,我们可以得到员工满意度评分对绩效评分的影响程度,以及其他可能影响绩效评分的因素。
结论:通过SPSS数据分析,我们发现员工满意度评分与绩效评分之间存在显著的正相关关系,即员工满意度评分越高,其绩效评分也越高。
这为公司提高员工绩效提供了重要的参考依据,可以通过提升员工满意度来提高整体绩效水平。
总结:在本案例中,我们利用SPSS软件进行了员工满意度和绩效之间的数据分析。
spss数据分析简单案例

spss数据分析简单案例SPSS数据分析简单案例。
在社会科学研究中,SPSS(统计分析软件包)被广泛应用于数据分析。
本文将通过一个简单的案例来介绍如何使用SPSS进行数据分析。
首先,我们收集了一份关于学生学习成绩的数据,包括学生的性别、年龄、每周学习时间和期末考试成绩。
我们的研究问题是探讨性别、年龄和每周学习时间对学习成绩的影响。
我们首先打开SPSS软件,导入我们收集的数据。
然后,我们可以使用SPSS 的数据编辑功能对数据进行清洗和整理,确保数据的准确性和完整性。
接下来,我们可以使用SPSS的描述性统计功能对数据进行分析。
我们可以计算每个变量的均值、标准差、最大值和最小值,从而对数据的分布和特征有一个直观的了解。
然后,我们可以使用SPSS的相关分析功能来探讨不同变量之间的相关性。
我们可以计算不同变量之间的皮尔逊相关系数,从而了解它们之间的线性关系。
在接下来的分析中,我们可以使用SPSS的回归分析功能来探讨性别、年龄和每周学习时间对学习成绩的影响。
我们可以建立一个多元线性回归模型,从而探讨不同变量对学习成绩的预测作用。
最后,我们可以使用SPSS的图表功能来进行数据可视化分析。
我们可以绘制散点图、柱状图和折线图,从而直观地展示不同变量之间的关系和趋势。
通过以上步骤,我们可以利用SPSS对学生学习成绩的数据进行全面的分析,从而回答我们的研究问题。
在实际研究中,我们还可以进一步探讨其他统计分析方法,如方差分析、卡方检验等,以深入挖掘数据的内在规律。
总之,SPSS作为一款功能强大的统计分析软件,为社会科学研究提供了重要的数据分析工具。
通过本文的简单案例,希望读者能够对SPSS的数据分析功能有一个初步的了解,并能够在实际研究中灵活运用,从而为研究工作提供有力的支持。
spss统计分析与行业应用案例

spss统计分析与行业应用案例SPSS是一款统计分析软件,其强大的数据处理和分析功能,使得它在各个行业中得到广泛应用。
下面将以医疗行业为例,说明SPSS在统计分析中的应用。
在医疗行业中,SPSS可以用于患者数据的统计分析。
假设某医院想要研究某种疾病在不同年龄段的患病情况,可以通过SPSS对患者数据进行处理和分析。
首先,医院可以将收集到的病历数据导入SPSS,根据患者的年龄信息将数据进行分组。
然后,通过SPSS的交叉报表功能,可以统计每个年龄段的患者数量和患病率。
此外,SPSS还可以进行相关性分析,帮助医院了解患者年龄与疾病的相关性。
通过SPSS的相关性分析功能,医院可以知道年龄与患病风险是否存在关联,从而进一步为临床治疗提供参考依据。
SPSS还可以用于医院对医疗资源的分配和利用。
医院可以通过SPSS分析患者的挂号、住院和就诊数据,统计不同科室的就诊次数和人数。
通过对这些数据的分析,医院可以得到每个科室的就诊情况和资源利用情况。
比如,医院可以通过SPSS得知某个科室的就诊量过高,而其他科室的利用率较低,从而调整医疗资源的配置,提高资源利用效率。
此外,SPSS还可以通过群组分析功能,将患者按病情和诊断结果进行分类,从而为医院提供更精确的资源分配建议。
另外,SPSS在医学研究中也有广泛的应用。
医学研究常需要进行大量的数据处理和分析,SPSS可以提供相应的统计分析工具和技术支持。
例如,一个医学研究团队想要研究某种药物的疗效,可以通过SPSS对临床试验的数据进行统计分析。
首先,团队可以将试验数据导入SPSS,进行数据清洗和整理。
然后,通过SPSS的描述性统计和推论统计功能,可以对药物的疗效进行评估。
此外,SPSS还可以进行假设检验、回归分析等高级统计分析,帮助研究团队得出科学准确的结论。
综上所述,SPSS在医疗行业中的应用非常广泛。
无论是患者数据分析,医疗资源的分配和利用,还是医学研究数据的分析,SPSS都能提供合适的统计分析方法和工具。
spss的数据分析案例

精心整理关于某公司474名职工综合状况的统计分析报告一、数据介绍:本次分析的数据为某公司474名职工状况统计表,其中共包含^一变量,分别是:id (职工编号),gender(性别),bdate(出生日期),edcu (受教育水平程度),jobcat (职务等级),salbegin (起始工资),salary (现工资),jobtime(本单位工作经历<月>),prevexp(以前工作经历<月>),minority(民族类型),age(年龄)<通过运用spss统计软件,对变量进行频数分析、描述性统计、方差分析、相关分析、I ■以了解该公司职工上述方面的综合状况,并分析个变量的分布特点及相互间的关系。
二、数据分析■■ ] I ■.1、频数分析。
基本的统计分析往往从频数分析开始。
通过频数分析能够了解变量的取值状况,对把握数据的分布特征非常有用。
此次分析利用了某公司474名职工基本状况的统计数据表,在gender(性别)、edcu (受教育水平程度)、不同的状况下的频数分析,从而了解该公司职工的男女职工数量、受教育状况的基本分布。
精心整理上表说明,在该公司的474名职工中,有216名女性,258名男性,男女比例分别为45.6%和54.4%,该公司职工男女数量差距不大,男性略多于女性。
/ 「’--了/其次对原有数据中的受教育程度进行频数分析,结果如下表:Educati on alLevel(years).4 .4 99.8 20 2上表及其直方图说I I明,被调查的474名职工中,受过12年教育的职工是该组频数最高的,为190人,占 总人数的40.1%,其次为15年,共有116人,占中人数的24.5%。
且接受过高于20年的 教育的人数只有1人,比例很低。
2、描述统计分析。
再通过简单的频数统计分析了解了职工在性别和受教育水平• J ' P t ,- J上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识, 这就需要通过计算基本描述统计的方法来实现。
SPSS统计分析分析案例

SPSS统计分析分析案例案例:影响学生学业成绩的因素分析1.引言学业成绩作为评估学生学习成绩的重要指标,对于学校和家庭来说具有重要意义。
了解影响学生学业成绩的因素,对于制定有效的教学和管理措施具有指导意义。
本研究旨在通过SPSS统计软件对影响学生学业成绩的因素进行分析。
2.方法2.1参与者本研究的参与者为100名来自不同年级和专业的大学生。
2.2变量本研究共选取了以下影响学生学业成绩的因素作为自变量:学习时间、课堂参与度、家庭背景、学习动机、学习方法、自律性等。
学业成绩作为依变量。
2.3测量工具为了获取相关数据,本研究使用了以下测量工具:-学习时间:参与者填写每周学习时间的小时数。
-课堂参与度:参与者填写自己在课堂上的活跃程度,范围从1(非常低)到5(非常高)。
-家庭背景:参与者填写自己的家庭收入水平,范围从1(非常低)到5(非常高)。
-学习动机:参与者填写自己的学习动机程度,范围从1(非常低)到5(非常高)。
-学习方法:参与者选择自己使用的学习方法,包括书本阅读、听讲座、做练习等。
-自律性:参与者填写自己对学习的自律性程度,范围从1(非常低)到5(非常高)。
2.4数据分析为了分析影响学生学业成绩的因素,本研究将使用SPSS统计软件进行多元线性回归分析。
首先,我们将通过描述性统计分析了解参与者的学习时间、课堂参与度、家庭背景、学习动机、学习方法、自律性的情况。
然后,将进行相关分析,以评估各个因素之间的相关性。
最后,通过多元线性回归分析,确定各个因素对学业成绩的影响。
3.结果通过数据分析得到的初步结果显示,学习时间、课堂参与度、学习动机、自律性对学业成绩有显著的正向影响,而家庭背景因素对学业成绩影响较小。
具体来说,多元线性回归分析结果显示,学习时间、课堂参与度、学习动机和自律性对学业成绩的影响是显著的(p<0.05)。
然而,家庭背景对学业成绩的影响不显著(p>0.05)。
此外,学习方法与学业成绩之间的关系也需要进一步研究。
spss数据分析案例

spss数据分析案例SPSS是一种常用的统计分析软件,它可以对大规模数据进行处理和分析。
以下是一个使用SPSS进行数据分析的案例。
假设有一家电商公司想要了解其在线购买行为的一些关键指标,以便他们能够做出更好的决策。
为了达到这个目标,该公司收集了一些关于客户在线购买的信息,包括购买金额、购买时间、购买地点等。
为了更好地理解数据,他们将这些信息保存在一个CSV文件中,并使用SPSS对数据进行分析。
首先,他们导入CSV文件到SPSS中,并通过查看数据的前几行对数据进行初步了解。
然后,他们对数据的各个字段进行描述性统计分析,包括平均值、中位数、最大值、最小值等。
这样他们可以对数据的分布和变化有一个整体的了解。
接下来,他们为每个字段制作了一些图表,以更直观地了解数据。
例如,他们可以绘制一个柱状图来表示每个地点的购买次数,从而了解销售最好的地点。
他们还可以制作一个折线图来显示每月的购买金额,以发现季节性变化。
然后,他们对数据进行了透视分析,以找出一些有用的信息。
例如,他们可以对数据按照购买地点进行透视分析,并计算每个地点的总购买金额。
这样他们可以确定哪些地点对总销售额做出了更大的贡献。
此外,他们还可以使用SPSS进行相关性分析,以找出一些字段之间的关系。
例如,他们可以计算购买金额和购买时间之间的相关系数,以了解购买金额是否受到购买时间的影响。
最后,他们对数据进行了回归分析,以预测未来的销售情况。
他们可以使用购买金额作为因变量,其他字段作为自变量,构建一个回归模型,并通过模型预测未来的销售额。
通过以上的分析,该电商公司可以更好地了解其在线购买行为,找到销售最好的地点和销售最好的时间,并预测未来的销售情况。
基于这些信息,他们可以做出更好的决策,例如增加在销售最好的地点的推广活动或优化在销售最好的时间的库存管理。
综上所述,SPSS可以帮助企业对大规模数据进行分析,从而更好地了解数据,做出更好的决策。
这个案例只是SPSS数据分析的一个示例,实际应用可以更加多样化和复杂化。
spss数据分析简单案例

spss数据分析简单案例SPSS数据分析简单案例。
在实际的数据分析工作中,SPSS(Statistical Package for the Social Sciences)是一个非常常用的统计分析软件。
它提供了丰富的统计分析功能,可以帮助研究者对各种数据进行深入的分析和挖掘。
下面我们将通过一个简单的案例来介绍如何使用SPSS进行数据分析。
案例背景:假设我们是一家电商公司的数据分析师,我们需要分析一组销售数据,以便更好地了解产品销售情况,为未来的销售策略提供支持。
第一步,数据导入。
首先,我们需要将待分析的数据导入SPSS软件中。
在SPSS中,我们可以通过“文件”菜单中的“打开”命令来打开Excel或者CSV格式的数据文件。
在导入数据的过程中,我们需要注意数据的格式是否正确,确保数据的准确性。
第二步,数据清洗。
一般来说,原始数据中会存在一些缺失值、异常值或者重复值,这些数据对于我们的分析是不利的。
因此,在进行数据分析之前,我们需要对数据进行清洗。
在SPSS中,我们可以通过“数据”菜单中的“数据清理”命令来进行数据清洗工作。
在数据清洗的过程中,我们需要注意保留数据的完整性和准确性。
第三步,描述性统计分析。
在数据清洗完成之后,我们可以开始进行描述性统计分析。
描述性统计分析可以帮助我们了解数据的基本情况,包括数据的分布、中心趋势和离散程度等。
在SPSS中,我们可以通过“分析”菜单中的“描述统计”命令来进行描述性统计分析。
在描述性统计分析的过程中,我们可以生成各种统计指标,如均值、标准差、最大最小值等,以便更好地了解数据的特征。
第四步,相关性分析。
除了描述性统计分析之外,我们还可以进行相关性分析,以了解不同变量之间的相关关系。
在SPSS中,我们可以通过“分析”菜单中的“相关”命令来进行相关性分析。
在相关性分析的过程中,我们可以生成相关系数矩阵或者散点图,以便更好地了解变量之间的相关关系。
第五步,回归分析。
最后,我们还可以进行回归分析,以了解自变量和因变量之间的关系。
大学生spss数据分析案例

大学生spss数据分析案例SPSS数据分析是大学生在进行学术研究和毕业论文撰写过程中常常需要掌握的技能之一。
本文将以一个实际案例为例,介绍如何使用SPSS软件进行数据分析,以帮助大学生更好地理解和运用SPSS进行数据处理和分析。
首先,我们需要明确案例研究的背景和目的。
假设我们要研究大学生学习成绩与每周学习时间的关系,我们收集了一批大学生的学习成绩和每周学习时间的数据,现在需要用SPSS进行分析。
第一步,我们需要导入数据。
在SPSS软件中,点击“文件”-“导入数据”-“从数据库导入数据”,选择相应的文件并导入数据。
第二步,进行数据清洗。
在数据清洗过程中,我们需要检查数据是否存在缺失值、异常值等情况,可以使用SPSS中的数据查看功能和描述统计功能进行检查和处理。
第三步,进行描述性统计分析。
在SPSS中,我们可以使用“描述统计”功能来计算学习成绩和每周学习时间的均值、标准差、频数分布等统计指标,以便对数据有一个整体的了解。
第四步,进行相关性分析。
我们可以使用SPSS中的“相关分析”功能来计算学习成绩和每周学习时间之间的相关系数,以判断它们之间是否存在显著的相关性。
第五步,进行回归分析。
如果我们想进一步探究学习成绩与每周学习时间之间的因果关系,可以使用SPSS中的“线性回归”功能来进行回归分析,得出它们之间的回归方程和相关系数。
最后,我们需要对分析结果进行解释和总结。
在解释和总结过程中,我们需要使用清晰、准确的语言对分析结果进行解释,并结合案例研究的背景和目的进行合理的总结和结论。
通过以上案例分析,我们可以看到,SPSS软件作为一款专业的统计分析工具,能够帮助我们快速、准确地进行数据分析,为我们的学术研究和毕业论文撰写提供了有力的支持。
希望本文能够对大学生在SPSS数据分析方面有所帮助,引起大家对SPSS数据分析的重视和学习兴趣。
spss统计分析实例分析PPT课件
• 调用命令Analyze\Descriptive Statistics \Descriptives
• 选择“人均面积”作为分析变量 • 选择必要的分析指标
• 根据户口状况对数据进行拆分(Split File) • 重新调用命令\Descriptives计算不同户口状况的
第29页/共89页
标准正态评分值,并以变量形式存入数据文件中,以便后续分析时应用。
在多元统计分析中,对均值差异较大的变量,采 用变量标准化后的数据进行分析,可以消除均值 差异带来的影响。
第31页/共89页
第11页/共89页
SPSS
频数分析
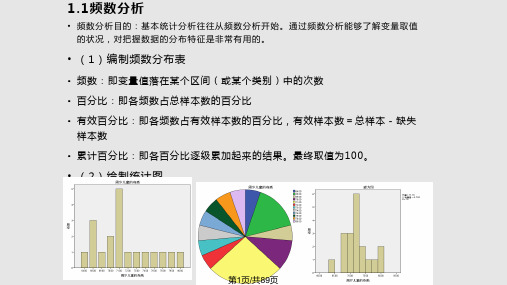
的 操 作 步 骤
1、菜单中点分析/描述统计/频率,进入频 率对话框
第12页/共89页
SPSS
的 操 作 步 骤
2、将变量选入变量 窗口,再点击统计 量,进行设置,完 成后点继续返回
第13页/共89页
SPSS
的 操 作 步 骤
2、在频率主对话框中分别进入图表和格式进 行设置,完成后点继续返回,最后点确定
• 峰度:描述变量取值分布形态陡峭程度的统计量。
• 当数据分布与标准正态分布的陡峭程度相同时,峰度值等于0;峰度大于 0表示数据的分布比标准正态分布更陡峭,为尖峰分布;峰度小于0表示 数 据 的 分 布 比 标 准 正 态 分 布 平 缓第2,5页为/共平89峰页 分 布 。
偏态
峰态
左左偏偏分分布布
Ku rto si s
7.739
Skewness
.045
Ku rto si s
.089
Descriptiv e Statistics
户口 状况 本市户口 外地户口
N
2024版SPSS数据案例分析

通过方差分析,发现不同社会群体在态度上存在显著差异, 并进一步通过事后检验(Post hoc tests)确定哪些群体之 间存在差异
26
聚类分析在社会科学领域应用举例
研究问题
能否将受访者按照他们在某一社会现象上的行为特征进行分类?
分析方法
采用K-means聚类分析对受访者的行为特征进行聚类
2024/1/27
20
假设检验在医学领域应用举例
假设检验的基本原理
假设检验是一种统计推断方法,用于检验某个假设是否成立。在医学领域中,假设检验常用于比较两组或多组患 者的治疗效果是否有显著差异。
应用举例
例如,一项研究旨在比较两种不同药物对某种疾病的治疗效果。研究人员可以将患者随机分为两组,分别接受两 种不同的药物治疗。通过收集患者的治疗结果数据,并使用假设检验方法进行分析,可以确定哪种药物的治疗效 果更好。
SPSS数据案例分析
2024/1/27
1
CATALOGUE
目 录
2024/1/27
• 数据导入与预处理 • 数据分析方法介绍 • SPSS软件操作指南 • 案例一:医学领域数据分析应用举
例 • 案例二:社会科学领域数据分析应
用举例 • 总结与展望
2
01
CATALOGUE
数据导入与预处理
2024/1/27
多因素方差分析
研究多个自变量对一个因变量的 影响,通过比较不同组间的均值 差异来判断哪些自变量对因变量 有显著影响。
2024/1/27
10
回归分析
线性回归分析
研究一个或多个自变量对一个因变量的线性关系,通过建立线性回 归方程来预测因变量的值。
多元线性回归分析
研究多个自变量对一个因变量的线性关系,通过建立多元线性回归 方程来预测因变量的值,并可以分析自变量之间的交互作用。
SPSS统计分析分析案例

SPSS统计分析案例一、我国城镇居民现状近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施和实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。
本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。
二、我国居民消费结构的横向分析第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。
但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。
第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。
衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。
随着收入的增加,衣着支出比重呈现先上升后下降的走势。
事实上,在当前的价格水平和服装业的发展水平下,城镇居民的穿着是有一定限度的,而且居民对衣着的需求也不是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。
第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务和杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高和改善。
第四,医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。
这是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。
第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点是相吻合的,同时与恩格尔定律的引申也是一致的。
- 1、下载文档前请自行甄别文档内容的完整性,平台不提供额外的编辑、内容补充、找答案等附加服务。
- 2、"仅部分预览"的文档,不可在线预览部分如存在完整性等问题,可反馈申请退款(可完整预览的文档不适用该条件!)。
- 3、如文档侵犯您的权益,请联系客服反馈,我们会尽快为您处理(人工客服工作时间:9:00-18:30)。
SPSS统计分析案例一、我国城镇居民现状近年来,我国宏观经济形势发生了重大变化,经济发展速度加快,居民收入稳定增加,在国家连续出台住房、教育、医疗等各项改革措施与实施“刺激消费、扩大内需、拉动经济增长”经济政策的影响下,全国居民的消费支出也强劲增长,消费结构发生了显著变化,消费结构不合理现象得到了一定程度的改善。
本文通过相关数据分析总结出了我国城镇居民消费呈现富裕型、娱乐教育文化服务类消费攀升的趋势特点。
二、我国居民消费结构的横向分析第一,食品消费支出比重随收入增加呈现出明显的下降趋势,这与恩格尔定律的表述一致。
但最低收入户与最高收入恩格尔系数相差太过悬殊,城镇最低收入户刚刚解决了温饱问题,而最高收入户的生活水平按照恩格尔系数的评价标准早已达到了富裕型,甚至接近最富裕型。
第二,衣着消费支出比重随收入增加缓慢上升,到高收入户又有所下降,但各收入组支出比重相差不大。
衣着支出比重没有更多的递增且最高收入户的支出比重有所下降,这些都符合恩格尔定律关于衣着消费的引申。
随着收入的增加,衣着支出比重呈现先上升后下降的走势。
事实上,在当前的价格水平与服装业的发展水平下,城镇居民的穿着就是有一定限度的,而且居民对衣着的需求也不就是无限膨胀的,即使收入水平继续提高,也不需要将更大的比例用于购买服饰用品了。
第三,家庭设备用品及服务、交通通讯、娱乐教育文化服务与杂项商品与服务的支出比重呈逐组上升趋势,说明居民的生活水平随收入的增加而不断提高与改善。
第四,医疗保健支出比重随收入水平提高呈现一种两端高、中间低的走势。
这就是因为医疗保健支出作为生活必须支出,不论居民生活水平高低,都要将一定比例的收入用于维持自身健康,而且由于医疗制度改革,加重了个人负担的同时,也减小了旧制度可能造成的不同行业、不同体制下居民医疗保健支出的差别,因而不同收入等级的居民在医疗保健支出比重上差别不大。
第五,居住支出比重基本上呈先上升后下降的趋势,这与我国居民消费能级不断提升,住宅商品正在越来越成为城镇居民关注的热点就是相吻合的,同时与恩格尔定律的引申也就是一致的。
可以瞧出,城镇居民的消费状况虽然受价格水平、消费习惯、消费环境、消费心理预期等诸多因素的影响,但归根结底仍取决于居民的收入水平,要提高城镇居民的消费支出,必须增加居民收入。
因此,采取切实有效的措施增加城镇居民的可支配收入,不仅可以提高全国城镇居民的总体消费水平,促进消费结构向着更加健康、合理的方向发展,而且在启动内需,促进我国的经济发展方面有着重大的现实意义。
三、我国居民消费结构的纵向分析进入21世纪以来,随着经济体制改革的深入,国民经济的迅速发展,我国城乡居民的消费水平显著提高,居民的各项支出显著增加。
随着消费水平的提高,我国城乡居民消费从注重量的满足到追求质的提高,从以衣食消费为主的生存型到追求生活质量的享受型、发展型,消费质量与消费结构都发生了明显的变化。
城镇居民在食品、衣着、家庭设备用品三项支出在消费支出中的比重呈现明显的下降趋势,其中食品类支出比重降幅最大;衣着类有所下降;家庭设备用品类下降幅度不就是很大。
与此同时,医疗保健、交通通讯、文化娱乐教育服务、居住及杂项商品支出在消费支出中的比例均有上升,富裕阶段的消费特征开始显现。
四、我国城镇居民消费结构及趋势的统计分析下图就是出自《中国统计年鉴—2009》这一资料性年刊,它系统收录了全国与各省、自治区、直辖市2008年经济、社会各方面的统计数据,以及近三十年与其她重要历史年份的全国主要统计数据。
此年鉴正文内容分为24个篇章,本文选取其中的第九篇章-人民生活,用以探究我国城镇居民消费结构及其趋势。
表1 《中国统计年鉴—2009》统计表9-5 城镇居民家庭基本情况#可支配收入1510、16 4282、95 6279、98 13785、81 15780、76平均每人消费性支出(元) 1278、89 3537、57 4998、00 9997、47 11242、85 食品693、77 1771、99 1971、32 3628、03 4259、81衣着170、90 479、20 500、46 1042、00 1165、91居住60、86 283、76 565、29 982、28 1145、41 家庭设备用品及服务108、45 263、36 374、49 601、80 691、83 医疗保健25、67 110、11 318、07 699、09 786、20 交通通信40、51 183、22 426、95 1357、41 1417、12 教育文化娱乐服务112、26 331、01 669、58 1329、16 1358、26 杂项商品与服务66、57 114、92 171、83 357、70 418、31 平均每人消费性支出构成(人均消费性支出=100)食品54、25 50、09 39、44 36、29 37、89衣着13、36 13、55 10、01 10、42 10、37居住6、98 8、02 11、31 9、83 10、19 家庭设备用品及服务10、14 7、44 7、49 6、02 6、15 医疗保健2、01 3、11 6、36 6、99 6、99交通通信1、20 5、18 8、54 13、58 12、60 教育文化娱乐服务11、12 9、36 13、40 13、29 12、08 杂项商品与服务0、94 3、25 3、44 3、58 3、72注:1、本表至9-17表为城镇住户抽样调查资料。
2、从2002年起,城镇住户调查对象由原来的非农业人口改为城市市区与县城关镇住户,本篇章相关资料均按新口径计算,历史数据作了相应调整。
五、SPSS统计分析图一给出了基本的描述性统计图,图中显示各个变量的全部观测量的Mean(均值)、Std、D eviation(标准差)与观测值总数N。
图2给出了相关系数矩阵表,其中显示3个自变量两两间的Pearson相关系数,以及关于相关关系等于零的假设的单尾显著性检验概率。
图1 描述性统计表图2 相关系数矩阵从表中瞧到因变量家庭设备用品及服务与自变量食品、衣着之间相关关系数依次为0、869、0、684,反映家庭设备用品及服务与食品、衣着之间存在显著的相关关系。
说明食品与衣着对于家庭设备用品及服务条件的好转有显著的作用。
自变量居住于因变量家庭设备用品及服务之间的相关系数为-0、894,它于其她几个自变量之间的相关系数也都为负,说明它们之间的线性关系不显著。
此外,食品与衣着之间的相关系数为0、950,这也说明它们之间存在较为显著的相关关系。
按照常识,它们之间的线性相关关系也就是符合事实的。
图3给出了进入模型与被剔除的变量的信息,从表中我们可以瞧出,所有3个自变量都进入模型,说明我们的解释变量都就是显著并且就是有解释力的。
图3 变量进入/剔除信息表图4给出了模型整体拟合效果的概述,模型的拟合优度系数为0、982,反映了因变量于自变量之间具有高度显著的线性关系。
表里还显示了R平方以及经调整的R值估计标准误差,另外表中还给出了杜宾-瓦特森检验值DW=2、632,杜宾-瓦特森检验统计量DW就是一个用于检验一阶变量自回归形式的序列相关问题的统计量,DW在数值2到4之间的附近说明模型变量无序列相关。
图4 模型概述表图4给出了方差分析表,我们可以瞧到模型的设定检验F统计量的值为9、229,显著性水平的P值为0、236。
图5 方差分析表图6给出了回归系数表与变量显著性检验的T值,我们发现,变量居住的T值太小,没有达到显著性水平,因此我们要将这个变量剔除,从这里我们也可以瞧出,模型虽然通过了设定检验,但很有可能不能通过变量的显著性检验。
图6 回归系数表图7给出了残差分析表,表中显示了预测值、残差、标准化预测值、标准化残差的最小值、最大值、均值、标准差及样本容量等,根据概率的3西格玛原则,标准化残差的绝对值最大为1、618,小于3,说明样本数据中没有奇异值。
图7 残差统计表图8给出了模型的直方图,由于我们在模型中始终假设残差服从正态分布,因此我们可以从这张图中直观地瞧出回归后的实际残差就是否符合我们的假设,从回归残差的直方图于附于图上的正态分布曲线相比较,可以认为残差的分布不就是明显地服从正态分布。
尽管这样也不能盲目的否定残差服从正态分布的假设,因为我们用了进行分析的样本太小,样本容量仅为5。
图8 残差分布直方图从上面图4的分析结果瞧,我们的模型需要剔除居住这个变量,用本次实验中的方法与步骤重新令家庭设备用品及服务对食品与衣着回归,得到的主要结果如图9、图10与图11所示,跟上面的分析类似,从中可以瞧出,剔除居住这个变量后,模型拟合优度为0、964,比原来有所降低;而方差分析的F检验为27、071,新模型与原来的模型相比,各个系数都通过了显著性T检验,因此更加合理,从而我们可以得出结论:剔除居住这个变量后的模型更加合理,因此在做预测过程中要使用剔除不显著变量后的模型。
图9 模型概述图10 方差分析表图11 回归系数表六、我国居民消费变化的趋势特点(1)食品消费质量提高,衣着消费支出比重下降。
食品消费水平由过去简单的吃饱吃好,转变为品种更加丰富,营养更加全面。
一方面由于食品供应的日益充足。
另一方面由于在外饮食的增加,粮食消费比重减小,购买量大幅度下降。
衣着就是两项基本生存资料之一,衣着消费向时装化、名牌化、个性化发展的倾向更加明显,成衣化倾向成为主流。
从衣着与食品消费比重的下降可以瞧出城镇居民满足基本生活的支出并没有随着收入水平的提高而提高,这表明我国城镇居民满足吃、穿为主的生存型消费需求阶段已经结束,逐步向以发展型与享受型消费的阶段过渡。
(2) 居民收入迅速增长,消费水平大幅度提高,消费结构呈现明显的富裕型特征消费就是收入的函数,收入的增加就是消费水平提高与消费结构变化的前提。
随着我国经济的发展,我国居民的收入水平不断提高,特别就是21世纪以来,我国居民的收入水平迅速提高。
伴随着收入水平的提高,城乡居民各项支出全面增加,消费性支出大幅度增长。
今后5—10年以至更长时间,我国经济保持一个较高的增长速度就是完全可能的,城乡居民的消费水平将大幅度提高。
(3)消费能级不断提高,消费内容日益丰富,住房与轿车消费同时升温,可望提前成为消费热点在消费水平提高与消费结构改善的同时,城乡居民的消费能级不断提高。
(4)以教育为龙头的娱乐教育文化服务类消费继续攀升随着人们对知识认知程度的提高与自我完善意识的增强,对教育的投入仍会保持增长。
目前从子女教育在人们储蓄目的位居前列的情况瞧,对教育及教育产品的投入仍就是今后一个时期的消费热点。
大力发展教育事业,特别就是高等教育、成人教育、职业教育应就是政府长期坚持与倡导的提高城镇居民收入水平,缩小收入差距,应做到:1、进一步强化收入分配的宏观调控力度采取切实措施努力提高低收入群体的收入水平。